
On the Use of Machine Learning Algorithms to Predict the Corrosion Behavior of Stainless Steels in Lactic Acid


Abstract
1. Introduction
- Resistant: Corresponding to a mass loss rate of less than 0.1 g/h/m2 or less than 0.11 mm/year decrease in thickness.
- Good: Corresponding to a mass loss rate ranges from 0.1 to 1.0 g/h/m2 or 0.11 to 1.10 mm/year decrease in thickness.
- Poor: Corresponding to a mass loss rate ranges from 1.0 to 10.0 g/h/m2 or 1.1 to 11.0 mm/year decrease in thickness.
- Questionable: Corresponding to a mass loss rate exceeding 10.0 g/h/m2 or 11.0 mm/year decrease in thickness, or being susceptible to local corrosion, pitting, crevice, or stress corrosion.
2. Methodology
2.1. Corrosion Data Preprocessing
2.2. ML Approach
2.3. Feature Reduction
3. Results and Discussion
3.1. DT Model
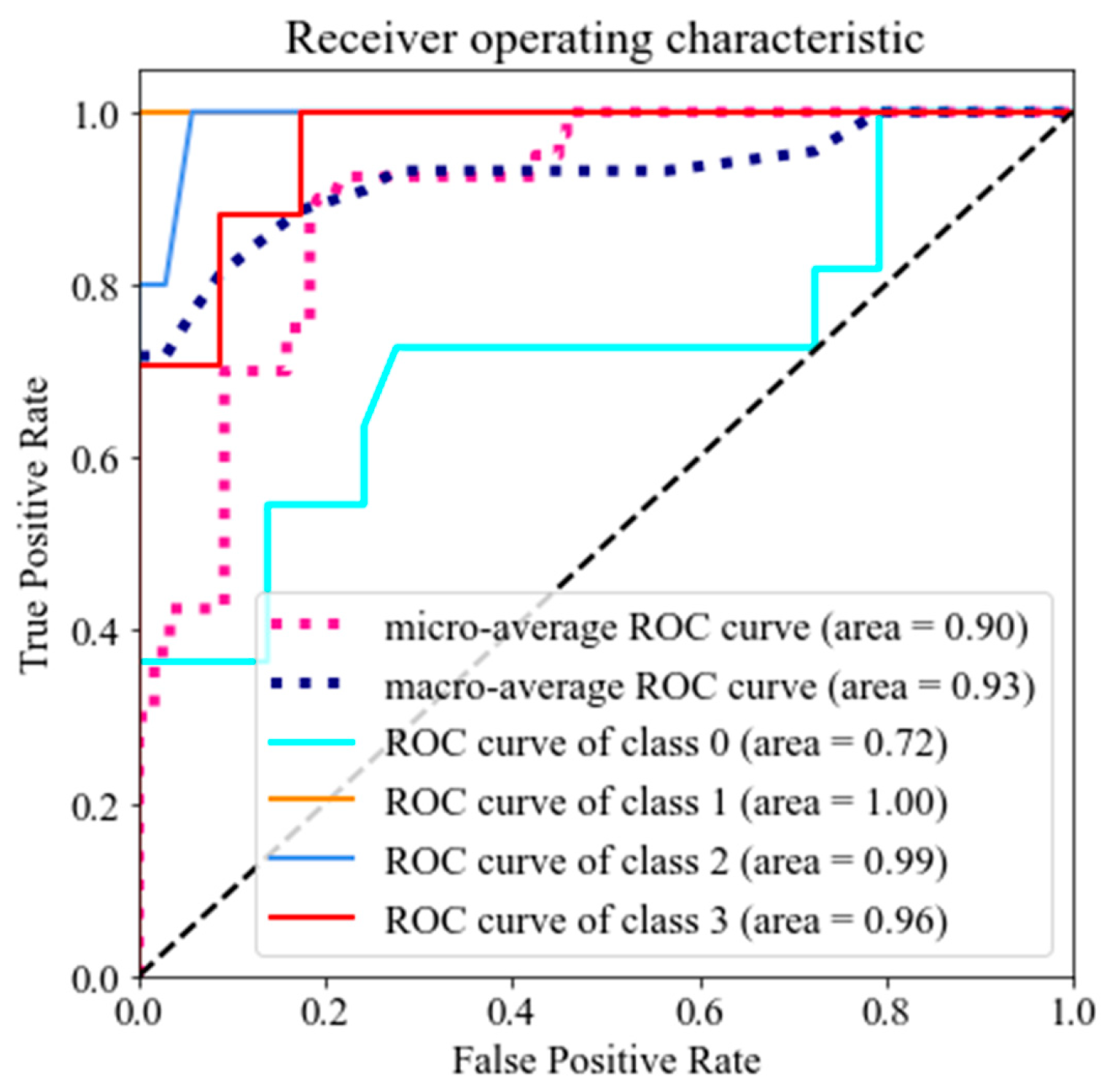
3.2. RF Model
3.3. SVM Model
3.4. Feature Reduction
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dastgerdi, A.A.; Brenna, A.; Ormellese, M.; Pedeferri, M.P.; Bolzoni, F. Experimental Design to Study the Influence of Temperature, PH, and Chloride Concentration on the Pitting and Crevice Corrosion of UNS S30403 Stainless Steel. Corros. Sci. 2019, 159, 108160. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, L.; Zhang, Z.; Lu, M. Combined Effect of PH and H2S on the Structure of Passive Film Formed on Type 316L Stainless Steel. Appl. Surf. Sci. 2018, 458, 686–699. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, Q.; Yang, X.; Wang, Z.; Liu, J.; Li, Z. The Journal of Supercritical Fluids Impact of Surface Roughness and Humidity on X70 Steel Corrosion in Supercritical CO2 Mixture with SO. J. Supercrit. Fluids 2016, 107, 286–297. [Google Scholar] [CrossRef]
- Patel, S.; Rogalsky, A.; Vlasea, M. Towards Understanding Side-Skin Surface Characteristics in Laser Powder Bed Fusion. J. Mater. Res. 2020, 35, 2055–2064. [Google Scholar] [CrossRef]
- Xu, W.; Li, Y.; Li, H.; Wang, K.; Zhang, C.; Jiang, Y.; Qiang, S. Corrosion Mechanism and Damage Characteristic of Steel Fiber Concrete under the Effect of Stray Current and Salt Solution. Constr. Build. Mater. 2022, 314, 125618. [Google Scholar] [CrossRef]
- Huang, S.; Yang, Y.; Li, Z.; Liu, Y.; Su, D. Corrosion Behavior and Mechanism of P110 Casing Steel in Alkaline-Activated Persulfate-Based Preflush Fluid. Eng. Fail. Anal. 2023, 152, 107482. [Google Scholar] [CrossRef]
- Sun, J.; Tang, H.; Wang, C.; Han, Z.; Li, S. Effects of Alloying Elements and Microstructure on Stainless Steel Corrosion: A Review. Steel Res. Int. 2022, 93, 2100450. [Google Scholar] [CrossRef]
- Jiménez-Come, M.J.; de la Luz Martín, M.; Matres, V. A Support Vector Machine-Based Ensemble Algorithm for Pitting Corrosion Modeling of EN 1.4404 Stainless Steel in Sodium Chloride Solutions. Mater. Corros. 2019, 70, 19–27. [Google Scholar] [CrossRef]
- Yan, L.; Diao, Y.; Lang, Z.; Gao, K. Corrosion Rate Prediction and Influencing Factors Evaluation of Low-Alloy Steels in Marine Atmosphere Using Machine Learning Approach. Sci. Technol. Adv. Mater. 2020, 21, 359–370. [Google Scholar] [CrossRef]
- Pei, Z.; Zhang, D.; Zhi, Y.; Yang, T.; Jin, L.; Fu, D.; Cheng, X.; Terryn, H.A.; Mol, J.M.C.; Li, X. Towards Understanding and Prediction of Atmospheric Corrosion of an Fe/Cu Corrosion Sensor via Machine Learning. Corros. Sci. 2020, 170, 108697. [Google Scholar] [CrossRef]
- Gedge, G. Structural Uses of Stainless Steel—Buildings and Civil Engineering. J. Constr. Steel Res. 2008, 64, 1194–1198. [Google Scholar] [CrossRef]
- Zaffora, A.; Di Franco, F.; Santamaria, M. Corrosion of Stainless Steel in Food and Pharmaceutical Industry. Curr. Opin. Electrochem. 2021, 29, 100760. [Google Scholar] [CrossRef]
- Moradi, M.; Guimarães, J.T.; Sahin, S. Current Applications of Exopolysaccharides from Lactic Acid Bacteria in the Development of Food Active Edible Packaging. Curr. Opin. Food Sci. 2021, 40, 33–39. [Google Scholar] [CrossRef]
- Alsaheb, R.A.A.; Aladdin, A.; Othman, Z.; Malek, R.A.; Leng, O.M.; Aziz, R.; Enshasy, H.A. El Lactic Acid Applications in Pharmaceutical and Cosmeceutical Industries. J. Chem. Pharm. Res. 2015, 7, 729–735. [Google Scholar]
- Diao, Y.; Yan, L.; Gao, K. Improvement of the Machine Learning-Based Corrosion Rate Prediction Model through the Optimization of Input Features. Mater. Des. 2021, 198, 109326. [Google Scholar] [CrossRef]
- Lv, Y.J.; Wang, J.W.; Wang, J.; Xiong, C.; Zou, L.; Li, L.; Li, D.W. Steel Corrosion Prediction Based on Support Vector Machines. Chaos Solitons Fractals 2020, 136, 109807. [Google Scholar] [CrossRef]
- Wang, A.Y.T.; Murdock, R.J.; Kauwe, S.K.; Oliynyk, A.O.; Gurlo, A.; Brgoch, J.; Persson, K.A.; Persson, K.A.; Sparks, T.D. Machine Learning for Materials Scientists: An Introductory Guide toward Best Practices. Chem. Mater. 2020, 32, 4954–4965. [Google Scholar] [CrossRef]
- Kamrunnahar, M.; Urquidi-Macdonald, M. Prediction of Corrosion Behavior Using Neural Network as a Data Mining Tool. Corros. Sci. 2010, 52, 669–677. [Google Scholar] [CrossRef]
- Wen, Y.F.; Cai, C.Z.; Liu, X.H.; Pei, J.F.; Zhu, X.J.; Xiao, T.T. Corrosion Rate Prediction of 3C Steel under Different Seawater Environment by Using Support Vector Regression. Corros. Sci. 2009, 51, 349–355. [Google Scholar] [CrossRef]
- Hakimian, S.; Pourrahimi, S.; Bouzid, A.H.; Hof, L.A. Application of Machine Learning for the Classification of Corrosion Behavior in Different Environments for Material Selection of Stainless Steels. Comput. Mater. Sci. 2023, 228, 112352. [Google Scholar] [CrossRef]
- Cavanaugh, M.K.; Buchheit, R.G.; Birbilis, N. Modeling the Environmental Dependence of Pit Growth Using Neural Network Approaches. Corros. Sci. 2010, 52, 3070–3077. [Google Scholar] [CrossRef]
- Li, X.; Jia, R.; Zhang, R.; Yang, S.; Chen, G. A KPCA-BRANN Based Data-Driven Approach to Model Corrosion Degradation of Subsea Oil Pipelines. Reliab. Eng. Syst. Saf. 2022, 219, 108231. [Google Scholar] [CrossRef]
- Shi, J.; Wang, J.; Macdonald, D.D. Prediction of Primary Water Stress Corrosion Crack Growth Rates in Alloy 600 Using Artificial Neural Networks. Corros. Sci. 2015, 92, 217–227. [Google Scholar] [CrossRef]
- Chico, B.; Díaz, I.; Simancas, J.; Morcillo, M. Annual Atmospheric Corrosion of Carbon Steel Worldwide. An Integration of ISOCORRAG, ICP/UNECE and MICAT Databases. Materials 2017, 10, 601. [Google Scholar] [CrossRef]
- Cai, Y.; Zhao, Y.; Ma, X.; Zhou, K.; Wang, H. Application of Hierarchical Linear Modelling to Corrosion Prediction in Different Atmospheric Environments. Corros. Eng. Sci. Technol. 2019, 54, 266–275. [Google Scholar] [CrossRef]
- Pruksawan, S.; Lambard, G.; Samitsu, S.; Sodeyama, K.; Naito, M. Prediction and Optimization of Epoxy Adhesive Strength from a Small Dataset through Active Learning. Sci. Technol. Adv. Mater. 2019, 20, 1010. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Fu, D.; Zhou, X.; Yang, T.; Zhi, Y.; Pei, Z.; Zhang, D.; Shao, L. Data Mining to Online Galvanic Current of Zinc/Copper Internet Atmospheric Corrosion Monitor. Corros. Sci. 2018, 133, 443–450. [Google Scholar] [CrossRef]
- Pintos, S.; Queipo, N.V.; Troconis De Rincón, O.; Rincón, A.; Morcillo, M. Artificial Neural Network Modeling of Atmospheric Corrosion in the MICAT Project. Corros. Sci. 2000, 42, 35–52. [Google Scholar] [CrossRef]
- Singh, S.; Singhania, S.; Pandya, V.; Singal, A.; Biwalkar, A. East Meets West: Sentiment Analysis for Election Prediction. Stud. Comput. Intell. 2022, 1027, 9–20. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Kaufmann, M. Data Mining: Concepts and Techniques, 2nd ed.; Classification and Prediction; Morgan Kaufmann: San Francisco, CA, USA, 2006. [Google Scholar]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Gill, S.; Pathwar, P. Prediction of Diabetes Using Various Feature Selection and Machine Learning Paradigms. Stud. Comput. Intell. 2022, 1027, 133–146. [Google Scholar] [CrossRef]
- Jalal, N.; Mehmood, A.; Choi, G.S.; Ashraf, I. A Novel Improved Random Forest for Text Classification Using Feature Ranking and Optimal Number of Trees. J. King Saud. Univ.-Comput. Inf. Sci. 2022, 34, 2733–2742. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A Survey of Decision Tree Classifier Methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G.; Askarian, B.; Hasanipanah, M.; Tarinejad, R.; Van Huynh, V. Examining Hybrid and Single SVM Models with Different Kernels to Predict Rock Brittleness. Sustainability 2020, 12, 2229. [Google Scholar] [CrossRef]
- Mennitt, D.; Sherrill, K.; Fristrup, K. A Geospatial Model of Ambient Sound Pressure Levels in the Contiguous United States. J. Acoust. Soc. Am. 2014, 135, 2746–2764. [Google Scholar] [CrossRef]
- Craig, B.D.; Anderson, D.B. Lactic Acid. In Handbook of Corrosion Data, 2nd ed.; ASM International: Almere, The Netherlands, 1995; pp. 488–492. ISBN 978-0-87170-518-1. [Google Scholar]
- Society of Automotive Engineers; American Society for Testing and Materials. Metals & Alloys in the Unified Numbering System; SAE International: Warrendale, PA, USA, 2008; p. 583. [Google Scholar]
- Pedregosa, F.; Michel, V.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; Cournapeau, D.; Pedregosa, F.; Varoquaux, G.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hanley, J.A.; McNeil, B.J. The Meaning and Use of the Area under a Receiver Operating Characteristic (ROC) Curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef]
- Cortes, C.; Mohri, M. AUC Optimization vs. Error Rate Minimization. Adv. Neural Inf. Process. Syst. 2003, 16, 313–320. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; pp. 1–600. [Google Scholar]
- Lin, H.; Chen, W. Prediction of Thermophilic Proteins Using Feature Selection Technique. J. Microbiol. Methods 2011, 84, 67–70. [Google Scholar] [CrossRef] [PubMed]
- Ding, H.; Guo, S.H.; Deng, E.Z.; Yuan, L.F.; Guo, F.B.; Huang, J.; Rao, N.; Chen, W.; Lin, H. Prediction of Golgi-Resident Protein Types by Using Feature Selection Technique. Chemom. Intell. Lab. Syst. 2013, 124, 9–13. [Google Scholar] [CrossRef]
- Ding, H.; Feng, P.M.; Chen, W.; Lin, H. Identification of Bacteriophage Virion Proteins by the ANOVA Feature Selection and Analysis. Mol. Biosyst. 2014, 10, 2229–2235. [Google Scholar] [CrossRef] [PubMed]
- Olefjord, I.; Elfstrom, B.O. The Composition of the Surface during Passivation of Stainless Steels. Corrosion 1982, 38, 46–52. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stainless Steels | %C | %Mn | %Si | %P | %S | %Cr | %Mo | %Ni | %N | %Ti | %Nb + Ta | %Al | %Fe |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 301 | 0.15 | 2 | 1 | 0.045 | 0.03 | 16 | - | 6 | - | - | - | - | 74.77 |
| 302 | 0.15 | 2 | 0.75 | 0.05 | 0.03 | 17 | - | 8 | 0.1 | - | - | - | 71.92 |
| 303 | 0.15 | 2 | 1 | 0.2 | 0.35 | 17 | - | 8 | - | - | - | - | 71.3 |
| 304 | 0.08 | 2 | 0.75 | 0.05 | 0.03 | 18 | - | 8 | 0.1 | - | - | - | 70.99 |
| 304L | 0.03 | 2 | 0.75 | 0.05 | 0.03 | 18 | - | 8 | 0.1 | - | - | - | 71.04 |
| 304LN | 0.03 | 2 | 0.75 | 0.05 | 0.03 | 18 | - | 8 | 0.16 | - | - | - | 70.98 |
| 316 | 0.08 | 2 | 0.75 | 0.05 | 0.03 | 16 | 2 | 10 | 0.1 | - | - | - | 68.99 |
| 316L | 0.03 | 2 | 0.75 | 0.05 | 0.03 | 16 | 2 | 10 | 0.1 | - | - | - | 69.04 |
| 316LN | 0.03 | 2 | 1 | 0.05 | 0.03 | 16 | 2 | 10 | 0.3 | - | - | - | 68.59 |
| 316 Ti | 0.08 | 2 | 1 | 0.05 | 0.03 | 16 | 2 | 10 | 0.1 | 0.7 | - | - | 68.04 |
| 317L | 0.03 | 2 | 1 | 0.05 | 0.03 | 18 | 3 | 11 | 0.1 | - | - | - | 64.79 |
| 317LN | 0.03 | 2 | 1 | 0.05 | 0.03 | 18 | 3 | 11 | 0.22 | - | - | - | 64.67 |
| 321 | 0.08 | 2 | 0.75 | 0.05 | 0.03 | 17 | - | 9 | 0.1 | 0.7 | - | - | 70.29 |
| 329 | 0.05 | 2 | 1 | 0.05 | 0.02 | 25 | 1.3 | 4.5 | 0.05 | - | - | - | 66.04 |
| 347 | 0.08 | 2 | 1 | 0.05 | 0.03 | 17 | - | 9 | - | - | 1 | - | 69.84 |
| 403 | 0.15 | 2 | 1 | 0.05 | 0.03 | 11.5 | - | - | - | - | - | - | 85.27 |
| 405 | 0.08 | 1 | 1 | 0.05 | 0.03 | 11.5 | - | - | - | - | - | 0.1 | 86.24 |
| 409 | 0.08 | 1 | 1 | 0.05 | 0.05 | 10.5 | - | 0.5 | - | 0.7 | - | - | 86.13 |
| 410 | 0.15 | 1 | 1 | 0.05 | 0.03 | 11.5 | - | 0.75 | - | - | - | - | 85.52 |
| 416 | 0.15 | 1.25 | 1 | 0.06 | 0.15 | 12 | - | - | - | - | - | - | 85.39 |
| 420 | 0.15 | 1 | 1 | 0.05 | 0.03 | 12 | - | - | - | - | - | - | 85.77 |
| 430 | 0.12 | 1 | 1 | 0.05 | 0.03 | 16 | - | - | - | - | - | - | 81.8 |
| 434 | 0.08 | 1 | 1 | 0.05 | 0.03 | 16 | 0.75 | - | - | - | - | - | 81.09 |
| F51 | 0.03 | 2 | 1 | 0.05 | 0.03 | 21 | 2.5 | 4.5 | 0.08 | - | - | - | 68.81 |
| Feature | Unit | Descriptions |
|---|---|---|
| Material | wt% | C amount Mn amount Si amount P amount S amount Cr amount Mo amount Ni amount N amount Ti amount Nb and Ta amount Al amount Fe amount |
| Lactic acid concentration | % | - |
| Temperature | °C | - |
| Corrosion behavior | Qualitative | Questionable Poor Good Resistant |
| Labels | Number of Labels | Defined Value |
|---|---|---|
| Questionable | 23 | 2 |
| Poor | 22 | 1 |
| Good | 58 | 0 |
| Resistant | 95 | 3 |
| Rank | Feature Name | Rank | Feature Name | Rank | Feature Name |
|---|---|---|---|---|---|
| 1 | Fe | 6 | C | 11 | Al |
| 2 | Ni | 7 | N | 12 | S |
| 3 | Cr | 8 | Mo | 13 | P |
| 4 | Temperature | 9 | Lactic acid concentration | 14 | Nb, Ta |
| 5 | Mn | 10 | Si | 15 | Ti |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pourrahimi, S.; Hakimian, S.; Bouzid, A.-H.; Hof, L.A. On the Use of Machine Learning Algorithms to Predict the Corrosion Behavior of Stainless Steels in Lactic Acid. Metals 2023, 13, 1459. https://doi.org/10.3390/met13081459
Pourrahimi S, Hakimian S, Bouzid A-H, Hof LA. On the Use of Machine Learning Algorithms to Predict the Corrosion Behavior of Stainless Steels in Lactic Acid. Metals. 2023; 13(8):1459. https://doi.org/10.3390/met13081459
Chicago/Turabian StylePourrahimi, Shamim, Soroosh Hakimian, Abdel-Hakim Bouzid, and Lucas A. Hof. 2023. "On the Use of Machine Learning Algorithms to Predict the Corrosion Behavior of Stainless Steels in Lactic Acid" Metals 13, no. 8: 1459. https://doi.org/10.3390/met13081459
APA StylePourrahimi, S., Hakimian, S., Bouzid, A.-H., & Hof, L. A. (2023). On the Use of Machine Learning Algorithms to Predict the Corrosion Behavior of Stainless Steels in Lactic Acid. Metals, 13(8), 1459. https://doi.org/10.3390/met13081459