
AI Response Quality in Public Services: Temperature Settings and Contextual Factors


Abstract
1. Introduction
The New Frontiers of Artificial Intelligence: Technology or Social Construct?
2. Theoretical Background
2.1. Artificial Intelligence in Public Services
2.2. Chatbots as a Key Application of AI in Public Services
3. Materials and Methods
3.1. Generative Technology in Public Services: The Govern-AI Program
3.2. Design of the Empirical Phase
- Micro- vs. macro-level, which distinguished between prompts focused on specific, localized issues and those that concerned broader, strategic matters at the regional or national level;
- Informational vs. operational nature, which depended on whether the prompt aimed at gathering explanations and factual information or at eliciting actionable guidance.
3.3. Language Model and Technical Infrastructure
3.4. Evaluation of Prompts and Responses
- Accuracy, which was defined as the factual correctness and precision of the information provided (rated on a scale from 0 to 5);
- Comprehensibility, which referred to the readability and clarity of the text—this is crucial for enabling rapid and effective interpretation in professional settings (rated on a scale from 0 to 5).
3.5. Analytical Approach
4. Results
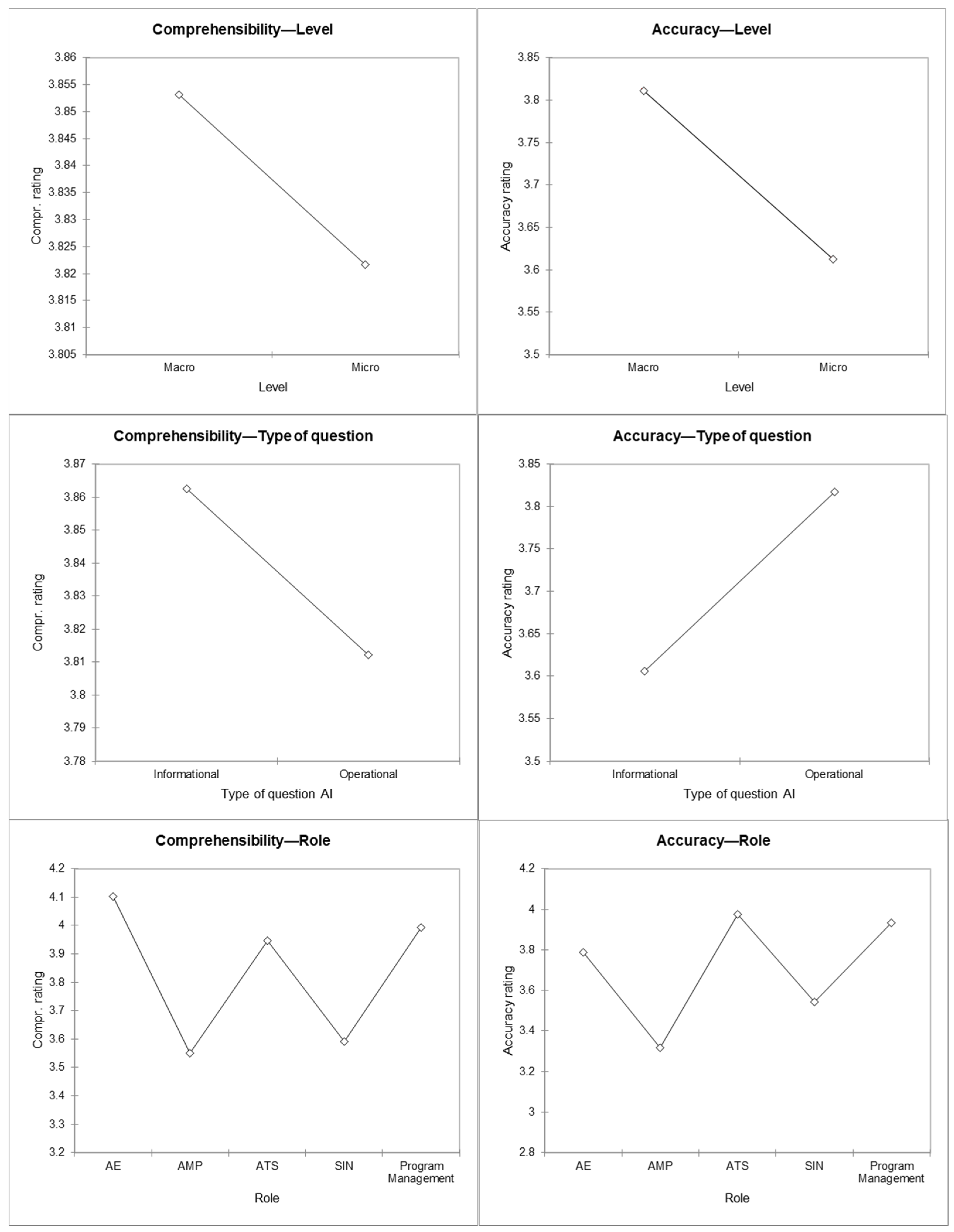
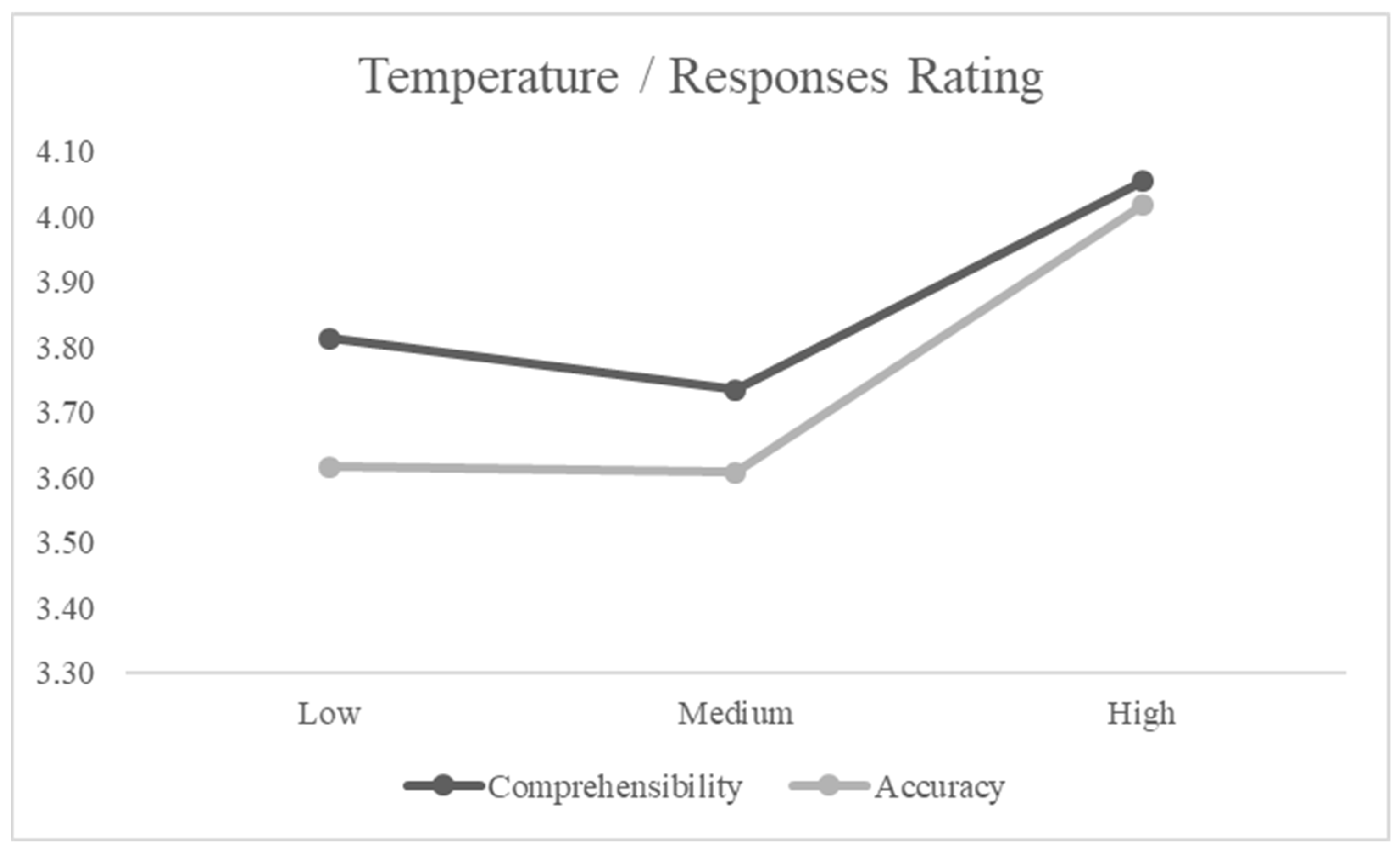
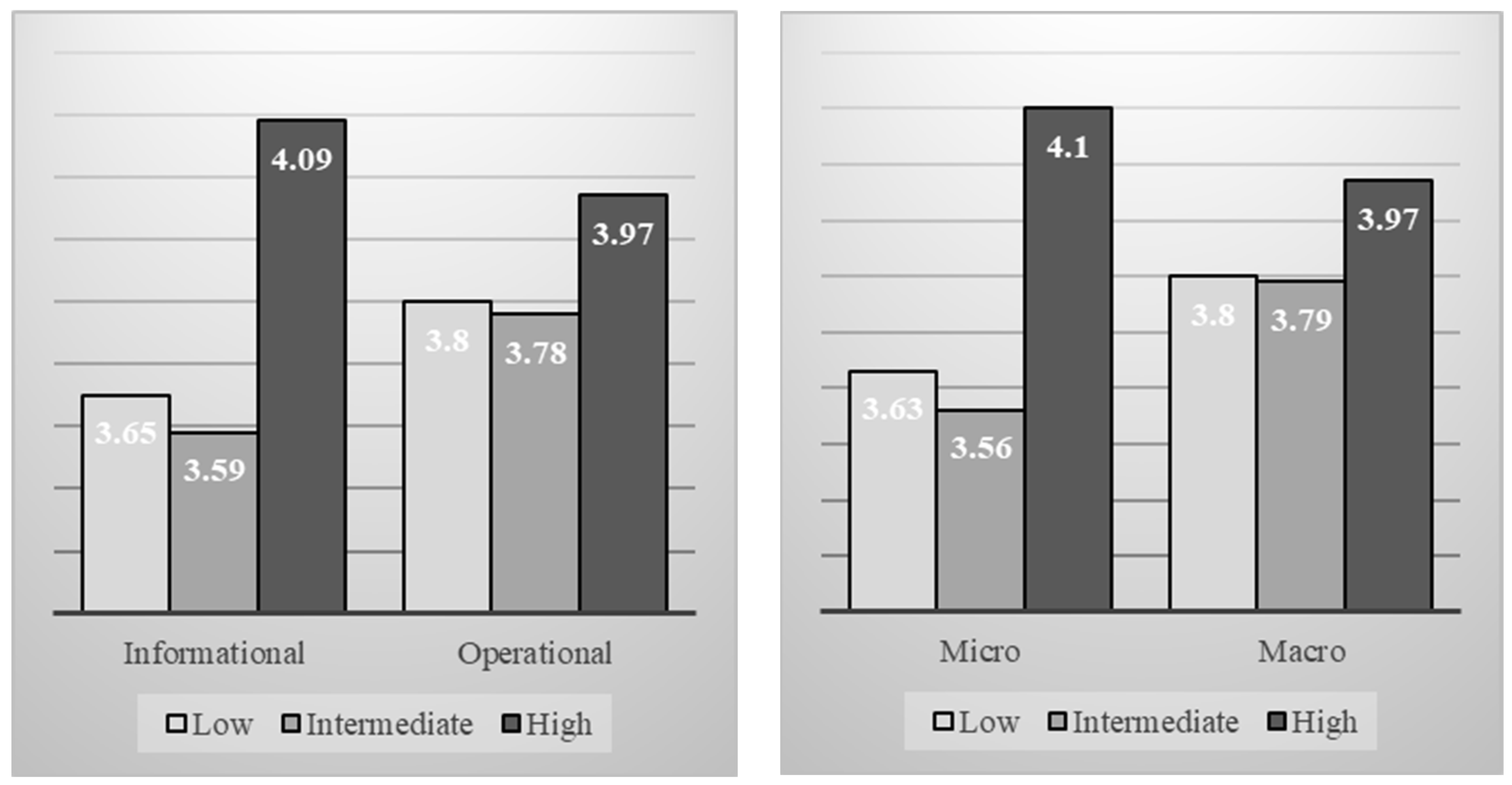
4.1. General Descriptive Analysis
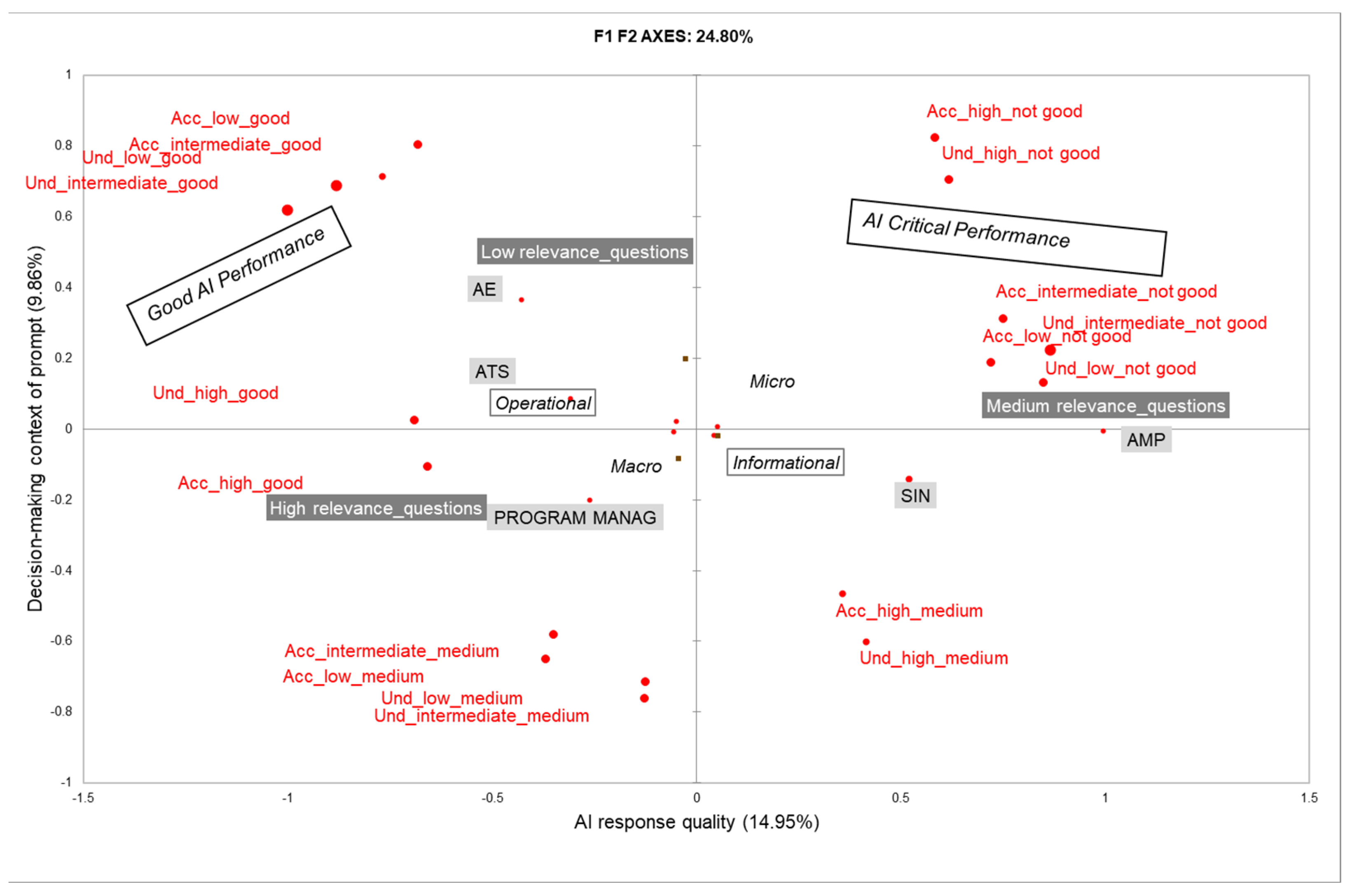
4.2. Multiple Correspondence Analysis
- Factor 1, “AI response quality”, distinguished between the clear and reliable outputs (mostly associated with operational and macro-level prompts concerning the CPIA and local welfare issues) and less stable responses, which were primarily linked to informational prompts related to regional policy and union domains.
- Factor 2, “decision-making context of the prompt”, separated low-relevance prompts (more operational and easily manageable by AI) from highly relevant prompts, which were often tied to strategic decisions.
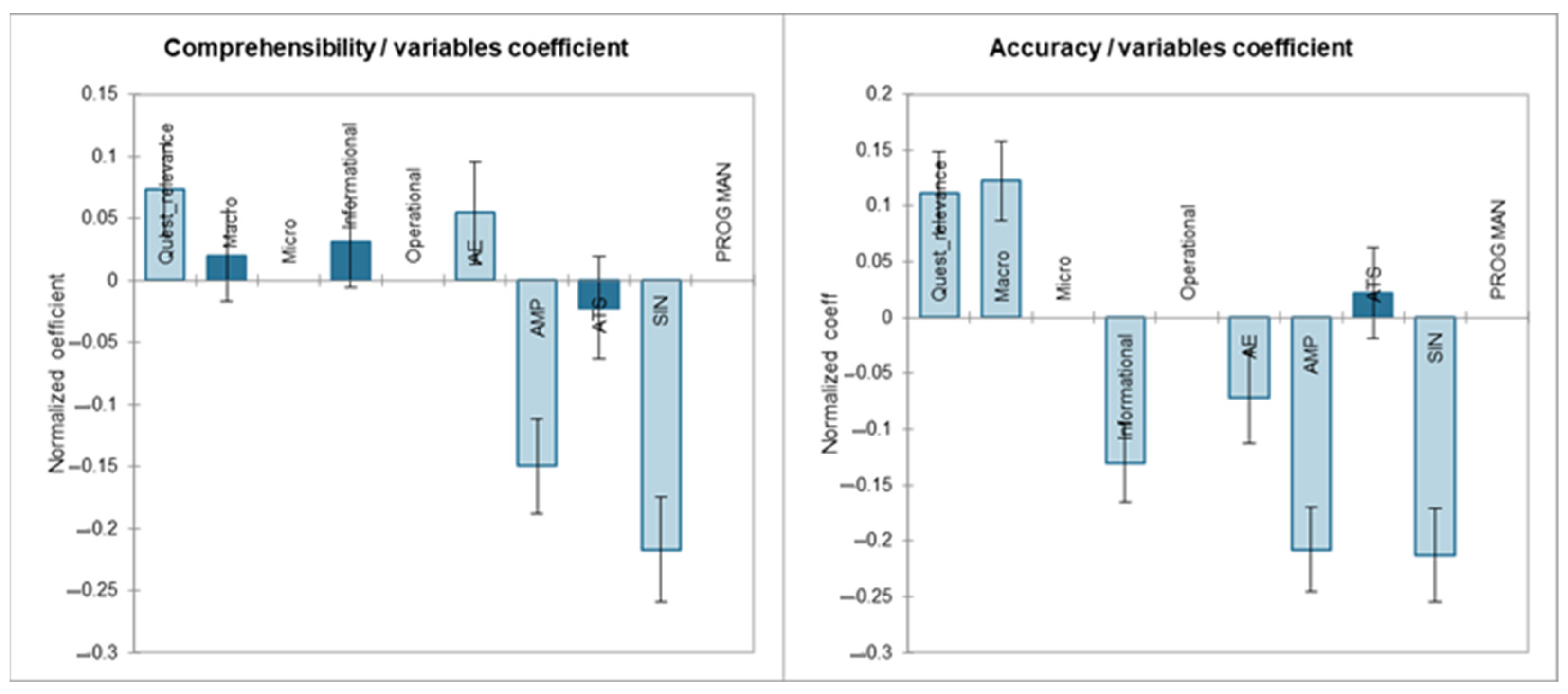
4.3. Regression Models on AI Response Quality
- Comprehensibility = 3.722 + 0.066·Relevance + 0.031·macro + 0.050·inform + 0.110·role-AE − 0.442·role-AMP − 0.045·role-ATS − 0.400·role-SIN;
- Accuracy = 3.589 + 0.100·Relevance + 0.198·macro − 0.211·inform − 0.146·role-AE − 0.615·role-AMP + 0.044·role-ATS − 0.391·role-SIN.
- The professionals in adult education (role-AE) assigned slightly higher scores for the comprehensibility (+0.110), but lower ones for the accuracy (−0.146), suggesting that while they found the responses readable, they questioned their factual correctness.
- The regional policy staff (role-AMP) exhibited the strongest negative impact on both dimensions (−0.442 for the comprehensibility and −0.615 for the accuracy), confirming that this group tended to provide the most critical evaluations of the AI responses.
- The trade union representatives (role-SIN) also showed significant negative evaluations (−0.400 for the comprehensibility and −0.391 for the accuracy), indicating that the AI responses may not have sufficiently reflected the specificities of their domain.
- The social area professionals (role-ATS) showed no significant effect on the comprehensibility (−0.045), but a slightly positive one on the accuracy (+0.044), indicating a tendency to rate the AI outputs as somewhat more precise than the other groups.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | www.governai.it (accessed on 2 May 2025). |
| 2 | This overall figure includes the evaluation of all three responses associated with each prompt. On average, each of the 33 participants assessed approximately 269 responses. |
References
- Latour, B. Reassembling the Social: An Introduction to Actor-Network-Theory; Oxford University Press: Oxford, UK, 2005. [Google Scholar]
- Amaturo, E.; Aragona, B. Per un’epistemologia del digitale: Note sull’uso di big data e computazione nella ricerca sociale. Quad. Sociol. 2019, 81, 71–90. [Google Scholar] [CrossRef]
- Floridi, L. Etica Dell’intelligenza Artificiale: Sviluppi, Opportunità, Sfide; Raffaello Cortina Editore: Milan, Italy, 2022. [Google Scholar]
- Seaver, N. Computing taste: Algorithms and the makers of music recommendation. In Computing Taste; University of Chicago Press: Chicago, IL, USA, 2022. [Google Scholar]
- Amato, F.; Aragona, B.; De Angelis, M. Factors and possible application scenarios of Explainable AI. Riv. Digit. Politics 2023, 3, 543–564. [Google Scholar] [CrossRef]
- Zuboff, S. Surveillance capitalism and the challenge of collective action. In New Labor Forum; Sage Publications: Los Angeles, CA, USA, 2019; Volume 28, pp. 10–29. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Peeperkorn, M.; Kouwenhoven, T.; Brown, D.; Jordanous, A. Is temperature the creativity parameter of large language models? arXiv 2024, arXiv:2405.00492. [Google Scholar]
- Senadheera, S.; Yigitcanlar, T.; Desouza, K.C.; Mossberger, K.; Corchado, J.; Mehmood, R.; Li, R.Y.; Cheong, P.H. Understanding Chatbot Adoption in Local Governments: A Review and Framework. J. Urban Technol. 2024, 31, 1–35. [Google Scholar] [CrossRef]
- Van Noordt, C.; Misuraca, G. Artificial intelligence for the public sector: Results of landscaping the use of AI in government across the European Union. Gov. Inf. Q. 2022, 39, 101714. [Google Scholar] [CrossRef]
- Neumann, O.; Guirguis, K.; Steiner, R. Exploring artificial intelligence adoption in public organizations: A comparative case study. Public Manag. Rev. 2022, 26, 114–141. [Google Scholar] [CrossRef]
- European Parliament. Artificial Intelligence: How Does It Work, Why Does It Matter, and What Can We Do About It? European Parliamentary Research Service: Brussels, Belgium, 2020. Available online: https://www.europarl.europa.eu/RegData/etudes/STUD/2020/641547/EPRS_STU(2020)641547_EN.pdf (accessed on 2 May 2025).
- Wirtz, B.W.; Weyerer, J.C.; Geyer, C. Artificial Intelligence and the Public Sector—Applications and Challenges. Int. J. Public Adm. 2019, 42, 596–615. [Google Scholar] [CrossRef]
- Wirtz, B.W.; Langer, P.F.; Fenner, C. Artificial Intelligence in the Public Sector—A Research Agenda. Int. J. Public Adm. 2021, 44, 1103–1128. [Google Scholar] [CrossRef]
- Vatamanu, A.F.; Tofan, M. Integrating Artificial Intelligence into Public Administration: Challenges and Vulnerabilities. Adm. Sci. 2025, 15, 149. [Google Scholar] [CrossRef]
- Madan, R.; Ashok, M. AI adoption and diffusion in public administration: A systematic literature review and future research agenda. Gov. Inf. Q. 2023, 40, 101774. [Google Scholar] [CrossRef]
- European Commission. Ethics Guidelines for Trustworthy AI; Publications Office: Luxembourg, 2019. Available online: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (accessed on 2 May 2025).
- Contissa, G.; Galli, F.; Godano, F.; Sartor, G. IL REGOLAMENTO EUROPEO SULL’INTELLIGENZA ARTIFICIALE: Analisi informatico-giuridica. I-LEX 2021, 14, 1–36. [Google Scholar]
- Madan, R.; Ashok, M. A public values perspective on the application of Artificial Intelligence in government practices: A Synthesis of case studies. In Handbook of Research on Artificial Intelligence in Government Practices and Processes; IGI Global Scientific Publishing: Hershey, PA, USA, 2022; pp. 162–189. [Google Scholar]
- Aoki, N. An experimental study of public trust in AI chatbots in the public sector. Gov. Inf. Q. 2020, 37, 101490. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int. J. Inf. Manag. 2021, 57, 101994. [Google Scholar] [CrossRef]
- Maragno, G.; Tangi, L.; Gastaldi, L.; Benedetti, M. AI as an organizational agent to nurture: Effectively introducing chatbots in public entities. Public Manag. Rev. 2023, 25, 2135–2165. [Google Scholar] [CrossRef]
- Mehr, H.; Ash, H.; Fellow, D. Artificial Intelligence for Citizen Services and Government; Harvard Kennedy School: Cambridge, MA, USA, 2017; pp. 1–12. [Google Scholar]
- Mergel, I.; Edelmann, N.; Haug, N. Defining digital transformation: Results from expert interviews. Gov. Inf. Q. 2019, 36, 101385. [Google Scholar] [CrossRef]
- Di Franco, G. Corrispondenze Multiple e Altre Tecniche Multivariate per Variabili Categoriali; FrancoAngeli: Milan, Italy, 2006; Volume 15. [Google Scholar]
- Poston, D.L.; Poston, D.L., Jr.; Conde, E.; Field, L.M. Applied Regression Models in the Social Sciences; Cambridge University Press: Cambridge, UK, 2023. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompts | Responses | ||
|---|---|---|---|
| Relevance | Relevance of the question concerning the professional’s actual needs (scale 0–5) | Accuracy | Factual adherence and precision of the provided information (scale 0–5) |
| Comprehensibility | Clarity and readability of the response (scale 0–5) | ||
| Variables | Categories | nr | % |
|---|---|---|---|
| Level | Macro | 1412 | 47.7 |
| Micro | 1548 | 52.3 | |
| Type | Informational | 1617 | 54.6 |
| Operational | 1343 | 45.4 | |
| Role | AE | 589 | 19.9 |
| AMP | 239 | 8.1 | |
| ATS | 592 | 20.0 | |
| SIN | 767 | 25.9 | |
| PROG.MAN | 773 | 26.1 |
| AI Content | Rating | avg | Sd |
|---|---|---|---|
| Prompt | Relevance | 3.50 | 0.90 |
| Responses_temperature | Compr_low | 3.81 | 1.04 |
| Compr_intermediate | 3.74 | 1.10 | |
| Compr_high | 4.06 | 1.06 | |
| Acc_low | 3.62 | 1.12 | |
| Acc_intermediate | 3.61 | 1.07 | |
| Acc_high | 4.02 | 1.11 |
| Variables Categories | F1 (AI Response Quality) | F2 (Decision-Making Context of Prompt) |
|---|---|---|
| Macro | −2.947 | −0.428 |
| Micro | 2.947 | 0.428 |
| Informational | 2.499 | −1.051 |
| Operational | −2.499 | 1.051 |
| AE | −11.634 | 9.886 |
| AMP | 16.053 | −0.087 |
| ATS | −8.380 | 2.326 |
| SIN | 16.725 | −4.586 |
| PROG.MAN. | −8.435 | −6.475 |
| Compr_low_good | −30.978 | 24.223 |
| Compr_low_medium | −4.953 | −28.482 |
| Compr_low_not good | 34.406 | 5.304 |
| Compr _intermediate_good | −34.217 | 21.122 |
| Compr _intermediate_medium | −4.956 | −29.782 |
| Compr _intermediate_not good | 36.615 | 9.484 |
| Compr _high_good | −32.119 | 1.172 |
| Compr _high_medium | 15.468 | −22.360 |
| Compr _high_not good | 19.815 | 22.528 |
| Acc_low_good | −19.497 | 22.984 |
| Acc_low_medium | −15.761 | −27.872 |
| Acc_low_not good | 32.028 | 8.311 |
| Acc_intermediate_good | −19.738 | 18.290 |
| Acc_intermediate_medium | −16.551 | −27.501 |
| Acc_intermediate_not good | 32.471 | 13.471 |
| Acc_high_high | −29.677 | −4.787 |
| Acc_high_medium | 14.122 | −18.382 |
| Acc_high_not good | 18.218 | 25.680 |
| High relevance | −1.824 | −3.649 |
| Low relevance | −0.746 | 5.521 |
| Medium relevance | 2.417 | −0.979 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trezza, D.; De Luca Picione, G.L.; Sergianni, C. AI Response Quality in Public Services: Temperature Settings and Contextual Factors. Societies 2025, 15, 127. https://doi.org/10.3390/soc15050127
Trezza D, De Luca Picione GL, Sergianni C. AI Response Quality in Public Services: Temperature Settings and Contextual Factors. Societies. 2025; 15(5):127. https://doi.org/10.3390/soc15050127
Chicago/Turabian StyleTrezza, Domenico, Giuseppe Luca De Luca Picione, and Carmine Sergianni. 2025. "AI Response Quality in Public Services: Temperature Settings and Contextual Factors" Societies 15, no. 5: 127. https://doi.org/10.3390/soc15050127
APA StyleTrezza, D., De Luca Picione, G. L., & Sergianni, C. (2025). AI Response Quality in Public Services: Temperature Settings and Contextual Factors. Societies, 15(5), 127. https://doi.org/10.3390/soc15050127