
Deep Learning-Based Extraction of Biomarkers for the Prediction of the Functional Outcome of Ischemic Stroke Patients


Abstract
:1. Introduction
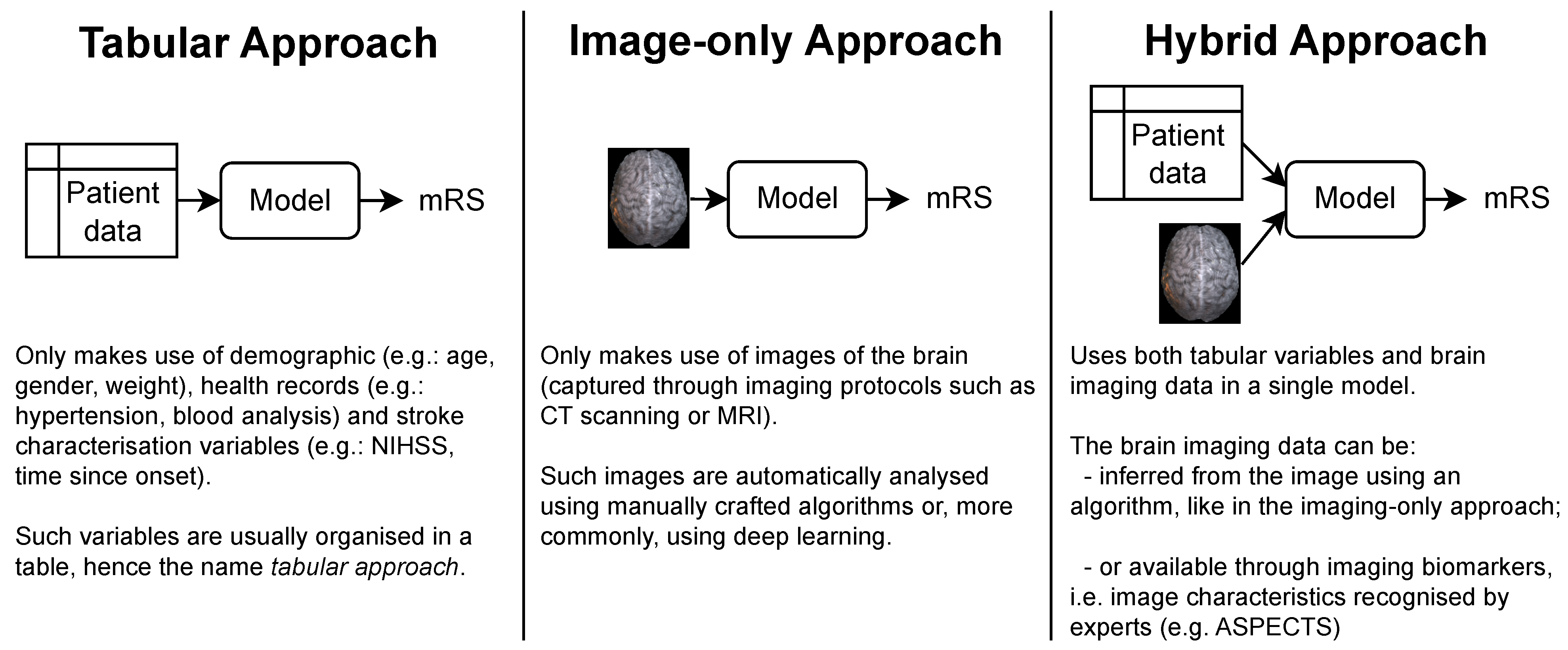
- Tabular approach: only demographic, health records and stroke characterization variables;
- Image-only approach: only brain imaging data;
- Hybrid approach: both tabular variables and brain imaging data.
2. Literature Review
2.1. Modified Rankin Scale Prediction
2.2. Deep Learning for Brain Imaging
3. Materials and Methods
3.1. Dataset
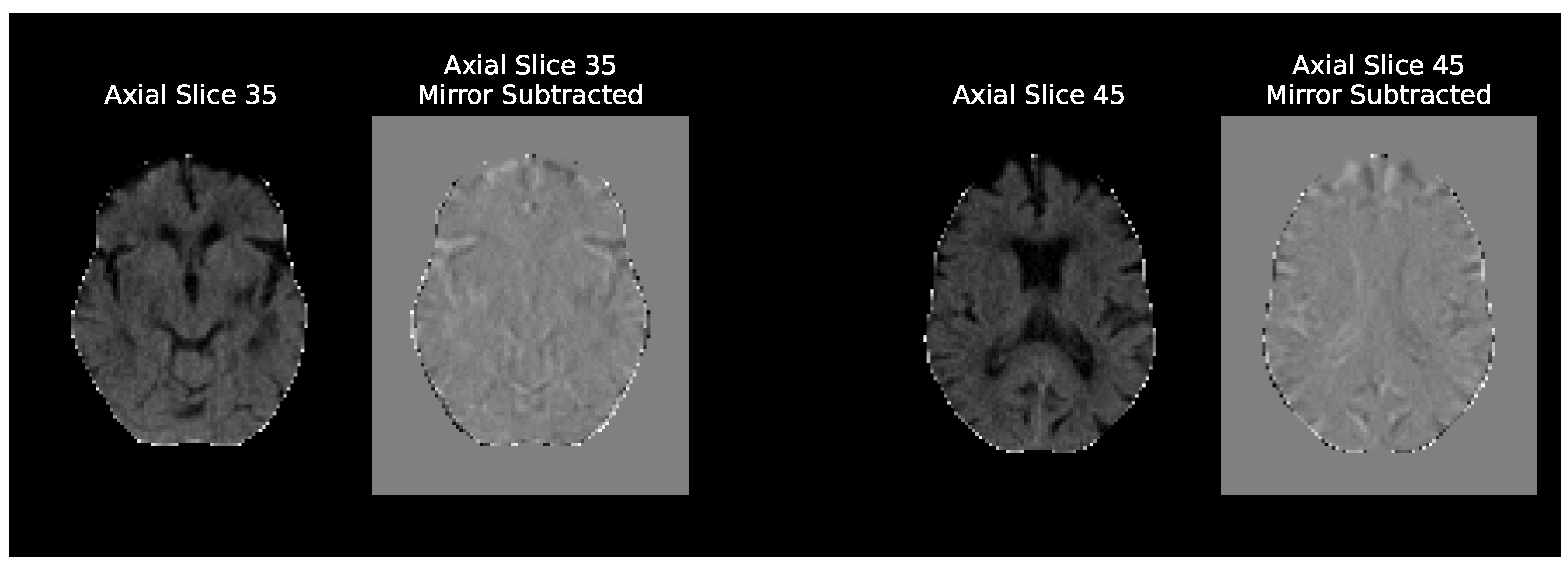
3.2. CT Preprocessing
3.3. mRS Prediction Models
3.3.1. Image-Only Approach
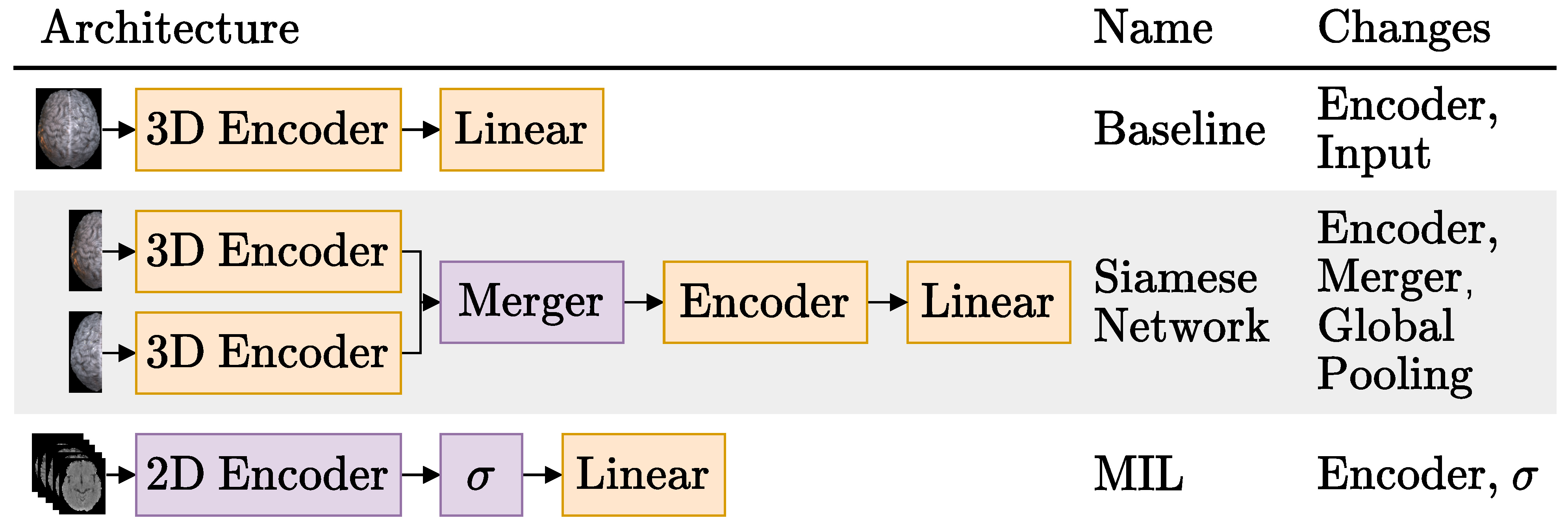
3.3.1.1. Baseline
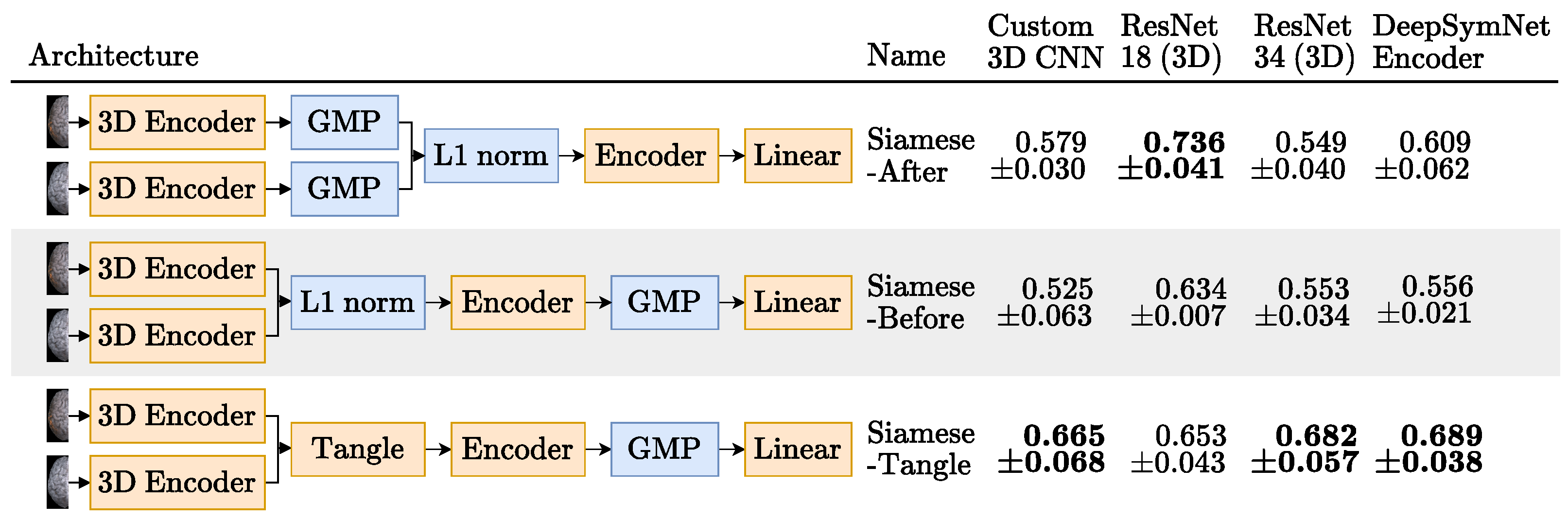
3.3.1.2. Siamese Network
- Hemisphere encoder: A 3D CNN. The same encoders that were tried for the Baseline experiments were also tried here with the exception of the ResNet 50 [15].
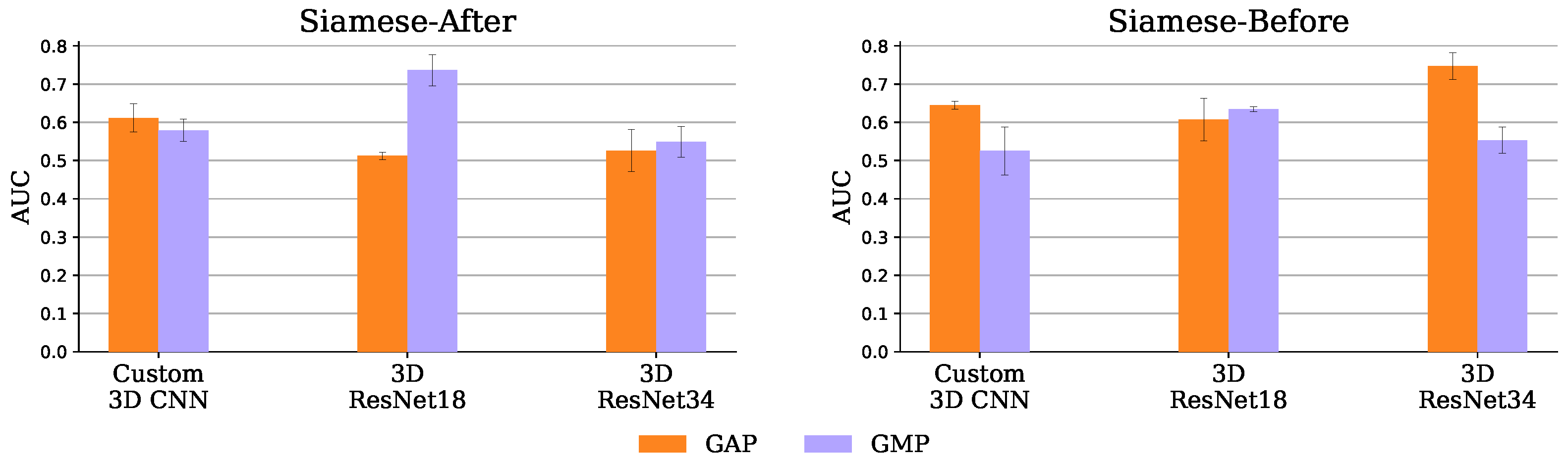
- Merger: Responsible for comparing the representations generated by the encoder. For example, the DeepSymNet [24] computes the L1 difference between the hemispheres representations, before applying the pooling operation and thus we call it Siamese-Before (row two of Figure 4). In contrast, in the Siamese-After approach, the L1 difference is computed after the global pooling is applied (row one of Figure 4).A third merge function, further explained in Figure A1 in the Appendix A, was considered. This approach tangles the features maps of the two encoders, and is named Siamese-Tangle, after this operation. Unlike the other two approaches, the Siamese-Tangle does not use the L1 Norm, but instead uses a learned comparison using group convolutions (due to memory limitations, the Siamese-Tangle experiment using the DeepSymNet encoder was run with a batch size of 16).
- Global pooling: An operation which converts the feature maps (with spatial information) into feature vectors (without spatial information). We tried both global max pooling (GMP), which is the pooling operation used by the DeepSymNet [24], and global average pooling (GAP). Each operation convert the maps into features by computing the max and mean values of each map, respectively.
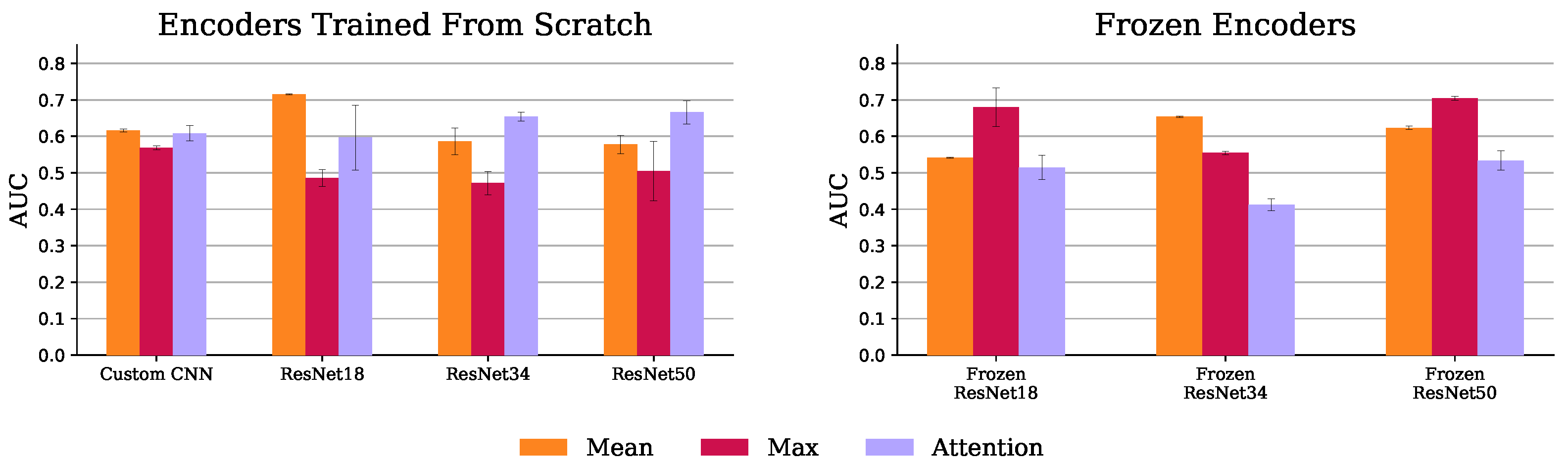
3.3.1.3. Multiple Instance Learning (MIL)
3.3.2. Hybrid Approach
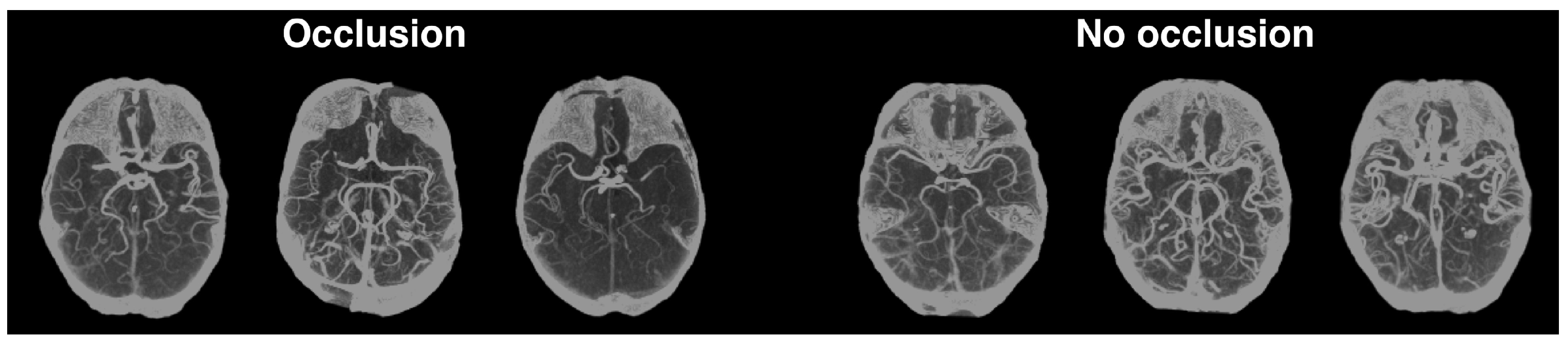
3.3.2.1. Occlusion Prediction
4. Results and Discussion
4.1. Image-Only Approach
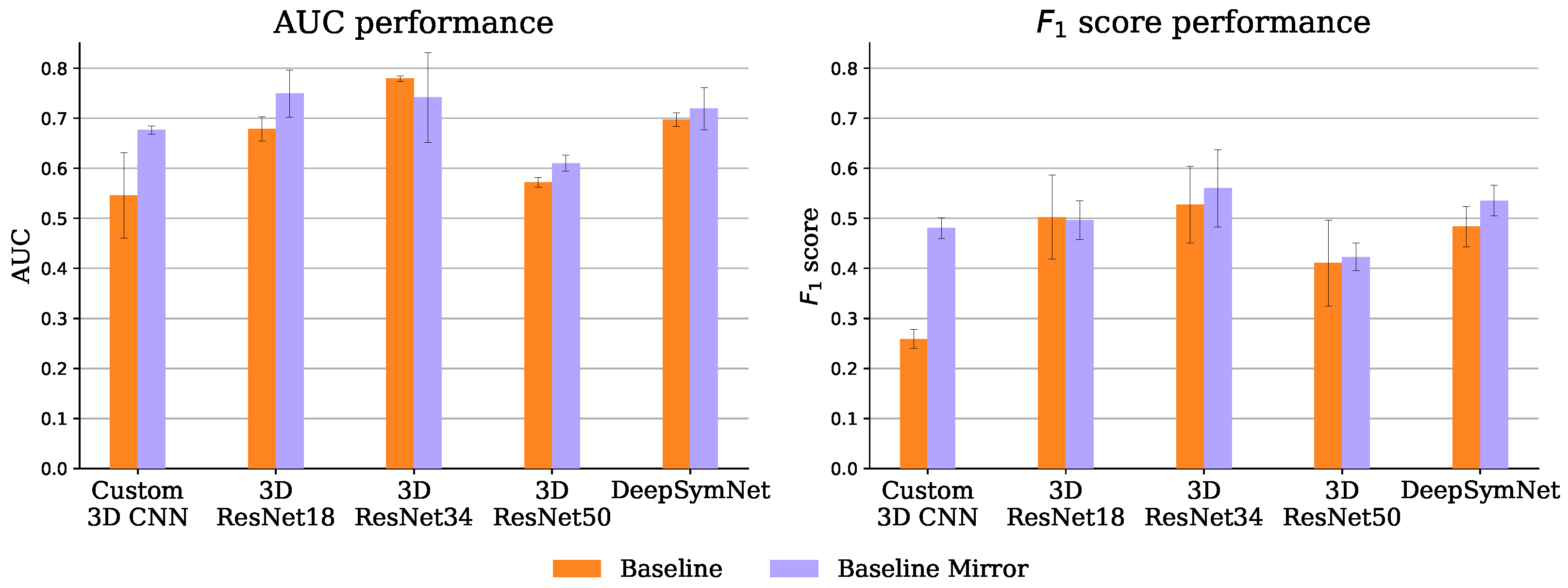
4.1.1. Baseline
4.1.2. Siamese Network
4.1.3. Multiple Instance Learning (MIL)
4.2. Hybrid Approach
Occlusion Prediction
5. Discussion
5.1. Image-Only Approach Underperformance
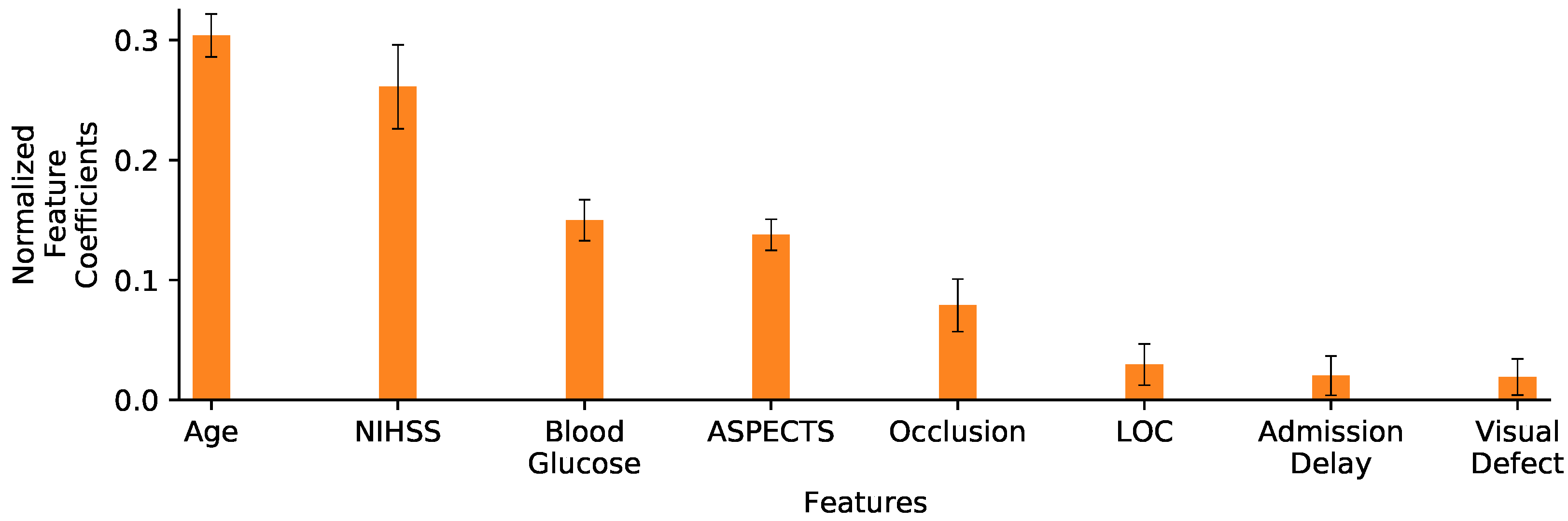
5.2. Imaging Biomarkers
5.3. Feature Selection
5.4. Limitations
5.5. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | artificial neural network |
| ASPECT | Alberta stroke programme early computed tomography |
| ASTRAL | Acute Stroke Registry and Analysis of Lausanne |
| AUC | area under the curve |
| BET | brain extraction tool |
| CNN | convolutional neural network |
| CT | computed tomography |
| CTA | computed tomography angiography |
| DICOM | Digital Imaging and Communications in Medicine |
| FLIRT | FMRIB’s Linear Image Registration Tool |
| FSL | FMRIB Software Library |
| GAP | global average pooling |
| GMP | global max pooling |
| HU | Hounsfield unit |
| IM | inception module |
| INR | international normalized ratio |
| LOC | level of consciousness |
| LR | logistic regression |
| MCA | middle cerebral artery |
| MIL | multiple instance learning |
| MIP | maximum intensity projection |
| ML | machine learning |
| MNI | Montreal Neurosciences Institute |
| MSP | mid-sagittal plane |
| NCCT | non-contrast computed tomography |
| NIHSS | National Institutes of Health Stroke Scale |
| NIfTI | Neuroimaging Informatics Technology Initiative |
| RFNN | receptive field neural network |
| ROC | receiver operating characteristic |
| ReLU | rectified linear unit |
| mRS | Modified Rankin Scale |
| timm | Pytorch Image Models |
Appendix A. Merge Function
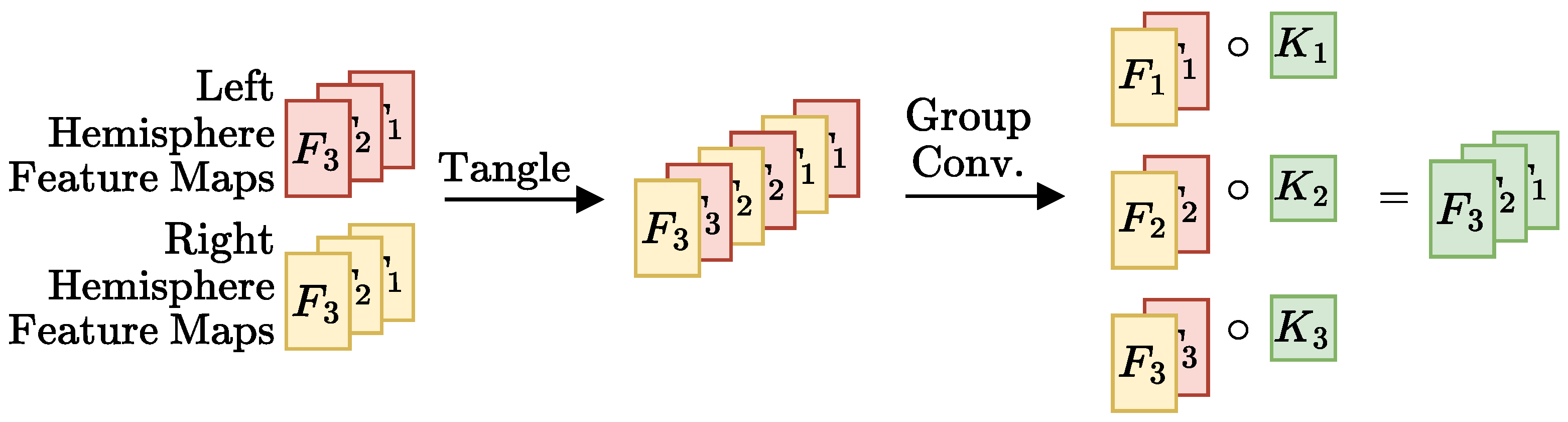
Appendix B. NCCT Augmentations

Appendix C. Implementation Details
Appendix D. Image-Only Experiments Results Tables

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment Name | Parameters | Accuracy | AUC |
|---|---|---|---|
| Baseline | Name = “Baseline”, Encode = “3D Custom CNN” | 0.622 ± 0.059 | 0.546 ± 0.085 |
| Baseline | Name = “Baseline”, Encode = “3D ResNet 18” | 0.728 ± 0.051 | 0.679 ± 0.024 |
| Baseline | Name = “Baseline”, Encode = “3D ResNet 34” | 0.711 ± 0.035 | 0.779 ± 0.006 |
| Baseline | Name = “Baseline”, Encode = “3D ResNet 50” | 0.528 ± 0.042 | 0.572 ± 0.010 |
| Baseline | Name = “Baseline”, Encode = “DeepSymNet Encoder” | 0.694 ± 0.010 | 0.697 ± 0.014 |
| Baseline | Name = “Baseline Mirror”, Encode = “3D Custom CNN” | 0.567 ± 0.067 | 0.677 ± 0.008 |
| Baseline | Name = “Baseline Mirror”, Encode = “3D ResNet 18” | 0.689 ± 0.025 | 0.749 ± 0.047 |
| Baseline | Name = “Baseline Mirror”, Encode = “3D ResNet 34” | 0.767 ± 0.033 | 0.741 ± 0.090 |
| Baseline | Name = “Baseline Mirror”, Encode = “3D ResNet 50” | 0.617 ± 0.073 | 0.610 ± 0.016 |
| Baseline | Name = “Baseline Mirror”, Encode = “DeepSymNet Encoder” | 0.656 ± 0.051 | 0.719 ± 0.042 |
| Siamese Network | Name = “Siamese After”, Encoder = “3D Custom CNN”, Global Pooling = “GMP” | 0.617 ± 0.050 | 0.579 ± 0.030 |
| Siamese Network | Name = “Siamese After”, Encoder = “3D ResNet 18”, Global Pooling = “GMP” | 0.600 ± 0.060 | 0.736 ± 0.041 |
| Siamese Network | Name = “Siamese After”, Encoder = “3D ResNet 34”, Global Pooling = “GMP” | 0.483 ± 0.173 | 0.549 ± 0.040 |
| Siamese Network | Name = “Siamese After”, Encoder = “DeepSymNet Encoder”, Global Pooling = “GMP” | 0.572 ± 0.035 | 0.609 ± 0.062 |
| Siamese Network | Name = “Siamese After”, Encoder = “3D Custom CNN”, Global Pooling = “GAP” | 0.644 ± 0.042 | 0.611 ± 0.037 |
| Siamese Network | Name = “Siamese After”, Encoder = “3D ResNet 18”, Global Pooling = “GAP” | 0.567 ± 0.000 | 0.513 ± 0.010 |
| Siamese Network | Name = “Siamese After”, Encoder = “3D ResNet 34”, Global Pooling = “GAP” | 0.511 ± 0.146 | 0.526 ± 0.055 |
| Siamese Network | Name = “Siamese After”, Encoder = “DeepSymNet Encoder”, Global Pooling = “GAP” | 0.661 ± 0.048 | 0.668 ± 0.079 |
| Siamese Network | Name = “Siamese Before”, Encoder = “3D Custom CNN”, Global Pooling = “GMP” | 0.600 ± 0.017 | 0.525 ± 0.063 |
| Siamese Network | Name = “Siamese Before”, Encoder = “3D ResNet 18”, Global Pooling = “GMP” | 0.650 ± 0.073 | 0.634 ± 0.007 |
| Siamese Network | Name = “Siamese Before”, Encoder = “3D ResNet 34”, Global Pooling = “GMP” | 0.622 ± 0.054 | 0.553 ± 0.034 |
| Siamese Network | Name = “Siamese Before”, Encoder = “DeepSymNet Encoder”, Global Pooling = “GMP” | 0.600 ± 0.017 | 0.556 ± 0.021 |
| Siamese Network | Name = “Siamese Before”, Encoder = “3D Custom CNN”, Global Pooling = “GAP” | 0.583 ± 0.117 | 0.645 ± 0.010 |
| Siamese Network | Name = “Siamese Before”, Encoder = “3D ResNet 18”, Global Pooling = “GAP” | 0.661 ± 0.084 | 0.607 ± 0.056 |
| Siamese Network | Name = “Siamese Before”, Encoder = “3D ResNet 34”, Global Pooling = “GAP” | 0.744 ± 0.069 | 0.747 ± 0.035 |
| Siamese Network | Name = “Siamese Tangle”, Encoder = “3D Custom CNN”, Global Pooling = “GMP” | 0.611 ± 0.086 | 0.665 ± 0.068 |
| Siamese Network | Name = “Siamese Tangle”, Encoder = “3D ResNet 18”, Global Pooling = “GMP” | 0.561 ± 0.077 | 0.653 ± 0.043 |
| Siamese Network | Name = “Siamese Tangle”, Encoder = “3D ResNet 34”, Global Pooling = “GMP” | 0.600 ± 0.076 | 0.682 ± 0.057 |
| Siamese Network | Name = “Siamese Tangle”, Encoder = “DeepSymNet Encoder”, Global Pooling = “GMP” | 0.706 ± 0.042 | 0.689 ± 0.038 |
| MIL | Encoder = “2D Custom CNN”, Frozen ImageNet Weights = “N/A”, = “Max” | 0.583 ± 0.017 | 0.569 ± 0.006 |
| MIL | Encoder = “ResNet 18”, Frozen ImageNet Weights = “No”, = “Max” | 0.561 ± 0.059 | 0.486 ± 0.023 |
| MIL | Encoder = “ResNet 18”, Frozen ImageNet Weights = “Yes”, = “Max” | 0.583 ± 0.044 | 0.680 ± 0.053 |
| MIL | Encoder = “ResNet 34”, Frozen ImageNet Weights = “No”, = “Max” | 0.472 ± 0.063 | 0.472 ± 0.032 |
| MIL | Encoder = “ResNet 34”, Frozen ImageNet Weights = “Yes”, = “Max” | 0.450 ± 0.029 | 0.554 ± 0.005 |
| MIL | Encoder = “ResNet 50”, Frozen ImageNet Weights = “No”, = “Max” | 0.461 ± 0.059 | 0.505 ± 0.081 |
| MIL | Encoder = “ResNet 50”, Frozen ImageNet Weights = “Yes”, = “Max” | 0.706 ± 0.010 | 0.705 ± 0.005 |
| MIL | Encoder = “2D Custom CNN”, Frozen ImageNet Weights = “N/A”, = “Mean” | 0.289 ± 0.025 | 0.616 ± 0.003 |
| MIL | Encoder = “ResNet 18”, Frozen ImageNet Weights = “No”, = “Mean” | 0.672 ± 0.067 | 0.715 ± 0.001 |
| MIL | Encoder = “ResNet 18”, Frozen ImageNet Weights = “Yes”, = “Mean” | 0.294 ± 0.010 | 0.542 ± 0.001 |
| MIL | Encoder = “ResNet 34”, Frozen ImageNet Weights = “No”, = “Mean” | 0.656 ± 0.025 | 0.586 ± 0.036 |
| MIL | Encoder = “ResNet 34”, Frozen ImageNet Weights = “Yes”, = “Mean” | 0.617 ± 0.000 | 0.653 ± 0.002 |
| MIL | Encoder = “ResNet 50”, Frozen ImageNet Weights = “No”, = “Mean” | 0.528 ± 0.054 | 0.578 ± 0.025 |
| MIL | Encoder = “ResNet 50”, Frozen ImageNet Weights = “Yes”, = “Max” | 0.711 ± 0.010 | 0.623 ± 0.004 |
| MIL | Encoder = “2D Custom CNN”, Frozen ImageNet Weights = “N/A”, = “Attention” | 0.633 ± 0.000 | 0.608 ± 0.021 |
| MIL | Encoder = “ResNet 18”, Frozen ImageNet Weights = “No”, = “Attention” | 0.589 ± 0.042 | 0.597 ± 0.089 |
| MIL | Encoder = “ResNet 18”, Frozen ImageNet Weights = “Yes”, = “Attention” | 0.422 ± 0.010 | 0.515 ± 0.034 |
| MIL | Encoder = “ResNet 34”, Frozen ImageNet Weights = “No”, = “Attention” | 0.706 ± 0.025 | 0.654 ± 0.013 |
| MIL | Encoder = “ResNet 34”, Frozen ImageNet Weights = “Yes”, = “Attention” | 0.378 ± 0.019 | 0.412 ± 0.016 |
| MIL | Encoder = “ResNet 50”, Frozen ImageNet Weights = “No”, = “Attention” | 0.650 ± 0.033 | 0.666 ± 0.032 |
| MIL | Encoder = “ResNet 50”, Frozen ImageNet Weights = “Yes”, = “Attention” | 0.611 ± 0.042 | 0.534 ± 0.027 |
References
- Feigin, V.L.; Brainin, M.; Norrving, B.; Martins, S.; Sacco, R.L.; Hacke, W.; Fisher, M.; Pandian, J.; Lindsay, P. World Stroke Organization (WSO): Global Stroke Fact Sheet 2022. Int. J. Stroke 2022, 17, 18–29. [Google Scholar] [CrossRef] [PubMed]
- Wardlaw, J.M.; Murray, V.; Berge, E.; de Zoppo, G.J. Thrombolysis for acute ischaemic stroke. Cochrane Database Syst. Rev. 2014, 7, CD000213. [Google Scholar] [CrossRef]
- Monteiro, M.; Fonseca, A.C.; Freitas, A.T.; Melo, T.; Francisco, A.P.; Ferro, J.M.; Oliveira, A.L. Using Machine Learning to Improve the Prediction of Functional Outcome in Ischemic Stroke Patients. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 15, 1953–1959. [Google Scholar] [CrossRef] [PubMed]
- van Swieten, J.C.; Koudstaal, P.J.; Visser, M.C.; Schouten, H.J.; van Gijn, J. Interobserver agreement for the assessment of handicap in stroke patients. Stroke 1988, 19, 604–607. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, G.; Fonseca, A.C.; Ferro, J.M.; Oliveira, A.L. Potential and limitations of computed tomography images as predictors of the outcome of ischemic stroke events: A review. Front. Stroke 2023, 2, 1242901. [Google Scholar] [CrossRef]
- Hopyan, J.; Ciarallo, A.; Dowlatshahi, D.; Howard, P.; John, V.; Yeung, R.; Zhang, L.; Kim, J.; MacFarlane, G.; Lee, T.-Y.; et al. Certainty of Stroke Diagnosis: Incremental Benefit with CT Perfusion over Noncontrast CT and CT Angiography. Radiology 2010, 255, 142–153. [Google Scholar] [CrossRef]
- de Lucas, E.M.; Sánchez, E.; Gutiérrez, A.; Mandly, A.G.; Ruiz, E.; Flórez, A.F.; Izquierdo, J.; Arnáiz, J.; Piedra, T.; Valle, N.; et al. CT Protocol for Acute Stroke: Tips and Tricks for General Radiologists. RadioGraphics 2008, 28, 1673–1687. [Google Scholar] [CrossRef]
- Barber, P.A.; Demchuk, A.M.; Zhang, J.; Buchan, A.M. Validity and reliability of a quantitative computed tomography score in predicting outcome of hyperacute stroke before thrombolytic therapy. Lancet 2000, 355, 1670–1674. [Google Scholar] [CrossRef]
- Fonseca, A.C.; Ferro, J.M. (Eds.) Precision Medicine in Stroke; Springer: Berlin/Heidelberg, Germany, 2021; ISBN 9783030707613. [Google Scholar]
- Ntaios, G.; Faouzi, M.; Ferrari, J.; Lang, W.; Vemmos, K.; Michel, P. An integer-based score to predict functional outcome in acute ischemic stroke: The ASTRAL score. Neurology 2012, 78, 1916–1922. [Google Scholar] [CrossRef]
- Kent, T.A. Predicting Outcome of IV Thrombolysis–Treated Ischemic Stroke Patients: The Dragon Score. Neurology 2012, 78, 427–432. [Google Scholar] [CrossRef]
- Flint, A.C.; Cullen, S.P.; Faigeles, B.S.; Rao, V.A. Predicting Long-Term Outcome after Endovascular Stroke Treatment: The Totaled Health Risks in Vascular Events Score. Am. J. Neuroradiol. 2010, 31, 1192–1196. [Google Scholar] [CrossRef] [PubMed]
- Hilbert, A.; Ramos, L.A.; van Os, H.J.A.; Olabarriaga, S.D.; Tolhuisen, M.L.; Wermer, H.J.H.; Barros, R.S.; van der Schaaf, I.; Dippel, D.; Roos, Y.B.W.E.M.; et al. Data-efficient deep learning of radiological image data for outcome prediction after endovascular treatment of patients with acute ischemic stroke. Comput. Biol. Med. 2019, 115, 103516. [Google Scholar] [CrossRef] [PubMed]
- Fishman, E.K.; Ney, D.R.; Heath, D.G.; Corl, F.M.; Horton, K.M.; Johnson, P.T. Volume Rendering versus Maximum Intensity Projection in CT Angiography: What Works Best, When, and Why. RadioGraphics 2006, 26, 905–922. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 23–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Jacobsen, J.-H.; Gemert, V.; Lou, Z.; Smeulders, A.W.M. Structured Receptive Fields in CNNs. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 23–30 June 2016; pp. 2610–2619. [Google Scholar] [CrossRef]
- Bacchi, S.; Zerner, T.; Oakden-Rayner, L.; Kleinig, T.; Patel, S.; Jannes, J. Deep Learning in the Prediction of Ischaemic Stroke Thrombolysis Functional Outcomes. Acad. Radiol. 2020, 27, e19–e23. [Google Scholar] [CrossRef] [PubMed]
- Samak, Z.A.; Clatworthy, P.; Mirmehdi, M. Prediction of Thrombectomy Functional Outcomes Using Multimodal Data. In Proceedings of the Medical Image Understanding and Analysis, 24th Annual Conference, MIUA 2020, Oxford, UK, 15–17 July 2020; Volume 1248, pp. 267–279. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Samak, Z.A.; Mirmehdi, P.; Clatworthy, M. FeMA: Feature matching auto-encoder for predicting ischaemic stroke evolution and treatment outcome. Comput. Med. Imaging Graph. 2022, 99, 102089. [Google Scholar] [CrossRef] [PubMed]
- Brugnara, G.; Mihalicz, P.; Herweh, C.; Schönenberger, S.; Purrucker, J.; Nagel, S.; Ringleb, P.A.; Bendszus, M.; Möhlenbruch, M.A.; Neuberger, U. Clinical value of automated volumetric quantification of early ischemic tissue changes on non-contrast CT. J. Neurointerv. Surg. 2022, 15, e178–e183. [Google Scholar] [CrossRef] [PubMed]
- Ramos, L.A.; van Os, H.; Hilbert, A.; Olabarriaga, S.D.; Lugt, A.; Roos, Y.B.W.E.; Zwam, W.H.; Walderveen, M.A.A.; Zwinderman, A.H.; Strijkers, G.J.; et al. Combination of Radiological and Clinical Baseline Data for Outcome Prediction of Patients With an Acute Ischemic Stroke. Front. Neurol. 2022, 13, 809343. [Google Scholar] [CrossRef] [PubMed]
- Barman, A.; Inam, M.E.; Lee, S.; Savitz, S.; Sheth, S.; Giancardo, L. Determining Ischemic Stroke From CT-Angiography Imaging Using Symmetry-Sensitive Convolutional Networks. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 1873–1877. [Google Scholar] [CrossRef]
- Bromley, J.; Guyon, J.W.; LeCun, L.; Sickinger, E.; Shah, R. Signature Verification using a “Siamese” Time Delay Neural Network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Ilse, M.; Tomczak, J.M.; Welling, M. Attention-based Deep Multiple Instance Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2127–2136. [Google Scholar] [CrossRef]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Perez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef]
- Remedios, S.; Wu, Z.; Bermudez, C.; Kerley, C.I.; Roy, S.; Patel, M.B.; Butman, J.A.; Landman, B.A.; Pham, D.L. Extracting 2D weak labels from volume labels using multiple instance learning in CT hemorrhage detection. In Proceedings of the Medical Imaging 2020: Image Processing, Houston, TX, USA, 15–20 February 2020; Volume 11313, p. 113130F. [Google Scholar] [CrossRef]
- Brett, M.; Johnsrude, I.S.; Owen, A.M. The problem of functional localization in the human brain. Nat. Rev. Neurosci. 2002, 3, 243–249. [Google Scholar] [CrossRef]
- Li, X.; Morgan, P.S.; Ashburner, J.; Smith, J.; Rorden, C. The first step for neuroimaging data analysis: DICOM to NIfTI conversion. J. Neurosci. Methods 2016, 264, 47–56. [Google Scholar] [CrossRef] [PubMed]
- Jenkinson, M.; Smith, S. A global optimisation method for robust affine registration of brain images. Med. Image Anal. 2001, 5, 143–156. [Google Scholar] [CrossRef] [PubMed]
- Jenkinson, M.; Bannister, P.; Brady, M.; Smith, S. Improved Optimization for the Robust and Accurate Linear Registration and Motion Correction of Brain Images. NeuroImage 2002, 17, 825–841. [Google Scholar] [CrossRef] [PubMed]
- Smith, S.M. Fast robust automated brain extraction. Hum. Brain Mapp. 2002, 17, 143–155. [Google Scholar] [CrossRef] [PubMed]
- Jenkinson, M.; Pechaud, M.; Smith, S. BET2: MR-Based Estimation of Brain, Skull and Scalp Surfaces. In Proceedings of the Eleventh Annual Meeting of the Organization for Human Brain Mapping, Toronto, ON, Canada, 12–16 June 2005. [Google Scholar]
- Muschelli, J.; Ullman, N.L.; Mould, W.A.; Vespa, P.; Hanley, D.F.; Crainiceanu, C.M. Validated automatic brain extraction of head CT images. NeuroImage 2015, 114, 379–385. [Google Scholar] [CrossRef] [PubMed]
- Pérez-García, F.; Sparks, R.; Ourselin, S. TorchIO: A Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. Comput. Methods Programs Biomed. 2021, 208, 106236. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Mingxing, M.; Quoc, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, J.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Griethuysen, J.J.M.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.H.; Fillion-Robin, J.-C.; Pieper, S.; Aerts, H.J.W.L. Computational Radiomics System to Decode the Radiographic Phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef]
- Kuang, H.; Najm, M.; Chakraborty, D.; Maraj, N.; Sohn, S.I.; Goyal, M.; Hill, M.D.; Demchuk, A.M.; Menon, B.K.; Qiu, W. Automated ASPECTS on Noncontrast CT Scans in Patients with Acute Ischemic Stroke Using Machine Learning. Am. J. Neuroradiol. 2018, 40, 33–38. [Google Scholar] [CrossRef]
- Yu, Z.; Chen, Z.; Yu, Y.; Zhu, H.; Tong, D.; Chen, Y. An automated ASPECTS method with atlas-based segmentation. Comput. Methods Programs Biomed. 2021, 210, 106376. [Google Scholar] [CrossRef]
- Hoelter, P.; Muehlen, I.; Goelitz, P.; Beuscher, V.; Schwab, S.; Doerfler, A. Automated ASPECT scoring in acute ischemic stroke: Comparison of three software tools. Neuroradiology 2020, 62, 1231–1238. [Google Scholar] [CrossRef]
- Maegerlein, C.; Fischer, J.; Mönch, S.; Berndt, M.; Wunderlich, S.; Seifert, C.L.; Lehm, M.; Boeckh-Behrens, T.; Zimmer, C.; Friedrich, B. Automated Calculation of the Alberta Stroke Program Early CT Score: Feasibility and Reliability. Radiology 2019, 291, 141–148. [Google Scholar] [CrossRef] [PubMed]
- Mockus, J.; Tiesis, V.; Zilinskas, V. The application of Bayesian methods for seeking the extremum. In Proceedings of the IFIP Technical Conference on Optimization Techniques, Atlanta, GA, USA, 23–26 June 2014; Volume 2, pp. 117–129. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; McGraw-Hill Series in Computer Science; McGraw-Hill Professional: New York, NY, USA, 1997; ISBN 9780070428072. [Google Scholar]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better ImageNet Models Transfer Better? In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2656–2666. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Vital, M. Stroke: Hope through Research; U.S. Dept. of Health and Human Services, Public Health Service, National Institute of Neurological Disorders and Stroke: Bethesda, MD, USA, 1999; ISBN 9780756707859.
- Saver, J.L.; Altman, H. Relationship between Neurologic Deficit Severity and Final Functional Outcome Shifts and Strengthens during First Hours after Onset. Stroke 2012, 43, 1537–1541. [Google Scholar] [CrossRef]
- Hanczar, B.; Hua, J.; Sima, C.; Weinstein, J.; Bittner, M.; Dougherty, E.R. Small-sample precision of ROC-related estimates. Bioinformatics 2010, 26, 822–830. [Google Scholar] [CrossRef] [PubMed]
- van Os, H.J.A.; Ramos, L.A.; Hilbert, A.; Leeuwen, M.; Walderveen, M.A.A.; Kruyt, N.D.; Dippel, D.W.J.; Steyerberg, E.W.; Schaaf, I.C.; Lingsma, H.F.; et al. Predicting Outcome of Endovascular Treatment for Acute Ischemic Stroke: Potential Value of Machine Learning Algorithms. Front. Neurol. 2018, 9, 784. [Google Scholar] [CrossRef] [PubMed]
- Heo, J.; Yoon, J.G.; Park, H.; Kim, Y.; Nam, H.S.; Heo, J.H. Machine Learning-Based Model for Prediction of Outcomes in Acute Stroke. Stroke 2019, 50, 1263–1265. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Liu, H. Feature selection for high-dimensional data: A fast correlation-based filter solution. In Proceedings of the Twentieth International Conference on Machine Learning (ICML-2003), Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Cheplygina, V.; de Bruijne, M.; Pluim, J.P.W. Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 2019, 54, 280–296. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, Z.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]



| Occurrence (%) N = 743 | Missing n (%) | |
|---|---|---|
| ASTRAL [10] Variables | ||
| Age in years, median (IQR) | 71 (57–80) | 11 (1) |
| NIHSS, median (IQR) | 7.5 (3–14) | 45 (6) |
| Onset-to-admission delay in hours, median (IQR) | 2 (1–5) | 205 (28) |
| Visual Defect, n (%) | 286 (38) | 45 (6) |
| LOC, n (%) | 59 (8) | 45 (6) |
| Blood Glucose in milligrams per deciliter, median (IQR) | 120 (101–154) | 142 (19) |
| Imaging Variables | ||
| ASPECTS, median (IQR) | 10 (8–10) | 156 (21) |
| Occlusion, n (%) | 377 (50) | 48 (6) |
| Other Variables (not considered in the analysis) | ||
| Female sex, n (%) | 307 (41) | 6 (1) |
| Arterial Hypertension, n (%) | 531 (71) | 20 (3) |
| Diabetes, n (%) | 553 (74) | 16 (2) |
| Previous Ischemic Stroke, n (%) | 112 (15) | 19 (3) |
| Ischemic Heart Disease, n (%) | 97 (13) | 40 (5) |
| Outcome Variable | ||
| 90-day mRS, median (IQR) | 1 (0–3) | 0 (0) |
| 90-day mRS > 2, n (%) | 252 (34) | 0 (0) |
| Model Name | AUC | -Score |
|---|---|---|
| LR 5vars SN | 0.806± 0.082 | 0.611 ± 0.113 |
| LR 8vars | 0.796 ± 0.077 | 0.602 ± 0.118 |
| LR 2vars | 0.791 ± 0.090 | 0.586 ± 0.135 |
| LR 5vars | 0.809 ± 0.084 | 0.646 ± 0.141 |
| ASTRAL | 0.784 ± 0.099 | 0.601 ± 0.115 |
| LR 8vars | LR 2vars | LR 5vars | LR 5vars SN | |
|---|---|---|---|---|
| ASTRAL | 0.327 | 0.471 | 0.024 * | 0.062 |
| LR 8vars | 0.681 | 0.021 * | 0.039 * | |
| LR 2vars | 0.130 | 0.216 | ||
| LR 5vars | 0.128 |
| LR 8vars | LR 2vars | LR 5vars | LR 5vars SN | |
|---|---|---|---|---|
| ASTRAL | 0.986 | 0.088 | 0.191 | 0.743 |
| LR 8vars | 0.642 | 0.028 * | 0.505 | |
| LR 2vars | 0.087 | 0.415 | ||
| LR 5vars | 0.021 † |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oliveira, G.; Fonseca, A.C.; Ferro, J.; Oliveira, A.L. Deep Learning-Based Extraction of Biomarkers for the Prediction of the Functional Outcome of Ischemic Stroke Patients. Diagnostics 2023, 13, 3604. https://doi.org/10.3390/diagnostics13243604
Oliveira G, Fonseca AC, Ferro J, Oliveira AL. Deep Learning-Based Extraction of Biomarkers for the Prediction of the Functional Outcome of Ischemic Stroke Patients. Diagnostics. 2023; 13(24):3604. https://doi.org/10.3390/diagnostics13243604
Chicago/Turabian StyleOliveira, Gonçalo, Ana Catarina Fonseca, José Ferro, and Arlindo L. Oliveira. 2023. "Deep Learning-Based Extraction of Biomarkers for the Prediction of the Functional Outcome of Ischemic Stroke Patients" Diagnostics 13, no. 24: 3604. https://doi.org/10.3390/diagnostics13243604
APA StyleOliveira, G., Fonseca, A. C., Ferro, J., & Oliveira, A. L. (2023). Deep Learning-Based Extraction of Biomarkers for the Prediction of the Functional Outcome of Ischemic Stroke Patients. Diagnostics, 13(24), 3604. https://doi.org/10.3390/diagnostics13243604