
Deep-Learning for the Diagnosis of Esophageal Cancers and Precursor Lesions in Endoscopic Images: A Model Establishment and Nationwide Multicenter Performance Verification Study

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Methods
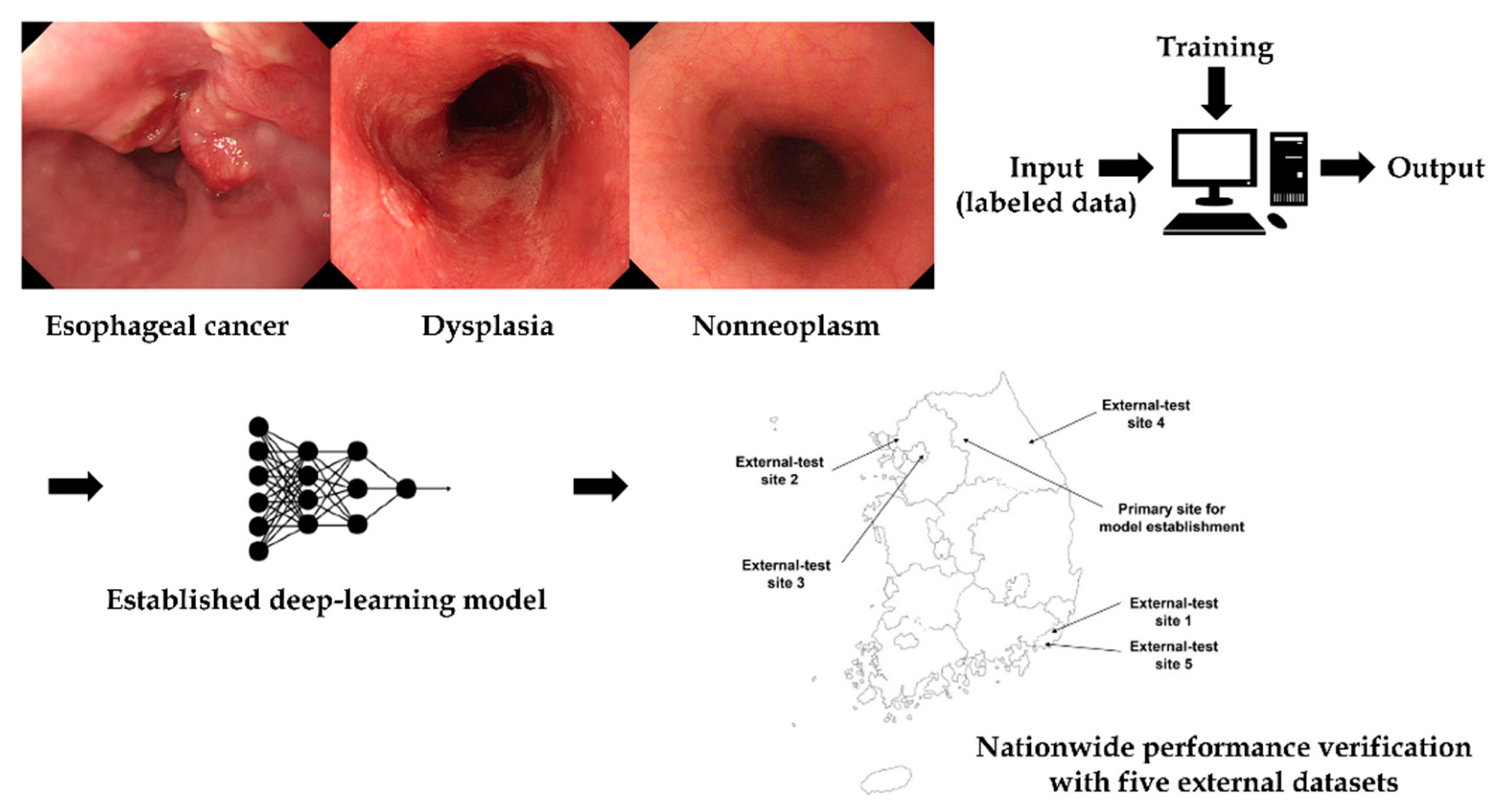
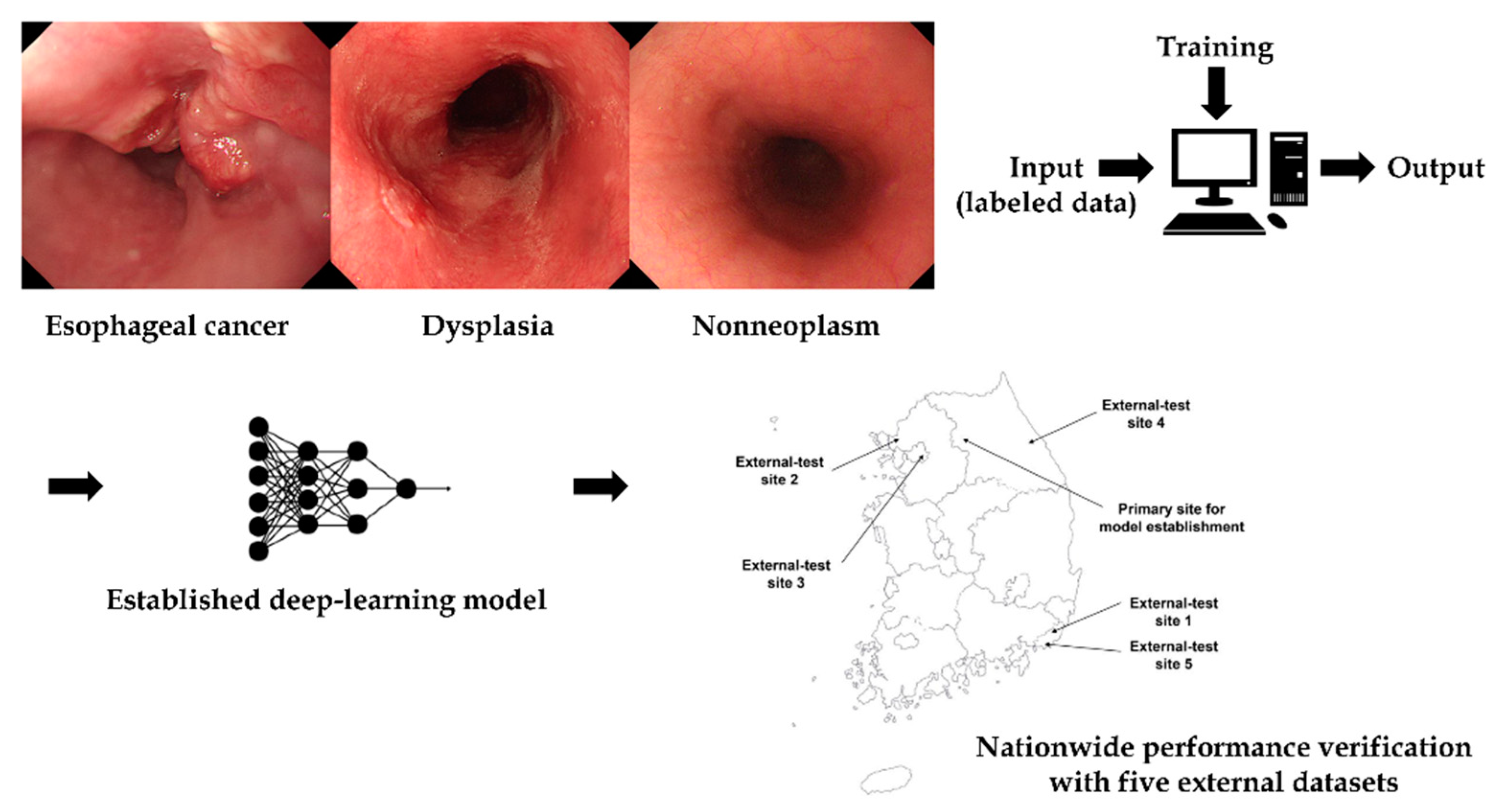
2.1. Collection and Construction of the Training and Internal-Test Datasets
2.2. Deep-Learning Tool Used for the Model Establishment
2.3. Preprocessing of Collected Training or Internal-Testing Images and Training Parameters
2.4. Training of the Deep-Learning Model
2.5. Datasets for Nationwide Multicenter Prospective External-Tests
2.6. Primary Performance Metric and Statistics
2.7. Attention Map for Explainability
3. Results
3.1. Characteristics of the Datasets
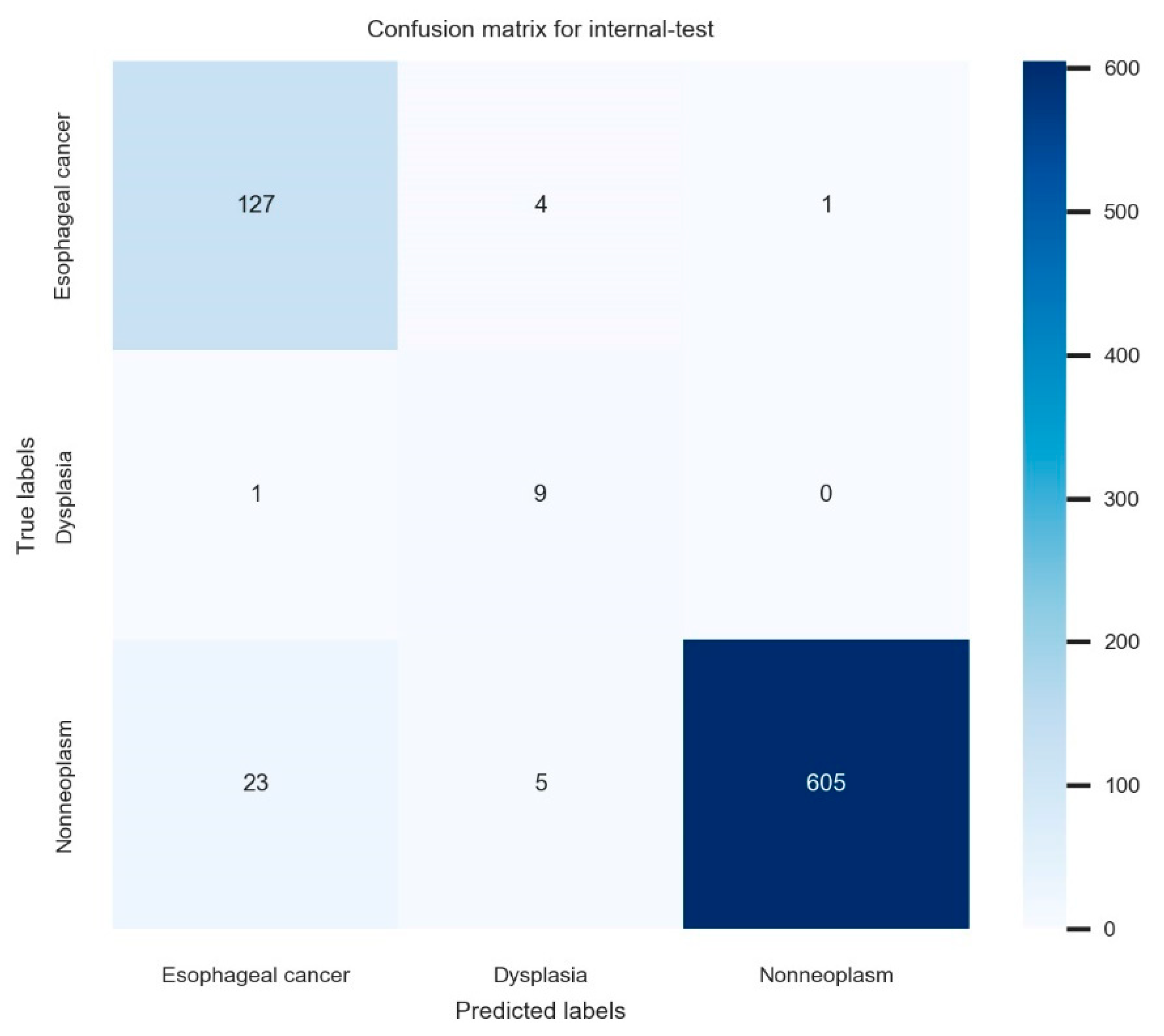
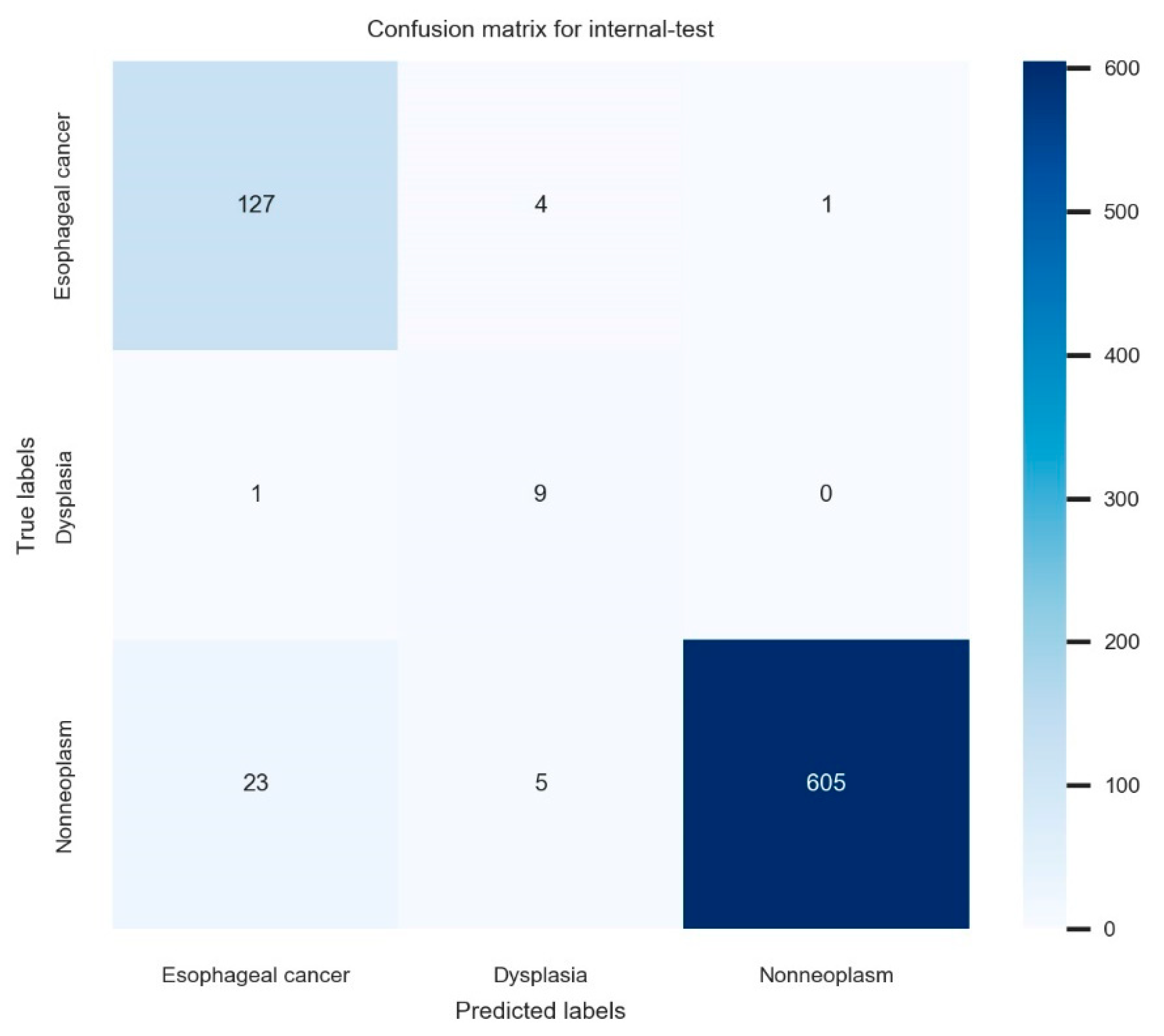
3.2. Classification Performance of the Established Deep-Learning Model
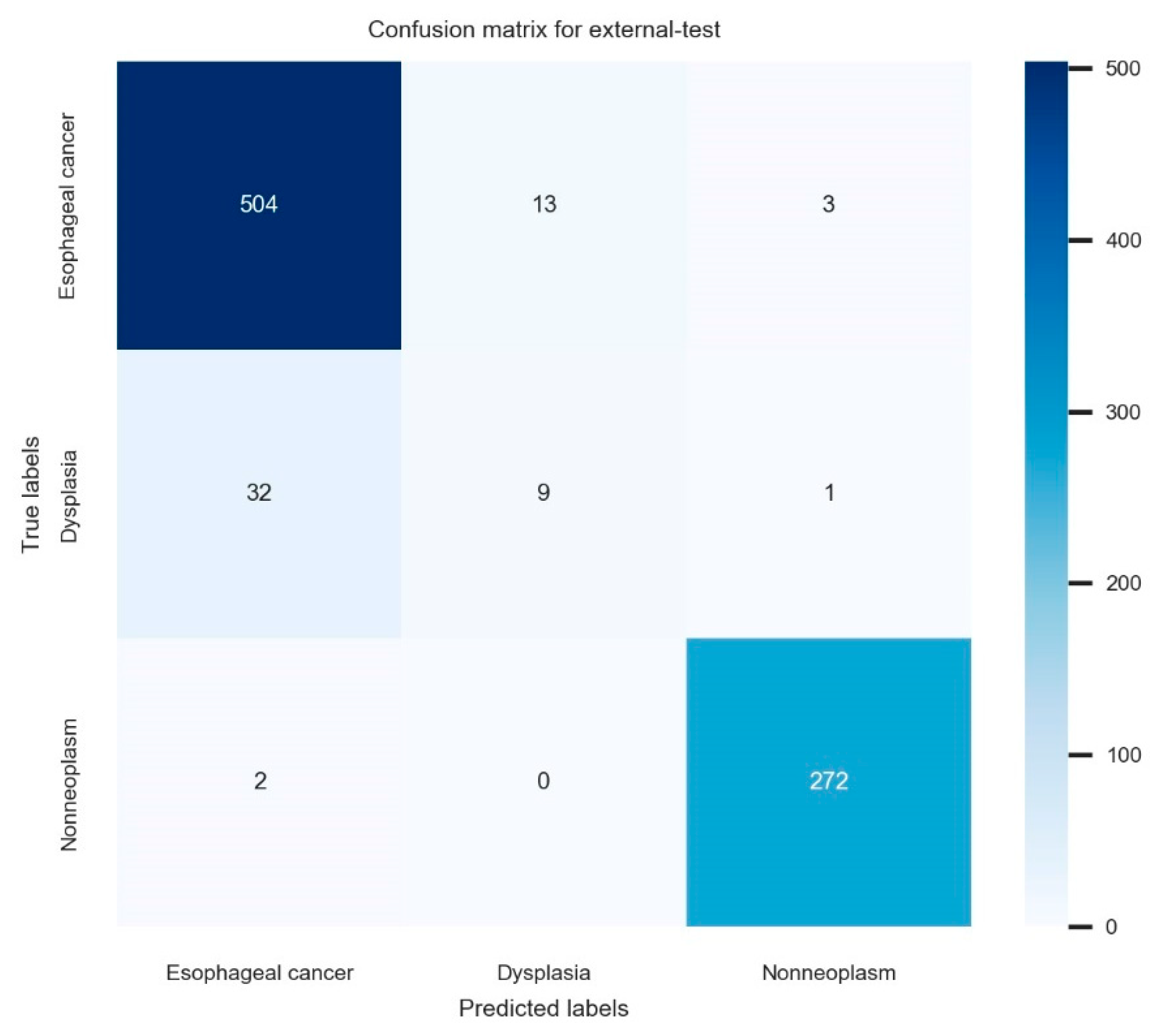
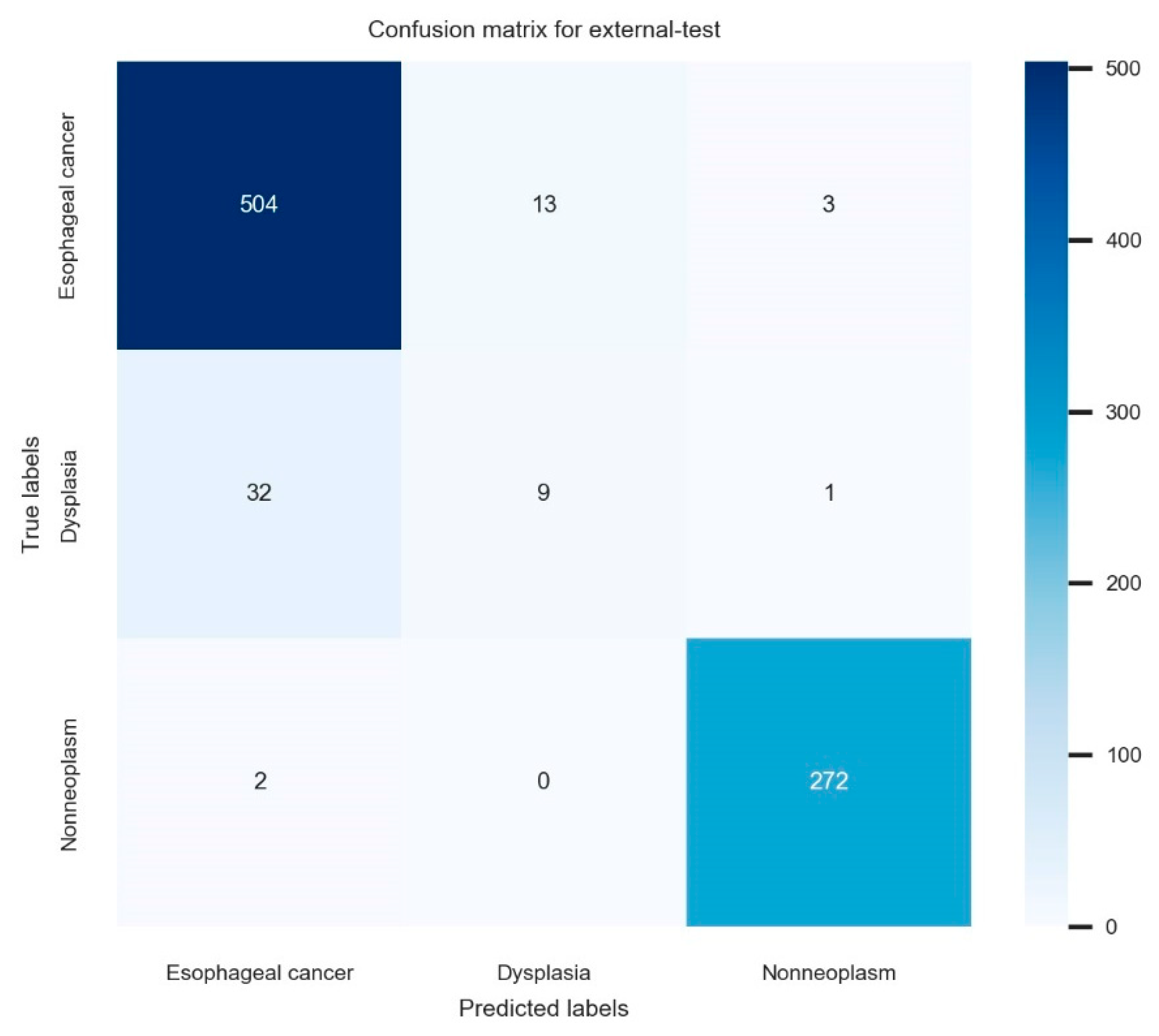
3.3. Nationwide Prospective Multicenter Performance Verification
3.4. Attention Map for the Explainability
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ROC | receiver operating characteristic |
| AUC | area under the curve |
| Grad-CAM | gradient-weighted class activation map |
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bang, C.S.; Lee, J.J.; Baik, G.H. Computer-aided diagnosis of esophageal cancer and neoplasms in endoscopic images: A systematic review and meta-analysis of diagnostic test accuracy. Gastrointest. Endosc. 2021, 93, 1006–1015.e13. [Google Scholar] [CrossRef] [PubMed]
- Ruan, R.; Chen, S.; Tao, Y.; Yu, J.; Zhou, D.; Cui, Z.; Shen, Q.; Wang, S. Retrospective analysis of predictive factors for lymph node metastasis in superficial esophageal squamous cell carcinoma. Sci. Rep. 2021, 11, 16544. [Google Scholar] [CrossRef] [PubMed]
- Inoue, T.; Ishihara, R. Photodynamic Therapy for Esophageal Cancer. Clin. Endosc. 2021, 54, 494–498. [Google Scholar] [CrossRef] [PubMed]
- Gong, E.J.; Kim, D.H. Endoscopic treatment for esophageal cancer. Korean J. Helicobacter Up. Gastrointest. Res. 2019, 19, 156–160. [Google Scholar] [CrossRef] [Green Version]
- Hamel, C.; Ahmadzai, N.; Beck, A.; Thuku, M.; Skidmore, B.; Pussegoda, K.; Bjerre, L.; Chatterjee, A.; Dennis, K.; Ferri, L.; et al. Screening for esophageal adenocarcinoma and precancerous conditions (dysplasia and Barrett’s esophagus) in patients with chronic gastroesophageal reflux disease with or without other risk factors: Two systematic reviews and one overview of reviews to inform a guideline of the Canadian Task Force on Preventive Health Care (CTFPHC). Syst. Rev. 2020, 9, 20. [Google Scholar] [PubMed]
- Nagami, Y.; Tominaga, K.; Machida, H.; Nakatani, M.; Kameda, N.; Sugimori, S.; Okazaki, H.; Tanigawa, T.; Yamagami, H.; Kubo, N.; et al. Usefulness of non-magnifying narrow-band imaging in screening of early esophageal squamous cell carcinoma: A prospective comparative study using propensity score matching. Am. J. Gastroenterol. 2014, 109, 845–854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bang, C.S.; Lim, H.; Jeong, H.M.; Hwang, S.H. Use of Endoscopic Images in the Prediction of Submucosal Invasion of Gastric Neoplasms: Automated Deep Learning Model Development and Usability Study. J. Med. Internet Res. 2021, 23, e25167. [Google Scholar] [CrossRef] [PubMed]
- Cho, B.-J.; Bang, C.S.; Lee, J.J.; Seo, C.W.; Kim, J.H. Prediction of Submucosal Invasion for Gastric Neoplasms in Endoscopic Images Using Deep-Learning. J. Clin. Med. 2020, 9, 1858. [Google Scholar] [CrossRef] [PubMed]
- Cho, B.-J.; Bang, C.S.; Park, S.W.; Yang, Y.J.; Seo, S.I.; Lim, H.; Shin, W.G.; Hong, J.T.; Yoo, Y.T.; Hong, S.H.; et al. Automated classification of gastric neoplasms in endoscopic images using a convolutional neural network. Endoscopy 2019, 51, 1121–1129. [Google Scholar] [CrossRef] [PubMed]
- Kim, G.H. Diagnosis and Clinical Management of Esophageal Squamous Dysplasia. Korean J. Helicobacter Up. Gastrointest. Res. 2020, 21, 4–9. [Google Scholar] [CrossRef]
- Yang, Y.J.; Bang, C.S. Application of artificial intelligence in gastroenterology. World J. Gastroenterol. 2019, 25, 1666–1683. [Google Scholar] [CrossRef] [PubMed]
- Bang, C.S. Artificial Intelligence in the Analysis of Upper Gastrointestinal Disorders. Korean J. Helicobacter Up. Gastrointest. Res. 2021, 21, 300–310. [Google Scholar] [CrossRef]
- Bang, C.S. Deep Learning in Upper Gastrointestinal Disorders: Status and Future Perspectives. Korean J. Gastroenterol. 2020, 75, 120–131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khamparia, A.; Singh, K.M. A systematic review on deep learning architectures and applications. Expert Syst. 2019, 36, e12400. [Google Scholar] [CrossRef]
- Boyer, K.; Wies, J.; Turkelson, C.M. Effects of bias on the results of diagnostic studies of carpal tunnel syndrome. J. Hand Surg. Am. 2009, 34, 1006–1013. [Google Scholar] [CrossRef] [PubMed]
- Savant, D.; Zhang, Q.; Yang, Z. Squamous neoplasia in the esophagus. Arch. Pathol. Lab. Med. 2021, 145, 554–561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taylor, P.R.; Abnet, C.C.; Dawsey, S.M. Squamous dysplasia—The precursor lesion for esophageal squamous cell carcinoma. Cancer Epidemiol. Biomark. Prev. 2013, 22, 540–552. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.-L.; Xie, S.-H.; Wahlin, K.; Lagergren, J. Global time trends in the incidence of esophageal squamous cell carcinoma. Clin. Epidemiol. 2018, 10, 717–728. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, D.; Wang, L.; Jiang, J.; Liu, Y.; Ni, M.; Fu, Y.; Guo, H.; Wang, Z.; An, F.; Zhang, K.; et al. A Novel Deep Learning System for Diagnosing Early Esophageal Squamous Cell Carcinoma: A Multicenter Diagnostic Study. Clin. Transl. Gastroenterol. 2021, 12, e00393. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Dataset (Number of Images) | Internal-Test Dataset (Number of Images) | Total (Number of Images) | |
|---|---|---|---|
| Overall | 4387 | 775 | 5162 |
| Esophageal cancer | 746 | 132 | 878 (17.0%) |
| Dysplasia | 56 | 10 | 66 (1.3%) |
| Nonneoplasm | 3585 | 633 | 4218 (81.7%) |
| Number of Images (%) | Overall | External-Test Dataset 1 (Pusan National University Yangsan Hospital) | External-Test Dataset 2 (Inje University Ilsan Paik Hospital) | External-Test Dataset 3 (Hallym University Kangdong Sacred Heart Hospital) | External-Test Dataset 4 (Ulsan University Gangneung Asan Hospital) | External-Test Dataset 5 (Kosin University Hospital) |
|---|---|---|---|---|---|---|
| Overall | 836 | 119 | 126 | 78 | 363 | 150 |
| Esophageal cancer | 520 (62.2%) | 48 (40.3%) | 69 (54.8%) | 26 (33.3%) | 292 (80.4%) | 85 (56.7%) |
| Dysplasia | 42 (5.0%) | 8 (6.7%) | 3 (2.4%) | 3 (3.8%) | 17 (4.7%) | 11 (7.3%) |
| Nonneoplasm | 274 (32.8%) | 63 (52.9%) | 54 (42.9%) | 49 (62.8%) | 54 (14.9%) | 54 (36.0%) |
| (Values with 95% Confidence Interval) | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Internal-test performance (n = 775) | 95.6 (94.2–97.0) | 78.0 (75.1–80.9) | 93.9 (92.2–95.6) | 85.2 (82.7–87.7) |
| Overall external-test performance (n = 836) | 93.9 (92.3–95.5) | 77.7 (74.9–80.5) | 72.5 (69.5–75.5) | 75.0 (72.1–77.9) |
| External-test performance 1 (n = 119) | 95.8 (92.2–99.4) | 90.7 (85.5–95.9) | 82.6 (75.8–89.4) | 86.5 (80.4–92.6) |
| External-test performance 2 (n = 126) | 95.2 (91.5–98.9) | 64.0 (55.6–72.4) | 65.2 (56.9–73.5) | 64.6 (56.3–72.9) |
| External-test performance 3 (n = 78) | 94.9 (90.0–99.8) | 94.3 (89.2–99.4) | 65.4 (54.8–76.0) | 77.2 (67.9–86.5) |
| External-test performance 4 (n = 363) | 94.8 (92.5–97.1) | 78.6 (74.4–82.8) | 73.8 (69.3–78.3) | 76.1 (71.7–80.5) |
| External-test performance 5 (n = 150) | 90.0 (85.2–94.8) | 68.5 (61.1–75.9) | 67.7 (60.2–75.2) | 68.1 (60.6–75.6) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, E.J.; Bang, C.S.; Jung, K.; Kim, S.J.; Kim, J.W.; Seo, S.I.; Lee, U.; Maeng, Y.B.; Lee, Y.J.; Lee, J.I.; et al. Deep-Learning for the Diagnosis of Esophageal Cancers and Precursor Lesions in Endoscopic Images: A Model Establishment and Nationwide Multicenter Performance Verification Study. J. Pers. Med. 2022, 12, 1052. https://doi.org/10.3390/jpm12071052
Gong EJ, Bang CS, Jung K, Kim SJ, Kim JW, Seo SI, Lee U, Maeng YB, Lee YJ, Lee JI, et al. Deep-Learning for the Diagnosis of Esophageal Cancers and Precursor Lesions in Endoscopic Images: A Model Establishment and Nationwide Multicenter Performance Verification Study. Journal of Personalized Medicine. 2022; 12(7):1052. https://doi.org/10.3390/jpm12071052
Chicago/Turabian StyleGong, Eun Jeong, Chang Seok Bang, Kyoungwon Jung, Su Jin Kim, Jong Wook Kim, Seung In Seo, Uhmyung Lee, You Bin Maeng, Ye Ji Lee, Jae Ick Lee, and et al. 2022. "Deep-Learning for the Diagnosis of Esophageal Cancers and Precursor Lesions in Endoscopic Images: A Model Establishment and Nationwide Multicenter Performance Verification Study" Journal of Personalized Medicine 12, no. 7: 1052. https://doi.org/10.3390/jpm12071052
APA StyleGong, E. J., Bang, C. S., Jung, K., Kim, S. J., Kim, J. W., Seo, S. I., Lee, U., Maeng, Y. B., Lee, Y. J., Lee, J. I., Baik, G. H., & Lee, J. J. (2022). Deep-Learning for the Diagnosis of Esophageal Cancers and Precursor Lesions in Endoscopic Images: A Model Establishment and Nationwide Multicenter Performance Verification Study. Journal of Personalized Medicine, 12(7), 1052. https://doi.org/10.3390/jpm12071052