A Comparative Assessment of Six Machine Learning Models for Prediction of Bending Force in Hot Strip Rolling Process

Abstract
1. Introduction
2. Case Study and Data
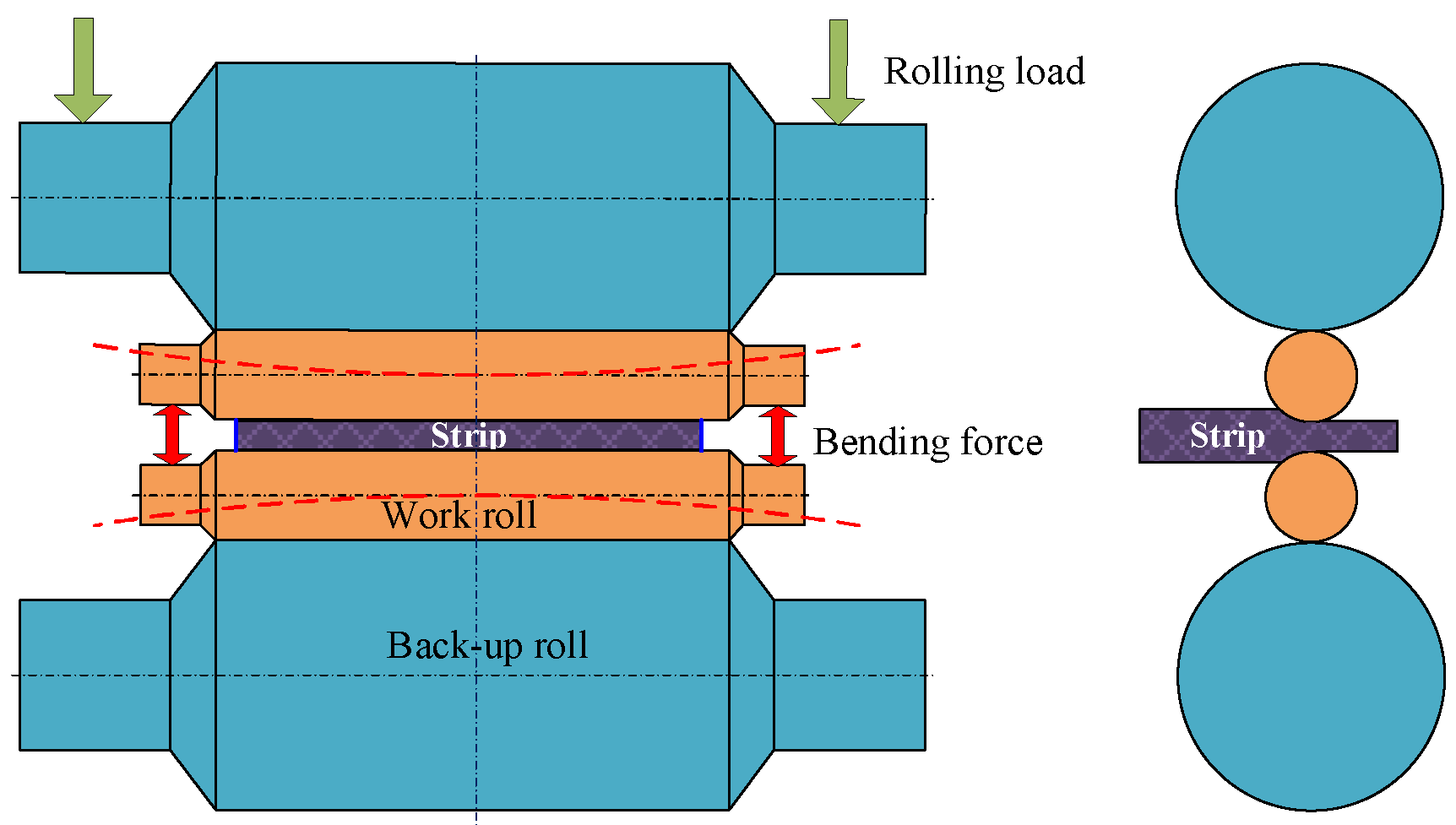
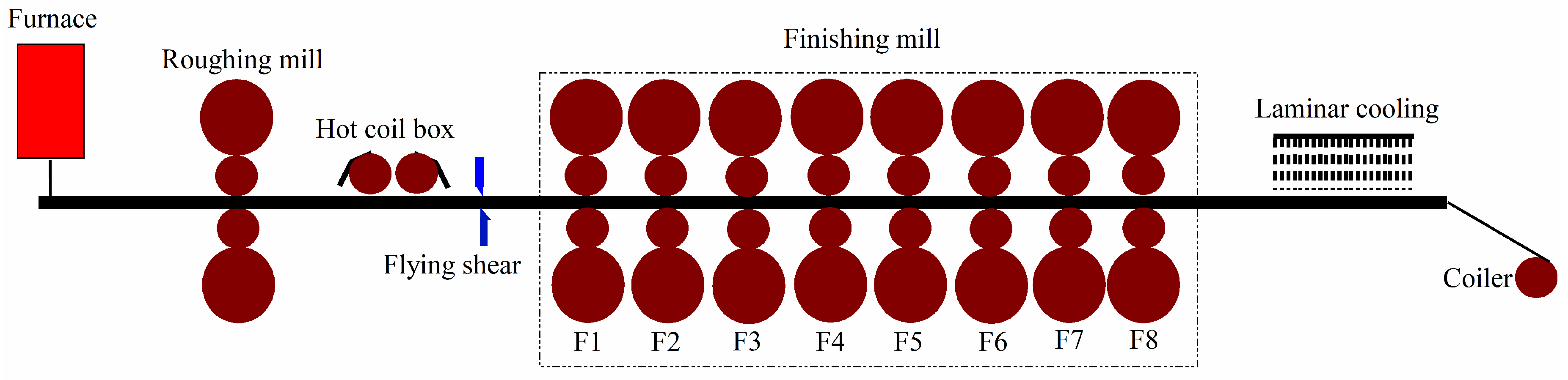
2.1. Hot Rolling Technology and Bending Force
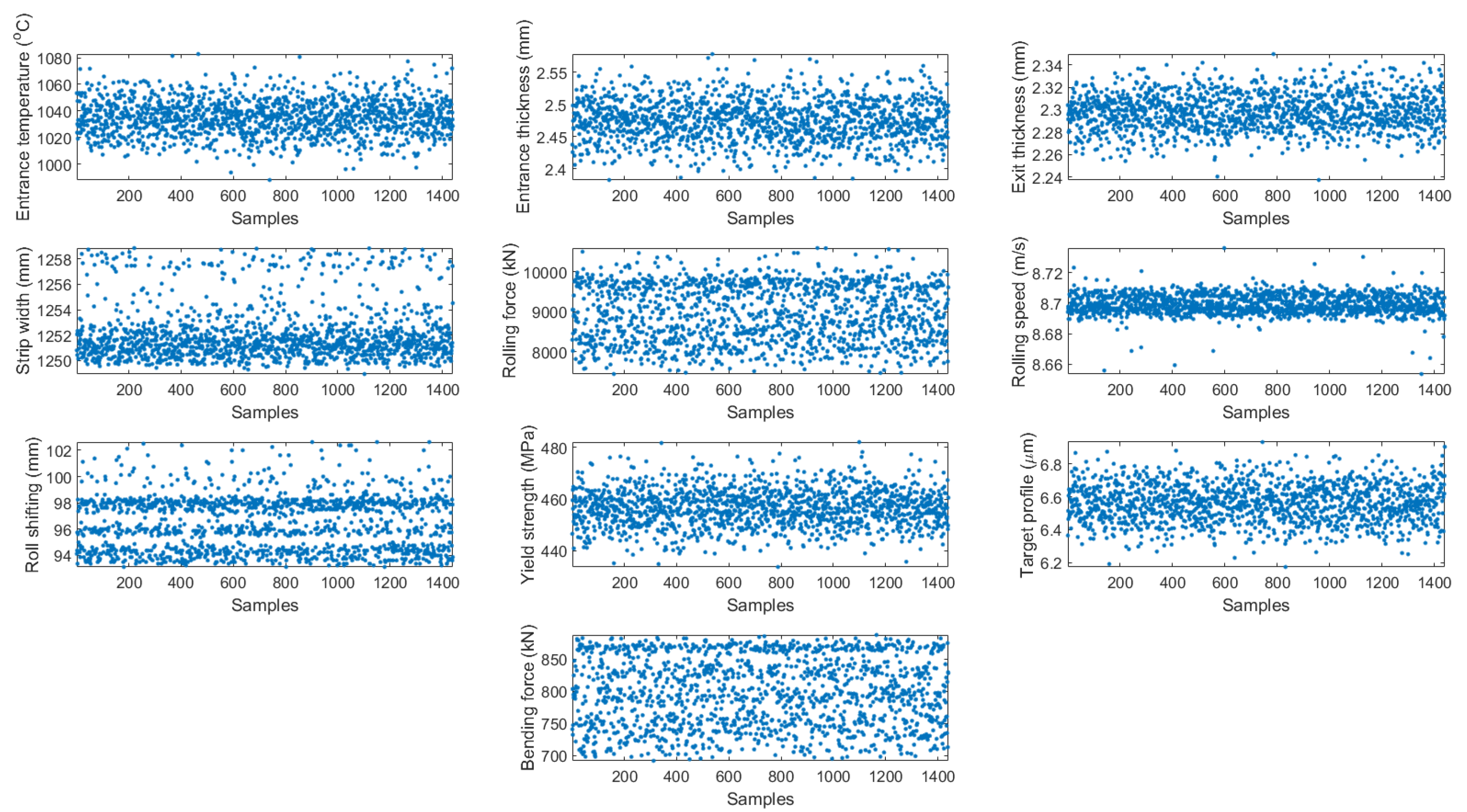
2.2. Data Collection and Analysis
3. Methodology
3.1. Artificial Neural Network (ANN)
3.2. Support Vector Machine (SVM)
3.3. Classification and Regression Tree (CART)
3.4. Bagging Regression Tree (BRT)
3.5. Least Absolute Shrinkage and Selection Operator (LASSO)
3.6. Gaussian Process Regression (GPR)
3.7. Model Information
3.8. Comparison of Model and Statistical Error Analysis
4. Results
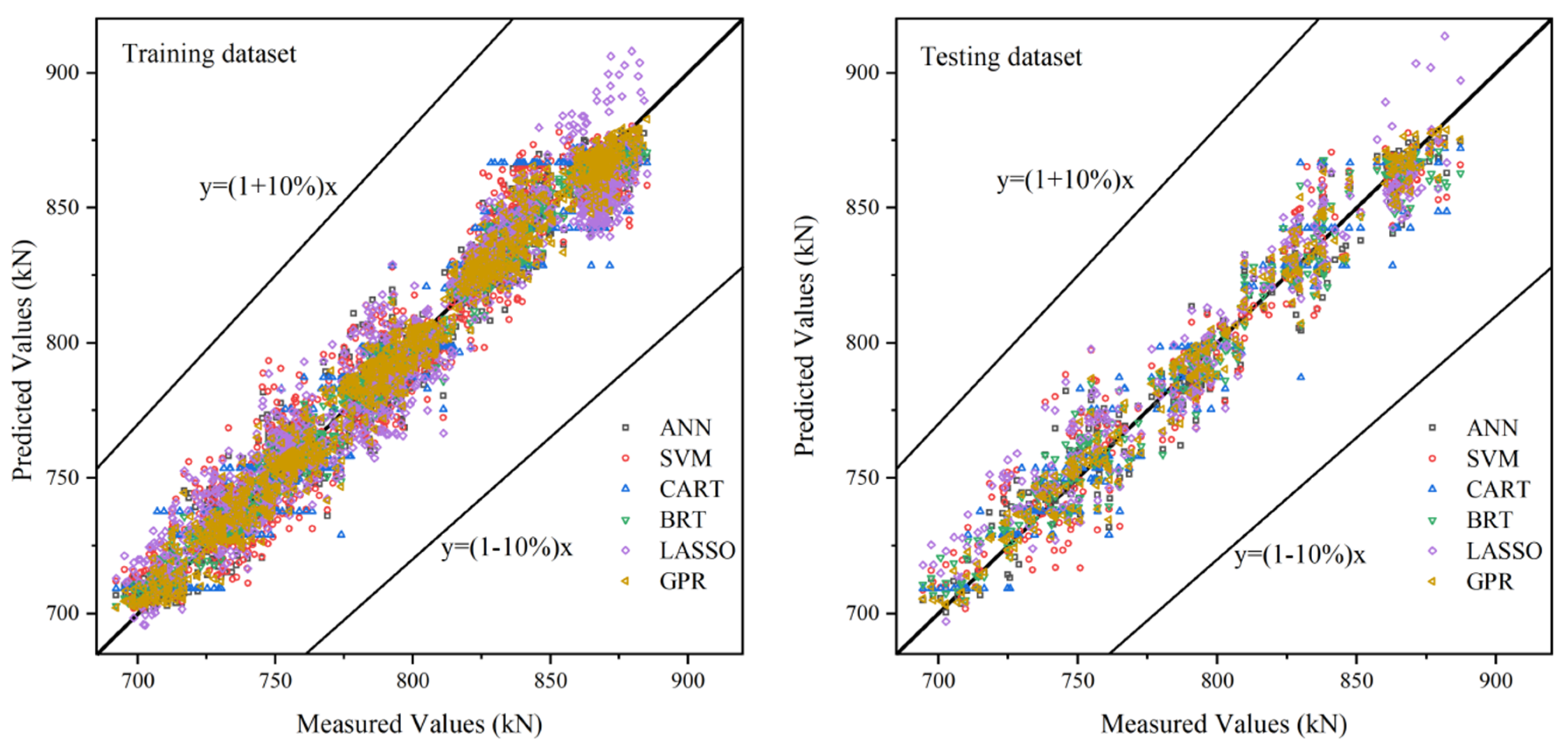
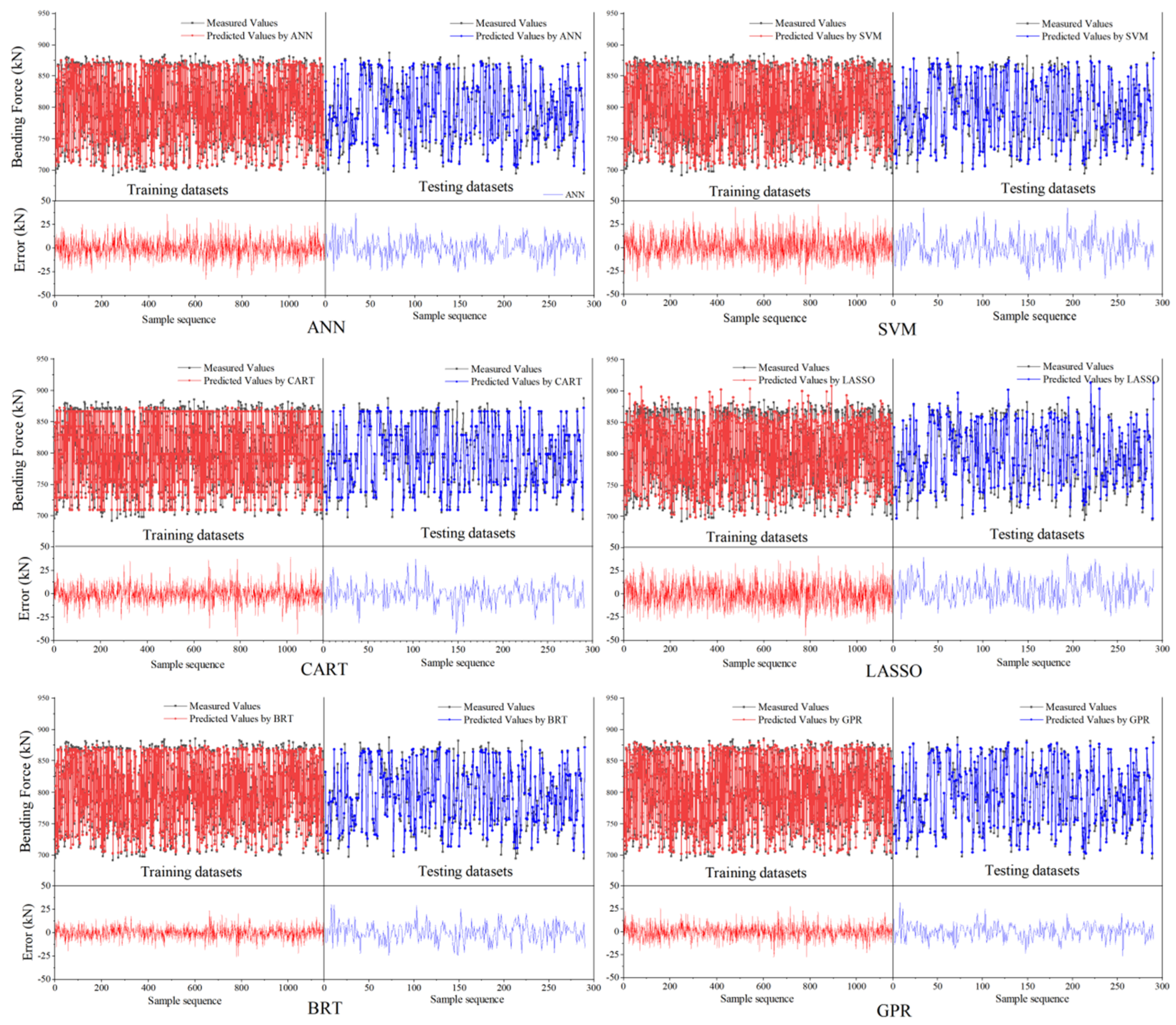
4.1. Prediction Accuracy of Various Models
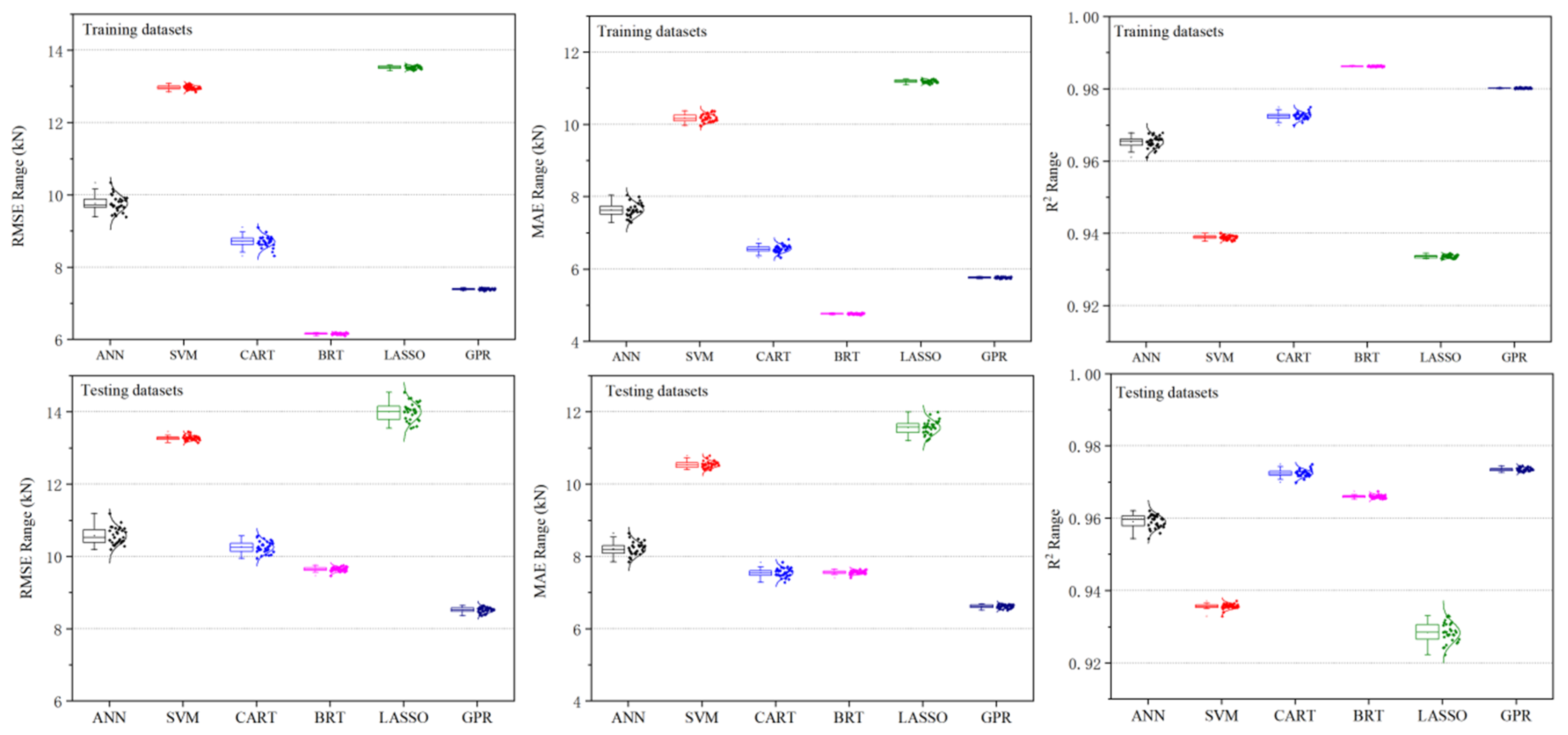
4.2. Stability of Various Models
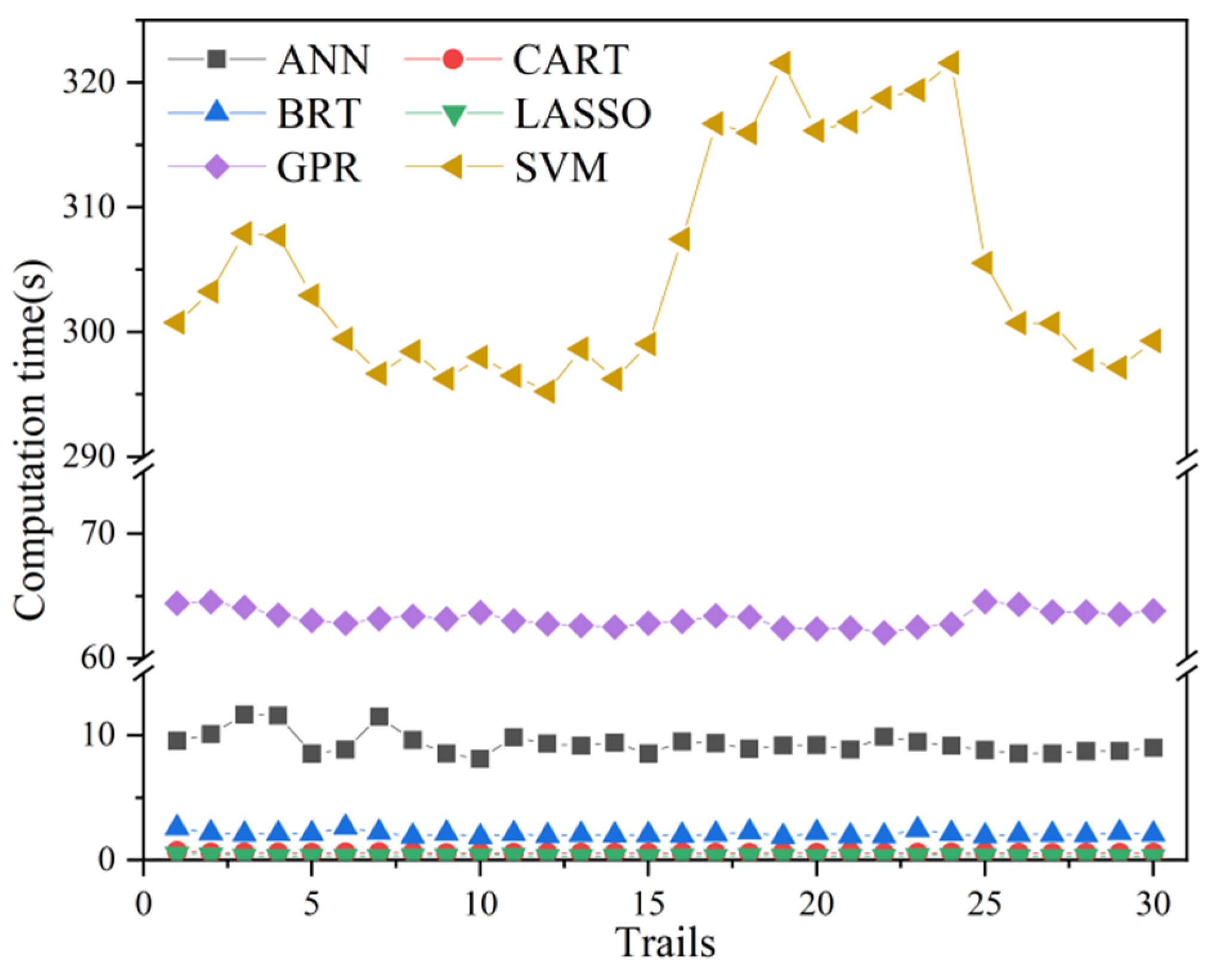
4.3. Computational Costs of Various Models
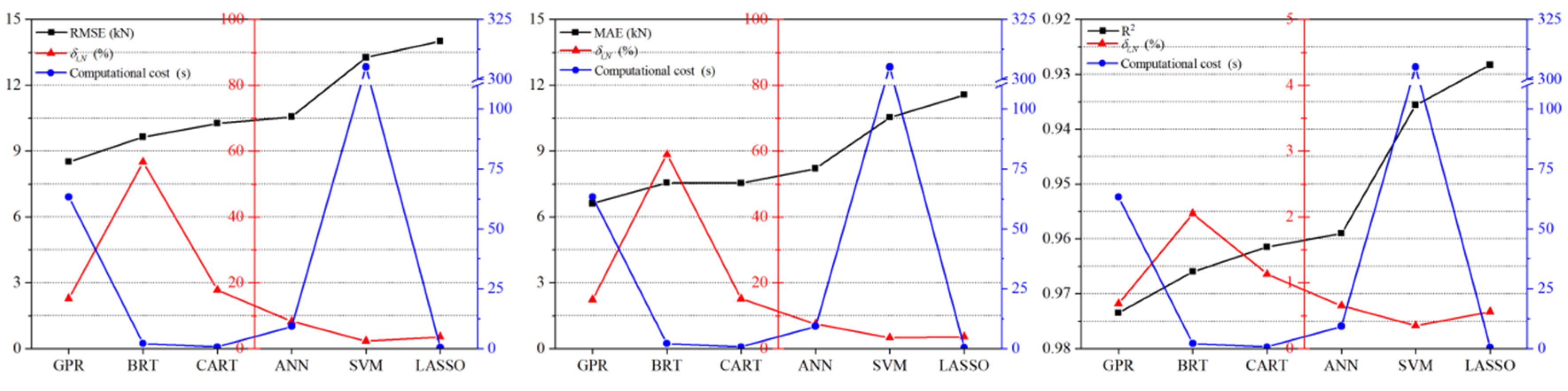
4.4. Comprehensive Evaluation of Various Models
5. Discussion
6. Conclusions
- (1)
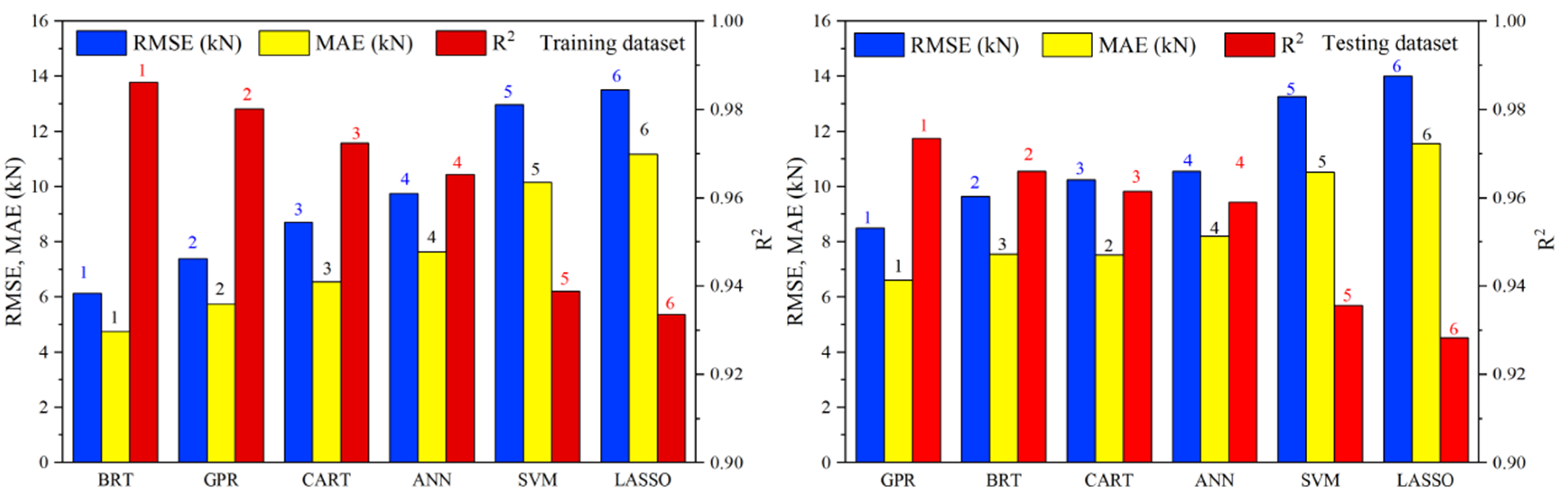
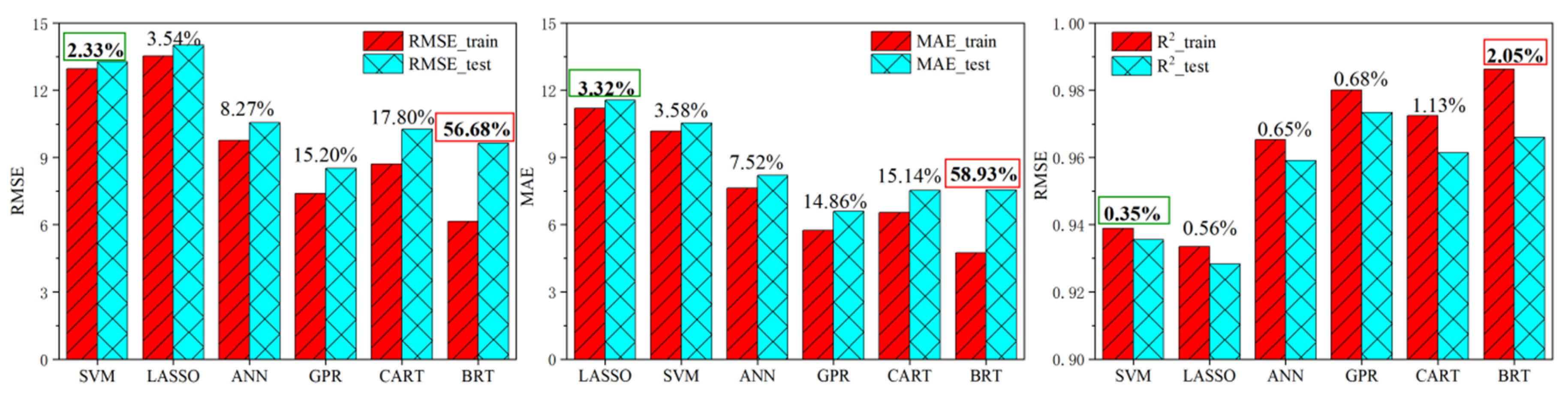
- The comparison results of prediction accuracy show that the accuracy ranking results in testing dataset are slightly different under the three evaluation metrics. However, considering that GPR performs best, followed by BRT, CART, ANN, SVM, and LASSO respectively. The bending force measured by experiment is 690~890 kN, while the prediction error of GPR is only 8.51 kN (RMSE) and 6.61 kN (MAE).
- (2)
- The ranking results of stability show inconsistency in the three evaluation metrics. However, considering comprehensively, SVM shows the most stable performance with the γ of 2.33% (RMSE), 0.32% (MAE) and 0.35% (R2). The stability decreases in the order of LASSO, ANN, GPR, CART, and BRT. BRT shows the most unstable performance with the γ of 56.68% (RMSE), 58.93% (MAE), and 2.05% (R2).
- (3)
- The computational cost of the six models presents three levels. The computational costs of LASSO, CART, BRT, and ANN are increasing gradually, but they are all within ten seconds. The computational cost of GPR model is slightly higher, at about 63 s. However, the computational cost of SVM has reached more than 300 s.
- (4)
- Comprehensively considering the prediction accuracy, stability, and computational cost of the six models, GPR can be considered the most promising machine learning model for predicting bending force. The prediction accuracy and stability of CART and ANN is slightly lower than GPR, but the computational cost is relatively small, so it can also be used as an alternative. In addition, BRT also shows the better combination of prediction accuracy and computational cost, but the stability of BRT is the worst among the six models. SVM not only performs poorly in prediction accuracy, but also has the greatest computational cost. While LASSO has good stability and small computational cost, but it also has the worst prediction accuracy.
Author Contributions
Funding
Conflicts of Interest
References
- Takahashi, R.R. State of the art in hot rolling process control. Control Eng. Pract. 2001, 9, 987–993. [Google Scholar] [CrossRef]
- Zhu, H.T.; Jiang, Z.Y.; Tieu, A.K.; Wang, G.D. A fuzzy algorithm for flatness control in hot strip mill. J. Mater. Process. Technol. 2003, 140, 123–128. [Google Scholar] [CrossRef]
- Wang, Q.L.; Sun, J.; Liu, Y.M.; Wang, P.F.; Zhang, D.H. Analysis of symmetrical flatness actuator efficiencies for UCM cold rolling mill by 3D elastic-plastic FEM. Int. J. Adv. Manuf. Technol. 2017, 92, 1371–1389. [Google Scholar] [CrossRef]
- Jia, C.Y.; Shan, X.Y.; Cui, Y.C.; Bai, T.; Cui, F.J. Modeling and Simulation of Hydraulic Roll Bending System Based on CMAC Neural Network and PID Coupling Control Strategy. J. Iron Steel Res. Int. 2013, 20, 17–22. [Google Scholar] [CrossRef]
- Zhang, S.H.; Deng, L.; Zhang, Q.Y.; Li, Q.H.; Hou, J.X. Modeling of rolling force of ultra-heavy plate considering the influence of deformation penetration coefficient. Int. J. Mech. Sci. 2019, 159, 373–381. [Google Scholar] [CrossRef]
- Zhang, S.H.; Song, B.N.; Gao, S.W.; Guan, M.; Zhao, D.W. Upper bound analysis of a shape-dependent criterion for closing central rectangular defects during hot rolling. Appl. Math. Model. 2018, 55, 674–684. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Y.; Sum, M. Modeling and Simulation of Electric-Hydraulic Control System for Bending Roll System. In Proceedings of the 2008 IEEE Conference on Robotics, Automation and Mechatronics (RAM), Chengdu, China, 21–24 September 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Sterjovski, Z.; Nolan, D.; Carpenter, K.R.; Dunne, D.P.; Norrish, J. Artificial neural networks for modeling the mechanical properties of steels in various applications. J. Mater. Process. Technol. 2015, 170, 536–544. [Google Scholar] [CrossRef]
- Wang, P.; Huang, Z.Y.; Zhang, M.Y.; Zhao, X.W. Mechanical Property Prediction of Strip Model Based on PSO-BP Neural Network. J. Iron Steel Res. Int. 2008, 15, 87–91. [Google Scholar] [CrossRef]
- Ozerdem, M.S.; Kolukisa, S. Artificial Neural Network approach to predict mechanical properties of hot rolled, nonresulfurized, AISI 10xx series carbon steel bars. J. Mater. Process. Technol. 2008, 199, 437–439. [Google Scholar] [CrossRef]
- Bagheripoor, M.; Bisadi, H. Application of artificial neural networks for the prediction of roll force and roll torque in hot strip rolling process. Appl. Math. Model. 2013, 37, 4593–4607. [Google Scholar] [CrossRef]
- Lee, D.; Lee, Y. Application of neural-network for improving accuracy of roll-force model in hot-rolling mill. Control Eng. Pract. 2002, 10, 473–478. [Google Scholar] [CrossRef]
- Mahmoodkhani, Y.; Wells, M.A.; Song, G. Prediction of roll force in skin pass rolling using numerical and artificial neural network methods. Ironmak. Steelmak. 2017, 44, 281–286. [Google Scholar] [CrossRef]
- Yang, Y.Y.; Linkens, D.A.; Talamantes-Silva, J.; Howard, I.C. Roll force and torque prediction using neural network and finite element modelling. ISIJ Int. 2003, 43, 1957–1966. [Google Scholar] [CrossRef]
- Laurinen, P.; Röning, J. An adaptive neural network model for predicting the post roughing mill temperature of steel slabs in the reheating furnace. J. Mater. Process. Technol. 2005, 168, 423–430. [Google Scholar] [CrossRef]
- John, S.; Sikdar, S.; Swamy, P.K.; Das, S.; Maity, B. Hybrid neural-GA model to predict and minimise flatness value of hot rolled strips. J. Mater. Process. Technol. 2008, 195, 314–320. [Google Scholar] [CrossRef]
- Deng, J.F.; Sun, J.; Peng, W.; Hu, Y.H.; Zhang, D.H. Application of neural networks for predicting hot-rolled strip crown. Appl. Soft Comput. 2019, 78, 119–131. [Google Scholar] [CrossRef]
- Kim, D.H.; Lee, Y.; Kim, B.M. Application of ANN for the dimensional accuracy of workpiece in hot rod rolling process. J. Mater. Process. Technol. 2002, 130–131, 214–218. [Google Scholar] [CrossRef]
- Alaei, H.; Salimi, M.; Nourani, A. Online prediction of work roll thermal expansion in a hot rolling process by a neural network. Int. J. Adv. Manuf. Technol. 2016, 85, 1769–1777. [Google Scholar] [CrossRef]
- Sikdar, S.; Kumari, S. Neural network model of the profile of hot-rolled strip. Int. J. Adv. Manuf. Technol. 2009, 42, 450–462. [Google Scholar] [CrossRef]
- Wang, Z.H.; Gong, D.Y.; Li, X.; Li, G.; Zhang, D. Prediction of bending force in the hot strip rolling process using artificial neural network and genetic algorithm (ANN-GA). Int. J. Adv. Manuf. Technol. 2017, 93, 3325–3338. [Google Scholar] [CrossRef]
- Laha, D.; Ren, Y.; Suganthan, P.N. Modeling of steelmaking process with effective machine learning techniques. Expert Syst. Appl. 2015, 42, 4687–4696. [Google Scholar] [CrossRef]
- Hu, Z.Y.; Wei, Z.H.; Sun, H.; Yang, J.M.; Wei, L.X. Optimization of Metal Rolling Control Using Soft Computing Approaches: A Review. Arch. Comput. Methods Eng. 2019, 11, 1–17. [Google Scholar] [CrossRef]
- Shardt, Y.A.W.; Mehrkanoon, S.; Zhang, K.; Yang, X.; Suykens, J.; Ding, S.X.; Peng, K. Modelling the strip thickness in hot steel rolling mills using least-squares support vector machines. Can. J. Chem. Eng. 2018, 96, 171–178. [Google Scholar] [CrossRef]
- Peng, K.X.; Zhong, H.; Zhao, L.; Xue, K.; Ji, Y.D. Strip shape modeling and its setup strategy in hot strip mill process. Int. J. Adv. Manuf. Technol. 2014, 72, 589–605. [Google Scholar] [CrossRef]
- Leaman, R.; Dogan, R.I.; Lu, Z.Y. Dnorm: Disease name normalization with pairwise learning to rank. Bioinformatics 2013, 29, 2909–2917. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Shrestha, N.K.; Shukla, S. Support vector machine based modeling of evapotranspiration using hydro-climatic variables in a sub-tropical environment. Agric. Forest Meteorol. 2015, 200, 172–184. [Google Scholar] [CrossRef]
- Ghorbani, M.A.; Shamshirband, S.; Haghi, D.Z.; Azani, A.; Bonakdari, H.; Ebtehaj, I. Application of firefly algorithm-based support vector machines for prediction of field capacity and permanent wilting point. Soil Tillage Res. 2017, 172, 32–38. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. Forest Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Gordon, A.D. Classification and Regression Trees. In Biometrics; Breiman, L., Friedman, J.H., ROlshen, A., Stone, C.J., Eds.; International Biometric Society: Washington, DC, USA, 1984; Volume 40, p. 874. [Google Scholar] [CrossRef]
- Brezigar-Masten, A.; Masten, I. CART-based selection of bankruptcy predictors for the logic model. Expert Syst. Appl. 2012, 39, 10153–10159. [Google Scholar] [CrossRef]
- Vondra, M.; Touš, M.; Teng, S.Y. Digestate evaporation treatment in biogas plants: A techno-economic assessment by Monte Carlo, neural networks and decision trees. J. Clean. Prod. 2019, 238, 117870. [Google Scholar] [CrossRef]
- Günay, M.E.; Türker, L.; Tapan, N.A. Decision tree analysis for efficient CO2 utilization in electrochemical systems. J. CO2 Util. 2018, 28, 83–95. [Google Scholar] [CrossRef]
- Madhusudana, C.K.; Kumar, H.; Narendranath, S. Fault Diagnosis of Face Milling Tool using Decision Tree and Sound Signal. Mater. Today Proc. 2018, 5, 12035–12044. [Google Scholar] [CrossRef]
- Wang, G.; Hao, J.; Mab, J.; Jiang, H. A comparative assessment of ensemble learning for credit scoring. Exp. Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Bühlmann, P.; Yu, B. Analyzing Bagging. Ann. Stat. 2002, 30, 927–961. [Google Scholar] [CrossRef]
- Hothorn, T.; Lausen, B.; Benner, A.; Radespiel-Troger, M. Bagging survival trees. Stat. Med. 2004, 23, 77–91. [Google Scholar] [CrossRef]
- Chan, C.W.; Huang, C.; Defries, R. Enhanced algorithm performance for land cover classification from remotely sensed data using bagging and boosting. IEEE Trans. Geosci. Remote 2001, 39, 693–695. [Google Scholar] [CrossRef]
- Wang, X.J.; Yuan, P.; Mao, Z.Z.; You, M.S. Molten steel temperature prediction model based on bootstrap Feature Subsets Ensemble Regression Trees. Knowl.-Based Syst. 2016, 1011, 48–59. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B Met. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Spencer, B.; Alfandi, O.; Al-Obeidat, F. A Refinement of Lasso Regression Applied to Temperature Forecasting. Procedia Comput. Sci. 2018, 130, 728–735. [Google Scholar] [CrossRef]
- Zhang, R.Q.; Zhang, F.Y.; Chen, W.C.; Yao, H.M.; Guo, J.; Wu, S.C.; Wu, T.; Du, Y.P. A new strategy of least absolute shrinkage and selection operator coupled with sampling error profile analysis for wavelength selection. Chemometr. Intell. Lab. 2018, 17515, 47–54. [Google Scholar] [CrossRef]
- Chu, H.B.; Wei, J.H.; Wu, W.Y. Streamflow prediction using LASSO-FCM-DBN approach based on hydro-meteorological condition classification. J. Hydrol. 2020, 580, 124253. [Google Scholar] [CrossRef]
- Sniekers, S.; Vaart, A.V.D. Adaptive Bayesian credible sets in regression with a Gaussian process prior. Statistics 2015, 9, 2475–2527. [Google Scholar] [CrossRef]
- Liu, H.T.; Cai, J.F.; Ong, Y.S.; Wang, Y. Understanding and comparing scalable Gaussian process regression for big data. Knowl.-Based Syst. 2019, 164, 324–335. [Google Scholar] [CrossRef]
- Kong, D.; Chen, Y.; Li, N. Gaussian process regression for tool wear prediction. Mech. Syst. Signal Pr. 2018, 104, 556–574. [Google Scholar] [CrossRef]
- Wang, B.; Chen, T. Gaussian process regression with multiple response variables. Chemometr. Intell. Lab. 2015, 142, 159–165. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, H.; Zhao, X.; Liu, T.; Zhang, K. A Gaussian process regression based hybrid approach for short-term wind speed prediction. Energy Convers. Manag. 2016, 126, 1084–1092. [Google Scholar] [CrossRef]
- Aye, S.A.; Heyns, P.S. An integrated Gaussian process regression for prediction of remaining useful life of slow speed bearings based on acoustic emission. Mech. Syst. Signal Pr. 2017, 84, 485–498. [Google Scholar] [CrossRef]
- Liu, Y.Q.; Pan, Y.P.; Huang, D.P.; Wang, Q.L. Fault prognosis of filamentous sludge bulking using an enhanced multi-output gaussian processes regression. Control Eng. Pract. 2017, 62, 46–54. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Detection Equipment | Specifications | Brand |
|---|---|---|---|
| Entrance temperature | Infrared thermometer | SYSTEM4 | LAND |
| Exit thickness | X-ray thickness gauge | RM215 | TMO |
| Strip width | Width gauge | ACCUBAND | KELK |
| Rolling force | Load Cell | Rollmax | KELK |
| Rolling speed | Incremental Encoder | FGH6 | HUBNER |
| Roll shifting | Position Sensor | Tempsonics | MTS |
| Target profile | Profile Gauge | RM312 | TMO |
| Bending force | Pressure Transducer | HDA3839 | HYDAC |
| Parameter | Unit | Mean | Range of Value |
|---|---|---|---|
| Entrance temperature | °C | 1035.2 | 988.05~1082.8 |
| Entrance thickness | mm | 2.4750 | 2.3827~2.5782 |
| Exit thickness | mm | 2.2981 | 2.2374~2.3494 |
| Strip width | mm | 1252.0 | 1248.9~1258.8 |
| Rolling force | kN | 8940.4 | 7438.4~10,590 |
| Rolling speed | m/s | 8.6995 | 8.6535~8.7362 |
| Roll shifting | mm | 96.436 | 93.125~102.625 |
| Yield strength | MPa | 456.71 | 433.74~482.02 |
| Target profile | μm | 65.613 | 61.740~69.315 |
| Model | Training Dataset | Testing Dataset | |||||
|---|---|---|---|---|---|---|---|
| RMSE (kN) | MAE (kN) | R2 | RMSE (kN) | MAE (kN) | R2 | ||
| ANN | Max | 10.3392 | 8.0444 | 0.9678 | 11.1894 | 8.6467 | 0.9621 |
| Min | 9.3885 | 7.2853 | 0.9611 | 10.1867 | 7.8557 | 0.9543 | |
| Mean | 9.7603 | 7.6325 | 0.9653 | 10.5676 | 8.2064 | 0.9590 | |
| SVM | Max | 13.0896 | 10.3777 | 0.9400 | 13.4531 | 10.7890 | 0.9371 |
| Min | 12.8499 | 9.9659 | 0.9378 | 13.1528 | 10.3986 | 0.9328 | |
| Mean | 12.9733 | 10.1730 | 0.9389 | 13.2755 | 10.5367 | 0.9356 | |
| CART | Max | 9.1048 | 6.8205 | 0.9749 | 10.5625 | 7.8368 | 0.9640 |
| Min | 8.3138 | 6.3089 | 0.9699 | 9.9445 | 7.2870 | 0.9591 | |
| Mean | 8.7054 | 6.5526 | 0.9724 | 10.2547 | 7.5449 | 0.9615 | |
| BRT | Max | 6.1908 | 4.7867 | 0.9865 | 9.7559 | 7.6485 | 0.9674 |
| Min | 6.1018 | 4.7222 | 0.9861 | 9.4643 | 7.4094 | 0.9653 | |
| Mean | 6.1552 | 4.7561 | 0.9862 | 9.6441 | 7.5587 | 0.9660 | |
| LASSO | Max | 13.5908 | 11.2526 | 0.9345 | 14.5408 | 11.9976 | 0.9330 |
| Min | 13.4307 | 11.0978 | 0.9329 | 13.5506 | 11.1993 | 0.9222 | |
| Mean | 13.5261 | 11.1914 | 0.9336 | 14.0047 | 11.5624 | 0.9283 | |
| GPR | Max | 7.4269 | 5.7891 | 0.9805 | 8.6418 | 6.6802 | 0.9745 |
| Min | 7.3335 | 5.7243 | 0.9800 | 8.3605 | 6.5054 | 0.9726 | |
| Mean | 7.3887 | 5.7580 | 0.9802 | 8.5121 | 6.6137 | 0.9735 | |
| Model | Computational Cost (s) | ||
|---|---|---|---|
| Max | Min | Mean | |
| ANN | 11.66 | 8.12 | 9.35 |
| SVM | 321.59 | 295.24 | 305.09 |
| CART | 0.71 | 0.56 | 0.59 |
| BRT | 2.64 | 1.87 | 2.11 |
| LASSO | 0.51 | 0.31 | 0.35 |
| GPR | 64.55 | 62.06 | 63.25 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Luan, F.; Wu, Y. A Comparative Assessment of Six Machine Learning Models for Prediction of Bending Force in Hot Strip Rolling Process. Metals 2020, 10, 685. https://doi.org/10.3390/met10050685
Li X, Luan F, Wu Y. A Comparative Assessment of Six Machine Learning Models for Prediction of Bending Force in Hot Strip Rolling Process. Metals. 2020; 10(5):685. https://doi.org/10.3390/met10050685
Chicago/Turabian StyleLi, Xu, Feng Luan, and Yan Wu. 2020. "A Comparative Assessment of Six Machine Learning Models for Prediction of Bending Force in Hot Strip Rolling Process" Metals 10, no. 5: 685. https://doi.org/10.3390/met10050685
APA StyleLi, X., Luan, F., & Wu, Y. (2020). A Comparative Assessment of Six Machine Learning Models for Prediction of Bending Force in Hot Strip Rolling Process. Metals, 10(5), 685. https://doi.org/10.3390/met10050685