1. Introduction
Monkeypox (Mpox) is a difficult-to-detect disease whose clinical symptoms are similar to those of varicella and has become a global public health problem since 2022 [
1]. Skin lesions, rashes, and high fever are important symptoms in patients infected with monkeypox virus [
2]. Considering the rate of transmission of the disease and vulnerable populations, it is an important public health problem facing the world after COVID-19. The disease has spread to more than forty countries, and the travel warning level in the United States has been raised to protect against the disease. Traditional medical methods use polymerase chain reaction (PCR) and serologic testing to diagnose Mpox [
3]. However, these methods are slow and resource-intensive. The recent COVID-19 pandemic has shown the impact of early diagnosis of infectious diseases on the spread of the disease [
4,
5,
6]. Early detection of the disease can make important contributions to the protection of public health. For these reasons, it is necessary to develop autonomous systems that can detect Mpox disease in skin images.
Deep learning architectures, a subfield of artificial intelligence, have been successfully used in many areas of human life, such as medicine, engineering, and agriculture. Researchers are trying to solve many challenging tasks, such as classification [
7], segmentation [
8], and object detection [
9], using deep learning architectures and medical images. Doctors can get support from deep-learning-based systems during the diagnosis of diseases. The support received by doctors from an autonomous system during the diagnosis of diseases can increase their diagnostic success and prevent incorrect treatments. Processing skin images with deep learning architectures and using them to diagnose Mpox disease will progress very quickly compared to traditional methods. By using them in hospitals where diagnostic tests are not available, many patients will be able to receive early diagnosis and treatment.
Studies aimed at training deep learning architectures with skin images have been recently reported by some researchers in the literature. Ali et al. focused on developing a web-based system for the detection of skin lesions and the related Mpox disease [
10]. The researchers classified six classes of skin images using a self-collected and openly available dataset. They trained a total of seven different architectures using the weights of ImageNet and HAM1000 datasets. As a result of their classification using popular deep learning architectures based on convolutional neural networks, they achieved the highest success with the DenseNet121 architecture. The researchers achieved the highest classification accuracy of 81.70 using ImageNet weights and 82.26 using HAM1000 weights. Another study focusing on the detection of Mpox disease from skin images was conducted by Biswas et al. [
11]. In two-class and six-class studies, the researchers tried to diagnose Mpox and other diseases, and in this sense, they conducted their research in two different branches. The two-class studies address the issue as a two-class classification problem focusing only on the relevant disease that provides information about the presence or absence of Mpox disease. They carried out the training process with a model they named BinaryDNet53 based on the DarkNet53 deep learning model. They achieved an accuracy of 95.05 for two-class classification and 85.78 for six-class classification.
Bala et al. considered monkeypox as a four-class classification problem [
12]. Images labeled as chickenpox, measles, monkeypox, and normal were trained with an architecture called MonkeyNet, which was created with DenseNet blocks. The researchers achieved an accuracy of 93.19 with the four-class classification method. Another study focusing on classifying four-class Mpox images was conducted by Akram et al. [
13]. The researchers achieved 90% success in the accuracy evaluation metric with their transfer learning-based architecture called SkinMarkNet.
Although two- and four-class classification studies are important in classifying images of Mpox disease, they are insufficient in identifying skin diseases. There are six different classes that can be identified from skin images. There is a need for new studies covering all skin diseases. Studies that include all of these classes do not have high enough success to be used in clinical studies. In this context, the motivation of our study is that there is still a need for a deep learning architecture that has a flexible structure and can achieve high accuracy in detecting Mpox images on six-class skin images. In addition, the studies reviewed in the literature are based on popular architectures from convolutional neural networks. However, transformer-based architectures are more suitable for use in medical images with their flexible structure. Transformer-based deep learning architectures provide advantages to researchers who want to focus on medical images due to their customizable structures, multilayer structures, and attention mechanisms.
This study aims to diagnose Mpox disease from skin lesion images using transformer-based deep learning architectures, specifically ViT, MAE, DINO, and SwinTransformer. The performances of these architectures are analyzed in detail, highlighting their strengths and weaknesses in classifying skin lesion images. The study demonstrates the superiority of transformer-based models over CNN-based architectures in diagnosing Mpox disease and provides new approaches for this application that have not been previously explored in the literature. Furthermore, the contributions of specific techniques, such as the masked autoencoder approach in MAE and the self-supervised learning method in DINO, to the classification of Mpox and other skin lesion images are extensively studied. The effectiveness of shifted windows in transducer-based architectures is also examined in the context of skin lesion classification. The study also provides insight into the relative computational costs of ViT, MAE, DINO, and SwinTransformer architectures by evaluating their computational efficiency and training time under identical conditions.
3. Results
In order to observe the classification success of skin lesion images, including Mpox disease, with transformer-based deep learning architectures, a training and test environment was prepared using the Python programming language. All the architectures studied in the experimental environment were trained using a P100 GPU. The Kaggle platform was used as the development environment for faster and more reliable execution of deep learning codes. Kaggle is a developer platform by Google that allows researchers to run Python codes and also offers significant GPU support. P100 GPU was selected from the Kaggle platform at the training stage and the experimental environment was prepared. The batch size was 16 and the optimization algorithm was Adam. In all algorithms, the learning rate was chosen as 2 × 10⁻⁵. ImageNet pre-trained weights were used in the study. This feature is intended to improve model generalization performance when working with limited data. Training models from scratch requires much higher computational power, and the ImageNet weights used to overcome this disadvantage significantly reduce the training time of the model. In addition, the use of ImageNet weights is an important advantage in areas with limited data sources, such as medical image analysis. The subject of our study is also a new field of study with limited data. ImageNet weights were used in our study to improve performance, achieve faster training times, and improve generalization capability. The hyperparameters used in the studies are given in
Table 2.
One of the most important representations of the success of our classification study with skin lesion images in the test results is the confusion matrix. The confusion matrix is the prediction of the model using test images that are not used in the training and validation processes, and the results obtained are placed in a dimensional matrix. The number of dimensions of the matrix is equal to the number of classes in order to represent all classes. The confusion matrix provides an environment for the calculation of other evaluation metrics. In addition, for each transformer-based architecture studied, class-based precision, recall, and F1 score evaluation metrics were also calculated.
Table 3 shows the confusion matrix consisting of the class representations obtained for the vision transformer architecture, as well as the class-based classification results for the precision, recall, and F1 score evaluation metrics.
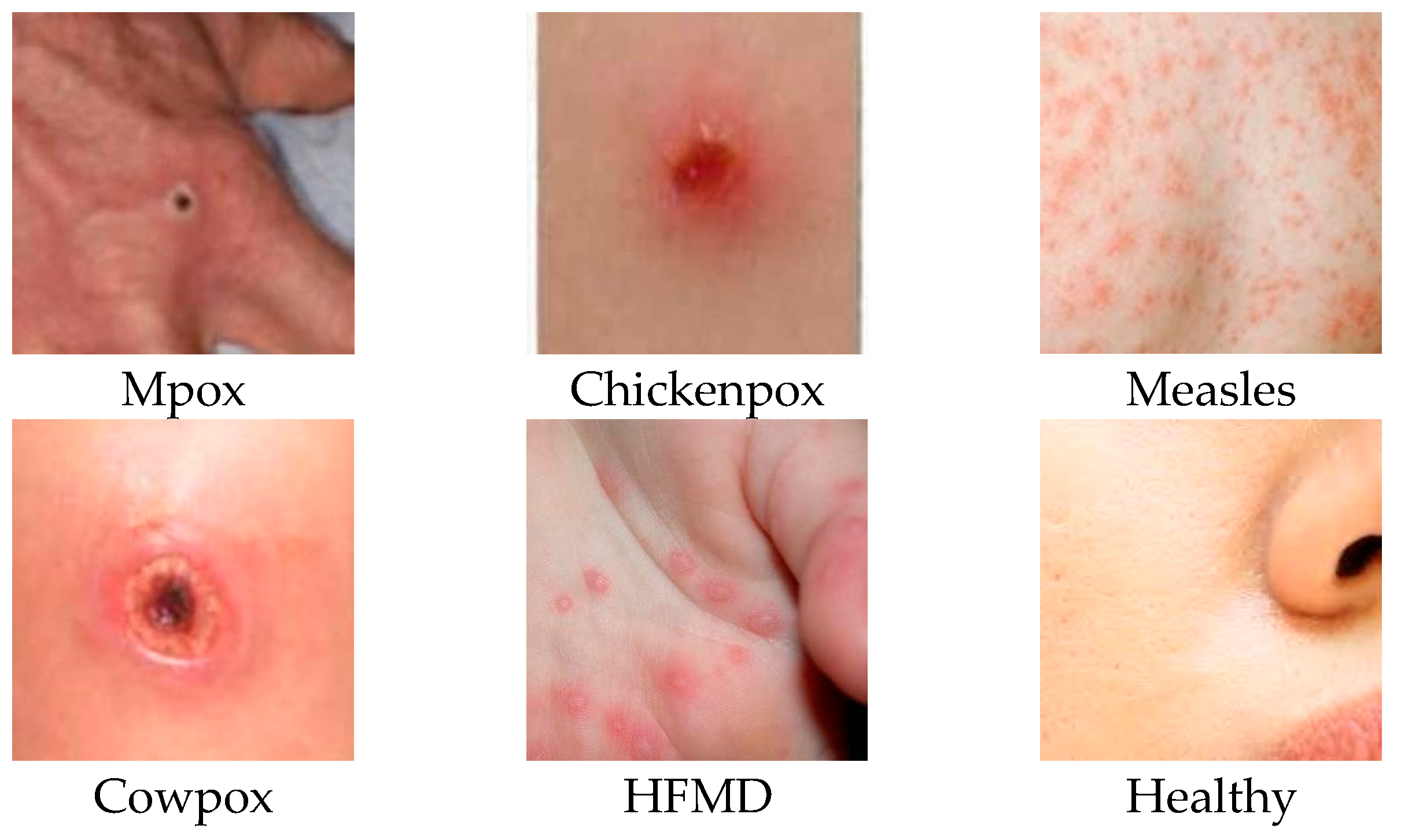
Classes 0, 1, 2, 3, 4, and 5 in the table represent Mpox, Chickenpox, Measles, Cowpox, HFMD, and a Healthy class, respectively. The labels P, R, and F1 stand for precision, sensitivity, and F1 score evaluation metrics, respectively. The researchers who created the data set published the images by dividing them into 5 different folds. Therefore, all experiments were conducted using a similar approach. By using a similar approach, the classification success of our study could be compared with other studies in the literature. For this reason, the dataset was divided into five folds, and each fold was analyzed separately and averaged. The data presented in
Table 3,
Table 4,
Table 5 and
Table 6 were obtained by taking the arithmetic mean and applying normalization to the results obtained from the 5-fold analysis.
Table 4 shows the normalized confusion matrix and classification results obtained from the MAE architecture trained on skin lesion images.
When the disease-based results are analyzed, it is observed that the vision transformer architecture performs better than the MAE architecture with the addition of self-supervised learning and masking features. For Mpox disease with a 0 class label, the ViT architecture prediction was about 8% better than the MAE architecture prediction—while the true positive values for Mpox disease were 0.79% in the ViT architecture, this rate decreased to 0.71% in the MAE architecture. The precision evaluation metric labeled with P in the tables is used in the medical field, especially in cases where false positives should be low. Relying on high results for this metric is important to prevent false positives when diagnosing a serious disease. Diagnostic cost in the medical field is minimized by using this metric. When the values obtained in the test phases of MAE and ViT architectures are compared, it is seen that the ViT architecture is ahead, with a significant difference of 31% in the precision evaluation metric. In addition to the ViT and MAE architectures, training and testing processes were also carried out using the DINO architecture. In
Table 5, the results obtained in the test phase of the DINO architecture are shared on a class basis and as a classification report.
When the results of the DINO deep learning architecture are analyzed, it is observed that it achieves better results than the MAE architecture. The DINO architecture achieved 28% higher Mpox disease diagnosis success with the precision evaluation metric compared to the MAE architecture. There is a difference of about 3% in the precision evaluation metric between the results obtained by the DINO architecture and the results obtained by the ViT architecture when classifying Mpox images. In this context, it can be said that DINO and ViT architectures achieve close results when classifying Mpox images. SwinTransformer architecture, which is a transformer-based architecture using a shifted window, was also used in our study. The class-based normalized confusion matrix and classification report for the test results obtained after training with the SwinTransformer architecture are given in
Table 6.
When evaluated specifically for Mpox disease, it is seen that ViT and SwinTransformer architectures achieve similar results. When other skin lesions are evaluated together, it is observed that the SwinTransformer architecture achieves more inclusive results and achieves higher classification success than the ViT architecture. When Chickenpox disease, which is labeled as class 1 in the dataset, is examined, it is seen that the SwinTransformer architecture achieves 100% precision classification success, while the ViT architecture achieves 93% classification success.
The confusion matrix is an important representation in machine learning and deep learning architectures that is used to measure their performance.
Figure 6 shows the complexity matrices of four different deep learning architectures (ViT, MaeViT, DinoViT, and SwinTransformer) on multi-class skin lesion images. In order to more accurately compare the performances of deep learning architectures with existing studies in the literature, preserve the original structure of the dataset, and increase the confidence index, the datasets were divided into folds. The confusion matrix given in the figure was formed by taking the arithmetic mean of the folds studied. The confusion matrix visualizes the classification performance of the relevant model and provides a basis for calculating correct classifications and error rates. High values in the diagonal data in the complexity matrix mean that the model is correctly classified for the relevant classes. In all four models, diagonal elements are dominant and the classification performance of the architectures is high. In the SwinTransformer deep learning architecture, which has the highest disease diagnosis success, there are only four images that are outside the diagonal axis, that is, incorrectly predicted.
4. Discussion
This study was carried out to investigate the success of transformer-based deep learning architectures in classifying images of skin lesion diseases, including images of Mpox disease. In our study, ViT, MAE, DINO, and SwinTransformer architectures were used to train skin lesion images, and the results were analyzed in detail. In this section, the success and efficiency of our study will be analyzed by comparing the architectures used in the experiments with the results of other studies in the literature that used the same dataset.
The vision transformer (ViT) is a pioneering architecture in the field in which transformers, which have achieved significant success in text processing, are applied to image processing. However, over a short time, researchers have made many additions to the ViT architecture and, in some aspects, have created more powerful architectures. This study aims to analyze the effectiveness of four different transformer-based architectures based on their strengths and weaknesses. ViT, MAE, DINO, and SwinTransformer architectures have been developed in recent years and have been used in numerous papers worldwide.
Within the scope of the study, the four different transformer-based deep learning architectures were compared with other studies in the literature trained using similar parameters. Each of the transformer-based deep learning architectures selected in the study was chosen by the research team due to its different features. The ViT architecture is an important architecture preferred by many researchers who first used transformer architectures for image processing.
The MAE architecture is an architecture that has been extensively studied by researchers recently, where ViT architecture is improved with self-supervised learning and masking techniques. The DINO architecture is a hybrid, innovative, and groundbreaking architecture that combines self-distillation and self-supervised learning approaches with vision transformer architecture. The SwinTransformer architecture is an important architecture that has a reputation for achieving high success in many areas, powered by sliding windows and window-based self-attention mechanisms. Using the aforementioned features, the effect of the transformer-based architectures used in the study on the success of important innovations in the field on the classification of Mpox disease is also examined.
There are also important metrics that influence the choice of deep learning models, revealing which model is more efficient. These metrics evaluate important parameters, such as computational complexity, storage requirements, learning capacity, and speed, and guide researchers in model selection. FLOPs are a measure of the computational load of the model and represent the total floating point operations that the model undergoes while processing the input. Model size refers to the storage requirement of the model and represents how much disk space the model takes up. The model size parameter also determines the usability of the model on memory-constrained devices. The parameter count indicates the complexity and learning capacity of the model. Increasing the parameter count not only improves model performance but also requires more computational power and memory. Although models with small parameters achieve lower performance, in some cases, they may be preferable for memory-constrained or mobile devices. Inference time is defined as the time it takes to process an input and then generate a prediction. This metric can be critical for real-time applications.
Table 7 shows the results of model parameters, model size (MB), FLOPs (GMac), and inference time (ms) model evaluation parameters obtained during the experiments on ViT, MaeViT, DinoVit, and SwinTransformer deep learning architectures.
In the literature, there are only two studies that focus on disease diagnosis from Mpox images and address the problem as a multi-class classification problem. Addressing the problem as a multi-class classification problem is a more difficult problem to solve. In order to diagnose other skin lesions along with Mpox and to propose an overarching framework that can support doctors in decision-making, the problem is considered a multi-class classification problem.
Table 8 shows a comparison of the architectures in which we conducted training, validation, and testing processes within the scope of our study, as well as similar studies in the literature using the same evaluation metrics.
In the original version of the dataset, the test images were fold-sorted in five separate folders and published publicly. In order to accurately compare the results given in
Table 7 with other studies in the literature, the test process was carried out without disturbing the assumed flod structure of the dataset, and weighted averages were taken and compared with other studies.
In the article describing the BinaryDNet53 architecture given in
Table 8, it was not clear whether the pretrain network was used or not, so it could not be added to the table. In Ali et al. [
10], the recall evaluation metric and results are not shared, and the confusion matrix shared in the study is normalized. For this reason, data on the recall evaluation metric could not be added in the first two rows of the table. When the results obtained with the accuracy evaluation metric are compared, the SwinTransformer architecture proposed in our study achieved the highest classification success (93.71%). The ViT architecture, on the other hand, achieved 0.6% lower accuracy evaluation metric success than the SwinTransformer architecture. DINO and MAE architectures ranked third and fourth in terms of classification success. In the literature, there are two studies published in 2024 that try to classify images of Mpox disease as a multi-class classification problem. The test results obtained in the experiments conducted within the scope of our study had much higher classification success compared to existing studies in the literature. While the BinaryDNet53 architecture, which has the highest success rate in the literature addressing the problem as a multi-class classification problem, achieved 85.78% accuracy, the SwinTransformer architecture proposed in our study achieved 93.71% accuracy. This shows that the proposed work achieves about 8% higher classification success than its competitors in the literature.
Table 8 compares the results obtained from the four deep learning models on which the experiments were performed with the studies in the literature using the Mpox Skin Lesion Dataset Version 2.0 (MSLD v2.0). The reason for choosing this dataset is that it is the dataset that approaches the problem from the widest perspective. The dataset we used in our study approaches skin lesions, including Mpox, as a six-class classification problem. In our study, there are six different disease classes: Mpox, Chickenpox, Measles, Cowpox, HFMD, and Healthy. A solution to the problem of autonomous diagnosis of these diseases using transformer-based deep learning architectures is sought. When the literature is examined, there are some studies that deal with Mpox disease as a two-class classification problem that only approaches Mpox disease as disease present and disease absent [
34]. There are also some studies that deal with skin lesions, including Mpox disease, as a four-class classification problem [
35]. Two and four-class classification studies evaluate the subject with a lower number of classes and work on older datasets. In this study, a newer set published in the second half of 2024 was used, and a comparison was made with studies using this dataset, which constitutes the limitations of our study in this context.
SwinTransformer has the highest success on the six-class classification problem, with an accuracy of 0.9371; however, this success is also directly related to the fact that the architecture has 86,749,374 parameters. The high number of parameters in the architecture is directly related to the higher learning capacity of the model and, thus, the higher success rate. On the other hand, the high number of parameters increases the computational cost. For this reason, researchers working on disease diagnosis from medical images should evaluate computational load and classification success together when choosing a transformer-based deep learning model. SwinTransformer is an innovative deep learning architecture that divides the attention mechanism into local sliding windows, but its computational cost is high compared to other popular transformer-based architectures. In healthcare applications, misdiagnosis or underdiagnosis of diseases can sometimes lead to disease progression and permanent harm to the patient. In some cases, incorrect or incomplete diagnoses can also lead to an undesirable situation, such as the loss of the patient’s life. For this reason, it is very important to have high diagnostic success in diagnostic applications in medical fields. For these reasons, experiments have shown that SwinTransformer, one of the popular transformer-based architectures, achieves the highest classification success with the highest computational cost in skin lesion images, including Mpox disease.
Mpox Skin Lesion Dataset Version 2.0 (MSLD v2.0), a new dataset published in the second semester of 2024, was used in this study. The fact that the images in the dataset are prepared in accordance with the multi-class classification problem and that it is the most up-to-date dataset containing Mpox disease is an important positive aspect that distinguishes the dataset from others. The training, validation, and testing processes of the study were carried out using the images in this dataset. In future studies, the researchers plan to collect their own data and expand their experiments by obtaining ethics committee permission. However, the images in the Mpox Skin Lesion Dataset Version 2.0 (MSLD v2.0) used in this version of the study constitute the limits of the study.
The dataset used in our study includes a total of 755 different images obtained from 541 patients. More than one image was obtained from some patients and used in the dataset. However, the process of obtaining multiple images from a patient was not computer-aided with image enhancement algorithms. As is known, skin lesions can spread to different organs and different surfaces of the body. Multiple images obtained from one patient were created by using images taken from different body parts of the patients. The same images were not used in the training, validation, and testing processes of the dataset, and the reliability of the study was considered. The use of the MSLD v2.0 dataset containing 755 different images from 541 different patients constitutes the limits of our study.
5. Conclusions
The main purpose of this study was to present a framework for autonomous disease diagnosis with transformer-based deep learning methods by treating skin lesion images, including Mpox disease, as a multi-class classification problem. The Mpox Skin Lesion Dataset Version 2.0, which was publicly released in 2024, was used for training, validation, and testing. ViT, MAE, DINO, and SwinTransformer architectures, which have been preferred by many researchers in recent years and have achieved high success in many studies, were trained for disease diagnosis from skin lesion images. The results obtained are analyzed in detail and shared in the publication. In the default version of the dataset, the test procedures were carried out by sticking to the 5-fold division of the test images, so that an accurate comparison with previous papers in the literature could be made. The SwinTransformer architecture we proposed in our study achieved about 8% higher accuracy evaluation metric classification success compared to its closest competitor in the literature. ViT, MAE, DINO, and SwinTransformer architectures achieved 93.10%, 84.60%, 90.40%, and 93.71% classification success, respectively.
The main contribution of the study to the literature is to investigate the success of transformer-based deep learning architectures in classifying Mpox disease as a multi-class classification problem. Rapid diagnosis of Mpox disease, which is an important health problem faced by the world after the COVID-19 pandemic, is important to prevent the spread of the disease. This study contains important results as it can detect Mpox disease among multi-class skin lesions with high success compared to other studies in the literature.
The limitations of our study are the use of multi-class skin lesion images of Mpox disease and the use of transformer-based architectures. The two-class classification problem was not included in the comparison tables by the research team because the coverage of the studies that addressed the problem as a two-class classification problem was low, and it was not a real-life problem. In addition, the studies examined in the literature are CNN-based studies. Transformer-based architectures were preferred in our study in order to eliminate the gap in the literature and to reveal the success of transformer-based architectures. In future studies, research will be conducted on new hybrid transformer-based architectures enhanced with distillation techniques to improve classification success.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}