1. Introduction
Meningioma is recognized as one of the most common intracranial neoplasms, accounting for 30% of primary intracranial lesions, with an annual incidence of 5/100,000 [
1,
2]. Based on their biological behaviors, the lesions can be categorized as either low-grade lesions (grade I meningioma), which are correlated with better survival prognosis, or high-grade lesions (grade II and grade III meningiomas), which are correlated with aggressive behaviors along with increased recurrence risk following treatment [
2,
3,
4]. When intervention is required, surgery is usually the optimal choice, considering that the majority of patients can be cured with surgery alone, especially for grade I tumor patients with favorable locations. Radiotherapy approaches are also recommended, especially for high-grade meningiomas, to increase local control when surgery alone seems insufficient [
5,
6]. The high spatial resolution and excellent soft-tissue resolution of MRIs provide the necessary information for clinicians to facilitate treatment decisions [
5]. The image patterns of tumors on MRIs are usually described as solitary round tissues that are in close contact with the dura mater, with apparent/homogeneous enhancement after gadolinium injection. The thickening of the dura mater around the tumor, known as the dural tail, is also present in contrast-enhanced T1 images with contrast injection [
7]. Empirically, aggressive meningiomas usually present with heterogeneous patterns accompanied by irregular shapes and larger volumes, when compared with benign meningiomas [
8]. However, the consensual radiological criteria that can be applied to distinguish meningiomas of different grades accurately are not yet clear [
5].
The patient diagnostic assessment usually focuses on two points: tumor progression, which indicates that an automated evaluation of tumors should improve image reading, and grading prediction, which is significantly relevant to treatment strategy and patient prognosis. In the current study, we established an operable MRI-based system for meningioma assessment using deep-learning technology. The system comprises an automatic detection module, a 3D-rendering module, and an automatic grading prediction module. We hope that it can help clinicians make individual surgery plans, evaluate the risk of surgery, and predict patient outcomes.
2. Materials and Methods
2.1. Dataset
Two datasets from two institutions were used in this study. We chose contrast-enhanced images of the three-dimensional magnetization-prepared rapid gradient-echo (MPRAGE) sequence in the following research, given that the segmentation required clear presentation on the tumor boundary and location. Moreover, a slice thickness of 1 mm for this sequence was sufficiently thin to meet the requirements for 3D spatial reconstruction.
In the first dataset, the researchers retrospectively collected preoperative MRI scans of 625 patients in the neurosurgery department between 2008 and 2018. All patients underwent surgery and were pathologically diagnosed with meningioma. After an initial evaluation, some patients were excluded from the study for the following reasons: (1) images with noticeable motion artifacts; (2) untraceable treatment history in other hospitals (such as radiotherapy or surgery); and (3) recorded intracranial disease history (such as subarachnoid hemorrhage, cerebral infarction, etc.). Two scanners performed standard MR scans in the radiology department, and the detailed protocols are summarized as follows:
3.0T Siemens Trio Scanner, MPRAGE sequence, parameters as: TR/TE/TI = 1900/2.26/900 ms, flip angle = 9°, 176 axial slices with thickness = 1 mm, axial FOV = 25.6 × 25.6 cm2 and data matrix = 256 × 256.
3.0T GE SIGNA MRI scanner, MPRAGE sequence, parameters as: TR/TE = 8.5/3.4 ms, flip angle = 12°, 156 axial slices with thickness = 1 mm, axial FoV = 24 × 24 cm2, and data matrix = 512 × 512.
Contrast-enhanced images were acquired following the injection of gadopentetate dimeglumine (dose: 0.1 mmol/kg). Based on these principles, 97,500 images of 625 patients were collected as the image dataset. In addition, the clinical characteristics of the patients were collected, as listed in
Table 1.
The second dataset included 2808 images of 18 low-grade meningioma patients from another institution, whose MRI scans were obtained with a Siemens MAGNETOM Symphony 1.5T MRI System (7 patients) or Siemens MAGNETOM Skyra 3T MRI System (11 patients). Unfortunately, because of institutional data protection laws, the data had been desensitized, and all information related to patient privacy or MR protocols were removed. Therefore, we were unable to share more detailed MR sequence parameters or patient characteristics. Considering the small cohort of this dataset, it served as the external validation group for this research.
This study was approved by the institutional review boards of West China Hospital, Sichuan University, who granted a waiver of informed consent (2021-S-851).
2.2. Human Segmentation
The tumor images were manually segmented by two experienced neurosurgeons in a consensus reading using the LIFEx software [
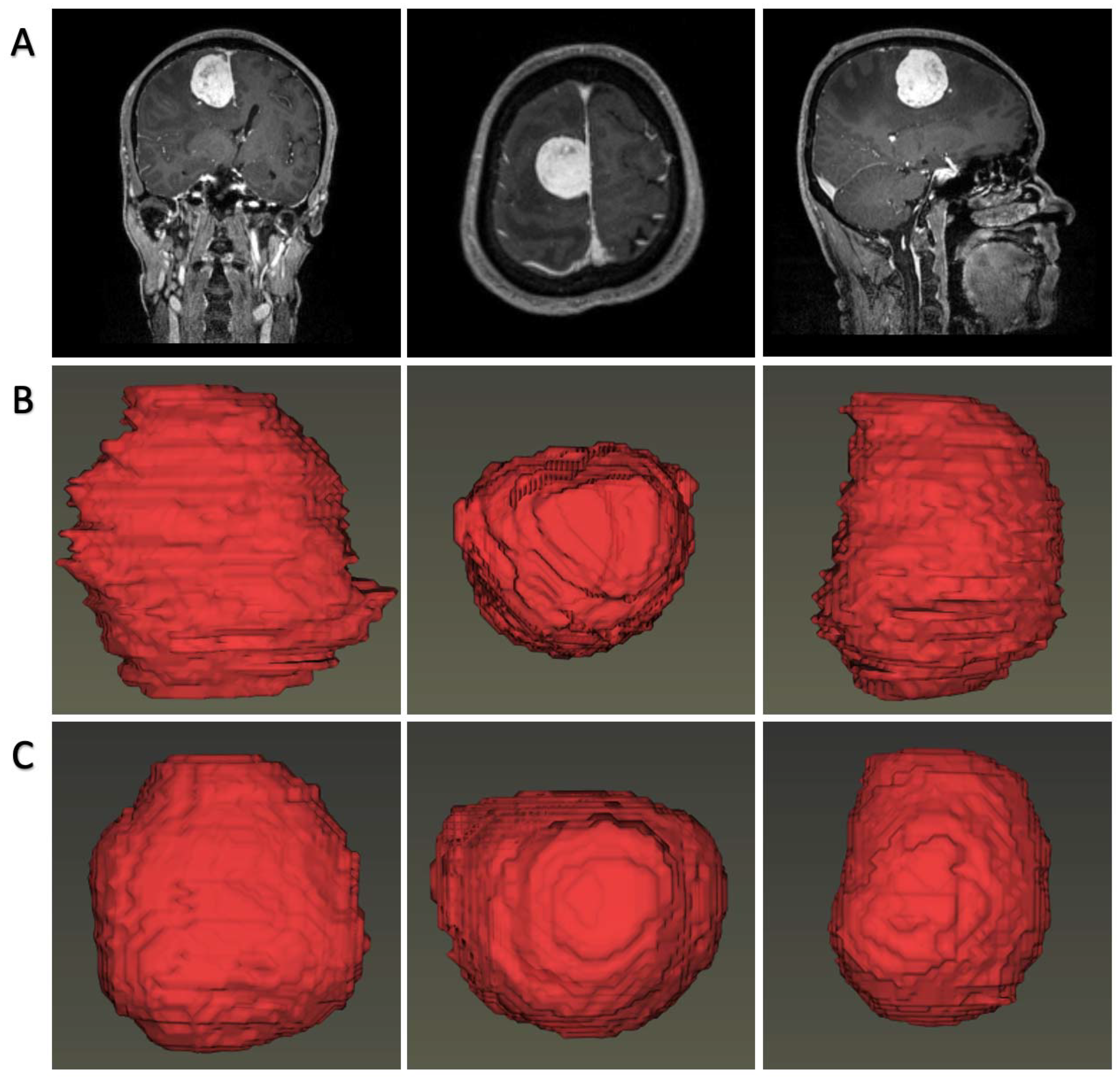
9]. Following the software instructions, the surgeons were asked to accurately delineate the region of interest (ROI) along the tumor boundary slice by slice on axial view images. The adjacent structure invasion and peritumoral edema band were separated from the ROI by the different enhanced patterns in contrast enhancement, whereas vessels and necrosis inside the tumors were included in the ROI. When the authors were in disagreement with each other, they recorded it and consulted senior neurosurgeons and senior radiologists. Finally, the labels were checked by the corresponding authors to make final decisions.
2.3. Establishment of the Deep-Learning System
As mentioned above, the system was established with a cascade structure consisting of three modules (
Figure 1A). The parameters of the models or algorithms were set as follows.
2.3.1. Automatic Detection and Segment Model
The segment model was designed with a modified U-Net, a convolutional deep neural network (CNN), showing promising ability in segmentation tasks of medical images (
Figure 1B) [
10]. The inputs could be selected as a 3D stack or a single 2D image depending on the task needs. To compare their performances, we established two models with both 2D-U-net and 3D-U-net, and the parameters were set as follows:
The basic structures of the 2D-U-Net architecture consist of cascading layers of learnable convolutional filters. The configuration included five down-sampling steps, which reduced the 512 × 512 input images into 16 × 16 × 196 representations, and five up-sampling steps, which up-sampled the representations into 512 × 512 × 6 outputs. As in down-sampling steps, each layer consisted of two consecutive 3 × 3 convolutions, following a normalization of values to the range of −1 to +1 with a hyperbolic tangent (tanh) activation function. The features of down-sampling were max-pooled using a 2 × 2-pixel kernel. As in up-sampling steps, operations were performed via 2 × 2 nearest-neighbor interpolation and two tanh-activated convolutional layers. The final layer consisted of a convolution with a 1 × 1 kernel and a sigmoid function to output the score for the tissue classes. The segmentation of tumor tissue was achieved by selecting the class with the highest score. We experimentally determined the optimal hyperparameters and randomly initialized the network parameters [
11]. The batch size of the sections was 48, and the learning rate was constant at 0.005 [
12]. Segment performances of the training and validation sets were evaluated using categorical cross-entropy. The model was trained using a constant cycle of 80.
The structure of 3D-U-Net was similar to that of 2D-U-Net, the difference being the involvement of spatial information in the input images. Specifically, down-sampling reduced the 512 × 512 × 10 input images into 16 × 16 × 196 × 8 representations, with two consecutive 3 × 3 × 3 convolutions and max-pooling by a 2 × 2 × 2-pixel kernel. Up-sampling recovered the representations into 512 × 512 × 6 × 8 outputs, with 2 × 2 × 2 nearest-neighbor interpolation and two tanh-activated convolutional layers. The batch size of the sections was four, and the learning rate was 0.005 at decay every five rounds. The model of 3D-U-Net was trained at a constant cycle of 40.
The 5-fold cross validation was adapted to verify the performances of the models. Manual segment labels were used as the ground truth. The performances of the two models were analyzed using the following parameters: dice score, Jaccard score, true-positive fraction (TPF), false-positive fraction (FPF), and calculation time. These models were programmed using the Python programming language, and the hardware platform was an NVIDIA Tesla P100 data center accelerator.
2.3.2. Automatic 3D-Rendering Module
The reconstruction module consisted of two parts.
The first part focused on the demonstration of the tumor, for which we proposed an automatic rendering system focusing on visualizing brain tissue and tumor body spatially. Tumor image labels were produced by the segmentation model, and brain image labels were extracted using a CNN model reported previously [
13]. Then, the segmentations and image volumes were introduced into a 3D Slicer for construction using a composite with shading technology [
14].
The second part focused on the relationship between tumors and intracranial vessels, considering that the principle of surgical intervention for meningioma was safe maximal tumor removal. An insight toolkit (Itk) reader was introduced, followed by importing into a visualization toolkit (vtk) converter. We employed the isosurface-rendering algorithm to reconstruct the tumor spatially and the maximal intensity projection (MIP) algorithm to reconstruct the intracranial vessels. This part was written in the C++ programming language.
2.3.3. Grading Prediction Model
The grading model was constructed using classic DenseNet 121, a network with promising performance in classification tasks [
15]. In contrast to previous CNN networks, DenseNet introduced direct connections from any layer to all subsequent layers. The basic structures of this network are dense blocks and transition layers (
Figure 1C). Each dense block contained batch normalization (BN), rectified linear unit (ReLU), and convolution layers (convolution kernel: 3 × 3), while the selected features were transferred into transition layers to achieve a pooling operation. In the last layer, the tumor grading classification was determined using a neuron designed with a sigmoid activation function. The optimal hyperparameters were determined experimentally, and the parameters of the network were initialized by pre-training in ImageNet. The batch size was set to 64, and the learning rate was 0.0005 at decay every five rounds. The classification model was trained using a constant cycle of 200.
DenseNet inputs could be either completed images (Plan A) or segmented images (Plan B). In the current study, we evaluated both plans to select the optimal one. The area under the curve (AUC), accuracy, FPR, TPR, and calculation time were adapted to evaluate the classification performance. Grading models were written in the Python programming language, operated in the NVIDIA Tesla P100 data center accelerator.
2.4. System Test on the External Dataset
To verify the robustness of previous research, we tested the system on the second dataset from another institution to explore the performance of the modules. As stated, the MR images were acquired from two platforms with different protocols in the second institution. One of the platforms was a 3.0T MRI scanner, while the other was a 1.5T MRI scanner with which the images were of lower quality. Because all patients in the second dataset were diagnosed with low-grade meningioma, the test results of the grading prediction modules seemed unreliable. Therefore, the test focused on the segmentation modules and 3D rendering modules.
4. Discussion
In this study, we proposed a meningioma assessment system based on routine MR scan images combined with deep-learning technology. The system was fully automated and capable of detecting tumors on MRIs, displaying tumor structure/intracranial blood vessels, and predicting tumor grade. It is reasonable to consider that the system was mature and stable, as the models were trained with the largest sample size so far and the system was tested on an external dataset. Given that MRI is the necessary radiological examination for intracranial tumors, our system could be potentially utilized in clinical work to facilitate treatment decisions without financially burdening patients.
Our research showed that deep learning is a feasible technology for meningioma assessment by neurosurgeons and neuro-oncologists. Tumor rendering can improve clinical assessment in routine imaging approaches, as it might allow for enhanced detection, improved monitoring, and precise surgery planning [
16]. In addition, automated 3D rendering allows for standardized tumor volume definition as it avoids inter- and intra-rater subjective assessment, which has been demonstrated as high [
17]. Combined with the grading prediction module, the system can be used for tumor progress monitoring and assessment. For neurosurgeons, a system with vessel rendering could also be potentially applied for operation planning [
5]. However, the rendering module still requires modifications at two points. First, manual corrections of predicted labels were still needed to make a more precise delineation where the segmentation module did not work well. The other was that vessel rendering still needs to be improved to automatically recognize the specific arteries and show/hide a particular artery when the clinician needs. We aim to solve these problems in future studies.
The system could also be used to enhance the pre-surgery communication between neurosurgeons and patients, which has been reported to be clinically significant but difficult. Indirect visualization of intracranial tumors using MR images is difficult for patients, as it requires professional knowledge or skill obtained from years of practice. Ineffective communication can lead to patients failing to truly understand their condition, followed by arguments, followed by complaints. Previous research reported that neurosurgeons were much more likely to generate unsolicited patient complaints than other surgical specialties, and 71.6% of neurosurgeons had at least one complaint during their study [
18]. Rendering structures could provide better, clearer demonstrations for patients by providing basic information about the tumor, including size, location, shape, and grading prediction. It is reasonable to consider that this technology has great potential in clinical practice.
The results indicated that the high performance of this system, regardless of the automatic reconstruction modules or grading prediction modules, primarily relied on accurate segmentation by the U-net model. Automatic detection and segmentation of meningiomas were performed in a previous study, and with good performances [
19]. There were two significant improvements between the previous model and our segmentation models [
19]. First, our models were entirely trained on the large sample meningioma dataset, while the previous work employed pre-training, an implemented option that may alleviate the limitation of small datasets on the glioma dataset [
20,
21]. Second, our models were “end-to-end” methods without requiring extra pipelines for extensive image post-processing and registration. These points improved the segment performance and reduced the calculation time. Above all, it is reasonable to consider that our models outperformed previous automatic/semiautomatic segmentation methods developed for meningiomas.
Automatic grading of meningiomas using deep-learning technology has been reported in previous research [
22,
23,
24,
25]. We introduced the second deep-learning model with the classic DenseNet architecture in the third module, which was proposed as an excellent network for classification tasks in medical image datasets. DenseNet architecture was highlighted for the design of a dense block, in which each layer collected all feature maps from all preceding layers and passed on its own outputs as “collective knowledge” to all subsequent layers to preserve the feed-forward nature. It strengthens feature propagation, encourages feature reuse, and alleviates the vanishing-gradient problem [
15]. Our research suggested that the DenseNet architecture network exhibited excellent performance with an AUC of 0.996 and accuracy of 0.969 in the validation group when classifying the tumors into low-grade and high-grade meningiomas. It should be noted that the improvements in classification accuracy were significant when the inputs were segmented images rather than completed images. The segmentation eliminated redundant information unrelated to the tumor image and encouraged feature extraction to be conducive to classification. When this module was integrated with the previous two modules, an intelligent system with a cascade structure was established for meningioma assessment.
The current study had several limitations. First, the system was built using deep-learning technology, but all patients were involved in the training set from a single institution. A large-scale multicenter study is required in the future. Second, the CNN architectures used in the research were all classic without too much modification, and we believe more novel network architectures should be explored in the future. Third, other intellectual tasks, such as brain cancer classification, should be integrated into the system in future research.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}