1. Introduction
The wear of human joint prostheses significantly contributes to implant failure [
1]. The materials commonly used for hip and knee joint implants include metallic alloys like Cobalt-Chromium-Molybdenum (CoCrMo) and polymeric materials like Ultra-High Molecular Weight Polyethylene (UHMWPE) [
2]. UHMWPE is chosen as an artificial joint material due to its excellent mechanical properties, particularly its resistance to wear, corrosion, and biocompatibility [
3]. CoCrMo, on the other hand, is selected for its exceptional resistance to wear and corrosion. CoCrMo alloys are generally produced by casting or forging. When these two materials come into contact, forming artificial joints, natural lubricants like synovial fluid help to reduce friction [
4]. The observed wear mechanisms occurring in the contact between UHMWPE and CoCrMo encompass both two-body and third-body abrasive wear of UHMWPE [
5,
6,
7] Abrasive wear typically occurs when a hard surface or a third-body particle rubs against a softer surface [
5,
6,
7]. Weight loss analysis is a commonly employed method for measuring wear in these materials. This approach entails measuring the worn pin’s dimensions and then calculating wear volume alterations utilizing techniques such as optical profilometry [
2]. Despite the fact that the wear rates within such tribological contacts are relatively low [
8,
9,
10], wear is one of the main reasons for implant failure, as evidenced by osteolysis, followed by implant loosening [
11]. Therefore, comprehending the alterations in surface conditions that transpire during the wear process holds significant importance.
Uni-directional sliding tests on UHMWPE have demonstrated that strain hardening occurs due to polymer chain reorientation at the surface [
12]. Saikko et al. demonstrated that many parameters, such as contact pressure, slide track shape, contact area, and counterpart surface roughness, affect the tribological behavior of biomaterials [
8,
9,
10,
12]. For polymeric materials, previous research has demonstrated that the contact area and cross shear emerge as the foremost critical factors influencing wear [
13]. However, in an actual knee joint, movement occurs in multiple directions with significant cross-shear (CS) [
9,
14]. For a rectangular path, CS is calculated as CS = A/(A + B), where A is the smaller dimension, and B is the larger dimension [
2,
9]. Studies have shown that the range of CS impacts the amount of wear in knee joint implants [
1,
15]. Hence, utilizing laboratory test equipment featuring a multi-directional pin-on-disc (flat-on-flat) configuration is of paramount importance [
16,
17]. A rectangular path with a CS of 0.12 is often employed to investigate UHMWPE wear.
Consequently, the need to monitor wear to avert implant failure and establish regular replacement schedules for metallic or polymeric materials is imperative. Essential to this endeavor is exploring the gradual wear of UHMWPE through a real-time monitoring technique. Adopting a more dynamic approach to monitoring wear in real-time could pave the way for early detection and classification of UHMWPE wear, enhancing our understanding of the underlying damage mechanisms. These real-time monitoring techniques offer invaluable insights into the wear process, facilitating timely interventions and enhancing maintenance strategies for knee joint implants.
Various sensorization methods, including acoustic [
18] and ultrasonic sensors [
19], have been utilized to predict failure and classify wear [
20]. Ultrasonic sensors have been previously employed for detecting the wear of Polyethylene (PE) [
19]. For instance, one study focused on ultrasonic testing of pre-strained PE, while another investigated the plasticity and damage of PE during tensile tests [
21]. Acoustic Emission (AE) has been established as a reliable real-time monitoring method in solid-solid contacts [
22]. When a solid material undergoes plastic or elastic deformation, elastic waves propagate through it, generating AE signals [
17]. These signals can be captured using acoustic sensors as temporal signals, providing detailed information about the wear process depending on the amount of data recorded, associated noise level and type of analysis [
20]. Earlier studies have showcased the generation of AE waves in non-metallic materials like ceramics, Polyether Ether Ketone (PEEK), Polytetrafluoroethylene (PTFE), and plasma-sprayed coatings. This underscores the relevance of AE in discerning damage mechanisms [
23]. AE has been utilized in various studies to identify and characterize failure modes and further estimate the remaining useful life of components [
19,
20,
21]. For example, AE identified failure modes in self-reinforced PE composite laminates under tensile loading, revealing damage mechanisms such as fibre-matrix debonding, fibre pullout, fibre breakage, matrix cracking, and delamination [
24]. AE has been employed to explore the tribological behavior of Thermoplastic Polyurethanes (TPU) and steel contacts. It was observed that contact conditions influenced AE signals, and wear was characterized by a third-body mode [
25]. In a study involving steel against Polyetherketoneketone (PEKK) contact, AE signals were found to exhibit higher amplitudes in high-friction regions compared to low-friction regions, with plowing generating AE signals with characteristic frequencies [
23]. AE has also found application in monitoring bone failure under compressive loading, demonstrating heightened sensitivity compared to micro-radiology in detecting internal damage to bone cement and loosening the metal stem from bone cement. It has facilitated distinct differentiation between compromised and intact knees while accounting for factors like arthritis, prior surgeries, age groups, and activity levels [
26]. These investigations underscore AEs effectiveness as a means of identifying and comprehending wear failure mechanisms.
Machine Learning (ML) has been extensively utilized with diverse sensor data acquired from laboratory-scale simulated wear tests [
19,
21,
27,
28,
29,
30,
31]. One of the previous studies involved using Artificial Neural Networks (ANN) to predict wear loss in molybdenum coatings [
32]. AE and ML algorithms have been gaining attention in tribology [
18,
19,
20,
21,
22]. AE has been used to monitor wear in real-time and gain insights into the wear mechanisms involved [
20,
33]. Supervised, semi-supervised, and unsupervised ML techniques have been employed to perform prognosis of the type of failure mechanism as well as classify and predict wear mechanisms such as scuffing, fretting, abrasive wear, etc. [
19,
20,
24,
25,
26,
27,
34,
35]. Through analyzing AE signals generated during the wear process, ML algorithms can discern patterns and provide predictions regarding the nature and intensity of wear. Employing AE enables researchers to comprehend the evolution of surface conditions from the running-in phase (initial wear) to the stable state, ultimately culminating in failure [
36]. AE monitoring involves the deployment of sensors to capture acoustic signals generated during the interaction of surfaces. These signals are then processed using signal processing techniques to extract relevant features [
37]. Machine Learning algorithms are employed to classify and forecast wear mechanisms based on these extracted features. The ongoing monitoring of wear through AE signals enables the detection of abrupt or recurring alterations in surface conditions, which could signify potential impending failure. This holds particular importance in scenarios such as knee joints to detect osteoarthritis, where wear in the contact substantially influences, the criticality of wear monitoring via AE signals [
29,
30]. Intermittent monitoring of AE signals allows for early identification of wear issues, enabling timely interventions such as the detection of diseases and further component replacement to prevent further damage [
29,
30]. Another facet of laboratory-scale monitoring involves the potential to comprehend and characterize pre-failure regimes [
38,
39,
40]. This knowledge can be harnessed to formulate material compositions that bypass unfavorable transitional phases, thus averting the progression towards failure. Kiselev et al. [
41] have previously demonstrated that AE analysis could be successfully used to detect osteoarthritis faster than any other state-of-the-art technique.
This paper uses AE signals and ML techniques to explore progressive wear classification in the UHMWPE-CoCrMo interaction. The objective is to address a research gap by investigating wear classification within a multi-directional pin-on-disc tribometer under complete lubricant immersion. The proposed study integrates a multi-directional pin-on-disc wear tester, AE signal acquisition and analysis, and ML algorithms to categorize progressive wear in the UHMWPE-CoCrMo tribological system. It examines two distinct feature extraction methodologies and seeks to offer insights into the most efficacious approach for wear classification.
This article is divided into six sections.
Section 1 introduces the topic of the wear of knee joint prosthesis materials, wear issues, and the use of real-time monitoring techniques to monitor the progressive wear of UHMWPE.
Section 2 discusses the methodology, experimental setup, conditions, and characterization techniques used to measure wear and record the AE data.
Section 3 reports the wear analysis, raw AE signals, time domain, frequency domain, and time frequency domain analysis.
Section 4 discusses the various ML classifiers for classifying the analyzed data after hand-picked feature extraction.
Section 5 talks about contrastive learning-based feature extraction, where a Convolutional Neural Network (CNN) is used to extract and classify the features using the ML algorithms.
Section 6 concludes this work from the results and discussions presented, as well as an outlook on future work and perspectives for this approach.
2. Materials and Methods
In this section, the materials and methods utilized for conducting the experiments are presented. It encompasses details regarding the tribometer, materials, lubricant, characterization techniques, and the ML framework employed for wear classification. The experiments use a multi-directional pin-on-disc wear tester with AE sensors mounted on the bottom of the CoCrMo discs to measure AE signals. The wear is quantified regarding volume and weight loss, employing standard characterization tools like gravimetric analysis and interferometry. These serve as the ground truth data for correlation with the extracted features. Due to identical wear measurements for each interval, traditional wear characterization tools are insufficient, necessitating the application of ML to understand and classify different wear stages and mechanisms. To achieve this, two frameworks for feature extraction and classification are proposed. The first framework manually computes AE features, while the second framework automatically leverages a contrastive deep learning network to learn meaningful representations from the AE signals [
38] and neural networks [
24,
25,
34]. The performance of the classifiers is assessed in terms of classification accuracy. By comparing the performance of the classifiers using manually computed AE features and contrastive deep learning-based AE features, the research aims to determine the effectiveness and advantages of each feature extraction methodology in accurately classifying the different wear classes in the UHMWPE-CoCrMo tribological system.
2.1. Tribotests
Multi-directional pin-on-disc tribotests [
2] were performed using UHMWPE pins sliding against CoCrMo discs in lubricated conditions on a six-station multi-directional tribometer OrthoPOD
® (AMTI, Watertown, MA, USA,
Figure 1). OrthoPOD is a multi-directional pin-on-disc tribometer replicating complex human joint motions necessary for accurately simulating the wear of PE joint implants. This tribometer is primarily used to measure the wear of the implants and does not measure the friction coefficient reliably. This tribometer is based on cross-shear motions between implant components used for prostheses. This simulator was particularly used to simulate a rectangular path with lengths A = 2 mm and B = 15 mm, resulting in a cross-shear ratio of 0.12. This represents the typical physiological movement conditions in a human knee for level-walking, and an increase or decrease in the cross-shear ratio might lead to knee failures [
1,
12,
31]
CoCrMo discs were ground and polished to a mirror-like surface with a roughness of Ra < 5 nm. UHMWPE pins were machined from stock Sulene
®-PE (Zimmer Biomet, Winterthur, Switzerland) to be representative of the state obtained on PE lines for hips or knee joints. Initial pin observations using an optical microscope showed that they are not mirror polished and show scratches in the machining direction. UHMWPE pins were gamma sterilized with an irradiation dose of 25–40 kGy under a nitrogen atmosphere [
2]. The pins were pre-soaked in the test liquid for one week before the test.
A detailed description of the complete wear setup can be found in a recent study by Dreyer et al. [
2]. A normal load of 110 N was applied to the UHMWPE pins, whereas three pins had a diameter of 3.1 mm, and the other three had a diameter higher than 3.1 mm. Therefore, the contact pressure in the flat-on-flat contact was 14.6 MPa for the Ø 3.1 mm pins. The tribotests were performed simultaneously on the six stations of the OrthoPOD. The tests were run for slightly more than four weeks at a frequency of 1 Hz, with interruptions after each week for weighing and replacement of the test liquid. Each test was run for a total of 2.28 million cycles. The test was performed at 37 ± 1 °C in bovine calf serum (BCS, Hyclone™ Calf Serum Lot#AF29165348, GE Healthcare Lifesciences, Chicago, IL, USA), which was diluted with deionized water to a protein concentration of 20 g/L, a commonly used test liquid for knee joints according to ISO 14243-1 [
42]. In addition, 7.44 g/L ethylenediaminetetraacetic acid disodium salt dihydrate (Sigma Aldrich, St. Louis, MO, USA) and 2.4 g/L sodium azide (Sigma Aldrich, St. Louis, USA) were added according to the ASTM F732-17 [
2] standard to reduce precipitation of calcium phosphate and prevent bacterial growth, respectively. Eventually, a 0.7 µm filter was used to filter BCS with the added substances.
The test liquid was replaced weekly. To limit the evaporation of water from the test liquid, to inhibit dirt from entering the contact, and to avoid air entering the contact, a latex condom is used to seal the contact after the test fluid is added. The test conditions are summarized in
Table 1.
2.2. Data Acquisition
The CoCrMo discs were designed in such a way that they could hold an AE sensor at the bottom. A Poly-Oxy-Methylene (POM) spacer connected the discs to the test machine bed. Acoustic Emission data were recorded with a standard Vallen AMYS-6 multi-channel data acquisition system. This high-performance AE data acquisition system has been shown to be extremely effective for AE signal processing [
20]. A PICO AE micro-miniature sensor with a wide frequency range of 200–750 kHz from Physical Acoustics Corporation (PAC), was used at the bottom of the CoCrMo disc to acquire the AE signals. The sensor’s small size makes it an ideal candidate for applications requiring wideband AE response and sensitive measurements.
As shown in
Figure 1, two of the six CoCrMo discs (in articulation with Ø 3.1 mm pins) were fixed with the PICO AE sensor at the bottom to obtain AE signals. Both tests showed similar AE data after processing. Therefore, Acoustic Emission data from a single test was used for feature extraction and in Machine Learning algorithms for classification. A small-diameter, integral co-axial cable exits the sensor side with a BNC connector on the other end. This sensor ensured a wide range of frequencies over which wear mechanisms are known to occur [
20,
37]. The disc holders were made of Poly-Oxy-Methylene (POM) material, which ensures good AE signal transmission. Since the sensor was attached to the bottom of the sliding metallic contact surface using superglue, it also ensured good transmission of the signals to the Vallen data acquisition system. The other BNC end of the sensor was attached to a pre-amplifier. The sampling rate during AE data acquisition was 2 MHz to fulfill Nyquist’s theorem [
43]. An amplifier with an integrated bandpass filter between 95–1000 kHz (2/4 pre-amplifier) was used to amplify the AE signals generated during the test. A large dataset implies a better quality of wear classification of the surface states. A 40 dB gain was used in the amplifier as the signals in this contact have very low amplitudes. Recorded AE signals were obtained in continuous waveforms.
2.3. Wear Measurement
After each test period, both the disc and pin samples were thoroughly cleaned using ultrasonication with acetone and isopropanol as solvents. Then, according to ASTM standard F732-17 [
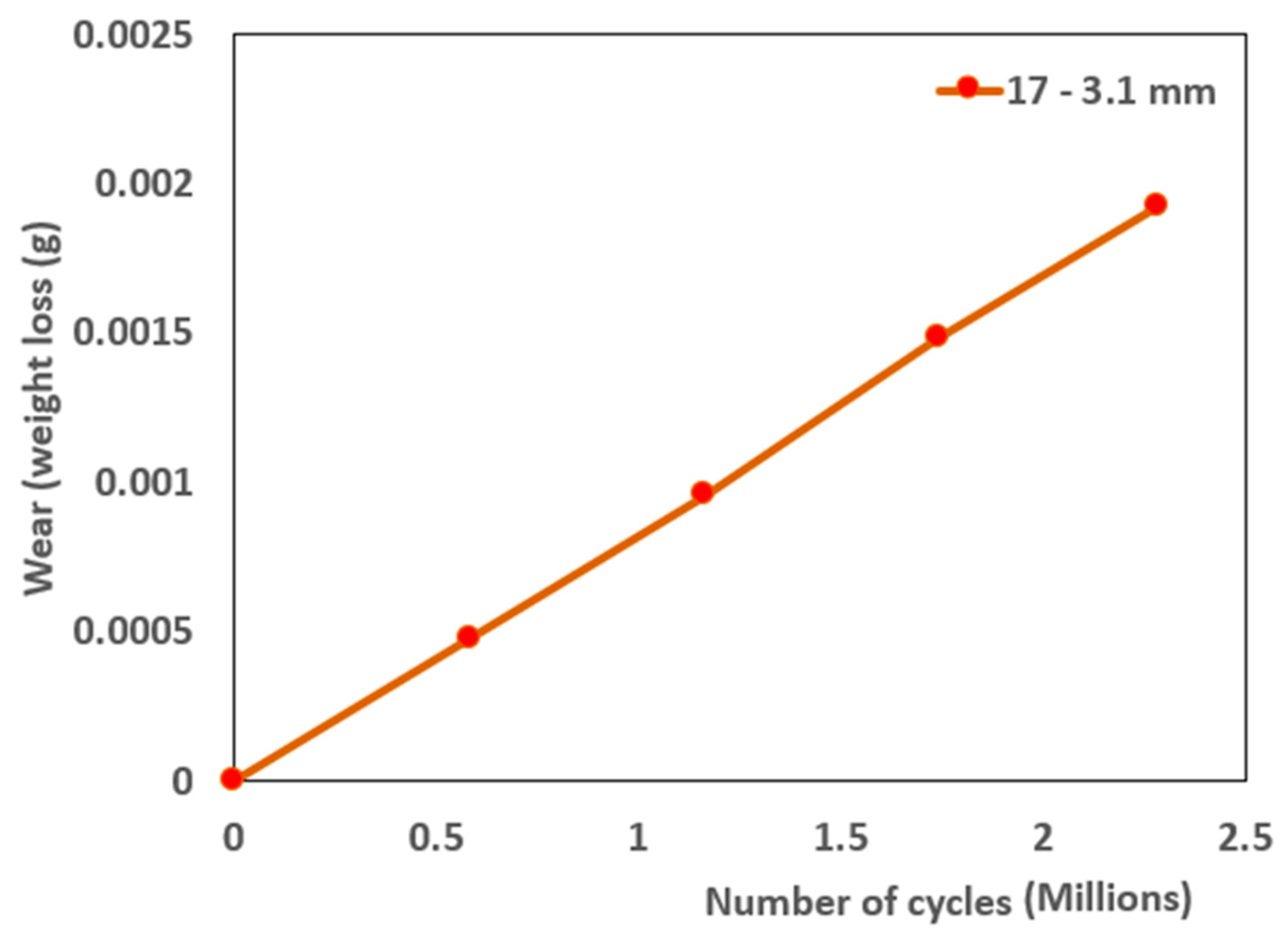
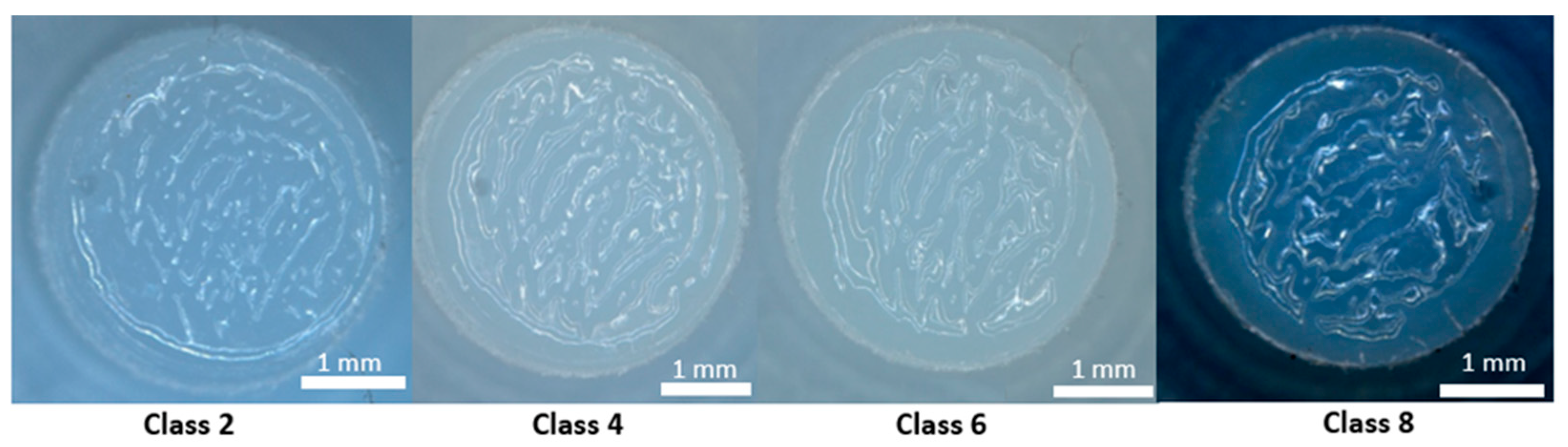
2], gravimetric analysis was performed on the pins using a Mettler Toledo precision balance. These wear measurements were performed on all six tested pins, and the wear rates were similar, with no significant differences. The surfaces of all the CoCrMo discs were observed to verify if third-body wear had occurred, scratching the surface of the discs. However, the wear track was not clearly visible, and the third-body wear was minimal on the metallic counter body. Moreover, the surface evolution of the UHMWPE pins was observed using a Leica optical microscope. The weight losses and the structural features of the optical images on all the UHMWPE pins were found to be similar. In addition, wear volume was measured only on UHMWPE pin no. 17 using an S Neox Sensofar optical profilometer. These were quantitative wear measurements on the protrusions observed on UHMWPE pins compared to qualitative wear measurements in the case of the optical microscope. Due to a lot of variation in the depths of protrusions, a focal variation technique was used to measure the volumes of the protrusions.
2.4. Wear Classification
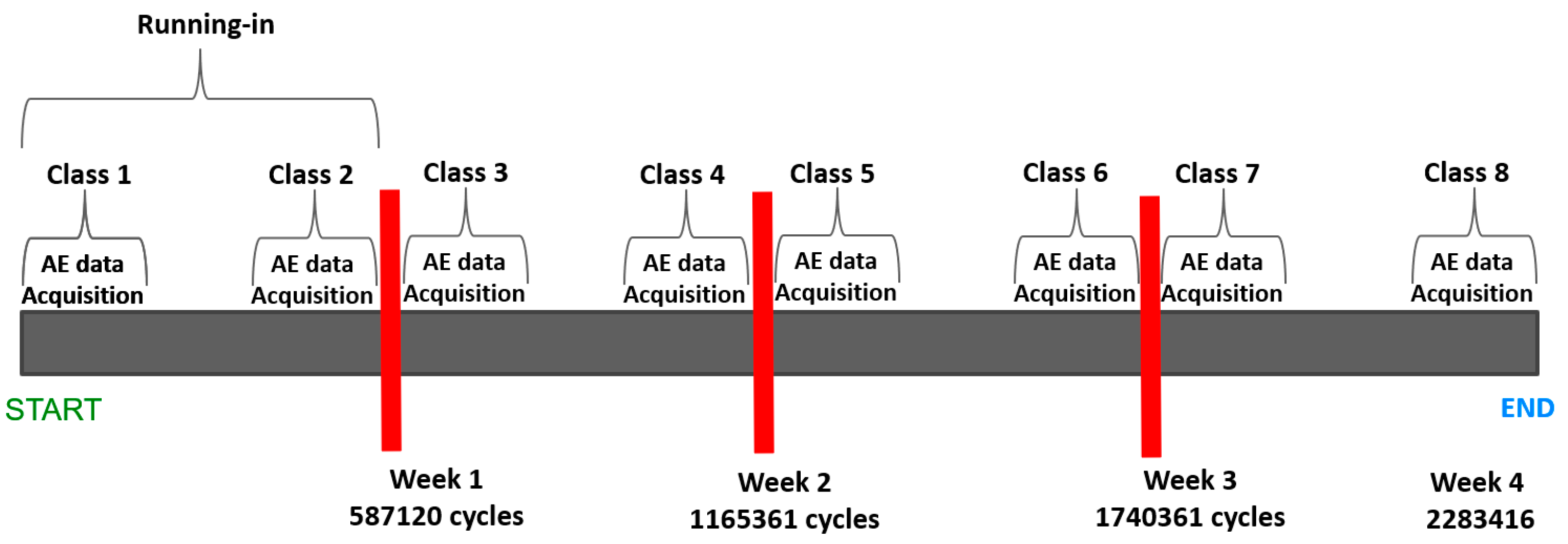
The stages of the AE data acquisition are defined into different wear classes as the surface states change over the course of the test. AE signals were collected in different test stages, as shown in
Figure 2. The effective contact surface changed when the rough pin surface was smoothened by wear at the beginning of the test. Samples were re-mounted on the OrthoPOD
® tribometer. A change in the surface states was expected during the entire test duration [
7,
30].
The red bars indicate the test interruptions. The first AE data acquisition at the test’s beginning is classified as Class 1. Class 1 involves the initial running-in period. Before stopping the test for the first time after close to half a million cycles, AE data are acquired for at least 5 min, and that is defined as Class 2. Class 1 and Class 2 involve a lot of asperity-asperity contact between the UHMWPE pin and CoCrMo disc. Class 3 is where the AE data are acquired just after stopping the test after week 1. Class 4 to Class 8 are defined similarly, as shown in
Figure 2. After each stoppage, the disc and the pin samples are thoroughly cleaned with solvents and put back in the pin and disc holders for further testing.
2.5. Data Processing Pipeline
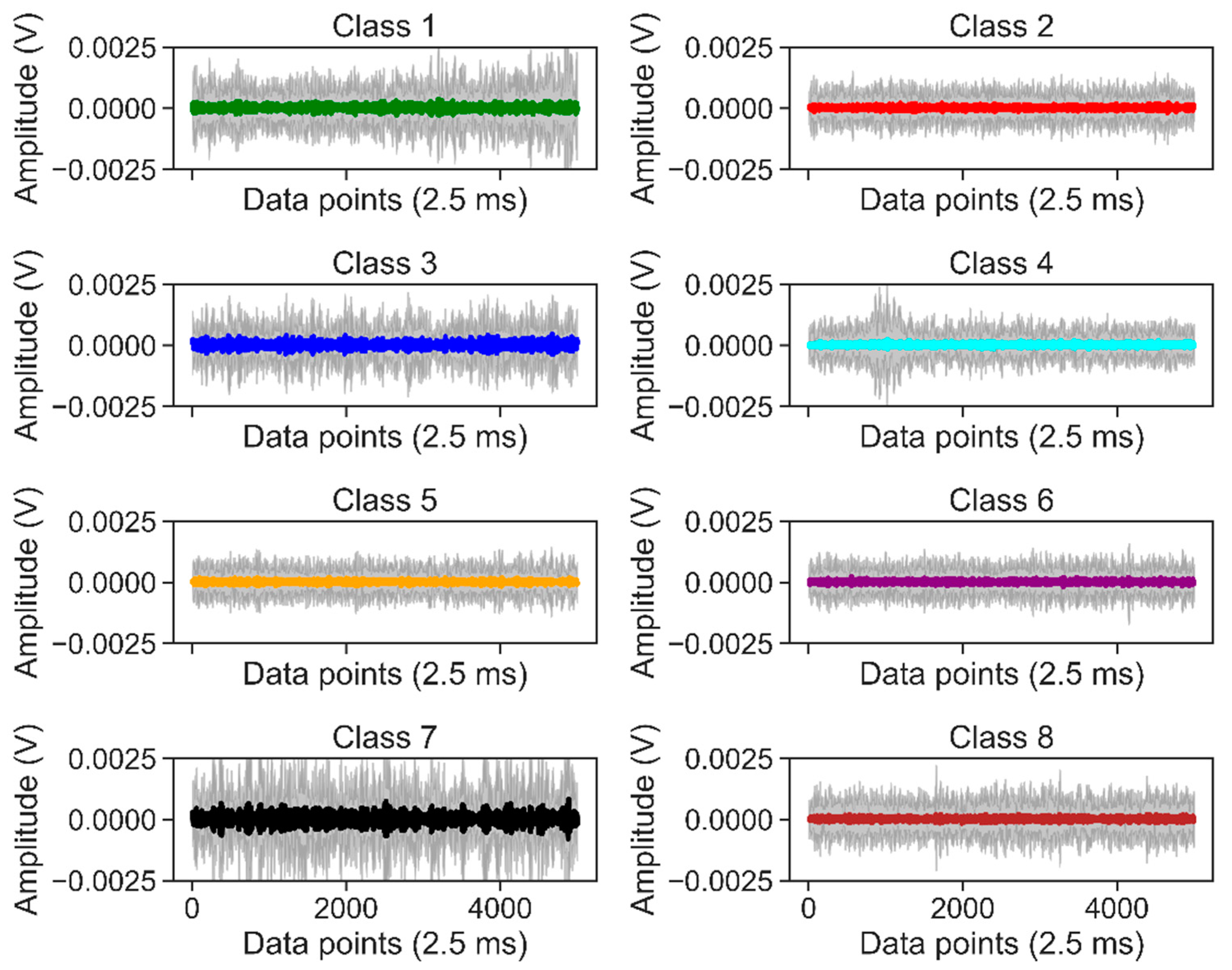
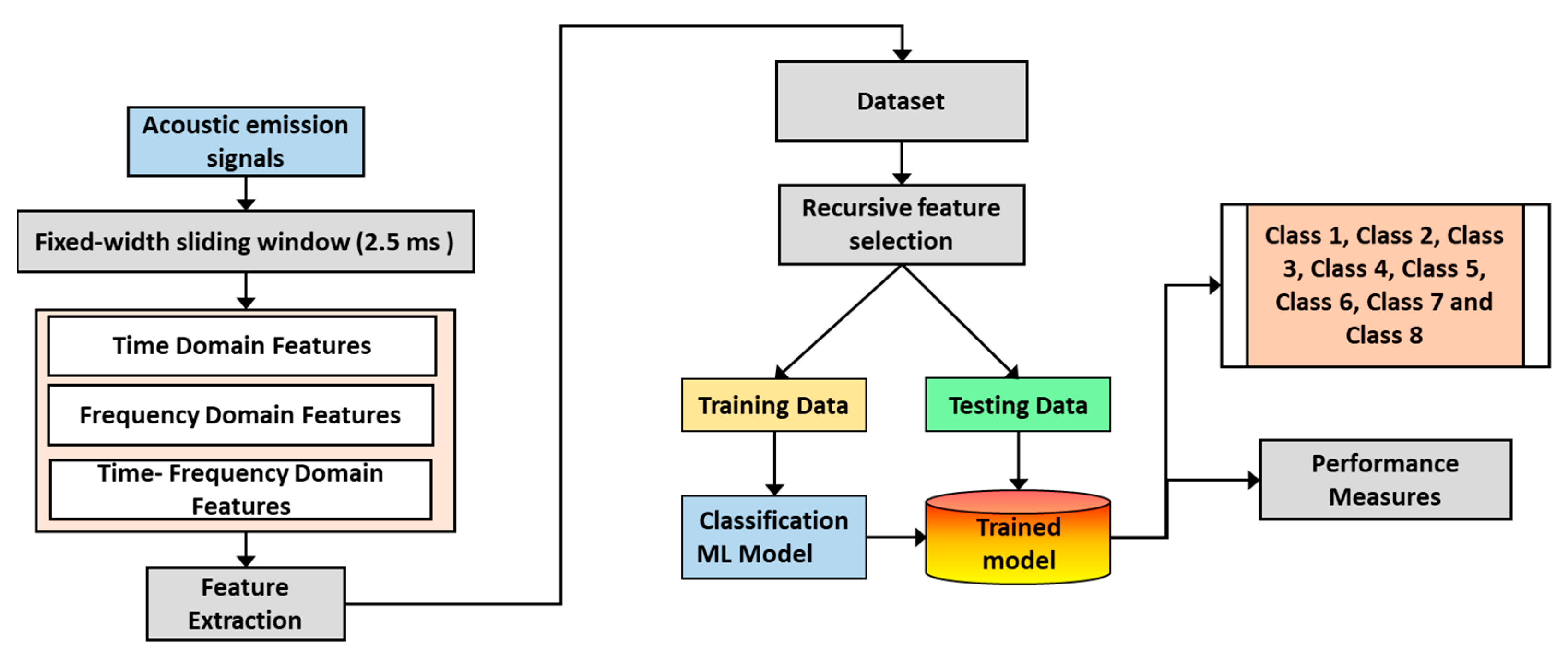
In this specific scenario, we focused on processing raw AE sensor data to extract meaningful features and perform classification based on wear volume measurements and gravimetric analysis. We initiated the process by segmenting the raw data into fixed sliding windows with a duration of 2.5 milliseconds, resulting in 5000 data points per window due to a sampling rate of 2 MHz. We then categorized these sliding windows into eight different classes based on the time at which AE signals were recorded during the test acquisition time. Finally, we proposed two frameworks for feature extraction and classification.
The first framework involved performing manual computations of AE features. Manually extracted vectors representing time, time-frequency, and frequency domain features from each sliding window were used. We applied normalization to ensure fair comparisons among the features, which standardized their scales and prevented any single feature from dominating the subsequent analysis. Following feature extraction and normalization, we employed a recursive feature elimination technique using Logistic Regression (LR). This iterative process involved evaluating each feature’s significance and predictive power using LR. We progressively eliminated less informative or less significant features, resulting in a refined feature set. After the recursive feature elimination, we obtained the top 32 features that were considered the most relevant for the classification task. In the second framework of this specific scenario, we introduced a contrastive deep learning network for feature extraction and classification of the AE sensor data. This approach aimed to automatically learn meaningful AE signal representations automatically without manual feature engineering. We utilized a deep learning network trained using a contrastive loss function. The network learned to map the raw AE signals into a lower-dimensional feature space where similar signals were clustered together and dissimilar signals were separated. This was achieved by encouraging similar AE signals to have nearby representations while pushing dissimilar signals apart. The contrastive loss function compared pairs of AE signals and calculated the similarity between their representations in the learned feature space. During training, the network adjusted its parameters to minimize the contrastive loss, effectively learning representations that captured relevant patterns and characteristics of the AE data. Once the deep learning network was trained, the learned representations were used as features for the classification task. These representations encoded the most informative aspects of the AE signals, enabling more accurate and efficient classification. By leveraging the power of deep learning and contrastive learning techniques, this framework aimed to automate the feature extraction process and capture intricate patterns in the raw AE sensor data. This approach eliminates the need for manual feature engineering. It allowed the model to learn directly from the data, potentially leading to improved performance and better predicting wear classes based on the AE sensor data.
These features, computed by two methodologies, served as inputs for classification algorithms. Following this pipeline, which included sliding window segmentation and feature extraction, our goal was to accurately predict wear classes based on the AE sensor data. We allocated 75% of the subset feature dataset for training the model and used the remaining 25% for testing. We validated this ML approach by using several ML algorithms such as LR, Support Vector Machines (SVMs), Neural Networks (NNs), Naïve Bayes (NB), k-Nearest Neighbor (k-NN), eXtreme Gradient Boosting (XGBoost), and Random Forest (RF).
4. Machine Learning Classifier
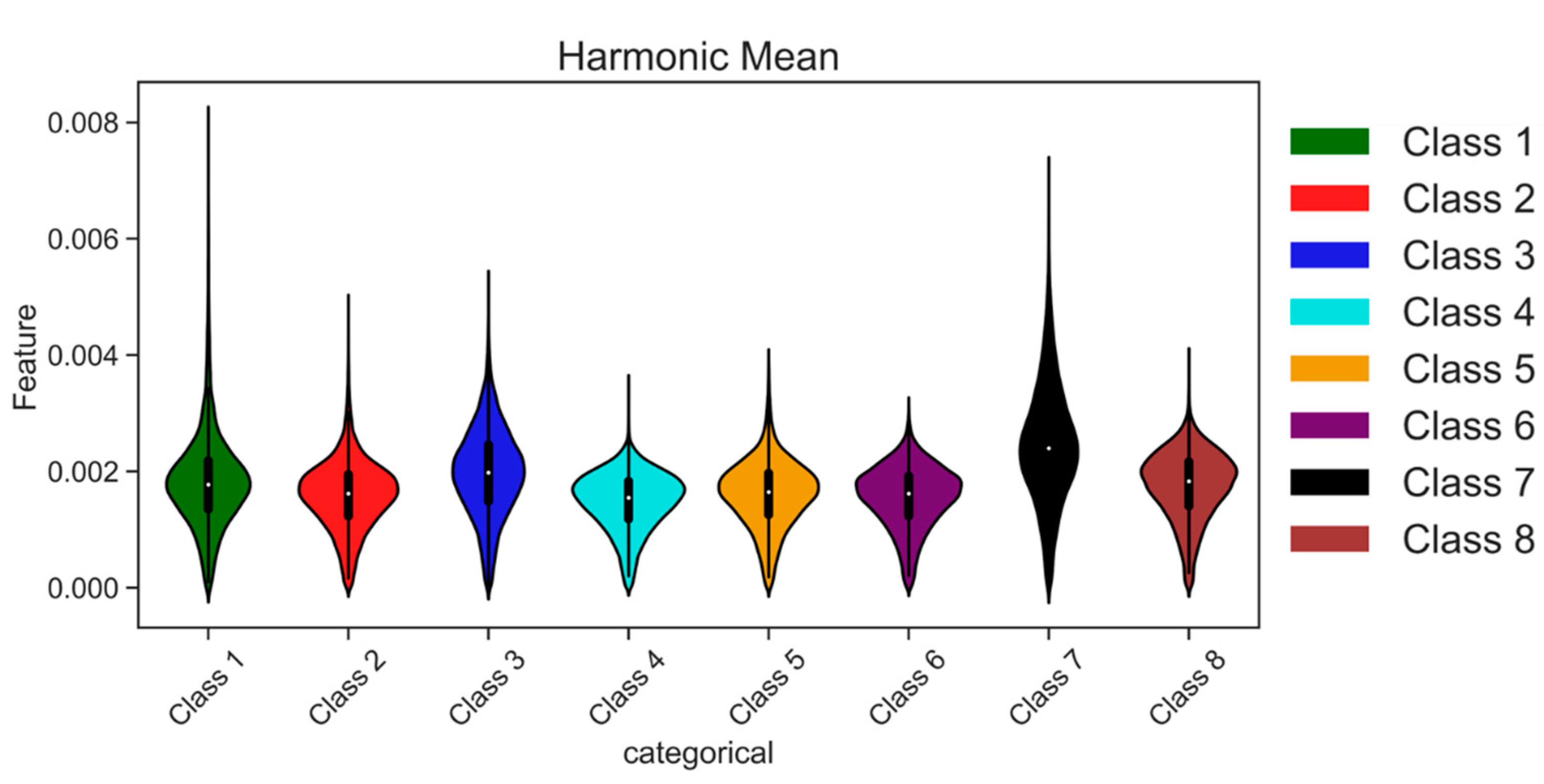
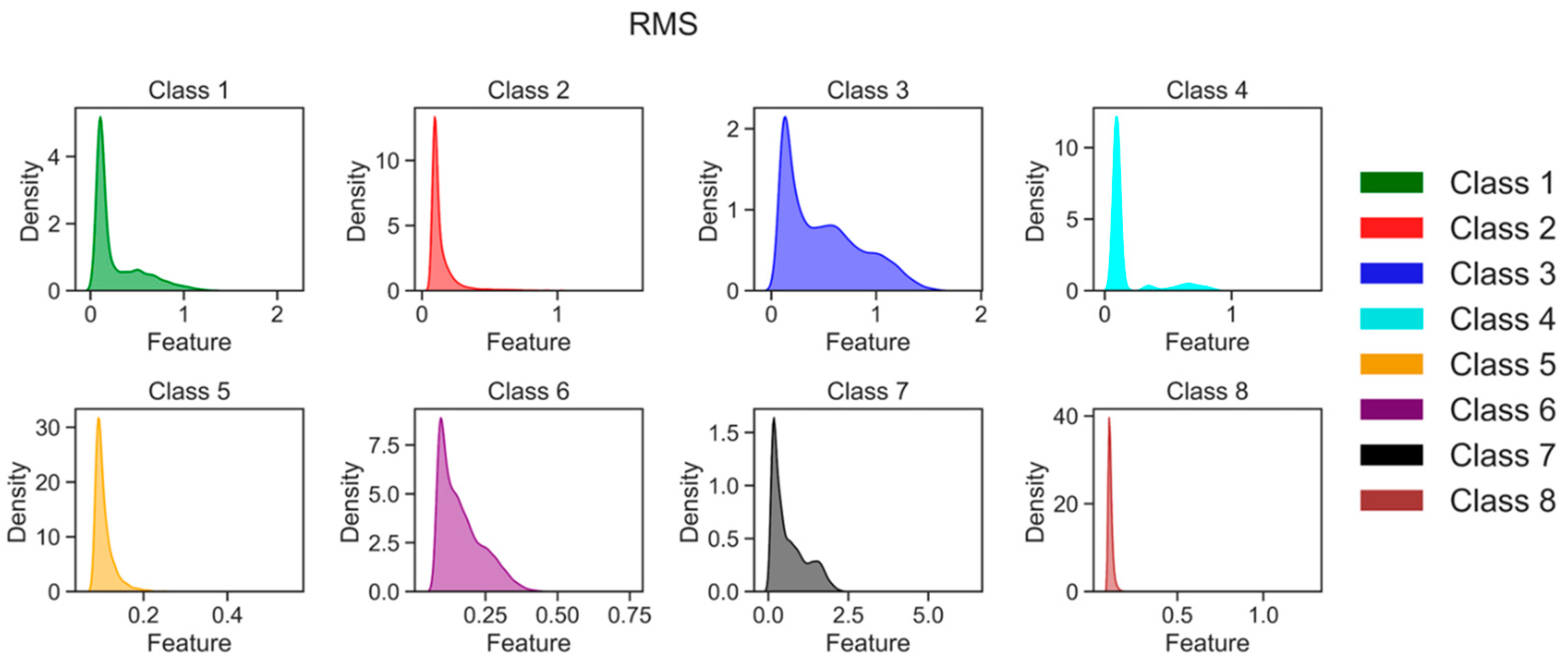
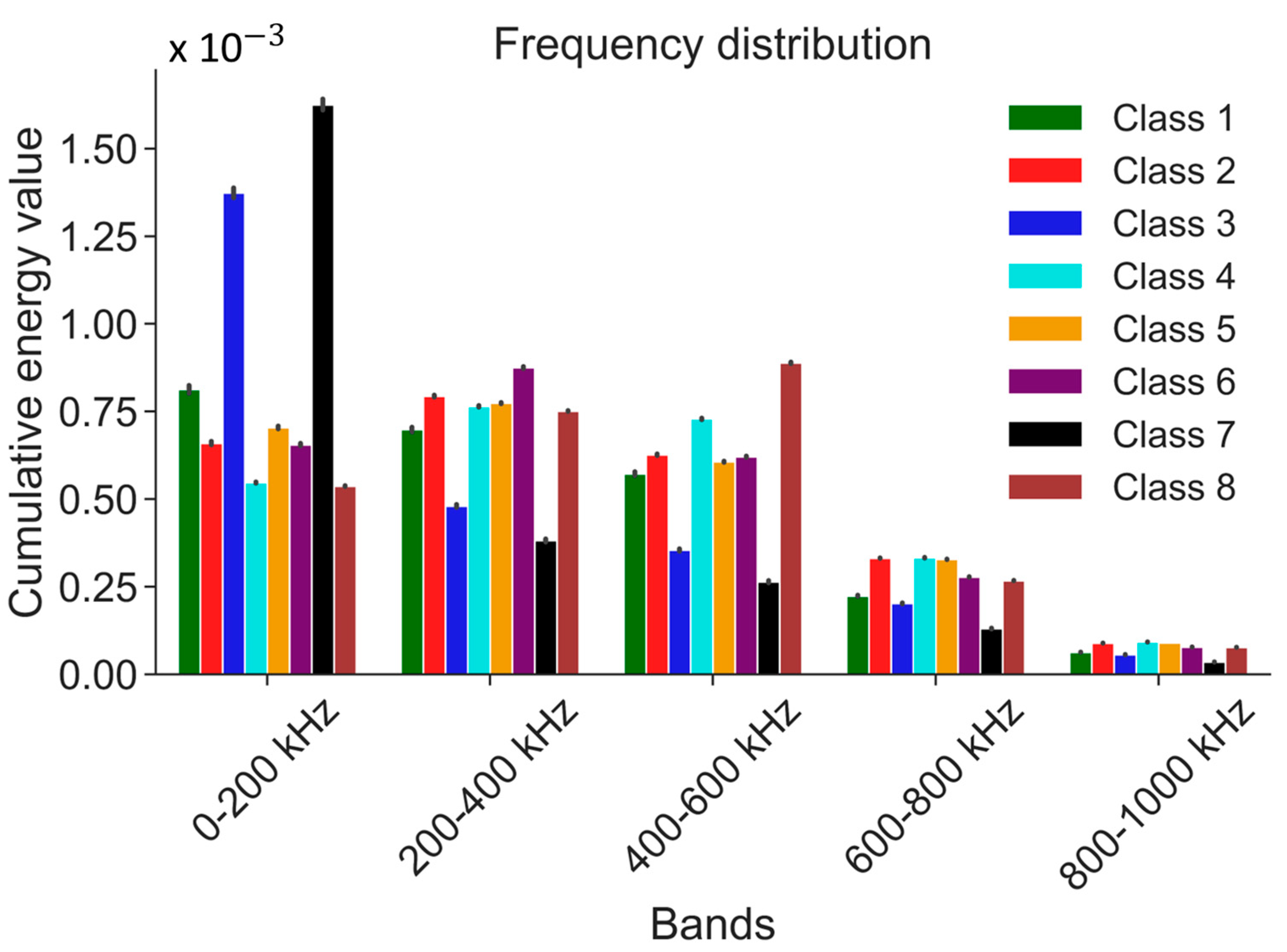
Feature extraction is vital in preparing AE time series data for ML classifiers. Its main objective is to extract specific attributes or characteristics that can provide meaningful information for classification, prediction, and other analytical tasks. In the context of AE time series data, the raw sensor data are divided into fixed-width sliding windows with a duration of 2.5 ms, facilitating subsequent analysis. Each sliding window yields a vector comprising multiple statistical features that capture valuable information across diverse domains, encompassing time, frequency, and time-frequency. These features serve as a means to gain insights into the underlying patterns and variations inherent within the AE signals. By harnessing these statistical features from distinct domains, ML classifiers are equipped to effectively analyze AE time series data, enabling tasks such as anomaly detection, fault diagnosis, and structural health monitoring. These extracted features play a pivotal role in aiding the classifiers in recognizing patterns, making precise predictions, and executing dependable classifications based on the rich information acquired. For specific details regarding the features and their calculations, kindly refer to
Table 2, which furnishes a comprehensive compilation of time, frequency, and time-frequency domain features extracted from each raw sliding window.
The ML classifier pipeline consists of several crucial steps for preprocessing and analyzing data, as shown in
Figure 10. It begins with sliding window segmentation, dividing the raw data into fixed-width sliding windows to capture temporal information and create smaller segments for analysis. Each window extracts a vector of features, including statistical measures, spectral characteristics, or time-frequency domain representations. In this work, 294 features were initially used. After feature extraction, recursive feature elimination is applied to select the most relevant features based on classifier performance or predefined criteria. This iterative process results in an optimal subset of features.
In this case, LR-based feature selection was used to pick 32 informative features to train the classifier, ensuring accuracy without compromising the feature subset. The next step involves preparing a new feature subset containing the selected 50 features for the classification task. Stochastic selection allocates 75% of the data for training and 25% for testing the models. Finally, the ML classifiers are trained and evaluated using the new feature subset, learning patterns, and relationships within the data to make accurate predictions or classifications. Performance evaluation is conducted using metrics such as classification accuracy. As illustrated in
Figure 10, this comprehensive data treatment pipeline ensures that relevant information is captured, irrelevant features are eliminated, and the classifier is trained on a focused and informative feature set, improving classification performance.
Classification Results
This study employed a combination of two linear and four non-linear ML classifiers: LR, SVM, k-NN, RF, NN, and XGBoost. The training parameters for the chosen classifiers were determined using empirical guidelines as outlined in
Table 3. Their performance was assessed by considering prediction accuracy. In future endeavors, the training parameters of these classifiers can be further refined, considering factors such as training time and prediction accuracy, which will be addressed in our upcoming research.
Table 4 provides a comprehensive overview of the classification results, including a confusion matrix and a comparison among six ML algorithms. The accuracies reported in the table represent the percentage of true positives out of the total number of tests for each class. On the other hand, the errors are calculated by dividing the number of true negatives by the total number of tests and are displayed in the non-diagonal cells. To interpret the above confusion matrix in
Table 4, XGBoost in the first column is considered an example. The average classification accuracy for the XGBoost algorithm is 87.75%. The extracted features from Class 1 are classified with a high accuracy of 93%. The classification accuracy is high in Class 1 for all the other algorithms, as the surface states are bound to be different in the running-in period. The classification errors are minimal and originate from slight misclassifications into Class 2 (2%), Class 4 (2%), Class 5 (2%), and Class 6 (1%). These misclassifications suggest a slight overlap of features between Class 1 and the other four classes. Similarly, for Class 3, Class 4, Class 5, Class 6, Class 7, and Class 8, the misclassification rates are minimal, indicating that the surface states for these classes are distinct and independent of other wear classes.
This suggests the progression of abrasive wear in the form of third-body abrasion occurs continuously as we move from Class 3 to Class 8. The UHMWPE debris particles cause third-body abrasive wear. Protrusions are formed through the folding of the UHMWPE, entrapping black debris contamination on the surface of the UHMWPE pins. The size of these protrusions increases with time until the test is completed. Additionally, it is essential to note that the poorest classification results occur at the beginning of the experiment (70% for Class 2) in XGBoost and in the case of all the other ML algorithms. This may be attributed to the running-in period, where changes in surface roughness are the most significant. However, after the running-in period (Class 3 onwards), the classification accuracy improved significantly, ranging from 82% to 100%. This demonstrates the effectiveness of our approach to classifying wear. Some misclassifications are observed between alternate classes, such as Class 1, Class 3, Class 5, and Class 7, as well as Class 2, Class 4, Class 6, and Class 8. These misclassifications may be attributed to variations in surface conditions, such as fresh and cleaned surfaces with less debris and lubricant contamination for Class 1, Class 3, Class 5, and Class 7, and lubricated and wear debris-filled protrusions constantly increasing in size for Class 2, Class 4, Class 6, and Class 8.
Table 4 illustrates the average classification accuracies obtained on all six ML algorithms, and they are found to be in a similar range and more than 80%. The performance of hand-picked features for classification was unsatisfactory, which may be attributed to the complexity and nuances of the labeled categories. However, these results suggest that our methodology has potential, especially considering the setup was not fully optimized. This combination of AE data processing with ML algorithms holds promise for real-time monitoring of progressive wear in UHMWPE materials used in human joint prostheses.
5. Contrastive Learning
The previous section presented classification results using various ML algorithms on hand-picked features. To overcome the limitations of manual feature extraction, the following section proposes using CNN for automatic feature map extraction. The study will compare the performance of hand-picked features with features computed using CNN. Contrastive learning trains a neural network to distinguish between positive and negative pairs, aiming to create a feature embedding space with closer proximity for similar examples and greater separation for dissimilar ones [
45,
46,
47]. Circle loss offers a different approach to achieving this goal than contrastive loss functions like contrastive loss, triplet loss, or N-pair loss. Circle loss introduces decision boundaries in the form of circles around each instance in the embedding space, intending to promote the inclusion of positive pairs within their respective circles and the exclusion of negative pairs from them [
48]. This decision boundary is represented as a circle around each instance, and the objective is to ensure that all positive samples lie inside their respective circles while negative samples lie outside. In summary, using Circle loss within contrastive learning optimizes the learning of feature representations, enabling the network to distinguish between different classes or categories in each dataset effectively.
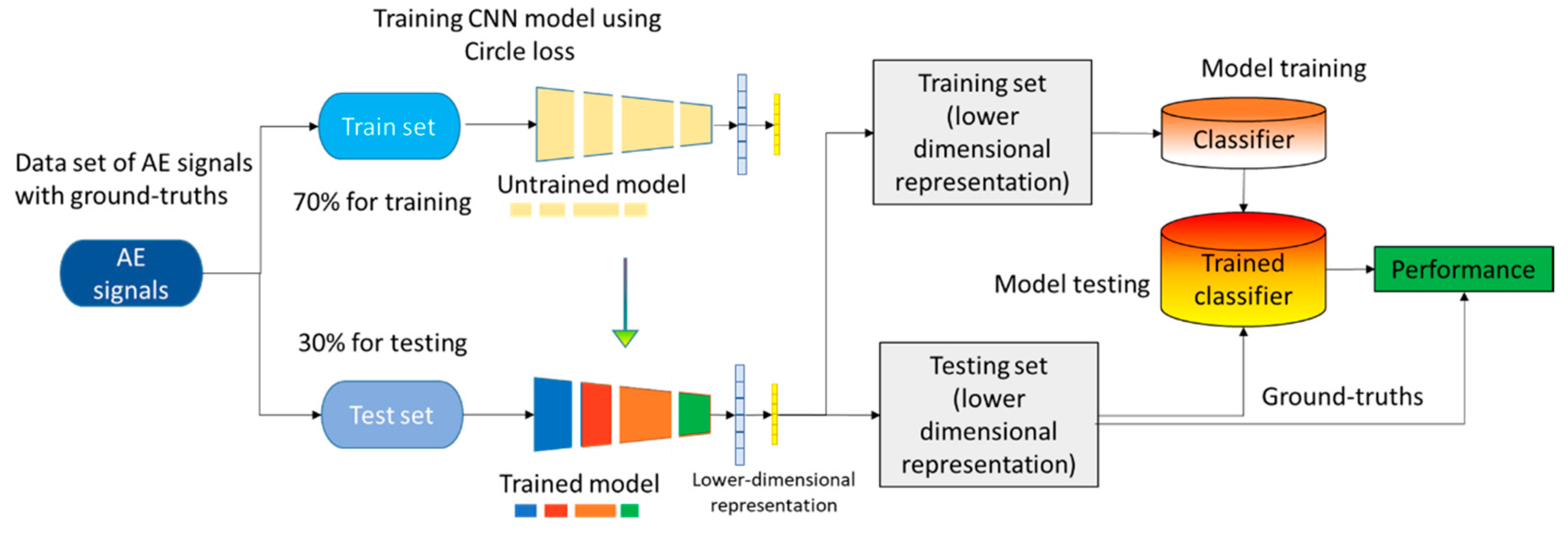
Training a CNN through contrastive learning, specifically employing circle loss, entails three primary steps, as depicted in
Figure 11. Firstly, the data preparation phase involves pairing AE signals from distinct categories within the process zone, guided by their degree of similarity or dissimilarity, facilitated by the application of contrastive loss. Pairs that pertain to the same category are marked with a Boolean value of 1, while pairs originating from different categories receive a Boolean value of 0. Subsequently, the subsequent step encompasses constructing a network crafted to capture a lower-dimensional representation of the AE signatures. This network inputs the paired AE signals and generates a feature map as its output. It aims to learn meaningful representations capable of distinguishing various categories based on distinctive AE signatures. Lastly, the network undergoes training employing circle loss, constituting a variation of contrastive loss specifically devised for deep metric learning. This final step ensures that the network’s learned representations effectively facilitate differentiation between the different categories. Circle loss encourages the network to learn discriminative features by forming tight clusters for each category while maximizing inter-class separability. During the training process, monitoring the magnitude of the loss is crucial. The loss should decrease with each epoch, indicating the convergence of the network learning. In the case of multi-class classification in a supervised manner, ML classifiers are trained on the feature map generated by the network. These trained classifiers map the learned features to the corresponding class labels. This approach allows for classifying unseen data based on the learned representations.
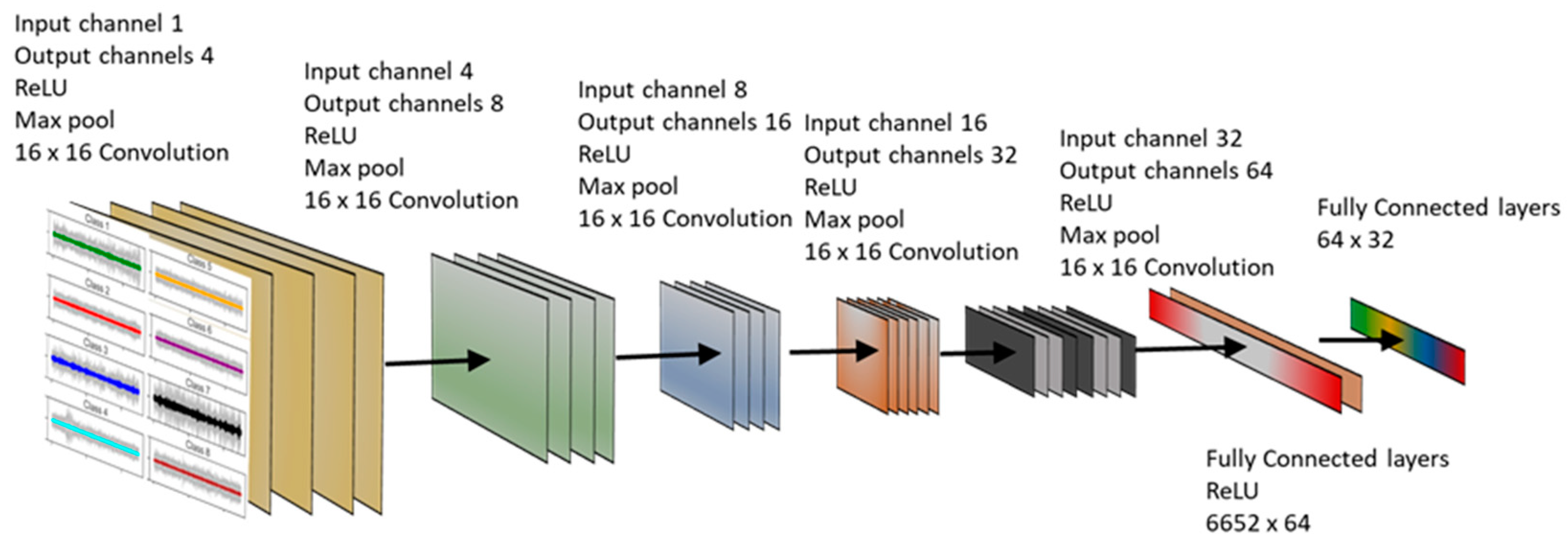
The CNN model was implemented using the PyTorch library (Meta, USA), with a meticulous fine-tuning of 3.5 million parameters to achieve optimal performance. After an extensive search for the optimal design, the final CNN network was developed, consisting of five convolution and three fully connected layers, as depicted in
Figure 12. The initial CNN layer takes a tensor of size B (Batch size) × 1 × 5000 as input, representing the length of the AE signal. The network then processes this input to generate a feature map with dimensions
B × 32, which is a compressed representation of the original signals. During training, the chosen optimizer was stochastic gradient descent with momentum, facilitating efficient convergence. To extract meaningful features, each convolution layer employed a 16 × 16 kernel. Additionally, a dropout rate of 10% was implemented between each epoch to alleviate the risk of overfitting. The Rectified Linear Unit (ReLU) activation function was applied to introduce non-linearity into the network. A batch size of 256 was used during training to ensure efficient processing. The entire training procedure was conducted on a high-performance Nvidia RTX Titan GPU (Nvidia, USA), enabling accelerated computations and enhancing training performance.
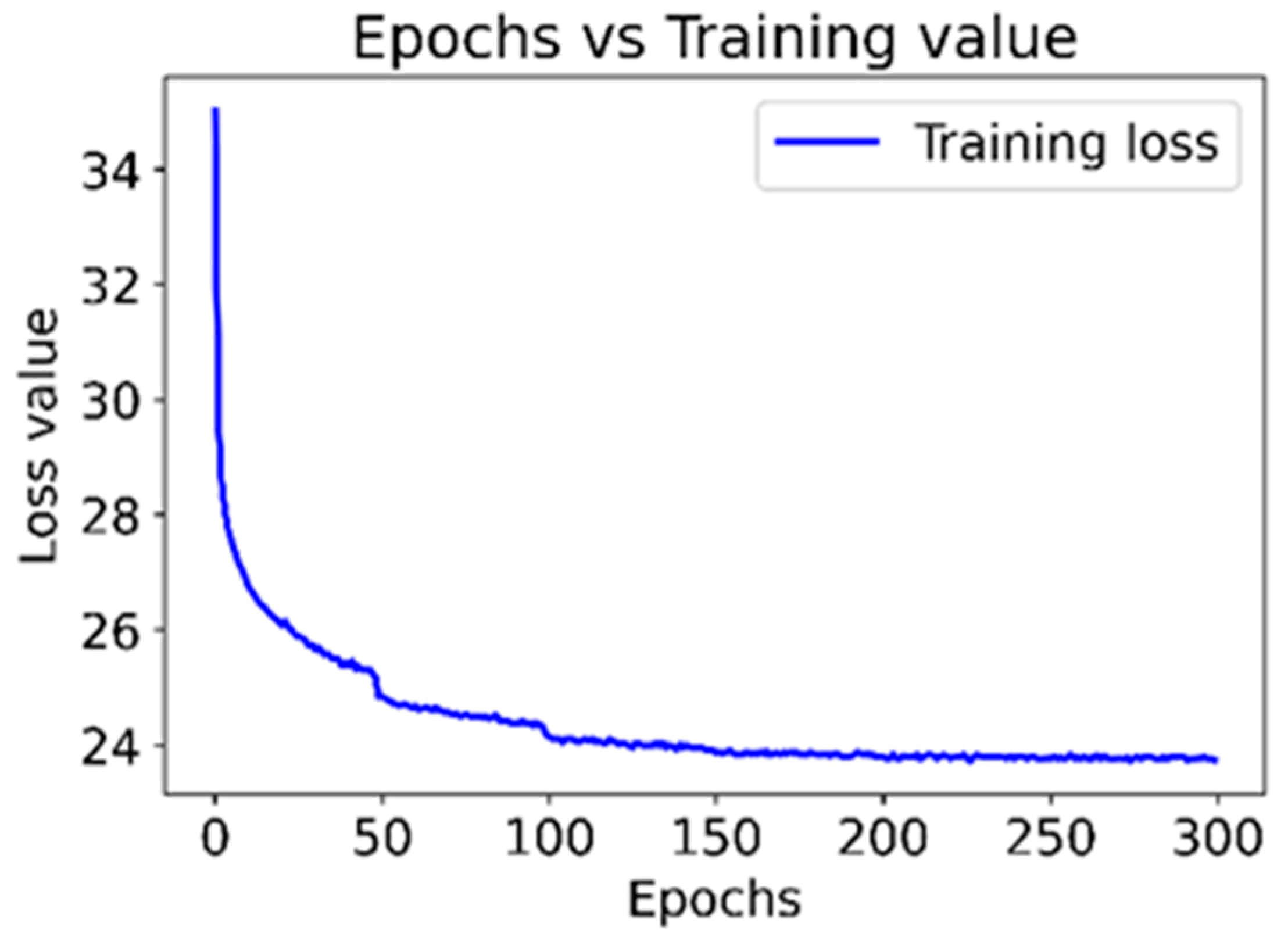
Figure 13 represents the progression of loss values throughout 300 training epochs for the CNN model. The loss values indicate how well the model learns and captures the underlying distributions present in the AE signals. The graph shows a consistent decline in the loss values during the initial 100 epochs, suggesting that the model significantly improves in capturing the desired patterns and features from the input data. Subsequently, no substantial improvement is observed beyond this point, as evidenced by the information depicted in
Figure 13. This plateauing of the loss values suggests that the model has likely reached a point of diminishing returns in terms of learning from the training data. Further training beyond this point may not lead to significant enhancements in performance.
While analyzing loss values is valuable, additional evaluation techniques, such as feature map visualization, can provide a more comprehensive understanding of a model’s performance. One approach to visualizing feature maps is reducing their dimensions and displaying them in a two-dimensional space.
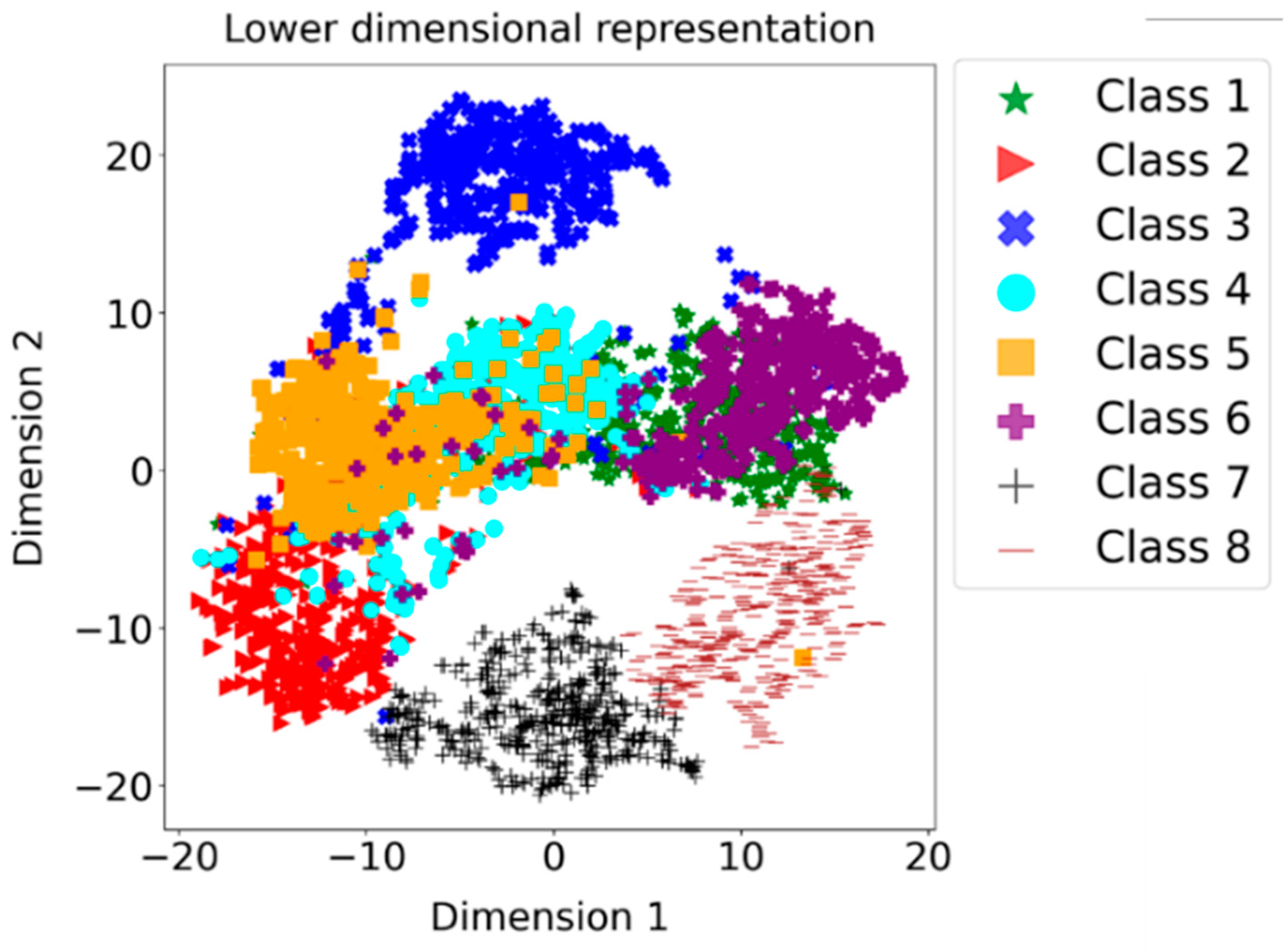
Figure 14 showcases the 2D visualization of a reduced-dimensional representation created using t-SNE (t-Distributed Stochastic Neighbor Embedding) on the feature map derived from a CNN trained with contrastive loss. The results presented in
Figure 14 reveal distinct clusters for each of the eight classes. This clustering indicates that the CNN, trained using contrastive learning, effectively captures and separates different classes based on their unique features.
This finding highlights the effectiveness of contrastive learning in addressing the monitoring problem. However, it is crucial to acknowledge the presence of certain overlaps in the visualization. These overlaps suggest similarities in the process dynamics that result in overlapping grades. It is essential to carefully analyze and consider these overlaps when interpreting the performance of the CNN model. Overlaps may indicate areas where the model faces challenges in accurately distinguishing between similar classes or where the data contains inherent complexities. By combining loss analysis with feature map visualization, we can better understand the model’s performance, its ability to learn and differentiate classes, and the inherent complexities and overlaps present in the data. This holistic evaluation allows for more informed interpretations and insights into the CNN model’s capabilities. The presence of distinct clusters within the lower-dimensional representation obtained from the CNN trained with circle loss through contrastive learning has motivated us to perform a supervised classification task. In line with the approach detailed in
Section 4, we have applied the six ML classifiers. These classifiers adhere to identical training parameters outlined in
Table 3, with the lower-dimensional representation employed as input. The classification results are summarized as a confusion matrix, presented in
Table 5. The average classification accuracy achieved by LR is 91.5%, indicating a high level of accuracy in classifying the data. However, it is essential to note that while the overall accuracy is high, there are instances of misclassifications. Most of these misclassifications occur between adjacent classes, suggesting that the model may struggle to distinguish between classes with similar characteristics or overlapping features. A similar pattern in prediction accuracy was also more pronounced in all other classifiers.
Indeed, analyzing signals in different domains and extracting handcrafted features have been widely used in various applications. However, traditional ML classifiers often struggle to achieve high accuracy when using these handcrafted features, despite the presence of statistical differences. Fortunately, the emergence of contrastive learning and the utilization of CNNs have provided a breakthrough in overcoming the limitations of handcrafted statistical features. A more robust and discriminative data representation can be obtained by training a CNN as a contrastive learner and computing feature maps. The resulting feature representation derived from the trained CNN demonstrates significantly higher accuracy than conventional handcrafted features. This highlights the ability of CNNs to learn and capture meaningful patterns and structures from the data, surpassing the performance of manually designed features. This innovation showcases the power of leveraging deep learning techniques, such as CNNs, to unlock more robust and effective feature representations. By allowing the network to learn and extract relevant features directly from the data, CNNs enable improved classification performance and offer a promising alternative to traditional handcrafted feature approaches.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}