
Improved of YOLOv8-n Algorithm for Steel Surface Defect Detection


Abstract

1. Introduction
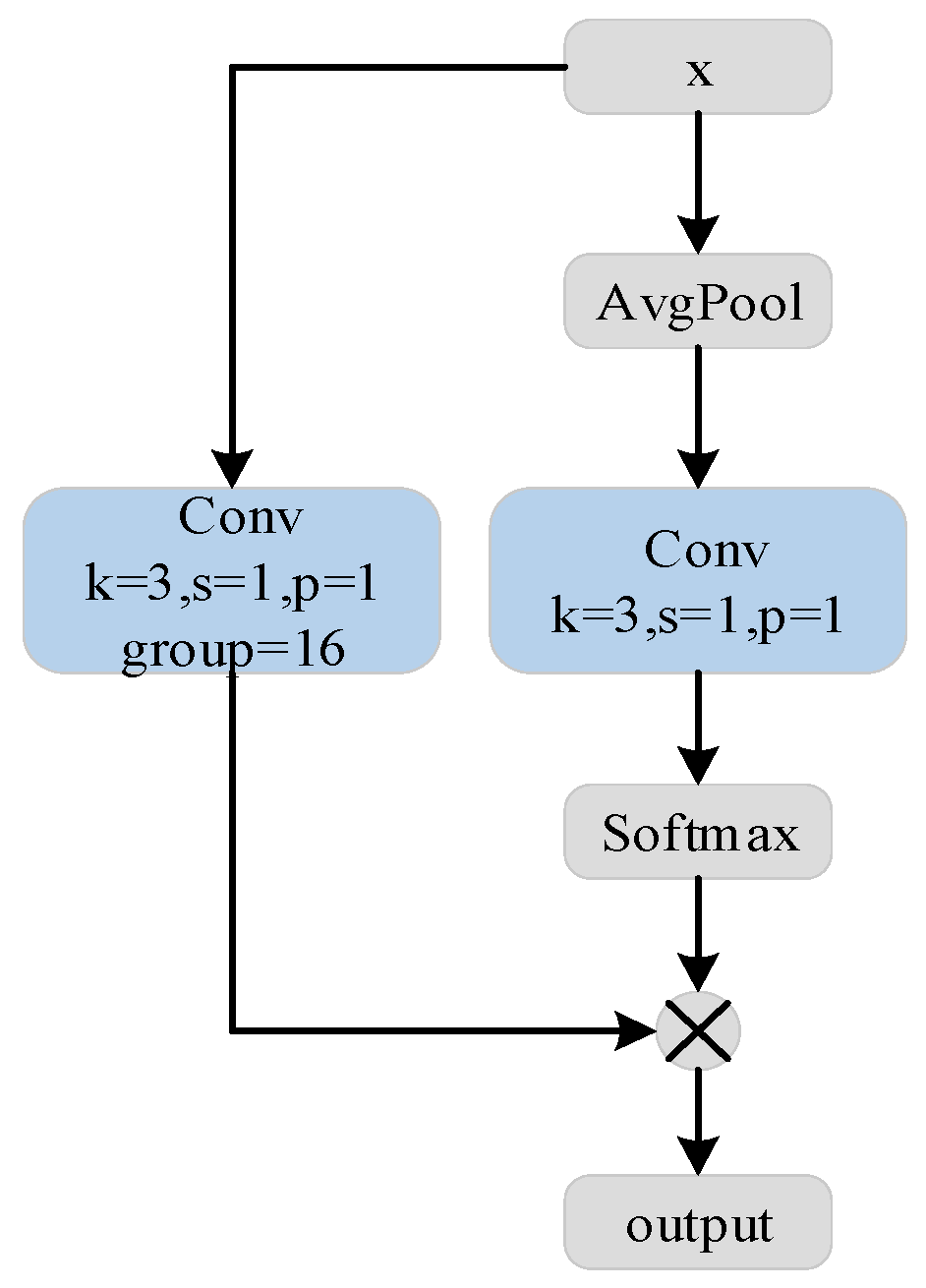
- Due to the wide variability in the shape and size of steel surface defects, this study proposed an adaptive weighted sampling (ADSConv) module. By dynamically adjusting the weighted combination of multi-scale feature maps, it enables the comprehensive capture of defect features to enhance the model’s adaptability to different types of defects.
- As defects occupy a minimal proportion of steel surface images, their identification is challenging under complex lighting and backgrounds. In this paper, the C2f [12] module in the feature extraction network is improved, and the original Bottleneck module is replaced by the simplified DWR [13] module. The optimized C2f_DWR enhances feature extraction from the network’s high-level variable receptive field via deep separable convolutions with different expansion rates.
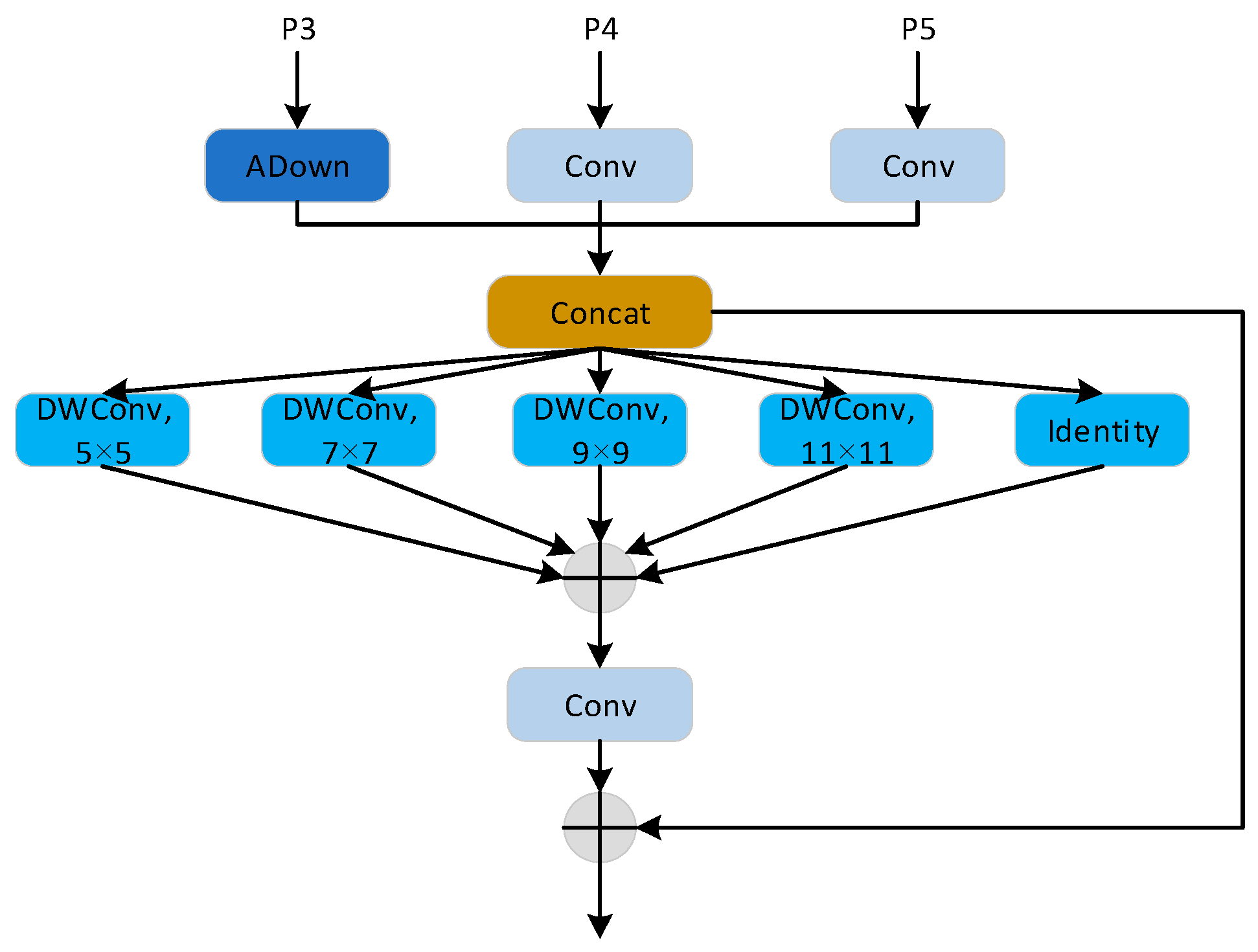
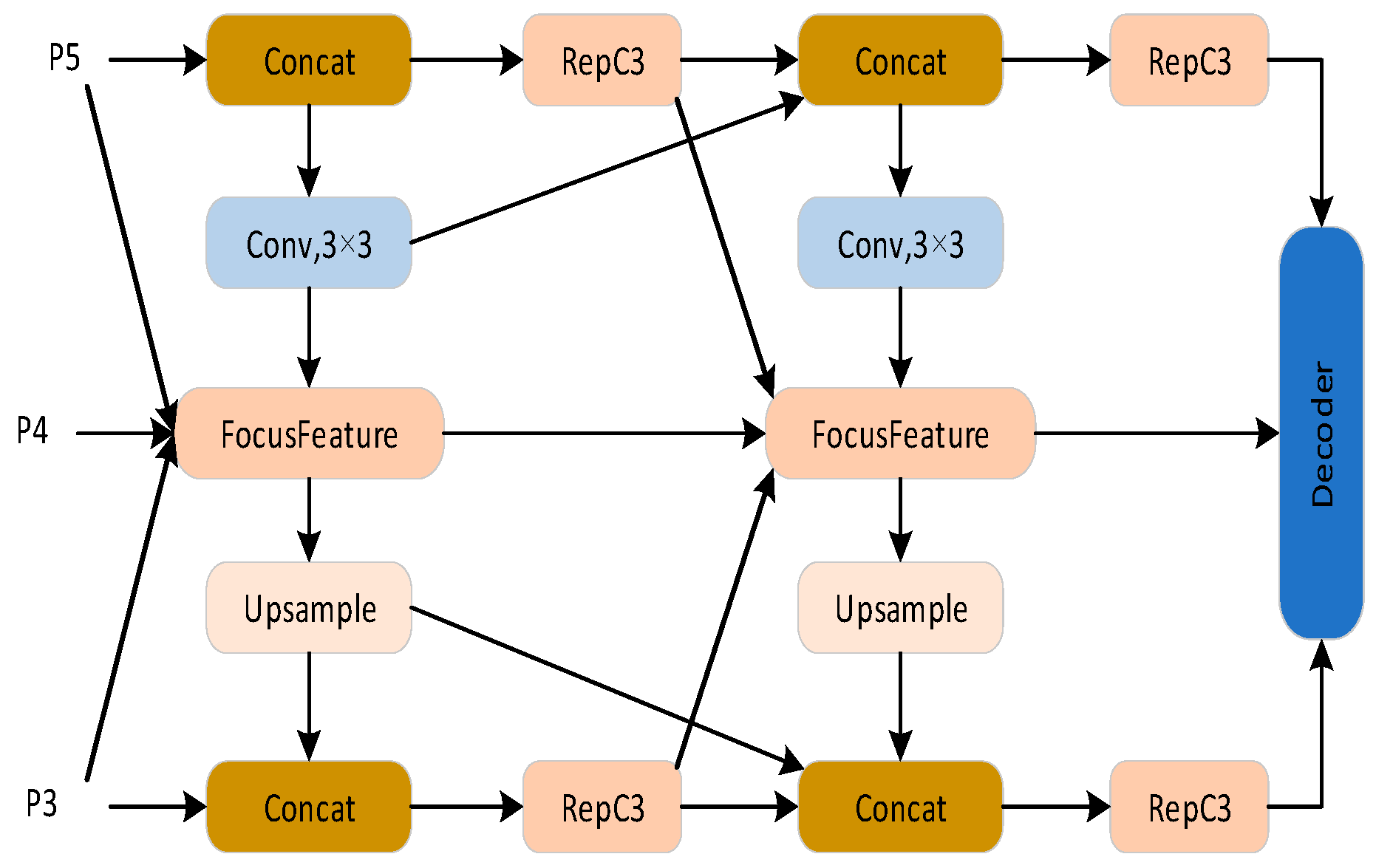
- Due to the fixed feature stitching and convolution operation of the traditional feature fusion module, there is a lack of adaptive optimization of targets of different sizes in the process of multi-scale feature fusion. This study designed a Multi-Scale-Focusing Diffusion Pyramid Network (MS-FDNet) to enable efficient multi-scale feature fusion.
2. Materials and Methods
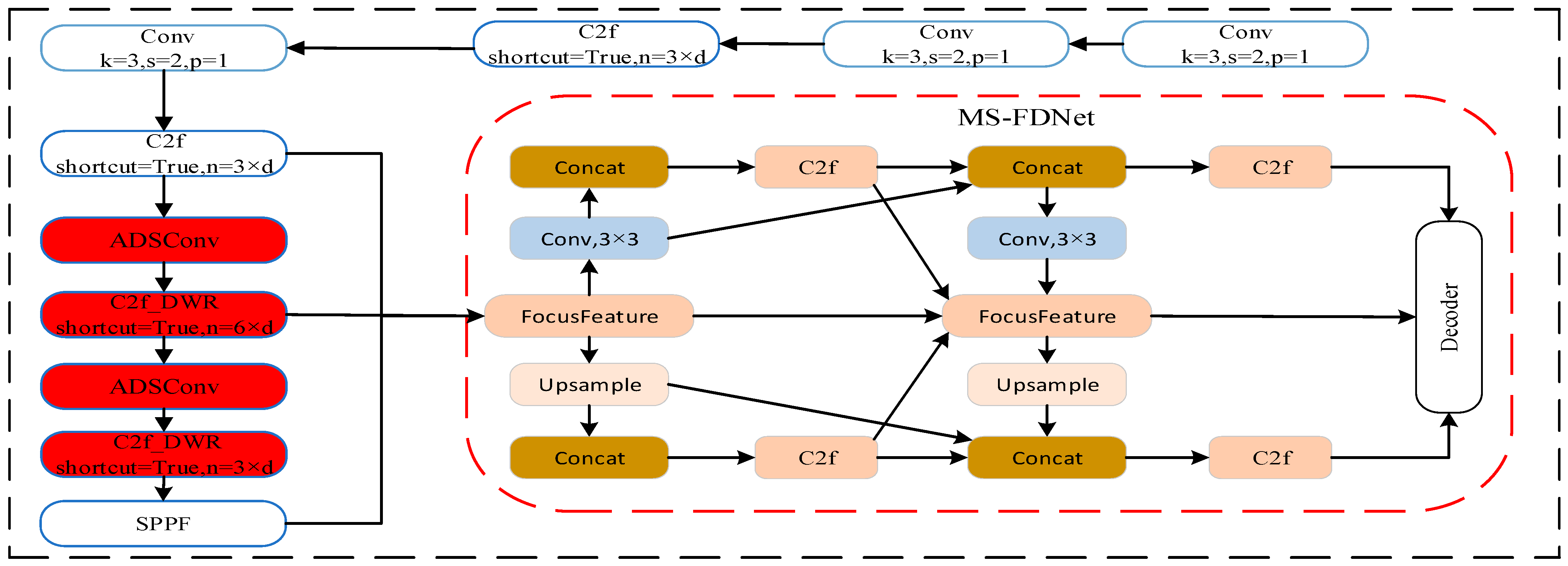
2.1. Improved Network Structure of the YOLOv8-n Algorithm
2.2. ADSConv Module Design of the YOLOv8-n Algorithm
2.3. C2f_DWR Module Designs of the YOLOv8-n Algorithm
2.4. Multi-Scale-Focus Diffusion Pyramid Network (MS-FDNet) Module
3. Experimental Results and Analysis
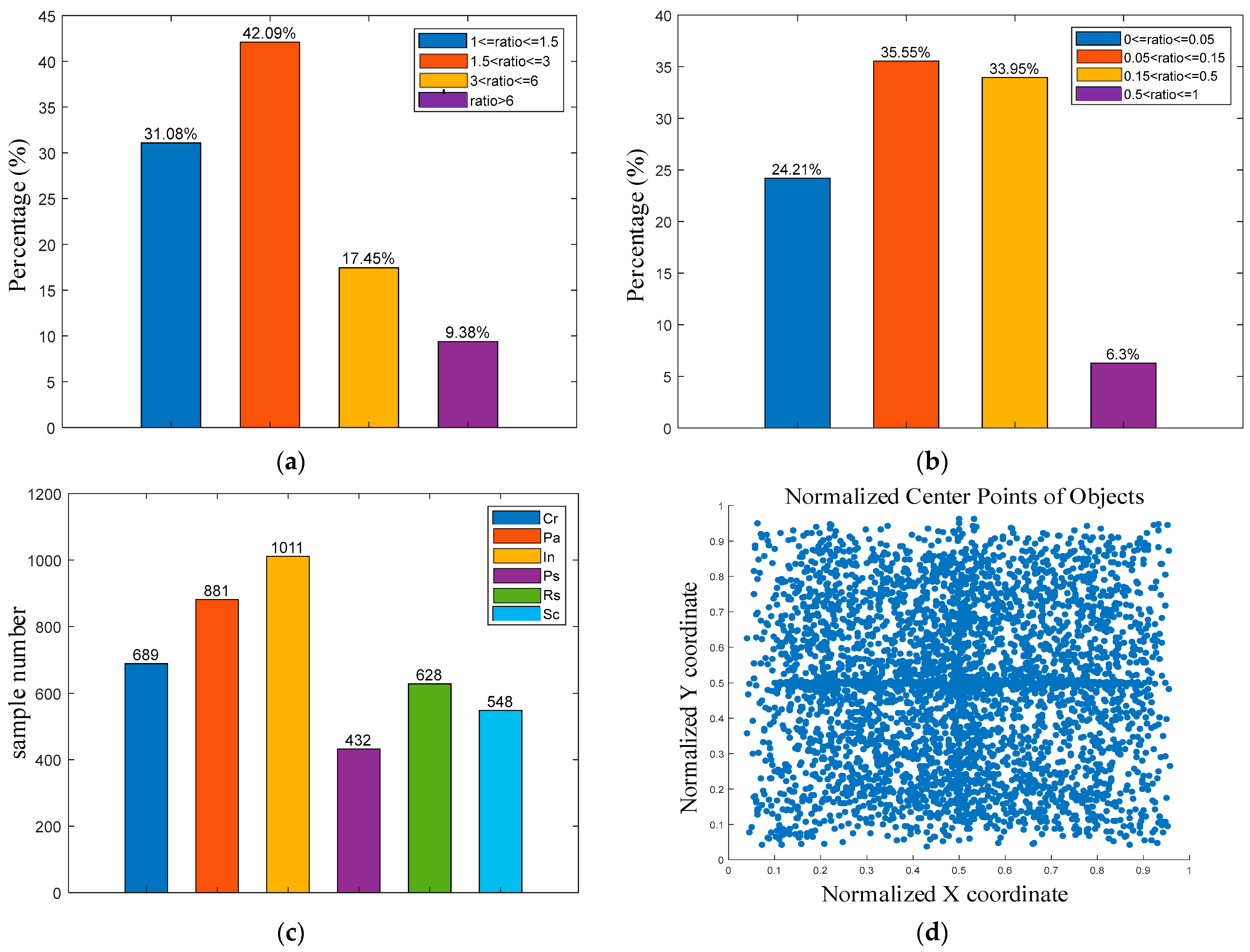
3.1. Experimental Details, Datasets, and Evaluation Indicators
3.2. Experimental Validation Analysis of the Improved Modules
3.2.1. ADSConv Module
3.2.2. C2f_DWR Module
3.2.3. MS-FDNet Module
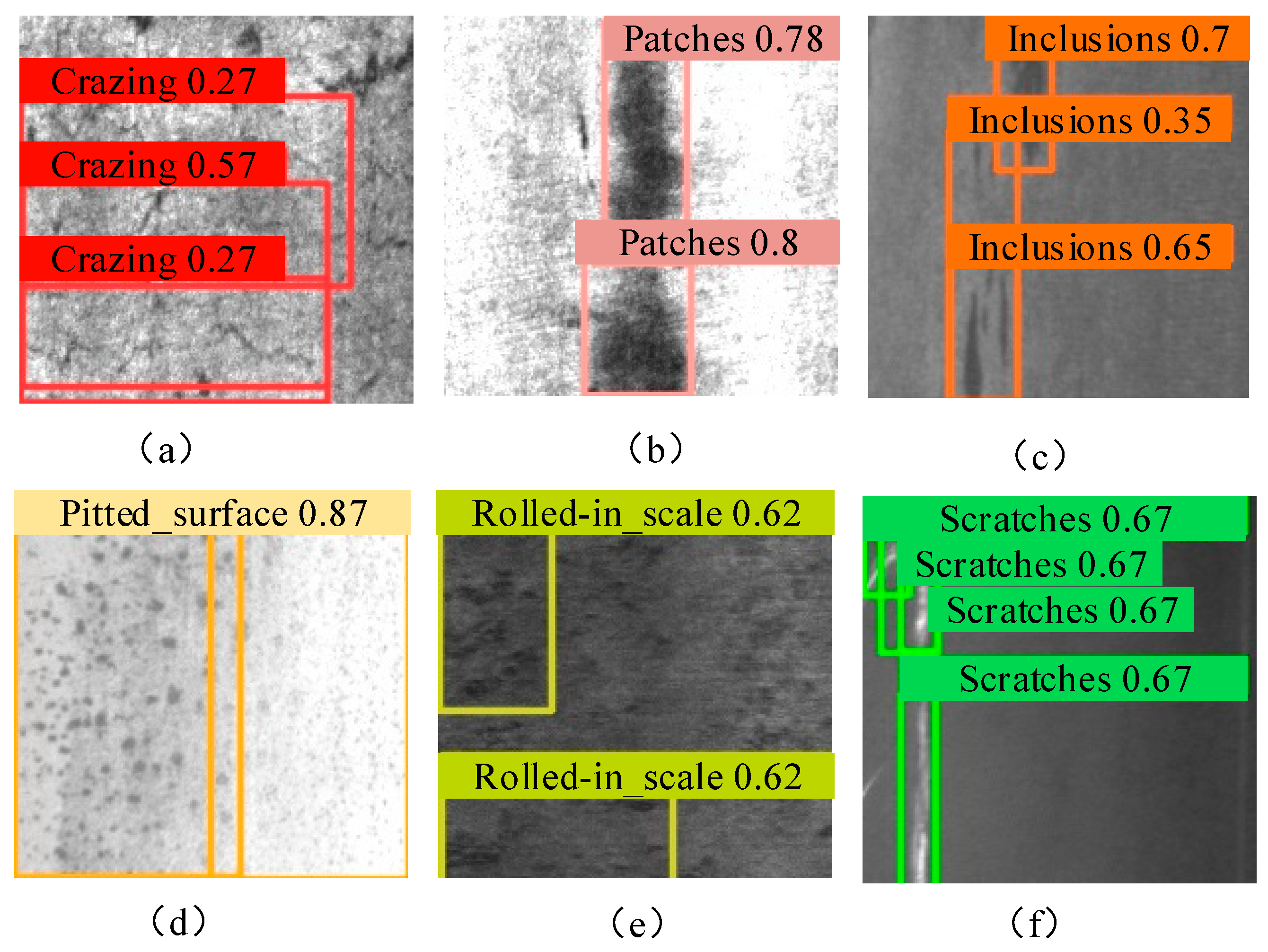
3.3. Comparative Analysis of Different Defect Detection Algorithms
3.4. Ablation Experiment
3.5. Validation Analysis of Improved Module Replacement Positions
3.5.1. ADSConv Module Analysis
3.5.2. Analysis of C2f_DWR Module
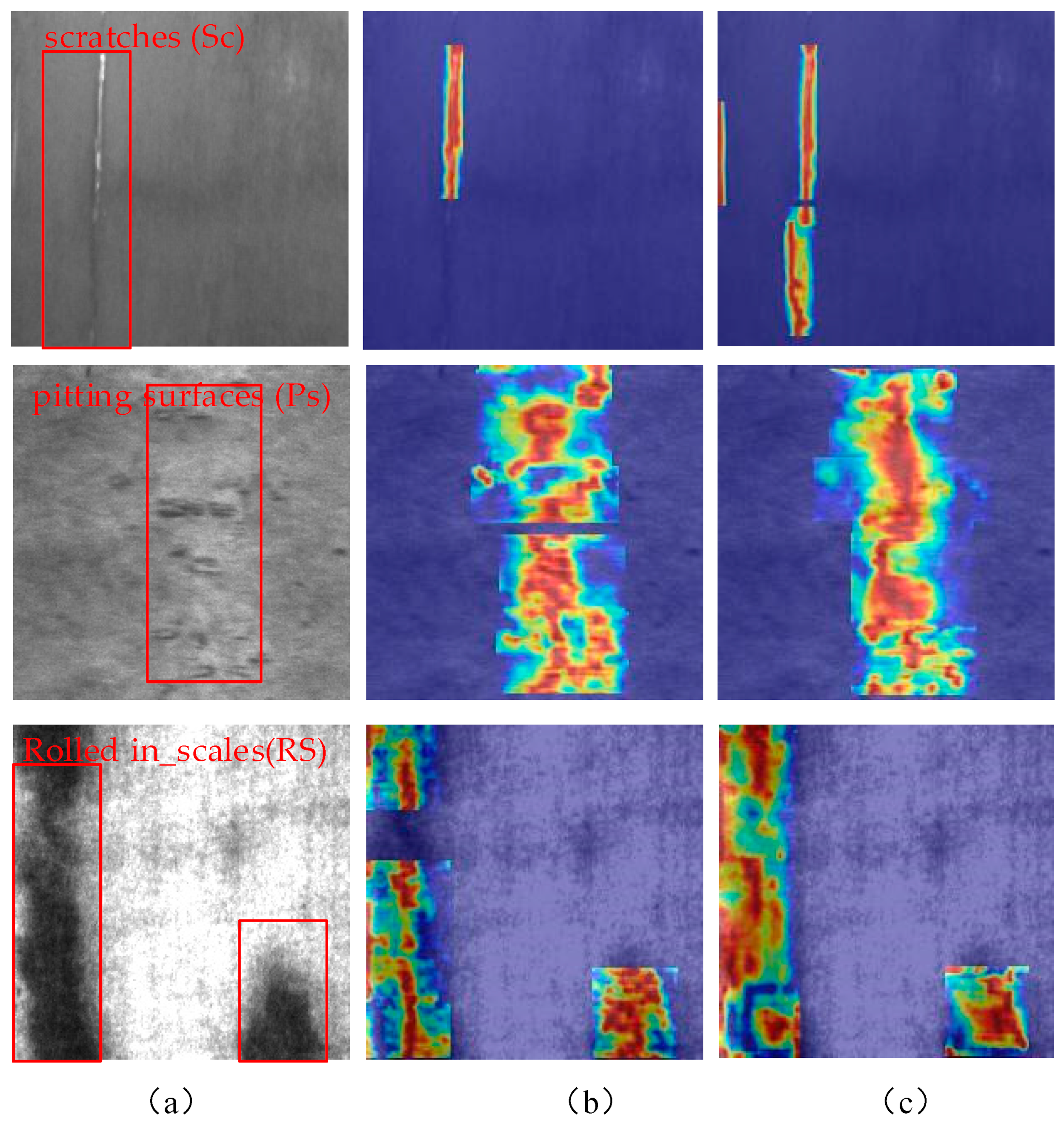
3.6. Result Analysis
4. Conclusions
- The comparative experiments among different detection algorithms reveal that two-stage detectors, such as the Faster R-CNN and Cascade, outperform one-stage detectors, including SSD, CenterNet, EfficientDet, and the YOLO series, in terms of detection accuracy. However, two-stage detectors are significantly slower in detection speed compared to one-stage detectors and also have larger model sizes.
- The proposed ADP-YOLOv8-n algorithm demonstrates superior performance, achieving a favorable balance between detection accuracy, speed, and model size, with a modest sacrifice in detection speed and model size. Specifically, the ADP-YOLOv8-n algorithm achieves the highest detection accuracy in terms of Ps (84.8%), Rs (74.4%), Sc (91.3%), and mAP (79.3%). Although its detection accuracy for the Cr feature is slightly lower than that of the EfficientDet detector (53.0% vs. 56.9%), and its accuracy for the Pa feature is marginally lower than that of the SSD detector (92.5% vs. 93.5%), it still exhibits remarkable performance. In terms of detection speed, the ADP-YOLOv8-n algorithm (163.2 frames/s) is slower than YOLOv8 (209.4 frames/s) and YOLOv7 (209.0 frames/s). Regarding model size, the ADP-YOLOv8-n algorithm (9.6 MB) is slightly larger than YOLOv8 (6.2 MB), but significantly smaller than other detectors.
- In this study, three improved modules (ADSConv, C2f_DWR, and MS-FDNet) were proposed to enhance the YOLOv8 detection model. Ablation studies demonstrated that ADSConv, C2f_DWR, and MS-FDNet individually improved detection accuracy by 1.1%, 0.7%, and 1.5%, respectively. In terms of detection speed, ADSConv led to a decrease of 62.6 frames/s, while C2f_DWR and MS-FDNet resulted in increases of 16.1 frames/s and 0.6 frames/s, respectively. When combined, ADSConv + C2f_DWR, ADSConv + MS-FDNet, C2f_DWR + MS-FDNet, and ADSConv + C2f_DWR + MS-FDNet achieved detection accuracy improvements of 2.6%, 1.7%, 2.7%, and 3.5%, respectively. However, their detection speeds decreased by 91.9 frames/s, 32.7 frames/s, 61.9 frames/s, and 46.2 frames/s, respectively. These results indicate that the ADP-YOLOv8-n algorithm sacrificed a certain degree of detection speed to enhance detection accuracy and reduce model size. Nevertheless, its detection speed remains superior to that of detectors other than YOLOv8 and YOLOv7.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADP-YOLOv8-n | Adaptive weight down-sampling YOLOv8-n |
| C2F | CSP Bottleneck with 2-convolution module |
| ADSConv | Adaptive Weighted Down sampling Convolution module |
| ROI | Regions of interest |
| DWR | Dilation-wise residual module |
| C2F_DWR | Combining the advantages of C2F and DWR modules. |
| MS-FDNet | Multi-Scale-Focus Diffusion Pyramid Network (MS-FDNet) module |
| Cr | Cracks |
| In | Inclusions |
| Pa | Patches |
| Ps | Pitting surfaces |
| Rs | Rolled oxide scales |
| Sc | Scratches |
| AP | Average precision |
| mAP | Mean average precision |
| FPS | Frames per second |
References
- Qiao, Q.; Hu, H.; Ahmad, A.; Wang, K. A Review of Metal Surface Defect Detection Technologies in Industrial Applications. IEEE Access 2025, 13, 48380–48400. [Google Scholar] [CrossRef]
- Shen, K.; Zhou, X.; Liu, Z. MINet: Multiscale Interactive Network for Real-Time Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Ind. Inform. 2024, 20, 7842–7852. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, M.; Sun, J.; Chen, D.; Shi, P. Review of Surface-Defect Detection Methods for Industrial Products Based on Machine Vision. IEEE Access 2025, 13, 90668–90697. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, H.; Guo, B.; Shi, H.; Yu, Z. Research on Real-Time Detection System of Rail Surface Defects Based on Deep Learning. IEEE Sens. J. 2024, 24, 21157–21167. [Google Scholar]
- Wang, L.; Liu, X.; Ma, J.; Su, W.; Li, H. Real-Time Steel Surface Defect Detection with Improved Multi-Scale YOLO-v5. Processes 2023, 11, 1357. [Google Scholar] [CrossRef]
- Kou, X.; Liu, S.; Cheng, K.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A new steel defect detection algorithm based on deep learning. Comput. Intell. Neurosci. 2021, 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Zhang, R.; Hsieh, M.Y.; Souri, A.; Li, K.-C. Average Sigmoid-Tanh Attention and Multi-filter Partially Decoupled Mechanism via YOLOv7 for Detecting Weld Proximity Defects. Met. Mater. Trans. 2025, 56, 4186–4200. [Google Scholar] [CrossRef]
- Lv, Z.; Zhao, Z.; Xia, K.; Gu, G.; Liu, K.; Chen, X. Steel surface defect detection based on MobileViTv2 and YOLOv8. J. Supercomput. 2024, 80, 18919–18941. [Google Scholar] [CrossRef]
- Ma, S.; Zhao, X.; Wan, L.; Zhang, Y.; Gao, H. A lightweight algorithm for steel surface defect detection using improved YOLOv8. Sci. Rep. 2025, 15, 8966. [Google Scholar] [CrossRef]
- Ruan, S.; Zhan, C.; Liu, B.; Wan, Q.; Song, K. A high precision YOLO model for surface defect detection based on PyConv and CISBA. Sci. Rep. 2025, 15, 15841. [Google Scholar] [CrossRef]
- Wang, C.; Wang, H.; Jiang, Y.; Yu, L.; Wang, X. CSCP-YOLO: A Lightweight and Efficient Algorithm for Real-Time Steel Surface Defect Detection. IEEE Access 2025, 13, 113517–113528. [Google Scholar] [CrossRef]
- Lu, X.; Zhou, Y.-K.; Qin, W.; Yang, W.-W.; Chen, J.-X. A Novel and Compact Dual-Orthogonal-Ridged Dielectric Waveguide Resonator and Its Applications to Bandpass Filters. IEEE Trans. Microw. Theory Tech. 2025, 73, 1671–1679. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Zhang, H.; Miao, Q.; Li, S.; Wang, C.; Chan, S.; Hu, J.; Bai, C. An efficient and real-time steel surface defect detection method based on single-stage detection algorithm. Multimed. Tools Appl. 2024, 83, 90595–90617. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 3490–3499. [Google Scholar]
- Li, Y.; Han, Z.; Wang, W.; Xu, H.; Wei, Y.; Zai, G. Steel surface defect detection based on sparse global attention transformer. Pattern Anal. Appl. 2024, 27, 152. [Google Scholar] [CrossRef]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Chan, S.; Li, S.; Zhang, H.; Zhou, X.; Mao, J.; Hong, F. Feature optimization-guided high-precision and real-time metal surface defect detection network. Sci. Rep. 2024, 14, 31941. [Google Scholar] [CrossRef]
- Zamanidoost, Y.; Ould-Bachir, T.; Martel, S. OMS-CNN: Optimized Multi-Scale CNN for Lung Nodule Detection Based on Faster R-CNN. IEEE J. Biomed. Health Inform. 2025, 29, 2148–2160. [Google Scholar] [CrossRef]
- Chai, B.; Nie, X.; Zhou, Q.; Zhou, X. Enhanced Cascade R-CNN for Multiscale Object Detection in Dense Scenes From SAR Images. IEEE Sens. J. 2024, 24, 20143–20153. [Google Scholar] [CrossRef]
- Zhong, X. CAL-SSD: Lightweight SSD object detection based on coordinated attention. Signal Image Video Process. 2025, 19, 31. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, H.; Wang, Y.; Song, L.; Ma, B.; Song, H. CenterNet-LW-SE net: Integrating lightweight CenterNet and channel attention mechanism for the detection of Camellia oleifera fruits. Multimed. Tools Appl. 2024, 83, 68585–68603. [Google Scholar] [CrossRef]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.; Yeh, I.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar] [CrossRef]
- Gu, Q.; Huang, H.; Han, Z.; Fan, Q. GLFE-YOLOX: Global and Local Feature Enhanced YOLOX for Remote Sensing Images. IEEE Trans. Instrum. Meas. 2024, 73, 1–12. [Google Scholar] [CrossRef]
- Zocco, F.; Lin, T.-C.; Huang, C.-I.; Wang, H.-C.; Khyam, M.O.; Van, M. Towards More Efficient EfficientDets and Real-Time Marine Debris Detection. IEEE Robot. Autom. Lett. 2023, 8, 2134–2141. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Cr/% | Pa/% | In/% | Ps/% | Rs/% | Sc/% | mAP/% | FPS/Frame/s | Volume/MB | P/% | R/% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Two-stage | |||||||||||
| Faster RCNN | 52.0 | 90.4 | 85.9 | 78.1 | 60.4 | 92.2 | 76.5 | 33.2 | 113.2 | 44.7 | 82.4 |
| Cascade | 38.3 | 88.4 | 76.0 | 81.3 | 67.8 | 88.2 | 73.3 | 21.3 | 88.3 | 77.2 | 64.3 |
| One-stage | |||||||||||
| SSD | 43.7 | 93.5 | 80.8 | 83.7 | 56.3 | 75.7 | 72.3 | 98.0 | 98.2 | 75.1 | 65.9 |
| CenterNet | 44.2 | 88.8 | 78.8 | 77.5 | 52.0 | 87.1 | 71.4 | 131.6 | 131.0 | 72.5 | 34.5 |
| Efficientdet | 56.9 | 91.7 | 81.8 | 80.9 | 55.4 | 26.5 | 65.6 | 97.8 | 15.8 | 88.2 | 47.8 |
| YOLOX | 37.5 | 90.6 | 82.4 | 75.0 | 58.8 | 90.7 | 72.5 | 136.4 | 36.0 | 86.4 | 42.1 |
| YOLOv5 | 37.0 | 91.1 | 82.6 | 77.3 | 69.6 | 90.5 | 74.7 | 139.8 | 14.5 | 78.6 | 48.9 |
| YOLOv7 | 35.3 | 90.6 | 82.6 | 71.1 | 70.7 | 85.0 | 72.5 | 209.0 | 71.4 | 77.8 | 69.2 |
| YOLOv9 | 40.9 | 93.0 | 80.7 | 79.1 | 70.6 | 90.2 | 75.8 | 106.4 | 122.4 | 76.7 | 63.1 |
| YOLOv8 | 45.6 | 90.0 | 81.0 | 78.4 | 70.3 | 89.3 | 75.8 | 209.4 | 6.2 | 77.0 | 69.5 |
| This Research | 53.0 | 92.5 | 79.6 | 84.8 | 74.4 | 91.3 | 79.3 | 163.2 | 9.6 | 79.3 | 70.7 |
| Method | mAP/% | Improve/% | FPS | Weight/MB |
|---|---|---|---|---|
| YOLOv8-n | 75.8 | - | 209.4 | 6.2 |
| YOLOv8-n + ADSConv | 76.9 | 1.1 | 146.8 | 5.4 |
| YOLOv8-n + C2f_DWR | 76.5 | 0.7 | 225.5 | 6.2 |
| YOLOv8-n + MS-FDNet | 77.3 | 1.5 | 210.0 | 9.9 |
| ADSConv | C2f_DWR | MS-FDNet | mAP/% | Improve/% | FPS | Weight/MB |
|---|---|---|---|---|---|---|
| - | - | - | 75.8 | - | 209.4 | 6.2 |
| ✓ | ✓ | - | 78.4 | 2.6 | 117.5 | 6.9 |
| ✓ | - | ✓ | 77.5 | 1.7 | 176.7 | 9.8 |
| - | ✓ | ✓ | 78.5 | 2.7 | 147.5 | 9.8 |
| ✓ | ✓ | ✓ | 79.3 | 3.5 | 163.2 | 9.6 |
| The Position Replaced by ADSConv | mAP/% | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| F | T | T | T | T | 76.3 |
| F | T | T | T | T | 76.6 |
| F | F | F | T | T | 79.3 |
| F | F | F | F | T | 78.2 |
| Calculation Amount/GFLOPs | Parameters/M | |
|---|---|---|
| Conv-4 | 0.12 | 0.04 |
| Conv-5 | 0.10 | 0.29 |
| ADSConv-4 | 0.18 | 0.07 |
| ADSConv-5 | 0.12 | 0.25 |
| YOLOv8 | 8.5 | 3.02 |
| YOLOv8-n + ADSConv | 8.7 | 3.15 |
| The Position Replaced by C2f_DWR | mAP/% | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| F | T | T | T | 76.6 |
| F | F | T | T | 79.3 |
| F | F | F | T | 75.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, Q.; Wu, G.; Liu, Z.; Zeng, X. Improved of YOLOv8-n Algorithm for Steel Surface Defect Detection. Metals 2025, 15, 843. https://doi.org/10.3390/met15080843
Xiang Q, Wu G, Liu Z, Zeng X. Improved of YOLOv8-n Algorithm for Steel Surface Defect Detection. Metals. 2025; 15(8):843. https://doi.org/10.3390/met15080843
Chicago/Turabian StyleXiang, Qingqing, Gang Wu, Zhiqiang Liu, and Xudong Zeng. 2025. "Improved of YOLOv8-n Algorithm for Steel Surface Defect Detection" Metals 15, no. 8: 843. https://doi.org/10.3390/met15080843
APA StyleXiang, Q., Wu, G., Liu, Z., & Zeng, X. (2025). Improved of YOLOv8-n Algorithm for Steel Surface Defect Detection. Metals, 15(8), 843. https://doi.org/10.3390/met15080843