
A Method for Detecting and Analyzing Facial Features of People with Drug Use Disorders


Abstract
:1. Introduction
Related Works
2. Materials and Methods
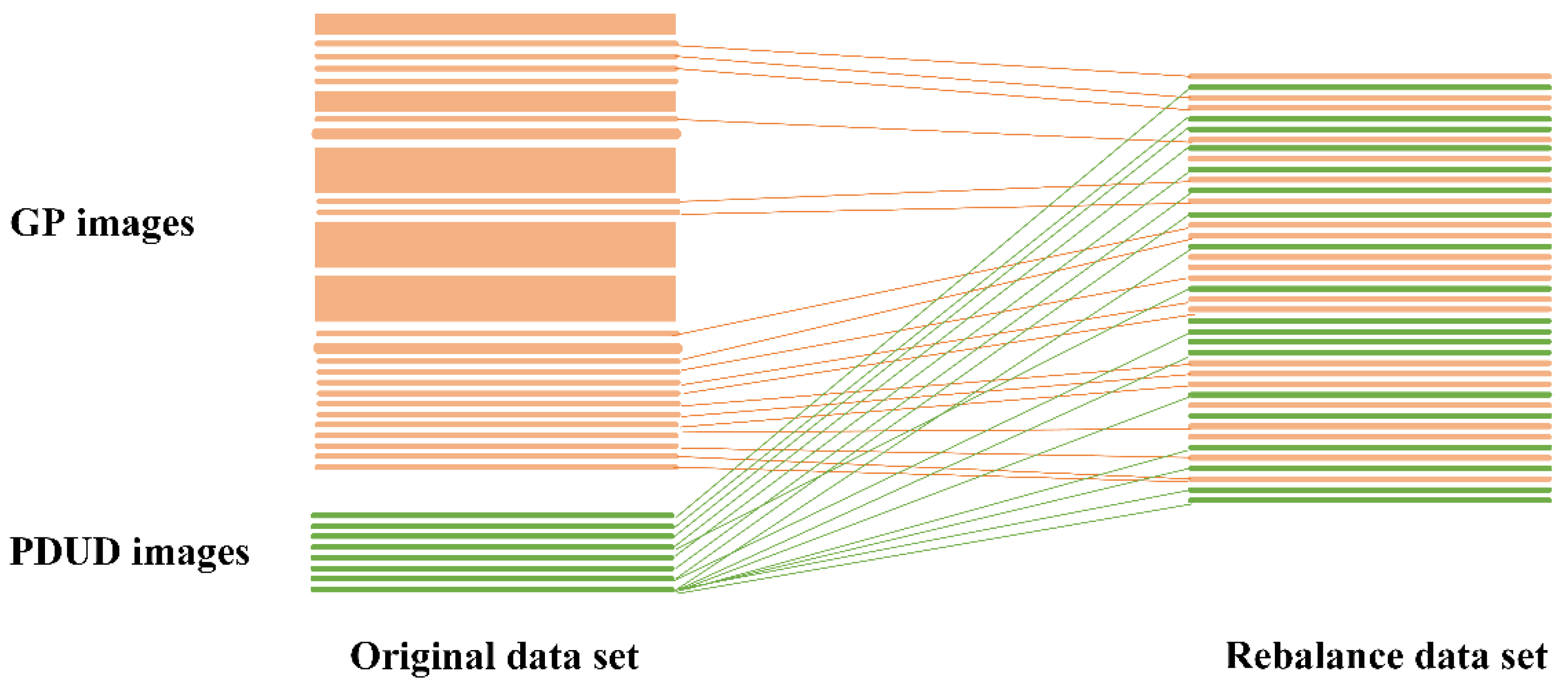
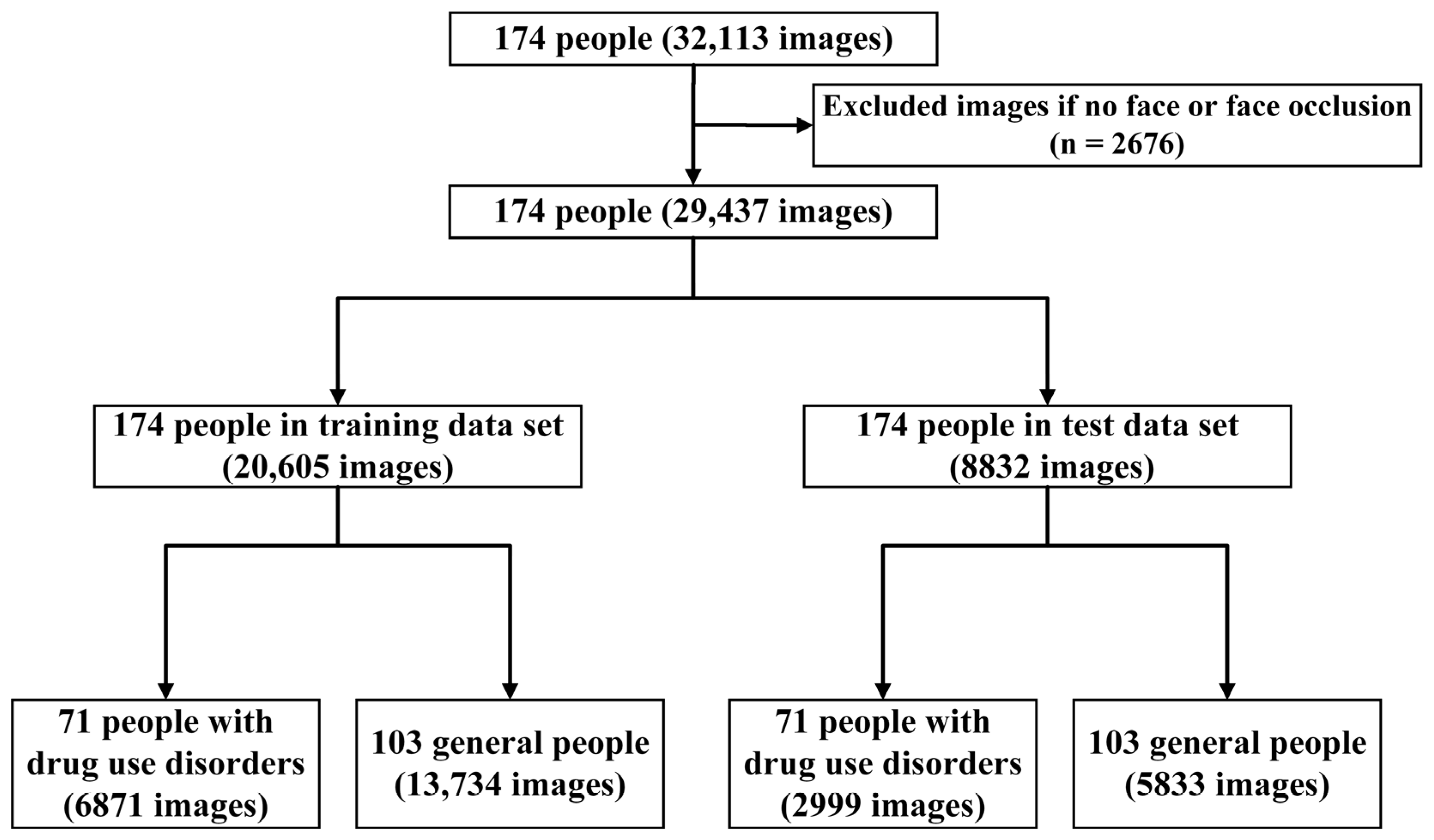
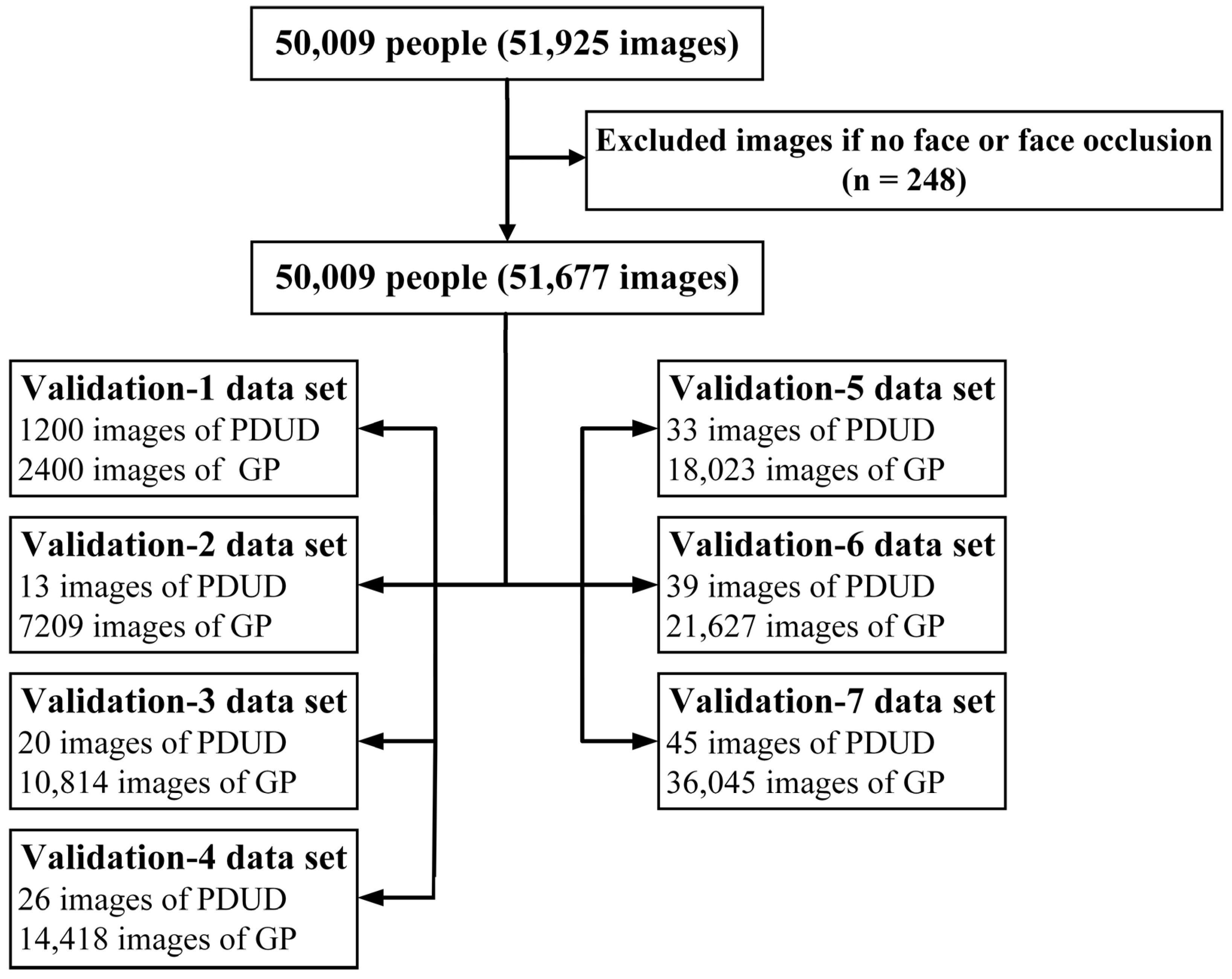
2.1. Study Design and Procedure
2.2. CNN Construction and Training
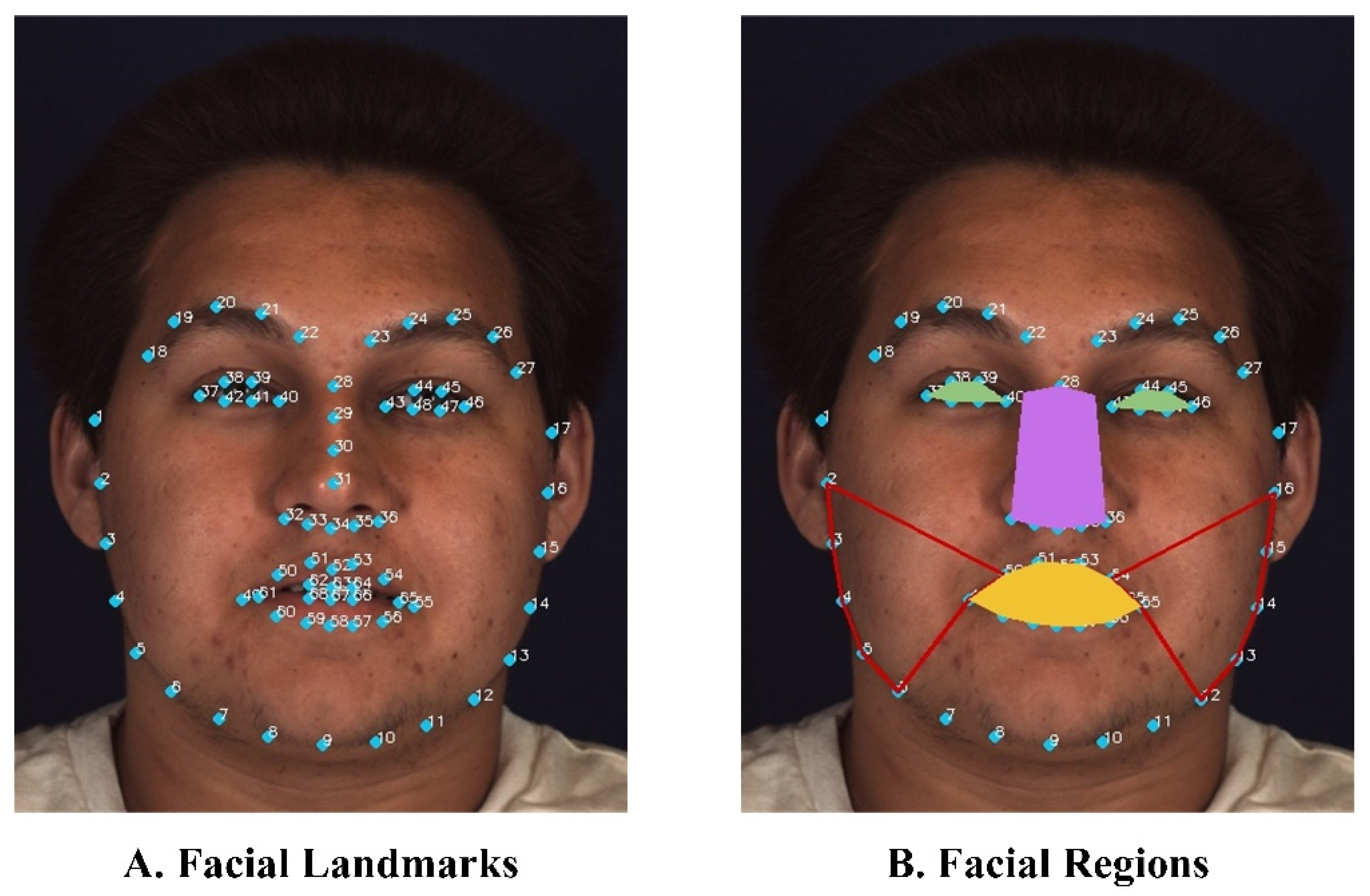
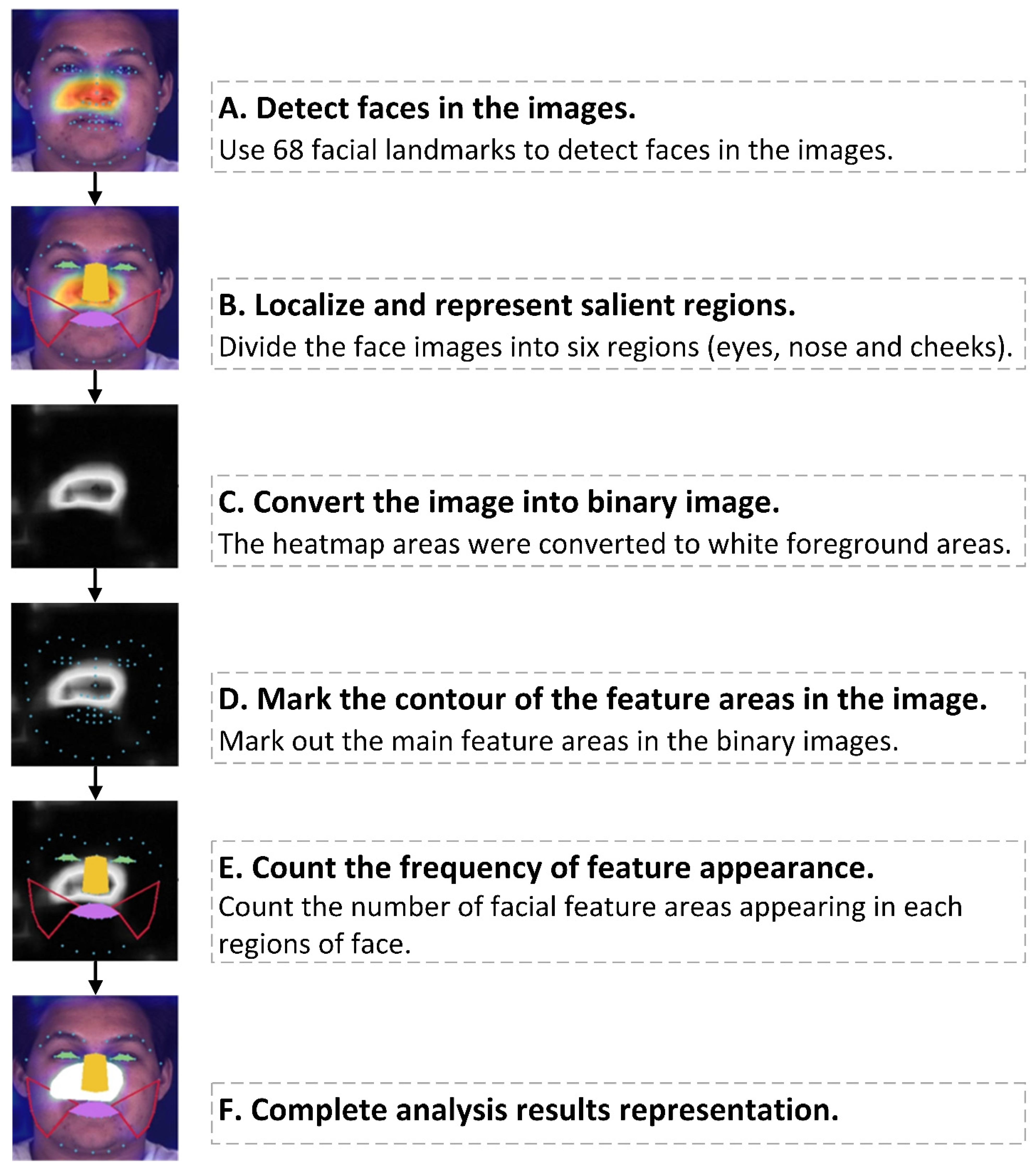
2.3. Quantitative Analysis of Facial Features and Visualization
3. Results
3.1. CNN Model Training and Performance
3.2. Typical Facial Features of PDUD and Visualization
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PDUD | people with drug use disorders |
| GP | the general population |
| CNN | convolutional neural networks |
| DALYs | disability-adjusted life-years |
| EDs | emergency departments |
| DR | diabetic retinopathy |
| AUC | area under the curve |
| mHealth | mobile health |
| LR | learning rates |
| BN | batch normalization |
| SGD | stochastic gradient descent |
| Adam | adaptive moment estimation |
| Grad-CAM | gradient weighted class activation mapping |
Appendix A
Appendix A.1. The Detailed Information of the App
Appendix B
Appendix B.1. Model Architecture Analysis and Selection
Appendix B.2. The Adjusted Strategy of Model Training
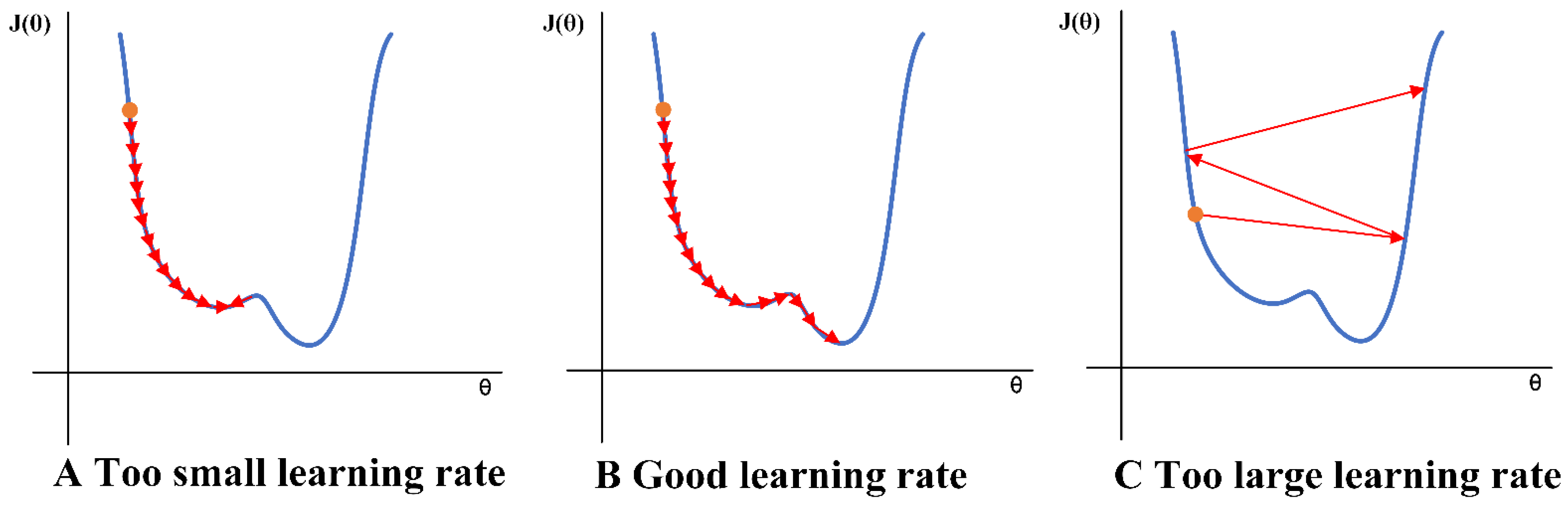
Appendix B.3. The Optimization Algorithms Analysis
Appendix B.4. The Data Augmentation of Images
| Algorithm A1. The pseudocodes of model training. |
| Input: load CNN model name MODEL, mini-batch size N, pre-trained config CONFIG, optimizer function OPTIM, loss function LOSS, data path PATH, training iteration EPOCH |
| 1 model = LoadModel(MODEL) |
| 2 if CONFIG has pre-trained parameters then |
| 3 Load pre-trained parameters |
| 4 if CONFIG need freeze some layers then |
| 5 Set requires_grad = False |
| 6 model.to(‘cuda:0’) |
| 7 if CONFIG has optimizer parameters then |
| 8 Set parameters of optimizer (include Adam or SGD) |
| 9 optimizer = OPTIM(learning_rate=0.1/0.01) |
| 10 if CONFIG need adjust learning rate then |
| 11 Set lr_scheduler to adjust learning rate |
| 12 if CONFIG has more fine-tuning setting then |
| 13 Add other fine-tuning setting (e.g. Batch Normalization) |
| 14 criterion = LOSS() |
| 15 if PATH is valid then |
| 16 Prepare train data loader |
| 17 train_loader = DataLoader(batch_size=N) |
| 18 Prepare validation data loader |
| 19 valid_loader = DataLoader(batch_size=N) |
| 20 for an epoch in EPOCH do |
| 21 for traing data in train_loader do |
| 22 train batch-size training data |
| 23 zero gradients buffers |
| 24 calculate training loss |
| 25 backpropagate the error |
| 26 update weight |
| 27 if log training history then |
| 28 Log accuracy and loss of each epoch in history |
| 29 Test the trained model in validation data set |
| 30 model.eval() |
| 31 for validation data in valid_loader do |
| 32 calculate the best accuracy |
| 33 Save the trained model |
| 34 Save procedure history |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiments | The Best Accuracy of the Experiment (%) |
|---|---|
| Experiment-1 | 51.03 |
| Experiment-2 | 51.25 |
| Experiment-3 | 61.23 |
| Experiment-4 | 79.72 |
| Experiment-5 | 81.64 |
| Experiment-6 | 60.43 |
| Experiment-7 | 79.13 |
| Experiment-8 | 50.55 |
| Experiment-9 | 78.88 |
| Experiment-10 | 84.68 |
| CNN Model | The Best Accuracy of the Experiment (%) |
|---|---|
| VGG-19 + Adam | 51.02 |
| VGG-19 + SGD | 61.23 |
| Inception + Adam | 54.99 |
| Inception + SGD | 79.13 |
| Resnet-18 + Adam | 71.61 |
| Resnet-18 + SGD | 79.72 |
Appendix C
Appendix C.1. Convolutional Neural Network
References
- Hasin, D.S.; O’Brien, C.P.; Auriacombe, M.; Borges, G.; Bucholz, K.; Budney, A.; Compton, W.M.; Crowley, T.; Ling, W.; Grant, B.F.; et al. DSM-5 criteria for substance use disorders: Recommendations and rationale. Am. J. Psychiatry 2013, 170, 834–851. [Google Scholar] [CrossRef] [Green Version]
- Degenhardt, L.; Hall, W. Extent of illicit drug use and dependence, and their contribution to the global burden of disease. Lancet 2012, 379, 55–70. [Google Scholar] [CrossRef]
- Health effects of dietary risks in 195 countries, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2019, 393, 1958–1972. [CrossRef] [Green Version]
- Polydorou, S.; Gunderson, E.W.; Levin, F.R. Training physicians to treat substance use disorders. Curr. Psychiatry Rep. 2008, 10, 399–404. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rockett, I.R.; Putnam, S.L.; Jia, H.; Smith, G.S. Declared and undeclared substance use among emergency department patients: A population-based study. Addiction 2006, 101, 706–712. [Google Scholar] [CrossRef]
- DuPont, R.L.; Baumgartner, W.A. Drug testing by urine and hair analysis: Complementary features and scientific issues. Forensic Sci. Int. 1995, 70, 63–76. [Google Scholar] [CrossRef]
- Yudko, E.; Lozhkina, O.; Fouts, A. A comprehensive review of the psychometric properties of the Drug Abuse Screening Test. J. Subst. Abus. Treat. 2007, 32, 189–198. [Google Scholar] [CrossRef]
- McNeely, J.; Kumar, P.C.; Rieckmann, T.; Sedlander, E.; Farkas, S.; Chollak, C.; Vega, A.; Waite, E.A.; Peccoralo, L.A.; Rotrosen, J.; et al. Barriers and facilitators affecting the implementation of substance use screening in primary care clinics: A qualitative study of patients, providers, and staff. Addict. Sci. Clin. Pract. 2018, 13, 8. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.B.; Busch, C. Impact of Drug Abuse on Face Recognition Systems: A Preliminary Study. In Proceedings of the 9th International Conference on Security of Information and Networks, New York, NY, USA, 20–22 July 2016; pp. 24–27. [Google Scholar]
- Tseng, W.; Sutter, M.E.; Albertson, T.E. Stimulants and the lung: Review of literature. Clin. Rev. Allergy Immunol. 2014, 46, 82–100. [Google Scholar] [CrossRef] [PubMed]
- Ersche, K.D.; Stochl, J.; Woodward, J.M.; Fletcher, P.C. The skinny on cocaine: Insights into eating behavior and body weight in cocaine-dependent men. Appetite 2013, 71, 75–80. [Google Scholar] [CrossRef] [Green Version]
- Bachi, K.; Sierra, S.; Volkow, N.D.; Goldstein, R.Z.; Alia-Klein, N. Is biological aging accelerated in drug addiction? Opin. Behav. Sci. 2017, 13, 34–39. [Google Scholar] [CrossRef] [Green Version]
- Yadav, D.; Kohli, N.; Pandey, P.; Singh, R.; Vatsa, M.; Noore, A. Effect of illicit drug abuse on face recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Harastani, M.; Benterkia, A.; Zadeh, F.M.; Nait-Ali, A. Methamphetamine drug abuse and addiction: Effects on face asymmetry. Comput. Biol. Med. 2020, 116, 103475. [Google Scholar] [CrossRef] [PubMed]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 113. [Google Scholar] [CrossRef] [Green Version]
- Ks, A.; Arws, B.; Dg, C.; Skl, D.; Ak, C.; Hmp, E. Automated detection and classification of fundus diabetic retinopathy images using synergic deep learning model. Pattern Recognit. Lett. 2020, 133, 210–216. [Google Scholar] [CrossRef]
- Lotter, W.; Diab, A.R.; Haslam, B.; Kim, J.G.; Grisot, G.; Wu, E.; Onieva, O.; Boyer, Y.; Boxerman, J.L.; Sorensen, A.G.; et al. Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach. Nat. Med. 2021, 27, 244–249. [Google Scholar] [CrossRef]
- Collins, G.S.; de Groot, J.A.; Dutton, S.; Omar, O.; Shanyinde, M.; Tajar, A.; Voysey, M.; Wharton, R.; Yu, L.; Altman, D.G.; et al. External validation of multivariable prediction models: A systematic review of methodological conduct and reporting. BMC Med. Res. Methodol. 2014, 14, 40. [Google Scholar] [CrossRef] [Green Version]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence, Los Alamitos, CA, USA, 2 February 2020. [Google Scholar] [CrossRef] [Green Version]
- Commission OoCNNC. Drug Situation in China (2018). Office of China National Narcotics Control Commission. 2019. Available online: http://www.nncc626.com/2019-06/17/c_1210161797.htm (accessed on 17 June 2019).
- Sharma, S.; Shanmugasundaram, K.; Ramasamy, S.K. FAREC—CNN Based Efficient Face Recognition Technique using Dlib. In Proceedings of the 2016 International Conference on Advanced Communication Control and Computing Technologies, Ramanathapuram, India, 25–27 May 2016. [Google Scholar]
- Obuchowski, N.A.; Zhou, X.H. Prospective studies of diagnostic test accuracy when disease prevalence is low. Biostatistics 2002, 3, 477–492. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Fine, J. On sample size for sensitivity and specificity in prospective diagnostic accuracy studies. Stat. Med. 2004, 23, 2537–2550. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.-H.; McClish, D.K.; Obuchowski, N.A. Statistical Methods in Diagnostic Medicine; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. (Eds.) Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Shin, H.C.; Roth, H.R.; Gao, M.C.; Lu, L.; Xu, Z.Y.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.D.; Zhang, L.; Hu, Y.X.; He, X.D.; Gao, J.F. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. In European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Germany, 2016; pp. 87–102. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alche-Buc, F., Fox, E., Garnett, R., Eds.; Neural Information Processing Systems (Nips): La Jolla, CA, USA, 2019. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Newton, MA, USA, 2008. [Google Scholar]
- Xing, Z.; Lijun, Y.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P. A high-resolution spontaneous 3D dynamic facial expression database. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013. [Google Scholar]
- Zhang, X.; Yin, L.J.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M. BP4D-Spontaneous: A high-resolution spontaneous 3D dynamic facial expression database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Połap, D.; Włodarczyk-Sielicka, M.; Wawrzyniak, N. Automatic ship classification for a riverside monitoring system using a cascade of artificial intelligence techniques including penalties and rewards. ISA Trans. 2021. [Google Scholar] [CrossRef]
- Shapiro, B.; Coffa, D.; McCance-Katz, E.F. A primary care approach to substance misuse. Am. Fam. Physician 2013, 88, 113–121. [Google Scholar] [PubMed]
- Bakhshaee, M.; Khadivi, E.; Naseri Sadr, M.; Esmatinia, F. Nasal Septum Perforation due to Methamphetamine abuse. Iran. J. Otorhinolaryngol. 2013, 25, 53–56. [Google Scholar] [PubMed]
- Djupesland, P.G. Nasal drug delivery devices: Characteristics and performance in a clinical perspective-a review. Drug Deliv. Transl. Res. 2013, 3, 42–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moreno-Artero, E.; Querol-Cisneros, E.; Rodríguez-Garijo, N.; Tomás-Velázquez, A.; Antoñanzas, J.; Secundino, F.; Pilar Gil-Sánchez, M.; España, A. Mucocutaneous manifestations of cocaine abuse: A review. JEADV 2018, 32, 1420–1426. [Google Scholar] [CrossRef]
- Verhaegen, A.A.; Van Gaal, L.F.; Feingold, K.R. Drugs that Affect Body Weight, Body Fat Distribution, and Metabolism; Anawalt, B., Boyce, A., Chrousos, G., de Herder, W.W., Dungan, K., Eds.; Endotext: South Dartmouth, MA, USA, 2000. [Google Scholar]
- Guo, H.X.; Li, Y.J.; Shang, J.; Gu, M.Y.; Huang, Y.Y.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]

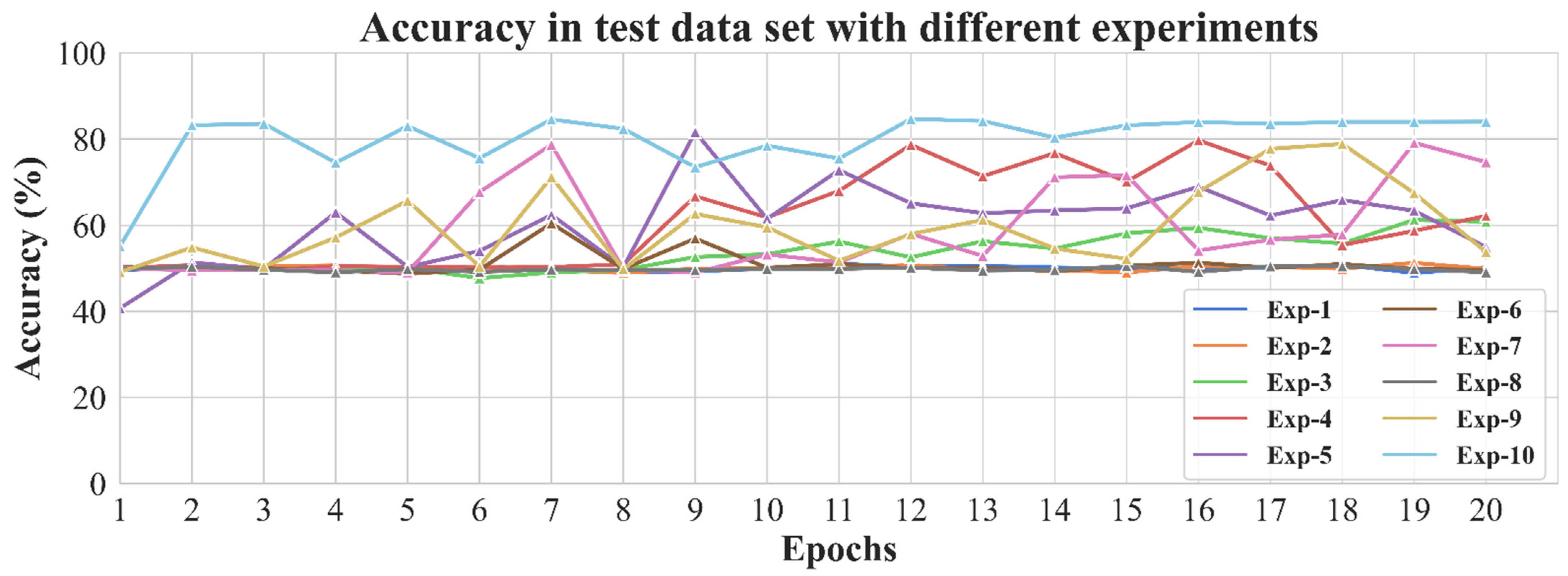
| Experiment | Backbone | Learning Rate | Batch Normalization | Pre-trained | Weight Initialization |
|---|---|---|---|---|---|
| Exp a-1 | Vgg-19 | 0.1 | ○ | ○ | ○ |
| Exp a-2 | Vgg-19 | 0.01 | ○ | ○ | ○ |
| Exp a-3 | Vgg-19 | 0.01 | ● | ○ | ○ |
| Exp a-4 | Resnet-18 | 0.1 | ● | ○ | ○ |
| Exp a-5 | Resnet-18 | 0.01 | ● | ○ | ○ |
| Exp a-6 | Resnet-18 | 0.1 | ● | ○ | ● |
| Exp a-7 | Inception | 0.01 | ● | ○ | ○ |
| Exp a-8 | Inception | 0.1 | ● | ○ | ○ |
| Exp a-9 | Resnet-18 + Attention | 0.1 | ● | ○ | ○ |
| Exp a-10 * | Resnet-18 | 0.1 | ● | ● | ○ |
| CNN Model | From Scratch (%) | Only Fully Connected (%) | The Last Five Convolutional Layers (%) |
|---|---|---|---|
| VGG-19 | 51.03 | 58.53 | 51.02 |
| Inception | 52.13 | 53.84 | 59.90 |
| Resnet-18 | 60.43 | 60.97 | 74.63 |
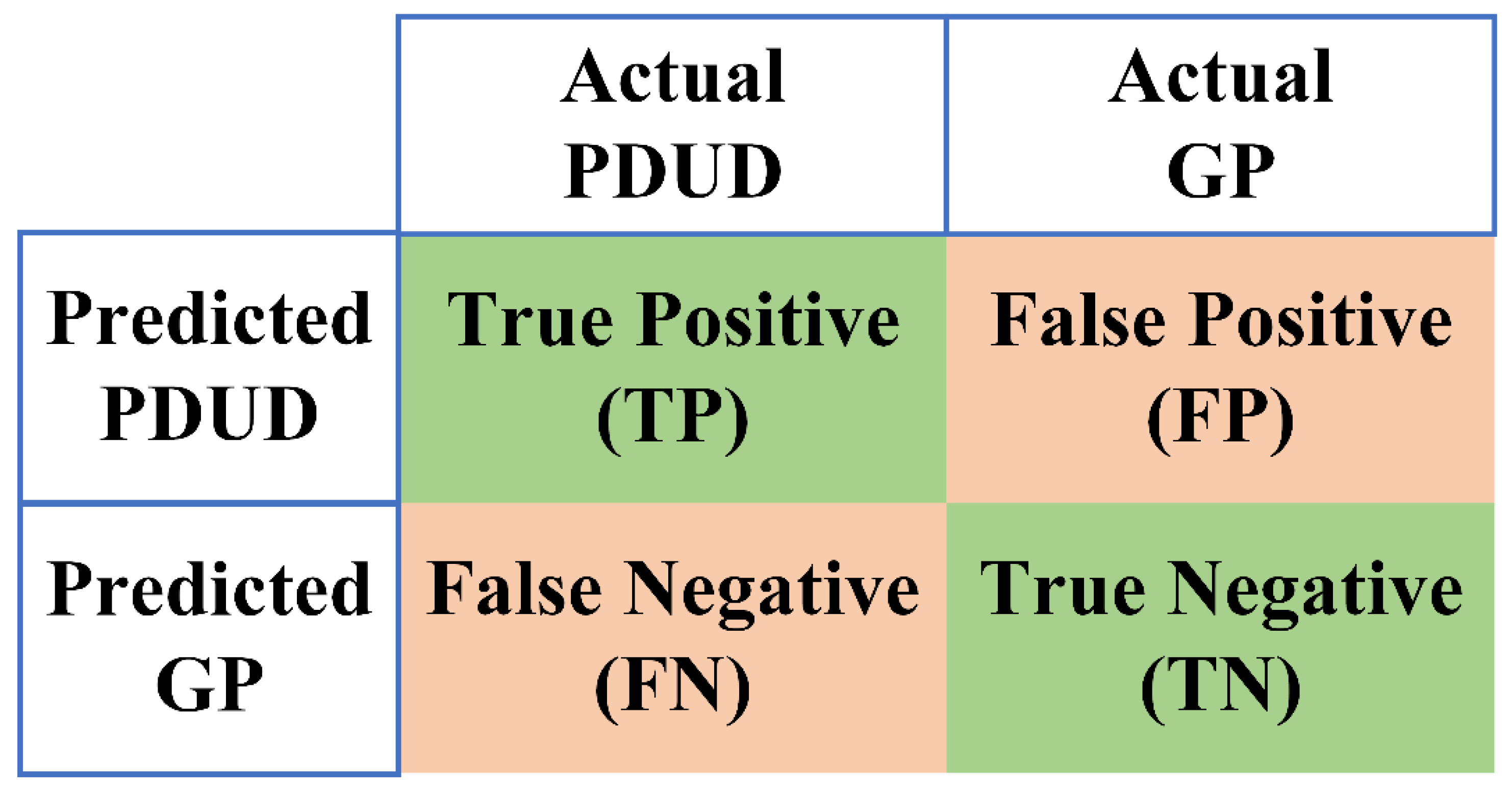
| Dataset | TP a, n (%) | FN b, n (%) | FP c, n (%) | TN d, n (%) | ACC e (%) | SEN f (%) | SPE g (%) |
|---|---|---|---|---|---|---|---|
| Test dataset | 2637 (29.86) | 362 (4.10) | 991 (11.22) | 4842 (54.82) | 84.68 | 87.93 | 83.01 |
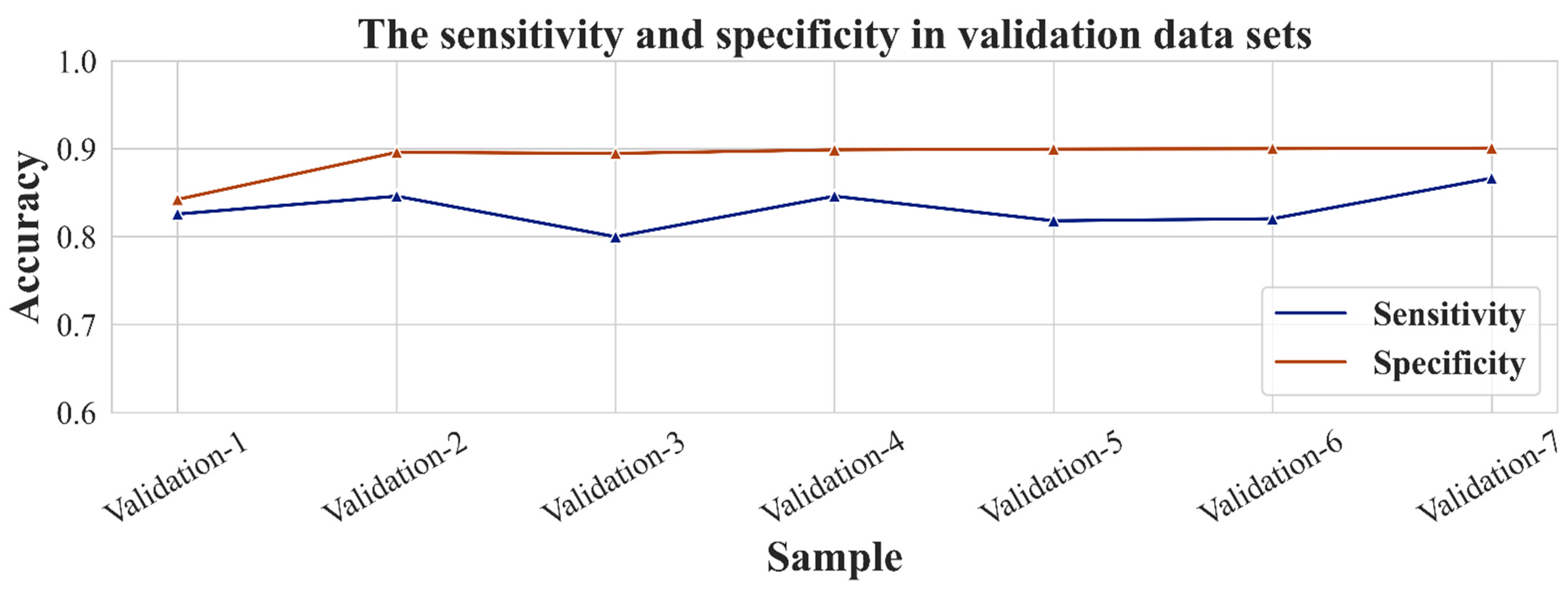
| Validation 1 dataset | 991 (27.53) | 209 (5.81) | 378 (10.50) | 2022 (56.17) | 83.69 | 82.58 | 84.25 |
| Validation 2 dataset | 11 (0.15) | 2 (0.02) | 749 (10.37) | 6460 (89.45) | 89.60 | 84.62 | 89.61 |
| Validation 3 dataset | 16 (0.15) | 4 (0.04) | 1136 (10.49) | 9678 (89.33) | 89.48 | 80.00 | 89.50 |
| Validation 4 dataset | 22 (0.15) | 4 (0.03) | 1456 (10.08) | 12,962 (89.74) | 89.89 | 84.62 | 89.90 |
| Validation 5 dataset | 27 (0.15) | 5 (0.02) | 1805 (10.00) | 16,218 (89.82) | 89.98 | 81.82 | 89.99 |
| Validation 6 dataset | 32 (0.15) | 7 (0.03) | 2156 (10.00) | 19,471 (89.87) | 90.02 | 82.05 | 90.03 |
| Validation 7 dataset | 39 (0.10) | 6 (0.02) | 3567 (9.88) | 32,478 (90.00) | 90.10 | 86.67 | 90.10 |
| Facial Area | People with Drug Use Disorders | General Population | ||
|---|---|---|---|---|
| Number | Proportion (%) | Number | Proportion (%) | |
| Left-eye | 661 | 22.04 * | 2095 | 35.92 |
| Right-eye | 786 | 26.21 * | 2526 | 43.31 |
| Mouth | 936 | 31.21 * | 2390 | 40.97 |
| Nose | 1289 | 42.98 ** | 1693 | 29.02 |
| Left-cheek | 1347 | 44.91 ** | 2004 | 34.36 |
| Right-cheek | 1345 | 44.85 ** | 2069 | 35.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Yan, X.; Zhang, B.; Wang, Z.; Su, H.; Jia, Z. A Method for Detecting and Analyzing Facial Features of People with Drug Use Disorders. Diagnostics 2021, 11, 1562. https://doi.org/10.3390/diagnostics11091562
Li Y, Yan X, Zhang B, Wang Z, Su H, Jia Z. A Method for Detecting and Analyzing Facial Features of People with Drug Use Disorders. Diagnostics. 2021; 11(9):1562. https://doi.org/10.3390/diagnostics11091562
Chicago/Turabian StyleLi, Yongjie, Xiangyu Yan, Bo Zhang, Zekun Wang, Hexuan Su, and Zhongwei Jia. 2021. "A Method for Detecting and Analyzing Facial Features of People with Drug Use Disorders" Diagnostics 11, no. 9: 1562. https://doi.org/10.3390/diagnostics11091562
APA StyleLi, Y., Yan, X., Zhang, B., Wang, Z., Su, H., & Jia, Z. (2021). A Method for Detecting and Analyzing Facial Features of People with Drug Use Disorders. Diagnostics, 11(9), 1562. https://doi.org/10.3390/diagnostics11091562