
Evolution of an Artificial Intelligence-Powered Application for Mammography

 , , , , ,
, , , , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Setting
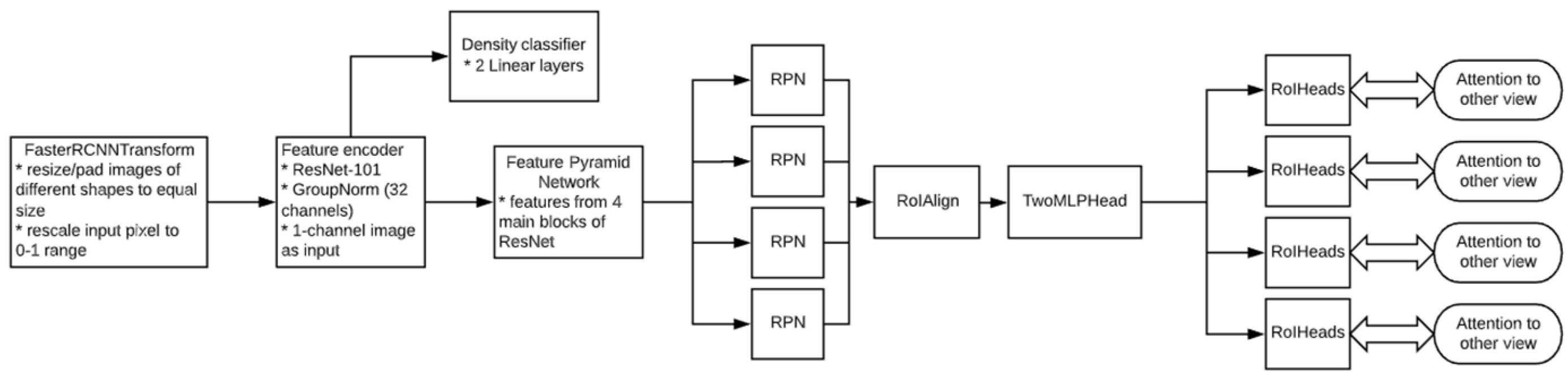
2.2. AI Solution Overview
2.3. Study Design
2.4. External Data
2.4.1. Data Sources and Collection Period
2.4.2. Eligibility Criteria
2.4.3. Anonymization Methods and Data Preprocessing
2.4.4. Equipment Manufacturers and Image Acquisition Protocol
2.4.5. Data Subsets and Sample Size Justification
2.4.6. Experts, Annotation, and Reference Standard
2.4.7. Demographic and Clinical Characteristics of the Dataset
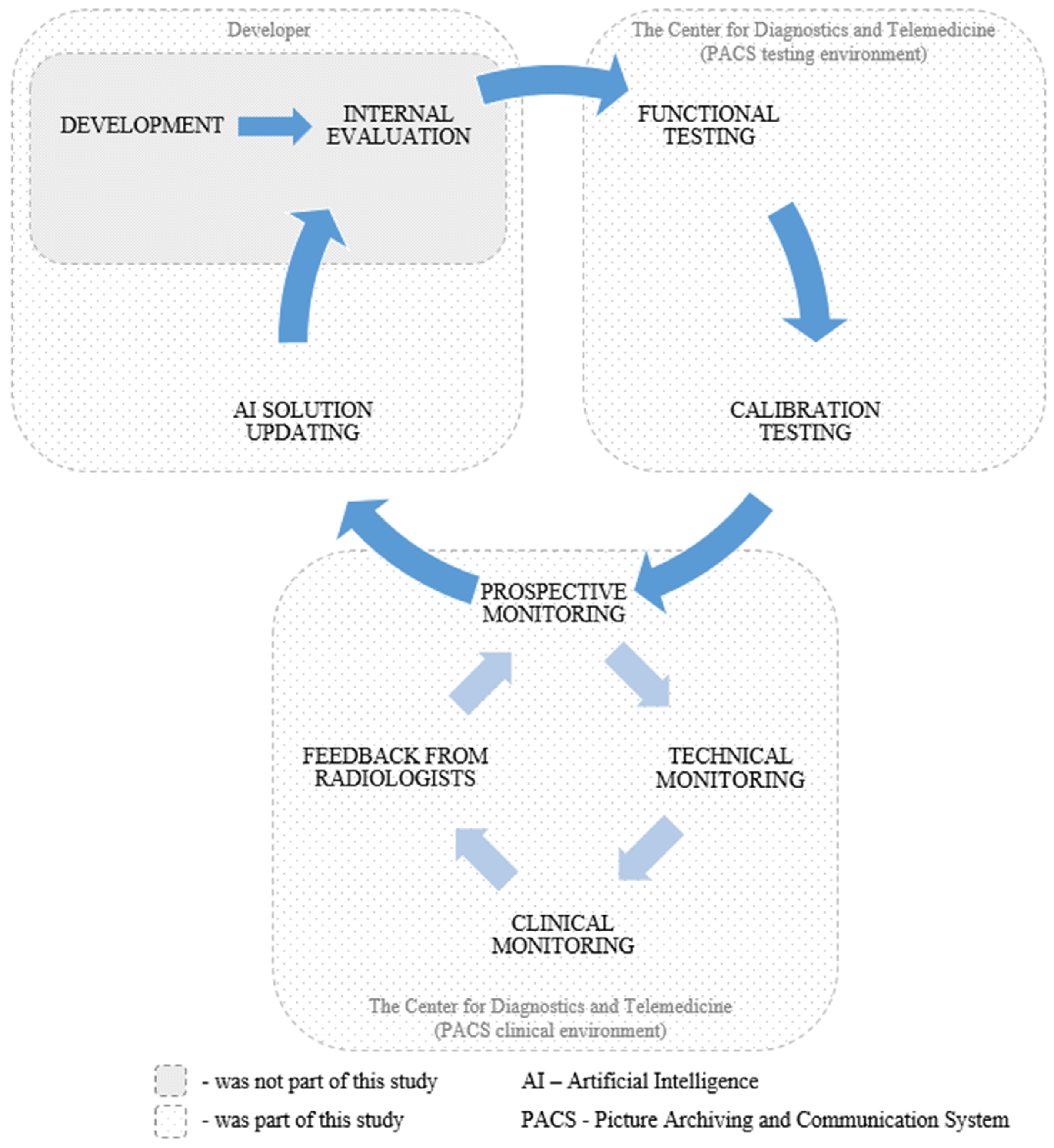
2.5. Testing and Monitoring Methodology
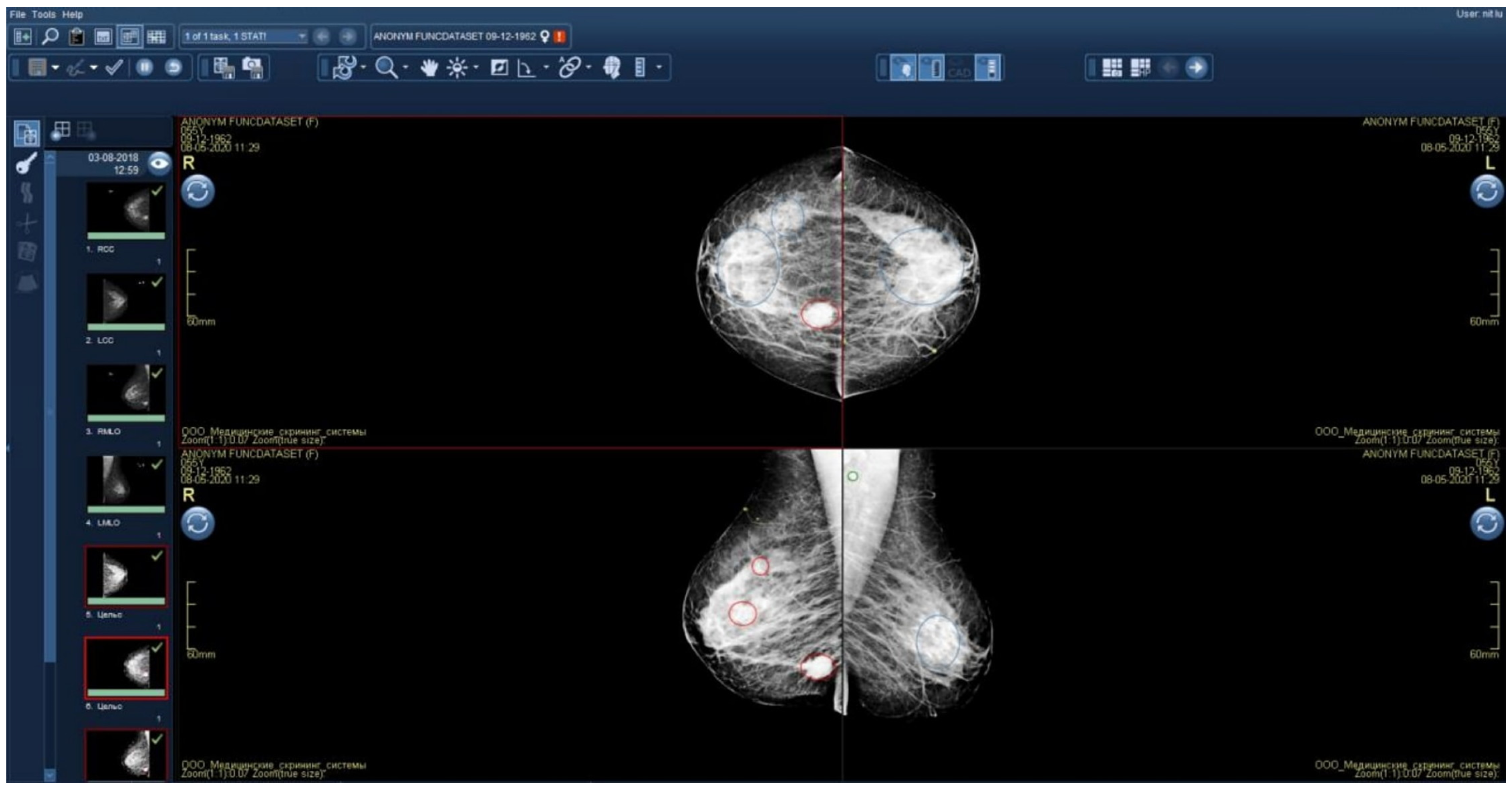
2.5.1. Technical Integration of the AI Solution into the PACS
2.5.2. Functional Testing
2.5.3. Calibration Testing: Methodology and Statistics
2.5.4. Technical Monitoring: Methodology and Statistics
2.5.5. Clinical Monitoring: Methodology and Statistics
2.5.6. Collecting Feedback from Radiologists and Developers
2.5.7. Updating the AI Model—Developer’s Perspective
3. Results
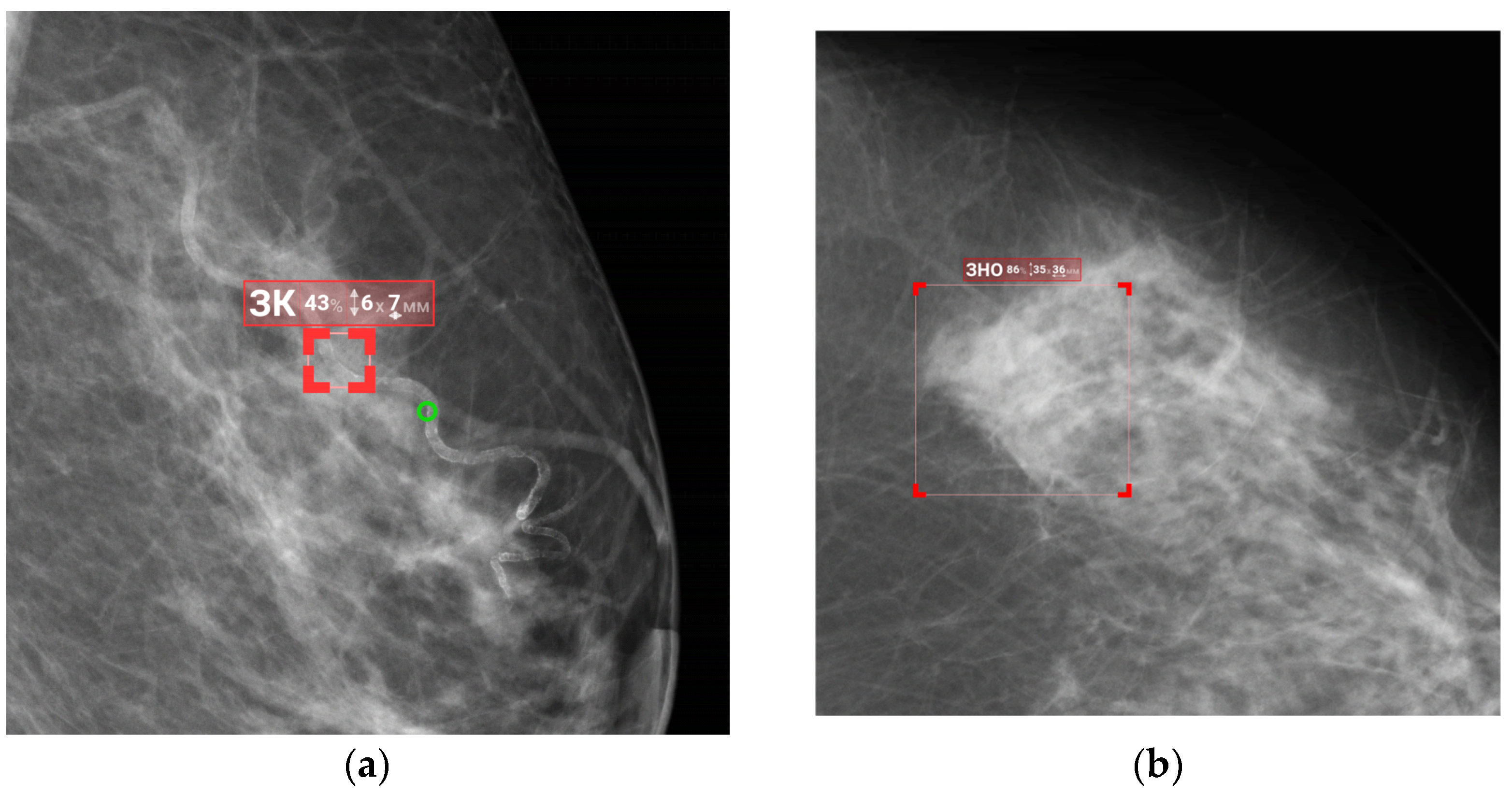
3.1. Functional Testing and Initial Update of the AI Model
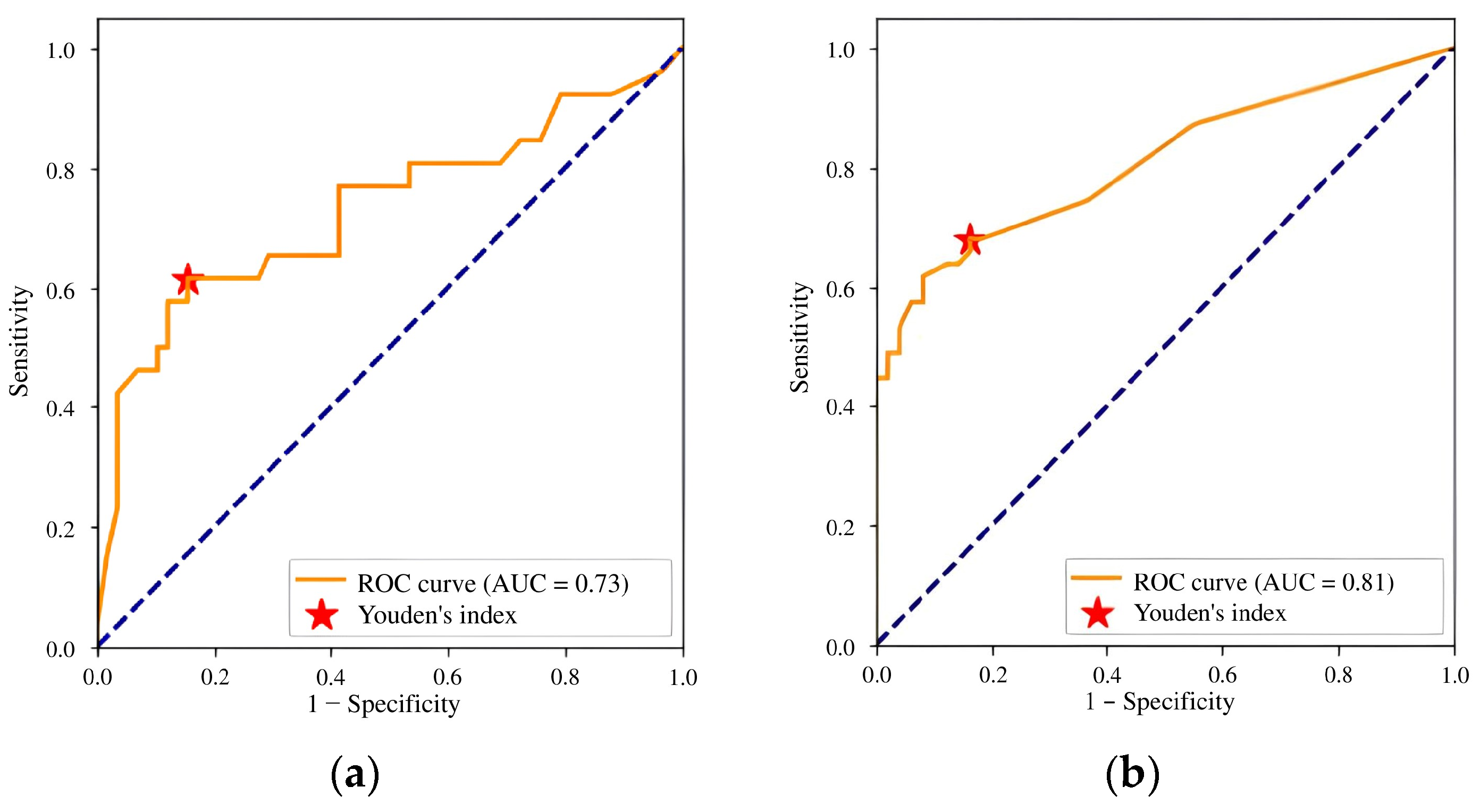
3.2. Calibration Testing and Subsequent Update of the AI Solution
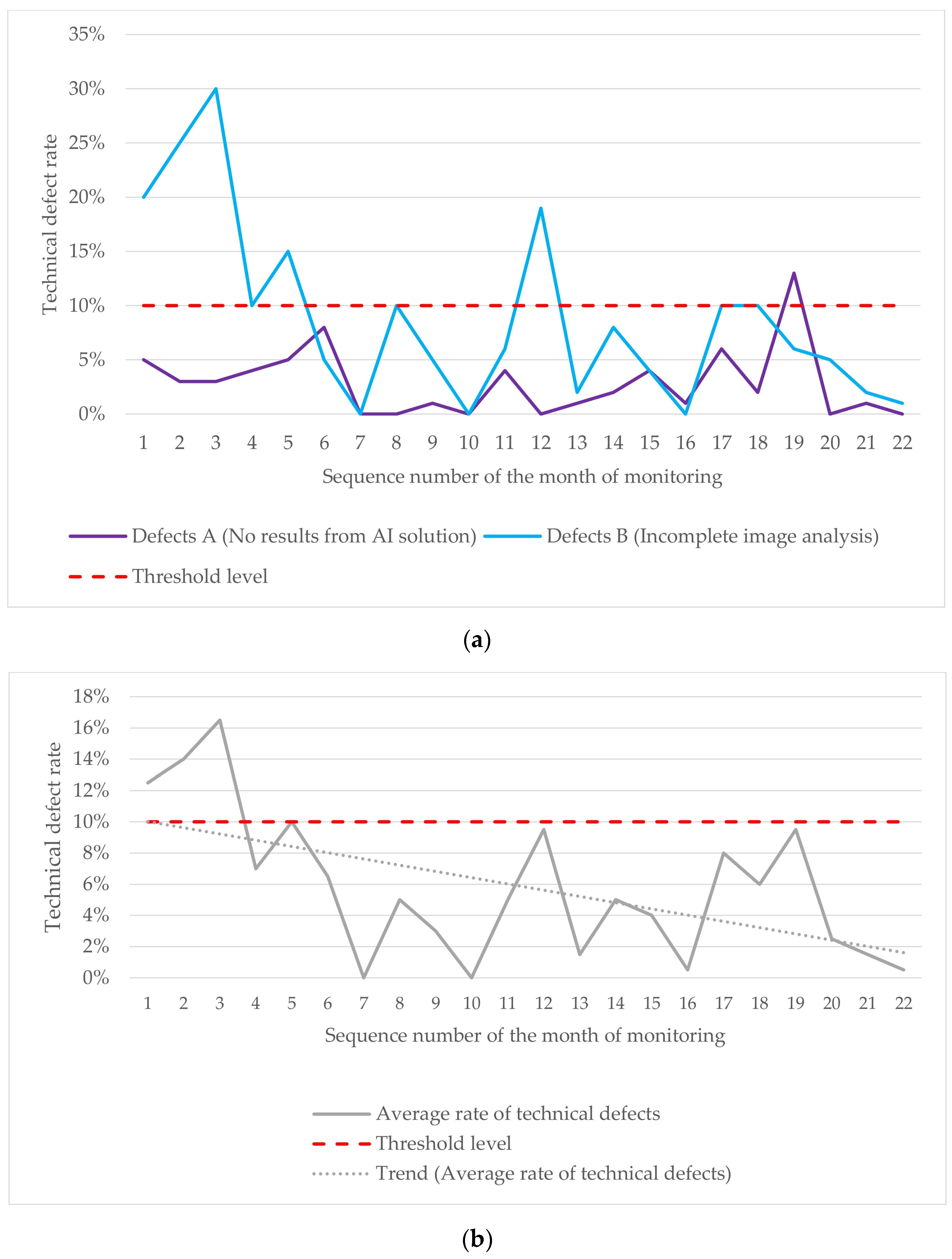
3.3. Technical Monitoring Results
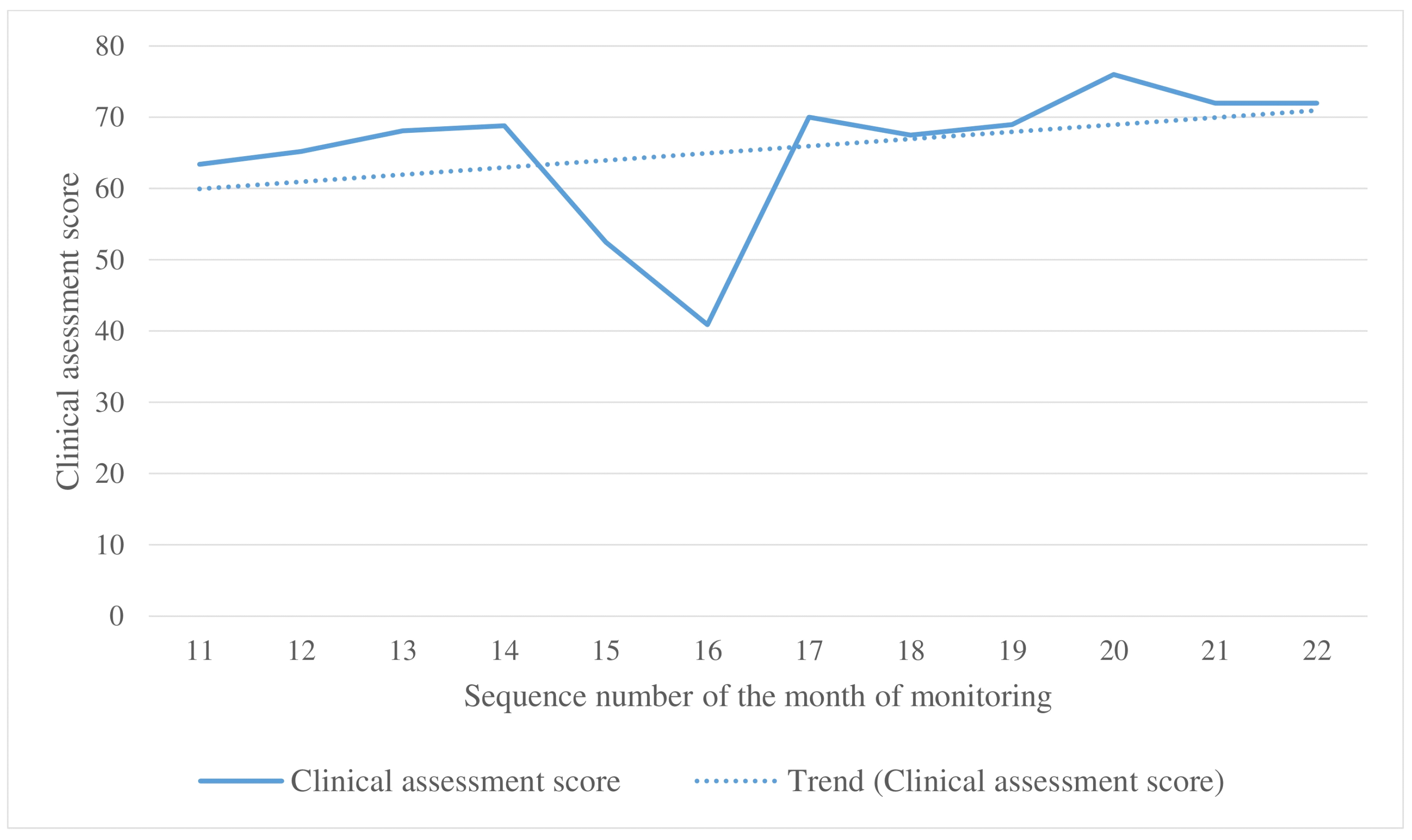
3.4. Clinical Monitoring Results
3.5. Updates to the AI Model During Prospective Technical and Clinical Monitoring
3.6. Feedback from Radiologists and the Developer
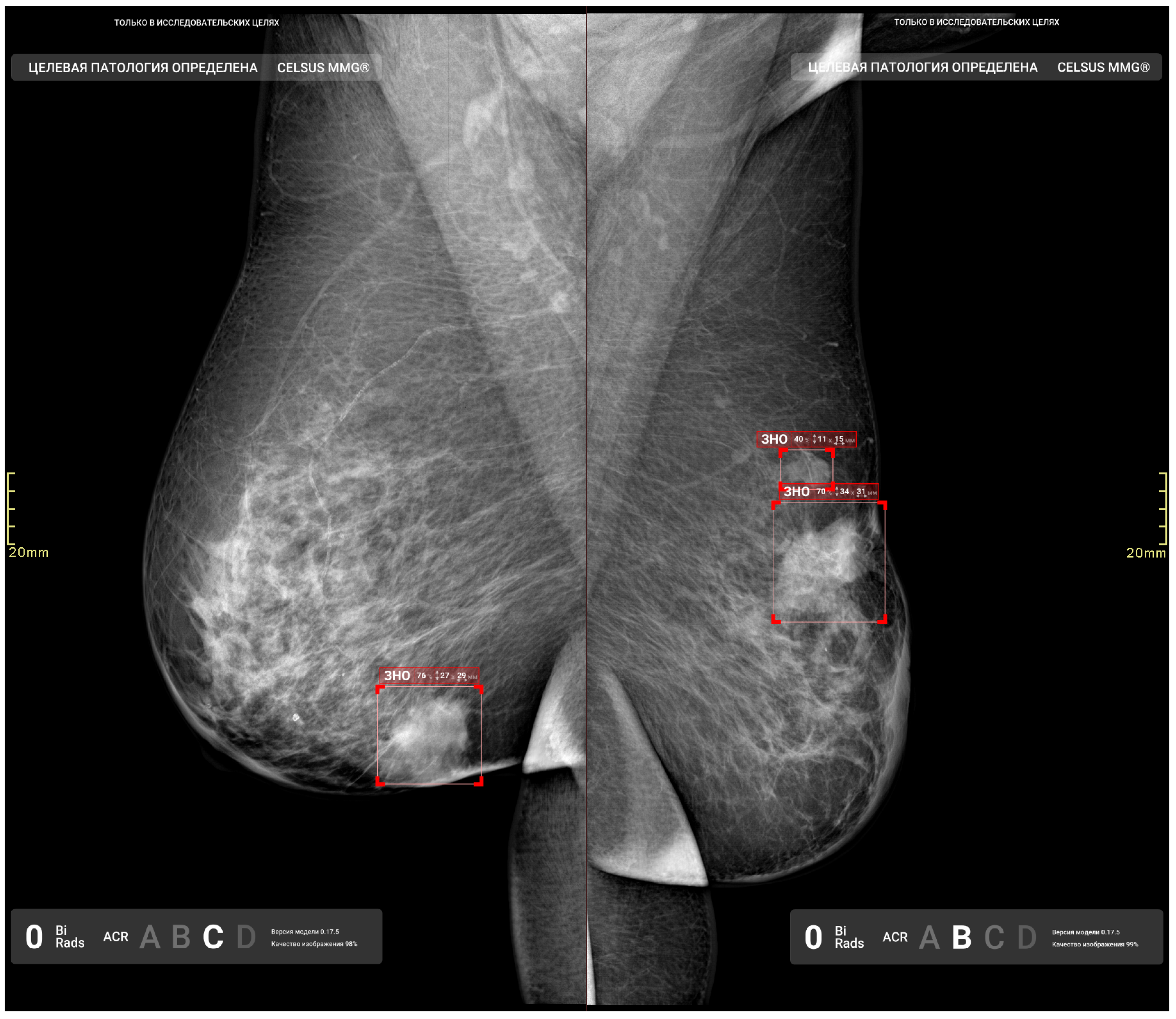
3.7. Additional Study Results
4. Discussion
4.1. Discussion of the Study Results
4.2. Study Limitations
4.3. Future Prospects
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Katsika, L.; Boureka, E.; Kalogiannidis, I.; Tsakiridis, I.; Tirodimos, I.; Lallas, K.; Tsimtsiou, Z.; Dagklis, T. Screening for Breast Cancer: A Comparative Review of Guidelines. Life 2024, 14, 777. [Google Scholar] [CrossRef] [PubMed]
- Akwo, J.; Hadadi, I.; Ekpo, E. Diagnostic Efficacy of Five Different Imaging Modalities in the Assessment of Women Recalled at Breast Screening—A Systematic Review and Meta-Analysis. Cancers 2024, 16, 3505. [Google Scholar] [CrossRef]
- Ding, L.; Greuter, M.J.W.; Truyen, I.; Goossens, M.; Van der Vegt, B.; De Schutter, H.; Van Hal, G.; de Bock, G.H. Effectiveness of Organized Mammography Screening for Different Breast Cancer Molecular Subtypes. Cancers 2022, 14, 4831. [Google Scholar] [CrossRef] [PubMed]
- Nicosia, L.; Gnocchi, G.; Gorini, I.; Venturini, M.; Fontana, F.; Pesapane, F.; Abiuso, I.; Bozzini, A.C.; Pizzamiglio, M.; Latronico, A.; et al. History of Mammography: Analysis of Breast Imaging Diagnostic Achievements over the Last Century. Healthcare 2023, 11, 1596. [Google Scholar] [CrossRef] [PubMed]
- Magnus, M.C.; Ping, M.; Shen, M.M.; Bourgeois, J.; Magnus, J.H. Effectiveness of Mammography Screening in Reducing Breast Cancer Mortality in Women Aged 39–49 Years: A Meta-Analysis. J. Women’s Health 2011, 20, 845–852. [Google Scholar] [CrossRef]
- Marmot, M.G.; Altman, D.G.; Cameron, D.A.; Dewar, J.A.; Thompson, S.G.; Wilcox, M. The Benefits and Harms of Breast Cancer Screening: An Independent Review. Br. J. Cancer 2013, 108, 2205–2240. [Google Scholar] [CrossRef]
- Nelson, H.D.; Fu, R.; Cantor, A.; Pappas, M.; Daeges, M.; Humphrey, L. Effectiveness of Breast Cancer Screening: Systematic Review and Meta-Analysis to Update the 2009 U.S. Preventive Services Task Force Recommendation. Ann. Intern. Med. 2016, 164, 244–255. [Google Scholar] [CrossRef]
- Dibden, A.; Offman, J.; Duffy, S.W.; Gabe, R. Worldwide Review and Meta-Analysis of Cohort Studies Measuring the Effect of Mammography Screening Programmes on Incidence-Based Breast Cancer Mortality. Cancers 2020, 12, 976. [Google Scholar] [CrossRef]
- Hirani, R.; Noruzi, K.; Khuram, H.; Hussaini, A.S.; Aifuwa, E.I.; Ely, K.E.; Lewis, J.M.; Gabr, A.E.; Smiley, A.; Tiwari, R.K.; et al. Artificial Intelligence and Healthcare: A Journey through History, Present Innovations, and Future Possibilities. Life 2024, 14, 557. [Google Scholar] [CrossRef]
- Najjar, R. Redefining Radiology: A Review of Artificial Intelligence Integration in Medical Imaging. Diagnostics 2023, 13, 2760. [Google Scholar] [CrossRef]
- Avanzo, M.; Stancanello, J.; Pirrone, G.; Drigo, A.; Retico, A. The Evolution of Artificial Intelligence in Medical Imaging: From Computer Science to Machine and Deep. Learning. Cancers 2024, 16, 3702. [Google Scholar] [CrossRef] [PubMed]
- Pinto-Coelho, L. How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications. Bioengineering 2023, 10, 1435. [Google Scholar] [CrossRef] [PubMed]
- Obuchowicz, R.; Strzelecki, M.; Piórkowski, A. Clinical Applications of Artificial Intelligence in Medical Imaging and Image Processing—A Review. Cancers 2024, 16, 1870. [Google Scholar] [CrossRef] [PubMed]
- Karalis, V.D. The Integration of Artificial Intelligence into Clinical Practice. Appl. Biosci. 2024, 3, 14–44. [Google Scholar] [CrossRef]
- Khan, S.D.; Hoodbhoy, Z.; Raja, M.H.R.; Kim, J.Y.; Hogg, H.D.J.; Manji, A.A.A.; Gulamali, F.; Hasan, A.; Shaikh, A.; Tajuddin, S.; et al. Frameworks for Procurement, Integration, Monitoring, and Evaluation of Artificial Intelligence Tools in Clinical Settings: A Systematic Review. PLoS Digit. Health 2024, 3, e0000514. [Google Scholar] [CrossRef]
- Maleki Varnosfaderani, S.; Forouzanfar, M. The Role of AI in Hospitals and Clinics: Transforming Healthcare in the 21st Century. Bioengineering 2024, 11, 337. [Google Scholar] [CrossRef]
- Al-Karawi, D.; Al-Zaidi, S.; Helael, K.A.; Obeidat, N.; Mouhsen, A.M.; Ajam, T.; Alshalabi, B.A.; Salman, M.; Ahmed, M.H. A Review of Artificial Intelligence in Breast Imaging. Tomography 2024, 10, 705–726. [Google Scholar] [CrossRef]
- Zhu, Z.; Sun, Y.; Honarvar Shakibaei Asli, B. Early Breast Cancer Detection Using Artificial Intelligence Techniques Based on Advanced Image Processing Tools. Electronics 2024, 13, 3575. [Google Scholar] [CrossRef]
- Shamir, S.B.; Sasson, A.L.; Margolies, L.R.; Mendelson, D.S. New Frontiers in Breast Cancer Imaging: The Rise of AI. Bioengineering 2024, 11, 451. [Google Scholar] [CrossRef]
- Khalid, A.; Mehmood, A.; Alabrah, A.; Alkhamees, B.F.; Amin, F.; AlSalman, H.; Choi, G.S. Breast Cancer Detection and Prevention Using Machine Learning. Diagnostics 2023, 13, 3113. [Google Scholar] [CrossRef]
- Carriero, A.; Groenhoff, L.; Vologina, E.; Basile, P.; Albera, M. Deep. Learning in Breast Cancer Imaging: State of the Art. and Recent. Advancements in Early 2024. Diagnostics 2024, 14, 848. [Google Scholar] [CrossRef] [PubMed]
- Adachi, M.; Fujioka, T.; Ishiba, T.; Nara, M.; Maruya, S.; Hayashi, K.; Kumaki, Y.; Yamaga, E.; Katsuta, L.; Hao, D.; et al. AI Use in Mammography for Diagnosing Metachronous Contralateral Breast Cancer. J. Imaging 2024, 10, 211. [Google Scholar] [CrossRef] [PubMed]
- Wing, P.; Langelier, M.H. Workforce Shortages in Breast Imaging: Impact on Mammography Utilization. Am. J. Roentgenol. 2009, 192, 370–378. [Google Scholar] [CrossRef]
- Kalidindi, S.; Gandhi, S. Workforce Crisis in Radiology in the UK and the Strategies to Deal. With It: Is. Artificial Intelligence the Saviour? Cureus 2023, 15, e43866. [Google Scholar] [CrossRef]
- Kwee, T.C.; Kwee, R.M. Workload of Diagnostic Radiologists in the Foreseeable Future Based on Recent Scientific Advances: Growth Expectations and Role of Artificial Intelligence. Insights Imaging 2021, 12, 88. [Google Scholar] [CrossRef]
- Gastounioti, A.; Eriksson, M.; Cohen, E.A.; Mankowski, W.; Pantalone, L.; Ehsan, S.; McCarthy, A.M.; Kontos, D.; Hall, P.; Conant, E.F. External Validation of a Mammography-Derived AI-Based Risk Model in a U.S. Breast Cancer Screening Cohort of White and Black Women. Cancers 2022, 14, 4803. [Google Scholar] [CrossRef]
- Yu, A.C.; Mohajer, B.; Eng, J. External Validation of Deep Learning Algorithms for Radiologic Diagnosis: A Systematic Review. Radiol. Artif. Intell. 2022, 4, e210064. [Google Scholar] [CrossRef]
- Martin-Noguerol, T.; Luna, A. External Validation of AI Algorithms in Breast Radiology: The Last Healthcare Security Checkpoint? Quant. Imaging Med. Surg. 2021, 11, 2888–2892. [Google Scholar] [CrossRef]
- Vasilev, Y.; Vladzymyrskyy, A.; Omelyanskaya, O.; Blokhin, I.; Kirpichev, Y.; Arzamasov, K. AI-Based CXR First Reading: Current Limitations to Ensure Practical Value. Diagnostics 2023, 13, 1430. [Google Scholar] [CrossRef]
- Kim, D.W.; Jang, H.Y.; Kim, K.W.; Shin, Y.; Park, S.H. Design Characteristics of Studies Reporting the Performance of Artificial Intelligence Algorithms for Diagnostic Analysis of Medical Images: Results from Recently Published Papers. Korean J. Radiol. 2019, 20, 405–410. [Google Scholar] [CrossRef]
- Petersson, L.; Larsson, I.; Nygren, J.M.; Nilsen, P.; Neher, M.; Reed, J.E.; Tyskbo, D.; Svedberg, P. Challenges to Implementing Artificial Intelligence in Healthcare: A Qualitative Interview Study with Healthcare Leaders in Sweden. BMC Health Serv. Res. 2022, 22, 850. [Google Scholar] [CrossRef] [PubMed]
- Ramwala, O.A.; Lowry, K.P.; Cross, N.M.; Hsu, W.; Austin, C.C.; Mooney, S.D.; Lee, C.I. Establishing a Validation Infrastructure for Imaging-Based Artificial Intelligence Algorithms Before Clinical Implementation. J. Am. Coll. Radiol. 2024, 21, 1569–1574. [Google Scholar] [CrossRef] [PubMed]
- Freeman, K.; Geppert, J.; Stinton, C.; Todkill, D.; Johnson, S.; Clarke, A.; Taylor-Phillips, S. Use of Artificial Intelligence for Image Analysis in Breast Cancer Screening Programmes: Systematic Review of Test Accuracy. BMJ 2021, 374, n1872. [Google Scholar] [CrossRef]
- Hickman, S.E.; Baxter, G.C.; Gilbert, F.J. Adoption of Artificial Intelligence in Breast Imaging: Evaluation, Ethical Constraints and Limitations. Br. J. Cancer 2021, 125, 15–22. [Google Scholar] [CrossRef] [PubMed]
- Dikici, E.; Bigelow, M.; Prevedello, L.M.; White, R.D.; Erdal, B.S. Integrating AI into Radiology Workflow: Levels of Research, Production, and Feedback Maturity. J. Med. Imaging 2020, 7, 016502. [Google Scholar] [CrossRef]
- Brady, A.P.; Allen, B.; Chong, J.; Kotter, E.; Kottler, N.; Mongan, J.; Oakden-Rayner, L.; dos Santos, D.P.; Tang, A.; Wald, C.; et al. Developing, Purchasing, Implementing and Monitoring AI Tools in Radiology: Practical Considerations. A Multi-Society Statement from the ACR, CAR, ESR, RANZCR & RSNA. Insights Imaging 2024, 68, 7–26. [Google Scholar] [CrossRef]
- Pianykh, O.S.; Langs, G.; Dewey, M.; Enzmann, D.R.; Herold, C.J.; Schoenberg, S.O.; Brink, J.A. Continuous Learning AI in Radiology: Implementation Principles and Early Applications. Radiology 2020, 297, 6–14. [Google Scholar] [CrossRef]
- Sinha, S.; Lee, Y.M. Challenges with Developing and Deploying AI Models and Applications in Industrial Systems. Discov. Artif. Intell. 2024, 4, 55. [Google Scholar] [CrossRef]
- Smith, A.; Severn, M. An Overview of Continuous Learning Artificial Intelligence-Enabled Medical Devices. Can. J. Health Technol. 2022, 2, 341. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Su, H.; Zhu, J. A Comprehensive Survey of Continual Learning: Theory, Method and Application. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 14, 5362–5383. [Google Scholar] [CrossRef]
- Harvey, H.; Heindl, A.; Khara, G.; Korkinof, D.; O’Neill, M.; Yearsley, J.; Karpati, E.; Rijken, T.; Kecskemethy, P.; Forrai, G. Deep Learning in Breast Cancer Screening. In Artificial Intelligence in Medical Imaging: Opportunities, Applications and Risks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 187–215. ISBN 9783319948782. [Google Scholar]
- Gichoya, J.W.; Thomas, K.; Celi, L.A.; Safdar, N.; Banerjee, I.; Banja, J.D.; Seyyed-Kalantari, L.; Trivedi, H.; Purkayastha, S. AI Pitfalls and What Not to Do: Mitigating Bias in AI. Br. J. Radiol. 2023, 96, 20230023. [Google Scholar] [CrossRef] [PubMed]
- Tejani, A.S.; Ng, Y.S.; Xi, Y.; Rayan, J.C. Understanding and Mitigating Bias in Imaging Artificial Intelligence. Radiographics 2024, 44, e230067. [Google Scholar] [CrossRef] [PubMed]
- Vrudhula, A.; Kwan, A.C.; Ouyang, D.; Cheng, S. Machine Learning and Bias in Medical Imaging: Opportunities and Challenges. Circ. Cardiovasc. Imaging 2024, 17, e015495. [Google Scholar] [CrossRef]
- Park, S.H.; Han, K.; Jang, H.Y.; Park, J.E.; Lee, J.G.; Kim, D.W.; Choi, J. Methods for Clinical Evaluation of Artificial Intelligence Algorithms for Medical Diagnosis. Radiology 2023, 306, 20–31. [Google Scholar] [CrossRef]
- Cardoso, M.J.; Moosbauer, J.; Cook, T.S.; Erdal, B.S.; Genereaux, B.; Gupta, V.; Landman, B.A.; Lee, T.; Somasundaram, E.; Summers, R.M.; et al. RAISE-Radiology AI Safety, an End-to-End Lifecycle Approach. [CrossRef]
- Ng, M.Y.; Kapur, S.; Blizinsky, K.D.; Hernandez-Boussard, T. The AI Life Cycle: A Holistic Approach to Creating Ethical AI for Health Decisions. Nat. Med. 2022, 28, 2247–2249. [Google Scholar] [CrossRef]
- De Silva, D.; Alahakoon, D. An Artificial Intelligence Life Cycle: From Conception to Production. Patterns 2022, 3, 100489. [Google Scholar] [CrossRef]
- Experiment on the Introduction of Artificial Intelligence Technologies. Available online: https://telemedai.ru/en/proekty/eksperiment-po-vnedreniyu-tehnologij-iskusstvennogo-intellekta (accessed on 15 January 2025).
- Celsus Mammography. Available online: https://celsus.ai/en/products-mammography/ (accessed on 15 January 2025).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- CELS® Software. Registration Certificate for a Medical Device 2021/14449. Available online: https://nevacert.ru/reestry/med-reestr/rzn-202114449-46522.html (accessed on 15 January 2025).
- The Celsus Medical Decision Support System Has Received a CE Mark. Available online: https://celsus.ai/en/news/the-celsus-medical-decision-support-system-has-received-a-ce-mark/ (accessed on 15 January 2025).
- Vasilev, Y.A.; Vladzymyrskyy, A.V.; Omelyanskaya, O.V.; Arzamasov, K.M.; Chetverikov, S.F.; Rumyantsev, D.A.; Zelenova, M.A. Methodology for Testing and Monitoring Artificial Intelligence-Based Software for Medical Diagnostics. Digit. Diagn. 2023, 4, 252–267. [Google Scholar] [CrossRef]
- Mongan, J.; Moy, L.; Kahn, C.E. Checklist for Artificial Intelligence in Medical Imaging (CLAIM): A Guide for Authors and Reviewers. Radiol. Artif. Intell. 2020, 2, e200029. [Google Scholar] [CrossRef]
- Avrin, D. HIPAA Privacy and DICOM Anonymization for Research. Acad. Radiol. 2008, 15, 273. [Google Scholar] [CrossRef]
- DICOM Standards Committee. Application Level Confidentiality Profile Attributes. Available online: https://dicom.nema.org/medical/dicom/current/output/html/part15.html#table_E.1-1 (accessed on 15 January 2025).
- Vasiliev, Y.A.; Vladzimirskyy, A.V.; Omelyanskaya, O.V.; Arzamasov, K.M.; Savkina, E.F.; Kasimov, S.D.; Kosov, P.N.; Ponomarenko, A.P.; Medvedev, K.E.; Burtsev, T.A.; et al. Certificate of State Registration of Computer Program No. 2025610804 Russian Federation. Dataset Preparation Platform: No. 2024691653: Declared 20 December 2024: Published 14 January 2025. Available online: https://www.elibrary.ru/item.asp?id=80277623 (accessed on 15 January 2025).
- Bobrovskaya, T.M.; Nikitin, N.Y.; Vladzymyrskyy, A.V.; Omelyanskaya, O.V. Sample Size for Assessing a Diagnostic Accuracy of AI-Based Software in Radiology. Sib. J. Clin. Exp. Med. 2024, 39, 188–198. [Google Scholar] [CrossRef]
- Arzamasov, K.; Vasilev, Y.; Zelenova, M.; Pestrenin, L.; Busygina, Y.; Bobrovskaya, T.; Chetverikov, S.; Shikhmuradov, D.; Pankratov, A.; Kirpichev, Y.; et al. Independent Evaluation of the Accuracy of 5 Artificial Intelligence Software for Detecting Lung Nodules on Chest X-Rays. Quant. Imaging Med. Surg. 2024, 14, 5288–5303. [Google Scholar] [CrossRef] [PubMed]
- MosMedData: MMG with and without Signs of Breast Malignancies, Enriched with Clinical Information. Available online: https://mosmed.ai/en/datasets/mosmeddata-mmg-s-nalichiem-i-otsutstviem-priznakov-zlokachestvennih-novoobrazovanii-molochnoi-zhelezi-obogaschennii-klinicheskoi-informatsiei/ (accessed on 15 January 2024).
- Chetverikov, S.F.; Arzamasov, K.M.; Andreichenko, A.E.; Novik, V.P.; Bobrovskaya, T.M.; Vladzimirskyy, A.V. Approaches to Sampling for Quality Control of Artificial Intelligence in Biomedical Research. Sovrem. Tehnol. Med. 2023, 15, 19–25. [Google Scholar] [CrossRef]
- Spak, D.A.; Plaxco, J.S.; Santiago, L.; Dryden, M.J.; Dogan, B.E. BI-RADS® Fifth Edition: A Summary of Changes. Diagn. Interv. Imaging 2017, 98, 179–190. [Google Scholar]
- Chang Sen, L.Q.; Mayo, R.C.; Lesslie, M.D.; Yang, W.T.; Leung, J.W.T. Impact of Second-Opinion Interpretation of Breast Imaging Studies in Patients Not Currently Diagnosed with Breast Cancer. J. Am. Coll. Radiol. 2018, 15, 980–987. [Google Scholar] [CrossRef]
- Kaprin, A.D.; Chissov, V.I.; Starinsky, V.V.; Gretsova, O.P.; Petrova, G.V.; Prostov, Y.I. The Information Analytical System for Registration of Cancer Patients in the Russian Federation. P.A. Herzen J. Oncol. 2015, 4, 40–43. [Google Scholar] [CrossRef]
- Baseline Functional and Diagnostic Requirements for AI Services. Available online: https://mosmed.ai/en/ai/docs/ (accessed on 15 January 2025).
- Baratloo, A.; Hosseini, M.; Negida, A.; El Ashal, G. Part 1: Simple Definition and Calculation of Accuracy, Sensitivity and Specificity. Emergency 2015, 3, 48–49. [Google Scholar]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On Evaluation Metrics for Medical Applications of Artificial Intelligence. Sci. Rep. 2022, 12, 1–9. [Google Scholar] [CrossRef]
- Ruopp, M.D.; Perkins, N.J.; Whitcomb, B.W.; Schisterman, E.F. Youden Index and Optimal Cut-Point Estimated from Observations Affected by a Lower Limit of Detection. Biom. J. 2008, 50, 419–430. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 14 September 2018. [Google Scholar] [CrossRef]
- Cao, J.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Pang, Y.; Shao, L. D2DET: Towards High Quality Object Detection and Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Vasiliev, Y.A.; Vladzimirskyy, A.V.; Arzamasov, K.M.; Shulkin, I.M.; Aksenova, L.E.; Pestrenin, L.D.; Semenov, S.S.; Bondarchuk, D.V.; Smirnov, I.V. The First 10,000 Mammography Exams Performed as Part of the “Description and Interpretation of Mammography Data Using Artificial Intelligence” Service. Manag. Zdr. 2023, 8, 54–67. [Google Scholar] [CrossRef]
- Branco, P.E.S.C.; Franco, A.H.S.; de Oliveira, A.P.; Carneiro, I.M.C.; de Carvalho, L.M.C.; de Souza, J.I.N.; Leandro, D.R.; Cândido, E.B. Artificial Intelligence in Mammography: A Systematic Review of the External Validation. Rev. Bras. Ginecol. Obstet. 2024, 46, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Borisov, A.A.; Arzamasov, K.M.; Semenov, S.S.; Vladzimirsky, A.V.; Vasiliev, Y.A. Investigation of the Capabilities of Algorithms for Automated Quality Assurance of DICOM Metadata of Chest X-ray Examinations. Med. Vis. 2024, 28, 134–144. [Google Scholar] [CrossRef]
- Zeng, A.; Houssami, N.; Noguchi, N.; Nickel, B.; Marinovich, M.L. Frequency and Characteristics of Errors by Artificial Intelligence (AI) in Reading Screening Mammography: A Systematic Review. Breast Cancer Res. Treat. 2024, 207, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Dembrower, K.; Crippa, A.; Colón, E.; Eklund, M.; Strand, F. Artificial Intelligence for Breast Cancer Detection in Screening Mammography in Sweden: A Prospective, Population-Based, Paired-Reader, Non-Inferiority Study. Lancet Digit. Health 2023, 5, e703–e711. [Google Scholar] [CrossRef] [PubMed]
- Lång, K.; Josefsson, V.; Larsson, A.M.; Larsson, S.; Högberg, C.; Sartor, H.; Hofvind, S.; Andersson, I.; Rosso, A. Artificial Intelligence-Supported Screen Reading versus Standard Double Reading in the Mammography Screening with Artificial Intelligence Trial (MASAI): A Clinical Safety Analysis of a Randomised, Controlled, Non-Inferiority, Single-Blinded, Screening Acc. Lancet Oncol. 2023, 24, 936–944. [Google Scholar] [CrossRef]
- Allen, B.; Gish, R.; Dreyer, K. The Role of an Artificial Intelligence Ecosystem in Radiology. In Artificial Intelligence in Medical Imaging: Opportunities, Applications and Risks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 291–327. ISBN 9783319948782. [Google Scholar]
- Waller, J.; O’connor, A.; Rafaat, E.; Amireh, A.; Dempsey, J.; Martin, C.; Umair, M. Applications and Challenges of Artificial Intelligence in Diagnostic and Interventional Radiology. Polish J. Radiol. 2022, 87, e113–e117. [Google Scholar] [CrossRef]
- Chang, J.Y.; Makary, M.S. Evolving and Novel Applications of Artificial Intelligence in Thoracic Imaging. Diagnostics 2024, 14, 1456. [Google Scholar] [CrossRef]
- Brady, A.P.; Neri, E. Artificial Intelligence in Radiology-Ethical Considerations. Diagnostics 2020, 10, 231. [Google Scholar] [CrossRef]
- Allen, B.; Dreyer, K.; Stibolt, R.; Agarwal, S.; Coombs, L.; Treml, C.; Elkholy, M.; Brink, L.; Wald, C. Evaluation and Real-World Performance Monitoring of Artificial Intelligence Models in Clinical Practice: Try It, Buy It, Check It. J. Am. Coll. Radiol. 2021, 18, 1489–1496. [Google Scholar] [CrossRef]
- Isa, I.G.T.; Ammarullah, M.I.; Efendi, A.; Nugroho, Y.S.; Nasrullah, H.; Sari, M.P. Constructing an Elderly Health Monitoring System Using Fuzzy Rules and Internet of Things. AIP Adv. 2024, 14, 1–15. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| № | Stage | Objective | Pass Criteria |
|---|---|---|---|
| 1. | Functional testing | Initial evaluation of the AI model’s core functions by radiologists | No discrepancies with the Baseline Functional and Diagnostic Requirements |
| 2. | Calibration testing | Assessing the diagnostic accuracy metrics using an external histopathologically verified dataset; comparing the results with the metrics claimed by the AI developer | AUC ≥ 0.81; decrease in metric performance does not exceed 10% compared to those claimed by the developer (including AUC, accuracy, sensitivity, specificity) |
| 3. | Technical monitoring | Evaluating the performance stability of the AI model during operation in routine settings | The proportion of studies with technical defects is less than 10% of the monthly study flow |
| 4. | Clinical monitoring | Assessing the clinical effectiveness of the AI model in routine settings | NA * |
| 5. | Collecting feedback from radiologists | Gathering feedback from radiologists who use the AI model in routine practice | NA * |
| Data Type | Technical Monitoring Dataset | Clinical Monitoring Dataset |
|---|---|---|
| Years of acquisition | 2021–2022 | 2021–2022 |
| Total patients | 593,261 | 1160 |
| Age group | ||
| ≤29 | 271 | 0 |
| 30–39 | 8758 | 14 |
| 40–49 | 139,911 | 290 |
| 50–59 | 151,488 | 291 |
| 60–69 | 179,042 | 321 |
| 70–79 | 91,889 | 199 |
| ≥80 | 21,902 | 45 |
| BI-RADS category | ||
| BI-RADS 1 | 118,672 | 190 |
| BI-RADS 2 | 383,053 | 742 |
| BI-RADS 3 | 37,268 | 109 |
| BI-RADS 4 | 13,273 | 38 |
| BI-RADS 5 | 1771 | 4 |
| BI-RADS 6 | 1013 | 5 |
| NA | 38,211 | 72 |
| Medical facilities | 112 | 96 |
| Equipment manufactures | 10 | 10 |
| № | Evaluation Parameter |
|---|---|
| Requirements for Additional Image Series | |
| 1 | Additional series contains a modified image regardless of the presence of pathological findings |
| 2 | Additional series contains graphical masks highlighting a target finding |
| 3 | Graphical masks do not extend beyond the target organ |
| 4 | For each finding, the graphical mask is labeled by color-coding or a numerical identifier |
| 5 | All image series (views) are processed |
| 6 | Images in the additional series are not cropped |
| Requirements for DICOM SR | |
| 1 | DICOM SR template (including modality, region of interest, unique study identifier, clinical task for the AI model, technical parameters, and a brief user manual) |
| 2 | The DICOM SR template meets the Baseline Diagnostic Requirements |
| Requirements for additional image series and DICOM SR | |
| 1 | Additional series and DICOM SR generated by the AI model for each processed study |
| 2 | Additional series and DICOM SR contain the name and version of the AI model |
| 3 | Additional series and DICOM SR contain the date and time of analysis completion |
| 4 | Additional series and DICOM SR contain the “For research purpose only” notification |
| 7 | No contradicting data in the additional series and DICOM SR (for example, report contains no impression of the labeled findings) |
| Other | |
| 1 | No other critical errors in AI operation (including error messages, non-diagnostic radiology report, poor graphical mask visibility, overly long loading time of additional series, etc.) |
| № | AI Response | Response Format | Response Form |
|---|---|---|---|
| 1 | Detection, segmentation, and classification (benign/malignant) of masses | Graphical mask, text | DICOM, DICOM SR, Apache Kafka message |
| 2 | Detection, segmentation, and classification (benign/malignant) of calcifications | ||
| 3 | Detection and segmentation of enlarged lymph nodes | ||
| 4 | ACR category of breast density for each breast | Text | DICOM SR |
| 5 | Probability of breast cancer in the entire study | Number | Apache Kafka message |
| Evaluation Criteria | Description | Score | |
|---|---|---|---|
| Localization | Interpretation | ||
| Agreement | AI accurately labeled and interpreted all abnormalities | 1 | 1 |
| Incorrect assessment | Not all target abnormalities detected | 0.5 | 0.5 |
| False positive | Detected abnormalities that were not there | 0.25 | 0.25 |
| False negative | Failure to detect target abnormalities | 0 | 0 |
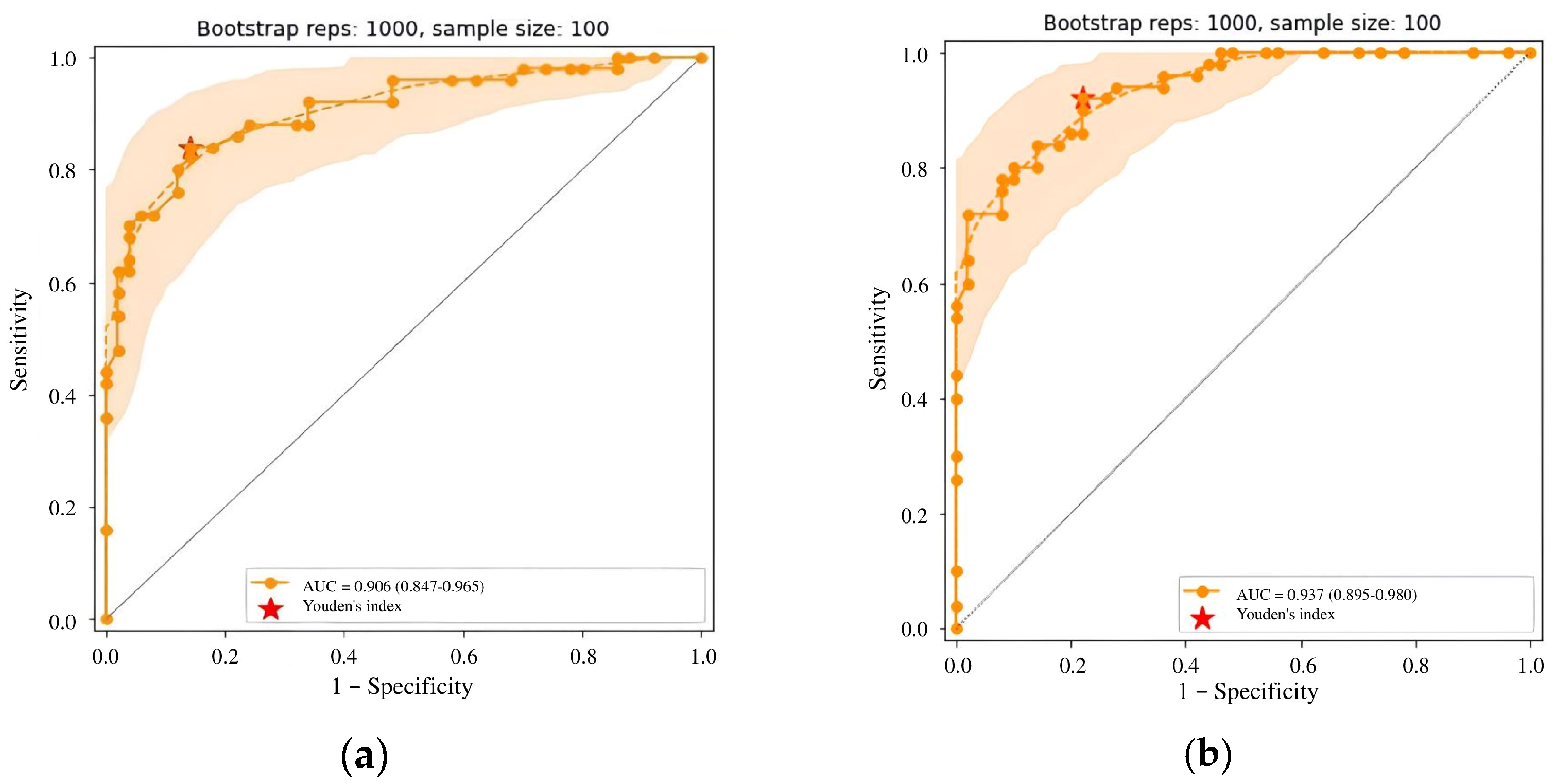
| Metric | CalT1 (Claimed) | CalT1 (Obtained) | Rel. Diff. (%) | CalT 2 (Claimed) | CalT 2 (Obtained) | Rel. Diff. (%) |
|---|---|---|---|---|---|---|
| AUC | NA | 0.73 | NA | NA | 0.81 | NA |
| Acc. | 0.71 | 0.73 | +3% | 0.71 | 0.76 | +7% |
| Sens. | 0.72 | 0.62 | −14% | 0.72 | 0.68 | −6% |
| Spec. | 0.68 | 0.84 | +24% | 0.68 | 0.84 | +24% |
| Precision | NA | 0.79 | NA | NA | 0.81 | NA |
| F1 score | NA | 0.70 | NA | NA | 0.74 | NA |
| Metric | CalT3 (Claimed) | CalT3 (Obtained) | Rel. Diff. (%) | CalT4 (Claimed) | CalT4 (Obtained) | Rel. Diff. (%) |
|---|---|---|---|---|---|---|
| AUC | 0.857 | 0.91 | +6% | 0.886 | 0.94 | +6% |
| Acc. | 0.57 | 0.85 | +27% | 0.82 | 0.85 | +4% |
| Sens. | 0.87 | 0.84 | −3% | 0.82 | 0.92 | +12% |
| Spec. | 0.66 | 0.86 | +30% | 0.82 | 0.78 | −5% |
| Precision | NA | 0.86 | NA | NA | 0.81 | NA |
| F1 score | NA | 0.86 | NA | NA | 0.86 | NA |
| Metric | CalT5 (Claimed) | CalT5 (Obtained) | Rel. Diff. (%) |
|---|---|---|---|
| AUC | 0.89 | 0.91 | +2.3% |
| Acc. | 0.82 | 0.89 | +8.5% |
| Sens. | 0.82 | 0.85 | +3.7% |
| Spec. | 0.82 | 0.93 | +13.4% |
| Precision | NA | 0.91 | NA |
| F1 score | NA | 0.88 | NA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vasilev, Y.; Rumyantsev, D.; Vladzymyrskyy, A.; Omelyanskaya, O.; Pestrenin, L.; Shulkin, I.; Nikitin, E.; Kapninskiy, A.; Arzamasov, K. Evolution of an Artificial Intelligence-Powered Application for Mammography. Diagnostics 2025, 15, 822. https://doi.org/10.3390/diagnostics15070822
Vasilev Y, Rumyantsev D, Vladzymyrskyy A, Omelyanskaya O, Pestrenin L, Shulkin I, Nikitin E, Kapninskiy A, Arzamasov K. Evolution of an Artificial Intelligence-Powered Application for Mammography. Diagnostics. 2025; 15(7):822. https://doi.org/10.3390/diagnostics15070822
Chicago/Turabian StyleVasilev, Yuriy, Denis Rumyantsev, Anton Vladzymyrskyy, Olga Omelyanskaya, Lev Pestrenin, Igor Shulkin, Evgeniy Nikitin, Artem Kapninskiy, and Kirill Arzamasov. 2025. "Evolution of an Artificial Intelligence-Powered Application for Mammography" Diagnostics 15, no. 7: 822. https://doi.org/10.3390/diagnostics15070822
APA StyleVasilev, Y., Rumyantsev, D., Vladzymyrskyy, A., Omelyanskaya, O., Pestrenin, L., Shulkin, I., Nikitin, E., Kapninskiy, A., & Arzamasov, K. (2025). Evolution of an Artificial Intelligence-Powered Application for Mammography. Diagnostics, 15(7), 822. https://doi.org/10.3390/diagnostics15070822