
Risk of Bias Assessment of Diagnostic Accuracy Studies Using QUADAS 2 by Large Language Models



Abstract
1. Introduction
2. Materials and Methods
2.1. Article Selection
2.2. Risk of Bias Evaluation
2.3. Human Risk of Bias Assessment
2.4. Artificial Risk of Bias Intelligence Assessment
2.5. Data Extraction
2.6. Verification of the Correctness of Artificial Intelligence Assessments
2.7. Statistical Analysis
3. Results
3.1. Study Characteristics
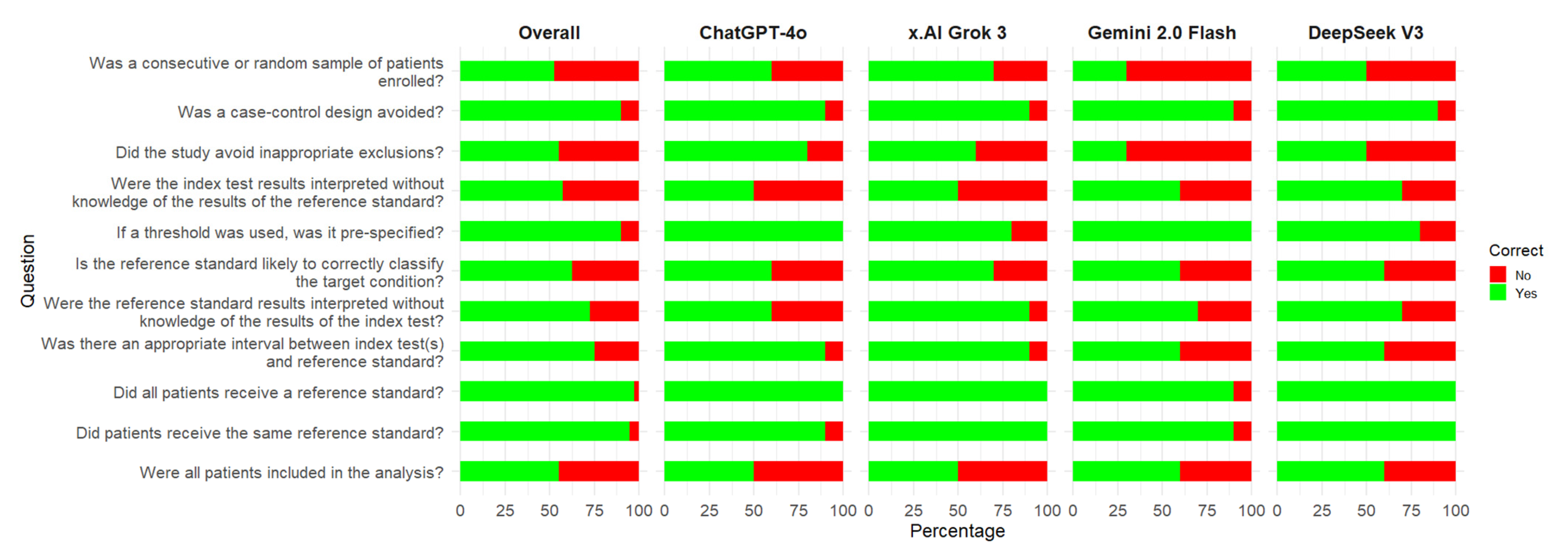
3.2. Risk of Bias Assessment of Individual Studies
3.3. Quantitative Accuracy Assessment of LLMs Evaluations Compared to Human Experts
3.4. Assessment of Reasoning Errors of LLMs
3.4.1. Patient Selection Reasoning Errors
- Misunderstanding of consecutive sampling in case-control or subgroup design.LLMs incorrectly concluded that consecutive sampling did not occur when authors declare a case-control design. However, consecutive sampling can be applied within case and control groups. Furthermore, there is a specific signaling question regarding the case-control design. Within the same framework, in one case, an LLM misinterpreted that having a target percentage of enrollment per group is incompatible with consecutive sampling. As stated before, within groups, consecutive sampling can be implemented. Consecutive sampling can and should be evaluated separately within each group (case-control or other design).Incorrectly assuming that using inclusion and exclusion criteria invalidates the possibility of having consecutive sampling. The selection criteria are essential in research methodology. One cannot include a participant who has exclusion criteria, just to make a sample “consecutive”.
- Inference errors concerning consecutive sampling based on the author’s explicit reporting.Incorrectly reporting that consecutive sampling occurred, when the authors did not explicitly state it.Assuming the absence of explicitly stated sampling methods as evidence of their non-use.Missing a clearly reported use of consecutive sampling by the authors.
- Ambiguity in authors’ descriptions of sampling methods. Choosing one of the authors’ statements as proof for the study design in case of ambiguity. In one case, one article stated that the sample was “convenience” and later that it was “consecutive”. These two are obviously contradicting each other. The LLM chose only one of them as an argument for the study design. The correct rationale would have been to consider that the design cannot be correctly interpreted based on this ambiguity.
- Misinterpreting representativeness. In some cases, the LLM considered that the sample is not representative, since the authors stated they included patients with a suspicion of a certain diagnosis. For diagnostic tests, the population represented by those with a suspicion of a certain diagnosis is very common and has great utility for clinicians.
- Incorrectly deciding that the design was case-control, focusing only on the authors’ declarations about the design of the study, instead of carefully assessing how the participants were selected. In one case, the authors declared the design as case-control. Later, it became clear that all the participants were representing one sample. After each participant was assessed regarding the presence of the disease, the participants were categorized as having or being without the disease. However, this does not represent a case-control design, where the source of the two samples should be separate.
- Incorrect labeling of justified clinical exclusions is considered inappropriate. There were cases where the LLMs would consider that a specific exclusion is inappropriate, without presenting a medical argument. Upon clinical assessment, there were reasonable arguments in favor of the exclusion. Keeping those participants might have induced bias in the study. Thus, the exclusion was in fact appropriate.
- Misinterpretation of missing information about exclusions.In some cases, the LLM could state there were no exclusions. But the absence of any statement of exclusions does not necessarily mean that the authors did not actually use exclusions, but failed to report them.Misunderstanding exclusions at the patient selection moment, and those after selection for the questions within the flow and timing domain. Exclusions can be made during patient selection. After the patients are selected, further exclusions can be made, which can be identified in the flow and timing domain with the following question: Were all the patients included in the analysis? In some cases, the LLM considered an exclusion made after the use of the index test (clearly after patient selection), as a patient selection bias instead of a flow and timing bias.Failing to recognize that the exclusion of unclear situations can induce bias. In some cases, the LLMs did not consider that the exclusion of patients due to poor-quality images would induce bias. In real-world settings, poor-quality images can occur. Their exclusion would artificially inflate the accuracy of diagnostic tests that do not have to deal with technical difficulties.
3.4.2. Index Test Domain Reasoning Errors
- Misinterpreting the objectivity of the index test. In some cases, the LLM did not observe that certain tests are clearly objective (e.g., biomarkers, serum evaluations), and they cannot be influenced by the reference standard results.
- Misinterpreting of test sequencing regarding the standard test. In some cases, the LLM did not observe that the standard test was carried out after the index test, thus making it impossible for the index test results to be influenced by the standard test.
- Inversing the direction of blinding. In some cases, the LLM acknowledged that the observer who performed the standard test was blinded to the index test results. The LLM then incorrectly concluded that this implies that the one who performed the index test was blinded to the standard too.
- Misunderstanding of data-driven thresholds as prespecified. In some cases, the LLM considered the use of tertiles, or several operational thresholds (high specificity, high sensitivity, maximum gain points), as prespecified thresholds. In reality, these thresholds are calculated after the data are collected, not when writing the study protocol.
3.4.3. Reference Standard Domain Reasoning Errors
- Confusing frequent use of diagnostic tests as arguments for their validity. In some cases, the LLM would use as arguments for high diagnostic accuracy the fact that the test is widely used, or frequently applied, or a preferred method in clinical settings.
- Confusing guideline-supported methods as arguments for a gold standard. In some cases, the LLM indicated that a test can be considered a gold standard because it is supported by a guideline. Some tests are less invasive, and this is why they are supported by guidelines, but they are not necessarily the gold standard for specific diagnostics.
- Not knowing what a gold standard is in specific cases. In some cases, the LLM was not aware that a clinical test without imaging methods cannot accurately make a diagnosis.
- Confusing high reliability with validity. In some cases, the LLM argued for the use of a test because of the high intra-rater agreement. High agreement, although desirable, does not imply high accuracy.
- Influenced by the use of the word “standardized”. In some cases, the LLM considered the fact that the authors used the word standardized is an argument for a good standard test. The context was “standardized clinical history”. This word is not enough to guarantee high accuracy, and a standard test.
- Failed to recognize that moderate agreement is problematic. In some cases, the LLM did not observe that the agreement between raters was moderate. While high agreement does not guarantee high accuracy, low agreement impacts accuracy.
- Inversing the direction of blinding. In some cases, the LLM acknowledged that the observer who performed the index test was blinded to the reference test results. The LLM then incorrectly concluded that this implies that the one who performed the reference test was blinded to the index test.
- Misunderstanding of the logic of time and the sequence of the tests regarding the standard test. In some cases, the LLM did not observe that the standard test was carried out before the index test (in some retrospective studies), thus making it impossible for the standard test results to be influenced by the index test.
- Misunderstanding of blinding contexts. In some cases, the LLM identified that the observer lacked blinding for the study aim, and it interpreted that blinding was not employed for the reference standard. The absence of blinding for the aim is a different type of bias, one that is not concerning the test.
- Correct answers with incorrect arguments. In some cases, the LLM gave correct answers, but used incorrect logic for the arguments.
3.4.4. Flow and Timing Domain Reasoning Errors
- Misinterpretation of time intervals due to the presence of specific wording. In some cases, the LLM observed that the authors stated that the design was cross-sectional, and used this as an argument for an appropriate interval between the tests. But, even in cross-sectional designs, the time between the two tests can be large enough to allow the disease to progress, and thus the tests to measure different things. The correct assessment should be based on specific information that clearly indicates the time, ignoring the reported design. In some cases of cohort studies, the LLM considered that the expression “collected during the same NHANES examination cycle or cohort (2017–2020)” implies that the timing between the index and standard test is short enough.
- Failing to acknowledge the absence of reporting of timing between tests. In some cases, the LLM did not observe the absence of explicit reporting of timing between tests. Then, it assigned a low risk of bias instead of assigning an unclear risk of bias.
- Incorrect assumption of time between tests based on ambiguous wording. In some cases, the authors stated that a test was performed in a “single session” or a “single sitting”. The other test was performed at another time. The LLM incorrectly inferred, based on that expression, that both tests were performed in the same sitting.
- Misjudgment about the clinical relevance of timing intervals. In some cases, the LLM did not understand that, within a hospitalization time for a disease (which is usually not very long), although the time between the two assessments was not specified, due to the fact that the disease progression is very slow, the time elapsed between the tests is not problematic.
- Failing to understand the time between assessments of the same imagistic method. In some cases, the study assessed the same medical images by humans and by algorithms. The LLM argued that the authors failed to mention the delay between the tests. But this does not make any sense in this context.
- Misclassification of exclusions at enrollment vs. after enrollment. In some cases, the LLM incorrectly considered participant exclusions at patient selection time, as missing at analysis time.
- Misinterpreting the selection of participants. In some cases, the LLM observed that from an initial sample of participants, only some of the participants were assessed by the authors in the study. This subgroup was assessed using both the index and standard tests. Thus, in reality, the apparent subgroup was in fact the actual patient selection group. The LLM, instead, considered that there was a problem of not applying the reference test to all participants.
- Failing to identify multiple reference standard tests that were used. In some cases, the LLM missed recognizing that there were two groups of assessors from different countries with different coefficients of agreement between their assessments of images.
- Failing to verify the completeness of data tables. In some cases, the LLMs did not check in the tables what the numbers were, so that exclusion could be deducted, even though they weren’t mentioned in the text.
- Failing to recognize post-index-test exclusions. In some cases, the LLMs, did not identify that there was a problem of exclusion, in case where exclusions were made at the time of using the index test (to exclude poor quality images, or difficult cases). This is clearly not an exclusion relevant to patient selection time.
- Failing to correctly differentiate exclusions at patient selection moment from those after enrolment, concerning the flow and timing domain.
3.5. Assessment of Articles That Are Not of the Correct Study Type
4. Discussion
4.1. Limitations
4.2. Strengths
4.3. Future Perspectives
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| LLM | Large Language Model |
| QUADAS | Quality Assessment of Diagnostic Accuracy Studies |
| RoB | Risk of Bias |
| PubMed | Public/Publisher MEDLINE (medical literature database) |
| NHANES | National Health and Nutrition Examination Survey |
| ROBINS-I | Risk Of Bias In Non-randomized Studies—of Interventions |
| CLARITY | Clinical Advances through Research and Information Translation at McMaster University |
References
- Whiting, P.; Rutjes, A.W.; Reitsma, J.B.; Bossuyt, P.M.; Kleijnen, J. The Development of QUADAS: A Tool for the Quality Assessment of Studies of Diagnostic Accuracy Included in Systematic Reviews. BMC Med. Res. Methodol. 2003, 3, 25. [Google Scholar] [CrossRef] [PubMed]
- Whiting, P.F.; Rutjes, A.W.S.; Westwood, M.E.; Mallett, S.; Deeks, J.J.; Reitsma, J.B.; Leeflang, M.M.G.; Sterne, J.A.C.; Bossuyt, P.M.M.; the QUADAS-2 Group. QUADAS-2: A Revised Tool for the Quality Assessment of Diagnostic Accuracy Studies. Ann. Intern. Med. 2011, 155, 529–536. [Google Scholar] [CrossRef] [PubMed]
- University of Bristol. QUADAS. Available online: https://www.bristol.ac.uk/population-health-sciences/projects/quadas/ (accessed on 12 May 2025).
- Artificial Intelligence (AI) | Definition, Examples, Types, Applications, Companies, & Facts | Britannica. Available online: https://www.britannica.com/technology/artificial-intelligence (accessed on 12 May 2025).
- What Is Artificial Intelligence (AI)? | IBM. Available online: https://www.ibm.com/think/topics/artificial-intelligence (accessed on 12 May 2025).
- Large Language Model—Oxford Learners Dictionaires. Available online: https://www.oxfordlearnersdictionaries.com/definition/english/large-language-model?q=large+language+model (accessed on 12 May 2025).
- Lu, Z.; Peng, Y.; Cohen, T.; Ghassemi, M.; Weng, C.; Tian, S. Large Language Models in Biomedicine and Health: Current Research Landscape and Future Directions. J. Am. Med. Inform. Assoc. 2024, 31, 1801–1811. [Google Scholar] [CrossRef]
- Xie, Q.; Luo, Z.; Wang, B.; Ananiadou, S. A Survey for Biomedical Text Summarization: From Pre-Trained to Large Language Models. arXiv 2023, arXiv:2304.08763. [Google Scholar]
- ChatGPT. Available online: https://chatgpt.com (accessed on 12 May 2025).
- Grok. Available online: https://grok.com/ (accessed on 12 May 2025).
- Gemini. Available online: https://gemini.google.com (accessed on 12 May 2025).
- DeepSeek. Available online: https://www.deepseek.com/ (accessed on 12 May 2025).
- Tang, L.; Sun, Z.; Idnay, B.; Nestor, J.G.; Soroush, A.; Elias, P.A.; Xu, Z.; Ding, Y.; Durrett, G.; Rousseau, J.F.; et al. Evaluating Large Language Models on Medical Evidence Summarization. NPJ Digit. Med. 2023, 6, 158. [Google Scholar] [CrossRef]
- Van Veen, D.; Van Uden, C.; Blankemeier, L.; Delbrouck, J.-B.; Aali, A.; Bluethgen, C.; Pareek, A.; Polacin, M.; Reis, E.P.; Seehofnerová, A.; et al. Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization. Nat. Med. 2024, 30, 1134–1142. [Google Scholar] [CrossRef]
- Fariba, F.; Hadei, S.K.; ForughiMoghadam, H.; Alvandi, M.; Zebarjadi, S. Myocardial Perfusion Imaging Versus Coronary CT Angiography for the Detection of Coronary Artery Disease. Med. J. Islam. Repub. Iran. 2024, 38, 136. [Google Scholar] [CrossRef]
- Li, C.; Huang, Q.; Zhuang, Y.; Chen, P.; Lin, Y. Association between Metrnl and Carotid Atherosclerosis in Patients with Type 2 Diabetes Mellitus. Front. Endocrinol. 2024, 15, 1414508. [Google Scholar] [CrossRef] [PubMed]
- Van Kleef, L.A.; Pustjens, J.; Janssen, H.L.A.; Brouwer, W.P. Diagnostic Accuracy of the LiverRisk Score to Detect Increased Liver Stiffness Among a United States General Population and Subgroups. J. Clin. Exp. Hepatol. 2025, 15, 102512. [Google Scholar] [CrossRef]
- Vamja, R.; Vala, V.; Ramachandran, A.; Nagda, J. Diagnostic Accuracy of Fatty Liver Index (FLI) for Detecting Metabolic Associated Fatty Liver Disease (MAFLD) in Adults Attending a Tertiary Care Hospital, a Cross-Sectional Study. Clin. Diabetes Endocrinol. 2024, 10, 46. [Google Scholar] [CrossRef]
- Subramani, A.; Periasamy, P.; Gunasekaran, S. A Comparative Analysis of Diagnostic Accuracy: Vibration Perception Threshold vs. Diabetic Neuropathy Examination for Diabetic Neuropathy. J. Pharm. Bioallied Sci. 2024, 16, S4536–S4539. [Google Scholar] [CrossRef] [PubMed]
- King, L.K.; Stanaitis, I.; Hung, V.; Koppikar, S.; Waugh, E.J.; Lipscombe, L.; Hawker, G.A. National Institute of Health and Care Excellence Clinical Criteria for the Diagnosis of Knee Osteoarthritis: A Prospective Diagnostic Accuracy Study in Individuals With Type 2 Diabetes. Arthritis Care Res. 2025, 77, 623–630. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.; Huang, W.; Yang, B. Association between METS-IR Index and Obstructive Sleep Apnea: Evidence from NHANES. Sci. Rep. 2025, 15, 6654. [Google Scholar] [CrossRef]
- Willems, S.A.; van Bennekom, O.O.; Schepers, A.; van Schaik, J.; van der Vorst, J.R.; Hamming, J.F.; Brouwers, J.J.W.M. A Diagnostic Comparison Study between Maximal Systolic Acceleration and Acceleration Time to Detect Peripheral Arterial Disease. Ann. Vasc. Surg. 2025, 111, 203–211. [Google Scholar] [CrossRef]
- Grzybowski, A.; Brona, P.; Krzywicki, T.; Ruamviboonsuk, P. Diagnostic Accuracy of Automated Diabetic Retinopathy Image Assessment Software: IDx-DR and RetCAD. Ophthalmol. Ther. 2025, 14, 73–84. [Google Scholar] [CrossRef]
- Dos Reis, M.A.; Künas, C.A.; da Silva Araújo, T.; Schneiders, J.; de Azevedo, P.B.; Nakayama, L.F.; Rados, D.R.V.; Umpierre, R.N.; Berwanger, O.; Lavinsky, D.; et al. Advancing Healthcare with Artificial Intelligence: Diagnostic Accuracy of Machine Learning Algorithm in Diagnosis of Diabetic Retinopathy in the Brazilian Population. Diabetol. Metab. Syndr. 2024, 16, 209. [Google Scholar] [CrossRef]
- Muntean, A.L.; Vuinov, O.; Popovici, C. Impact of COVID-19 Pandemic on Physical Activity Levels and Mental Health in University Students. Balneo PRM Res. J. 2025, 16, 792. [Google Scholar] [CrossRef]
- Popovici, C.; Bordea, I.R.; Inchingolo, A.D.; Inchingolo, F.; Inchingolo, A.M.; Dipalma, G.; Muntean, A.L. Dental Splints and Sport Performance: A Review of the Current Literature. Dent. J. 2025, 13, 170. [Google Scholar] [CrossRef] [PubMed]
- Kaizik, M.A.; Garcia, A.N.; Hancock, M.J.; Herbert, R.D. Measurement Properties of Quality Assessment Tools for Studies of Diagnostic Accuracy. Braz. J. Phys. Ther. 2020, 24, 177–184. [Google Scholar] [CrossRef]
- Scherbakov, D.; Hubig, N.; Jansari, V.; Bakumenko, A.; Lenert, L.A. The Emergence of Large Language Models as Tools in Literature Reviews: A Large Language Model-Assisted Systematic Review. J. Am. Med. Inform. Assoc. 2025, 32, 1071–1086. [Google Scholar] [CrossRef]
- Siemens, W.; Von Elm, E.; Binder, H.; Böhringer, D.; Eisele-Metzger, A.; Gartlehner, G.; Hanegraaf, P.; Metzendorf, M.-I.; Mosselman, J.-J.; Nowak, A.; et al. Opportunities, Challenges and Risks of Using Artificial Intelligence for Evidence Synthesis. BMJ EBM 2025. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, R.; Shaughnessy, D.; Gill, K.A.R.; Robinson, K.A.; Li, T.; Agai, E. Are ChatGPT and Large Language Models “the Answer” to Bringing Us Closer to Systematic Review Automation? Syst. Rev. 2023, 12, 72. [Google Scholar] [CrossRef] [PubMed]
- Lai, H.; Ge, L.; Sun, M.; Pan, B.; Huang, J.; Hou, L.; Yang, Q.; Liu, J.; Liu, J.; Ye, Z.; et al. Assessing the Risk of Bias in Randomized Clinical Trials With Large Language Models. JAMA Netw. Open 2024, 7, e2412687. [Google Scholar] [CrossRef] [PubMed]
- Tool to Assess Risk of Bias in Randomized Controlled Trials DistillerSR. DistillerSR. Available online: https://www.distillersr.com/resources/methodological-resources/tool-to-assess-risk-of-bias-in-randomized-controlled-trials-distillersr (accessed on 18 May 2025).
- Introducing Claude. Available online: https://www.anthropic.com/news/introducing-claude (accessed on 18 May 2025).
- Lai, H.; Liu, J.; Bai, C.; Liu, H.; Pan, B.; Luo, X.; Hou, L.; Zhao, W.; Xia, D.; Tian, J.; et al. Language Models for Data Extraction and Risk of Bias Assessment in Complementary Medicine. NPJ Digit. Med. 2025, 8, 74. [Google Scholar] [CrossRef]
- Hasan, B.; Saadi, S.; Rajjoub, N.S.; Hegazi, M.; Al-Kordi, M.; Fleti, F.; Farah, M.; Riaz, I.B.; Banerjee, I.; Wang, Z.; et al. Integrating Large Language Models in Systematic Reviews: A Framework and Case Study Using ROBINS-I for Risk of Bias Assessment. BMJ Evid.-Based Med. 2024, 29, 394–398. [Google Scholar] [CrossRef]
- Sterne, J.A.; Hernán, M.A.; Reeves, B.C.; Savović, J.; Berkman, N.D.; Viswanathan, M.; Henry, D.; Altman, D.G.; Ansari, M.T.; Boutron, I.; et al. ROBINS-I: A Tool for Assessing Risk of Bias in Non-Randomised Studies of Interventions. BMJ 2016, 355, i4919. [Google Scholar] [CrossRef]
- Chen, Y.; Benton, J.; Radhakrishnan, A.; Uesato, J.; Denison, C.; Schulman, J.; Somani, A.; Hase, P.; Wagner, M.; Roger, F.; et al. Reasoning Models Don’t Always Say What They Think. arXiv 2025, arXiv:2505.05410. [Google Scholar]

{kind=link}
{kind=link}
| QUADAS 2 Domains, Signaling Questions/Study | Van Kleef, 2025 [17] | Subramani, 2025 [19] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Assessor | Humans | ChatGPT4o | x.AI Grok 3 | Gemini 2.0 Flash | DeepSeek V3 | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 Flash | DeepSeek V3 |
| Patient selection | ||||||||||
| Was a consecutive or random sample of patients enrolled? | Yes | Yes | Yes | Yes | Yes | Unclear | No | Unclear | No | Unclear |
| Was a case-control design avoided? | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
| Did the study avoid inappropriate exclusions? | Yes | Yes | Yes | No | Yes | Yes | Yes | Yes | No | Yes |
| Risk of bias assessment | Low | Low | Low | Unclear | Low | High | High | High | High | High |
| Index test | ||||||||||
| Were the index test results interpreted without knowledge of the results of the reference standard? | Yes | Unclear | Yes | Yes | Unclear | Unclear | Unclear | Unclear | Unclear | Unclear |
| If a threshold was used, was it pre-specified? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Risk of bias assessment | Low | Unclear | Low | Low | Low | Unclear | Unclear | Unclear | Unclear | Unclear |
| Reference standard | ||||||||||
| Is the reference standard likely to correctly classify the target condition? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were the reference standard results interpreted without knowledge of the results of the index test? | Yes | Unclear | Unclear | Yes * | Unclear | Unclear | Unclear | Unclear | Unclear | Unclear |
| Risk of bias assessment | Low | Unclear | Unclear | Low | Low | Unclear | Unclear | Unclear | Unclear | Unclear |
| Flow and timing | ||||||||||
| Was there an appropriate interval between index test(s) and reference standard? | Yes | Yes | Yes | Yes * | Yes * | Unclear | Unclear | Unclear | Unclear | Unclear |
| Did all patients receive a reference standard? | Yes | Yes | Yes | No | Yes | Yes | Yes | Yes | Yes | Yes |
| Did patients receive the same reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were all patients included in the analysis? | Yes | Yes | No | No | Yes | No | Yes | Yes | Yes | Yes |
| Risk of bias assessment | Low | Low | Low | Unclear | Low | Low | Low | Low | Low | Low |
| QUADAS 2 domains, signaling questions/Study | Vamja, 2025 [18] | King, 2025 [20] | ||||||||
| Assessor | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 |
| Patient selection | ||||||||||
| Was a consecutive or random sample of patients enrolled? | Yes | Yes | Yes | Yes | Yes | Unclear | No | No | No | No |
| Was a case-control design avoided? | Yes | Yes | Yes | Yes | Yes | Unclear | Yes | Yes | Yes | Yes |
| Did the study avoid inappropriate exclusions? | Yes | Yes | No | No | Unclear | Unclear | Yes | Yes | No | Unclear |
| Risk of bias assessment | Low | Low | High | High | Low | Unclear | Low | High | Unclear | High |
| Index test | ||||||||||
| Were the index test results interpreted without knowledge of the results of the reference standard? | Yes | Unclear | Unclear | Unclear | Unclear | Yes | Yes | Yes * | Yes * | Yes |
| If a threshold was used, was it pre-specified? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Risk of bias assessment | Low | Unclear | Unclear | Low | Low | Low | Low | Low | Low | Low |
| Reference standard | ||||||||||
| Is the reference standard likely to correctly classify the target condition? | No | Yes | No | Yes | Yes | No | Yes | Yes | Yes | Yes |
| Were the reference standard results interpreted without knowledge of the results of the index test? | Unclear | Unclear | Unclear | Unclear | Unclear | Yes | Yes | Yes | Yes | No |
| Risk of bias assessment | High | Unclear | High | Unclear | Unclear | High | Low | Low | Low | Unclear |
| Flow and timing | ||||||||||
| Was there an appropriate interval between index test(s) and reference standard? | Unclear | Yes | Unclear | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did all patients receive a reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did patients receive the same reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were all patients included in the analysis? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Risk of bias assessment | Low | Low | Unclear | Low | Low | Low | Low | Low | Low | Low |
| QUADAS 2 domains, signaling questions/Study | Yin, 2025 [21] | Fariba, 2024 [15] | ||||||||
| Assessor | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 |
| Patient selection | ||||||||||
| Was a consecutive or random sample of patients enrolled? | No | No | Yes | No * | No | Yes | Yes | Yes | Yes | Unclear |
| Was a case-control design avoided? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did the study avoid inappropriate exclusions? | No | No | No | No | Unclear | Yes | Yes | No | No | No |
| Risk of bias assessment | Unclear | High | High | Unclear | Low | Low | Low | High | Unclear | High |
| Index test | ||||||||||
| Were the index test results interpreted without knowledge of the results of the reference standard? | Yes | Unclear | Yes * | Yes | Yes | Yes | Unclear | Unclear | Unclear | Unclear |
| If a threshold was used, was it pre-specified? | No | No | Yes | No | Yes | Yes | Yes | Yes | Yes | Yes |
| Risk of bias assessment | High | High | Low | Unclear | Low | Low | Unclear | Unclear | Unclear | Unclear |
| Reference standard | ||||||||||
| Is the reference standard likely to correctly classify the target condition? | No | No | No | No | No | Yes | Yes | Yes | Yes | Yes |
| Were the reference standard results interpreted without knowledge of the results of the index test? | Yes | Unclear | Yes | Yes | Unclear | Unclear | Unclear | Unclear | Unclear | Unclear |
| Risk of bias assessment | High | High | High | High | High | Unclear | Unclear | Unclear | Unclear | Unclear |
| Flow and timing | ||||||||||
| Was there an appropriate interval between index test(s) and reference standard? | Yes | Yes | Yes | Not applicable | Not applicable | Yes | Yes | Yes | Yes | Yes |
| Did all patients receive a reference standard? | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
| Did patients receive the same reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were all patients included in the analysis? | Yes | No | No | No | No | No | Yes | No * | No * | Yes |
| Risk of bias assessment | Low | High | High | Unclear | Unclear | High | High | High | High | High |
| QUADAS 2 domains, signaling questions/Study | Li, 2025 [16] | Willems, 2025 [22] | ||||||||
| Assessor | Humans | ChatGPT4o | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 |
| Patient selection | ||||||||||
| Was a consecutive or random sample of patients enrolled? | Unclear | Unclear | Unclear | No | Unclear | Unclear | Yes | Unclear | No | No |
| Was a case-control design avoided? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did the study avoid inappropriate exclusions? | Yes | Yes | Yes | No | Yes | Yes | Yes | Yes | No | Unclear |
| Risk of bias assessment | Unclear | Low | Unclear | High | Low | Unclear | Low | Unclear | Unclear | High |
| Index test | ||||||||||
| Were the index test results interpreted without knowledge of the results of the reference standard? | Yes | Unclear | Unclear | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| If a threshold was used, was it pre-specified? | No | No | No | No | No | Yes | Yes | Yes | Yes | Yes |
| Risk of bias assessment | High | High | High | Unclear | High | Low | Low | Low | Low | Low |
| Reference standard | ||||||||||
| Is the reference standard likely to correctly classify the target condition? | No | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were the reference standard results interpreted without knowledge of the results of the index test? | Unclear | Unclear | Unclear | Yes | Unclear | Unclear | Yes | Unclear | Yes | Unclear |
| Risk of bias assessment | High | Unclear | Unclear | Low | Unclear | Unclear | Low | Unclear | Low | Unclear |
| Flow and timing | ||||||||||
| Was there an appropriate interval between index test(s) and reference standard? | Yes | Yes | Unclear | Unclear | Yes | Yes | Yes | Yes | Yes | Yes |
| Did all patients receive a reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did patients receive the same reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were all patients included in the analysis? | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes | No | No |
| Risk of bias assessment | Low | Low | Unclear | Unclear | Low | High | Low | Low | Unclear | High |
| QUADAS 2 domains, signaling questions/Study | Grzybowski, 2024 [23] | dos Reis, 2024 [24] | ||||||||
| Assessor | Humans | ChatGPT4o | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 | Humans | ChatGPT | x.AI Grok 3 | Gemini 2.0 flash | DeepSeek V3 |
| Patient selection | ||||||||||
| Was a consecutive or random sample of patients enrolled? | Yes | Yes | Yes | Yes * | Unclear | Unclear | No | Yes | No | Yes |
| Was a case-control design avoided? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did the study avoid inappropriate exclusions? | No | No | No | No | No | No | Yes | Yes | No | Yes |
| Risk of bias assessment | High | High | High | Unclear | High | High | High | Low | High | Low |
| Index test | ||||||||||
| Were the index test results interpreted without knowledge of the results of the reference standard? | Yes | Yes | Yes | Yes * | Yes | Yes | Yes | Yes | Yes | Yes |
| If a threshold was used, was it pre-specified? | Yes | Yes | Yes | Yes | Yes | No | No | Yes | No | Yes |
| Risk of bias assessment | Low | Low | Low | Low | Low | Unclear | Unclear | Low | Unclear | Low |
| Reference standard | ||||||||||
| Is the reference standard likely to correctly classify the target condition? | No | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Were the reference standard results interpreted without knowledge of the results of the index test? | Yes | Yes | Yes | Yes | Yes | Yes | Yes * | Yes | Yes | Yes |
| Risk of bias assessment | High | Low | Low | Low | Low | Low | Low | Low | Low | Low |
| Flow and timing | ||||||||||
| Was there an appropriate interval between index test(s) and reference standard? | Yes | Yes | Yes | Yes | Yes * | Yes | Yes | Yes | Yes | Yes |
| Did all patients receive a reference standard? | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Did patients receive the same reference standard? | No | Yes | No | Yes | No | Yes | Yes | Yes | Yes | Yes |
| Were all patients included in the analysis? | No | No | No | No | No | No | Yes | No | No | Yes |
| Risk of bias assessment | High | High | High | Unclear | High | High | Low | High | Unclear | Low |
| Characteristic | Number (%) (n = 110) |
|---|---|
| x.AI Grok 3 | 85/110 (77.27) |
| ChatGPT4o | 83/110 (75.45) |
| DeepSeek V3 | 79/110 (71.82) |
| Gemini 2.0 flash | 74/110 (67.27) |
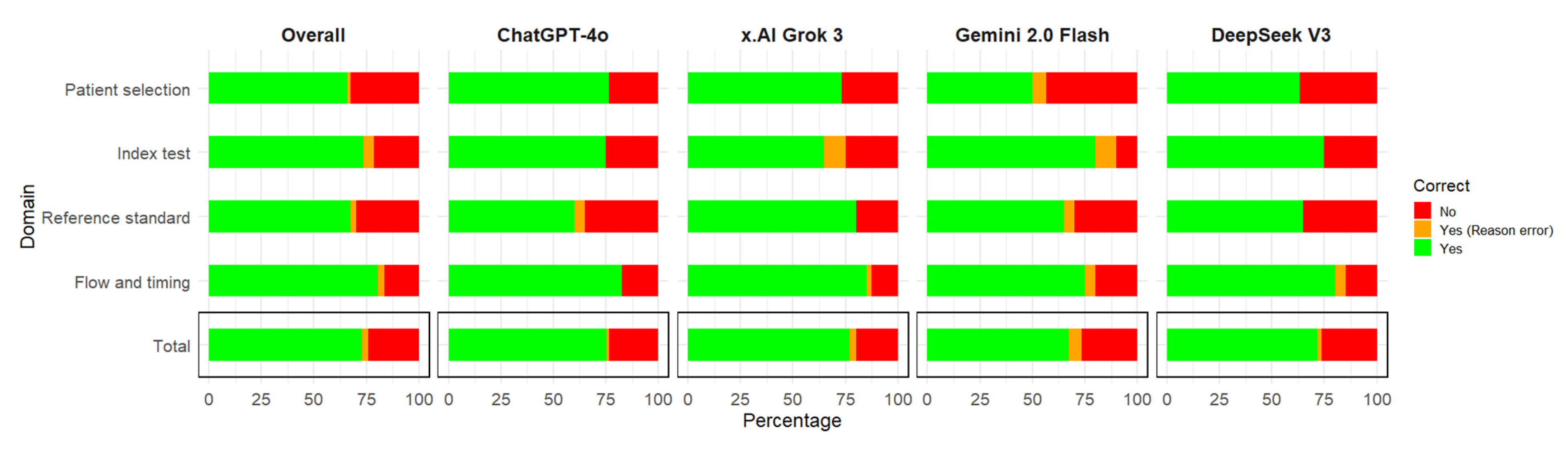
| Domain | Patient Selection (n = 30) | Index Test (n = 20) | Reference Standard (n = 20) | Flow and Timing (n = 40) |
|---|---|---|---|---|
| ChatGPT 4o, n (%) | 23 (76.67) | 15 (75) | 12 (60) | 33 (82.5) |
| x.AI Grok 3, n (%) | 22 (73.33) | 13 (65) | 16 (80) | 34 (85) |
| Gemini 2.0 flash, n (%) | 15 (50) | 16 (80) | 13 (65) | 30 (75) |
| DeepSeek V3, n (%) | 19 (63.33) | 15 (75) | 13 (65) | 32 (80) |
| Total | 79 (65.83) | 59 (73.75) | 51 (63.75) | 129 (80.63) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leucuța, D.-C.; Urda-Cîmpean, A.E.; Istrate, D.; Drugan, T. Risk of Bias Assessment of Diagnostic Accuracy Studies Using QUADAS 2 by Large Language Models. Diagnostics 2025, 15, 1451. https://doi.org/10.3390/diagnostics15121451
Leucuța D-C, Urda-Cîmpean AE, Istrate D, Drugan T. Risk of Bias Assessment of Diagnostic Accuracy Studies Using QUADAS 2 by Large Language Models. Diagnostics. 2025; 15(12):1451. https://doi.org/10.3390/diagnostics15121451
Chicago/Turabian StyleLeucuța, Daniel-Corneliu, Andrada Elena Urda-Cîmpean, Dan Istrate, and Tudor Drugan. 2025. "Risk of Bias Assessment of Diagnostic Accuracy Studies Using QUADAS 2 by Large Language Models" Diagnostics 15, no. 12: 1451. https://doi.org/10.3390/diagnostics15121451
APA StyleLeucuța, D.-C., Urda-Cîmpean, A. E., Istrate, D., & Drugan, T. (2025). Risk of Bias Assessment of Diagnostic Accuracy Studies Using QUADAS 2 by Large Language Models. Diagnostics, 15(12), 1451. https://doi.org/10.3390/diagnostics15121451