Abstract
Background: Stress is a critical determinant of mental health, yet conventional monitoring approaches often rely on subjective self-reports or physiological signals that lack real-time responsiveness. Recent advances in large language models (LLMs) offer opportunities for speech-driven, adaptive stress detection, but existing systems are limited to retrospective text analysis, monolingual settings, or detection-only outputs. Methods: We developed a real-time, speech-driven stress detection framework that integrates audio recording, speech-to-text conversion, and linguistic analysis using transformer-based LLMs. The system provides multimodal outputs, delivering recommendations in both text and synthesized speech. Nine LLM variants were evaluated on five benchmark datasets under zero-shot and few-shot learning conditions. Performance was assessed using accuracy, precision, recall, F1-score, and misclassification trends (false-negatives and false-positives). Real-time feasibility was analyzed through latency modeling, and user-centered validation was conducted across cross-domains. Results: Few-shot fine-tuning improved model performance across all datasets, with Large Language Model Meta AI (LLaMA) and Robustly Optimized BERT Pretraining Approach (RoBERTa) achieving the highest F1-scores and reduced false-negatives, particularly for suicide risk detection. Latency analysis revealed a trade-off between responsiveness and accuracy, with delays ranging from ~2 s for smaller models to ~7.6 s for LLaMA-7B on 30 s audio inputs. Multilingual input support and multimodal output enhanced inclusivity. User feedback confirmed strong usability, accessibility, and adoption potential in real-world settings. Conclusions: This study demonstrates that real-time, LLM-powered stress detection is both technically robust and practically feasible. By combining speech-based input, multimodal feedback, and user-centered validation, the framework advances beyond traditional detection only models toward scalable, inclusive, and deployment-ready digital mental health solutions.
1. Introduction
1.1. Background
Stress is a pervasive factor contributing to a wide range of physical and mental health disorders, including headaches, cardiovascular diseases, anxiety, and depression [1,2]. The increasing societal burden of stress highlights the urgent need for effective and timely detection and management strategies [3]. However, conventional stress monitoring techniques largely rely on subjective self-reports or physiological measurements, both of which present notable limitations. Self-reported data can be inconsistent and unreliable, as individuals may be unaware of their own emotional states or unable to articulate them accurately [4,5]. Physiological signals, such as heart rate variability and skin conductance, though objective, often fail to capture the evolving and context-sensitive nature of stress in real-world settings [6,7].
Given these challenges, there is a growing interest in developing AI-driven approaches to enhance stress detection capabilities.
Artificial intelligence (AI), particularly natural language processing (NLP), offers new avenues for stress detection by analyzing linguistic markers in speech and writing. Large Language Models (LLMs), a significant advancement in artificial intelligence, have demonstrated remarkable proficiency in understanding and generating human language [8]. Trained on vast corpora of text data, LLMs can detect nuanced patterns associated with emotional states, including stress [9]. These models have recently shown remarkable ability to detect subtle emotional patterns in language [8,9]. Unlike static text analyses, speech-driven approaches have the potential to capture stress in real time.
1.2. Research Gap
Traditional methods that rely on self-reports or physiological proxies frequently lack real-time responsiveness, limiting their utility in dynamic environments [10,11]. The emergence of natural language processing (NLP) methods offers new possibilities by analyzing the linguistic expression of stress in speech or writing. Studies have shown that the language individuals use, such as the prevalence of negative words, disrupted sentence structure, or accelerated speech rate, can serve as strong indicators of emotional strain [12,13]. Nevertheless, most prior work has focused on analyzing static text sources, such as social media posts, which capture stress retrospectively rather than in the moment or real-time assessment.
1.3. Objectives of the Study
To address this gap, this study proposes a real-time stress detection system that captures spoken audio, transcribes it into text, and analyzes the linguistic markers of stress using LLMs [14,15]. By examining features such as word choice, tone, and sentence organization, the system classifies stress levels into mild, moderate, and severe categories [16,17], enabling a more detailed and immediate understanding of an individual’s emotional state [18,19].
In addition to detection, the system provides tailored, actionable recommendations based on the identified stress level [20]. For instance, users classified with moderate stress may be encouraged to engage in breathing exercises, take mindful breaks, or listen to calming music, whereas severe cases may be guided toward more structured interventions. These personalized suggestions are designed to be practical, easily implementable, and context-aware, aiming to reduce stress in real time [21].
The use of LLMs in this context introduces a new dimension to stress management by combining linguistic analysis with psychological assessment principles [22,23]. This integration allows for a more accurate, accessible, and effective approach to understanding and managing emotional well-being.
Through this research, we aim to significantly contribute to the growing body of literature on AI applications in mental health, providing a foundation for future advancements in real time, responsive emotional support technologies [24,25].
The objectives of this study were:
- To design and implement a real-time stress detection system based on large language models (LLMs), integrating audio recording, speech-to-text conversion, and multimodal input–output capabilities (text and synthesized speech).
- To evaluate and compare transformer-based models across multiple benchmark stress-related datasets, analyzing accuracy, precision, recall, F1-score, and error rates in both zero-shot and few-shot learning settings.
- To examine real-time feasibility by quantifying latency–accuracy trade-offs across different model sizes and audio input lengths.
- To validate system usability and acceptance in real-world contexts through real-time user feedback from cross-domains.
By combining linguistic analysis with psychological principles, the framework seeks to move beyond detection-only systems and deliver context-aware, personalized digital interventions [22,23].
2. Related Work
2.1. Language-Based Stress Detection
Online platforms, particularly social media, have increasingly been recognized as valuable resources for understanding individuals’ psychological states, health behaviors, and overall well-being [26,27]. Over the past decade, extensive research has explored the use of content analysis and social interaction patterns to predict risks associated with mental health conditions such as anxiety, depression, and suicidal ideation [28,29]. The archival nature of social media provides opportunities to track psychological risk factors over time, while minimizing self-reporting biases [30,31].
Early investigations into mental health monitoring primarily employed basic linguistic analysis techniques to examine correlations between online language and psychological conditions [32,33].
2.2. Machine Learning and Deep Learning Approaches
As research progressed, more sophisticated machine learning and deep learning models were introduced to enhance predictive capabilities [34,35,36]. For example, Support Vector Machines (SVMs) were utilized to predict depressive symptoms, while architectures such as Long Short-Term Memory (LSTM)- Convolutional Neural Networks (CNNs) networks were deployed for detecting suicidal ideation on platforms like Reddit [37,38].
2.3. Large Language Models (LLMs) in Mental Health Prediction
The recent advent of pre-trained language models, such as Bidirectional Encoder Representations from Transformers (BERTs), has revolutionized mental health prediction tasks by providing models trained on massive corpora and subsequently fine-tuned for specific applications [39,40]. Additionally, multitask learning approaches have emerged, allowing models to simultaneously predict multiple mental health conditions [41,42], although such systems often remain constrained to fixed task sets [43,44]. Building on this foundation, the current research aims to explore next-generation LLMs fine-tuned with specific instructions, assessing their potential in mental health prediction across diverse and dynamic data sources.
Following the success of Transformer-based architectures like BERT and Generative Pre-Trained Transformers (GPTs), research and industry have increasingly focused on developing larger, more capable models such as GPT-3 and Text-to-Text Transfer Transformer (T5) [45]. Techniques such as instruction fine-tuning have further expanded model versatility by exposing LLMs to diverse datasets and prompt types, enabling generalized task adaptation [46,47]. Models such as GPT-4, Pathways Language Model (PaLM), Fine-Tuned Language Net—T5 (FLAN-T5), LLaMA, and Alpaca, each containing tens to hundreds of billions of parameters, have demonstrated state-of-the-art performance in a variety of tasks, including question answering, logical reasoning, and machine translation [48,49].
Recent efforts have also explored the application of LLMs in healthcare settings [50]. For instance, models like PaLM-2 and LLaMA have been fine-tuned on medical datasets, achieving promising results in clinical question answering and decision support tasks [49,51]. However, the use of LLMs in the mental health domain remains relatively underexplored. Early studies evaluated LLMs such as ChatGPT (GPT-3.5) for tasks involving sentiment analysis, emotional reasoning, and preliminary mental health assessments [52]. Despite showing considerable promise, existing models exhibit notable performance gaps, typically 5–10% lower in accuracy and F1-score, when applied to complex emotional prediction tasks [53].
More recently, specialized models such as Mental-LLaMA, fine-tuned specifically on mental health datasets, have been introduced. However, these efforts have primarily focused on limited models (e.g., LLaMA or GPT-3.5) and mostly explored zero-shot learning paradigms without systematically investigating alternative techniques for performance enhancement. In this context, the present research comprehensively explores the potential of multiple LLMs for real-time mental health prediction, with a focus on refining their capabilities through task-specific fine-tuning and instruction-based optimization.
3. Methodology
3.1. System Overview
This research proposes a comprehensive system for real-time stress detection and personalized management by integrating audio signal processing, natural language analysis, and advanced large language modeling (LLM) techniques. The methodological pipeline consists of five primary stages as shown in Figure 1: audio acquisition, speech-to-text conversion, text preprocessing, stress analysis using LLMs, and personalized recommendation generation.
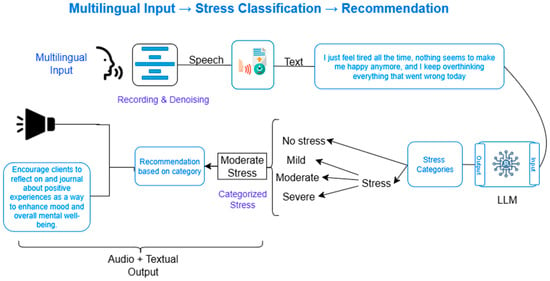
Figure 1.
A schematic overview of the end-to-end system workflow. (Multilingual input  Speech Text conversion LLM Stress detection and its classification Recommendation based on categorized stress level Audio + Textual Output).
Speech Text conversion LLM Stress detection and its classification Recommendation based on categorized stress level Audio + Textual Output).
Speech Text conversion LLM Stress detection and its classification Recommendation based on categorized stress level Audio + Textual Output).
3.2. Audio Acquisition and Speech-to-Text Conversion
The system initiates by capturing real-time audio inputs through microphone-enabled devices such as smartphones, tablets, or computers. Users are prompted to describe their feelings, experiences, or current emotional states verbally. To ensure high-fidelity transcription, a state-of-the-art speech-to-text (STT) engine is employed, capable of handling diverse accents, variable speech rates, and background noise conditions.
The transcribed text forms the basis for subsequent linguistic and emotional analysis.
3.3. Text Preprocessing
The textual data undergoes a multi-stage preprocessing pipeline to enhance quality and readiness for analysis:
- Noise Removal: Elimination of non-informative components such as filler words, long pauses, or repeated phrases.
- Normalization: Standardization procedures including lowercasing, punctuation correction, and removal of extraneous characters.
- Error Correction: Correction of potential transcription inaccuracies using linguistic and grammatical tools.
- Tokenization: Division of text into structured units (tokens) suitable for input into large language models.
This preprocessing ensures that the input accurately captures the user’s linguistic expressions while minimizing artifacts.
3.4. Stress Analysis Using Large Language Models
The preprocessed text is analyzed by a fine-tuned LLM trained for sentiment detection and stress classification. The model examines multiple linguistic dimensions, including:
- Lexical choice (e.g., prevalence of negative language)
- Syntactic structure (e.g., sentence complexity, disruptions)
- Emotional tone and semantic coherence
Based on these features, the system classifies the user’s emotional state into three stress levels:
- Mild Stress
- Moderate Stress
- Severe Stress
The classification enables nuanced, real-time monitoring of emotional well-being.
3.5. Personalized Recommendation Generation
Following stress classification, the system delivers actionable interventions tailored to the user’s current emotional state. Recommendations may include:
- Mild Stress: Reflective journaling, gratitude exercises, or short mindful activities.
- Moderate Stress: Structured breathing exercises, mindfulness practices, or guided relaxation.
- Severe Stress: Encouragement to seek professional mental health support, crisis helpline resources, or urgent self-care strategies.
The personalized feedback mechanism aims to provide immediate emotional support and promote proactive stress management.
3.6. Web-Based User Interface
To ensure accessibility and ease of interaction, a web-based user interface (UI) has been developed, screenshot of UI is depicted in Figure 2 and Figure 3. Figure 2 shows the user interface while Figure 3 shows the working of user interface.
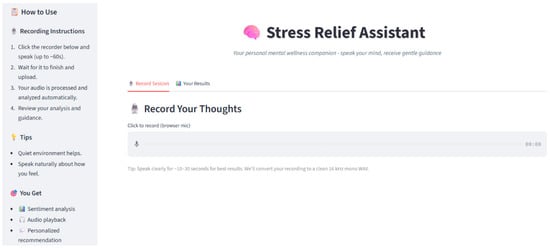
Figure 2.
Screenshot of User-Interface (UI) for user engagement.
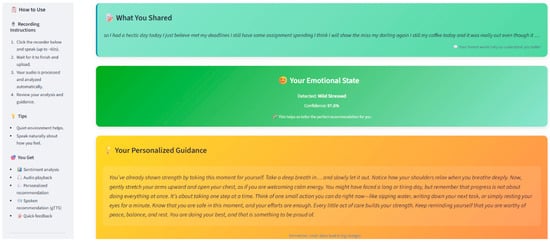
Figure 3.
Screenshot of working User-Interface (UI).
Key features of the interface include:
- Real-time audio recording and transcription display
- Visualization of emotional and stress analysis results
- Delivery of personalized, dynamic intervention suggestions
The intuitive design ensures that users across diverse backgrounds can seamlessly access real-time stress detection and management services through internet-enabled devices.
3.7. Validation of the Proposed Model Using Benchmark Datasets
The validation of the proposed real-time stress detection system was conducted using five benchmark datasets, each targeting different dimensions of stress and mental health assessment. The evaluation process was structured around two learning paradigms: zero-shot learning and few-shot learning. The primary objective was to assess the model’s generalization capabilities and its adaptability to task-specific nuances using limited labeled data. In addition to benchmark dataset evaluation, a real-time pilot usability test was conducted with 25 voluntary participants, including students, educators, and healthcare professionals. Participants were recruited via convenience sampling (probability method, i.e., simple random sampling). Since this was an exploratory usability validation, no formal sample size calculation was performed. The focus was to assess practical feasibility and user experience rather than hypothesis testing.
3.8. Benchmark Datasets
The datasets selected for validation provided comprehensive coverage across social, clinical, and high-risk emotional contexts:
- Stress Annotated Dataset (SAD): Focused on identifying social anxiety from online forum posts [54].
- Dreaddit: A Reddit-based dataset annotated for varying stress levels [55].
- DepSeverity: A dataset measuring the severity of depressive symptoms [56].
- Suicide Depression Classification with Noisy Labels (SDCNL): Counseling transcript data annotated for stress and emotional distress [57].
- Columbia-Suicide Severity Rating Scale (CSSRS)-Suicide: A dataset derived from the Columbia-Suicide Severity Rating Scale to classify suicidal risk levels [58].
The diversity of these datasets ensured a robust and multi-dimensional evaluation of the model’s capabilities.
3.9. Learning Paradigms
Two learning paradigms were employed:
- Zero-Shot Learning: The model was evaluated without any task-specific fine-tuning, relying purely on pre-trained knowledge representations. This assessed the system’s inherent ability to generalize to unseen domains.
- Few-Shot Learning: The model underwent fine-tuning using a limited number of labeled examples from each dataset. This approach evaluated the model’s adaptability and its capacity to learn task-specific features from minimal data exposure.
4. Experimental Results
The proposed system’s performance was benchmarked against several established models, including Gemma, BERT, RoBERTa, DistilBERT, XLNet, T5, DeBERTa, and Electra [59,60].
Key observations include:
- LLaMA consistently demonstrated competitive or superior performance across most datasets.
- While RoBERTa slightly outperformed LLaMA on SAD after fine-tuning, LLaMA showed better robustness on diverse and more challenging datasets like SDCNL and CSSRS-Suicide.
These findings emphasize the robustness of the proposed system, especially under real-world noisy data conditions. The performance results are summarized in Figure 4, detailing accuracy values across all datasets before and after fine-tuning. Figure 4 graphically illustrates the model’s performance plot improvements with zero-shot learning and few-shot learning.
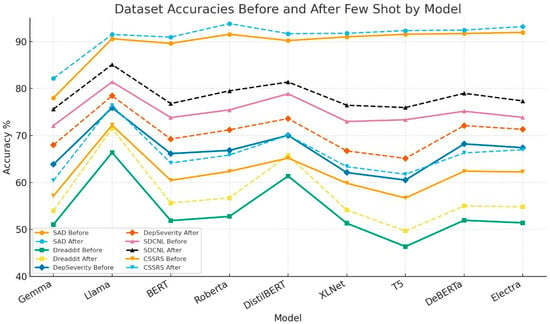
Figure 4.
Comparison of Performance Plot Before and After Fine-Tuning Across Datasets.
4.1. Comprehensive Metric Evaluation
To comprehensively assess the robustness of the proposed system, we evaluated nine transformer-based models (Gemma, LLaMA, BERT, RoBERTa, DistilBERT, XLNet, T5, DeBERTa, and Electra) across five benchmark datasets: SAD, SDCNL, CSSRS-Suicide, DepSeverity, and Dreaddit. Each model was tested under both zero-shot and few-shot paradigms. Performance metrics included Accuracy, Precision, Recall, F1-score, along with False Negative (FN) and False Positive (FP) rates, thereby providing a balanced evaluation of predictive capability and error tendencies. This approach provided a multi-dimensional view of performance, capturing not only predictive capability but also the reliability of classification under different conditions. Table 1 shows the model performance on SAD dataset including performance metrics like accuracy, precision, recall, F1-score, along with false negative (FN) and false positive (FP) rates.

Table 1.
Performance of Models on SAD (Accuracy, FN rate, FP rate, Precision, Recall, and F1-score in Zero-Shot and Few-Shot learning).
On the SAD, LLaMA and RoBERTa achieved the strongest results, with RoBERTa reaching 93.8% accuracy and balanced precision-recall in the few-shot setting. DistilBERT and DeBERTa also performed competitively, whereas Gemma lagged behind with significantly lower scores. Few-shot fine-tuning notably reduced FN and FP rates across all models, improving robustness. Table 2 shows the model performance on SDCNL dataset including performance metrics like accuracy, precision, recall, F1-score, along with false negative (FN) and false positive (FP) rates.
Table 2.
Performance of Models on SDCNL Dataset (Accuracy, FN rate, FP rate, Precision, Recall, and F1-score in Zero-Shot and Few-Shot learning).
In the SDCNL dataset (counseling transcripts), LLaMA again showed superior performance, improving from 81.4% to 85.1% accuracy after few-shot fine-tuning. DistilBERT achieved competitive recall (81.4%), but with slightly higher FP rates. Overall, models demonstrated consistent improvements with few-shot training, indicating adaptability to structured conversational data. Table 3 shows the model performance on CSSRS-Scuicide dataset including performance metrics like accuracy, precision, recall, F1-score, along with false negative (FN) and false positive (FP) rates.
Table 3.
Performance of Models on CSSRS-Suicide Dataset (Accuracy, FN rate, FP rate, Precision, Recall, and F1-score in Zero-Shot and Few-Shot learning).
The CSSRS-Suicide dataset posed the greatest challenge due to its high-risk nature. LLaMA delivered the highest performance with an F1-score of 84.54% after fine-tuning, followed closely by RoBERTa and DeBERTa. Smaller models such as Gemma and T5 showed weaker results, with high FN rates that could risk under-detection. This highlights the importance of larger models for sensitive clinical tasks. Table 4 shows the model performance on DepSeverity dataset including performance metrics like accuracy, precision, recall, F1-score, along with false negative (FN) and false positive (FP) rates.
Table 4.
Performance of Models on DepSeverity Dataset (Accuracy, FN rate, FP rate, Precision, Recall, and F1-score in Zero-Shot and Few-Shot learning).
In DepSeverity, LLaMA outperformed others, achieving 78.4% accuracy with improved F1 and reduced FN rates in the few-shot setup. BERT and RoBERTa demonstrated moderate gains but remained below LLaMA. DistilBERT offered reasonable precision and recall balance, while Gemma consistently underperformed. Table 5 shows the model performance on Dreaddit dataset including performance metrics like accuracy, precision, recall, F1-score, along with false negative (FN) and false positive (FP) rates.
Table 5.
Performance of Models on Dreaddit Dataset (Accuracy, FN rate, FP rate, Precision, Recall, and F1-score in Zero-Shot and Few-Shot learning).
The Dreaddit dataset (social media posts) was the most noisy and unstructured. Baseline performance was generally low, with most models below 60% accuracy in the zero-shot setting. After fine-tuning, LLaMA improved to 71.5% accuracy, outperforming all others. DistilBERT showed solid improvements as well, while Gemma and T5 had the weakest results. This reinforces that fine-tuning is critical for handling noisy, real-world text.
Summary of findings across all datasets:
- Few-shot fine-tuning consistently boosted performance, lowering FN/FP rates.
- LLaMA and RoBERTa emerged as the most reliable models, especially for high-risk and structured datasets.
- Smaller models (Gemma, T5) underperformed, making them less suitable for stress-sensitive tasks.
- The trade-off between model size, accuracy, and latency (as noted in the latency analysis) is crucial when considering real-time deployment.
4.2. Real-Time Performance Evaluation
To evaluate practical feasibility, we tested the system in real-time conditions with spoken input from individual participants.
4.2.1. Latency Analysis
Latency is a critical factor in evaluating the real-time applicability of stress detection systems. Our analysis indicates that latency grows with both audio length and model size. Processing longer audio requires handling more frames, while larger models perform more computation per frame, leading to increased delays.
Using a simple estimate for a 30 s audio clip, latency can be approximate as:
Latency (seconds) = 2.0 + (0.8 × Model Size in Billions of Parameters)
Based on this formula, latency values range from approximately 2.05 s for a distilled model to 7.60 s for LLaMA 7 billion. This trade-off underscores the balance between achieving high classification accuracy and maintaining responsiveness in real-time applications. Figure 5 illustrates latency distribution and overall real-time performance trends.
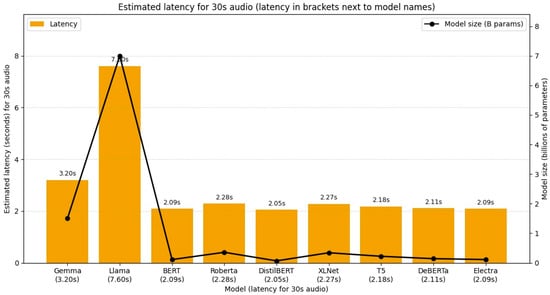
Figure 5.
Illustrates latency distribution and overall real-time performance trends.
4.2.2. Multilingual Support
The speech recognition and LLM modules demonstrated the ability to process inputs in multiple languages. This indicates that the system is robust across diverse linguistic contexts, an essential feature for real-world deployment where users may not always communicate in English. Future work will expand this capability by incorporating training data from additional languages and dialects to further improve accuracy and inclusivity.
4.2.3. Input and Output Modes
The system successfully received input in speech and generated responses in both text and synthesized speech formats. The input and output of the system did not store anywhere, therefore, removes privacy concerns as well. This dual-mode functionality enhances accessibility by ensuring that users with different preferences and needs, such as those with visual impairments or literacy barriers, can still benefit from real-time stress detection and intervention. Delivering feedback in multiple modalities also improves user engagement and adaptability in various use cases.
4.3. Case Studies from Benchmark Datasets
To further validate system performance, representative instances from each dataset were analyzed. The model not only classified the stress levels correctly but also generated contextually appropriate personalized recommendations.
Examples include:
- In SAD, expressions of social anxiety were classified as moderate stress, prompting journaling and exposure-therapy suggestions.
- In CSSRS-Suicide, signs of suicidal ideation were flagged, and immediate intervention recommendations were generated.
These examples, summarized in Table 6, illustrate the practical applicability of the system in providing real-time emotional support.
Table 6.
Stress Analysis Examples and Personalized Recommendations Across Datasets.
4.4. User Feedback from Different Domains
To complement quantitative evaluation, we gathered user feedback from individuals across multiple domains who interacted with the real-time stress detection system. Feedback analysis highlighted the following trends:
- Healthcare professionals appreciated the potential for non-invasive monitoring but emphasized the importance of clear disclaimers regarding clinical use.
- Students and educators valued multilingual processing and immediate coping suggestions, reporting increased engagement compared to static self-report tools.
- Corporate employees particularly favored the speech-based interface for quick stress check-ins during work hours, citing improved accessibility over text-only methods.
Graphical summary of this feedback is provided in Figure 6. Overall, users reported that the system was intuitive, accessible, and responsive.
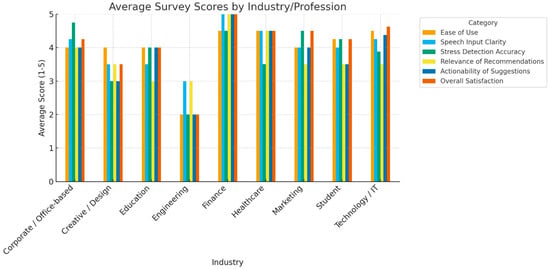
Figure 6.
Average user feedback summary across multiple professional domains (healthcare, education, and corporate). The figure illustrates overall satisfaction with system usability, accessibility, multilingual support, and effective intervention, highlighting consistent positive reception across diverse user groups.
5. Discussion
This Discussion is structured around the four objectives of the study: (i) to design and implement a real-time stress detection system integrating audio acquisition and multimodal outputs; (ii) to evaluate transformer-based LLMs across multiple stress-related datasets; (iii) to examine latency–accuracy trade-offs in real-time conditions; and (iv) to validate system usability through cross-domain user feedback.
This study introduced a real-time, speech-driven stress detection and management system powered by large language models (LLMs), addressing critical gaps left by previous approaches that were often retrospective, text-only, or monolingual [4,5,6,7,11,52]. By leveraging few-shot fine-tuning, the system achieved robust performance across benchmark datasets, notably improving recall and F1 in high-risk contexts such as suicidal ideation detection [61]. Beyond accuracy, the system demonstrated practical feasibility by analyzing latency-accuracy trade-offs [62], supporting multilingual inputs, and providing dual output modes. User-centered validation underscored strong usability, highlighting its readiness for real-world applications.
This study advances the field of computational mental health by presenting and validating a real-time stress detection and management system that integrates speech recognition, text preprocessing, and fine-tuned large language models (LLMs). The results across five benchmark datasets and real-time evaluations provide compelling evidence for both the technical robustness and the practical feasibility of the proposed approach. The following subsections analyze and interpret the results in relation to these objectives.
5.1. LLM Robustness Across Diverse Contexts
The comparative evaluation across nine transformer-based architectures demonstrates that larger LLMs (LLaMA, RoBERTa, DeBERTa) consistently outperform smaller counterparts such as Gemma and T5, particularly on high-risk datasets like CSSRS-Suicide. This is not surprising, as larger models leverage broader contextual representations, enabling them to capture subtle linguistic markers of stress and suicidality. Importantly, the few-shot learning paradigm proved indispensable, markedly reducing false negatives and false positives across all datasets. From a clinical perspective, reducing false negatives is crucial because under-detection of severe stress or suicidal ideation may carry significant risks. The superior performance of LLaMA (F1 = 84.54% on CSSRS-Suicide after few-shot tuning) therefore underscores the potential of such models in sensitive, safety-critical applications.
5.2. Trade-Offs Between Model Size, Accuracy, and Latency
The latency analysis highlights the practical tension between computational cost and predictive performance. While distilled or smaller models deliver near-instantaneous results (~2 s), their weaker accuracy renders them less suitable for clinical or high-stakes use. Conversely, larger models such as LLaMA-7B, despite yielding the highest accuracies, introduce latencies up to ~7.6 s for a 30 s clip. In real-world contexts, such delays are acceptable for self-monitoring applications but may hinder high-frequency workplace monitoring or clinical triage. This trade-off suggests that hybrid deployment strategies, using lightweight models for low-stakes screening and larger models for high-risk or flagged cases, could maximize both responsiveness and reliability.
5.3. Multilingual and Multimodal Strengths
The system’s ability to handle multilingual speech inputs and to provide dual-mode outputs (text and synthesized speech) is a critical innovation. These capabilities extend accessibility to diverse populations, including non-English speakers, visually impaired individuals, and those with literacy challenges. Unlike prior stress detection systems limited to text-only inputs or single-language corpora, [33,38], this approach demonstrates scalable inclusivity, making it adaptable for deployment in multilingual societies and global mental health initiatives.
5.4. User-Centered Evaluation
The incorporation of user feedback across professional domains adds a practical validation layer often missing in computational mental health studies. Healthcare professionals highlighted the promise of non-invasive monitoring but also raised the need for clear clinical disclaimers, a caution against premature medicalization. Educators and students valued the immediacy of multilingual feedback and coping suggestions, aligning with the push for mental health support in educational institutions. Corporate users praised the ease of speech-based interaction, reinforcing the system’s potential in workplace well-being programs. Importantly, the consistently positive reception across groups indicates strong usability and social acceptability, which are essential for real-world adoption.
5.5. Comparative Advantages over Previous Studies
- Integration of Real-Time Speech + LLMs vs. Retrospective Text-Based Methods: Many earlier stress-detection systems focus on textual or physiological signals retrospectively but do not include real-time speech input [4,5,6,7,11]. Moreover, while several studies have developed chatbot systems for mental health [52], our model extends beyond static conversational agents by integrating stress-level classification and adaptive response generation. This aligns with calls for more intelligent, context-aware digital interventions in psychological care [48,50]. However, our system integrates live audio acquisition, speech-to-text conversion, and immediate stress classification, making detection timely and context-aware.
- Multi-Metric Evaluation (Accuracy, FN/FP, Precision, Recall, F1) vs. Accuracy-Only or Binary Metrics: Several studies report only accuracy or binary classification (stress vs. non-stress) and often without detailed error analysis for false negatives/positives [63]. Our work goes further by examining FN rate, FP rate, precision, recall, and F1 in both zero-shot and few-shot settings across multiple datasets, providing a more nuanced view of model reliability, especially important in sensitive contexts such as suicidal ideation detection.
- Few-Shot Fine-Tuning Improves Generalization vs. Models Requiring Large Labeled Data: Traditional machine learning (ML) and deep learning (DL)-based methods (e.g., using Support Vector Machine (SVM), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN)) often require substantial annotated data for each domain or dataset [64]. Our study shows that with few-shot fine-tuning, even with limited new examples, performance improves significantly across datasets. This suggests better adaptability to new domains, and less dependence on large annotation efforts.
- Multilingual Support and Dual Output Modes vs. Monolingual, Text-Only Systems: Many previous works assume English input or text only [65]. Our model supports multilingual speech and outputs in both text and synthesized speech. This improves accessibility (for non-English users, those who prefer voice feedback), an important advance over prior systems that were more constrained.
- Latency Analysis & Real-Time Feasibility vs. High Accuracy Alone: Some prior work achieves high accuracy but do not report or consider latency or real-time usability. For example, many machine learning (ML)/Deep Learning (DL) methods in the literature focus purely on feature extraction + classification (speech signal, physiological data) without considering audio length/model size trade-offs [61]. We provide a latency model (Latency = 2.0 + 0.8 × model size in billions), highlighting how larger models incur longer delays. This allows for a practical assessment of trade-offs required for deployment in real-world scenarios.
- Domain Diversity and Risk-Sensitive Datasets vs. Simpler Data: Several studies use relatively clean datasets or those not involving high risk (e.g., general stress, depression). Our validation includes CSSRS-Suicide dataset, which addresses suicidal ideation, a high-risk domain where false negatives have severe consequences. The performance on CSSRS-Suicide (with few-shot fine-tuning) demonstrating high recall and F1 is an important strength.
Having compared our system with prior work, we next discuss its broader positioning against the state of the art and the implications for clinical and practical deployment
5.6. Positioning Against State of the Art
Relative to existing literature, the present study makes three strong contributions:
- It establishes that few-shot fine-tuned LLMs outperform both traditional ML and smaller transformer baselines in detecting stress across varied linguistic contexts.
- It introduces multilingual, multimodal, real-time capabilities, bridging a critical gap in accessibility and inclusivity.
- It validates not only algorithmic performance but also human-centered usability across professional domains, strengthening the case for real-world deployment.
- The input and output of the system do not store and therefore removes privacy concerns as well.
5.7. Limitations
While the findings are promising, several methodological and practical limitations must be acknowledged to assess both internal and external validity. Taken together, these findings argue for a paradigm shift in stress monitoring from retrospective, text-only analysis toward real-time, speech-driven, LLM-powered systems. The improvements demonstrated with few-shot learning suggest that future systems can be rapidly adapted to domain-specific environments. However, several limitations warrant consideration. First, the real-time evaluation involved a modest sample size (n = 25) using probability (simple random) sampling, which restricts external validity. Second, latency constraints highlight the need for edge-optimized LLMs that preserve accuracy without compromising speed. Third, although performance improved with few-shot fine-tuning, zero-shot results remain weaker, which may limit generalizability without domain-specific adaptation. Fourth, while multilingual support was tested, only a subset of languages and dialects were covered, requiring further cultural and linguistic validation. Fifth, multilingual support was tested, but not all languages/dialects were represented, further cultural/linguistic validation is needed. Sixth, the study was conducted under controlled usability settings and did not include longitudinal financial or access-related feasibility studies.
5.8. Future Directions
Building on these findings and limitations, the following directions are proposed for future research and system development.
- Extend evaluation to more languages, dialects, and speech styles (slang, colloquial speech).
- Explore on-device or edge computing strategies to reduce latency while preserving accuracy.
- Incorporate additional modalities (e.g., facial expression, physiological signals) to strengthen detection and reduce false negatives in high-risk categories.
- Conduct larger-scale longitudinal validation across diverse populations to evaluate the sustained effectiveness, reliability, and clinical impact of the system over extended periods of real-world use.
6. Conclusions
This study introduced a real-time, speech-driven stress detection and management system powered by large language models (LLMs), addressing critical gaps left by previous approaches that were often retrospective, text-only, monolingual, or focused solely on accuracy. By leveraging few-shot fine-tuning, the system achieved robust performance across five benchmark datasets, with notable improvements in reducing false negatives for high-risk contexts such as suicidal ideation detection.
Beyond technical robustness, the system demonstrated practical feasibility by analyzing latency-accuracy trade-offs, supporting multilingual speech inputs, and providing dual output modes (text and synthesized speech). Importantly, it incorporated user feedback from healthcare, education, and corporate domains, underscoring strong usability and acceptance, an aspect rarely emphasized in prior work.
The findings highlight that LLMs, when carefully adapted, can provide accurate, inclusive, and responsive solutions for mental health monitoring. This positions our work as a deployment-ready framework rather than a purely experimental system.
Nevertheless, challenges remain. Performance under zero-shot settings on noisy data requires further improvement and latency optimization is needed for large-scale deployment is essential. Future research should explore edge-optimized deployment, integration of multimodal signals (e.g., physiological or visual), and longitudinal clinical studies to assess sustained real-world impact.
In conclusion, this study provides evidence that real-time, LLM-powered stress detection systems represent a transformative step forward in mental health technology, offering not only technical advancement but also practical pathways for safe, inclusive, and scalable adoption across diverse domains.
Author Contributions
L.U. and Y.A.: Conceptualization and Investigation. L.U., Y.A. and J.I.: Methodology and Validation. Y.A.: Resources. Y.A. and J.I.: Supervision. L.U. and Y.A.: Visualization. L.U.: Writing—original draft and Software. A.A., H.I., U.A., Y.A. and L.U.: Writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study did not require institutional ethical approval as it was non-clinical, involved no patients or identifiable personal data, and used only publicly available anonymized datasets and voluntary usability testing.
Informed Consent Statement
Written informed consent has been obtained from the participants involving in reviewing of user interface (UI).
Data Availability Statement
The datasets used in this study are publicly available and can be accessed through the following sources: SAD [54], Dreaddit [55], DepSeverity [56], SDCNL [57], and CSSRS-Suicide [58]. No new data was generated or collected for this study.
Acknowledgments
The authors would like to express their sincere gratitude to the National University of Sciences and Technology (NUST), Pakistan, and the National Center of Artificial Intelligence (NCAI), Pakistan, for their invaluable support in conducting this research. The computational resources and research infrastructure provided by NCAI played a crucial role in the development and implementation of deep learning models for ocular toxoplasmosis classification.
Conflicts of Interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
References
- Raj, G.; Sharma, A.K.; Arora, Y. Analyzing the effect of digital technology on mental health. In Strategies for E-Commerce Data Security: Cloud, Blockchain, AI, and Machine Learning; IGI Global: Hershey, PA, USA, 2024; pp. 54–82. [Google Scholar] [CrossRef]
- Wu, J.R.; Chan, F.; Iwanaga, K.; Myers, O.M.; Ermis-Demirtas, H.; Bloom, Z.D. The transactional theory of stress and coping as a stress management model for students in Hispanic-serving universities. J. Am. Coll. Health 2025, 1–8. [Google Scholar] [CrossRef]
- Mazumdar, H.; Sathvik, M.; Chakraborty, C.; Unhelkar, B.; Mahmoudi, S. Real-time mental health monitoring for metaverse consumers to ameliorate the negative impacts of escapism and post-trauma stress disorder. IEEE Trans. Consum. Electron. 2024, 70, 2129–2136. [Google Scholar] [CrossRef]
- Keszei, A.P.; Novak, M.; Streiner, D.L. Introduction to health measurement scales. J. Psychosom. Res. 2010, 68, 319–323. [Google Scholar] [CrossRef]
- Singh, A.; Kumar, P. Student stress and mental health crisis: Higher education institutional perspective. In Student Stress in Higher Education; IGI Global: Hershey, PA, USA, 2024; pp. 218–229. [Google Scholar] [CrossRef]
- Facca, D.; Smith, M.J.; Shelley, J.; Lizotte, D.; Donelle, L. Exploring the ethical issues in research using digital data collection strategies with minors: A scoping review. PLoS ONE 2020, 15, e0237875. [Google Scholar] [CrossRef]
- Ozyildirim, G. Teachers’ occupational health: A structural model of work-related stress, depressed mood at work, and organizational commitment. Psychol. Sch. 2024, 61, 2930–2948. [Google Scholar] [CrossRef]
- Lu, Y.; Aleta, A.; Du, C.; Shi, L.; Moreno, Y. LLMs and generative agent-based models for complex systems research. Phys. Life Rev. 2024, 51, 283–293. [Google Scholar] [CrossRef]
- Yechuri, S.; Vanambathina, S. A subconvolutional U-net with gated recurrent unit and efficient channel attention mechanism for real-time speech enhancement. Wirel. Pers. Commun. 2024. [Google Scholar] [CrossRef]
- Haque, Y.; Zawad, R.S.; Rony, C.S.A.; Al Banna, H.; Ghosh, T.; Kaiser, M.S.; Mahmud, M. State-of-the-art of stress prediction from heart rate variability using artificial intelligence. Cogn. Comput. 2024, 16, 455–481. [Google Scholar] [CrossRef]
- Nijhawan, T.; Attigeri, G.; Ananthakrishna, T. Stress detection using natural language processing and machine learning over social interactions. J. Big Data 2022, 9, 33. [Google Scholar] [CrossRef]
- Montejo-Ráez, A.; Molina-González, M.D.; Jiménez-Zafra, S.M.; García-Cumbreras, M.Á.; García-López, L.J. A survey on detecting mental disorders with natural language processing: Literature review, trends and challenges. Comput. Sci. Rev. 2024, 53, 100654. [Google Scholar] [CrossRef]
- Can, Y.S.; Arnrich, B.; Ersoy, C. Stress detection in daily life scenarios using smart phones and wearable sensors: A survey. J. Biomed. Inform. 2019, 92, 103139. [Google Scholar] [CrossRef]
- Bucur, A.-M. Leveraging LLM-generated data for detecting depression symptoms on social media. In International Conference of the Cross-Language Evaluation Forum for European Languages; Springer: Berlin/Heidelberg, Germany, 2024; pp. 193–204. [Google Scholar] [CrossRef]
- Baran, K. Smartphone thermal imaging for stressed people classification using CNN+ MobileNetV2. Procedia Comput. Sci. 2023, 225, 2507–2515. [Google Scholar] [CrossRef]
- Geetha, R.; Gunanandhini, S.; Srikanth, G.U.; Sujatha, V. Human stress detection in and through sleep patterns using machine learning algorithms. J. Inst. Eng. India Ser. B 2024, 105, 1691–1713. [Google Scholar] [CrossRef]
- Gupta, M.V.; Vaikole, S.; Oza, A.D.; Patel, A.; Burduhos-Nergis, D.P.; Burduhos-Nergis, D.D. Audio-visual stress classification using cascaded RNN-LSTM networks. Bioengineering 2022, 9, 510. [Google Scholar] [CrossRef]
- Bromuri, S.; Henkel, A.P.; Iren, D.; Urovi, V. Using AI to predict service agent stress from emotion patterns in service interactions. J. Serv. Manag. 2024, 32, 581–611. [Google Scholar] [CrossRef]
- Xefteris, V.-R.; Dominguez, M.; Grivolla, J.; Tsanousa, A.; Zaffanela, F.; Monego, M.; Symeonidis, S.; Diplaris, S.; Wanner, L.; Vrochidis, S.; et al. Stress detection based on physiological sensor and audio signals, and a late fusion framework: An experimental study and public dataset. Res. Sq. 2023. [Google Scholar] [CrossRef]
- Lopez, F.S.; Condori-Fernandez, N.; Catala, A. Towards real-time automatic stress detection for office workplaces. In Information Management and Big Data, Proceedings of the 5th International Conference, SIMBig 2018, Lima, Peru, 3–5 September 2018; Springer: Cham, Switzerland, 2018; pp. 273–288. [Google Scholar] [CrossRef]
- Suneetha, C. A survey of machine learning techniques on speech-based emotion recognition and post-traumatic stress disorder detection. NeuroQuantology 2022, 20, 69–79. [Google Scholar]
- Sohail, S.S.; Farhat, F.; Himeur, Y.; Nadeem, M.; Madsen, D.Ø.; Singh, Y.; Atalla, S.; Mansoor, W. Decoding ChatGPT: A taxonomy of existing research, current challenges, and possible future directions. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 101675. [Google Scholar] [CrossRef]
- Arushi; Dillon, R.; Teoh, A.N.; Dillon, D. Detecting public speaking stress via real-time voice analysis in virtual reality: A review. In Proceedings of the Sustainability, Economics, Innovation, Globalisation and Organisational Psychology Conference, Singapore, 1–3 March 2023; Springer: Singapore, 2023; pp. 117–152. [Google Scholar] [CrossRef]
- Al-Saadawi, H.F.; Das, B.; Das, R. A systematic review of trimodal affective computing approaches: Text, audio, and visual integration in emotion recognition and sentiment analysis. Expert Syst. Appl. 2024, 255, 124852. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef]
- Denecke, K.; Reichenpfader, D. Sentiment analysis of clinical narratives: A scoping review. J. Biomed. Inform. 2023, 140, 104336. [Google Scholar] [CrossRef]
- Epel, E.S.; Crosswell, A.D.; Mayer, S.E.; Prather, A.A.; Slavich, G.M.; Puterman, E.; Mendes, W.B. More than a feeling: A unified view of stress measurement for population science. Front. Neuroendocrinol. 2018, 49, 146–169. [Google Scholar] [CrossRef]
- Bentley, K.H.; Franklin, J.C.; Ribeiro, J.D.; Kleiman, E.M.; Fox, K.R.; Nock, M.K. Anxiety and its disorders as risk factors for suicidal thoughts and behaviors: A meta-analytic review. Clin. Psychol. Rev. 2016, 43, 30–46. [Google Scholar] [CrossRef]
- Nguyen, T.; Phung, D.; Dao, B.; Venkatesh, S.; Berk, M. Affective and content analysis of online depression communities. IEEE Trans. Affect. Comput. 2014, 5, 217–226. [Google Scholar] [CrossRef]
- Panagiotopoulos, P.; Barnett, J.; Bigdeli, A.Z.; Sams, S. Social media in emergency management: Twitter as a tool for communicating risks to the public. Technol. Forecast. Soc. Change 2016, 111, 86–96. [Google Scholar] [CrossRef]
- Palen, L.; Hughes, A.L. Social media in disaster communication. In Handbook of Disaster Research; Rodríguez, H., Donner, W., Trainor, J.E., Eds.; Springer: Cham, Switzerland, 2018; pp. 497–518. [Google Scholar] [CrossRef]
- Khan, A.; Ali, R. Unraveling minds in the digital era: A review on mapping mental health disorders through machine learning techniques using online social media. Soc. Netw. Anal. Min. 2024, 14, 78. [Google Scholar] [CrossRef]
- Uban, A.-S.; Chulvi, B.; Rosso, P. An emotion and cognitive-based analysis of mental health disorders from social media data. Future Gener. Comput. Syst. 2021, 124, 480–494. [Google Scholar] [CrossRef]
- Poudel, U.; Jakhar, S.; Mohan, P.; Nepal, A. AI in Mental Health: A Review of Technological Advancements and Ethical Issues in Psychiatry. Issues Ment. Health Nurs. 2025, 46, 693–701. [Google Scholar] [CrossRef]
- Iyortsuun, N.K.; Kim, S.-H.; Jhon, M.; Yang, H.-J.; Pant, S. A review of machine learning and deep learning approaches on mental health diagnosis. Healthcare 2023, 11, 285. [Google Scholar] [CrossRef]
- Balraj, C.S.; Nagaraj, P. Prediction of Mental Health Issues and Challenges Using Hybrid Machine and Deep Learning Techniques. In Proceedings of the International Conference on Mathematics and Computing, Krishnankoil, India, 2–7 January 2024; Springer Nature: Singapore, 2024; pp. 15–27. [Google Scholar] [CrossRef]
- Saidi, A.; Othman, S.B.; Saoud, S.B. Hybrid CNN-SVM classifier for efficient depression detection system. In Proceedings of the 2020 4th International Conference on Advanced Systems and Emergent Technologies (IC ASET), Hammamet, Tunisia, 15–18 December 2020; IEEE: New York, NY, USA, 2020; pp. 229–234. [Google Scholar] [CrossRef]
- Xie, W.; Wang, C.; Lin, Z.; Luo, X.; Chen, W.; Xu, M.; Liang, L.; Liu, X.; Wang, Y.; Luo, H.; et al. Multimodal fusion diagnosis of depression and anxiety based on CNN-LSTM model. Comput. Med. Imaging Graph. 2022, 102, 102128. [Google Scholar] [CrossRef]
- Garg, M. Mental health analysis in social media posts: A survey. Arch. Comput. Methods Eng. 2023, 30, 1819–1842. [Google Scholar] [CrossRef]
- Kuttala, R.; Subramanian, R.; Oruganti, V.R.M. Multimodal hierarchical CNN feature fusion for stress detection. IEEE Access 2023, 11, 6867–6878. [Google Scholar] [CrossRef]
- Wang, X.; Liu, K.; Wang, C. Knowledge-enhanced pre-training large language model for depression diagnosis and treatment. In Proceedings of the 2023 IEEE 9th International Conference on Cloud Computing and Intelligent Systems (CCIS), Beijing, China, 12–13 August 2023; IEEE: New York, NY, USA, 2023; pp. 532–536. [Google Scholar] [CrossRef]
- Naegelin, M.; Weibel, R.P.; Kerr, J.I.; Schinazi, V.R.; La Marca, R.; von Wangenheim, F.; Hoelscher, C.; Ferrario, A. An interpretable machine learning approach to multimodal stress detection in a simulated office environment. J. Biomed. Inform. 2023, 139, 104299. [Google Scholar] [CrossRef]
- Haque, F.; Nur, R.U.; Al Jahan, S.; Mahmud, Z.; Shah, F.M. A transformer-based approach to detect suicidal ideation using pre-trained language models. In Proceedings of the 2020 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; IEEE: New York, NY, USA, 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sadeghi, M.; Egger, B.; Agahi, R.; Richer, R.; Capito, K.; Rupp, L.H.; Schindler-Gmelch, L.; Berking, M.; Eskofier, B.M. Exploring the capabilities of a language model-only approach for depression detection in text data. In Proceedings of the 2023 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), Pittsburgh, PA, USA, 15–18 October 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Qiu, J.; Lam, K.; Li, G.; Acharya, A.; Wong, T.Y.; Darzi, A.; Yuan, W.; Topol, E.J. LLM-based agentic systems in medicine and healthcare. Nat. Mach. Intell. 2024, 6, 1418–1420. [Google Scholar] [CrossRef]
- Anisuzzaman, D.M.; Malins, J.G.; Friedman, P.A.; Attia, Z.I. Fine-tuning llms for specialized use cases. Mayo Clin. Proc. Digit. Health 2024, 3, 100184. [Google Scholar] [CrossRef]
- Wang, Y.; Fu, T.; Xu, Y.; Ma, Z.; Xu, H.; Du, B.; Lu, Y.; Gao, H.; Wu, J.; Chen, J. TWIN-GPT: Digital twins for clinical trials via large language model. ACM Trans. Multimed. Comput. Commun. Appl. 2024. [Google Scholar] [CrossRef]
- Xiao, H.; Zhou, F.; Liu, X.; Liu, T.; Li, Z.; Liu, X.; Huang, X. A comprehensive survey of large language models and multimodal large language models in medicine. Inf. Fusion 2025, 117, 102888. [Google Scholar] [CrossRef]
- Mellouk, W.; Handouzi, W. Multimodal Contactless Human Stress Detection Using Deep Learning. In Proceedings of the International Conference on Computing Systems and Applications, Sousse, Tunisia, 22–26 October 2024; Springer Nature: Cham, Switzerland, 2024; pp. 3–12. [Google Scholar] [CrossRef]
- Wals Zurita, A.J.; Miras del Rio, H.; Ugarte Ruiz de Aguirre, N.; Nebrera Navarro, C.; Rubio Jimenez, M.; Muñoz Carmona, D.; Miguez Sanchez, C. The transformative potential of large language models in mining electronic health records data: Content analysis. JMIR Med. Inform. 2025, 13, e58457. [Google Scholar] [CrossRef]
- Nassiri, K.; Akhloufi, M.A. Recent advances in large language models for healthcare. BioMedInformatics 2024, 4, 1097–1143. [Google Scholar] [CrossRef]
- Yu, H.; McGuinness, S. An experimental study of integrating fine-tuned LLMs and prompts for enhancing mental health support chatbot system. J. Med. Artif. Intell. 2024, 7, 1–16. [Google Scholar] [CrossRef]
- Xiang, J.Z.; Wang, Q.Y.; Fang, Z.B.; Esquivel, J.A.; Su, Z.X. A multi-modal deep learning approach for stress detection using physiological signals: Integrating time and frequency domain features. Front. Physiol. 2025, 16, 1584299. [Google Scholar] [CrossRef]
- Mauriello, M.L.; Lincoln, T.; Hon, G.; Simon, D.; Jurafsky, D.; Paredes, P. Sad: A stress annotated dataset for recognizing everyday stressors in sms-like conversational systems. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Turcan, E.; McKeown, K. Dreaddit: A Reddit dataset for stress analysis in social media. arXiv 2019, arXiv:1911.00133. [Google Scholar] [CrossRef]
- Naseem, U.; Dunn, A.G.; Kim, J.; Khushi, M. Early identification of depression severity levels on reddit using ordinal classification. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022; pp. 2563–2572. [Google Scholar] [CrossRef]
- Haque, A.; Reddi, V.; Giallanza, T. Deep learning for suicide and depression identification with unsupervised label correction. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2021: 30th International Conference on Artificial Neural Networks, Part V, Bratislava, Slovakia, 14–17 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 436–447. [Google Scholar] [CrossRef]
- Barzilay, S.; Yaseen, Z.S.; Hawes, M.; Kopeykina, I.; Ardalan, F.; Rosenfield, P.; Murrough, J.; Galynker, I. Determinants and predictive value of clinician assessment of short-term suicide risk. Suicide Life-Threat. Behav. 2019, 49, 614–626. [Google Scholar] [CrossRef]
- Delobelle, P.; Winters, T.; Berendt, B. Robbert: A dutch roberta-based language model. arXiv 2020, arXiv:2001.06286. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Varma, S.; Shivam, S.; Ray, B.; Banerjee, A. Few-Shot Learning with Fine-Tuned Language Model for Suicidal Text Detection. In Proceedings of the International Conference on Frontiers in Computing and Systems, Himachal Pradesh, India, 16–17 October 2023; Springer Nature: Singapore, 2023; pp. 139–151. [Google Scholar] [CrossRef]
- Rozand, V.; Lebon, F.; Papaxanthis, C.; Lepers, R. Effect of mental fatigue on speed–accuracy trade-off. Neuroscience 2015, 297, 219–230. [Google Scholar] [CrossRef]
- Kumar, A.; Shaun, M.A.; Chaurasia, B.K. Identification of psychological stress from speech signal using deep learning algorithm. E-Prime-Adv. Electr. Eng. Electron. Energy 2024, 9, 100707. [Google Scholar] [CrossRef]
- Shahapur, S.S.; Chitti, P.; Patil, S.; Nerurkar, C.A.; Shivannagol, V.S.; Rayanaikar, V.C.; Sawant, V.; Betageri, V. Decoding minds: Estimation of stress level in students using machine learning. Indian J. Sci. Technol. 2024, 17, 2002–2012. [Google Scholar] [CrossRef]
- Ali, A.A.; Fouda, A.E.; Hanafy, R.J.; Fouda, M.E. Leveraging audio and text modalities in mental health: A study of LLMs performance. arXiv 2024, arXiv:2412.10417. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).