

Sequence-Type Classification of Brain MRI for Acute Stroke Using a Self-Supervised Machine Learning Algorithm

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources and Dataset
2.2. Generation of Human Expert Labeling
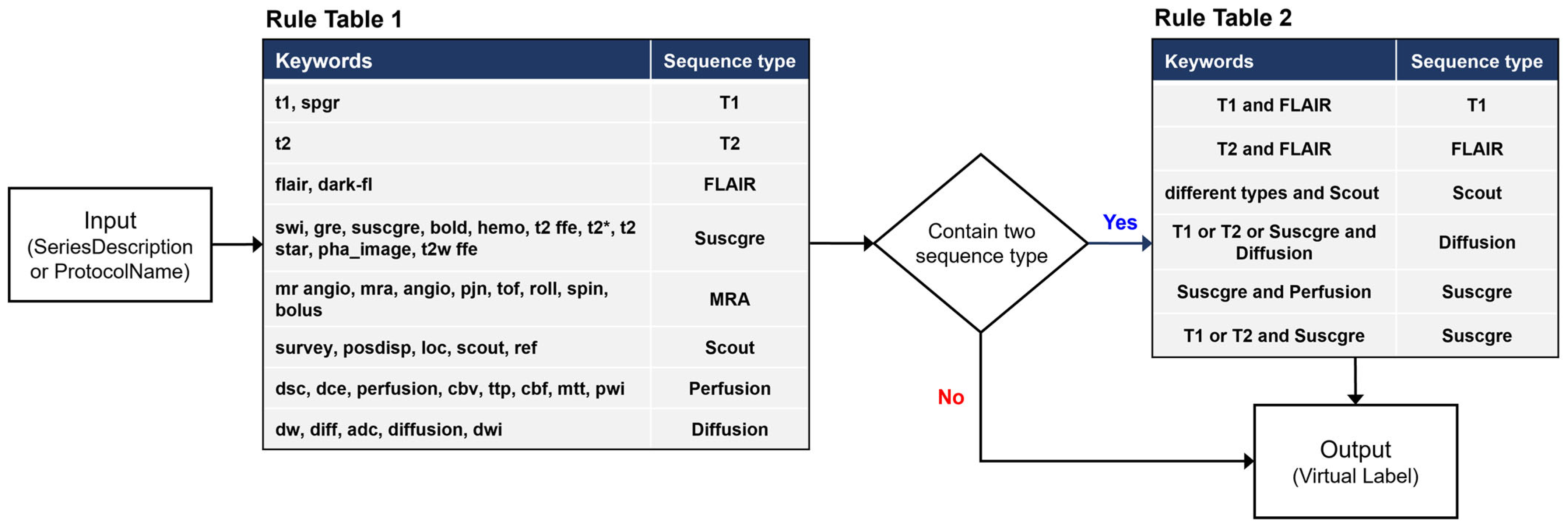
2.3. Development of a Rule-Based Labeling System
2.4. Design of ImageSort-Net Architecture
- (1)
- The pre-processing step extracts various DICOM metadata, including the SeriesDescription attribute, the ProtocolName attribute, and many other attributes associated with MR acquisition parameters.
- (2)
- Training preparation step, which prepares necessary data for supervised learning of the ML algorithm, including virtual labels derived from our rule-based labeling system and features derived from normalization of DICOM attributes.
- (3)
- Training step that trains the random forest ML algorithm.

2.5. Pre-Processing Step
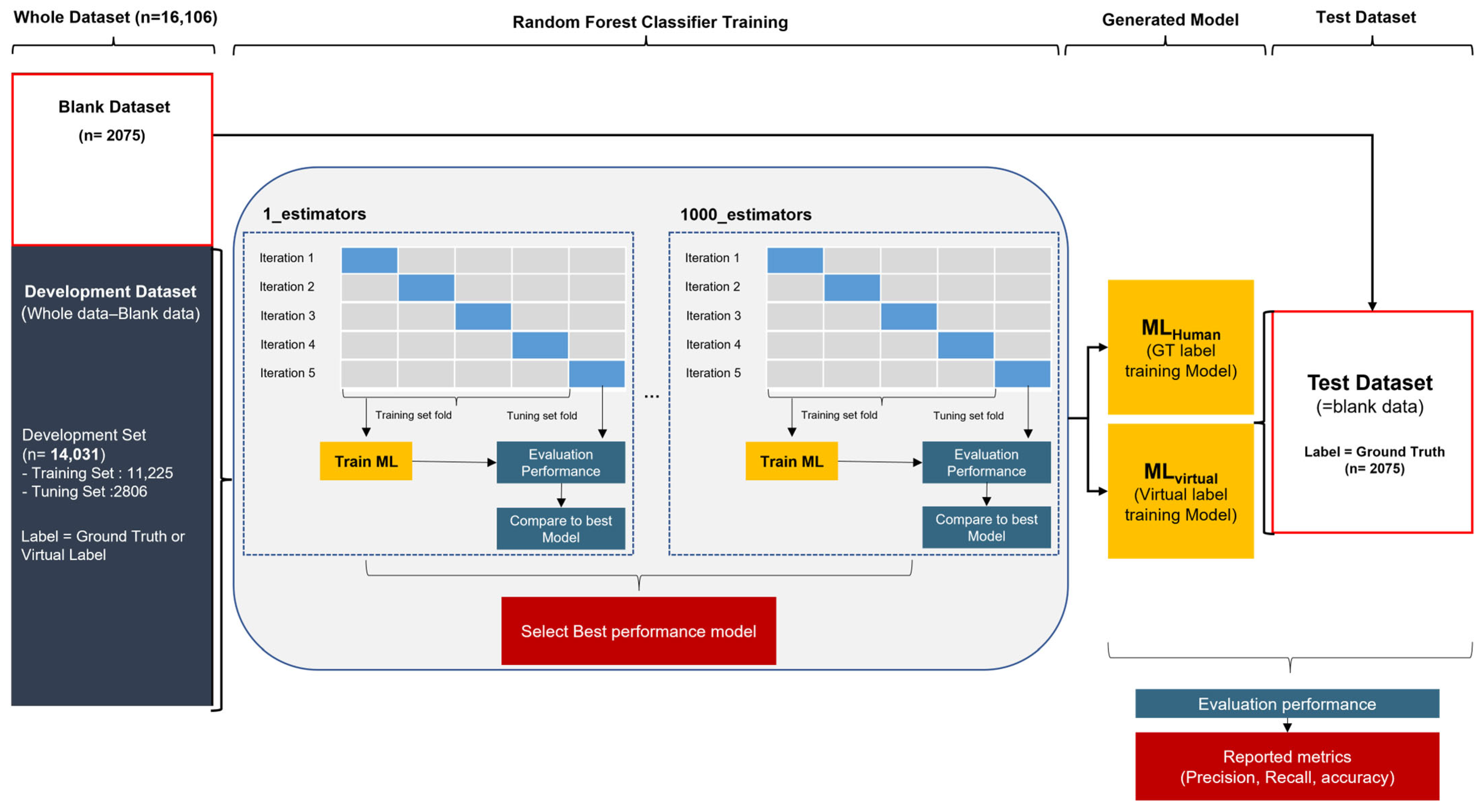
2.6. Training Preparation Step
2.7. Training Step
2.8. Classification and Performance Evaluation
- (a)
- F1-score = 2 × (presicion × recall) ÷ (precision + Recall)
- (b)
- Precision = TP/(TP + FP)
- (c)
- Recall = TP/(TP + FN)
- (d)
- Overall accuracy = (TP + TN)/(TP + TN + FP + FN)
2.9. Feasibility Experiment for Sustainable Self-Learning MLvirtual Algorithm
3. Results
3.1. Classification Performance of a Rule-Based Labeling System
3.2. Classification Performance of the Initial ML Algorithm on the Hospital Dataset
3.3. Classification Performance of Subsequent ML Algorithms with Additional Dataset
3.4. Clinical Effectiveness of ImageSort-Net
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sui, J.; Jiang, R.; Bustillo, J.; Calhoun, V. Neuroimaging-based Individualized Prediction of Cognition and Behavior for Mental Disorders and Health: Methods and Promises. Biol. Psychiatry 2020, 88, 818–828. [Google Scholar] [CrossRef] [PubMed]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef] [PubMed]
- Prevedello, L.M.; Halabi, S.S.; Shih, G.; Wu, C.C.; Kohli, M.D.; Chokshi, F.H.; Erickson, B.J.; Kalpathy-Cramer, J.; Andriole, K.P.; Flanders, A.E. Challenges Related to Artificial Intelligence Research in Medical Imaging and the Importance of Image Analysis Competitions. Radiol. Artif. Intell. 2019, 1, e180031. [Google Scholar] [CrossRef] [PubMed]
- van Ooijen, P.M. Quality and curation of medical images and data. In Artificial Intelligence in Medical Imaging: Opportunities, Applications and Risks; Springer: Cham, Switzerland, 2019; pp. 247–255. [Google Scholar]
- Lambin, P.; Leijenaar, R.T.H.; Deist, T.M.; Peerlings, J.; de Jong, E.E.C.; van Timmeren, J.; Sanduleanu, S.; Larue, R.; Even, A.J.G.; Jochems, A.; et al. Radiomics: The bridge between medical imaging and personalized medicine. Nat. Rev. Clin. Oncol. 2017, 14, 749–762. [Google Scholar] [CrossRef] [PubMed]
- Gorgolewski, K.J.; Auer, T.; Calhoun, V.D.; Craddock, R.C.; Das, S.; Duff, E.P.; Flandin, G.; Ghosh, S.S.; Glatard, T.; Halchenko, Y.O.; et al. The brain imaging data structure, a format for organizing and describing outputs of neuroimaging experiments. Sci. Data 2016, 3, 160044. [Google Scholar] [CrossRef] [PubMed]
- Paszkiel, S. Applications of Brain-Computer Interfaces in Intelligent Technologies; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Gauriau, R.; Bridge, C.; Chen, L.; Kitamura, F.; Tenenholtz, N.A.; Kirsch, J.E.; Andriole, K.P.; Michalski, M.H.; Bizzo, B.C. Using DICOM metadata for radiological image series categorization: A feasibility study on large clinical brain MRI datasets. J. Digit. Imaging 2020, 33, 747–762. [Google Scholar] [CrossRef] [PubMed]
- van der Voort, S.R.; Smits, M.; Klein, S. DeepDicomSort: An Automatic Sorting Algorithm for Brain Magnetic Resonance Imaging Data. Neuroinformatics 2021, 19, 159–184. [Google Scholar] [CrossRef] [PubMed]
- Spathis, D.; Perez-Pozuelo, I.; Marques-Fernandez, L.; Mascolo, C. Breaking away from labels: The promise of self-supervised machine learning in intelligent health. Patterns 2022, 3, 100410. [Google Scholar] [CrossRef] [PubMed]
- Alwassel, H.; Mahajan, D.; Korbar, B.; Torresani, L.; Ghanem, B.; Tran, D. Self-supervised learning by cross-modal audio-video clustering. Adv. Neural Inf. Process. Syst. 2020, 33, 9758–9770. [Google Scholar] [CrossRef]
- Mongan, J.; Moy, L.; Kahn, C.E., Jr. Checklist for artificial intelligence in medical imaging (CLAIM): A guide for authors and reviewers. Radiology. Artif. Intell. 2020, 2, e200029. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.S.; Lee, K.B.; Park, J.H.; Sung, S.M.; Oh, K.; Kim, E.G.; Chang, D.I.; Hwang, Y.H.; Lee, E.J.; Kim, W.K.; et al. Safety and Efficacy of Otaplimastat in Patients with Acute Ischemic Stroke Requiring tPA (SAFE-TPA): A Multicenter, Randomized, Double-Blind, Placebo-Controlled Phase 2 Study. Ann. Neurol. 2020, 87, 233–245. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Sun, L.; Guo, L.; Hua, L.; Yang, Z. Label embedding semantic-guided hashing. Neurocomputing 2022, 477, 1–13. [Google Scholar] [CrossRef]
- van Wynsberghe, A. Sustainable AI: AI for sustainability and the sustainability of AI. AI Ethics 2021, 1, 213–218. [Google Scholar] [CrossRef]
- Na, S.; Sung, Y.S.; Ko, Y.; Shin, Y.; Lee, J.; Ha, J.; Ham, S.J.; Yoon, K.; Kim, K.W. Development and validation of an ensemble artificial intelligence model for comprehensive imaging quality check to classify body parts and contrast enhancement. BMC Med. Imaging 2022, 22, 87. [Google Scholar] [CrossRef] [PubMed]
- Cluceru, J.; Lupo, J.M.; Interian, Y.; Bove, R.; Crane, J.C. Improving the Automatic Classification of Brain MRI Acquisition Contrast with Machine Learning. J. Digit. Imaging 2022, 36, 289–305. [Google Scholar] [CrossRef] [PubMed]
- Sugimori, H. Classification of Computed Tomography Images in Different Slice Positions Using Deep Learning. J. Healthc. Eng. 2018, 2018, 1753480. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Centers | Patients | MRI Scans | Manufacturers |
|---|---|---|---|---|
| Hospital dataset * | 1 | 1528 | 1531 | Philips (933), Siemens (507), GE (67), Hitachi (10), Toshiba (12), Medinus (2) |
| Multi-center trial dataset | 8 | 59 | 256 | Philips (57), Siemens (110), GE (87) |
| DICOM Attribute | DICOM Standard Attribute Description | |
|---|---|---|
| Rule-based system | SeriesDescription | Description of the Series |
| ProtocolName | User-defined description of the conditions under which the Series was performed. | |
| Machine Learning | ScanningSequence | Description of the type of data taken. |
| SequenceVariant | Variant of the scanning sequence. | |
| MRAcquisitionType | Identification of a spatial data encoding scheme. | |
| ImageType | Image identification characteristics. | |
| RepetitionTime | Time in ms between the beginning of a pulse sequence and the beginning of the succeeding (essentially identical) pulse sequence. | |
| EchoTime | Time in ms between the middle of the excitation pulse and the peak of the echo produced | |
| FlipAngle | Steady state angle in degrees to which the magnetic vector is flipped from the magnetic vector of the primary field. | |
| ImagingFrequency | Precession frequency in MHz of the nucleus being addressed | |
| NumberOfPhaseEncodingSteps | Total number of lines in k-space in the ‘y’ direction collected during acquisition. | |
| Rows | Number of rows in the image. | |
| Columns | Number of columns in the image. | |
| InversionTime | Time in msec after the middle of inverting the RF pulse to the middle of the excitation pulse to detect the amount of longitudinal magnetization. | |
| SliceThickness | Nominal slice thickness, in mm. | |
| ScanOption | Parameters of the scanning sequence. | |
| BodyPartExamined | Text description of the part of the body examined. | |
| ScliceNum * | The number of slices per series instance |
| Sequence Type | Hospital Dataset | Multi-Center Trial Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | No of Blanks * | Precision | Recall | F1-Score | No of Blanks * | |
| T1 | 99.6% | 99.5% | 99.6% | 329/4071 | 99.7% | 95.1% | 97.3% | 10/420 |
| T2 | 99.2% | 99.6% | 99.4% | 14/1496 | 100% | 99.3% | 99.6% | 0/146 |
| FLAIR | 99.8% | 99.4% | 99.6% | 3/1422 | 99.2% | 100% | 99.6% | 0/266 |
| suscgre | 99.7% | 99.6% | 99.6% | 83/1752 | 99.7% | 96.3% | 98% | 23/354 |
| MRA | 99.5% | 99.6% | 99.6% | 962/3763 | 97.2% | 99.4% | 98.3% | 258/1100 |
| Scout | 96.5% | 92.6% | 94.5% | 13/308 | 98.4% | 100% | 99.2% | 0/127 |
| Perfusion | 92.7% | 100% | 96.2% | 4/55 | 86% | 100% | 92.5% | 21/64 |
| Diffusion | 99.6% | 100% | 99.8% | 667/3239 | 99.7% | 99.8% | 99.8% | 35/669 |
| Total † | 98.3% | 98.8% | 98.5% | 2075/16,106 | 97.5% | 98.7% | 98% | 347/3146 |
| Performances | MLvirtual | MLhuman | ||||
|---|---|---|---|---|---|---|
| Only Hospital Dataset | Only Multi-Center Trial Dataset | Combined Dataset * | Only Hospital Dataset | Only Multi-Center Trial Dataset | Combined Dataset * | |
| Overall accuracy | 98.5% | 95.6% | 99.7% | 99% | 99.4% | 99.7% |
| Precision | 88.6% | 86.8% | 99% | 89.7% | 98.2% | 99% |
| Recall | 86.1% | 98.4% | 99.9% | 92.8% | 99.8% | 99.9% |
| F1-score | 86.3% | 90% | 99.5% | 90% | 99% | 99.5% |
| MLvirtual | MLhuman | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Initial dataset (hospital dataset only) | ||||||
| Diffusion | 100% | 100% | 100% | 100% | 100% | 100% |
| FLAIR | 66.6% | 100% | 80% | 66.6% | 100% | 80% |
| MRA | 98.4% | 99.2% | 98.8% | 99.1% | 99.6% | 99.4% |
| Perfusion | 100% | 66.6% | 80% | 100% | 100% | 100% |
| Scout | 46% | 54.5% | 50% | 54% | 70% | 60% |
| suscgre | 100% | 92.2% | 96% | 100% | 91.2% | 95.4% |
| T1 | 97.8% | 98.4% | 98.1% | 98.4% | 99% | 98.7% |
| T2 | 100% | 77.8% | 87.5% | 100% | 82.3% | 90% |
| Subsequently added dataset (multi-center trial dataset only) | ||||||
| Diffusion | 100% | 97.2% | 98.6% | 100% | 100% | 100% |
| FLAIR | - | - | - | - | - | - |
| MRA | 100% | 94.5% | 97.3% | 100% | 99.2% | 99.6% |
| Perfusion | 95.2% | 100% | 97.5% | 95.2% | 100% | 97.5% |
| Scout | - | - | - | - | - | - |
| suscgre | 40% | 100% | 56.2% | 95.6% | 100% | 97.7% |
| T1 | 100% | 100% | 100% | 100% | 100% | 100% |
| T2 | - | - | - | - | - | - |
| Combined dataset * (hospital dataset + multi-center trial dataset) | ||||||
| Diffusion | 100% | 100% | 100% | 100% | 100% | 100% |
| FLAIR | - | - | - | - | - | - |
| MRA | 100% | 99.6% | 99.8% | 100% | 99.6% | 99.8% |
| Perfusion | 95.2% | 100% | 97.5% | 95.2% | 100% | 97.5% |
| Scout | - | - | - | - | - | - |
| suscgre | 100% | 100% | 100% | 100% | 100% | 100% |
| T1 | 100% | 100% | 100% | 100% | 100% | 100% |
| T2 | - | - | - | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Na, S.; Ko, Y.; Ham, S.J.; Sung, Y.S.; Kim, M.-H.; Shin, Y.; Jung, S.C.; Ju, C.; Kim, B.S.; Yoon, K.; et al. Sequence-Type Classification of Brain MRI for Acute Stroke Using a Self-Supervised Machine Learning Algorithm. Diagnostics 2024, 14, 70. https://doi.org/10.3390/diagnostics14010070
Na S, Ko Y, Ham SJ, Sung YS, Kim M-H, Shin Y, Jung SC, Ju C, Kim BS, Yoon K, et al. Sequence-Type Classification of Brain MRI for Acute Stroke Using a Self-Supervised Machine Learning Algorithm. Diagnostics. 2024; 14(1):70. https://doi.org/10.3390/diagnostics14010070
Chicago/Turabian StyleNa, Seongwon, Yousun Ko, Su Jung Ham, Yu Sub Sung, Mi-Hyun Kim, Youngbin Shin, Seung Chai Jung, Chung Ju, Byung Su Kim, Kyoungro Yoon, and et al. 2024. "Sequence-Type Classification of Brain MRI for Acute Stroke Using a Self-Supervised Machine Learning Algorithm" Diagnostics 14, no. 1: 70. https://doi.org/10.3390/diagnostics14010070
APA StyleNa, S., Ko, Y., Ham, S. J., Sung, Y. S., Kim, M.-H., Shin, Y., Jung, S. C., Ju, C., Kim, B. S., Yoon, K., & Kim, K. W. (2024). Sequence-Type Classification of Brain MRI for Acute Stroke Using a Self-Supervised Machine Learning Algorithm. Diagnostics, 14(1), 70. https://doi.org/10.3390/diagnostics14010070