
Deep Neural Network-Based Automatic Dicentric Chromosome Detection Using a Model Pretrained on Common Objects

 , , and
, , and
Abstract
:1. Introduction
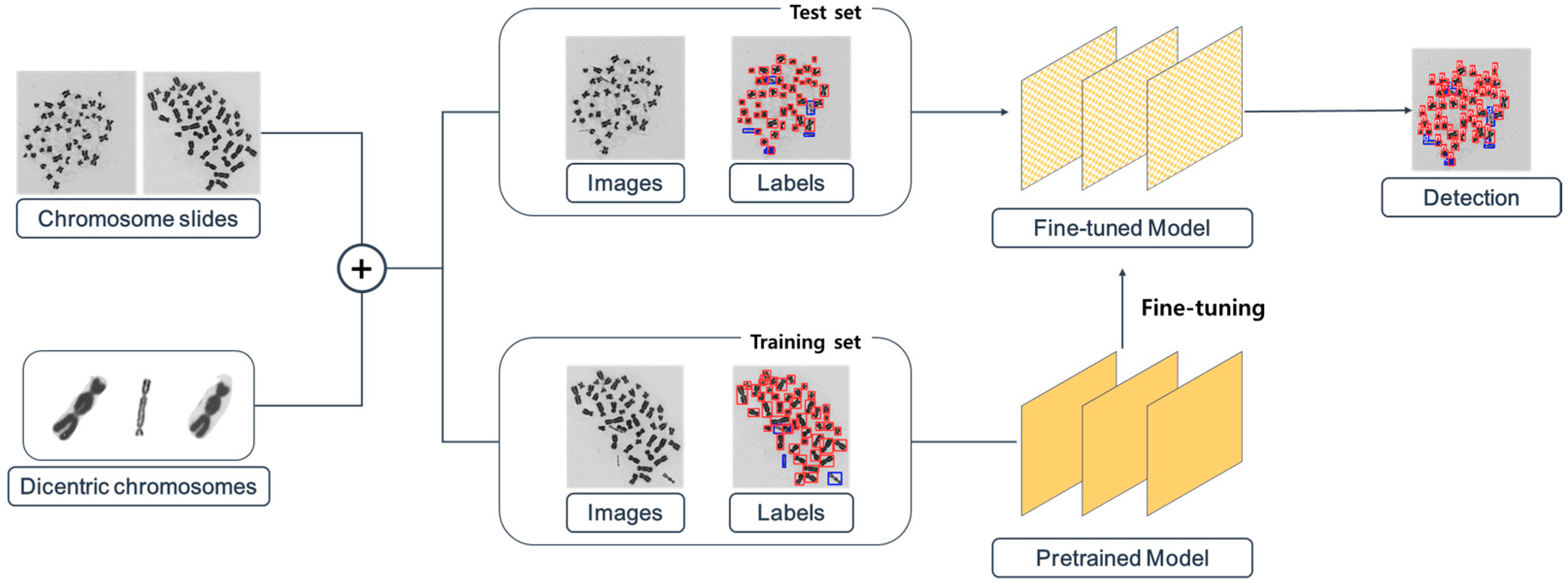
2. Materials and Methods
3. Results
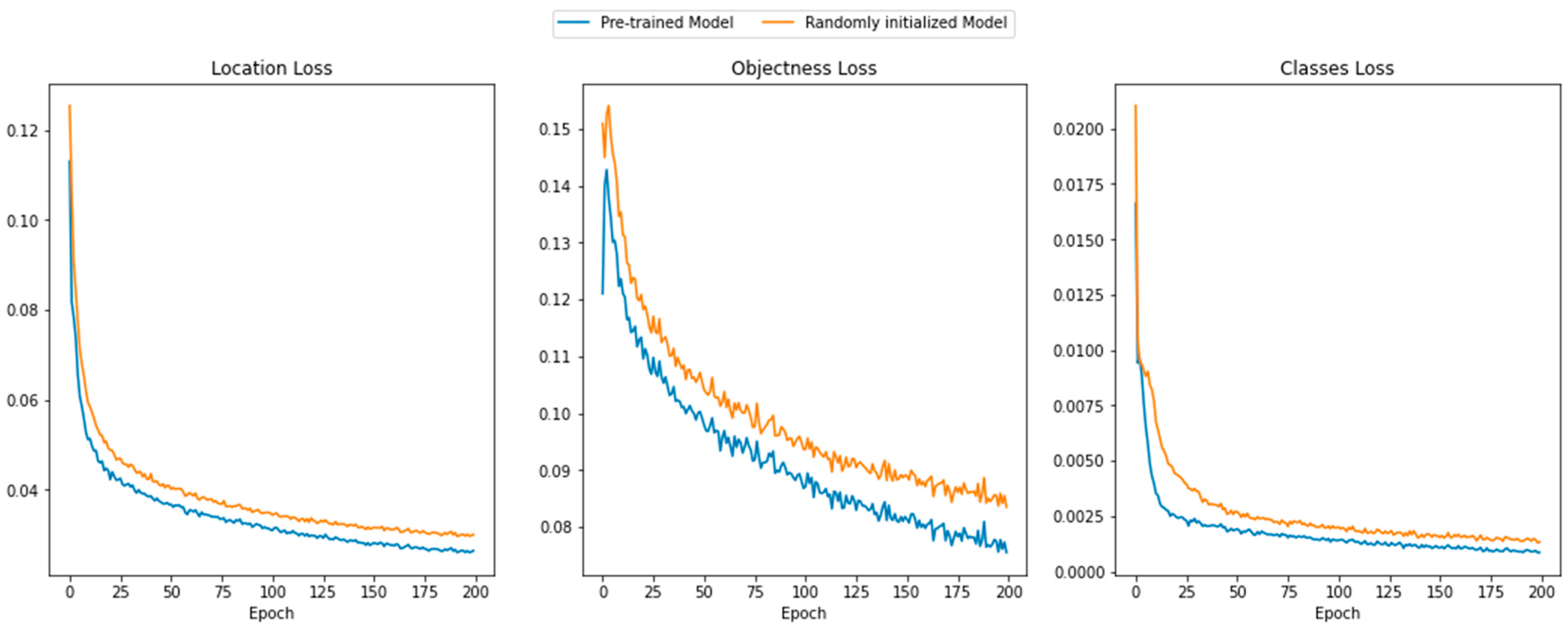
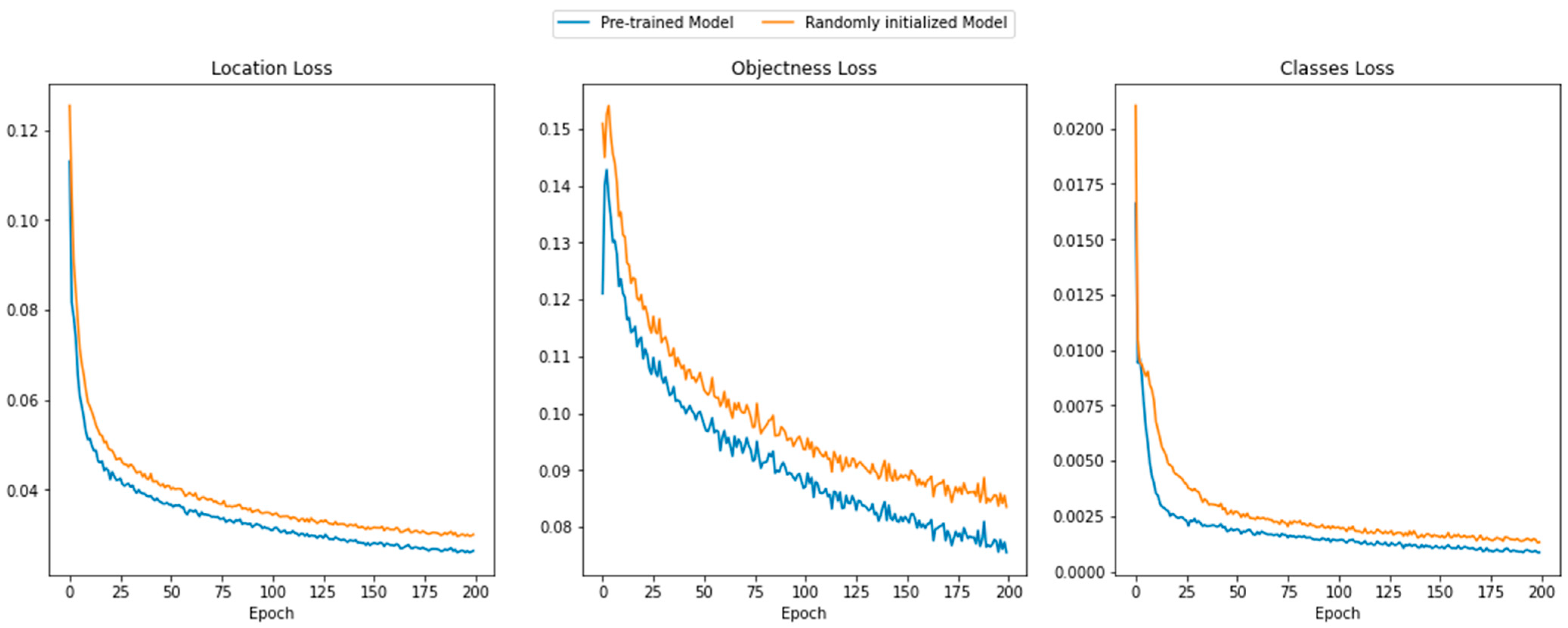
3.1. Convergence in Training
3.2. Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gnanasekaran, T.S. Cytogenetic Biological Dosimetry Assays: Recent Developments and Updates. Radiat. Oncol. J. 2021, 39, 159. [Google Scholar] [CrossRef] [PubMed]
- Téoule, R. Radiation-Induced DNA Damage and Its Repair. Int. J. Radiat. Biol. Relat. Stud. Phys. Chem. Med. 1987, 51, 573–589. [Google Scholar] [CrossRef] [PubMed]
- Lomax, M.E.; Folkes, L.K.; O’Neill, P. Biological Consequences of Radiation-Induced DNA Damage: Relevance to Radiotherapy. Clin. Oncol. 2013, 25, 578–585. [Google Scholar] [CrossRef] [PubMed]
- Hall, J.; Angèle, S. Radiation, DNA Damage and Cancer. Mol. Med. Today 1999, 5, 157–164. [Google Scholar] [CrossRef]
- Pfeiffer, P.; Goedecke, W.; Obe, G. Mechanisms of DNA Double-Strand Break Repair and Their Potential to Induce Chromosomal Aberrations. Mutagenesis 2000, 15, 289–302. [Google Scholar] [CrossRef] [PubMed]
- Iliakis, G.; Wang, H.; Perrault, A.R.; Boecker, W.; Rosidi, B.; Windhofer, F.; Wu, W.; Guan, J.; Terzoudi, G.; Panteliasc, G. Mechanisms of DNA Double Strand Break Repair and Chromosome Aberration Formation. Cytogenet. Genome Res. 2004, 104, 14–20. [Google Scholar] [CrossRef] [PubMed]
- Durante, M.; Bedford, J.S.; Chen, D.J.; Conrad, S.; Cornforth, M.N.; Natarajan, A.T.; van Gent, D.C.; Obe, G. From DNA Damage to Chromosome Aberrations: Joining the Break. Mutat. Res. Toxicol. Environ. Mutagen. 2013, 756, 5–13. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, D.C.; Edwards, A.A.; Moquet, J.E.; Guerrero-Carbajal, Y.C. The Role of Cytogenetics in Early Triage of Radiation Casualties. Appl. Radiat. Isot. 2000, 52, 1107–1112. [Google Scholar] [CrossRef] [PubMed]
- Voisin, P.; Benderitter, M.; Claraz, M.; Chambrette, V.; Sorokine-Durm, I.; Delbos, M.; Durand, V.; Leroy, A.; Paillole, N. The Cytogenetic Dosimetry of Recent Accidental Overexposure. Cell. Mol. Biol. 2001, 47, 557–564. [Google Scholar]
- Shirley, B.; Li, Y.; Knoll, J.H.M.; Rogan, P.K. Expedited Radiation Biodosimetry by Automated Dicentric Chromosome Identification (ADCI) and Dose Estimation. JoVE J. Vis. Exp. 2017, 2017, e56245. [Google Scholar] [CrossRef]
- Shuryak, I.; Royba, E.; Repin, M.; Turner, H.C.; Garty, G.; Deoli, N.; Brenner, D.J. A Machine Learning Method for Improving the Accuracy of Radiation Biodosimetry by Combining Data from the Dicentric Chromosomes and Micronucleus Assays. Sci. Rep. 2022, 12, 21077. [Google Scholar] [CrossRef] [PubMed]
- Jang, S.; Shin, S.G.; Lee, M.J.; Han, S.; Choi, C.H.; Kim, S.; Cho, W.S.; Kim, S.H.; Kang, Y.R.; Jo, W.; et al. Feasibility Study on Automatic Interpretation of Radiation Dose Using Deep Learning Technique for Dicentric Chromosome Assay. Radiat. Res. 2021, 195, 163–172. [Google Scholar] [CrossRef] [PubMed]
- Jeong, S.K.; Oh, S.J.; Kim, S.H.; Jang, S.; Kang, Y.R.; Kim, H.J.; Kye, Y.U.; Lee, S.H.; Lee, C.G.; Park, M.T.; et al. Dicentric Chromosome Assay Using a Deep Learning-Based Automated System. Sci. Rep. 2022, 12, 22097. [Google Scholar] [CrossRef]
- Wadhwa, A.S.; Tyagi, N.; Chowdhury, P.R. Deep Learning Based Automatic Detection of Dicentric Chromosome. arXiv 2022, arXiv:2204.08029. [Google Scholar]
- Zhang, W.; Song, S.; Bai, T.; Zhao, Y.; Ma, F.; Su, J.; Yu, L. Chromosome Classification with Convolutional Neural Network Based Deep Learning. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018. [Google Scholar] [CrossRef]
- Wang, C.; Yu, L.; Zhu, X.; Su, J.; Ma, F. Extended ResNet and Label Feature Vector Based Chromosome Classification. IEEE Access 2020, 8, 201098–201108. [Google Scholar] [CrossRef]
- Liu, Y.; Han, G.; Liu, X. Lightweight Compound Scaling Network for Nasopharyngeal Carcinoma Segmentation from MR Images. Sensors 2022, 22, 5875. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Liu, X.; Zhang, H.; Lin, Q.; Xu, L.; Shi, C.; Gao, Z.; Guzzo, A.; Fortino, G. Causal Knowledge Fusion for 3D Cross-Modality Cardiac Image Segmentation. Inf. Fusion 2023, 99, 101864. [Google Scholar] [CrossRef]
- Zhuang, Z.; Yang, Z.; Raj, A.N.J.; Wei, C.; Jin, P.; Zhuang, S. Breast Ultrasound Tumor Image Classification Using Image Decomposition and Fusion Based on Adaptive Multi-Model Spatial Feature Fusion. Comput. Methods Programs Biomed. 2021, 208, 106221. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019. [Google Scholar] [CrossRef]
- Zhiqiang, W.; Jun, L. A Review of Object Detection Based on Convolutional Neural Network. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 11104–11109. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Huk, D.; Andrew, P.; Dmitry, Z.; Pinterest, K. Toward Transformer-Based Object Detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Based YOLO for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Online, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring Plain Vision Transformer Backbones for Object Detection. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Volume 13669 LNCS, pp. 280–296. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; NanoCode012; TaoXie; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J.; et al. Ultralytics/Yolov5: V6.0—YOLOv5n “Nano” Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support. Zenodo 2021. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. Proc.—Int. Conf. Pattern Recognit. 2006, 3, 850–855. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef]
- Lee, Y.; Jin, Y.W.; Wilkins, R.C.; Jang, S. Validation of the Dicentric Chromosome Assay for Radiation Biological Dosimetry in South Korea. J. Radiat. Res. 2019, 60, 555–563. [Google Scholar] [CrossRef]
- Lee, Y.; Seo, S.; Jin, Y.W.; Jang, S. Assessment of Working Environment and Personal Dosimeter-Wearing Compliance of Industrial Radiographers Based on Chromosome Aberration Frequencies. J. Radiol. Prot. 2019, 40, 151. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Volume 8693 LNCS, pp. 740–755. [Google Scholar]
- van Engelen, J.E.; Hoos, H.H. A Survey on Semi-Supervised Learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Zhou, Z.-H. Semi-Supervised Learning. In Machine Learning; Springer: Singapore, 2021; pp. 315–341. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Ma, C.-Y.; He, Z.; Kuo, C.-W.; Chen, K.; Zhang, P.; Wu, B.; Kira, Z.; Vajda, P. Unbiased Teacher for Semi-Supervised Object Detection. arXiv 2021. [Google Scholar] [CrossRef]
- Tang, P.; Ramaiah, C.; Wang, Y.; Xu, R.; Xiong, C. Proposal Learning for Semi-Supervised Object Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2291–2301. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initialization | Dataset | F1 Score | mAP |
|---|---|---|---|
| Pretrained | Validation | 0.94 | 0.961 |
| Test | 0.80 | 0.788 | |
| Random | Validation | 0.82 | 0.873 |
| Test | 0.66 | 0.678 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, K.; Kim, K.S.; Jang, W.I.; Jang, S.; Hwang, G.T.; Woo, S.-K. Deep Neural Network-Based Automatic Dicentric Chromosome Detection Using a Model Pretrained on Common Objects. Diagnostics 2023, 13, 3191. https://doi.org/10.3390/diagnostics13203191
Kim K, Kim KS, Jang WI, Jang S, Hwang GT, Woo S-K. Deep Neural Network-Based Automatic Dicentric Chromosome Detection Using a Model Pretrained on Common Objects. Diagnostics. 2023; 13(20):3191. https://doi.org/10.3390/diagnostics13203191
Chicago/Turabian StyleKim, Kangsan, Kwang Seok Kim, Won Il Jang, Seongjae Jang, Gil Tae Hwang, and Sang-Keun Woo. 2023. "Deep Neural Network-Based Automatic Dicentric Chromosome Detection Using a Model Pretrained on Common Objects" Diagnostics 13, no. 20: 3191. https://doi.org/10.3390/diagnostics13203191
APA StyleKim, K., Kim, K. S., Jang, W. I., Jang, S., Hwang, G. T., & Woo, S.-K. (2023). Deep Neural Network-Based Automatic Dicentric Chromosome Detection Using a Model Pretrained on Common Objects. Diagnostics, 13(20), 3191. https://doi.org/10.3390/diagnostics13203191