Abstract
Breast cancer is the most common cancer among women worldwide, after lung cancer. However, early detection of breast cancer can help to reduce death rates in breast cancer patients and also prevent cancer from spreading to other parts of the body. This work proposes a new method to design a bio-marker integrating Bayesian predictive models, pyRadiomics System and genetic algorithms to classify the benign and malignant lesions. The method allows one to evaluate two types of images: The radiologist-segmented lesion, and a novel automated breast cancer detection by the analysis of the whole breast. The results demonstrate only a difference of 12% of effectiveness for the cases of calcification between the radiologist generated segmentation and the automatic whole breast analysis, and a 25% of difference between the lesion and the breast for the cases of masses. In addition, our approach was compared against other proposed methods in the literature, providing an AUC = 0.86 for the analysis of images with lesions in breast calcification, and AUC = 0.96 for masses.
1. Introduction
Artificial Intelligence may help in the detection and diagnosis of any disease. Moreover, in cancer diseases, early detection is essential to prevent the spread of cancer in the body, resulting in the patient’s death. Breast cancer is one of the most aggressive types of cancer, and is responsible for almost 685,000 deaths in females worldwide [1]. In Mexico, breast cancer has increased between the years from 2013 to 2016, with 24,695 women deaths [2]. Thus, an early diagnosis is critical for breast cancer survival [3]. Screening mammography is the preferred early detection strategy for reducing breast cancer mortality [4]. Mammography screening has had a positive impact in about of breast cancer detection [5]. On the other hand, the CAD’s systems try to emulate the process realized by the radiologist for detecting the cancer. Detection of early breast cancer signals is a routine and repetitive procedure. From the typical radiologist breast cancer subjects, only of the cases are malignant [6].
Aiming to reduce the load of work for the radiologist, computer-aided detection (CAD) systems are designed to assess the radiologist, as a second opinion, and it may aid in the correct interpretation of suspicious findings [7,8,9,10]. This process is not a trivial task due to the heterogeneity of abnormalities and the darkening under dense masses, making it difficult to identify a possible breast cancer. Mammography analysis helps to analyze the internal structure of the breast, with the aim of studying the tissues and injuries such as nodules, classifications, asymmetries in breast density and distortion of the architecture of the breast [11,12,13,14]. The features seek to provide information about the shape, contour, density, and perimeter and correspond to the input of an artificial intelligence system to classify the lesion into benign or cancer [15]. The relationship between breast lesion analysis and morphological description has been widely investigated [16]. Other research has been focused on extracting features with the viogram function as a texture feature descriptor. Other features are extracted using a new hybrid of scheme of texture, co-occurrence matrix and geometric features with a neural network [17].
On the other hand, pyRadiomics is a tool for medical imaging that allows feature extraction. The pyRadiomics toolkit was used for tissue characterization investigated by Granzier [18]. Gao et al. have performed a similar series of experiments using the pyRadiomics platform for prediction of the auxiliary lymph node tumor burden in breast cancer patients [19]. Vamvakas investigated the utility of boosting ensemble classification methods for increasing the diagnostic in differentiating benign and malignant breast lesions [20]. The fist idea is to reduce the quantity of features, which give the benefit to obtain low computational costs. For example, in the investigation proposed by Galván-Tejada et al. [21]. Galvan proposed a multivariate model that classifies the lesion into benign or malignant tumors using a genetic algorithm that analyze the morphological characteristics of the lesions to obtain an optimal classification. Genetic algorithms as an optimization tool for feature selection models have been revealed as an efficient technique using a computer-assisted diagnosis, so this approach will be also used in this investigation [22,23,24].
Refs. [25,26]: Reports demonstrate that ML models allow one to reduce false positives when classifying lesions, using optimization techniques on images. Moreover, some cross-sectional studies suggest an association between fatty and fatty-glandular for the analysis of mammography using a set of micro calcification features. Other research, which is based on texture description, spectral clustering, and Support Vector Machine (SVM) for the detection of breast masses [27], also aims to obtain more informative features. Other multivariate analysis approaches have demonstrated that prognostic information and predictive factors can be obtained to identify breast cancer in its early stages [28]. Among the different techniques of digital image processing and pattern recognition that have been applied in breast cancer, the use of mutual information and a greedy selection are used for this diagnosis when the information is uniformly distributed [29]. The feature selection for classifying benign and malignant lesions could also be made by using standard classification algorithms such as: K-nearest neighbors (KNN), decision trees, and naive Bayes [30]. On the other hand, Haralick et al. [31] introduced for the time the concept of Co-Occurrence Matrix (GLCM) for the analysis of texture patterns and their spatial classification. These relationships are specified in the built-in co-occurrence matrix for breast texture classification, since in recent works, the co-occurrence matrix for texture classification in breast images has been incorporated [32]; this concept will be also considered in our proposition.
On the other hand, Tsochatzidis et al. investigated the performance of multiple networks for breast cancer diagnosis from mammograms with mass lesions [33]. The incorporation of a margin-specific content-based image retrieval approach into a computer-aided diagnosis scheme of mammographic masses is investigated for the same authors in [34]. Andrik proposed a method, which is based on AlexNet with some modifications and has been adapted to our classification problem [35]. A deep ensemble transfer learning and neural network classifier for automatic feature extraction and classification was proposed by Aurora [36]. It should be mentioned that the authors also work with the CBIS-DDSM images. Furthermore, three data sets investigated a CAD system based on deep Convolutional Neural Networks (CNN) for classifying mammography mass lesions [37].
Feature analysis plays an important role in developing a specialized software for extracting the key features and building a robust classification scheme; numerous experiments have been implemented in the pyRadiomic system [38]. In this work, a predictive model was implemented for the detection of lesions in calcification to classify between the benign and malignant breast. The focus of the work is to speed up the diagnosis of breast cancer using the genetic algorithm and PyRadiomics System. Subsequently, the diagnosis can be confirmed by radiology through workflow.
The remainder of the paper is organized according to the following sections: The first section of this paper will examine other investigations in the literature Section 1. Section 2 describes the materials and methods. The experimental design is presented in Section 3. The results and discussion are presented in the Section 4 and Section 5. Finally, the last gives a conclusion in Section 6.
2. Materials and Methods
The proposed methodology is presented in the block diagram on Figure 1. In the first stage (1), the mammography data set used in this methodology is described and it corresponds to the input data. The feature extraction method is based on a set of data extracted on the image using the PyRadiomics System (2). The process to reducing the number of features is proposed in stage (3). The classification between benign or malign is described in the stage (4). Finally, in stage, the validation of the model was realized through proof measures of efficacy, to correctly predict two models: calcification and masses for benign and malignant lesions (5). All previous stages are detailed in the following subsections.

Figure 1.
Block diagram of the proposed methodology.
2.1. Data Acquisition and Segmentation
2.1.1. Data Description
The Digital Data base for Screening Mammography (DDSM) is a data base collection of 2620 study cases at the University of South Florida [39]. This data set includes two images of each breast, patient information and an image information system. Recently, another data base was extracted and standardized to test scientific methodologies, and evaluate their performance [40]. This CBIS-DDSM (Curated Breast Imaging Subset of DDSM) is a data subset of the original DDSM database. The digital mammography was decompressed and converted to a Digital Imaging and Communications in Medicine (DICOM) format (as shown in Figure 2). The data set imaging contains the left and right of the craniocaudal view (CC) and medial lateral oblique view (MLO) of the breast images for each patient. The data set also includes descriptions of the location of the breast lesion on calcifications and masses, bounding boxes, and pathology diagnosis for training test images. In order to complete the first stage, it is also necessary to provide a region-of-interest (ROI) segmentation on the breast lesion. Abnormalities were cropped by determining the bounding rectangle of the abnormality with respect to its ROI. The data set contains 753 calcification cases and 891 mass cases. There are Breast Imaging Reporting and Data System (BI-RADS) descriptors for mass shape, mass margin, calcification type, calcification distribution, and breast density. Table 1 shows some characteristics of the CBI-DDSM.
Figure 2.
Original mammogram (CC) obtained from CBIS-DDSM data-sets.

Table 1.
DICOM information.
2.1.2. ROI Segmentation
The data base CBIS-DDSM includes a mask of the region of interest which represents the location of the lesion and its pathology. DDSM outlines provide only a general location and not a precise mass boundary. Subsequently, a segmentation algorithm was proposed to provide the exact delineation of the mass from the surrounding tissue. This segmentation was realized only for masses and not for calcifications. All images in the DDSM were provided from several different scanners at different institutions. We used the image with the same scanner to avoid contrast problems. The data set thus contains a binary mask segmented for the radiologist where the value 255 (white color) represent the segmented lesion and 0 (black color) correspond to the background information, as shown in the Figure 3.

Figure 3.
ROI segmentation.
2.1.3. Breast Regions
The mammography analysis by a specialist allows for the diagnosis of cancer. However, the long time period of the work flow performed by the radiologist allows the disease to progress, or to spread it throughout the body. In this research, It proposes a methodology based on the analysis of the breast, and with the help of artificial intelligence algorithms, predicts whether there is a benign or malignant lesion in the breast. This would allow the radiologist to have a rapid diagnostic response. Reducing delays in diagnosis or performing repetitive tasks is the main goal of the proposed research.
In this subsection, It will perform the segmentation of the breast for subsequently introducing it to the PyRadiomics tool and then changing it to the feature extraction (second stage). Firstly, the segmentation is focused on the characterization of the background image to create a binary image to be used as segmentation mask, then the segmentation technique validates a pixel group based on a global threshold. The method consists in finding the target region that can be an approximation of the whole area of the breast. This technique also allows one to find a global threshold. Therefore, the selected targets have a threshold value higher than 50 bits. The biggest area in the image has been chosen, which represents the breast or ROI, as shown in Equation (1). As a result of the image segmentation process, one mask has been generated with normalized intensity from 0 to 1 (where 1 represent information into the image and zero corresponds to the background).
The Equation (2) defines as the original image. Let be the set of integer values ranging from 0 to 255, then a digital image in DICOM format, where is the set of pixels in the original image, whose elements are pairs of natural integer numbers, whose components correspond to the relative position of each pixel in the image. The i values represent the raw and j the columns. M represents the segmentation mask normalized between . Finally, & represents the binary operation, and is the resulting image.
In this research, the analysis is focused on the lesion segmentation and over the region of the breast. Then, the previous results of the segmentation process provide the mask and the ROI breast, and the CBIS-DDSM data set provide mask lesions, which indicate the region where the lesion is located. A medical image and segmentation mask with format DICOM are the input data for PyRadiomics System (see Figure 4). On the input, it takes an initial input of binary masks, which are defined as follows: The mask is realized by the experience of the radiologist to segment the lesion, as shown in Figure 4a). Subsequently, in the Figure 4b),the breast segmentation is demonstrated, as realized by the authors.
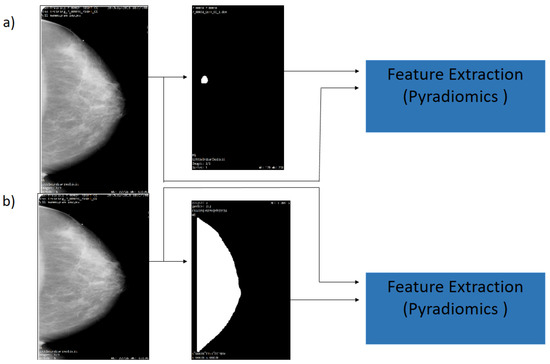
Figure 4.
Flowchart of the mammography segmentation. (a) Original image and ROI Segmentation (b) Original image and whole breast.
2.2. Feature Extraction
The PyRadiomics System is a specialized package for radiomics feature extraction from medical imaging [41]. The extracted radiomics characteristics have been validated by researchers trying to establish a standard framework into the Imaging Biomarker Standardization Initiative document (IBSI) [38]. The installation of the PyRadiomics System has been made by a compilation of source archives in python version . Then, one can proceed to extract features from medical images, conduct 2D and 3D segmentation, and the binary mask (as shown in Figure 5). This system allows one to obtain 8-based-classes into a morphological context; it is also possible to obtain texture features, and the relationships between pixels or voxels. Further morphology features, first order statics, can also be extracted.
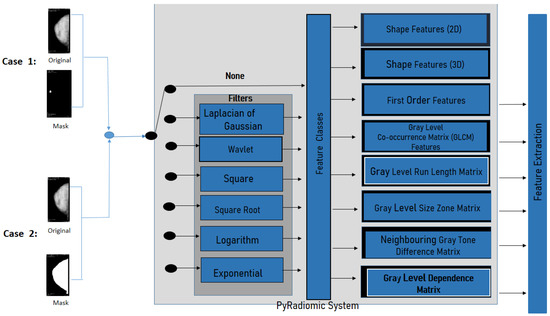
Figure 5.
PyRadiomics System configuration for this work.
Feature Extraction is based on texture analysis and the geometry of the ROI; some of these characteristics are demonstrated in Table 2.
Table 2.
Radiomics features for each class (See Appendix A).
Furthermore, PyRadiomics developed an optional platform, which uses built-in filters as Laplacian of Gaussian, Wavelet, Square, Square Root, Logarithm, Exponential, Gradient, and Local Binary Patterns 2D or 3D. For this investigation, the geometric feature was eliminated, and filter was chosen (as shown in the filtering stage in Figure 5).
2.3. Feature Selection
2.3.1. Removing Features with Zero Variance
The PyRadiomics System generates a high dimensional space of features, as shown in the feature matrix of Equation (3). With the aim to reduce the size of features, it was realized as removing process, and thus the feature selection (third stage) consists in two steps. In the first step, only those columns with zero variance were removed, subsequently, in the second step, the feature selection was carried out using genetic algorithms and considering the remaining elements of the feature matrix. The extracted data set is represented by the following feature matrix (3).
Let us write this matrix as an ordered set of column vectors, where the matrix represents the j-th row of features and the i-th sample vector. In order to compute the covariance matrix , where , and where is the diagonal variance, which leads to a new covariance matrix when .
2.3.2. Data Whitening
In the third stage, it is important to center the extracted data set ; this process is well known as data whitening, and it considers that data must have a zero mean and variance one.
The Equation (4) is defined as the test data , where is the arithmetic average, and is the standard deviation of giving, as result, the standard normalization.
2.4. Feature Selection Based in a Genetic Algorithm
Feature selection is a method implemented to select the best features and then ensure a better classification. One of these feature selection methods are the so-called Genetic Algorithms.
Genetic algorithms (GA) are optimization techniques based on natural selection where certain genetic information is transmitted from one generation to the next. This process of evolution modifies a set of solutions (chromosomes) by selecting individuals with the best features (gens). The selection is performed using a “fitness” function. The selected individuals (parents) will produce the next generation (children). This evolutionary process will eventually achieve an optimal solution.
It implement the genetic algorithm using Galgo [23]. This software is an object-oriented programming (OOP) implementation in R. Further, it includes the code to develop models using Random Forest [28,45].
The stages of the protocol used by Galgo are described below (Figure 6):
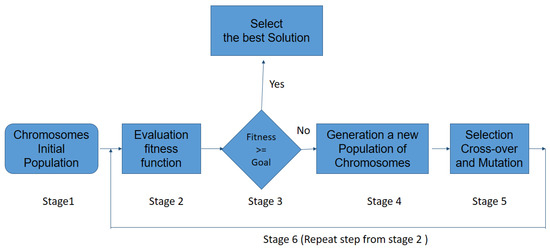
Figure 6.
Schematic representation of the GA procedure.
- 1
- An initial population consisting of possible solutions to the problem, also called individuals, is randomly generated. This variable is called chromosomes , with .
- 2
- Calculate the fitness function F of each chromosome in the population, and evaluated for the ability to predict the group membership of sample ().
- 3
- If the chromosome is selected and the procedure stops; otherwise, the procedure (stage 1) continues to stage.
- 4
- Cross-Over: the two selected individuals generate new offspring with a higher fitness score (see Figure 7).
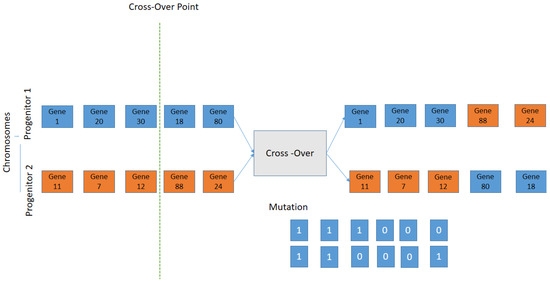 Figure 7. Schematic representation of the Crossover; the selection criteria is used by exchanging the genes of parents from one generation to the next.
Figure 7. Schematic representation of the Crossover; the selection criteria is used by exchanging the genes of parents from one generation to the next. - 5
- The mutation process is to add a new individual to the new population. The new gene generated by the mutation is aggregated at the chromosomes.
- 6
- The process is repeated from stage 2 until an accurate chromosome is obtained [46].
2.5. Model Generation
For the estimation of the parameters, the maximum-likelihood framework has been chosen, using the logistic regression model (see Equation (5)). Where Y is the variable to predict, and are the n predictor variables, the logistic regression paradigm is expressed as follows:
2.6. Validation
The cross-validation is the technique used to evaluate the results of the predictive model by partitioning between the data into training and test sub-sets (see Figure 8).
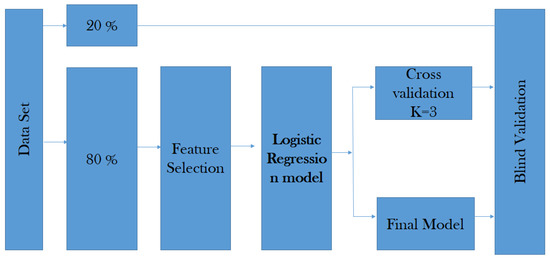
Figure 8.
Proposed validation strategy.
The data is randomly mixed, forming a number of k data. The model uses K folds for each iteration to test the model, and the remaining K data set to train the model. The fold helps to test the data set and the other one supports the training process (see Equation (7)).
where f represents K-Fold Cross Validation, and N is the fold’s number of the data set into sets, training, testing, and validation (in our case, ).
The validation of the model is carried out from prediction measures, such as: Area under the curve, predictive measures over the classifier with the aim to distinguish between classes, and specificity and sensitivity are also used to calculate the positive and negative predictive values. Finally, accuracy provides the percentage of correct predictions for the prediction models.
3. Experimental Setup
In this research, some independent studies were used to explore between two types of breast lesion, benign or malignant, in images of calcification and mass. Left or right breast images with suspicious regions were only selected in the proposed experiments; a total of 400 left and right breast mammograms were used with the CC projection. For the calcification, the first sub-set (CS1) was obtained by using only the data contained inside the ROI segmentation provided by the radiologist; then, for the second classification sub-set (CS2), the whole breast segmentation was obtained. The same process was also used for the both sub-sets of the mass data set (MS1, MS2) (as shown in Figure 4).
The segmentation process is used to eliminate artifacts and labels from the mammogram image, and to select the breast ROI. A threshold value was used to extract the binary mask. Moreover, some morphological operations were applied for the segmentation mask to finally obtain the region of interest of the breast. The process feature extraction on images was realized using the PyRadiomics System. The PyRadiomics required the image and the mask input; for these experimental results, the cases CS1 and MS1 were used for the mask provided by the radiologist. On the other hand, in the MS1 and MS2 cases, the mask breast segmentation was used.
Once the mammography features were extracted by PyRadiomics, 141 features were selected with the basis of texture information from the lesion and from the breast segmentation, and the 21 shape descriptors were removed. Gray Level Co-occurrence Matrix, Gray level Run Length Matrix, Gray level Size Zone Matrix, Neighbouring Gray Tone Difference Matrix, and Gray level feature was selected for this experiment.
Then, in order to select the best features to construct a robust model, a feature selection process was implemented into two stages; in the first one, the no-variance features were removed, then on the second stage, a genetic algorithm (GALGO) [23] was used to search for the best combination of features that correctly classify the samples.
Then, a validation was carried out by means of cross-validation for each CS1, CS2, MS1 and MS2 sub-sets. A cross-validation with a strategy was used, then a series of metrics were computed in order to assess the performance of the models on unseen data for this, and the AUC, sensitivity, specificity, and accuracy were calculated. Firstly, we shuffled the data set to make up k different sub-sets for the training and test phases.
4. Results
In this section, some results are obtained considering four sub-set cases of images with mass and calcification. This process allows one to read DICOM images converted into a binary image from a gray level. The experiment consisted of 400 images; two types of malignant and benign lesions between right or left images are considered for all cases, ROI segmentation is provided by the radiologist and breast segmentation is obtained according to the proposed methodology.
The breast segmentation process was based on contour detection; first, the algorithm finds all the objects inside the input image, then the area containing such objects is computed, next, the biggest area is selected as a candidate for the breast organ. Once the breast organ is selected, all other objects are eliminated leaving only the breast organ. Nevertheless, several of the input images have noise or unwanted tissue on the frame boundary, and to eliminate such artifacts, 5% of the edge of the image is removed, creating a segmentation mask that only contains breast tissue; the Figure 9 shows an example of this process.
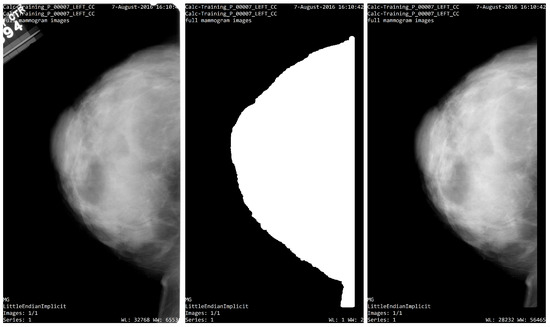
Figure 9.
Segmentation process. (left) Image from CBIS_DDSM; (center) segmentation mask; (right) ROI segmentation.
To start with the feature extraction, the four groups CS1, CS2, MS1 and MS2 and their corresponding binary masks were selected as the input for the pyRadiomics system. The pyRadiomics process extracted 110 features; these features were related to the shape, and those with zero variance were removed, giving a grand total of 88 texture features. The GA (Galgo) algorithm analyzes different models obtained through evolution, with a maximum of 300 generations. The obtained models from the evolution process of the algorithm are shown in the Figure 10, Figure 11, Figure 12 and Figure 13. Horizontal axis genes ordered by rank and vertical axis shows the gene frequency and the colour-coded rank of each gene in previous evolutions. Changes in ranks are marked by different colours. These figures summarize the population of chromosomes within each generation, where the black color represents the most stable chromosome in all generated models.
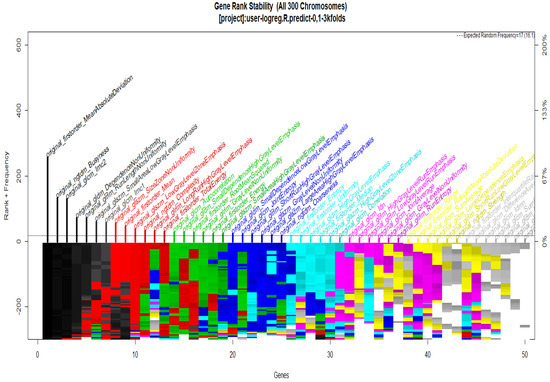
Figure 10.
Gene Rank Stability graph with calcification model by radiologist segmentation; the gene rank shows the stability of the top-ranked 50 variables. The horizontal axis shows the genes ordered by rank, and the vertical axis shows the gene frequency. The bottom color—coded rank represents the genetic stability where features with no change in the color represent a stable feature; changing color features represent unstable features (i.e., not always contributing to the performance).
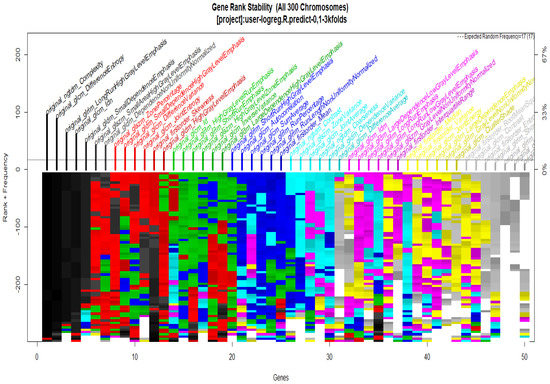
Figure 11.
Gene Rank Stability graph with calcification model by radiologist segmentation; the gene rank shows the stability of the top-ranked 50 variables. The horizontal axis shows the genes ordered by rank, and the vertical axis shows the gene frequency. The bottom color—coded rank represents the genetic stability where features with no change in color represent a stable feature; changing color features represent unstable features.
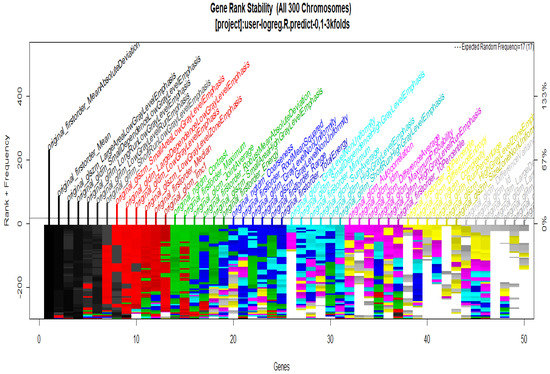
Figure 12.
Gene Rank Stability graph with calcification model by radiologist segmentation; the gene rank shows the stability of the top-ranked 50 variables. The horizontal axis shows the genes ordered by rank, and the vertical axis shows the gene frequency. The bottom color—coded rank represents the genetic stability, where features with no change in color represent a stable feature; changing color features represent unstable features.
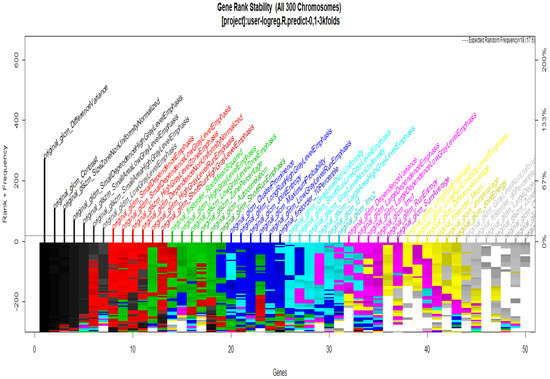
Figure 13.
Gene Rank Stability graph with calcification model by radiologist segmentation; the gene rank shows the stability of the top-ranked 50 variables. The horizontal axis shows the genes ordered by rank, and the vertical axis shows the gene frequency. The bottom—coded rank represents the genetic stability, where features with no change in color represent a stable feature; changing color features represent unstable features.
In Figure 11 and Figure 13, seven black stable chromosomes were generated for ROI segmentation. However, for segmentation by the radiologist, as shown in Figure 10 and Figure 12, seven black stable chromosomes were obtained. Finally, Table 3 and Table 4 show a comparison of chromosomes generated in each model.
Table 3.
Comparison between models with CS1 and CS2 calcifications.
Table 4.
Comparison between models with MS1 and MS2 mass.
The global AUC criteria was also calculated by taking the average of all implemented models.
Table 5 shows a comparison between the results of the experiments with the CS1 and the CS2 data set.
Table 5.
Comparison between models with CS1 and CS2 calcifications.
The same comparison process as above is performed but now using the mass data set, as shown in Table 6. Features of black color represent the importance of predicting cancer.
Table 6.
Comparison between models with MS1 and MS2.
In Table 7, the best predictors for the classification between benign or malignant using logistic regression for each CS1, CS2, MS1 and MS2 models are shown.
Table 7.
The following table compares those features (in bold) that repeat in the different models (CS1, CS2, MS1 and MS2). These features provide better and more meaningful results for the classification of malignant cancer.
Moreover, to validate the results obtained with the proposed methodology, the accuracy and AUC results are compared with other proposals; the results are shown in Table 8.
Table 8.
CBIS-DDSM segmentation show the comparison of the results obtained using the methodologies proposed in [33,34,35,36].
5. Discussion
Results obtained when using the sub-sets CS1, CS2, MS1 and MS2 to classify calcification and masses were as good as it could be expected, which means, for example, that the obtained AUC was at least 0.8 for calcification and at least 0.9 for masses. The whole predictive measures obtained by the data set of calcification and mass between regions of interest are shown in Table 5 and Table 6. As shown, the predictive accuracy between the data set of CS1 is 86% and CS2 is 76%. The minimal difference is 12% according to the two models to predict malignant or benign images. On the other hand, for the results from Table 6, the predictive accuracy between the models MS1 is 95% and MS2 is 74%. In the comparison between the two previous models, the difference was 22% in accuracy. Finally, the evidence suggests that the prediction model CS2 (Calcification) has a higher probability of predicting the MS2 (Malignant) with a percentage of 10% of error.
According to Table 7, the results demonstrate that, for classification purposes, the measures of GLCM Difference Entropy, GLCM Contrast and GLCM Difference Variance are strongly correlated in the cases of CS1, MS1, and MS2 models. The relation between CS1 and MS2 models is given with NGTDM Business features. Finally, CS1 and MS1 models are correlated by GLCM Id and First Order Total Energy features. GLCM Difference Entropy is other measure of correlation that presents MS1 and MS2 cases. This experiment demonstrates that the GLCM class provides strong prediction measures to classify between malignant or benign class models. The most important result that emerges from the analysis in this section is the relationship between breast mass and cancer, and, respectively, between breast calcification and cancer; there are three radiomic features from the classes such as GLRLM, GLSZM, and GLCM, which are considered stable. Another advantage of the selection procedure used in the proposed methodology, is the dimensionality reduction with a 20% in the generation of a new optimal model.
The results provided in Table 8 give a comparison with respect to other state-of-the-art methodologies. In order to observe the veracity of the proposed methodology, some comparisons are made with respect to the other four methods, which employ the same database used in this research (CBIS_DDSM). It is important to say that these methods evaluate benign and malignant lesions according to calcification and mass mammograms images using two projections, MLO and CC. The obtained results with the proposed methodology outperform those results reported by [34,36], for benign and malignant lesions, for example for the MS1 case, and the area under the curve (AUC) given by our proposition is about 0.95 and 0.96 of accuracy. The AIC score (CS1, CS2, MS1 and MS2) is given for the MS2 model with 166—the lowest score as the best.
Feature extraction provides information for classifying breast lesions, and it is possible to make a good feature selection using logistic regression classification based on the texture image. This study found that the mass provides more information for classification, but the calcifications do not necessarily give more information. The calcifications could be segmented and, subsequently, features were extracted. The relationship between mass, calcification and cancer has the best classification rates when it is evaluated by the Gray Level Co-occurrence Matrix.
On the other hand, the image analysis performed by [35] also evaluates two types of lesions for calcification and masses with two projections, obtaining an AUC of 0.84 and 0.8 of accuracy. Moreover, in this comparison for the CS1 case, the proposed method gives a better result, since it obtained an AUC of 0.86 and 0.82 of accuracy. However, the AIC score (CS1, CS2, MS1 and MS2) is given for the MS2 model with 166—the lowest score as the best.
It has been demonstrated that the CC projection analysis provide the best information for the benign and malignant lesions classification, making an optimal feature extraction from the mammal tissue.
6. Conclusions
The detection of breast cancer at an early stage can be prevented from spreading to other parts of the body or avoiding death in the patient. The integration of predictive models in the diagnosis of breast cancer have allowed the radiologist to make quick decisions. Comparing a lesion breast analysis realized by a radiologist and the segmentation of the breast on mammography made by the classification models implemented in this work, there is no substantial difference in decision making. The implementation of genetic algorithms was considered in order to help to choose the best predictors in the detection of breast cancer; the results of the models implemented have a 86% AUC for calcification models and 95% of AUC for mass models.
Although there is much research focused mainly on finding the region of interest, this type of analysis would allow finding types of lesions in a very restricted area. In this new methodology, we propose an automated segmentation based on the analysis of the whole breast region to classify between benign and malignant lesions. The results demonstrate that between the lesion and the whole breast there is around a 10% of difference for cases of calcifications, and a 20% of difference in the case of masses. Based on the previous results, the radiologist would focus on the cases where the system finds malignant cases, and carry out a more in-depth study of the case. Our proposal allows us to speed up the work of the radiologist in decision-making.
The purpose of the present investigation is not to change the opinion of the radiologist, but to motivate the use of an alternative tool that allows one to improve the response time of the analysis in the detection of malignant or benign lesions in images with calcification or mass. The Pyradiomics system provided optimal features for a good classification. However, this system is limited by both the processing speed and the amount of memory available.
Author Contributions
Methodology, M.d.l.L.E., J.I.D.l.R., C.E.G.-T. and J.M.C.-P.; Validation, D.d.l.R.G.; Formal analysis, M.d.l.L.E.; Investigation, M.d.l.L.E. and C.E.G.-T.; Writing—review & editing, J.I.D.l.R., H.L.-G. and J.M.C.-P.; Supervision, H.G.-R.; Project administration, J.I.G.-T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
https://wiki.cancerimagingarchive.net/display/Public/CBIS-DDSM accessed on 22 May 2021.
Acknowledgments
Technical supports engineers at the Autonomous University of Zacatecas.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ROI | A Region Of Interest |
| ROC | Area under the curve |
| DDSM | The Digital Database for Screening Mammography |
| CBIS-DDSM | Curated Breast Imaging Subset of DDSM |
| DICOM | Digital Imaging and Communication In Medicine |
| IBSI | Imaging Biomarker Standardization Initiative |
| GA | Gentic Algorithm |
| AUC | Area under the ROC Curve |
| CC | Craniocaudal |
| LD | Linear dichroism |
| GLCM | A Gray Level Co-occurrence Matrix |
| GLRLM | Gray level Run Length Matrix |
| GLSZM | Gray level Size Zone Matrix |
| NGTDM | Neighbouring Gray Tone Difference Matrix |
| GLDM | Gray level Dependence Matrix |
| TIFF | Tagged Image File Format |
| CNNs | Deep Convolutional Neural Networks |
| DNN | Deep neural network |
| SVM | Support vector Machines |
| CNN | Convolutional Neural Networks |
Appendix A
Table A1.
Radiomic Features.
Table A1.
Radiomic Features.
| Abbreviation for Feature | Definition |
|---|---|
| NGTDM Coarseness | Contrast Feature indicates the level of the spatial rate of change in intensity. |
| NGTDM Busyness | Feature describe the changes in the intensity between neighbouring pixels. |
| NGTDM Complexity | Features describe how are common are the non uniformity and rapid changes in the gray levels. |
| GLCM Energy | Angular second Momentum, Uniformity. |
| GLCM Contrast Variance | |
| GLCM Difference Entropy | Difference Average measures the relationship between occurrences of pairs with similar intensity values and occurrences of pairs with differing intensity values. |
| GLCM ID | Inverse difference normalizes the difference between the neighboring intensity values by dividing over the total number of discrete intensity values. |
| GLCM Maximum Probability | Maximum Probability is occurrences of the most predominant pair of neighboring intensity values. |
| GLCM Joint Entropy | Joint entropy is a measure of the randomness/variability in neighborhood intensity values. |
| GLCM Joint Energy | Energy is a measure of homogeneous patterns in the image |
| GLRLM Long Run Emphasis | LREis a measure of the distribution of long run lengths, with a greater value indicative of longer run lengths and more coarse structural textures. |
| GLRLM Gray Level Non-Uniformity | GLN measures the similarity of gray-level intensity values in the image. |
| GLRLM Gray Level Non-Uniformity Normalized (GLNN) | GLNN measures the similarity of gray-level intensity values in the image |
| GLRLM Run Length Non-Uniformity (RLN) | RLN measures the similarity of run lengths throughout the image. |
| GLRLM Run Length Non-Uniformity Normalized (RLNN) | RLNN measures the similarity of run lengths throughout the image. |
| GLRLM Run Percentage (RP) | RP measures the coarseness of the texture by taking the ratio of number of runs and number of voxels in the ROI. |
| GLRLM Gray Level Variance (GLV) | GLV measures the variance in gray level intensity for the runs. |
| GLRLM Run Entropy (RE) | RE measures the uncertainty/randomness in the distribution of run lengths and gray levels. |
| GLRLM Low Gray Level Run Emphasis (LGLRE) | HGLRE measures the distribution of the higher gray-level values. |
| GLRLM Short Run Low Gray Level Emphasis (SRLGLE) | RLGLE measures the joint distribution of shorter run lengths with lower gray-level values. |
| GLRLM Short Run High Gray Level Emphasis (SRHGLE) | measures the joint distribution of shorter run lengths with higher gray-level values. |
| GLRLM Long Run Low Gray Level Emphasis (LRLGLE) | measures the joint distribution of long run lengths with lower gray-level values. |
| GLRLM Long Run High Gray Level Emphasis (LRHGLE) | LRHGLRE measures the joint distribution of long run lengths with higher gray-level values. |
| NGTDM Coarseness | Coarseness is a measure of average difference between the center voxel and its neighbourhood and is an indication of the spatial rate of change. |
| NGTDM Contrast | Contrast is a measure of the spatial intensity change, but is also dependent on the overall gray level dynamic range. |
| NGTDM Busyness | Busyness a measure of the change from a pixel to its neighbour. |
| NGTDM Complexity | An image is considered complex when there are many primitive components in the image. |
| NGTDM Strength | Strength is a measure of the primitives in an image. |
| GLDM Small Dependence Emphasis (SDE) | A measure of the distribution of small dependencies, with a greater value indicative of smaller dependence and less homogeneous textures. |
| GLDM Large Dependence Emphasis (LDE) | Large Dependence Emphasis a measure of the distribution of large dependencies, with a greater value indicative of larger dependence and more homogeneous textures. |
| GLDM Gray Level Non-Uniformity (GLN) | Gray Level Non-Uniformity measures the similarity of gray-level intensity values in the image |
References
- Wilkinson, L.; Gathani, T. Understanding breast cancer as a global health concern. Br. J. Radiol. 2022, 95, 20211033. [Google Scholar] [CrossRef] [PubMed]
- Navarrete-Valero, C.; Navarrete-Vázquez, C. Mortalidad por cáncer mamario, prostático y cervicouterino, años perdidos y costos de los programas. México, 2013 a 2016. Gac. Medica Mex. 2018, 154, 665–670. [Google Scholar] [CrossRef] [PubMed]
- Ginsburg, O.; Yip, C.H.; Brooks, A.; Cabanes, A.; Caleffi, M.; Dunstan Yataco, J.A.; Gyawali, B.; McCormack, V.; McLaughlin de Anderson, M.; Mehrotra, R.; et al. Breast cancer early detection: A phased approach to implementation. Cancer 2020, 126, 2379–2393. [Google Scholar] [CrossRef]
- Kalager, M.; Zelen, M.; Langmark, F.; Adami, H.O. Effect of screening mammography on breast-cancer mortality in Norway. N. Engl. J. Med. 2010, 363, 1203–1210. [Google Scholar] [CrossRef] [PubMed]
- Broeders, M.; Moss, S.; Nystrom, L.; Njor, S.; Jonsson, H.; Paap, E.; Massat, N.; Duffy, S.; Lynge, E.; Paci, E. The impact of mammographic screening on breast cancer mortality in Europe: A review of observational studies. J. Med. Screen. 2012, 19, 14–25. [Google Scholar] [CrossRef]
- Varela, C.; Tahoces, P.G.; Méndez, A.J.; Souto, M.; Vidal, J.J. Computerized detection of breast masses in digitized mammograms. Comput. Biol. Med. 2007, 37, 214–226. [Google Scholar] [CrossRef]
- Freer, T.W.; Ulissey, M.J. Screening mammography with computer-aided detection: Prospective study of 12,860 patients in a community breast center. Radiology 2001, 220, 781–786. [Google Scholar] [CrossRef]
- Leung, J.W.; Margolin, F.R.; Dee, K.E.; Jacobs, R.P.; Denny, S.R.; Schrumpf, J.D. Performance parameters for screening and diagnostic mammography in a community practice: Are there differences between specialists and general radiologists? Am. J. Roentgenol. 2007, 188, 236–241. [Google Scholar] [CrossRef]
- Oeffinger, K.C.; Fontham, E.T.H.; Etzioni, R.; Herzig, A.; Michaelson, J.S.; Shih, Y.C.T.; Walter, L.C.; Church, T.R.; Flowers, C.R.; LaMonte, S.J.; et al. Breast Cancer Screening for Women at Average Risk. JAMA 2015, 314, 1599–1614. [Google Scholar] [CrossRef]
- Gardezi, S.J.S.; Elazab, A.; Lei, B.; Wang, T. Breast cancer detection and diagnosis using mammographic data: Systematic review. J. Med. Internet Res. 2019, 21, e14464. [Google Scholar] [CrossRef]
- Eadie, L.H.; Taylor, P.; Gibson, A.P. A systematic review of computer-assisted diagnosis in diagnostic cancer imaging. Eur. J. Radiol. 2012, 81, e70–e76. [Google Scholar] [CrossRef] [PubMed]
- Dromain, C.; Boyer, B.; Ferré, R.; Canale, S.; Delaloge, S.; Balleyguier, C. Computed-aided diagnosis (CAD) in the detection of breast cancer. Eur. J. Radiol. 2013, 82, 417–423. [Google Scholar] [CrossRef] [PubMed]
- Karssemeijer, N. Computer-Aided Detection in Mammography. Imaging Decis. MRI 2008, 12, 23–28. [Google Scholar] [CrossRef]
- Dheeba, J.; Albert Singh, N.; Tamil Selvi, S. Computer-aided detection of breast cancer on mammograms: A swarm intelligence optimized wavelet neural network approach. J. Biomed. Inform. 2014, 49, 45–52. [Google Scholar] [CrossRef]
- Yu, S.N.; Huang, Y.K. Detection of microcalcifications in digital mammograms using combined model-based and statistical textural features. Expert Syst. Appl. 2010, 37, 5461–5469. [Google Scholar] [CrossRef]
- Liney, G.P.; Sreenivas, M.; Gibbs, P.; Garcia-Alvarez, R.; Turnbull, L.W. Breast lesion analysis of shape technique: Semiautomated vs. manual morphological description. J. Magn. Reson. Imaging 2006, 23, 493–498. [Google Scholar] [CrossRef]
- Al-masni, M.A.; Al-antari, M.A.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef]
- Granzier, R.W.; Verbakel, N.M.; Ibrahim, A.; van Timmeren, J.E.; van Nijnatten, T.J.; Leijenaar, R.T.; Lobbes, M.B.; Smidt, M.L.; Woodruff, H.C. MRI-based radiomics in breast cancer: Feature robustness with respect to inter-observer segmentation variability. Sci. Rep. 2020, 10, 14163. [Google Scholar] [CrossRef]
- Gao, Y.; Luo, Y.; Zhao, C.; Xiao, M.; Ma, L.; Li, W.; Qin, J.; Zhu, Q.; Jiang, Y. Nomogram based on radiomics analysis of primary breast cancer ultrasound images: Prediction of axillary lymph node tumor burden in patients. Eur. Radiol. 2021, 31, 928–937. [Google Scholar] [CrossRef]
- Vamvakas, A.; Tsivaka, D.; Logothetis, A.; Vassiou, K.; Tsougos, I. Breast Cancer Classification on Multiparametric MRI—Increased Performance of Boosting Ensemble Methods. Technol. Cancer Res. Treat. 2022, 21, 15330338221087828. [Google Scholar] [CrossRef]
- Galván-Tejada, C.; Zanella-Calzada, L.; Galván-Tejada, J.; Celaya-Padilla, J.; Gamboa-Rosales, H.; Garza-Veloz, I.; Martinez-Fierro, M. Multivariate Feature Selection of Image Descriptors Data for Breast Cancer with Computer-Assisted Diagnosis. Diagnostics 2017, 7, 9. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Rincon, A.; Mendoza-Maldonado, L.; Martinez-Archundia, M.; Schönhuth, A.; Kraneveld, A.D.; Garssen, J.; Tonda, A. Machine learning-based ensemble recursive feature selection of circulating mirnas for cancer tumor classification. Cancers 2020, 12, 1785. [Google Scholar] [CrossRef] [PubMed]
- Trevino, V.; Falciani, F. GALGO: An R package for multivariate variable selection using genetic algorithms. Bioinformatics 2006, 22, 1154–1156. [Google Scholar] [CrossRef]
- Chaudhuri, A.K.; Das, A. Variable Selection in Genetic Algorithm Model with Logistic Regression for Prediction of Progression to Diseases. In Proceedings of the 2020 IEEE International Conference for Innovation in Technology, INOCON 2020, Bangaluru, India, 6–8 November 2020. [Google Scholar] [CrossRef]
- Wu, Y.; Giger, M.L.; Doi, K.; Vyborny, C.J.; Schmidt, R.A.; Metz, C.E. Artificial neural networks in mammography: Application to decision making in the diagnosis of breast cancer. Radiology 1993, 187, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Eltoukhy, M.M.; Faye, I. An adaptive threshold method for mass detection in mammographic images. In Proceedings of the IEEE ICSIPA 2013—IEEE International Conference on Signal and Image Processing Applications, Melaka, Malaysia, 8–10 October 2013. [Google Scholar] [CrossRef]
- Ketabi, H.; Ekhlasi, A.; Ahmadi, H. A computer-aided approach for automatic detection of breast masses in digital mammogram via spectral clustering and support vector machine. Phys. Eng. Sci. Med. 2021, 44, 277–290. [Google Scholar] [CrossRef] [PubMed]
- Domínguez, M.A.; Marcos, M.; Meiriño, R.; Villafranca, E.; Dueñas, M.T.; Arias, F.; Martínez, E. Prognostic and predictive factors in early breast cancer. Oncologist 2001, 9, 80–89. [Google Scholar] [CrossRef]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ.—Comput. Inf. Sci. 2019, 34, 1060–1073. [Google Scholar] [CrossRef]
- Uyun, S.; Choridah, L. Feature selection mammogram based on breast cancer mining. Int. J. Electr. Comput. Eng. 2018, 8. [Google Scholar] [CrossRef]
- Haralick, R.M.; Dinstein, I.; Shanmugam, K. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Li, H.; Giger, M.L.; Olopade, O.I.; Margolis, A.; Lan, L.; Chinander, M.R. Computerized texture analysis of mammographic parenchymal patterns of digitized mammograms. Acad. Radiol. 2005, 12, 863–873. [Google Scholar] [CrossRef]
- Tsochatzidis, L.; Costaridou, L.; Pratikakis, I. Deep learning for breast cancer diagnosis from mammograms—A comparative study. J. Imaging 2019, 5, 37. [Google Scholar] [CrossRef]
- Tsochatzidis, L.; Zagoris, K.; Arikidis, N.; Karahaliou, A.; Costaridou, L.; Pratikakis, I. Computer-aided diagnosis of mammographic masses based on a supervised content-based image retrieval approach. Pattern Recognit. 2017, 71, 106–117. [Google Scholar] [CrossRef]
- Rampun, A.; Scotney, B.W.; Morrow, P.J.; Wang, H. Breast mass classification in mammograms using ensemble convolutional neural networks. In Proceedings of the 2018 IEEE 20th International Conference on e-Health Networking, Applications and Services, Healthcom 2018, Ostrava, Czech Republic, 17–20 September 2018. [Google Scholar] [CrossRef]
- Arora, R.; Rai, P.K.; Raman, B. Deep feature-based automatic classification of mammograms. Med. Biol. Eng. Comput. 2020, 58, 1199–1211. [Google Scholar] [CrossRef] [PubMed]
- Chougrad, H.; Zouaki, H.; Alheyane, O. Deep Convolutional Neural Networks for breast cancer screening. Comput. Methods Programs Biomed. 2018, 157, 19–30. [Google Scholar] [CrossRef] [PubMed]
- Hatt, M.; Vallieres, M.; Visvikis, D.; Zwanenburg, A. IBSI: An international community radiomics standardization initiative. J. Nucl. Med. 2018, 59, 287. [Google Scholar]
- Heath, M.; Bowyer, K.; Kopans, D.; Kegelmeyer, P.; Moore, R.; Chang, K.; Munishkumaran, S. Current Status of the Digital Database for Screening Mammography. In Digital Mammography. Computational Imaging and Vision; Springer: Dordrecht, The Netherlands, 1998. [Google Scholar] [CrossRef]
- Lee, R.S.; Gimenez, F.; Hoogi, A.; Miyake, K.K.; Gorovoy, M.; Rubin, D.L. Data Descriptor: A curated mammography data set for use in computer-aided detection and diagnosis research. Sci. Data 2017, 4, 170177. [Google Scholar] [CrossRef]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef]
- Galloway, M.M. Texture analysis using gray level run lengths. Comput. Graph. Image Process. 1975, 4, 172–179. [Google Scholar] [CrossRef]
- Chu, A.; Sehgal, C.M.; Greenleaf, J.F. Use of gray value distribution of run lengths for texture analysis. Pattern Recognit. Lett. 1990, 11, 415–419. [Google Scholar] [CrossRef]
- Thibault, G.; Fertil, B.; Navarro, C.; Pereira, S.; Cau, P.; Levy, N.; Sequeira, J.; Mari, J.l. Texture Indexes and Gray Level Size Zone Matrix Application to Cell Nuclei Classification. Pattern Recognit. Inf. Process. 2009. Available online: https://www.semanticscholar.org/paper/Texture-indexes-and-gray-level-size-zone-matrix.-to-Thibault-Fertil/fec6bd9b7f5d6a50410109991857494c8d25f290 (accessed on 22 May 2021).
- Rozmus, D. Comparison of the Accuracy of the Probabilistic Distance Clustering Method and Cluster Ensembles. Acta Univ. Lodz. Folia Oeconomica 2016, 3. [Google Scholar] [CrossRef]
- Taylor, C.E. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. Complex Adaptive Systems. John H. Holland. Q. Rev. Biol. 1994, 69, 88–89. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).