2. Artificial Intelligence: Is This Technology Truly an Embodiment of Artificial Intelligence?
The search for the true meaning of this technology has led to a series of classifications. Some authors categorise it based on its strength, use, function, forms, history, or stage of development (
Collins et al. 2021). Other authors classify it based on mode of training and learning (
Turing 1950). AI’s mode of training and learning falls into two categories. These are symbolic AI and connectionist AI (
Belew 1987). Symbolic AI involves training AI on the logical appreciation of facts and rules (
Ilkou and Koutraki 2020). Connectionism, on the other hand, is the numerical embodiment of knowledge in a neural circuit or network. It constitutes the mode of training the AI system to autonomously appreciate patterns using “statistics” and “immersion” (
Minsky 1991). This training and learning AI approach is synonymous with the way the neural circuits (neurons) in the human brain learn, store, and retrieve information (
Kerrigan 2022). Whichever classification is favoured, it is argued that ‘learning’ through experiential and contextual modulated systems of information receipt, retention, processing, retrieval, transmission, and communication constitute the underlying substance of AI. The difficulties in ascribing intelligence to an entity that functions like human intelligence was largely unconvincing (
Broussard 2019). However, in conceiving AI, policy makers, practitioners, governments, and researchers have taken inspiration from the most intelligent entity they could think of, the human brain (
Russell and Norvig 2020;
Boucher 2020). AI is considered closely linked to neuroscience (the study of the biology of the brain).
Regrettably, none of the above classifications interrogate the notion of intelligence and the perceive attribution of intelligence to inanimate objects. There is also the absence of a clear methodological basis to justify the attribution of intelligence to inanimate objects. This challenge is reflected in the conception of artificial intelligence.
3. The Various Conceptions of Artificial Intelligence
The pursuit of conceptual certainty and process clarity have inspired several attempts at defining AI. Although definitions have been the locus for AI conception, these efforts have suffered disagreements because of contradictions in the policy, academic, practice-based, and legal definitions of the concept (
Krafft et al. 2020). In response to these problems, several authors developed classification criteria for assessing artificial intelligence development to determine its existence across domains. Defining AI is inhibited by the inability to locate its existence within the context of intelligence as a concept. Although modes of clarifying the existence of intelligence have been proposed by looking into what truly makes human distinct from machines, this approach erroneously assumes that human nature is the sole source and standard for all intelligence (
Beerends and Aydin 2024). Difficulties have resulted from futile attempts to extricate AI as a distinct tool from other tools that embody it.
1 Therefore, the co-relationship approach (
Johnson and Verdicchio 2024) is easier to rationalise in view of the difficulties in ascertaining the locus of intelligence. Equally challenging are the constraints associated with distinguishing the substantive nature of AI from its applied or integrated forms in other technologies. The absence of clear separation of the concept from its environment also increases the risk of solely appropriating emergent properties derived from its interactions with other systems (
Kerrigan 2022). Conceiving AI is also impeded by the disagreement on the approaches that informed its development. Rodney Brooks identified three principles that inform the cycle of AI development (
Brooks 1991) Firstly, he reflects on the principle of embodiment, which posits that intelligence needs to be embodied or warehoused within a body because true intelligence requires “perception and interaction”. This principle reflects the difficult view that AI cannot be truly intelligent without some form of external human agency. It is also implausible to ascribe agency to artificial entity without some form of human involvement in the chain. Therefore, conceiving AI without capturing the involvement of human intelligence reduces its level of acceptance. Conversely, the inclusion of human intelligence in the definitional conception of AI minimises wholesale reliance on the word “artificial” as a reliable descriptor of the concept.
The second principle of situatedness means that AI development should exist within a real-world context, and not in a prescribed, simulated, and formalist world of games. This also aligns with the scalability argument of Charles Kerrigan, namely that (
Kerrigan 2022) working within the predictable world of games is unrepresentative of the real world. Therefore, if AI is to be defined as true intelligence, then its adaptability within the real-world context is crucial.
Thirdly, the principle of bottom-up design argues that AI should have been gradually developed from its most basic structure, ability, and simple system of knowing to more complex systems like the human brain (
Wallach et al. 2008). This is, however, not the case, as AI scientists have developed models that mimic the brain. The difficulties associated with this development are that it largely underestimates the capacity of the brain and overestimates the ability of AI systems to function like the brain (intelligence) (
Chen et al. 2022). This poses constraints on the capacity to conceive AI as truly intelligent.
Another basic attempt at conceiving AI is informed by the semiotic debate. This argument raises the semiotic doubt as to whether machines can be truly intelligent without human agency (
Firt 2024;
Nöth 2002;
Searle 1980;
Broussard 2019;
Agrawal et al. 2018). They further argue that ability for pattern recognition and capacity to manipulate information or “indexical references” is not the same as demonstrating understanding of the information shared or an appreciation for the language of communication. It is unclear, however, whether the capacity for pattern recognition is not in itself a form of intelligence. It is also unclear why understanding patterns cannot be characterised as intelligence, but the mere ability to understand language is. This is without the consideration that language itself has underlying patterns (
Chomsky 1965). The controversy on what constitutes intelligence therefore does not rest with mere understanding. There are, however, other considerations. Some ascribe this to the ability to reason, plan, and learn (
Deary 2013). Others see it as capacity to perceive, reason, predict, and adapt to changes (
Tjøstheim and Stephens 2022). Whichever approach is adopted, the concept of intelligence remains elusive as well as its corresponding attempts to define artificial intelligence. Arthur S. Reber’s approach to the definition of intelligence as consciousness (
Reber 2018) remains inconclusive without clarity on the meaning of consciousness and sentience (
Chalmers 1995;
Kihlstrom 1996). This inconclusiveness equally finds expression in the disparate definitions of AI as several organisations and academics have advanced their understanding of the concept. Whilst it is argued that AI is simply a prediction machine, its nature seems to have advanced beyond mere prediction into what seems like pseudo-consciousness. If Mark Solms’ description of “consciousness as just a feeling” is accepted (
Solms and Friston 2018;
Solms 1997), then AI may only assume a unique position in the realm of consciousness where there is evidence of perception. Some rulemaking bodies have captured perception as one of the properties of AI in their several definitional attempts at the concept; however, it is unclear whether perception without awareness is justified as a form of intelligence. These conceptions of AI have given rise to several definitions of the concept.
The first lap of AI definitions captures the concept in terms of the exercise of human intelligent behaviour exhibited by non-human entities. For example, the
United Nations Commission on International Trade Law (
2023) has defined AI in the following terms:
“The term AI is used to refer both to the capacity of a machine to exhibit or simulate intelligent human behaviour and a branch of computer science concerned with this capability”.
The Commission, however, mentioned that the technologies that underpin AI are in various stages of development. Therefore, disagreement will exist as to what constitutes “intelligent human behaviour” that can be attributed to AI. The circumstances when a machine is deemed to have solely exhibited or simulated this behaviour to the exclusion of human intelligence is also unclear. If it is the case that AI is a combination of technologies interacting within a given space to produce outcomes, the extent of human input in its outcome needs to be measured to enable accurate attribution of what constitutes AI’s sole outcome and human-enabled outcomes. This controversy informs the definition of AI by the European Commission’s appointed Independent High-Level Expert Group on AI in terms of AI systems. The Group defines AI systems as follows:
“As a software and possibly also hardware system designed by humans that given a complex goal, acts in the physical or digital dimensions by perceiving the environment”.
This carefully worded definition ignores the quest to attribute the outcome to the machine. Rather, it introduces the more dominant role of humans in the creative dimension of AI. This view is partly re-echoed by the International Organisation for Standardisation, which defines AI as follows:
“An interdisciplinary field, usually regarded as a branch of computer science, dealing with models and systems for the performance of functions generally associated with human intelligence, such as reasoning and learning”. The capacity of a functional unit to perform functions that are generally associated with human intelligence such as reasoning and learning”.
The second lap of definitions ascribe human-type intelligence in reasoning and learning to the AI system. This is controversial because of the difficulties it presents. Firstly, the characterisation of reasoning and learning as the sole characteristics of human intelligence is problematic. Growing evidence seems to suggest the presence of reasoning and learning from non-human entities (
Samuel 1959). Secondly, the delineation between what constitutes human intelligence and human-like intelligence is confusing and lacks basic clarity. The third anomaly is in the degree of attribution of human-like intelligence entirely to the machine with its resultant legislative, judicial, and operational uncertainties (
Thaler 2023). The definitions so far do not consider the different categories of AI, which are Narrow AI, also known as weak AI, and Artificial General Intelligence (AGI), also known as strong AI. Whilst Narrow AI seeks to mimic human reasoning and learning by automating single tasks usually undertaken by humans, the AGI can achieve tasks across multiple domains with the capacity to learn from the experience. Although these General AI protagonists seek to compare AGI’s inherent capacity to that of humans by setting the benchmarks for measurement (
Morris et al. 2023), scientists are generally not in agreement on the feasibility of this technology and the framework for its measurement and classification. Some argue that AGI is simply a myth (
Joshi 2022) because the system is incapable of human learning and reasoning (superintelligence). They argue that till date, questions on what constitutes reasoning and learning as branches of human intelligence are still controversial. The OECD (Organisation for Economic Co-operation and Development) identifies the characteristics of learning and reasoning to include “interpreting collected structured or unstructured data, reasoning on the knowledge, or processing the information derived from this data and deciding the best actions to take to achieve a goal” (
Grobelnik et al. 2024). The organisation further captures the activities to include “predictions, recommendations and decisions” (
Grobelnik et al. 2024). UNCITRAL believes that AI learning and reasoning is informed by its use of algorithms and capacity to process big data from various sources (
United Nations Commission on International Trade Law 2023).
The above definitions do not acknowledge the separation between the interface where AI and other technologies interact to carry out tasks and the distinctive capabilities of AI itself. Thus, the hasty capture of AI as one monolithic set of technology capable of human intelligence inhibits a layered understanding of this concept. One example is the definition given by the House of Lords Select Committee on AI below:
“AI is defined as artificial neural network and deep learning algorithms to replicate human abilities such as visual or perception, recognition of objects and faces, speech recognition, language translation”.
This definition further reinforces the stereotype that AI exhibits human-like intelligence across the listed domains entirely attributed to the machine rather than human input into the machine. There is no mention of how human-engineered data and human training of the algorithms modulate its function to deliver on tasks. Even the Alan Turing Institute made the same mistake (
Leslie 2019) when it defined AI as follows:
“AI systems are algorithmic models that carry out cognitive or perceptual functions in the world that were previously reserved for thinking, judging, and reasoning human beings”.
There is a palpable sense of escapism in those that seek to advance AI as some form of human-like intelligence external to humans to avoid potential legal liabilities. Once AI is seen as alien to humans, then its value is considered independent of human agency. This is unlikely to guarantee complete insulation from legal liability as several lawsuits have commenced against OpenAI for the activities of its ChatGPT programme (
The New York Times 2023). Conversely, the UK Supreme Court seems to establish the existence of human agency for an invention purportedly attributed to AI (
Thaler 2023). There are economic and market-related reasons for this strenuous attempt to disentangle AI from human agency to achieve the market valuation of AI as an independent intelligent machine. Hence, Microsoft (
Microsoft 2018) defines AI as follows:
“a set of technologies that enable computers to perceive, learn, reason, and assist in decision-making to solve problems in ways that are similar to what people do”.
This practice-based definition is also re-echoed by James X Dempsey of the Berkely Centre for Law & Technology in his work entitled ‘An introduction to the legal, policy and ethical issues of AI’, where it is described as a “computerised system that exhibit behaviours that are commonly thought of as requiring intelligence” (
Dempsey 2020).
The human element is completely removed from this definition. Emphasis is placed on intelligence itself. However, the European approach in the European Union AI Act 2020 Art 3(1) defines AI in more elaborate terms:
“AI system’ means a machine-based system that is designed to operate with varying levels of autonomy and that may exhibit adaptiveness after deployment, and that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments”.
This definition captures several elements.
AI is a system.
It operates with autonomy.
It is based on machine- and/or human-provided data and input.
To achieve a given set of objective function using learning techniques (machine learning) and reasoning techniques (logic and probability) and knowledge-based approaches.
To produce system-generated outputs (content, prediction, recommendation)
The outcomes can influence the environment where the AI systems interact.
This is supported by general principles that should apply to all AI systems. They are given as follows:
‘(1) human agency and oversight, (2) technical robustness and safety, (3) respect for privacy and data governance, (4) transparency to ensure appropriate traceability and reasoning, (5) diversity, non-discrimination, and fairness, (6) social and environmental well-being’.
The European approach is further reinforced by the OECD’s recently updated definition, which seeks to clarify the anomalies in the definition captured in the EU AI Act:
“An AI system is a machine-based system that, for explicit or implicit objective infers, from the input it receives, how to generate output such as prediction, content, recommendation, or decision that influence physical and virtual environment. Different AI systems vary is their level of autonomy and adaptiveness after deployment”.
The OECD’s definition conveys the following elements:
AI is a machine-based system.
For explicit or implicit objectives (explicit or implicit objective function), it infers from the input it receives how to generate an output.
- 7.
The output generated includes the following:
- (a)
Predictions;
- (b)
Contents;
- (c)
Recommendations;
- (d)
Decisions.
- 8.
These outputs must be capable of influencing both the physical and virtual environment.
- 9.
Different AI systems vary in their level of autonomy and adaptiveness after deployment.
3.1. AI as a System with Objective Function
As a system, AI is a combination of technologies working in alignment and interacting with one another to achieve learning, perception, reasoning, and language processing. These technologies include the following: (a) algorithms, (b) machine learning, (c) deep learning, (d) neural networks, and (e) natural language processing. Capturing these technologies as a system is itself incomplete without discussing the nature of the interaction and alignment threshold. The prescribed objective function determines the nature of interaction. While the EU AI Act describes this in terms of machine autonomy derived from machine- and/or human-provided data, the OECD’s definition captures the objective as either explicit (directly programmed in machines by humans) or implicit, (where the machine simply complies and learns specific rules and objectives set by human intelligence) (
Russell et al. 2023).
3.2. Elements of Autonomy
Whilst the definition given in the EU AI Act emphasises autonomy, this is missing in the OECD’s definition of AI. The EU AI Act does not provide clarity on what it means by autonomy. However, the United States approach cites an ‘automated manner’ in reference to the analysis of human input into a machine as distinct from describing the system as autonomous. This disagreement highlights the controversial nature of the quest to describe AI systems as distinct and autonomous of human agency.
3.3. Capacity to Infer from Input Received from Either Human or Machine
The capacity of the system to draw inferences from either human or machine input to generate output is inherent. In this case, the EU AI Act refers to machine- and/or human-provided data and input to achieve the objective function using learning (supervised, unsupervised, reinforcement), reasoning techniques (logic, probability, rational, symbolic), and knowledge-based approaches (representation, inference, classification, formation, sequence, application, relationship, iteration, estimation) to generate output. The AI system leverages various models (deep learning models like RNN, CNN, LSTM, GAN, VAE, Auto Encoders, GRU, BERT, GPT, Fast.ai, DQN), (machine learning models like PCA, SVM, GBM, KNN, Decision Tree, XGBoost, Neural Network, Linear Regression, Logistic Regression, Clustering, Random Forest, Support Vector Machine, Nearest Neighbour) and algorithms to process inputs across text, speech (audio), sound, vibration, images (including video), smell, colour, and linguistic modalities. These are achieved either on structured, rhythmic, randomised, or uniform data across the six domains of computer science (natural language processing, knowledge representation (for example, data vectorisation, data tokenisation), automated reasoning, machine learning, computer vision, and robotics) to deliver outputs. In fact, the EU AI Act and the (
National Telecommunications and Information Administration 2024) define AI models as follows: “The term AI model means an information system that implements AI technology and uses computational statistics, and machine learning techniques to produce outputs from a given set of inputs”.
3.4. Output
The definitions provided by the EU AI Act and OECD generally identified ‘outputs’ as ‘content, prediction, and recommendations’. However, the OECD’s approach extended it by including decisions without indicating who makes the decision. It could be argued that the outputs are essentially products derived from the internal processes of the AI system in response to the objective function, but the GDPR places an obligation on the data controller
2. This is where there was no meaningful and significant human involvement. It is unclear what this means within the context of solely automated decision when these algorithms are products of human effort. The absence of definite answers to this problem further undermines the definitional framing of AI in the EU AI Act and the OECD’s approach. Although an attempt at addressing this issue of accountability for decision making is advanced in Article 22(1) and Article 15(1) of the GDPR, this merely scratches the surface. Whilst Article 22(1)
3 and Art 15(1) seek to protect the data subject from the ‘
legal or similarly significant effects’ of automated decision making and further guarantee the right of access to information obtained therefrom, this protection is limited. The decision in SCHUFA’s case (
SCHUFA Holding (Scoring) 2023a) underscores this point as the Court of Justice of the European Union simply interpreted the scoring system as predominantly the automated decision of the algorithm to which the defendant solely relied on in reaching a decision. This is without reference to the managerial and technical inputs of the AI developers and modellers in the framing of the system’s objective function, choices, and behaviour. In this judgement, there was largely no clear objective qualification of the output credentials to delineate what should constitute the sole decision of a machine- and human-enabled decision. It is doubtful if the legal reasoning advanced by the court in SCHUFA’s case can be applied to all other circumstances outside of a ‘scoring system’ (
SCHUFA Holding (Scoring) 2023b) or decision making in employment (
Dun and Bradstreet Austria 2024). Therefore, a threshold test is necessary to provide the needed clarity as well as to produce a critical measure of what would constitute the ‘capacity to influence the physical or virtual environment’ and society at large as captured in the definition.
3.5. Capacity to Influence Environment
According to the OECD, the output must be capable of influencing the physical and virtual environment while the EU AI Act provides that the output should be able to influence the environment that the AI system interacts with. This phrase is unsupported by any benchmark or criteria to establish and measure what constitutes the ‘capacity to influence’. It is unclear whether this phrase should be read into or interpreted in conjunction with the ‘
legal or similarly significant effects’ as discussed in paragraph 3.4 above, or read into the risk categories the EU AI Act,
4 or the general lawfulness, fairness, and transparency principles of GDPR.
5 China has also restricted the use of automated decision making. Article 24 of its Personal Information Protection Law specifically prohibits reliance on automated decision making where such could infringe the right and interests of an individual. Like with GDPR, the data handler is under a duty to provide information on the use (
Personal Information Protection Law 2021). The OECD extends its provision by indicating that different AI systems vary in their level of autonomy and adaptiveness after deployment. This phrase further complicates the definition with the uncertainties on ‘capacity to influence’ doctrine and failure to set a bright-line test on what should constitute an acceptable level of autonomy and adaptiveness.
This is the point where the threshold test become important. This is the test of the capacity of the AI system to influence environments (whether deterministic, non-deterministic, episodic, sequential, static, dynamic, discrete, continuous, known, or unknown environments, necessitate a basic assessment of internal and external environments (
Russell and Norvig 2020). For the internal environment, an assessment of the AI system’s capacity, based on meeting certain internal thresholds to alter or adapt its internal structures (neural network) in response to internal signals triggered by external stimuli or input, is crucial. In terms of the external environment, an assessment of AI system’s capacity upon activation of internal threshold and output to influence physical and virtual environments is also important. The threshold in this sense is the degree of sensitivity of a neuron to a signal, which is dependent on prior experiences, knowledge, and ground truths either programmed into data or documented through a set of rules and stored as data in the database.
3.6. Adaptiveness
The OECD’s definition references the AI system’s ability to ‘operate with varying levels’. This indicates its capacity to scale from single agency to multiple agencies depending on the nature of the task environment. This capacity for adaptiveness carries a modicum of autonomy where the system can self-regulate, carry out operations, and execute tasks independently. However, legal, and ethical questions could arise as to when a system can bypass, resist, or ignore human pre-classifications to initiate and execute its own objective function.
The European approach is slightly different from the definitional framework adopted in the United States.
Section 3 of the President’s Executive Order of 30th of October 2023 (
Biden 2023)
6 and the National Artificial Intelligence Initiative Act 2020 defined AI as follows:
The term “Artificial Intelligence” or “AI” has the meaning set forth in 15 USC 9401 (3):
a machine-based system that can for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environment. Artificial Intelligence Systems use machine—and human input to perceive real and virtual environments, abstract such perceptions into models through analysis in an automated manner, and use model inference to formulate options for information or action”.
This is to address the vagueness created by the AI definition in the Blueprint for an AI Bill of Rights 2022, which is provided as follows: ‘This framework applies to automated system that have the potential to meaningfully impact the American public’s rights, opportunities, or access to critical resources or services.
’ Whilst the National Intelligence Initiative Act of 2020 defined the AI as a machine that relies on human-defined objectives, the Blueprint fell short of providing a definition. Instead, it highlights a five-principled guide for the development, deployment, use of AI and other autonomous systems. These are given as follows:
‘(1) safe and effective systems, (2) algorithmic discrimination protections, (3) data privacy, (4) notice and explanation, (5) human alternatives, consideration, and fallback’.
This is like the United Kingdom’s pro-innovation approach to regulation in the AI White Paper, 3rd August 2023 which also sets out five principles to include‘(1) safety, security and robustness, (2) appropriate transparency and explainability, (3) fairness, (4) accountability and governance, (5) contestability and redress’.
Whilst no definition for AI was proffered in the White Paper, the United Kingdom’s Information Commissioner’s Office defined AI as follows:
‘as an umbrella term for a range of algorithm-based technologies that solve complex tasks by carrying out functions that previously required human thinking’.
The differences in definitions underscore disagreements both at the global, continental, and even national level. China, for instance, is careful in advancing a full definition. In July 2023, the Cyberspace Administration of China (CAC) only provided a definition for Generative AI in its ‘Interim Measures for the Management of Generative Artificial Intelligence Services’ (
Interim Measures for the Management of Generative Artificial Intelligence 2023). The country conceives AI as a strategic technology for geopolitics and economic development with guiding principles, which are as follows:
‘(1) data security and personal information protection, (2) transparency, (3) content management and labelling, (4) technical security’.
This development extends to the regulation of the AI industry across different regions (Shenzhen and its Special Economic Zones 2022), deep synthesis provision to address deep fakes, the Algorithm provision of 2023, Ethical Guidelines 2021, and Shenzhen AI Regulation 2022 to become effective in November 2024 (
Center for Security and Emerging Technology 2022). Japan is also cautious in providing a definition but describes AI as ‘computer software capable of performing tasks that normally require human intelligence (mimic human behaviour)’ (
Lundin and Eriksson 2016). The incompleteness in this definition is obvious from the imprecision and vagueness. Japan instead advances a set of social principles for human–human centric AI to include the following:
‘(1) human centricity, (2) education/literacy, (3) data protection, (4) safety, (5) fair competition, (6) fairness, accountability, and transparency, (7) innovation’.
This is the same vague definition as provided by Canada. The 28 November 2023 amendments proposed to the Artificial Intelligence and Data Act (AIDA) Bill provide an extremely cautious definition of AI. Section 2 of the Short Title under Definitions and Application defines AI as follows:
‘Artificial intelligence system means a technological system that using a model, makes inferences in order to generate output including predictions, recommendations or decisions’.
The country also advances guiding principles, which are as follows:
‘(1) promoting openness about how, why, and when AI is used, (2) prioritizing human and community needs including indigenous people and considering the institutional and public benefits of AI, (3)assessing and mitigating the risk of AI to legal rights and democratic norms early in the lifecycle of AI system, (4) ensuring training or other input data used by AI system is lawfully collected, used, and disclosed, taking account of applicable privacy and intellectual property rights, (5) evaluating the output of AI systems, including generative tools, to minimise biases and inaccuracies, and enabling users to distinguish AI and human outputs, (6) publishing legal or ethical impact assessments, source code, training data, independent audits or reviews, or other relevant documentation about AI systems, while protecting privacy, government and national security, and intellectual property, (7) explaining automated decisions to people impacted by them and providing them with opportunities to contest decisions and seek remedies, which could involve human review, where applicable, (8) encouraging the creation of controlled test environments to foster responsible research and innovation, (9) establishing oversight mechanism for AI systems to ensure accountability and foster effective monitoring and governance throughout the lifecycle, (10) assessing and mitigating the environmental impacts of the training and use of AI systems, and where appropriate opting for zero-emissions systems, (11) providing training to civil servants developing or using AI so that they understand legal, ethical, and operational issues, including privacy and security, and are equipped to adopt AI systems responsibly, (12) creating processes for inclusive and meaningful public engagement on AI policies or projects with a view to raising awareness, building trust, and addressing digital divides’
These differences in conception as elicited in the definitional framing and guiding principles underscore the need for a theoretical consensus on the development of universally acceptable benchmark criteria to locate and measure the existence of AI within a system. Functional contextualism provides a vent to examine the nature of intelligence and the mental state of machines as a necessary condition for legal liability and social responsibility.
4. A Case for Functional Contextualism
As deduced in the analysis above, the disagreements on AI as a distinct form of intelligence are linked to two fundamental flaws in its conception. Firstly, there is lack of clarity on the source of intelligence upon which AI’s existence is ascertained. Secondly, there is an absence of benchmark criteria for the location of AI’s existence to ensure appropriate allocation of liabilities and responsibility are unsettled and not sufficiently adapted to varied contexts. Therefore, functionalism is an epistemological tool that construct the reality of a phenomena from its observable behaviour (
Cummins 2000;
Putnam 1991) and in this case is used to ascertain whether AI is an intelligent form (
Piccinini 2004;
Milkowski 2013). Contextualism, on the other hand, is designed to provide specific clarity on the existence of knowledge, the source, the state of ‘knowing’, and its attribution
7 in order to perceive observable intelligent behaviour. This is with to the aim of developing an adaptive framework with benchmark requirements for AI attribution. To achieve this purpose, functional contextualism seeks to resolve the questions of how intelligence is exhibited, how it is represented and in what features, and how it is transformed or computed from one form to the other and transmitted from one location to another.
Functional contextualist assessment of computationalism reveals two themes that runs across Classical Theory of the Mind (CTM), Connectionism, and Computational Neuroscience (CN) theories constituting intelligent behaviour. They are as follows:
- (1)
A causal relationship
8 between input, output, and the transformative processes in between to constitute a learning system (
Charmers 2011).
This is partly due to the nature of architecture, the material components of the architecture, and the context of the modeller. The transformative process within the architecture is achieved through simultaneous causal interactions, which are captured in the three interrelated explanatory accounts:
- -
The mechanistic account (multi-layered account) (
Piccinini 2004;
Milkowski 2013,
2015;
Craver 2007) is composed of three causally connected sub-explanations (
Machamer et al. 2000;
Bechtel 2008;
Craver 2007). The first is the mechanism, which is the general account, that sees causal relevant connections between structures within a system and components.
9 The second, and closely connected to the first, is the constitutive explanation (
Bechtel 2008), which is composed of three levels of compositionality to include the following:
- (a)
Constitutive level −1, which is the analysis of the microsystem of constantly interacting causally related sub-components;
- (b)
The isolated level 0, which sees the causal relationship and interaction between various components within the architecture;
- (c)
The contextual level +1, which sees the causal relationship between the function of the architecture and the broader surrounding contexts.
The third mechanistic explanation is the computational mode that sees the causal linkage between the input and output within a defined architecture to deliver unique information processing capabilities (
Machamer et al. 2000;
Milkowski 2015).
- -
The semantic account, as distinct from syntactic explanation, sees the causal connection between the modeller or design architect, the design architecture, the material component of the system, the tasks, and the transformative output.
10- -
The causal account sees the causal relationship between the physical state and mental processes expressed based on whether the causal relationship is causally relevant or contextual
Charmers (
2011).
- (2)
Representation through language and other modalities derived from the causally connected and related-variables learning system. This is the causal interaction between the record of activities, context, and established value system within thresholds that are unique to the specific contextual architecture. The NEF expresses this approach in the Eliasmith Functional Brain Model and the semantic Spawn described below (
Eliasmith 2013).
On the question of how intelligence is exhibited, Warren McCulloh and Walter Pitts argue that the human mind is the source of intelligence, and this is demonstrated through computation in the form of ‘information processing, cognition, and consciousness’ (
McCulloch and Pitts 1943). In other words, intelligence is described as a neural computation that clarifies and represents cognition (
Piccinini 2010). For the CTM standpoint, the notion of universality establishes a causal relationship between the mind, informal processes, and the Turing machine.
11 Representation of intelligence and its features, on the other hand, is established through the Language of Thought (LOT) (
Fodor 1975;
Aizawa 2003). Fodor and Aizawa see the LOT as some sort of productive system (
Fodor 1975;
Aizawa 2003). They believe that it is governed by production rules and a set of concurrent rules which are capable of cognitive representation by exploring the compositionality of language through a symbolic relationship. In this sense, CTM attempts a symbolic representation of semantic and syntactic properties using the LOT as a means of formalisation on the premise that both properties are structurally equivalent. Searle agrees that semantics can be explained through computation in a semantically interpretative manner (
Seale 1992). Fodor, however, disagrees, and argues that cognitive processes are not explainable computationally (
Fodor 1975). The connectionist viewpoint maintains a contrary view and posits that Artificial Neural Networks (ANNs) provide better form of computation and modelling of ‘perceptual, cognitive and modular processes. The connectionist approach establishes a causal relationship between neural networks and digital systems by relying on the connection of the weights. This approach is also criticised by functionalists as they apply an analogue approach to the computation of weight. This approach also argues that these weights are continuous values, with some level of discreteness in the form of approximation of values, and an approximation of the measures used by to apparatus of measurement is needed before successful measurement of those values. Hence, connectionist AI is merely an approximation machine and is synonymous with CTM.
Computational Neuroscience establishes a causal relationship through a hybrid of neural, analogue, and digital systems, drawing analogies from segments of the human brain and diverse computational functions in response to internal and external stimuli. Reliance is placed on the Bayesian Brain Theory and the Neural Engineering Framework. Whilst the Bayesian Brain Theory sees the brain as a hierarchical predictive machine reliant on a system of causally connected input and outputs to achieve coding, it suffers from the criticism of the CTM. The NEF, however, believes that the causal relationship is fundamentally representative and offers a more comprehensive functional neural approach through the Eliasmith Functional Brain model (
Eliasmith 2013). This model highlights three basic principles to underpin representation and transformation. They are as follows:
- (a)
“A system of non-linear encoding and optimal linear decoding to capture neural representation of temporal and population”.
- (b)
Computation (transformation) is a function of variables represented by population.
- (c)
Neural dynamics are described with neural representation as control–theoretic state variables.
12
Functional contextualism sees representational causal relationships as a central observable theme (in all these approaches described above); it seeks to explain causal connections between input, output, the nature of architecture, material components of the architecture, physical/external environment and context of the modeller, and transformative processes. The next section utilises causal relations to explain human brain and machine functions to ascertain the extent to which the observable behaviour of machines constitutes distinct intelligence.
5. A Functional Contextualist Location of the Source of Human and Machine Intelligence
- (a)
Representational Causal Relationships of Human Architecture
Conceiving AI based on brain function has its antagonists. Some neuro- and behavioural scientists are dismissive of the biological explanation as analogous to AI function and argue that it is difficult to understand how the brain truly functions (
Prescott and Wilson 2023). In fact,
Beerends and Aydin (
2024) framed the definitional dilemma of the concept of intelligence and AI as a product of “
authenticity negotiation process” between ‘
authentic’ and ‘
inauthentic intelligence negotiation’. For the former, intelligence is attributed to machines with the following characteristics: (1) human-like features, (2) ‘aesthetical moral construction without mechanical aspects’, and (3) ‘naturalness and untouchedness’ ideals not pre-programmed into machines. The latter holds the idea of attributing intelligence to machines to be inauthentic due to the inherent limitation of input data and their unrepresentative nature in a real-world context. There are outright dissimilarities between neural network function and brain function. There is a difference between ‘
simulated intelligence and real intelligence’ which seems to be confused in the Turing Test. Therefore, machine intelligence is distinguished from human intelligence (
Beerends and Aydin 2024). On the contrary,
Johnson and Verdicchio (
2024) hold the view that true conception of AI and intelligence will only emanate from conceiving AI as a co-relationship between machine and societal values where the machine is perceived as a ‘sociotechnical system’ rather than purely a machine system (
Machamer et al. 2000;
Bechtel 2008;
Craver 2007). Both views hold distinct weight in shaping the current debate on the conceptualisation of AI. However, there is a need to prescribe the source of intelligence, its characteristics, and criteria for determining intelligent behaviour in machines or sociotechnical systems. Other groups of neuro- and computer scientists attempts to fill this knowledge gap by ascribing intelligence to the adaptive learning function of the brain (
Hinton and McClelland 1987). They maintain that the brain learns through a series of backward steps known as back propagation, which is like the function of the artificial neural network (
Chen et al. 2022;
Lillicrap et al. 2020;
Hinton and McClelland 1987;
Rosenblatt 1957;
Boucher 2020).
This controversy on the mode of learning constitutes a significant barrier to conceiving AI. This is because learning is identified as the sole determinant of intelligence. Therefore, the best approach to conceiving AI should be derived from its mode of learning. It is worthy to note that the architectures of biological and artificial neural networks for learning are slightly similar (
Boucher 2020). The brain is an extremely complex organ composed of billions of causally connected neurons which are responsible for the efficient sensing, computing, and transferring of information in all animals (
Leslie 2019;
Abbott and Nelson 2000;
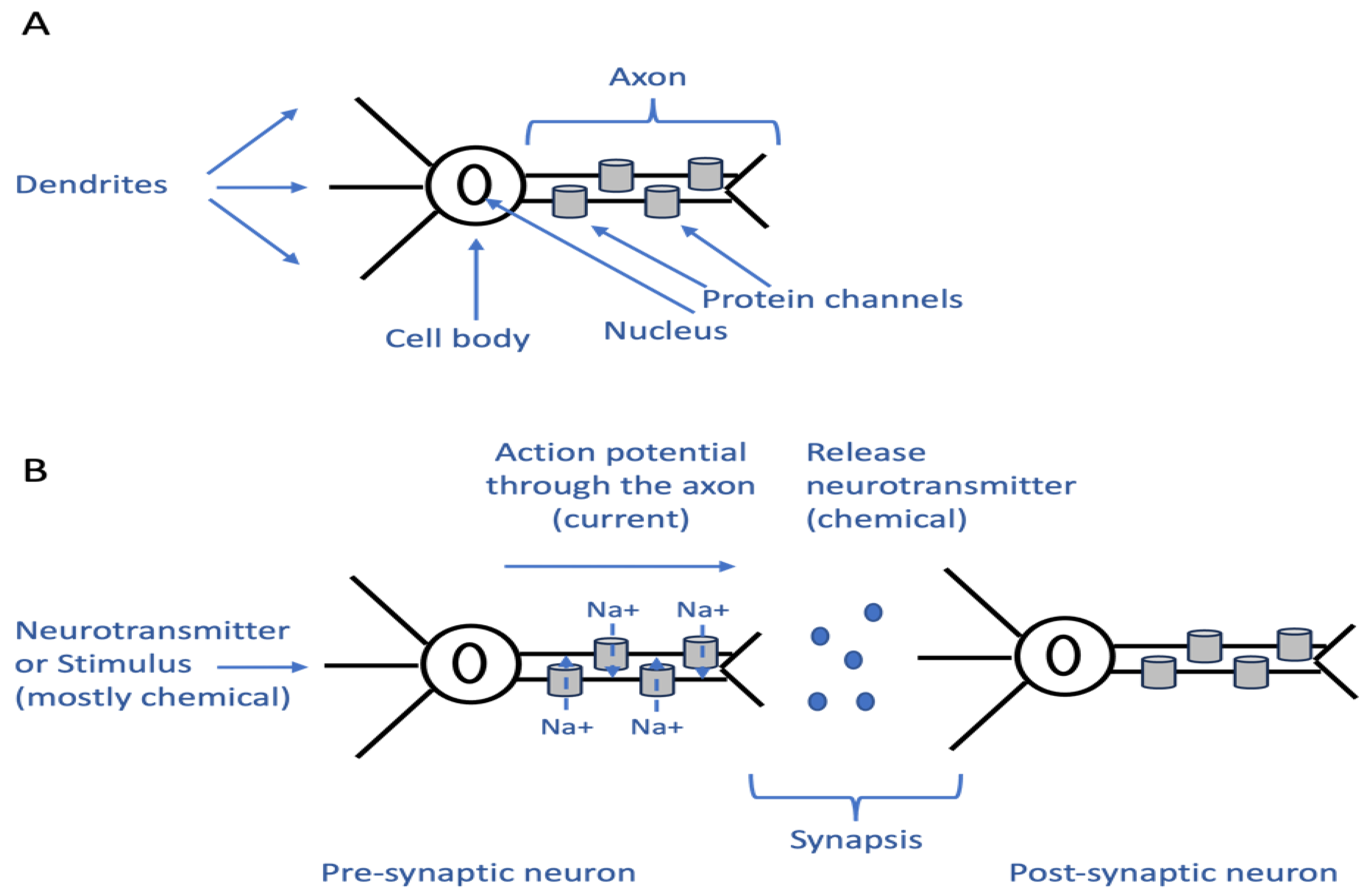
Sterling and Laughlin 2017). Each neuron is a specialised cell evolved to maximise the speed and minimise the cost of these activities. A neuron consists of dendrites, which are cell bodies with a nucleus and a long axon (
Figure 1A). Typically, the dendrites are the sensing part of the neuron, while the cell body is responsible for the production of the materials and energy that the neuron needs to perform its function. The axon, on the other hand, is specialised in transferring information quickly through an electrical current, much like a cable in electrical circuits. Therefore, a neuron can switch between chemical and electrical signals to perform computation and transfer information. A neuron will sense stimuli in a chemical way, usually through the effects that these stimuli have on certain proteins within the neuron. This effect causes other changes downstream of the neural circuit, and if these changes are significant, they typically cause a response from the circuit.
In a neuron, an input which is either a chemical signal or another stimulus is sensed by the dendrites, usually through the effect that the stimulus has on certain proteins. If the stimulus passes a certain threshold, it creates a secondary effect that ultimately results in the opening of protein channels in the membrane. The movement of charged ions across these channels will generate an electrical current to travel through the axon. This is called an ‘action potential’. When the current reaches the end of the axon, it causes the release of a neurotransmitter, which is, again, a chemical signal (
Figure 1B). The neurotransmitter can then act on the dendrites of another neuron and repeat the cycle. A neuron can also integrate the signals from different neurons, and only if a certain threshold is met. This causes the opening of the channels and transferring of information in the form of an electric current ‘action potential’. From this analysis, it is clear how a single neuron can perform computation which is mostly chemical by relying on the ability of proteins to sense certain stimuli and change their conformation in response; this causes secondary effects, ultimately leading to the opening or lack of opening of channels. Therefore, depending on what kind of channels are opened and the charged ions that flow through them, a stimulus can either favour the production of an action potential (excitatory) or diminish the chances that an action potential will be generated (inhibitory).
In the brain, neurons that are close to each other form neural networks (
Ford 2018;
Leslie 2019). This is where the neurotransmitter produced by one neuron (pre-synaptic) and released in a space called a synapsis can act on downstream (post-synaptic) neurons, causing their activation or silencing (
Figure 2, left panel). Many neurons will be activated or silenced at once, and the connection between certain neurons is stronger than with others. At the end of the process, the integration of multiple stimuli within each neuron and of all the responses from the various neurons will cause a response, which could be the contraction of a muscle to move an arm.
In terms of functionality of the neural architecture to galvanise the needed activity, it should be noted that chemical computation is more efficient and energetically more cost-effective than action potentials, but action potentials are needed to transfer information fast enough for long distances (
Sterling and Laughlin 2017). To maximise efficiency, the brains of higher-intelligence animals, including humans, send only the information necessary for the shortest distance possible. To achieve this, they organise specialised centres to deal with the task of collecting the neurons that need to work together, thus minimising the length of the axons that are the most energy-consuming (
Sterling and Laughlin 2017). There is also a progressive reduction in information where rich stimuli from the environment are reduced in complexity by progressive levels of abstraction. This basically summarises complex stimuli and, in conclusion, allows the brain to make sense of the external environment and find useful patterns based on current observations and previous experience (
Beerends and Aydin 2024). A rather similar principle is also applied to effector behaviours. For example, the small centre of the brain used for integration, the hypothalamus, can induce different kinds of complex behaviours by using simple instructions to recall already-coded patterns of behaviour stored elsewhere and closer to the effector organs (
Beerends and Aydin 2024;
Kerrigan 2022).
- (b)
Representational Causal Relationships of Machine Architecture
An artificial neural network (ANN) architecture is extremely reminiscent of the basic architecture found in the brain with its series of causally connected nodes (which by analogy are also called neurons) organised in layers. When the neurons in the first layer receive an input of sufficient strength, they transmit the information to the neurons in the next layer, causing a response that is then further transmitted layer by layer until a final output is generated. The strength of the connection between different neurons in the artificial networks is also not fixed but determined by the weights which are represented in
Figure 2 as different widths of arrows (
Figure 2, right panel). The computation in artificial neural networks is based on silicon rather than on proteins. As this is not restricted by biological principles, ANN’s transmission and communication of information is faster, but utilises more energy than biological systems. Electrical currents are still responsible for the transferring of information between nodes, but they are currents generated by electrons rather than the slower current generated by the movement of ions through a membrane in biological systems (
Graupe 2013). Another similarity between the brain and AI is in the way these systems learn. As highlighted above, the different neurons connect with different strengths. These strengths are modulated based on experience through a process called synaptic plasticity (
Abbott and Nelson 2000). When a pre-synaptic and a post-synaptic neuron are producing currents that are synchronised, this leads to the strengthening of the connection (long-term potentiation). Conversely, when they are not synchronised, it leads to a reduction in the strength (long-term depression). These mechanisms are quite reminiscent of one of the most common algorithms used to train AI systems called backpropagation. In an AI network, the strength of the connection (the weights) in the first instance is random or primarily pre-established. However, it becomes refined through training. For instance, if the objective function is to train an AI system for image recognition and it is required to be able to classify images in categories, the system will be trained on a huge number of images that were already pre-classified by humans. Since the images are already classified, the correct answer is known (ground truth). An image is presented to the system with the expectation that it determines the correct answer based on the weights for each node. The answer is deemed accurate or inaccurate based on the ground truth. If the outcome from the system is considered incorrect, the weights of the different nodes will be adjusted to ascertain the right answer starting from the final layers and progressing backwards (backpropagation) towards the initial layers. In the case of natural intelligence, the ability of proteins to sense stimuli based on a certain threshold causing it to automatically change conformation is part of its shared functionality (backpropagation) with artificial intelligence. The threshold is informed by the experience and outcome stored in the memory in the case of the natural system, and the data stored in the databases for artificial intelligence. Whilst the artificial neural system demonstrates inefficiencies in energy usage, the speed of transmission through the electrical current and the network frequency between neurons exceed natural capabilities. The inbuilt ability in the natural system (brain) to exploit the most efficient and adaptive means of achieving these tasks in terms of material (proteins) is another unique feature of natural intelligence. Its adoption of effective communication within neurons in the right manner, speed, and proportion is also one peculiarity with natural intelligence. Therefore, the sense of decision and responses based on self-regulated thresholds in direct reaction to environmental stimuli is the hallmark of natural intelligence that is unmatched by artificial intelligence. The efficient, effective, and adaptive coordination of communication across the neutral network produces the effect across the human body through the cells, organs, tissues, and systems which is still unattainable by artificial intelligence.
- (c)
Determination of Threshold Criteria that underscore Intelligence.
From the explanation given above, intelligence is deemed to exist if the following are identified: (1) autonomy, self-regulation, and autonomous response based on the threshold test, (2) adaptive means of task delivery within task environment modulated by experiential and contextual threshold, (3) effective and efficient communication and informational flow modulated by experiential and contextual thresholds, (4) self-control and communication across networks modulated by experiential and contextual threshold, (5) pre-classification, reasoning, and learning based on past experiences and contextual perception of future risks. The threshold is informed by human instincts, values, and experiences. For natural intelligence, autonomy is informed by the threshold test based on consciousness, emotions, past knowledge encoded in memory, and independent future perception of risks based on experience (synaptic plasticity). On the other hand, for artificial intelligence, autonomy is informed by thresholds based on (1) past knowledge encoded in data stored in databases (these databases created and engineered by human intelligence based on human instincts and values), (2) the perception of future risks based on pattern recognition and probabilistic reasoning derived from data stored in databases (databases created by human intelligence; data engineered by human intelligence based on human instincts and values), and (3) machines programmed by human intelligence based on human instincts and values. Since artificial intelligence requires human input, it therefore raises questions on the extent to which artificial intelligence is truly artificial. This conceptual difficulty underscores the definitional problem and elevates the controversy over the nature of this intelligence. In addition, the contrarian description of artificial intelligence as simply an extension of human intelligence created by humans to enable an efficient and effective delivery of tasks seems more convincing. As a result, the mere use of the word ‘artificial’ is simply misleading and is designed to avoid any form of human attribution and possible legal liabilities. The absence of agreed benchmark criteria to specifically identify and underscore intelligence has been a major constraint in its conception.
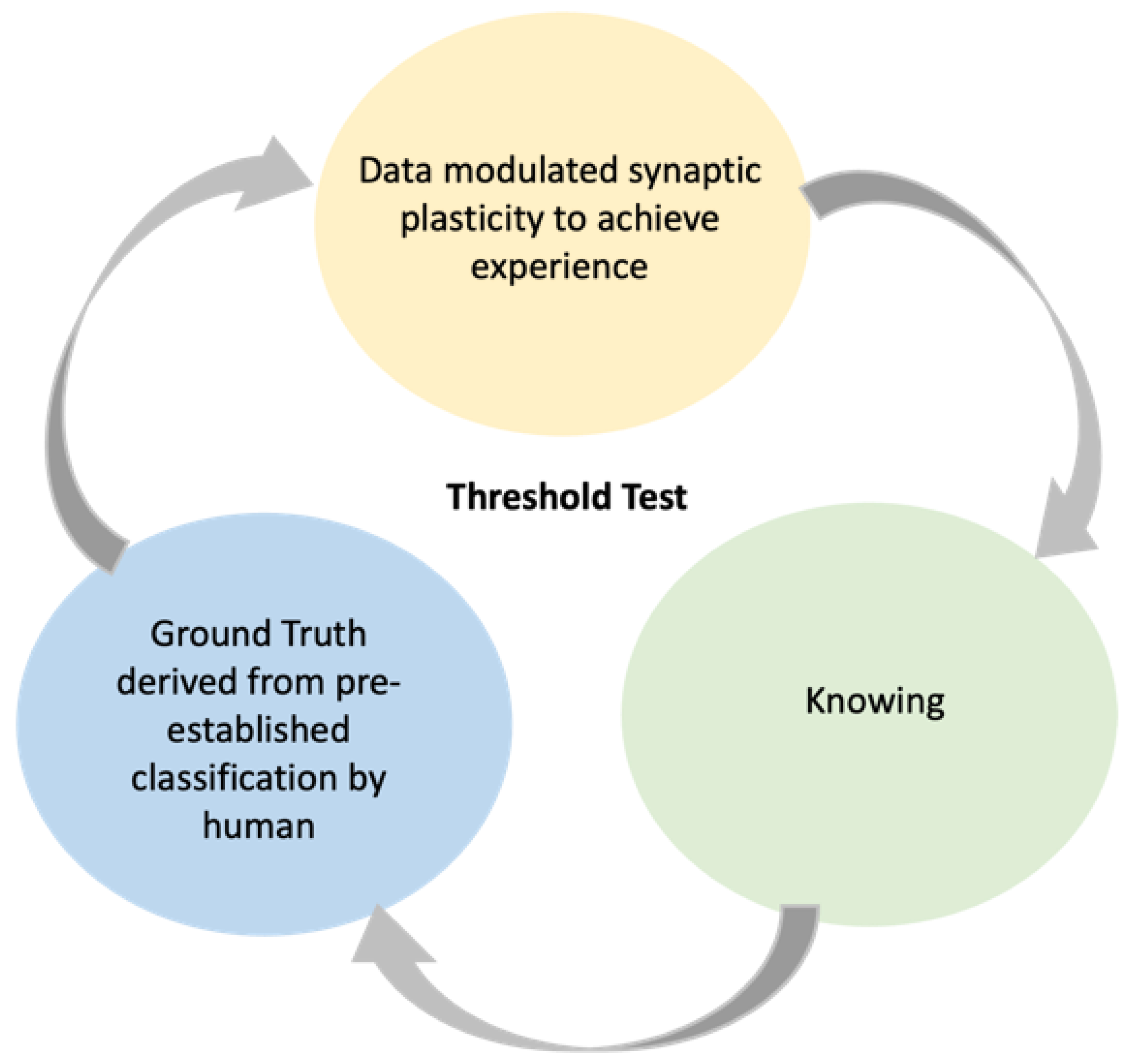
Fashioning a Benchmark Model for AI’s Contextual Function
The recognition of the existence of artificial intelligence is critical to resolving the conceptual incoherence and regulatory challenges. This is partly due to global variations in the conception of intelligence and its application to inanimate entities. It is proposed, therefore, that a universally acceptable conception of ‘intelligence’ that is considered ‘artificial’ in this context must have three causal related elements. These are (1) experience derived from data modulated synaptic plasticity in the neural network, (2) contextual knowing (derived from principles of embodiment, situatedness, bottom-up design, and awareness), and (3) ground truths derived from pre-established classifications by human intelligence. These elements must co-exist and interact to determine the existence and type of AI, as well as the potential benefits and risks. In fact, the elements are in constant symbiotic interaction and evolution, while mutually reinforcing one another in response to changing contexts. Ground truths continuously reinforce checks and balances by experience and knowing, and vice versa. This is how they take advantage of current and future benefits while addressing present and future risks. The measure of good law is both in the level of sensitivity to ground truth and the degree of compatibility of established ground truth with the traditional legal, regulatory, and ethical framework for the control of AI in any given contextual task environment. This is to avert any potential harm to pre-existing societal structures. Therefore, the ground truth that is triggered determines the type and extent of legal, regulatory, and ethical responses that are generated.
- (a)
Data modulated synaptic plasticity to achieve experience.
Capacity to learn based on the ability to perceive and adapt in response to perceptive experience is at the core of intelligence.
Figure 3 above illustrates how synaptic plasticity enables learning in both natural and artificial systems to achieve the experience needed for future learning and actions. The thickness of the connections in the neuron is a product of data-inspired signals to the neurons reaching a certain threshold and the resultant positive or negative reinforcements received after the action precipitated by the neurons. Therefore, the artificial system must be capable of distilling insights and building experiences from data of all shapes, textures, configurations, and sizes. This is because the determination of the threshold for the firing of signals and modifications in the neuron is a data-driven response based on the perceptive capacity and sensitivity of the neuron to both the internal and external contextual environments. Therefore, a system that lacks this ingredient cannot be termed intelligent.
- (b)
Contextual knowing
This entails achieving a true and justified belief in the existence of an intelligent system that is considered artificial as distinct from human intelligence. This requires the establishment of four principled criteria, which are the principle of embodiment, situatedness, the bottom-up approach, and awareness. Firstly, for intelligence to exist, it must be embodied within a recognisable physical or virtual entity. However, there is no consensus on the principle of embodiment of AI. This is because attempts at defining AI ascribe its activities to distinct human-like machine intelligence without describing what constitutes intelligence. The closest description to intelligence is pattern-recognition which is dissimilar to the traditional understanding that reflects it as a sum of human, thought, rational thinking, and rational behaviour (
Russell and Norvig 2020). Others see intelligence as observed behaviour distilled from experience (
Zaman 2023). However, Rodney Brooks description of intelligence is one of “
perception and interaction” (
Brooks 1991). The extent to which pattern recognition constitutes perception is debatable. Creating AI as intelligence that exists within a machine outside of human agency produces legal and regulatory difficulties. The OECD’s explicit and implicit objective function is somewhat vague as it seeks to specifically alienate those involved in the generation of these functions. The EU AI Act on the other hand, captured human agency in the form of data input, which is a structure that is largely absent in many of the definitions of AI. The indication that machines are capable of independent judgement is a unique feature that restricts legal and regulatory attempts to control AI. Therefore, the principle of embodiment is one of the strong determinants of the existence of artificial intelligence, as true intelligence cannot exist without a system that embodies it.
Also within the principle of embodiment are questions around liability and attribution. There are other questions as to whether liability should solely rest with either the developer of the distinct technology, the aggregator of all the technologies to make the AI system, or the corporation or individual that deploys or utilises the technology. To ascribe some intelligence to transformative processes without regard to the nature and components within the architecture, as well as context of the modeller, undermines the context of knowing.
Secondly, in all definitions of AI outside of the OECD’s, there are fundamental disagreements on the principle of situatedness.
This principle seeks to understand the locus of AI to access whether the technologies only emanate and exist in the virtual world of machines or emanate from the real world and apply to the real-world context. The capacity of this technology to exist, function, and command influence in the real world (not merely in the world of games) is an essential component of intelligence. Whilst the OECD’s definition prescribes the element of scalability in both the real and virtual world, by which an AI is expected to be adaptive after deployment and variation in their level of autonomy, this element is largely missing in other definitions. The EU AI Act simply refers to the question of scalability within the purview of AI’s expected capacity to influence the environment where the AI interacts (
European Commission 2023). “Capacity to influence” has not been defined in the Act, and one would imagine what the likely threshold that must be set to assess and attribute “influence” and what would constitute influence in the context of AI interaction. Also, the meaning of adaptiveness after deployment is beset with vagueness. Is this a question of the system’s ability to learn from previous experiences and that consequent decisions based on previous outcomes or simply its capacity to regurgitate and implement tasks based on previous instructions. Given the extremely fluid nature of real-world contexts, it is indeed unclear to what extent AI can understand and implement all the varied real-world contexts within its limited modalities.
The locus of these technologies will determine the nature of the regulations. Also, AI is a system made up of different technologies at different stages of formation. Therefore, the question remains regarding which of the technologies is/are targeted for regulation. If the law or technology seeks to regulate the output of the technology’s likely influence on society and virtual environment, then what is the threshold test for determining the level of influence to attract specific types of regulation? How do regulators attribute the influence solely to the activities/outcomes of AI to expect a truly reliable assessment?
If the locus is both internal and external of the machine, can successful attribution of outcome be achieved when ascribed to AI only without capturing the contribution of environmental influences or stimuli? If this is the case, can AI truly be artificial intelligence where a large chunk of its intelligence is attributable to the influence of physical and human activities?
The characterisation of AI based on its influence on both virtual and human environments assumes a unidirectional relationship in which AI is assigned as the controlling force in the power relations that shapes this influence. There is less thought invested in the capacity of the human/physical world to influence the moulding of this technology as an extension of itself. It is argued, therefore, that AI should be seen as a mere extension of some aspects of human abilities programmed into tools to enable the efficient and effective performance of human tasks in the real world. Therefore, the identification of the locus is an important ingredient in defining and determining the existence of intelligence.
Thirdly, the bottom-up principle is addressed.
The adoption of the connectionist bottom-up approach where the intelligent inanimate entity is designed to mimic and replicate brain function points to the existence of artificial intelligence. This constitutes evidence of the existence of intelligence.
Fourthly, the principle of awareness is addressed.
This entails knowing of the existence of artificial intelligence and capacity of the machine to gain recognition of its own existence and achieve justified belief of that existence in a task environment. Robinson (
Robinson 1971) captures some basic features related to knowledge. They include the capacity to ‘learn, forget, recall, realise, apprehend, see, perceive, observe, recognise, and understand’. These are unique features of an intelligent entity.
- (c)
Ground Truth—Pre-Established Classifications by Humans
The third element in the contextual sensor is ground truth. Ground truths are sets of pre-established classifications derived from societal values, norms, guiding principles, and standards. As seen in the definitions above, countries have developed and continuously fine-tune guiding principles for ‘responsible’ AI that align with pre-existing societal values, norm, and standards. These vary across cultures and systems and therefore susceptible to contextual determination. However, the establishment of ground truth is susceptible to power relations considerations and not necessarily a product of agreement by all social actors. Pre-established classifications could reflect the views of the dominant players in the society and not representative of the collective position of all citizens and inhabitants in that society. Uhumuavbi, in his research (
Uhumuavbi 2023), utilises the ‘Ubuntu’ philosophy to develop a model to support an accountable, collaborative, representative, and consultative communal relations that guarantee mutual, equitable, reliable, and acceptable ground truths in society. Therefore, this tool is appropriate for assigning responsibilities, liabilities, and power distribution in the quest to achieve ground truth.
6. Applying the Adaptive Contextual Model to Achieve Responsible AI
Mistakes are being made in the haste to design legal, regulatory, and ethical framework for AI without a thorough understanding of the concept. This explains the conceptual difficulties and constantly changing attempts at defining the concept. Current efforts are considered kneejerk reactions that run the risk of stifling the technology (
Hacker 2023). The dilemma on whether to regulate the developers, development, deployment, or usage further illustrates this challenge. There is also the question of the type of legislative, regulatory, and ethical arrangement that is necessary to elevate the benefits and curtail the risks. It is unclear if new specialised legislation will serve better than strengthening existing legislation or adopting a hybrid approach. The use of risk-based, rule-based, or principled-based regulatory models is assessed against the use of a hybrid method, even as an experimentalist regulatory approach is considered against the use of context-specific or command and control.
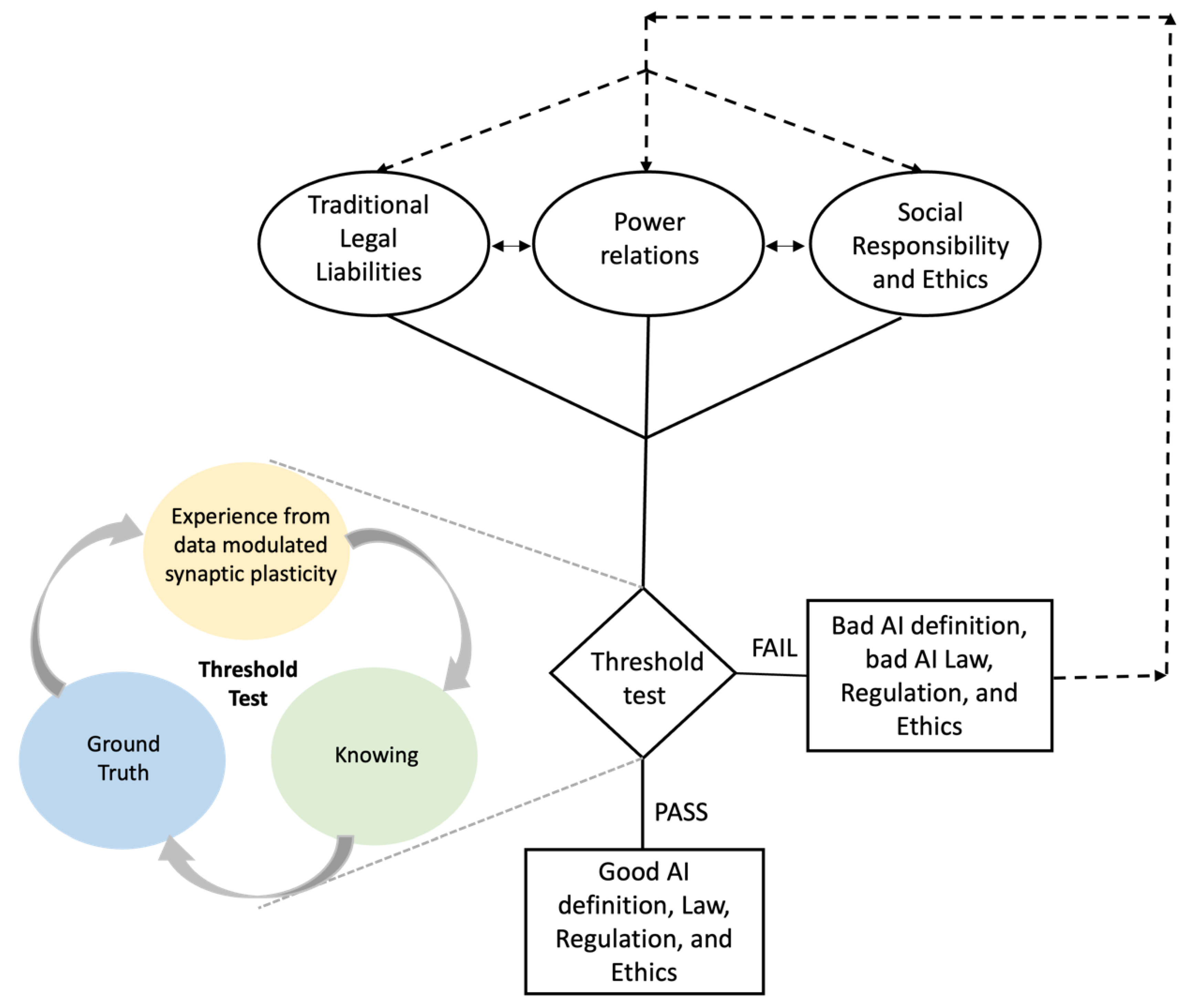
Designing a responsible AI framework requires context-sensitive causally related three-stepped processes.
Every framework must possess three components to ensure effective control. These are laws to create legal rights and liabilities, power relations, and social responsibilities and ethics. When determining an effective framework for definition, legislation, and regulation of AI, the capture and remodelling of traditional legal rules, social responsibility, and ethical principles are required. Traditional legal rules that produce legal rights and well as criminal, civil (tortious, contractual) liabilities, statutory liability, and public liability encompass the following traditional law subject areas: competition law/antitrust, data and intellectual property law, equality (discrimination, autonomy, dignity, privacy, bias), ownership and property law, international law (sovereignty and national security), agency law, competition and consumer protection law, and governance (public and private). These laws have inbuilt governance systems to ensure effective allocation of power and necessary checks and balances. Therefore, the determination of the effectiveness of the law is measured by the level of equality guaranteed by the law, the level of involvement and consensus reached in making it, and the availability of checks on likely abuses of power. This underscores the need to ensure that the ground truths that underpin the formation of laws are also not a product of uneven power relations dominated by some individuals, corporations, government, multilateral agencies, and institutions (
Sadek et al. 2024;
Uhumuavbi 2023). Therefore, corporate social responsibility and ethical framework should be designed to ensure the advancement of ground truths whilst ensuring the balance of corporate and government power through systems of legal rules and checks and balances placed on power relations. The power of corporations to influence ground truths must be checked by legal liability, along with collective checks on power relations using corporate social responsibility and ethical standards. This can be achieved through the conduct of the threshold test in Step 2 of the Contextual Decision Tool in
Figure 4.
The threshold test is used to determine the existence of artificial intelligence as well as its risks and benefits. The test is also used to clarify the basis for the transmission of information derived from the new conception of AI, as well as traditional laws, regulations, and ethical rules and principles. The threshold test is the measure of sensitivity of the task environment to the benefits and risks presented by AI. It also assesses the capacity of existing legal rules, regulation, and ethical principles to adapt in such a way as to protect established ground truths.
The threshold test is a three-staged process:
Stage 1 is the determination of whether AI exists, including the nature and extent of risks and benefits, and the determination as to whether the risk and benefits so identified required legal regulatory and ethical intervention. This is tested using the contextual sensor shown in
Figure 3 to establish if the characteristics exhibited mean that it is capable of learning and transmitting information based on experience deduced from inherent data or human-inputted data. If this is the case, then it must be determined whether this capability is embodied by an entity and situated in the real-world context and not merely virtual, and, as such, is able to perceive the task environment and demonstrate awareness of its existence (
Pelletier 1978). If this is achieved, then the test makes a further determination as to whether its inputs, processes, and output run against established societal values, norms, guiding principles, and standards that are collectively agreed by all in that contextual task environment. If this is not achieved, then it fails. This means that there is no artificial intelligence. However, where all the conditions are met, it passes the test, indicating the existence of AI.
Stage 2—Once stage 1 is passed, then a stage 2 assessment is conducted to determine whether traditional laws, regulations, and ethical frameworks are sufficient to elevate the benefit and control risks identified in stage 1. The threshold is measured based on the following: (a) the degree of sensitivity of ground truth to the risks and benefits of AI so that if the input, process, and outputs are likely to affect the task environment and violate the ground truth, then a commensurate legal, regulatory, and ethical responses are developed that meet the contextual task environment. This is based on the risks posed by the outputs, input, and process of AI to existing ground truths. The measure of this risk is derived from experience from data-modulated synaptic plasticity. (b) The degree of compatibility of the ground truth within an AI contextual task environment, and the traditional legal rights and liabilities, power relations, and ethical principles. (c) The degree of alignment between the existing legal, regulatory, ethical, and power relations framework, and the ground truth reinforced by experience and knowing.
Stage 3—If any of the above stages in step 2 fail, then it repeats the process from step 1 because the definition, law, regulation, and ethics surrounding AI are deemed to be bad. However, if the step 2 passes, then it moves to step 3.
In this step, a careful assessment, introduction, and adaptation of the legal rules, regulation, ethical framework, and power relation into the contextual task environment are developed and achieved.
7. Conclusions
The development of AI emerged from an intuitive response to the human quest for rational intelligence to enhance human efforts towards a beneficial direction. This desire for rationality that has existed from the time in evolutionary history where living organisms sought to survive by developing understanding of their environment led to the production of philosophies that created different subject disciplines (biology, chemistry, physics, mathematics, psychology, economics, engineering). The development of these disciplines was enabled by the application of four dimensions of intelligence which evolved over time out of human evolutionary experience. These dimensions are human, rational, thought, and behaviour. Human and thought are a product of reflection, behavioural experimentation, and brain imaging. Rational thinking is achieved through logic and probability, while natural behaviour is captured through agency. These dimensions are brought together by the human capacity to learn, reason, and perceive. Therefore, the quest for rationality gave rise to distinct ways of learning, reasoning, and perceiving. For learning, the natural sciences developed and adopted the theory of mind, learning, consciousness, and behaviour, while the social sciences developed syllogism and then logic. Syllogism and logic as modes of learning and reasoning could only work effectively in an environment of informational certainty. However, real-world dynamics are more complex and uncertain, hence the need to introduce probability as way of learning and reasoning. Therefore, both sciences have developed probability as a way of learning and reasoning to make sense of real-world uncertainty in thoughts and behaviour. The outcomes of reasoning and learning are represented using notations. To address the uncertainty in behaviour, the concept of rational behaviour is developed and captured using the concept of rational agents. This is what led to the attempt to develop AI as a “rational agent”. However, achieving rational agency is dependent on the capacity of the technology to pass the three-element test proposed within the Contextual Decision Tool in
Figure 4 of this paper.
The deployment of systems of logical and probabilistic reasoning, learning, and perception into unlocking the six domains of computer science to develop a “rational agent” is to enable human, rational, thought, and behaviour to create rational artificial agents as extensions of humans. This is to the extent that they can derive rights, liabilities, and responsibilities by virtue of their association with humans and the context task environment. Through the use of these rational agents, AI is expected to learn, perceive, and reason in distinct ways across different task environments and encode the outcomes towards solving problems based on the objective functions that are compliant with the three-elements test. Since society seeks to derive benefits from this technology, it should consider AI future framing around rational agency so that the three-element test can guarantee AI’s compatibility with societal norm, standard, values, and principles. Rational agency requires that AI makes decisions that are of benefit and satisfaction to society. As a single or multi-modal agent, AI is expected to optimise tasks and processes through its varied agency function of perceiving, acting in reaction to physical and virtual environmental stimuli. Therefore, its capacity to learn, source, and aggregate information, and perform tasks across non-deterministic, episodic, sequential, static, dynamic, discrete, continuous, known, or unknown task environments, improves it utility as a rational agent. The three-element test is designed to advance this purpose by minimising the “value misalignment problem”. The threshold test is designed to ensure that the alignment of AI input, process, and output are compliant with the ground truth. This removes machine- or human-induced incorrect objective function that creates risks across the task environment. Hence, there is a need to regulate AI using this model to minimise the risks and enhance the benefits across the domains, dimensions, modalities, task environments, and agency spectrums within and outside the task environment.




{kind=link}
{kind=link}
{kind=link}
{kind=link}