


Inter- and Intra-Observer Agreement When Using a Diagnostic Labeling Scheme for Annotating Findings on Chest X-rays—An Early Step in the Development of a Deep Learning-Based Decision Support System

 , , ,
, , , 
 and
and 
Abstract
:1. Introduction
2. Materials and Methods
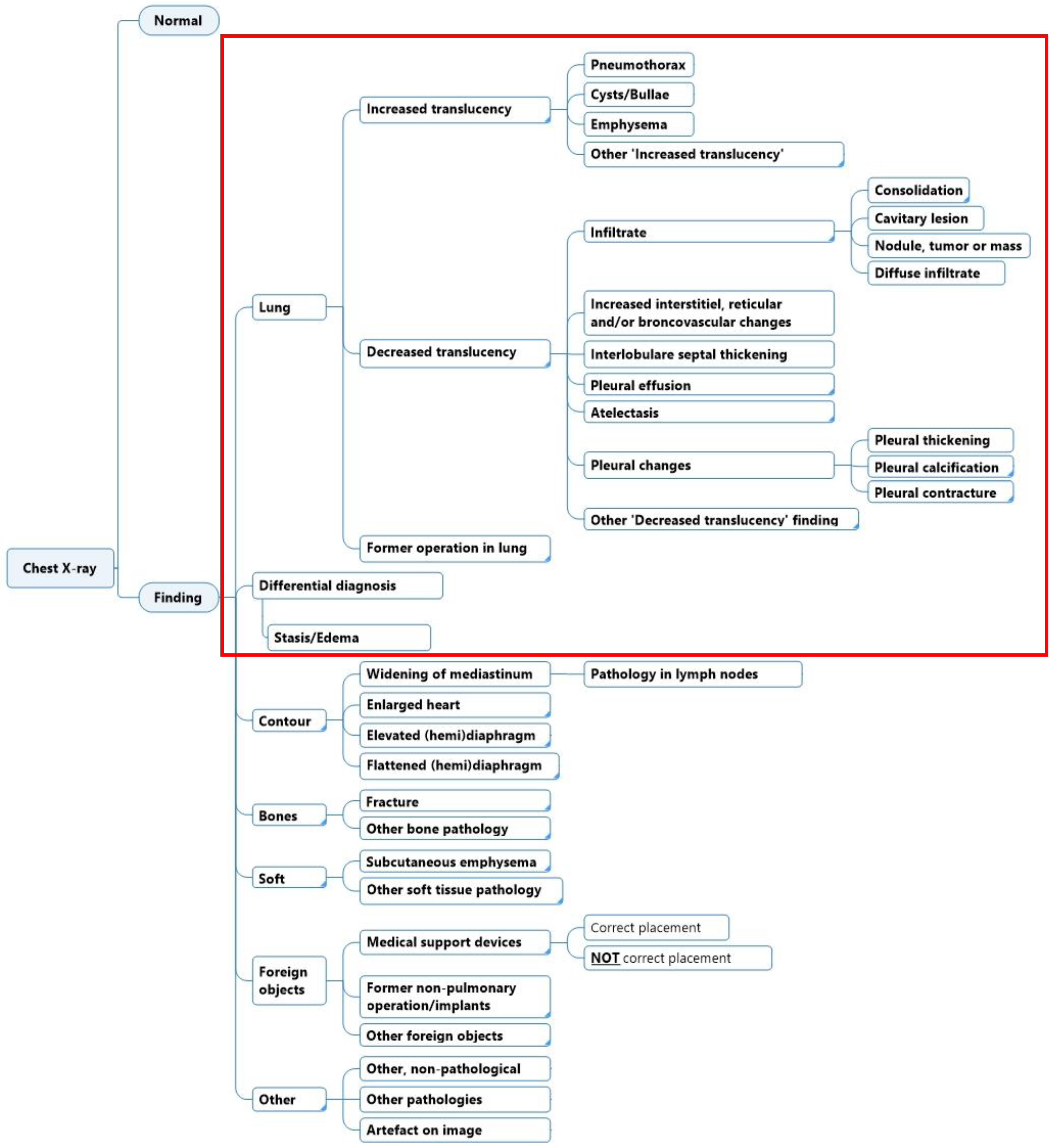
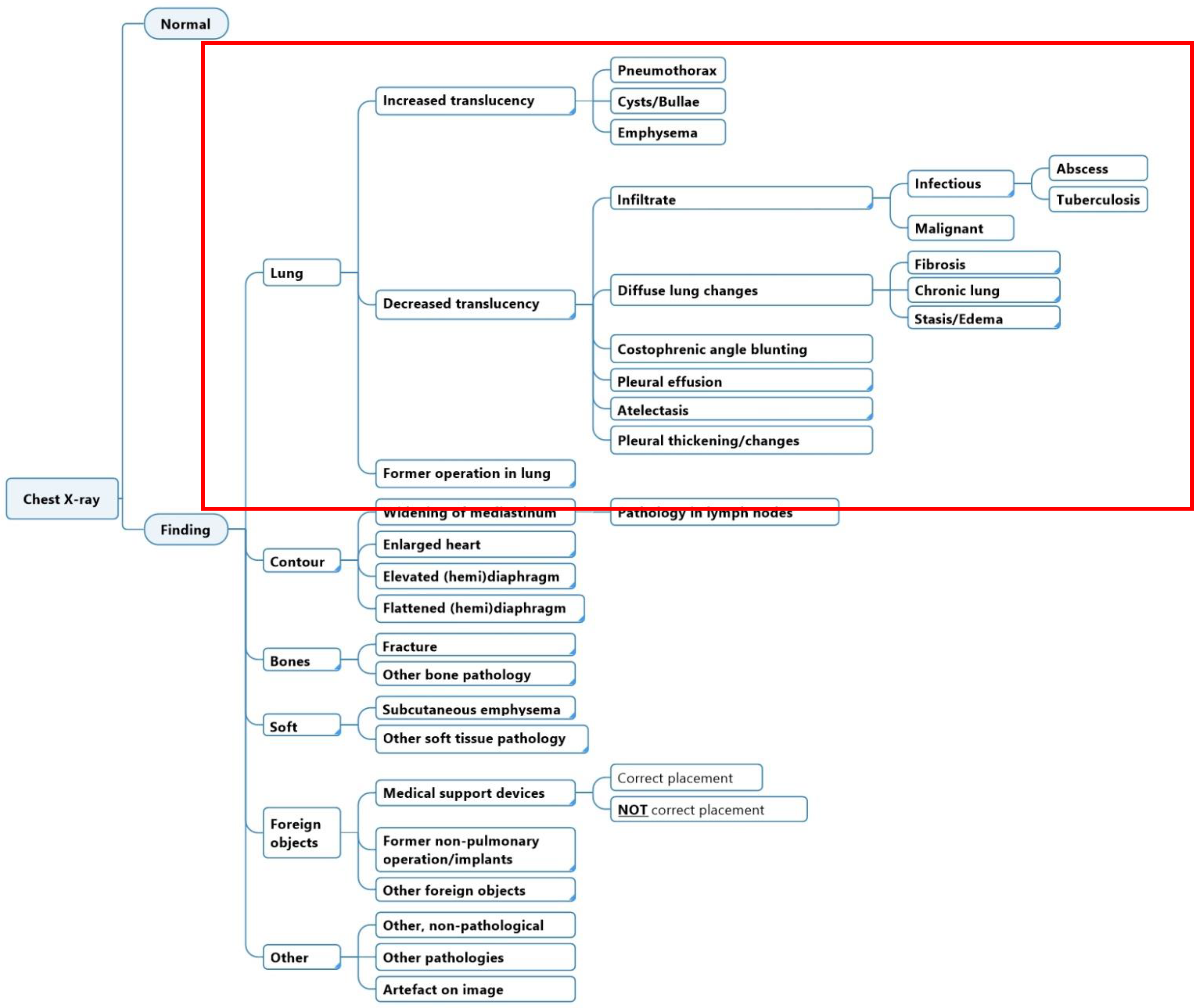
2.1. Diagnostic Labeling Scheme
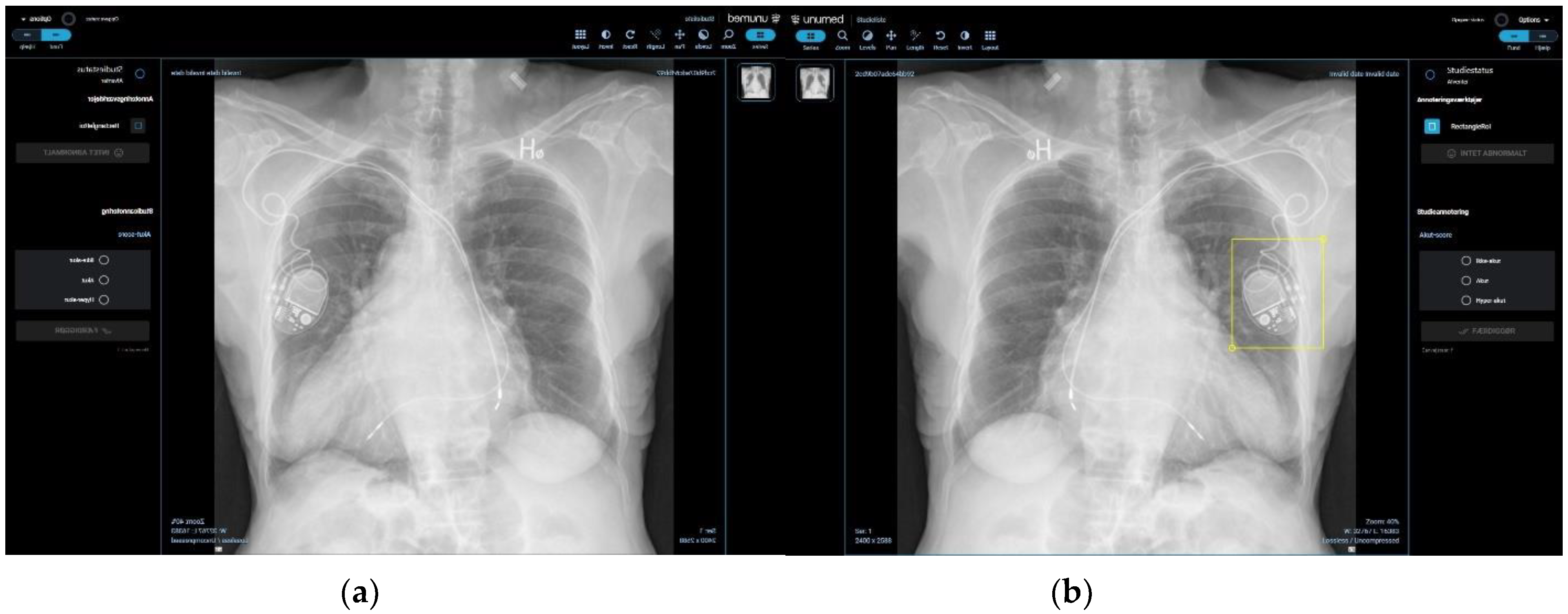
2.2. Dataset and Annotation Software
2.3. Participants and Image Annotation Process
2.4. Statistical Analysis
3. Results
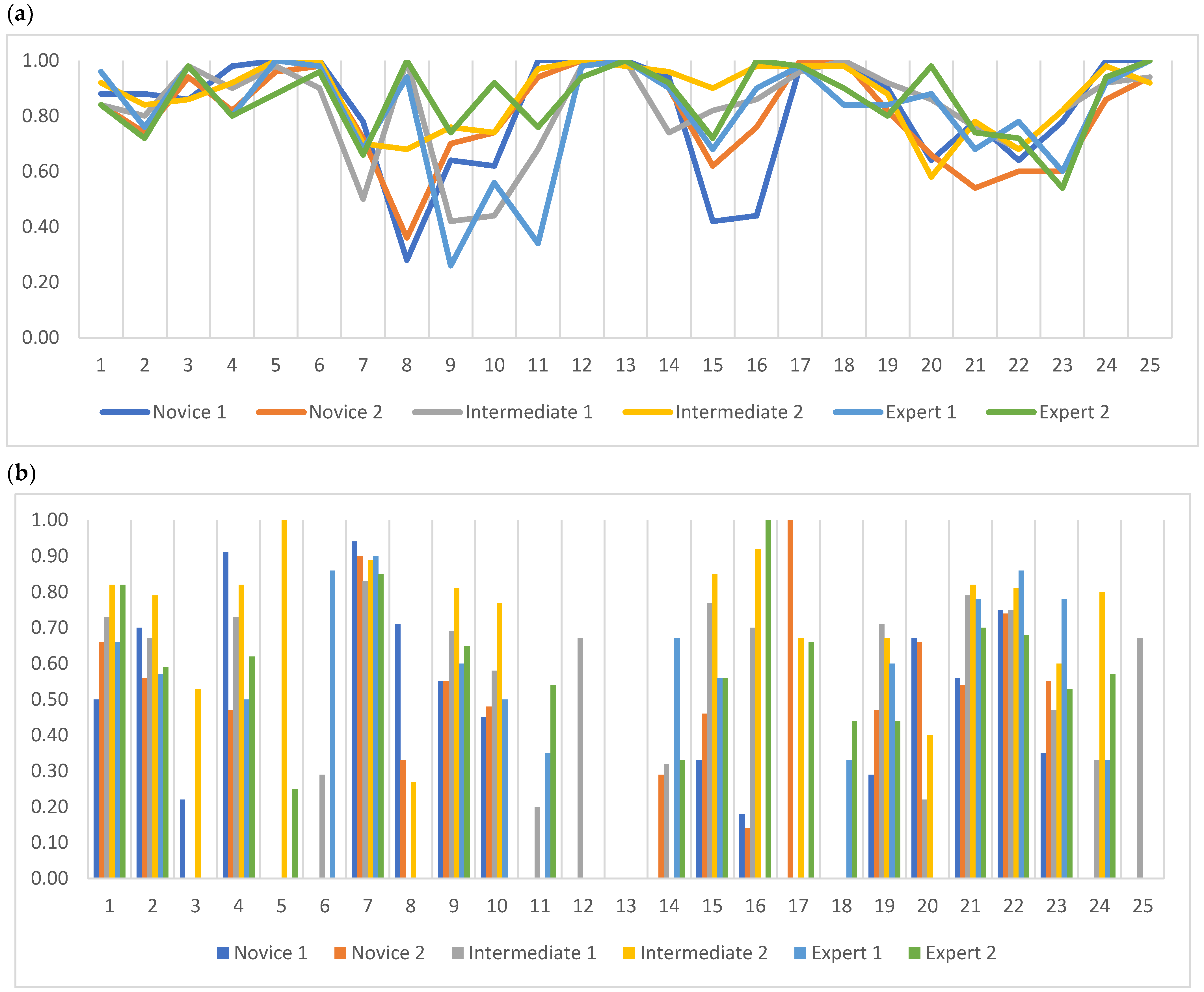
3.1. Inter-Reader Agreement
3.1.1. Agreement between Multiple Readers
3.1.2. Agreement between Two Readers with the Same Experience Level
3.2. Intra-Reader Agreement
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PABAK | Novice 1 vs. Novice 2 | Intermediate 1 vs. Intermediate 2 | Experienced 1 vs. Experienced 2 |
|---|---|---|---|
| Normal | 0.78 | 0.80 | 0.76 |
| Increased Translucency incl. sub-categories | 0.66 | 0.80 | 0.78 |
| Increased Translucency | 0.80 | 0.84 | 1 |
| Pneumothorax | 0.82 | 0.90 | 0.82 |
| Cyst/Bullae | 0.98 | 0.98 | 0.96 |
| Emphysema | 0.98 | 0.94 | 0.92 |
| Decreased Translucency incl. sub-categories | 0.48 | 0.64 | 0.50 |
| Decreased Translucency | 0.12 | 0.78 | 1 |
| Infiltrate incl. sub-categories | 0.62 | 0.56 | 0.22 |
| Infiltrate | 0.66 | 0.46 | 0.48 |
| Infection | 0.96 | 0.86 | 0.24 |
| Abscess | 1 | 0.98 | 0.94 |
| Tuberculosis | 1 | 0.98 | 1 |
| Malignant | 0.90 | 0.82 | 0.88 |
| Diffuse Lung Changes incl. sub-categories | 0.28 | 0.70 | 0.54 |
| Diffuse Lung Changes | 0.36 | 0.84 | 0.98 |
| Fibrosis | 0.94 | 0.96 | 0.94 |
| Chronic Lung Changes | 0.98 | 0.98 | 0.86 |
| Stasis/Edema | 0.84 | 0.86 | 0.70 |
| Costophrenic Angle Blunting | 0.44 | 0.54 | 0.94 |
| Pleural Effusion | 0.68 | 0.84 | 0.66 |
| Costophrenic Angle Blunting AND Pleural Effusion | 0.50 | 0.56 | 0.62 |
| Atelectasis | 0.44 | 0.72 | 0.38 |
| Pleural Changes | 0.86 | 0.88 | 0.94 |
| Former Operation in Lung Tissue | 0.96 | 0.84 | 1 |
| Specific Agreement | Novice 1 vs. Novice 2 | Intermediate 1 vs. Intermediate 2 | Experienced 1 vs. Experienced 2 | |||
|---|---|---|---|---|---|---|
| PPA | PNA | PPA | PNA | PPA | PNA | |
| Normal | 0.27 | 0.94 | 0.67 | 0.94 | 0.65 | 0.92 |
| Increased Translucency incl. sub-categories | 0.19 | 0.91 | 0.69 | 0.94 | 0.56 | 0.94 |
| Increased Translucency | 0 | 0.95 | 0 | 0.96 | — | 1 |
| Pneumothorax | 0.31 | 0.96 | 0.76 | 0.97 | 0.52 | 0.95 |
| Cyst/Bullae | 0 | 0.99 | 0 | 0.99 | 0 | 0.99 |
| Emphysema | 0 | 0.99 | 0 | 0.98 | 0 | 0.98 |
| Decreased Translucency incl. sub-categories | 0.84 | 0.32 | 0.87 | 0.72 | 0.81 | 0.62 |
| Decreased Translucency | 0.46 | 0.63 | 0 | 0.94 | — | 1 |
| Infiltrate incl. sub-categories | 0.56 | 0.88 | 0.68 | 0.83 | 0.43 | 0.70 |
| Infiltrate | 0.48 | 0.89 | 0.53 | 0.81 | 0 | 0.85 |
| Infection | 0 | 0.99 | 0.22 | 0.96 | 0.14 | 0.76 |
| Abscess | — | 1 | 0 | 0.99 | 0 | 0.98 |
| Tuberculosis | — | 1 | 0 | 0.99 | — | 1 |
| Malignant | 0.44 | 0.97 | 0.19 | 0.95 | 0.25 | 0.97 |
| Diffuse Lung Changes incl. sub-categories | 0.25 | 0.76 | 0.59 | 0.91 | 0.21 | 0.87 |
| Diffuse Lung Changes | 0 | 0.81 | 0.56 | 0.96 | 0 | 0.99 |
| Fibrosis | 0 | 0.98 | 0.50 | 0.98 | 0 | 0.98 |
| Chronic Lung Changes | 0 | 0.99 | 0 | 0.99 | 0 | 0.96 |
| Stasis/Edema | 0.33 | 0.96 | 0.53 | 0.96 | 0.21 | 0.92 |
| Costophrenic Angle Blunting | 0.46 | 0.81 | 0.21 | 0.87 | 0 | 0.98 |
| Pleural Effusion | 0.47 | 0.91 | 0.86 | 0.94 | 0.74 | 0.87 |
| Costophrenic Angle Blunting AND Pleural Effusion | 0.64 | 0.81 | 0.71 | 0.82 | 0.72 | 0.86 |
| Atelectasis | 0.22 | 0.83 | 0.36 | 0.92 | 0.59 | 0.75 |
| Pleural Changes | 0 | 0.96 | 0.25 | 0.97 | 0.57 | 0.98 |
| Former Operation in Lung Tissue | 0 | 0.99 | 0 | 0.96 | — | 1 |
References
- Performance Analysis Team, NHS England. Diagnostic Imaging Dataset Statistical Release; NHS: London, UK, 2020/2021; Available online: https://www.england.nhs.uk/statistics/statistical-work-areas/diagnostic-imaging-dataset/diagnostic-imaging-dataset-2021-22-data/ (accessed on 15 October 2022).
- Metlay, J.P.; Kapoor, W.N.; Fine, M.J. Does this patient have community-acquired pneumonia? Diagnosing pneumonia by history and physical examination. JAMA 1997, 278, 1440–1445. [Google Scholar] [CrossRef]
- Kent, C. Can Tech Solve the UK Radiology Staffing Shortage? Medical Device Network: London, UK, 2021. [Google Scholar]
- Sánchez-Marrè, M. Intelligent Decision Support Systems; Springer Nature Swtizerland AG: Cham, Swtizerland, 2022. [Google Scholar]
- Li, D.; Mikela Vilmun, B.; Frederik Carlsen, J.; Albrecht-Beste, E.; Ammitzbol Lauridsen, C.; Bachmann Nielsen, M.; Lindskov Hansen, K. The Performance of Deep Learning Algorithms on Automatic Pulmonary Nodule Detection and Classification Tested on Different Datasets That Are Not Derived from LIDC-IDRI: A Systematic Review. Diagnostics 2019, 9, 207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Willemink, M.J.; Koszek, W.A.; Hardell, C.; Wu, J.; Fleischmann, D.; Harvey, H.; Folio, L.R.; Summers, R.M.; Rubin, D.L.; Lungren, M.P. Preparing Medical Imaging Data for Machine Learning. Radiology 2020, 295, 4–15. [Google Scholar] [CrossRef] [PubMed]
- Brealey, S.; Westwood, M. Are you reading what we are reading? The effect of who interprets medical images on estimates of diagnostic test accuracy in systematic reviews. Br. J. Radiol. 2007, 80, 674–677. [Google Scholar] [CrossRef] [PubMed]
- Sakurada, S.; Hang, N.T.; Ishizuka, N.; Toyota, E.; le Hung, D.; Chuc, P.T.; Lien, L.T.; Thuong, P.H.; Bich, P.T.; Keicho, N.; et al. Inter-rater agreement in the assessment of abnormal chest X-ray findings for tuberculosis between two Asian countries. BMC Infect. Dis. 2012, 12, 31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lindman, K.; Rose, J.F.; Lindvall, M.; Lundstrom, C.; Treanor, D. Annotations, Ontologies, and Whole Slide Images—Development of an Annotated Ontology-Driven Whole Slide Image Library of Normal and Abnormal Human Tissue. J. Pathol. Inform. 2019, 10, 22. [Google Scholar] [CrossRef] [PubMed]
- Bustos, A.; Pertusa, A.; Salinas, J.-M.; de la Iglesia-Vayá, M. Padchest: A large chest X-ray image dataset with multi-label annotated reports. Med. Image Anal. 2020, 66, 101797. [Google Scholar] [CrossRef] [PubMed]
- Putha, P.; Tadepalli, M.; Reddy, B.; Raj, T.; Chiramal, J.A.; Govil, S.; Sinha, N.; Ks, M.; Reddivari, S.; Jagirdar, A. Can artificial intelligence reliably report chest X-rays? Radiologist validation of an algorithm trained on 2.3 million X-rays. arXiv 2018, arXiv:1807.07455. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 590–597. [Google Scholar]
- Hansell, D.M.; Bankier, A.A.; MacMahon, H.; McLoud, T.C.; Muller, N.L.; Remy, J. Fleischner Society: Glossary of terms for thoracic imaging. Radiology 2008, 246, 697–722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Leeuwen, K.G.; Schalekamp, S.; Rutten, M.J.; van Ginneken, B.; de Rooij, M. Artificial intelligence in radiology: 100 commercially available products and their scientific evidence. Eur. Radiol. 2021, 31, 3797–3804. [Google Scholar] [CrossRef] [PubMed]
- AI for Radiolgy—Products. Available online: https://grand-challenge.org/aiforradiology/?subspeciality=Chest&modality=X-ray&ce_under=All&ce_class=All&fda_class=All&sort_by=ce%20certification&search= (accessed on 2 February 2022).
- ChestEye AI Chest X-ray Radiology—Oxipit. Available online: https://oxipit.ai/products/chesteye/ (accessed on 2 February 2022).
- Annalise.AI—Our Algorithm Can Detect Following Findings. Available online: https://annalise.ai/solutions/annalise-cxr/ (accessed on 2 February 2022).
- Randolph, J.J. Free-Marginal Multirater Kappa (multirater K[free]): An Alternative to Fleiss’ Fixed-Marginal Multirater Kappa. Available online: file:///C:/Users/dana_/Downloads/Free-Marginal_Multirater_Kappa_multirater_kfree_An%20(1).pdf (accessed on 8 December 2022).
- Byrt, T.; Bishop, J.; Carlin, J.B. Bias, prevalence and kappa. J. Clin. Epidemiol. 1993, 46, 423–429. [Google Scholar] [CrossRef] [PubMed]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cicchetti, D.V.; Feinstein, A.R. High agreement but low kappa: II. Resolving the paradoxes. J. Clin. Epidemiol. 1990, 43, 551–558. [Google Scholar] [CrossRef]
- De Vet, H.C.W.; Dikmans, R.E.; Eekhout, I. Specific agreement on dichotomous outcomes can be calculated for more than two raters. J. Clin. Epidemiol. 2017, 83, 85–89. [Google Scholar] [CrossRef]
- Randolph, J.J. Online Kappa Calculator [Computer Software]. Available online: http://justus.randolph.name/kappa (accessed on 2 July 2022).
- Rudolph, J.; Fink, N.; Dinkel, J.; Koliogiannis, V.; Schwarze, V.; Goller, S.; Erber, B.; Geyer, T.; Hoppe, B.F.; Fischer, M.; et al. Interpretation of Thoracic Radiography Shows Large Discrepancies Depending on the Qualification of the Physician-Quantitative Evaluation of Interobserver Agreement in a Representative Emergency Department Scenario. Diagnostics 2021, 11, 1868. [Google Scholar] [CrossRef] [PubMed]
- Christiansen, J.M.; Gerke, O.; Karstoft, J.; Andersen, P.E. Poor interpretation of chest X-rays by junior doctors. Dan. Med. J 2014, 61, A4875. [Google Scholar] [PubMed]
- Boersma, W.G.; Daniels, J.M.; Lowenberg, A.; Boeve, W.J.; van de Jagt, E.J. Reliability of radiographic findings and the relation to etiologic agents in community-acquired pneumonia. Respir. Med. 2006, 100, 926–932. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salvatore, C.; Interlenghi, M.; Monti, C.B.; Ippolito, D.; Capra, D.; Cozzi, A.; Schiaffino, S.; Polidori, A.; Gandola, D.; Ali, M.; et al. Artificial Intelligence Applied to Chest X-ray for Differential Diagnosis of COVID-19 Pneumonia. Diagnostics 2021, 11, 530. [Google Scholar] [CrossRef] [PubMed]
- Codlin, A.J.; Dao, T.P.; Vo, L.N.Q.; Forse, R.J.; Van Truong, V.; Dang, H.M.; Nguyen, L.H.; Nguyen, H.B.; Nguyen, N.V.; Sidney-Annerstedt, K.; et al. Independent evaluation of 12 artificial intelligence solutions for the detection of tuberculosis. Sci. Rep. 2021, 11, 23895. [Google Scholar] [CrossRef]
- Qure.AI. qXR—Artificial Intelligence for Chest X-ray. Available online: https://www.qure.ai/product/qxr/ (accessed on 6 June 2022).
- Aidoc. Radiology AI. Available online: https://www.aidoc.com/ (accessed on 8 June 2022).
- Lunit. Lunit INSIGHT CXR. Available online: https://www.lunit.io/en/products/insight-cxr (accessed on 8 June 2022).
- Chen, H.; Miao, S.; Xu, D.; Hager, G.D.; Harrison, A.P. Deep hierarchical multi-label classification of chest X-ray images. In Proceedings of the International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019; pp. 109–120. [Google Scholar]
- Miglioretti, D.L.; Gard, C.C.; Carney, P.A.; Onega, T.L.; Buist, D.S.; Sickles, E.A.; Kerlikowske, K.; Rosenberg, R.D.; Yankaskas, B.C.; Geller, B.M.; et al. When radiologists perform best: The learning curve in screening mammogram interpretation. Radiology 2009, 253, 632–640. [Google Scholar] [CrossRef] [Green Version]
- Fabre, C.; Proisy, M.; Chapuis, C.; Jouneau, S.; Lentz, P.A.; Meunier, C.; Mahe, G.; Lederlin, M. Radiology residents’ skill level in chest X-ray reading. Diagn. Interv. Imaging 2018, 99, 361–370. [Google Scholar] [CrossRef] [PubMed]
- SimplyJob.com. Medical Student Assistant for Data Annotation—Cerebriu. Available online: https://simplyjob.com/729014/cerebriu/medical-student-assistant-for-data-annotation (accessed on 14 June 2022).
- Myles-Worsley, M.; Johnston, W.A.; Simons, M.A. The influence of expertise on X-ray image processing. J. Exp. Psychol. Learn. Mem. Cogn. 1988, 14, 553–557. [Google Scholar] [CrossRef]
- Miranda, A.C.G.; Monteiro, C.C.P.; Pires, M.L.C.; Miranda, L.E.C. Radiological imaging interpretation skills of medical interns. Rev. Bras. Educ. Méd. 2019, 43, 145–154. [Google Scholar] [CrossRef]
- Doubilet, P.; Herman, P.G. Interpretation of radiographs: Effect of clinical history. Am. J. Roentgenol. 1981, 137, 1055–1058. [Google Scholar] [CrossRef]
- Test, M.; Shah, S.S.; Monuteaux, M.; Ambroggio, L.; Lee, E.Y.; Markowitz, R.I.; Bixby, S.; Diperna, S.; Servaes, S.; Hellinger, J.C.; et al. Impact of clinical history on chest radiograph interpretation. J. Hosp. Med. 2013, 8, 359–364. [Google Scholar] [CrossRef] [PubMed]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]




| Lung Tissue Findings | Novice 1 | Novice 2 | Intermediate 1 | Intermediate 2 | Experienced 1 | Experienced 2 |
|---|---|---|---|---|---|---|
| Normal | 4 | 11 | 11 | 19 | 11 | 23 |
| Increased Translucency | 7 | 3 | 8 | 0 | 0 | 0 |
| Pneumothorax | 5 | 8 | 11 | 10 | 10 | 9 |
| Cyst/Bullae | 0 | 1 | 1 | 0 | 5 | 2 |
| Emphysema | 0 | 1 | 0 | 3 | 4 | 0 |
| Decreased Translucency | 51 | 31 | 11 | 0 | 0 | 0 |
| Infiltrate | 21 | 12 | 24 | 33 | 24 | 2 |
| Infection | 0 | 2 | 3 | 6 | 30 | 13 |
| Abscess | 0 | 0 | 0 | 1 | 0 | 3 |
| Tuberculosis | 0 | 0 | 1 | 0 | 0 | 0 |
| Malignant | 3 | 6 | 1 | 10 | 5 | 3 |
| Diffuse Lung Changes | 26 | 6 | 7 | 11 | 0 | 1 |
| Fibrosis | 1 | 2 | 2 | 2 | 1 | 2 |
| Chronic Lung Changes | 1 | 0 | 1 | 0 | 5 | 2 |
| Stasis/Edema | 5 | 7 | 9 | 6 | 10 | 9 |
| Costophrenic Angle Blunting | 31 | 21 | 24 | 5 | 3 | 0 |
| Pleural Effusion | 8 | 22 | 32 | 24 | 38 | 27 |
| Atelectasis * | 14 | 22 | 13 | 9 | 50 | 25 |
| Pleural Thickening/Changes | 0 | 7 | 3 | 5 | 3 | 4 |
| Former Operation in Lung Tissue | 0 | 5 | 3 | 5 | 0 | 0 |
| All (n = 6) | Randolph’s Free-Marginal Multirater Kappa | 95% CI for Randolph’s Free-Marginal Multirater Kappa | Proportion of Positive Agreement | Proportion of Negative Agreement |
|---|---|---|---|---|
| Normal | 0.79 | 0.71–0.86 | 0.59 | 0.94 |
| Increased Translucency incl. sub-categories | 0.73 | 0.64–0.81 | 0.47 | 0.92 |
| Increased Translucency | 0.88 | 0.83–0.93 | 0 | 0.97 |
| Pneumothorax | 0.83 | 0.76–0.91 | 0.53 | 0.95 |
| Cyst/Bullae | 0.98 | 0.95–1.00 | 0.1 | 0.99 |
| Emphysema | 0.95 | 0.91–0.99 | 0.05 | 0.99 |
| Decreased Translucency incl. sub-categories | 0.55 | 0.45–0.64 | 0.84 | 0.59 |
| Decreased Translucency | 0.46 | 0.38–0.55 | 0.13 | 0.84 |
| Infiltrate incl. sub-categories | 0.40 | 0.31–0.48 | 0.50 | 0.78 |
| Infiltrate | 0.49 | 0.40–0.58 | 0.34 | 0.84 |
| Infection | 0.67 | 0.60–0.75 | 0.11 | 0.91 |
| Abscess | 0.97 | 0.95–1.00 | 0 | 0.99 |
| Tuberculosis | 0.99 | 0.98–1.00 | 0 | 1 |
| Malignant | 0.87 | 0.82–0.93 | 0.33 | 0.97 |
| Diffuse Lung Changes incl. sub-categories | 0.54 | 0.45–0.63 | 0.40 | 0.85 |
| Diffuse Lung Changes | 0.70 | 0.62–0.78 | 0.12 | 0.92 |
| Fibrosis | 0.95 | 0.91–0.99 | 0.28 | 0.99 |
| Chronic Lung Changes | 0.94 | 0.90–0.98 | 0 | 0.98 |
| Stasis/Edema | 0.79 | 0.71–0.86 | 0.31 | 0.94 |
| Costophrenic Angle Blunting | 0.58 | 0.49–0.67 | 0.25 | 0.88 |
| Pleural Effusion | 0.61 | 0.51–0.71 | 0.61 | 0.87 |
| Costophrenic Angle Blunting AND Pleural Effusion | 0.53 | 0.43–0.62 | 0.67 | 0.81 |
| Atelectasis | 0.40 | 0.30–0.50 | 0.32 | 0.81 |
| Pleural Thickening/Changes | 0.88 | 0.83–0.94 | 0.20 | 0.97 |
| Former Operation in Lung Tissue | 0.94 | 0.90–0.98 | 0.04 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Pehrson, L.M.; Tøttrup, L.; Fraccaro, M.; Bonnevie, R.; Thrane, J.; Sørensen, P.J.; Rykkje, A.; Andersen, T.T.; Steglich-Arnholm, H.; et al. Inter- and Intra-Observer Agreement When Using a Diagnostic Labeling Scheme for Annotating Findings on Chest X-rays—An Early Step in the Development of a Deep Learning-Based Decision Support System. Diagnostics 2022, 12, 3112. https://doi.org/10.3390/diagnostics12123112
Li D, Pehrson LM, Tøttrup L, Fraccaro M, Bonnevie R, Thrane J, Sørensen PJ, Rykkje A, Andersen TT, Steglich-Arnholm H, et al. Inter- and Intra-Observer Agreement When Using a Diagnostic Labeling Scheme for Annotating Findings on Chest X-rays—An Early Step in the Development of a Deep Learning-Based Decision Support System. Diagnostics. 2022; 12(12):3112. https://doi.org/10.3390/diagnostics12123112
Chicago/Turabian StyleLi, Dana, Lea Marie Pehrson, Lea Tøttrup, Marco Fraccaro, Rasmus Bonnevie, Jakob Thrane, Peter Jagd Sørensen, Alexander Rykkje, Tobias Thostrup Andersen, Henrik Steglich-Arnholm, and et al. 2022. "Inter- and Intra-Observer Agreement When Using a Diagnostic Labeling Scheme for Annotating Findings on Chest X-rays—An Early Step in the Development of a Deep Learning-Based Decision Support System" Diagnostics 12, no. 12: 3112. https://doi.org/10.3390/diagnostics12123112
APA StyleLi, D., Pehrson, L. M., Tøttrup, L., Fraccaro, M., Bonnevie, R., Thrane, J., Sørensen, P. J., Rykkje, A., Andersen, T. T., Steglich-Arnholm, H., Stærk, D. M. R., Borgwardt, L., Hansen, K. L., Darkner, S., Carlsen, J. F., & Nielsen, M. B. (2022). Inter- and Intra-Observer Agreement When Using a Diagnostic Labeling Scheme for Annotating Findings on Chest X-rays—An Early Step in the Development of a Deep Learning-Based Decision Support System. Diagnostics, 12(12), 3112. https://doi.org/10.3390/diagnostics12123112