1. Introduction
Brain tumors represent a significant clinical challenge due to their heterogeneity, potential malignancy, and often non-specific symptom presentation [
1,
2]. Accurate and early classification of brain tumors is essential for treatment planning, prognostic evaluation, and therapy monitoring [
3,
4]. Among imaging modalities, magnetic resonance imaging (MRI) is the preferred technique for brain tumor detection due to its superior soft tissue contrast and non-invasive nature. Particularly, T1-weighted contrast enhancement sequences are widely used in clinical practice to visualize tumor boundaries and assess contrast uptake patterns [
5,
6].
In recent years, the integration of artificial intelligence (AI), particularly deep learning, into medical image analysis has revolutionized the field of radiological diagnostics [
7]. Convolutional neural networks (CNNs) have demonstrated exceptional capabilities in extracting hierarchical features from complex image data, making them ideal for tumor classification tasks [
8]. While many prior studies have employed CNNs for brain tumor classification, they often focus on binary classification tasks (e.g., tumor vs. no tumor or benign vs. malignant) and rely on a limited number of network architectures [
9]. Moreover, such studies frequently lack model robustness and generalization, especially when tested across different datasets or imaging conditions [
10].
To address these limitations, this study explores a multiclass brain tumor classification framework using deep CNNs, targeting four distinct categories: glioblastoma, meningioma, pituitary adenoma, and no tumor. We systematically evaluate the classification performance of seven prominent CNN architectures—ResNet-18, ResNet-50, ResNet-101, GoogLeNet, MobileNet-v2, EfficientNet-b0, and Inception-v3 [
11,
12,
13,
14,
15]. These models are selected based on their established use in medical imaging literature and their structural diversity, which allows for a broad performance comparison [
16,
17]. Furthermore, each model is trained with two different optimization algorithms, SGDM and ADAM, to assess the impact of learning strategies on classification outcomes [
18].
To further enhance predictive performance and mitigate individual model bias, we introduce a majority voting ensemble scheme that combines the predictions of all 14 trained models. Ensemble methods are known to increase classification robustness and reduce the risk of overfitting by leveraging model diversity [
10,
19]. While ensemble learning has been successfully applied in other domains, its application in multiclass brain tumor classification using MRI remains underexplored [
20].
While it is true that ensemble learning has been explored in previous studies, this work presents several distinct contributions that enhance both novelty and clinical relevance:
- (1)
Two-Dataset Strategy (Training and External Testing):
We trained our models using the Kaggle dataset by Pratham Grover and validated performance on an independent, external open-source dataset (rm1000). This cross-dataset design significantly improves generalizability and robustness.
- (2)
Systematic Comparison Across Seven Architectures:
A total of 14 models (seven CNN architectures, each trained with SGDM and ADAM) were evaluated in a unified ensemble framework, enabling comprehensive architectural comparison.
- (3)
Robustness Through Majority Voting Across Optimizers and Architectures:
Unlike prior studies that often rely on homogeneous ensembles, we introduced both model-level and optimizer-level diversity in the voting ensemble to improve predictive stability.
- (4)
Reproducibility Using Open Datasets and Pretrained Models:
Our framework is based entirely on publicly available datasets and transfer learned models, which ensure transparency, reproducibility, and ease of integration into clinical workflows. By combining architectural diversity, cross-dataset validation, and ensemble techniques, our method advances classification accuracy, generalizability, and clinical applicability of AI-assisted diagnosis. We believe the findings have strong potential to assist radiologists with high-performance and reliable tools for brain tumor detection and classification.
3. Materials and Methods
3.1. Dataset Description
This study utilized the publicly available Brain Tumor Classification dataset sourced from Kaggle (
https://www.kaggle.com/datasets/prathamgrover/brain-tumor-classification, obtained at 5 November 2024) for training and building the CNN models. The primary dataset consists of 3261 contrast-enhanced T1-weighted MRI images classified into four categories: glioblastoma (926 images), meningioma (934 images), pituitary adenoma (901 images), and no tumor (500 images). For external testing and generalizability assessment, a second open-source dataset was employed (
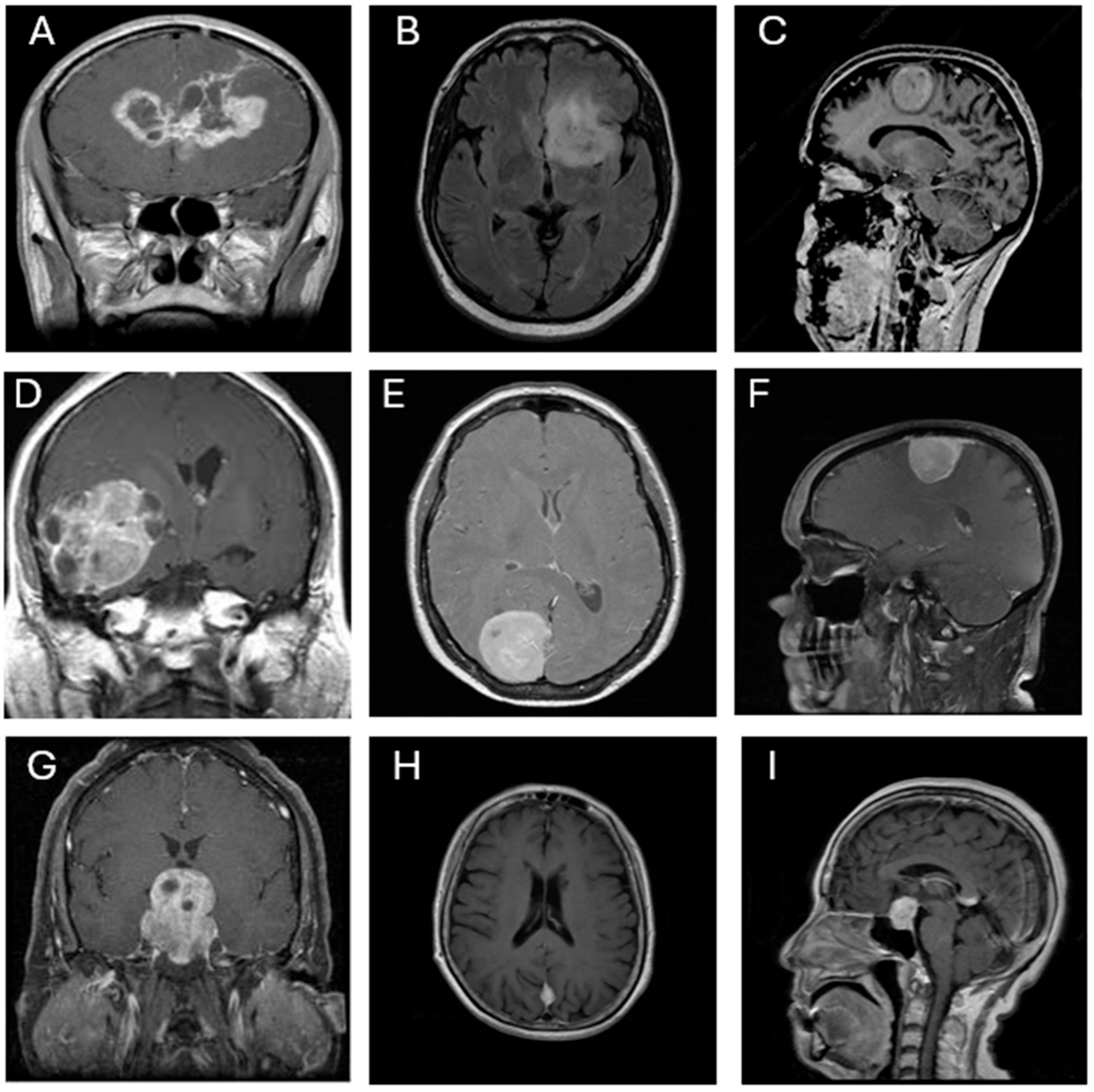
https://www.kaggle.com/datasets/rm1000/brain-tumor-mri-scans, obtained at 4 July 2025). This dataset comprises 7023 contrast-enhanced T1-weighted MRI images, also classified into four categories: glioblastoma (1261 images), meningioma (1645 images), pituitary adenoma (1757 images), and no tumor (2000 images). All images are grayscale and were pre-annotated based on confirmed clinical/surgical diagnoses. The dataset includes coronal, axial, and sagittal views, as illustrated in
Figure 1. Each image was resized to 300 × 300 pixels and normalized to ensure consistent input across all CNN architectures.
3.2. The Flow of This Research
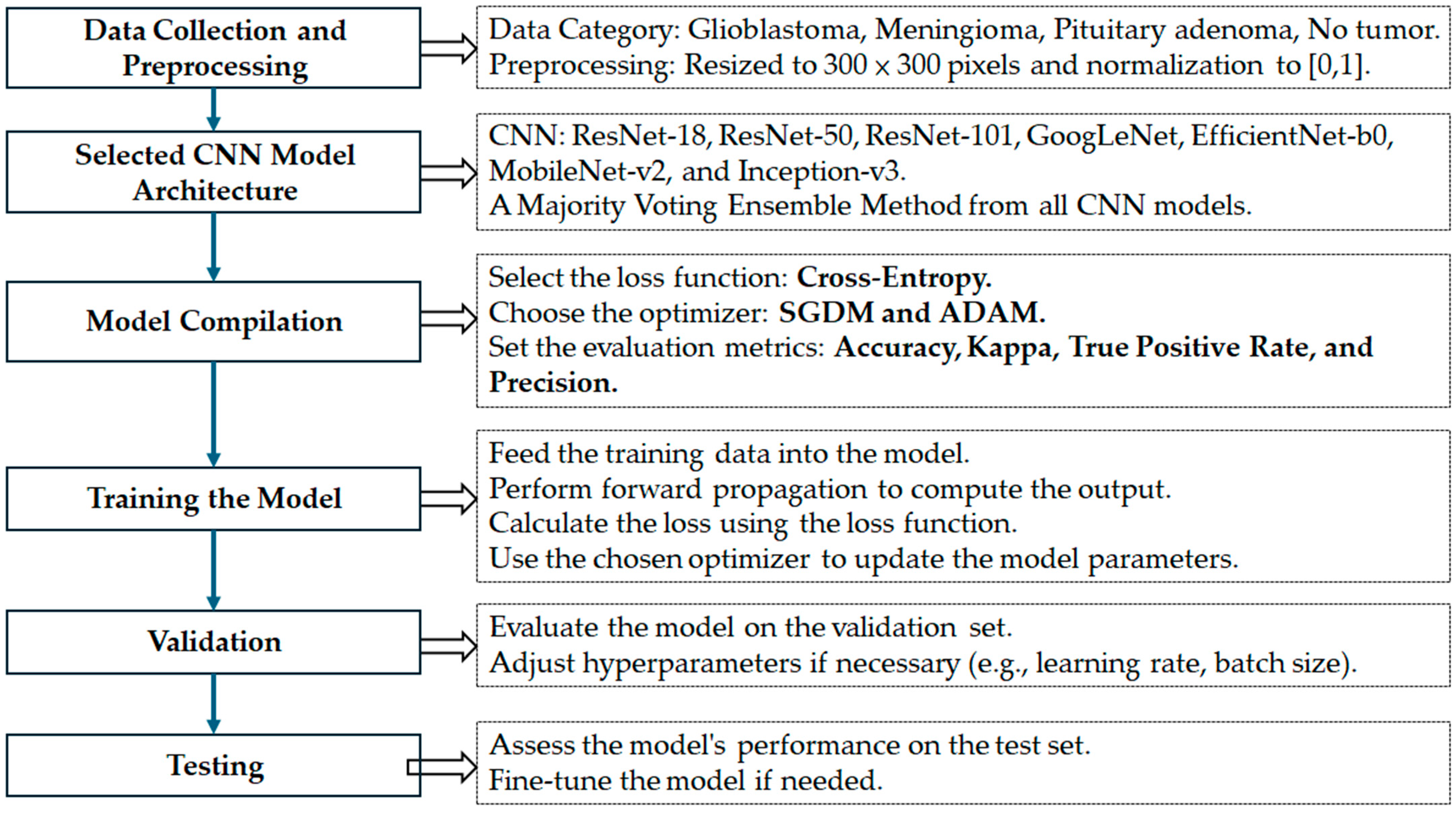
The overall research framework adopted in this study is illustrated in
Figure 2. The process is divided into seven key stages, each designed to ensure a robust and generalizable deep learning model for brain tumor classification below.
- (1)
Data Collection and Preprocessing:
Two publicly available MRI datasets were used in this study. The training dataset comprises contrast-enhanced T1-weighted MRI images categorized into four groups: glioblastoma, meningioma, pituitary adenoma, and no tumor. All images were resized to 300 × 300 pixels and normalized to the [0, 1] range to ensure uniformity across inputs and compatibility with deep CNN architectures.
- (2)
Selection of CNN Model Architectures:
Seven well-established CNN architectures were selected for evaluation: ResNet-18, ResNet-50, ResNet-101, GoogLeNet, MobileNet-v2, EfficientNet-b0, and Inception-v3. These architectures were chosen for their diverse structural properties and proven effectiveness in medical image classification tasks. To enhance performance and model robustness, a majority voting ensemble was developed by integrating predictions from all CNN models.
- (3)
Model Compilation:
Each CNN model was compiled with a categorical cross-entropy loss function, appropriate for multiclass classification problems. Two optimizers—Stochastic Gradient Descent with Momentum (SGDM) and Adam—were used to train each network, allowing comparison of their influence on model performance. Evaluation metrics included accuracy, Kappa statistics, true positive rate, and precision.
- (4)
Model Training:
The models were trained using preprocessed training data. During this phase, forward propagation was used to compute the output, the loss function was calculated, and model parameters were updated using the selected optimizers.
- (5)
Validation:
A portion of the training data was allocated for validation to assess intermediate performance. Based on validation results, hyperparameters such as learning rate and batch size were adjusted where necessary.
- (6)
Testing:
The final model ensemble was evaluated on an independent external dataset to assess generalizability. Testing results were used to compute all performance metrics and verify model robustness.
- (7)
Fine-tuning (if needed):
Post-testing analysis allowed for minor refinements and re-evaluation to ensure optimal classification performance, especially in terms of minimizing inter-class misclassification.
This systematic pipeline was designed not only to ensure methodological rigor and reproducibility but also to provide meaningful insights into the comparative effectiveness of various CNN architectures and optimization strategies in a multiclass brain tumor classification task.
3.3. Selected CNN Architectures and Voting Schema
Seven convolutional neural network (CNN) architectures were selected for this study based on their widespread use and demonstrated effectiveness in medical image classification: ResNet-18, ResNet-50, ResNet-101 [
11], GoogLeNet [
12], EfficientNet-b0 [
13], MobileNet-v2 [
14], and Inception-v3 [
15]. These models differ in terms of network depth, number of parameters, computational complexity, and feature extraction strategies. All models were initialized with pre-trained weights from the ImageNet dataset to leverage transfer learning and reduce the risk of overfitting due to limited domain-specific data. To adapt each architecture for the four-class brain tumor classification task (glioblastoma, meningioma, pituitary, and no tumor), the final fully connected layer was replaced with a new output layer containing four neurons, followed by a softmax activation function for multiclass classification. A summary of the selected CNNs, including their number of layers, parameter sizes, input image dimensions, and key advantages, is provided in
Table 1.
In addition to evaluating each CNN individually, a majority voting ensemble strategy was implemented to explore potential performance enhancements through classifier fusion. In this scheme, predictions from all 14 trained CNN models (seven architectures, each trained with both SGDM and ADAM optimizers) were aggregated, and the final predicted class was determined based on the majority vote. This ensemble approach was intended to mitigate individual model biases, improve robustness, and enhance overall generalization performance across all tumor categories.
3.4. Data Splitting and Training Configuration
To ensure consistency and comparability across all CNN architectures, a standardized training protocol was implemented. Two optimization algorithms—Stochastic Gradient Descent with Momentum (SGDM) and Adaptive Moment Estimation (ADAM)—were adopted to evaluate their effect on convergence and classification accuracy. For all models, the training hyperparameters were set as follows: an initial learning rate of 1 × 10−4, a mini-batch size of 10, and a maximum of 150 training epochs.
The dataset was randomly divided into three stratified subsets to maintain a class balance across tumor categories:
Training set: 70% of the data used for weight optimization.
Validation set: 10% used to monitor generalization performance and apply early stopping.
Testing set: 20% used exclusively for final model evaluation.
All MRI images were resized to 300 × 300 pixels, normalized, and input as single-channel (grayscale) data to the CNNs. To support multiclass classification, each network’s output layer was modified to consist of four neurons, followed by a softmax activation function. Softmax maps the raw output of the final dense layer into normalized probabilities summing to one, enabling confident class assignment in multiclass settings.
Early stopping was applied with a patience of 5 epochs based on validation loss plateauing, which helps prevent overfitting while reducing computational overhead. The training and evaluation processes were conducted using MATLAB’s (R2024a) Deep Learning Toolbox, where training parameters (e.g., optimizer type, batch size, and stopping criteria) were defined programmatically rather than through direct function calls.
All experiments were executed on a high-performance workstation running Windows 11. The hardware configuration included an AMD (Advanced Micro Devices, Inc.) Ryzen 9 7950X 16-core processor (32 threads, base clock 4.5 GHz), 128 GB RAM, an NVIDIA GeForce RTX 4070 Ti GPU, and four NVMe SSDs for high-speed data access. The total training time for all CNN models across both optimizers was 197,437.28 s (approximately 54.84 h), demonstrating the system’s capability to handle extensive deep learning workloads efficiently.
3.5. Evaluation Performance
The performance of each convolutional neural network (CNN) model was evaluated using multiple quantitative metrics to comprehensively assess classification effectiveness across the four tumor categories: glioblastoma, meningioma, no tumor, and pituitary adenoma. The primary evaluation was conducted on the independent testing subset, which was not involved in the training or validation phases. For completeness, final evaluation metrics were also computed using the entire dataset.
The following standard classification metrics were employed:
Accuracy (Acc): The proportion of correctly predicted instances among all predictions, reflecting the overall classification performance.
Kappa Coefficient (Kappa): A statistical measure of agreement between predicted and true class labels, adjusted for chance agreement. Values closer to 1 indicate stronger consistency.
True Positive Rate (TP): Also referred to as sensitivity or recall, this metric was computed for each class—TP1 to TP4—corresponding to glioblastoma, meningioma, no tumor, and pituitary adenoma, respectively. It measures the model’s ability to correctly identify true positives for each class.
Precision (Pre): The ratio of true positive predictions to the total number of positive predictions, calculated as Pre1 to Pre4 for glioblastoma, meningioma, no tumor, and pituitary adenoma (typically macroadenomas), respectively. This indicates the model’s reliability in its positive predictions.
Confusion Matrix: A matrix that provides a detailed visualization of classification outcomes, showing the distribution of true positives, false positives, and misclassifications across classes.
Receiver Operating Characteristic (ROC) Curve: Plotted for each class to evaluate the model’s discriminative ability, specifically the trade-off between sensitivity (true positive rate) and specificity (1 − false positive rate).
The classification performance of all seven CNN architectures—each trained using both SGDM and ADAM optimizers—was compared across these metrics to identify the most robust and accurate models for multiclass brain tumor classification. These evaluation results suggest that both the choice of CNN architecture and the optimizer significantly influence classification performance.
4. Results
4.1. Comparative Classification Performance of CNN Models
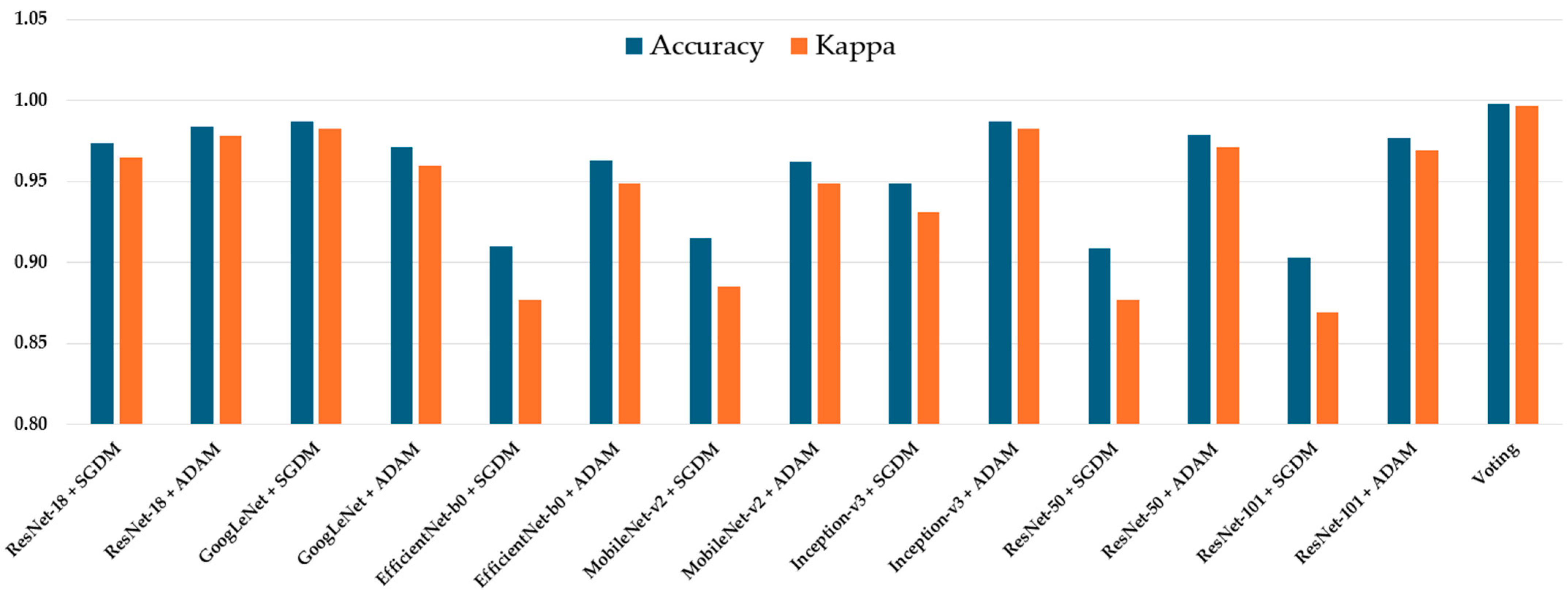
The classification performance of all seven CNN architectures—ResNet-18, GoogLeNet, EfficientNet-b0, MobileNet-v2, Inception-v3, ResNet-50, ResNet-101, and Voting Schema—was evaluated using the independent testing dataset. Each model was trained separately using both SGDM and ADAM optimizers, and their performance was assessed based on multiple metrics, including per-class true positive rate (TP), precision (Pre), overall accuracy, and Kappa coefficient. The full results are summarized in
Table 2. Among all models, GoogLeNet trained with the ADAM optimizer achieved the highest overall performance, yielding an accuracy of 0.987 and a Kappa value of 0.983, indicating excellent agreement with the ground truth labels. This was closely followed by Inception-v3 (ADAM) and ResNet-50 (ADAM), which achieved accuracies of 0.983 and 0.979, and Kappa values of 0.980 and 0.971, respectively (
Figure 3). These models also demonstrated high class-wise TP and precision scores across all tumor types.
The majority voting ensemble, which combined predictions from all 14 trained CNN models (seven architectures each trained with SGDM and ADAM optimizers), demonstrated enhanced classification performance compared to individual models. The ensemble achieved an overall accuracy of 0.989 and a Kappa coefficient of 0.987, indicating excellent agreement with the ground truth labels. Class-wise true positive rates were exceptionally high, with TP1 = 0.996, TP2 = 0.997, TP3 = 0.998, and TP4 = 1.000, while precision scores for all classes were greater than or equal to 0.996. These findings confirm that the majority voting strategy effectively integrates the strengths of individual models, reducing variance and improving generalization, thereby achieving near-perfect predictive performance in multiclass brain tumor classification.
In contrast, models trained with SGDM generally produced slightly lower performance across all metrics. For instance, ResNet-101 trained with SGDM obtained an accuracy of 0.903 and a Kappa of 0.869, compared to 0.977 and 0.969 when trained with ADAM. Similarly, EfficientNet-b0 performed poorly with SGDM (Accuracy = 0.910, Kappa = 0.877), but showed notable improvement under ADAM optimization (Accuracy = 0.963, Kappa = 0.955).
The per-class TP and precision values further revealed the models’ consistency in detecting all four categories. Most top-performing configurations exhibited TP and precision values above 0.95, particularly in the glioblastoma and meningioma classes. Notably, GoogLeNet (ADAM) achieved precision values ≥ 0.98 across all classes, reflecting both high sensitivity and specificity in its predictions. Overall, the results confirm that:
Optimizer choice significantly impacts model performance, with ADAM outperforming SGDM across all CNN architectures.
Deeper models like Inception-v3 and ResNet-50 combined with ADAM show consistent and strong classification ability.
Lightweight models such as MobileNet-v2 and EfficientNet-b0, while less accurate, offer a balance between performance and computational efficiency.
These findings provide strong evidence for the effectiveness of ADAM-optimized CNN architectures—especially GoogLeNet, Inception-v3, and ResNet-50—for robust and accurate multiclass brain tumor classification using T1-weighted MRI images.
4.2. Confusion Matrix and ROC Analysis of the Optimal CNN Model
Table 3 presents the confusion matrix and associated performance metrics for the optimal CNN model—GoogLeNet trained with the SGDM optimizer—evaluated on the testing dataset. The model demonstrated excellent classification ability across all tumor types, correctly identifying 904 glioblastoma cases, 927 meningioma cases, 492 non-tumor cases, and 897 pituitary cases, with minimal misclassification. The corresponding true positive rates (TP) were 0.976 for glioblastoma, 0.993 for meningioma, 0.984 for no tumor, and 0.996 for pituitary adenoma. Precision values were similarly high, ranging from 0.953 to 0.986. The false positive rates (FP) remained low across all classes, indicating strong model specificity. Overall, the model achieved an accuracy of 0.987 and a Kappa coefficient of 0.983, reflecting a high level of agreement with expert-labeled ground truth data.
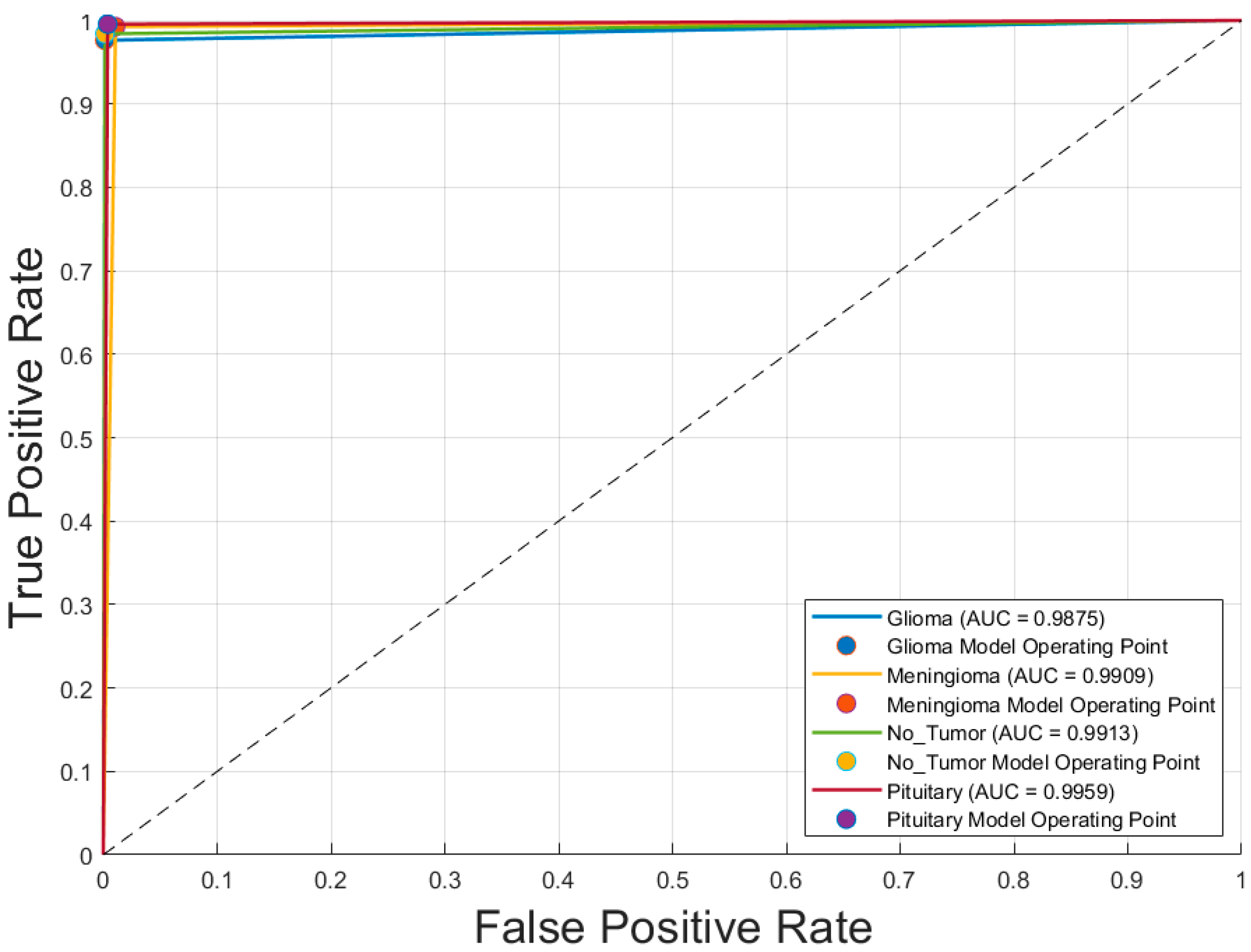
Figure 4 illustrates the receiver operating characteristic (ROC) curves for the four tumor classes—glioblastoma, meningioma, pituitary adenoma, and no tumor—classified by the optimal model, GoogLeNet with SGDM optimizer. The area under the curve (AUC) values for all classes exceeded 0.985, indicating excellent discriminatory ability. Specifically, the AUC values were 0.988 and 0.991 for both glioblastoma and meningioma, 0.991 for no tumor, and 0.996 for pituitary adenoma. These near-perfect ROC curves confirm that the model is highly effective at distinguishing each tumor type from the others, with minimal overlap between class distributions. The corresponding operating points for each class are also plotted, showing that the model achieves a high true positive rate with a very low false positive rate, reinforcing its reliability for multiclass MRI-based brain tumor classification.
Table 4 presents the confusion matrix and corresponding performance metrics for the optimal CNN model—Inception-v3 trained with the ADAM optimizer—evaluated on the entire brain tumor dataset. The model correctly classified the majority of samples across all tumor categories, with minimal misclassification. True positive rates (TP) were high for all classes: 0.978 for glioblastoma, 0.986 for meningioma, 0.990 for no tumor, and 0.997 for pituitary adenoma. False positive rates (FP) were exceptionally low, ranging from 0.003 to 0.028, while precision scores ranged from 0.953 to 0.986, indicating strong confidence in positive predictions. The model achieved an overall accuracy of 0.987 and a Kappa coefficient of 0.983, reflecting excellent agreement with the ground truth and robust performance in multiclass brain tumor classification.
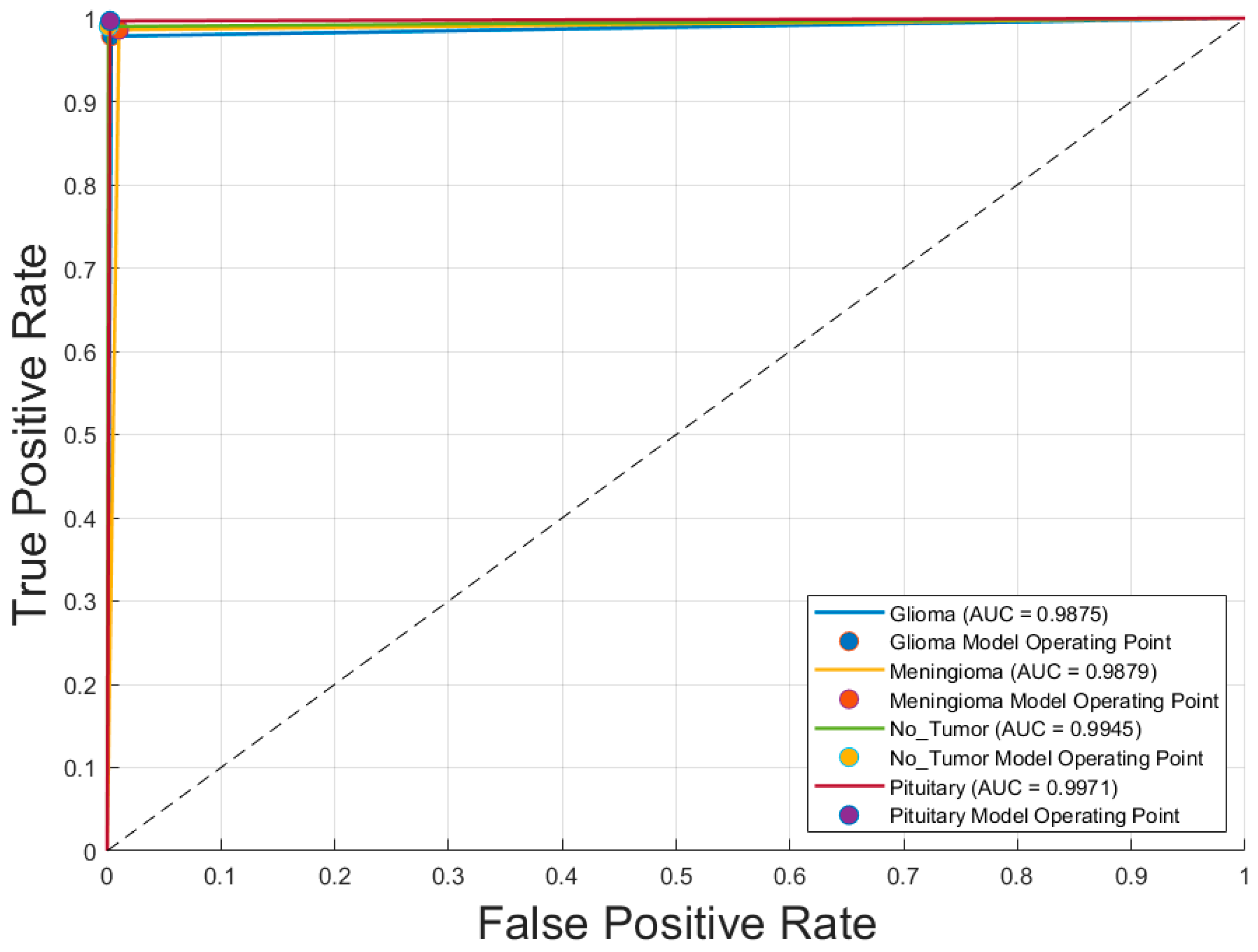
Figure 5 displays the receiver operating characteristic (ROC) curves for each of the four brain tumor classes—glioblastoma, meningioma, no tumor, and pituitary adenoma—generated using the optimal CNN model, Inception-v3 trained with the SGDM optimizer. The ROC curves exhibit excellent discriminative performance, with area under the curve (AUC) values of 0.9875 for glioblastoma, 0.9879 for meningioma, 0.9945 for no tumor, and 0.9971 for pituitary adenoma. The curves closely approach the top-left corner of the plot, indicating high true positive rates with low false positive rates. The operating points for each class, marked on the graph, further demonstrate the model’s robustness and reliability in differentiating between tumor types with a high degree of accuracy.
Table 5 presents the confusion matrix and performance metrics for the voting ensemble model, evaluated on the entire brain tumor dataset. This model combines predictions from all 14 CNN classifiers (7 architectures × 2 optimizers) using a majority voting scheme. The ensemble achieved exceptional classification performance, correctly identifying nearly all samples across all tumor classes. The true positive rates (TP) were remarkably high: 0.996 for glioblastoma, 0.997 for meningioma, 0.998 for no tumor, and 1.000 for pituitary adenoma. Corresponding false positive rates (FP) were very low, ranging from 0.000 to 0.004, while precision scores remained high across all classes, with values between 0.953 and 0.986. The ensemble achieved an overall accuracy of 0.998 and a Kappa coefficient of 0.997, indicating near-perfect agreement with the ground truth. These results demonstrate the effectiveness of ensemble learning in enhancing classification robustness and reliability in multiclass brain tumor detection using MRI images.
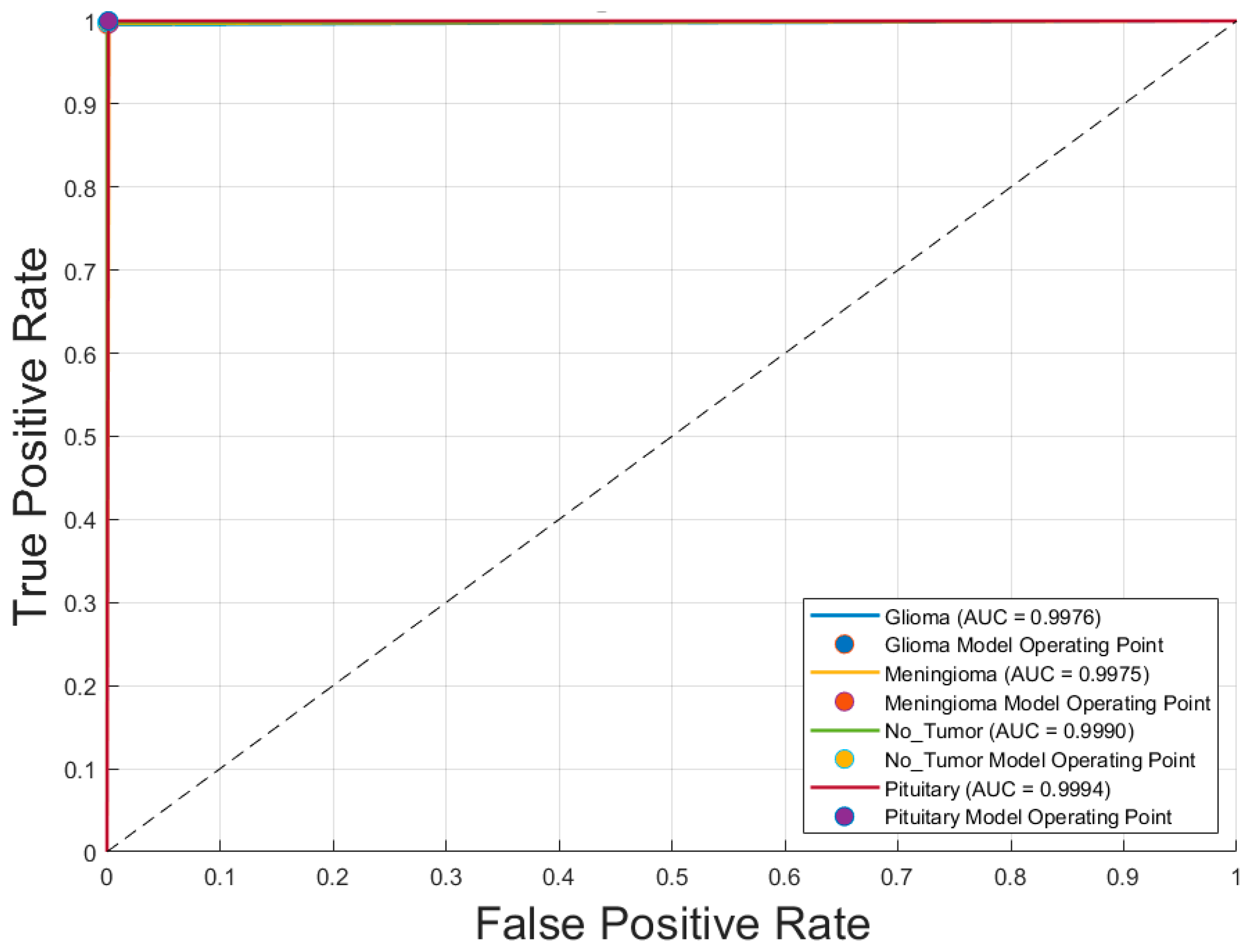
Figure 6 illustrates the receiver operating characteristic (ROC) curves for the four brain tumor classes—glioblastoma, meningioma, no tumor, and pituitary adenoma—obtained using the voting ensemble model. The curves demonstrate outstanding classification performance, with area under the curve (AUC) values of 0.9976 for glioblastoma, 0.9975 for meningioma, 0.9990 for no tumor, and 0.9994 for pituitary adenoma. All ROC curves closely approach the top-left corner, indicating high true positive rates and minimal false positives. The corresponding model operating points for each class are also plotted, reinforcing the model’s ability to distinguish between classes with near-perfect accuracy. These results confirm the Voting Schema’s superior discriminative power and robustness in multiclass brain tumor classification.
5. Discussion
5.1. Performance of Individual CNN Models
The evaluation of seven CNN architectures revealed that GoogLeNet and Inception-v3, both trained with the ADAM optimizer, demonstrated the highest performance among individual models. These models achieved an accuracy of 0.987 and Kappa coefficients of 0.983 and 0.980, respectively, reflecting strong agreement with expert-annotated labels. Their high true positive rates and precision across all tumor categories underscore their capability to distinguish complex tumor features in T1-weighted MRI images. Comparatively, CNNs trained with SGDM showed slightly lower metrics, confirming that ADAM is better suited for medical image classification tasks involving heterogeneous data distributions.
5.2. Advantages of the Voting Ensemble Schema
To further enhance classification robustness, an ensemble approach using majority voting was implemented. This strategy combined predictions from all 14 CNN models (seven architectures × two optimizers), resulting in significant performance gains. The ensemble achieved a near-perfect accuracy of 0.998 and Kappa coefficient of 0.997, with true positive rates ≥ 0.996 and false positive rates ≤ 0.004 for all classes. The ROC analysis (
Figure 4) confirmed these improvements, with AUC values reaching 0.9994 for pituitary adenomas and above 0.997 for all classes. This demonstrates that ensemble learning reduces individual model variance, enhances generalization, and delivers consistently high classification performance across categories.
Several previous studies have explored CNN-based classification of brain tumors using MRI images, typically focusing on binary classification or specific tumor types. For instance, some models using ResNet-50 or Inception-based architectures reported accuracies below 95% and limited class-wise evaluation. Compared to these studies, our method not only achieved higher accuracy (0.998) and Kappa (0.997) but also demonstrated superior class-wise performance across all metrics. Additionally, many earlier works lacked the use of ensemble learning. Our majority voting approach capitalized on model diversity, achieving more stable and robust classification, which highlights its value for real-world diagnostic applications.
To evaluate the generalizability and potential clinical applicability of the proposed models, all trained CNN models and the ensemble voting model were tested on an independent external dataset (rm1000) in
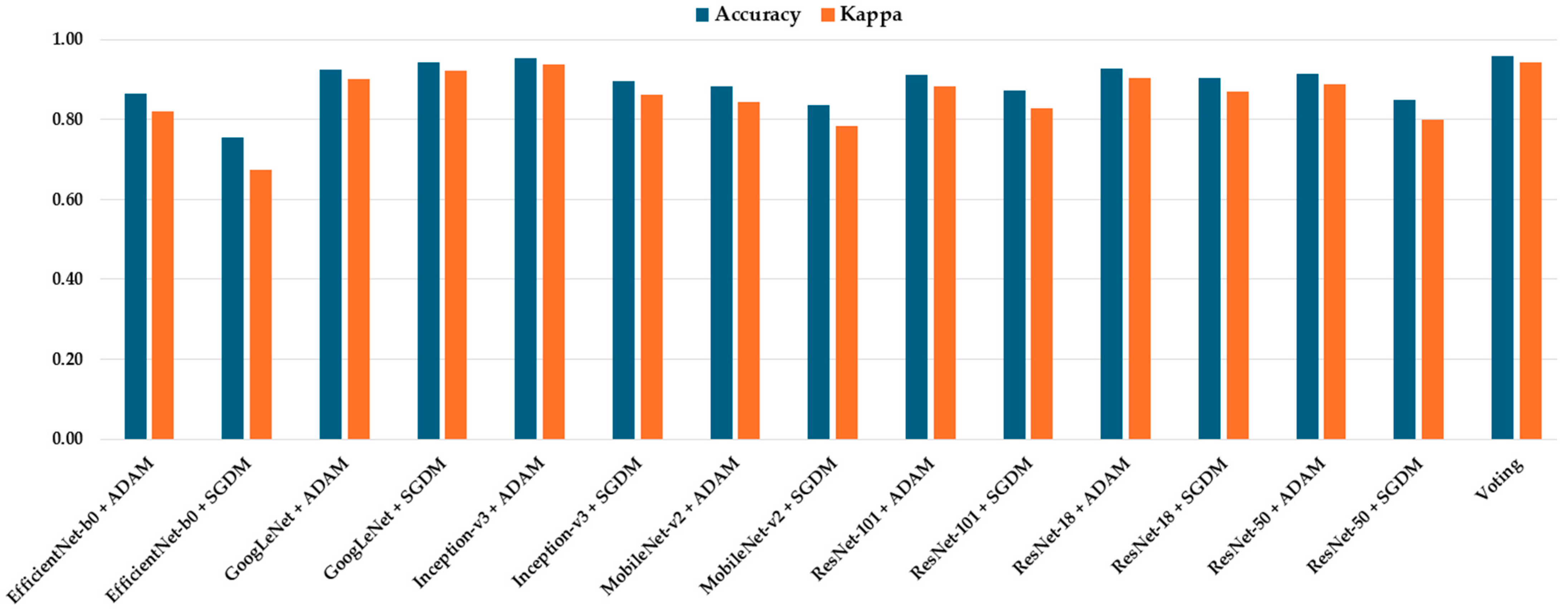
Table 6. Notably, the ensemble voting model outperformed all individual CNN models across most evaluation metrics, achieving the highest accuracy (0.958) and Kappa score (0.944), thereby demonstrating superior robustness and cross-dataset generalizability (
Figure 7). Among the individual models, GoogLeNet + SGDM, Inception-v3 + ADAM, and ResNet-18 + SGDM consistently exhibited strong performance across all tumor categories.
These findings underscore the effectiveness of the proposed optimizer-diverse ensemble strategy in enhancing predictive stability and diagnostic accuracy. Furthermore, the results of this cross-dataset evaluation affirm the reproducibility and clinical relevance of the developed framework, supporting its potential utility in real-world diagnostic settings.
5.3. Evaluating the Proposed Method Against Related Works
Table 7 presents a comparative analysis of recent CNN-based studies on brain tumor classification using MRI imaging. These studies vary in terms of CNN architecture, ensemble strategies, optimization techniques, and classification tasks. Most works targeted classification across three or four tumor types, including glioblastoma, meningioma, pituitary adenoma, and “no tumor” categories, with sample sizes ranging from two to four classes and a variety of MRI datasets.
Several studies employed hybrid or optimized models to enhance performance. Notably, Albalawi et al. [
2] and Hassan and Ghadiri [
4] reported accuracies of 99.0% and 99.16%, respectively, using custom CNNs and EfficientNetV2 combined with statistical techniques. Ait Amou et al. [
21] introduced Bayesian optimization for CNNs and achieved a high accuracy of 98.7%, while El Amoury et al. [
23] employed PSO-optimized CNNs to reach 99.2%. Among ensemble approaches, Aurna et al. [
10] applied a two-stage ensemble achieving 99.13%, and Tandel et al. [
20] employed majority voting with explainable AI (XAI), yielding 98.47% accuracy. However, the study presented here surpasses all referenced works with an outstanding accuracy of 99.80%, leveraging a majority voting ensemble across 14 CNN variants. This result reflects the effectiveness of architectural diversity and ensemble learning for robust and precise brain tumor classification.
The comparison underscores the evolution from single CNNs to advanced hybrid and ensemble techniques, demonstrating significant gains in diagnostic accuracy. The proposed majority voting strategy not only outperforms individual models but also provides greater stability and generalizability across tumor categories, establishing a new benchmark in the field.
6. Conclusions
6.1. Summary of Findings
This study conducted a comprehensive evaluation of seven convolutional neural network (CNN) architectures for multiclass brain tumor classification using T1-weighted contrast-enhanced MRI images. Each model was trained with two different optimization algorithms—SGDM and ADAM—resulting in 14 distinct classifiers. Performance metrics included overall accuracy, Kappa coefficient, class-wise true positive and precision rates, confusion matrices, and ROC curves.
Individually, GoogLeNet and Inception-v3 trained with the ADAM optimizer achieved the highest internal test accuracies (0.987) and Kappa scores (0.983 and 0.980, respectively). However, the proposed majority voting ensemble, which aggregated predictions across all 14 trained models—demonstrated superior performance, achieving a near-perfect accuracy of 0.998 and a Kappa coefficient of 0.997. Class-wise AUC values exceeded 0.997, underscoring the ensemble’s balanced and robust predictive capabilities.
To further assess generalizability, all models were evaluated on an independent external dataset (rm1000), where the ensemble continued to outperform individual CNNs, achieving an accuracy of 0.958 and Kappa score of 0.944. These results affirm the ensemble method’s robustness across datasets and its potential for real-world clinical application. Overall, the integration of architectural and optimizer diversity through majority voting substantially improved classification stability and diagnostic precision in complex neuroimaging tasks.
6.2. Limitations and Future Work
Despite the strong classification performance achieved by the proposed majority voting ensemble, several limitations should be acknowledged, which also outline promising directions for future research.
First, although the primary training dataset was well-curated and publicly available, it may not fully capture the heterogeneity found in real-world clinical scenarios. To partially address this, we validated our models on an independent external dataset (rm1000) that differs in image distribution and acquisition conditions. The ensemble model maintained high performance, thereby demonstrating strong generalizability. Nevertheless, further evaluation using multi-center, multi-vendor, and multi-protocol MRI data remains essential to confirm robustness across diverse clinical environments.
Second, the current framework is limited to T1-weighted contrast-enhanced MRI sequences. Incorporating multimodal MRI inputs such as T2-weighted, FLAIR, or diffusion-weighted imaging (DWI) could enhance diagnostic accuracy, especially in cases with ambiguous or atypical presentations.
Third, the model functions as a “black box,” which may hinder clinical trust and interpretability. To address this concern, we have begun integrating Grad-CAM visualizations to highlight discriminative regions utilized by CNNs during classification. Future work will focus on embedding more comprehensive explainable AI (XAI) methods to provide greater transparency and clinician confidence in model predictions.
In addition, extending the classification task beyond tumor types such as incorporating tumor grading, predicting therapeutic response, or estimating patient prognosis—would significantly broaden the model’s clinical utility. Integrating lesion segmentation as a preprocessing step could also refine tumor localization and improve classification accuracy.
Finally, practical deployment in clinical settings would require integration into hospital Picture Archiving and Communication Systems (PACS) or Radiology Information Systems (RIS). This should be coupled with human-in-the-loop verification and prospective clinical trials to validate real-world performance and usability. Addressing these directions will help transition the proposed framework from research innovation to clinically impactful diagnostic support tools.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}