1. Introduction
Glaucoma is a common visual disorder that can damage the optic nerve and result in vision loss and blindness [
1,
2,
3,
4]. Glaucoma is the second leading cause of blindness in the world; the World Health Organization estimated that about 80 million people suffer from this disease [
5]. In the USA, about three million people have glaucoma, and it is expected that the number of patients will increase to 4.2 million by 2030 [
4]. In general, there is a higher risk of glaucoma for people over the age of 60 years, while African Americans face the risk earlier in life at over 40 years of age [
1,
4]. Early detection is critical for timely treatment to delay disease progression. Open-angle glaucoma is asymptomatic, and therefore regular eye examinations, including appropriate imaging of the optic disc, are vital for reducing the risk of reduced vision or blindness [
6].
Clinical evaluation of structural damage to the optic nerve head is a key to the diagnosis and management of glaucoma [
7].
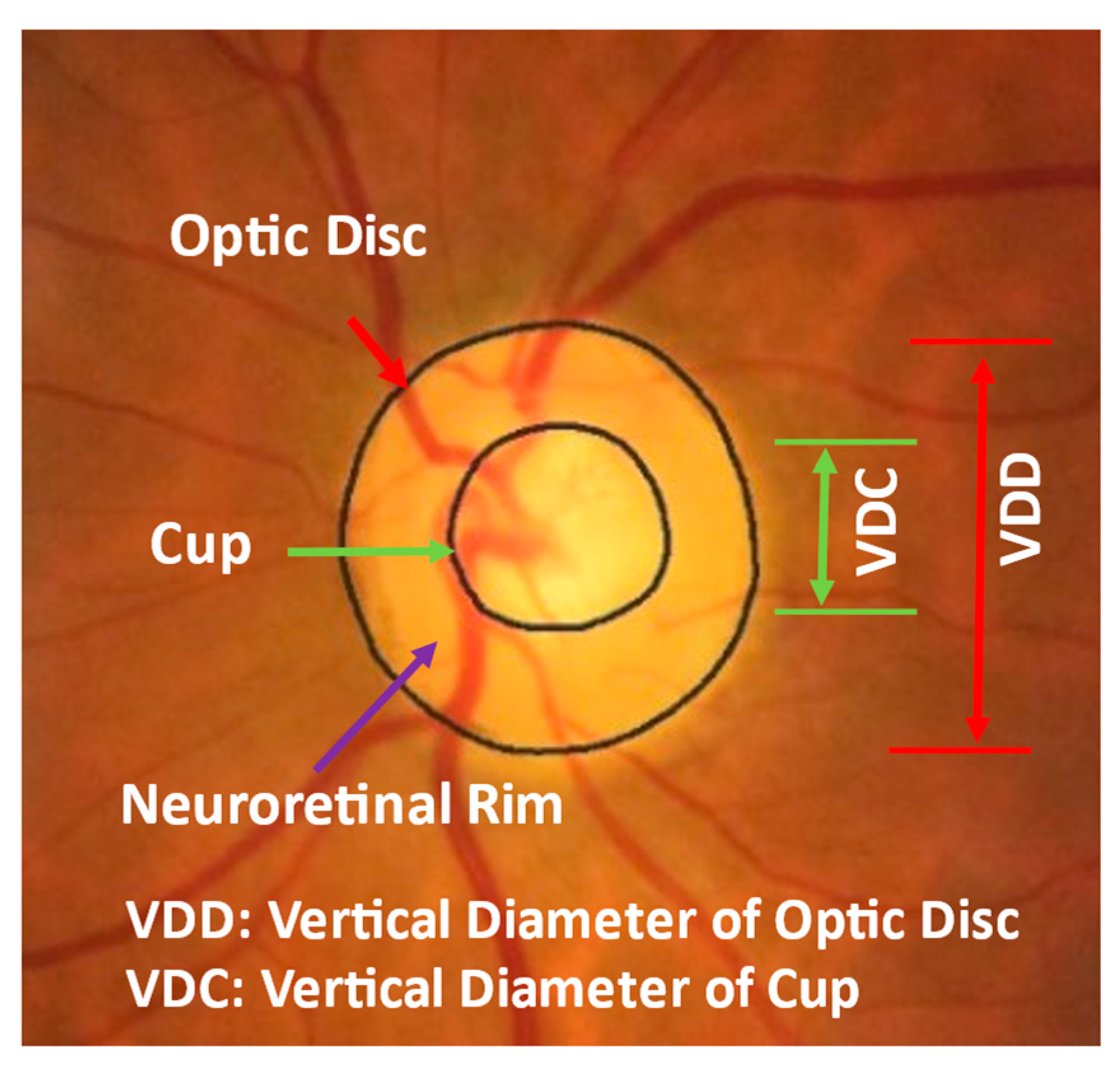
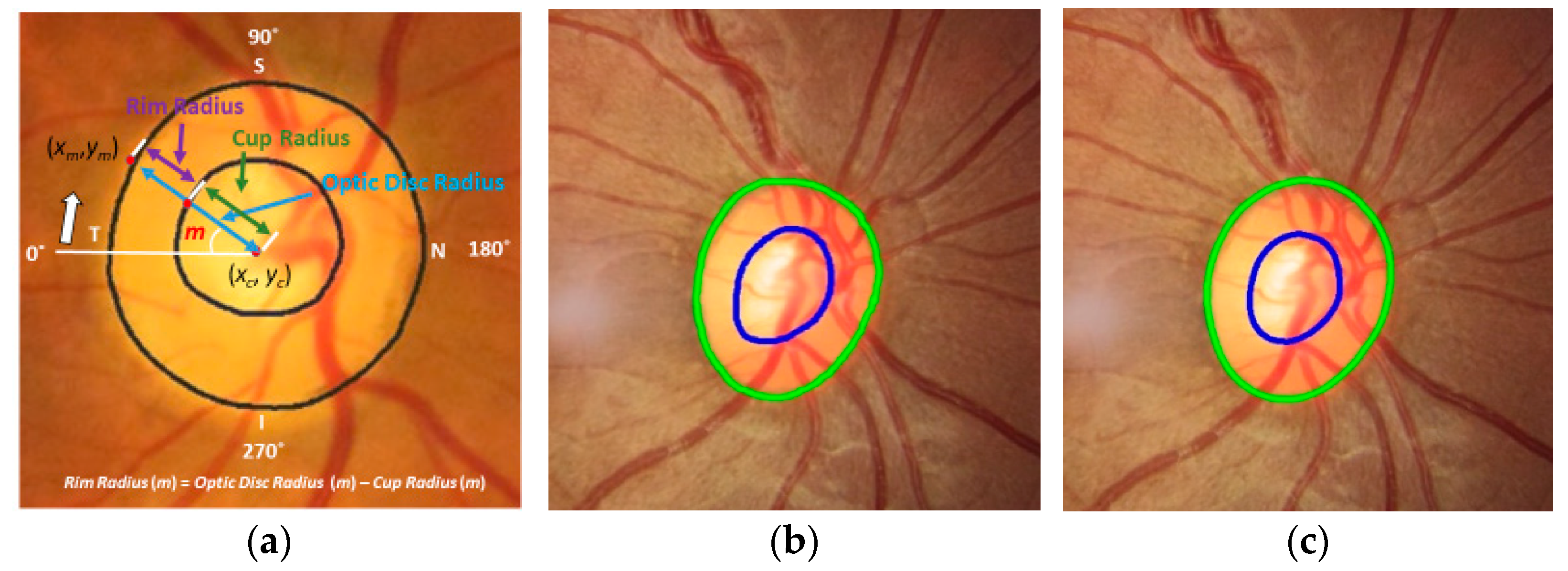
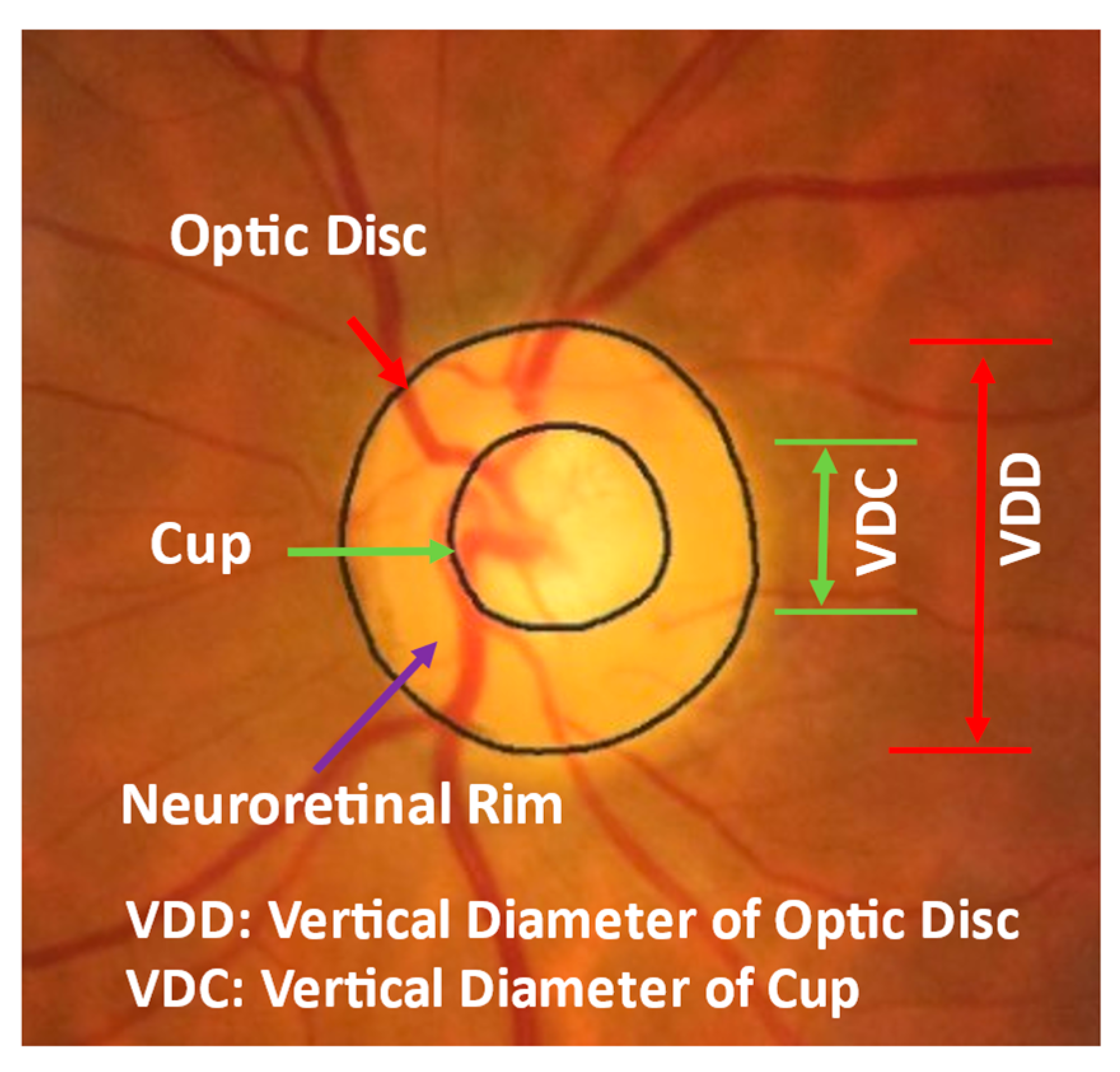
Figure 1 shows an example of a fundus image, where the optic disc (or optic nerve head) is the area where blood vessels and optic nerve fibers enter and exit the eye. The tissue between the cup and optic disc margin is called the neuroretinal rim. Most glaucoma patients with visible signs of the disease have a larger cup compared with the optic disc area, and a non-uniform rim width due to optic nerve damage. Ophthalmologists use the vertical diameter of cup to optic disc (CD) ratio, rim to optic disc (RD) area ratio, Inferior Superior Nasal Temporal (ISNT) area and its thickness, and the ISNT rule as indicators for discriminating between those with and without potential damage [
8,
9,
10]. A CD ratio greater than 0.6 is cause for suspicion of glaucoma [
1] and these patients will undergo further testing to establish a diagnosis.
High variability has been noted among ophthalmologists’ decision making based on optic disc images. The average inter-reader agreement for the optic disc is 0.643, and for the cup is even more variable with 0.633 [
11]. Correct annotation of the optic disc and cup is time consuming and requires considerable expertise even for trained technicians or clinicians [
12].
Several automated computer algorithms have been proposed to segment optic disc and cup areas from fundus images, and to measure the CD ratio automatically. Roychowdhury et al. [
13] use morphology to extract bright regions near blood vessels from a fundus image, and then use the Gaussian mixture model to extract the final optic disc from the bright regions. Ellipse fitting is used for post-processing. Morales et al. [
14] remove blood vessels from input images using principal component analysis and image enhancement. Then, they segment the optic disc using stochastic watershed transformation. Circular fitting is used in post-processing. Almazroa et al. [
15] extract blood vessels using top-hat transformation and Otsu threshold from a fundus image, remove the blood vessels in the image, and segment the cup using fuzzy threshold. Hough transform is applied to estimate the approximate cup boundary in post-processing. Cheng et al. [
16] use superpixels, histogram, and statistics surrounding the optic nerve center to segment the optic disc, and superpixels, histogram, statistics, and location information to segment the cup. The Support Vector Machine is used to classify the superpixels, and ellipse fitting is used to finalize the boundaries of the optic disc and cup. The performance of the abovementioned algorithms depends on binarization for estimating the candidate optic discs and cups, and good blood vessel detection algorithms. In addition, ellipse fitting is necessary as post-processing to further improve algorithm performance.
Deep learning has been increasingly applied in medical image processing. Fully Connected Networks (FCNs) (called U-Nets) [
17] and their modified architectures are commonly used in the segmentation of medical images. Lim et al. [
12] use convolutional neural networks (CNN) to classify every pixel in a region of interest (ROI) in fundus images to classify the optic disc, cup, and other retinal areas. Agrawal et al. [
18] use U-shape convolutional networks that have 57 layers and train the networks twice using two different inputs: one uses original images and spatial coordinates, and the other uses two images generated by the Contrast Limited Adaptive Histogram Equalization (CLAHE) operator [
19] with different parameters. Ensemble learning (EL) is also used to combine the optic disc and cup segmentation from the two inputs [
18]. Sevastopolsky et al. [
20] use CLAHE as a preprocessor to improve the input image contrast and a modified U-Net for the segmentation of the optic disc and cup. Fu et al. [
21] localize the ROI area and use modified M-shape convolutional networks (called M-Net) and polar coordinates to segment the optic disc and cup. M-Net uses four different sizes of ROIs as inputs to generate four outputs. The final segmentation result is estimated by combining the four outputs. Al-Bander et al. [
22] adapts a fully convolutional DenseNet for the segmentation of the optic disc and cup from ROI in a fundus image. They use a post-processing method that selects the largest blob as the optic disc and cup area in the ROI to compensate for segmentation errors in their deep learning model. Yu et al. [
23] use modified U-Nets based on ResNet34. Two U-Nets are used: one for ROI detection from a fundus image and the other for optic disc and cup segmentation from the ROI. They use post-morphological processing to select the largest blobs for the optic disc and cup to reduce segmentation errors from the U-Nets. Orlando et al. [
24] evaluate twelve different deep learning algorithms for the segmentation of the optic disc and cup from fundus images obtained through the REFUGE challenge. These include networks such as FCNs based on ResNet [
25], M-Net [
26], Faster R-CNN [
27], Mask RCNN [
28], and U-Net [
17]. Among them, U-Net and Deep LabV3+ [
29] show the best performance in optic disc segmentation, and Mask R-CNN shows the best performance in cup segmentation. Four algorithms in their work use EL to improve overall performance.
Most deep learning algorithms use two steps for segmentation. The first step estimates ROI from a fundus image and the next step estimates the optic disc and cup from the ROI. The diameter of the optic disc estimated in the first step is used to crop ROI from a fundus image for the second step. One to three times the optic disc diameter estimated in the first step is commonly used as the width and height of the ROI [
18,
21,
23]. In addition, post-processing algorithms are used after the second step to select the largest blob areas as the final segmentation of the optic disc and cup to alleviate unexpected segmentation errors from their deep learning algorithms [
22,
23].
A reliable and accurate ROI, where the optic disc is in the center, generates more accurate segmentation results since the segmentation algorithms are trained under the assumption that the optic disc is in the center. The size of the ROI can affect segmentation [
30,
31]. The optic disc area (pixels) becomes larger than other retina areas when the ROI size is small, and the optic disc area becomes smaller than other retina areas when the ROI size is large. A large ROI includes more geometric information surrounding the optic disc in the ROI. Additionally, a single segmentation algorithm occasionally generates unexpected segmentation errors such as isolated blobs outside of the optic disc in the ROI.
The CD ratio is a measure commonly used to confirm suspicion of glaucoma and monitor progression. However, it only considers vertical diameters of the cup and optic disc. There are other key measures for a suspicious optic disc such as the CD area ratio, RD area ratio, and rim width ratio [
8,
9,
10]. Therefore, analysis of optic disc and cup boundaries is also necessary, especially for the neuroretinal rim area and its thickness. However, few studies have focused on estimating and evaluating this information.
This may be the first step in developing an algorithm for screening for glaucoma. A large proportion of glaucoma remains undiagnosed. It can be a silent disease and often is not diagnosed until the disease is quite severe despite the availability of therapies that can reduce the disease progression and vision loss once glaucoma has been identified. There is already a shortage of physicians with a projected greater shortage in the future. The diagnosis of glaucoma currently requires individual examination by an experienced physician. There is no screening algorithm with high enough sensitivity to identify patients with varying stages of severity of glaucoma.
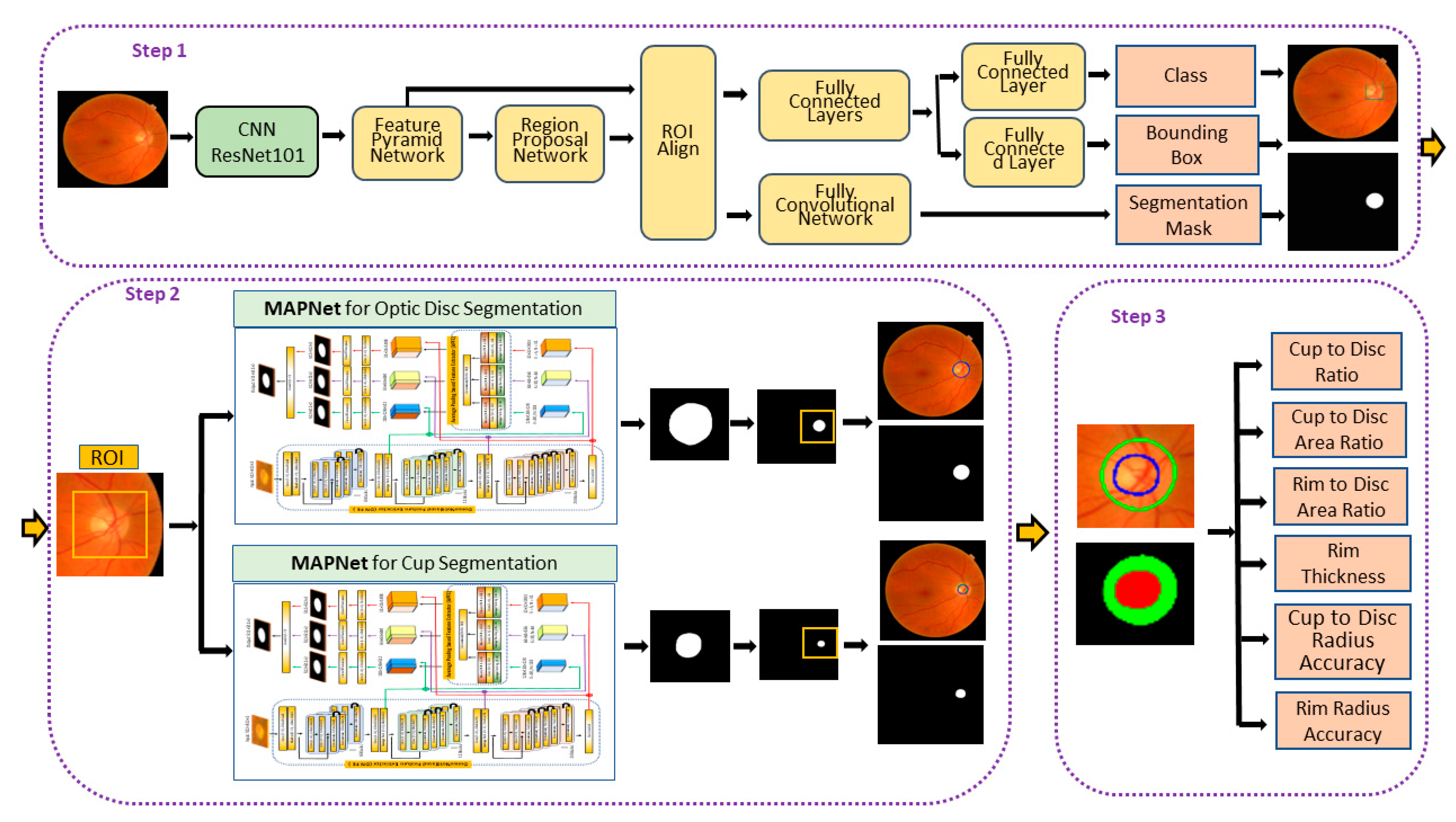
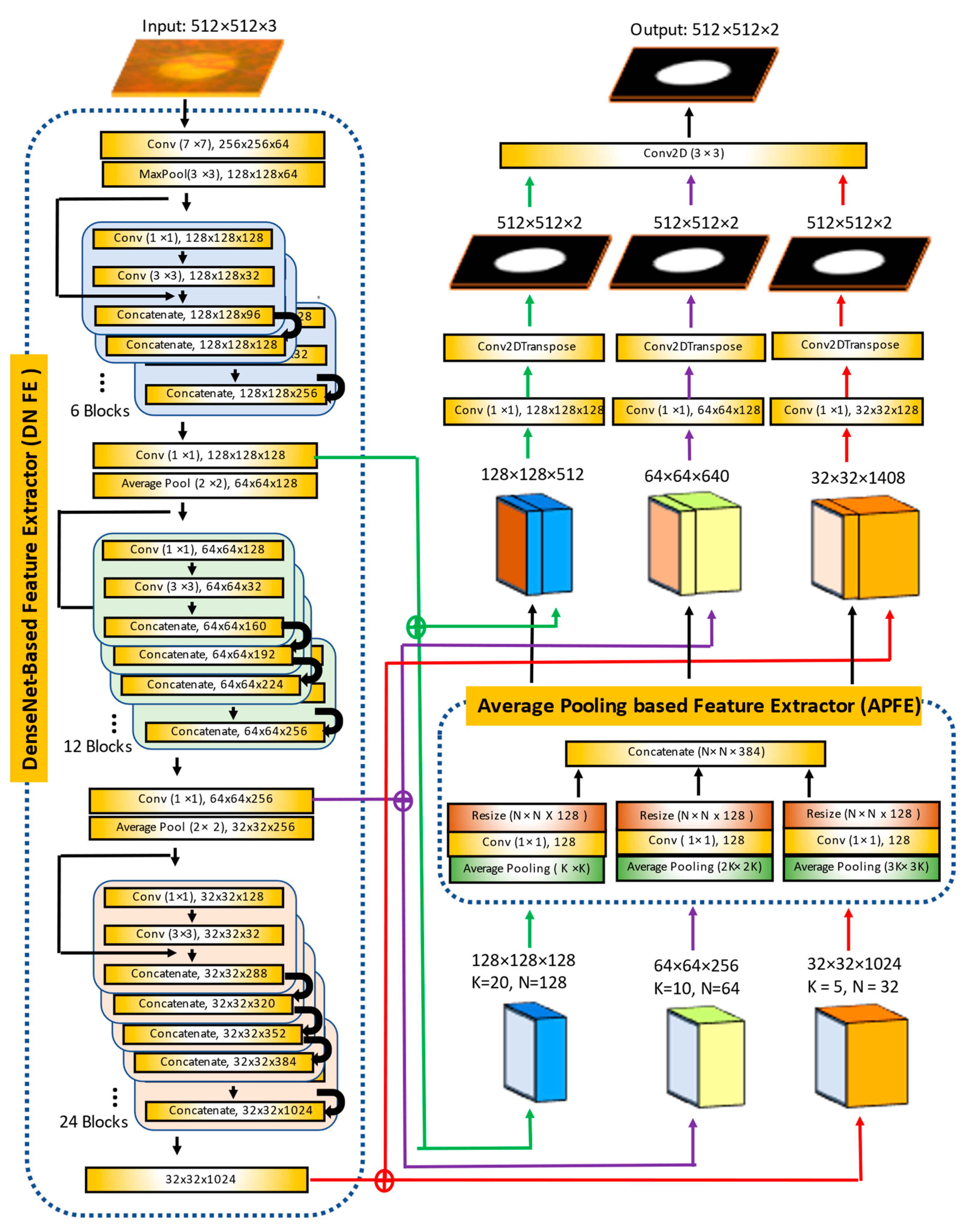
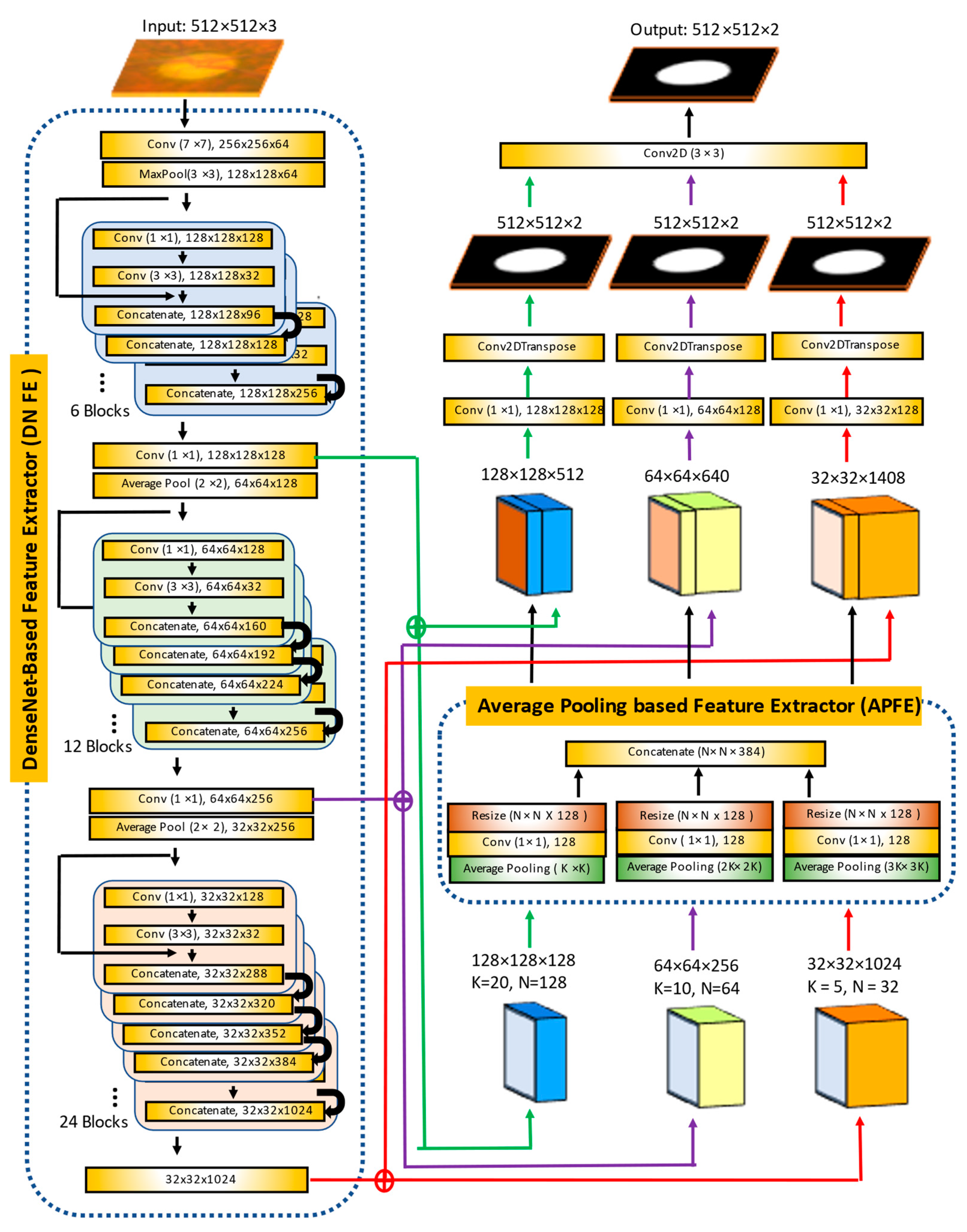
In this paper, we propose a method to segment the optic disc and cup from fundus images in order to improve the above issues. We adapt Mask R-CNN to estimate accurate and reliable ROIs from fundus images and propose a new segmentation algorithm called the Multiscale Average Pooling Net (MAPNet). The MAPNet uses outputs from three different sizes of convolutional layers (from three Dense Blocks) in DenseNet121 [
22] as features and three different sizes of average pooling layers to collect deeper features from the outputs. The MAPNet generates three segmentation outputs from three different sizes of features and adapts an ensemble learning method to combine the segmentation outputs.
The proposed Mask R-CNN allows us to estimate reliable and accurate ROI providing detailed optic disc information such as candidate optic disc mask, ROI coordinates, and probability of optic disc for each candidate mask (or ROI). The proposed MAPNet provides more reliable and consistent segmentation results because it adapts an ensemble learning architecture by combining three segmentation outputs from the three different sizes of features. Based on the segmentation results, we further estimate and evaluate more key measures such as CD area ratio, RD ratio, neuroretinal rim width (for ISNT area and ISNT rules), radius of optic disc, cup, and neuroretinal rim for all directions to provide more clear evidence to confirm suspicion for glaucoma.
The remainder of this paper is organized as follows.
Section 2 describes our methods and the dataset used in this experiment in detail. We present the experimental results and discussion in
Section 3 and
Section 4 and conclude in
Section 5.
3. Results
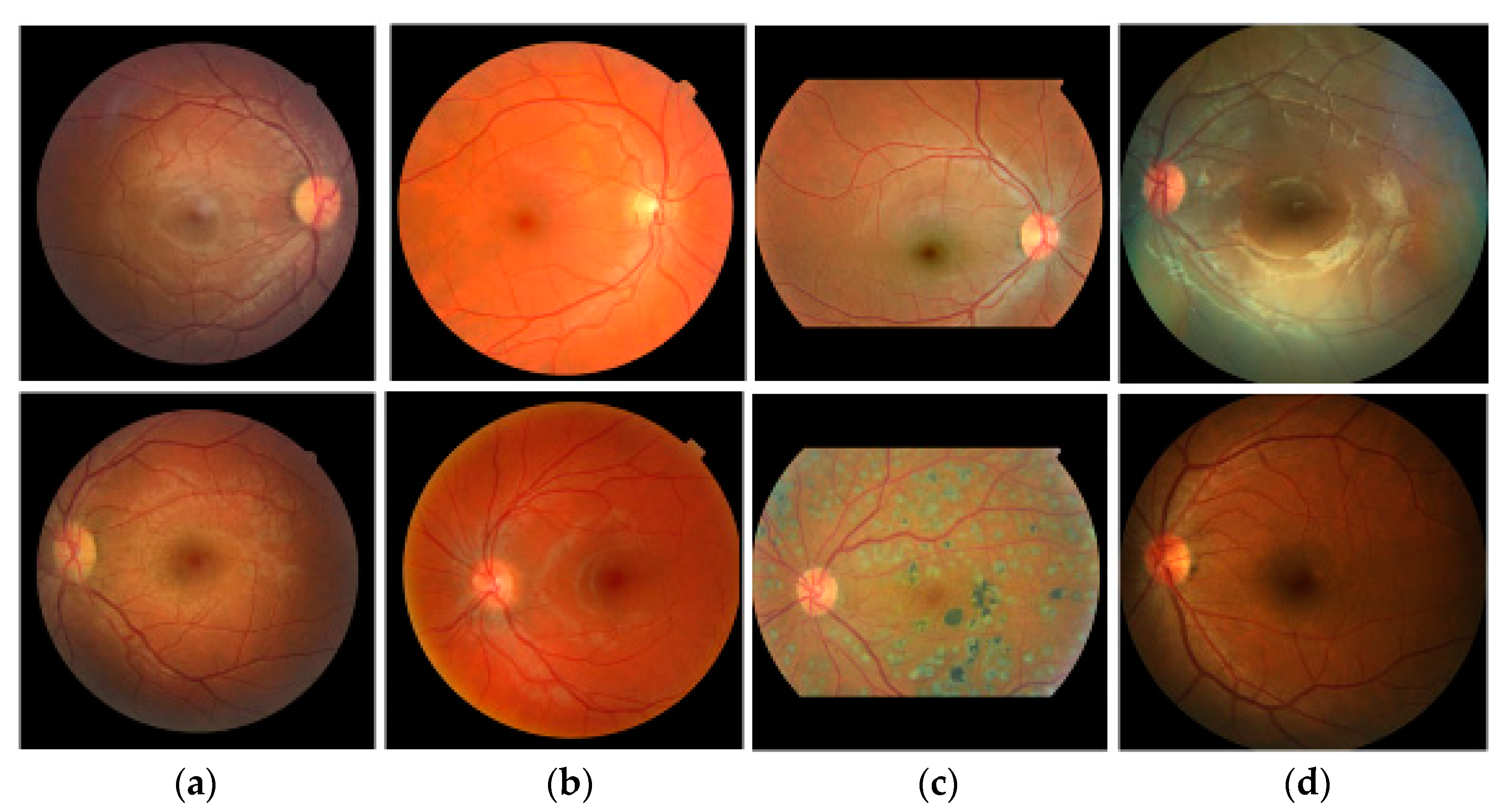
We use two datasets, RIGA and REFUGE, which contain 1099 images and use ten-fold cross-validation to generate ten test sets. The first set contains 987 images for training and 112 images for testing. The images in each dataset are also assigned to each fold equally after sorting the images using random numbers. Since most deep learning algorithms use a square shape as the input, we crop the original fundus images to make a square shape as shown in
Figure 2.
Several metrics are used to evaluate our optic disc and cup segmentation performance such as Jaccard Index (JI), Dice Coefficient (DC), Sensitivity, Specificity, and Accuracy as shown in the equations from Equation (14) to Equation (18). TP, FN, FP, and TN mean true-positive, false-negative, false-positive, and true-negative, respectively.
Python and TensorFlow’s Keras APIs [
37,
38] are used to implement the proposed model. The hardware configuration used for this experiment is 2 × Intel Xeon Gold 5218 processors 2.3 GHz, 64 hyper-thread processors, 8 × RTX 2080 Ti, and Red Hat Enterprise Linux 7.
3.1. ROI Detection Using Mask R-CNN
Mask R-CNN is used to segment the optic disc from the fundus images to estimate the ROI. To train the model, we augment each training image into ten using a vertical flip and five rotations (−20°, −10°, 0°, 10°, and 20°) to increase the number of images in the training dataset. Since ten-fold cross-validation is adapted, ten training/test sets are used in this experiment. In each training set, 80% of the images are used for training and 20% are for validation. Input images are reshaped to a square shape (1200 × 1200). We use ResNet101 as a backbone, five backbone strides (4, 8, 16, 32, and 64), epochs = 100, batch size = 1, learning rate = 0.001, learning rate2 = 0.0001, learning momentum = 0.9, and weight decay = 0.001 to train the network. For the Region Proposal Net (RPN), we use three RPN anchor ratios (0.5, 1.0, and 2.0), five RPN anchor scales (128, 192, 256, 184, and 512), and the RPN non-max suppression (NMS) threshold = 0.7. Equal weights are used for the Mask R-CNN class, Mask R-CNN bounding box, and Mask R-CNN mask losses for the optimization of the model.
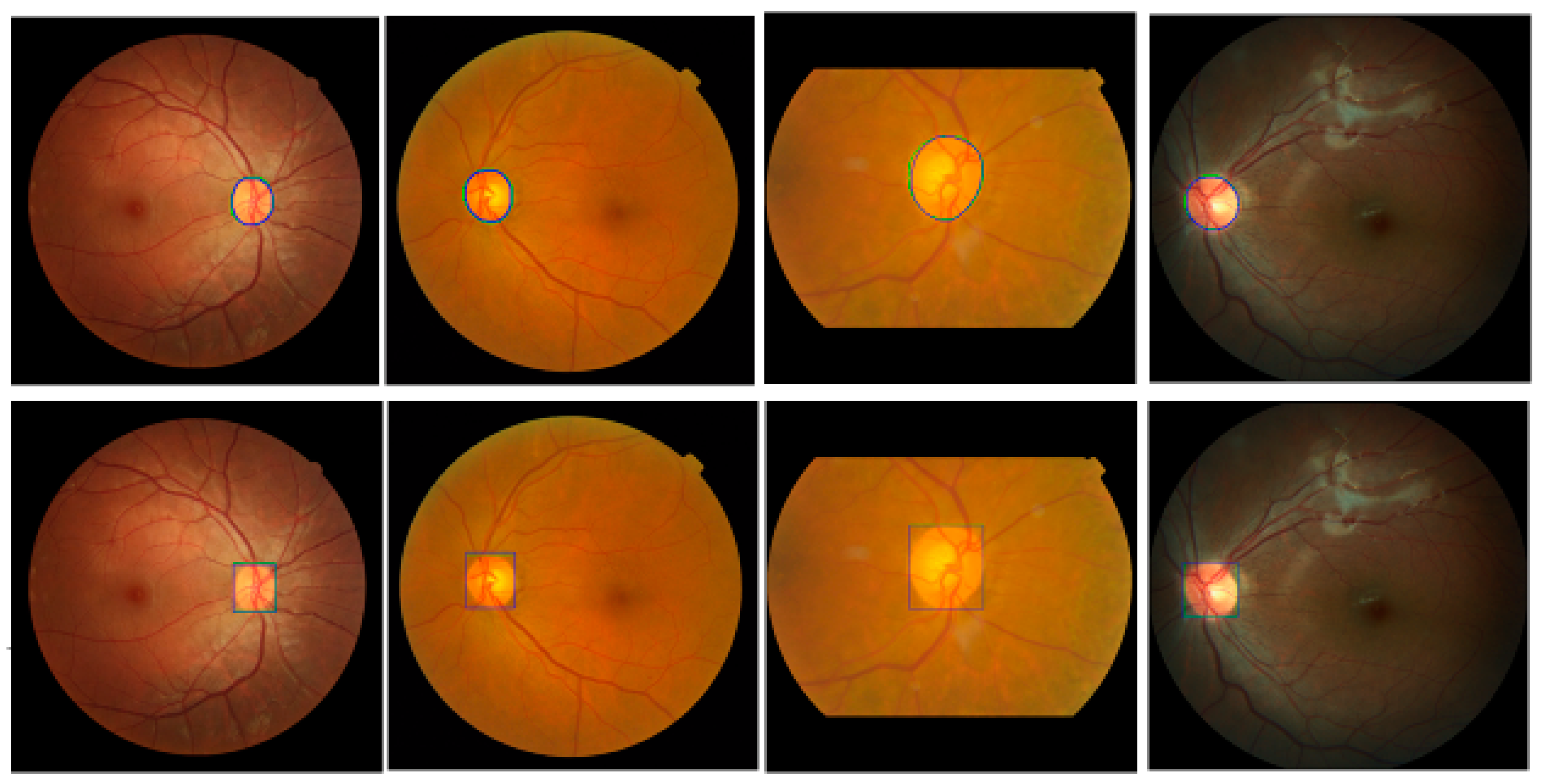
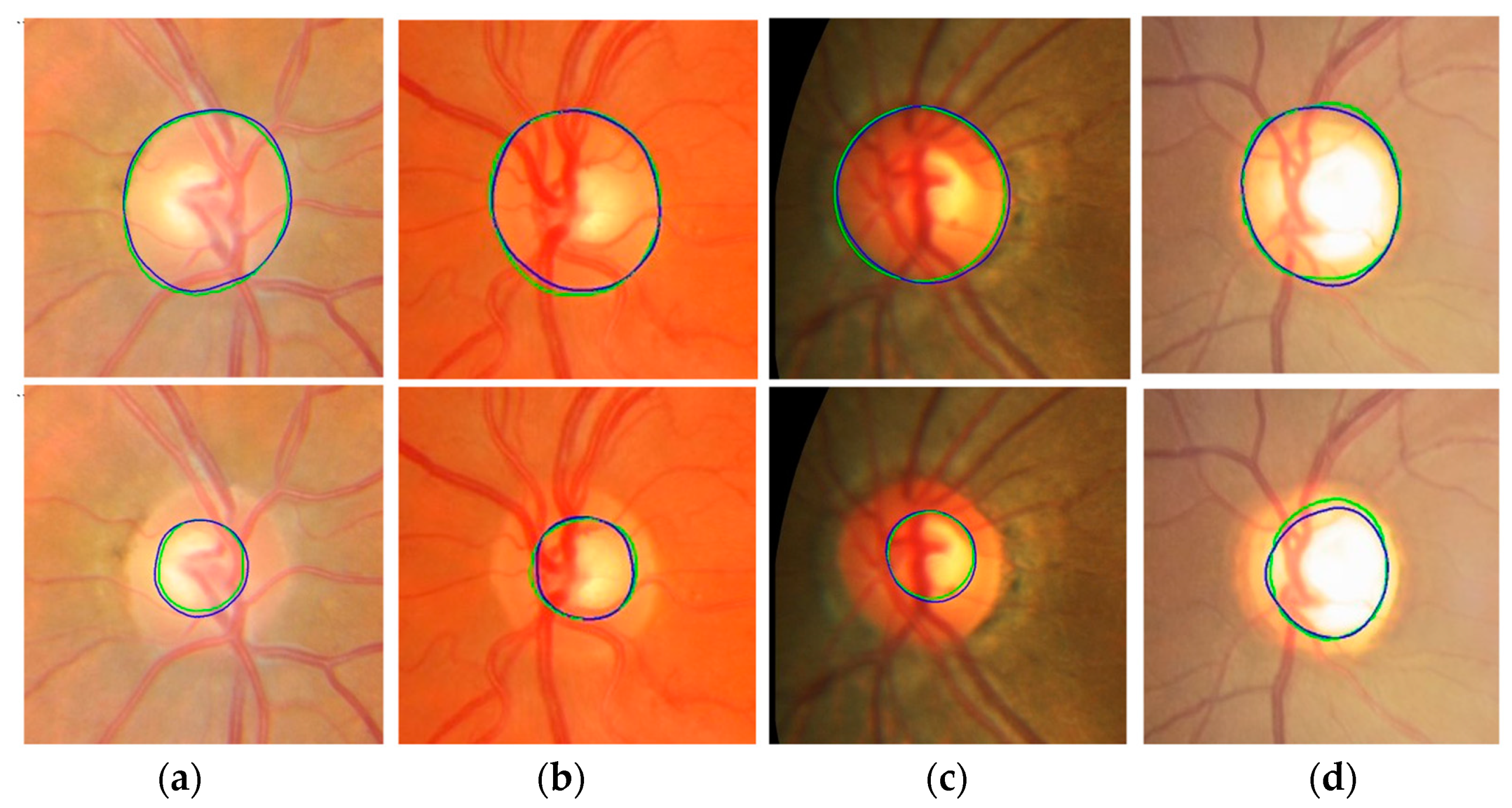
Figure 8 shows the results using images from four different datasets. Green is GT data and blue is the proposed Mask R-CNN output. The top row shows outputs of the optic disc boundary, and the bottom row shows ROI outputs. Although there is a small discrepancy between the GT data and the Mask R-CNN outputs, the outputs show relatively accurate results. Overall, the proposed Mask R-CNN shows 0.9037 JI, 0.9489 DC, 0.9231 Sensitivity, 0.9996 Specificity, and 0.9983 Accuracy.
The Mask R-CNN has complex architecture and is computationally expensive in training compared with other deep learning segmentation algorithms. However, this step is necessary to estimate reliable and consistent ROIs from all input images for accurate optic disc and cup segmentation. Wrong ROI results in this step cannot provide any chance in the next segmentation step. Since the proposed Mask R-CNN provides the probability of each class for each candidate ROI (mask) as one of their outputs, the real optic disc ROI (mask) can be selected easily even in the situation of over labeling. From this point of view, the Mask R-CNN is a more reliable method in our experiments. Therefore, the Mask R-CNN is adapted for the ROI detection.
3.2. Training the Proposed MAPNet
Two MAPNets are used to segment the optic disc and cup from an ROI independently. The input size of the MAPNet is 512 × 512 × 3 color images and outputs are 512 × 512 × 2 images as shown in
Figure 5. We augment each ROI into ten using a vertical flip and five rotations (−10°, −5°, 0°, 5°, and 10°) to increase the number of images in the training dataset. In each training set, 80% of the images are used for training and 20% for validation. We first use a pretrained DenseNet121 weight from ImageNet [
39]. However, the results using transfer learning do not show good performance. Therefore, we train all layers in the proposed model (encoder and decoder) to improve the performance. We use a maximum of 100 epochs, batch size = 20, Adam optimization algorithm (learning rate = 10
−4, first beta = 0.9, second beta = 0.999, epsilon = 10
−7, and decay = 0.0) for training, and save the best training results as an output during the training time.
Since the images used in our experiments are from four different datasets, the size of images and distribution of color intensities are different as shown in
Figure 2. To normalize the variation in color intensity, the mean and standard deviation of each image are used before training as shown in Equation (19).
where
I(
i,
j,
k) is an input image,
IN(
i,
j,
k) is a normalized input image of
I(
i,
j,
k),
i and
j are coordinates of the images
I and
IN,
k = Red, Green, or Blue channel,
is the mean of pixel values of channel
k, and
σk is the standard deviation of pixel values of channel
k.
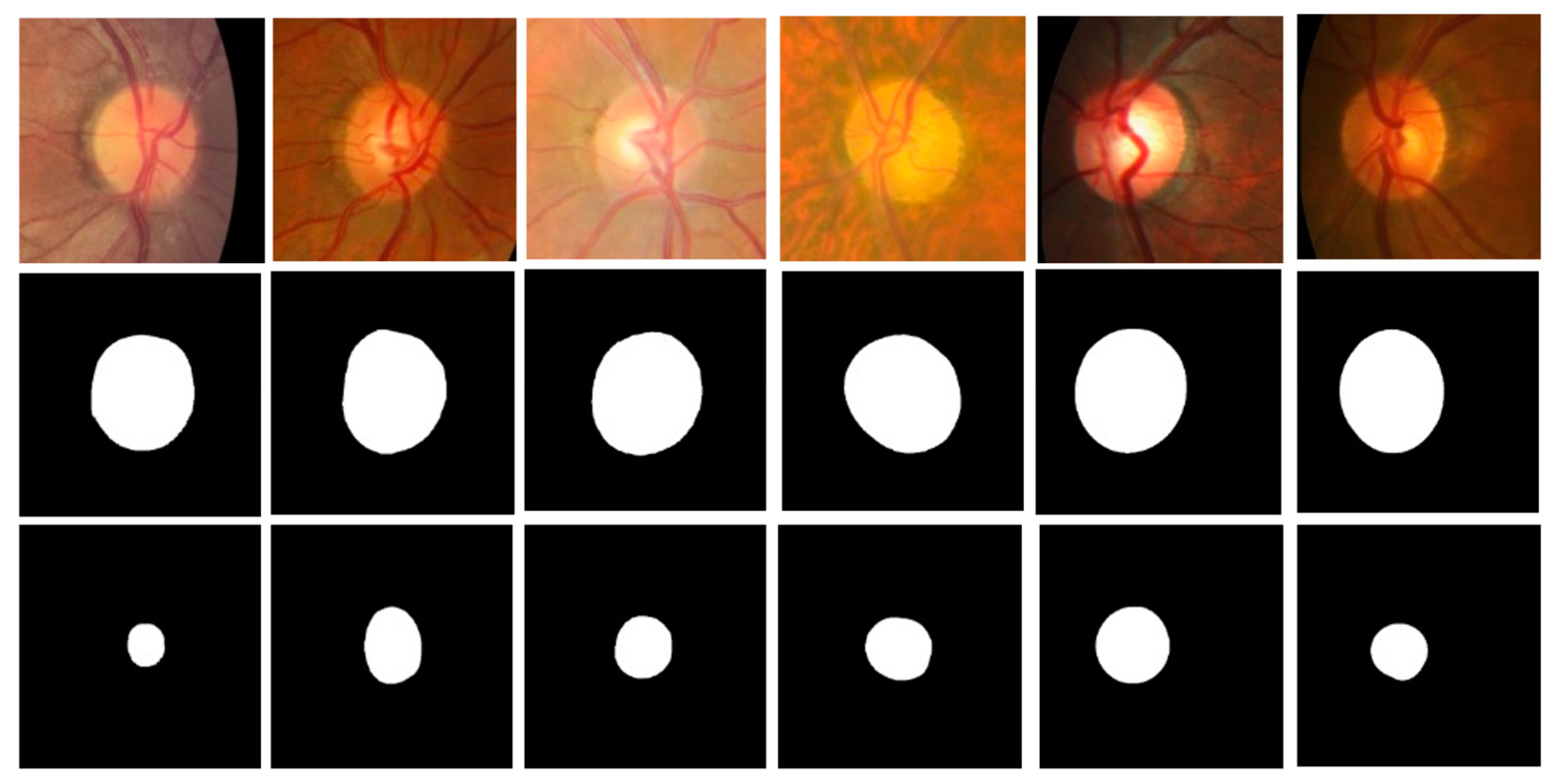
Figure 9 shows six ROI images and their corresponding ground truth labels of the optic disc and cup used in this experiment. The first row shows ROI images (ROI size = 2.00 times of the longest side of optic disc diameter). The second and third rows are for ground truth labels of the optic disc and cup, respectively. All images are resized to 512 × 512 for the MAPNet. The ROI images are cropped from the Mask R-CNN outputs of fundus images.
Several different sizes of ROIs are tried to find the best sizes for the segmentation.
Table 2 shows the optic disc segmentation results of MAPNet for four different ROI sizes (1.25, 1.50, 1.75, and 2.00 times of the longest side of optic disc diameter) for a dataset. A small ROI has more information (pixels) for optic disc and cup, but less information (pixels) for other retina areas. A large ROI has less information for the optic disc and cup, but more information for other retina areas. The MAPNet using ROI size = 2.00 shows the best performance in JI (0.9355) and DC (0.9665). Since JI and DC are the most important metrics in image segmentation, we choose ROI size = 2.00 as the best size for the proposed MAPNet.
3.3. Segmentation of the Proposed MAPNet
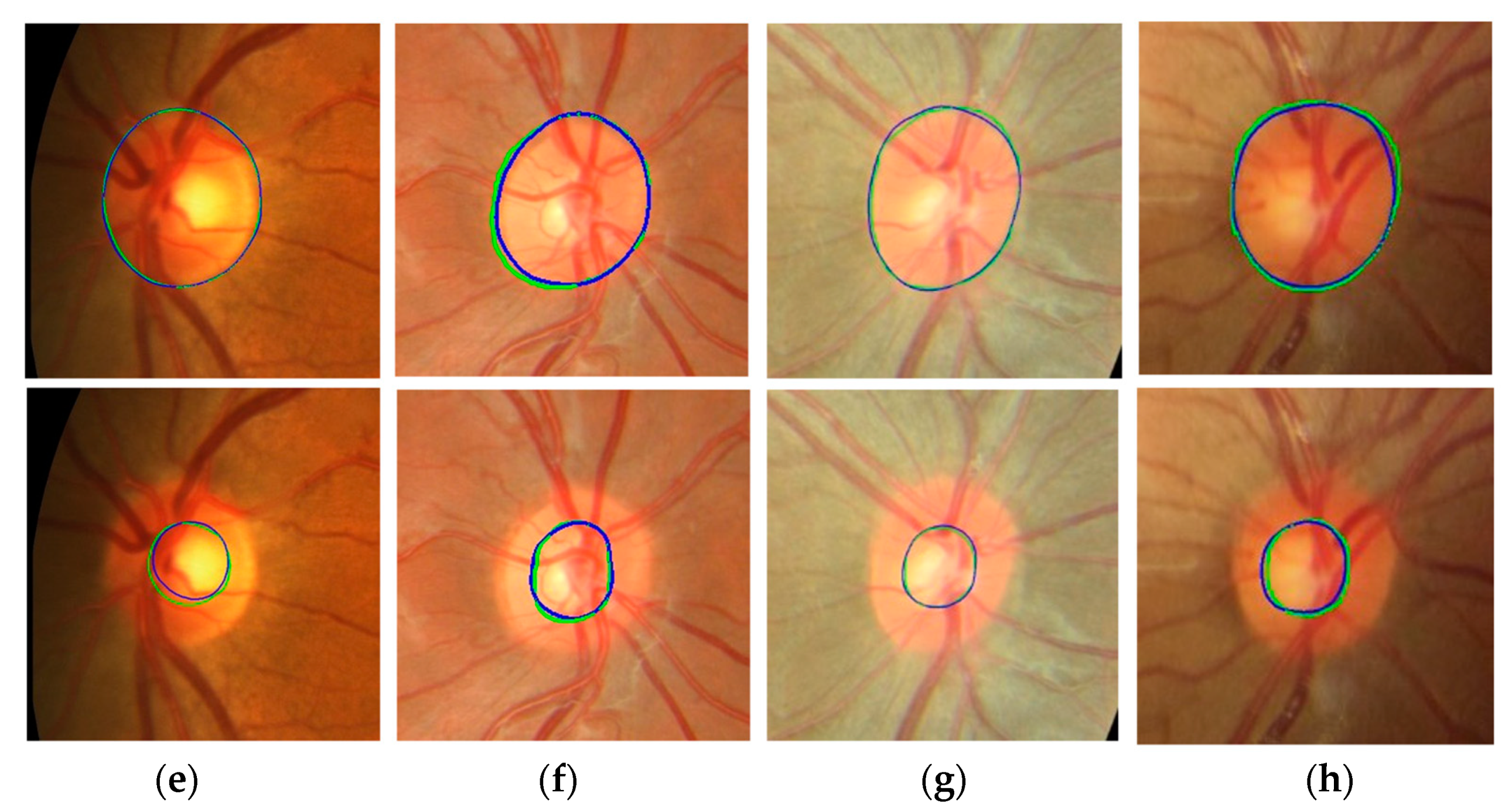
Figure 10 shows the segmentation results of the proposed method. In output images, green represents the GT annotation and blue represents the results of the proposed method. The first column (a) shows input fundus images. The second and third columns (b and c) show outputs of the proposed method for optic disc and cup segmentation, respectively. The magnified images of the optic disc output (b) are shown in column (d) and the magnified images of the cup segmentation output (c) are shown in column (e). The boundaries of the GT annotations and the results of the proposed method are very close to each other.
Figure 11 shows more optic disc and cup segmentation outputs of the proposed method. Two images are collected from each of the four datasets. All images in the figure are obtained after magnifying the ROI areas of the proposed model outputs. In the images, green and blue have the same meaning as in
Figure 10. The first rows are the optic disc segmentation results, and the second rows are the cup segmentation results. In the first and second rows, the two images in the same column are the results from the same fundus image. The optic disc segmentation result of (a) (first row) has 0.9373 JI and 0.9677 DC, and the cup segmentation result of (a) (second row) has 0.8691 JI and 0.9300 DC. The optic disc segmentation result of (b) has 0.9452 JI and 0.9718 DC and the cup segmentation result of (b) has 0.9115 JI and 0.9537 DC. Among all the results, the optic disc segmentation result of (e) shows the best accuracy with 0.9807 JI and 0.9902 DC, and the cup segmentation result of (g) shows the best accuracy with 0.9333 JI and 0.9655 DC.
3.3.1. Optic Disc Segmentation
Table 3 shows a comparison of the proposed optic disc segmentation results with other methods. The second column shows methods used by other developers. Among the methods, two algorithms use n-fold cross validation to verify their performances, but five do not. “[4-fold CV]” in the first row means four-fold cross-validation is used for evaluation and “[1-fold]” in the second row means no cross-validation is used. The third column shows datasets used for training and/or testing. The fourth column is the number of images (Train Images) used to train, the fifth column (Test Images) shows the number of images used to test, and the metrics estimated from the test results are shown in columns six and seven. In the case of methods using n-fold cross-validation, numbers in the columns of Train Images and Test Images are the same since all images are used for training and testing at least once. Several methods estimate their performances after independent training and testing for each database. These performances have different metric values for each dataset. Therefore, we estimate the average (weighted average) of all datasets using the numbers in Test Images as weights as shown in Equation (20).
where
metric (
i) is the metric estimated from the dataset
i, and
n(
i) is the number of Test Images in the dataset
i.
Lim et al. [
12] have 0.8780 JI for 1200 MESSIDOR images and 0.9157 JI for 235 SEED DB images. Therefore, the average JI becomes 0.8842 ((0.8780 × 1200 + 0.9157 × 235)/1435 = 0.8842) as shown in the table. Agrawal et al. [
18] train EL models and have 0.8800 DC from 40 REFUGE images. Yu et al. [
23] train modified U-Nets using two datasets (MESSIDOR and Bin Rushed). Then, they fine tune the U-Nets in each dataset using 50% of DRISHTI images and 80% of RIM ONE images. Their average results show 0.9410 JI and 0.9694 DC. Orlando et al. [
24] show the results of the top three teams from the REFUGE challenge: 400 images are used for training, another 400 images for validation, and the other 400 images for testing. The three teams which have the best performance are shown in the table, and the best DC is 0.9602.
We test deep learning algorithms based on Modified U-Nets and/or Mask R-CNN to compare them with the proposed MAPNet. We use the REFUGE and RIGA (MESSIDOR, Bin Rushed, and Magrabi) datasets and ten-fold cross-validation (ten training/testing sets) to evaluate our performance as shown in rows eight to ten. Unlike other methods, we make one overall dataset by combining the four datasets and use it to train our models to make more general and reliable methods for fundus images in any datasets. Since ten-fold cross-validation is adapted in our experiment, our result is estimated by averaging the results of ten (training/test) sets.
In the three results of Kim et al. [
31], we use modified U-Nets that we previously developed: U-Net2 for two class classification and U-Net3 for three class classification. The first two results use Modified U-Net3 or Mask R-CNN to segment the optic disc from the fundus images. The third result uses Mask R-CNN to crop the ROIs from the fundus images and Modified U-Net2 to segment the optic disc from the ROIs. Among the three results, the result using Mask R-CNN and Modified U-Net2 shows better performance with 0.9234 JI and 0.9597 DC than other algorithms.
The last two rows (Proposed Method) show the performance of our proposed method. We also use the same datasets and ten-fold cross-validation method (used in the results of Kim et al. [
31]) to evaluate our performance. The first row among the two is the result estimated by averaging the results from the ten training/testing sets and the second row is the best result among the ten sets. The average result shows 0.9381 JI and 0.9679 DC and the best result shows 0.9432 JI and 0.9707 DC.
The proposed method shows good performance compared with other methods. It is hard to compare the performance of each method since each uses different datasets and different evaluation methods. Our best result shows the best performance and our average result shows the second-best performance. The performance from Yu et al. [
23] comes from a small test data without using cross-validation. For example, in the case of RIM-ONE results, 400 MESSIDOR, 195 Bin Rushed, and 97 RIM-One images are used for training, and 32 RIM-ONE images are used for the test. Since the performance of our method is estimated from the largest data (1099 images) from four different datasets, we expect that it may produce more reliable, robust, and consistent results for fundus images from other datasets.
3.3.2. Cup Segmentation
Table 4 shows a comparison of cup segmentation results. The column information in the table is the same as in
Table 3. Equation (20) is also used to estimate the average of each metric for the table. In the second row, Agrawal et al. [
18] use EL methods and two datasets for training and have 0.6400 DC from 40 REFUGE images. Yu et al. [
23] use two datasets (MESSIDOR and Bin Rushed) for training a CNN. Then, they fine tune the CNNs in each dataset using 50% of DRISHTI images and 80% of RIM ONE images. Their average results show 0.7973 JI and 0.8725 DC. Orlando et al. [
24] show results of the top three teams from the REFUGE challenge: 400 images are used for training, another 400 images for validation, and the other 400 images for testing. The top three teams which have the best performance are shown in the table, and the best DC is 0.8837.
We test several deep learning algorithms based on Modified U-Nets and/or Mask R-CNN as shown in the three results of Kim et al. [
31]. We also use the same datasets and ten-fold cross-validation method used for the optic disc segmentation to evaluate our performance. The results of the Modified U-Net3 and Mask R-CNN are estimated from the fundus images. The third result uses Mask R-CNN to crop ROIs from fundus images and Modified U-Net2 to segment the cup from the ROIs. Among the three results, the result using Mask R-CNN and Modified U-Net2 shows the best performance with 0.7833 JI and 0.8742 DC.
The last two rows (Proposed Method) show the performance of our proposed method. The first row among the two is the result estimated by averaging the results from the ten training/testing sets and the second row is the best result among the ten sets. The average result shows 0.8222 JI and 0.8996 DC, and the best result shows 0.8355 JI and 0.9082 DC. The proposed method shows the best performance. Unlike other algorithms [
22,
23] that use post-processing to improve the output of their deep learning algorithms, our proposed method produces robust results without using post-processing for the results since it produces results from three outputs from three different sizes of features.
3.4. Key Measures Estimated from the Proposed Ensemble Learning Results
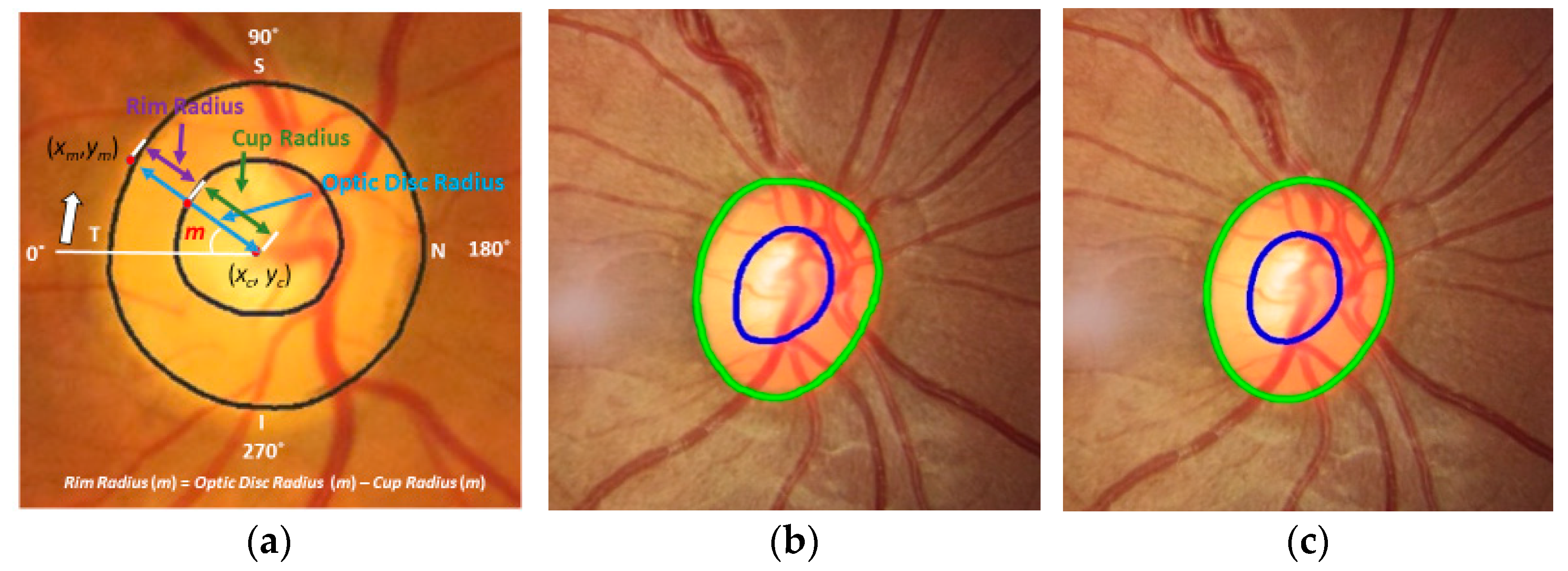
We estimate several important measures from the proposed segmentation results to confirm suspicion of glaucoma: cup to disc ratio, cup to disc area ratio, neuroretinal rim to disc ratio, disc radius, cup radius, and neuroretinal rim radius (thickness). Then, we compare them to the measures estimated from the GT data. Equations (2)–(13) (in
Section 2.5) show formulas to estimate the difference (error) of the two measures. Among the measures, the neuroretinal rim radius (
Figure 7c) is one of the key measures since we can estimate the neuroretinal rim area, and the ISNT rules can be applied from the information in the graph.
Table 5 shows the mean error of the measures estimated from the proposed model outputs. We estimate each measure for each dataset and the whole dataset. We could not compare the measures with other algorithms since few studies use similar measures for the evaluation, and the formulas for the neuroretinal rim radius (thickness) and radiuses of the optic disc and cup are proposed for the first time to our knowledge. The cup to disc ratio error (CDRE) in the first row shows 0.0451 in total. This means that the proposed algorithms show over 0.9549 accuracy. Sun et al. [
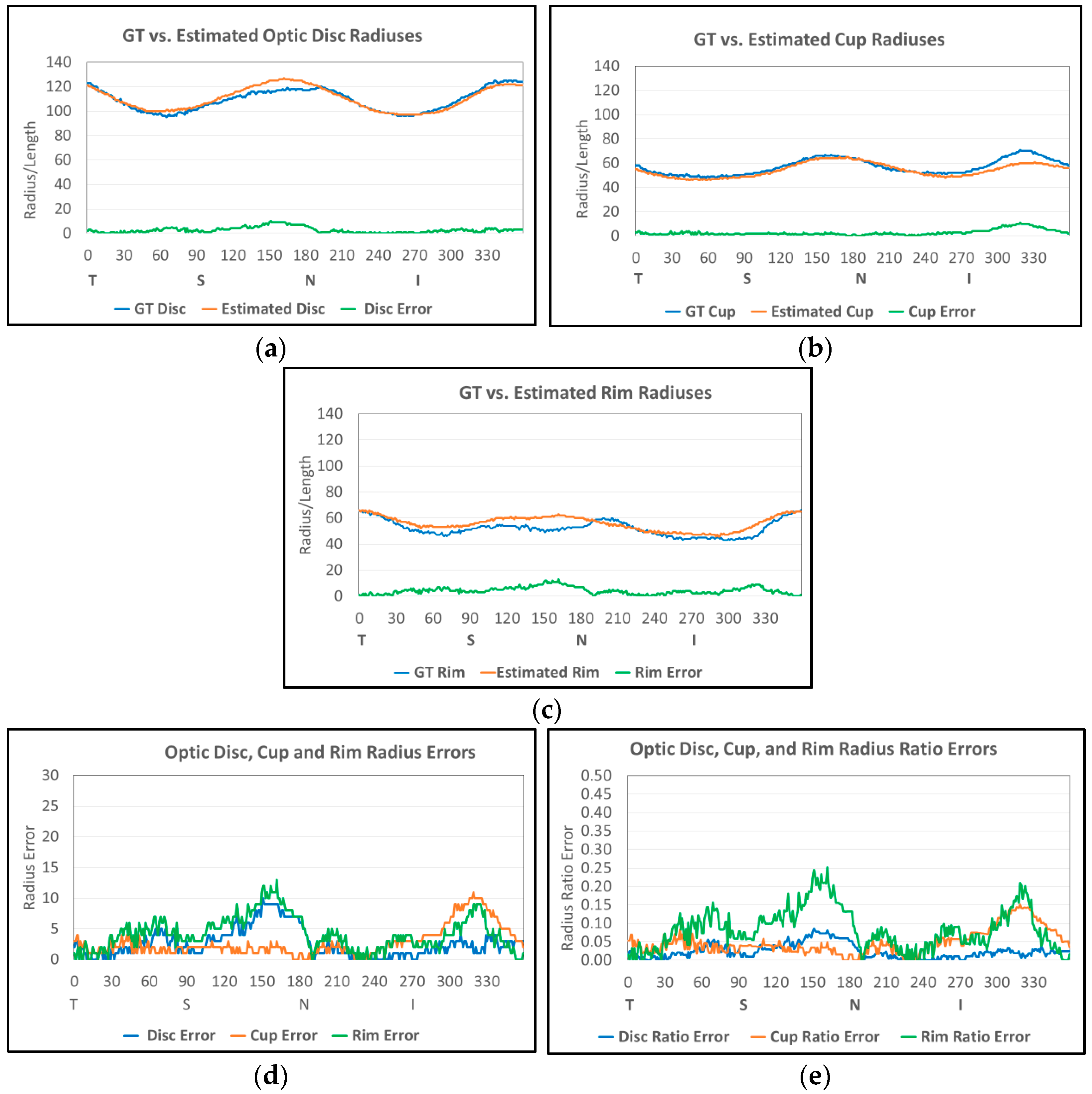
40] also measured the CDRE for Drishti-GS and RIM-One datasets, which showed 0.0499 and 0.0630. All CDRE errors of the four datasets from the proposed model show less error values than the two errors.
The cup to disc area ratio error (CDARE) in the second row shows 0.0376; this ratio is better than CDRE as the area ratio considers all areas of optic and disc. The rim to disc area ratio error (RDARE) in the third row has the same performance as CDARE. The fourth to sixth rows show errors related to the optic disc, cup, and rim radiuses. The average disc radius ratio error (ADRRE) in the fourth row shows 0.0500 in total, which means the proposed algorithms show 0.9500 accuracy in the optic disc boundary estimation. The average cup radius ratio error (ACRRE) in the fifth row shows a relatively high error rate of 0.2257 when compared to the error of the optic disc (ADRRE). This demonstrates that cup boundary estimation is more challenging work compared to optic disc boundary estimation. The average rim radius ratio error (ARRRE) in the sixth row shows 0.2166 in total. The error ratio is higher than the error of the optic disc (ADRRE) but less than the error of the cup (ACRRE). Overall, the proposed algorithms show robustness in CDRE, CDARE, RDARE, and ADRRE but less accuracy in ACRRE and ARRRE. Therefore, further studies are needed to improve segmentation accuracy, especially in the cup, to have more accurate measures and to screen suspicious glaucoma based on the measures.
We analyze our results further using histograms as shown in
Figure 12.
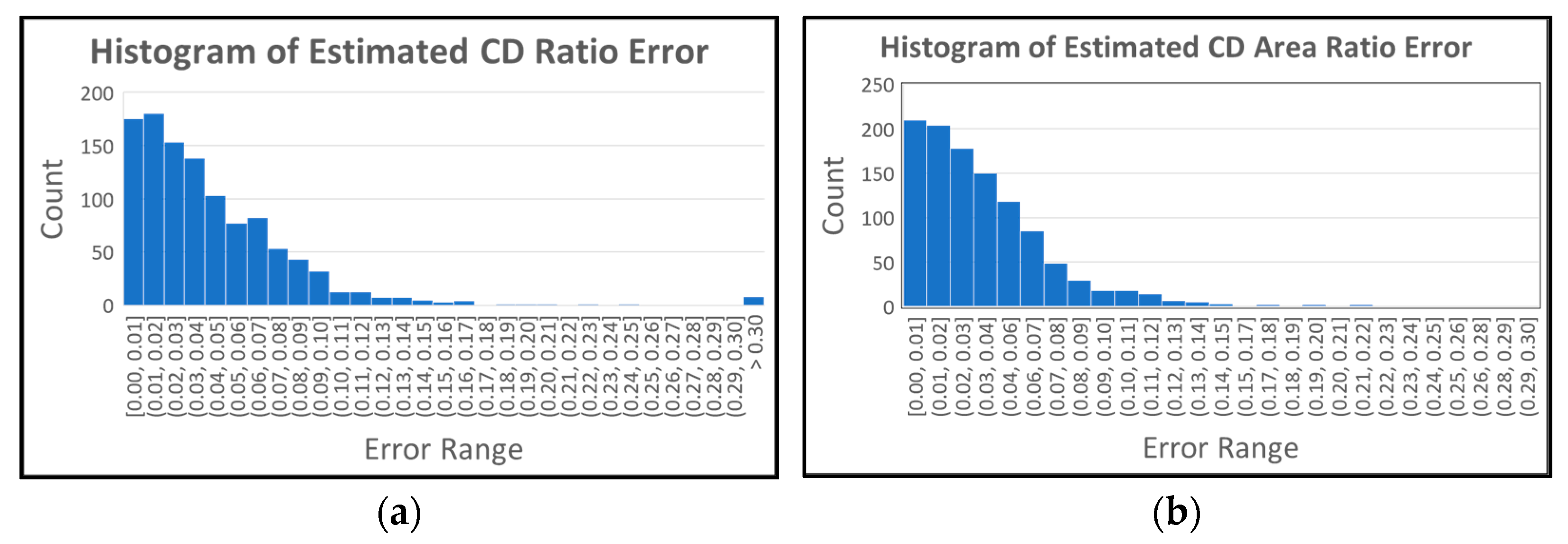
Figure 12a shows the histogram of the estimated CD ratio error. The horizontal axis shows the interval for the error, and the vertical axis shows the count for each range. As shown in the table, 44.22% of the results have less than 3% error (first three bars in error range [0.00, 0.03]), and 94.27% of the results have less than 10% error (error range [0.00, 0.10]). This shows that the proposed algorithm produces reliable results in CD ratio estimation.
Figure 12b shows the histogram of the estimated CD area ratio error. As shown in the table, 53.87% of the results have less than 3% error (first three bars in error range [0.00, 0.03]), and 94.81% of the results have less than 10% error (error range [0.00, 0.10]). The proposed algorithm also shows reliable results in the CD area ratio estimation. When we compare the histograms of CDRE and CDARE, CDARE shows slightly better performance since it considers all data (pixels) instead of considering pixels in the vertical direction.
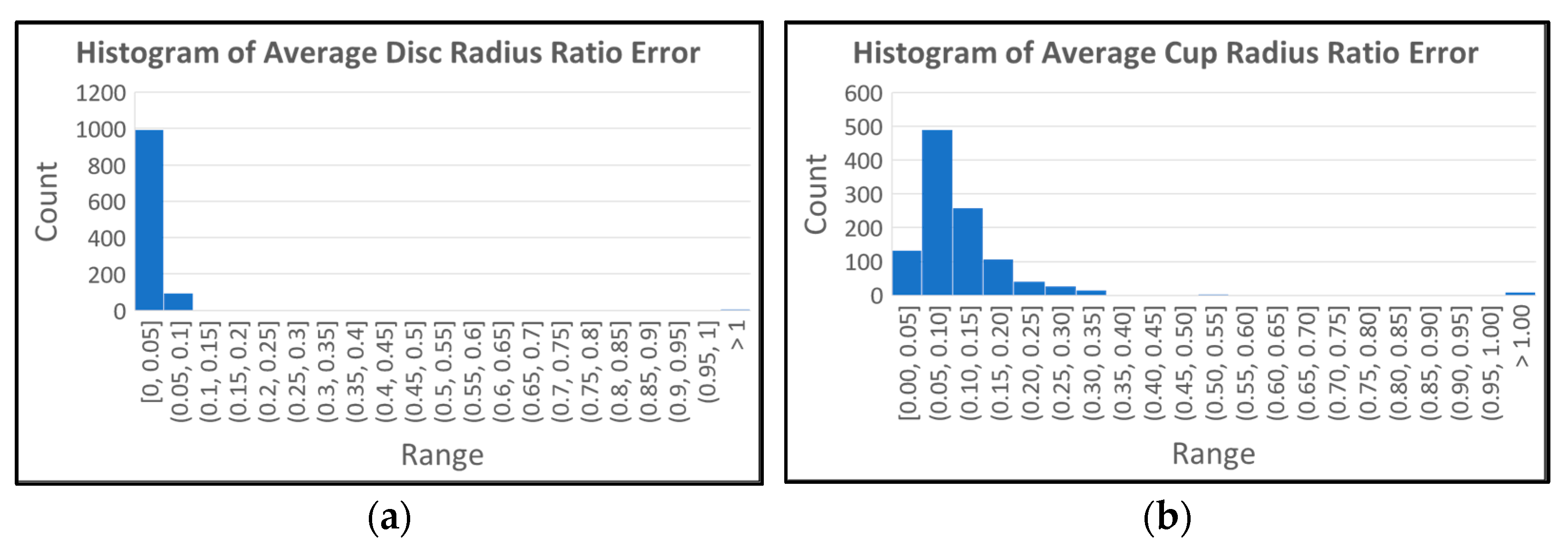
Figure 13 shows the histograms of the average optic disc, cup, and neuroretinal rim radius ratio errors. The histogram for the optic disc (
Figure 13a) shows that 90.54% of the results are within the 5% error range ([0.00, 0.05]). In the case of the cup shown in
Figure 13b, 90.01% of the results are within the 20% error range ([0.00, 0.20]). In the case of the neuroretinal rim shown
Figure 13c, 84.80% of the results are within the 20% error range and 91.72% of the results are within the 25% error range ([0.00, 0.25]). The histograms show higher accuracy in the estimation of the optic disc boundary than the cup or rim boundaries.
4. Discussion
We propose a deep learning method to segment the optic disc, cup, and neuroretinal rim to resolve the inter-reader variability issue of human annotators. Mask R-CNN is adapted to estimate the ROIs from the fundus images and MAPNet is proposed for the segmentation of the optic disc and cup from the ROIs. The proposed MAPNet uses outputs of the first three Dense Blocks of DenseNet121 and three APFEs for feature extractors and combines three segmentation outputs to estimate the final robust results. The proposed method analyzes the accuracy of neuroretinal rim thickness, and optic disc and cup boundaries for the first time to our knowledge.
Several important issues are observed for the segmentation and analysis of the optic disc and cup. Through our empirical experiments, we find that accurate and reliable ROI detection improves the optic disc and cup segmentation accuracy. We compare the proposed Mask R-CNN with an FCN with U-Net architecture (Modified U-Net) in ROI detection (optic disc segmentation). In both deep learning methods, the smallest rectangle covering the estimated optic disc output becomes an ROI output of each method. Therefore, both optic disc outputs are compared with the GT optic disc mask. The FCN shows a slightly better performance (JI = 0.9068 and DC = 0.9499) overall than the proposed Mask R-CNN. However, the FCN has issues when it generates unexpected extra masks (over labeling) as the output of the optic disc. The FCN only provides optic disc masks as outputs. Therefore, extra post-processing is needed to find the real optic disc mask (ROI) and to remove other over labeled masks. The FCN can generate more issues for choosing the real ROI, especially when large drusen or lesions are over labeled as ROIs. However, the proposed Mask R-CNN provides candidate ROIs (optic disc masks) and the probability of the optic disc for each ROI (mask) as outputs. We choose the ROI with the highest probability as the real ROI output. Therefore, the proposed Mask R-CNN provides more reliable ROIs for the next step, which estimates the real optic disc and cup from the ROIs using the proposed methods.
The proposed MAPNet is used to segment the optic disc and cup from the ROIs as the next step. We find that ROI size also affects the segmentation accuracy since different size ROIs include different geometric information of fundus images. Four different sizes of ROIs (1.25, 1.50, 1.75, and 2.00 times of the longest side of optic disc diameter) are evaluated and the ROI size = 2.00 provides the best optic disc segmentation results for the proposed model. Cup segmentation is a more challenging issue than optic disc segmentation since the boundary between the optic disc and cup is more ambiguous than that of the optic disc and other retina areas.
The MAPNet for three classes (optic disc, cup, and other classes) is also implemented to segment the optic disc and cup simultaneously. However, results from the MAPNet for two classes show better performance than the results from MAPNet for three classes. Therefore, MAPNet for two classes is adapted in the proposed method.
Designing the decoding part of the proposed MAPNet is another challenging issue. Since occasional over/under labeling is a common issue when using a single FCN algorithm, ensemble learning is frequently adapted to alleviate the issue. Therefore, the proposed model generates three outputs from three different types/sizes of features and combine the three outputs to estimate the final segmentation results.
In addition to the optic disc to cup ratio, optic disc to cup area ratio, neuroretinal rim to disc area ratio, neuroretinal rim thickness, and optic disc and cup boundaries (radiuses) are critical measures to confirm suspicion of glaucoma. Since JI and DC do not correlate with the accuracy of the optic disc and cup boundaries, we propose formulas to analyze the accuracy of the neuroretinal rim, optic disc, and cup radiuses of all directions for the first time to our knowledge. These will enable us to estimate the lengths and areas of inferior, Superior, Nasal, and Temporal, minimum neuroretinal rim distance, and to apply ISNT rules to find notching in the fundus images. There are limits to this study. The collection of reliable fundus image annotations is challenging due to high inter-reader variability. Therefore, annotations from several experienced experts are necessary to develop and improve the performance of the proposed deep learning models. Additionally, the number of images in the dataset is still small compared to the datasets used in other deep learning applications. Thus, the proposed algorithms may have generalization and robustness issues since the dataset does not cover a diverse range of fundus images and patterns of the optic disc and cup. A large-scale collection of fundus images is necessary to make more robust deep learning models.
Studies on other measures are also necessary for using different modalities such as post-illumination pupil response [
41], swinging flashlight test [
42], and pupillary signal [
43]. Combined analysis of these measures with our key measures will help to improve the diagnosis of glaucomatous features more accurately.
Optic disc and cup annotation requires the judgment of professional graders and is considered time-consuming work. It requires about eight minutes per eye based on the Klein protocol [
44]. The proposed method needs about 13.37 s on average per fundus image estimating all the key measures including the optic disc and cup segmentation. Among the time, 10 s is for ROI detection and the remaining 3.37 s is for the segmentation of the optic disc/cup and estimation of the key measures. The proposed method adapts Mask R-CNN for the ROI detection to focus more on accuracy than processing time. The processing time can be further improved by adapting other DL algorithms for the detection. When comparing the processing time of the grader and the proposed method, the proposed method is much faster than professional graders. Therefore, this shows a potential benefit for using the proposed method if it is fully implemented and is used in the real field.
5. Conclusions
This paper proposes an automatic method to segment the optic disc and cup from fundus images using deep learning algorithms. We also propose several measures to evaluate segmentation results and to use as key factors for the diagnosis of glaucomatous features. The method comprises three steps. A Mask R-CNN is adapted to estimate the ROI from a fundus image. The proposed MAPNet is used for the segmentation of the optic disc and cup from the ROI. The cup to disc ratio, cup to disc area ratio, neuroretinal rim to disc area ratio, optic disc radius, cup radius, and neuroretinal rim radius are estimated as the last step. The MAPNet uses three DNFEs and three APFEs for feature extraction (encoding process) and uses an ensemble learning architecture in the decoding process to combine three segmentation results.
We evaluate the performance of our proposed method, using four datasets and ten-fold cross-validation. The proposed method shows 0.9381 JI and 0.9679 DC in optic disc segmentation, and 0.8222 JI and 0.8996 DC in cup segmentation. We have a 0.0451 error on average for CD ratio estimation, 0.0376 error on average for CD area ratio estimation, and 0.0376 error for neuroretinal RD area ratio estimation. We also analyze the boundaries of the optic disc, cup, and neuroretinal rim for the first time to our knowledge, and have 0.050 for the optic disc radius ratio error, 0.2257 for the cup radius ratio error, and 0.2165 for the cup radius ratio error.
The proposed method demonstrates the effectiveness in the segmentation of the optic disc and cup when compared with other state-of-the-art methods and provides several key measures to screen potential glaucomatous damage. It also shows the potential that the proposed method can work as a second reader for ophthalmologists. We plan to explore different FCNs and hand-made features to further improve the performance of the proposed method.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}