
A Trust-Based Methodology to Evaluate Deep Learning Models for Automatic Diagnosis of Ocular Toxoplasmosis from Fundus Images

 , ,
, ,  ,
,  , ,
, ,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
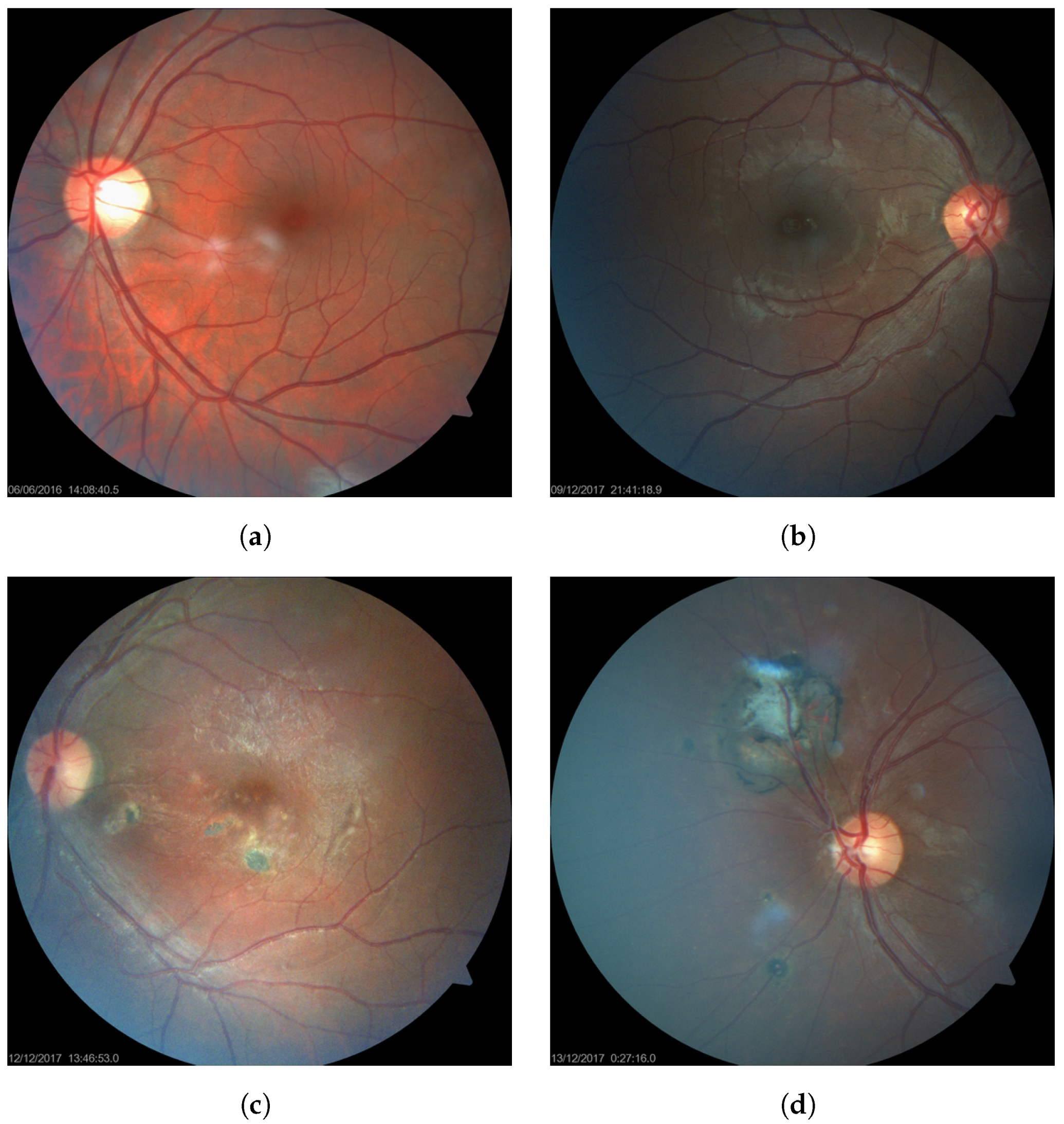
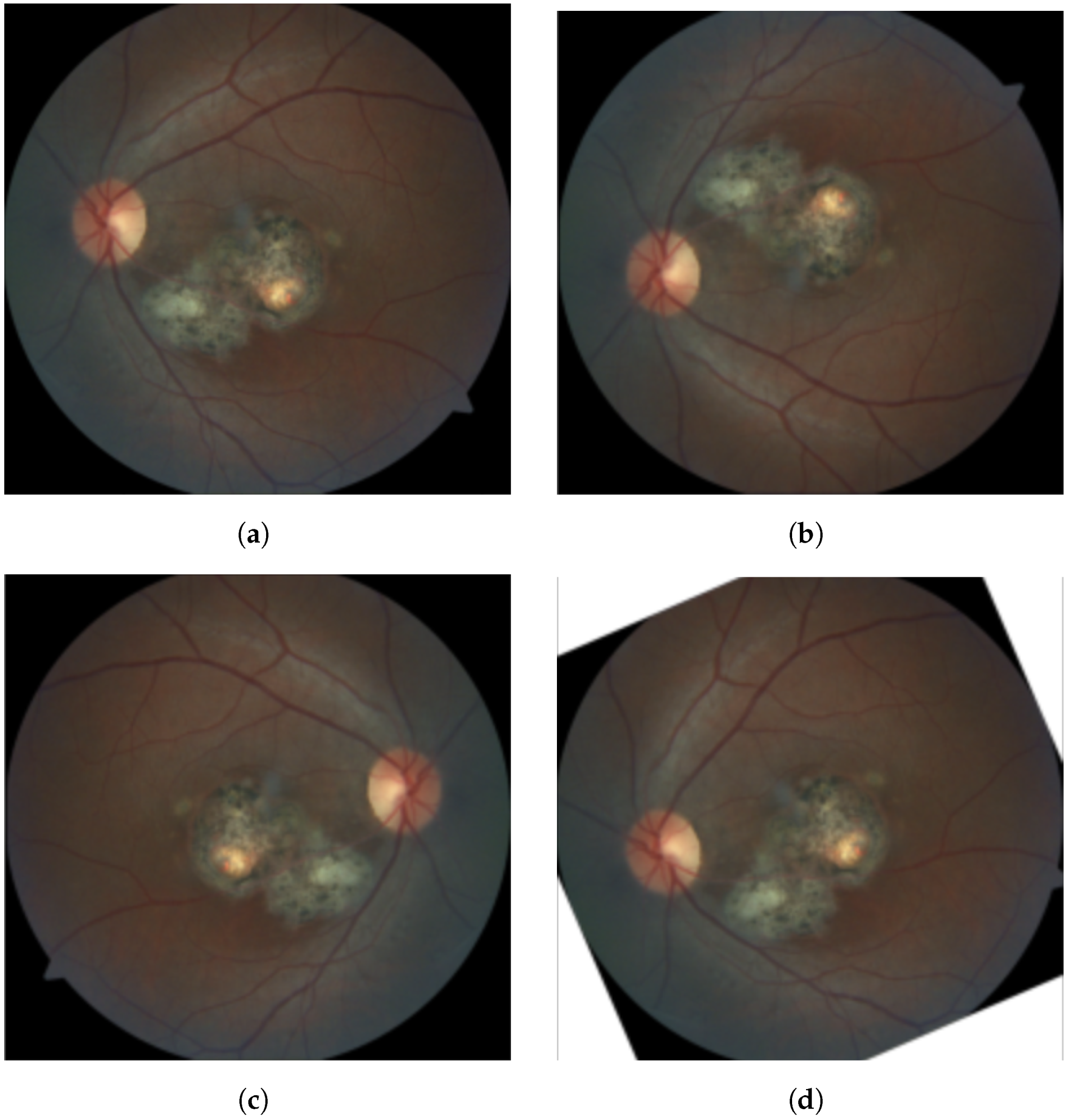
2.1. Dataset
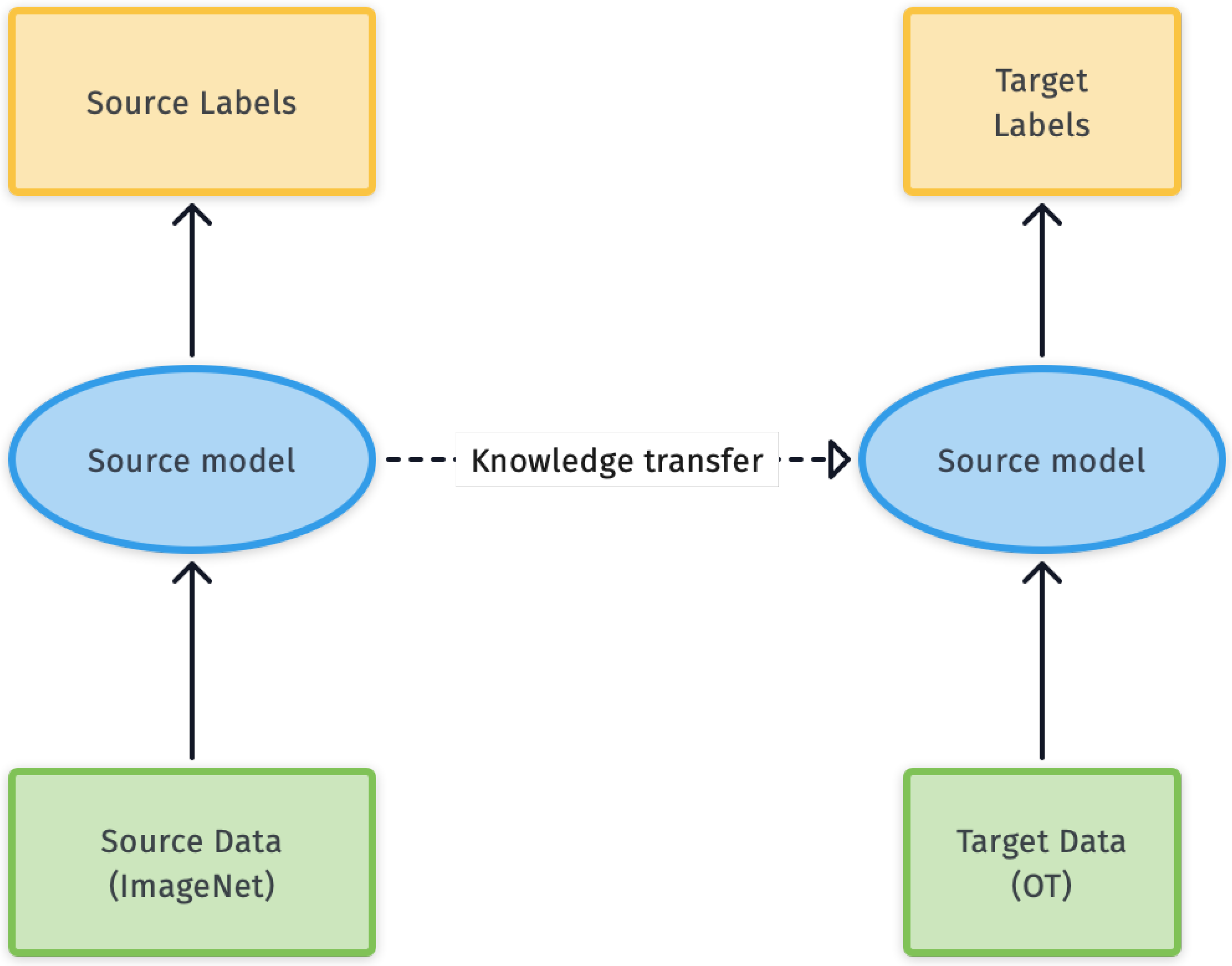
2.2. Model Training
- Convolutional layers: capture local features by sliding a set of kernels over their input.
- Pooling layers: are used to downsample the output of convolutional layers.
- Fully-connected layers: are often used as the final layers of the model, to perform the final prediction.
2.3. Model Evaluation
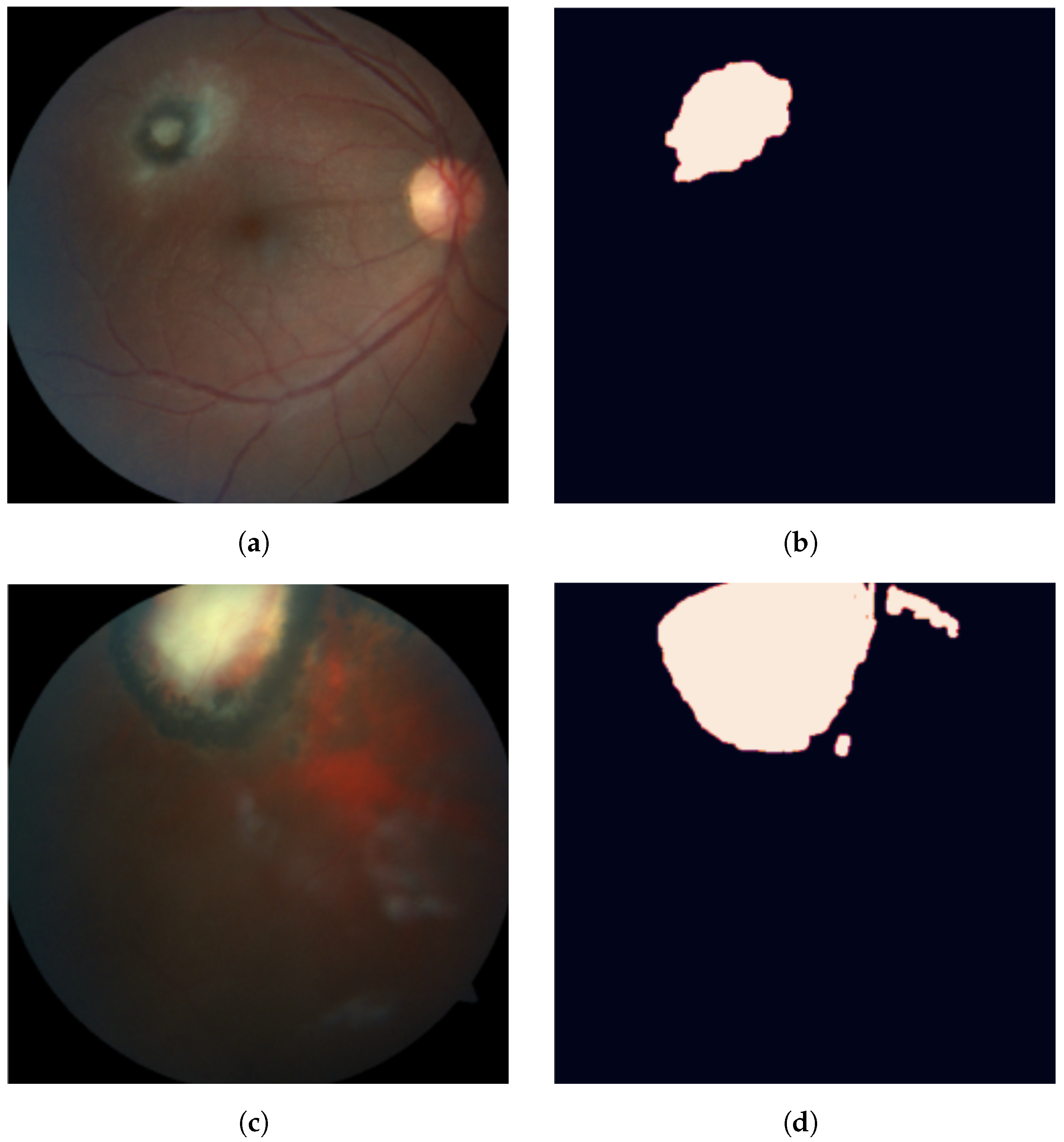
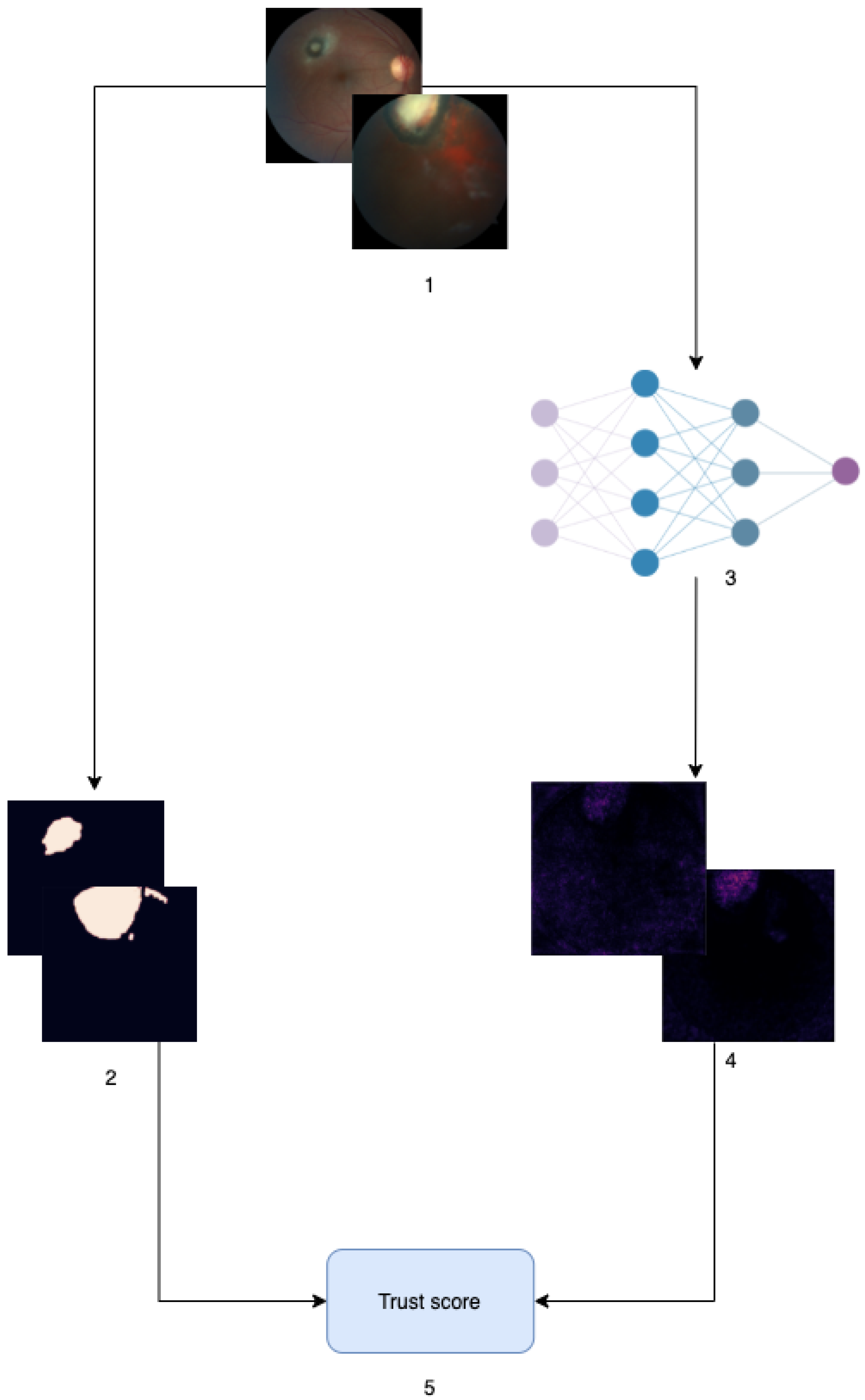
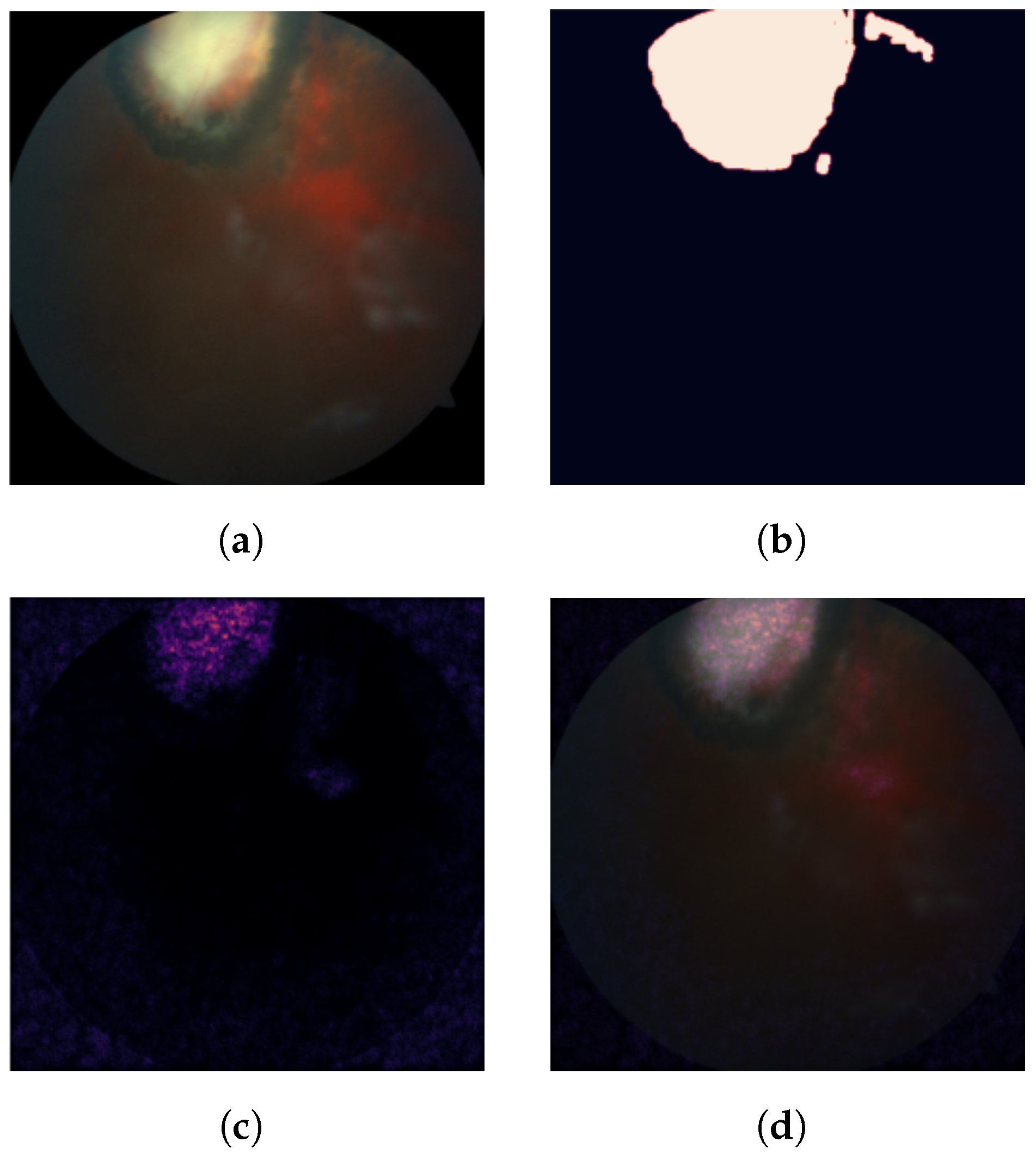
2.3.1. Measuring Feature Importance: Pixel Attribution Scores
2.3.2. Evaluating a Prediction: To Trust or Not to Trust?
2.3.3. Evaluating a Model Given a Dataset: Aggregating Our Results
3. Results
- Models were trained and evaluated with respect to accuracy, sensitivity and specificity, to contrast them with the results of the proposed trust metric and then,
- Models were evaluated using the proposed trust score on all correctly-predicted sick images from the test set.
3.1. Common Predictive Metrics
3.2. Trust Score
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DL | Deep Learning |
| OT | Ocular Toxoplamosis |
| CNN | Convolutional Neural Network |
| IG | Integrated Gradients |
Appendix A. Detailed Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IID | Vanilla CNN | VGG16 | Resnet18 |
|---|---|---|---|
| 81 | Mean lesion attribution: 0.00034721767224766176 Mean non-lesion attribution: −6.601 419 281 104 99 × 10−6 Mann–Whitney p-value: 0.0 | Mean lesion attribution: 0.0023451965695009515 Mean non-lesion attribution: −1.505 774 503 219 224 6 × 10−5 Mann–Whitney p-value: 2.182 831 996 769 315 × 10−7 | Mean lesion attribution: −6.291 439 449 744 539 × 10−5 Mean non-lesion attribution: 4.173 565 166 532 544 × 10−6 Mann–Whitney p-value: 0.8461449179567923 |
| 156 | misclassified | Mean lesion attribution: 7.608 095 877 901 965 × 10−5 Mean non-lesion attribution: 9.139 120 141 825 367 × 10−6 Mann–Whitney p-value: 0.8894574555554062 | Mean lesion attribution: 1.026 627 135 195 600 7 × 10−5 Mean non-lesion attribution: 1.283 862 080 623 880 5 × 10−5 Mann–Whitney p-value: 0.5119256881011157 |
| 148 | Mean lesion attribution: 6.443 540 099 421 086 × 10−5 Mean non-lesion attribution: −3.871 953 049 444 241 × 10−6 Mann–Whitney p-value: 0.0 | Mean lesion attribution: 0.0004341474669653702 Mean non-lesion attribution: −2.815 535 276 382 608 5 × 10−5 Mann–Whitney p-value: 0.12678531658770215 | misclassified |
| 144 | Mean lesion attribution: 2.284 996 167 701 541 6 × 10−5 Mean non-lesion attribution: −1.224 208 807 727 668 7 × 10−7 Mann–Whitney p-value: 2.1783883659119423 × 10−143 | Mean lesion attribution: 9.005 965 358 771 226 × 10−5 Mean non-lesion attribution: 7.268116949538503 × 10−6 Mann–Whitney p-value: 0.2580941242701976 | Mean lesion attribution: 2.337 102 520 230 451 4 × 10−5 Mean non-lesion attribution: 1.267864040454379 × 10−5 Mann–Whitney p-value: 0.9355251360530437 |
| 97 | Mean lesion attribution: 6.336 514 502 731 98 × 10−5 Mean non-lesion attribution: 1.0295273698471493 × 10−6 Mann–Whitney p-value: 0.0 | Mean lesion attribution: 0.00031431523156589153 Mean non-lesion attribution: −9.295 814 133 027 072 × 10−7 Mann–Whitney p-value: 0.4886499718139443 | Mean lesion attribution: 8.424 714 848 856 002 × 10−6 Mean non-lesion attribution: 1.2007089850336847 × 10−5 Mann–Whitney p-value: 0.976338912018821 |
| 151 | Mean lesion attribution: 8.273 648 382 325 341 × 10−5 Mean non-lesion attribution: −1.5860174859485157 × 10−6 Mann–Whitney p-value: 0.0 | Mean lesion attribution: 0.00021355240374255574 Mean non-lesion attribution: 4.000 040 678 326 502 × 10−6 Mann–Whitney p-value: 0.03181811783986231 | Mean lesion attribution: 5.638 891 517 729 174 × 10−5 Mean non-lesion attribution: 6.625146340744238 × 10−6 Mann–Whitney p-value: 0.40842097615151357 |
| 142 | Mean lesion attribution: 9.391 440 979 266 882 × 10−5 Mean non-lesion attribution: 5.0270287766254336 × 10−6 Mann–Whitney p-value: 4.48215423628502 × 10−230 | Mean lesion attribution: 0.0008307758169506642 Mean non-lesion attribution: 1.188 879 169 016 227 2 × 10−5 Mann–Whitney p-value: 0.11516303087912255 | Mean lesion attribution: 0.00015584305846376865 Mean non-lesion attribution: 6.200 042 851 696 207 × 10−6 Mann–Whitney p-value: 0.3019700368885526 |
| 118 | Mean lesion attribution: −2.179 597 111 096 857 7 × 10−5 Mean non-lesion attribution: 1.2655909104444177 × 10−5 Mann–Whitney p-value: 1.0 | Mean lesion attribution: 0.00016869457829025018 Mean non-lesion attribution: 7.862 114 094 452 912 × 10−6 Mann–Whitney p-value: 0.7708368497428252 | Mean lesion attribution: 9.424 270 874 506 554 × 10−5 Mean non-lesion attribution: 3.1994922104513376 × 10−7 Mann–Whitney p-value: 0.6965993050535022 |
| 150 | Mean lesion attribution: −7.918 849 021 031 336 × 10−5 Mean non-lesion attribution: 1.583 111 698 817 516 7 × 10−5 Mann–Whitney p-value: 1.0 | Mean lesion attribution: 0.00013991786062732565 Mean non-lesion attribution: 9.315 094 828 690 027 × 10−6 Mann–Whitney p-value: 0.6484420024657709 | Mean lesion attribution: 1.135 622 422 691 986 × 10−5 Mean non-lesion attribution: 1.0066499735435533 × 10−5 Mann–Whitney p-value: 0.5955185797651998 |
| 94 | misclassified | Mean lesion attribution: 0.00046278512907457894 Mean non-lesion attribution: −6.857 434 254 485 007 × 10−6 Mann–Whitney p-value: 1.6871382541385086 × 10−9 | Mean lesion attribution: 2.319106013366875 × 10−5 Mean non-lesion attribution: 1.304 558 028 864 510 6 × 10−6 Mann–Whitney p-value: 0.7233509758415473 |
| 132 | misclassified | Mean lesion attribution: 0.0007116612771495348 Mean non-lesion attribution: −5.007 881 843 520 115 × 10−6 Mann–Whitney p-value: 0.9661658611357002 | Mean lesion attribution: 3.984 074 887 705 268 × 10−6 Mean non-lesion attribution: 1.8449527437055958 × 10−7 Mann–Whitney p-value: 0.9659463877638184 |
| 146 | Mean lesion attribution: 6.460267789192614 × 10−5 Mean non-lesion attribution: 5.149 698 277 781 459 5 × 10−5 Mann–Whitney p-value: 3.629556224709794 × 10−15 | Mean lesion attribution: 0.00033481917634950995 Mean non-lesion attribution: −5.838 907 669 173 114 × 10−6 Mann–Whitney p-value: 0.9474421613415959 | Mean lesion attribution: 3.984 074 887 705 268 × 10−6 Mean non-lesion attribution: 1.8449527437055958 × 10−7 Mann–Whitney p-value: 0.05547639441097111 |
| 99 | Mean lesion attribution: 1.0623468091879256 × 10−5 Mean non-lesion attribution: −8.381 454 520 194 11 × 10−7 Mann–Whitney p-value: 8.705342309642405 × 10−12 | Mean lesion attribution: 0.00011561437034381344 Mean non-lesion attribution: 1.122 893 524 636 988 8 × 10−6 Mann–Whitney p-value: 0.9991945637023955 | Mean lesion attribution: 4.387 994 697 815 6 × 10−5 Mean non-lesion attribution: 5.952850761770384 × 10−6 Mann–Whitney p-value: 0.8881489550295014 |
| 117 | Mean lesion attribution: −3.639 901 875 997 307 6 × 10−5 Mean non-lesion attribution: 1.4487363899890637 × 10−5 Mann–Whitney p-value: 1.0 | Mean lesion attribution: 0.0001403303076260771 Mean non-lesion attribution: 1.199 786 422 310 879 6 × 10−5 Mann–Whitney p-value: 0.8978942267882748 | Mean lesion attribution: 6.2256477107090875 × 10−6 Mean non-lesion attribution: 1.240 475 023 789 905 8 × 10−5 Mann–Whitney p-value: 0.503937509947166 |
| 111 | Mean lesion attribution: 6.573 892 462 999 344 × 10−10 Mean non-lesion attribution: 6.415230420503763 × 10−6 Mann–Whitney p-value: 0.9986524555283746 | misclassified | Mean lesion attribution: 0.00011425205913621127 Mean non-lesion attribution: −2.209 874 594 196 942 × 10−6 Mann–Whitney p-value: 0.024341820096032026 |
References
- Tenter, A.M.; Heckeroth, A.R.; Weiss, L.M. Toxoplasma gondii: From animals to humans. Int. J. Parasitol. 2000, 30, 1217–1258. [Google Scholar] [CrossRef] [Green Version]
- Park, Y.H.; Nam, H.W. Clinical features and treatment of ocular toxoplasmosis. Korean J. Parasitol. 2013, 51, 393–399. [Google Scholar] [CrossRef] [PubMed]
- Garweg, J.G.; de Groot-Mijnes, J.D.F.; Montoya, J.G. Diagnostic approach to ocular toxoplasmosis. Ocul. Immunol. Inflamm. 2011, 19, 255–261. [Google Scholar] [CrossRef] [PubMed]
- Tong, Y.; Lu, W.; Yu, Y.; Shen, Y. Application of machine learning in ophthalmic imaging modalities. Eye Vis. 2020, 7, 22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahony, N.O.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Velasco-Hernandez, G.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Proceedings of the Science and Information Conference, Las Vegas, NV, USA, 25–26 April 2019. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Pead, E.; Megaw, R.; Cameron, J.; Fleming, A.; Dhillon, B.; Trucco, E.; MacGillivray, T. Automated detection of age-related macular degeneration in color fundus photography: A systematic review. Surv. Ophthalmol. 2019, 64, 498–511. [Google Scholar] [CrossRef] [Green Version]
- Alyoubi, W.L.; Shalash, W.M.; Abulkhair, M.F. Diabetic retinopathy detection through deep learning techniques: A review. Inform. Med. Unlocked 2020, 20, 100377. [Google Scholar] [CrossRef]
- Tsiknakis, N.; Theodoropoulos, D.; Manikis, G.; Ktistakis, E.; Boutsora, O.; Berto, A.; Scarpa, F.; Scarpa, A.; Fotiadis, D.I.; Marias, K. Deep learning for diabetic retinopathy detection and classification based on fundus images: A review. Comput. Biol. Med. 2021, 135, 104599. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Li, T.; Li, W.; Zhang, W. Lesion Detection and Grading of Diabetic Retinopathy via Two-Stages Deep Convolutional Neural Networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2017; pp. 533–540. [Google Scholar]
- Hasanreisoglu, M.; Halim, M.S.; Chakravarthy, A.D.; Ormaechea, M.S.; Uludag, G.; Hassan, M.; Ozdemir, H.B.; Ozdal, P.C.; Colombero, D.; Rudzinski, M.N.; et al. Ocular Toxoplasmosis Lesion Detection on Fundus Photograph using a Deep Learning Model. Invest. Ophthalmol. Vis. Sci. 2020, 61, 1627. [Google Scholar]
- Parra, R.; Ojeda, V.; Vázquez Noguera, J.L.; García Torres, M.; Mello Román, J.C.; Villalba, C.; Facon, J.; Divina, F.; Cardozo, O.; Castillo, V.E.; et al. Automatic Diagnosis of Ocular Toxoplasmosis from Fundus Images with Residual Neural Networks. Stud. Health Technol. Inform. 2021, 281, 173–177. [Google Scholar]
- Lockey, S.; Gillespie, N.; Holm, D.; Someh, I.A. A Review of Trust in Artificial Intelligence: Challenges, Vulnerabilities and Future Directions. In Proceedings of the 54th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2021. [Google Scholar]
- Asan, O.; Bayrak, A.E.; Choudhury, A. Artificial Intelligence and Human Trust in Healthcare: Focus on Clinicians. J. Med. Internet Res. 2020, 22, e15154. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Shrikumar, A.; Greenside, P.; Shcherbina, A.; Kundaje, A. Not Just a Black Box: Learning Important Features Through Propagating Activation Differences. arXiv 2016, arXiv:1605.01713. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. Towards better understanding of gradient-based attribution methods for Deep Neural Networks. arXiv 2017, arXiv:1711.06104. [Google Scholar]
- Sayres, R.; Taly, A.; Rahimy, E.; Blumer, K.; Coz, D.; Hammel, N.; Krause, J.; Narayanaswamy, A.; Rastegar, Z.; Wu, D.; et al. Using a Deep Learning Algorithm and Integrated Gradients Explanation to Assist Grading for Diabetic Retinopathy. Ophthalmology 2019, 126, 552–564. [Google Scholar] [CrossRef] [Green Version]
- Mehta, P.; Lee, A.Y.; Wen, J.; Bannit, M.R.; Chen, P.P.; Bojikian, K.D.; Petersen, C.; Egan, C.A.; Lee, S.I.; Balazinska, M.; et al. Automated detection of glaucoma using retinal images with interpretable deep learning. Invest. Ophthalmol. Vis. Sci. 2020, 61, 1150. [Google Scholar]
- Wong, A.; Wang, X.Y.; Hryniowski, A. How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks. arXiv 2020, arXiv:2009.05835. [Google Scholar]
- Hryniowski, A.; Wang, X.Y.; Wong, A. Where Does Trust Break Down? A Quantitative Trust Analysis of Deep Neural Networks via Trust Matrix and Conditional Trust Densities. arXiv 2020, arXiv:2009.14701. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018. [Google Scholar]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning based prediction models in healthcare. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]
- Merrill, J.; Ward, G.; Kamkar, S.; Budzik, J.; Merrill, D. Generalized Integrated Gradients: A practical method for explaining diverse ensembles. arXiv 2019, arXiv:1909.01869. [Google Scholar]








| Model | Parameters (Millions) | Layers |
|---|---|---|
| Vanilla CNN | 5.6 | 6 |
| VGG16 | 138 | 16 |
| Resnet18 | 11 | 152 |
| Model | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| Vanilla CNN | 0.75 | 0.75 | 0.75 |
| VGG16 | 0.96875 | 1.0 | 0.9375 |
| Resnet18 | 0.9375 | 0.9375 | 0.9375 |
| Model | Accuracy | Sensitivity | Specificity | Trust |
|---|---|---|---|---|
| Vanilla CNN | 0.75 | 0.75 | 0.75 | 0.67 |
| VGG16 | 0.96875 | 1.0 | 0.9375 | 0.21 |
| Resnet18 | 0.9375 | 0.9375 | 0.9375 | 0.14 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parra, R.; Ojeda, V.; Vázquez Noguera, J.L.; García-Torres, M.; Mello-Román, J.C.; Villalba, C.; Facon, J.; Divina, F.; Cardozo, O.; Castillo, V.E.; et al. A Trust-Based Methodology to Evaluate Deep Learning Models for Automatic Diagnosis of Ocular Toxoplasmosis from Fundus Images. Diagnostics 2021, 11, 1951. https://doi.org/10.3390/diagnostics11111951
Parra R, Ojeda V, Vázquez Noguera JL, García-Torres M, Mello-Román JC, Villalba C, Facon J, Divina F, Cardozo O, Castillo VE, et al. A Trust-Based Methodology to Evaluate Deep Learning Models for Automatic Diagnosis of Ocular Toxoplasmosis from Fundus Images. Diagnostics. 2021; 11(11):1951. https://doi.org/10.3390/diagnostics11111951
Chicago/Turabian StyleParra, Rodrigo, Verena Ojeda, Jose Luis Vázquez Noguera, Miguel García-Torres, Julio César Mello-Román, Cynthia Villalba, Jacques Facon, Federico Divina, Olivia Cardozo, Verónica Elisa Castillo, and et al. 2021. "A Trust-Based Methodology to Evaluate Deep Learning Models for Automatic Diagnosis of Ocular Toxoplasmosis from Fundus Images" Diagnostics 11, no. 11: 1951. https://doi.org/10.3390/diagnostics11111951
APA StyleParra, R., Ojeda, V., Vázquez Noguera, J. L., García-Torres, M., Mello-Román, J. C., Villalba, C., Facon, J., Divina, F., Cardozo, O., Castillo, V. E., & Matto, I. C. (2021). A Trust-Based Methodology to Evaluate Deep Learning Models for Automatic Diagnosis of Ocular Toxoplasmosis from Fundus Images. Diagnostics, 11(11), 1951. https://doi.org/10.3390/diagnostics11111951