

Automatic Detection of Sorbite Content in High Carbon Steel Wire Rod

Abstract
1. Introduction
2. Acquisition and Calibration of Data Set
2.1. Sample Preparation
2.2. Image Calibration
3. Model and Method
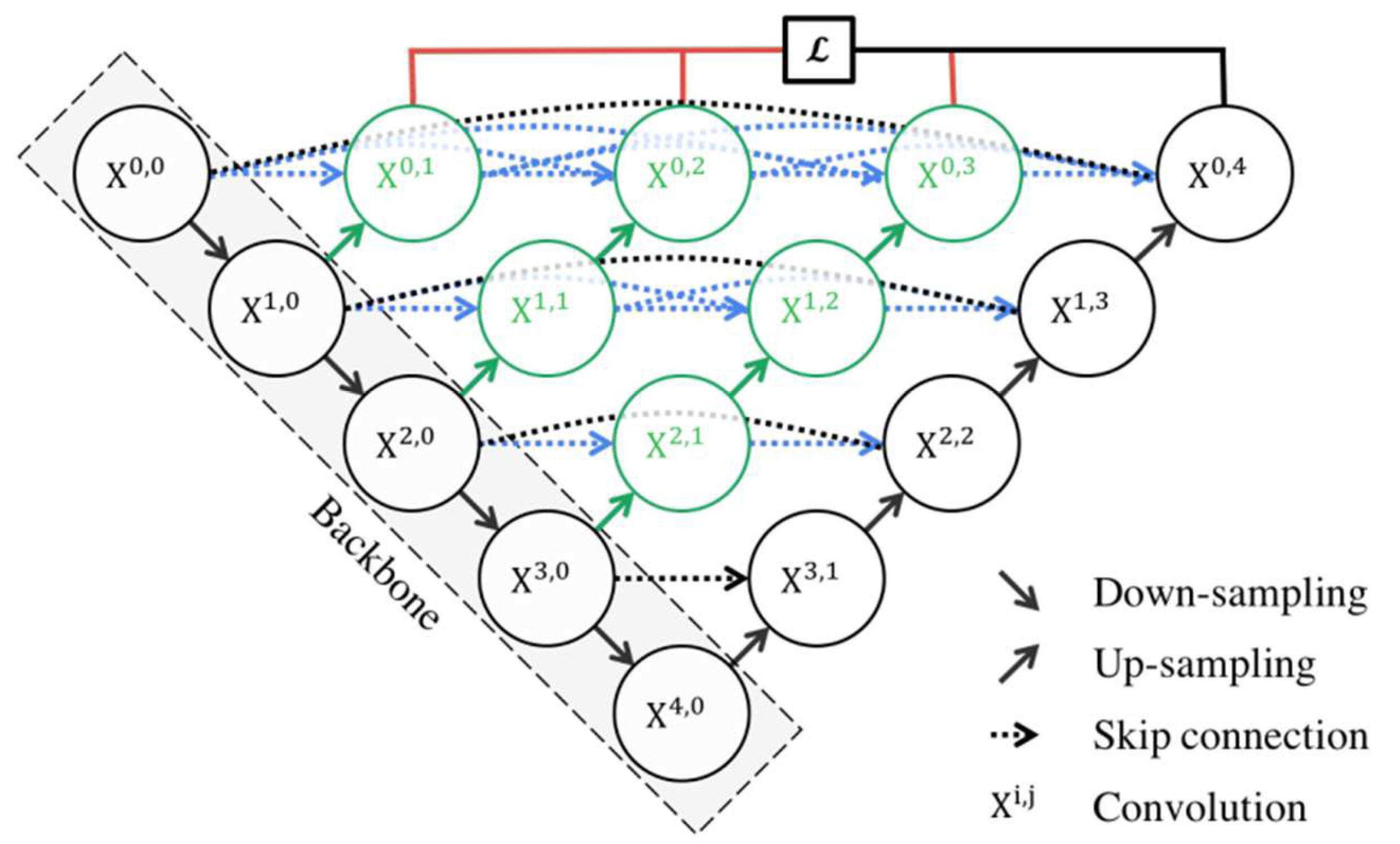
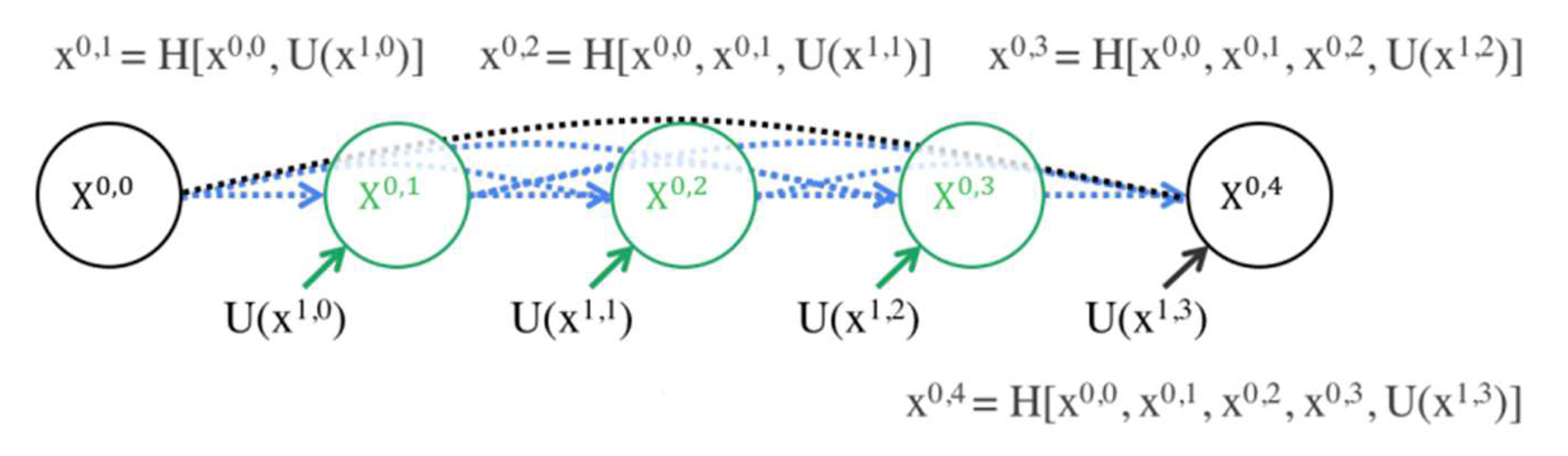
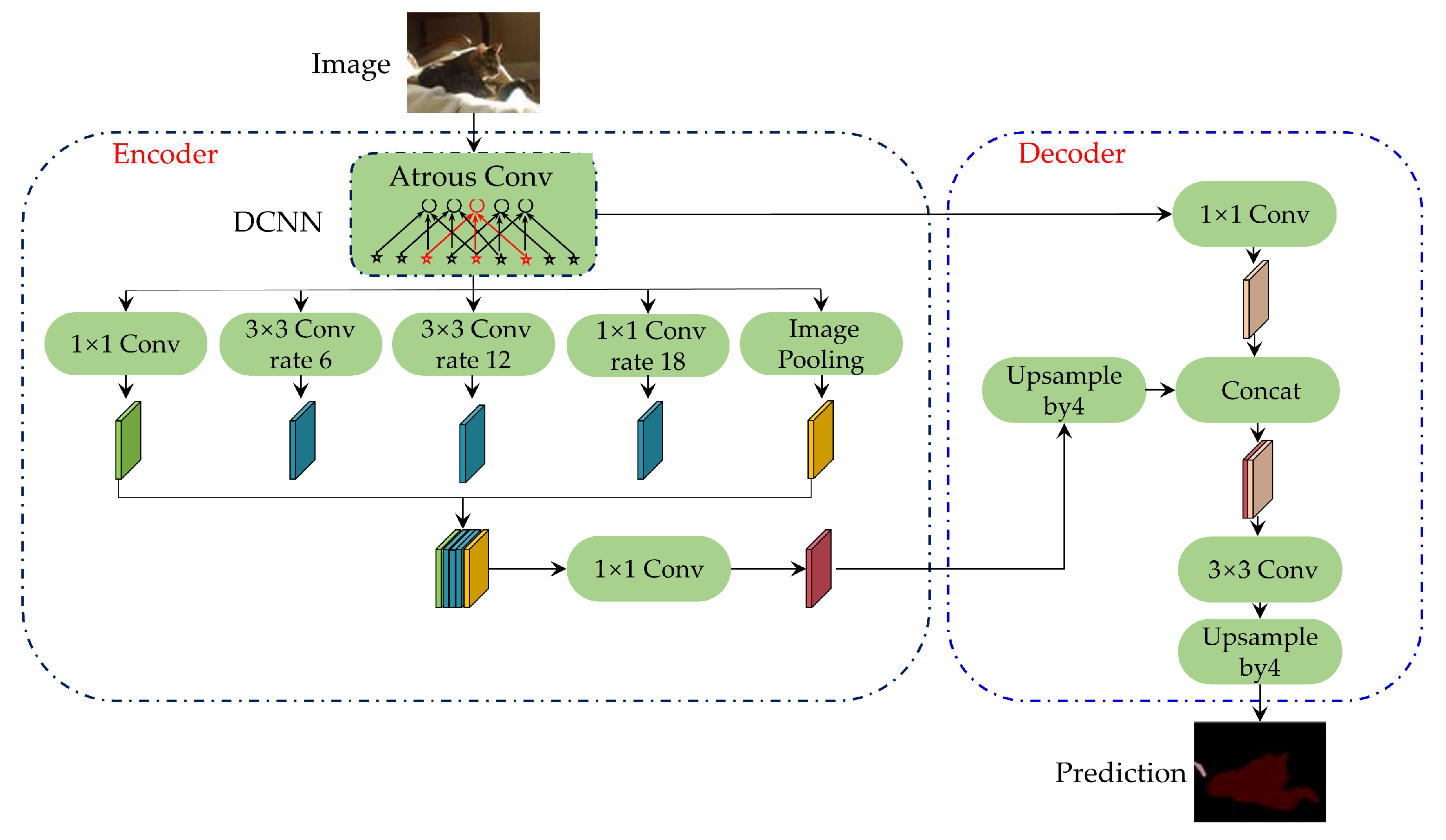
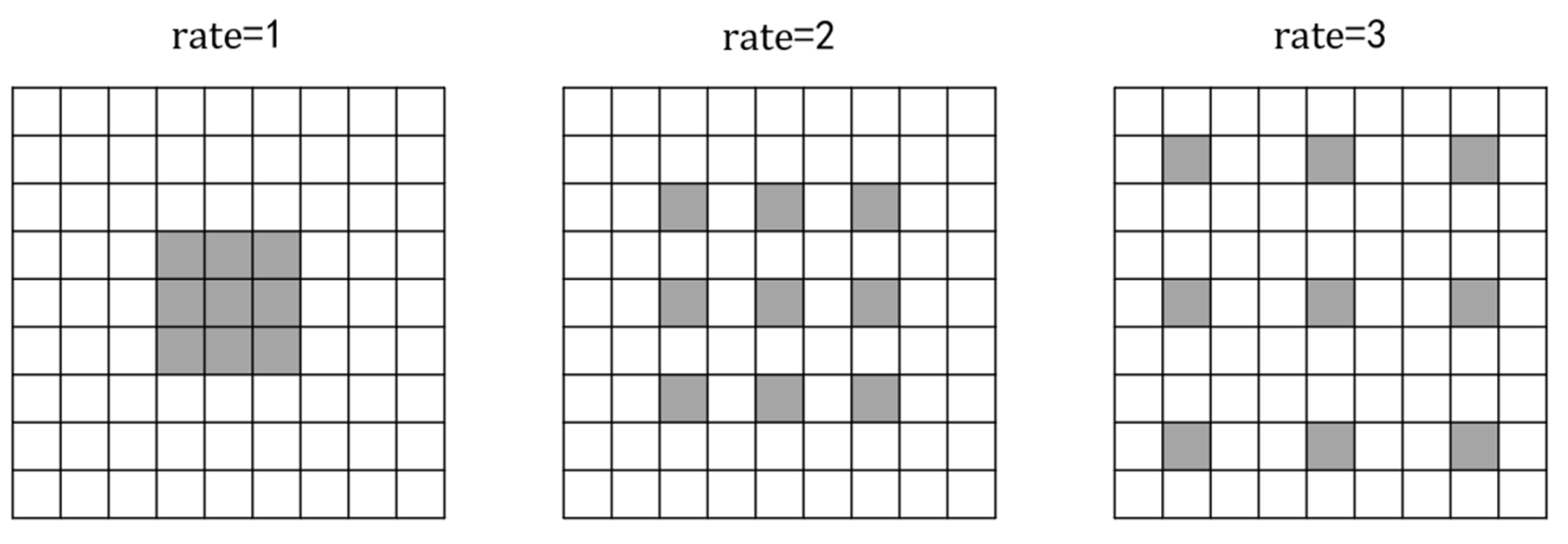
3.1. Network Architecture
3.2. Loss Function
3.3. Data Augmentation
3.4. Training and Evaluation Indexes of the Model
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, X.Z.; Xiao, M.D.; Zhang, Z.Y.; Li, F.Q.; Zhu, X.R. Recognition discussion about sorbite in high-carbon wire rod steel based on artificial intelligence. Phys. Exam. Test. 2021, 39, 34–37. [Google Scholar] [CrossRef]
- YB/T 169-2014; Metallographic Test Method of Sorbite in High Carbon Steel Wire Rod. National Steel Standardization Technical Committee: Beijing, China, 2014.
- Wang, K.J.; Liu, H.Y. Categories and Morphological Features of Metallographic Microstructure in High Carbon Stelmor Wire Rods. Phys. Exam. Test. 2013, 31, 1–5. [Google Scholar] [CrossRef]
- Ren, Z.G.; Ren, G.Q.; Wu, D.H. Deep Learning Based Feature Selection Algorithm for Small Targets Based on mRMR. Micromachines 2022, 13, 1765. [Google Scholar] [CrossRef] [PubMed]
- Vaiyapuri, T.; Srinivasan, S.; Sikkandarn, M.Y.; Balaji, T.S.; Kadry, S.; Meqdad, M.N.; Nam, Y.Y. Intelligent Deep Learning Based Multi-Retinal Disease Diagnosis and Classification Framework. Comput. Mater. Contin. 2022, 73, 5543–5557. [Google Scholar] [CrossRef]
- Chowdhury, A.; Kautz, E.; Yener, B.; Lewis, D. Image driven machine learning methods for microstructure recognition. Comput. Mater. Sci. 2016, 123, 176–187. [Google Scholar] [CrossRef]
- Azimi, S.M.; Britz, D.; Engstler, M.; Fritz, M.; Mücklich, F. Advanced steel microstructural classification by deep learning methods. Sci. Rep. 2018, 8, 2128. [Google Scholar] [CrossRef] [PubMed]
- Park, H.; Öztürk, A. Machine Learning Approach on Steel Microstructure Classification. In Proceedings of the Europe-Korea Conference on Science and Technology, Vienna, Austria, 15–18 July 2021; pp. 13–23. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Zhou, Z.W.; Rahman, S.M.M.; Tajbakhsh, N.; Liang, J.M. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Proceedings of the DLMIA ML-CDS, Granada, Spain, 20 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Huo, Y.; Li, X.; Tu, B. Image Measurement of Crystal Size Growth during Cooling Crystallization Using High-Speed Imaging and a U-Net Network. Crystals 2022, 12, 1690. [Google Scholar] [CrossRef]
- Li, Z.Z.; Yin, H.; Zuo, J.K.; Sun, Y.F. Ship Detection Model Based on UNet++ Network and Multiple Side-Output Fusion Strategy. Comput. Eng. 2022, 48, 276–283. [Google Scholar]
- Lv, B.L.; Li, Z.F.; Xi, Z.H.; Yao, Y.M.; Ji, J.J. Component Analysis of Coal Rock Microscopic Image Based on UNet++. Comput. Digit. Eng. 2022, 50, 389–393, 404. [Google Scholar]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice Loss for Data-Imbalanced NLP Tasks. In Proceedings of the Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar]
- Sun, Y.Q.; Chen, X.Y.; Zhang, P.; Zhou, Y. Analysis and discussion on the sorbite volume fraction measurement method of 72A steel wire rod. Phys. Exam. Test. 2015, 33, 25–28. [Google Scholar] [CrossRef]
- Cai, W.; Zheng, J.W.; Qiao, L.; Qiang, L.Q. Indentification on Sorbite Structure in 82A High Carbon Steel Wire. Spec. Steel 2010, 31, 59–62. [Google Scholar] [CrossRef]
- Zhao, X.P.; Liu, Z.P.; Xiao, J.; Wu, H.L. Application of Digital Image Storage Technology in the Determination of Sorbite Content in High Carbon Wire Rod. Liugang Sci. Technol. 2017, 4, 42–45. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sorbite Content/% | [0–50) | [50–60) | [60–70) | [70–80) | [80–90) | (≥90) |
| Sample Proportion/% | 0 | 4.7 | 12.2 | 26.6 | 38.3 | 18.2 |
| Seg_Model | Backbone | mPA | MIoU | MAE | Epoch Time(s) |
|---|---|---|---|---|---|
| DeepLabv3+ | ResNet34 | 94.28% | 74.89% | 4.17 | 9 |
| U-Net++ | ResNet34 | 93.58% | 73.24% | 4.68 | 9 |
| No. | Prediction | Truth | MAE |
|---|---|---|---|
| 1 | 81.18 | 85.69 | 4.51 |
| 2 | 85.79 | 85.43 | 0.36 |
| 3 | 87.11 | 86.62 | 0.49 |
| 4 | 90.71 | 88.99 | 1.71 |
| 5 | 91.58 | 89.32 | 2.26 |
| 6 | 92.35 | 90.29 | 2.06 |
| 7 | 92.08 | 90.36 | 1.72 |
| 8 | 90.05 | 89.63 | 0.42 |
| 9 | 90.11 | 87.98 | 2.13 |
| 10 | 90.67 | 88.70 | 1.96 |
| 11 | 88.31 | 86.57 | 1.73 |
| 12 | 87.65 | 85.89 | 1.75 |
| 13 | 85.06 | 89.95 | 4.88 |
| 14 | 91.27 | 91.27 | 0.00 |
| 15 | 90.34 | 87.14 | 3.20 |
| Loss | mPA | MIoU | MAE | Epoch Time(s) |
|---|---|---|---|---|
| Focal Loss + Dice Loss | 94.28% | 74.89% | 4.17 | 9 |
| Focal Loss | 94.18% | 73.18% | 4.46 | 9 |
| Dice Loss | 71.01% | 52.76% | 21.89 | 9 |
| Training Set\Test Set | Test Set 1 | Test Set 2 | Test Set 3 |
|---|---|---|---|
| Training set 1 | 3.36 | 3.84 | 4.18 |
| Training set 2 | 7.40 | 5.77 | 8.09 |
| Training set 3 | 8.56 | 9.19 | 4.43 |
| Training Set\Test Set | Test Set 1 | Test Set 2 | Test Set 3 |
|---|---|---|---|
| Training set 1 | 3.47 | 3.79 | 3.51 |
| Training set 2 | 6.65 | 5.50 | 7.19 |
| Training set 3 | 7.82 | 8.02 | 4.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Qian, L.; Yao, Q.; Huang, G.; Xu, F.; Chen, X.; Yao, Z. Automatic Detection of Sorbite Content in High Carbon Steel Wire Rod. Metals 2023, 13, 990. https://doi.org/10.3390/met13050990
Zhu X, Qian L, Yao Q, Huang G, Xu F, Chen X, Yao Z. Automatic Detection of Sorbite Content in High Carbon Steel Wire Rod. Metals. 2023; 13(5):990. https://doi.org/10.3390/met13050990
Chicago/Turabian StyleZhu, Xiaolin, Ling Qian, Qiang Yao, Guanxi Huang, Fan Xu, Xue Chen, and Zhengjun Yao. 2023. "Automatic Detection of Sorbite Content in High Carbon Steel Wire Rod" Metals 13, no. 5: 990. https://doi.org/10.3390/met13050990
APA StyleZhu, X., Qian, L., Yao, Q., Huang, G., Xu, F., Chen, X., & Yao, Z. (2023). Automatic Detection of Sorbite Content in High Carbon Steel Wire Rod. Metals, 13(5), 990. https://doi.org/10.3390/met13050990