An Approach to Data Acquisition for Urban Building Energy Modeling Using a Gaussian Mixture Model and Expectation-Maximization Algorithm




Abstract
1. Introduction
2. Necessities and Challenges of Building Performance Modeling with Big Data
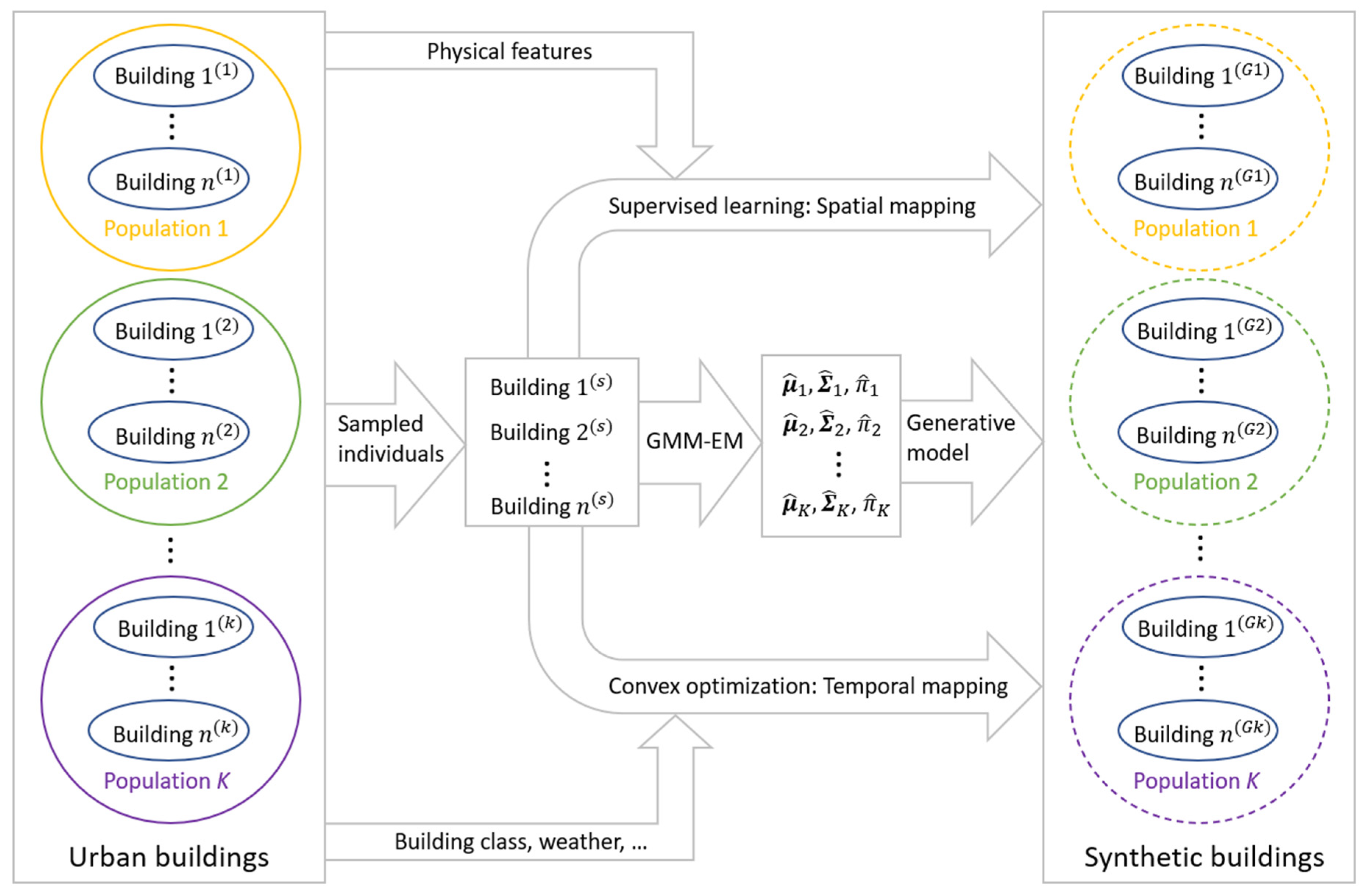
3. Methods for Acquiring Building Energy Performance Data
3.1. Collecting Energy Performance Data
3.2. Data Augmentation
3.2.1. Energy Consumption
3.2.2. Short-Term Load Forecasting
3.2.3. Learning-Based Methods
3.2.4. Simulation
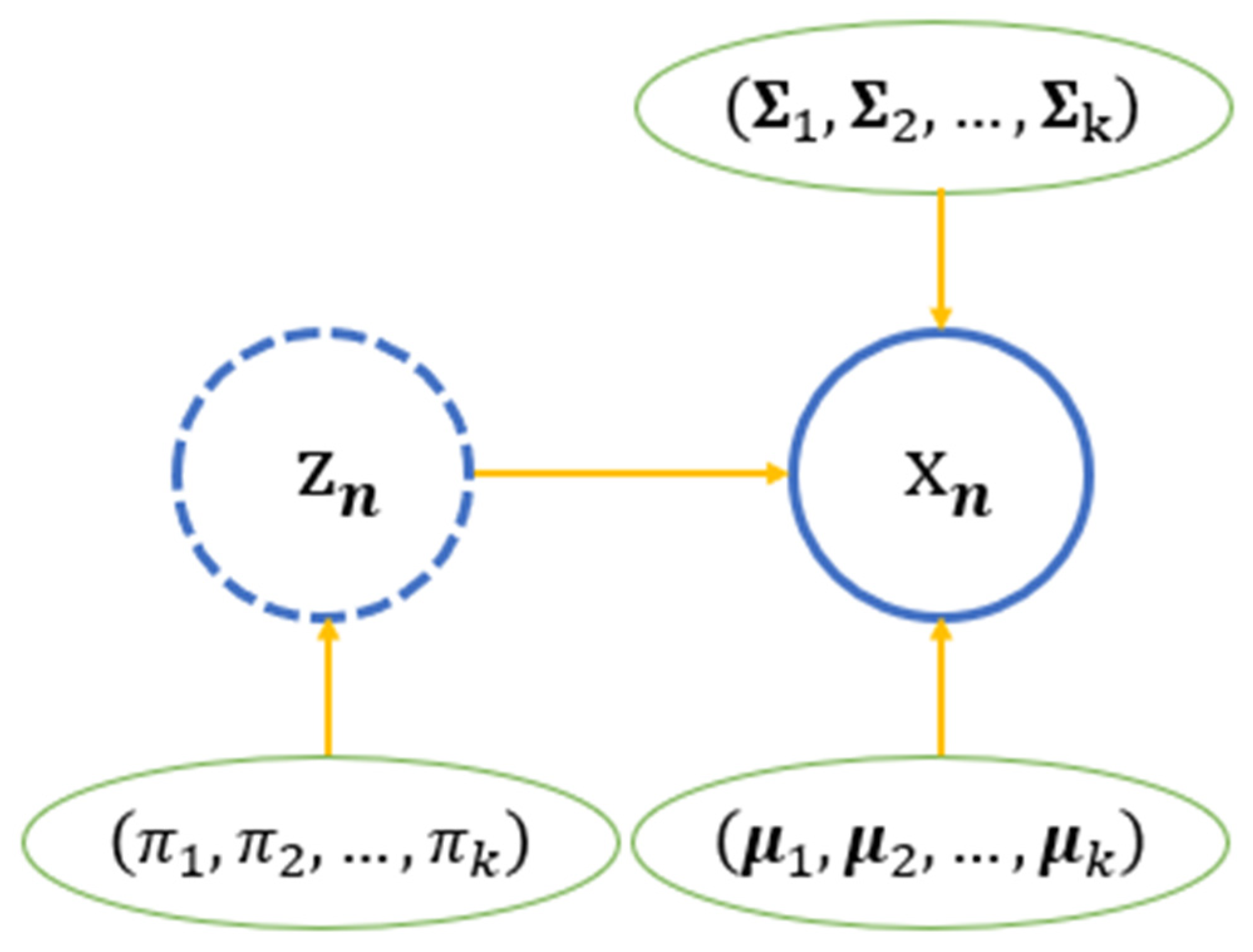
4. The Gaussian Mixture Model and Expectation-Maximization Method
4.1. Gaussian Mixture Model
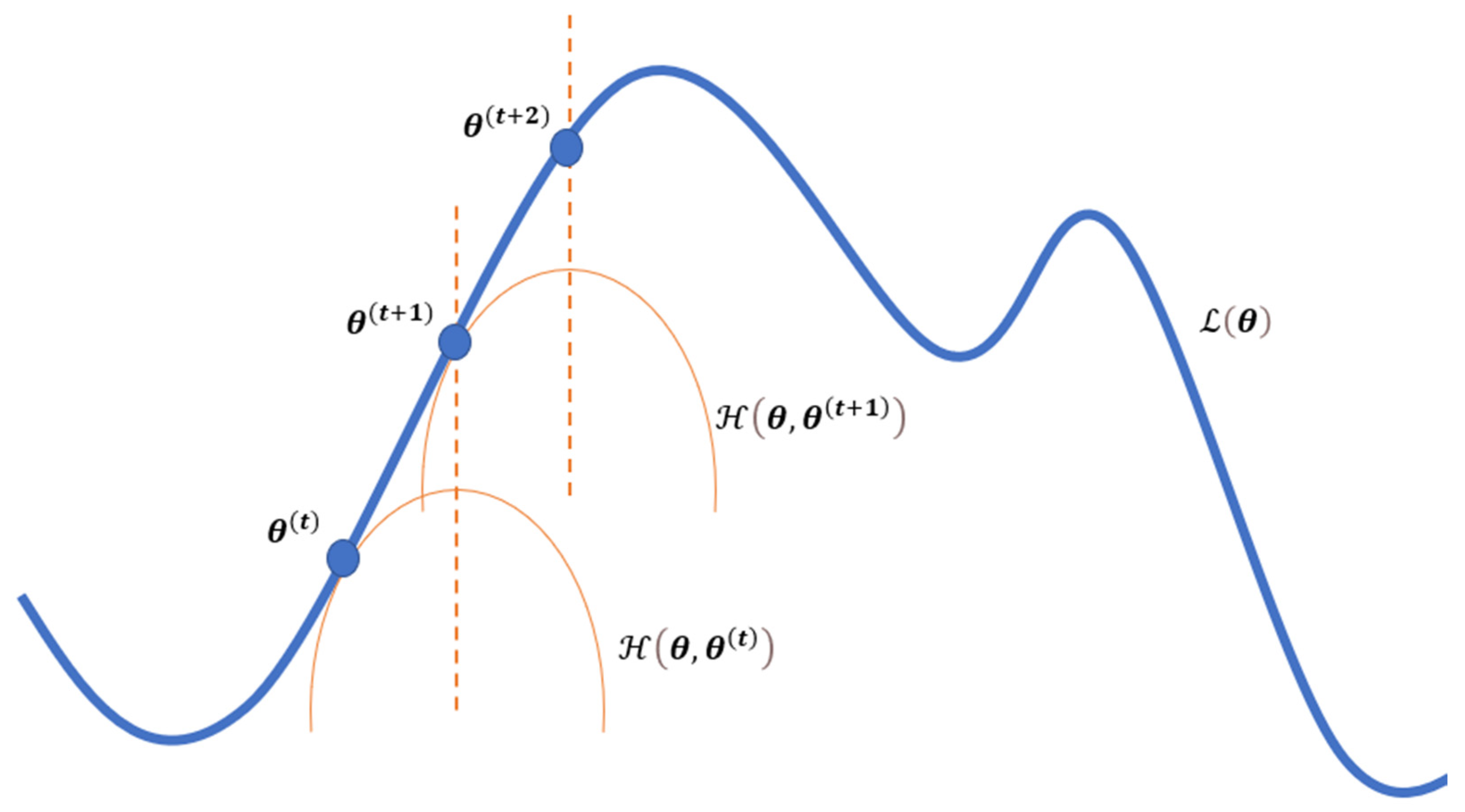
4.2. The Expectation-Maximization (EM) Algorithm
4.3. Parameter Estimation for GMM
5. Data and Performance
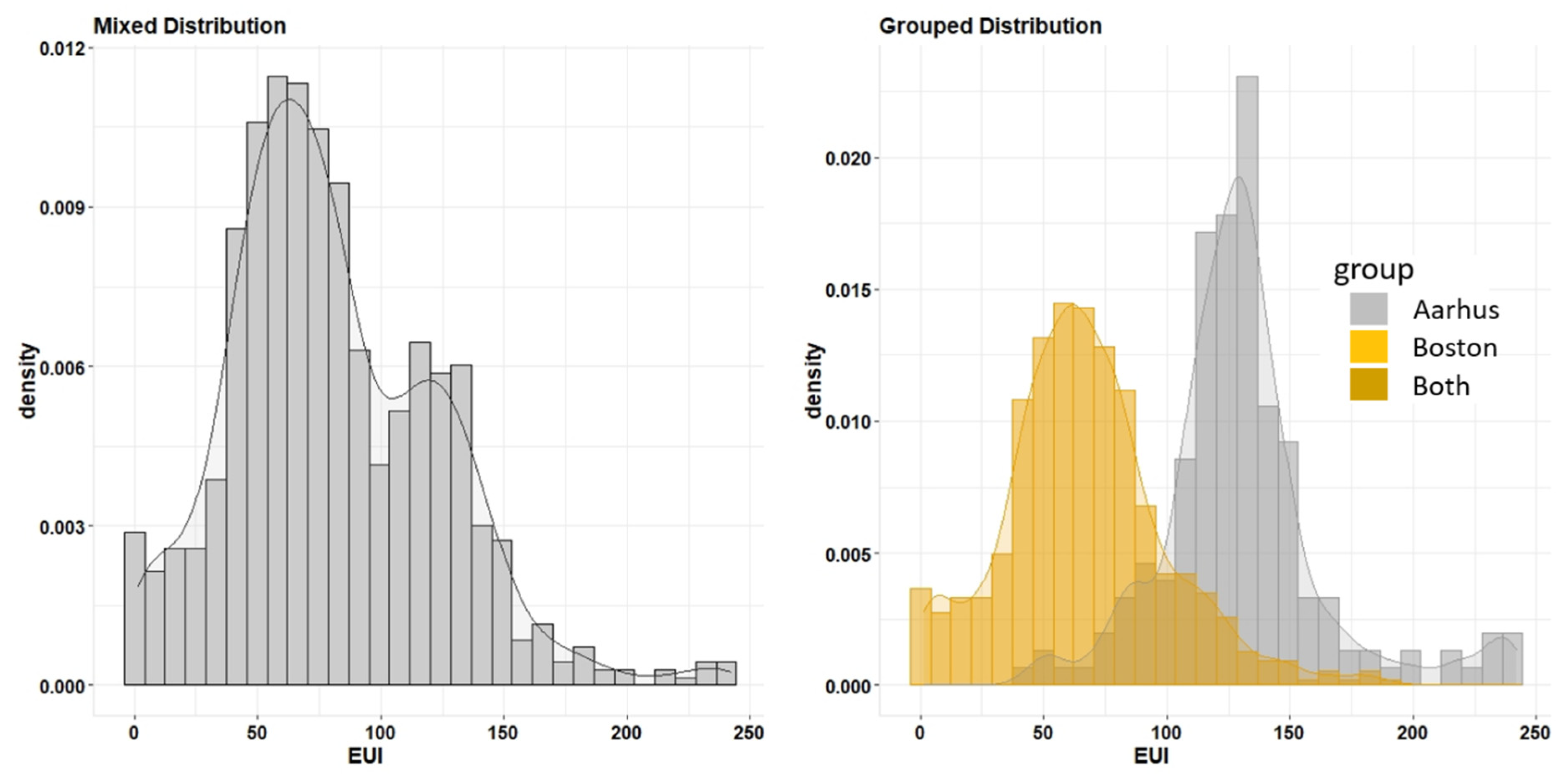
5.1. Test Datasets
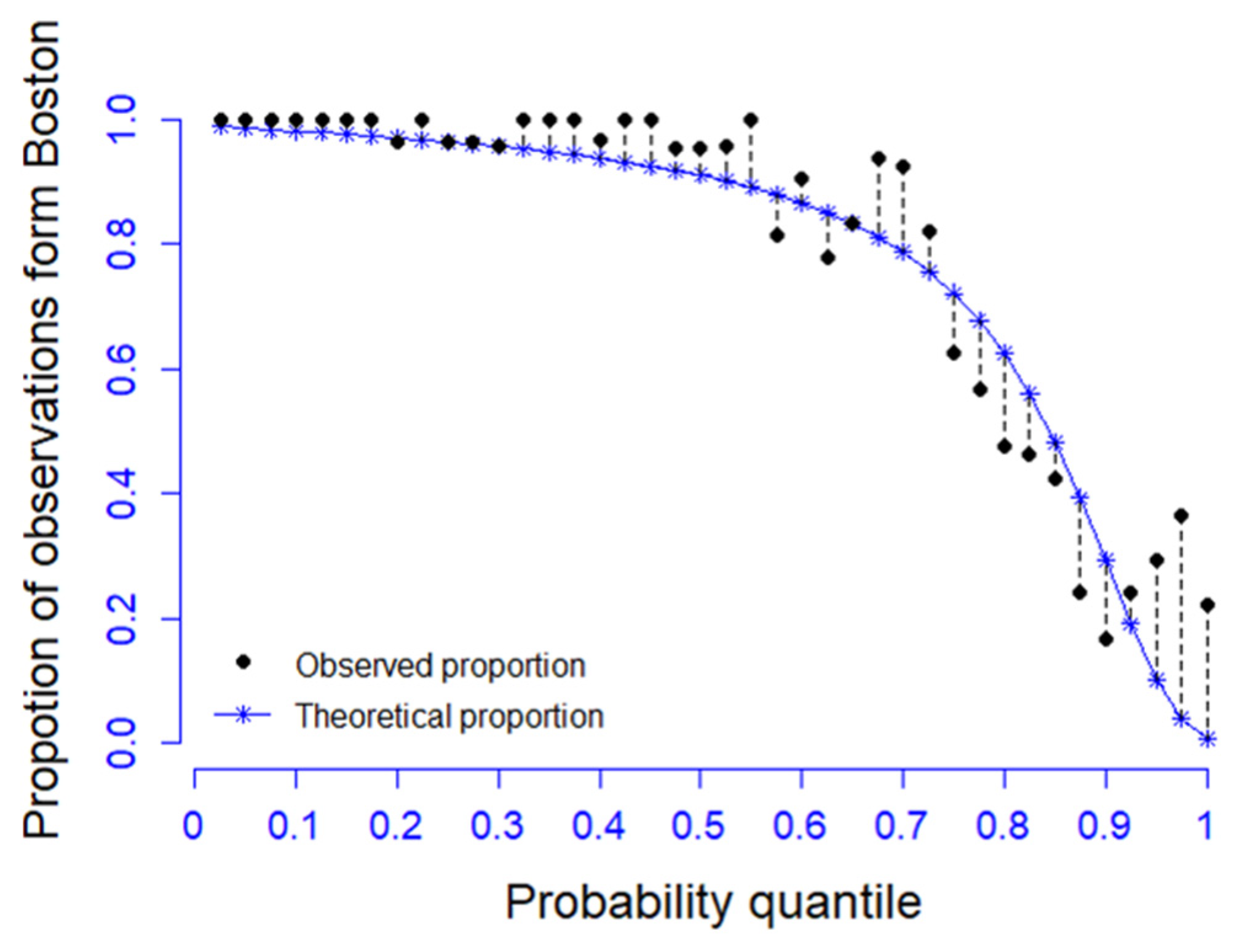
5.2. The Performance of EM Algorithm
5.2.1. The Univariate Case
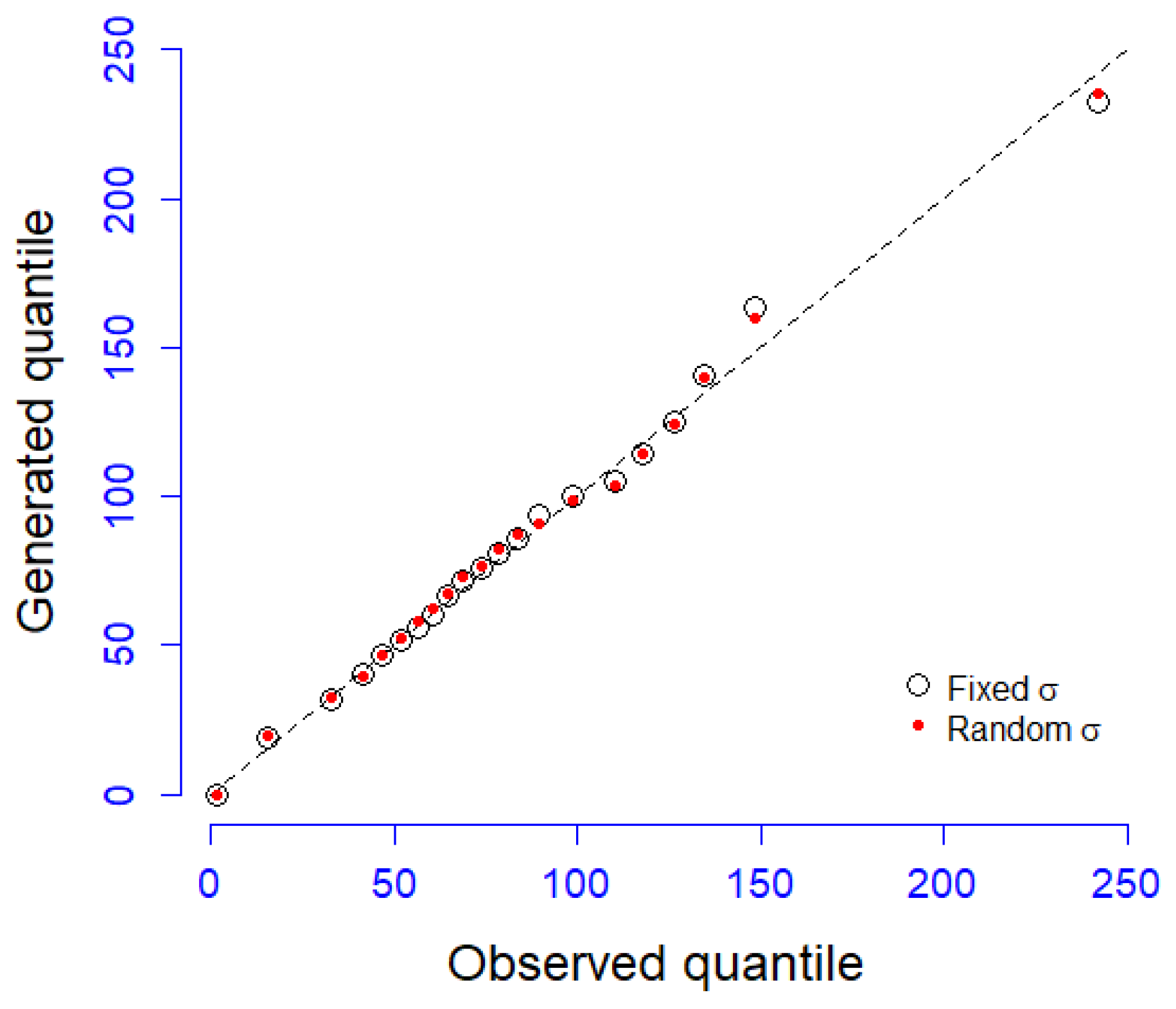
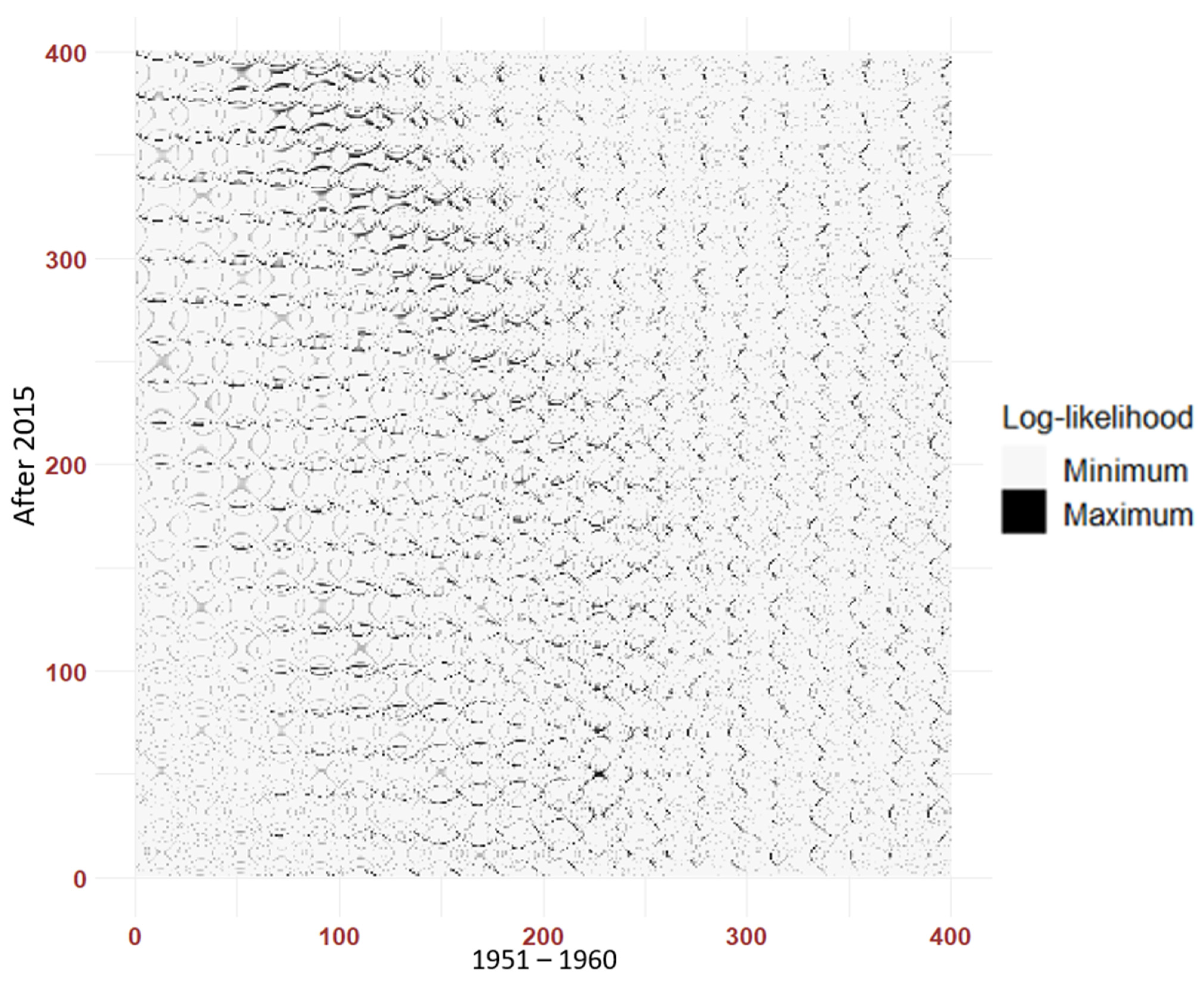
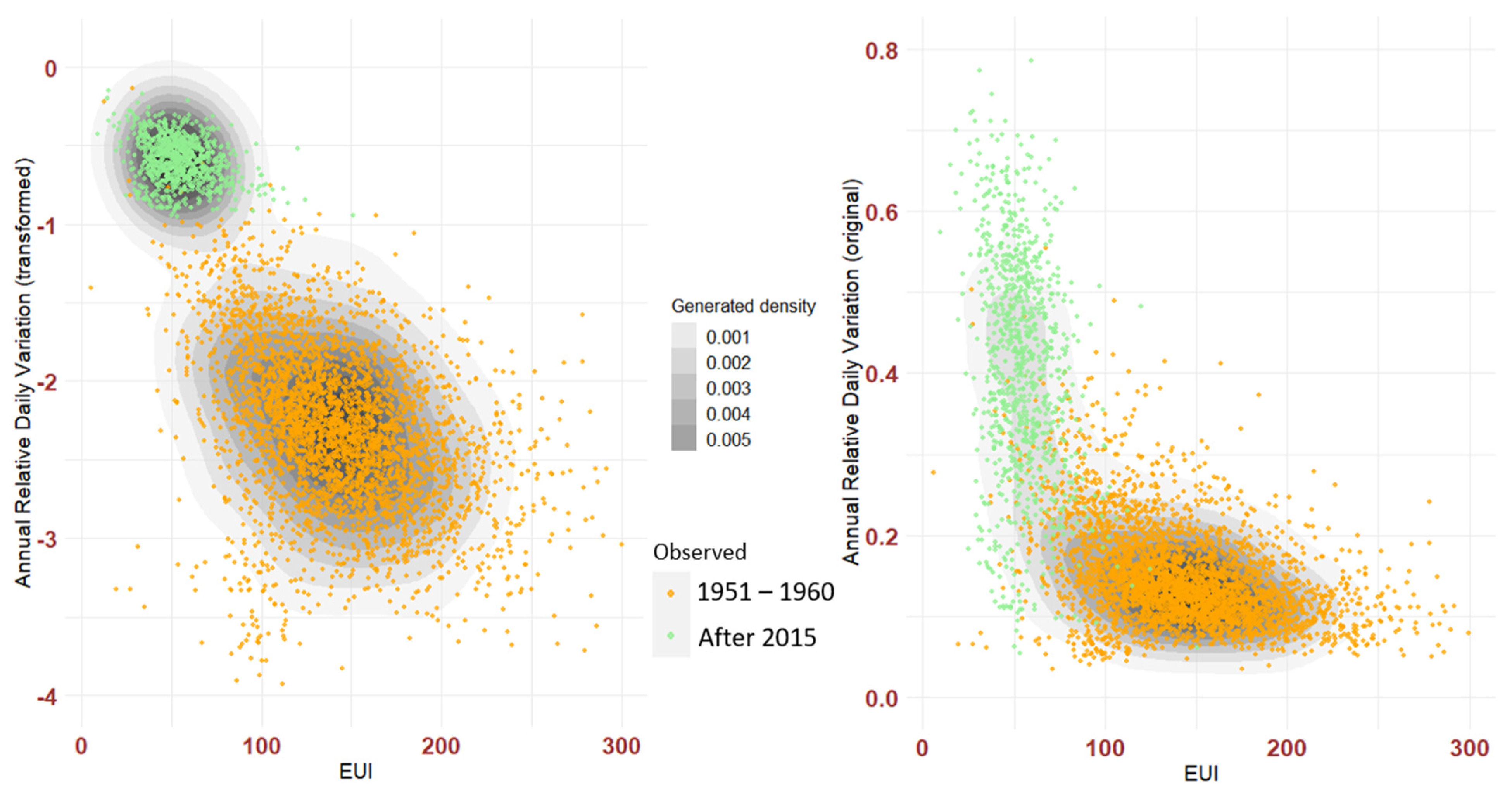
5.2.2. The Bivariate Case
6. Discussion
7. Conclusions
- Firstly, in this paper we assumed that the number of populations was known. An interesting investigation would be to detect the optimal number of populations by introducing an objective function. Since Akaike information criterion (AIC) or Bayesian information criterion (BIC) reduces the effect on penalizing the model with small number of parameters, it is still an unsolved issue when the number of populations is small.
- Secondly, we suggest that other indicators of building energy use need to be considered because overall building performance is usually affected by multiple factors.
- Finally, it is also appealing that more probability distributions could be studied instead of using data transformation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Nomenclature
| DL | deep learning |
| ELBO | evidence lower bound |
| EM | Expectation-Maximization |
| EUI | Energy Use Intensity |
| Ga | daily heat load variation |
| GAN | Generative Adversarial Network |
| GMM | Gaussian mixture model |
| UBEM | urban building energy modeling |
| Notations | |
| expectation | |
| objective function of | |
| indicator of population | |
| a category of latent variable | |
| Kullback–Leibler divergence | |
| log-likelihood function | |
| sample size | |
| Gaussian density function | |
| a density function of | |
| , | iteration state |
| an observation of | |
| a quantile of | |
| observable variable | |
| quantile segmentation | |
| latent variable for each | |
| latent variable | |
| responsibility probability | |
| set of unknown parameters | |
| mean vector of | |
| , | estimates of mean parameter |
| marginal distribution of | |
| vector of marginal probabilities | |
| covariance matrix of | |
References
- Cao, X.; Dai, X.; Liu, J. Building Energy-Consumption Status Worldwide and the State-of-the-Art Technologies for Zero-Energy Buildings during the Past Decade. Energy Build. 2016, 128, 198–213. [Google Scholar] [CrossRef]
- Castillo-Calzadilla, T.; Macarulla, A.M.; Kamara-Esteban, O.; Borges, C.E. A Case Study Comparison between Photovoltaic and Fossil Generation Based on Direct Current Hybrid Microgrids to Power a Service Building. J. Clean. Prod. 2020, 244, 118870. [Google Scholar] [CrossRef]
- D’Agostino, D.; Mazzarella, L. What Is a Nearly Zero Energy Building? Overview, Implementation and Comparison of Definitions. J. Build. Eng. 2019, 21, 200–212. [Google Scholar] [CrossRef]
- Tabar, V.S.; Hagh, M.T.; Jirdehi, M.A. Achieving a Nearly Zero Energy Structure by a Novel Framework Including Energy Recovery and Conversion, Carbon Capture and Demand Response. Energy Build. 2021, 230, 110563. [Google Scholar] [CrossRef]
- Hermelink, A.; Schimschar, S.; Boermans, T.; Pagliano, L.; Zangheri, P.; Armani, R.; Voss, K.; Musall, E. Towards Nearly Zero-Energy Buildings; European Commission: Köln, Germany, 2012. [Google Scholar]
- Magrini, A.; Lentini, G.; Cuman, S.; Bodrato, A.; Marenco, L. From Nearly Zero Energy Buildings (NZEB) to Positive Energy Buildings (PEB): The next Challenge—The Most Recent European Trends with Some Notes on the Energy Analysis of a Forerunner PEB Example. Dev. Built Environ. 2020, 3, 100019. [Google Scholar] [CrossRef]
- De Luca, G.; Ballarini, I.; Lorenzati, A.; Corrado, V. Renovation of a Social House into a NZEB: Use of Renewable Energy Sources and Economic Implications. Renew. Energy 2020, 159, 356–370. [Google Scholar] [CrossRef]
- Kurnitski, J.; Saari, A.; Kalamees, T.; Vuolle, M.; Niemelä, J.; Tark, T. Cost Optimal and Nearly Zero (NZEB) Energy Performance Calculations for Residential Buildings with REHVA Definition for NZEB National Implementation. Energy Build. 2011, 43, 3279–3288. [Google Scholar] [CrossRef]
- Li, W.; Zhou, Y.; Cetin, K.; Eom, J.; Wang, Y.; Chen, G.; Zhang, X. Modeling Urban Building Energy Use: A Review of Modeling Approaches and Procedures. Energy 2017, 141, 2445–2457. [Google Scholar] [CrossRef]
- Pasichnyi, O.; Wallin, J.; Kordas, O. Data-Driven Building Archetypes for Urban Building Energy Modelling. Energy 2019, 181, 360–377. [Google Scholar] [CrossRef]
- Ali, U.; Shamsi, M.H.; Bohacek, M.; Hoare, C.; Purcell, K.; Mangina, E.; O’Donnell, J. A Data-Driven Approach to Optimize Urban Scale Energy Retrofit Decisions for Residential Buildings. Appl. Energy 2020, 267, 114861. [Google Scholar] [CrossRef]
- Fathi, S.; Srinivasan, R.; Fenner, A.; Fathi, S. Machine Learning Applications in Urban Building Energy Performance Forecasting: A Systematic Review. Renew. Sustain. Energy Rev. 2020, 133, 110287. [Google Scholar] [CrossRef]
- Nutkiewicz, A.; Yang, Z.; Jain, R.K. Data-Driven Urban Energy Simulation (DUE-S): Integrating Machine Learning into an Urban Building Energy Simulation Workflow. Energy Procedia 2017, 142, 2114–2119. [Google Scholar] [CrossRef]
- Hong, T.; Chen, Y.; Luo, X.; Luo, N.; Lee, S.H. Ten Questions on Urban Building Energy Modeling. Build. Environ. 2020, 168, 106508. [Google Scholar] [CrossRef]
- Zhang, X.; Lovati, M.; Vigna, I.; Widén, J.; Han, M.; Gal, C.; Feng, T. A Review of Urban Energy Systems at Building Cluster Level Incorporating Renewable-Energy-Source (RES) Envelope Solutions. Appl. Energy 2018, 230, 1034–1056. [Google Scholar] [CrossRef]
- Salim, F.D.; Dong, B.; Ouf, M.; Wang, Q.; Pigliautile, I.; Kang, X.; Hong, T.; Wu, W.; Liu, Y.; Rumi, S.K.; et al. Modelling Urban-Scale Occupant Behaviour, Mobility, and Energy in Buildings: A Survey. Build. Environ. 2020, 183, 106964. [Google Scholar] [CrossRef]
- Perera, A.T.D.; Nik, V.M.; Chen, D.; Scartezzini, J.-L.; Hong, T. Quantifying the Impacts of Climate Change and Extreme Climate Events on Energy Systems. Nat. Energy 2020, 5, 150–159. [Google Scholar] [CrossRef]
- Yang, Z.; Roth, J.; Jain, R.K. DUE-B: Data-Driven Urban Energy Benchmarking of Buildings Using Recursive Partitioning and Stochastic Frontier Analysis. Energy Build. 2018, 163, 58–69. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.P. Estimation of the Building Energy Use Intensity in the Urban Scale by Integrating GIS and Big Data Technology. Appl. Energy 2016, 183, 182–192. [Google Scholar] [CrossRef]
- Risch, S.; Remmen, P.; Müller, D. Influence of Data Acquisition on the Bayesian Calibration of Urban Building Energy Models. Energy Build. 2021, 230, 110512. [Google Scholar] [CrossRef]
- Goy, S.; Maréchal, F.; Finn, D. Data for Urban Scale Building Energy Modelling: Assessing Impacts and Overcoming Availability Challenges. Energies 2020, 13, 4244. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; MIT Press Ltd: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Chen, C.L.P.; Zhang, C. Data-Intensive Applications, Challenges, Techniques and Technologies: A Survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.P.; Jiang, F.; Chen, W.; Wang, M.; Zhai, C. A Bi-Directional Missing Data Imputation Scheme Based on LSTM and Transfer Learning for Building Energy Data. Energy Build. 2020, 216, 109941. [Google Scholar] [CrossRef]
- Marta, M.; Belinda, L. Simplified Model to Determine the Energy Demand of Existing Buildings. Case Study of Social Housing in Zaragoza, Spain. Energy Build. 2017, 149, 483–493. [Google Scholar] [CrossRef]
- Cho, K.; Kim, S. Energy Performance Assessment According to Data Acquisition Levels of Existing Buildings. Energies 2019, 12, 1149. [Google Scholar] [CrossRef]
- Guerra-Santin, O.; Tweed, C.A. In-Use Monitoring of Buildings: An Overview of Data Collection Methods. Energy Build. 2015, 93, 189–207. [Google Scholar] [CrossRef]
- Laroca, R.; Barroso, V.; Diniz, M.A.; Goncalves, G.R.; Schwartz, W.R.; Menotti, D. Convolutional Neural Networks for Automatic Meter Reading. J. Electron. Imaging 2019, 28, 013023. [Google Scholar] [CrossRef]
- Oti, A.H.; Kurul, E.; Cheung, F.; Tah, J.H.M. A Framework for the Utilization of Building Management System Data in Building Information Models for Building Design and Operation. Autom. Constr. 2016, 72, 195–210. [Google Scholar] [CrossRef]
- Afroz, Z.; Burak Gunay, H.; O’Brien, W. A Review of Data Collection and Analysis Requirements for Certified Green Buildings. Energy Build. 2020, 226, 110367. [Google Scholar] [CrossRef]
- Despotovic, M.; Koch, D.; Leiber, S.; Döller, M.; Sakeena, M.; Zeppelzauer, M. Prediction and Analysis of Heating Energy Demand for Detached Houses by Computer Vision. Energy Build. 2019, 193, 29–35. [Google Scholar] [CrossRef]
- Wei, S.; Tien, P.W.; Calautit, J.K.; Wu, Y.; Boukhanouf, R. Vision-Based Detection and Prediction of Equipment Heat Gains in Commercial Office Buildings Using a Deep Learning Method. Appl. Energy 2020, 277, 115506. [Google Scholar] [CrossRef]
- Gao, Y.; Ruan, Y.; Fang, C.; Yin, S. Deep Learning and Transfer Learning Models of Energy Consumption Forecasting for a Building with Poor Information Data. Energy Build. 2020, 223, 110156. [Google Scholar] [CrossRef]
- Ryu, S.; Noh, J.; Kim, H. Deep Neural Network Based Demand Side Short Term Load Forecasting. Energies 2017, 10, 3. [Google Scholar] [CrossRef]
- Lu, J.; Qian, J.; Zhang, Q.; Liu, S.; Xie, F.; Xu, H. Best Practices in China Southern Power Grid Competition of AI Short-Term Load Forecasting. In Proceedings of the 2020 12th IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Nanjing, China, 20–23 September 2020; pp. 1–5. [Google Scholar]
- Wang, Y.; Liu, M.; Bao, Z.; Zhang, S. Short-Term Load Forecasting with Multi-Source Data Using Gated Recurrent Unit Neural Networks. Energies 2018, 11, 1138. [Google Scholar] [CrossRef]
- Zhang, Y.; Ai, Q.; Li, Z.; Yin, S.; Huang, K.; Yousif, M.; Lu, T. Data Augmentation Strategy for Small Sample Short-term Load Forecasting of Distribution Transformer. Int. Trans. Electr. Energ. Syst. 2020, 30, 1–18. [Google Scholar] [CrossRef]
- Acharya, S.K.; Wi, Y.; Lee, J. Short-Term Load Forecasting for a Single Household Based on Convolution Neural Networks Using Data Augmentation. Energies 2019, 12, 3560. [Google Scholar] [CrossRef]
- Lai, C.S.; Mo, Z.; Wang, T.; Yuan, H.; Ng, W.W.Y.; Lai, L.L. Load Forecasting Based on Deep Neural Network and Historical Data Augmentation. IET Gener. Transm. Distrib. 2020. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. arXiv 2020, arXiv:2001.06937. [Google Scholar]
- Wang, Z.; Hong, T. Generating Realistic Building Electrical Load Profiles through the Generative Adversarial Network (GAN). Energy Build. 2020, 224, 110299. [Google Scholar] [CrossRef]
- Fekri, M.N.; Ghosh, A.M.; Grolinger, K. Generating Energy Data for Machine Learning with Recurrent Generative Adversarial Networks. Energies 2019, 13, 130. [Google Scholar] [CrossRef]
- Gong, X.; Tang, B.; Zhu, R.; Liao, W.; Song, L. Data Augmentation for Electricity Theft Detection Using Conditional Variational Auto-Encoder. Energies 2020, 13, 4291. [Google Scholar] [CrossRef]
- Hong, T.; Chou, S.K.; Bong, T.Y. Building Simulation: An Overview of Developments and Information Sources. Building Environ. 2000, 35, 347–361. [Google Scholar] [CrossRef]
- Maile, T.; Bazjanac, V.; Fischer, M. A Method to Compare Simulated and Measured Data to Assess Building Energy Performance. Building Environ. 2012, 56, 241–251. [Google Scholar] [CrossRef]
- Abuimara, T.; O’Brien, W.; Gunay, B.; Carrizo, J.S. Towards Occupant-Centric Simulation-Aided Building Design: A Case Study. Build. Res. Inf. 2019, 47, 866–882. [Google Scholar] [CrossRef]
- Schiefelbein, J.; Rudnick, J.; Scholl, A.; Remmen, P.; Fuchs, M.; Müller, D. Automated Urban Energy System Modeling and Thermal Building Simulation Based on OpenStreetMap Data Sets. Building Environ. 2019, 149, 630–639. [Google Scholar] [CrossRef]
- Hong, T.; Langevin, J.; Sun, K. Building Simulation: Ten Challenges. Build. Simul. 2018, 11, 871–898. [Google Scholar] [CrossRef]
- Solmaz, A.S. A Critical Review on Building Performance Simulation Tools. Int. J. Sustain. Trop. Des. Res. Pract. UPM 2019, 12, 7–20. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science+Business Media, LLC: New York, NY, USA, 2006. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Ghahramani, Z.; Jordan, M.I. Supervised Learning from Incomplete Data via an EM Approach; Morgan Kaufmann: San Francisco, CA, USA, 1994. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–96. [Google Scholar] [CrossRef]
- Wu, C.F.J. On the Convergence Properties of the EM Algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Kristensen, M.H.; Petersen, S. District Heating Energy Efficiency of Danish Building Typologies. Energy Build. 2021, 231, 110602. [Google Scholar] [CrossRef]
- Blömer, J.; Bujna, K. Simple Methods for Initializing the EM Algorithm for Gaussian Mixture Models. arXiv 2013, arXiv:1312.5946v3. [Google Scholar]
- Box, G.E.P.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. Ser. B (Methodol.) 1964, 26, 211–252. [Google Scholar] [CrossRef]
- Roth, J.; Martin, A.; Miller, C.; Jain, R.K. SynCity: Using Open Data to Create a Synthetic City of Hourly Building Energy Estimates by Integrating Data-Driven and Physics-Based Methods. Appl. Energy 2020, 280, 115981. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Population | Parameter | Min | Max | Mean | True Value | Error |
|---|---|---|---|---|---|---|
| Boston | 66.03 | 67.07 | 66.71 | 66.68 | 0.04% | |
| 30.99 | 31.60 | 31.39 | 32.62 | 3.77% | ||
| 0.76 | 0.78 | 0.77 | 0.78 | 1.28% | ||
| Aarhus | 126.84 | 129.23 | 128.33 | 130.46 | 1.63% | |
| 39.33 | 39.48 | 39.38 | 34.00 | 15.8% | ||
| 0.22 | 0.24 | 0.23 | 0.22 | 4.55% |
| Population | Parameter | Min | Max | Mean | True Value | Error |
|---|---|---|---|---|---|---|
| Boston | 66.00 | 67.42 | 66.59 | 66.68 | 0.13% | |
| 30.98 | 31.80 | 31.32 | 32.62 | 3.98% | ||
| 0.76 | 0.79 | 0.77 | 0.78 | 1.28% | ||
| Aarhus | 126.65 | 129.97 | 128.00 | 130.46 | 1.88% | |
| 39.35 | 39.48 | 39.42 | 34.00 | 15.9% | ||
| 0.21 | 0.24 | 0.23 | 0.22 | 4.55% |
| Population (Predicted) | ||||
|---|---|---|---|---|
| Boston | Aarhus | Boston | Aarhus | |
| Boston | 72.92% | 7.13% | 73.40% | 7.72% |
| Aarhus | 5.34% | 14.61% | 4.87% | 14.01% |
| Building Age Group | Parameter | Min | Max | Mean | True Value | Error |
|---|---|---|---|---|---|---|
| 1951−1960 | 142.43 | 142.51 | 142.46 | 142.36 | 0.07% | |
| (transformed) | −2.31 | −2.31 | −2.31 | −2.31 | 0.00% | |
| 1706.44 | 1713.20 | 1710.78 | 1728.90 | 1.05% | ||
| 0.26 | 0.26 | 0.26 | 0.26 | 0.00% | ||
| −8.03 | −7.81 | −7.98 | −8.17 | 2.33% | ||
| 0.79 | 0.79 | 0.79 | 0.79 | 0.00% | ||
| After 2015 | 54.12 | 54.24 | 54.19 | 54.86 | 1.22% | |
| (transformed) | −0.59 | −0.59 | −0.59 | −0.59 | 0.00% | |
| 213.28 | 217.99 | 215.87 | 248.95 | 13.29% | ||
| 0.02 | 0.02 | 0.02 | 0.02 | 0.00% | ||
| −0.62 | −0.58 | −0.60 | −0.67 | 10.45% | ||
| 0.21 | 0.21 | 0.21 | 0.21 | 0.00% |
| Age Group (Predicted) | True Population | |
|---|---|---|
| 1951–1960 | After 2015 | |
| 1951–1960 | 78.56% | 0.20% |
| After 2015 | 0.32% | 20.92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, M.; Wang, Z.; Zhang, X. An Approach to Data Acquisition for Urban Building Energy Modeling Using a Gaussian Mixture Model and Expectation-Maximization Algorithm. Buildings 2021, 11, 30. https://doi.org/10.3390/buildings11010030
Han M, Wang Z, Zhang X. An Approach to Data Acquisition for Urban Building Energy Modeling Using a Gaussian Mixture Model and Expectation-Maximization Algorithm. Buildings. 2021; 11(1):30. https://doi.org/10.3390/buildings11010030
Chicago/Turabian StyleHan, Mengjie, Zhenwu Wang, and Xingxing Zhang. 2021. "An Approach to Data Acquisition for Urban Building Energy Modeling Using a Gaussian Mixture Model and Expectation-Maximization Algorithm" Buildings 11, no. 1: 30. https://doi.org/10.3390/buildings11010030
APA StyleHan, M., Wang, Z., & Zhang, X. (2021). An Approach to Data Acquisition for Urban Building Energy Modeling Using a Gaussian Mixture Model and Expectation-Maximization Algorithm. Buildings, 11(1), 30. https://doi.org/10.3390/buildings11010030