
Performance of Convolutional Neural Networks for Polyp Localization on Public Colonoscopy Image Datasets

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
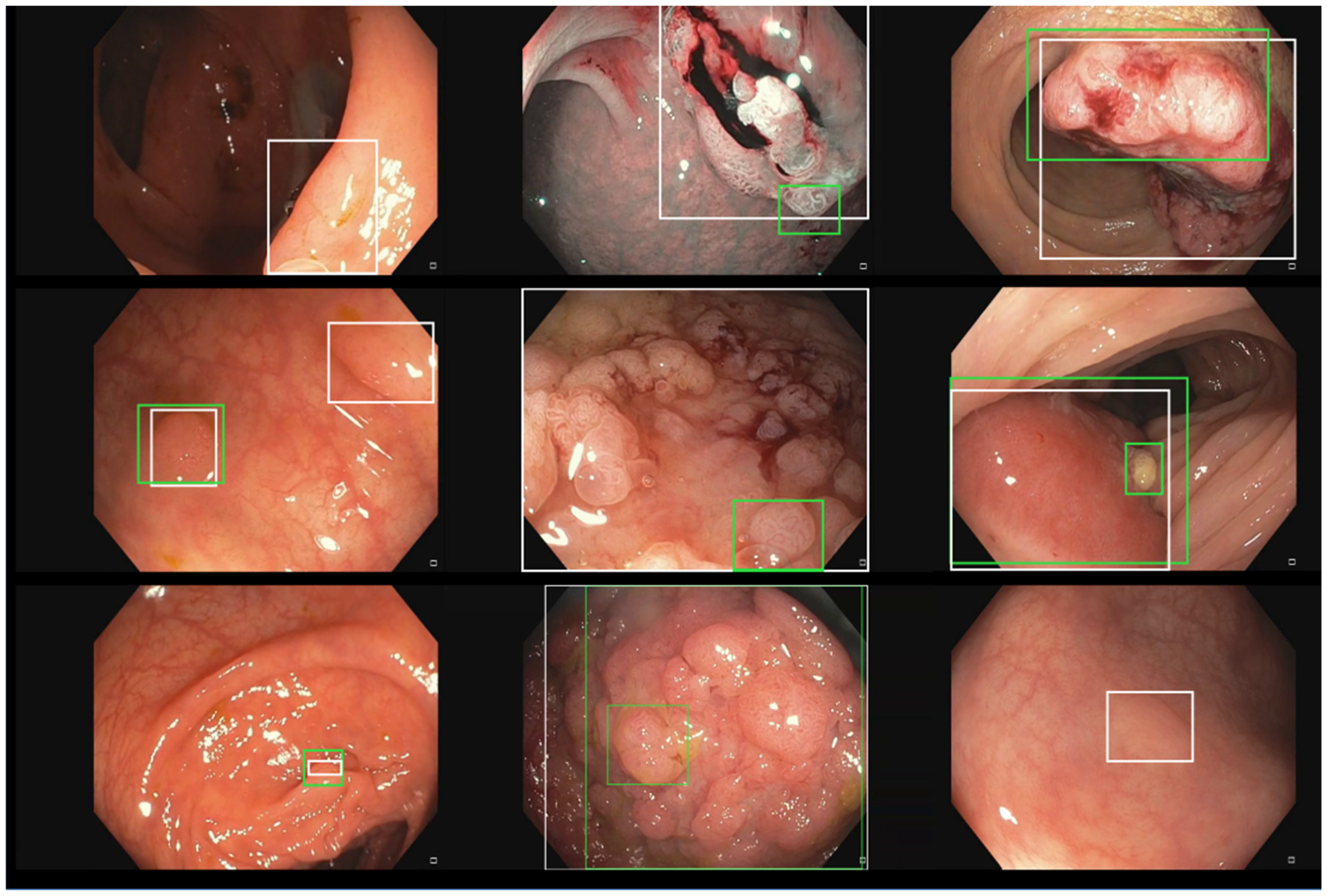
2.1. Our Polyp Localization Network
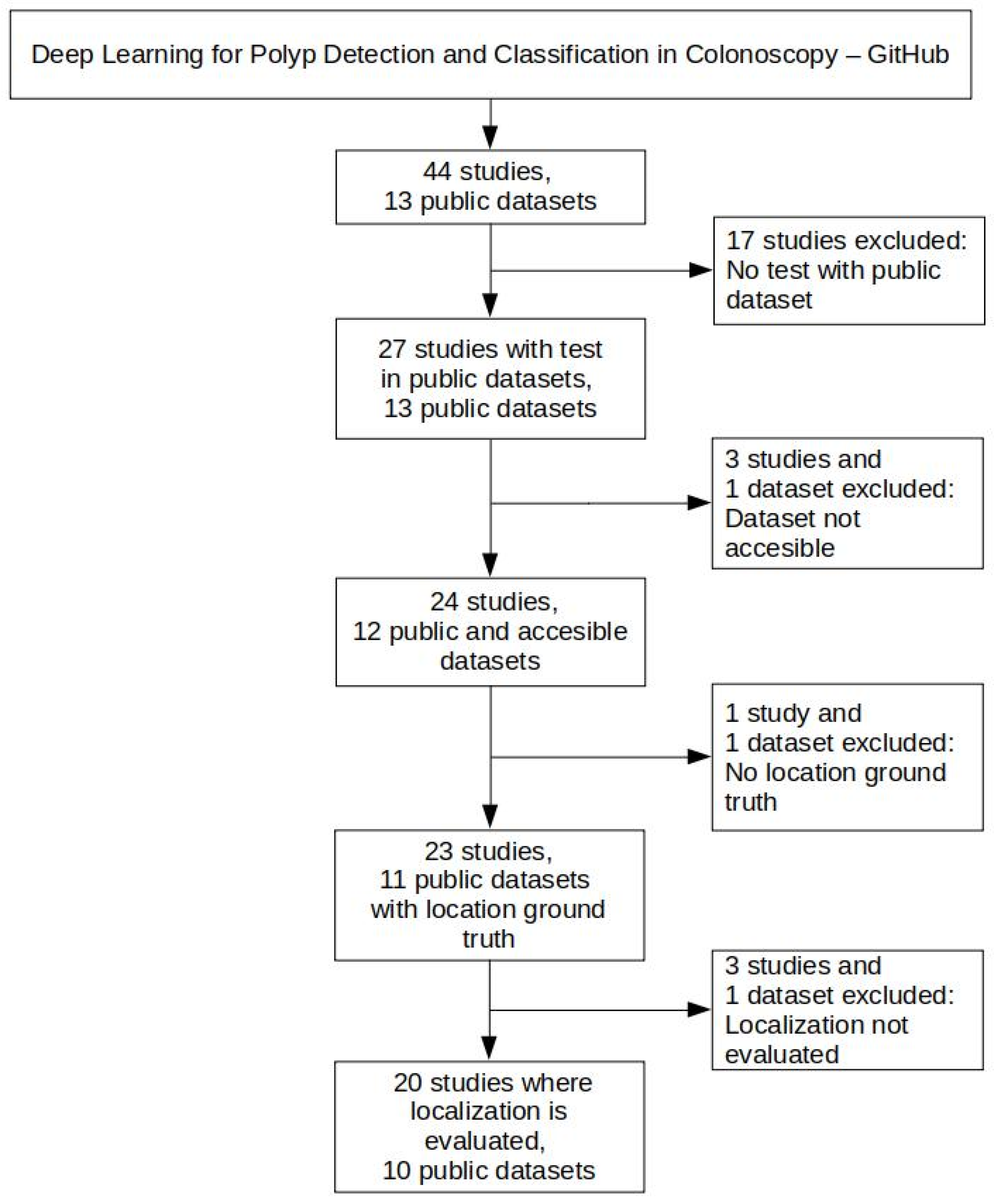
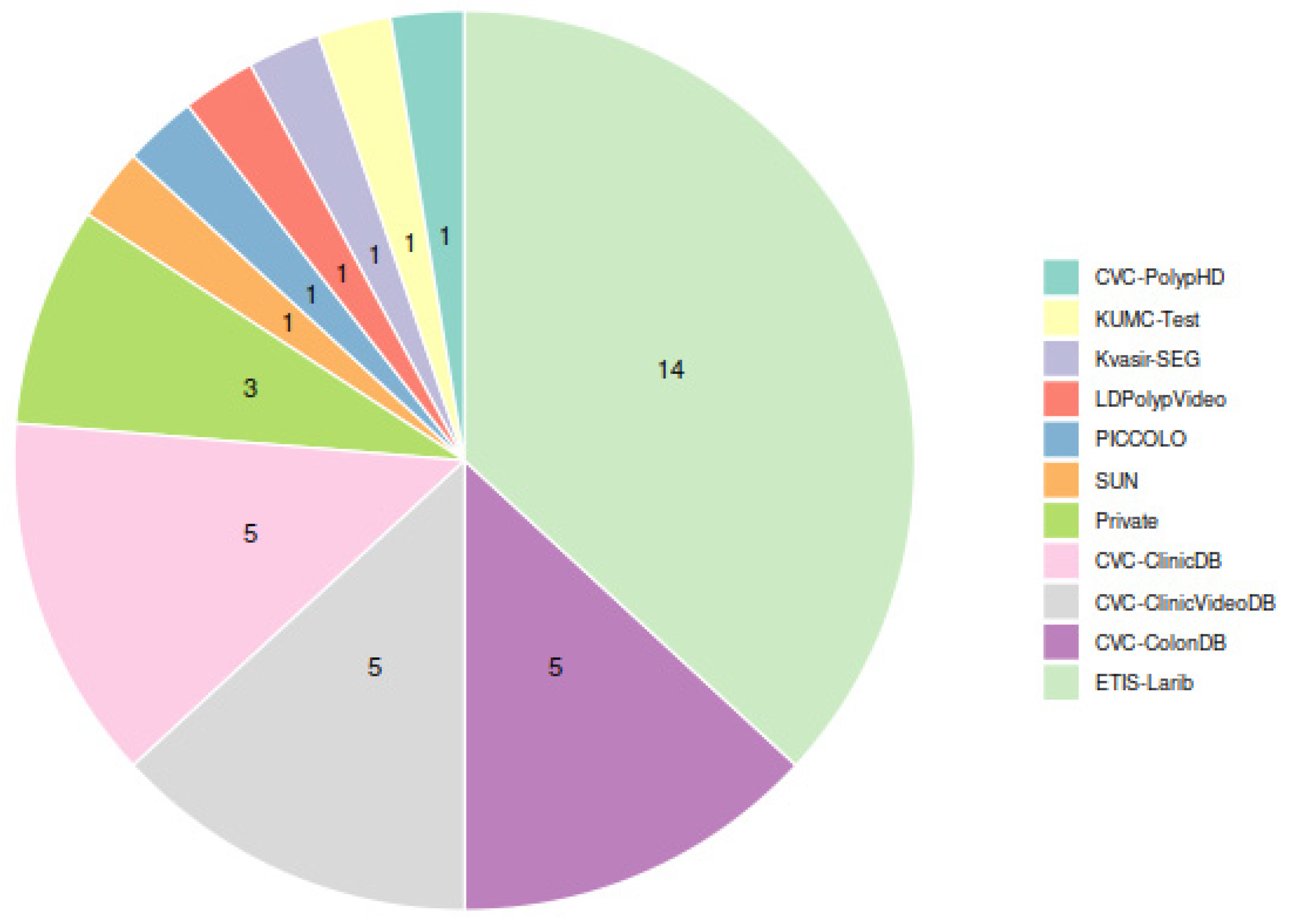
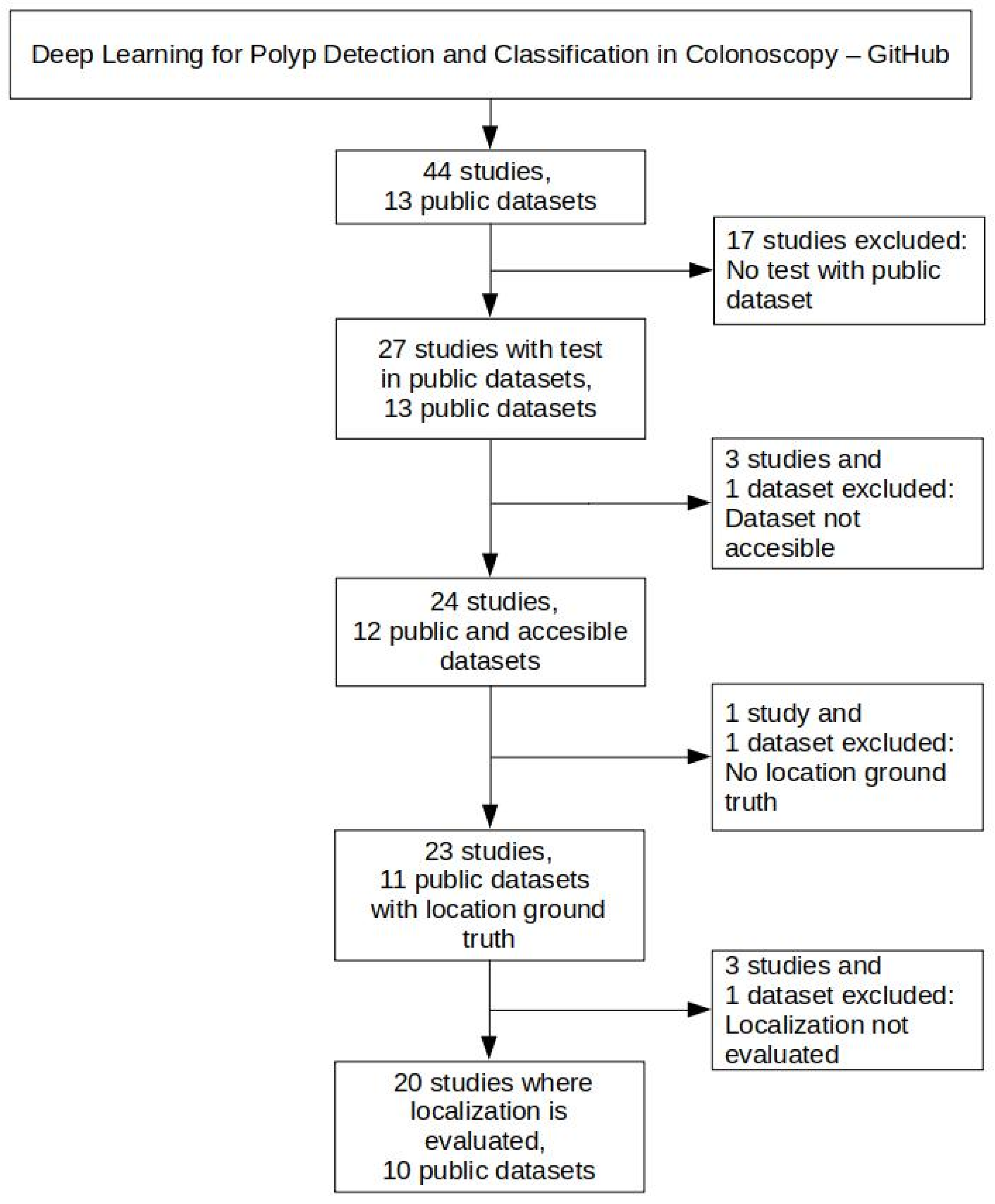
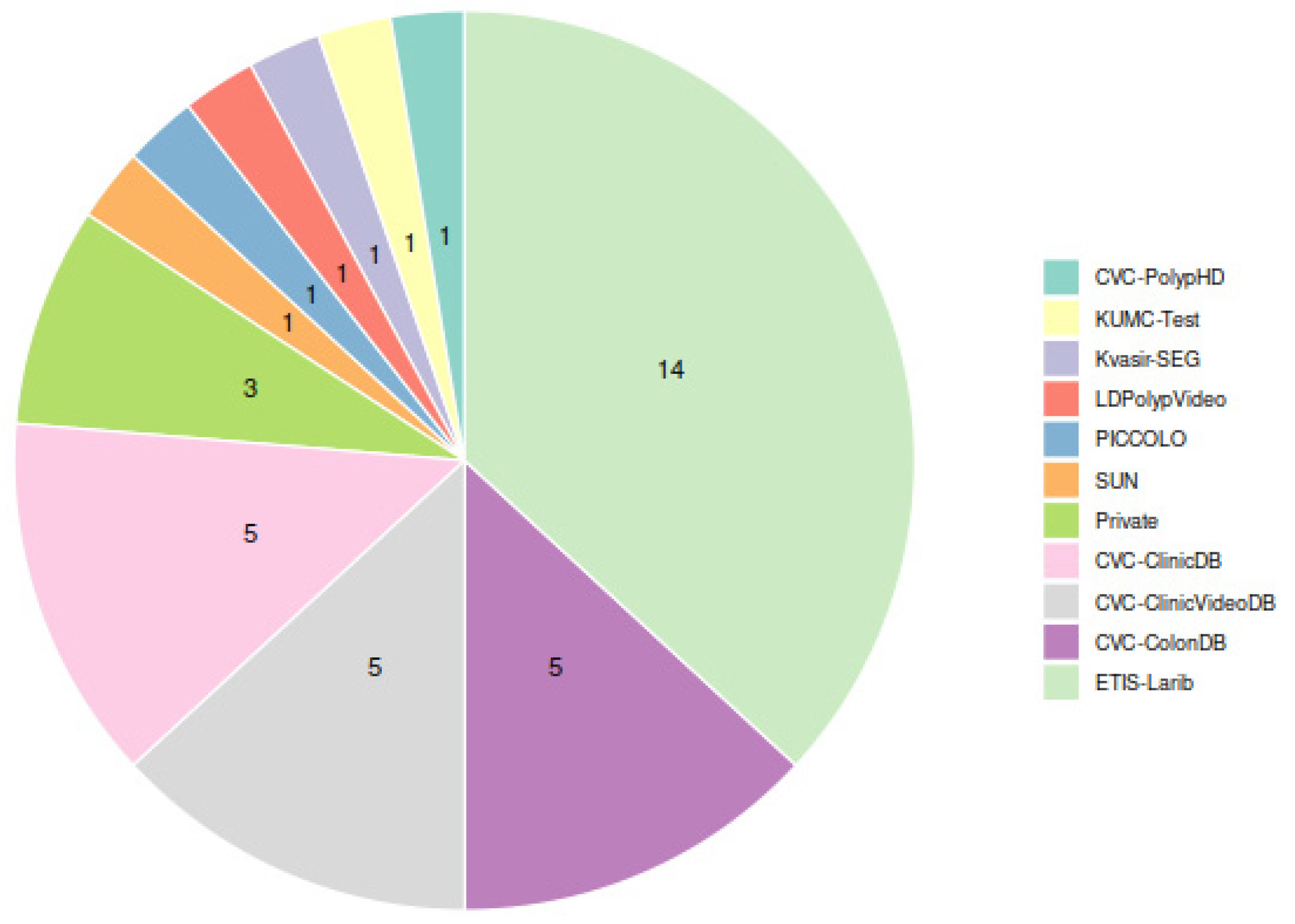
2.2. Public Colonoscopy Image Datasets and Polyp Localization Studies Selection
2.3. Public Colonoscopy Image Datasets Description and Preprocessing
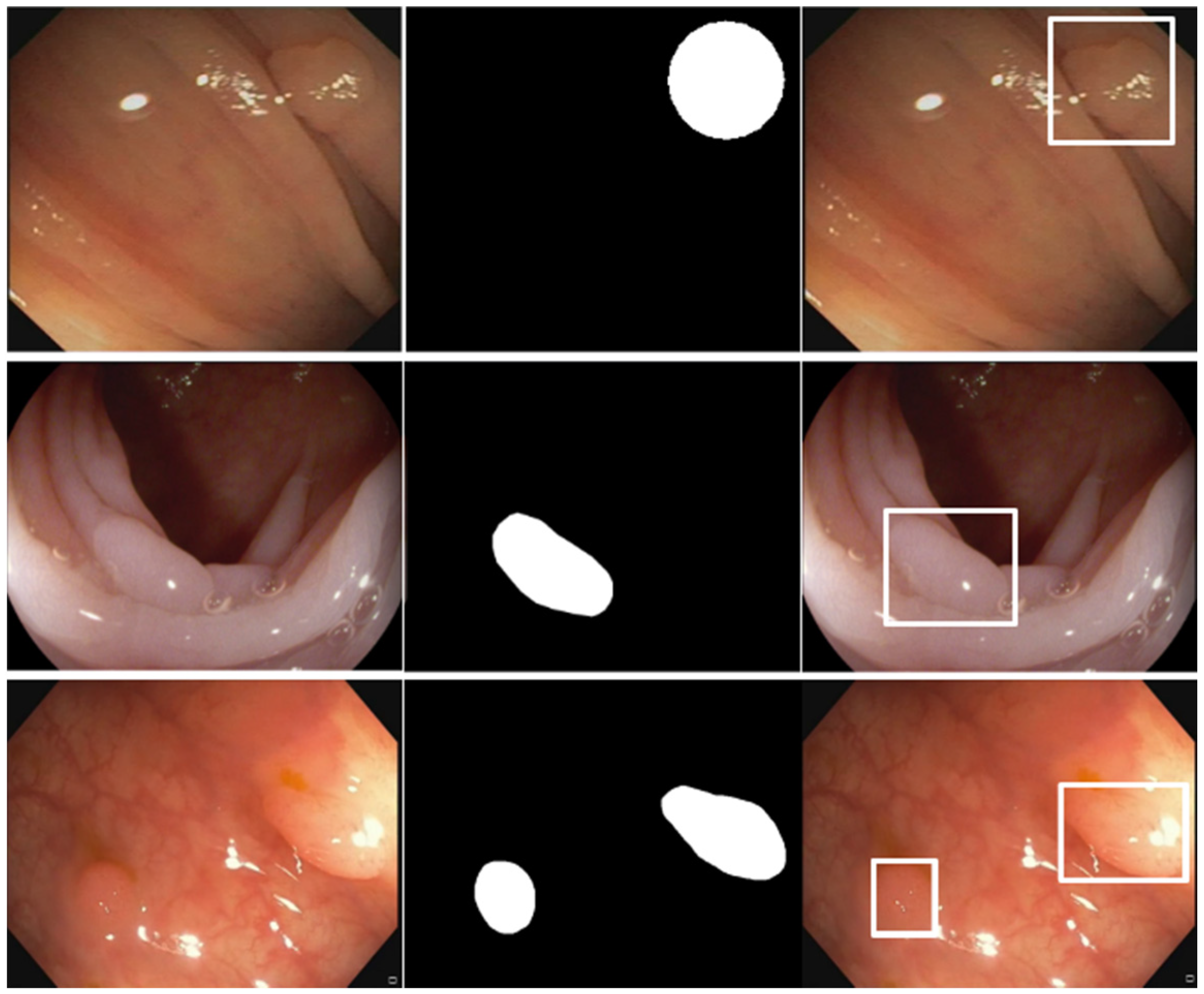
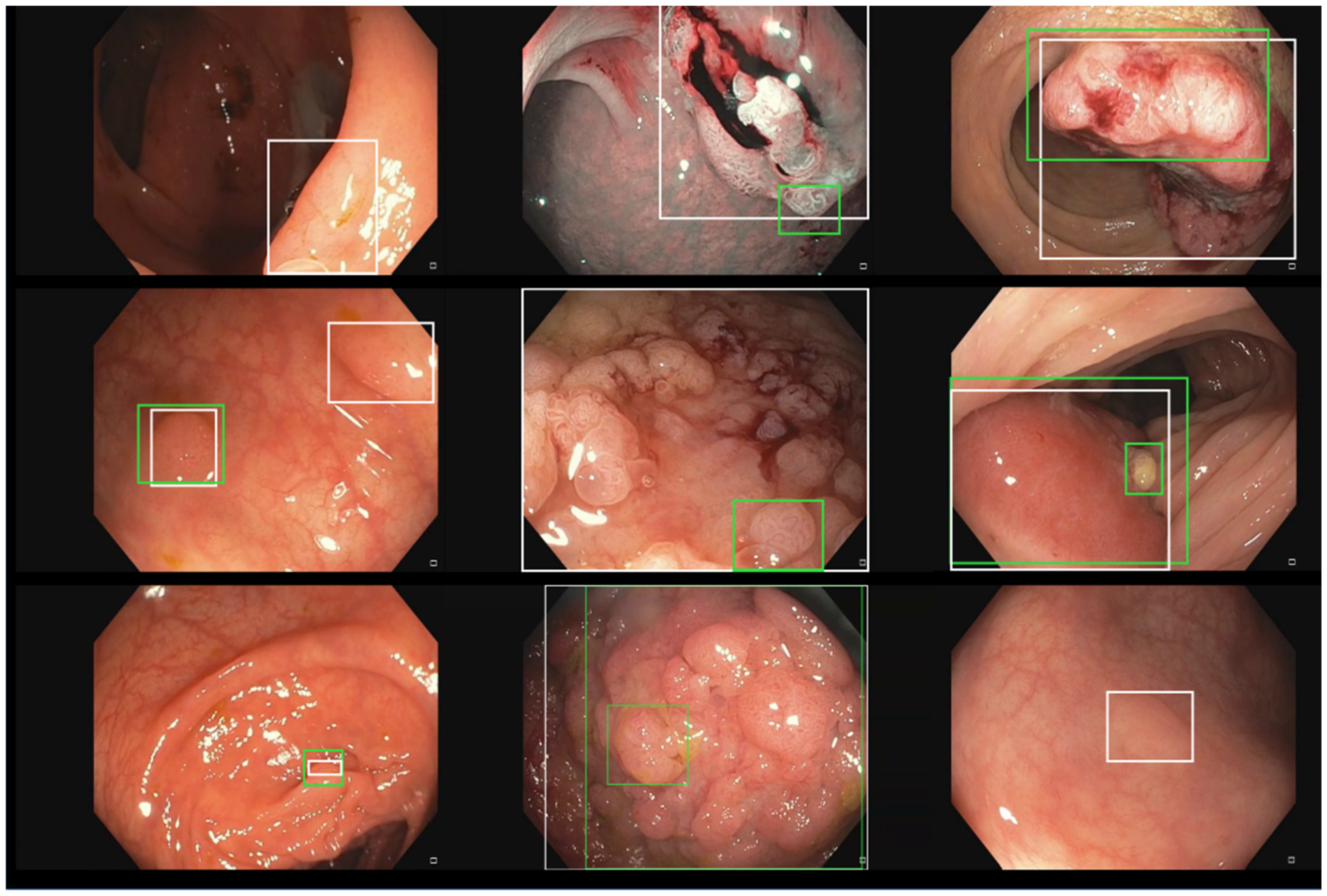
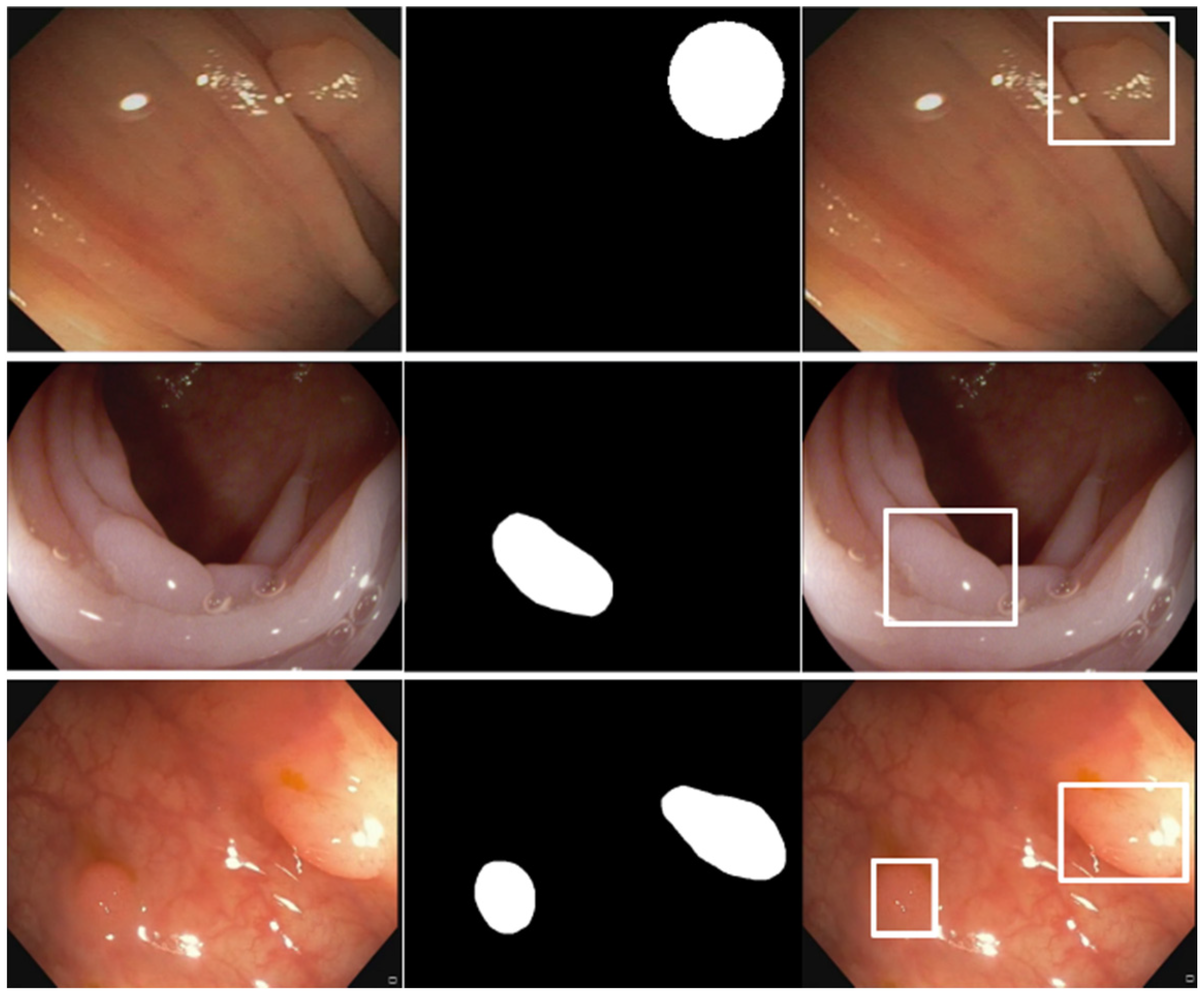
2.4. Experiments
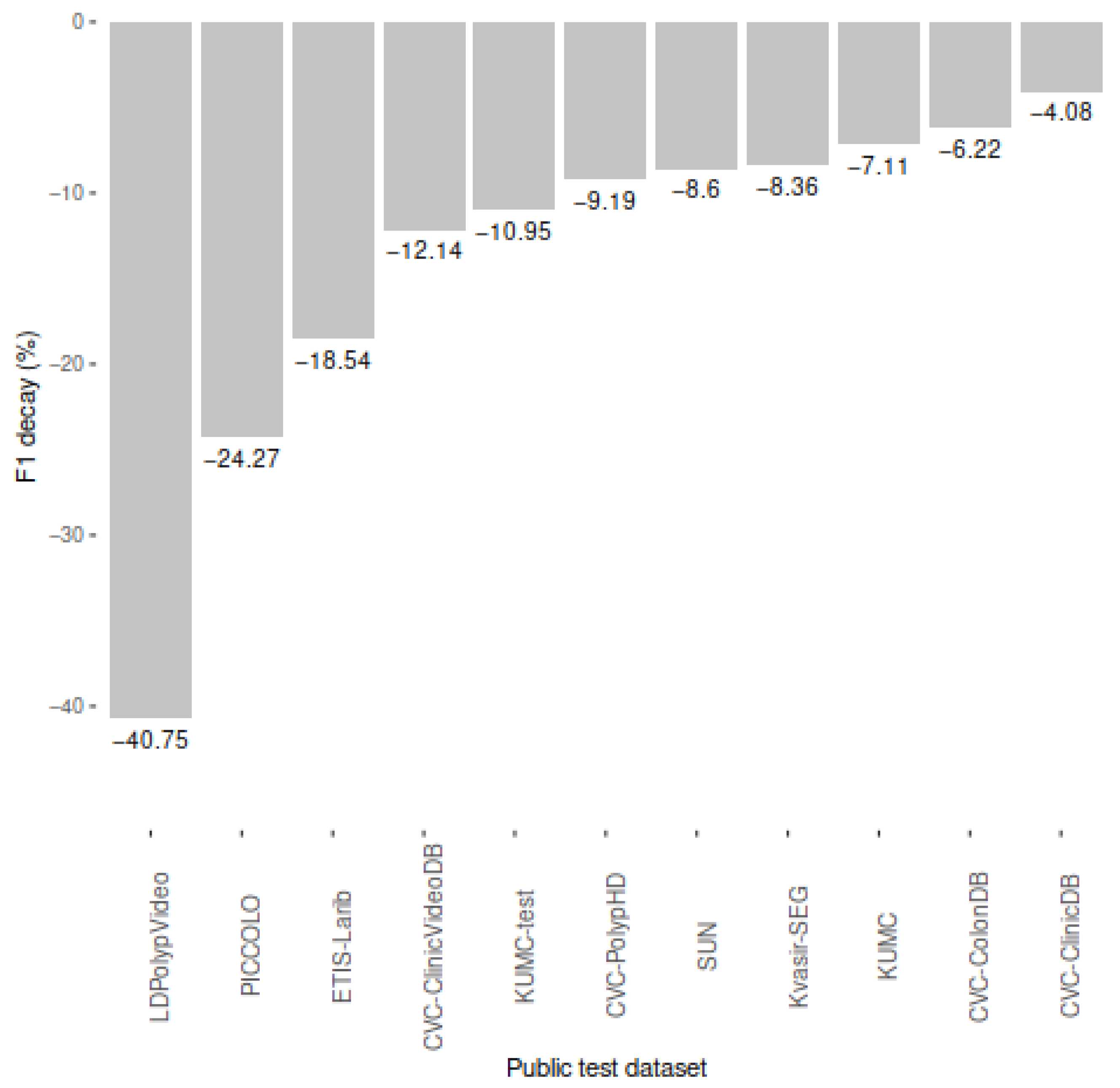
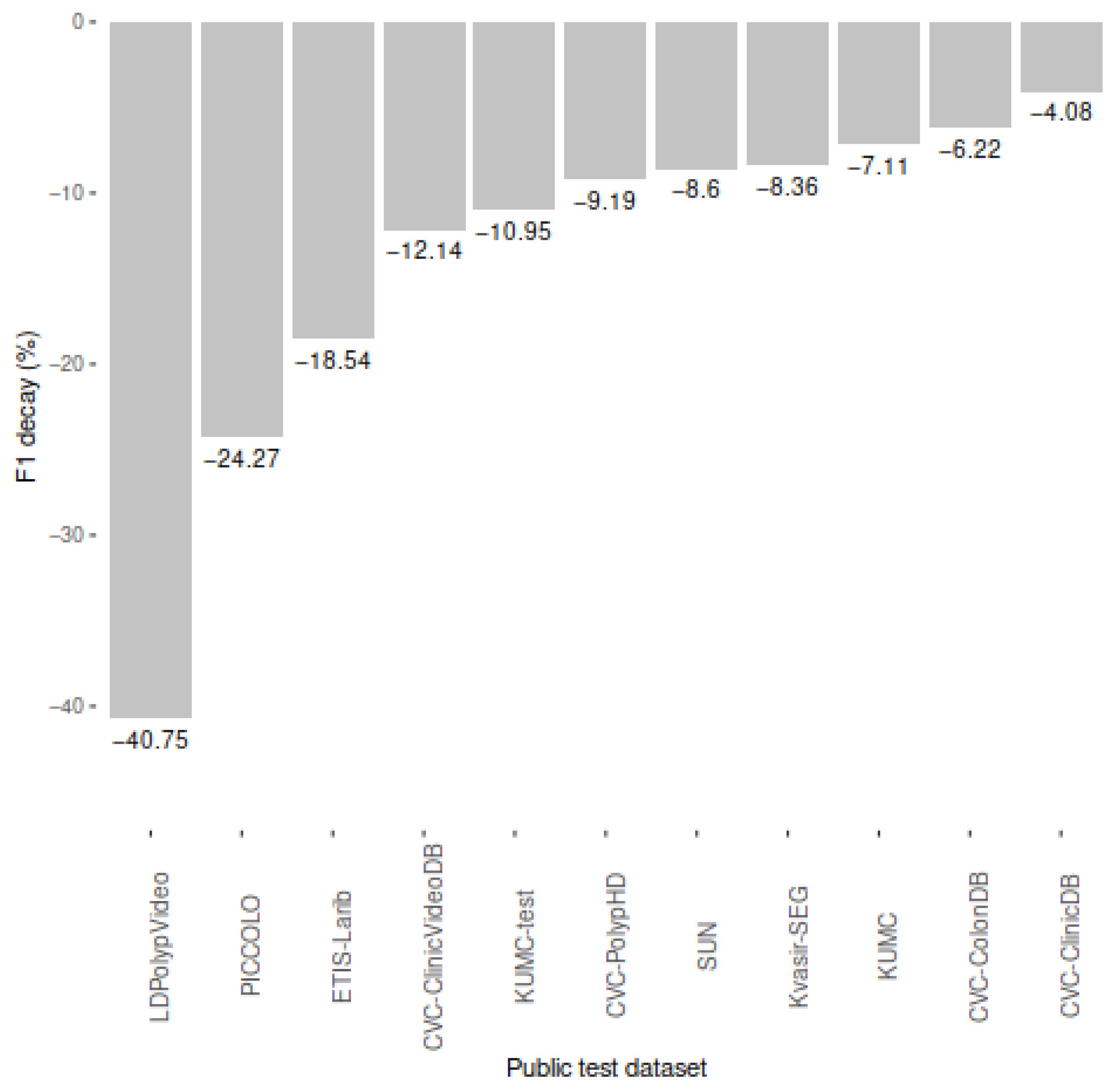
2.5. Performance of Studies on Public Colonoscopy Image Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Train | Test | Results | |||
|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | F2-Score | |||
| Brandao et al., 2018 [38] | CVC-ClinicDB + ASU-Mayo | ETIS-Larib | 0.90 | 0.73 | 0.81 | 0.86 |
| CVC-ColonDB | 0.90 | 0.80 | 0.85 | 0.88 | ||
| Zheng Y. et al., 2018 [39] | CVC-ClinicDB + CVC-ColonDB | ETIS-Larib | 0.74 | 0.77 | 0.76 | 0.75 |
| Shin Y. et al., 2018 [34] | CVC-ClinicDB | ETIS-Larib | 0.80 | 0.87 | 0.83 | 0.82 |
| CVC-Clinic VideoDB | 0.84 | 0.90 | 0.87 | 0.85 | ||
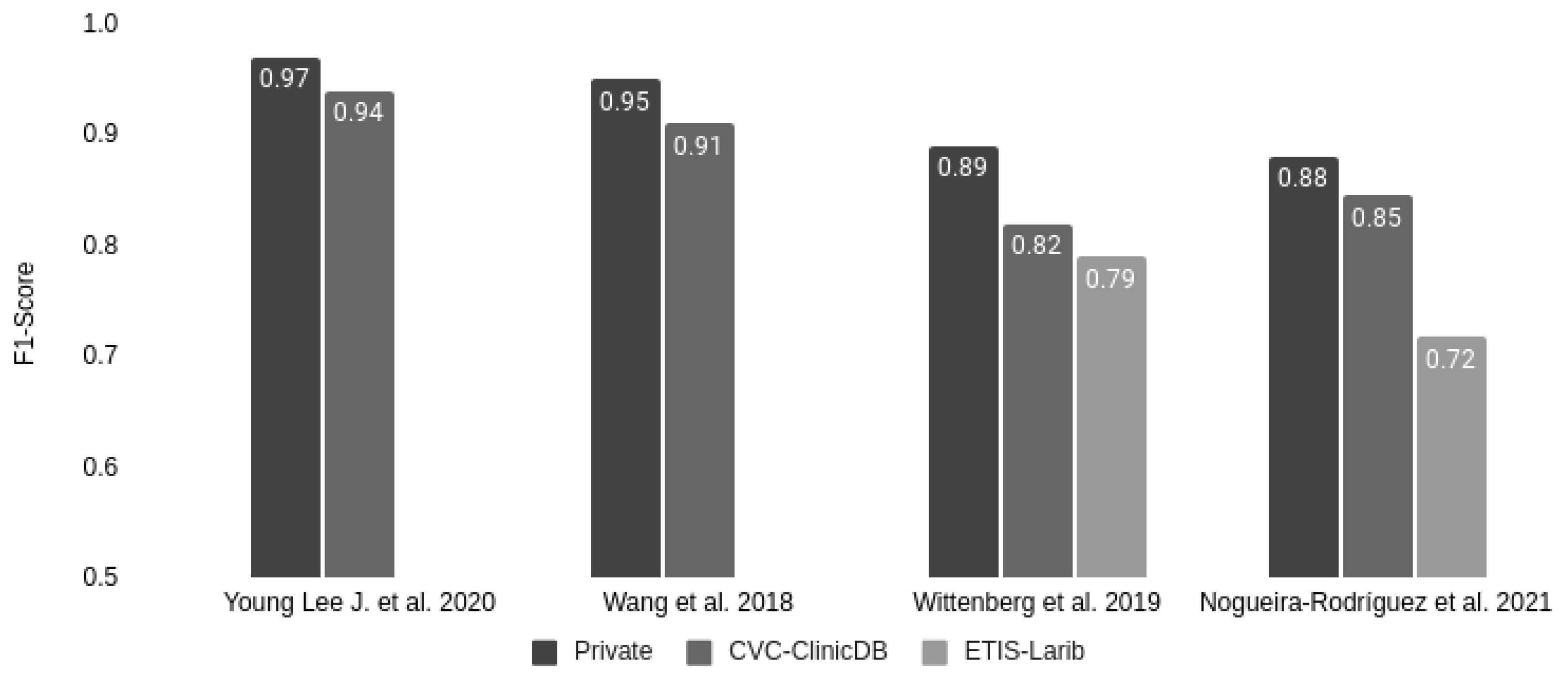
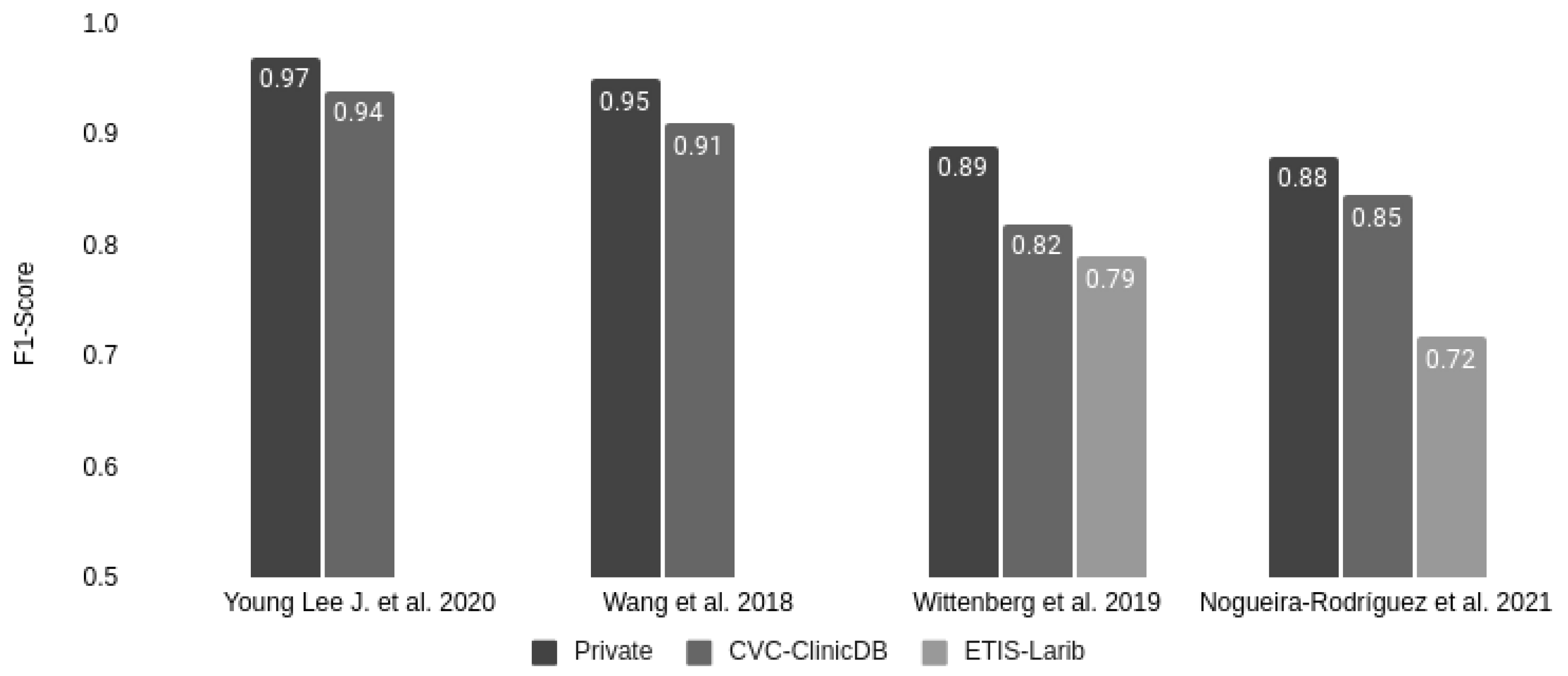
| Wang et al., 2018 [35] | Private | CVC-ClinicDB | 0.88 | 0.93 | 0.91 | 0.89 |
| Private * | 0.94 | 0.96 | 0.95 | 0.95 | ||
| Qadir et al., 2019 [40] | CVC-ClinicDB | CVC-ClinicVideoDB | 0.84 | 0.90 | 0.87 | 0.85 |
| Tian Y. et al., 2019 [41] | Private | ETIS-Larib | 0.64 | 0.74 | 0.69 | 0.66 |
| Ahmad et al., 2019 [42] | Private | ETIS-Larib | 0.92 | 0.75 | 0.83 | 0.88 |
| Sornapudi et al., 2019 [43] | CVC-ClinicDB | ETIS-Larib | 0.80 | 0.73 | 0.76 | 0.79 |
| CVC-ColonDB | 0.92 | 0.90 | 0.91 | 0.91 | ||
| CVC-PolypHD | 0.78 | 0.83 | 0.81 | 0.79 | ||
| Wittenberg et al., 2019 [36] | Private | ETIS-Larib | 0.83 | 0.74 | 0.79 | 0.81 |
| CVC-ClinicDB | 0.86 | 0.80 | 0.82 | 0.85 | ||
| Private | 0.93 | 0.86 | 0.89 | 0.92 | ||
| Jia X. et al., 2020 [44] | CVC-ColonDB | CVC-ClinicDB | 0.92 | 0.85 | 0.88 | 0.91 |
| CVC-ClinicDB | ETIS-Larib | 0.82 | 0.64 | 0.72 | 0.77 | |
| Ma Y. et al., 2020 [45] | CVC-ClinicDB | CVC-ClinicVideoDB | 0.92 | 0.88 | 0.90 | 0.91 |
| Young Lee J. et al., 2020 [37] | Private | CVC-ClinicDB | 0.90 | 0.98 | 0.94 | 0.96 |
| Private | 0.97 | 0.97 | 0.97 | 0.97 | ||
| Podlasek J. et al., 2020 [46] | Private | ETIS-Larib | 0.67 | 0.79 | 0.73 | 0.69 |
| CVC-ClinicDB | 0.91 | 0.97 | 0.94 | 0.92 | ||
| CVC-ColonDB | 0.74 | 0.92 | 0.82 | 0.77 | ||
| Hyper-Kvasir | 0.88 | 0.98 | 0.93 | 0.90 | ||
| Qadir et al., 2021 [47] | CVC-ClinicDB | ETIS-Larib | 0.87 | 0.86 | 0.86 | 0.86 |
| CVC-ColonDB | 0.91 | 0.88 | 0.90 | 0.90 | ||
| Xu J. et al., 2021 [48] | CVC-ClinicDB | ETIS-Larib | 0.72 | 0.83 | 0.77 | 0.74 |
| CVC-ClinicVideoDB | 0.66 | 0.89 | 0.76 | 0.70 | ||
| Pacal et al., 2021 [49] | CVC-ClinicDB | ETIS-Larib | 0.83 | 0.92 | 0.87 | 0.84 |
| CVC-ColonDB | 0.97 | 0.96 | 0.96 | 0.97 | ||
| Liu et al., 2021 [50] | CVC-ClinicDB | ETIS-Larib | 0.88 | 0.78 | 0.82 | 0.85 |
| Li K. et al., 2021 [23] | KUMC | KUMC-Test ** | 0.86 | 0.91 | 0.89 | 0.87 |
| Ma Y. et al., 2021 [21] | CVC-ClinicDB | CVC-ClinicVideoDB | 0.64 | 0.85 | 0.73 | 0.67 |
| LDPolypVideo | 0.47 | 0.65 | 0.55 | 0.50 | ||
| Pacal et al., 2022 [51] | SUN + PICCOLO + CVC-ClinicDB | ETIS-Larib | 0.91 | 0.91 | 0.91 | 0.91 |
| SUN | SUN *** | 0.86 | 0.96 | 0.91 | 0.88 | |
| PICCOLO | PICCOLO | 0.80 | 0.93 | 0.86 | 0.82 | |
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nogueira-Rodríguez, A.; Domínguez-Carbajales, R.; López-Fernández, H.; Iglesias, A.; Cubiella, J.; Fdez-Riverola, F.; Reboiro-Jato, M.; Glez-Peña, D. Deep Neural Networks approaches for detecting and classifying colorectal polyps. Neurocomputing 2020, 423, 721–734. [Google Scholar] [CrossRef]
- Viscaino, M.; Bustos, J.T.; Muñoz, P.; Cheein, C.A.; Cheein, F.A. Artificial intelligence for the early detection of colorectal cancer: A comprehensive review of its advantages and misconceptions. World J. Gastroenterol. 2021, 27, 6399–6414. [Google Scholar] [CrossRef] [PubMed]
- Hann, A.; Troya, J.; Fitting, D. Current status and limitations of artificial intelligence in colonoscopy. United Eur. Gastroenterol. J. 2021, 9, 527–533. [Google Scholar] [CrossRef] [PubMed]
- Ashat, M.; Klair, J.S.; Singh, D.; Murali, A.R.; Krishnamoorthi, R. Impact of real-time use of artificial intelligence in improving adenoma detection during colonoscopy: A systematic review and meta-analysis. Endosc. Int. Open 2021, 9, E513–E521. [Google Scholar] [CrossRef]
- Wang, P.; Berzin, T.M.; Brown, J.R.G.; Bharadwaj, S.; Becq, A.; Xiao, X.; Liu, P.; Li, L.; Song, Y.; Zhang, D.; et al. Real-time automatic detection system increases colonoscopic polyp and adenoma detection rates: A prospective randomised controlled study. Gut 2019, 68, 1813–1819. [Google Scholar] [CrossRef] [Green Version]
- Gong, D.; Wu, L.; Zhang, J.; Mu, G.; Shen, L.; Liu, J.; Wang, Z.; Zhou, W.; An, P.; Huang, X.; et al. Detection of colorectal adenomas with a real-time computer-aided system (ENDOANGEL): A randomised controlled study. Lancet Gastroenterol. Hepatol. 2020, 5, 352–361. [Google Scholar] [CrossRef]
- Wang, P.; Liu, X.; Berzin, T.M.; Brown, J.R.G.; Liu, P.; Zhou, C.; Lei, L.; Li, L.; Guo, Z.; Lei, S.; et al. Effect of a deep-learning computer-aided detection system on adenoma detection during colonoscopy (CADe-DB trial): A double-blind randomised study. Lancet Gastroenterol. Hepatol. 2020, 5, 343–351. [Google Scholar] [CrossRef]
- Huang, J.; Liu, W.-N.; Zhang, Y.-Y.; Bian, X.-Q.; Wang, L.-J.; Yang, Q.; Zhang, X.-D. Study on detection rate of polyps and adenomas in artificial-intelligence-aided colonoscopy. Saudi J. Gastroenterol. 2020, 26, 13–19. [Google Scholar] [CrossRef]
- Su, J.-R.; Li, Z.; Shao, X.-J.; Ji, C.-R.; Ji, R.; Zhou, R.-C.; Li, G.-C.; Liu, G.-Q.; He, Y.-S.; Zuo, X.-L.; et al. Impact of a real-time automatic quality control system on colorectal polyp and adenoma detection: A prospective randomized controlled study (with videos). Gastrointest. Endosc. 2019, 91, 415–424.e4. [Google Scholar] [CrossRef]
- Repici, A.; Badalamenti, M.; Maselli, R.; Correale, L.; Radaelli, F.; Rondonotti, E.; Ferrara, E.; Spadaccini, M.; Alkandari, A.; Fugazza, A.; et al. Efficacy of Real-Time Computer-Aided Detection of Colorectal Neoplasia in a Randomized Trial. Gastroenterology 2020, 159, 512–520.e7. [Google Scholar] [CrossRef]
- Bernal, J.; Tajkbaksh, N.; Sánchez, F.J.; Matuszewski, B.J.; Chen, H.; Yu, L.; Angermann, Q.; Romain, O.; Rustad, B.; Balasingham, I.; et al. Comparative Validation of Polyp Detection Methods in Video Colonoscopy: Results from the MICCAI 2015 Endoscopic Vision Challenge. IEEE Trans. Med. Imaging 2017, 36, 1231–1249. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, M.G.; Gil, D.; Rodríguez, C.; Vilariño, F. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 2015, 43, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Silva, J.S.; Histace, A.; Romain, O.; Dray, X.; Granado, B. Toward embedded detection of polyps in WCE images for early diagnosis of colorectal cancer. Int. J. Comput. Assist. Radiol. Surg. 2013, 9, 283–293. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Gurudu, S.R.; Liang, J. Automated Polyp Detection in Colonoscopy Videos Using Shape and Context Information. IEEE Trans. Med. Imaging 2015, 35, 630–644. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Sánchez, J.; Vilariño, F. Towards automatic polyp detection with a polyp appearance model. Pattern Recognit. 2012, 45, 3166–3182. [Google Scholar] [CrossRef]
- Vázquez, D.; Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, M.G.; López, A.M.; Romero, A.; Drozdzal, M.; Courville, A. A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images. J. Health Eng. 2017, 2017, 1–9. [Google Scholar] [CrossRef]
- Angermann, Q.; Bernal, J.; Sánchez-Montes, C.; Hammami, M.; Fernández-Esparrach, G.; Dray, X.; Romain, O.; Sánchez, F.J.; Histace, A. Towards Real-Time Polyp Detection in Colonoscopy Videos: Adapting Still Frame-Based Methodologies for Video Sequences Analysis. In Computer Assisted and Robotic Endoscopy and Clinical Image-Based Procedures; Cardoso, M.J., Arbel, T., Luo, X., Wesarg, S., Reichl, T., González Ballester, M.Á., McLeod, J., Drechsler, K., Peters, T., Erdt, M., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 29–41. [Google Scholar] [CrossRef]
- Bernal, J.J.; Histace, A.; Masana, M.; Angermann, Q.; Sánchez-Montes, C.; Rodriguez, C.; Hammami, M.; Garcia-Rodriguez, A.; Córdova, H.; Romain, O.; et al. Polyp Detection Benchmark in Colonoscopy Videos using GTCreator: A Novel Fully Configurable Tool for Easy and Fast Annotation of Image Databases. In Proceedings of the 32nd CARS Conference, Berlin, Germany, 22–23 June 2018. [Google Scholar]
- Sánchez-Peralta, L.F.; Pagador, J.B.; Picón, A.; Calderón, Á.J.; Polo, F.; Andraka, N.; Bilbao, R.; Glover, B.; Saratxaga, C.L.; Sánchez-Margallo, F.M. PICCOLO White-Light and Narrow-Band Imaging Colonoscopic Dataset: A Performance Comparative of Models and Datasets. Appl. Sci. 2020, 10, 8501. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; de Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-SEG: A Segmented Polyp Dataset. Int. Conf. Multimed. Model. 2019, 11962, 451–462. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.; Chen, X.; Cheng, K.; Li, Y.; Sun, B. LDPolypVideo Benchmark: A Large-Scale Colonoscopy Video Dataset of Diverse Polyps. Int. Conf. Med. Image Comput. Comput.-Assist. Interv. 2021, 12905, 387–396. [Google Scholar] [CrossRef]
- Misawa, M.; Kudo, S.-E.; Mori, Y.; Hotta, K.; Ohtsuka, K.; Matsuda, T.; Saito, S.; Kudo, T.; Baba, T.; Ishida, F.; et al. Development of a computer-aided detection system for colonoscopy and a publicly accessible large colonoscopy video database (with video). Gastrointest. Endosc. 2020, 93, 960–967.e3. [Google Scholar] [CrossRef]
- Li, K.; Fathan, M.I.; Patel, K.; Zhang, T.; Zhong, C.; Bansal, A.; Rastogi, A.; Wang, J.S.; Wang, G. Colonoscopy polyp detection and classification: Dataset creation and comparative evaluations. PLoS ONE 2021, 16, e0255809. [Google Scholar] [CrossRef]
- Mesejo, P.; Pizarro, D.; Abergel, A.; Rouquette, O.; Beorchia, S.; Poincloux, L.; Bartoli, A. Computer-Aided Classification of Gastrointestinal Lesions in Regular Colonoscopy. IEEE Trans. Med Imaging 2016, 35, 2051–2063. [Google Scholar] [CrossRef] [PubMed]
- Ali, S.; Jha, D.; Ghatwary, N.; Realdon, S.; Cannizzaro, R.; Salem, O.E.; Lamarque, D.; Daul, C.; Riegler, M.A.; Anonsen, K.V.; et al. PolypGen: A multi-center polyp detection and segmentation dataset for generalisability assessment. arXiv 2021, arXiv:2106.04463. [Google Scholar] [CrossRef]
- Nogueira-Rodríguez, A.; Domínguez-Carbajales, R.; Campos-Tato, F.; Herrero, J.; Puga, M.; Remedios, D.; Rivas, L.; Sánchez, E.; Iglesias, A.; Cubiella, J.; et al. Real-time polyp detection model using convolutional neural networks. Neural Comput. Appl. 2021, 1–22. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Guo, J.; He, H.; He, T.; Lausen, L.; Li, M.; Lin, H.; Shi, X.; Wang, C.; Xie, J.; Zha, S.; et al. GluonCV and GluonNLP: Deep Learning in Computer Vision and Natural Language Processing. J. Mach. Learn. Res. 2020, 21, 1–7. [Google Scholar]
- Wang, W.; Tian, J.; Zhang, C.; Luo, Y.; Wang, X.; Li, J. An improved deep learning approach and its applications on colonic polyp images detection. BMC Med. Imaging 2020, 20, 83. [Google Scholar] [CrossRef]
- Tashk, A.; Herp, J.; Nadimi, E. Fully Automatic Polyp Detection Based on a Novel U-Net Architecture and Morphological Post-Process. In Proceedings of the 2019 International Conference on Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO), Athens, Greece, 8–10 December 2019; pp. 37–41. [Google Scholar] [CrossRef]
- López-Fernández, H.; Graña-Castro, O.; Nogueira-Rodríguez, A.; Reboiro-Jato, M.; Glez-Peña, D. Compi: A framework for portable and reproducible pipelines. PeerJ Comput. Sci. 2021, 7, e593. [Google Scholar] [CrossRef] [PubMed]
- Nogueira-Rodríguez, A.; López-Fernández, H.; Graña-Castro, O.; Reboiro-Jato, M.; Glez-Peña, D. Compi Hub: A Public Repository for Sharing and Discovering Compi Pipelines. In Practical Applications of Computational Biology & Bioinformatics, 14th International Conference (PACBB 2020); Panuccio, G., Rocha, M., Fdez-Riverola, F., Mohamad, M.S., Casado-Vara, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 51–59. [Google Scholar] [CrossRef]
- Shin, Y.; Qadir, H.A.; Aabakken, L.; Bergsland, J.; Balasingham, I. Automatic Colon Polyp Detection Using Region Based Deep CNN and Post Learning Approaches. IEEE Access 2018, 6, 40950–40962. [Google Scholar] [CrossRef]
- Wang, P.; Xiao, X.; Brown, J.R.G.; Berzin, T.M.; Tu, M.; Xiong, F.; Hu, X.; Liu, P.; Song, Y.; Zhang, D.; et al. Development and validation of a deep-learning algorithm for the detection of polyps during colonoscopy. Nat. Biomed. Eng. 2018, 2, 741–748. [Google Scholar] [CrossRef] [PubMed]
- Wittenberg, T.; Zobel, P.; Rathke, M.; Mühldorfer, S. Computer Aided Detection of Polyps in Whitelight- Colonoscopy Images using Deep Neural Networks. Curr. Dir. Biomed. Eng. 2019, 5, 231–234. [Google Scholar] [CrossRef]
- Lee, J.Y.; Jeong, J.; Song, E.M.; Ha, C.; Lee, H.J.; Koo, J.E.; Yang, D.-H.; Kim, N.; Byeon, J.-S. Real-time detection of colon polyps during colonoscopy using deep learning: Systematic validation with four independent datasets. Sci. Rep. 2020, 10, 8379. [Google Scholar] [CrossRef] [PubMed]
- Brandao, P.; Zisimopoulos, O.; Mazomenos, E.; Ciuti, G.; Bernal, J.; Visentini-Scarzanella, M.; Menciassi, A.; Dario, P.; Koulaouzidis, A.; Arezzo, A.; et al. Towards a Computed-Aided Diagnosis System in Colonoscopy: Automatic Polyp Segmentation Using Convolution Neural Networks. J. Med Robot. Res. 2018, 3, 1840002. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Zhang, R.; Yu, R.; Jiang, Y.; Mak, T.W.C.; Wong, S.H.; Lau, J.Y.W.; Poon, C.C.Y. Localisation of Colorectal Polyps by Convolutional Neural Network Features Learnt from White Light and Narrow Band Endoscopic Images of Multiple Databases. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4142–4145. [Google Scholar] [CrossRef]
- Qadir, H.A.; Balasingham, I.; Solhusvik, J.; Bergsland, J.; Aabakken, L.; Shin, Y. Improving Automatic Polyp Detection Using CNN by Exploiting Temporal Dependency in Colonoscopy Video. IEEE J. Biomed. Health Inform. 2019, 24, 180–193. [Google Scholar] [CrossRef]
- Tian, Y.; Pu, L.Z.; Singh, R.; Burt, A.D.; Carneiro, G. One-Stage Five-Class Polyp Detection and Classification. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 70–73. [Google Scholar] [CrossRef]
- Ahmad, O.F.; Brandao, P.; Sami, S.S.; Mazomenos, E.; Rau, A.; Haidry, R.; Vega, R.; Seward, E.; Vercauteren, T.K.; Stoyanov, D.; et al. Tu1991 Artificial intelligence for real-time polyp localisation in colonoscopy withdrawal videos. Gastrointest. Endosc. 2019, 89, AB647. [Google Scholar] [CrossRef]
- Sornapudi, S.; Meng, F.; Yi, S. Region-Based Automated Localization of Colonoscopy and Wireless Capsule Endoscopy Polyps. Appl. Sci. 2019, 9, 2404. [Google Scholar] [CrossRef] [Green Version]
- Jia, X.; Mai, X.; Cui, Y.; Yuan, Y.; Xing, X.; Seo, H.; Xing, L.; Meng, M.Q.-H. Automatic Polyp Recognition in Colonoscopy Images Using Deep Learning and Two-Stage Pyramidal Feature Prediction. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1570–1584. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, X.; Sun, B. Polyp Detection in Colonoscopy Videos by Bootstrapping Via Temporal Consistency. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1360–1363. [Google Scholar] [CrossRef]
- Podlasek, J.; Heesch, M.; Podlasek, R.; Kilisiński, W.; Filip, R. Real-time deep learning-based colorectal polyp localization on clinical video footage achievable with a wide array of hardware configurations. Endosc. Int. Open 2021, 09, E741–E748. [Google Scholar] [CrossRef]
- Qadir, H.A.; Shin, Y.; Solhusvik, J.; Bergsland, J.; Aabakken, L.; Balasingham, I. Toward real-time polyp detection using fully CNNs for 2D Gaussian shapes prediction. Med. Image Anal. 2020, 68, 101897. [Google Scholar] [CrossRef]
- Xu, J.; Zhao, R.; Yu, Y.; Zhang, Q.; Bian, X.; Wang, J.; Ge, Z.; Qian, D. Real-time automatic polyp detection in colonoscopy using feature enhancement module and spatiotemporal similarity correlation unit. Biomed. Signal. Process. Control. 2021, 66, 102503. [Google Scholar] [CrossRef]
- Pacal, I.; Karaboga, D. A robust real-time deep learning based automatic polyp detection system. Comput. Biol. Med. 2021, 134, 104519. [Google Scholar] [CrossRef]
- Liu, X.; Guo, X.; Liu, Y.; Yuan, Y. Consolidated domain adaptive detection and localization framework for cross-device colonoscopic images. Med. Image Anal. 2021, 71, 102052. [Google Scholar] [CrossRef] [PubMed]
- Pacal, I.; Karaman, A.; Karaboga, D.; Akay, B.; Basturk, A.; Nalbantoglu, U.; Coskun, S. An efficient real-time colonic polyp detection with YOLO algorithms trained by using negative samples and large datasets. Comput. Biol. Med. 2021, 141, 105031. [Google Scholar] [CrossRef] [PubMed]

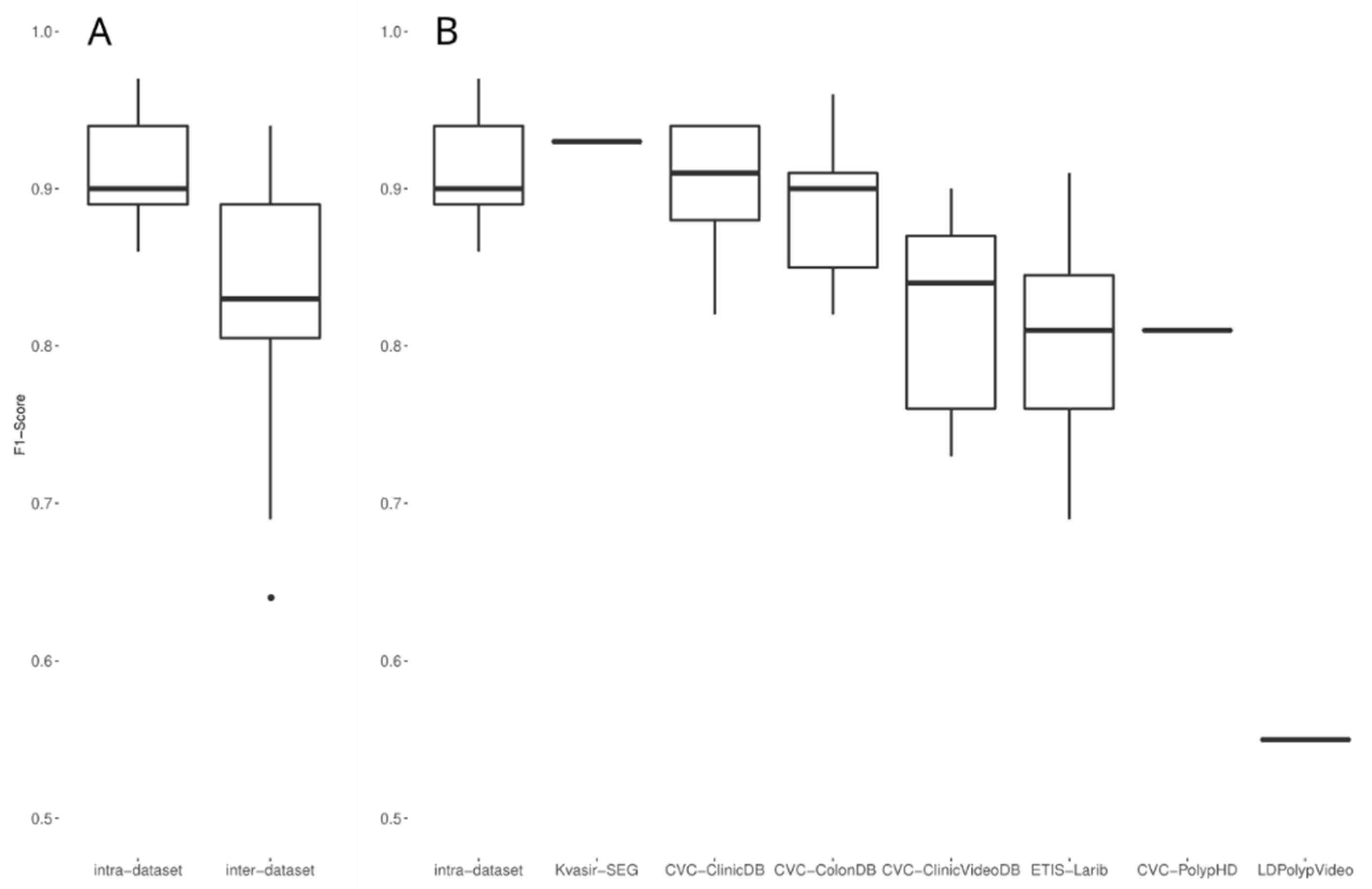
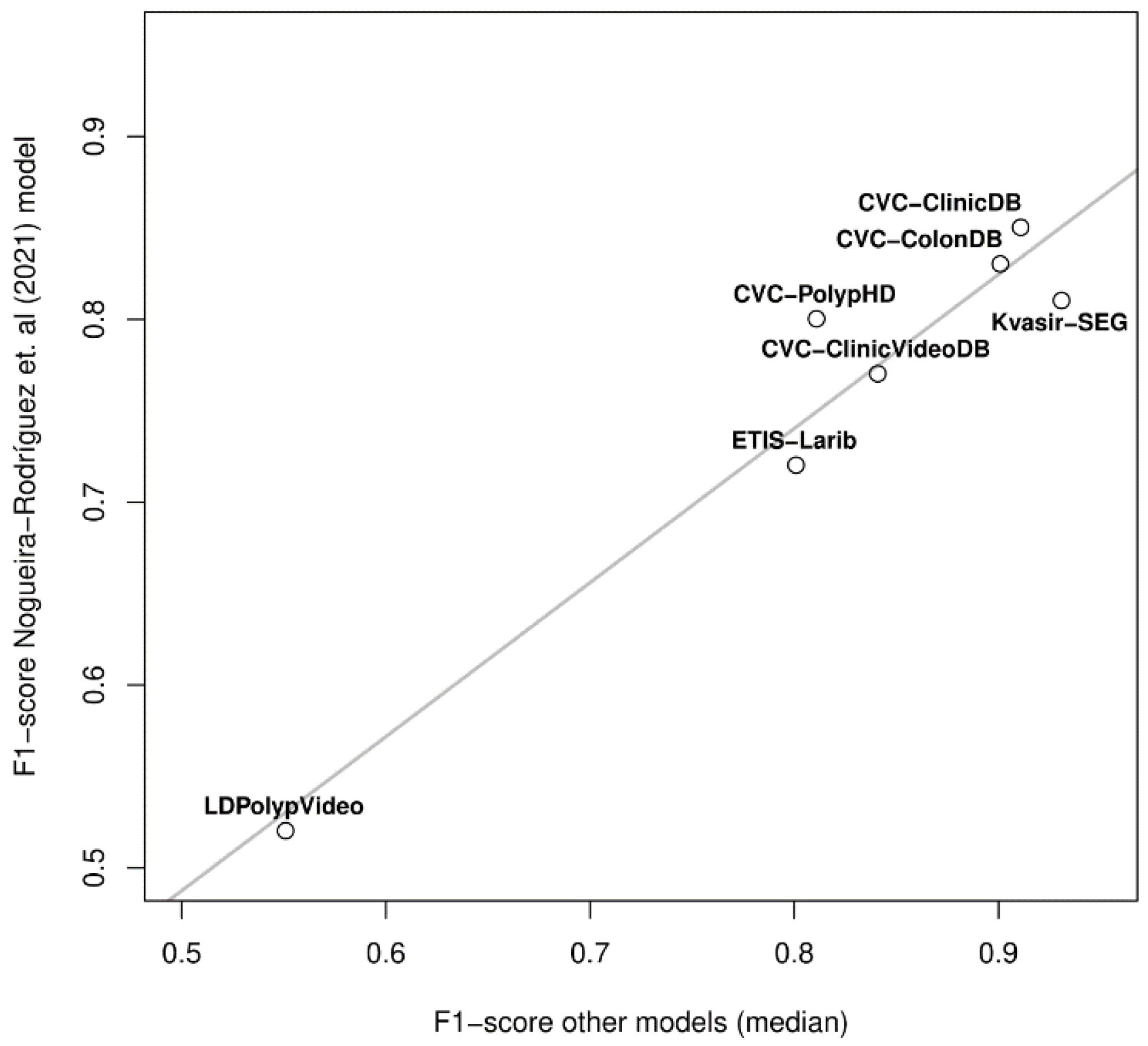
| Dataset | Paper Publication Year | Description | Resolution | Ground Truth | Presence of Multiple Polyp Images | Presence of Non-Polyp Images |
|---|---|---|---|---|---|---|
| CVC-ClinicDB [12] | 2015 | 612 sequential WL images with polyps extracted from 31 sequences (23 patients) with 31 different polyps | 384 × 288 | Binary mask to locate the polyp | yes | no |
| CVC-ColonDB [15,16] | 2012 | 300 sequential WL images with polyps extracted from 13 sequences (13 patients) | 574 × 500 | Binary mask to locate the polyp | no | no |
| CVC-PolypHD [15,16] | 2018 | 56 WL images | 1920 × 1080 | Binary mask to locate the polyp | yes | no |
| ETIS-Larib [13] | 2014 | 196 WL images with polyps extracted from 34 sequences with 44 different polyps | 1225 × 966 | Binary mask to locate the polyp | yes | no |
| Kvasir-SEG [20] | 2020 | 1000 polyp images | 332 × 487 1920 × 1072 | Binary mask and bounding box to locate the polyp | yes | no |
| CVC-ClinicVideoDB [17,18] | 2017 | 11,954 images in total with 10,025 images of polyps | 384 × 288 | Binary mask to locate the polyp | no | yes |
| PICCOLO [19] | 2020 | 3433 images (2131 WL and 1302 NBI) from 76 lesions from 40 patients | 854 × 480 1920 × 1080 | Binary mask to locate the polyp | yes | yes |
| KUMC dataset [23] | 2021 | 37,899 images in total, including the CVC-ColonDB, ASU-Mayo Clinic Colonoscopy Video, and Colonoscopic Dataset datasets | Various resolutions | Bounding box to locate the polyp | no | yes |
| SUN [22] | 2021 | 49,136 images with polyps. The polyp samples of 100 cases | 1240 × 1080 | Bounding box to locate the polyp | no | no * |
| LDPolypVideo [21] | 2021 | 160 videos (40,187 frames: 33,876 polyp images and 6311 non-polyp images) with 200 labeled polyps. | 560 × 480 | Bounding box to locate the polyp | yes | yes |
| Dataset | Number of Images for Test | Results | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | F2-Score | AP | ||
| CVC-ClinicDB | 612 | 0.82 | 0.87 | 0.85 | 0.83 | 0.82 |
| CVC-ColonDB | 300 | 0.84 | 0.81 | 0.83 | 0.83 | 0.85 |
| CVC-PolypHD | 56 | 0.75 | 0.86 | 0.80 | 0.77 | 0.79 |
| ETIS-Larib | 196 | 0.72 | 0.71 | 0.72 | 0.72 | 0.69 |
| Kvasir-SEG | 1000 | 0.78 | 0.84 | 0.81 | 0.82 | 0.79 |
| PICCOLO | 3433 | 0.60 | 0.76 | 0.67 | 0.62 | 0.63 |
| CVC-ClinicVideoDB | 11,954 | 0.80 | 0.75 | 0.77 | 0.79 | 0.77 |
| KUMC dataset | 37,899 | 0.81 | 0.83 | 0.82 | 0.81 | 0.83 |
| KUMC dataset–Test | 4872 | 0.76 | 0.81 | 0.78 | 0.77 | 0.79 |
| SUN | 49,136 | 0.78 | 0.83 | 0.81 | 0.79 | 0.81 |
| LDPolypVideo | 40,186 | 0.49 | 0.56 | 0.52 | 0.50 | 0.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nogueira-Rodríguez, A.; Reboiro-Jato, M.; Glez-Peña, D.; López-Fernández, H. Performance of Convolutional Neural Networks for Polyp Localization on Public Colonoscopy Image Datasets. Diagnostics 2022, 12, 898. https://doi.org/10.3390/diagnostics12040898
Nogueira-Rodríguez A, Reboiro-Jato M, Glez-Peña D, López-Fernández H. Performance of Convolutional Neural Networks for Polyp Localization on Public Colonoscopy Image Datasets. Diagnostics. 2022; 12(4):898. https://doi.org/10.3390/diagnostics12040898
Chicago/Turabian StyleNogueira-Rodríguez, Alba, Miguel Reboiro-Jato, Daniel Glez-Peña, and Hugo López-Fernández. 2022. "Performance of Convolutional Neural Networks for Polyp Localization on Public Colonoscopy Image Datasets" Diagnostics 12, no. 4: 898. https://doi.org/10.3390/diagnostics12040898
APA StyleNogueira-Rodríguez, A., Reboiro-Jato, M., Glez-Peña, D., & López-Fernández, H. (2022). Performance of Convolutional Neural Networks for Polyp Localization on Public Colonoscopy Image Datasets. Diagnostics, 12(4), 898. https://doi.org/10.3390/diagnostics12040898