1. Introduction
Internal combustion engines (ICE) are employed as energy converters in manifold applications such as transportation of goods and people, machinery and power generation [
1,
2,
3,
4]. Their widespread utilization is due to advantageous key characteristics such as high power-to-weight ratio, robustness, efficiency, affordability and large-scale fuel supply infrastructure availability [
2,
3,
5]. Global issues such as climate change, environmental pollution and scarcity of resources are currently posing major challenges to engine manufacturers, who must meet the requirements of substantially reduced emissions of CO
2 and other greenhouse gases, elimination of pollutant emissions and increased service life of ICEs [
3,
4,
6]. Because the development of entirely new ICE concepts requires extensive research and development work, engine manufactures are focusing on increasing the efficiency of existing ICE technology in the short term [
7]. One possible solution employs newly developed low viscosity oils that have the potential to reduce friction and thus increase engine efficiency [
7]. However, such oils in turn pose new challenges for sliding bearings in ICEs and their lubrication.
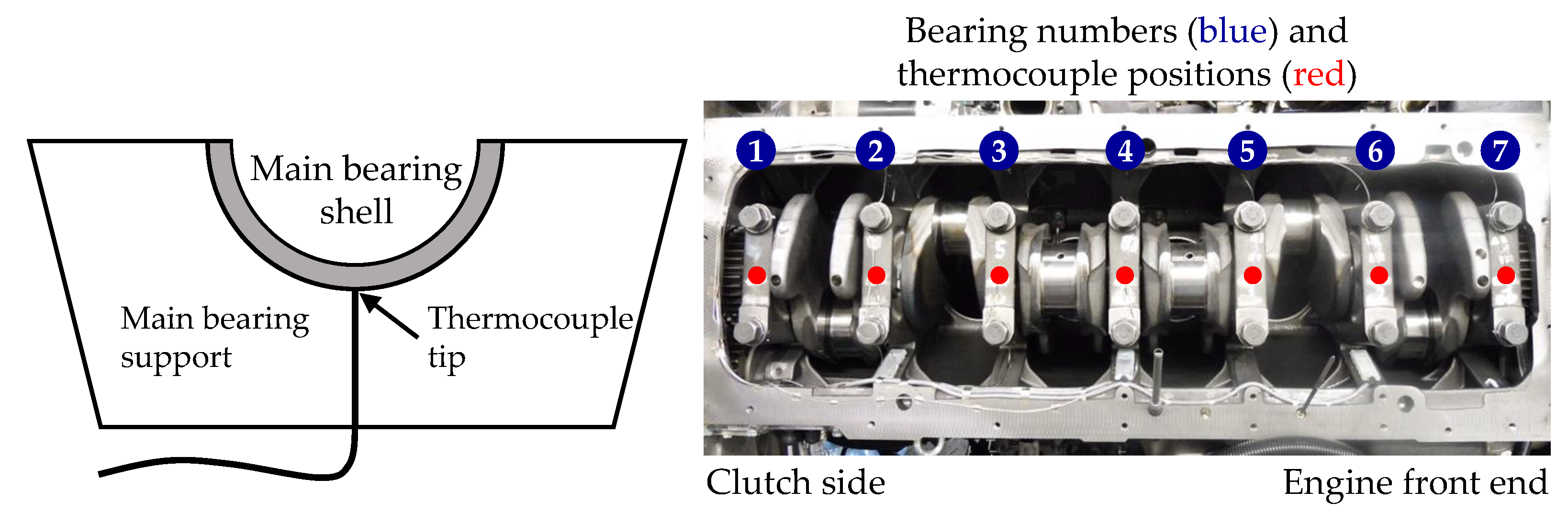
Shafts in multicylinder ICEs, such as crankshafts or camshafts, are generally supported by sliding bearings (also known as journal or plain bearings) [
8]. This bearing type is hydrodynamically lubricated, i.e., due to the convergence of the bearing surfaces, their relative motion and the viscosity of the lubricant fluid, a positive pressure is developed that separates the surfaces by a lubricant film [
9]. Sliding bearings have a high capability to withstand and dampen shocks, may be divided for easy assembly, come with low space requirements and are insensitive to grime [
8,
9,
10]. Compared to roller bearings, sliding bearings cost less but have higher friction [
8]. During normal engine operation, the lubricant film is generally thick enough that the shaft surface does not come into contact with the opposing bearing surface; hence near-zero bearing wear can be expected [
9]. During engine start or stop, there is no or too little relative motion, so the lubricant film is either non-existent or too small to completely separate the surfaces. In such cases, metal-to-metal contacts between the shaft and the opposing bearing surface and thus wear can occur [
8,
10,
11,
12,
13]. Although the use of low viscosity oils has the potential to reduce overall friction, it also decreases the lubricant oil film thickness and therefore increases the risk of metal-to-metal contacts [
14,
15,
16]. This in turn can lead to increased wear, then reduced engine performance and eventually bearing and engine failure [
17]. Therefore, appropriate tools for monitoring and assessing the bearing condition will play a key role in increasing engine durability, avoiding critical engine operation and preventing engine failure, thereby avoiding unnecessary engine downtime [
17,
18,
19]. Digital technologies have the potential to accomplish such tasks [
20,
21].
In the past decades, with the advent and widespread distribution of electronics and integrated circuits, ICE manufacturers have already developed sophisticated digital systems which serve to improve efficiency, power output and emissions behavior of ICEs [
21,
22,
23,
24]. Such systems are used to control fuel injection, air/fuel ratio and ignition [
25,
26,
27]; exhaust gas recirculation and variable geometry turbochargers [
28,
29,
30]; and diesel particulate filters and SCR catalytic converters [
31]. More recently, advanced digital technologies such as machine learning have enabled an effective and beneficial analysis of the large amounts of data generated by an ever-increasing number of sensors inside ICEs [
32,
33,
34]. The insights gained and the predictive power of such methods can in turn help to meet the high requirements placed on ICEs by using them for applications such as controls [
35,
36] as well as condition monitoring (CM) and predictive maintenance (PdM) [
37,
38,
39,
40,
41].
According to Mechefske [
42], condition monitoring (and fault diagnostics) of machinery can be defined as “the field of technical activity in which selected physical parameters, associated with machinery operation, are observed for the purpose of determining machinery integrity”. The author further describes that a PdM strategy “requires that some means of assessing the actual condition of the machinery is used in order to optimally schedule maintenance, in order to achieve maximum production, and still avoid unexpected catastrophic failures”. According to Weck [
43], CM is divided into the following three subtasks:
- 1.
Condition detection refers to the acquisition of one or more informative parameters which reflect the current condition of the machinery.
- 2.
Condition comparison consists of comparing the actual condition with a reference condition of the same parameter.
- 3.
Diagnosis evaluates the results of the condition comparison and determines the type and location of failure. Based on the diagnosis, compensation measures or maintenance activities can be initiated at an early stage.
Besides the diagnosis to determine the type and location of failure, there are other evaluation goals for a CM system as well. Beyond the diagnosis task, Vanem [
44] and Mechefske [
42] introduce prognostics as a task that provides information about the possible future of the condition of the machinery. Furthermore, condition monitoring can generally be classified as either permanent or intermittent monitoring [
43,
45].
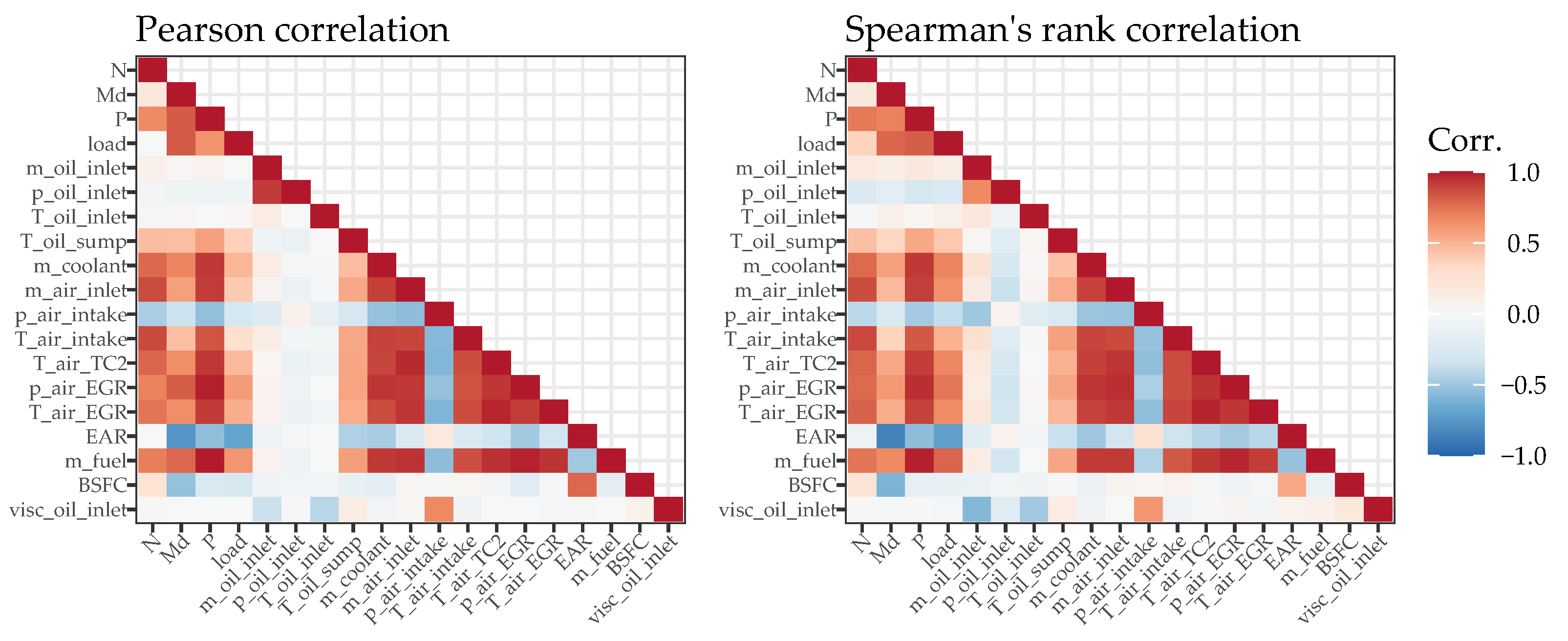
Existing literature proposes several measurement parameters that can help in detecting the sliding bearing condition. Two main categories are observed. First, there are significant parameters such as vibration, acoustic emission and oil contaminants [
46,
47,
48,
49], which can be measured at a certain distance from the bearing. Second, there are informative parameters that have to be measured directly at or inside the bearing. These include bearing temperature [
19,
50,
51], bearing deformation and vibration [
19], oil film temperature [
19,
51], oil film pressure and thickness [
50,
52,
53] and metal-to-metal contact [
47]. With the second category, information can be obtained about the condition of each individual bearing, and the signal quality is higher and transient response faster in case of a rapid change in bearing condition compared to measurement parameters acquired at a distance from the bearing [
51,
54]. At the same time, it likely requires a larger effort for instrumentation due to the restricted access to the bearings and the need to not influence bearing functionality [
7]. In the existing literature, bearing temperature measurement with instruments such as thermocouples has proven to be a reliable, continuous, fast responding measurement method that is comparatively simple to apply [
15,
50,
55]. With these characteristics, the method is particularly useful to diagnose bearing failure modes which lead to a rapid change in bearing temperature [
47,
56,
57].
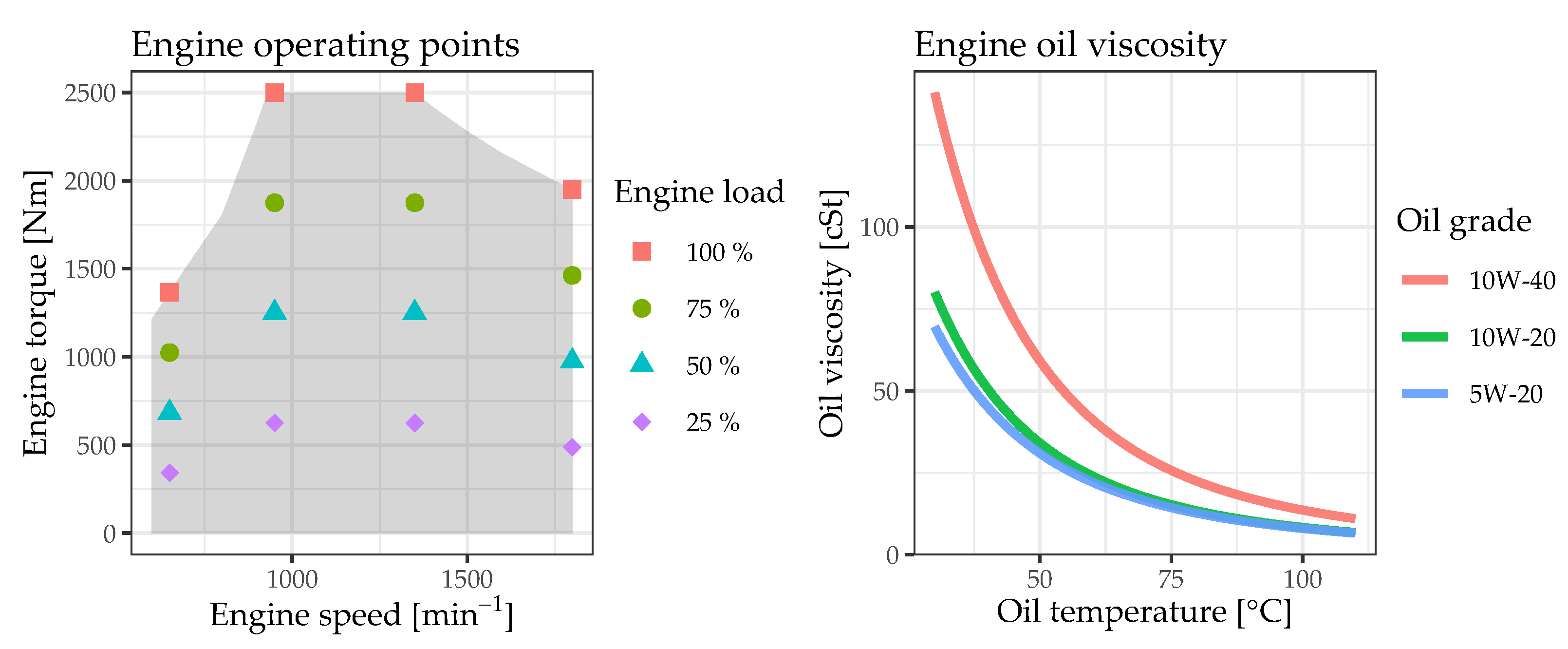
A straightforward approach to condition comparison of bearing temperature values would simply employ a global temperature limit which may not be exceeded during engine operation. With this approach in particular, anomalies in bearing temperature behavior may not be detected if the defined temperature limit is not reached during the anomaly. On the contrary, a bearing temperature model that incorporates the current engine operation would enable the identification of anomalies in bearing temperature as soon as the measured temperature is outside the limits of a comparatively small tolerance range around the predicted model value. For such a model, transient engine operation poses a specific challenge: Due to the thermal inertia of the engine components and the engine operating media, the bearing temperature reacts slowly to swift changes in engine operating conditions such as engine speed and engine torque. However, this is beyond the scope of this paper with its focus on steady-state engine operation. There are two main types of approaches for deriving a bearing temperature model: data-driven approaches and physics-based approaches (also referred to as model-based or model-driven) [
44]. While the latter apply physical domain knowledge to formulate a mathematical model of the monitored machinery condition [
58], data-driven approaches simply utilize the inherent information in the available data [
44]. Finally, the combination of a physics-based and a data-driven approach is often referred to as a hybrid approach [
44].
Today artificial intelligence (AI) and in particular machine learning (ML) form the backbone of data-driven approaches. Although AI and ML emerged in recent times, their origins date back to the 1950s and even earlier [
59,
60]. Machine learning refers to the ability of an AI system to extract its own knowledge from raw data [
60]. Therefore, statistical learning methods such as (linear) regression models are usually included in ML [
60,
61,
62]. For machine fault diagnosis, CM or PdM data-driven methods have been proven to work in various engineering application scenarios [
63,
64,
65], yet the simple application and training of data-driven methods is usually not straightforward because proper data and knowledge are required to train a suitable model. Consequently, it is common to use more controllable experimental data rather than data from a real-world application for model training [
58]. However, by taking into account the application-specific background and the underlying structure of the experimental data, it is possible to derive a model that can be generalized for real-world applications or at least taken as the basis for further developments.
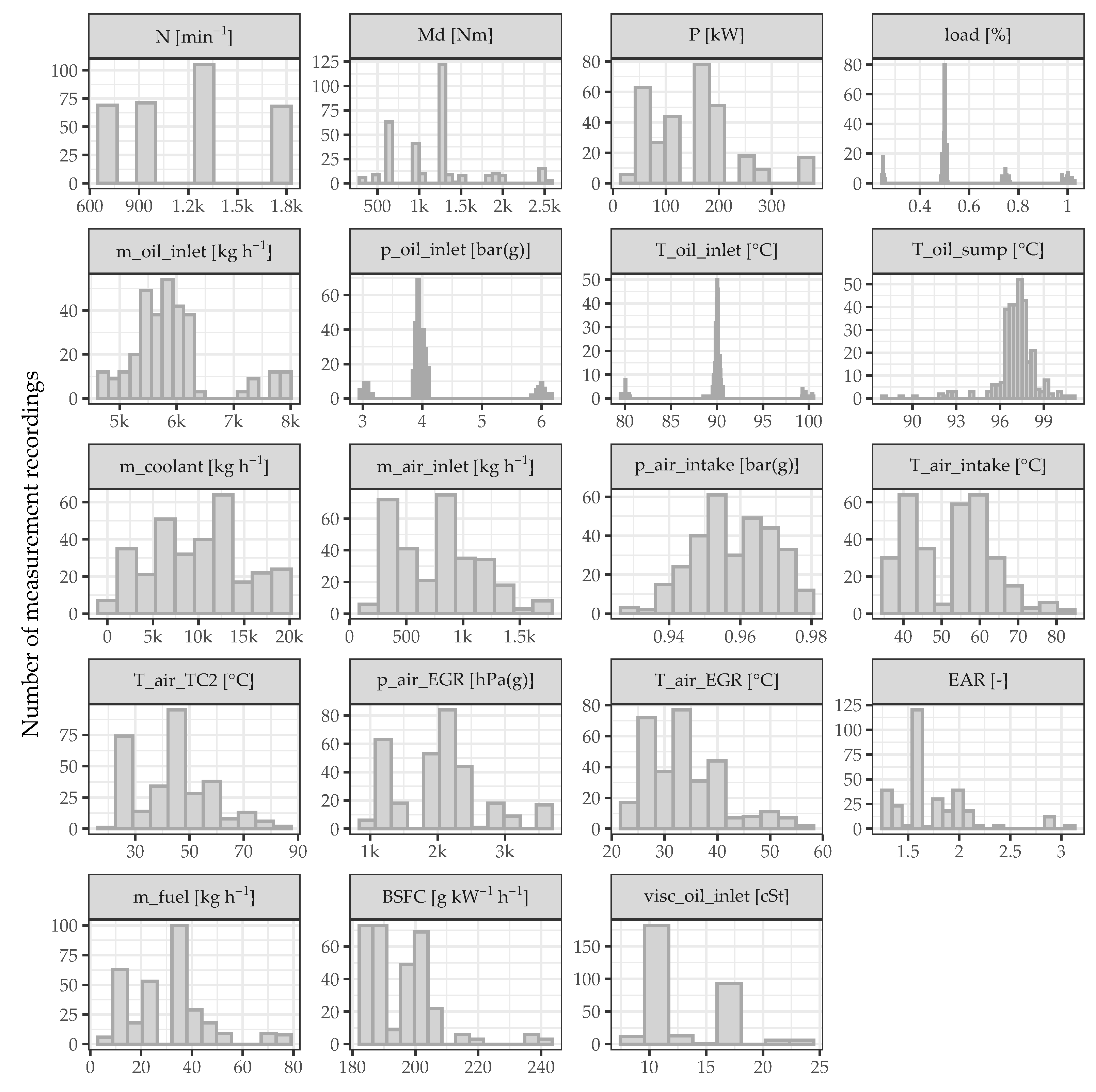
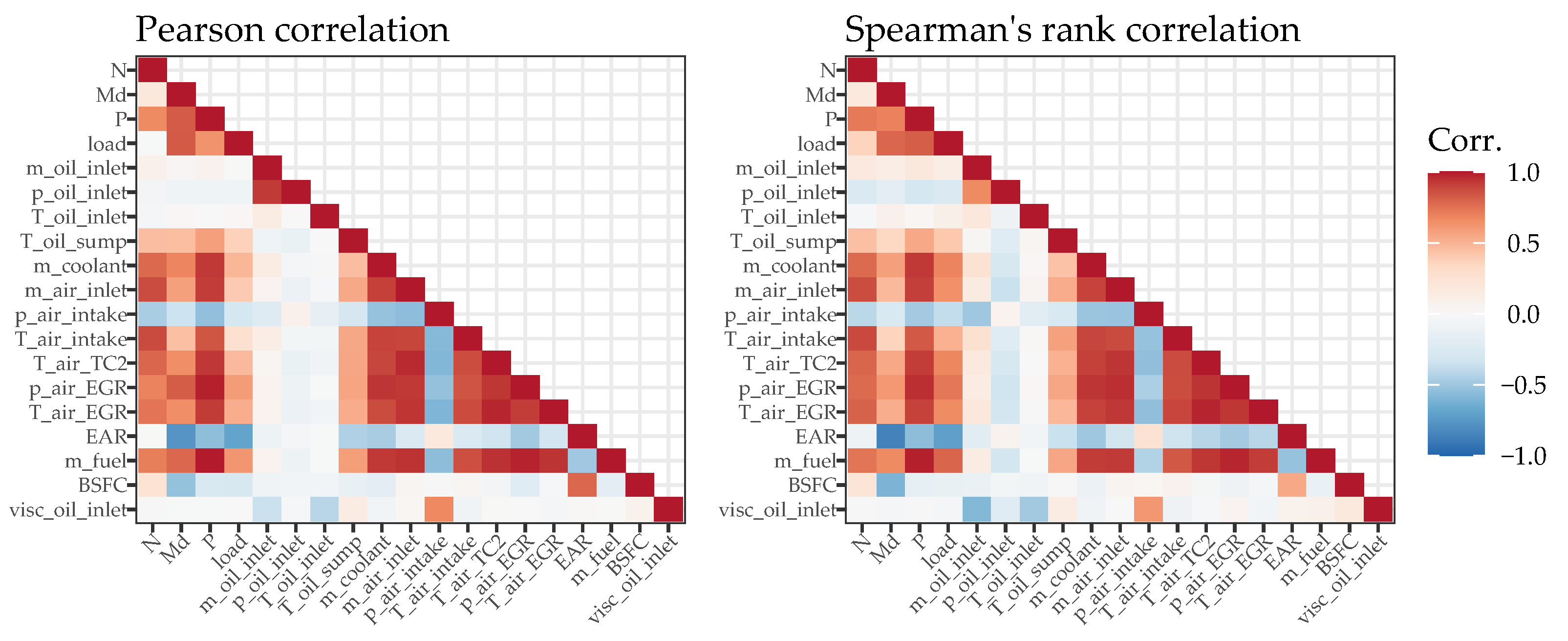
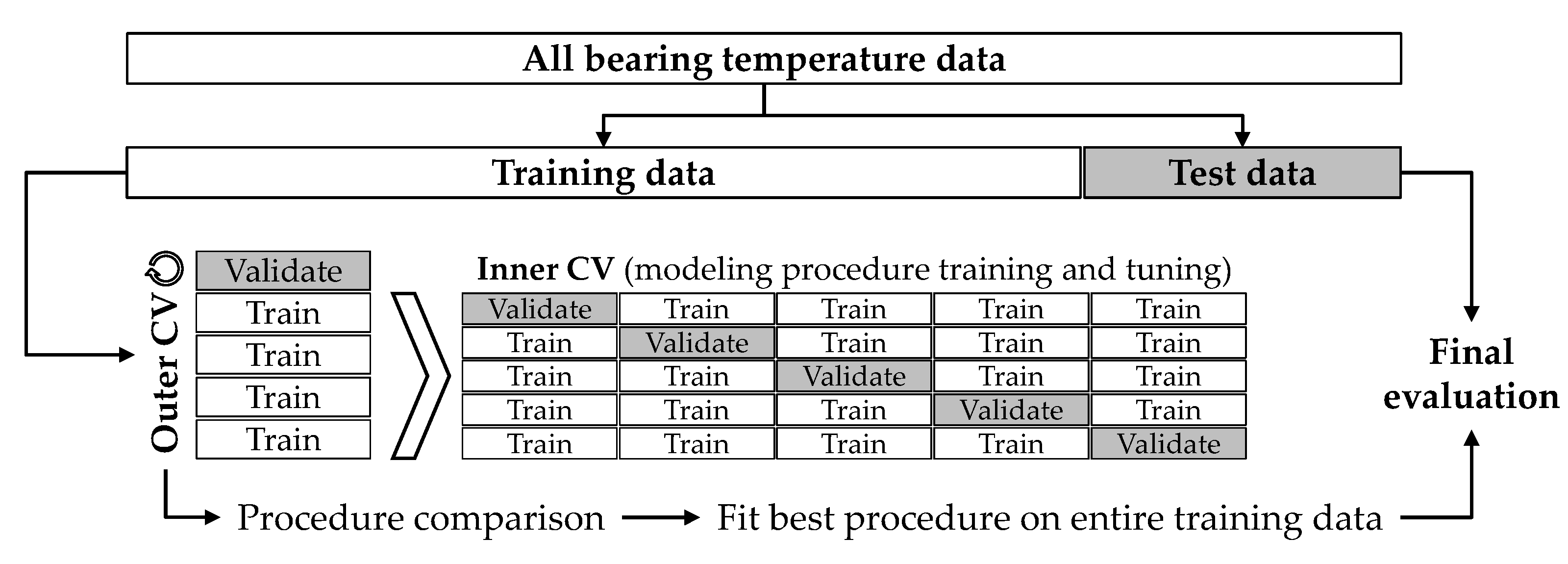
The goal of this paper is to demonstrate that the combination of a data-driven bearing temperature model and thermocouple-based temperature measurements forms a powerful tool for monitoring the condition of sliding bearings in ICEs. The data-driven model of the crankshaft main bearing temperatures under steady-state engine operation is derived based on experimental data. In order to obtain a model that is realistic for real-world applications, only measured or calculated parameters that would also be available on a production engine are considered as model inputs. In
Section 2, information on the experimental investigations is provided and the acquired data are analyzed. In addition, the requirements for a suitable data-driven model, the considered ML methods as well as the model training and selection approach are discussed. The results of the modeling process are then presented and analyzed in
Section 3. Finally, the main conclusions and possible next steps are discussed and summarized in
Section 4 and
Section 5.
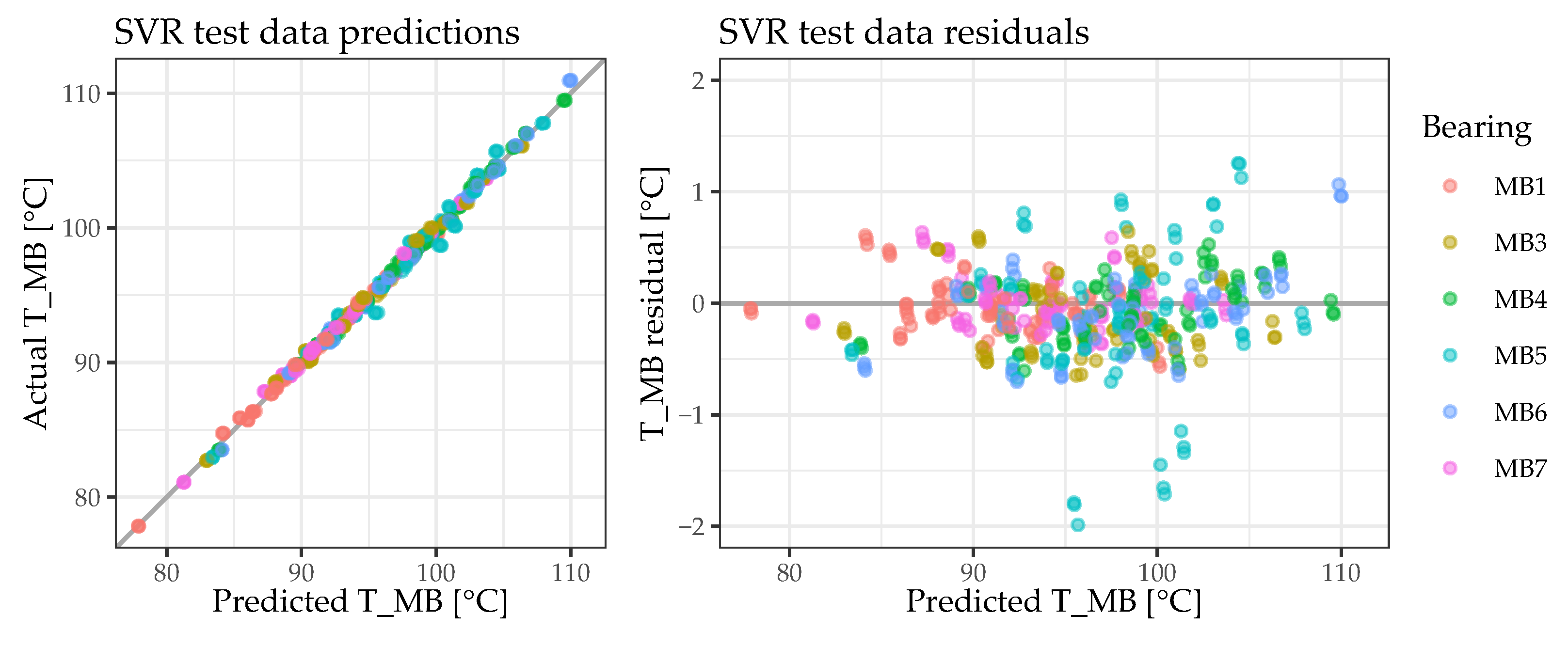
4. Discussion
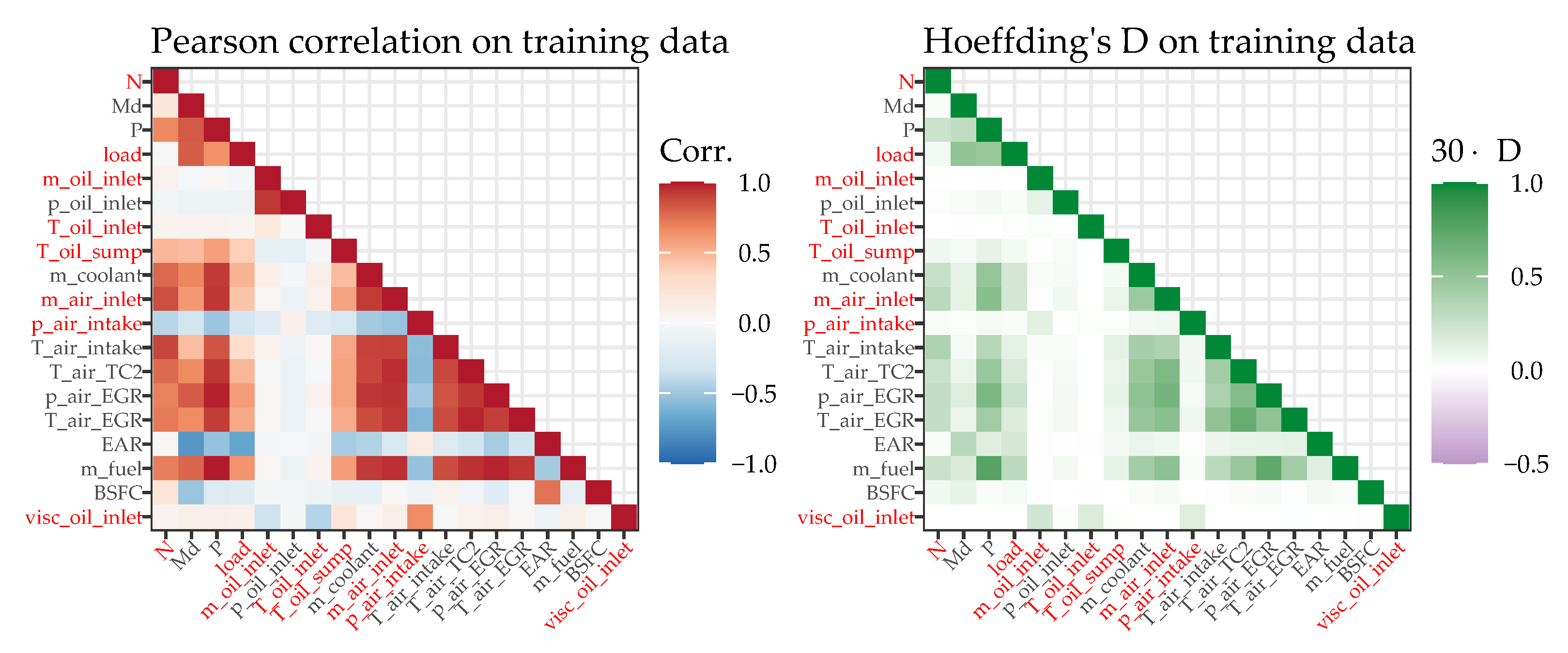
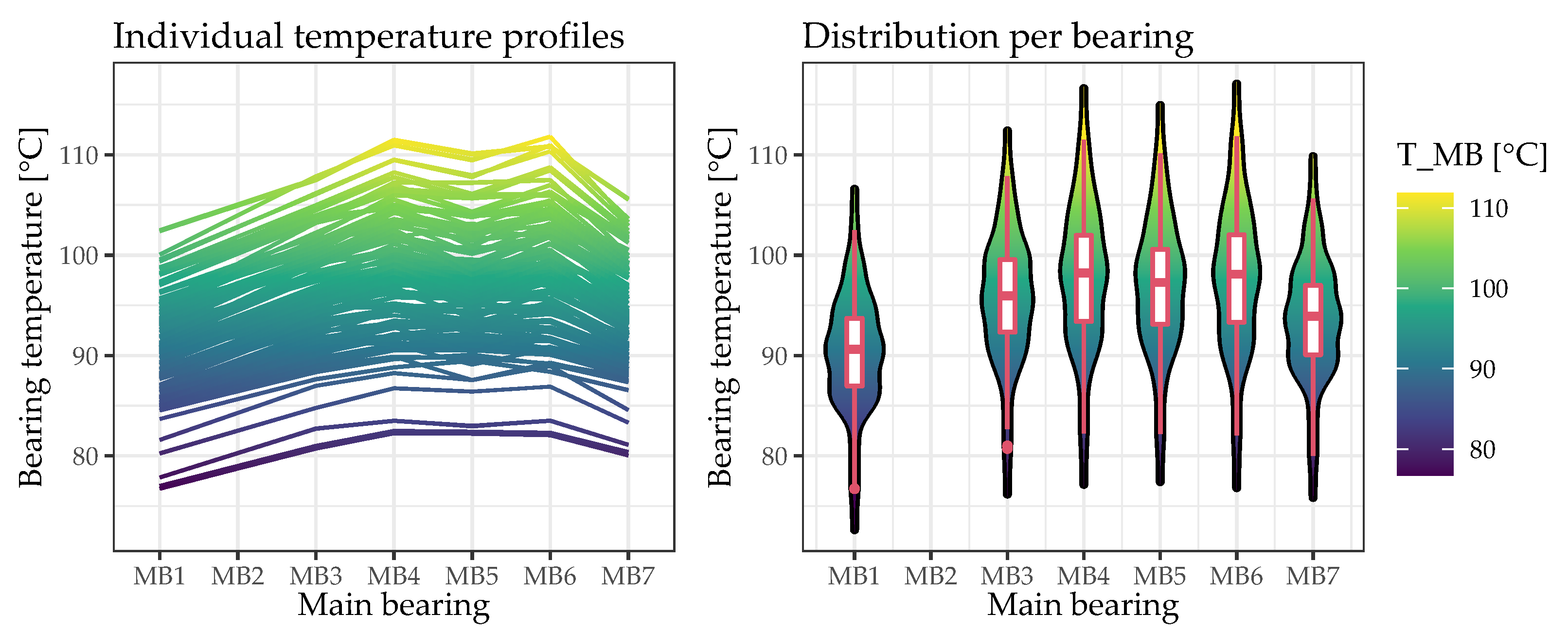
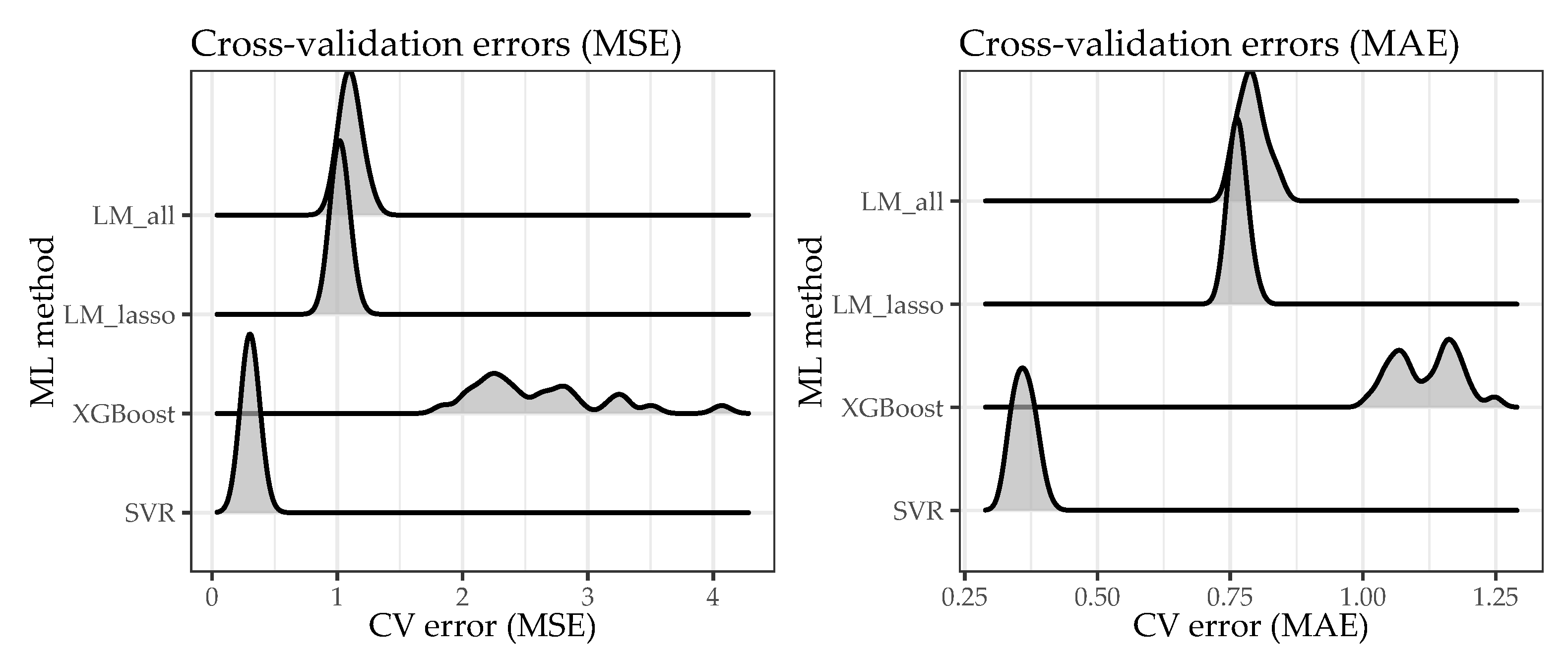
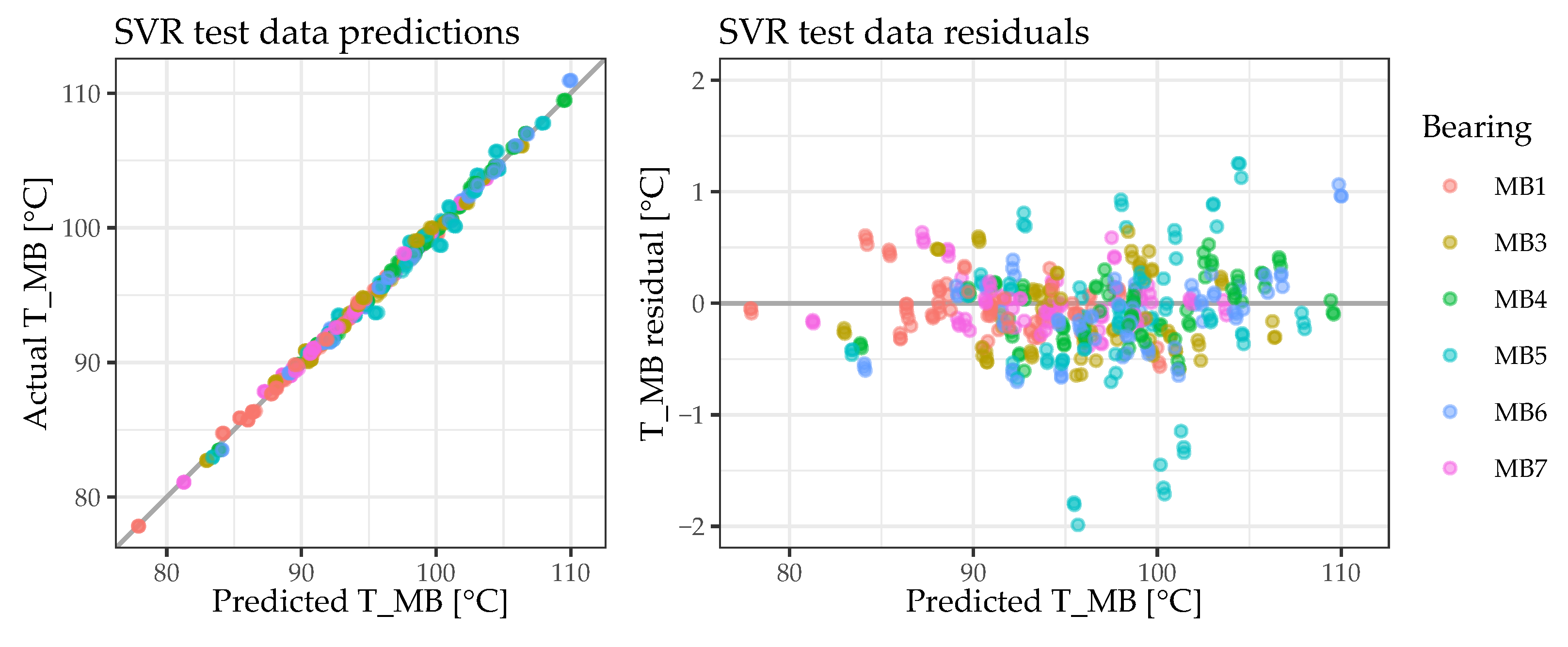
Considering the temperature range from approximately 76 °C to 112 °C, with a prediction error of 0.3995 °C (RMSE on previously unseen test data), the results presented above show that it is possible to reliably predict bearing temperatures on the basis of engine operation parameters. However, the results also demonstrate that there is often a trade-off between the interpretability and the predictive quality of a data-driven approach. While the best model obtained (an SVR with a radial basis kernel) does indeed perform excellently as it predicts the bearing temperatures on the basis of engine operation parameters, it does not allow for a direct interpretation of their importance. Nevertheless, given the wide range of ML methods applied, it has also been demonstrated that a simpler and more easily interpretable approach (the LM with lasso regularization) serves as an understandable approximation of the best model obtained. Since only a subset of the engine parameters is used for predicting the bearing temperatures, the simpler approach would also be more robust to potential sensor failures.
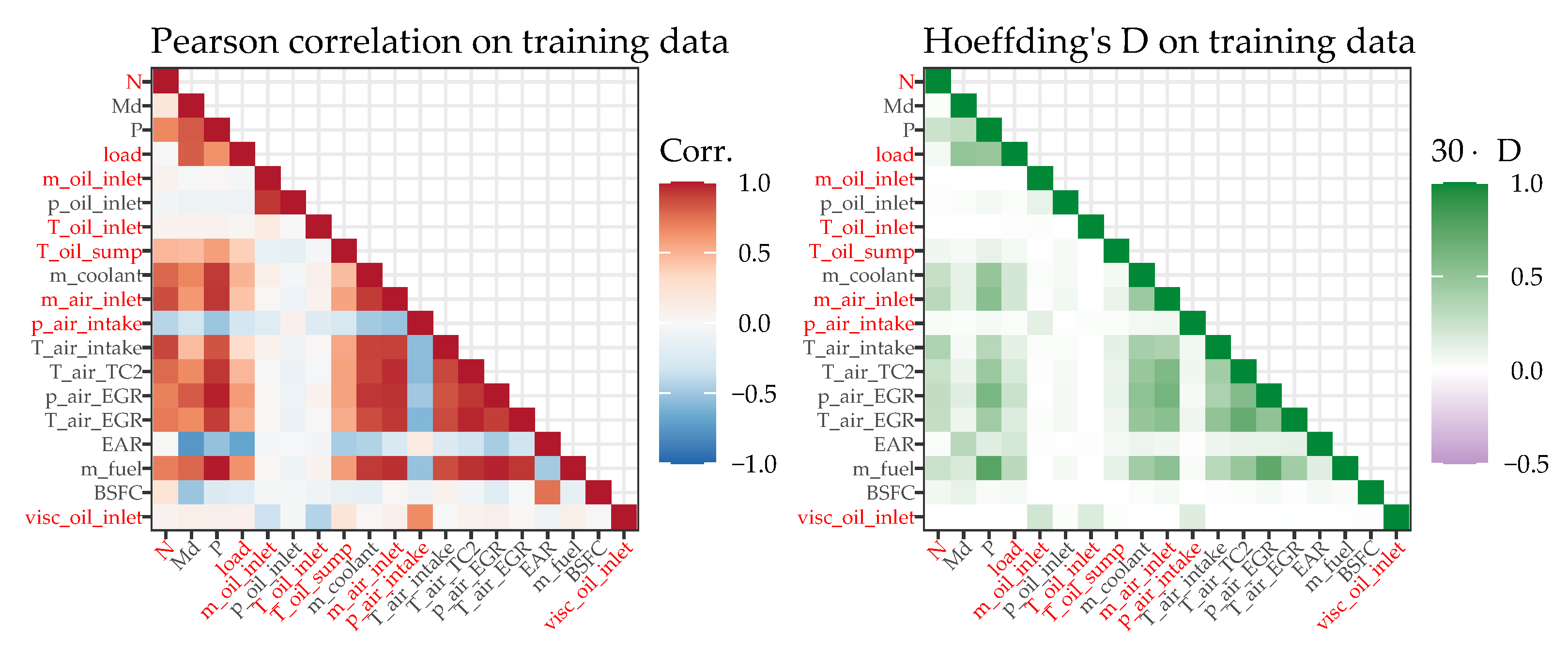
Considering the comparatively small amount of data available for an ML application, more data will be acquired in a follow-up measurement campaign to improve and validate the derived data-driven CM model as well as to acquire data from the currently missing bearing position #2. Hence, the bearing position correlation and encoding will be reevaluated. With the insights already gained (especially from the interpretable ML approach), meaningful data can be efficiently acquired and very low or high bearing temperatures can be specifically studied.
To further improve the performance of the predictive model, additional ML methods such as kernel ridge regression or random forests could be evaluated as well. It might also be beneficial to enhance the LM approaches by using parameter transformations or interaction terms. Linear additive models, for example, also permit modeling of the nonlinearity of certain features. Additional preprocessing steps such as principal component analysis may help to further improve the performance of a modeling procedure. All these model types and methods could easily be implemented in the previously created modeling pipeline. Of course other ML methods such as artificial neural networks could improve the predictions as well, yet such methods usually require even greater training effort, which would necessitate an adapted framework.
The present paper does not address data from transient engine operation. Since bearing temperature reacts comparatively slowly to swift changes in engine operating conditions such as engine speed and engine torque, transient operation poses special challenges to both data collection and experimental design. For reliably modeling transient engine operation, it will probably be necessary to consider time-dependent effects and correlations. In order to reflect all possible engine operating modes, future investigations will focus on transient engine operation as well.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}