

Uncertain-CAM: Uncertainty-Based Ensemble Machine Voting for Improved COVID-19 CXR Classification and Explainability



Abstract
1. Introduction
- A novel CNN training scheme to maximize ensembled model performance and minimize generalization error.
- A novel uncertainty evaluation ensemble method.
- A novel uncertainty-based Gradient-weighted Class Activation Mapping (Grad-CAM) ensemble explanation to for a better explanation of the CNN decisions compared to Grad-CAM.
- A new image processing technique to study the feasibility of the proposed Uncertain-CAM and compare it to normal Gras-CAM.
2. Related Literature
3. Materials and Methods
3.1. Data Preparation
- 11,956 COVID-19 samples
- 11,263 cases of pneumonia caused by viruses or bacteria that are not COVID-19
- 10,701 normal (healthy) samples
3.2. Ensemble Learning
| Algorithm 1. Machine weighted voting algorithm. |
| Inputs: Entire Data set ; base learning algorithms Output: Machines Vote initialization; Split into for do for do Split into for the th split. Basic classifier train on and validate on for do Create snapshots of Predict on Concatenate predictions on Compute the simple average ensemble predictions End Concatenate predictions End Use to compute optimal voting weights Apply weighted voting ensemble on (4). End |
3.3. Optimal Voting Weights
3.3.1. Best Combination
3.3.2. Priori Recognition Performance Statistics
3.3.3. Model Calibration
Calibration Evaluation
Uncertainty Evaluation
3.4. Optimal Voting Weights
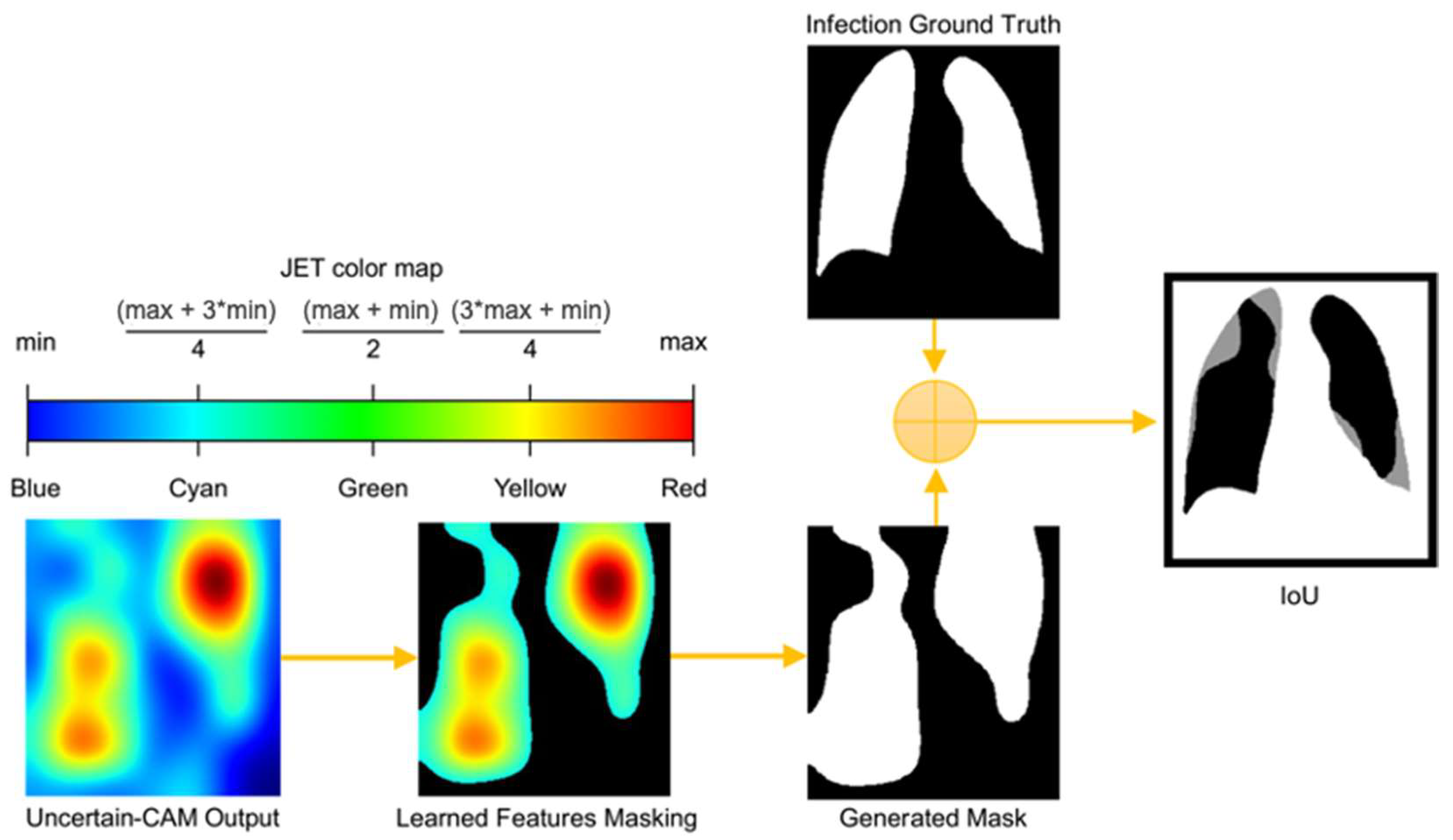
3.5. Uncertain-CAM Evaluation Metrics
| Algorithm 2: Uncertain-CAM evaluation algorithm. |
| ; Output: IoU initialization; for do 1: Read 2: Convert to HSV Colorspace. 3: Set Color range boundaries 4: Create new binary mask 5: Compute IoU using (30) end |
4. Results
4.1. Data Processing
- GGOs.
- Odd paving pattern.
- Consolidation of the airspace.
- Thickening of bronchovascular bundles.
- Traction bronchiectasis.
- GGOs.
- Reticular opacities.
- Vascular thickness.
- Additional widespread distribution along the bronchovascular bundles.
- Thickness in bronchial wall.
4.2. Learning COVID
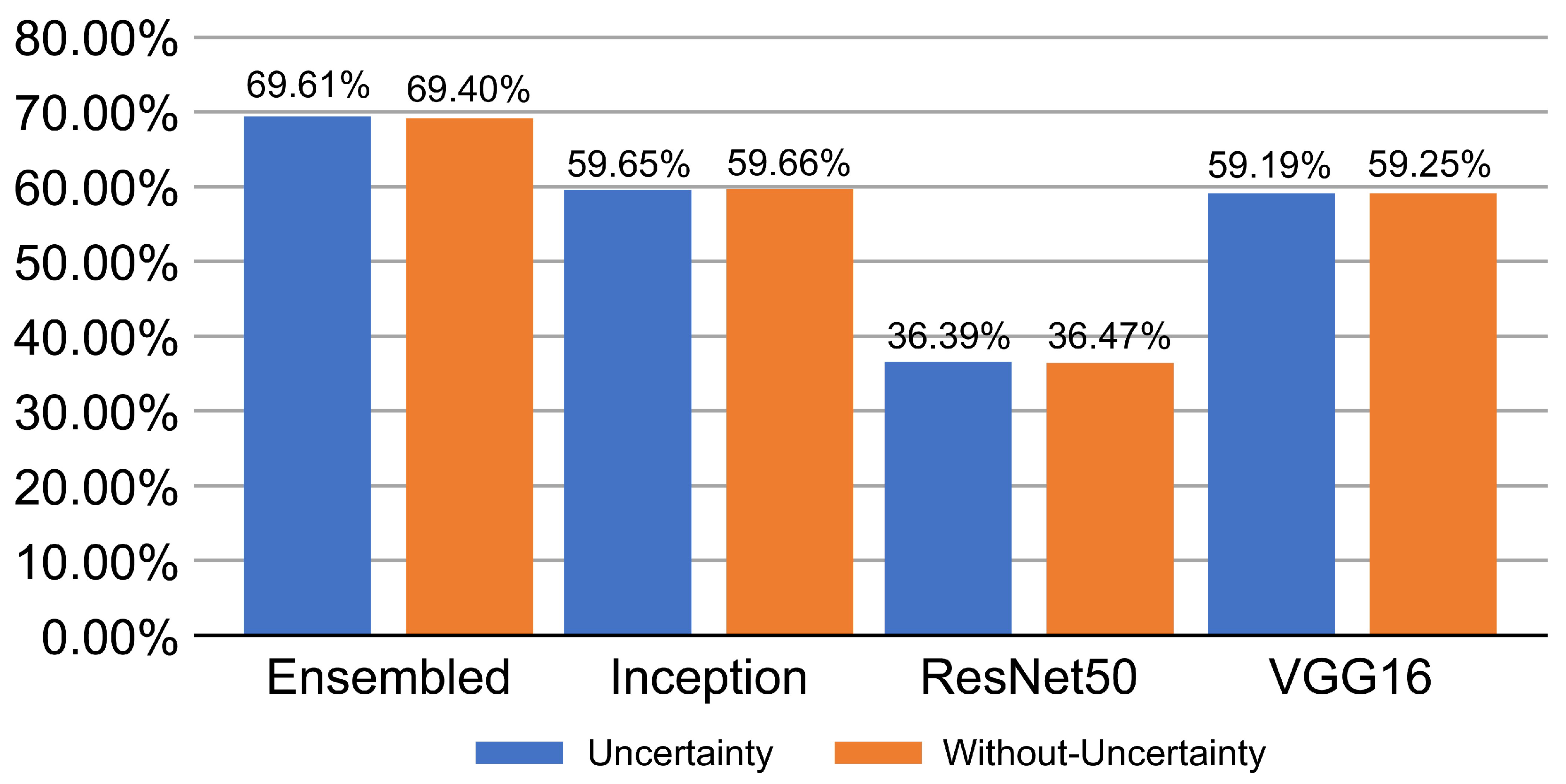
4.3. Performance Evaluation Metrics
4.4. Performance Evaluation
4.5. Explaining COVID-19
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Coronavirus Research is Being Published at a Furious Pace. Available online: https://www.economist.com/graphic-detail/2020/03/20/coronavirus-research-is-being-published-at-a-furious-pace (accessed on 31 May 2022).
- Mahmoud, G.M.; Majigo, M.V.; Njiro, B.J.; Mawazo, A. Detection Profile of SARS-CoV-2 Using RT-PCR in Different Types of Clinical Specimens: A Systematic Review and Meta-Analysis. J. Med. Virol. 2020, 93, 719–725. [Google Scholar] [CrossRef]
- Brihn, A.; Chang, J.; Yong, K.O.; Balter, S.; Terashita, D.; Rubin, Z.; Yeganeh, N. Diagnostic Performance of an Antigen Test with RT-PCR for the Detection of SARS-CoV-2 in a Hospital Setting—Los Angeles County, California, June–August 2020. MMWR. Morb. Mortal. Wkly. Rep. 2021, 70, 702–706. [Google Scholar] [CrossRef] [PubMed]
- Rehman, A.; Saba, T.; Tariq, U.; Ayesha, N. Deep Learning-Based COVID-19 Detection Using CT and X-Ray Images: Current Analytics and Comparisons. IT Prof. 2021, 23, 63–68. [Google Scholar] [CrossRef]
- Hassaballah, M.; Awad, A.I. Deep Learning in Computer Vision: Principles and Applications; CRC Press: Boca Raton, FL, USA; Taylor and Francis: Boca Raton, FL, USA, 2020. [Google Scholar]
- Ciaparrone, G.; Luque Sánchez, F.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep Learning in Video Multi-Object Tracking: A Survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef]
- Kamra, A. A Survey on Face Analysis and Its Applications (Face Recognition & Facial Age Estimation). Turk. J. Comput. Math. Educ. 2021, 12, 462–466. [Google Scholar] [CrossRef]
- Kasa, K.; Burns, D.; Goldenberg, M.G.; Selim, O.; Whyne, C.; Hardisty, M. Multi-Modal Deep Learning for Assessing Surgeon Technical Skill. Sensors 2022, 22, 7328. [Google Scholar] [CrossRef] [PubMed]
- Ulhaq, A.; Born, J.; Khan, A.; Gomes, D.P.S.; Chakraborty, S.; Paul, M. COVID-19 Control by Computer Vision Approaches: A Survey. IEEE Access 2020, 8, 179437–179456. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, N.; Elharrouss, O.; Al-Maadeed, S.; Chowdhury, M. A Review of Deep Learning-Based Detection Methods for COVID-19. Comput. Biol. Med. 2022, 143, 105233. [Google Scholar] [CrossRef]
- Das, D.; Santosh, K.C.; Pal, U. Truncated Inception Net: COVID-19 Outbreak Screening Using Chest X-Rays. Phys. Eng. Sci. Med. 2020, 43, 915–925. [Google Scholar] [CrossRef]
- Tahir, A.M.; Chowdhury, M.E.H.; Qiblawey, Y.; Khandakar, A.; Rahman, T.; Kiranyaz, S.; Khurshid, U.; Ibtehaz, N.; Mahmud, S.; Ezeddin, M. COVID-QU [Data Set]. Kaggle. 2021. Available online: https://www.kaggle.com/datasets/cf77495622971312010dd5934ee91f07ccbcfdea8e2f7778977ea8485c1914df (accessed on 20 February 2022).
- Sudhan, M.B.; Sinthuja, M.; Pravinth Raja, S.; Amutharaj, J.; Charlyn Pushpa Latha, G.; Sheeba Rachel, S.; Anitha, T.; Rajendran, T.; Waji, Y.A. Segmentation and Classification of Glaucoma Using U-Net with Deep Learning Model. J. Healthc. Eng. 2022, 2022, 1601354. [Google Scholar] [CrossRef]
- Nayak, D.R.; Padhy, N.; Mallick, P.K.; Bagal, D.K.; Kumar, S. Brain Tumour Classification Using Noble Deep Learning Approach with Parametric Optimization through Metaheuristics Approaches. Computers 2022, 11, 10. [Google Scholar] [CrossRef]
- Largent, A.; De Asis-Cruz, J.; Kapse, K.; Barnett, S.D.; Murnick, J.; Basu, S.; Andersen, N.; Norman, S.; Andescavage, N.; Limperopoulos, C. Automatic Brain Segmentation in Preterm Infants with Post-Hemorrhagic Hydrocephalus Using 3D Bayesian U-Net. Hum. Brain Mapp. 2022, 43, 1895–1916. [Google Scholar] [CrossRef] [PubMed]
- Fei-Fei, L.; Deng, J.; Li, K. ImageNet: Constructing a Large-Scale Image Database. J. Vis. 2010, 9, 1037. [Google Scholar] [CrossRef]
- Ozturk, T.; Talo, M.; Yildirim, E.A.; Baloglu, U.B.; Yildirim, O.; Rajendra Acharya, U. Automated Detection of COVID-19 Cases Using Deep Neural Networks with X-Ray Images. Comput. Biol. Med. 2020, 121, 103792. [Google Scholar] [CrossRef]
- Polat, Ç.; Karaman, O.; Karaman, C.; Korkmaz, G.; Balcı, M.C.; Kelek, S.E. COVID-19 Diagnosis from Chest X-Ray Images Using Transfer Learning: Enhanced Performance by Debiasing Dataloader. J. X-ray. Sci. Technol. 2021, 29, 19–36. [Google Scholar] [CrossRef]
- Maheshwari, S.; Sharma, R.R.; Kumar, M. LBP-Based Information Assisted Intelligent System for COVID-19 Identification. Comput. Biol. Med. 2021, 134, 104453. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, S.; Murali, B.; Mitra, A.K. An Efficient Deep Learning Model to Detect COVID-19 Using Chest X-Ray Images. Int. J. Environ. Res. Public Health 2022, 19, 2013. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, N.K.; Kabir, M.A.; Rahman, M.M.; Rezoana, N. ECOVNet: A Highly Effective Ensemble Based Deep Learning Model for Detecting COVID-19. PeerJ Comput. Sci. 2021, 7, e551. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, S.; Qiang, Y. Ensemble deep learning method for Covid-19 detection via chest X-rays. In 2021 Ethics and Explainability for Responsible Data Science (EE-RDS); IEEE: New York, NY, USA, 2021; pp. 1–3. [Google Scholar]
- Shamsi, A.; Asgharnezhad, H.; Jokandan, S.S.; Khosravi, A.; Kebria, P.M.; Nahavandi, D.; Nahavandi, S.; Srinivasan, D. An Uncertainty-Aware Transfer Learning-Based Framework for COVID-19 Diagnosis. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1408–1417. [Google Scholar] [CrossRef]
- Calderon-Ramirez, S.; Yang, S.; Moemeni, A.; Colreavy-Donnelly, S.; Elizondo, D.A.; Oala, L.; Rodriguez-Capitan, J.; Jimenez-Navarro, M.; Lopez-Rubio, E.; Molina-Cabello, M.A. Improving Uncertainty Estimation with Semi-Supervised Deep Learning for COVID-19 Detection Using Chest X-Ray Images. IEEE Access 2021, 9, 85442–85454. [Google Scholar] [CrossRef] [PubMed]
- Dong, S.; Yang, Q.; Fu, Y.; Tian, M.; Zhuo, C. RCoNet: Deformable Mutual Information Maximization and High-Order Uncertainty-Aware Learning for Robust COVID-19 Detection. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3401–3411. [Google Scholar] [CrossRef] [PubMed]
- Rahman, T.; Khandakar, A.; Qiblawey, Y.; Tahir, A.; Kiranyaz, S.; Abul Kashem, S.B.; Islam, M.T.; Al Maadeed, S.; Zughaier, S.M.; Khan, M.S.; et al. Exploring the Effect of Image Enhancement Techniques on COVID-19 Detection Using Chest X-ray Images. Comput. Biol. Med. 2021, 132, 104319. [Google Scholar] [CrossRef] [PubMed]
- Mohammed, K. Automated Detection of Covid-19 Coronavirus Cases Using Deep Neural Networks with CT Images. Al-Azhar Univ. J. Virus Res. Stud. 2020, 2, 1–12. [Google Scholar] [CrossRef]
- Paul, A.; Basu, A.; Mahmud, M.; Kaiser, M.S.; Sarkar, R. Inverted Bell-Curve-Based Ensemble of Deep Learning Models for Detection of COVID-19 from Chest X-Rays. Neural Comput. Appl. 2022, 5, 1–15. [Google Scholar] [CrossRef]
- Shahhosseini, M.; Hu, G.; Pham, H. Optimizing Ensemble Weights and Hyperparameters of Machine Learning Models for Regression Problems. Mach. Learn. Appl. 2022, 7, 100251. [Google Scholar] [CrossRef]
- Sun, J.; Li, H. Listed Companies’ Financial Distress Prediction Based on Weighted Majority Voting Combination of Multiple Classifiers. Expert Syst. Appl. 2008, 35, 818–827. [Google Scholar] [CrossRef]
- Huang, G.; Li, Y.; Pleiss, G.; Liu, Z.; Hopcroft, J.E.; Weinberger, K.Q. Snapshot ensembles: Train 1, get m for free. arXiv 2017, arXiv:1704.00109. [Google Scholar]
- Perrone, M.P.; Cooper, L.N.; National Science Foundation, U.S. When Networks Disagree: Ensemble Methods for Hybrid Neural Networks; U.S. Army Research Office: Research Triangle Park, NC, USA, 1992. [Google Scholar]
- Boyd, S. Convex Optimization (9780521833783); Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Liang, G.; Zhang, Y.; Wang, X.; Jacobs, N. Improved Trainable Calibration Method for Neural Networks on Medical Imaging Classification. arXiv 2020, arXiv:2009.04057. [Google Scholar] [CrossRef]
- Küppers, F.; Kronenberger, J.; Schneider, J.; Haselhoff, A. Bayesian Confidence Calibration for Epistemic Uncertainty Modelling. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 466–472. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Fan, S.; Zhao, Z.; Yu, H.; Wang, L.; Zheng, C.; Huang, X.; Yang, Z.; Xing, M.; Lu, Q.; Luo, Y. Applying Probability Calibration to Ensemble Methods to Predict 2-Year Mortality in Patients with DLBCL. BMC Med. Informatics Decis. Mak. 2021, 21, 14. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shi, X.J. A Simple and Effective Histogram Equalization Approach to Image Enhancement. Digit. Signal Process. 2004, 14, 158–170. [Google Scholar] [CrossRef]
- Yang, L.; Wang, S.-H.; Zhang, Y.-D. EDNC: Ensemble Deep Neural Network for COVID-19 Recognition. Tomography 2022, 8, 869–890. [Google Scholar] [CrossRef]
- Shi, H.; Han, X.; Jiang, N.; Cao, Y.; Alwalid, O.; Gu, J.; Fan, Y.; Zheng, C. Radiological Findings from 81 Patients with COVID-19 Pneumonia in Wuhan, China: A Descriptive Study. Lancet Infect. Dis. 2020, 20, 425–434. [Google Scholar] [CrossRef]
- Bai, H.X.; Hsieh, B.; Xiong, Z.; Halsey, K.; Choi, J.W.; Tran, T.M.L.; Pan, I.; Shi, L.-B.; Wang, D.-C.; Mei, J.; et al. Radiologists’ performance in differentiating COVID-19 from viral pneumonia on chest CT. Radiology 2020, 296, 200823. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2017; pp. 5987–5995. [Google Scholar] [CrossRef]
- Wu, K.; Xiao, J.; Ni, L.M. Rethinking the Architecture Design of Data Center Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition, Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–11 September 2015; BMVA Press: London, UK, 2015; pp. 1–12. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Zhou, S.K.; Greenspan, H.; Davatzikos, C.; Duncan, J.S.; van Ginneken, B.; Madabhushi, A.; Prince, J.L.; Rueckert, D.; Summers, R.M. A Review of Deep Learning in Medical Imaging: Imaging Traits, Technology Trends, Case Studies with Progress Highlights, and Future Promises. Proc. IEEE 2021, 109, 820–838. [Google Scholar] [CrossRef]
- Wang, L.; Lin, Z.Q.; Wong, A. COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-Ray Images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef]
- Khan, A.I.; Shah, J.L.; Bhat, M.M. CoroNet: A Deep Neural Network for Detection and Diagnosis of COVID-19 from Chest X-Ray Images. Comput. Methods Programs Biomed. 2020, 196, 105581. [Google Scholar] [CrossRef] [PubMed]
- Makris, A.; Kontopoulos, I.; Tserpes, K. COVID-19 detection from chest X-Ray images using Deep Learning and Convolutional Neural Networks. In Proceedings of the 11th Hellenic Conference on Artificial Intelligence, New York, NY, USA, 2–4 September 2020; pp. 60–66. [Google Scholar] [CrossRef]
- Luz, E.; Silva, P.; Silva, R.; Silva, L.; Guimarães, J.; Miozzo, G.; Moreira, G.; Menotti, D. Towards an Effective and Efficient Deep Learning Model for COVID-19 Patterns Detection in X-Ray Images. Res. Biomed. Eng. 2021, 38, 149–162. [Google Scholar] [CrossRef]
- Manokaran, J.; Zabihollahy, F.; Hamilton-Wright, A.; Ukwatta, E. Detection of COVID-19 from chest x-ray images using transfer learning. J. Med. Imaging 2021, 8, 017503. [Google Scholar] [CrossRef]
- Monshi, M.M.A.; Poon, J.; Chung, V.; Monshi, F.M. CovidXrayNet: Optimizing Data Augmentation and CNN Hyperparameters for Improved COVID-19 Detection from CXR. Comput. Biol. Med. 2021, 133, 104375. [Google Scholar] [CrossRef] [PubMed]
- Pham, T.D. Classification of COVID-19 Chest X-Rays with Deep Learning: New Models or Fine Tuning? Health Inf. Sci. Syst. 2020, 9, 2. [Google Scholar] [CrossRef] [PubMed]
- Abdar, M.; Salari, S.; Qahremani, S.; Lam, H.K.; Karray, F.; Hussain, S.; Nahavandi, S. Uncertaintyfusenet: Robust Uncertainty-aware Hierarchical Feature Fusion with Ensemble Monte Carlo Dropout for COVID-19 Detection. arXiv 2021, arXiv:2105.08590. [Google Scholar] [CrossRef]
- Aslan, M.F.; Sabanci, K.; Durdu, A.; Unlersen, M.F. COVID-19 Diagnosis Using State-of-The-Art CNN Architecture Features and Bayesian Optimization. Comput. Biol. Med. 2022, 142, 105244. [Google Scholar] [CrossRef] [PubMed]
- Karim, A.M.; Kaya, H.; Alcan, V.; Sen, B.; Hadimlioglu, I.A. New Optimized Deep Learning Application for COVID-19 Detection in Chest X-ray Images. Symmetry 2022, 14, 1003. [Google Scholar] [CrossRef]
- Saxena, A.; Singh, S.P. A Deep Learning Approach for the Detection of COVID-19 from Chest X-Ray Images Using Convolutional Neural Networks. Adv. Mach. Learn. Artif. Intell. 2022, 3, 52–65. [Google Scholar] [CrossRef]
- Banerjee, A.; Bhattacharya, R.; Bhateja, V.; Singh, P.K.; Lay-Ekuakille, A.; Sarkar, R. COFE-Net: An Ensemble Strategy for Computer-Aided Detection for COVID-19. Measurement 2022, 187, 110289. [Google Scholar] [CrossRef] [PubMed]
- Gour, M.; Jain, S. Uncertainty-Aware Convolutional Neural Network for COVID-19 X-Ray Images Classification. Comput. Biol. Med. 2022, 140, 105047. [Google Scholar] [CrossRef] [PubMed]
- Ibrokhimov, B.; Kang, J.-Y. Deep Learning Model for COVID-19-Infected Pneumonia Diagnosis Using Chest Radiography Images. BioMedInformatics 2022, 2, 654–670. [Google Scholar] [CrossRef]
- Constantinou, M.; Exarchos, T.; Vrahatis, A.G.; Vlamos, P. COVID-19 Classification on Chest X-Ray Images Using Deep Learning Methods. Int. J. Environ. Res. Public Health 2023, 20, 2035. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Voters | ECE-B | ECE-A | MCE-B | MCE-A | ||
|---|---|---|---|---|---|---|
| VGG16 | 61.83 (61.47–62.90) | 0.83 (0.28–0.96) | 64.60 (64.51–65.01) | 21.16 (20.72–21.39) | 92.57 (92.20–92.91) | 4.74 (4.33–4.97) |
| ResNet50 | 61.93 (61.76–62.30) | 0.48 (0.09–0.45) | 64.55 (64.12–64.67) | 47.86 (47.64–48.18) | 90.66 (89.97–91.14) | 5.96 (5.31–6.20) |
| Inception | 56.63 (56.63–56.83) | 1.09 (1.07–1.57) | 63.52 (63.16–63.70) | 37.77 (37.48–38.13) | 90.83 (90.81–91.61) | 6.85 (6.38–6.91) |
| Voters | Precision | Recall | F1 | ACC | AUC |
|---|---|---|---|---|---|
| VGG16 | 96.37 (96.01–96.95) | 96.44 (95.95–96.69) | 96.38 (96.25–96.93) | 96.40 (96.27–96.68) | 97.33 (96.60–97.41) |
| ResNet50 | 97.13 (96.84–97.47) | 97.18 (96.72–97.64) | 97.14 (96.95–97.52) | 97.17 (96.67–97.43) | 97.89 (97.38–98.10) |
| Inception | 94.42 (94.35–94.75) | 94.43 (94.37–94.83) | 94.42 (94.19–94.65) | 94.46 (94.46–94.95) | 95.84 (95.45–95.82) |
| Strategy | ECE-B | ECE-A | MCE-B | MCE-A | ||
|---|---|---|---|---|---|---|
| Majority Voting | 58.88 (58.89–59.23) | 0.65 (0.62–0.69) | 62.55 (62.41–62.78) | 53.92 (53.47–53.93) | 72.86 (63.6–81.17) | 7.96 (4.6–10.69) |
| Best Combination | 58.48 (58.02–58.78) | 0.73 (0.70–0.76) | 62.36 (61.92–62.54) | 21.44 (20.70–22.08) | 68.43 (62.81–74.21) | 4.59 (2.33–5.91) |
| Priori Recognition Performance | 54.82 (54.79–54.85) | 0.24 (0.22–0.27) | 89.45 (89.40–89.46) | 42.33 (42.29–42.37) | 37.61 (36.78–41.71) | 5.55 (2.32–5.33) |
| ECE (ours) | 98.35 (98.32–98.38) | 0.86 (0.85–0.88) | 62.47 (62.41–62.52) | 53.85 (53.8–53.89) | 70.51 (66.52–73.78) | 3.66 (1.72–6.14) |
| MCE (ours) | 58.96 (58.9–58.98) | 0.58 (0.51–0.62) | 62.69 (62.64–62.77) | 13.79 (13.71–13.89) | 64.67 (63.29–67.48) | 4.76 (2.76–6.86) |
| PICP (ours) | 59.15 (58.7–59.54) | 0.60 (0.43–0.81) | 63.00 (62.62–63.49) | 19.57 (19.03–19.81) | 77.25 (69.25–82.19) | 4.16 (1.52–6.63) |
| Strategy | Precision | Recall | ACC | F1 | MCC | AUC |
|---|---|---|---|---|---|---|
| Majority Voting | 97.71 (97.27–98.09) | 97.75 (97.57–97.97) | 97.76 (97.37–98.30) | 97.73 (97.46–98.14) | 98.32 (98.10–98.57) | 97.71 (97.27–98.09) |
| Best Combination | 97.87 (97.47–98.03) | 97.95 (97.92–97.96) | 97.95 (97.93–97.97) | 97.92 (97.88–97.97) | 98.47 (98.44–98.50) | 97.87 (97.47–98.03) |
| Priori Recognition Performance | 97.70 (97.66–97.74) | 97.77 (97.71–97.81) | 97.74 (97.68–97.79) | 97.75 (97.73–97.78) | 98.31 (98.27–98.36) | 97.70 (97.66–97.74) |
| ECE (ours) | 98.11 (98.04–98.14) | 98.18 (98.14_98.2) | 98.20 (98.16–98.24) | 98.12 (98.07–98.17) | 98.67 (98.66–98.73) | 98.11 (98.04–98.14) |
| MCE (ours) | 98.15 (98.09–98.2) | 98.18 (98.12–98.2) | 98.19 (98.16–98.21) | 98.13 (98.09–98.16) | 98.63 (98.58–98.66) | 98.15 (98.09–98.2) |
| PICP (ours) | 98.18 (98.12–98.23) | 98.17 (98.11–98.22) | 98.24 (98.2–98.27) | 98.20 (98.13–98.29) | 98.71 (98.66–98.76) | 98.18 (98.12–98.23) |
| Strategy | Class | Precision | Recall | ACC | F1 | AUC |
|---|---|---|---|---|---|---|
| VGG16 | COVID-19 | 95.63 (95.54–95.69) | 95.68 (95.59–95.76) | 98.21 (98.18–98.23) | 97.36 (97.31–97.43) | 97.59 (97.55–97.63) |
| Pneumonia | 96.36 (96.33–96.41) | 96.07 96.03–96.12) | 97.47 (97.4–97.54) | 96.24 (96.18–96.31) | 97.17 (97.15–97.23) | |
| Normal | 93.52 (93.46–93.57) | 97.62 (97.55–97.66) | 97.13 (97.1–97.17) | 95.54 (95.51–95.6) | 97.21 (97.13–97.29) | |
| ResNet50 | COVID-19 | 99.13 (99.07–99.2) | 97.22 (97.19–97.27) | 98.73 (98.65–98.78) | 98.19 (98.12–98.24) | 98.44 (98.42–98.5) |
| Pneumonia | 97.57 (97.47–97.64) | 96.70 (96.64–96.75) | 98.13 (98.04–98.21) | 97.17 (97.13–97.23) | 97.74 (97.69–97.79) | |
| Normal | 94.65 (94.6–94.67) | 97.54 (97.47–97.63) | 97.53 (97.47–97.56) | 96.05 (95.97–96.1) | 97.55 (97.5–97.61) | |
| Inception | COVID-19 | 95.72 (95.67–95.81) | 95.03 (94.96–95.11) | 96.78 (96.7–96.87) | 95.47 (95.4–95.5) | 96.32 (96.26–96.37) |
| Pneumonia | 96.01 (95.95–96.07) | 94.68 (94.64–94.73) | 96.94 (96.91–97) | 95.38 (95.3–95.44) | 96.35 (96.32–96.38) | |
| Normal | 91.46 (91.42–91.49) | 93.53 (93.48–93.59) | 95.23 (95.17–95.28) | 92.55 (92.52–92.58) | 94.80 (94.76–94.85) | |
| Majority Voting | COVID-19 | 99.23 (99.04–99.72) | 98.70 (98.16–99.5) | 99.38 (98.9–99.7) | 98.60 (98.03–99.26) | 99.03 (98.44–99.44) |
| Pneumonia | 97.81 (97.48–98.32) | 97.32 (96.99–97.61) | 98.50 (98–99.17) | 97.57 (96.88–98.07) | 98.32 (97.86–98.69) | |
| Normal | 95.46 (94.59–96.4) | 97.64 (97.2–97.76) | 97.77 (97.28–98.52) | 97.26 (97.06–97.62) | 97.97 (97.08–98.89) | |
| Best Combination | COVID-19 | 99.49 (99.45–99.54) | 97.82 (97.8–97.86) | 98.99 (98.87–99.46) | 98.65 (98.58–98.72) | 98.60 (98.1–99.22) |
| Pneumonia | 98.45 (98.45–98.47) | 97.91 (97.64–98.34) | 98.70 (98.07–99.33) | 98.12 (98–98.89) | 98.27 (97.8–98.7) | |
| Normal | 95.98 (95.42–96.49) | 98.87 (98.36–99.38) | 98.08 (97.74–98.57) | 97.19 (96.56–97.84) | 97.77 (97.47–98.24) | |
| Priori Recognition Performance | COVID-19 | 98.91 (97.61–100.02) | 98.14 (97.47–98.75) | 99.16 (98.95–99.42) | 98.90 (98.73–99.18) | 98.92 (98.75–99.14) |
| Pneumonia | 98.07 (97.77–98.77) | 97.00 (96.89–97.17) | 98.54 (98.32–98.63) | 97.45 (97.18–97.81) | 98.08 (97.89–98.25) | |
| Normal | 95.70 (95.29–96) | 98.00 (97.76–98.24) | 97.98 (97.49–98.39) | 96.74 (96.55–97.16) | 97.90 (97.81–98.15) | |
| ECE (ours) | COVID-19 | 99.53 (99.32–99.74) | 98.12 (97.83–98.21) | 99.17 (98.88–99.42) | 98.81 (98.44–99.01) | 99.04 (98.74–99.49) |
| Pneumonia | 98.32 (98.25–98.39) | 97.57 (97.3–97.83) | 98.75 (98.44–99.08) | 98.02 (97.87–98.12) | 98.44 (98.32–98.69) | |
| Normal | 96.16 (95.96–96.32) | 98.57 (98.09–98.96) | 98.30 (98.17–98.49) | 97.37 (97.22–97.72) | 98.39 (97.91–98.73) | |
| MCE (ours) | COVID-19 | 99.52 (99.31–99.73) | 98.46 (98.04–98.77) | 99.32 (99.15–99.58) | 99.01 (98.58–99.42) | 99.11 (98.84–99.27) |
| Pneumonia | 98.66 (98.48–98.83) | 97.41 (97.19–97.66) | 98.68 (98.38–98.93) | 98.02 (97.79–98.3) | 98.37 (98.13–98.7) | |
| Normal | 96.15 (95.96–96.25) | 98.59 (98.35–98.75) | 98.32 (98.17–98.45) | 97.35 (97.09–97.65) | 98.41 (98.08–98.82) | |
| PICP (ours) | COVID-19 | 99.65 (99.46–99.84) | 98.43 (98.2–98.75) | 99.48 (99.35–99.65) | 99.20 (98.81–99.53) | 99.27 (98.99–99.4) |
| Pneumonia | 98.89 (98.68–99.14) | 97.65 (97.37–97.73) | 98.81 (98.58–98.99) | 98.15 (97.81–98.47) | 98.54 (98.43–98.59) | |
| Normal | 96.33 (95.96–96.65) | 98.66 (98.4–99.13) | 98.47 (98.04–98.82) | 97.59 (97.26–98.03) | 98.58 (98.35–98.86) |
| X-ray | VGG16 | ResNet50 | Inception | Ensembled (Ours) | Uncertain-CAM (Ours) | Ground Truth |
|---|---|---|---|---|---|---|
 |  |  |  |  |  |  |
 |  |  |  |  |  |  |
 |  |  |  |  |  |  |
| Method | Technique | ACC | Recall | Precision | F1 | AUC |
|---|---|---|---|---|---|---|
| (Wang et al., 2020) [49] | COVID-Net | 93.3 | 91.0 | 92.80 | - | - |
| (Ozturk et al., 2020) [17] | DarkCovidNet | 87.02 | 85.35 | 89.96 | 87.37 | - |
| (Khan et al., 2020) [50] | CoroNet | 95.0 | 96.9 | 95.0 | 95.60 | - |
| (Makris et al., 2020) [51] | Deep Learning | 95.88 | 96.0 | 96.0 | 96.0 | - |
| (Luz et al., 2021) [52] | EfficientNet-B3 | 93.94 | 80.6 | - | - | |
| (Chowdhury et al., 2021) [21] | Ensemble Snapshots | 96.07 | 97.00 | 94.17 | 86.0 | 99.71 |
| (Manokaran et al., 2021) [53] | DenseNet201 | 92.19 | 94.00 | - | 90.00 | 98.33 |
| (Monshi et al., 2021) [54] | CovidXrayNet | 95.82 | 95.43 | 96.93 | 96.16 | 99.29 |
| (Pham et al., 2021) [55] | SqueezeNet | 97.47 | 98.48 | 94.20 | 96.30 | 99.9 |
| (Chaudhary et al., 2021) [22] | Ensemble Deep Learning | 95.92 | 95.92 | - | - | - |
| (Abdar et al., 2021) [56] | UncertaintyFuseNet | 96.35 | 96.37 | 96.35 | 96.36 | 100 |
| (Aslan et al., 2022) [57] | Deep Learning and Machine Learning | 96.29 | 96.42 | 96.42 | 96.41 | - |
| (Karim et al., 2022) [58] | CNN + ALO + NB | 98.01 | 96.04 | 97.87 | 97.45 | - |
| (Saxena et al., 2022) [59] | CNN | 92.63 | 91.87 | 95.76 | 93.78 | - |
| (Chakraborty et al. 2022) [20] | Transfer Learning | 96.43 | 93.68 | - | 93.0 | - |
| (Yang et al., 2022) [41] | Ensemble Deep Learning | 97.75 | 97.95 | 97.55 | 97.75 | - |
| (Banerjee et al., 2022) [60] | Ensemble Deep Learning | 96.39 | 95.69 | 96.97 | 96.30 | - |
| (Gour and Jain, 2022) [61] | UA-ConvNet | 97.67 | 98.15 | 97.87 | 97.99 | 99.65 |
| (Ibrokhimov and Youngwook Kang) [62] | Deep Learning | 95.85 | 95.82 | 97.95 | 95.80 | 97.33 |
| (Constantinou et al., 2023) [63] | Deep Learning | 95.65 | 95.63 | 97.85 | 95.60 | - |
| Proposed | Uncertain-CAM | 98.24 | 98.17 | 98.18 | 98.20 | 98.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldhahi, W.; Sull, S. Uncertain-CAM: Uncertainty-Based Ensemble Machine Voting for Improved COVID-19 CXR Classification and Explainability. Diagnostics 2023, 13, 441. https://doi.org/10.3390/diagnostics13030441
Aldhahi W, Sull S. Uncertain-CAM: Uncertainty-Based Ensemble Machine Voting for Improved COVID-19 CXR Classification and Explainability. Diagnostics. 2023; 13(3):441. https://doi.org/10.3390/diagnostics13030441
Chicago/Turabian StyleAldhahi, Waleed, and Sanghoon Sull. 2023. "Uncertain-CAM: Uncertainty-Based Ensemble Machine Voting for Improved COVID-19 CXR Classification and Explainability" Diagnostics 13, no. 3: 441. https://doi.org/10.3390/diagnostics13030441
APA StyleAldhahi, W., & Sull, S. (2023). Uncertain-CAM: Uncertainty-Based Ensemble Machine Voting for Improved COVID-19 CXR Classification and Explainability. Diagnostics, 13(3), 441. https://doi.org/10.3390/diagnostics13030441