
Optimizing Artificial Intelligence Thresholds for Mammographic Lesion Detection: A Retrospective Study on Diagnostic Performance and Radiologist–Artificial Intelligence Discordance


Abstract
1. Introduction
1.1. Background
1.2. Literature Review
1.3. Study Rationale and Objectives
- -
- Establish BI-RADS-specific AI thresholds using both Youden-optimal and sensitivity-prioritized criteria, enabling tailored clinical applications.
- -
- Explore clinical performance trade-offs across threshold values to support optimal decision-making in real-world settings.
- -
- Analyze radiologist–AI discordance in BI-RADS 4A and 4B/4C subgroups to identify scenarios in which AI may diverge from human judgment.
2. Materials and Methods
2.1. Study Design and Ethical Considerations
2.2. Patient Selection and Data Collection
2.3. Imaging Protocol and Interpretation
2.4. Radiologist Review and Comparative Analysis
2.5. Discordance Analysis
2.6. Statistical Analysis
3. Results
3.1. Baseline Characteristics and Group Comparisons
3.2. AI Score Distribution by Lesion Category
3.3. Lesion Characteristics and AI Score Correlation
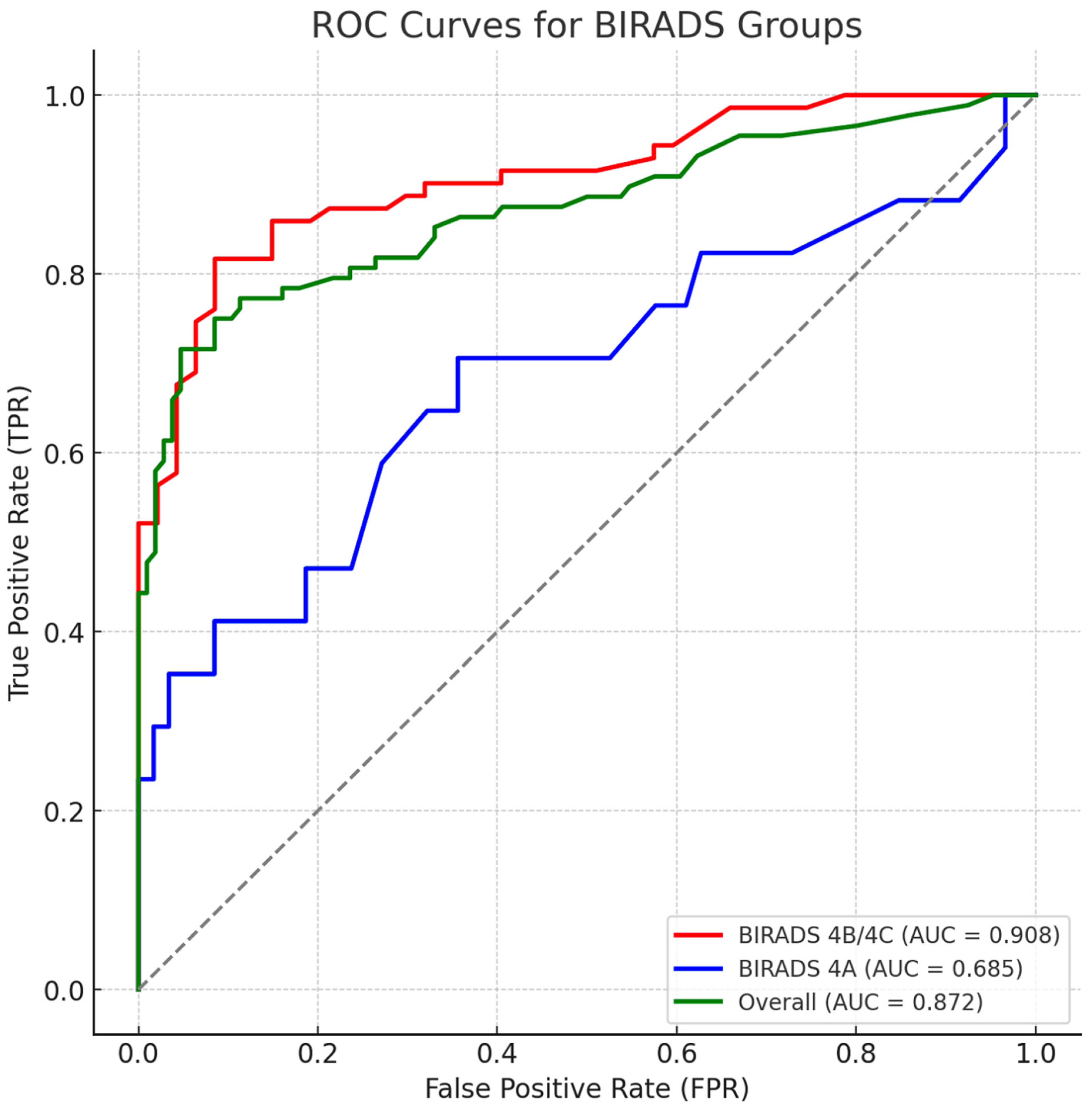
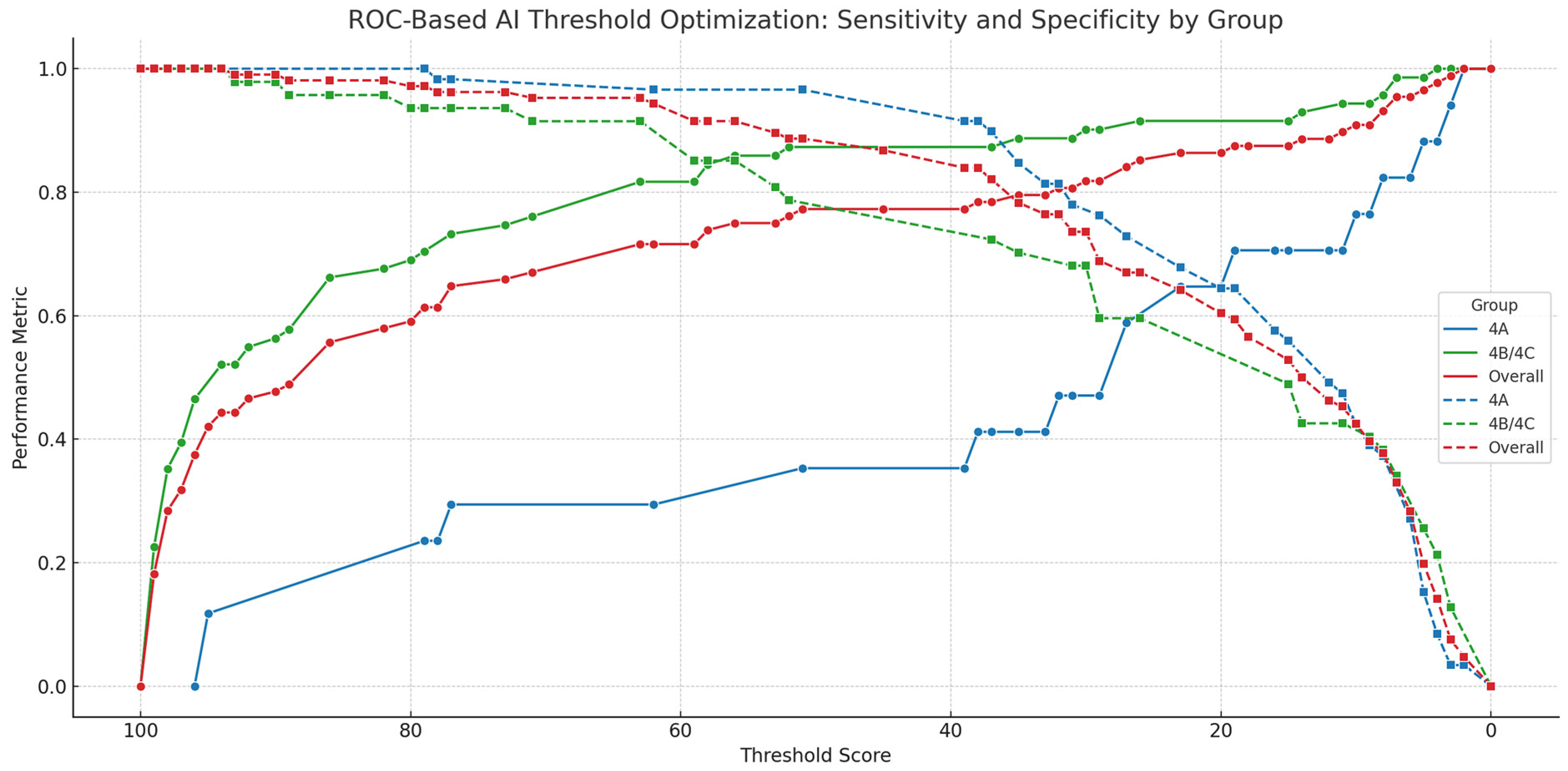
3.4. ROC Analysis and Threshold Optimization
3.5. Discordance Analysis Between AI and Radiologists
4. Discussion
4.1. Interpretation of Diagnostic Thresholds and AI Performance
4.2. Clinical Utility and Triage Implications
4.3. Discordance Patterns in BI-RADS Subgroups
4.4. Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AUC | Area Under the Curve |
| BI-RADS | Breast Imaging Reporting and Data System |
| CADe/x | Computer-Aided Detection/Diagnosis |
| CC | Craniocaudal (Mammographic View) |
| CI | Confidence Interval |
| DCIS | Ductal Carcinoma In Situ |
| FDA | Food and Drug Administration |
| IDC | Invasive Ductal Carcinoma |
| IRB | Institutional Review Board |
| KoNIBP | Korea National Institute for Bioethics Policy |
| LCIS | Lobular Carcinoma In Situ |
| MFDS | Ministry of Food and Drug Safety |
| MLO | Mediolateral Oblique (Mammographic View) |
| ROC | Receiver Operating Characteristic |
| SD | Standard Deviation |
| US | Ultrasound |
References
- Kim, J.; Harper, A.; McCormack, V.; Sung, H.; Houssami, N.; Morgan, E.; Mutebi, M.; Garvey, G.; Soerjomataram, I.; Fidler-Benaoudia, M.M. Global Patterns and Trends in Breast Cancer Incidence and Mortality across 185 Countries. Nat. Med. 2025, 31, 1154–1162. [Google Scholar] [CrossRef] [PubMed]
- Anderson, B.O.; Braun, S.; Lim, S.; Smith, R.A.; Taplin, S.; Thomas, D.B. Global Summit Early Detection Panel Early Detection of Breast Cancer in Countries with Limited Resources. Breast J. 2003, 9 (Suppl. S2), S51–S59. [Google Scholar] [CrossRef] [PubMed]
- Marmot, M.G.; Altman, D.G.; Cameron, D.A.; Dewar, J.A.; Thompson, S.G.; Wilcox, M. The Benefits and Harms of Breast Cancer Screening: An Independent Review. Br. J. Cancer 2013, 108, 2205–2240. [Google Scholar] [CrossRef]
- Lehman, C.D.; Wellman, R.D.; Buist, D.S.M.; Kerlikowske, K.; Tosteson, A.N.A.; Miglioretti, D.L. Breast Cancer Surveillance Consortium Diagnostic Accuracy of Digital Screening Mammography with and Without Computer-Aided Detection. JAMA Intern. Med. 2015, 175, 1828–1837. [Google Scholar] [CrossRef]
- Schaffter, T.; Buist, D.S.M.; Lee, C.I.; Nikulin, Y.; Ribli, D.; Guan, Y.; Lotter, W.; Jie, Z.; Du, H.; Wang, S.; et al. Evaluation of Combined Artificial Intelligence and Radiologist Assessment to Interpret Screening Mammograms. JAMA Netw. Open 2020, 3, e200265. [Google Scholar] [CrossRef] [PubMed]
- Kontos, D.; Conant, E.F. Can AI Help Make Screening Mammography “Lean”? Radiology 2019, 293, 47–48. [Google Scholar] [CrossRef]
- Rodríguez-Ruiz, A.; Krupinski, E.; Mordang, J.-J.; Schilling, K.; Heywang-Köbrunner, S.H.; Sechopoulos, I.; Mann, R.M. Detection of Breast Cancer with Mammography: Effect of an Artificial Intelligence Support System. Radiology 2019, 290, 305–314. [Google Scholar] [CrossRef]
- Kim, H.-E.; Kim, H.H.; Han, B.-K.; Kim, K.H.; Han, K.; Nam, H.; Lee, E.H.; Kim, E.-K. Changes in Cancer Detection and False-Positive Recall in Mammography Using Artificial Intelligence: A Retrospective, Multireader Study. Lancet Digit. Health 2020, 2, e138–e148. [Google Scholar] [CrossRef]
- Lee, J.H.; Kim, K.H.; Lee, E.H.; Ahn, J.S.; Ryu, J.K.; Park, Y.M.; Shin, G.W.; Kim, Y.J.; Choi, H.Y. Improving the Performance of Radiologists Using Artificial Intelligence-Based Detection Support Software for Mammography: A Multi-Reader Study. Korean J. Radiol. 2022, 23, 505–516. [Google Scholar] [CrossRef]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International Evaluation of an AI System for Breast Cancer Screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef]
- Conant, E.F.; Toledano, A.Y.; Periaswamy, S.; Fotin, S.V.; Go, J.; Boatsman, J.E.; Hoffmeister, J.W. Improving Accuracy and Efficiency with Concurrent Use of Artificial Intelligence for Digital Breast Tomosynthesis. Radiol. Artif. Intell. 2019, 1, e180096. [Google Scholar] [CrossRef]
- Larsen, M.; Aglen, C.F.; Lee, C.I.; Hoff, S.R.; Lund-Hanssen, H.; Lång, K.; Nygård, J.F.; Ursin, G.; Hofvind, S. Artificial Intelligence Evaluation of 122 969 Mammography Examinations from a Population-Based Screening Program. Radiology 2022, 303, 502–511. [Google Scholar] [CrossRef]
- Lee, S.E.; Hong, H.; Kim, E.-K. Positive Predictive Values of Abnormality Scores From a Commercial Artificial Intelligence-Based Computer-Aided Diagnosis for Mammography. Korean J. Radiol. 2024, 25, 343–350. [Google Scholar] [CrossRef] [PubMed]
- Dembrower, K.; Wåhlin, E.; Liu, Y.; Salim, M.; Smith, K.; Lindholm, P.; Eklund, M.; Strand, F. Effect of Artificial Intelligence-Based Triaging of Breast Cancer Screening Mammograms on Cancer Detection and Radiologist Workload: A Retrospective Simulation Study. Lancet Digit. Health 2020, 2, e468–e474. [Google Scholar] [CrossRef] [PubMed]
- American College of Radiology. Breast Imaging Reporting and Data System (BI-RADS). ACR.org. Available online: https://www.acr.org/Clinical-Resources/Clinical-Tools-and-Reference/Reporting-and-Data-Systems/BI-RADS (accessed on 15 April 2025).
- Koch, H.W.; Larsen, M.; Bartsch, H.; Kurz, K.D.; Hofvind, S. Artificial Intelligence in BreastScreen Norway: A Retrospective Analysis of a Cancer-Enriched Sample Including 1254 Breast Cancer Cases. Eur. Radiol. 2023, 33, 3735–3743. [Google Scholar] [CrossRef] [PubMed]
- Kwon, M.-R.; Chang, Y.; Ham, S.-Y.; Cho, Y.; Kim, E.Y.; Kang, J.; Park, E.K.; Kim, K.H.; Kim, M.; Kim, T.S.; et al. Screening Mammography Performance According to Breast Density: A Comparison between Radiologists versus Standalone Intelligence Detection. Breast Cancer Res. BCR 2024, 26, 68. [Google Scholar] [CrossRef]
- Dahlblom, V.; Andersson, I.; Lång, K.; Tingberg, A.; Zackrisson, S.; Dustler, M. Artificial Intelligence Detection of Missed Cancers at Digital Mammography That Were Detected at Digital Breast Tomosynthesis. Radiol. Artif. Intell. 2021, 3, e200299. [Google Scholar] [CrossRef]
- Kizildag Yirgin, I.; Koyluoglu, Y.O.; Seker, M.E.; Ozkan Gurdal, S.; Ozaydin, A.N.; Ozcinar, B.; Cabioğlu, N.; Ozmen, V.; Aribal, E. Diagnostic Performance of AI for Cancers Registered in A Mammography Screening Program: A Retrospective Analysis. Technol. Cancer Res. Treat. 2022, 21, 15330338221075172. [Google Scholar] [CrossRef]
- Seker, M.E.; Koyluoglu, Y.O.; Ozaydin, A.N.; Gurdal, S.O.; Ozcinar, B.; Cabioglu, N.; Ozmen, V.; Aribal, E. Diagnostic Capabilities of Artificial Intelligence as an Additional Reader in a Breast Cancer Screening Program. Eur. Radiol. 2024, 34, 6145–6157. [Google Scholar] [CrossRef]
- Chang, Y.-W.; An, J.K.; Choi, N.; Ko, K.H.; Kim, K.H.; Han, K.; Ryu, J.K. Artificial Intelligence for Breast Cancer Screening in Mammography (AI-STREAM): A Prospective Multicenter Study Design in Korea Using AI-Based CADe/x. J. Breast Cancer 2022, 25, 57–68. [Google Scholar] [CrossRef]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Youden, W.J. Index for Rating Diagnostic Tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Fu, C.; Song, W.; Sham, C.-W. RGGC-UNet: Accurate Deep Learning Framework for Signet Ring Cell Semantic Segmentation in Pathological Images. Bioengineering 2024, 11, 16. [Google Scholar] [CrossRef]
- Zhao, T.; Fu, C.; Tian, Y.; Song, W.; Sham, C.-W. GSN-HVNET: A Lightweight, Multi-Task Deep Learning Framework for Nuclei Segmentation and Classification. Bioengineering 2023, 10, 393. [Google Scholar] [CrossRef] [PubMed]
- Gu, Y.; Fu, C.; Song, W.; Wang, X.; Chen, J. RTLinearFormer: Semantic Segmentation with Lightweight Linear Attentions. Neurocomputing 2025, 625, 129489. [Google Scholar] [CrossRef]
- Smith, M.; Heath Jeffery, R.C. Addressing the Challenges of Artificial Intelligence in Medicine. Intern. Med. J. 2020, 50, 1278–1281. [Google Scholar] [CrossRef]
- Dembrower, K.; Crippa, A.; Colón, E.; Eklund, M.; Strand, F. ScreenTrustCAD Trial Consortium Artificial Intelligence for Breast Cancer Detection in Screening Mammography in Sweden: A Prospective, Population-Based, Paired-Reader, Non-Inferiority Study. Lancet Digit. Health 2023, 5, e703–e711. [Google Scholar] [CrossRef]
- Zeng, A.; Houssami, N.; Noguchi, N.; Nickel, B.; Marinovich, M.L. Frequency and Characteristics of Errors by Artificial Intelligence (AI) in Reading Screening Mammography: A Systematic Review. Breast Cancer Res. Treat. 2024, 207, 1–13. [Google Scholar] [CrossRef]
- Schopf, C.M.; Ramwala, O.A.; Lowry, K.P.; Hofvind, S.; Marinovich, M.L.; Houssami, N.; Elmore, J.G.; Dontchos, B.N.; Lee, J.M.; Lee, C.I. Artificial Intelligence-Driven Mammography-Based Future Breast Cancer Risk Prediction: A Systematic Review. J. Am. Coll. Radiol. JACR 2024, 21, 319–328. [Google Scholar] [CrossRef]
- Pertuz, S.; Ortega, D.; Suarez, É.; Cancino, W.; Africano, G.; Rinta-Kiikka, I.; Arponen, O.; Paris, S.; Lozano, A. Saliency of Breast Lesions in Breast Cancer Detection Using Artificial Intelligence. Sci. Rep. 2023, 13, 20545. [Google Scholar] [CrossRef]
- Hayashida, T.; Odani, E.; Kikuchi, M.; Nagayama, A.; Seki, T.; Takahashi, M.; Futatsugi, N.; Matsumoto, A.; Murata, T.; Watanuki, R.; et al. Establishment of a Deep-Learning System to Diagnose BI-RADS4a or Higher Using Breast Ultrasound for Clinical Application. Cancer Sci. 2022, 113, 3528–3534. [Google Scholar] [CrossRef] [PubMed]
- Evans, K.K.; Birdwell, R.L.; Wolfe, J.M. If You Don’t Find It Often, You Often Don’t Find It: Why Some Cancers Are Missed in Breast Cancer Screening. PLoS ONE 2013, 8, e64366. [Google Scholar] [CrossRef] [PubMed]
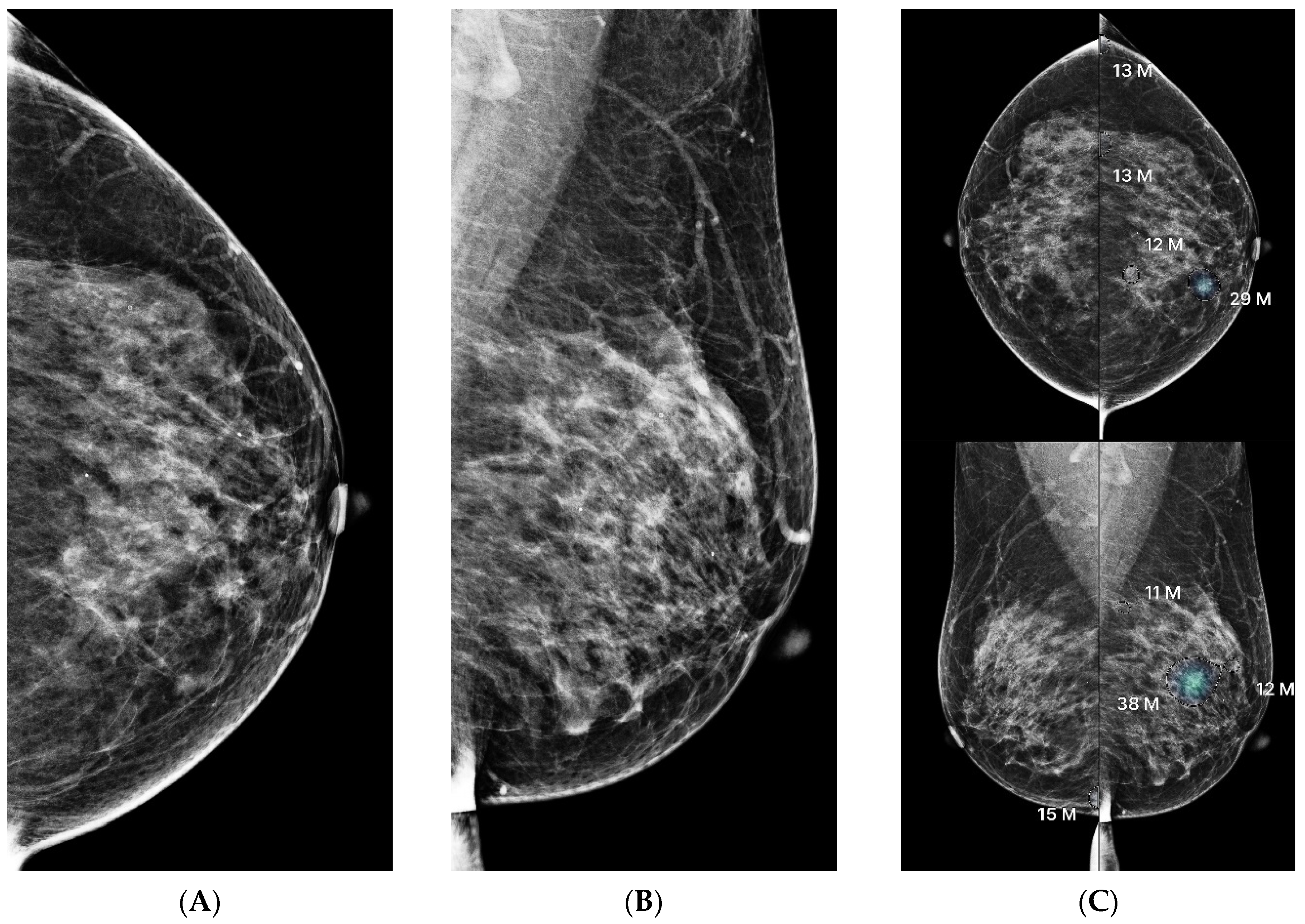

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | AI Tool | Threshold | Sensitivity | Specificity | BI-RADS-Specific? |
|---|---|---|---|---|---|
| Dahlblom et al. (2021) [18] | Not stated | 62 | 75% | 90.8% | No |
| Kizildag Yirgin et al. (2022) [19] | Commercial AI | 34.5 | 72.8% | 88.3% | No |
| Seker et al. (2024) [20] | Lunit | 30.4 | 72.4% | 92.9% | No |
| Category | n (%) | AI Score (Mean ± SD) | p-Value |
|---|---|---|---|
| BIRADS Category | <0.001 | ||
| BI-RADS A | 76 (39.2%) | 22.38 ± 22.74 | |
| BI-RADS B/C | 118 (60.8%) | 58.14 ± 37.93 | |
| Breast Density | 0.003 | ||
| Fatty breast (Density 1 and 2) | 39 (20.1%) | 61.90 ± 36.02 | |
| Dense breast (Density 3 and 4) | 155 (79.9%) | 39.66 ± 36.18 | |
| Mass Margins | <0.001 | ||
| Circumscribed | 14 (7.2%) | 46.29 ± 38.18 | |
| Irregular | 33 (17.0%) | 62.67 ± 36.78 | |
| Spiculated | 17 (8.8%) | 86.47 ± 23.91 | |
| Mass Density | 0.002 | ||
| Iso-dense | 24 (12.4%) | 51.62 ± 37.99 | |
| Hyper-dense | 40 (20.6%) | 73.67 ± 33.51 | |
| Architectural Distortion | 16 (8.2%) | 79.94 ± 31.47 | <0.001 |
| Microcalcifications-Distribution | 0.012 | ||
| Grouped | 87 (44.8%) | 34.24 ± 32.09 | |
| Segmental | 69 (35.6%) | 45.75 ± 39.10 | |
| Microcalcifications-Morphology | <0.001 | ||
| Punctate | 48 (24.7%) | 21.81 ± 22.08 | |
| Amorphous | 24 (12.4%) | 35.25 ± 33.35 | |
| Punctate/Amorphous | 58 (29.9%) | 33.59 ± 31.79 | |
| Coarse Heterogeneous | 8 (4.1%) | 78.25 ± 21.79 | |
| Fine Pleomorphic | 15 (7.7%) | 97.60 ± 2.44 | |
| Fine Linear/Branching | 3 (1.5%) | 68.33 ± 52.25 | |
| Biopsy Results | <0.001 | ||
| Benign Lesions | 106 (54.6%) | 20.91 ± 20.89 | |
| Malignant Lesions | 88 (45.4%) | 72.11 ± 32.67 | |
| Recommendations | <0.001 | ||
| Follow-Up (FU) | 43 (22.2%) | 18.93 ± 18.13 | |
| Biopsy or US (Recall) | 151 (77.8%) | 51.31 ± 38.07 | |
| Ultrasound Detectability | <0.001 | ||
| Detected on US | 87 (44.8%) | 66.36 ± 30.97 | |
| Not detected on US | 107 (55.2%) | 32.97 ± 28.06 |
| Group | Threshold Type | Threshold | Sensitivity | Specificity | Youden Index |
|---|---|---|---|---|---|
| 4A | Youden-optimal | 19 | 0.706 | 0.644 | 0.350 |
| 4A | Sensitivity-prioritized | 10 | 0.765 | 0.424 | 0.189 |
| 4A | Sensitivity-prioritized | 8 | 0.824 | 0.373 | 0.197 |
| 4B/4C | Youden-optimal | 63 | 0.817 | 0.915 | 0.732 |
| 4B/4C | Sensitivity-prioritized | 58 | 0.845 | 0.851 | 0.696 |
| Overall | Youden-optimal | 63 | 0.716 | 0.953 | 0.669 |
| Overall | Sensitivity-prioritized | 35 | 0.795 | 0.783 | 0.578 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, T.; Yun, H.; Sur, Y.K.; Park, H. Optimizing Artificial Intelligence Thresholds for Mammographic Lesion Detection: A Retrospective Study on Diagnostic Performance and Radiologist–Artificial Intelligence Discordance. Diagnostics 2025, 15, 1368. https://doi.org/10.3390/diagnostics15111368
Han T, Yun H, Sur YK, Park H. Optimizing Artificial Intelligence Thresholds for Mammographic Lesion Detection: A Retrospective Study on Diagnostic Performance and Radiologist–Artificial Intelligence Discordance. Diagnostics. 2025; 15(11):1368. https://doi.org/10.3390/diagnostics15111368
Chicago/Turabian StyleHan, Taesun, Hyesun Yun, Young Keun Sur, and Heeboong Park. 2025. "Optimizing Artificial Intelligence Thresholds for Mammographic Lesion Detection: A Retrospective Study on Diagnostic Performance and Radiologist–Artificial Intelligence Discordance" Diagnostics 15, no. 11: 1368. https://doi.org/10.3390/diagnostics15111368
APA StyleHan, T., Yun, H., Sur, Y. K., & Park, H. (2025). Optimizing Artificial Intelligence Thresholds for Mammographic Lesion Detection: A Retrospective Study on Diagnostic Performance and Radiologist–Artificial Intelligence Discordance. Diagnostics, 15(11), 1368. https://doi.org/10.3390/diagnostics15111368