
Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk

 , , , and
, , , and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Definition of the System
2.1.1. Prior Considerations
2.1.2. Database Usage
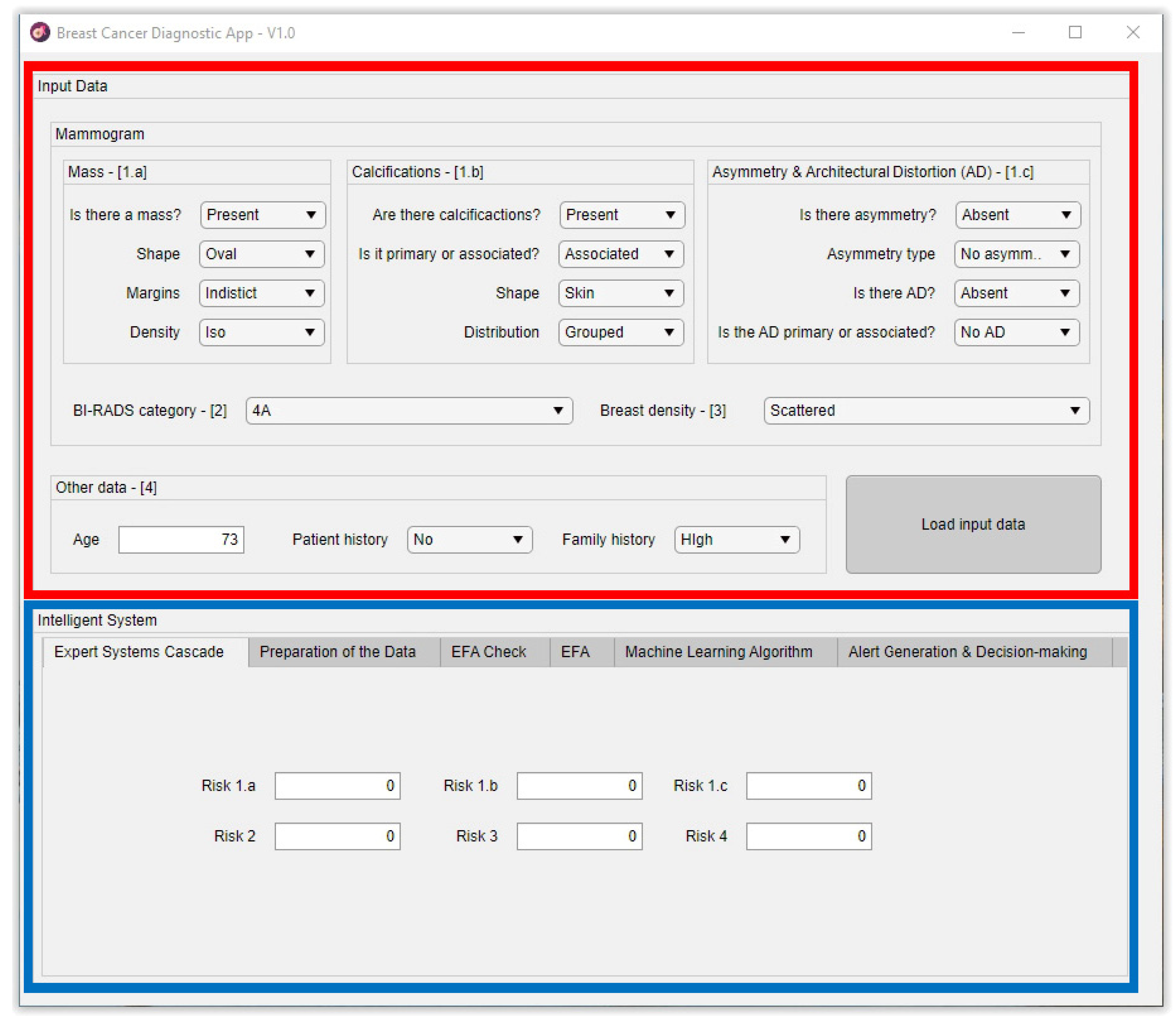
2.1.3. Conceptual Design and Description of the System
Stage 1: Compilation of Characteristics and Other Information of Interest, and Expert Interpretation
Stage 2: Data Processing and Interpretation
Stage 3: Generation of Alerts & Decision-Making
- Healthy patient → Schedule a routine revision.
- Dubious patient → Consider either to perform more tests or to schedule a new consultation after a specific time period.
- Cancer patient → Perform confirmatory diagnosis tests.
2.2. Implementation of the System
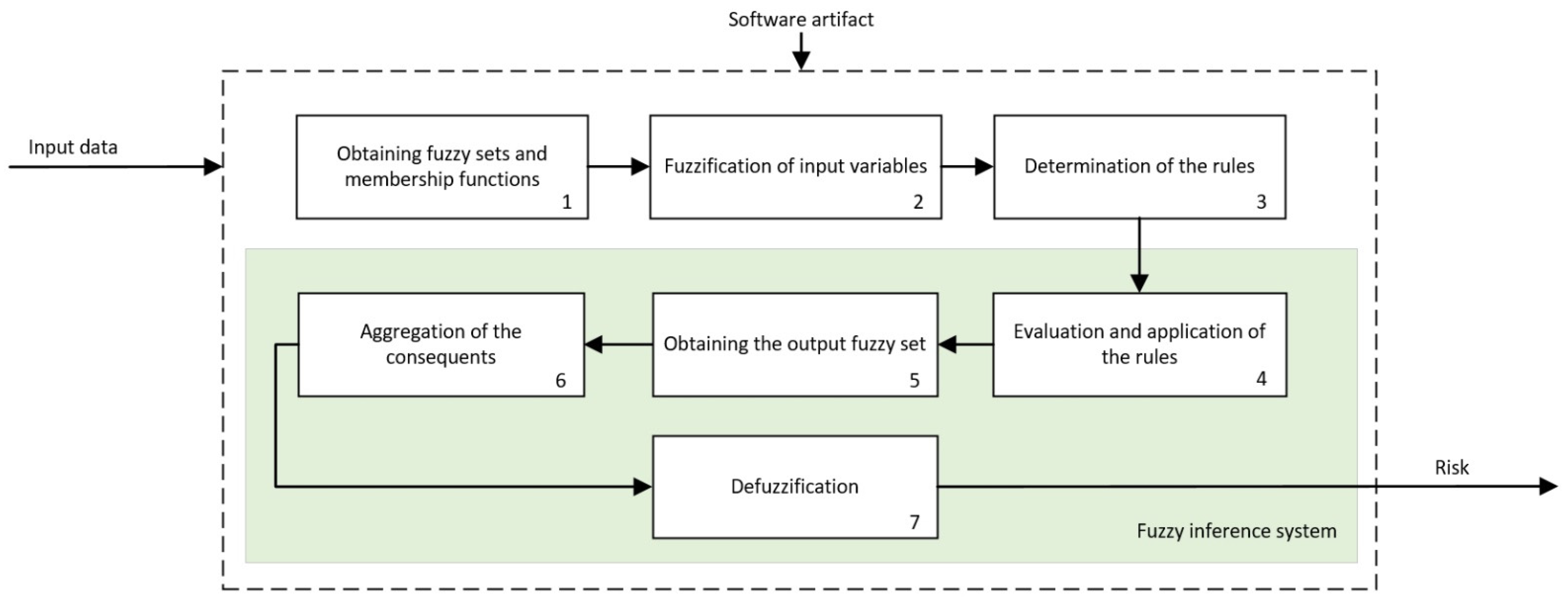
2.2.1. Cascaded Expert Systems
- Level 1: In the upper area of the cascade, in its first level, the processing of the information associated to masses, calcifications, asymmetries, and architectural distortions is carried out by means of three expert systems working concurrently [27,28,29,30,59,60], thus obtaining in each case, after the defuzzification process, an index value that expresses the risk level of cancer presence associated to each one of the groups of characteristics extracted from the mammogram.
- Level 2: In the second level of the cascade, the expert system carries out the processing of all the risk index values determined in the first level, those associated to the different mammogram characteristics, that is, to masses, calcifications, asymmetries, and architectural distortion. All of them are processed as inputs to the only expert system from this level, together with the BI-RADS© index established by the medical-healthcare experts. A cancer risk level associated to the BI-RADS© index and to the previously determined first-level risk indices is obtained after a defuzzification process, as an output of the second level expert system. It can be observed that even if the distribution is cascaded, the fact of incorporating the expert systems’ outputs as inputs of the following ones allows progressively grouping all the effects together.
- Level 3: The processing of the second-level risk, together with the information associated to the breast composition is carried out in the third level by the expert system. After performing the defuzzification, a cancer risk value is obtained that is associated to the composition itself of the breast and to the second-level risk, which was in turn associated to a BI-RADS© category and to the first-level risk indices.
- Level 4: In this last level of the cascade, the processing by the expert system is performed of the risk obtained in the third level together with the information related to the patient’s history. As happened in the previous cases, the risk obtained in this fourth level is associated to the patient’s history and to the risk obtained in the third level, which was in turn associated to the breast composition and to the second level risk, and this in turn was associated to the BI-RADS© index and to the first-level risks.
Calculation
2.2.2. Data Preparation: Normalization and Balancing
2.2.3. Determination of Latent Factors
- For Factor 1, the risks having a larger influence are R2, R3, and R4, that is, the risks obtained in levels 2, 3, and 4 of the expert systems cascade. As a result of this, Factor 1 may be understood as that factor representing the BI-RADS© index, representing the breast density and the patient’s history.
- For Factor 2, the risks presenting a larger influence are R1a and R1b, two out of the three risks concurrently calculated by the expert systems in the first cascade levels. Thus, Factor 2 may be understood as that factor representing the masses and calcifications.
- For Factor 3, without any question, the predominant risk is R1c, which is one of the three risks calculated in the first system of the cascade. Therefore, Factor 3 may be understood as that factor associated to the asymmetries and the breast architectural distortion.
2.2.4. The Machine Learning Algorithm
2.2.5. Generation of Alerts and Decision Making
- Status 1 is associated to a healthy patient, recommending the medical/healthcare professionals to propose a routine revision. This status will be recommended when the Hazard index value is in the [0-Limit_1) range.
- Status 2 is associated to a dubious or indeterminate patient status. A revision will be proposed to be held after a specific time period to re-evaluate the patient status and to make new decisions. This status will be recommended when the Hazard index value is in the [Limit_1-Limit_2] range.
- Status 3 is associated to a patient with a noticeable trend to suffer of cancer, recommending the performance of more tests to confirm the diagnosis. This status is recommended when the Hazard index value is in the (Limit_2-100] range.
3. Results
3.1. Compilation of Characteristics and Other Information of Interest, and Expert Interpretation
3.2. Data Processing and Interpretation
3.3. Generation of Alerts and Decision Making
3.4. Interpretation of the Results
Expansion and Confirmation of the Results
4. Discussion
- Expert Systems: Expert systems are the paradigm of deductive symbolic reasoning applied to the artificial engineering field. In this work, their diversification and formalization fundamentals are implemented by means of cascaded information management. These systems diversify information, as they not only allow compartmentalizing it while keeping a common goal but also incorporate the definition of the declarative rules that model knowledge at each risk assessment stage. The generation of these rules on which the reasoning is made must be always supported on logical structures representing compiled and evaluated facts in similar circumstances and making use of a knowledge that is similar as well. There is an inherent dependence between who creates the rules and the way of reasoning of an expert system, and that implies assuming the presence of doubt or error in the process. Thus, the generation of such rules always involves accepting some level of uncertainty, because of which an interpretation of the membership function associated to the formalization of information was considered. Precisely, as the formalization is an inherent feature of expert systems, it is achieved by sharing the consequents of the four cascade levels. All of them represent the risk of suffering of cancer, modeled as a technical variable, and in turn, they incorporate that same variable in the inputs of the consequent expert system but already represented as a qualitative variable. This distinction lies in the own groundings of the deductive reasoning that, by means of the fuzzy logic-based inference engines, feeds and provides logics to each expert system. As it was already mentioned in Section 2.2.1, the consideration of antecedent or consequent of the same premise or variable in a declarative rule must affect its fuzzy nature, which is inevitably associated to the indetermination of its quantitative representation. This is the way in which the expert systems cascade manages uncertainty (considered in this work as both a metric of the measurement uncertainty and the indetermination of knowledge) by means of a system where, in a formal way, the descriptors representing the input and output variables are subject to first-order logical considerations, while delimiting the scope of the represented knowledge and expertise themselves. The control of uncertainty is carried out by reducing the complexity of the logical construct representing the knowledge, but in turn accumulating it once such variability has been progressively reduced in the earlier cascade steps. According to the literature review carried out by the authors, nowadays, no cascaded expert systems model can be found in it, and thus, this work involves a differential and novel contribution.
- Exploratory factorial analysis: It might be convenient not to mix exploratory analysis with statistical inference models. The former, according to the initial approaches by Tukey [69,70], extends the variance and typical deviation-based analysis by including a deeper analysis on the variables’ correlations with respect to the subjacent non-measurable that group the variables themselves together. In this work, the exploratory analysis is used to reduce the dimensionality of the labeled risks set obtained after applying the expert systems cascade as well as finding hidden and significant relationships among variables. When the risks are obtained, both within an experimental measurement approach and within an observational approach, the exploratory analysis is able to correlate the risks and to group them together into latent factors, which in turn they explain. The knowledge model is probabilistic in this case, and the information is grouped according to the covariance matrices and the rotations orthogonality assumptions. However, the exploratory analysis shows a changing dependence on the conditions of the starting data, which is why Common Factor Analysis was applied in this work. Nevertheless, that involves accepting a series of restrictions to be fulfilled by data, as described in Section 2.2.3. The acceptance of that limitation must be justified in the results and in a representation symbolic model that, even being ambiguous, is represented by the variables’ commonalities themselves. The covariance with respect to a factor not only represents an explicative dependence of the factor’s conceptual significance, but it implicitly represents a consequent explanation of the other factors, which is emphasized after the rotation. This means that the risks are grouped together according to latent factors, difficult to categorize but representing an inductive reasoning that is similar to the one that a medical-healthcare professional would develop in a consultation. Before the absence of accuracy, the multi-criteria decisions are supported by discussable quantifications on the degree of fulfillment of those decision criteria. By using EFA, the criteria are the factors, while the degree of fulfillment is set by the covariance of its explanatory variables. The uncertainty appears here delimited in probabilistic explanatory terms for the EFA application assumptions. That is, if EFA is comparable to a multi-criteria analysis, then guaranteeing its statistical significance means also tacitly guaranteeing a certain metric for accuracy in its recommendation. Therefore, EFA, fed with values where the qualitative risk has been already delimited, provides a numeric control on the imperfection of information. Thus, the justification of EFA’s fulfillment will be a necessary condition.
- Data normalization and augmentation: Together with EFA, the data normalization and augmentation have a single objective in this work: to guarantee the applicability and relevance of the search for factors. Even being a clearly artificial approach in the application of the decision system, its justification is based on its conceptual representation. To practical effects, over-sampling generates an artificial dataset by using a metric approach as a generator. Even though this may mask, and even bias, the data, that is not always the case for medical datasets focused on the use of factorial analysis. In a medical consultation, in any diagnosis process, it is reasonable to think that the dataset will be inclined, as the number of collected data increases, toward the presence of distributions that are normal and show a trend for a low collinearity. Similarly, in all random and non-biased data collection, the data will be uniformly distributed around its mean point, reaching typical deviation values nearing 1 and means nearing 0. In fact, that is why hierarchization modes such as the Ordered Weighted Average [71] are based on normal models for their classifications. As a result of all that, Safe-Level SMOTE does not unreasonably alter the data, but it generates a dataset fulfilling the EFA precepts and, in the case of having available a large dataset, it even would not be necessary.
- Statistical inference systems: The last of the approaches that has been incorporated into the system that is proposed in this article is related to statistical inference, that is, with reaching plausible conclusions from the obtained data that characterize a specific problem. On a broader scope, the statistical inference is used in Machine Learning by means of different families of regression and classification algorithms that allow, after a supervised training process that involves labeling data into specific classes, to obtain a prediction that is based in that training and its validation. In this work, the determination of the classification algorithm is not especially relevant, as it may be in general claimed that any approach used (decision trees, Naïve Bayes, support vector machines, etc.) could achieve relevant results. The reason for that lies in the data that feed, train, and validate the algorithm. Beyond its non-parametrical design, these algorithms possess trustworthy capabilities for finding relationships in datasets that are asymmetric or that have distributions that are far from normality. However, this versatility does not exclude that balanced and normally distributed datasets could not reach significant results such as those shown in this work. In any case, and in the same way that happened when creating the knowledge base declarative rules, the datasets used for training, validation, and forecasting must meet the premise of being obtained in similar circumstances and fulfilling equal diagnosis criteria so that their relevance in this clinical process is analogue. The training must be performed using data having a meaning and a significance identical to that from the data using in the forecasting, as the algorithm objective would become distorted otherwise. Additionally, same as for the EFA, the processing of uncertainty is carried out both from the epistemological and from the random approaches, considering ambiguity and interaction [48] with a probabilistic approach to it. The excellent results shown in the ROC curves support, precisely, that chain of events that has been previously described.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global Cancer Statistics 2018: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef]
- DeSantis, C.E.; Ma, J.; Gaudet, M.M.; Newman, L.A.; Miller, K.D.; Goding Sauer, A.; Jemal, A.; Siegel, R.L. Breast Cancer Statistics, 2019. CA Cancer J. Clin. 2019, 69, 438–451. [Google Scholar] [CrossRef]
- Tabár, L.; Vitak, B.; Hsiu-Hsi Chen, T.; Ming-Fang Yen, A.; Cohen, A.; Tot, T.; Yueh-Hsia Chiu, S.; Li-Sheng Chen, S.; Ching-Yuan Fann, J.; Rosell, J.; et al. Swedish Two-County Trial: Impact of Mammographic Screening on Breast Cancer Mortality during 3 Decades. Radiology 2011, 260, 658–663. [Google Scholar] [CrossRef]
- Marmot, M.G.; Altman, D.G.; Cameron, D.A.; Dewar, J.A.; Thompson, S.G.; Wilcox, M. The Benefits and Harms of Breast Cancer Screening: An Independent Review. Br. J. Cancer 2013, 108, 2205–2240. [Google Scholar] [CrossRef]
- Canadian Task Force on Preventive Health Care. Recommendations on Screening for Breast Cancer in Average-Risk Women Aged 40–74 Years. CMAJ 2011, 183, 1991–2001. [Google Scholar] [CrossRef]
- Advisory Committee on Breast Cancer Screening. Screening for Breast Cancer in England: Past and Future. J. Med. Screen. 2006, 13, 59–61. [Google Scholar] [CrossRef]
- Duffy, S.W.; Tabar, L.; Olsen, A.H.; Vitak, B.; Allgood, P.C.; Chen, T.H.; Yen, A.M.; Smith, R.A. Cancer Mortality in the 50–69 Year Age Group before and after Screening. J. Med. Screen. 2010, 17, 159–160. [Google Scholar] [CrossRef]
- Jensena, A.R.; Ewertz, M.; Cold, S.; Storm, H.H.; Overgaard, J. Time Trends and Regional Differences in Registration, Stage Distribution, Surgical Management and Survival of Breast Cancer in Denmark. Eur. J. Cancer 2003, 39, 1783–1793. [Google Scholar] [CrossRef]
- Duffy, S.W.; Tabár, L.; Chen, T.H.H.; Smith, R.A.; Holmberg, L.; Jonsson, H.; Lenner, P.; Nyström, L.; Törnberg, S.; Frisell, J.; et al. Effect of Mammographic Service Screening on Stage at Presentation of Breast Cancers in Sweden. Cancer 2007, 109, 2205–2212. [Google Scholar] [CrossRef]
- Løberg, M.; Lousdal, M.L.; Bretthauer, M.; Kalager, M. Benefits and Harms of Mammography Screening. Breast Cancer Res. 2015, 17, 63. [Google Scholar] [CrossRef]
- Elmore, J.G.; Jackson, S.L.; Abraham, L.; Miglioretti, D.L.; Carney, P.A.; Geller, B.M.; Yankaskas, B.C.; Kerlikowske, K.; Onega, T.; Rosenberg, R.D.; et al. Variability in Interpretive Performance at Screening Mammography and Radiologists’ Characteristics Associated with Accuracy. Radiology 2009, 253, 641–651. [Google Scholar] [CrossRef] [PubMed]
- Elmore, J.G.; Wells, C.K.; Lee, C.H.; Howard, D.H.; Feinstein, A.R. Variability in Radiologists’ Interpretations of Mammograms. N. Engl. J. Med. 1994, 331, 1493–1499. [Google Scholar] [CrossRef] [PubMed]
- Beam, C.A. Variability in the Interpretation of Screening Mammograms by US Radiologists. Arch. Intern. Med. 1996, 156, 209. [Google Scholar] [CrossRef] [PubMed]
- Brewer, N.T.; Salz, T.; Lillie, S.E. Systematic Review: The Long-Term Effects of False-Positive Mammograms. Ann. Intern. Med. 2007, 146, 502–510. [Google Scholar] [CrossRef]
- Bond, M.; Pavey, T.; Welch, K.; Cooper, C.; Garside, R.; Dean, S.; Hyde, C.J. Psychological Consequences of False-Positive Screening Mammograms in the UK. Evid.-Based Med. 2013, 18, 54–61. [Google Scholar] [CrossRef]
- Nelson, H.D.; Pappas, M.; Cantor, A.; Griffin, J.; Daeges, M.; Humphrey, L. Harms of Breast Cancer Screening: Systematic Review to Update the 2009 U.S. Preventive Services Task Force Recommendation. Ann. Intern. Med. 2016, 164, 256–267. [Google Scholar] [CrossRef]
- Zagouri, F.; Sergentanis, T.N.; Gounaris, A.; Koulocheri, D.; Nonni, A.; Domeyer, P.; Fotiadis, C.; Bramis, J.; Zografos, G.C. Pain in Different Methods of Breast Biopsy: Emphasis on Vacuum-Assisted Breast Biopsy. Breast 2008, 17, 71–75. [Google Scholar] [CrossRef]
- Sickles, E.A.; D’Orsi, C.J.; Bassett, L.W.; Appleton, C.M.; Berg, W.A.; Burnside, E.S.; Feig, S.A.; Gavenonis, S.C.; Newell, M.S.; Trinh, M.M. BI-RADS Del ACR: Mamografía. In Atlas BI-RADS del ACR, Sistema Normalizado Para la Redacción de Informes de Estudios por Imágenes de la Mama; Colegio Estadounidense de Radiología: Reston, VA, USA, 2013. [Google Scholar]
- Anooj, P.K. Clinical Decision Support System: Risk Level Prediction of Heart Disease Using Weighted Fuzzy Rules. J. King Saud Univ.-Comput. Inf. Sci. 2012, 24, 27–40. [Google Scholar] [CrossRef]
- Montgomery, A.A.; Fahey, T.; Peters, T.J.; MacIntosh, C.; Sharp, D.J. Evaluation of Computer Based Clinical Decision Support System and Risk Chart for Management of Hypertension in Primary Care: Randomised Controlled Trial. Br. Med. J. 2000, 320, 686–690. [Google Scholar] [CrossRef]
- Durieux, P.; Nizard, R.; Ravaud, P.; Mounier, N.; Lepage, E. Clinical Decision Support System for Prevention of Venous Thromboembolism: Effect on Physician Behavior. J. Am. Med. Assoc. 2000, 283, 2816–2821. [Google Scholar] [CrossRef]
- Courbis, A.L.; Murray, R.B.; Arnavielhe, S.; Caimmi, D.; Bedbrook, A.; Van Eerd, M.; De Vries, G.; Dray, G.; Agache, I.; Morais-Almeida, M.; et al. Electronic Clinical Decision Support System for Allergic Rhinitis Management: MASK e-CDSS. Clin. Exp. Allergy 2018, 48, 1640–1653. [Google Scholar] [CrossRef] [PubMed]
- Hermsen, E.D.; Vanschooneveld, T.C.; Sayles, H.; Rupp, M.E. Implementation of a Clinical Decision Support System for Antimicrobial Stewardship. Infect. Control. Hosp. Epidemiol. 2012, 33, 412–415. [Google Scholar] [CrossRef]
- Nazari, S.; Fallah, M.; Kazemipoor, H.; Salehipour, A. A Fuzzy Inference- Fuzzy Analytic Hierarchy Process-Based Clinical Decision Support System for Diagnosis of Heart Diseases. Expert Syst. Appl. 2018, 95, 261–271. [Google Scholar] [CrossRef]
- Uzoka, F.M.E.; Osuji, J.; Obot, O. Clinical Decision Support System (DSS) in the Diagnosis of Malaria: A Case Comparison of Two Soft Computing Methodologies. Expert Syst. Appl. 2011, 38, 1537–1553. [Google Scholar] [CrossRef]
- DeJesus, R.S.; Angstman, K.B.; Kesman, R.; Stroebel, R.J.; Bernard, M.E.; Scheitel, S.M.; Hunt, V.L.; Rahman, A.S.; Chaudhry, R. Use of a Clinical Decision Support System to Increase Osteoporosis Screening. J. Eval. Clin. Pract. 2012, 18, 89–92. [Google Scholar] [CrossRef]
- Casal-Guisande, M.; Comesaña-Campos, A.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B. Design and Development of a Methodology Based on Expert Systems, Applied to the Treatment of Pressure Ulcers. Diagnostics 2020, 10, 614. [Google Scholar] [CrossRef]
- Comesaña-Campos, A.; Casal-Guisande, M.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.B. A Methodology Based on Expert Systems for the Early Detection and Prevention of Hypoxemic Clinical Cases. Int. J. Environ. Res. Public Health 2020, 17, 644. [Google Scholar] [CrossRef]
- Casal-Guisande, M.; Cerqueiro-Pequeño, J.; Comesaña-Campos, A.; Bouza-Rodríguez, J.B. Proposal of a Methodology Based on Expert Systems for the Treatment of Diabetic Foot Condition. In Proceedings of the Eighth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 21–23 October 2020; pp. 491–495. [Google Scholar] [CrossRef]
- Casal-Guisande, M.; Bouza-Rodríguez, J.B.; Comesaña-Campos, A.; Cerqueiro-Pequeño, J. Proposal and Definition of a Methodology for Remote Detection and Prevention of Hypoxemic Clinical Cases in Patients Susceptible to Respiratory Diseases. In Proceedings of the Seventh International Conference on Technological Ecosystems for Enhancing Multiculturality, León, Spain, 16–18 October 2019; pp. 331–338. [Google Scholar] [CrossRef]
- Berkan Sesen, M.; Nicholson, A.E.; Banares-Alcantara, R.; Kadir, T.; Brady, M. Bayesian Networks for Clinical Decision Support in Lung Cancer Care. PLoS ONE 2013, 8, e82349. [Google Scholar] [CrossRef]
- Wagholikar, K.B.; MacLaughlin, K.L.; Henry, M.R.; Greenes, R.A.; Hankey, R.A.; Liu, H.; Chaudhry, R.C. Clinical Decision Support with Automated Text Processing for Cervical Cancer Screening. J. Am. Med. Inform. Assoc. 2012, 19, 833–839. [Google Scholar] [CrossRef]
- Skevofilakas, M.T.; Nikita, K.S.; Templaleksis, P.H.; Birbas, K.N.; Kaklamanos, I.G.; Bonatsos, G.N. A Decision Support System for Breast Cancer Treatment Based on Data Mining Technologies and Clinical Practice Guidelines. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology—Proceedings, Shanghai, China, 1–4 September 2005; Institute of Electrical and Electronics Engineers Inc.: Shanghai, China, 2005; Volume 7 VOLS, pp. 2429–2432. [Google Scholar]
- Alaa, A.M.; Moon, K.H.; Hsu, W.; Van Der Schaar, M. ConfidentCare: A Clinical Decision Support System for Personalized Breast Cancer Screening. IEEE Trans. Multimed. 2016, 18, 1942–1955. [Google Scholar] [CrossRef]
- Jiang, X.; Wells, A.; Brufsky, A.; Neapolitan, R. A Clinical Decision Support System Learned from Data to Personalize Treatment Recommendations towards Preventing Breast Cancer Metastasis. PLoS ONE 2019, 14, e0213292. [Google Scholar] [CrossRef] [PubMed]
- Sesen, M.B.; Peake, M.D.; Banares-Alcantara, R.; Tse, D.; Kadir, T.; Stanley, R.; Gleeson, F.; Brady, M. Lung Cancer Assistant: A Hybrid Clinical Decision Support Application for Lung Cancer Care. J. R. Soc. Interface 2014, 11, 20140534. [Google Scholar] [CrossRef] [PubMed]
- Cooley, M.E.; Blonquist, T.M.; Catalano, P.J.; Lobach, D.F.; Halpenny, B.; McCorkle, R.; Johns, E.B.; Braun, I.M.; Rabin, M.S.; Mataoui, F.Z.; et al. Feasibility of Using Algorithm-Based Clinical Decision Support for Symptom Assessment and Management in Lung Cancer. J. Pain Symptom Manag. 2015, 49, 13–26. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, E.; Toro, C.; Artetxe, A.; Graña, M.; Sanin, C.; Szczerbicki, E.; Carrasco, E.; Guijarro, F. Bridging Challenges of Clinical Decision Support Systems with a Semantic Approach. A Case Study on Breast Cancer. Pattern Recognit. Lett. 2013, 34, 1758–1768. [Google Scholar] [CrossRef]
- Abou, A.; Ebrahim, S.; Awad, A. A Fuzzy Decision Support System for Management of Breast Cancer. Int. J. Adv. Comput. Sci. Appl. 2011, 2. [Google Scholar] [CrossRef]
- Fernandes, A.S.; Alves, P.; Jarman, I.H.; Etchells, T.A.; Fonseca, J.M.; Lisboa, P.J.G. A Clinical Decision Support System for Breast Cancer Patients. IFIP Adv. Inf. Commun. Technol. 2010, 314, 122–129. [Google Scholar] [CrossRef]
- Ferreira, P.; Dutra, I.; Salvini, R.; Burnside, E. Interpretable Models to Predict Breast Cancer. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2016, Shenzhen, China, 15–18 December 2016; Institute of Electrical and Electronics Engineers Inc.: Shenzhen, China, 2016; pp. 1507–1511. [Google Scholar]
- Côrte-Real, J.; Dutra, I.; Rocha, R. On Applying Probabilistic Logic Programming to Breast Cancer Data. In Inductive Logic Programming: Proceedings of the 27th International Conference, ILP 2017, Orléans, France, 2–4 September 2017; Lachiche, N., Vrain, C., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 31–45. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Duxbury Thomson Learning: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Cox, D.R. Principles of Statistical Inference; Cambridge University Press: New York, NY, USA, 2006; ISBN 9780511813559. [Google Scholar]
- Hevner, A.R.; Chatterjee, S. Design Research in Information Systems: Theory and Practice; Springer: New York, NY, USA, 2010; ISBN 978-1-4419-6107-5. [Google Scholar]
- Hevner, A.R.; March, S.T.; Park, J.; Ram, S. Design Science in Information Systems Research. MIS Q. Manag. Inf. Syst. 2004, 28, 75–105. [Google Scholar] [CrossRef]
- Breast Imaging Reporting & Data System|American College of Radiology. Available online: https://www.acr.org/Clinical-Resources/Reporting-and-Data-Systems/Bi-Rads (accessed on 28 May 2021).
- Thunnissen, D.P. Propagating and Mitigating Uncertainty in the Design of Complex Multidisciplinary Systems; California Institute of Technology: Pasadena, CA, USA, 2005. [Google Scholar]
- Mamdani, E.H.; Assilian, S. An Experiment in Linguistic Synthesis with a Fuzzy Logic Controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Mamdani, E.H. Advances in the Linguistic Synthesis of Fuzzy Controllers. Int. J. Man-Mach. Stud. 1976, 8, 669–678. [Google Scholar] [CrossRef]
- Mamdani, E.H. Application of Fuzzy Logic to Approximate Reasoning Using Linguistic Synthesis. IEEE Trans. Comput. 1977, C-26, 1182–1191. [Google Scholar] [CrossRef]
- Ross, T.J. Fuzzy Logic with Engineering Applications: Third Edition, 3rd ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2010; ISBN 9781119994374. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-Level-SMOTE: Safe-Level-Synthetic Minority over-Sampling Technique for Handling the Class Imbalanced Problem. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2009; Volume 5476 LNAI, pp. 475–482. [Google Scholar]
- Mohammed, A.J.; Hassan, M.M.; Kadir, D.H. Improving Classification Performance for a Novel Imbalanced Medical Dataset Using Smote Method. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 3161–3172. [Google Scholar] [CrossRef]
- Fuzzy Logic Toolbox—MATLAB. Available online: https://www.mathworks.com/products/fuzzy-logic.html (accessed on 29 May 2020).
- Oversampling Imbalanced Data: SMOTE Related Algorithms—File Exchange—MATLAB Central. Available online: https://www.mathworks.com/matlabcentral/fileexchange/75168-oversampling-imbalanced-data-smote-related-algorithms (accessed on 14 June 2021).
- FA—File Exchange—MATLAB Central. Available online: https://www.mathworks.com/matlabcentral/fileexchange/14115-fa (accessed on 14 June 2021).
- Comesaña-Campos, A.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J. The Value Index as a Decision Support Tool Applied to a New System for Evaluating and Selecting Design Alternatives. Expert Syst. Appl. 2018, 113, 278–300. [Google Scholar] [CrossRef]
- Cerqueiro-Pequeño, J.; Comesaña-Campos, A.; Casal-Guisande, M.; Bouza-Rodríguez, J.-B. Design and Development of a New Methodology Based on Expert Systems Applied to the Prevention of Indoor Radon Gas Exposition Risks. Int. J. Environ. Res. Public Health 2020, 18, 269. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Longadge, R.; Dongre, S. Class Imbalance Problem in Data Mining Review. arXiv Prepr. 2013, arXiv:1305.1707. [Google Scholar]
- Widaman, K.F. Common Factor Analysis Versus Principal Component Analysis: Differential Bias in Representing Model Parameters? Multivar. Behav. Res. 1993, 28, 263–311. [Google Scholar] [CrossRef]
- Yang, B. Factor Analysis Methods. In Research in Organization: Foundations and Methods of Inquiry; Swanson, R.A., Elwood Holton, F., Eds.; Berrett-Koehler Publishers, Inc.: San Francisco, CA, USA, 2005. [Google Scholar]
- Hair, J.F.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis, 7th ed; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2010; ISBN 9780138132637. [Google Scholar]
- Gorsuch, R.L. Factor Analysis, 2nd ed.; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1983. [Google Scholar]
- Gorsuch, R.L. Exploratory Factor Analysis: Its Role in Item Analysis. J. Personal. Assess. 2010, 68, 532–560. [Google Scholar] [CrossRef]
- Classification Learner App—MATLAB. Available online: https://www.mathworks.com/help/stats/classificationlearner-app.html (accessed on 18 June 2021).
- Hoaglin, D.C.; Mosteller, F.; Tukey, J.W. Fundamentals of Exploratory Analysis of Variance; John Wiley & Sons, Inc: Cambridge, MA, USA, 1991; ISBN 978-0-471-52735-0. [Google Scholar]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Yager, R.R. On Ordered Weighted Averaging Aggregation Operators in Multicriteria Decision-making. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of cases | 130 |
| Cancer cases | 21 |
| No cancer cases | 109 |
| Average age | 55.2 |
| Number of significative criteria used | 17 |
| Nature of data | Qualitative |
| Data | Comment |
|---|---|
| Age | - |
| Personal history | It aims to show if the person had/had not previously any cancer type or any cancer-related issue. |
| Family history | It assesses whether any breast cancer cases existed in the family’s first- or second-degree members. |
| Data | Comment |
|---|---|
| Masses | In the case any mass is present, then its shape, margins, and density are documented. |
| Calcifications | In a similar way to masses, in the case of calcifications, their morphology is documented (these are usually grouped into ‘typically benign’ and ‘suspicious morphology’ categories), and their distribution is characterized. It is also indicated whether the calcifications are either primary or associated, that is, if this is a predominant characteristic or, on the contrary, it is associated to other characteristic, thus having a minor entity. |
| Architectural distortion and asymmetries | In the case of distortion, it is indicated if the characteristic is present and if it is primary or associated. On the other hand, in the case of asymmetries, it is indicated if any is present, and then its type (focal, in development, etc.). |
| BI-RADS© indicator | The BI-RADS© (Breast Imaging Reporting and Data System) system is nowadays a widely accepted and used diagnosis instrument in the evaluation of breast cancer. It was developed by the American College of Radiology (ACR) [47] with the goal of homogenizing the assessments by providing a standard operation framework for the study of mammogram images through the use of a common vocabulary and a structuration of the evaluation process. Such system is explained in more detail in Section S2.3 of the Supplementary Materials. |
| Composition | The breast type, i.e., the tissue type, will also be taken into account. As commented in Section S2.3.1 of the Supplementary Materials, as the breast density increases, it is much more complicated to perform its evaluation, potentially hiding mammogram findings, which implies that the diagnosis might be erroneous. |
| Weighted KNN Model |
| Distance: Euclidean distance |
| Number of nearest neighbors in X used to classify each point: 10 |
| Distance weight: Squared inverse |
| Bagged Trees Model |
| Ensemble aggregation method: Bag |
| Number of ensemble learning cycles: 30 |
| Learners: Decision tree |
| Maximum number of splits: 218 |
| Mass | |
| Present/Absent | Absent |
| Shape | (None) |
| Margins | (None) |
| Density | (None) |
| Calcifications | |
| Present/Absent | Present |
| Primary/Associated | Associated |
| Shape | Coarse heterogeneous |
| Distribution | Segmental |
| Asymmetry | |
| Present/Absent | Present |
| Type | Focal |
| Architectural Distortion | |
| Present/Absent | Absent |
| Primary/Associated | (None) |
| BI-RADS category | 4A |
| Breast density | Scattered |
| Other data | |
| Age | 53 |
| Patient history | No |
| Family history | Minor |
| Mass | Calcifications | Asymmetry | Architectural Distortion | BI-RADS Category | Breast Density | Other Data | Hazard Index | System Advice | Real Chart | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Shape | Margin | Density | Type | Shape | Distribution | Age | Patient History | Family History | ||||||||
| 1 | - | - | - | Associated | Coarse heterogeneous | Segmental | Focal | . | 4A | Scattered | 53 | No | Minor | 66.67 | Cancer | Cancer |
| 2 | Oval | Circumscribed | High | - | - | - | - | - | 4B | Heterogeneously | 50 | N/A | N/A | 63.33 | Uncertain | No cancer |
| 3 | Irregular | Indistinct | High | - | - | - | - | - | 4B | Heterogeneously | 42 | No | None | 56.67 | No cancer | No cancer |
| 4 | Irregular | Spiculated | Equal | Associated | Coarse heterogeneous | Grouped | - | - | 4B | Scattered | 65 | No | None | 53.33 | No cancer | No cancer |
| 5 | - | - | - | Associated | Amorphous | Grouped | Focal | - | 4B | Heterogeneously | 31 | No | None | 56.67 | No cancer | No cancer |
| 6 | - | - | - | Primary | Amorphous | Grouped | - | - | 4B | Heterogeneously | 49 | Yes | N/A | 53.33 | No cancer | No cancer |
| 7 | - | - | - | - | - | - | - | Primary | 4C | Scattered | 62 | Yes | Major | 60 | Uncertain | No cancer |
| 8 | - | - | - | - | - | - | - | Primary | 4B | Scattered | 58 | No | None | 56.67 | No cancer | No cancer |
| 9 | - | - | - | - | - | - | Developing | - | 4B | Scattered | 64 | No | None | 50 | No cancer | No cancer |
| 10 | - | - | - | Primary | Fine pleomomophic | Grouped | - | - | 4B | Scattered | 58 | No | Major | 30 | No cancer | No cancer |
| 11 | Irregular | Indistinct | High | - | - | - | - | - | 4B | Heterogeneously | 53 | No | Major | 87.22 | Cancer | Cancer |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casal-Guisande, M.; Comesaña-Campos, A.; Dutra, I.; Cerqueiro-Pequeño, J.; Bouza-Rodríguez, J.-B. Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk. J. Pers. Med. 2022, 12, 169. https://doi.org/10.3390/jpm12020169
Casal-Guisande M, Comesaña-Campos A, Dutra I, Cerqueiro-Pequeño J, Bouza-Rodríguez J-B. Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk. Journal of Personalized Medicine. 2022; 12(2):169. https://doi.org/10.3390/jpm12020169
Chicago/Turabian StyleCasal-Guisande, Manuel, Alberto Comesaña-Campos, Inês Dutra, Jorge Cerqueiro-Pequeño, and José-Benito Bouza-Rodríguez. 2022. "Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk" Journal of Personalized Medicine 12, no. 2: 169. https://doi.org/10.3390/jpm12020169
APA StyleCasal-Guisande, M., Comesaña-Campos, A., Dutra, I., Cerqueiro-Pequeño, J., & Bouza-Rodríguez, J.-B. (2022). Design and Development of an Intelligent Clinical Decision Support System Applied to the Evaluation of Breast Cancer Risk. Journal of Personalized Medicine, 12(2), 169. https://doi.org/10.3390/jpm12020169