Design of Amorphous Carbon Coatings Using Gaussian Processes and Advanced Data Visualization

 ,
,  ,
,  and
and
Abstract

1. Introduction
2. Related Work and Main Research Questions
2.1. Amorphous Carbon Coating Design
2.2. Coating Process and Design Parameters
2.3. Research Questions
3. Materials and Methods
3.1. Experimental Setup
3.1.1. Materials
3.1.2. Coating Deposition
3.1.3. Mechanical Characterization
3.2. Machine Learning and Used Models
3.2.1. Supervised Learning
3.2.2. Polynomial Regression
3.2.3. Support Vector Machines
3.2.4. Neural Networks
3.2.5. Gaussian Process Regression
3.2.6. Python
4. Use Case with Practical Example in a-C:H Coating Design
4.1. Data Generation
4.2. Data Processing
4.2.1. Reading in and Preparing Data
4.2.2. Model Instantiation
4.2.3. Training the Model
4.2.4. Model Predictions
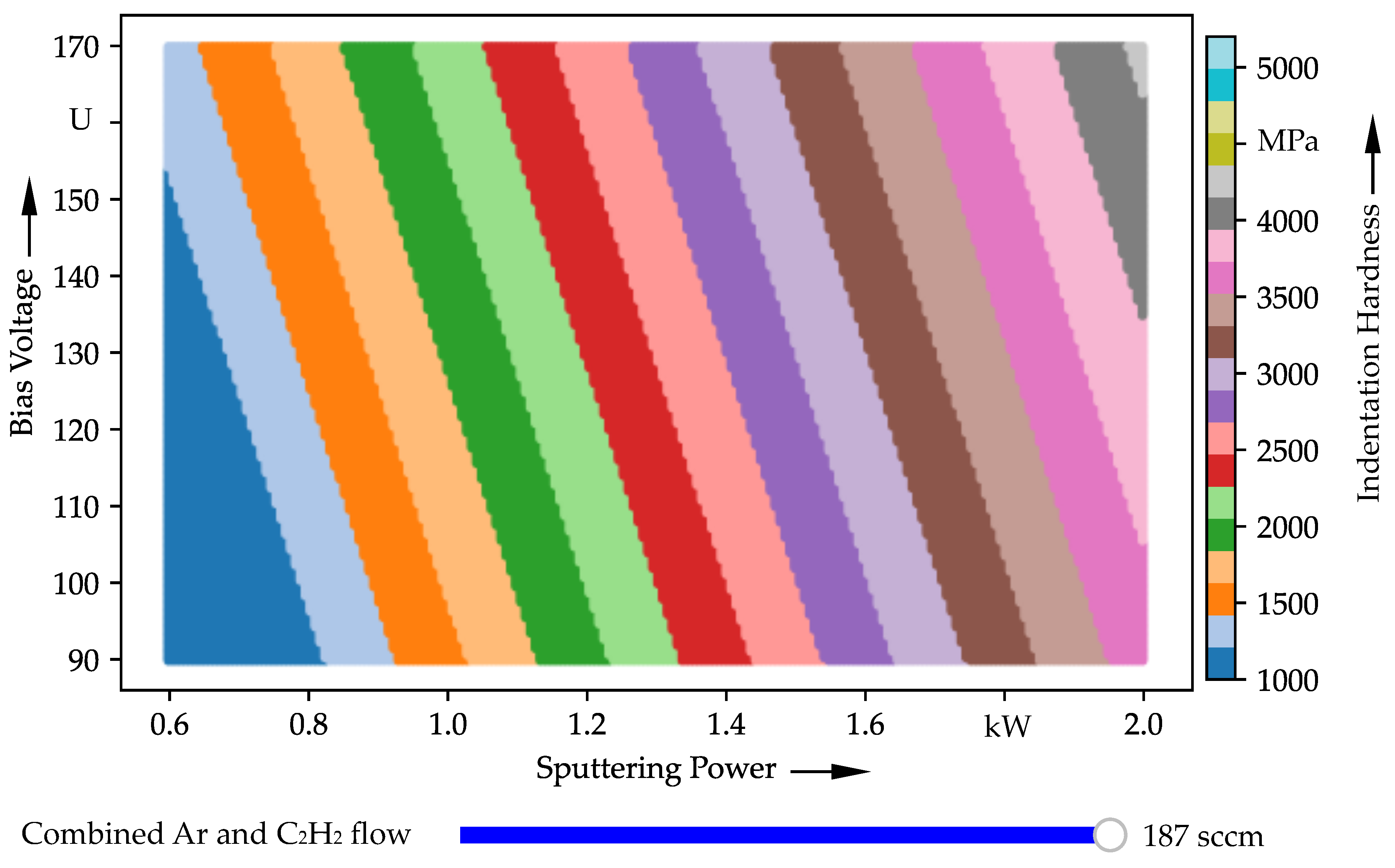
4.2.5. Visualization
5. Results and Discussion
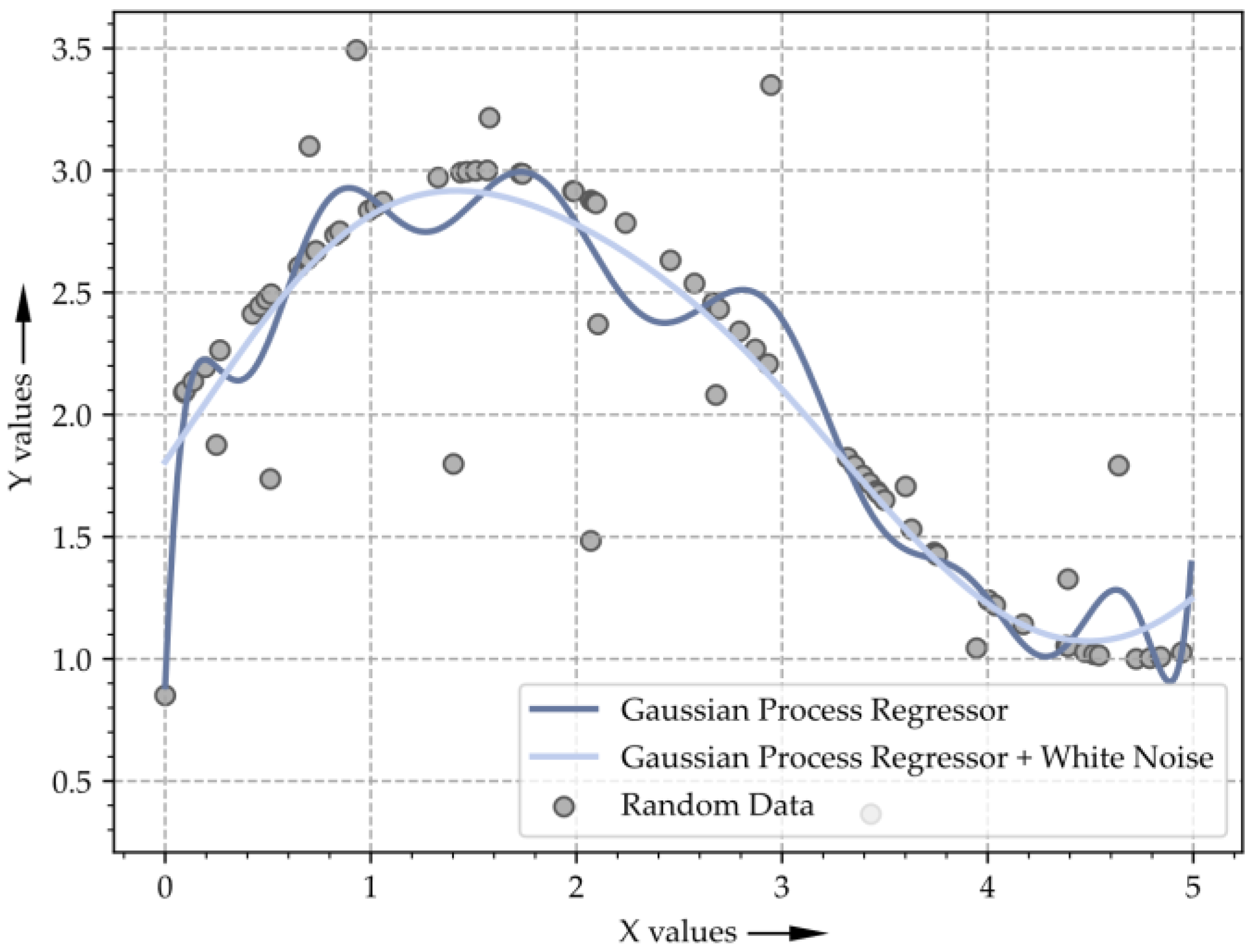
5.1. Gaussian Process Regression and Visualization
5.2. Comparison to Polynomial Regression, Support Vector Machines and Neural Network Models
6. Conclusions
- The GPR models and the materials used showed the potentials of the selected ML algorithms. One data visualization method using the GPR was detailed;
- The usage of ML looked very promising in this case, which can benefit the area of ML in coating technology and tribology. The prediction accuracy of the hardness values with our approach showed a high agreement with the experimentally determined hardness values;
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bertolini, M.; Mezzogori, D.; Neroni, M.; Zammori, F. Machine Learning for industrial applications: A comprehensive literature review. Expert Syst. Appl. 2021, 175, 114820. [Google Scholar] [CrossRef]
- Lynch, C.J.; Liston, C. New machine-learning technologies for computer-aided diagnosis. Nat. Med. 2018, 24, 1304–1305. [Google Scholar] [CrossRef]
- Marian, M.; Tremmel, S. Current Trends and Applications of Machine Learning in Tribology—A Review. Lubricants 2021, 9, 86. [Google Scholar] [CrossRef]
- Caro, M.A.; Csányi, G.; Laurila, T.; Deringer, V.L. Machine learning driven simulated deposition of carbon films: From low-density to diamondlike amorphous carbon. Phys. Rev. B 2020, 102, 174201. [Google Scholar] [CrossRef]
- Shah, R.; Gashi, B.; Hoque, S.; Marian, M.; Rosenkranz, A. Enhancing mechanical and biomedical properties of protheses—Surface and material design. Surf. Interfaces 2021, 27, 101498. [Google Scholar] [CrossRef]
- Kröner, J.; Kursawe, S.; Musayev, Y.; Tremmel, S. Analysing the Tribological Behaviour of DLC-Coated Dry-Running Deep Groove Ball Bearings with Regard to the Ball Material. Appl. Mech. Mater. 2016, 856, 143–150. [Google Scholar] [CrossRef]
- Khadem, M.; Penkov, O.V.; Yang, H.-K.; Kim, D.-E. Tribology of multilayer coatings for wear reduction: A review. Friction 2017, 5, 248–262. [Google Scholar] [CrossRef]
- Marian, M.; Weikert, T.; Tremmel, S. On Friction Reduction by Surface Modifications in the TEHL Cam/Tappet-Contact-Experimental and Numerical Studies. Coatings 2019, 9, 843. [Google Scholar] [CrossRef]
- Liu, K.; Kang, J.; Zhang, G.; Lu, Z.; Yue, W. Effect of temperature and mating pair on tribological properties of DLC and GLC coatings under high pressure lubricated by MoDTC and ZDDP. Friction 2020, 9, 1390–1405. [Google Scholar] [CrossRef]
- Häfner, T.; Rothammer, B.; Tenner, J.; Krachenfels, K.; Merklein, M.; Tremmel, S.; Schmidt, M. Adaption of tribological behavior of a-C:H coatings for application in dry deep drawing. MATEC Web Conf. 2018, 190, 14002. [Google Scholar] [CrossRef][Green Version]
- Krachenfels, K.; Rothammer, B.; Zhao, R.; Tremmel, S.; Merklein, M. Influence of varying sheet material properties on dry deep drawing process. IOP Conf. Ser. Mater. Sci. Eng. 2019, 651, 012012. [Google Scholar] [CrossRef]
- Hauert, R.; Thorwarth, K.; Thorwarth, G. An overview on diamond-like carbon coatings in medical applications. Surf. Coat. Technol. 2013, 233, 119–130. [Google Scholar] [CrossRef]
- Hauert, R. A review of modified DLC coatings for biological applications. Diam. Relat. Mater. 2003, 12, 583–589. [Google Scholar] [CrossRef]
- McGeough, J.A. The Engineering of Human Joint Replacements; John Wiley & Sons Ltd.: Chichester, UK, 2013; ISBN 978-1-118-53684-1. [Google Scholar]
- Döring, J.; Crackau, M.; Nestler, C.; Welzel, F.; Bertrand, J.; Lohmann, C.H. Characteristics of different cathodic arc deposition coatings on CoCrMo for biomedical applications. J. Mech. Behav. Biomed. Mater. 2019, 97, 212–221. [Google Scholar] [CrossRef] [PubMed]
- Dorner-Reisel, A.; Gärtner, G.; Reisel, G.; Irmer, G. Diamond-like carbon films for polyethylene femoral parts: Raman and FT-IR spectroscopy before and after incubation in simulated body liquid. Anal. Bioanal. Chem. 2017, 390, 1487–1493. [Google Scholar] [CrossRef]
- Wang, L.; Li, L.; Kuang, X. Effect of substrate bias on microstructure and mechanical properties of WC-DLC coatings deposited by HiPIMS. Surf. Coat. Technol. 2018, 352, 33–41. [Google Scholar] [CrossRef]
- Bociąga, D.; Sobczyk-Guzenda, A.; Szymanski, W.; Jedrzejczak, A.; Jastrzebska, A.; Olejnik, A.; Jastrzębski, K. Mechanical properties, chemical analysis and evaluation of antimicrobial response of Si-DLC coatings fabricated on AISI 316 LVM substrate by a multi-target DC-RF magnetron sputtering method for potential biomedical applications. Appl. Surf. Sci. 2017, 417, 23–33. [Google Scholar] [CrossRef]
- Bobzin, K.; Bagcivan, N.; Theiß, S.; Weiß, R.; Depner, U.; Troßmann, T.; Ellermeier, J.; Oechsner, M. Behavior of DLC coated low-alloy steel under tribological and corrosive load: Effect of top layer and interlayer variation. Surf. Coat. Technol. 2013, 215, 110–118. [Google Scholar] [CrossRef]
- Hetzner, H.; Schmid, C.; Tremmel, S.; Durst, K.; Wartzack, S. Empirical-Statistical Study on the Relationship between Deposition Parameters, Process Variables, Deposition Rate and Mechanical Properties of a-C:H:W Coatings. Coatings 2014, 4, 772–795. [Google Scholar] [CrossRef]
- Kretzer, J.P.; Jakubowitz, E.; Reinders, J.; Lietz, E.; Moradi, B.; Hofmann, K.; Sonntag, R. Wear analysis of unicondylar mobile bearing and fixed bearing knee systems: A knee simulator study. Acta Biomater. 2011, 7, 710–715. [Google Scholar] [CrossRef]
- Polster, V.; Fischer, S.; Steffens, J.; Morlock, M.M.; Kaddick, C. Experimental validation of the abrasive wear stage of the gross taper failure mechanism in total hip arthroplasty. Med. Eng. Phys. 2021, 95, 25–29. [Google Scholar] [CrossRef] [PubMed]
- Ruggiero, A.; Zhang, H. Editorial: Biotribology and Biotribocorrosion Properties of Implantable Biomaterials. Front. Mech. Eng. 2020, 6, 17. [Google Scholar] [CrossRef]
- Rufaqua, R.; Vrbka, M.; Choudhury, D.; Hemzal, D.; Křupka, I.; Hartl, M. A systematic review on correlation between biochemical and mechanical processes of lubricant film formation in joint replacement of the last 10 years. Lubr. Sci. 2019, 31, 85–101. [Google Scholar] [CrossRef]
- Rothammer, B.; Marian, M.; Rummel, F.; Schroeder, S.; Uhler, M.; Kretzer, J.P.; Tremmel, S.; Wartzack, S. Rheological behavior of an artificial synovial fluid—Influence of temperature, shear rate and pressure. J. Mech. Behav. Biomed. Mater. 2021, 115, 104278. [Google Scholar] [CrossRef]
- Nečas, D.; Vrbka, M.; Marian, M.; Rothammer, B.; Tremmel, S.; Wartzack, S.; Galandáková, A.; Gallo, J.; Wimmer, M.A.; Křupka, I.; et al. Towards the understanding of lubrication mechanisms in total knee replacements—Part I: Experimental investigations. Tribol. Int. 2021, 156, 106874. [Google Scholar] [CrossRef]
- Gao, L.; Hua, Z.; Hewson, R.; Andersen, M.S.; Jin, Z. Elastohydrodynamic lubrication and wear modelling of the knee joint replacements with surface topography. Biosurface Biotribol. 2018, 4, 18–23. [Google Scholar] [CrossRef]
- Rothammer, B.; Marian, M.; Neusser, K.; Bartz, M.; Böhm, T.; Krauß, S.; Schroeder, S.; Uhler, M.; Thiele, S.; Merle, B.; et al. Amorphous Carbon Coatings for Total Knee Replacements—Part II: Tribological Behavior. Polymers 2021, 13, 1880. [Google Scholar] [CrossRef]
- Ruggiero, A.; Sicilia, A. A Mixed Elasto-Hydrodynamic Lubrication Model for Wear Calculation in Artificial Hip Joints. Lubricants 2020, 8, 72. [Google Scholar] [CrossRef]
- Rosenkranz, A.; Marian, M.; Profito, F.J.; Aragon, N.; Shah, R. The Use of Artificial Intelligence in Tribology—A Perspective. Lubricants 2020, 9, 2. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.; Pal, C. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2017. [Google Scholar] [CrossRef]
- Fontaine, J.; Donnet, C.; Erdemir, A. Fundamentals of the Tribology of DLC Coatings. In Tribology of Diamond-Like Carbon Films; Springer: Boston, MA, USA, 2020; pp. 139–154. [Google Scholar] [CrossRef]
- Leyland, A.; Matthews, A. On the significance of the H/E ratio in wear control: A nanocomposite coating approach to optimised tribological behaviour. Wear 2000, 246, 1–11. [Google Scholar] [CrossRef]
- ISO 5834-2:2019; Implants for Surgery—Ultra-High-Molecular-Weight Polyethylene—Part 2: Moulded Forms. ISO: Geneva, Switzerland, 2019.
- Rothammer, B.; Neusser, K.; Marian, M.; Bartz, M.; Krauß, S.; Böhm, T.; Thiele, S.; Merle, B.; Detsch, R.; Wartzack, S. Amorphous Carbon Coatings for Total Knee Replacements—Part I: Deposition, Cytocompatibility, Chemical and Mechanical Properties. Polymers 2021, 13, 1952. [Google Scholar] [CrossRef] [PubMed]
- Oliver, W.C.; Pharr, G.M. An improved technique for determining hardness and elastic modulus using load and displacement sensing indentation experiments. J. Mater. Res. 1992, 7, 1564–1583. [Google Scholar] [CrossRef]
- Oliver, W.C.; Pharr, G.M. Measurement of hardness and elastic modulus by instrumented indentation: Advances in understanding and refinements to methodology. J. Mater. Res. 2004, 19, 3–20. [Google Scholar] [CrossRef]
- DIN EN ISO 14577-1:2015-11; Metallic Materials—Instrumented Indentation Test for Hardness and Materials Parameters—Part 1: Test Method. DIN: Berlin, Germany, 2015.
- DIN EN ISO 14577-4:2017-04; Metallic Materials—Instrumented Indentation Test for Hardness and Materials Parameters—Part 4: Test Method for Metallic and Non-Metallic Coatings. DIN: Berlin, Germany, 2017.
- Jiang, X.; Reichelt, K.; Stritzker, B. The hardness and Young’s modulus of amorphous hydrogenated carbon and silicon films measured with an ultralow load indenter. J. Appl. Phys. 1989, 66, 5805–5808. [Google Scholar] [CrossRef]
- Cho, S.-J.; Lee, K.-R.; Eun, K.Y.; Hahn, J.H.; Ko, D.-H. Determination of elastic modulus and Poisson’s ratio of diamond-like carbon films. Thin Solid Films 1999, 341, 207–210. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly: Beijing, China, 2017; ISBN 9781449369880. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2003; Volume 2, p. 4. ISBN 026218253X. [Google Scholar]
- Ostertagová, E. Modelling using Polynomial Regression. Procedia Eng. 2012, 48, 500–506. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Hinton, G.E. 20—Connectionist Learning Procedures. In Machine Learning: An Artificial Intelligence Approach; Elsevier: Amsterdam, The Netherlands, 1990; Volume III. [Google Scholar] [CrossRef]
- Ebden, M. Gaussian Processes: A Quick Introduction. arXiv 2015, arXiv:1505.02965. Available online: https://arxiv.org/abs/1505.02965 (accessed on 1 February 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Weikert, T.; Wartzack, S.; Baloglu, M.V.; Willner, K.; Gabel, S.; Merle, B.; Pineda, F.; Walczak, M.; Marian, M.; Rosenkranz, A.; et al. Evaluation of the surface fatigue behavior of amorphous carbon coatings through cyclic nanoindentation. Surf. Coat. Technol. 2021, 407, 126769. [Google Scholar] [CrossRef]
- Rothammer, B.; Weikert, T.; Tremmel, S.; Wartzack, S. Tribologisches Verhalten amorpher Kohlenstoffschichten auf Metallen für die Knie-Totalendoprothetik. Tribol. Schmierungstech. 2019, 66, 15–24. [Google Scholar] [CrossRef]
- Kügler, P.; Marian, M.; Schleich, B.; Tremmel, S.; Wartzack, S. tribAIn—Towards an Explicit Specification of Shared Tribological Understanding. Appl. Sci. 2020, 10, 4421. [Google Scholar] [CrossRef]
- McKinney, W. Data structures for statistical computing in Python. In Proceedings of the 9th Python in Science Conference (SCIPY 2010), Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Most, T.; Will, J. Metamodel of Optimal Prognosis—An automatic approach for variable reduction and optimal metamodel selection. Proc. Weimar. Optim. Stochastiktage 2008, 5, 20–21. [Google Scholar]
- Poliakov, V.P.; Siqueira, C.J.d.M.; Veiga, W.; Hümmelgen, I.A.; Lepienski, C.M.; Kirpilenko, G.G.; Dechandt, S.T. Physical and tribological properties of hard amorphous DLC films deposited on different substrates. Diam. Relat. Mater. 2004, 13, 1511–1515. [Google Scholar] [CrossRef]
- Martínez-Nogués, V.; Medel, F.J.; Mariscal, M.D.; Endrino, J.L.; Krzanowski, J.; Yubero, F.; Puértolas, J.A. Tribological performance of DLC coatings on UHMWPE. J. Phys. Conf. Ser. 2010, 252, 012006. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Designation | Coating | Sputtering Power/kW | Bias Voltage/V | Combined Ar and C2H2 Flow/sccm |
|---|---|---|---|---|
| Ref | a-C:H | 0.6 | −130 | 187 |
| C1 | 0.6 | −90 | 187 | |
| C2 | 2.0 | −170 | 91 | |
| C3 | 1.3 | −130 | 133 | |
| C4 | 2.0 | −90 | 187 | |
| C5 | 0.6 | −170 | 91 | |
| C6 | 2.0 | −170 | 187 | |
| C7 | 0.6 | −170 | 187 | |
| C8 | 0.6 | −90 | 91 | |
| C9 | 2.0 | −90 | 91 |
| Parameters | Settings for a-C:H Coatings |
|---|---|
| Maximum load/mN | 0.05 |
| Application time/s | 3 |
| Delay time after lowering/s | 30 |
| Poisson’s ratio ν | 0.3 |
| Model | Root Mean Squared Error | Mean Absolute Error | Coefficient of Prognosis |
|---|---|---|---|
| Gaussian Process Regressor | 540 MPa | 474 MPa | 91% |
| Polynomial Regression | 699 MPa | 653 MPa | 45% |
| Support Vector Machine | 955 MPa | 677 MPa | 29% |
| Neural Network | 3405 MPa | 3307 MPa | 16% |
| Designation | Coating | Sputtering Power/kW | Bias Voltage/V | Combined Ar and C2H2 Flow/Sccm | GPR Model Prediction of HIT/MPa | Experimentally Determined HIT/MPa |
|---|---|---|---|---|---|---|
| P1 | a-C:H | 2 | −230 | 108 | 3397 | 3040 ± 223 |
| P2 | 2 | −170 | 108 | 3355 | 2441 ± 537 | |
| P3 | 2 | −200 | 125 | 3363 | 3069 ± 401 | |
| P4 | 2 | −200 | 91 | 3389 | 2965 ± 328 | |
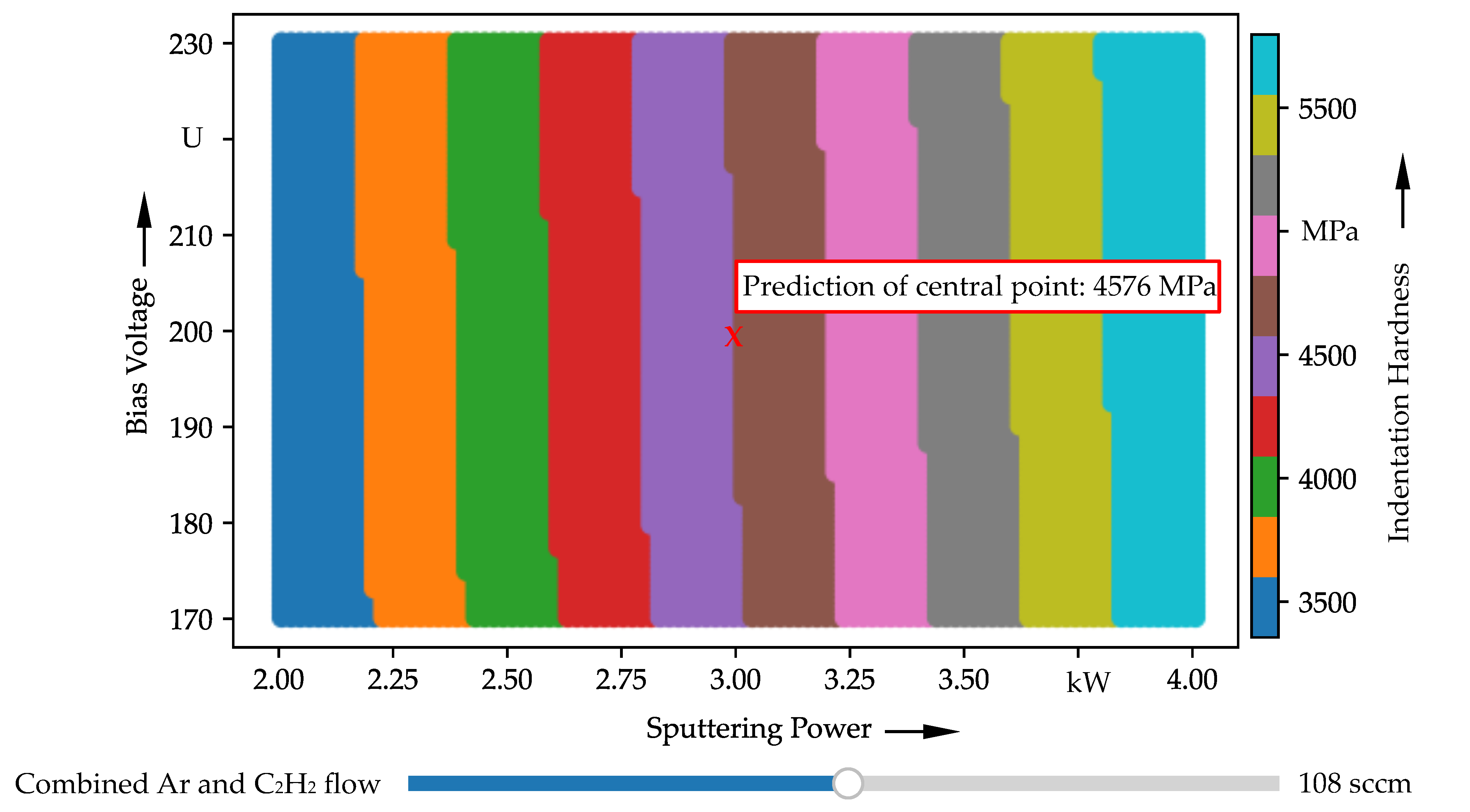
| P5.1 | 3 | −200 | 108 | 4576 | 4699 ± 557 | |
| P5.2 | 3 | −200 | 108 | 4576 | 4577 ± 731 | |
| P5.3 | 3 | −200 | 108 | 4576 | 4837 ± 634 | |
| P6 | 3 | −170 | 125 | 4542 | 4180 ± 399 | |
| P7 | 3 | −170 | 91 | 4568 | 4256 ± 622 | |
| P8 | 3 | −230 | 125 | 4584 | 4627 ± 1055 | |
| P9 | 3 | −230 | 91 | 4610 | 4415 ± 675 | |
| P10 | 4 | −170 | 108 | 5755 | 5081 ± 1361 | |
| P11 | 4 | −200 | 91 | 5789 | 5476 ± 1637 | |
| P12 | 4 | −230 | 108 | 5797 | 4313 ± 1513 | |
| P13 | 4 | −200 | 125 | 5763 | 6224 ± 1159 |
| Designation | Experimentally Determined HIT/MPa | GPR Model Prediction of HIT/MPa | PR Model Prediction of HIT/MPa | SVM Model Prediction of HIT/MPa | NN Model Prediction of HIT/MPa |
|---|---|---|---|---|---|
| P1 | 3040 ± 223 | 3397 | 3861 | 4220 | 1402 |
| P2 | 2441 ± 537 | 3355 | 3566 | 4218 | 1153 |
| P3 | 3069 ± 401 | 3363 | 3567 | 4219 | 1346 |
| P4 | 2965 ± 328 | 3389 | 4101 | 4219 | 1209 |
| P5.1 | 4699 ± 557 | 4576 | 4863 | 4219 | 1281 |
| P5.2 | 4577 ± 731 | 4576 | 4863 | 4219 | 1281 |
| P5.3 | 4837 ± 634 | 4576 | 4863 | 4219 | 1281 |
| P6 | 4180 ± 399 | 4542 | 4548 | 4217 | 1225 |
| P7 | 4256 ± 622 | 4568 | 4850 | 4218 | 1088 |
| P8 | 4627 ± 1055 | 4584 | 5063 | 4219 | 1475 |
| P9 | 4415 ± 675 | 4610 | 5376 | 4220 | 1336 |
| P10 | 5081 ± 1361 | 5755 | 4912 | 4218 | 1160 |
| P11 | 5476 ± 1637 | 5789 | 5447 | 4219 | 1216 |
| P12 | 4313 ± 1513 | 5797 | 5659 | 4220 | 1409 |
| P13 | 6224 ± 1159 | 5763 | 5366 | 4219 | 1354 |
| Model | Root Mean Squared Error | Mean Absolute Error | Coefficient of Prognosis |
|---|---|---|---|
| Gaussian Process Regressor | 551 MPa | 415 MPa | 78% |
| Polynomial Regression | 720 MPa | 587 MPa | 71% |
| Support Vector Machine | 991 MPa | 781 MPa | 0.1% |
| Neural Network | 3156 MPa | 2999 MPa | 1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sauer, C.; Rothammer, B.; Pottin, N.; Bartz, M.; Schleich, B.; Wartzack, S. Design of Amorphous Carbon Coatings Using Gaussian Processes and Advanced Data Visualization. Lubricants 2022, 10, 22. https://doi.org/10.3390/lubricants10020022
Sauer C, Rothammer B, Pottin N, Bartz M, Schleich B, Wartzack S. Design of Amorphous Carbon Coatings Using Gaussian Processes and Advanced Data Visualization. Lubricants. 2022; 10(2):22. https://doi.org/10.3390/lubricants10020022
Chicago/Turabian StyleSauer, Christopher, Benedict Rothammer, Nicolai Pottin, Marcel Bartz, Benjamin Schleich, and Sandro Wartzack. 2022. "Design of Amorphous Carbon Coatings Using Gaussian Processes and Advanced Data Visualization" Lubricants 10, no. 2: 22. https://doi.org/10.3390/lubricants10020022
APA StyleSauer, C., Rothammer, B., Pottin, N., Bartz, M., Schleich, B., & Wartzack, S. (2022). Design of Amorphous Carbon Coatings Using Gaussian Processes and Advanced Data Visualization. Lubricants, 10(2), 22. https://doi.org/10.3390/lubricants10020022