
Train-Time and Test-Time Computation in Large Language Models for Error Detection and Correction in Electronic Medical Records: A Retrospective Study




Abstract
1. Introduction
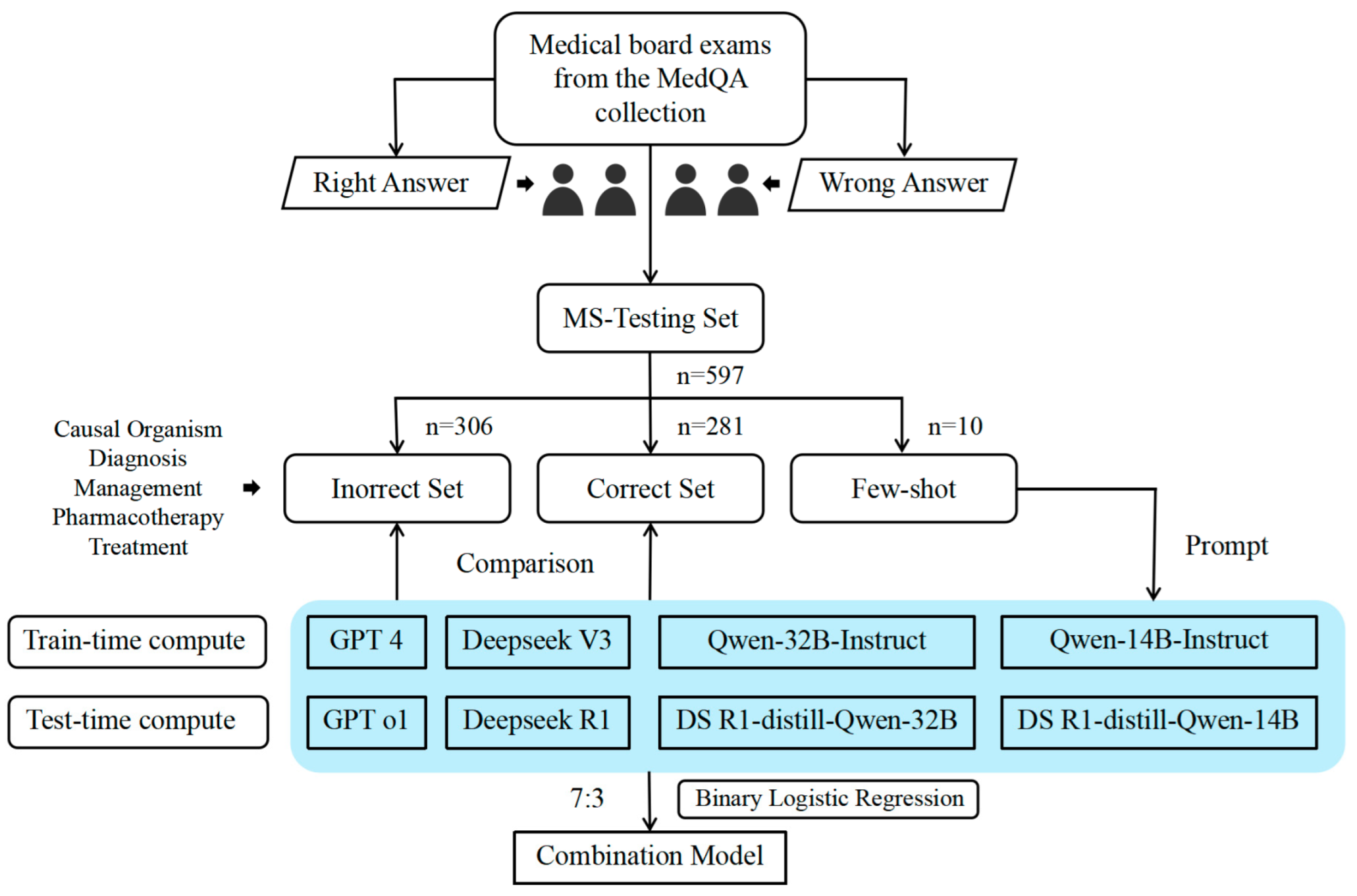
2. Data and Methods
2.1. Study Design and Data Source
2.2. Error Type Definitions
2.3. Model Selection
2.4. Experimental Methods
2.5. Model Evaluation and Statistical Analysis
3. Results
3.1. Detection–Correction of Medical Records
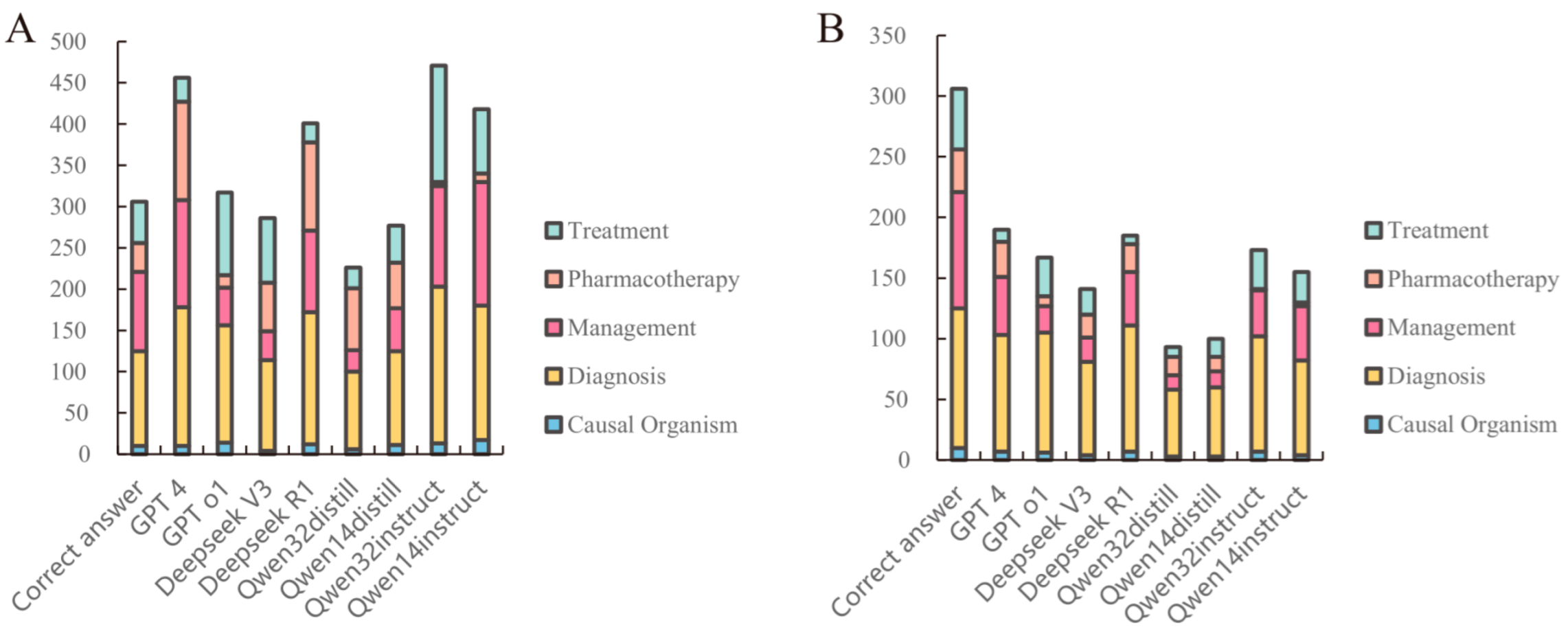
3.2. Analysis of Medical Record Error Detection and Correction
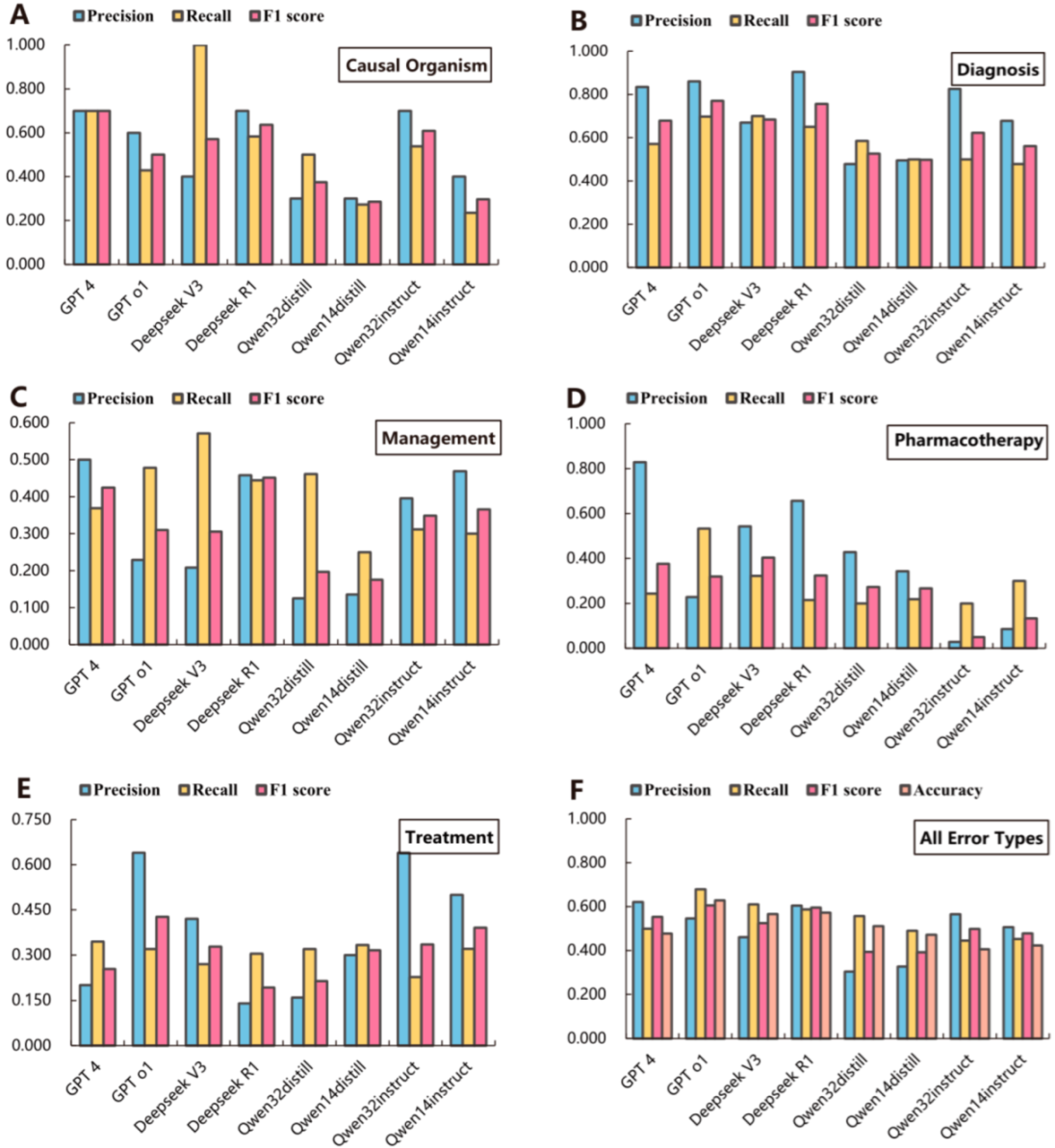
3.3. Performance of Large Language Models
3.4. Error Correction Accuracy of Large Language Models
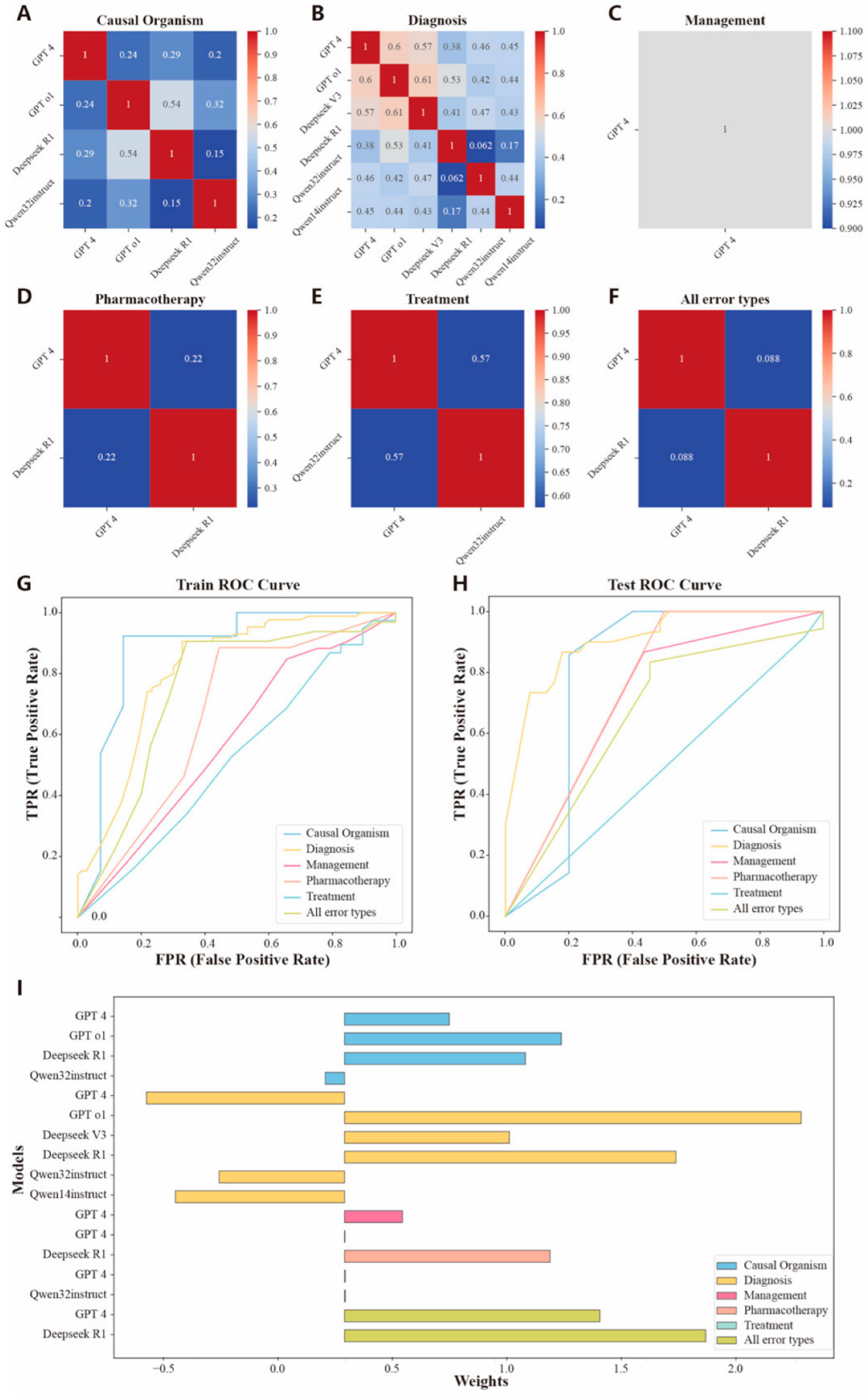
3.5. Assembly of Large Language Models
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EMRs | Electronic medical records |
| LLMs | Large language models |
| AUC | Area under the curve |
References
- Persaud, N. A national electronic health record for primary care. CMAJ 2019, 191, E28–E29. [Google Scholar] [CrossRef] [PubMed]
- Steinkamp, J.; Kantrowitz, J.J.; Airan-Javia, S. Prevalence and sources of duplicate information in the electronic medical record. JAMA Netw. Open 2022, 5, e2233348. [Google Scholar] [CrossRef] [PubMed]
- Nijor, S.; Rallis, G.; Lad, N.; Gokcen, E. Patient safety issues from information overload in electronic medical records. J. Patient Saf. 2022, 18, e999–e1003. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Keloth, V.K.; Xie, Q.; Qian, L.; Liu, Y.; Wang, Y.; Shi, R.; Zhou, W.; Yang, G.; Zhang, J.; et al. The Development Landscape of Large Language Models for Biomedical Applications. Annu. Rev. Biomed. Data Sci. 2025, 8. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhou, J.; Gao, Z.; Hua, W.; Fan, L.; Yu, H.; Hagen, L.; Zhang, Y.; Assimes, T.L.; Hemphill, L.; et al. A scoping review of using large language models (LLMs) to investigate electronic health records (EHRs). arXiv 2024, arXiv:2405.03066. [Google Scholar]
- Yu, W.; Xiong, L.; Feifei, Z.; Jiayu, L.; Shaoyong, C. Application of Medical Record Quality Control System Based on Artificial Intelligence. J. Sichuan Univ. (Med. Sci.) 2023, 54, 1263–1268. [Google Scholar]
- Omar, M.; Ullanat, V.; Loda, M.; Marchionni, L.; Umeton, R. ChatGPT for digital pathology research. Lancet Digit. Health 2024, 6, e595–e600. [Google Scholar] [CrossRef] [PubMed]
- Annevirta, J. Intelligent Patient Safety Incident Reporting–Process Design and Feasibility of Utilizing LLM for Report Generation. Master’s Thesis, Aalto university, Espoo, Finland, 2025. [Google Scholar]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Costa, A.B.; Flores, M.G.; et al. A large language model for electronic health records. NPJ Digit. Med. 2022, 5, 194. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Xu, R.; Zhuang, Y.; Yu, Y.; Zhang, J.; Wu, H.; Zhu, Y.; Ho, J.; Yang, C.; Wang, M.D. Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records. arXiv 2024, arXiv:2401.07128. [Google Scholar]
- Menezes, M.C.S.; Hoffmann, A.F.; Tan, A.L.; Nalbandyan, M.; Omenn, G.S.; Mazzotti, D.R.; Hernández-Arango, A.; Visweswaran, S.; Venkatesh, S.; Mandl, K.D.; et al. The potential of Generative Pre-trained Transformer 4 (GPT-4) to analyse medical notes in three different languages: A retrospective model-evaluation study. Lancet Digit. Health 2025, 7, e35–e43. [Google Scholar] [CrossRef] [PubMed]
- Xu, F.; Hao, Q.; Zong, Z.; Wang, J.; Zhang, Y.; Wang, J.; Lan, X.; Gong, J.; Ouyang, T.; Meng, F.; et al. Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models. arXiv 2025, arXiv:2501.09686. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. IMPROVING language Understanding by Generative Pre-Training. 2018. Available online: https://api.semanticscholar.org/CorpusID:49313245 (accessed on 9 May 2025).
- Peng, B.; Chena, K.; Zhangc, Y.; Wangd, T.; Bie, Z.; Yif, H.; Songg, X.; Zhanga, C.; Liuh, M.; Liang, C.X. Optimizing the Last Mile: Test-Time Compute Strategies for Next-Generation Language Models. Preprint 2025. [Google Scholar] [CrossRef]
- Snell, C.; Lee, J.; Xu, K.; Kumar, A. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv 2024, arXiv:2408.03314. [Google Scholar]
- Pitis, S.; Zhang, M.R.; Wang, A.; Ba, J. Boosted prompt ensembles for large language models. arXiv 2023, arXiv:2304.05970. [Google Scholar]
- Matarazzo, A.; Torlone, R. A Survey on Large Language Models with some Insights on their Capabilities and Limitations. arXiv 2025, arXiv:2501.04040. [Google Scholar]
- Abacha, A.B.; Yim, W.-w.; Fu, Y.; Sun, Z.; Yetisgen, M.; Xia, F.; Lin, T. Medec: A benchmark for medical error detection and correction in clinical notes. arXiv 2024, arXiv:2412.19260. [Google Scholar]
- Jin, D.; Pan, E.; Oufattole, N.; Weng, W.-H.; Fang, H.; Szolovits, P. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Appl. Sci. 2021, 11, 6421. [Google Scholar] [CrossRef]
- Mamunoor, R. New Mixture of Distillation Strategy for Knowledge Transfer. Master’s Thesis, Bangladesh University of Engineering and Technology, Dhaka, Bangladesh, 2023. [Google Scholar]
- Wang, Y.; Huang, Y.; Nimma, I.R.; Pang, S.; Pang, M.; Cui, T.; Kumbhari, V. Validation of GPT-4 for clinical event classification: A comparative analysis with ICD codes and human reviewers. J. Gastroenterol. Hepatol. 2024, 39, 1535–1543. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Li, Y.; Lu, S.; Van, H.; Aerts, H.J.; Savova, G.K.; Bitterman, D.S. Evaluating the ChatGPT family of models for biomedical reasoning and classification. J. Am. Med. Inform. Assoc. 2024, 31, 940–948. [Google Scholar] [CrossRef] [PubMed]
- Ntinopoulos, V.; Biefer, H.R.C.; Tudorache, I.; Papadopoulos, N.; Odavic, D.; Risteski, P.; Haeussler, A.; Dzemali, O. Large language models for data extraction from unstructured and semi-structured electronic health records: A multiple model performance evaluation. BMJ Health Care Inform. 2025, 32, e101139. [Google Scholar] [CrossRef] [PubMed]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Gertz, R.J.; Dratsch, T.; Bunck, A.C.; Lennartz, S.; Iuga, A.-I.; Hellmich, M.G.; Persigehl, T.; Pennig, L.; Gietzen, C.H.; Fervers, P.; et al. Potential of GPT-4 for detecting errors in radiology reports: Implications for reporting accuracy. Radiology 2024, 311, e232714. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Hadi, M.U.; Qureshi, R.; Shah, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; Mirjalili, S. Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects. Authorea Prepr. 2023, 1, 1–26. [Google Scholar]
- Gopalakrishnan, S.; Garbayo, L.; Zadrozny, W. Causality extraction from medical text using large language models (llms). Information 2024, 16, 13. [Google Scholar] [CrossRef]
- Kiciman, E.; Ness, R.; Sharma, A.; Tan, C. Causal reasoning and large language models: Opening a new frontier for causality. arXiv 2023, arXiv:2305.00050. [Google Scholar]
- Ji, Y.; Li, J.; Ye, H.; Wu, K.; Xu, J.; Mo, L.; Zhang, M. Test-time Computing: From System-1 Thinking to System-2 Thinking. arXiv 2025, arXiv:2501.02497. [Google Scholar]
- Liu, C.; Wu, J.; Wu, W.; Chen, X.; Lin, L.; Zheng, W.-S. Chain of Methodologies: Scaling Test Time Computation without Training. arXiv 2025, arXiv:2506.06982. [Google Scholar]
- Chen, Q.; Qin, L.; Liu, J.; Peng, D.; Guan, J.; Wang, P.; Hu, M.; Zhou, Y.; Gao, T.; Che, W. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models. arXiv 2025, arXiv:2503.09567. [Google Scholar]
- Li, Z.-Z.; Zhang, D.; Zhang, M.-L.; Zhang, J.; Liu, Z.; Yao, Y.; Xu, H.; Zheng, J.; Wang, P.-J.; Chen, X.; et al. From system 1 to system 2: A survey of reasoning large language models. arXiv 2025, arXiv:2502.17419. [Google Scholar]
- Zhang, Q.; Lyu, F.; Sun, Z.; Wang, L.; Zhang, W.; Hua, W.; Wu, H.; Guo, Z.; Wang, Y.; Muennighoff, N.; et al. A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well? arXiv 2025, arXiv:2503.24235. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Computing Resources |
|---|---|
| GPT 4 | Focusing on Train-time Computation |
| GPT o1 | Focusing on Test-time Computation |
| DeepSeek V3 | Focusing on Train-time Computation |
| DeepSeek R1 | Focusing on Test-time Computation |
| DeepSeek-R1-Distill-Qwen-32B | Focusing on Test-time Computation |
| DeepSeek-R1-Distill-Qwen-14B | Focusing on Test-time Computation |
| Qwen-32B-Instruct | Focusing on Train-time Computation |
| Qwen-14B-Instruct | Focusing on Train-time Computation |
| Medical Record ID | Medical Records | Error Type | Error Sentence ID | Error Sentence | Corrected Sentences |
|---|---|---|---|---|---|
| ms-0 | A 29-year-old internal medicine resident presents to the emergency department with complaints of fever, diarrhea, abdominal pain, and skin rash for 2 days. He feels fatigued and has lost his appetite. On further questioning, he says that he returned from his missionary trip to Brazil last week. He is excited as he talks about his trip. Besides a worthy clinical experience, he also enjoyed local outdoor activities, like swimming and rafting. His past medical history is insignificant. The blood pressure is 120/70 mm Hg, the pulse is 100/min, and the temperature is 38.3 °C (100.9 F). On examination, there is a rash on the legs. The patient’s symptoms are suspected to be due to hepatitis A. The rest of the examination is normal. | Causal Organism | 10 | Patient’s symptoms are suspected to be due to hepatitis A. | Patient’s symptoms are suspected to be due to Schistosoma mansoni. |
| ms-21 | A 3-year-old Cuban-American male has a history of recurrent Pseudomonas and Candida infections. Laboratory analysis reveals no electrolyte abnormalities. Examination of his serum shows decreased levels of IgG and CT scan reveals the absence of a thymus. The child likely has common variable immunodeficiency. | Diagnosis | 3 | The child likely has common variable immunodeficiency. | The child likely has severe combined immunodeficiency syndrome. |
| ms-281 | A 57-year-old man with a known angina pectoris starts to experience a severe burning retrosternal pain that radiates to his left hand. After 2 consecutive doses of sublingual nitroglycerin taken 5 min apart, there is no improvement in his symptoms, and the patient calls an ambulance. Emergency medical service arrives within 10 min and begins evaluation and prehospital management. The vital signs include the following: blood pressure 85/50 mm Hg, heart rate is 96/min, respiratory rate is 19/min, temperature is 37.1 °C (98.9 °F), and SpO2 89% in ambient air. Oxygen supply and intravenous access are established. Aspirin 81 mg is administered, and the patient is transported to a percutaneous coronary intervention center after an ECG shows the findings in the given image. | Management | 8 | Aspirin 81 mg is administered, and the patient is transported to a percutaneous coronary intervention center after an ECG shows the findings in the given image. | Aspirin 325 mg is administered, and the patient is transported to a percutaneous coronary intervention center after an ECG shows the findings in the given image. |
| ms-472 | A 65-year-old man is hospitalized after undergoing operative fixation of a left distal radius fracture due to a fall. On postoperative day 1, he reports having several episodes of palpitations with associated lightheadedness. He denies any chest pain and states that these episodes last for a few seconds each before resolving. On examination, his temperature is 98.4 °F (36.9 °C), blood pressure is 124/76 mmHg, pulse is 94/min, and respirations are 12/min. The patient is currently asymptomatic without palpitations. The patient is immediately connected to a cardiac monitor which shows normal sinus rhythm. Over the course of the night, the monitor demonstrates 3 more episodes of the rhythm shown below in the Figure, along with the associated palpitations and lightheadedness. Blood pressure and oxygen saturation are stable during these episodes. The patient is given intravenous magnesium and diltiazem after the decision is made to also start medical therapy. | Pharmacotherapy | 9 | The patient is given intravenous magnesium and diltiazem after the decision is made to also start medical therapy. | The patient is given intravenous magnesium and amiodarone after the decision is made to also start medical therapy. |
| ms-503 | A 14-year-old female notes that while her fever, malaise, and a sore throat have dissipated a week ago, her hacking cough persists. A chest radiograph (Figure) demonstrates a streaky infiltrate in her right lung that appears much worse than the symptoms she is experiencing. The patient is given vancomycin after a cold agglutination test conducted on her blood shows clumping together when placed at 4 degrees Celsius. | Treatment | 2 | The patient is given vancomycin after a cold agglutination test conducted on her blood shows clumping together when placed at 4 degrees Celsius. | The patient is given azithromycin after a cold agglutination test conducted on her blood shows clumping together when placed at 4 degrees Celsius. |
| Sample/Models | Thinking Time | Sentence ID | Error Sentence | Corrected Sentence | Score by GPT 4 |
|---|---|---|---|---|---|
| ms-4 | / | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is a commensal yeast that is catalase-positive. | / |
| ChatGPT-4 | 6.62 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is a regular, septate fungus with branching at narrow angles. | C |
| ChatGPT o1 | 13.58 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is a budding yeast with pseudohyphae, consistent with Candida species. | B |
| Deepseek V3 | 8.93 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is Candida albicans, a yeast that typically causes intertrigo in skin folds. | C |
| Deepseek R1 | 17.40 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is an oval-shaped budding yeast with pseudohyphae (Candida species). | B |
| Deepseek R1 -Distill-Qwen-32 B | 15.14 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is a Candida species, which is a round, septate yeast. | B |
| Deepseek R1 -Distill-Qwen-14B | 19.59 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is an irregular, non-septate yeast, likely Candida species. | B |
| Qwen-32B-Instruct | 5.89 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is a Candida species, which is a common yeast with irregular, non-septate hyphae. | B |
| Qwen-14B-Instruct | 4.25 s | 3 | The causative agent is an irregular, non-septate yeast with wide angles. | The causative agent is Candida, a common yeast that can cause intertrigo in obese individuals. | B |
| Error Types | Causal Organism | Diagnosis | Management | Pharmacotherapy | Treatment | All Error Types |
|---|---|---|---|---|---|---|
| Best individual LLMs | GPT-4 | Deepseek R1 | GPT-4 | GPT-4 | GPT o1 | GPT-4 |
| Precision | 0.700 (0.416, 0.984) | 0.904 (0.851, 0.958) *** | 0.500 (0.400, 0.600) | 0.829 (0.704, 0.953) *** | 0.640 (0.507, 0.773) | 0.621 (0.567, 0.675) *** |
| Recall | 0.700 (0.416, 0.984) | 0.650 (0.576, 0.724) *** | 0.369 (0.286, 0.452) ** | 0.244 (0.167, 0.321) *** | 0.320 (0.229, 0.411) *** | 0.499 (0.449, 0.549) |
| F1 score | 0.700 (0.499, 0.901) | 0.756(0.703, 0.810) | 0.425 (0.359, 0.491) | 0.377 (0.284, 0.470) | 0.427 (0.340, 0.513) | 0.553 (0.516, 0.591) |
| Accuracy | \ | \ | \ | \ | \ | 0.477 (0.437, 0.517) |
| Assembly Models | ||||||
| Precision | 0.857 (0.598, 1.000) * | 0.788 (0.648, 0.927) *** | 0.605 (0.459, 0.751) | 0.643 (0.392, 0.894) | 0.414 (0.235, 0.593) | 0.737 (0.539, 0.935) * |
| Recall | 0.857 (0.598, 1.000) * | 0.867(0.745, 0.988) *** | 0.867 (0.745, 0.988) *** | 1.000 (1.000, 1.000) ** | 1.000 (1.000, 1.000) ** | 0.778 (0.586, 0.979) * |
| F1 score | 0.857 (0.659, 1.000) | 0.825 (0.736, 0.915) | 0.712 (0.606, 0.819) | 0.783 (0.597, 0.968) | 0.585 (0.406, 0.765) | 0.757 (0.601, 0.913) |
| Accuracy | 0.833 (0.622, 1.000) * | 0.841 (0.754, 0.927) *** | 0.696 (0.587, 0.804) *** | 0.737 (0.539, 0.935) * | 0.414 (0.235, 0.593) | 0.690 (0.521, 0.858) * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Q.; Yang, L.; Xiao, J.; Ma, J.; Liu, M.; Pan, X. Train-Time and Test-Time Computation in Large Language Models for Error Detection and Correction in Electronic Medical Records: A Retrospective Study. Diagnostics 2025, 15, 1829. https://doi.org/10.3390/diagnostics15141829
Cai Q, Yang L, Xiao J, Ma J, Liu M, Pan X. Train-Time and Test-Time Computation in Large Language Models for Error Detection and Correction in Electronic Medical Records: A Retrospective Study. Diagnostics. 2025; 15(14):1829. https://doi.org/10.3390/diagnostics15141829
Chicago/Turabian StyleCai, Qiong, Lanting Yang, Jiangping Xiao, Jiale Ma, Molei Liu, and Xilong Pan. 2025. "Train-Time and Test-Time Computation in Large Language Models for Error Detection and Correction in Electronic Medical Records: A Retrospective Study" Diagnostics 15, no. 14: 1829. https://doi.org/10.3390/diagnostics15141829
APA StyleCai, Q., Yang, L., Xiao, J., Ma, J., Liu, M., & Pan, X. (2025). Train-Time and Test-Time Computation in Large Language Models for Error Detection and Correction in Electronic Medical Records: A Retrospective Study. Diagnostics, 15(14), 1829. https://doi.org/10.3390/diagnostics15141829