The use of fossil fuels continues to pose adverse environmental impacts on the ecosystem in terms of global warming and pollution. Renewable energy sources, such as solar, wind, biofuels and hydro, are expected to play a key role in transforming the harmful carbon-intensive energy generation systems into the more sustainable ones [
1]. Motivated by this fact, the share of renewable energy sources in electricity generation is increasing [
2]. For example, the share of renewables in electricity generation in the U.S. increased from 10.5% to 17.5% over the last ten years [
1]. This trend is expected to continue for a long time, because many countries have already set ambitious renewable energy targets for climate action [
3]. The rise of renewables, however, presents some new challenges to overcome. Primarily, the electricity generation from renewable energy sources is difficult to control and forecast due to their intermittent and stochastic nature, which may sometimes cause an imbalance between electricity supply and demand, and may consequently affect the stability of power grids. To fully exploit renewable energy sources, the potential imbalances between electricity supply and demand should be avoided. Transition from generation on demand to consumption on demand is a way to address this issue. In this regard, the flexibility of the demand side is a very important asset which can be harnessed by demand response (DR) programs.
DR programs incentivize end users to reduce or shift their electricity consumption during peak periods by means of time-based rates or direct load control [
4]. In time-based rates programs, local grid operators set higher prices during peak periods when electricity generation is expensive. In response, end users reduce their electricity consumption in these periods to save money. In direct load control programs, local grid operators are given the ability to shut off equipment during peak periods. In response, end users get discounted electricity bills or similar financial incentives for their participation. In all cases, an efficient control medium is essential to fully harness the flexibility of the demand side (as discussed in
Section 2.3). To facilitate this, the CTA-2045 standard was established as a universal communication module for gathering data and dispatching commands from/to devices. The CTA-2045 standard is used for many devices including water heaters, thermostats, electric vehicle chargers, and pool pumps [
5].
Being a prominent load in the U.S. residential buildings, electric water heaters are great assets for DR programs. Thanks to their storage tank, water heaters can store energy and provide demand flexibility to utilities when needed [
6]. Residential buildings are the largest end-use electricity consumer in the U.S. [
7]. Electric water heaters represent 14% of the electricity consumed in the U.S. residential buildings. Water heating is the third largest electricity end-use category, after air conditioning and space heating. On average, 46% of the residential buildings in the U.S. have an electric water heater [
8]. Water heaters are not only one of the largest end-use electricity consumers, but also account for a good portion of household expenses. For example, an average household in the U.S. spends about USD 400–600 (0.45 ¢/L–0.68 ¢/L) on water heating every year [
9]. For this reason, the use of heat pump water heaters (HPWHs), which is more energy efficient than standard electric water heaters, is on the rise [
10].
1.1. Literature Review
In recent years, a significant number of research efforts have been devoted to studying the control of water heater and heating ventilation, and air conditioning (HVAC) systems in the contexts of DR and building energy management system (BEMS) applications. The control of water heater and HVAC systems is a complex problem, as it requires a simultaneous consideration of many factors including cost saving, comfort, safety, and reliability. To date, many unique and powerful control approaches have been proposed, but the main ones can be broadly categorized as rule-based, model predictive control (MPC), and reinforcement learning (RL) approaches.
Rule-based approaches are simple yet can be effective, depending on the expertise and knowledge of the developer. In these approaches, occupant comfort can be maintained while potentially reducing electricity cost and/or reducing electricity consumption [
11]. For example, a rule-based approach can simply reduce the electricity cost of a water heater by decreasing its setpoint to the lower comfort band of the user during high price or unoccupied periods. Such rule-based approaches have been implemented by many studies. For example, Vanthournout et al. [
12] presented a rule-based controller for a time-of-use (TOU) billing program. Their controller relied on three main rules: turn on the water heater at times when the price is low until it is fully recharged; turn off the water heater at times when the price is high unless the comfort of the user is in danger; and turn on the water heater when the price is high for a very brief period to maintain the comfort of the user, if needed. Péan et al. [
13] evaluated a rule-based control strategy that adjusts water heater and indoor temperature setpoints according to electricity price and showed that their controller can save up to 20% through a simulation study. Perera and Skeie [
14] presented a set of rule-based controllers that set setpoint and setback temperatures based on predefined occupancy schedules. Delgado et al. [
15] provided a rule-based controller for maximizing self-consumption and reducing costs. Rule-based approaches, however, do not take any future information (e.g., future price, future hot water usage) into account, and therefore their efficacy is limited [
16].
MPC approaches consist of three main steps: modeling, predicting, and controlling. Modeling refers to the development of a model that represents the characteristics of the thermal system (e.g., water heater, HVAC) to be controlled. Predicting refers to the prediction of the disturbances (e.g., water draw, outdoor temperature). Controlling refers to the optimization of the control using the model and the prediction data resulting from the first two steps [
11]. Unlike rule-based approaches, MPC approaches can have multiple objectives and constraints. MPC approaches are the most popular among DR and BEMS applications and have been used for many applications in the area of water heater and HVAC control [
17]. For example, Tarragona [
18] proposed an MPC strategy to improve the operation of a space-heating system coupled with renewable resources. Gholamibozanjani et al. [
19] applied an MPC strategy for controlling a solar-assisted active HVAC system to minimize heating costs while providing the required comfortable temperature. Starke et al. [
20] proposed an MPC-based control approach for heat pump water heaters to reduce electricity cost while maintaining the comfort and reducing the cycling of the water heater. Their results showed that the MPC controller prevented power use during the high price and critical peak periods while maintaining the comfort of the end users. Wang et al. [
21] proposed an MPC-based controller to minimize the electricity bill while maintaining comfort for a real-time pricing (RTP) market under uncertain hot water demand and ambient temperature. Nazemi et al. [
22] presented an incentive-based multi-objective nonlinear optimization approach for load scheduling of time-shiftable assets (e.g., dishwasher, washing machine) and thermal assets (e.g., water heater, HVAC). MPC approaches, however, have two main limitations. First, these approaches require a significant amount of time and effort for accurate modeling of the system to be controlled and failure to do so results in a poor control strategy. Additionally, due to the limited generalizability of the models in representing the characteristics of different thermal systems, an individual model needs to be developed for each system. For this reason, despite its good performance, the use of MPC may be inconvenient for some applications. Second, MPC optimizes an objective function at each control time step, which is a computationally expensive task that requires relatively powerful computational resources for real-time applications. Additionally, in the case of non-convex problems, the implementation of MPC can be challenging [
23].
RL approaches can help addressing the many limitations associated with rule-based and MPC approaches. Parallel to the advancements in big data, machine learning algorithms, and computing infrastructure, RL approaches have become an important alternative for supporting DR and BEMS applications. On one hand, there exist many successful RL studies focusing on HVAC systems. These studies have already proved the feasibility and applicability of RL approaches to the various problems in the contexts of DR and BEMS. For example, [
24,
25,
26] developed RL-based controllers to control HVAC systems. On the other hand, water heater control still remains largely untapped, except for only a few studies [
17]. For example, Ruelens et al. [
6] applied the fitted Q-iteration (FQI) to the control of an electric water heater for reducing the energy cost of the water heater and achieved 15% saving in 40 days. Kazmi et al. [
27] proposed a model-based RL algorithm to optimize energy consumption of a set of water heaters and achieved a 20% saving while maintaining occupant comfort. Al-jabery et al. [
28] proposed a Q-learning-based approach to solving the multi-objective optimization problem of minimizing the total cost of the power consumed, reducing the power demand during the peak period, and achieving customer satisfaction. Zsembinszki et al. [
29] developed an RL-based controller to reduce the energy demand for heating, cooling and domestic hot water and compared the RL-based controller with a rule-based controller.
1.3. Study Contributions
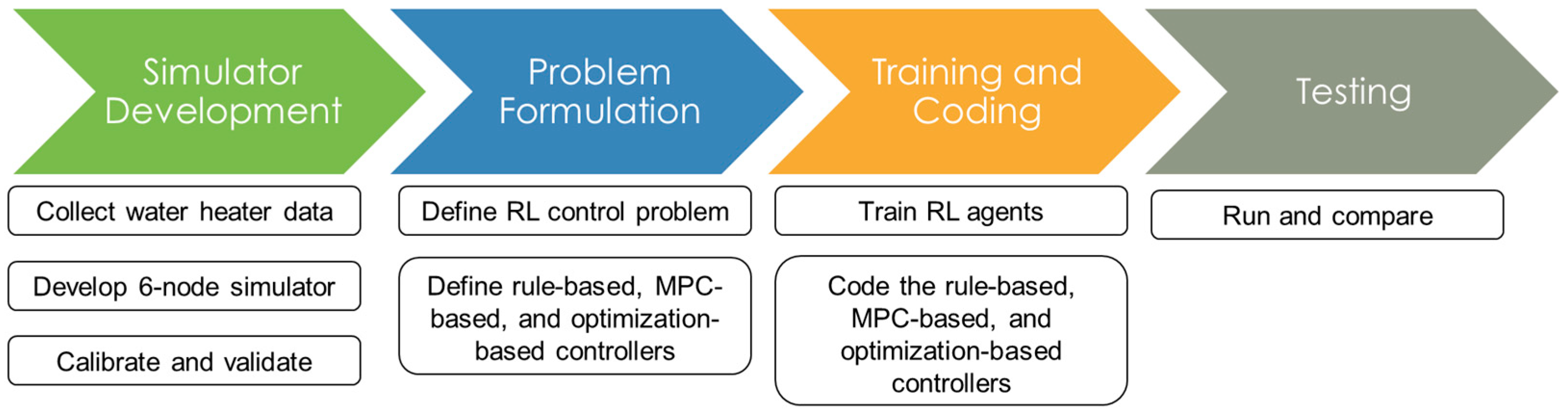
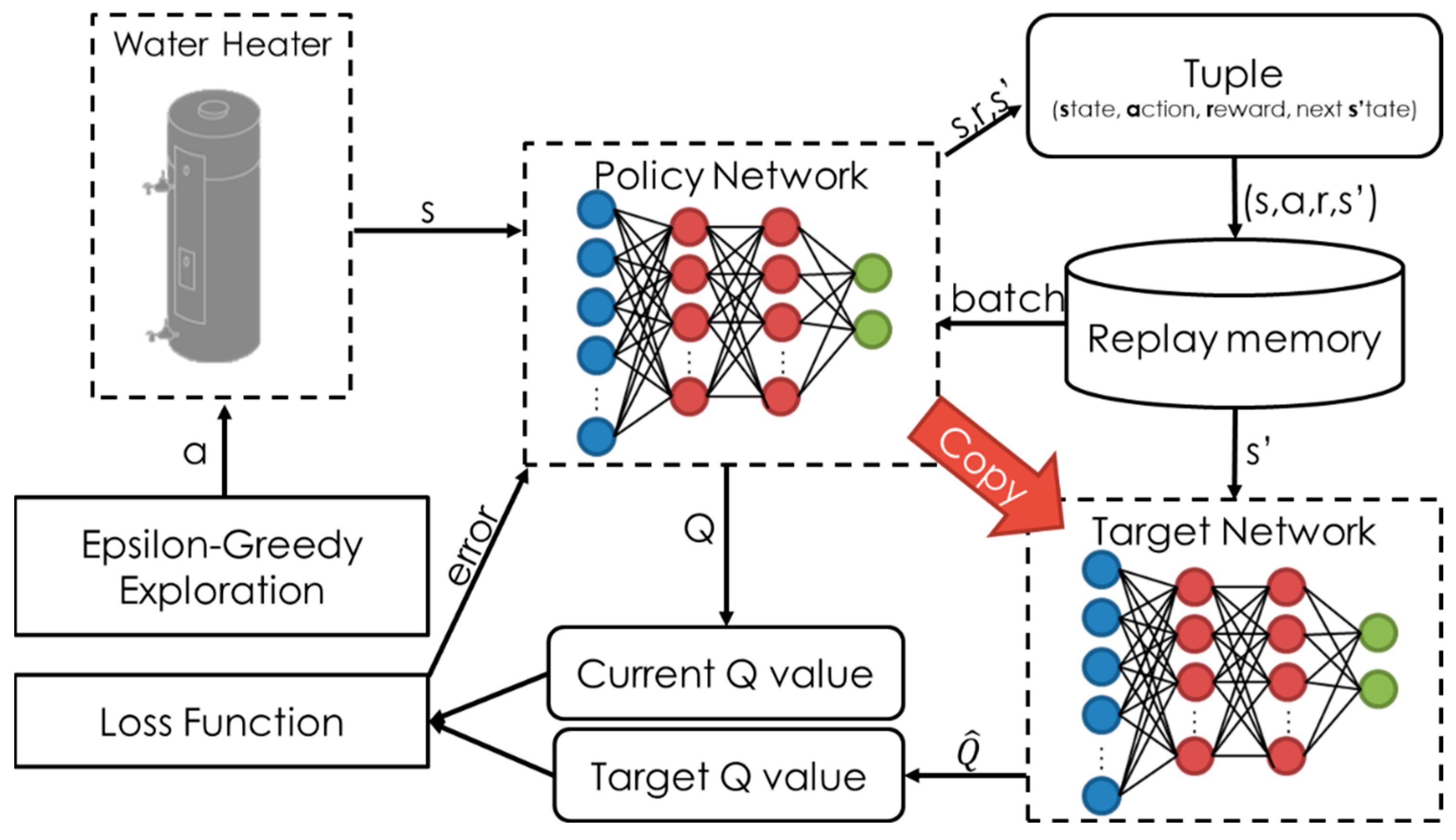
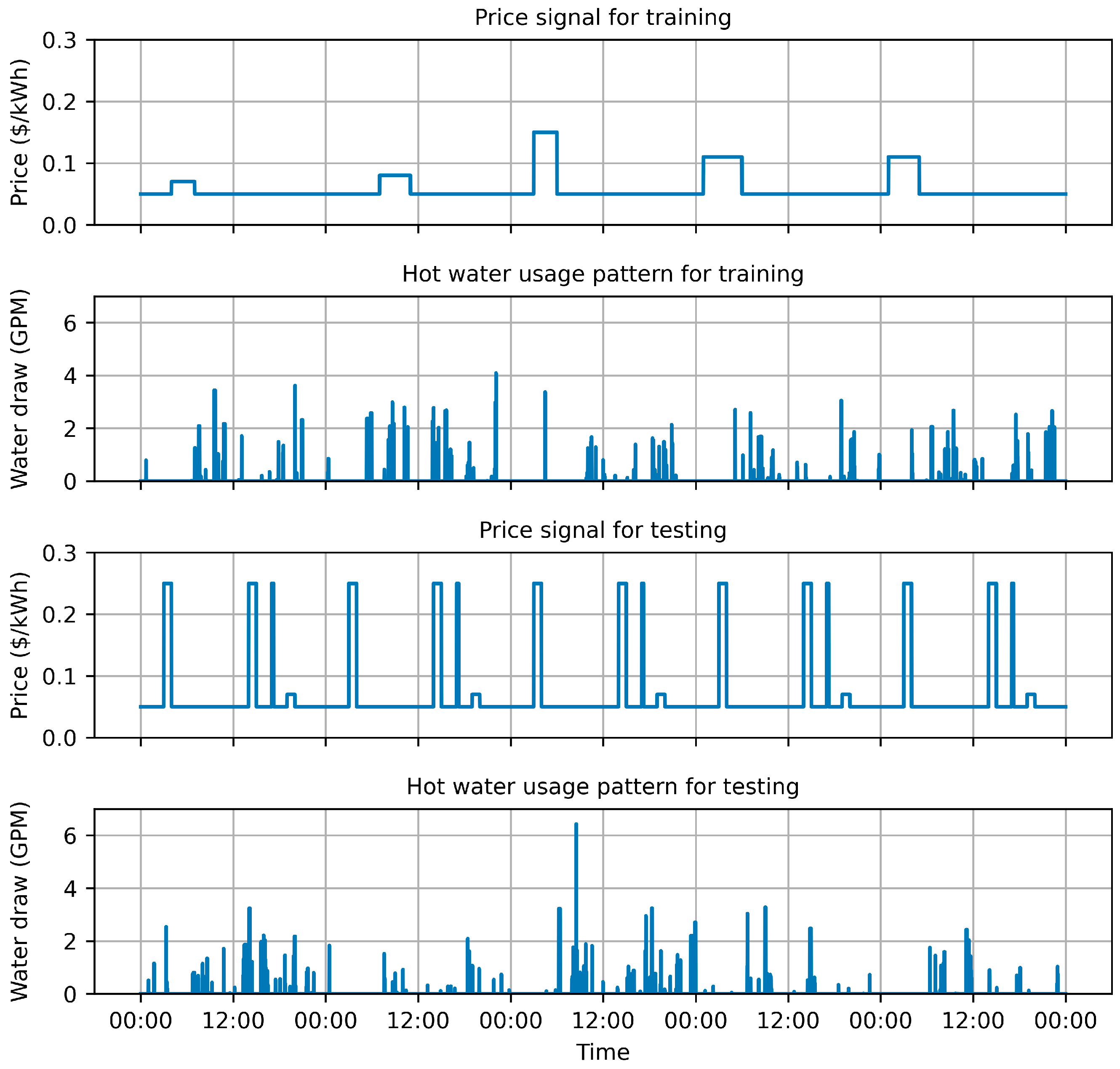
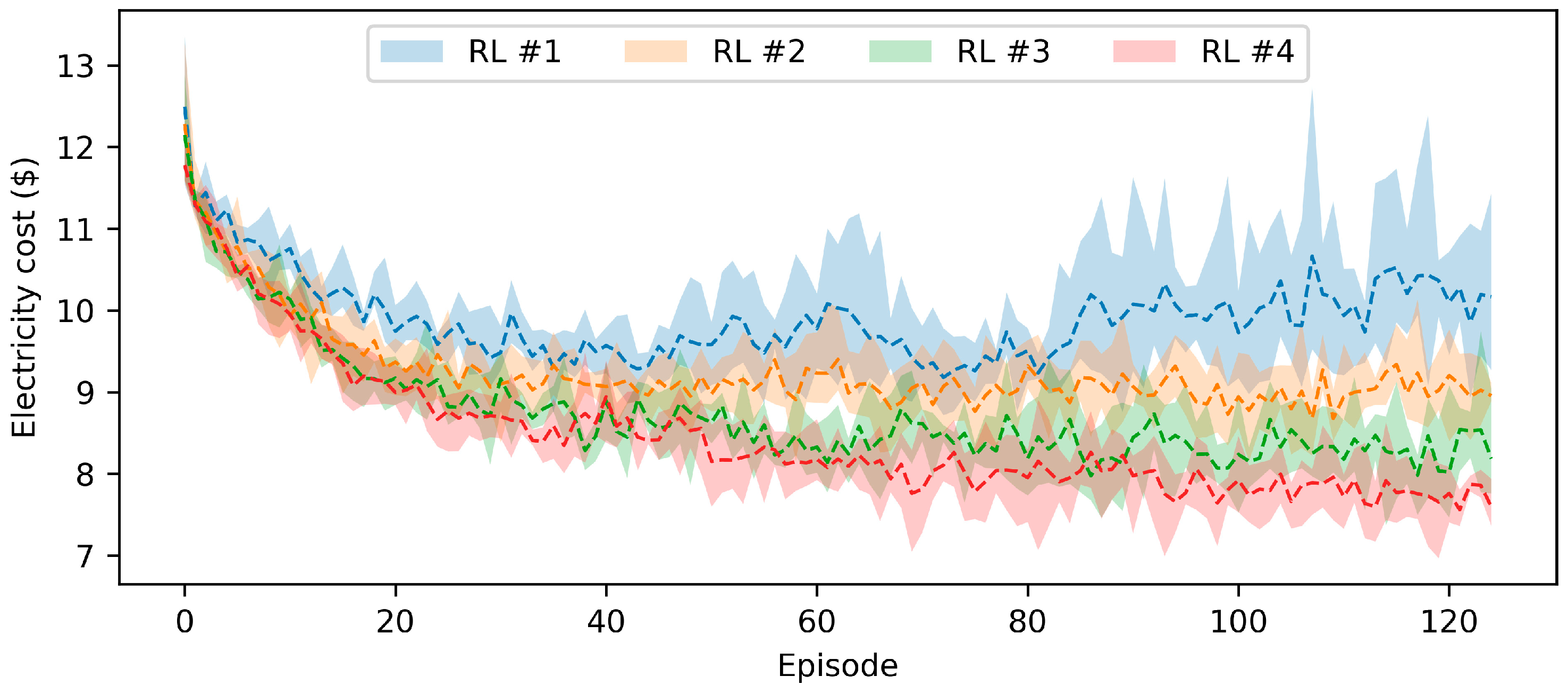
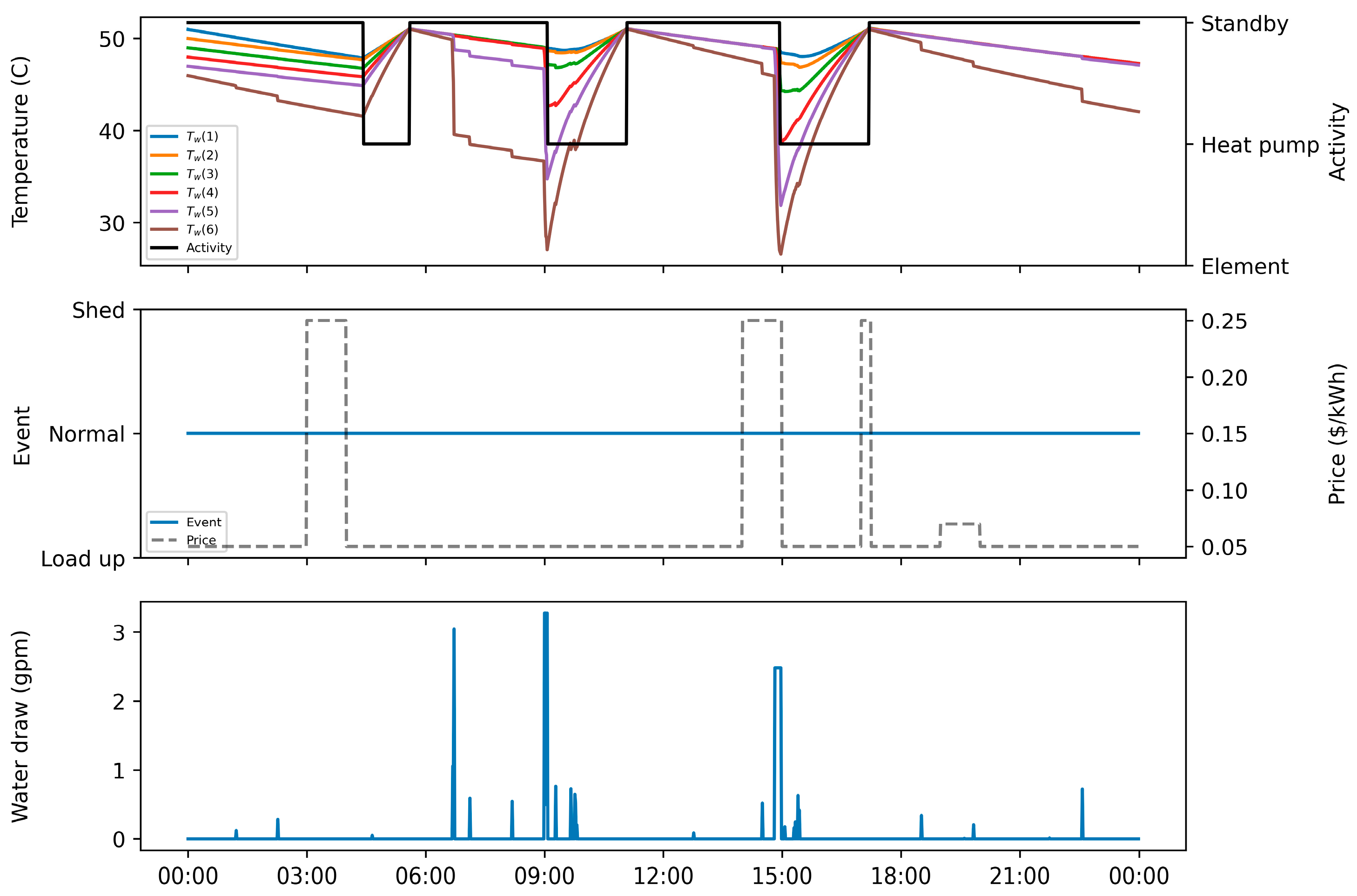
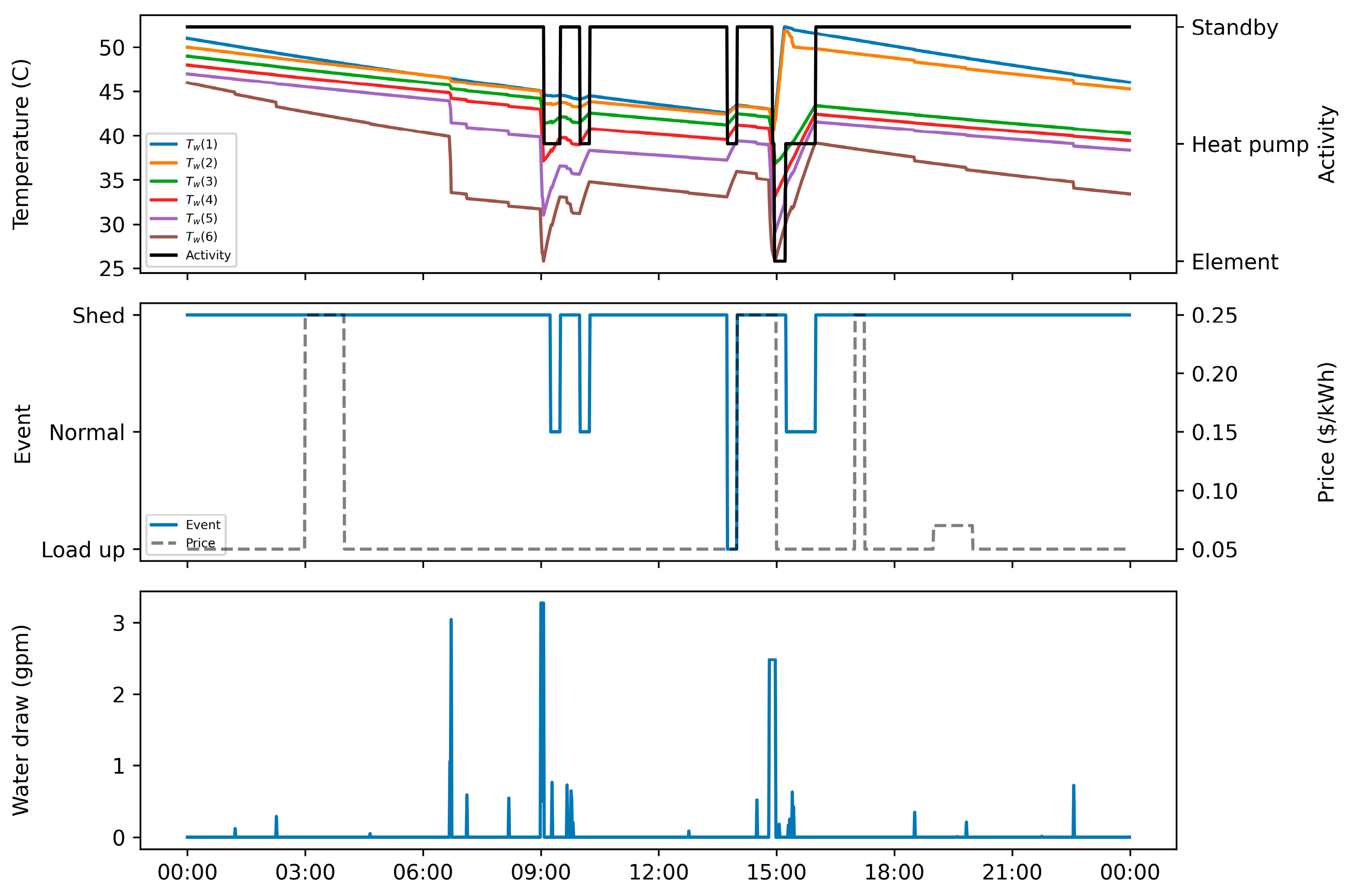
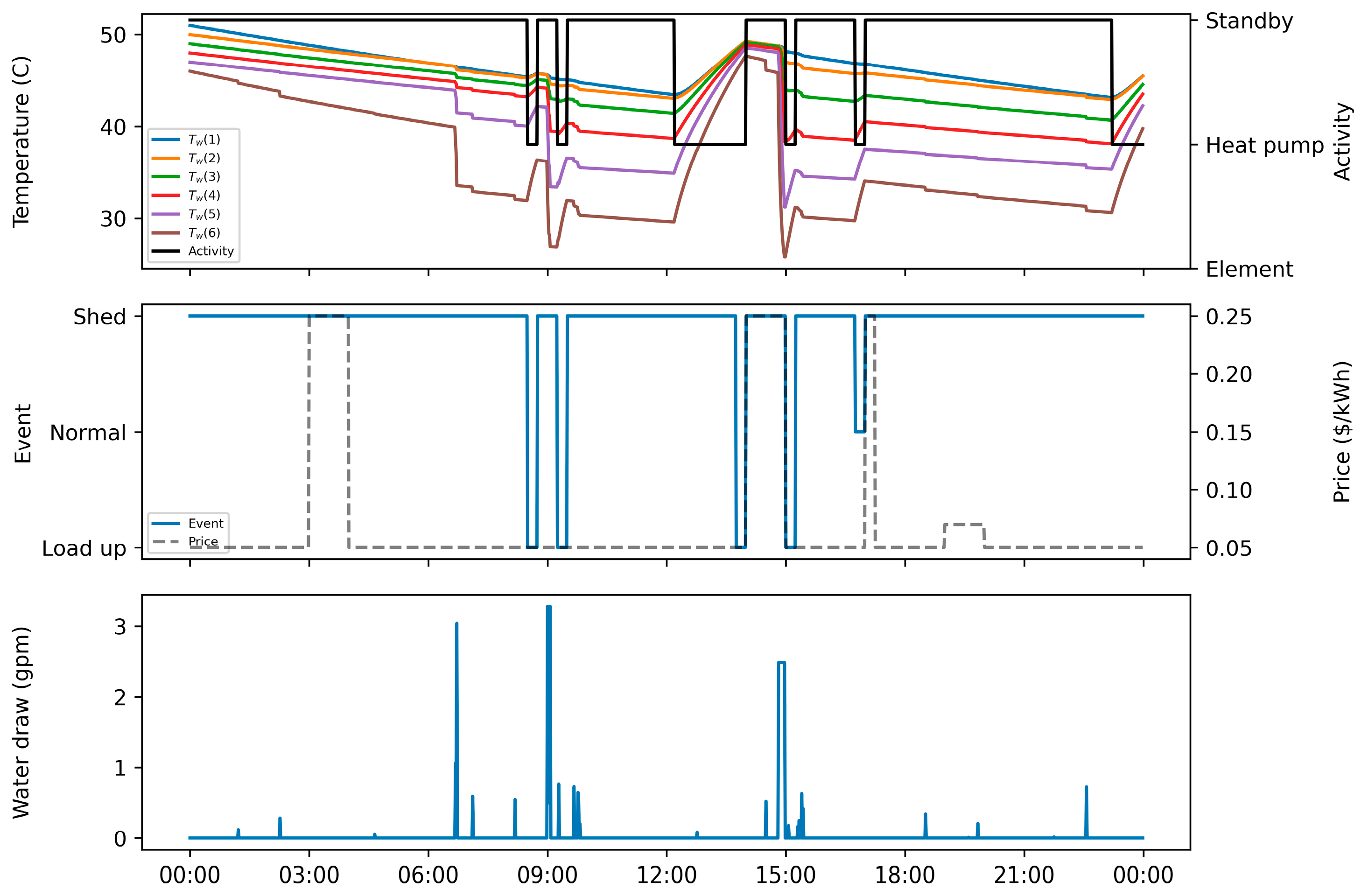
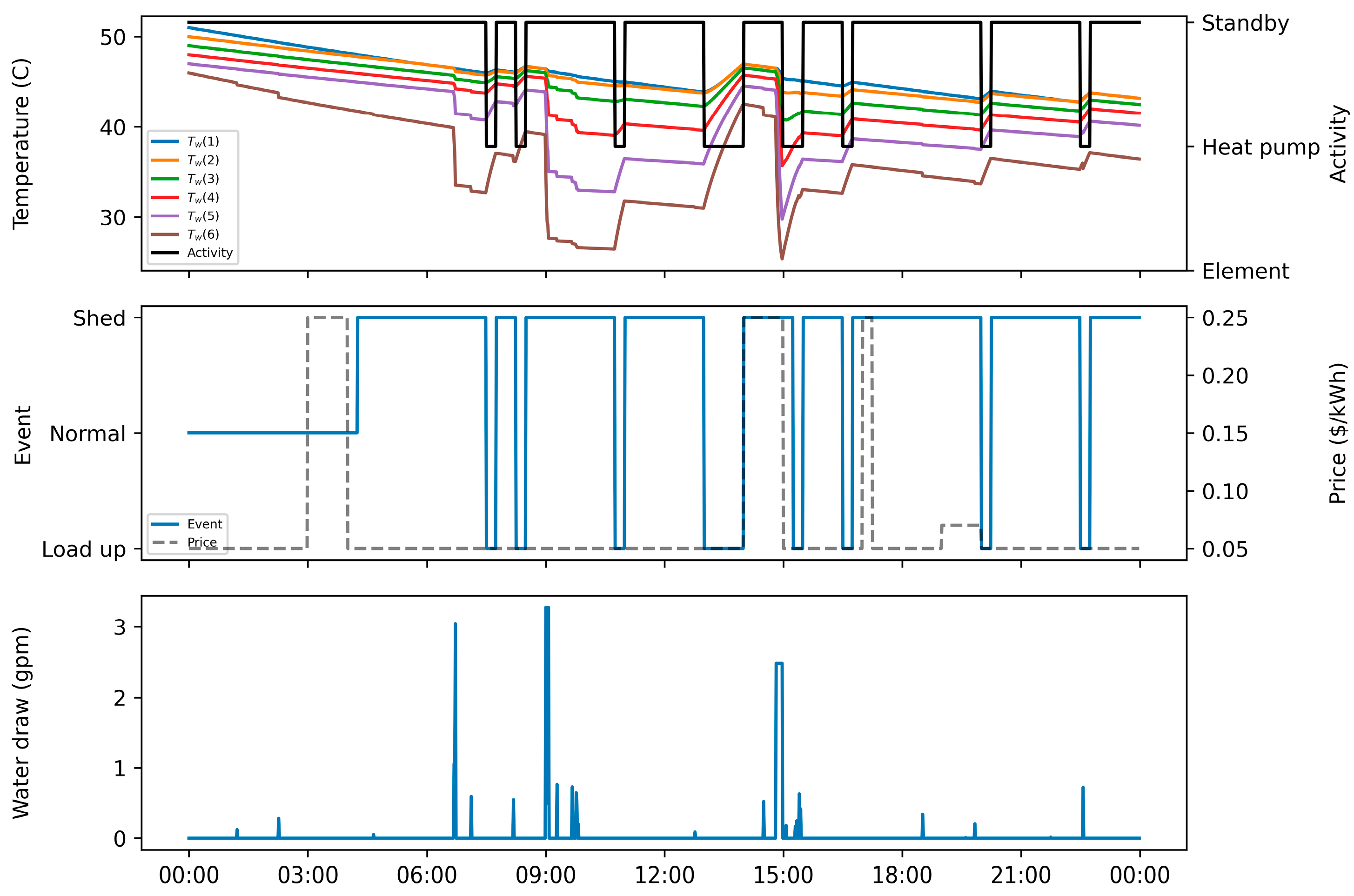
Towards addressing these research gaps, this study proposes a model-free RL approach that aims to minimize the electricity cost of a HPWH under a TOU electricity pricing policy by only using standard DR commands (e.g., shed, load up). In this approach, a set of RL agents, with different look ahead periods, were trained using the deep Q-networks (DQN) algorithm and their performance were tested on an unseen pair of price and hot water usage profiles. Additionally, the RL agents were compared to rule-based, MPC-based, and optimization-based controllers to further validate the performance of the proposed RL approach. This paper contributes to the body of knowledge in two main respects. First, this paper presents a model-free controller for a water heater based on standard DR commands to optimize its operation under TOU electricity pricing policy. Second, this paper compares the performance of the proposed model-free controller against a set of state-of-the-art rule-based, MPC-based and optimization-based controllers.
The paper is structured as follows.
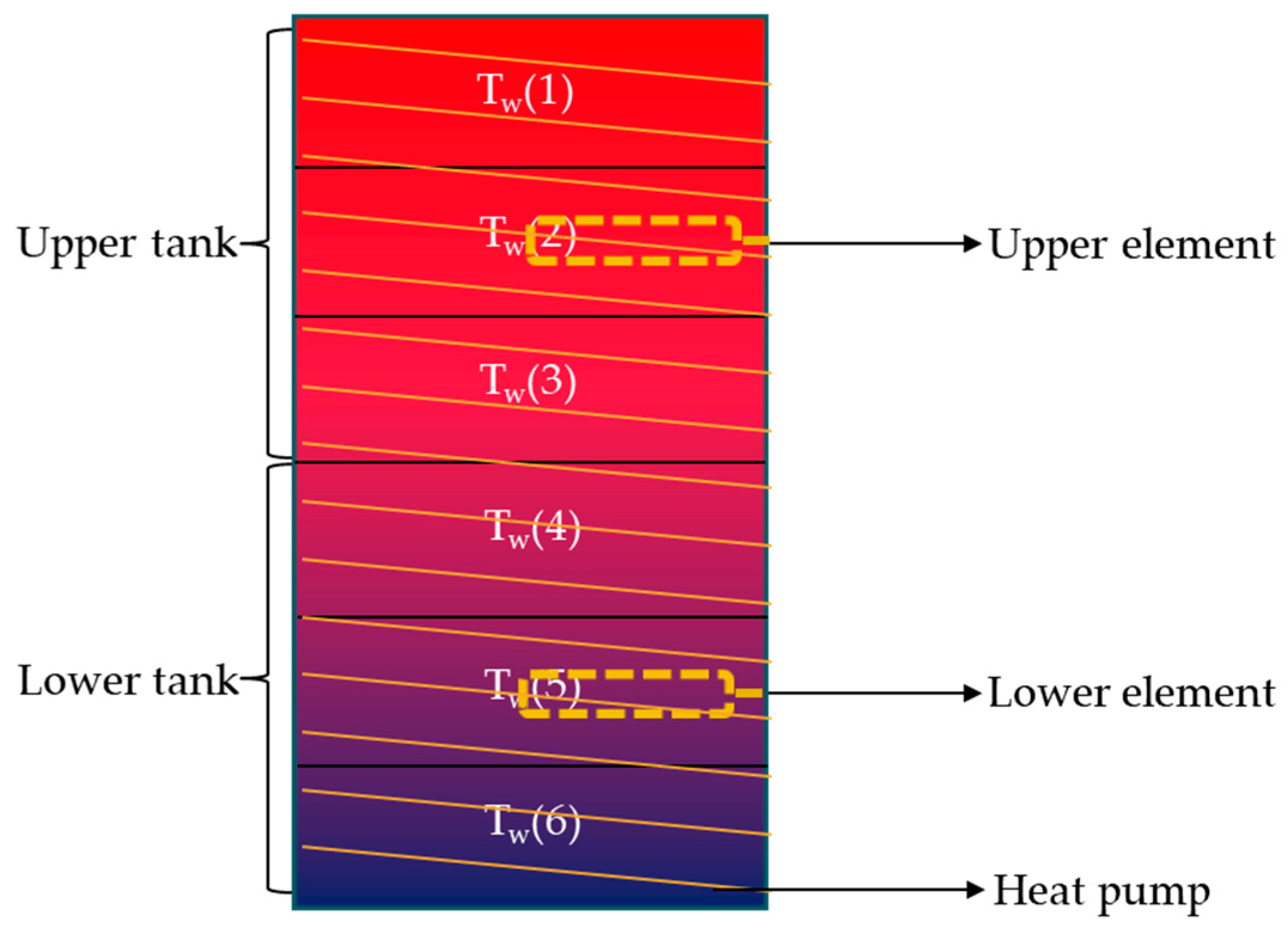
Section 2 provides a background about RL, HPWHs and the CTA-2045 standard that the DR commands are based on.
Section 3 describes the methodology that was followed to develop the RL agents, the rule-based, the MPC-based, and the optimization-based controllers.
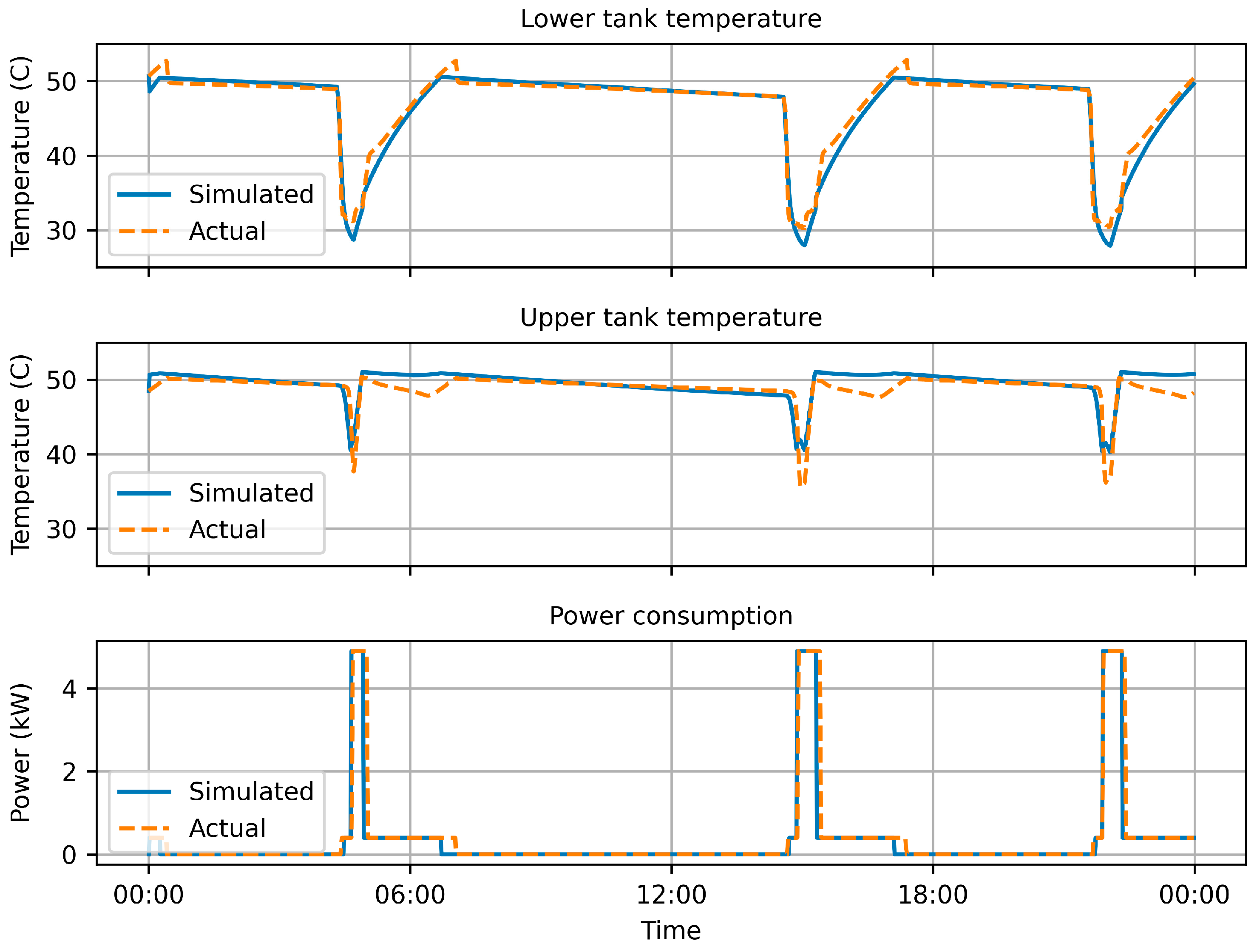
Section 4 presents the training and testing results of the RL agents and provides a comparison between the RL agents and other controllers. Finally,
Section 5 concludes the paper and discusses the limitations of this study.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}