
From Preliminary Urinalysis to Decision Support: Machine Learning for UTI Prediction in Real-World Laboratory Data


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Description
2.2. Data Preprocessing
- •
- Missing Data Handling: Only participants with complete laboratory data were included in the final analysis. We deliberately avoided imputation to ensure methodological transparency and to rely exclusively on observed values. This decision supports internal validity by avoiding bias introduced through statistical assumptions. While this approach reduced the available sample size, it ensured that all diagnostic metrics reflect true laboratory distributions. Importantly, even if imputation had been applied, the number of false negative cases in the dataset would still have remained insufficient for the robust training of cost-sensitive models or subgroup analyses.
- •
- Feature Engineering and Encoding: Categorical variables (gender, color, and clarity) were encoded using one-hot or ordinal encoding, depending on their characteristics. Numerical variables were standardized where appropriate [19]. All available variables were retained across models to ensure comparability, and no dimensionality reduction techniques were applied.
- •
- Class Imbalance Handling: Although the proportion of positive cultures (26.2%) did not constitute severe imbalance, it was sufficient to potentially bias model learning. Initial attempts using synthetic oversampling techniques such as SMOTE and ADASYN degraded precision and increased false positives due to noisy synthetic samples. Therefore, all models were ultimately trained using a balanced bagging classifier framework. This ensemble-based resampling method improves minority class representation while preserving the original data structure and avoiding synthetic artifacts. Its reliability in structured clinical datasets has been previously demonstrated [20,21,22].
2.3. Model Development
2.4. Evaluation Metrics
- •
- Accuracy: Proportion of correct predictions (true positives and true negatives) among all evaluated cases.
- •
- Balanced Accuracy: Mean of sensitivity and specificity. Suitable for imbalanced datasets, as it considers both classes equally.
- •
- Sensitivity (Recall): Proportion of actual positive cases correctly identified by the model.
- •
- Specificity: Proportion of actual negative cases correctly identified. High specificity reduces the likelihood of false positives.
- •
- Precision (Positive Predictive Value—PPV): Proportion of predicted positive cases that are true positives.
- •
- Negative Predictive Value (NPV): Proportion of predicted negative cases that are true negatives.
- •
- F1 Score: Harmonic mean of precision and recall. Useful when both false positives and false negatives carry clinical consequences.
- •
- ROC AUC: Area under the receiver operating characteristic curve. Reflects overall discrimination capacity of the model across thresholds.
- •
- Matthews Correlation Coefficient (MCC): A balanced measure that incorporates all components of the confusion matrix. Appropriate for imbalanced datasets.
- •
- Positive Likelihood Ratio (PLR): How much more likely a positive test result is in someone with the condition than in someone without it. Values > 10 are considered strong evidence to support a diagnosis.
- •
- Negative Likelihood Ratio (NLR): Ratio of the false negative rate to the true negative rate. Lower values suggest the test is effective at excluding disease; values < 0.1 are generally considered acceptable.
- •
2.5. Model Interpretation and Performance Visualization
2.6. Threshold Optimization Procedure
3. Results
4. Discussion
4.1. Overview of Findings
4.2. Diagnostic Implications
4.3. Impact of Threshold Optimization on Diagnostic Performance
4.4. Model Interpretability and Clinical Integration
4.5. Limitations
4.6. Future Directions
4.7. Clinical Applicability
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| UTIs | Urinary Tract Infections |
| ML | Machine Learning |
| SG | Specific Gravity |
| WBC | White Blood Cell |
| SMOTE | Synthetic Minority Over-sampling Technique |
| ADASYN | Adaptive Synthetic Sampling |
| XGBOOST | eXtreme Gradient Boosting |
| PPV | Positive Predictive Value |
| NPV | Negative Predictive Value |
| ROC-AUC | Receiver Operating Characteristic Area Under the Curve |
| MCC | Matthews Correlation Coefficient |
| PLR | Positive Likelihood Ratio |
| NLR | Negative Likelihood Ratio |
| DOR | Diagnostic Odds Ratio |
| PFI | Permutation Feature Importance |
| LIS | Laboratory Information Systems |
| EHR | Electronic Health Records |
| PCR | Polymerase Chain Reaction |
| XAI | Explainable Artificial Intelligence |
References
- Sánchez, X.; Latacunga, A.; Cárdenas, I.; Jimbo-Sotomayor, R.; Escalante, S. Antibiotic Prescription Patterns in Patients with Suspected Urinary Tract Infections in Ecuador. PLoS ONE 2023, 18, e0295247. [Google Scholar] [CrossRef]
- Fésüs, A.; Matuz, M.; Papfalvi, E.; Hambalek, H.; Ruzsa, R.; Tánczos, B.; Bácskay, I.; Lekli, I.; Illés, Á.; Benkő, R. Evaluation of the Diagnosis and Antibiotic Prescription Pattern in Patients Hospitalized with Urinary Tract Infections: Single-Center Study from a University-Affiliated Hospital. Antibiotics 2023, 12, 1689. [Google Scholar] [CrossRef]
- Medina, M.; Castillo-Pino, E. An Introduction to the Epidemiology and Burden of Urinary Tract Infections. Ther. Adv. Urol. 2019, 11, 1756287219832172. [Google Scholar] [CrossRef] [PubMed]
- Rowe, T.A.; Juthani-Mehta, M. Urinary Tract Infection in Older Adults. Aging Health 2013, 9, 515–528. [Google Scholar] [CrossRef] [PubMed]
- Kolodziej, L.M.; Kuil, S.D.; de Jong, M.D.; Schneeberger, C. Resident-Related Factors Influencing Antibiotic Treatment Decisions for Urinary Tract Infections in Dutch Nursing Homes. Antibiotics 2022, 11, 140. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention (CDC). Outpatient Antibiotic Prescribing in the United States. Available online: https://www.cdc.gov/antibiotic-use/hcp/data-research/antibiotic-prescribing.html (accessed on 28 March 2025).
- Parente, D.; Shanks, D.; Yedlinksy, N.; Hake, J.; Dhanda, G. Machine Learning Prediction of Urine Cultures in Primary Care. Ann. Fam. Med. 2023, 21 (Suppl. 1). [Google Scholar] [CrossRef]
- Dedeene, L.; Van Elslande, J.; Dewitte, J.; Martens, G.; De Laere, E.; De Jaeger, P.; De Smet, D. An Artificial Intelligence-Driven Support Tool for Prediction of Urine Culture Test Results. Clin. Chim. Acta 2024, 562, 119854. [Google Scholar] [CrossRef]
- Seheult, J.N.; Stram, M.N.; Contis, L.; Pontzer, R.E.; Hardy, S.; Wertz, W.; Baxter, C.M.; Ondras, M.; Kip, P.L.; Snyder, G.M.; et al. Development, Evaluation, and Multisite Deployment of a Machine Learning Decision Tree Algorithm to Optimize Urinalysis Parameters for Predicting Urine Culture Positivity. J. Clin. Microbiol. 2023, 61, e0029123. [Google Scholar] [CrossRef]
- Jeng, S.L.; Huang, Z.J.; Yang, D.C.; Teng, C.H.; Wang, M.C. Machine Learning to Predict the Development of Recurrent Urinary Tract Infection Related to Single Uropathogen, Escherichia coli. Sci. Rep. 2022, 12, 17216. [Google Scholar] [CrossRef]
- Yen, C.C.; Ma, C.Y.; Tsai, Y.C. Interpretable Machine Learning Models for Predicting Critical Outcomes in Patients with Suspected Urinary Tract Infection with Positive Urine Culture. Diagnostics 2024, 14, 1974. [Google Scholar] [CrossRef]
- Choi, M.H.; Kim, D.; Park, Y.; Jeong, S.H. Development and Validation of Artificial Intelligence Models to Predict Urinary Tract Infections and Secondary Bloodstream Infections in Adult Patients. J. Infect. Public Health 2024, 17, 10–17. [Google Scholar] [CrossRef]
- Abbasi, A.; Li, C.; Dekle, M.; Bermudez, C.A.; Brodie, D.; Sellke, F.W.; Sodha, N.R.; Ventetuolo, C.E.; Eickhoff, C. Interpretable machine learning-based predictive modeling of patient outcomes following cardiac surgery. J. Thorac. Cardiovasc. Surg. 2025, 169, 114–123.e28. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Ourani, M.; Honda, N.S.; MacDonald, W.; Roberts, J. Evaluation of Evidence-Based Urinalysis Reflex to Culture Criteria: Impact on Reducing Antimicrobial Usage. Int. J. Infect. Dis. 2021, 102, 40–44. [Google Scholar] [CrossRef]
- Tomlinson, E.; Ward, M.; Cooper, C.; James, R.; Stokes, C.; Begum, S.; Watson, J.; Hay, A.D.; Jones, H.E.; Thom, H.; et al. Point-of-Care Tests for Urinary Tract Infections to Reduce Antimicrobial Resistance: A Systematic Review and Conceptual Economic Model. Health Technol. Assess. 2024, 28, 1–109. [Google Scholar] [CrossRef] [PubMed]
- Sinawe, H.; Casadesus, D. Urine Culture. In StatPearls [Internet]; StatPearls Publishing: Treasure Island, FL, USA, 2025. Available online: https://www.ncbi.nlm.nih.gov/books/NBK557569/ (accessed on 28 March 2025).
- Bono, M.J.; Leslie, S.W.; Reygaert, W.C. Uncomplicated Urinary Tract Infections. In StatPearls [Internet]; StatPearls Publishing: Treasure Island, FL, USA, 2025. Available online: https://www.ncbi.nlm.nih.gov/books/NBK470195/ (accessed on 28 March 2025).
- Sabih, A.; Leslie, S.W. Complicated Urinary Tract Infections. In StatPearls [Internet]; StatPearls Publishing: Treasure Island, FL, USA, 2025. Available online: https://www.ncbi.nlm.nih.gov/books/NBK436013/ (accessed on 28 March 2025).
- Qiu, S.; Liu, Q.; Zhou, S.; Huang, W. Adversarial Attack and Defense Technologies in Natural Language Processing: A Survey. Neurocomputing 2022, 492, 278–307. [Google Scholar] [CrossRef]
- Roshan, S.E.; Asadi, S. Improvement of Bagging Performance for Classification of Imbalanced Datasets Using Evolutionary Multi-Objective Optimization. Eng. Appl. Artif. Intell. 2020, 87, 103319. [Google Scholar] [CrossRef]
- Edward, J.; Rosli, M.M.; Seman, A. A Comprehensive Analysis of a Framework for Rebalancing Imbalanced Medical Data Using an Ensemble-Based Classifier. Pertanika J. Sci. Technol. 2024, 32, 6. [Google Scholar] [CrossRef]
- Bozcuk, H.Ş.; Yıldız, M. A Balanced Bagging Classifier Machine Learning Model-Based Web Application to Predict Risk of Febrile Neutropenia in Cancer Patients. J. Cancer Sci. Clin. Ther. 2024, 8, 327–334. [Google Scholar] [CrossRef]
- Cearns, M.; Hahn, T.; Baune, B.T. Recommendations and Future Directions for Supervised Machine Learning in Psychiatry. Transl. Psychiatry 2019, 9, 271. [Google Scholar] [CrossRef]
- Mahesh, T.R.; Kumar, V.V.; Kumar, V.D.; Geman, O.; Margala, M.; Guduri, M. The Stratified K-Folds Cross-Validation and Class-Balancing Methods with High-Performance Ensemble Classifiers for Breast Cancer Classification. Healthc. Anal. 2023, 4, 100247. [Google Scholar] [CrossRef]
- Bey, R.; Goussault, R.; Grolleau, F.; Benchoufi, M.; Porcher, R. Fold-Stratified Cross-Validation for Unbiased and Privacy-Preserving Federated Learning. J. Am. Med. Inform. Assoc. 2020, 27, 1244–1251. [Google Scholar] [CrossRef] [PubMed]
- Bradshaw, T.J.; Huemann, Z.; Hu, J.; Rahmim, A. A Guide to Cross-Validation for Artificial Intelligence in Medical Imaging. Radiol. Artif. Intell. 2023, 5, e220232. [Google Scholar] [CrossRef]
- Ghazwani, M.; Begum, M.Y. Computational Intelligence Modeling of Hyoscine Drug Solubility and Solvent Density in Supercritical Processing: Gradient Boosting, Extra Trees, and Random Forest Models. Sci. Rep. 2023, 13, 10046. [Google Scholar] [CrossRef] [PubMed]
- Jijo, B.T.; Abdulazeez, A.M. Classification Based on Decision Tree Algorithm for Machine Learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Ramzan, M.F.; Ali, S.; Baseer, S.; Samad, A.; Husnain, M. Voting Classification-Based Diabetes Mellitus Prediction Using Hypertuned Machine-Learning Techniques. Mob. Inf. Syst. 2022, 2022, 6521532. [Google Scholar] [CrossRef]
- Srinivas, A.; Mosiganti, J.P. A Brain Stroke Detection Model Using Soft Voting-Based Ensemble Machine Learning Classifier. Meas. Sens. 2023, 29, 100871. [Google Scholar] [CrossRef]
- Ghasemieh, A.; Lloyed, A.; Bahrami, P.; Vajar, P.; Kashef, R. A Novel Machine Learning Model with Stacking Ensemble Learner for Predicting Emergency Readmission of Heart-Disease Patients. Decis. Anal. J. 2023, 7, 100242. [Google Scholar] [CrossRef]
- Zhang, H.-W.; Wang, Y.-R.; Hu, B.; Song, B.; Wen, Z.-J.; Su, L.; Chen, X.-M.; Wang, X.; Zhou, P.; Zhong, X.-M.; et al. Using Machine Learning to Develop a Stacking Ensemble Learning Model for the CT Radiomics Classification of Brain Metastases. Sci. Rep. 2024, 14, 28575. [Google Scholar] [CrossRef]
- Kent, P.; Hancock, M.J. Interpretation of Dichotomous Outcomes: Sensitivity, Specificity, Likelihood Ratios, and Pre-Test and Post-Test Probability. J. Physiother. 2016, 62, 231–233. [Google Scholar] [CrossRef]
- Marill, K.A. Diagnostic and Prognostic Test Assessment in Emergency Medicine: Likelihood and Diagnostic Odds Ratios. Emerg. Med. J. 2022, 39, 635–642. [Google Scholar] [CrossRef]
- Huang, Y.; Yin, J.; Samawi, H. Methods Improving the Estimate of Diagnostic Odds Ratio. Commun. Stat. Simul. Comput. 2018, 47, 353–366. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Molnar, C.; Feature Importance. In Interpretable Machine Learning [Internet]. 2019. Available online: https://christophm.github.io/interpretable-ml-book/feature-importance.html (accessed on 28 March 2025).
- Schisterman, E.F.; Faraggi, D.; Reiser, B.; Hu, J. Youden Index and the Optimal Threshold for Markers with Mass at Zero. Stat. Med. 2008, 27, 297–315. [Google Scholar] [CrossRef]
- Tu, J.B.; Liao, W.J.; Liu, W.C.; Gao, X.H. Using Machine Learning Techniques to Predict the Risk of Osteoporosis Based on Nationwide Chronic Disease Data. Sci. Rep. 2024, 14, 5245. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, G.; Wang, Y.; Wang, Y. Development and Evaluation of a Model for Predicting the Risk of Healthcare-Associated Infections in Patients Admitted to Intensive Care Units. Front. Public Health 2024, 12, 1444176. [Google Scholar] [CrossRef]
- Deeks, J.J.; Altman, D.G. Diagnostic tests 4: Likelihood ratios. BMJ 2004, 329, 168. [Google Scholar] [CrossRef]
- Florkowski, C.M. Sensitivity, specificity, receiver-operating characteristic (ROC) curves and likelihood ratios: Communicating the performance of diagnostic tests. Clin. Biochem. Rev. 2008, 29 (Suppl. 1), S83–S87. [Google Scholar] [PubMed] [PubMed Central]
- Zering, J.; Stohs, E.J. Urine polymerase chain reaction tests: Stewardship helper or hinderance? Antimicrob. Steward. Healthc. Epidemiol. 2024, 4, e77. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Kelly, B.N. UTI detection by PCR: Improving patient outcomes. J. Mass Spectrom. Adv. Clin. Lab. 2023, 28, 60–62. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Elia, J.; Hafron, J.; Holton, M.; Ervin, C.; Hollander, M.B.; Kapoor, D.A. The Impact of Polymerase Chain Reaction Urine Testing on Clinical Decision-Making in the Management of Complex Urinary Tract Infections. Int. J. Mol. Sci. 2024, 25, 6616. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Kapoor, D.A.; Holton, M.R.; Hafron, J.; Aljundi, R.; Zwaans, B.; Hollander, M. Comparison of Polymerase Chain Reaction and Urine Culture in the Evaluation of Patients with Complex Urinary Tract Infections. Biology 2024, 13, 257. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Hao, X.; Cognetti, M.; Patel, C.; Jean-Charles, N.; Tumati, A.; Burch-Smith, R.; Holton, M.; Kapoor, D.A. The Essential Role of PCR and PCR Panel Size in Comparison with Urine Culture in Identification of Polymicrobial and Fastidious Organisms in Patients with Complicated Urinary Tract Infections. Int. J. Mol. Sci. 2023, 24, 14269. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
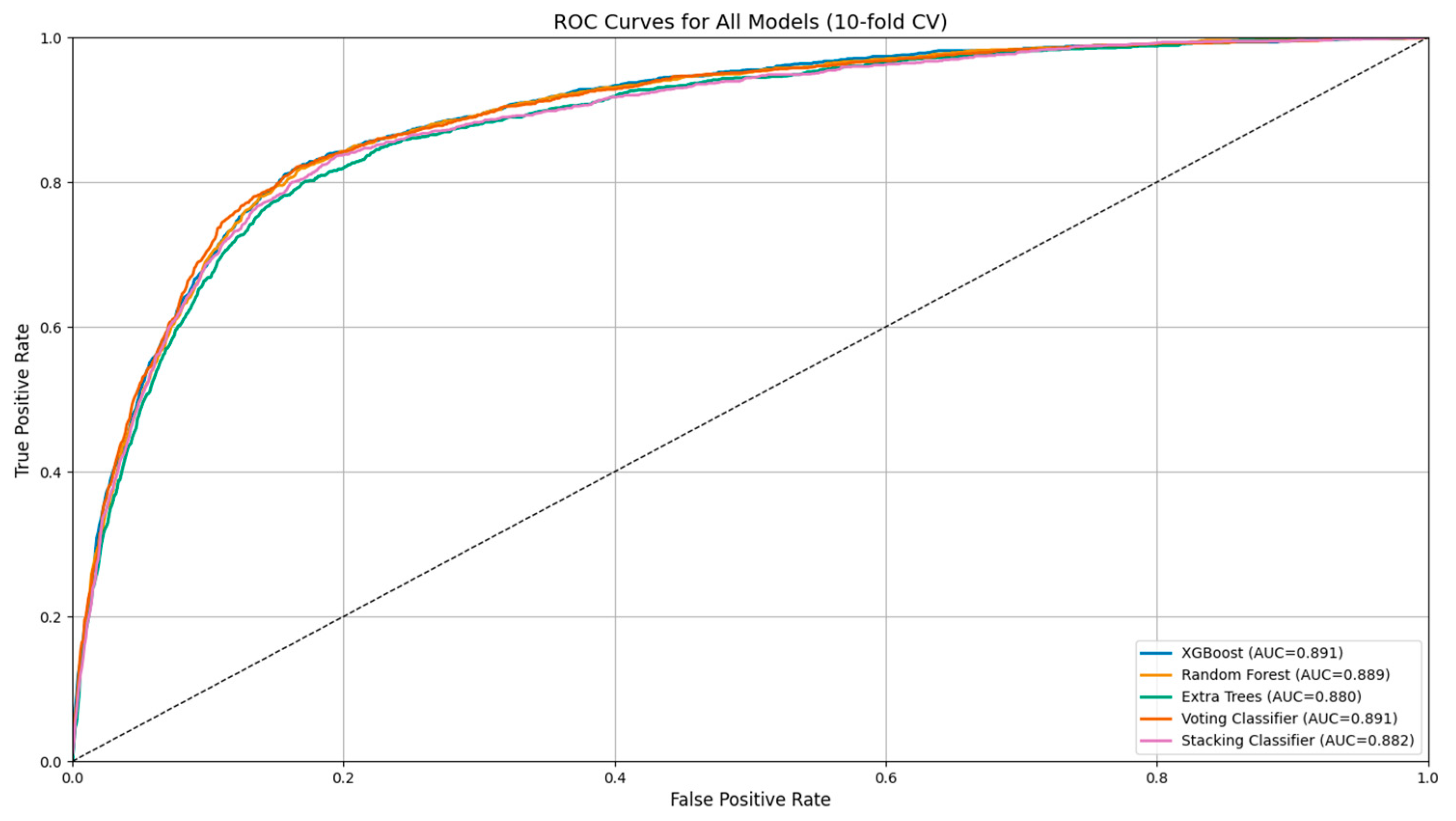
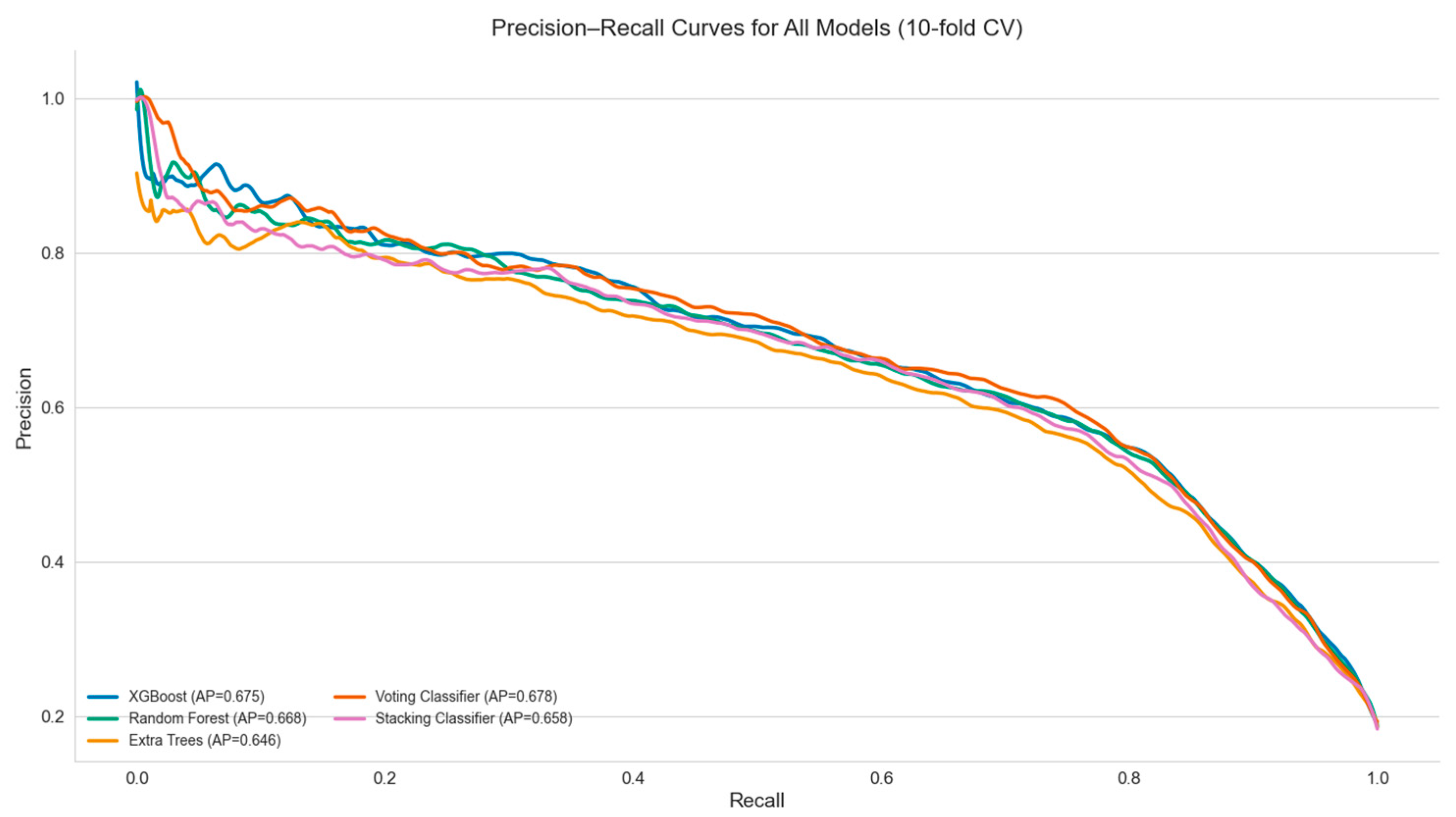
| Model | Accuracy | Balanced Accuracy | Precision (PPV) | Recall (Sensitivity) | Specificity | NPV | F1 Score | ROC AUC | MCC | PLR | NLR | DOR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forest | 0.856 | 0.808 | 0.596 | 0.731 | 0.885 | 0.934 | 0.657 | 0.888 | 0.572 | 6.42 | 0.30 | 21.65 |
| XGBoost | 0.859 | 0.799 | 0.610 | 0.702 | 0.896 | 0.928 | 0.670 | 0.892 | 0.575 | 6.79 | 0.33 | 21.20 |
| Extra Trees | 0.857 | 0.756 | 0.626 | 0.595 | 0.918 | 0.918 | 0.655 | 0.888 | 0.571 | 7.34 | 0.44 | 17.23 |
| Stacking Classifier | 0.864 | 0.714 | 0.706 | 0.473 | 0.954 | 0.887 | 0.566 | 0.883 | 0.503 | 10.69 | 0.552 | 19.77 |
| Voting Classifier | 0.868 | 0.721 | 0.717 | 0.486 | 0.956 | 0.889 | 0.579 | 0.891 | 0.518 | 11.29 | 0.538 | 21.63 |
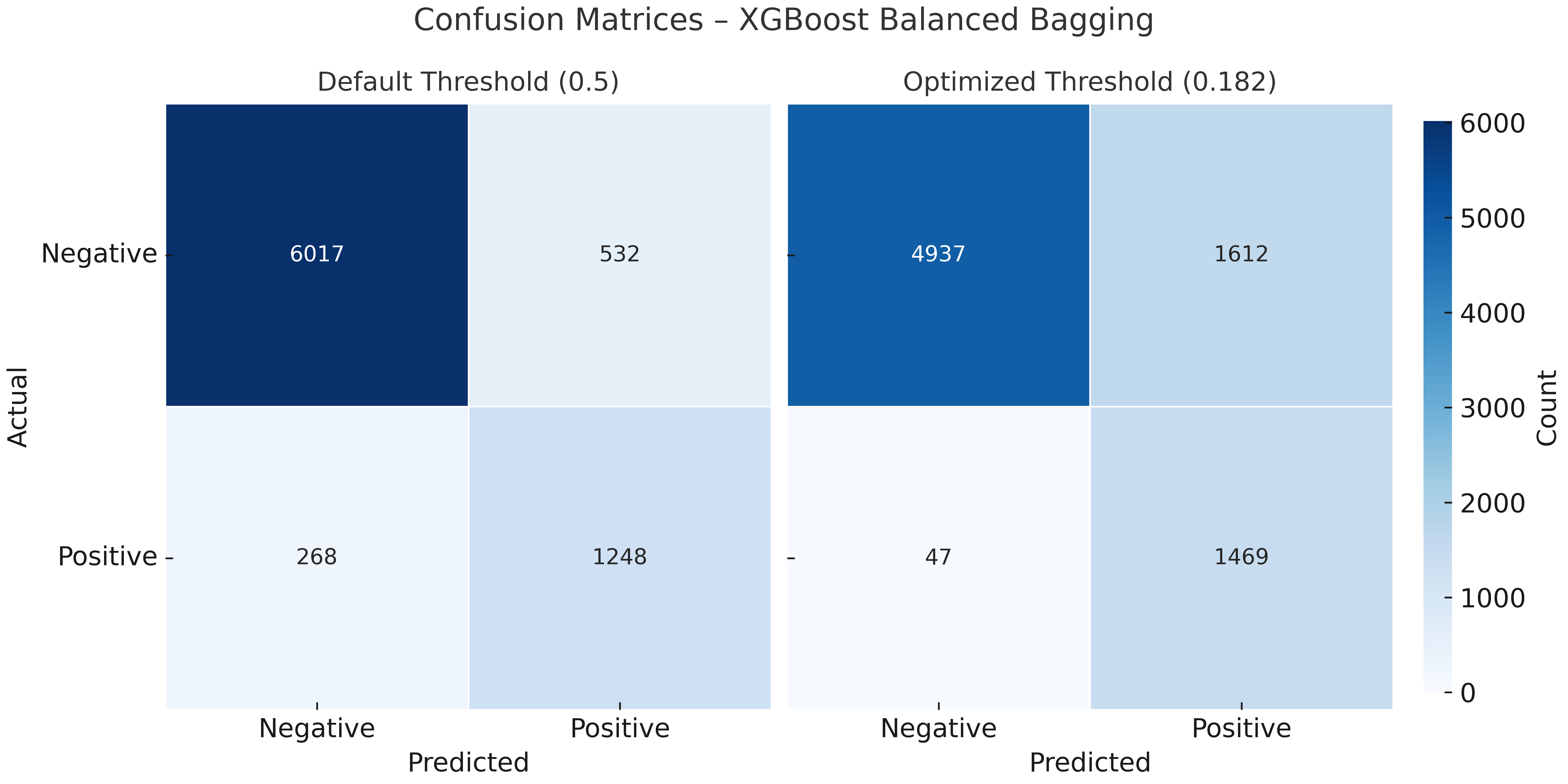
| Metric | XGBoost (Default Threshold) | XGBoost (Optimized Threshold) |
|---|---|---|
| Accuracy | 0.859 | 0.767 |
| Balanced Accuracy | 0.799 | 0.810 |
| Precision (PPV) | 0.609 | 0.441 |
| Recall (Sensitivity) | 0.702 | 0.879 |
| Specificity | 0.896 | 0.741 |
| Negative Predictive Value (NPV) | 0.928 | 0.964 |
| F1 Score | 0.652 | 0.587 |
| ROC AUC | 0.886 | 0.886 |
| Matthews Corr. Coef. (MCC) | 0.567 | 0.501 |
| Positive Likelihood Ratio (PLR) | 6.740 | 3.401 |
| Negative Likelihood Ratio (NLR) | 0.333 | 0.163 |
| Diagnostic Odds Ratio (DOR) | 20.250 | 20.893 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sergounioti, A.; Rigas, D.; Zoitopoulos, V.; Kalles, D. From Preliminary Urinalysis to Decision Support: Machine Learning for UTI Prediction in Real-World Laboratory Data. J. Pers. Med. 2025, 15, 200. https://doi.org/10.3390/jpm15050200
Sergounioti A, Rigas D, Zoitopoulos V, Kalles D. From Preliminary Urinalysis to Decision Support: Machine Learning for UTI Prediction in Real-World Laboratory Data. Journal of Personalized Medicine. 2025; 15(5):200. https://doi.org/10.3390/jpm15050200
Chicago/Turabian StyleSergounioti, Athanasia, Dimitrios Rigas, Vassilios Zoitopoulos, and Dimitrios Kalles. 2025. "From Preliminary Urinalysis to Decision Support: Machine Learning for UTI Prediction in Real-World Laboratory Data" Journal of Personalized Medicine 15, no. 5: 200. https://doi.org/10.3390/jpm15050200
APA StyleSergounioti, A., Rigas, D., Zoitopoulos, V., & Kalles, D. (2025). From Preliminary Urinalysis to Decision Support: Machine Learning for UTI Prediction in Real-World Laboratory Data. Journal of Personalized Medicine, 15(5), 200. https://doi.org/10.3390/jpm15050200