Improvement of Generative Adversarial Network and Its Application in Bearing Fault Diagnosis: A Review


Abstract
:1. Introduction
2. Research Methodology and Initial Analysis
2.1. Research Methodology
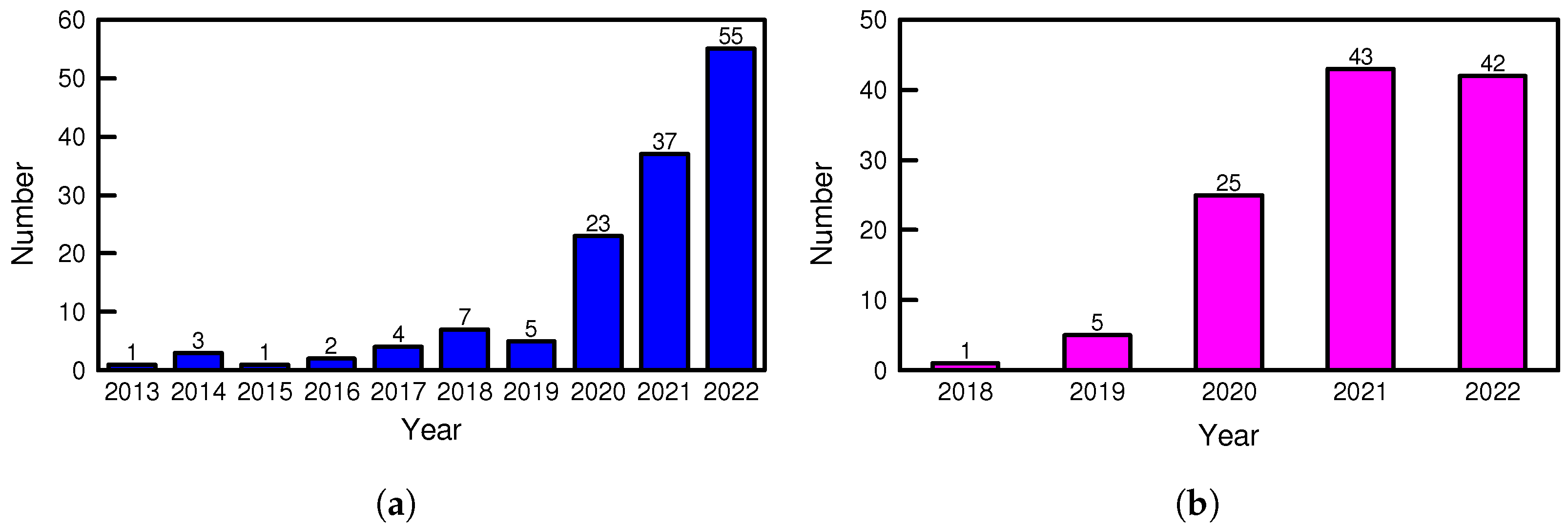
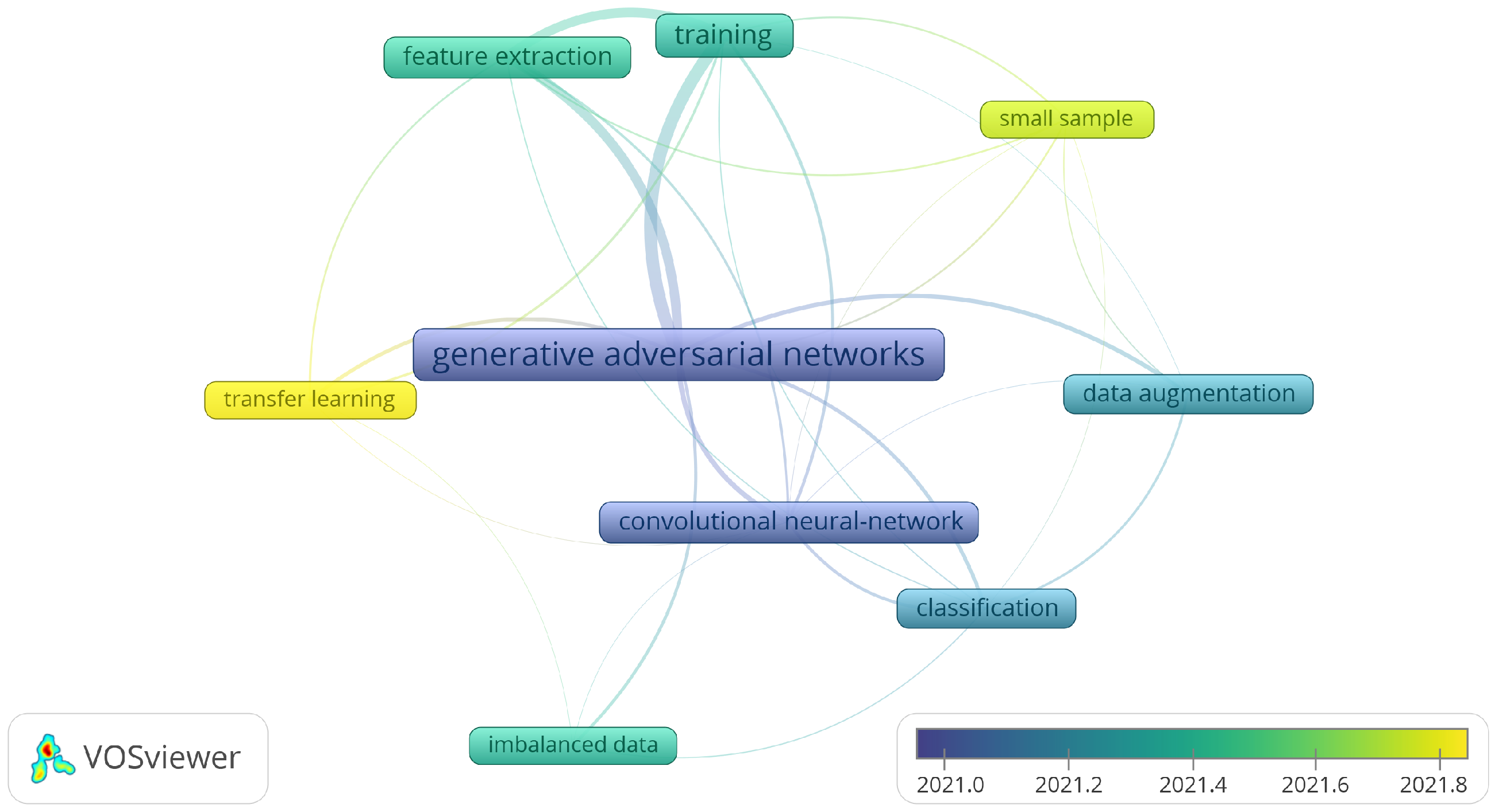
2.2. Initial Literature Analysis
3. Data Augmentation Methods for Bearing Fault Diagnosis
3.1. Data Augmentation Using Oversampling Techniques
3.2. Data Augmentation Using Data Transformations
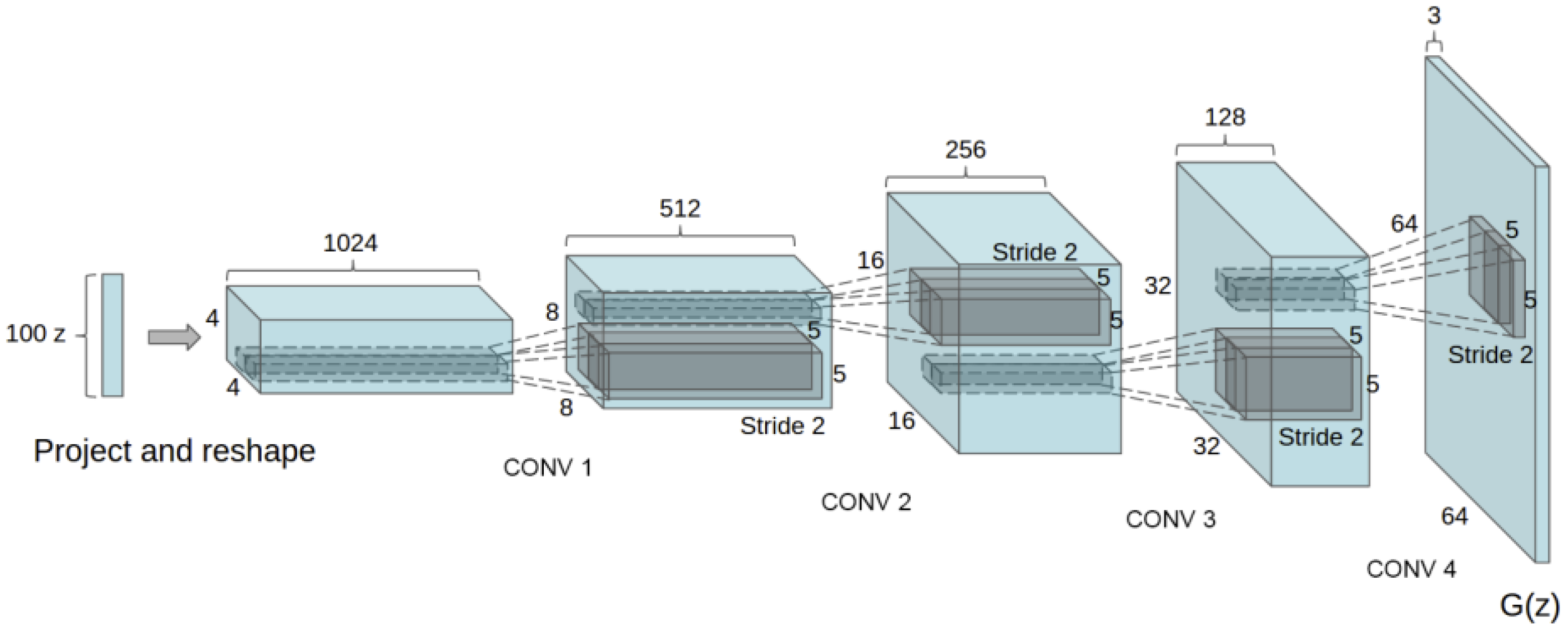
3.3. Data Augmentation Using GANs
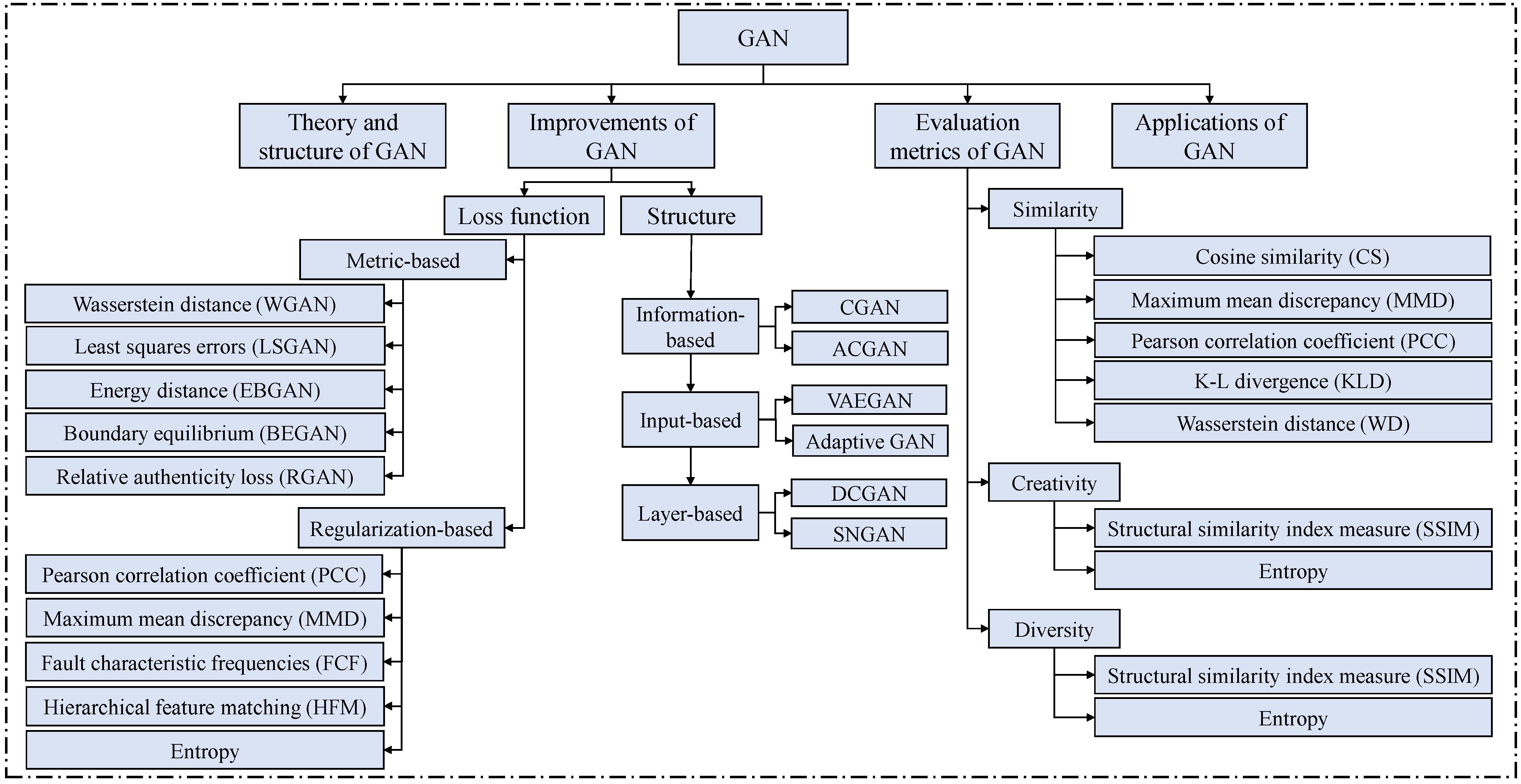
4. Improvements and Applications of GANs in Bearing Fault Diagnosis
4.1. Improvements in the Network Structure
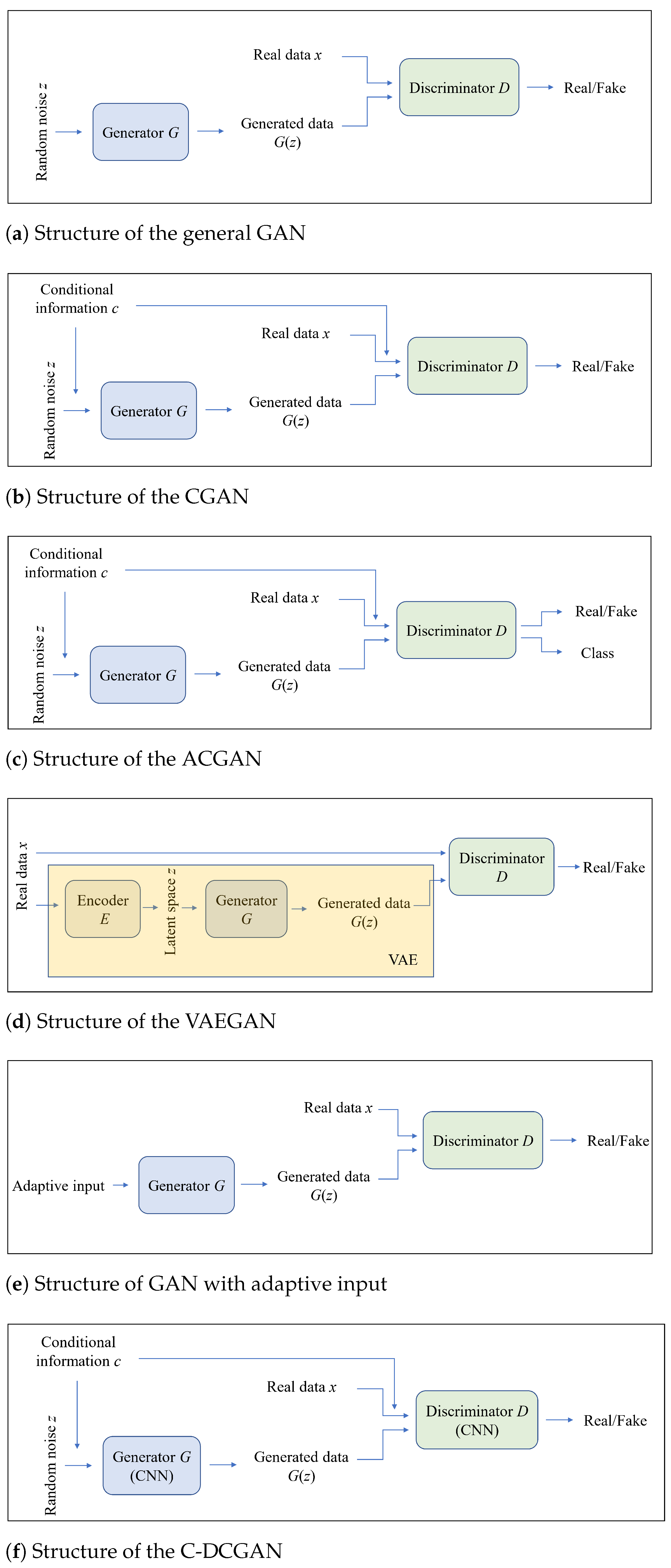
4.1.1. Information-Based Improvements
4.1.2. Input-Based Improvements
4.1.3. Layer-Based Improvements
4.2. Improvements in the Loss Function
4.2.1. Metric-Based Improvements
4.2.2. Regularization-Based Improvements
4.2.3. Summary
4.3. Evaluation of Generated Samples
4.4. Applications of GAN in Bearing Fault Diagnosis
5. Conclusions
5.1. Summary
5.2. Outlook
- •
- Explainability from physicsDue to the black-box properties of DL models, the generated samples lack physical interpretability. Based on our literature research, most studies do not take physical knowledge into account in their models. Although there is a large body of literature on physics-guided neural networks [88,89], there is still a lack of research on introducing physical knowledge into GANs. From our point of view, physics-guided GAN can be studied from two perspectives in the field of bearing fault diagnosis. Based on the taxonomy of improvements of GAN in this paper, the first idea belongs to the improvement of the network structure. For example, the bearing fault mechanism model can be integrated into GAN. The second idea aims to improve the loss function by adding physically interpretable regularization terms to the original loss function.
- •
- Advanced evaluation metricsTo date, the evaluation of the generated samples is not comprehensive. Almost all of the literature we researched only considered the similarity of the generated samples to the real samples. Apart from similarity, the creativity and diversity of the generated samples should be taken into account to achieve a more comprehensive evaluation. More appropriate evaluation metrics deserve further investigation.
- •
- Application for RUL predictionBased on our collation of the literature, there are still a number of promising variants or improvements in GAN that have not yet been applied to bearing fault diagnosis, which deserve further research. For the application in bearing fault diagnosis, the majority of reported GAN variants possess the potential to achieve satisfying results, even under imbalanced or small datasets through sample generation. However, concerning RUL prediction, it is quite another matter. In contrast to fault samples, which have obvious features such as different fault characteristic frequencies for different fault types, samples in the aging period do not have such distinct one-to-one features. Therefore, generating aging samples for bearing during the degradation process with GAN remains an open question. Improving the GAN to generate aging samples for RUL prediction under a dataset with limited run-to-failure trajectories is a challenging but rewarding research topic.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACGAN | Auxiliary classifier GAN |
| ACGAN-SN | Auxiliary classifier GAN with spectral normalization |
| AE | Stacked autoencoder |
| ANN | Artificial neural network |
| BEGAN | Boundary equilibrium GAN |
| CNN | Convolutional neural networks |
| CS | Cosine similarity |
| CGAN | Conditional GAN |
| C-DCGAN | DCGAN integrated with CGAN |
| DBN | Deep belief network |
| DCGAN | Deep convolutional GAN |
| DL | Deep learning |
| EM | Expectation maximization |
| EBGAN | Energy-based GAN |
| FCFs | Fault characteristic frequencies |
| GAN | Generative adversarial network |
| KLD | K-L divergence |
| LSTM | Long short-term memory |
| LSGAN | Least squares GAN |
| ML | Machine learning |
| MMD | Maximum mean discrepancy |
| MS-PGAN | Multi-scale progress GAN |
| PCC | Pearson correlation coefficient |
| PCWAN-GP | Parallel classification WGAN with gradient penalty |
| PHM | Prognostics and health management |
| PSNR | Peak signal-to-noise ratio |
| RGAN | Relativistic GAN |
| RNN | Recurrent neural network |
| RUL | Remaining useful life |
| SSIM | Structural similarity index measure |
| STFT | Short-time Fourier transform |
| SCOTE | Sample-characteristic oversampling technique |
| SI-SMOTE | Sample information-based SMOTE |
| SM | Self-modulation |
| SMOTE | Synthetic minority over-sampling technique |
| SNGAN | Spectral normalization GAN |
| SVM | Support vector machine |
| TL | Transfer learning |
| VAE | Variational autoencoder |
| VAEGAN | GAN combined with VAE |
| WGAN | Wasserstein GAN |
| WGAN-GP | WGAN with the gradient penalty |
| kNN | k-nearest neighbor |
| t-SNE | t-distributed stochastic neighbor embedding |
References
- Hakim, M.; Omran, A.A.B.; Ahmed, A.N.; Al-Waily, M.; Abdellatif, A. A systematic review of rolling bearing fault diagnoses based on deep learning and transfer learning: Taxonomy, overview, application, open challenges, weaknesses and recommendations. Ain Shams Eng. J. 2022, 14, 101945. [Google Scholar] [CrossRef]
- Nandi, S.; Toliyat, H.A.; Li, X. Condition monitoring and fault diagnosis of electrical motors—A review. IEEE Trans. Energy Convers. 2005, 20, 719–729. [Google Scholar] [CrossRef]
- Henao, H.; Capolino, G.A.; Fernandez-Cabanas, M.; Filippetti, F.; Bruzzese, C.; Strangas, E.; Pusca, R.; Estima, J.; Riera-Guasp, M.; Hedayati-Kia, S. Trends in fault diagnosis for electrical machines: A review of diagnostic techniques. IEEE Ind. Electron. Mag. 2014, 8, 31–42. [Google Scholar] [CrossRef]
- Choudhary, A.; Shimi, S.; Akula, A. Bearing fault diagnosis of induction motor using thermal imaging. In Proceedings of the 2018 international conference on computing, power and communication technologies (GUCON), Greater Noida, India, 28–29 September 2018; pp. 950–955. [Google Scholar]
- Barcelos, A.S.; Cardoso, A.J.M. Current-based bearing fault diagnosis using deep learning algorithms. Energies 2021, 14, 2509. [Google Scholar] [CrossRef]
- Harlişca, C.; Szabó, L.; Frosini, L.; Albini, A. Bearing faults detection in induction machines based on statistical processing of the stray fluxes measurements. In Proceedings of the 2013 9th IEEE International Symposium on Diagnostics for Electric Machines, Power Electronics and Drives (SDEMPED), Valencia, Spain, 27–30 August 2013; pp. 371–376. [Google Scholar]
- Wang, X.; Mao, D.; Li, X. Bearing fault diagnosis based on vibro-acoustic data fusion and 1D-CNN network. Measurement 2021, 173, 108518. [Google Scholar] [CrossRef]
- Inturi, V.; Sabareesh, G.; Supradeepan, K.; Penumakala, P. Integrated condition monitoring scheme for bearing fault diagnosis of a wind turbine gearbox. J. Vib. Control 2019, 25, 1852–1865. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar]
- Moosavian, A.; Ahmadi, H.; Tabatabaeefar, A.; Khazaee, M. Comparison of two classifiers; K-nearest neighbor and artificial neural network, for fault diagnosis on a main engine journal-bearing. Shock Vib. 2013, 20, 263–272. [Google Scholar] [CrossRef]
- Rezaeianjouybari, B.; Shang, Y. Deep learning for prognostics and health management: State of the art, challenges, and opportunities. Measurement 2020, 163, 107929. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Ruan, D.; Wu, Y.; Yan, J. Remaining Useful Life Prediction for Aero-Engine Based on LSTM and CNN. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 6706–6712. [Google Scholar]
- Liu, H.; Zhou, J.; Xu, Y.; Zheng, Y.; Peng, X.; Jiang, W. Unsupervised fault diagnosis of rolling bearings using a deep neural network based on generative adversarial networks. Neurocomputing 2018, 315, 412–424. [Google Scholar] [CrossRef]
- Clarivate. Citation Report of Bearing Fault Diagnosis and Data Augmentation- Web of Science Core Collection. Available online: https://www.webofscience.com/wos/woscc/citation-report/4bc631de-ab77-494c-a5bf-f8fa0b0176e0-588287e2 (accessed on 24 October 2022).
- Clarivate. Citation Report of Bearing Fault Diagnosis and GAN—Web of Science Core Collection. Available online: https://www.webofscience.com/wos/woscc/citation-report/44ace094-c782-4554-8934-ab2fe0af70e8-5882d97f (accessed on 24 October 2022).
- VOSViewer. VOSviewer—Visualizing Scientific Landscapes. Available online: https://www.vosviewer.com (accessed on 24 October 2022).
- Zhang, H.; Li, M. RWO-Sampling: A random walk over-sampling approach to imbalanced data classification. Inf. Fusion 2014, 20, 99–116. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Mao, W.; Liu, Y.; Ding, L.; Li, Y. Imbalanced fault diagnosis of rolling bearing based on generative adversarial network: A comparative study. IEEE Access 2019, 7, 9515–9530. [Google Scholar] [CrossRef]
- Jian, C.; Ao, Y. Imbalanced fault diagnosis based on semi-supervised ensemble learning. J. Intell. Manuf. 2022, 1–16. [Google Scholar] [CrossRef]
- Hao, W.; Liu, F. Imbalanced data fault diagnosis based on an evolutionary online sequential extreme learning machine. Symmetry 2020, 12, 1204. [Google Scholar] [CrossRef]
- Razavi-Far, R.; Farajzadeh-Zanjani, M.; Saif, M. An integrated class-imbalanced learning scheme for diagnosing bearing defects in induction motors. IEEE Trans. Ind. Inform. 2017, 13, 2758–2769. [Google Scholar] [CrossRef]
- Wei, J.; Huang, H.; Yao, L.; Hu, Y.; Fan, Q.; Huang, D. New imbalanced bearing fault diagnosis method based on Sample-characteristic Oversampling TechniquE (SCOTE) and multi-class LS-SVM. Appl. Soft Comput. 2021, 101, 107043. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- Kong, Y.; Qin, Z.; Han, Q.; Wang, T.; Chu, F. Enhanced dictionary learning based sparse classification approach with applications to planetary bearing fault diagnosis. Appl. Acoust. 2022, 196, 108870. [Google Scholar] [CrossRef]
- Qian, W.; Li, S.; Yi, P.; Zhang, K. A novel transfer learning method for robust fault diagnosis of rotating machines under variable working conditions. Measurement 2019, 138, 514–525. [Google Scholar] [CrossRef]
- Faysal, A.; Keng, N.W.; Lim, M.H. Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data. arXiv 2021, arXiv:2108.03288. [Google Scholar] [CrossRef]
- Yan, Z.; Liu, H. SMoCo: A Powerful and Efficient Method Based on Self-Supervised Learning for Fault Diagnosis of Aero-Engine Bearing under Limited Data. Mathematics 2022, 10, 2796. [Google Scholar] [CrossRef]
- Wan, W.; Chen, J.; Zhou, Z.; Shi, Z. Self-Supervised Simple Siamese Framework for Fault Diagnosis of Rotating Machinery With Unlabeled Samples. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Peng, T.; Shen, C.; Sun, S.; Wang, D. Fault Feature Extractor Based on Bootstrap Your Own Latent and Data Augmentation Algorithm for Unlabeled Vibration Signals. IEEE Trans. Ind. Electron. 2021, 69, 9547–9555. [Google Scholar] [CrossRef]
- Ding, Y.; Zhuang, J.; Ding, P.; Jia, M. Self-supervised pretraining via contrast learning for intelligent incipient fault detection of bearings. Reliab. Eng. Syst. Saf. 2022, 218, 108126. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, S.; Li, Q.; Liu, Y.; Gu, X.; Liu, W. A new bearing fault diagnosis method based on signal-to-image mapping and convolutional neural network. Measurement 2021, 176, 109088. [Google Scholar] [CrossRef]
- Yu, K.; Lin, T.R.; Ma, H.; Li, X.; Li, X. A multi-stage semi-supervised learning approach for intelligent fault diagnosis of rolling bearing using data augmentation and metric learning. Mech. Syst. Signal Process. 2021, 146, 107043. [Google Scholar] [CrossRef]
- Meng, Z.; Guo, X.; Pan, Z.; Sun, D.; Liu, S. Data segmentation and augmentation methods based on raw data using deep neural networks approach for rotating machinery fault diagnosis. IEEE Access 2019, 7, 79510–79522. [Google Scholar] [CrossRef]
- Ruan, D.; Zhang, F.; Yan, J. Transfer Learning Between Different Working Conditions on Bearing Fault Diagnosis Based on Data Augmentation. IFAC-PapersOnLine 2021, 54, 1193–1199. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. Deep learning-based bearing fault detection using 2-D illustration of time sequence. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 21–23 October 2020; pp. 562–566. [Google Scholar]
- Yang, R.; An, Z.; Huang, W.; Wang, R. Data Augmentation in 2D Feature Space for Intelligent Weak Fault Diagnosis of Planetary Gearbox Bearing. Appl. Sci. 2022, 12, 8414. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Wang, L.; Chen, W.; Yang, W.; Bi, F.; Yu, F.R. A state-of-the-art review on image synthesis with generative adversarial networks. IEEE Access 2020, 8, 63514–63537. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wang, Y. An intelligent diagnosis scheme based on generative adversarial learning deep neural networks and its application to planetary gearbox fault pattern recognition. Neurocomputing 2018, 310, 213–222. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Wang, J.; Han, B.; Bao, H.; Wang, M.; Chu, Z.; Shen, Y. Data augment method for machine fault diagnosis using conditional generative adversarial networks. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2020, 234, 2719–2727. [Google Scholar] [CrossRef]
- Guo, Q.; Li, Y.; Song, Y.; Wang, D.; Chen, W. Intelligent fault diagnosis method based on full 1-D convolutional generative adversarial network. IEEE Trans. Ind. Inform. 2019, 16, 2044–2053. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Pan, T.; He, S. A small sample focused intelligent fault diagnosis scheme of machines via multimodules learning with gradient penalized generative adversarial networks. IEEE Trans. Ind. Electron. 2020, 68, 10130–10141. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, H.; Wang, Y.; Wu, Z.; Liu, S. A conditional variational autoencoding generative adversarial networks with self-modulation for rolling bearing fault diagnosis. Measurement 2022, 192, 110888. [Google Scholar] [CrossRef]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA, 20–22 June 2016; pp. 1558–1566. [Google Scholar]
- Rathore, M.S.; Harsha, S. Non-linear Vibration Response Analysis of Rolling Bearing for Data Augmentation and Characterization. J. Vib. Eng. Technol. 2022. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, Q.; Chen, J.; He, S.; Li, F.; Zhou, Z. A multi-module generative adversarial network augmented with adaptive decoupling strategy for intelligent fault diagnosis of machines with small sample. Knowl.-Based Syst. 2022, 239, 107980. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, H.; Wu, Z.; Liu, Y.; Zhu, K. Machine fault diagnosis with small sample based on variational information constrained generative adversarial network. Adv. Eng. Inform. 2022, 54, 101762. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Liu, Y.T.; Tai, S.K. Synthetic Data generation using DCGAN for improved traffic sign recognition. Neural Comput. Appl. 2022, 34, 21465–21480. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Luo, J.; Huang, J.; Li, H. A case study of conditional deep convolutional generative adversarial networks in machine fault diagnosis. J. Intell. Manuf. 2021, 32, 407–425. [Google Scholar] [CrossRef]
- Zheng, M.; Chang, Q.; Man, J.; Liu, Y.; Shen, Y. Two-Stage Multi-Scale Fault Diagnosis Method for Rolling Bearings with Imbalanced Data. Machines 2022, 10, 336. [Google Scholar] [CrossRef]
- Tong, Q.; Lu, F.; Feng, Z.; Wan, Q.; An, G.; Cao, J.; Guo, T. A novel method for fault diagnosis of bearings with small and imbalanced data based on generative adversarial networks. Appl. Sci. 2022, 12, 7346. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, H.; Wu, Z.; Li, X. Data synthesis using deep feature enhanced generative adversarial networks for rolling bearing imbalanced fault diagnosis. Mech. Syst. Signal Process. 2022, 163, 108139. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Zhang, Y.; Ai, Q.; Xiao, F.; Hao, R.; Lu, T. Typical wind power scenario generation for multiple wind farms using conditional improved Wasserstein generative adversarial network. Int. J. Electr. Power Energy Syst. 2020, 114, 105388. [Google Scholar] [CrossRef]
- Zhang, T.; He, S.; Chen, J.; Pan, T.; Zhou, Z. Towards Small Sample Challenge in Intelligent Fault Diagnosis: Attention Weighted Multi-depth Feature Fusion Net with Signals Augmentation. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Zhu, H.; Huang, Z.; Lu, B.; Cheng, F.; Zhou, C. Imbalance domain adaptation network with adversarial learning for fault diagnosis of rolling bearing. Signal Image Video Process. 2022, 16, 2249–2257. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Dewi, C.; Chen, R.C.; Liu, Y.T.; Yu, H. Various generative adversarial networks model for synthetic prohibitory sign image generation. Appl. Sci. 2021, 11, 2913. [Google Scholar] [CrossRef]
- Anas, E.R.; Onsy, A.; Matuszewski, B.J. Ct scan registration with 3d dense motion field estimation using lsgan. In Proceedings of the Medical Image Understanding and Analysis: 24th Annual Conference, MIUA 2020, Oxford, UK, 15–17 July 2020; pp. 195–207. [Google Scholar]
- Wang, R.; Zhang, S.; Chen, Z.; Li, W. Enhanced generative adversarial network for extremely imbalanced fault diagnosis of rotating machine. Measurement 2021, 180, 109467. [Google Scholar] [CrossRef]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Yang, J.; Yin, S.; Gao, T. An efficient method for imbalanced fault diagnosis of rotating machinery. Meas. Sci. Technol. 2021, 32, 115025. [Google Scholar] [CrossRef]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Yu, Y.; Guo, L.; Gao, H.; Liu, Y. PCWGAN-GP: A New Method for Imbalanced Fault Diagnosis of Machines. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Ruan, D.; Song, X.; Gühmann, C.; Yan, J. Collaborative Optimization of CNN and GAN for Bearing Fault Diagnosis under Unbalanced Datasets. Lubricants 2021, 9, 105. [Google Scholar] [CrossRef]
- Guan, S.; Loew, M. Evaluation of generative adversarial network performance based on direct analysis of generated images. In Proceedings of the 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 15–17 October 2019; pp. 1–5. [Google Scholar]
- Hang, Q.; Yang, J.; Xing, L. Diagnosis of rolling bearing based on classification for high dimensional unbalanced data. IEEE Access 2019, 7, 79159–79172. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Jia, X.D.; Ma, H.; Luo, Z.; Li, X. Machinery fault diagnosis with imbalanced data using deep generative adversarial networks. Measurement 2020, 152, 107377. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, T.; Wang, Y.; Cao, Z.; Guo, Z.; Fu, H. A novel method for imbalanced fault diagnosis of rotating machinery based on generative adversarial networks. IEEE Trans. Instrum. Meas. 2020, 70, 1–17. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y.; Shao, Y. A novel bearing imbalance Fault-diagnosis method based on a Wasserstein conditional generative adversarial network. Measurement 2022, 192, 110924. [Google Scholar] [CrossRef]
- Pham, M.T.; Kim, J.M.; Kim, C.H. Rolling Bearing Fault Diagnosis Based on Improved GAN and 2-D Representation of Acoustic Emission Signals. IEEE Access 2022, 10, 78056–78069. [Google Scholar] [CrossRef]
- Ruan, D.; Chen, Y.; Gühmann, C.; Yan, J.; Li, Z. Dynamics Modeling of Bearing with Defect in Modelica and Application in Direct Transfer Learning from Simulation to Test Bench for Bearing Fault Diagnosis. Electronics 2022, 11, 622. [Google Scholar] [CrossRef]
- Ruan, D.; Wu, Y.; Yan, J.; Gühmann, C. Fuzzy-Membership-Based Framework for Task Transfer Learning Between Fault Diagnosis and RUL Prediction. IEEE Trans. Reliab. 2022. [Google Scholar] [CrossRef]
- Deng, Y.; Huang, D.; Du, S.; Li, G.; Zhao, C.; Lv, J. A double-layer attention based adversarial network for partial transfer learning in machinery fault diagnosis. Comput. Ind. 2021, 127, 103399. [Google Scholar] [CrossRef]
- Pei, X.; Su, S.; Jiang, L.; Chu, C.; Gong, L.; Yuan, Y. Research on Rolling Bearing Fault Diagnosis Method Based on Generative Adversarial and Transfer Learning. Processes 2022, 10, 1443. [Google Scholar] [CrossRef]
- Akhenia, P.; Bhavsar, K.; Panchal, J.; Vakharia, V. Fault severity classification of ball bearing using SinGAN and deep convolutional neural network. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2022, 236, 3864–3877. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Sun, B.; Wang, L. Prediction of Bearings Remaining Useful Life Across Working Conditions Based on Transfer Learning and Time Series Clustering. IEEE Access 2021, 9, 135285–135303. [Google Scholar] [CrossRef]
- Fu, B.; Yuan, W.; Cui, X.; Yu, T.; Zhao, X.; Li, C. Correlation analysis and augmentation of samples for a bidirectional gate recurrent unit network for the remaining useful life prediction of bearings. IEEE Sensors J. 2020, 21, 7989–8001. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Data alignments in machinery remaining useful life prediction using deep adversarial neural networks. Knowl.-Based Syst. 2020, 197, 105843. [Google Scholar] [CrossRef]
- Yu, J.; Guo, Z. Remaining useful life prediction of planet bearings based on conditional deep recurrent generative adversarial network and action discovery. J. Mech. Sci. Technol. 2021, 35, 21–30. [Google Scholar] [CrossRef]
- Karpatne, A.; Watkins, W.; Read, J.; Kumar, V. Physics-guided neural networks (pgnn): An application in lake temperature modeling. arXiv 2017, arXiv:1710.11431. [Google Scholar]
- Krupp, L.; Hennig, A.; Wiede, C.; Grabmaier, A. A Hybrid Framework for Bearing Fault Diagnosis using Physics-guided Neural Networks. In Proceedings of the 2020 27th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Scotland, UK, 23–25 November 2020; pp. 1–2. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Loss | Formulation | Source |
|---|---|---|---|
| 1 | PCWGAN-GP | [71] | |
| 2 | MS-PGAN | [56] | |
| 3 | FCFE | [72] | |
| 4 | WCGAN-HFM | [73] | |
| 5 | Entropy | [74] |
| Number | Metric | Formulation | Source |
|---|---|---|---|
| 1 | CS | [72] | |
| 2 | MMD | [56] | |
| 3 | PCC | [57,60,71] | |
| 4 | KLD | [51] | |
| 5 | WD | [57] | |
| 6 | PSNR | [51] | |
| 7 | SSIM | [51] |
| Number | Type | Advantages | Disadvantages |
|---|---|---|---|
| 1 | CGAN | To generate samples with specific attributes such as specific categories. | A large amount of training data with labels are required. |
| 2 | ACGAN | With auxiliary classifier, different classes of samples can be generated. | (1) Complex training; (2) Limited quality of generated samples. |
| 3 | VAEGAN | The generated samples can be controlled by the autoencoder. | The training is relatively more difficult. |
| 4 | DCGAN | The powerful feature extraction capability of CNN is exploited. | More computational resources are required for the training. |
| 5 | SNGAN | Exploding and vanishing gradient can be solved effectively. | (1) Slow training speed; (2) Limited diversity of generated samples. |
| 6 | WGAN | Wasserstein distance provides a better measure of the difference between distributions. | The training is not stable enough. |
| 7 | WGAN-GP | With gradient penalty integrated into WGAN, the stability is improved. | More training time and computational resources. |
| 8 | LSGAN | Effectively solves the problems of exploding gradient and vanishing gradient. | Excessive penalization of outliers may lead to a reduction in the diversity of samples being generated. |
| 9 | EBGAN | (1) Energy-based loss function allows better interpretability; (2) Improved stability and diversity of sample generation. | (1) Quite complex to implement and train; (2) Prone to mode collapse. |
| 10 | BEGAN | Mode collapse can be effectively alleviated. | (1) A relatively complex architecture; (2) Sensitive to hyperparameters. |
| 11 | RGAN | With relativistic loss, the quality of sample generation is improved and mode collapse is reduced. | (1) A relatively complex architecture; (2) The relativistic loss is difficult to interpret. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, D.; Chen, X.; Gühmann, C.; Yan, J. Improvement of Generative Adversarial Network and Its Application in Bearing Fault Diagnosis: A Review. Lubricants 2023, 11, 74. https://doi.org/10.3390/lubricants11020074
Ruan D, Chen X, Gühmann C, Yan J. Improvement of Generative Adversarial Network and Its Application in Bearing Fault Diagnosis: A Review. Lubricants. 2023; 11(2):74. https://doi.org/10.3390/lubricants11020074
Chicago/Turabian StyleRuan, Diwang, Xuran Chen, Clemens Gühmann, and Jianping Yan. 2023. "Improvement of Generative Adversarial Network and Its Application in Bearing Fault Diagnosis: A Review" Lubricants 11, no. 2: 74. https://doi.org/10.3390/lubricants11020074
APA StyleRuan, D., Chen, X., Gühmann, C., & Yan, J. (2023). Improvement of Generative Adversarial Network and Its Application in Bearing Fault Diagnosis: A Review. Lubricants, 11(2), 74. https://doi.org/10.3390/lubricants11020074