1. Introduction
Worldwide, millions of people of all ages and demographics suffer from bone fractures each year [
1]. Fractures constitute a substantial burden on healthcare systems worldwide, ranging from falls among the elderly to sports injuries in young individuals [
2]. A fracture diagnosis must be made quickly and accurately to start treatment on time, avoid complications, and promote the best possible recovery [
3]. Radiographic imaging, such as X-rays, is used in clinical practice to detect bone fractures. This architecture offers pathologists and automated systems a viable method for diagnosing and grading breast cancer’s aggressiveness [
4]. Deep learning transforms medical image processing by providing sophisticated pathological image analysis capabilities. It can recognize subtle features and patterns in images using advanced neural networks, enabling the early and accurate detection of various illnesses. This technology outperforms conventional methods in its field, with faster and more reliable results. Deep learning is, therefore, becoming crucial to modern pathology, improving patient care and diagnostic accuracy [
5,
6]. Deciphering X-ray images, however, may be challenging and time-consuming; qualified radiologists must carefully review each image to make a diagnosis. The need for automated systems to identify bone fractures is becoming more obvious.
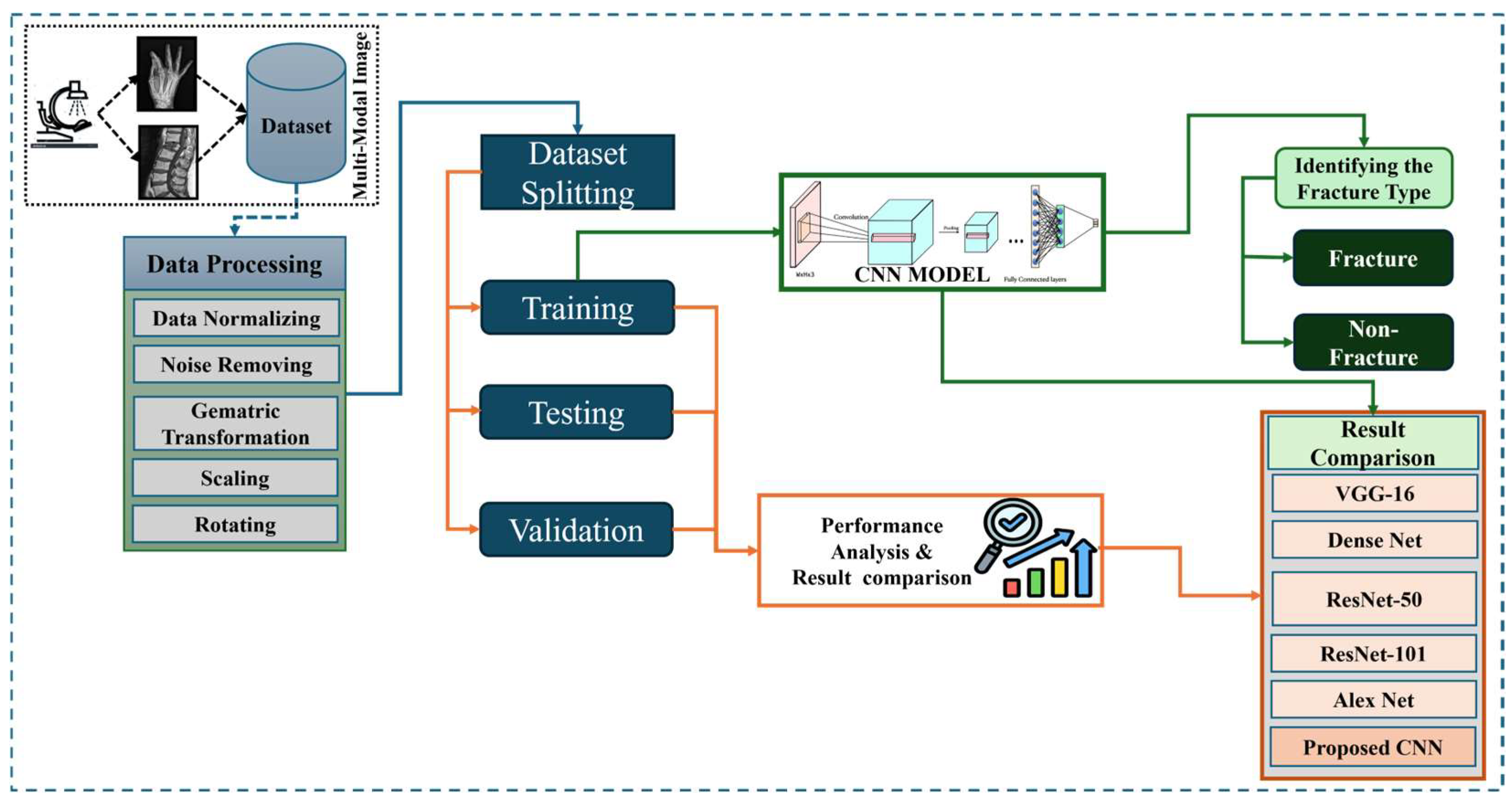
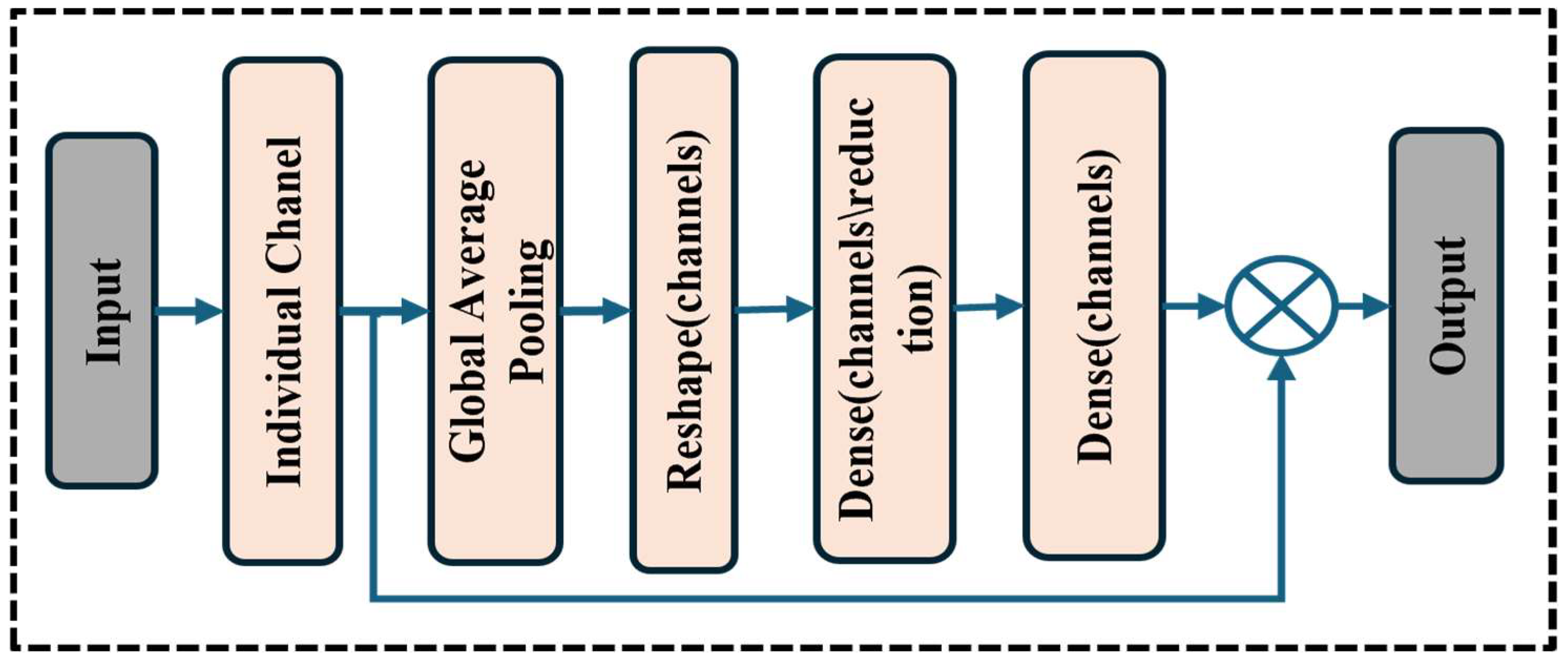
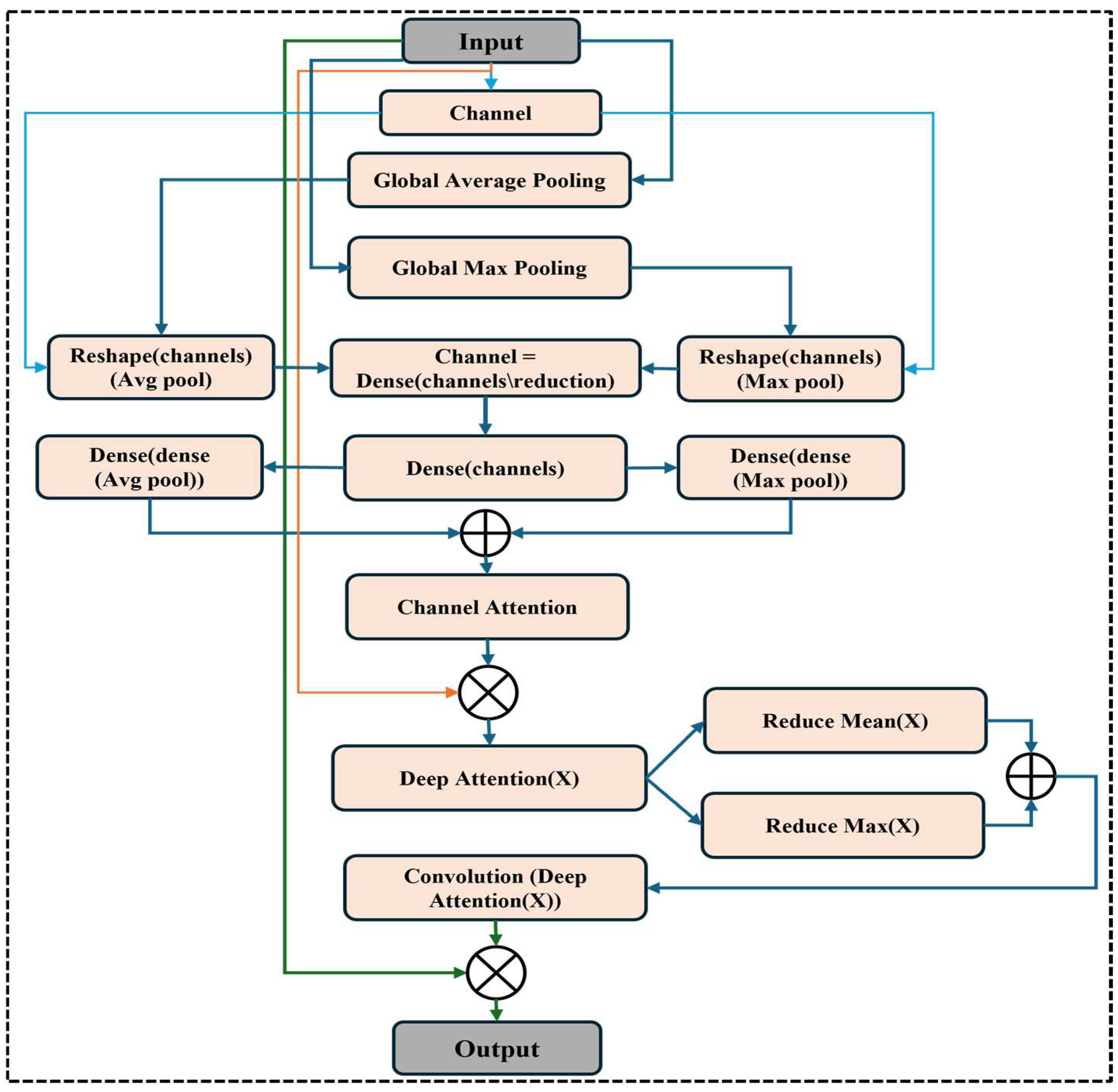
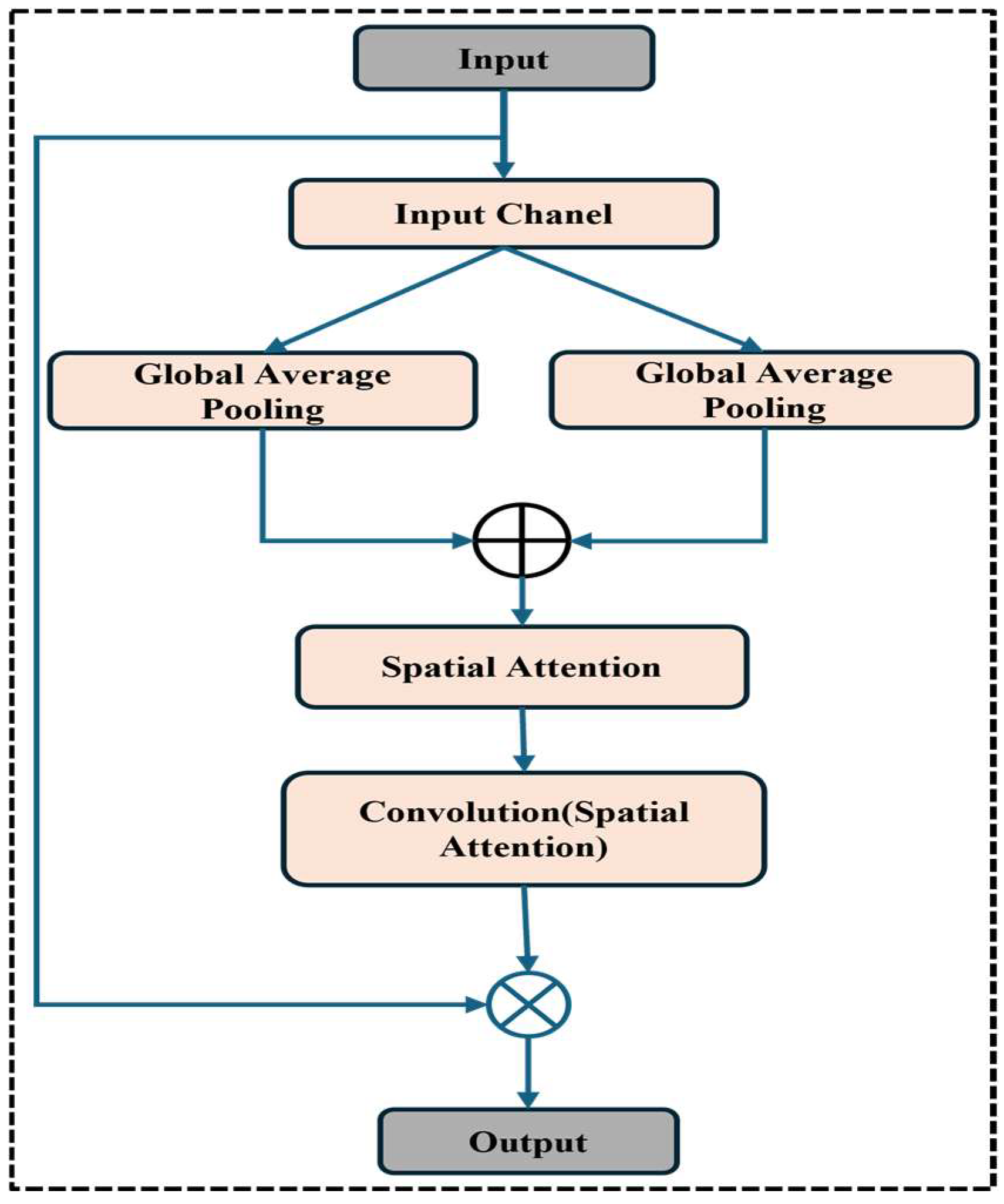
Figure 1 shows the wide workflow of the proposed automatic fracture detection system using integrated CNN-based deep learning approaches with several attention mechanisms. The process begins with a diverse dataset of X-ray images collected from various physiological areas, including the hips, knees, lumbar spine, and limbs. These images undergo essential preprocessing stages such as generalization, noise removal, geometric changes, scaling, and rotation to increase quality and stability. After preprocessing, the dataset is divided into training, verification, and test sets. The system’s core is a convolutional neural network (CNN) model enhanced with a squeeze-and-excitation block and a convolutional block attention module (CBAM), allowing the model to focus on the main fracture features. The trained model classifies images into fractured or non-fractured categories. Finally, the system’s performance is evaluated and compared against current architectures such as VGG-16, Dense-Net, ResNet-50, ResNet-101, and Alex-Net, showing the superiority of the proposed CNN in accuracy and clinical efficiency.
Automatic models can potentially improve diagnostic accuracy, shorten interpretation times, and relieve the workload of medical practitioners by utilizing advances in AI and machine learning [
7]. These devices can quickly and reliably analyze X-ray images, identify possible fractures for radiologists to examine further, or offer prompt preliminary evaluations in urgent care settings [
8]. As reported in this article, constructing a strong automatic model for bone fracture identification aims to enhance patient outcomes by optimizing the diagnostic process. This study addresses the diversity and complexity of fractures encountered in clinical practice using a dataset comprising X-ray images of fractured and non-fractured anatomical regions, including the lower and upper limbs, lumbar region, hips, and knees [
9]. The training, testing, and validation sets are carefully separated, offering a strong basis for the proposed automatic fracture identification system. Applying this automated detection approach could completely transform clinical operations and patient care. Improved diagnostic efficiency allows practitioners to improve treatment outcomes and intervene more quickly [
10]. Deep learning has transformed medical image analysis, especially convolutional neural networks (CNNs), which make it possible to automatically, accurately, and quickly interpret complicated visual data. CNNs are very good at identifying minor elements in medical imaging, including anomalies or disease signs, since they collect spatial hierarchies within images [
11,
12]. CNNs are essential in many diagnostic applications, such as organ segmentation, fracture recognition, and tumor detection, due to their capacity to learn from large datasets [
13,
14]. As a result, CNN-based models are helping medical practitioners identify patients more quickly and accurately [
15].
Additionally, this technology can be a helpful decision-support tool in emergencies or environments with limited resources, guaranteeing that patients receive timely and accurate assessments even in trying situations. Developing and validating an autonomous bone fracture detection model represent a significant advancement in medical imaging technology. Through artificial intelligence, this work contributes to ongoing efforts to enhance patient management and healthcare delivery in orthopedics and beyond [
16]. The rest of this paper is organized as follows:
Section 3 details the methodology of the deep learning approach.
Section 4 presents the experimental setup and evaluation results, followed by a conclusion and discussion in
Section 5 and
Section 6.
2. Literature Review
The application of deep learning, specifically convolutional neural networks (CNNs), in medical image research has grown enormously in recent years, with fracture detection as a major research area. Several investigations have demonstrated the prospects of CNNs in automating fracture diagnosis, facilitating the avoidance of diagnostic errors, and improving efficiency in clinical workflows. To classify fractures from X-ray images, early fracture detection algorithms employed handmade features and conventional machine learning approaches like Support Vector Machines (SVMs) and Random Forests [
17]. Regardless, variability in fracture forms, anatomical arrangements, and imaging requirements repeatedly introduced challenges for these methods [
18]. The advent of deep learning revolutionized medical imaging by enabling end-to-end learning of hierarchical features directly from raw pixel data. CNNs, in particular, have demonstrated tremendous success in fracture detection due to their capability to capture spatial reliance and subtle pathological patterns [
19].
For example, Rajpurkar et al. [
20] created a CNN-based model (CheXNet) to identify different lung diseases, suggesting that deep learning might perform as well as or better than radiologists. The viability of AI-assisted fracture diagnosis was also demonstrated by Olczak et al. [
21], who demonstrated a deep learning system for wrist fracture identification that achieved good sensitivity and specificity. While CNNs have shown promise, issues including class imbalance, false positives, and fracture appearance variability call for more complex structures. By allowing the model to concentrate on important areas while blocking out unimportant background noise, attention mechanisms have become a potent tool for improving CNN performance [
22]. Research by Yoon et al. [
23] showed that CBAM-integrated CNNs perform better than conventional CNNs in tasks like tumor segmentation and fracture identification that call for fine-grained localization. Squeeze-and-excitation (SE) blocks have also been utilized to improve model sensitivity to key regions by recalibrating feature responses [
24]. Most fracture detection models now in use are anatomically specialized and have only been trained on one location, such as the knee, hip, or wrist [
25]. However, generalizable models that can identify fractures across several anatomical sites are necessary for real-world clinical circumstances, using better particle herd adaptation (IPSO) with a hybrid CNN and LSTM architecture, including cloud-based fault classification systems [
26]. While these studies focus on high-voltage insulator diagnostics, they portray the growing ability of cloud-integrated and adaptable intensive learning structures to detect fractures in real time, with high compatibility [
27].
Similarly, our work contributes to this domain by proposing a multi-delay CNN model to detect fractures in diverse physical X-ray data. Unlike pre-domain-specific applications, our model integrates SE modules and CBAM to increase spatial- and channel-wise feature attention and improve clinical precision [
28]. Future work will incorporate cloud-preserving and metaheuristic optimization to further enhance scalability and utility for clinical purposes. Recent studies investigated multi-region fracture detection but encountered difficulties in maintaining high accuracy across various datasets [
29]. We present a sophisticated CNN model for multi-region fracture detection with several attention blocks (CBAM and squeeze modules) to address these shortcomings. In this work, we trained our model on a diverse, multi-region X-ray dataset, which increases generality. We also propose a unique combination of SE and CBAM attention modules within a CNN framework, which is rarely seen in fracture detection. Additionally, the model achieves high accuracy with low complexity, making it suitable for real-world clinical applications. Past approaches often failed to normalize well for multi-sector data, and there was a lack of attention mechanisms to refine the convenience of the representation.
In contrast, our proposed model introduces a hybrid attention–comprehensive CNN architecture that integrates SE and CBAM, which enables better channel and spatial attention. This allows the model to highlight clinically relevant areas in diverse physical regions. Additionally, the model acquires high clinical accuracy with low computational complications, providing a practical and scalable solution for the real world. This experiment achieves 99.98% training and 97.72% validation accuracy, presenting the effectiveness of attention mechanisms in improving fracture detection. This study builds upon earlier research while introducing novel architectural enhancements to bridge the gap between AI and clinical applicability in fracture diagnosis.
4. Experiment Results
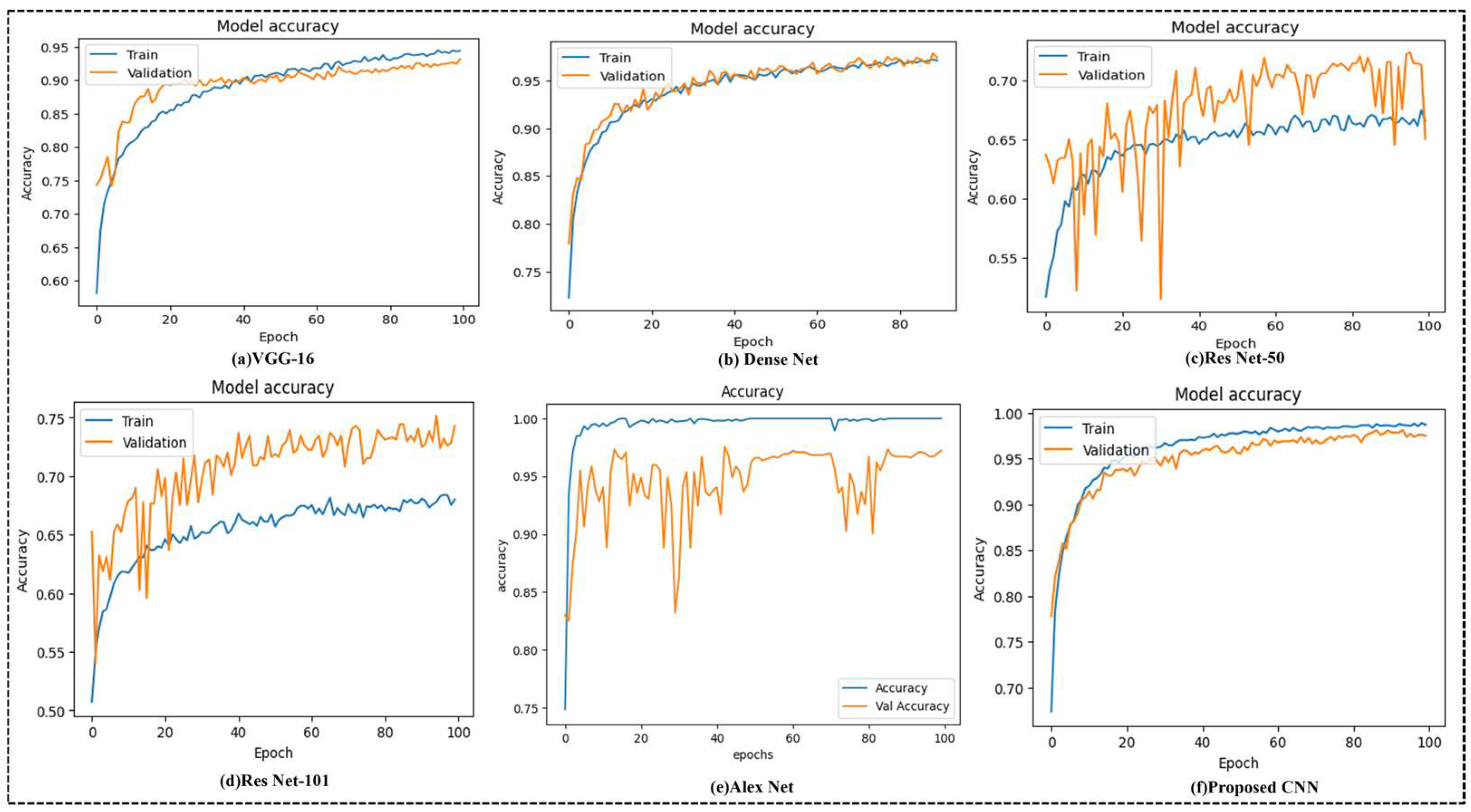
This study’s automated bone fracture detection model achieved exceptional performance across all evaluation metrics, demonstrating its efficacy and reliability in clinical applications. Training the model on a comprehensive dataset of fractured and non-fractured X-ray images from diverse anatomical regions yielded remarkable results. The model successfully learned to differentiate between images that depict fractures of the lower and upper limbs, the lumbar region, the hips, the knees, and other body parts, and those that do not. The model’s capacity to reduce errors while learning is further demonstrated by its minimal training loss (0.0010). The model’s generalizability and robustness were validated. The validation accuracy, 96.72%, demonstrated the model’s capacity to identify fractures in previously unknown X-ray images, as shown in
Figure 7. To assess the effectiveness of our model during the experimentation phase of this work, we used confusion matrices together with several related metric measures, including accuracy (Acc), precision (Pre), recall (Rec), the F1-score (F-Score), and the Cohen Kappa score (Ckp). The confusion matrix’s true positive (TP), false positive (FP), true negative (TN), and false negative (FN) parameters were used to calculate these measurements. The confusion metrics were calculated using the following formulas:
indicates that there is a high percentage of observed agreement between raters and classifiers. is the hypothetical probability of chance.
To determine the effectiveness of our proposed model, we compared its implementation against several widely used deep learning architectures, including VGG-16, DenseNet, ResNet-50, ResNet-101, and AlexNet.
Table 1 demonstrates the evaluation metrics of all models on the test set, which includes classification accuracy, precision, recall, the F1-score, Cohen’s Kappa (Ckp) score, the number of trainable parameters, model complexity, and total training time. The proposed attention-based CNN model exceeded all baseline architectures regarding classification performance. It gained the highest training accuracy of 99.98% and a test accuracy of 96.72%, indicating strong detection capabilities across multiple anatomical X-ray regions. In terms of precision and recall, the model showed a remarkable balance with 98.12% precision and 95.00% recall, leading to an F1-score of 97.00%. The Cohen’s Kappa score of 96.39% indicates excellent agreement beyond chance between the predicted and actual labels. While AlexNet achieved a slightly lower test accuracy (95.65%) and F1-score (94.97%), it required a considerably longer training time of 35,000 s and had a larger parameter count (4.67 million). Dense Net, known for its efficient parameter usage, showed competitive performance with 94.38% test accuracy and a 95.17% F1-score while falling short of the proposed model in most evaluation criteria. Our proposed model has a parameter count (1.58 million) and a reasonable training time (16,000 s), significantly outperforming others in diagnostic performance. Including CBAM and squeeze attention blocks likely contributed to its improved focus on relevant fracture features across diverse anatomical regions. These results demonstrate the proposed model’s robustness, efficiency, and excellent diagnostic ability, emphasizing its potential as an assistive tool in clinical environments for automatic fracture detection across multi-region X-ray data compared to traditional techniques like VGG-16, RESNET-50, RESNET-50, RESNET-50, DENSENET, and AlexNet, which are in the major matrix (accuracy, precision, recall, F1-score, and Cohen Kappa). These additions reveal the performance benefits of our model. In addition, we have included a radar chart to visually compare all models, which displays the proposed CNN’s high and more consistent performance in several assessment criteria. These enhancers strengthen the clarity and impact of our performance analysis.
Figure 7 illustrates the training and validation accuracy curves for different deep learning models used for the multi-region bone fracture data: (a) VGG-16, (b) DenseNet, (c) ResNet-50, (d) ResNet-101, (e) AlexNet, and (f) the proposed CNN model with 100 epochs. The proposed CNN model (f) performs best and most consistently. It reaches a nearly excellent training accuracy of 99.98% and an increased validation accuracy of 96.72%, with smooth and steady confluence throughout the training epochs. The proposed model has learned the complex patterns within the X-ray images and generalized well to unseen validation data without overfitting. ResNet-50 and ResNet-101, on the other hand, display slower intersections and greater variability, implying less consistent learning behavior. Even if DenseNet performs poorly, these other models are still not as accurate and consistent as the suggested model. These findings demonstrate the proposed methodology’s clinical potential, accuracy, and robustness in automating fracture identification across various anatomical locations.
These curves reflect the performance of the model on a dataset of 10,580 X-ray images from diverse physical areas (hips, knees, lumbar, upper/lower limbs), with the highest validation of 96.72% achieved with the proposed CNN (f), which achieves an accuracy and stable conversion of 96.72%, indicating strong generalizations. In contrast, Resnet-50 (c) displays a verification accuracy of 65.02%, characterized by significant variability and slow convergence, indicating potential overfitting. This stability highlights the effectiveness of the integrated attention mechanisms, including the concentration module (CBAM) and squeezed blocks, in increasing the ability of the model to detect fractures in diverse physical areas correctly. The proposed CNN model incorporates several regularization strategies to reduce overfitting. First, the dropout layers with a rate of 0.3 are applied randomly, and after dense layers, they are used to reduce dependence on specific characteristics and increase generalizations during training.
Comparisons of confusion matrices for VGG-16, Dense Net, ResNet-50, ResNet-101, Alex Net, and the suggested CNN in bone fracture classification are shown in
Figure 8. The proposed CNN performs best with a balanced true positive-to-true negative ratio and few misclassifications. Conversely, ResNet-50 exhibits the highest misclassification rate, whereas VGG-16 and ResNet-101 have reasonable accuracy with a few false positives. These findings support the suggested CNN’s ability to detect fractures in various anatomical locations reliably. With just 11 false positives and two false negatives, as well as 227 true positives and 266 true negatives, the suggested CNN model (f) outperformed all other architectures regarding classification performance. This demonstrates the model’s resilience, low error rate, and great promise for precise and trustworthy diagnosis in medical image classification methods. It also shows excellent precision and recall.
We conducted coupled T-testing on the test set to compare major demonstration metrics including accuracy, recall, the F1-score, and Cohen’s Kappa score. Additionally, we applied the McNemar test to the confusion matrices (
Figure 8), confirming that the proposed model’s low false rate is statistically important compared to other models (
p < 0.05).
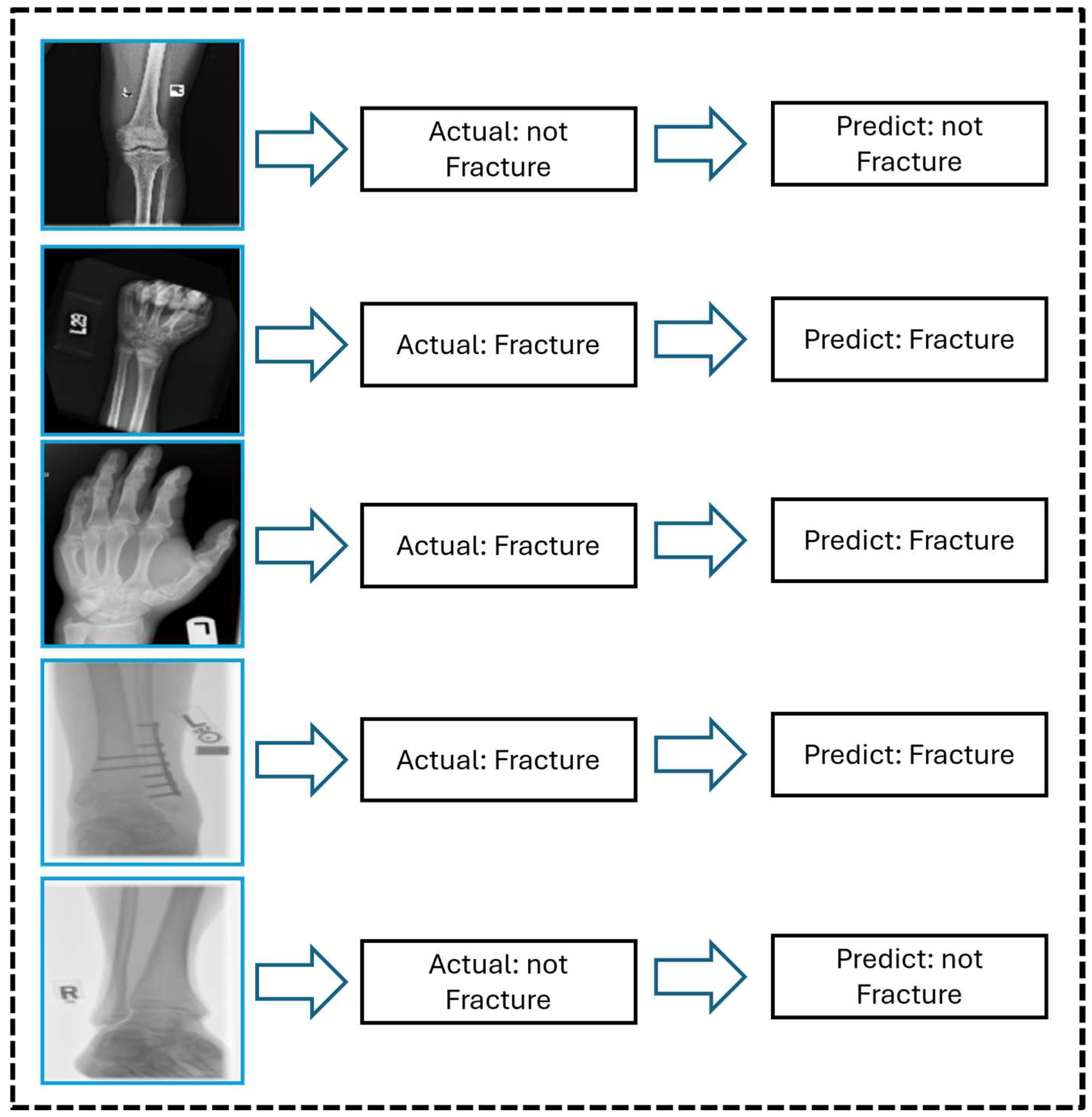
Figure 9 shows the graphical prediction results generated by the proposed CNN model on X-ray images, emphasizing its ability to accurately classify fractured and non-fractured cases. Most predictions align accurately with the labels, revealing the model’s robustness for real-world techniques. The model’s importance in supporting clinical diagnosis is demonstrated by its notable ability to detect small fractures, which are sometimes difficult to recognize. Overall, this study’s results highlight the potential of automated bone fracture detection models to enhance diagnostic efficiency and accuracy in medical imaging.
Figure 9 shows representative X-ray images with the model’s predicted classification results, both clear and fine, and the successful detection of clear and less-visible fractures. These examples highlight the model’s sensitivity for subtle dissection and structural variations in the areas of bones, especially in challenging cases where fractures are visually minimal and easily missed by the human eye. By incorporating these qualitative results, the proposed attention-based CNN results confirm the clinical reliability of the model and its potential utility in real-world clinical scenarios.
5. Discussion
This study proposes a novel CNN model integrating SE and CBAM attention modules for automated fracture detection. Unlike existing methods, which center on single areas, our model handles several anatomical areas within a structure. It is trained on a diverse X-ray dataset covering the hips, knees, spine, and organs. The model demonstrates high accuracy with low parameters to ensure performance and efficiency. This design addresses key gaps in generalization and clinical applicability. By leveraging advanced machine learning techniques, our model demonstrates significant progress toward supporting healthcare professionals in timely and accurate fracture diagnosis, ultimately improving patient outcomes and healthcare delivery. Continued research and development in this field promise further advancements, paving the way for more effective technological integration into clinical practice. The advantage of our model, integrating both SE blocks and CBAM, is that it enhances both channel-wise and spatial attention, allowing it to focus on the most relevant characteristics associated with fractures. This dual-focus strategy significantly improves the model’s ability to make micro-fracture patterns local, which can be remembered by a traditional CNN. The model was trained on a diverse, multi-field X-ray dataset (hips, knees, lumbar region, upper and lower limbs), which enables it to normalize in various physical structures. It contradicts many existing models limited to the same region and is less applicable to real-world clinical scenarios. The proposed network’s high classification performance (96.72% validation accuracy, 97.00% F1-score) enables a relatively low parameter count (1.58 million) and short training time with deep architectures such as ResNet-101 or AlexNet. This makes it computationally efficient and suitable for real-time or resource-limited clinical environments. This study systematically examined the performance of several deep learning architectures—VGG-16, DenseNet, ResNet-50, ResNet-101, AlexNet, and the proposed CNN model—on a medical image category assignment. The evaluation was conducted using training and validation accuracy curves (
Figure 7) and confusion matrices (
Figure 8), allowing a wide analysis of each model’s learning behavior and classification capabilities. The proposed CNN model demonstrated the best and most consistent performance during the training and validation stages. The proposed model demonstrated great learning efficiency and robust generalization without noticeable overfitting, as seen in
Figure 7f, with a training accuracy of over 99% and a validation accuracy that was nearly aligned. Models such as ResNet-50 (
Figure 7c) showed significant variance and discrepancies in validation accuracy, indicating fluctuation and possible overfitting problems. This emphasizes the proposed model’s reliability and precision in distinguishing between complex class allocations, making it a valuable solution for high-stakes applications such as medical diagnostics.
In summary, the proposed CNN architecture surpassed established state-of-the-art models in accuracy and robustness. Its superior learning curve and confusion matrix profile demonstrate its potential for deployment in real-world clinical environments, where precision and reliability are paramount. The outcomes demonstrate that a well-designed, task-specific CNN can outperform deeper and more complex pre-trained models when properly tuned and trained on domain-specific data.
The proposed CNN model was applied using an input resolution of 128 × 128 × 3, which balances computational efficiency and adequate spatial details for fracture localization. The network was trained using the Adam Optimizer with a learning rate of 0.001, which was chosen based on empirical verification in medical image classification works and its proven convergence stability. A batch size of 32 was used to maintain efficient GPU use while preserving generalization capacity. To prevent overfitting, dropout layers with a rate of 0.5 were applied after fully connected layers. The Relu activation function was employed in hidden layers, and sigmoid activation was used in the final output layer for binary classification. The number of filters in convolutional layers progressively increased (32, 64, 128, 256) to effectively remove both low- and high-level features. The significance of SE and CBAM was determined through ablation experiments, demonstrating their significant contribution to improving verification performance. All hyperparameters were adapted through recurrence and grid search, based on verification accuracy and training stability. These configurations reflect a carefully tuned design for multi-region X-ray fracture detection complications. A major limit is the dependence on the public dataset, which cannot accommodate a variety of clinical imaging conditions, such as different resolutions, noise levels, and patient demographics. This can affect the normality of models in various institutions or imaging devices.
Additionally, while the model performs well in binary classification (fracture versus non-fracture), it does not currently support fracture type localization or severity grading, which are important for clinical decisions. We plan to expand the model for future work by incorporating multi-class classification and fracture localization techniques using bounding boxes or segmentation maps. We aim to validate the model on an external, multi-institutional dataset to assess its strength in a broad clinical environment. In addition, integrating explainable AI techniques can help increase clinical interpretation and user trust.
6. Conclusions
In this study, we have explored the development and implementation of an automated bone fracture detection model using X-ray imaging to enhance diagnostic accuracy and streamline clinical workflows. Leveraging a dataset comprising fractured and non-fractured images across various anatomical regions, including the lower limb, upper limb, lumbar region, hips, and knees, our methodology involved rigorous training, testing, and validation phases. The Introduction highlighted the global prevalence of bone fractures and underscored the critical need for efficient and accurate diagnostic tools. Traditional methods of fracture detection rely heavily on radiographic interpretation by skilled professionals, which can be time-consuming and prone to variability. Our approach to developing an automated fracture detection model builds upon artificial intelligence and machine learning advancements. The results of our study suggest that our model can effectively detect fractures across various anatomical regions, offering consistent performance comparable to or exceeding that of human experts in preliminary assessments. These results provide a convincing path for using sophisticated computational methods in clinical settings, opening the door to more precise diagnoses and effective treatment plans. This research provides valuable insights into the process of developing computational techniques for the diagnosis of lung cancer. It also highlights the necessity for continued study and validation to develop clinical applications and the value of hybrid deep learning models in categorizing X-ray images. However, this study’s reliance on a single dataset for training and assessment may limit the model’s capacity to adapt to various clinical situations. Furthermore, deep learning architectures intended for medical image processing should be made simpler to optimize the computing economy without compromising diagnostic accuracy.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}