1. Introduction
In recent years, the rising incidence of skin disease mortality has garnered public attention [
1], and deep learning techniques such as ResNets [
2] have become dominant computer-aided dermatologic diagnosis methods. However, despite their promising success, deep models are often regarded as “black boxes,” as their decision-making process is not always transparent or clinically interpretable. Given an image of a skin lesion, they can predict the lesion category but cannot explain the prediction’s basis. To address this issue, many previous studies have used attention visualization (AV) methods, such as class activation maps (CAMs) [
3] and gradient-based class activation maps (Grad-CAM) [
4], to explain the prediction basis of deep models in dermatologic diagnosis [
5,
6,
7,
8]. AV refers to generating a heatmap to highlight the regions in the input image leading to the model’s prediction. For example, Jiang et al. [
6] added a CAM to some attention modules to generate a heatmap that identifies the lesion regions considered the decision basis. Wang et al. [
5] utilized Grad-CAM as a part of an interpretable module to produce a heatmap for explaining the dermatologic diagnostic results.
However, many recent studies have pointed out that the heatmap yielded by existing AV methods is imprecise [
9,
10,
11]. Existing AV methods usually employ a model’s deep layer to obtain a low-resolution activation map and up-sample it to create a heatmap of the same size as the input. This strategy requires the sampling results to be aligned with the input image spatially. However, the receptive field is very large in deep layers. For example, in ResNet50 [
2], the receptive field of each pixel of a deep feature map can be even larger than the original input [
12]. That is, in this case, from a theoretical point of view, each pixel of the deep activation maps may potentially sense any location on the input; thus it is not reasonable to use them to identify particular locations. From a practical point of view, deep activation maps somehow do correlate spatially with the input image. However, the underlying problem of too large receptive fields still causes many surface problems such as receptive field misalignment [
9]. These problems have also been observed previously by other researchers [
9,
10,
11].
Additionally, due to the large receptive field, most deep models are highly effective at capturing global features but struggle to capture fine-grained spatial details. However, for skin disease classification, these fine details are crucial. The differences between skin disease categories, such as melanoma and nevus, are often subtle and lie in fine-grained features like edge irregularity and color unevenness. While these diseases may appear similar in overall shape, it is these detailed characteristics that often determine whether a lesion is malignant or benign.
Another issue with today’s deep learning-based dermatologic diagnostics is the neglect of statistically-based traditional visual features derived from clinical experience, which are mathematically interpretable. For example, extracting edge information from a lesion and checking whether the pigment pattern shows a sharp, abrupt cutoff or a gradual, inconspicuous one is a crucial step in the clinical diagnostic process of a skin lesion [
13,
14]. Therefore, traditional computer-aided diagnostics often utilize edge information (EI) such as Sobel [
15] as part of the descriptors [
16]. Other examples include color–texture information (CTI), which also plays a crucial role in both clinical and traditional computer-aided diagnosis of skin lesions [
13]. Although it is possible for a deep model to implicitly acquire features with similar functionality to traditional ones during feature extraction, it remains uncertain whether they actually do so. Additionally, understanding how deep models base decisions on these features is unattainable.
In response to the above issues, we revisited the dermatological image diagnosis process used before the rise in deep learning. In this traditional approach, handcrafted features are first extracted from small image patches and then statistically analyzed before being aggregated into image-level representations [
17]. This method has two advantages: first, the extracted features from each patch are statistically interpretable; second, identifying the most influential patches helps pinpoint the visual cues contributing to the diagnosis. Inspired by this, we explore
whether modern deep learning systems can retain these advantages while maintaining their performance benefits. This led us to bag-of-feature (BoF) models [
18], which classify an image based on the occurrence of small local images, and we propose the edge- and color–texture-aware bag-of-local-features model (ECT-BoFM), which allows the BoF model to draw insights from traditional features without being constrained by them, thereby further enhancing performance.
Specifically, as shown in
Figure 1, in ECT-BoFM, a backbone network with a small receptive field extracts local features from small patches obtained by splitting an input image. The local features are then averaged to be the global descriptor for classification. In this way, each deep feature element strictly corresponds spatially to a particular patch of the input image. ECT-BoFM is trained with multiple tasks, including classification and the reconstruction of traditional EI and CTI features using deep features. The latter task not only enables the model to learn EI and CTI from the traditional features but also provides heatmaps from different perspectives. This allows us to understand not only where the model deems important but also the perspective (EI or CTI) upon which the model bases its importance assessment. Our contributions are as follows:
- (i)
We propose the novel ECT-BoFM for skin lesion diagnosis, which limits the size of the deep features’ receptive field to obtain precise heatmaps and learns CTI and EI from traditional features.
- (ii)
We propose a non-rigid reconstruction strategy that allows the model to learn from traditional features without being constrained by them.
- (iii)
ECT-BoFM, while sacrificing some capability in capturing global image information, significantly enhances the extraction of fine-grained features, which are more critical for skin lesion diagnosis, achieving high diagnostic performance. It surpassed recent state-of-the-art methods on two widely used public datasets, ISIC2018 [
19] and ISIC2019 [
19,
20].
- (iv)
ECT-BoFM yields precise and detailed heatmaps showing the prediction basis, potentially making clinical applications of computer-aided diagnosis more trustworthy.
- (v)
Our experiments show that using only a small subset of image regions selected by our algorithm enables global-feature-learning models such as Vision Transformers [
21] to achieve classification performance comparable to full-image inputs. This raises questions about the necessity and effectiveness of global learning mechanisms like self-attention and deep-stacked CNNs for skin disease diagnosis. We believe that this insight could inspire the development of more efficient network architectures in the future.
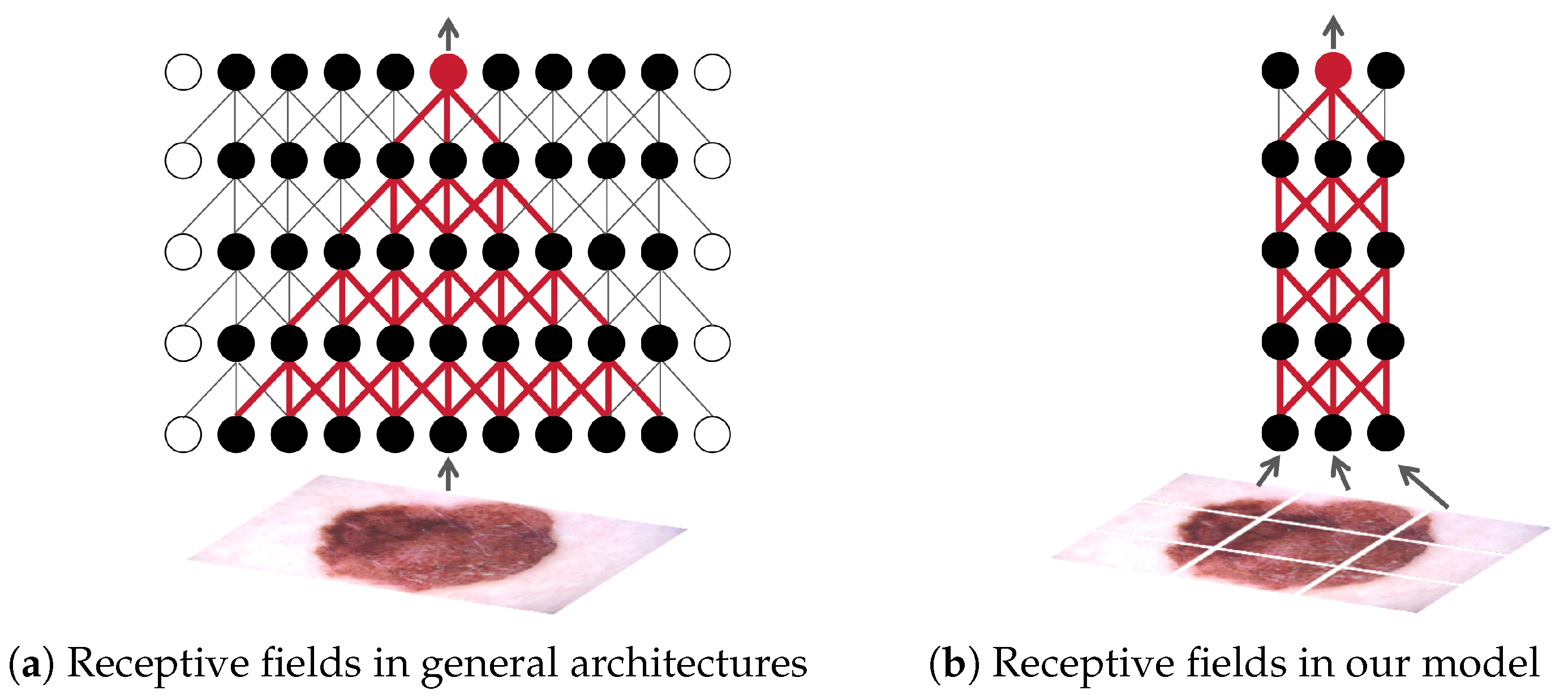
Figure 1.
A simplified illustration of the receptive fields [
22] of general convolutional neural networks (CNNs) and our model. For ease of understanding, a feature map is simplified as a row of solid circles and shown. The hollow circles represent padding. Here we use a 3 × 3 convolution with a stride of one as an example. In conventional CNNs, stacking multiple convolutional layers progressively enlarges the receptive field [
22,
23], allowing each pixel in the deep feature map to theoretically correspond to any location in the entire image. In contrast, our model divides the input image into independent patches, each processed by a network with a small receptive field and shared weights. The predictions (logits) from all patches are then averaged to produce the final output. This ensures that each pixel in the deep feature map strictly corresponds to a specific patch. Note that for illustration, we show a 3 × 3 grid of patches in this figure. In our actual work, a 225 × 225 input image is divided into 25 × 25 patches using a 33 × 33 window with a stride of eight, enabling more precise heatmap generation.
Figure 1.
A simplified illustration of the receptive fields [
22] of general convolutional neural networks (CNNs) and our model. For ease of understanding, a feature map is simplified as a row of solid circles and shown. The hollow circles represent padding. Here we use a 3 × 3 convolution with a stride of one as an example. In conventional CNNs, stacking multiple convolutional layers progressively enlarges the receptive field [
22,
23], allowing each pixel in the deep feature map to theoretically correspond to any location in the entire image. In contrast, our model divides the input image into independent patches, each processed by a network with a small receptive field and shared weights. The predictions (logits) from all patches are then averaged to produce the final output. This ensures that each pixel in the deep feature map strictly corresponds to a specific patch. Note that for illustration, we show a 3 × 3 grid of patches in this figure. In our actual work, a 225 × 225 input image is divided into 25 × 25 patches using a 33 × 33 window with a stride of eight, enabling more precise heatmap generation.
![Diagnostics 15 01883 g001]()
3. Method
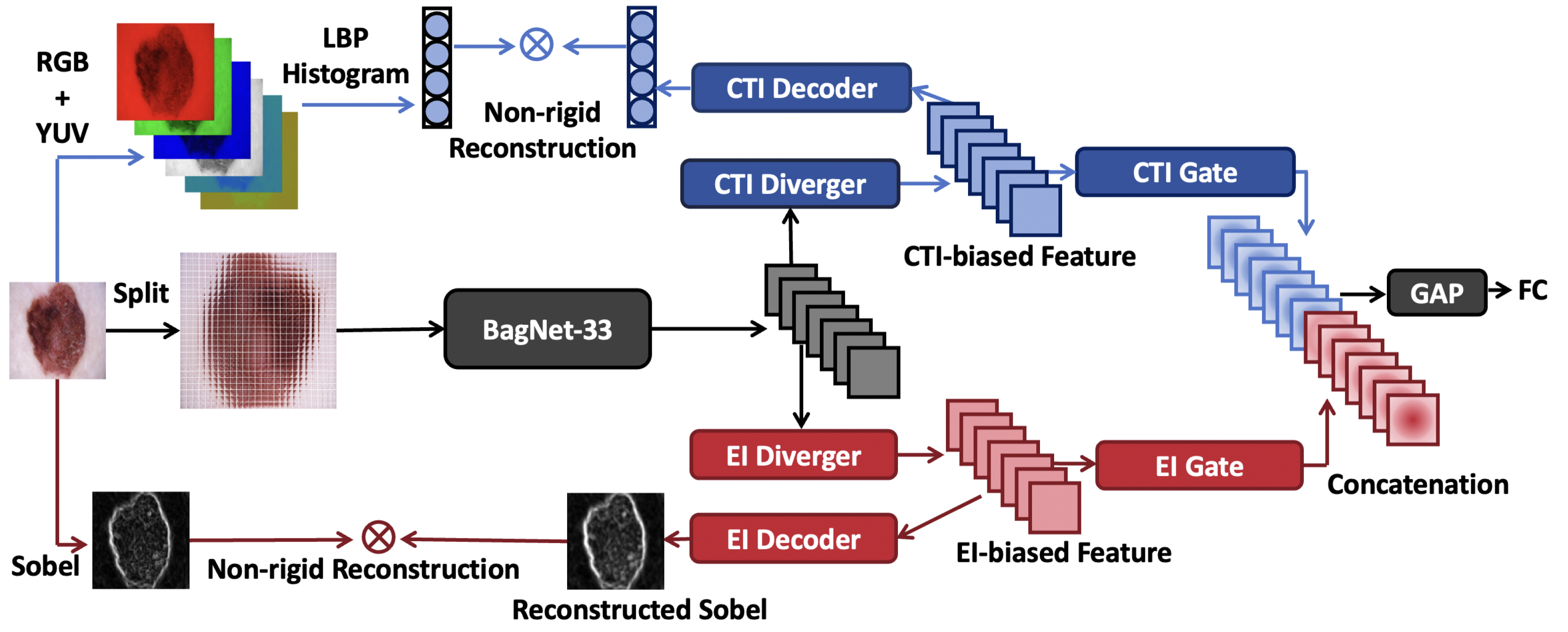
Figure 2 illustrates the overall framework of ECT-BoFM. Let
denote an input image. The framework conducts three main processes on
I: (i) extracting the RGB (red, green, and blue) and YUV (luma, chrominance blue, and chrominance red) channels from
I and concatenating the local binary pattern (LBP) histograms [
32] (59-D) computed on the six channels to form a color–texture descriptor
; (ii) obtaining a deep feature map
X using a backbone network
; and (iii) deriving an EI map
with the Sobel operator [
15].
The backbone network
is based on BagNet-33 [
18], so the receptive field is restricted to 33 × 33 pixels. In this paper, we set the stride for the 33 × 33 window as 8. The default input size of the original BagNet-33 model is 224 × 224, which results in the regions at the end of the input image not being traversed by the 33 × 33 window. To solve this problem, we set the size of
I as 225 × 225, making
. Each element
in
X strictly corresponds to a certain 33 × 33 region in
I.
Thereafter, a CTI diverger and an EI diverger take X as the input to generate a CTI-biased feature map and an EI-biased feature map , respectively. Then, a CTI decoder and an EI decoder take and as the input to reconstruct C and E, respectively. During training, the decoders are optimized with the proposed non-rigid reconstruction strategy, which can prevent the optimization of the decoders from harming the classification performance. Meanwhile, a CTI gate and an EI gate enhance the features in and that are beneficial for classification and weaken the unbeneficial features, respectively. The gated features are concatenated and then processed by global pooling (GAP) and fully connected (FC) layers for classification. During training, to obtain optimal results, we use a strategy called partial sharpness-aware minimization (PSAM) to optimize the whole framework. For inference, the decoders are removed, and the traditional features are not needed.
Divergers: The divergers are designed to diverge X into a CTI-biased feature map versus an EI-biased feature map. Let denote a convolutional layer, which has M input channels, N output channels, and a kernel size of . All the convolutional layers given in this section do not use padding layers and have a stride of 1, so we omit them in the equations. The CTI and EI divergers have the same structure but do not share the parameters. The functions can be written as , .
Decoders: The decoders are designed to reconstruct the color–texture descriptor
and edge map
. This design allows the model to learn about CTI and EI during training and subsequently analyze the classification results from the perspectives of CTI and EI through visualization. In a typical reconstruction task, the decoder generates an output of the same size as the target and minimizes the point-to-point difference between this output and the target using a loss function such as the widely used Smooth L1 Loss. However, the main task in this paper is the classification task. Directly applying the typical strategies in the reconstruction task may result in degraded classification performance. For example, there may be competition between the low-level vision task (reconstruction) and high-level vision task (classification). Also, traditional feature extractors such as LBP and Sobel have been behind deep models in terms of classification performance for a long time. Making deep features strictly approximate traditional features may limit their usefulness. To solve this problem, we propose non-rigid reconstruction (NRR), which does not view the traditional features as direct reconstruction targets of
and
, but rather as a special case in distributions defined by
and
. Given
and
, NRR first defines two Gaussian distributions,
and
, where
and
are
Here,
,
, and
represent fully connected, global average pooling, and ReLU operations, respectively. Thereafter, we generate new features
and
by randomly sampling from the obtained distributions. However, due to the non-differentiability of random sampling, we follow Kingma et al. [
33] to utilize reparameterization in practice. Let
denote one of the above distributions, with the feature dimensionality omitted. Instead of directly sampling from
, the reparameterization trick samples
from a standard normal distribution
and computes the desired sample
z as
.
z can refer to either
or
).
is then up-sampled as
where
is a transposed convolution layer, and its stride is set as 8. Thus, the up-sampling process of this layer is in strict spatial correspondence with the down-sampling process of
. The proposed reconstruction loss is
where
denotes a KL loss with a sum reduction, and the log function can prevent the loss value from being too large. The design of NRR avoids strictly forcing
and
to adhere to traditional features to the extent that it may limit classification performance. At the same time, this design enables
and
to learn macroscopic knowledge about CTI and EI during training that goes beyond the information covered by the traditional features [
33].
Gates: The gates are designed to enhance features in
and
that are beneficial for classification and weaken those that are unhelpful. The gated features
and
are obtained as
Here, ⊗ denotes the multiplication broadcast across the feature channels. and are CTI and EI gating weights, respectively. and then undergo concatenation, GAP, and FC operations to obtain categorical logits l.
Partial Sharpness-aware Minimization: During training, the overall loss can be written as
, where
denotes a softmax loss, and
l,
t are the predicted logits and target, respectively. Minimizing
is multi-task learning that encompasses both high-level and low-level vision tasks. To avoid pulling between tasks leading to suboptimal results, we propose PSAM, which is adapted from sharpness-aware minimization (SAM) [
34]. Generally, the optimization of a model is defined as looking for the weights
w that can result in the minimal loss such as
, where
is an L2 regularization term. Unlike this general optimization strategy, SAM seeks parameters that lie in neighborhoods that have a uniformly low loss such as
, where
, and
is a hyperparameter that defines the range of parameter neighborhoods that need to be searched. Instead of simply finding parameters leading to a low loss, SAM aims to find parameters where the entire neighborhood has a uniformly low training loss. This prevents the model from converging to sharp minima, where a parameter may lead to a low loss, but its neighboring parameters lead to a high loss. However, SAM may ignore some parameters that are in the sharp neighborhood but can actually lead to good performance. Thus, to further improve the results, we propose PSAM, which randomly selects 50% of the parameters to be updated with the general optimization strategy and the remaining 50% with SAM. PSAM also functions similarly to dropout by introducing noise as a form of regularization.
Visualization: In ECT-BoFM, each deep feature is in strict correspondence with a certain 33 × 33 patch in the input image. Given a 33 × 33 patch
p, the model infers one logit
for the predicted skin lesion class
k, together with one EI gating weight
and one CTI gating weight
(refer to Equations (
7) and (
8)). Thus, for each pixel of the heatmaps, we can obtain three types of values: (i)
, which denotes the model’s judgment of
p’s importance from a CTI perspective; (ii)
, which denotes the model’s judgment of
p’s importance from an EI perspective; and (iii)
, which denotes the model’s overall judgment of
p’s importance. Here,
and
, where
is the weights of the FC classifier for the predicted category
k, and its negative values are set to 0.
and
are the elements in
handling the features from the CTI and EI gates, respectively. To generate the heatmaps, we pad
I by 16 pixels on all sides with zeros and extract a total of 225 × 225 patches using a 33 × 33 window with a stride of 1. Then, we can obtain three heatmaps: a CTI heatmap, an EI heatmap, and an overall heatmap. The heatmaps are normalized with min-max normalization.
4. Experiments
4.1. Datasets and Implementation Details
Datasets: We evaluated the ECT-BoFM on two public dermoscopic datasets: ISIC2018 [
19] with 10,015 images across seven classes (melanoma, melanocytic nevus, basal cell carcinoma, actinic keratosis/Bowen’s disease, benign keratosis, dermatofibroma, and vascular lesion) and ISIC2019 [
19,
20] with 25,331 images across eight classes (melanoma, melanocytic nevus, basal cell carcinoma, actinic keratosis, benign keratosis, dermatofibroma, vascular lesion, and squamous cell carcinoma).
Implementation Details: We trained the models using stochastic gradient descent (SGD) with 100 epochs, a momentum of 0.9, a weight decay of
, and a mini-batch size of 16. The initial learning rate was 0.002, and it was updated with cosine annealing. During training, images are resized to
with random cropping and flipping as the only augmentations. For inference, we applied center cropping. We followed previous studies [
1,
35,
36] to use three common evaluation metrics: accuracy (Acc), macro f1-score (F1), and macro area under the curve (AUC). We repeated the experiments five times and reported the average results.
4.2. Comparison with State-of-the-Art Methods
To show the superiority of ECT-BoFM, we compared the diagnostic performance of ECT-BoFM with recent state-of-the-art (SOTA) methods on ISIC 2018 and 2019. Different studies have used various partitions of the ISIC 2018 dataset to evaluate performance. In our experiments, we followed the partitions used in previous studies [
1,
35,
36,
37] and compared our results against those obtained with the same partitions. Specifically, there were three partitions: (i) train/val/test = 1:1:1; (ii) train/val/test = 3:1:1; and (iii) using all 10,015 images as training or validating samples and testing the obtained model on the ISIC Task 3 validation set (193 images). For the third partition, we used 30% of the training data for validation. The previous SOTA methods on ISIC 2019 predominantly split this dataset into train/val/test = 3:1:1 [
1], and thus we followed this partition. The comparison results are shown in
Table 1,
Table 2,
Table 3 and
Table 4. On ISIC 2018, ECT-BoFM significantly outperformed other SOTA methods in all metrics. Overall, the closest competitor in performance to our method is CEM [
28]. However, our approach not only outperforms CEM significantly across all diagnostic metrics but also eliminates the need of manually labeling concept tags on large datasets and conducting additional training for generalization to other datasets, as required by CEM. On ISIC 2019, ECT-BoFM performed marginally lower than the previous best method, ECL [
1], in the F1 score but higher than all previous SOTA methods in the other two metrics. ECT-BoFM has a significant advantage with the highest level in most metrics.
Although ECT-BoFM achieves significant improvements over prior methods on ISIC2018, the performance gain on ISIC2019 is relatively limited. We attribute this to the increased number of diagnostic categories in ISIC2019, which introduces greater inter-class similarity and more complex decision boundaries. For example, actinic keratosis (AK), a precancerous condition, often shares visual characteristics with both benign keratosis (BKL) and squamous cell carcinoma (SCC), making it particularly difficult to distinguish. This visual ambiguity increases the challenge not just for our method, but for all competing approaches.
This trend is clearly reflected in our experimental results, as shown in
Table 3 and
Table 4; classification performance across all methods is consistently lower on ISIC2019 than on ISIC2018. Therefore, we believe the relatively smaller margin between our method and other state-of-the-art models on ISIC2019 does not reflect a specific limitation of our approach, but rather highlights a broader challenge faced by current techniques when dealing with fine-grained, high-confusion medical categories. These findings suggest that further methodological advances are still needed to address the inherent difficulty of multi-class skin lesion diagnosis in more diverse datasets.
4.3. Ablation Studies
The design of ECT-BoFM included a BagNet-based backbone
, a CTI stream, an EI stream, the non-rigid reconstruction strategy, and the PSAM training strategy. We conducted ablation studies to evaluate the components of this design. Additionally, to demonstrate the effectiveness of limiting receptive fields, we also constructed two backbones with unlimited receptive fields by inserting MlpFusion and TransFusion layers into the final two stages of the original backbone. These fusion layers reshape the input tensor for processing through MLP or Transformer layers designed to globally integrate the local features and then reshape back the output to maintain the original tensor dimensions. In these ablation experiments, we constructed a very challenging diagnosis task by randomly dividing ISIC-2018 into the training, validation, and test sets in a 1:1:1 ratio. The results are shown in
Table 5.
Adding a single CTI or EI stream to improved all three metrics, with the addition of both CTI and EI streams leading to a greater improvement in all three metrics compared to the original and to with the addition of a single CTI or EI stream. This result indicates that CTI and EI streams are complementary, and a fusion of them is beneficial for diagnostic performance. Whether using TransFusion or MlpFusion, the network’s performance decreases when the receptive field is not limited. This indicates that constraining the receptive field can enhance diagnostic performance. Then, when we trained with the addition of the two streams without NRR, the accuracy and F1 score were even lower than those of the original , indicating the effectiveness of NRR. Furthermore, introducing SAM decreased AUC and F1, while introducing PSAM improved all metrics.
4.4. Analysis of Interpretable Heatmaps
In this section, we analyze the fidelity of the generated interpretable heatmaps. All experimental results are based on a 3:1:1 train–val–test split of the ISIC 2018 dataset, with all relevant models trained using the SGD optimizer.
Visualization Results: Figure 3 shows the visualization results of our model as well as those of Resnet50-based CAM and Grad-CAM, which are common strategies for prior interpretable dermatological diagnosis methods [
3,
4]. The CTI and EI heatmaps can provide explanations of the categorical predictions from two separate perspectives, enabling us to move a step forward in understanding the perspective from which the model makes its decisions. The overall heatmap can be seen as a synthesis of the CTI and EI heatmaps, capturing more comprehensive information. For dermatologic diagnosis, comprehensive information is beneficial. Consider the first row in
Figure 3 as an example. The input image is a photo of a basal cell carcinoma (BCC). In this case, the EI stream mainly captures pigmented structures, such as a blue-gray ovoid nest, while the CTI stream mainly captures vascular structures, such as arborizing telangiectasias. Both are important for the diagnosis of BCC [
17].
Impact of Heatmap-Guided Masking on Accuracy. To quantitatively analyze the fidelity of the generated ECT-BoFM heatmaps, we examined how accuracy changes when masking the most predictive 33 × 33 image patches. We employed three methods for masking patches: (i) defining the masking locations based on the ECT-BoFM heatmaps; (ii) randomly masking patches from all possible 33 × 33 windows with a stride of eight; and (iii) generating a heatmap using ResNet50 + CAM (note that CAM is similar to Grad-CAM for skin lesion diagnosis tasks, as illustrated in
Figure 3; therefore we used CAM exclusively). For the third method, we traversed the generated heatmap with 33 × 33 windows and masked patches based on the highest sum of heatmap values within each window. We conducted these experiments on both the proposed ECT-BoFM and a trained ViT-B-16 model. The results, shown in
Figure 4, demonstrate that masking the predictive patches identified by ECT-BoFM leads to a significant drop in diagnostic performance for both ECT-BoFM and ViT-B-16, compared to masking patches using other methods. Notably, masking just 20 patches, which constituted a small portion of the original image, resulted in negligible performance degradation when conducted randomly. In contrast, masking 20 important patches identified by ECT-BoFM caused a substantial performance decline in both models, which highlighted that the predictive patches provided by ECT-BoFM were naturally crucial to the model’s performance and were not only important to specific models but also fundamentally important.
As mentioned above, we used CAM exclusively based on its visual similarity to Grad-CAM in our experiments (
Figure 3). To further support this choice, we note that dermoscopic images typically exhibit localized diagnostic features and relatively low spatial complexity, which naturally reduces the functional distinction between CAM- and gradient-based attribution methods. Previous studies in this domain, including Lucieri et al. [
8] and Jiang et al. [
6], have also observed that CAM and Grad-CAM tend to highlight nearly identical regions in skin lesion classification tasks. Hence, we adopted CAM throughout our framework to ensure simplicity and compatibility with our interpretable feature pathways, without compromising the quality or faithfulness of visual explanations.
Results of Training with Heatmap-Identified Key Regions on Diagnostic Performance.
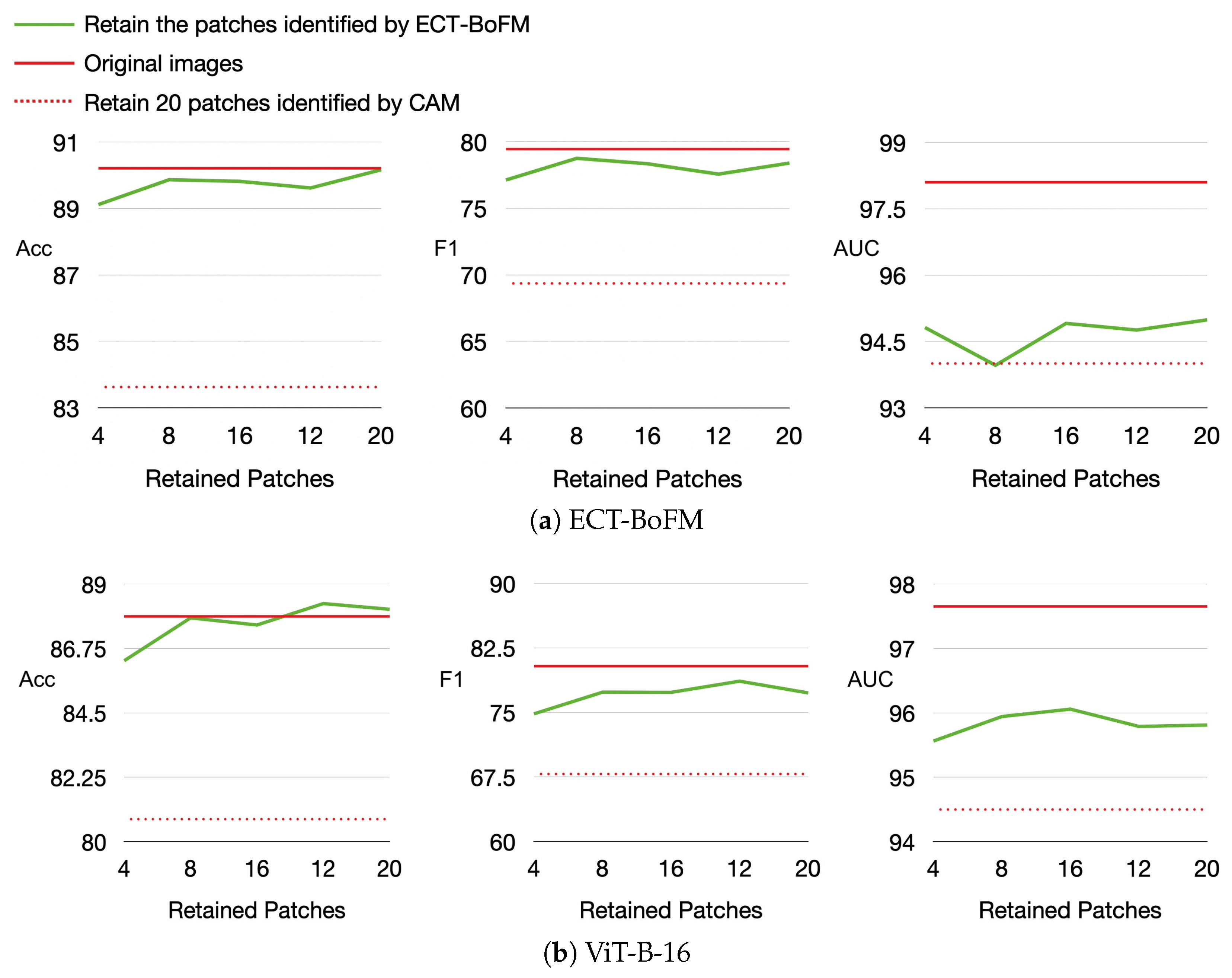
We leveraged the interpretability of ECT-BoFM to analyze the impact of global and local information captured by models in skin lesion diagnosis. Using a trained ECT-BoFM, we identified the most predictive 33 × 33 image patches, retaining only these small regions while masking out the rest of the image. These modified images were then used to train both ViT-B-16 and ECT-BoFM. We conducted experiments where only 4, 8, 12, 16, or 20 of the most predictive image patches were retained, with the results shown in
Figure 5. In
Figure 5, we also provide two reference baselines: (i) the performance using original, unmasked images and (ii) the performance when retaining the 20 most predictive image patches identified by ResNet50+CAM from all possible 33 × 33 windows with a stride of eight while masking out the remaining regions.
As shown in
Figure 5, whether training with ECT-BoFM or ViT-B-16, the diagnosis performance using the small number of patches identified by ECT-BoFM was significantly higher than that obtained using ResNet50+CAM. This indicated that the predictive patches identified by ECT-BoFM were genuinely critical regions, which is consistent with our earlier conclusions. Compared to the models trained on the original images, those using ECT-BoFM-identified patches achieved comparable or even superior accuracy, as well as similar F1 scores, but the AUC was better with models trained on the original images. These experimental results showed that for skin lesion diagnosis, a very small number of localized regions provide sufficient classification cues in most cases. While full input image information mainly enhanced the ability to differentiate some minority categories more comprehensively, the AUC improvement remained limited to about 2–3%. This phenomenon also applied to ViT models, which were designed to capture long-range dependencies between different local regions. Despite the extensive parameters and computations aimed at capturing such global information, the results in
Figure 5 suggested that this design, while theoretically promising, might be less effective or even wasteful in practical skin lesion diagnosis. Training a ViT model with images where most regions were masked still achieved high diagnostic performance, which raises questions about whether ViT’s long-range dependency capture truly benefited skin lesion tasks. Future skin lesion diagnosis algorithms might be more effective by focusing on extracting local features and supplementing them with appropriate global information to improve the distinction of minority classes, thereby making better use of model parameters and computational resources.
4.5. Rethinking the Necessity of Global Modeling in Skin Lesion Diagnosis
In recent years, deep learning models with global modeling capabilities—such as Transformers with self-attention mechanisms—have shown impressive performance across various vision tasks. These models are based on the assumption that modeling long-range dependencies and holistic context is essential for high-level understanding, including in medical imaging. However, our findings suggest that this assumption may not universally hold for all medical imaging scenarios, particularly for skin lesion classification tasks.
As demonstrated in our experiments, local modeling alone—guided by interpretable and clinically relevant heatmaps—can achieve strong classification performance. For instance,
Table 1 through
Table 4 show that ECT-BoFM consistently outperforms or matches state-of-the-art methods on both ISIC2018 and ISIC2019 across multiple backbones, despite operating with a local receptive field and a limited global context.
Figure 4 further shows that the removal of high-response regions, as highlighted by the interpretable channels, leads to substantial performance degradation, indicating that those localized regions carry essential diagnostic information.
Figure 5 also reveals that even when only a small number of high-response patches are retained for training, classification performance remains close to that of the full model, further supporting the sufficiency of local features.
Architecturally, our use of BagNet-33 limits the effective receptive field to 33 × 33 pixels, minimizing the aggregation of non-local information. The model explicitly integrates edge and color–texture priors, which encourage it to focus on fine-grained features such as border irregularities and pigmentation details. The combination of these elements results in a lightweight, interpretable framework that is surprisingly effective without deep semantic fusion.
Nonetheless, we acknowledge that certain global visual patterns do carry diagnostic value in clinical practice. For example, dermatologists often assess asymmetry, lesion size relative to the surrounding area, or overall texture heterogeneity—features that cannot be captured by small receptive fields alone. Therefore, we do not claim that global information is irrelevant. Rather, our findings suggest that existing generic global modeling mechanisms, such as standard self-attention layers, may not be well aligned with the domain-specific needs of skin lesion diagnosis.
At the same time, although our method achieves state-of-the-art or competitive performance across multiple settings, there remains a gap to perfection. This opens a promising direction: rethinking global modeling not by discarding it, but by designing new task-specific global mechanisms that complement strong local representations with clinically meaningful global cues. Our findings offer a step in this direction by highlighting when and how local features dominate in this task and by raising the broader question of what kinds of global structures are truly needed in dermatological AI systems.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}