
FedEHR: A Federated Learning Approach towards the Prediction of Heart Diseases in IoT-Based Electronic Health Records

 ,
,  , and
, and 
Abstract
:1. Introduction
- Device heterogeneity: Internet of Things gadgets come in many types and forms, with a wide range of equipment specs and software options. Due to this diversity, creating a Federated Learning model compatible with a wide range of hardware may be challenging.
- Data Privacy and Security: FL introduces several privacy and security concerns while working with private data. Robust security protocols are essential for Federated Learning to guarantee the confidentiality of student information at all times.
Contributions
- We present the cPDS federated optimisation framework, a new framework for federated optimisation aimed at overcoming the sparse Support Vector Machine (SVM) conundrum. This plan stands out for its scalability, a key quality important in adjusting to the expanding healthcare data landscape. A key strength of cPDS is its ability to avoid the requirement for raw data exchanges, which is crucial in the healthcare industry where data privacy is of utmost importance. Notably, our research reveals that cPDS has a higher convergence rate than other centralised and distributed alternatives, along with a more favourable communication cost.
- In order to analyse a large dataset made up of de-identified Electronic Heart Records coming from the prestigious Boston Medical Centre, our ground-breaking methodology is rigorously applied. This database includes a wide range of people suffering from conditions related to the heart. Each patient’s profile is carefully crafted using a variety of relevant details, such as clinically significant aspects of their medical history, diagnostic insights, past hospital admissions, and demographic information.
- We explore the area of predicting patient hospitalisation scenarios within a predetermined time frame—specifically, a target year—by utilising the strong capabilities of the cPDS architecture. Our research leads to a fine distinction between patients who are thought to be potential candidates for hospitalisation and those who are thought to be unlikely to encounter such a result. We next carefully explain the experimental results and implications resulting from our predictive models and discuss them.
- The cPDS framework’s conceptual foundation extends beyond the unique context of our current study. Instead, it is applicable to a wide range of learning issues that share a composite “non-smooth + non-smooth” loss function objective. This pervasiveness resonates in the field of machine learning, where the goal is to minimise the functions highlighted by irregular regularisers. Similar to this, the distributed model predictive control setting, where the goal is to solve issues with similar characteristics, finds application for the cPDS framework.
2. Related Work
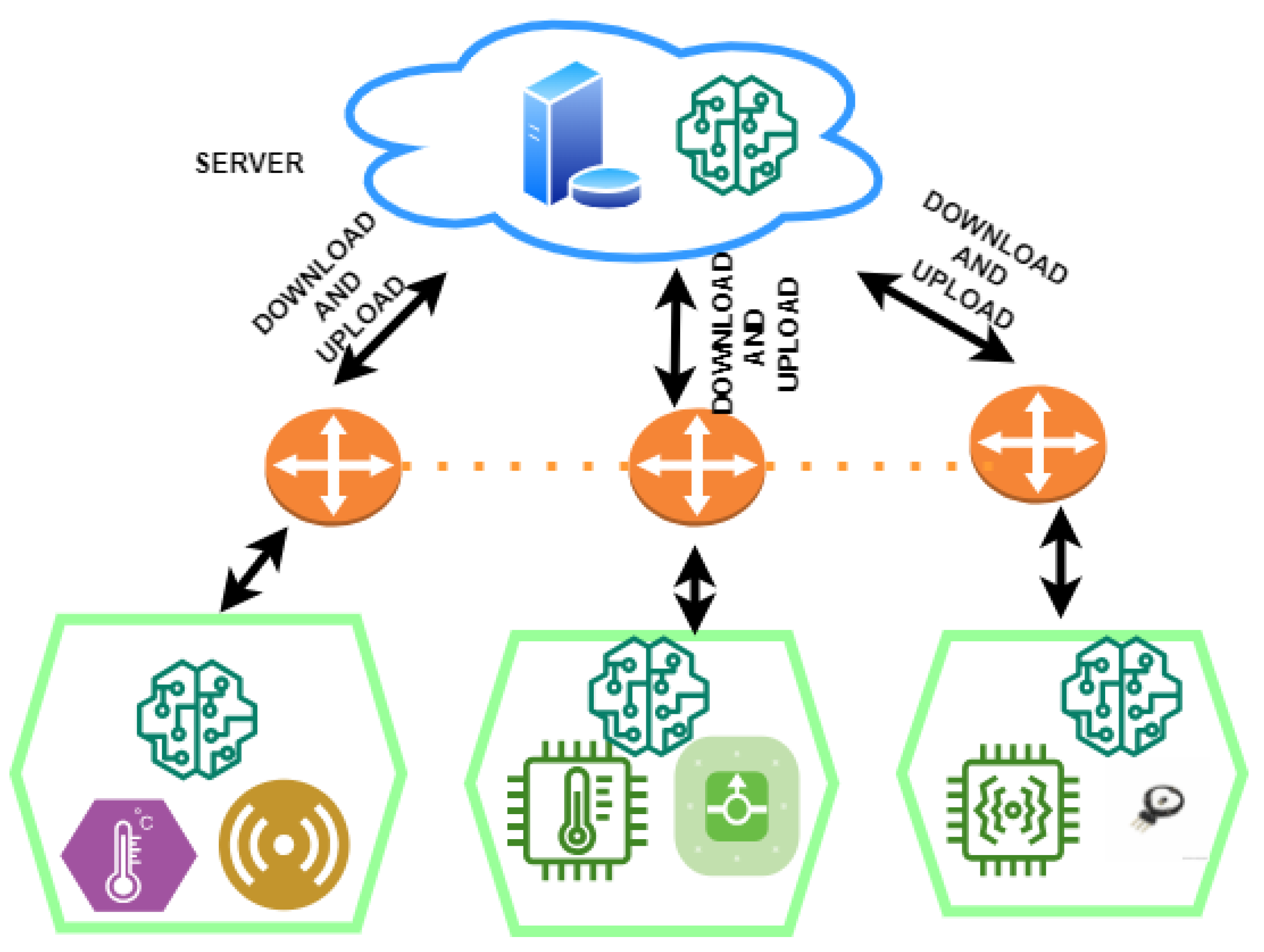
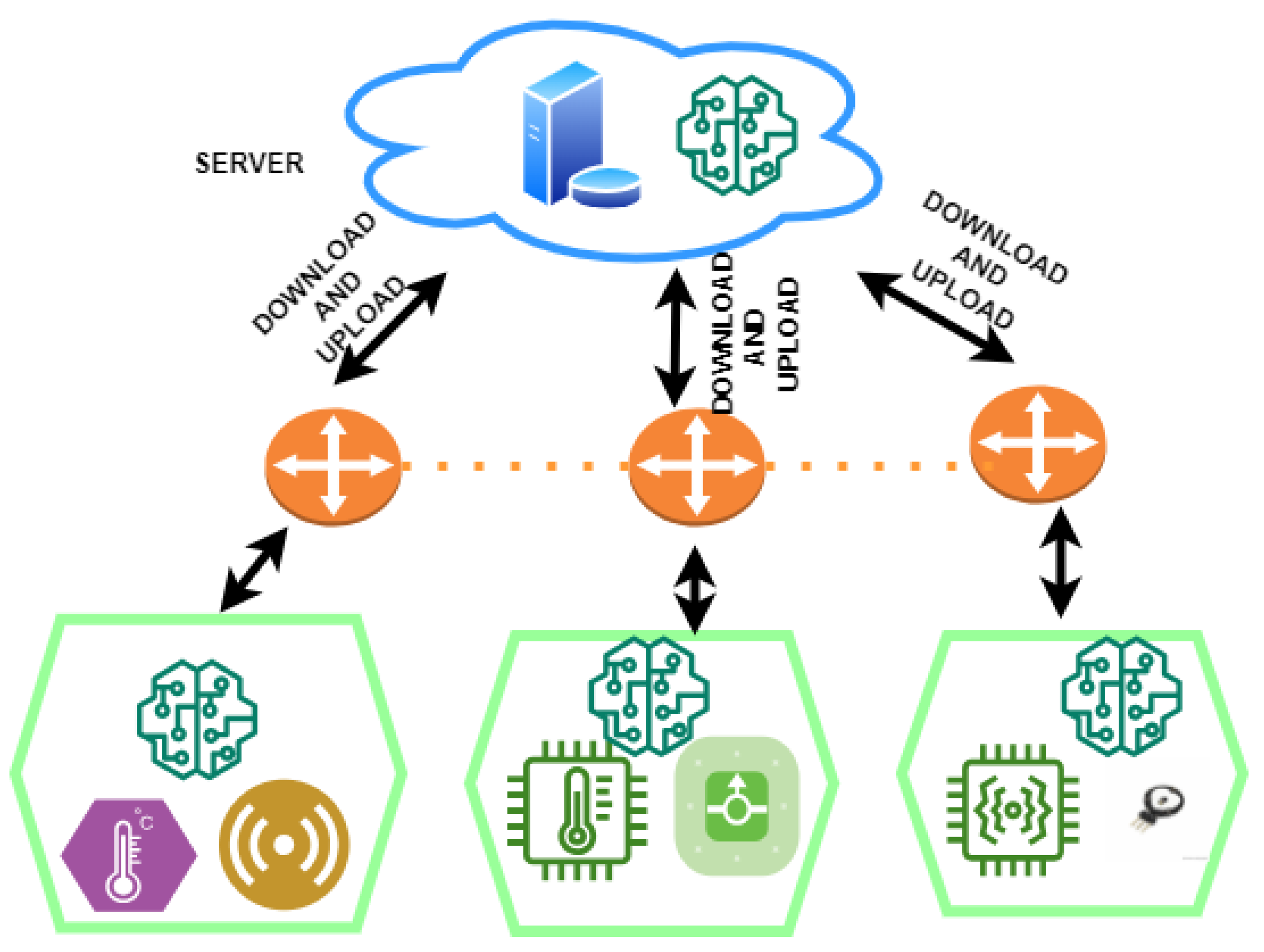
3. Proposed Framework
4. Problem Formulation
4.1. Cluster Primal–Dual Splitting Problem
4.2. Heuristic for Transmission Cost Reduction
| Algorithm 1 Round-Robin-algorithm-based traffic distribution |
|
5. Results
5.1. Experimental Analysis
5.2. Discussions
6. Limitations and Challenges
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Turjman, F.; Nawaz, M.H.; Ulusar, U.D. Intelligence in the Internet of Medical Things era: A systematic review of current and future trends. Comput. Commun. 2020, 150, 644–660. [Google Scholar] [CrossRef]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Nazir, M.; Yousafzai, A.; Khan, M.A.; Shaikh, A.A.; Algarni, A.D.; Elmannai, H. Modified Artificial Bee Colony Based Feature Optimized Federated Learning for Heart Disease Diagnosis in Healthcare. Appl. Sci. 2022, 12, 12080. [Google Scholar] [CrossRef]
- De la Torre, L. A Guide to the California Consumer Privacy Act of 2018. SSRN eLibrary 2018. [Google Scholar] [CrossRef]
- Yaqoob, M.M.; Nazir, M.; Khan, M.A.; Qureshi, S.; Al-Rasheed, A. Hybrid Classifier-Based Federated Learning in Health Service Providers for Cardiovascular Disease Prediction. Appl. Sci. 2023, 13, 1911. [Google Scholar] [CrossRef]
- Manickam, P.; Mariappan, S.A.; Murugesan, S.M.; Hansda, S.; Kaushik, A.; Shinde, R.; Thipperudraswamy, S.P. Artificial intelligence (AI) and internet of medical things (IoMT) assisted biomedical systems for intelligent healthcare. Biosensors 2022, 12, 562. [Google Scholar] [CrossRef]
- Singh, S.; Rathore, S.; Alfarraj, O.; Tolba, A.; Yoon, B. A framework for privacy preservation of iot healthcare data using federated learning and blockchain technology. Future Gener. Comput. Syst. 2022, 129, 380–388. [Google Scholar] [CrossRef]
- Houssein, H.E.; Sayed, A. Boosted federated learning based on improved Particle Swarm Optimization for healthcare IoT devices. Comput. Biol. Med. 2023, 2023, 107195. [Google Scholar] [CrossRef]
- Khan, M.; Glavin, F.G.; Nickles, M. Federated learning as a privacy solution-an overview. Procedia Comput. Sci. 2023, 217, 316–325. [Google Scholar] [CrossRef]
- Almanifi, O.R.A.; Chow, C.-O.; Tham, M.; Chuah, J.H.; Kanesan, J. Communication and computation efficiency in federated learning: A survey. Internet Things 2023, 22, 100742. [Google Scholar] [CrossRef]
- Wang, G.G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Askari, Q.; Saeed, M.; Younas, I. Heap-based optimizer inspired by corporate rank hierarchy for global optimization. Expert Syst. Appl. 2020, 161, 113702. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Gill, S.S.; Xu, M.; Ottaviani, C.; Patros, P.; Bahsoon, R.; Shaghaghi, A.; Golec, M.; Stankovski, V.; Wu, H.; Abraham, A.; et al. AI for next generation computing: Emerging trends and future directions. Internet Things 2022, 19, 100514. [Google Scholar] [CrossRef]
- Houssein, E.H.; Ibrahim, I.E.; Hassaballah, M.; Wazery, Y.M. Integration of internet of things and cloud computing for cardiac health recognition. In Metaheuristics in Machine Learning: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 645–661. [Google Scholar]
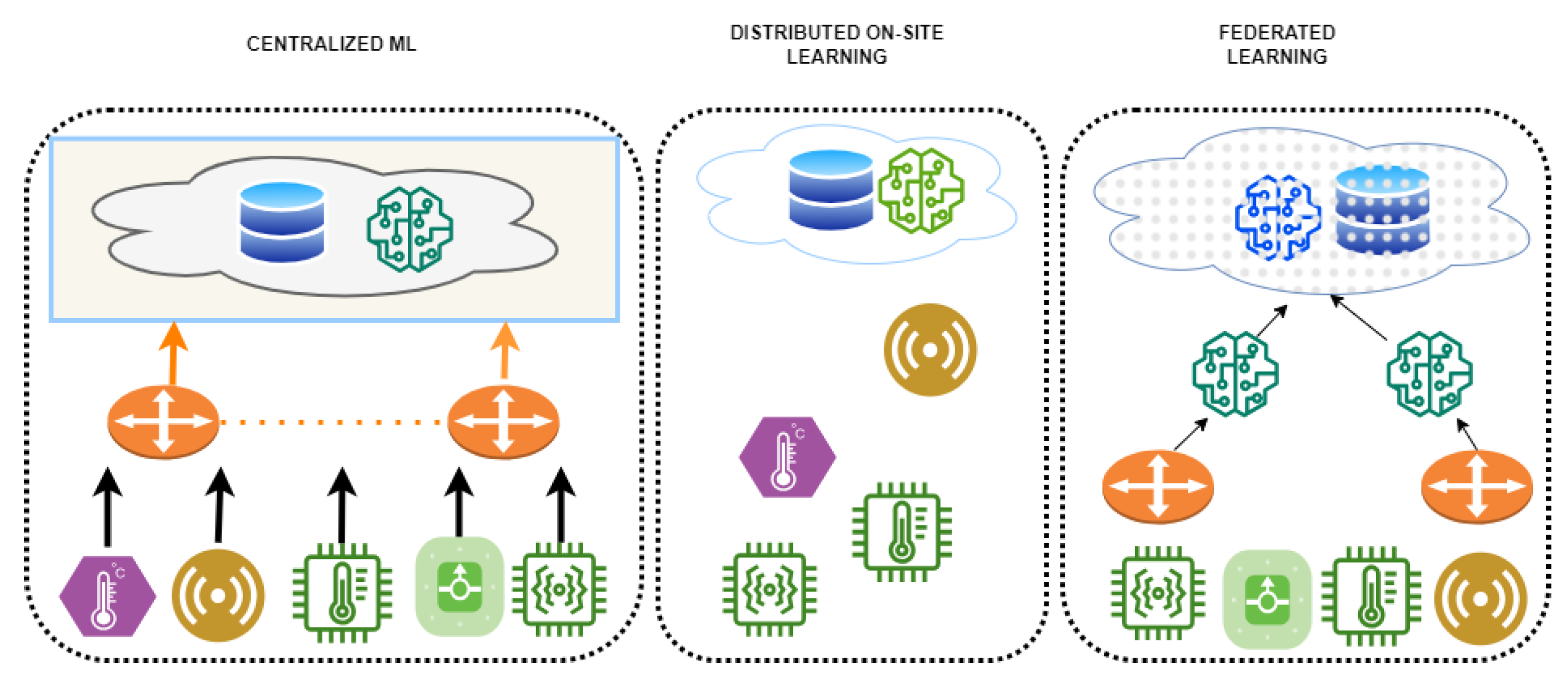
- Abdulrahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A Survey on Federated Learning: The Journey From Centralized to Distributed On-Site Learning and Beyond. IEEE Internet Things J. 2021, 8, 5476–5497. [Google Scholar] [CrossRef]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inform. 2018, 112, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning (DIDL), Rennes, France, 10–11 December 2018; ACM: New York, NY, USA, 2018; pp. 1–8. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Aledhari, M.; Razzak, R.; Parizi, R.; Saeed, F. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Ma, Z.; Mengying, Z.; Cai, X.; Jia, Z. Fast-convergent federated learning with class-weighted aggregation. J. Syst. Archit. 2021, 117, 102125. [Google Scholar] [CrossRef]
- Salam, M.A.; Taha, S.; Ramadan, M. COVID-19 detection using federated machine learning. PLoS ONE 2021, 16, e0252573. [Google Scholar]
- Cheng, W.; Ou, W.; Yin, X.; Yan, W.; Liu, D.; Liu, C. A Privacy-Protection Model for Patients. Secur. Commun. Netw. 2020, 2020, 6647562. [Google Scholar] [CrossRef]
- Chen, H.L.; Yang, B.; Liu, J.; Liu, D.-Y. A support vector machine classifier with rough set-based feature selection for breast cancer diagnosis. Expert Syst. Appl. 2011, 38, 9014–9022. [Google Scholar] [CrossRef]
- Patel, V.A.; Bhattacharya, P.; Tanwar, S.; Gupta, R.; Sharma, G.; Bokoro, P.N.; Sharma, R. Adoption of federated learning for healthcare informatics: Emerging applications and future directions. IEEE Access 2022, 10, 90792–90826. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Sehwag, V.; Hosseinalipour, S.; Brinton, C.; Chiang, M.; Poor, H.V. Fast-Convergent Federated Learning. IEEE J. Sel. Areas Commun. 2021, 39, 201–218. [Google Scholar] [CrossRef]
- Sharma, S.; Xing, C.; Liu, Y.; Kang, Y. Secure and efficient federated transfer learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2569–2576. [Google Scholar]
- Lai, F.; Dai, Y.; Singapuram, S.; Liu, J.; Zhu, X.; Madhyastha, H.; Chowdhury, M. Fedscale: Benchmarking model and system performance of federated learning at scale. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 11814–11827. [Google Scholar]
- Jiménez-Sánchez, A.; Tardy, M.; Ballester, M.A.G.; Mateus, D.; Piella, G. Memory aware curriculum federated learning for breast cancer classification. Comput. Methods Programs Biomed. 2023, 229, 107318. [Google Scholar] [CrossRef]
- Paul, J.J.; Jone, A.A.; Sagayam, M.; Packiavathy, V.; Sybiya, I.; Dang, H.; Pomplun, M. IoT based remote transit vehicle monitoring and seat display system. Prz. Elektrotechniczny 2021, 97, 5. [Google Scholar] [CrossRef]
- Rajesh, G.; Kritika, N.; Kavinkumar, A.; Sagayam, M.; Abd Wahab, M.H.; Som, M.M. Achieving Longevity in Wireless Body Area Network by Efficient Transmission Power Control for IoMT Applications. Int. J. Integr. Eng. 2022, 14, 80–89. [Google Scholar]


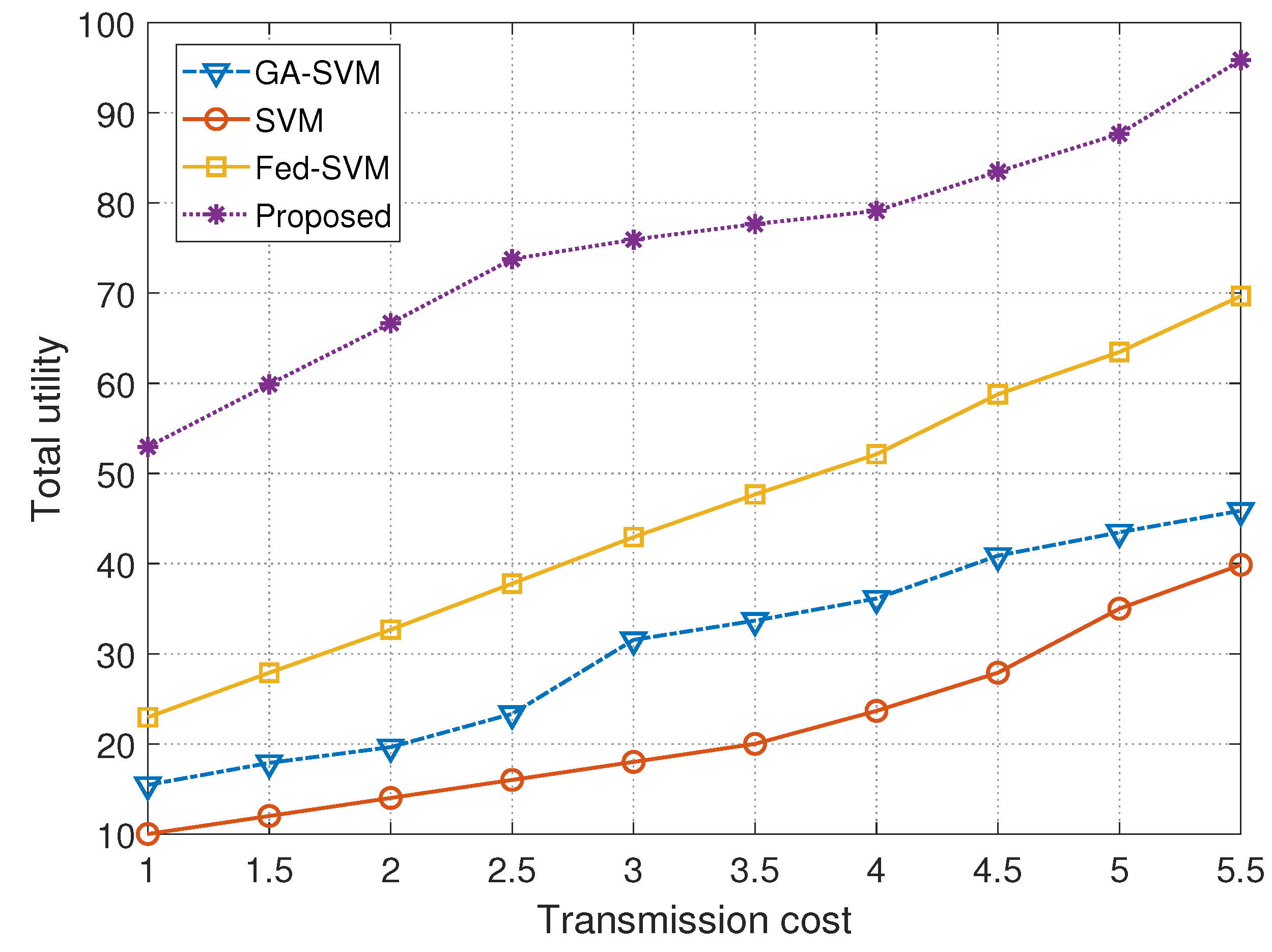

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
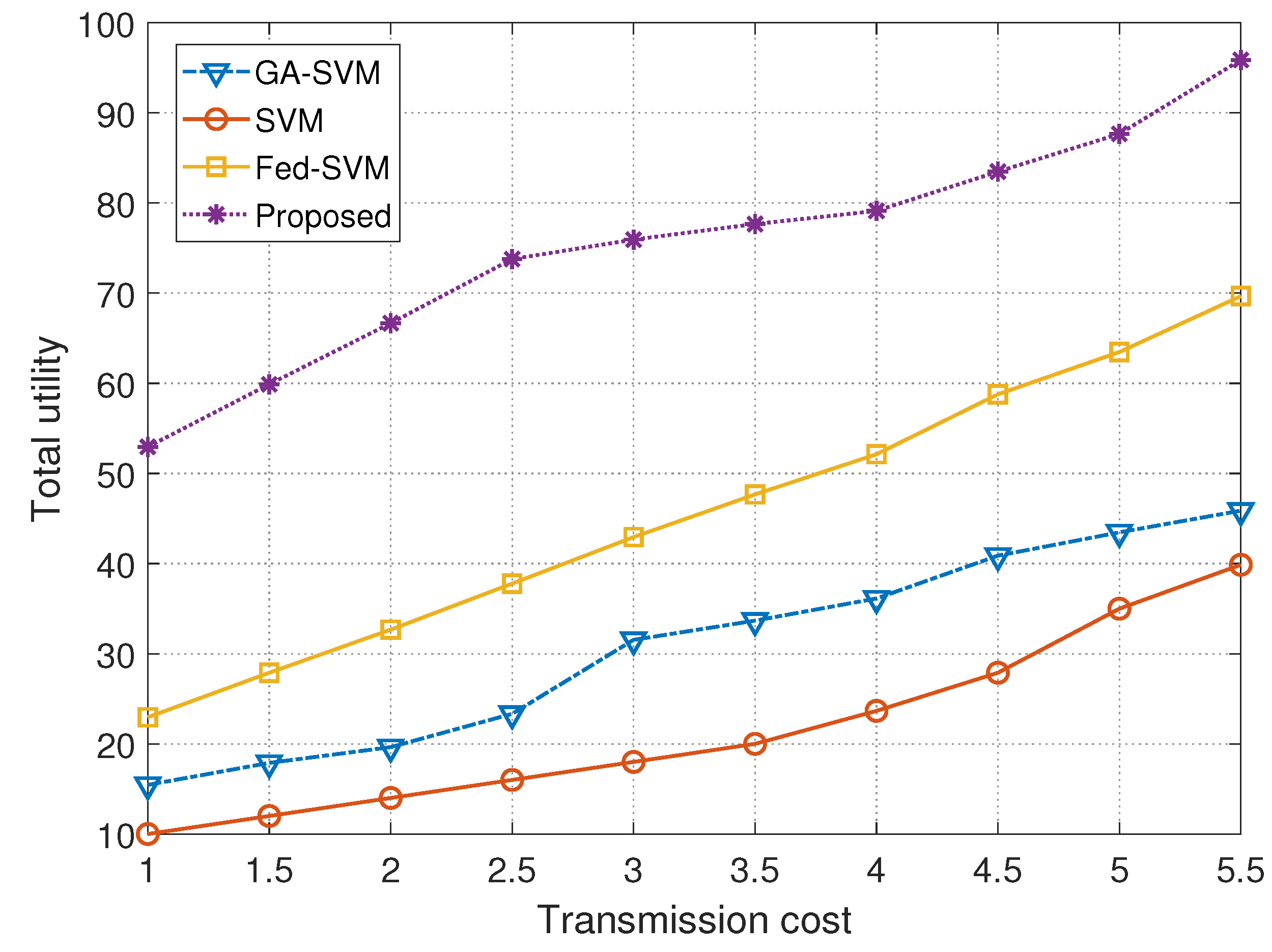{kind=link}
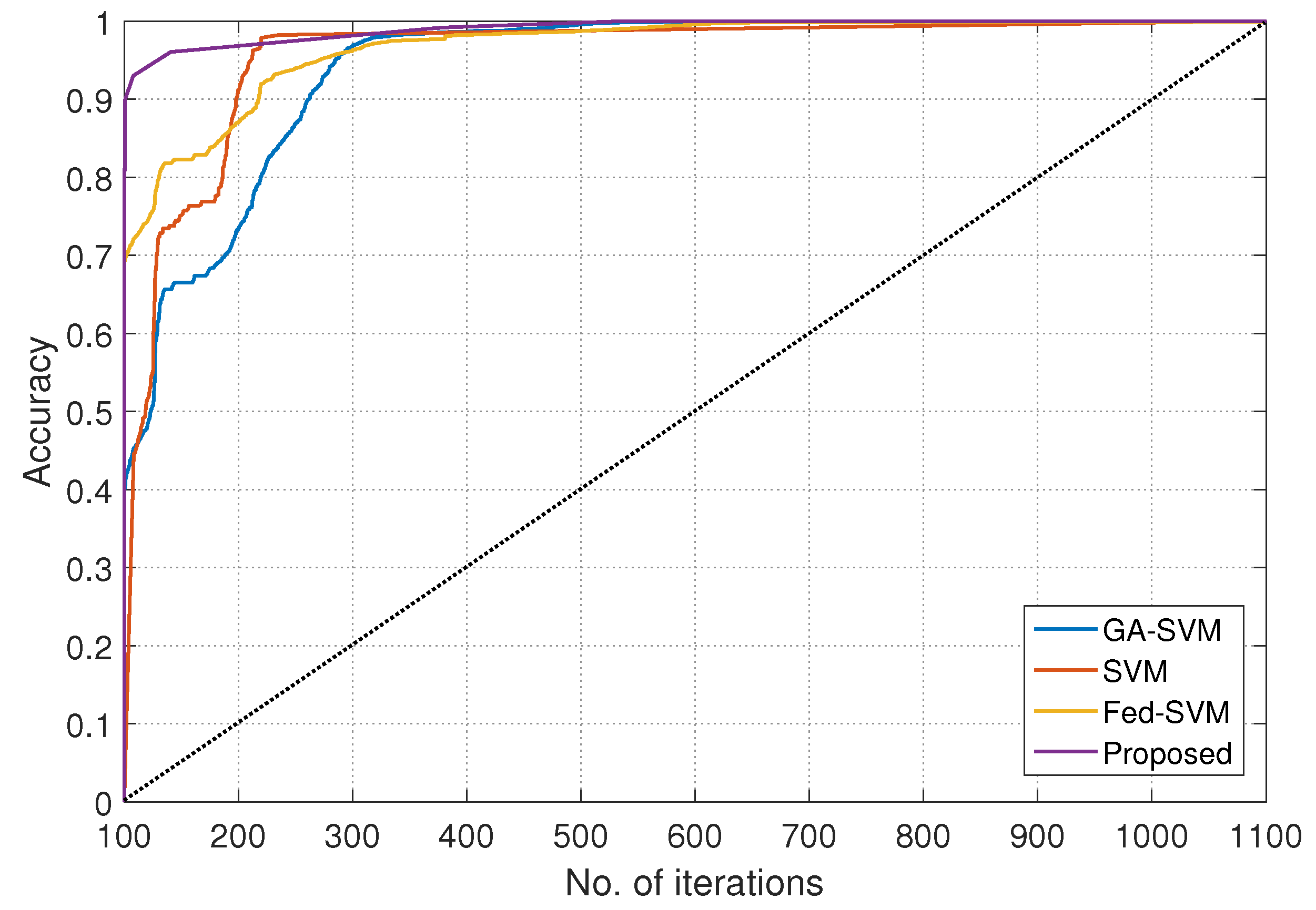
| Communication Rounds | Models | |||
|---|---|---|---|---|
| GA-SVM | SVM | Fed-SVM | Proposed | |
| 100 | 58.1106 | 55.4501 | 54.9512 | 60.9323 |
| 200 | 74.8933 | 71.8891 | 75.9001 | 85.8879 |
| 300 | 90.0010 | 87.6431 | 90.7001 | 95.6734 |
| 400 | 92.0141 | 88.3317 | 91.7810 | 96.7812 |
| 500 | 93.6111 | 90.5351 | 93.9372 | 97.9441 |
| 600 | 94.7801 | 91.6670 | 94.6711 | 98.5780 |
| 700 | 95.6616 | 92.1332 | 95.1470 | 99.2016 |
| 800 | 96.8900 | 93.8824 | 96.7816 | 99.4888 |
| 900 | 97.9951 | 94.4672 | 97.4777 | 99.6721 |
| 1000 | 98.8771 | 95.8689 | 98.6712 | 99.8582 |
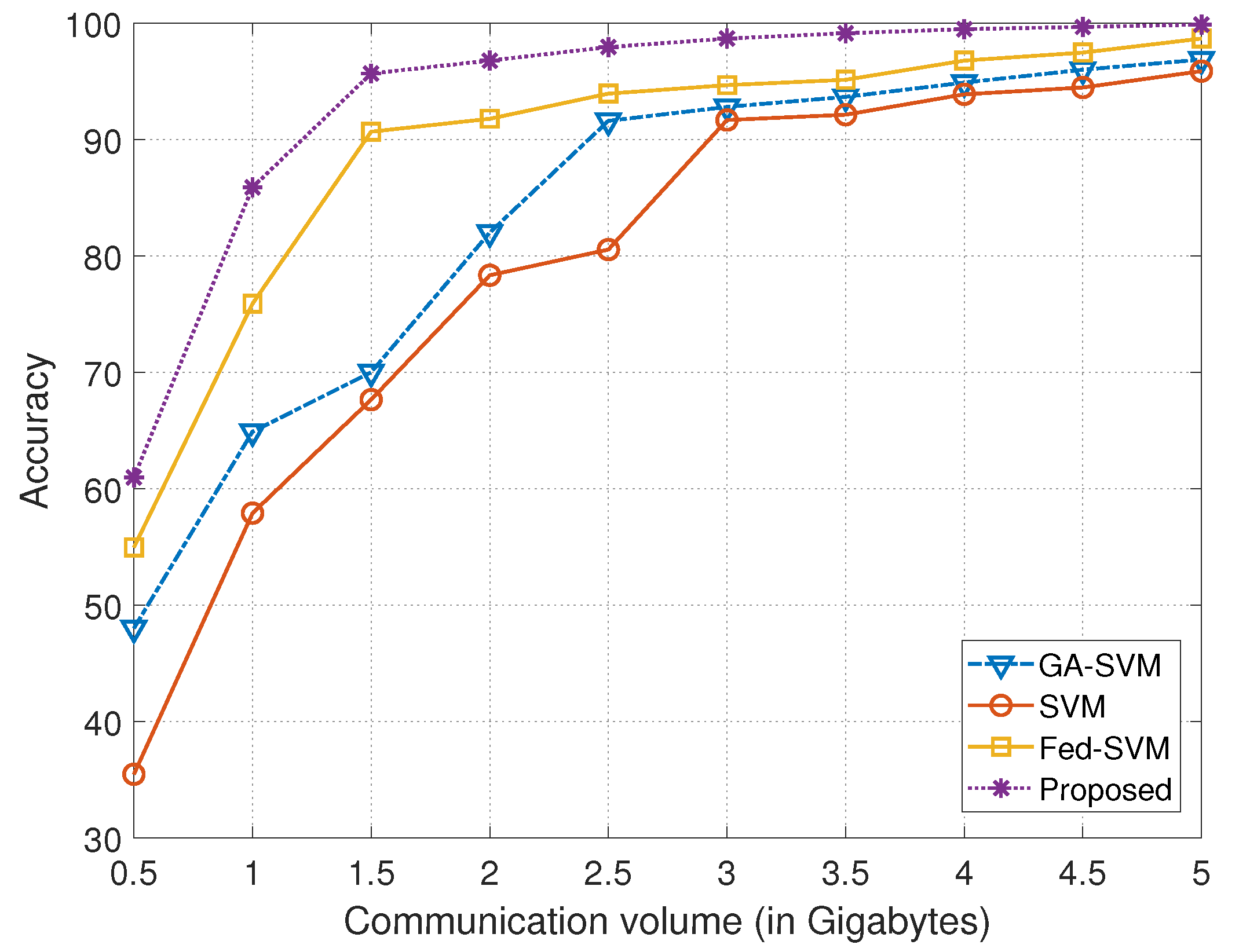
| Communication Volume (in Gigabytes) | Models | |||
|---|---|---|---|---|
| GA-SVM | SVM | Fed-SVM | Proposed | |
| 0.5 | 48.0122 | 35.4503 | 54.9550 | 60.9210 |
| 1.0 | 64.8910 | 57.8789 | 75.8991 | 85.9111 |
| 1.5 | 70.0000 | 67.6412 | 90.6753 | 95.7001 |
| 2.0 | 82.1462 | 78.3336 | 91.7825 | 96.8124 |
| 2.5 | 91.6186 | 80.5441 | 93.9409 | 97.9508 |
| 3.0 | 92.8201 | 91.6663 | 94.6720 | 98.7109 |
| 3.5 | 93.6609 | 92.1315 | 95.1333 | 99.1336 |
| 4.0 | 94.8900 | 93.8870 | 96.7898 | 99.4813 |
| 4.5 | 95.9951 | 94.4672 | 97.4671 | 99.6739 |
| 5.0 | 96.8720 | 95.8728 | 98.6733 | 99.8972 |
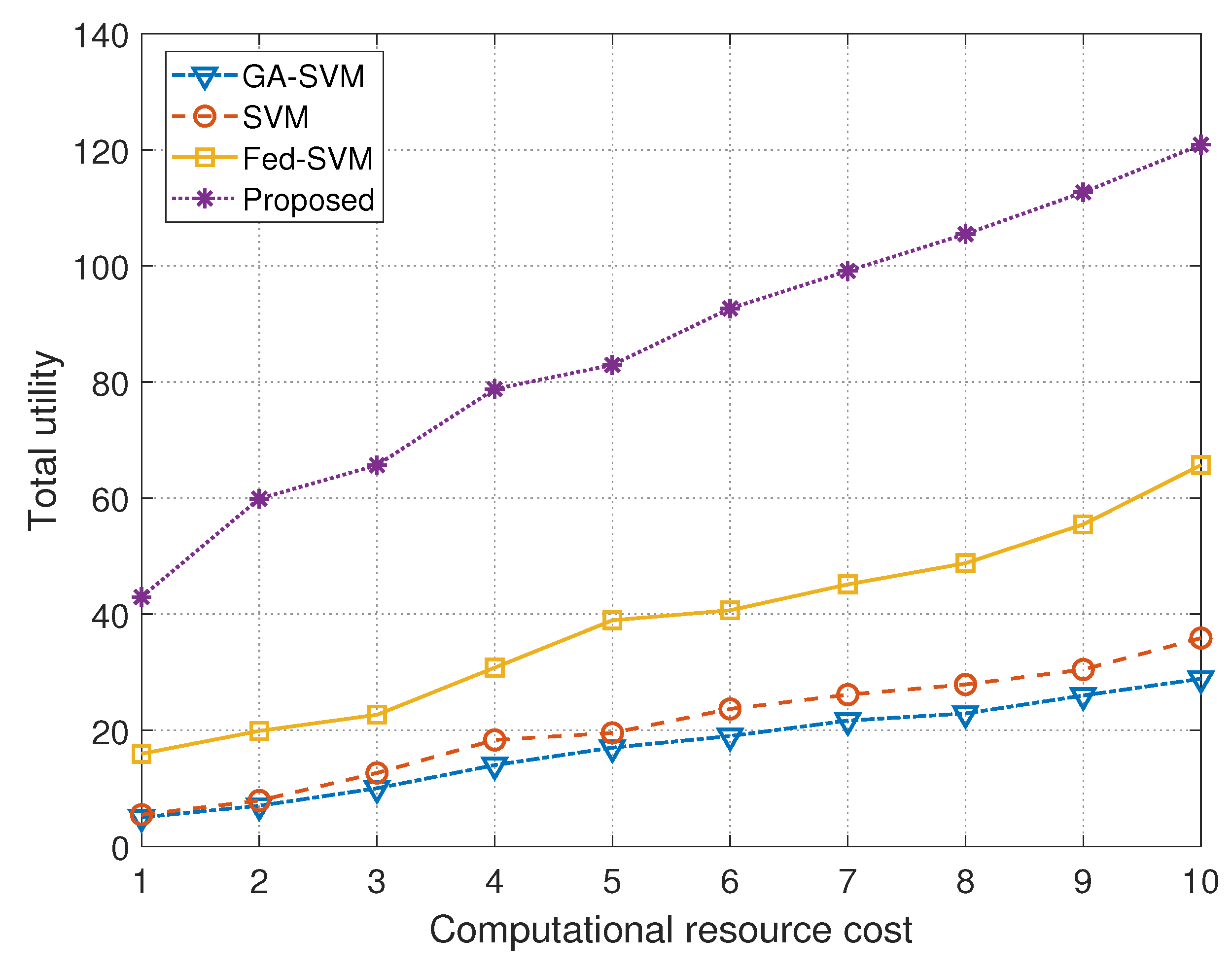
| Computational Resource Cost | Models | |||
|---|---|---|---|---|
| GA-SVM | SVM | Fed-SVM | Proposed | |
| 1 | 5.0010 | 5.4506 | 15.9513 | 42.9505 |
| 2 | 7.1006 | 7.8913 | 19.8862 | 59.8991 |
| 3 | 10.1141 | 12.6421 | 22.6771 | 65.7767 |
| 4 | 14.2011 | 18.3331 | 30.7888 | 78.7870 |
| 5 | 17.2112 | 19.5401 | 38.9332 | 82.9405 |
| 6 | 19.0233 | 23.6561 | 40.6661 | 92.6703 |
| 7 | 21.6653 | 26.1460 | 45.1333 | 99.1311 |
| 8 | 22.8925 | 27.8887 | 48.7802 | 105.4812 |
| 9 | 25.9895 | 30.4751 | 55.4870 | 112.6710 |
| 10 | 28.8763 | 35.8720 | 65.6725 | 120.8072 |
| Transmission Cost | Models | |||
|---|---|---|---|---|
| GA-SVM | SVM | Fed-SVM | Proposed | |
| 1.0 | 15.4459 | 10.0013 | 22.9504 | 52.9492 |
| 1.5 | 17.8920 | 12.1101 | 27.8889 | 60.0133 |
| 2.0 | 19.6433 | 14.1336 | 32.6666 | 66.6701 |
| 2.5 | 23.3313 | 16.0768 | 37.7779 | 73.7881 |
| 3.0 | 31.5400 | 18.0644 | 42.9421 | 75.9441 |
| 3.5 | 33.6702 | 20.1233 | 47.6567 | 77.6721 |
| 4.0 | 36.1333 | 23.6667 | 52.1280 | 79.1317 |
| 4.5 | 40.8867 | 27.8993 | 58.7801 | 83.4876 |
| 5.0 | 43.4670 | 34.9950 | 63.4669 | 87.6777 |
| 5.5 | 45.8720 | 39.8763 | 69.6770 | 95.9111 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bebortta, S.; Tripathy, S.S.; Basheer, S.; Chowdhary, C.L. FedEHR: A Federated Learning Approach towards the Prediction of Heart Diseases in IoT-Based Electronic Health Records. Diagnostics 2023, 13, 3166. https://doi.org/10.3390/diagnostics13203166
Bebortta S, Tripathy SS, Basheer S, Chowdhary CL. FedEHR: A Federated Learning Approach towards the Prediction of Heart Diseases in IoT-Based Electronic Health Records. Diagnostics. 2023; 13(20):3166. https://doi.org/10.3390/diagnostics13203166
Chicago/Turabian StyleBebortta, Sujit, Subhranshu Sekhar Tripathy, Shakila Basheer, and Chiranji Lal Chowdhary. 2023. "FedEHR: A Federated Learning Approach towards the Prediction of Heart Diseases in IoT-Based Electronic Health Records" Diagnostics 13, no. 20: 3166. https://doi.org/10.3390/diagnostics13203166
APA StyleBebortta, S., Tripathy, S. S., Basheer, S., & Chowdhary, C. L. (2023). FedEHR: A Federated Learning Approach towards the Prediction of Heart Diseases in IoT-Based Electronic Health Records. Diagnostics, 13(20), 3166. https://doi.org/10.3390/diagnostics13203166