
Prediction of Perforated and Nonperforated Acute Appendicitis Using Machine Learning-Based Explainable Artificial Intelligence

 ,
,  ,
, 
 and
and
Abstract
1. Introduction
- An ML model was created to accurately predict patients with AAp and perforated AAp.
- CatBoost performed well in distinguishing patients.
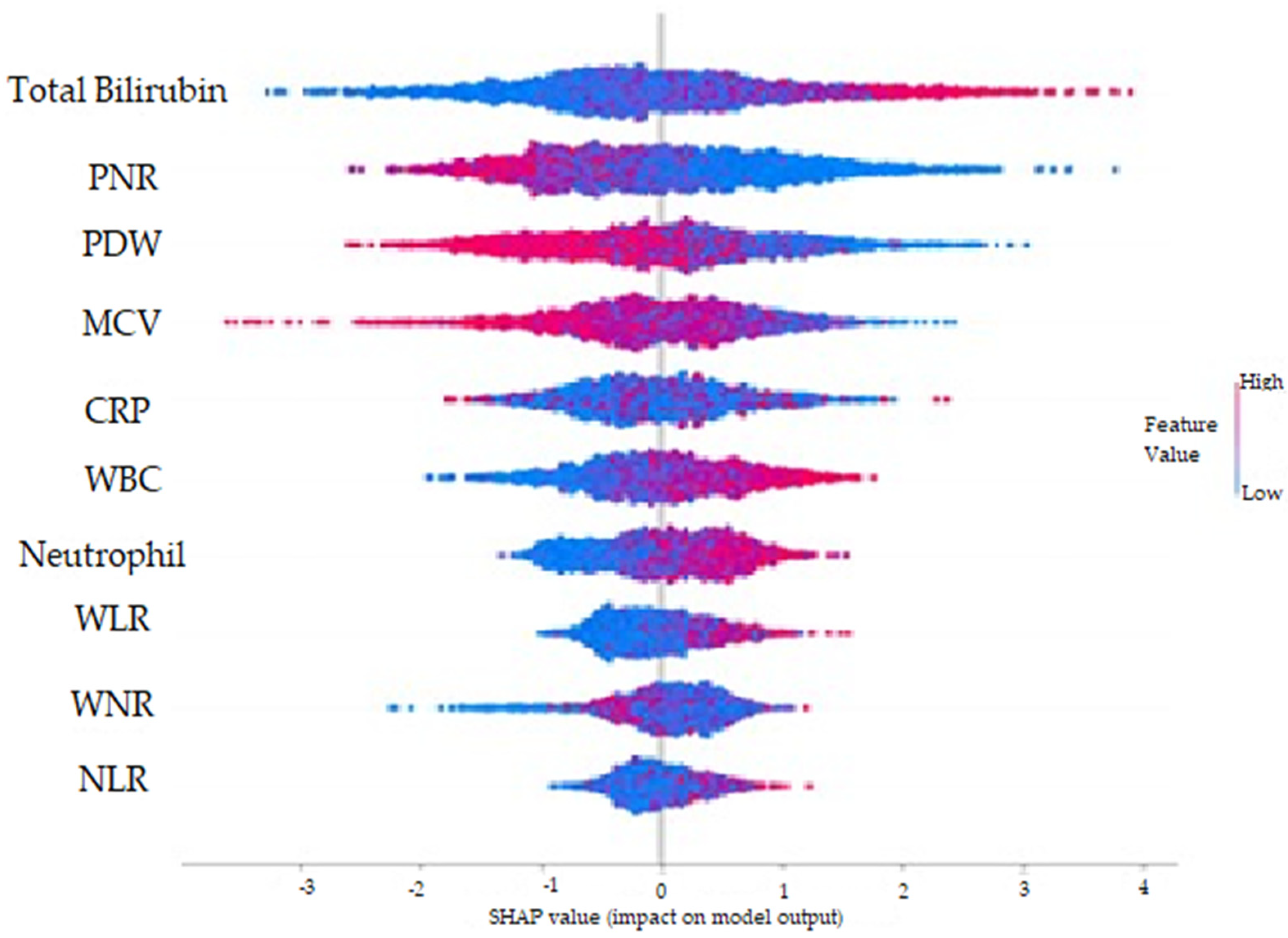
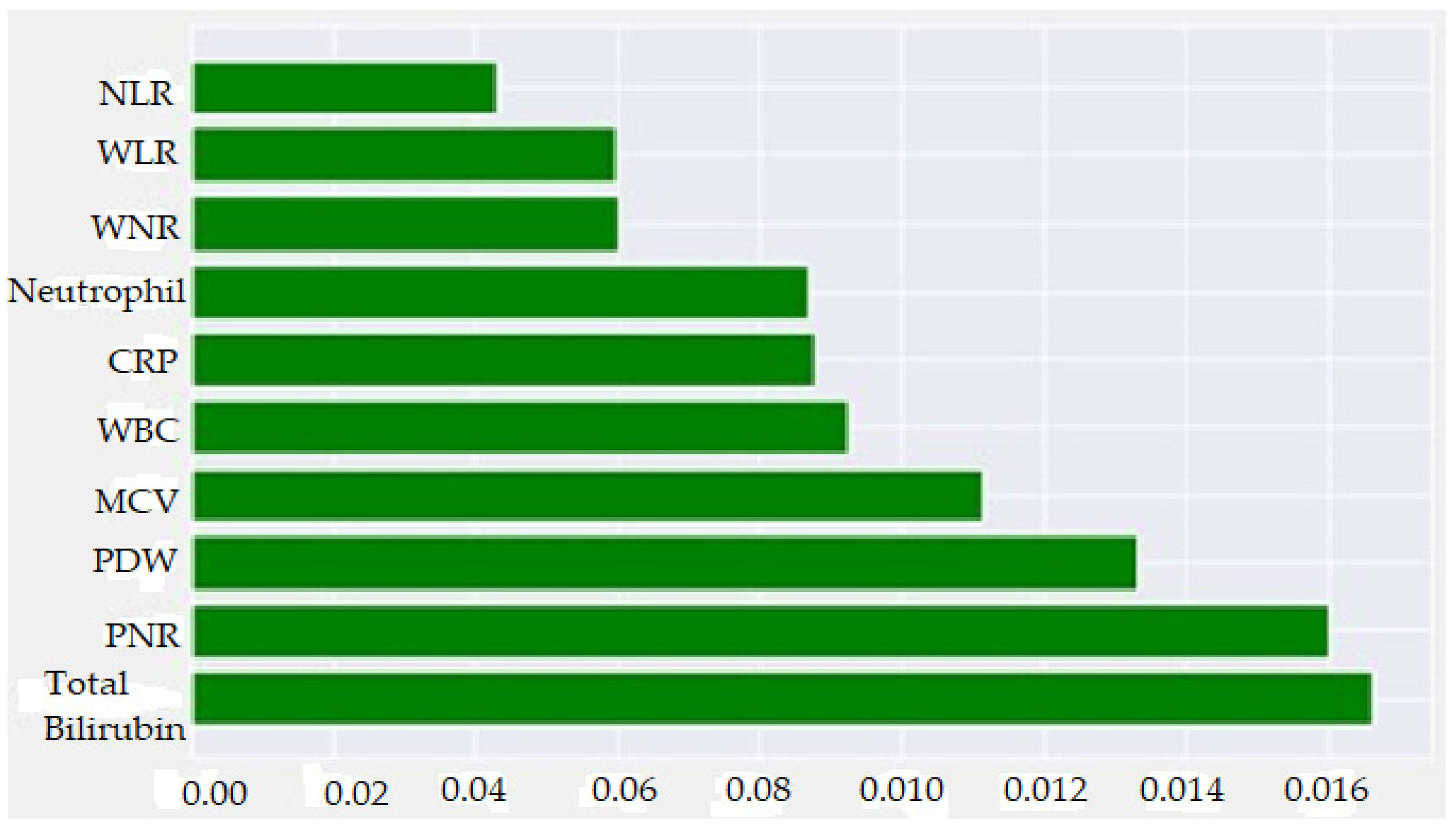
- With the SHAP method, it was determined that high total bilirubin, WBC, Neutrophil, WLR, NLR, CRP and WNR values and low PNR, PDW and MCV values increased the prediction of AAp biochemically.
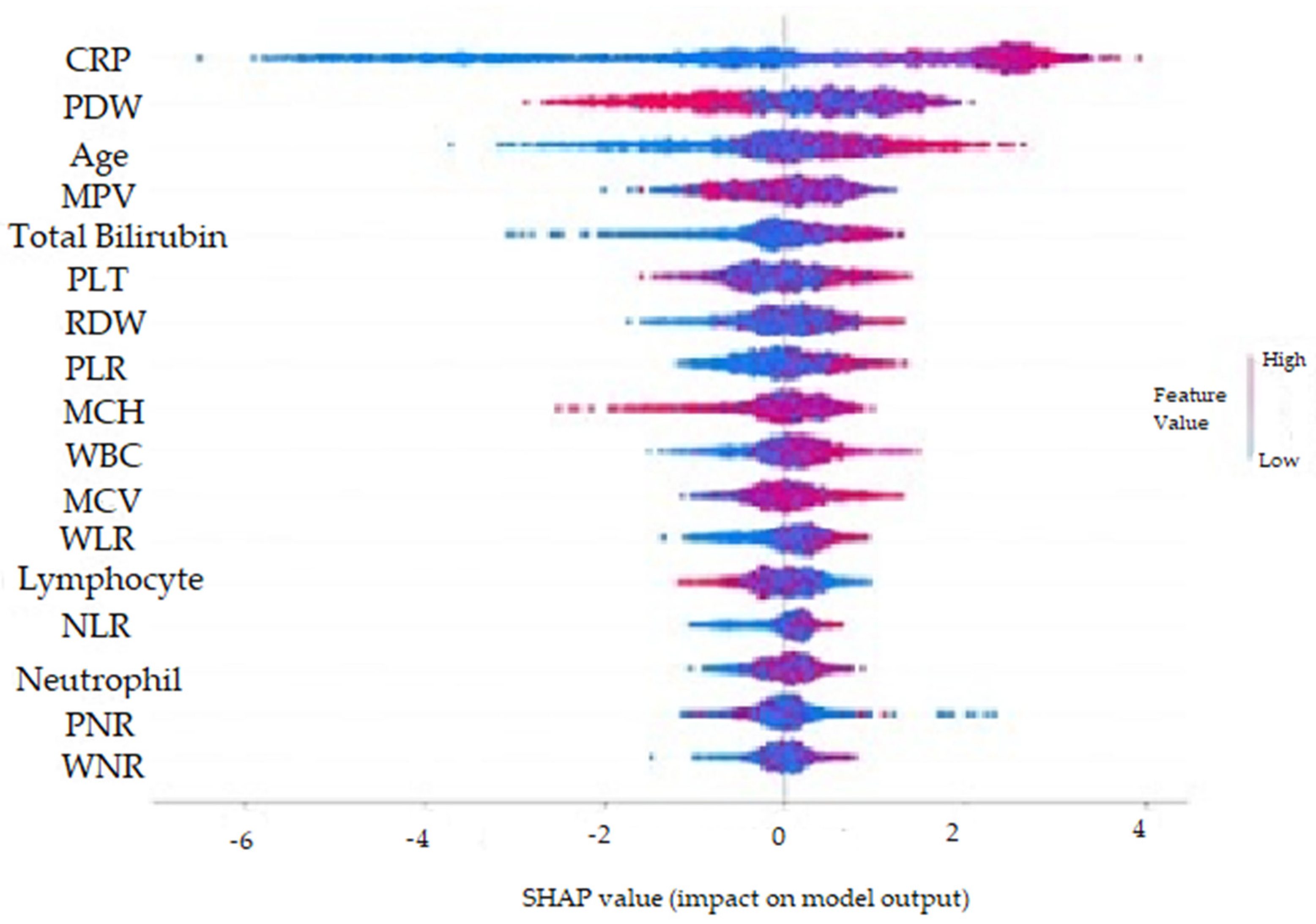
- It was observed that high CRP, Age, Total Bilirubin, PLT, RDW, WBC, MCV, WLR, NLR and Neutrophil values and low Lymphocyte, PDW, MPV and PNR values increased the prediction of perforated AAp.
- The importance of the SHAP-based methodology was examined to explain the model, which can assist clinicians in diagnosing AAp and perforated AAp.
- ML and SHAP are useful in diagnosing and treating AAp and perforated AAp, future treatment goals, and personalized medication administration.
2. Materials and Methods
2.1. Study Design and the Related Dataset
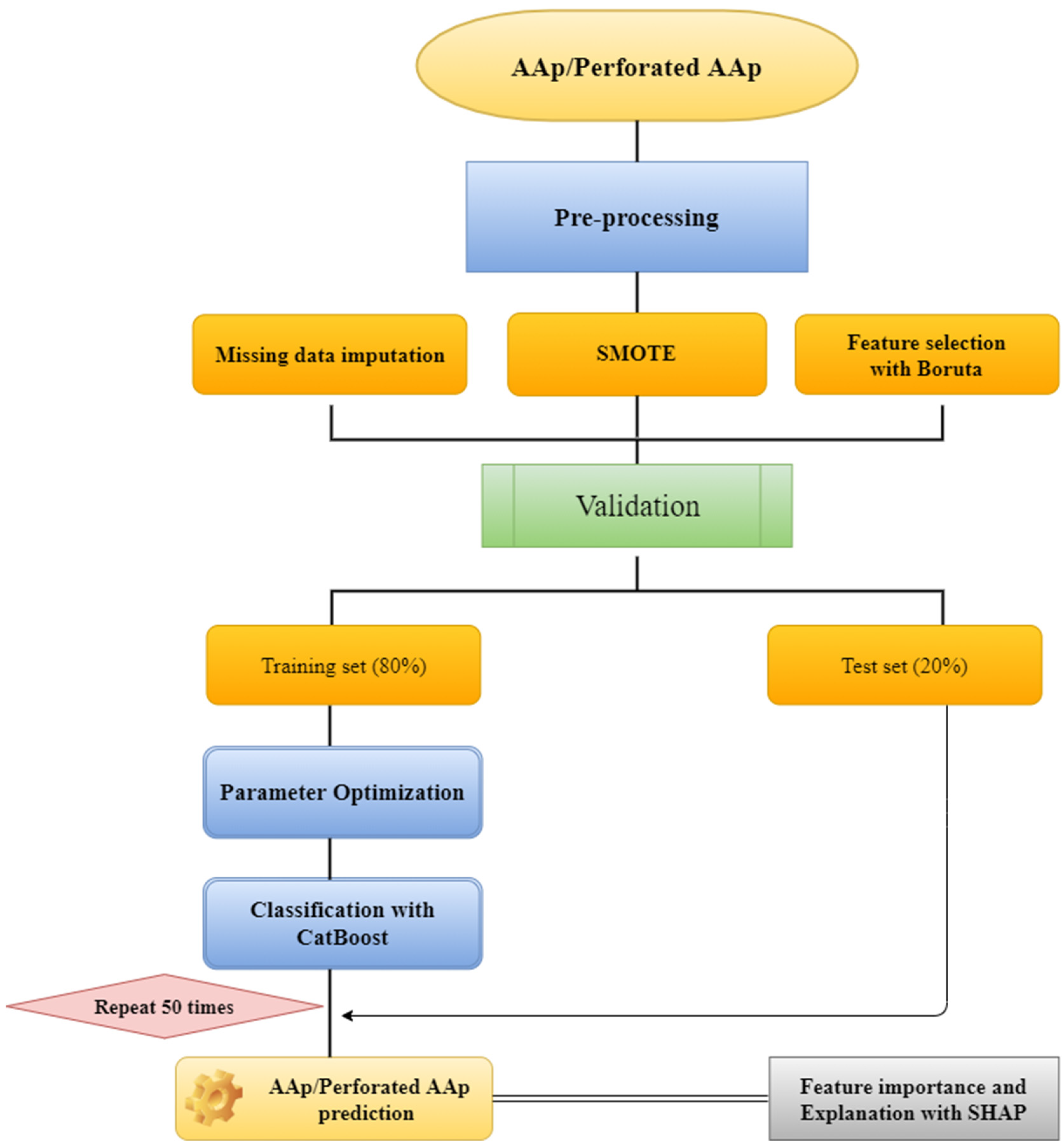
2.2. Data Preprocessing and Modeling
2.3. Random Forest Missing Value Imputation
2.4. Synthetic Minority Over-Sampling Technique (SMOTE)
2.5. Boruta Feature Selection
2.6. CatBoost
2.7. Explainable Artificial Intelligence (XAI)
2.8. Shapley Additive Explanations (SHAP)
2.9. Study Protocol and Ethics Committee Approval

3. Results
3.1. Acute Appendicitis versus Negative Acute Appendicitis
3.2. Nonperforated AAp versus Perforated AAp
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Akbulut, S.; Bahçe, Z.S.; Öztaş, T.; Gümüş, S.; Söğütçü, N.; Sakarya, H.; Gök, A.F.K.; Yağmur, Y. Assessment of demographic, clinical and histopathological features of patients who underwent appendectomy due to a presumed diagnosis of acute appendicitis. Ulus. Travma Acil Cerrahi Derg. 2021, 27, 315–324. [Google Scholar] [CrossRef]
- Akbulut, S.; Koc, C.; Kocaaslan, H.; Gonultas, F.; Samdanci, E.; Yologlu, S.; Yilmaz, S. Comparison of clinical and histopathological features of patients who underwent incidental or emergency appendectomy. World J. Gastrointest. Surg. 2019, 11, 19–26. [Google Scholar] [CrossRef] [PubMed]
- Koç, C.; Akbulut, S.; Coşkun, E.I.; Sarıcı, B.; Yılmaz, S. Comparison of the demographic and clinical features of pregnant and non-pregnant patients undergoing appendectomy. Ulus. Travma Acil Cerrahi Derg. 2020, 26, 555–562. [Google Scholar] [PubMed]
- Sarıcı, K.B.; Akbulut, S.; Koç, C.; Tuncer, A.; Yılmaz, S. Liver transplant versus non-liver transplant patients underwent appendectomy with presumed diagnosis of acute appendicitis: Case-control study. Ulus. Travma Acil Cerrahi Derg. 2020, 26, 705–712. [Google Scholar] [PubMed]
- Lin, K.-B.; Lai, K.R.; Yang, N.-P.; Chan, C.-L.; Liu, Y.-H.; Pan, R.-H.; Huang, C.-H. Epidemiology and socioeconomic features of appendicitis in Taiwan: A 12-year population-based study. World J. Emerg. Surg. 2015, 10, 42. [Google Scholar] [CrossRef]
- Wickramasinghe, D.P.; Xavier, C.; Samarasekera, D.N. The Worldwide Epidemiology of Acute Appendicitis: An Analysis of the Global Health Data Exchange Dataset. World J. Surg. 2021, 45, 1999–2008. [Google Scholar] [CrossRef]
- Akbulut, S.; Koç, C.; Şahin, T.T.; Şahin, E.; Tuncer, A.; Demyati, K.; Şamdancı, E.; Çolak, C.; Yılmaz, S. An investigation into the factors predicting acute appendicitis and perforated appendicitis. Ulus. Travma Acil Cerrahi Derg. 2021, 27, 434–442. [Google Scholar] [PubMed]
- Ferris, M.; Quan, S.; Kaplan, B.S.; Molodecky, N.; Ball, C.G.; Chernoff, G.W.; Bhala, N.; Ghosh, S.; Dixon, E.; Ng, S.; et al. The Global Incidence of Appendicitis: A Systematic Review of Population-based Studies. Ann. Surg. 2017, 266, 237–241. [Google Scholar] [CrossRef] [PubMed]
- Jeon, B.; Kim, H.; Heo, S. CT Scan Findings Can Predict the Safety of Delayed Appendectomy for Acute Appendicitis. J. Gastrointest. Surg. 2019, 23, 1856–1866. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, F.; Ai, S.; Wang, J.; Guan, W.; Liu, S. Meta-analysis of studies comparing conservative treatment with antibiotics and appendectomy for acute appendicitis in the adult. BMC Surg. 2019, 19, 110. [Google Scholar] [CrossRef]
- Akmese, O.; Dogan, G.; Kor, H.; Erbay, H.; Demir, E. The Use of Machine Learning Approaches for the Diagnosis of Acute Appendicitis. Emerg. Med. Int. 2020, 2020, 7306435. [Google Scholar] [CrossRef] [PubMed]
- Prabhudesai, S.G.; Gould, S.; Rekhraj, S.; Tekkis, P.P.; Glazer, G.; Ziprin, P. Artificial neural networks: Useful aid in diagnosing acute appendicitis. World J. Surg. 2008, 32, 305–309, discussion 10–11. [Google Scholar] [CrossRef] [PubMed]
- Unlu, C.; de Castro, S.; Tuynman, J.; Wust, A.; Steller, E.; van Wagensveld, B. Evaluating routine diagnostic imaging in acute appendicitis. Int. J. Surg. 2009, 7, 451–455. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Hu, P.; Cheng, T.; Huang, T.; Chuang, W. A preclustering-based ensemble learning technique for acute appendicitis diagnoses. Artif. Intell. Med. 2013, 58, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Jeon, B.G.; Kim, H.J.; Jung, K.H.; Lim, H.I.; Kim, S.W.; Park, J.S.; Kim, K.H.; Kim, I.D. Appendectomy: Should It Be Performed So Quickly? Am. Surg. 2016, 82, 65–74. [Google Scholar] [CrossRef]
- Capoglu, R.; Gonullu, E.; Bayhan, Z.; Coskun, M.; Harmantepe, T.; Kucuk, F. Comparison of scoring systems regarding the gender as a parameter with the traditional scoring systems for predicting appendicitis. Updates Surg. 2022, 74, 1035–1042. [Google Scholar] [CrossRef]
- Jose, T.; Rajesh, P.S. Appendicitis Inflammatory Response Score in Comparison to Alvarado Score in Acute Appendicitis. Surg. J. (N. Y.) 2021, 7, e127–e131. [Google Scholar] [CrossRef]
- Maghsoudi, L.H.; Soltanian, A.; Shirzadi, A.; Alizadeh-Kashani, R.; Ahmadinejad, M. Biomarker of urinary 5-HIAA as a valuable predictor of acute appendicitis. Pract. Lab. Med. 2021, 23, e00198. [Google Scholar] [CrossRef]
- Stankovic, N.; Surbatovic, M.; Stanojevic, I.; Simić, R.; Djuricic, S.; Milickovic, M.; Grujic, B.; Savic, D.; Marinovic, V.M.; Stankovic, M.; et al. Possible cytokine biomarkers in pediatric acute appendicitis. Ital. J. Pediatr. 2019, 45, 125. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. (Eds.) Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Sundararajan, M.; Najmi, A. (Eds.) The Many Shapley Values for Model Explanation. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; PMLR: Birmingham, UK, 2020. [Google Scholar]
- Ozen, H.; Bal, C. A study on missing data problem in random Forest. Osman. Tıp Derg. 2020, 42, 103–109. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Ahmadpour, H.; Bazrafshan, O.; Rafiei-Sardooi, E.; Zamani, H.; Panagopoulos, T. Gully Erosion Susceptibility Assessment in the Kondoran Watershed Using Machine Learning Algorithms and the Boruta Feature Selection. Sustainability 2021, 13, 10110. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. (Eds.) CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems 2018, Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: New York, NY, USA, 2018. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Jabeur, S.B.; Gharib, C.; Mefteh-Wali, S.; Arfi, W.B. CatBoost model and artificial intelligence techniques for corporate failure prediction. Technol. Forecast. Soc. Chang. 2021, 166, 120658. [Google Scholar] [CrossRef]
- Bakhareva, N.; Shukhman, A.; Matveev, A.; Polezhaev, P.; Ushakov, Y.; Legashev, L. (Eds.) Attack detection in enterprise networks by machine learning methods. In Proceedings of the 2019 international Russian Automation Conference (RusAutoCon), Sochi, Russia, 8–14 September 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.Z. XAI-Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef]
- Samek, W.; Müller, K.-R. Towards explainable artificial intelligence. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11700, pp. 5–22. [Google Scholar]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4793–4813. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, R.; Bajorath, J. Interpretation of machine learning models using shapley values: Application to compound potency and multi-target activity predictions. J. Comput. Aided Mol. Des. 2020, 34, 1013–1026. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.-I. (Eds.) A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Vandenbroucke, J.P.; von Elm, E.; Altman, D.G.; Gøtzsche, P.C.; Mulrow, C.D.; Pocock, S.J.; Poole, C.; Schlesselman, J.J.; Egger, M.; STROBE Initiative. Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): Explanation and elaboration. Int. J. Surg. 2014, 12, 1500–1524. [Google Scholar] [CrossRef]
- Busnatu, Ș.; Niculescu, A.-G.; Bolocan, A.; Petrescu, G.E.; Păduraru, D.N.; Năstasă, I.; Lupușoru, M.; Geantă, M.; Andronic, O.; Grumezescu, A.M.; et al. Clinical Applications of Artificial Intelligence—An Updated Overview. J. Clin. Med. 2022, 11, 2265. [Google Scholar] [CrossRef]
- Nakamura, T.; Sasano, T. Artificial intelligence and cardiology: Current status and perspective. J. Cardiol. 2022, 79, 326–333. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Wang, Z.; Yang, D.; Li, R.; Liang, G.; Chen, H.; Heidari, A.A.; Turabieh, H.; Mafarja, M.; Pan, Z. Performance optimization of support vector machine with oppositional grasshopper optimization for acute appendicitis diagnosis. Comput. Biol. Med. 2022, 143, 105206. [Google Scholar] [CrossRef] [PubMed]
- Mijwil, M.M.; Aggarwal, K. A diagnostic testing for people with appendicitis using machine learning techniques. Multimed. Tools Appl. 2022, 81, 7011–7023. [Google Scholar] [CrossRef]
- Reismann, J.; Romualdi, A.; Kiss, N.; Minderjahn, M.I.; Kallarackal, J.; Schad, M.; Reismann, M. Diagnosis and classification of pediatric acute appendicitis by artificial intelligence methods: An investigator-independent approach. PLoS ONE 2019, 14, e0222030. [Google Scholar] [CrossRef]
- El Hechi, M.W.; Eddine, S.A.N.; Maurer, L.R.; Kaafarani, H.M.J.S. Leveraging interpretable machine learning algorithms to predict postoperative patient outcomes on mobile devices. Surgery 2021, 169, 750–754. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Value | 95% CI Limits |
|---|---|---|
| Accuracy | 0.882 | 0.856–0.908 |
| F1-Score | 0.887 | 0.862–0.913 |
| Sensitivity | 0.842 | 0.798–0.880 |
| Specificity | 0.932 | 0.894–0.959 |
| AUC | 0.947 | 0.913–0.962 |
| Feature | Feature Importance (Normalized SHAP Values) |
|---|---|
| TBil | 0.1663400 |
| PNR | 0.1600970 |
| PDW | 0.1330800 |
| MCV | 0.1112450 |
| WBC | 0.0924013 |
| CRP | 0.0876078 |
| Neutrophil | 0.0867753 |
| WNR | 0.0599300 |
| WLR | 0.0594280 |
| NLR | 0.0430910 |
| Metric | Value | 95% CI Limits |
|---|---|---|
| Accuracy | 0.92 | 0.896–0.945 |
| F1-Score | 0.911 | 0.885–0.994 |
| Sensitivity | 0.941 | 0.899–0.969 |
| Specificity | 0.905 | 0.863–0.938 |
| AUC | 0.969 | 0.904–0.987 |
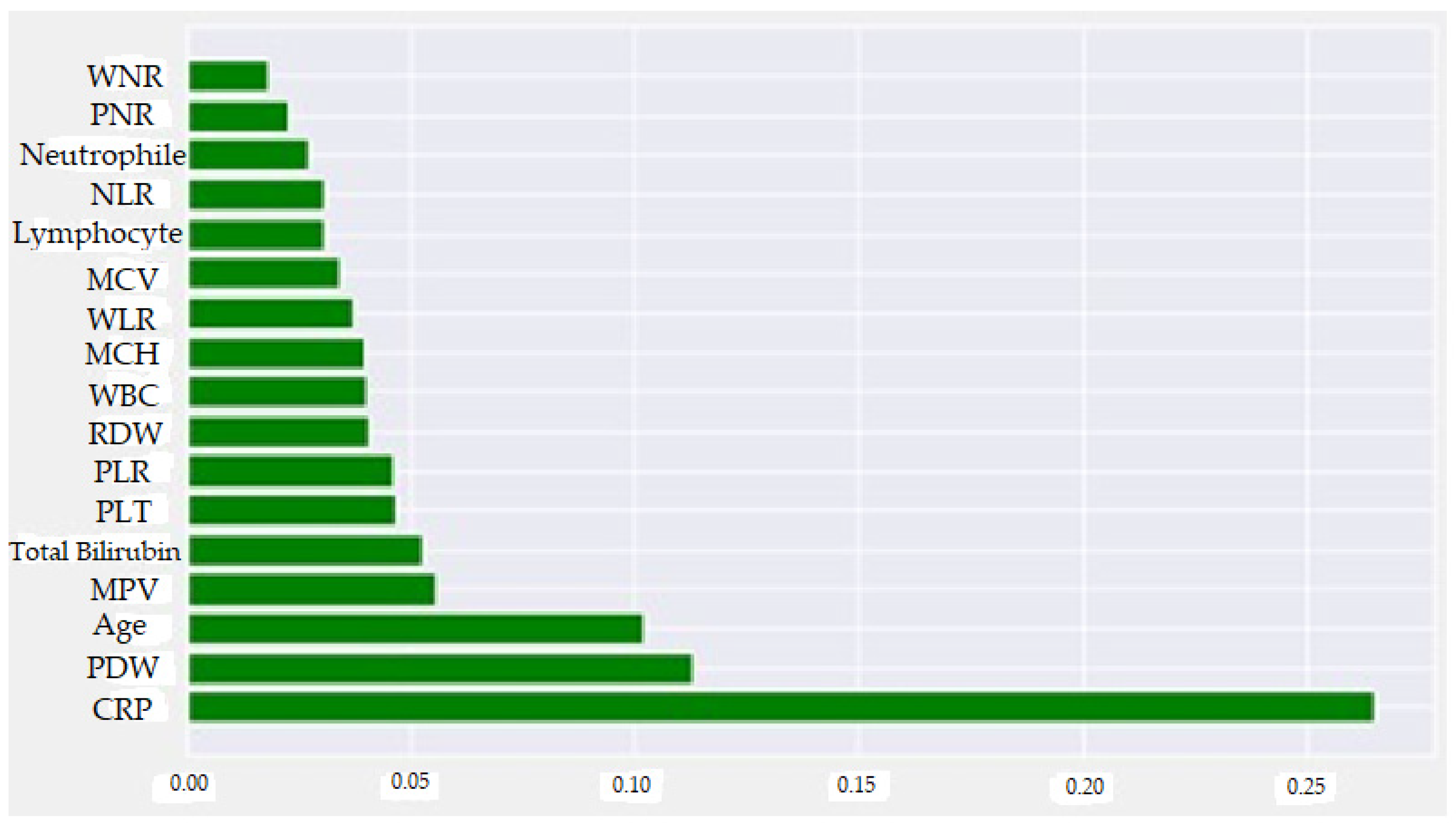
| Feature | Feature Importance (Normalized SHAP Values) |
|---|---|
| CRP | 0.265083 |
| PDW | 0.112824 |
| Age | 0.101890 |
| MPV | 0.055570 |
| TBil | 0.052502 |
| PLT | 0.046732 |
| PLR | 0.045915 |
| RDW | 0.040585 |
| WBC | 0.039910 |
| MCH | 0.039698 |
| WLR | 0.036890 |
| MCV | 0.033890 |
| Lymphocyte | 0.030395 |
| NLR | 0.030340 |
| Neutrophil | 0.026850 |
| PNR | 0.022790 |
| WNR | 0.018090 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akbulut, S.; Yagin, F.H.; Cicek, I.B.; Koc, C.; Colak, C.; Yilmaz, S. Prediction of Perforated and Nonperforated Acute Appendicitis Using Machine Learning-Based Explainable Artificial Intelligence. Diagnostics 2023, 13, 1173. https://doi.org/10.3390/diagnostics13061173
Akbulut S, Yagin FH, Cicek IB, Koc C, Colak C, Yilmaz S. Prediction of Perforated and Nonperforated Acute Appendicitis Using Machine Learning-Based Explainable Artificial Intelligence. Diagnostics. 2023; 13(6):1173. https://doi.org/10.3390/diagnostics13061173
Chicago/Turabian StyleAkbulut, Sami, Fatma Hilal Yagin, Ipek Balikci Cicek, Cemalettin Koc, Cemil Colak, and Sezai Yilmaz. 2023. "Prediction of Perforated and Nonperforated Acute Appendicitis Using Machine Learning-Based Explainable Artificial Intelligence" Diagnostics 13, no. 6: 1173. https://doi.org/10.3390/diagnostics13061173
APA StyleAkbulut, S., Yagin, F. H., Cicek, I. B., Koc, C., Colak, C., & Yilmaz, S. (2023). Prediction of Perforated and Nonperforated Acute Appendicitis Using Machine Learning-Based Explainable Artificial Intelligence. Diagnostics, 13(6), 1173. https://doi.org/10.3390/diagnostics13061173