
Improved Breast Cancer Classification through Combining Transfer Learning and Attention Mechanism
 , ,
, ,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Related Works
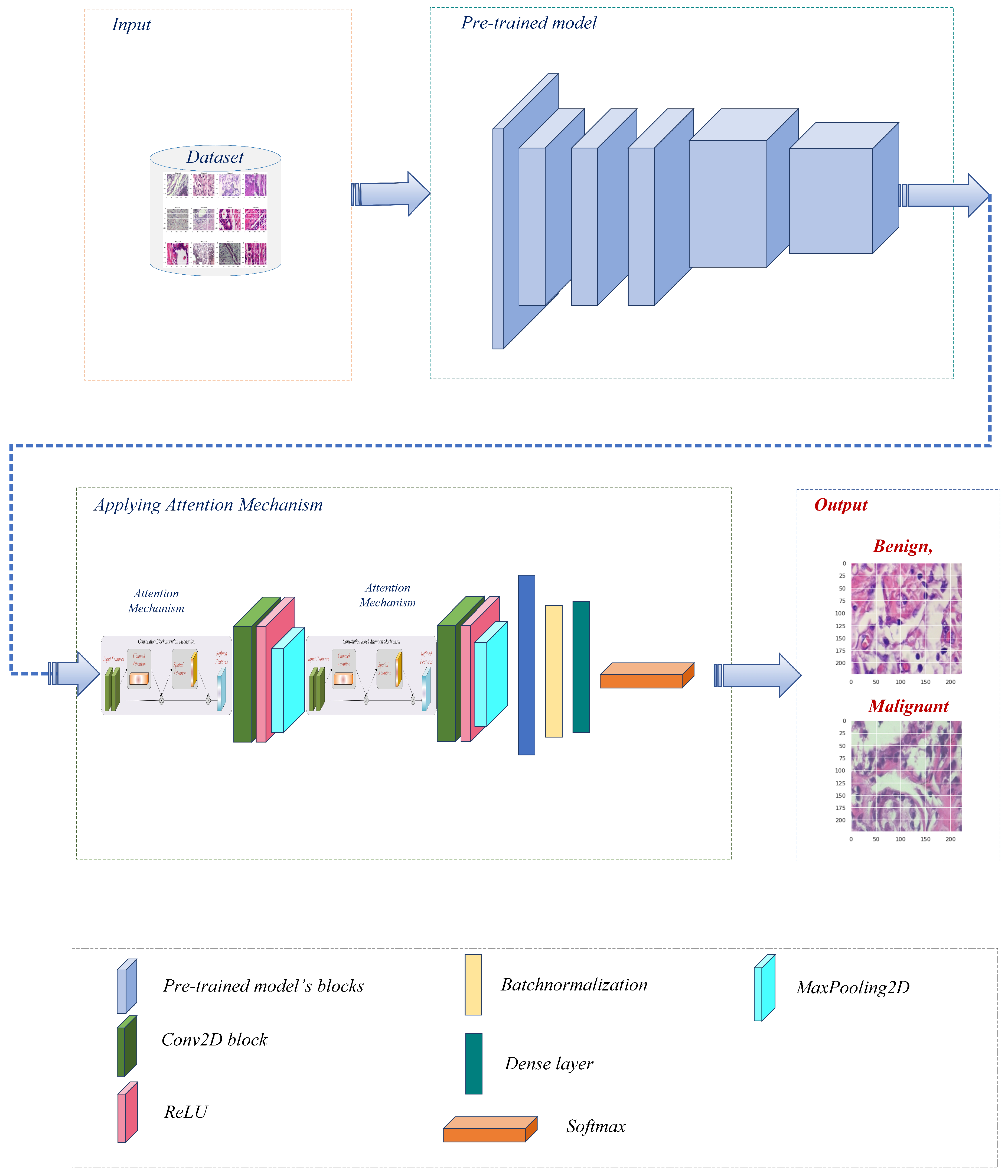
3. Materials and Methods
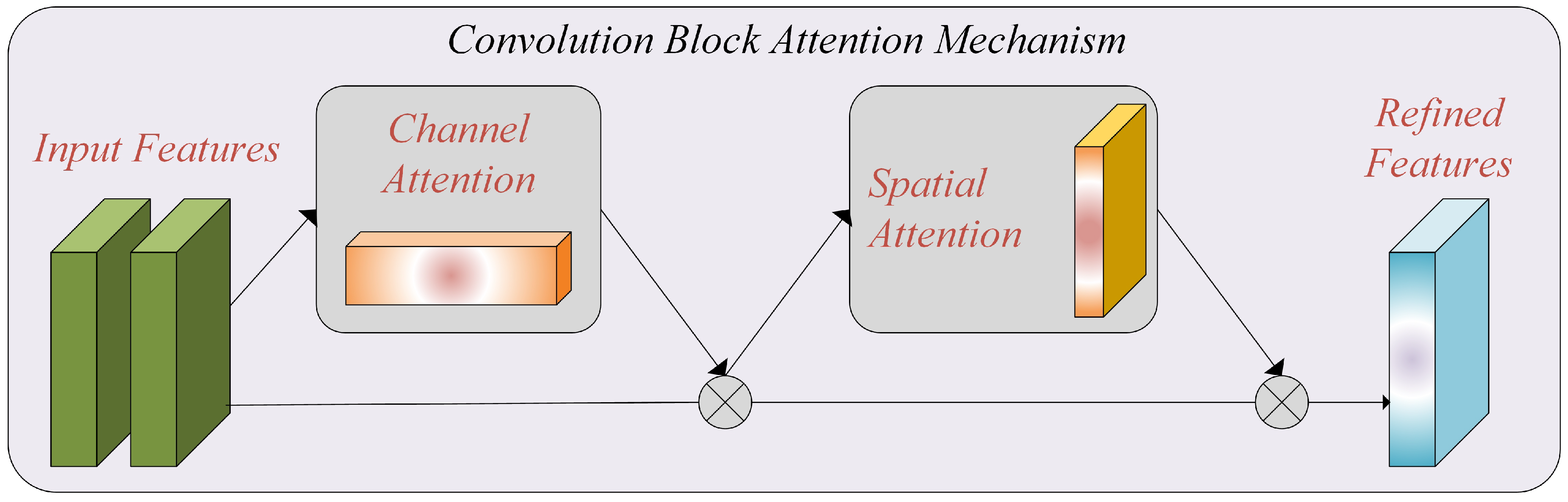
3.1. Attention Mechanism
3.2. Feature Extraction
3.3. Classification
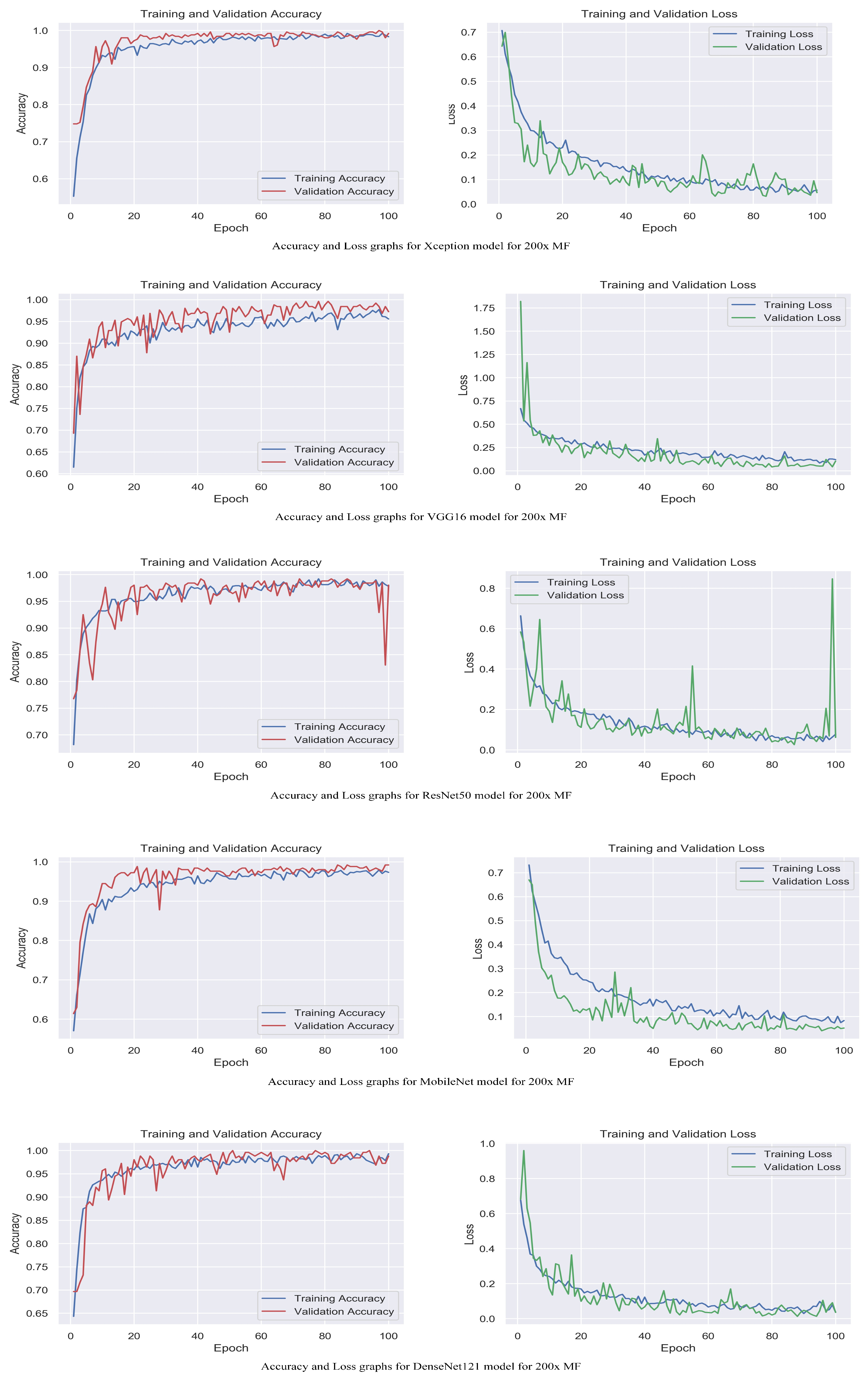
4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chou, L.B.; Johnson, B.; Shapiro, L.M.; Pun, S.; Cannada, L.K.; Chen, A.F.; Valone, L.C.; Van Nortwick, S.S.; Ladd, A.L.; Finlay, A.K. Increased prevalence of breast and all-cause cancer in female orthopaedic surgeons. JAAOS Glob. Res. Rev. 2022, 6, e22.00031. [Google Scholar] [CrossRef] [PubMed]
- Siegel, R.L.; Miller, K.D.; Jemal, A. R Cancer statistics. CA Cancer J. Clin. 2020, 70, 7–30. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Feng, W.; Chen, C.; Liu, M.; Qu, Y.; Yang, J. Classification of breast cancer histology images using MSMV-PFENet. Sci. Rep. 2022, 12, 17447. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Mei, L.; Long, M.; Liu, Y.; Sun, W.; Li, X.; Shen, H.; Zhou, F.; Ruan, X.; Wang, D.; et al. Bm-net: Cnn-based mobilenet-v3 and bilinear structure for breast cancer detection in whole slide images. Bioengineering 2022, 9, 261. [Google Scholar] [CrossRef] [PubMed]
- Samee, N.A.; Alhussan, A.A.; Ghoneim, V.F.; Atteia, G.; Alkanhel, R.; Al-Antari, M.A.; Kadah, Y.M. A Hybrid Deep Transfer Learning of CNN-Based LR-PCA for Breast Lesion Diagnosis via Medical Breast Mammograms. Sensors 2022, 22, 4938. [Google Scholar] [CrossRef]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef]
- Houssein, E.H.; Emam, M.M.; Ali, A.A.; Suganthan, P.N. Deep and machine learning techniques for medical imaging-based breast cancer: A comprehensive review. Expert Syst. Appl. 2021, 167, 114161. [Google Scholar] [CrossRef]
- Debelee, T.G.; Schwenker, F.; Ibenthal, A.; Yohannes, D. Survey of deep learning in breast cancer image analysis. Evol. Syst. 2020, 11, 143–163. [Google Scholar] [CrossRef]
- Yassin, N.I.; Omran, S.; El Houby, E.M.; Allam, H. Machine learning techniques for breast cancer computer aided diagnosis using different image modalities: A systematic review. Comput. Methods Programs Biomed. 2018, 156, 25–45. [Google Scholar] [CrossRef]
- Fatima, N.; Liu, L.; Hong, S.; Ahmed, H. Prediction of breast cancer, comparative review of machine learning techniques, and their analysis. IEEE Access 2020, 8, 150360–150376. [Google Scholar] [CrossRef]
- Asri, H.; Mousannif, H.; Al Moatassime, H.; Noel, T. Using machine learning algorithms for breast cancer risk prediction and diagnosis. Procedia Comput. Sci. 2016, 83, 1064–1069. [Google Scholar] [CrossRef]
- Liu, M.; Hu, L.; Tang, Y.; Wang, C.; He, Y.; Zeng, C.; Lin, K.; He, Z.; Huo, W. A deep learning method for breast cancer classification in the pathology images. IEEE J. Biomed. Health Inform. 2022, 26, 5025–5032. [Google Scholar] [CrossRef] [PubMed]
- Ramesh, S.; Sasikala, S.; Gomathi, S.; Geetha, V.; Anbumani, V. Segmentation and classification of breast cancer using novel deep learning architecture. Neural Comput. Appl. 2022, 34, 16533–16545. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, S. The Xception model: A potential feature extractor in breast cancer histology images classification. ICT Express 2022, 8, 101–108. [Google Scholar] [CrossRef]
- Liew, X.Y.; Hameed, N.; Clos, J. An investigation of XGBoost-based algorithm for breast cancer classification. Mach. Learn. Appl. 2021, 6, 100154. [Google Scholar] [CrossRef]
- Atban, F.; Ekinci, E.; Garip, Z. Traditional machine learning algorithms for breast cancer image classification with optimized deep features. Biomed. Signal Process. Control 2023, 81, 104534. [Google Scholar] [CrossRef]
- Ayana, G.; Park, J.; Jeong, J.W.; Choe, S.W. A novel multistage transfer learning for ultrasound breast cancer image classification. Diagnostics 2022, 12, 135. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, T.; Liang, S.; Karthiga, R.; Narasimhan, K.; Elamaran, V. Binary and multiclass classification of histopathological images using machine learning techniques. J. Med. Imaging Health Inform. 2020, 10, 2252–2258. [Google Scholar] [CrossRef]
- Dubey, A.; Singh, S.K.; Jiang, X. Leveraging CNN and Transfer Learning for Classification of Histopathology Images. In Proceedings of the International Conference on Machine Learning, Image Processing, Network Security and Data Sciences, Bhopal, India, 21–22 December 2022; Springer: Cham, Switzerland, 2022; pp. 3–13. [Google Scholar]
- Singh, S.; Kumar, R. Breast cancer detection from histopathology images with deep inception and residual blocks. Multimed. Tools Appl. 2022, 81, 5849–5865. [Google Scholar] [CrossRef]
- Venugopal, A.; Sreelekshmi, V.; Nair, J.J. Ensemble Deep Learning Model for Breast Histopathology Image Classification. In ICT Infrastructure and Computing: Proceedings of ICT4SD 2022; Springer: Singapore, 2022; pp. 499–509. [Google Scholar]
- Kumari, V.; Ghosh, R. A magnification-independent method for breast cancer classification using transfer learning. Healthc. Anal. 2023, 3, 100207. [Google Scholar] [CrossRef]
- Joshi, S.A.; Bongale, A.M.; Olsson, P.O.; Urolagin, S.; Dharrao, D.; Bongale, A. Enhanced Pre-Trained Xception Model Transfer Learned for Breast Cancer Detection. Computation 2023, 11, 59. [Google Scholar] [CrossRef]
- Karthik, R.; Menaka, R.; Siddharth, M. Classification of breast cancer from histopathology images using an ensemble of deep multiscale networks. Biocybern. Biomed. Eng. 2022, 42, 963–976. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, J.; Huang, S.; Liu, B. Breast cancer histopathological image classification using attention high-order deep network. Int. J. Imaging Syst. Technol. 2022, 32, 266–279. [Google Scholar] [CrossRef]
- Jadah, Z.; Alfitouri, A.; Chantar, H.; Amarif, M.; Aeshah, A.A. Breast Cancer Image Classification Using Deep Convolutional Neural Networks. In Proceedings of the 2022 International Conference on Engineering & MIS (ICEMIS), Istanbul, Turkey, 4–6 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Wang, X.; Chen, G.; Qian, G.; Gao, P.; Wei, X.Y.; Wang, Y.; Tian, Y.; Gao, W. Large-scale multi-modal pre-trained models: A comprehensive survey. In Machine Intelligence Research; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–36. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–2. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Gao, F.; Wu, T.; Li, J.; Zheng, B.; Ruan, L.; Shang, D.; Patel, B. SD-CNN: A shallow-deep CNN for improved breast cancer diagnosis. Comput. Med. Imaging Graph. 2018, 70, 53–62. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Wang, S.H.; Zhang, Y.D. A survey of convolutional neural network in breast cancer. Comput. Model. Eng. Sci. CMES 2023, 136, 2127. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Zhang, J.; Hu, D.; Qu, H.; Tian, Y.; Cui, X. Application of Deep Learning in Histopathology Images of Breast Cancer: A Review. Micromachines 2022, 13, 2197. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Magnification Level | 40× | 100× | 200× | 400× | Total | ||||
|---|---|---|---|---|---|---|---|---|---|
| Splitting to Train and Test Set | Training | Testing | Training | Testing | Training | Testing | Training | Testing | All |
| Benign | 370 | 255 | 383 | 261 | 368 | 255 | 351 | 237 | 2480 |
| Malignant | 880 | 490 | 938 | 499 | 901 | 489 | 814 | 418 | 5429 |
| Total | 1250 | 745 | 1321 | 760 | 1269 | 744 | 1165 | 655 | 7909 |
| Method\Magnification Level | 40× | 100× | 200× | 400× | ||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Loss | Accuracy | Loss | Accuracy | Loss | Accuracy | Loss | |
| Xception | 99.2 | 0.02 | 98.5 | 0.05 | 99.2 | 0.04 | 99.5 | 0.04 |
| VGG16 | 92.8 | 0.21 | 93.6 | 0.29 | 97.2 | 0.10 | 94.8 | 0.15 |
| ResNet50 | 98.8 | 0.06 | 98.1 | 0.09 | 98.0 | 0.06 | 98.2 | 0.05 |
| MobileNet | 92.4 | 0.17 | 96.2 | 0.06 | 99.2 | 0.05 | 91.4 | 0.26 |
| DenseNet121 | 97.2 | 0.07 | 95.5 | 0.12 | 98.8 | 0.11 | 99.6 | 0.02 |
| Magnification Level\Model | 40× | 100× | 200× | 400× | ||||
|---|---|---|---|---|---|---|---|---|
| Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | |
| Xception | 89.2 | 89.1 | 90.4 | 90.3 | 86.3 | 87.5 | 86.3 | 88.2 |
| VGG16 | 87.1 | 84.0 | 85.4 | 86.3 | 81.3 | 84.2 | 85.6 | 87.2 |
| ResNet50 | 91.7 | 88.2 | 91.6 | 90.1 | 89.0 | 89.4 | 86.3 | 88.1 |
| MobileNet | 87.7 | 89.5 | 90.2 | 88.2 | 86.6 | 88.3 | 86.1 | 88.4 |
| DenseNet121 | 86.5 | 87.4 | 85.4 | 86.6 | 88.2 | 88.5 | 87.3 | 88.1 |
| Model\Magnification Level | 40× | 100× | 200× | 400× | ||||
|---|---|---|---|---|---|---|---|---|
| Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | |
| Xception | 84.1 | 88.3 | 88.2 | 90.4 | 85.6 | 87.5 | 87.3 | 87.6 |
| VGG16 | 74.6 | 82.5 | 83.4 | 86.1 | 83.0 | 83.3 | 81.2 | 84.5 |
| ResNet50 | 85.5 | 89.4 | 87.7 | 90.1 | 86.3 | 89.1 | 87.2 | 87.1 |
| MobileNet | 88.4 | 88.2 | 80.1 | 86.3 | 86.2 | 88.2 | 88.5 | 87.6 |
| DenseNet121 | 86.8 | 87.3 | 85.2 | 86.1 | 84.4 | 88.3 | 86.9 | 88.6 |
| Model\Magnification Level | 40× | 100× | 200× | 400× | ||||
|---|---|---|---|---|---|---|---|---|
| Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | Macro Average (%) | Weighted Average (%) | |
| Xception | 86.5 | 88.3 | 89.1 | 90.3 | 85.7 | 87.6 | 87.2 | 88.1 |
| VGG16 | 77.9 | 88.3 | 84.6 | 86.6 | 82.4 | 83.2 | 82.1 | 84.8 |
| ResNet50 | 87.3 | 88.5 | 88.3 | 90.2 | 87.8 | 89.4 | 87.3 | 87.7 |
| MobileNet | 87.8 | 88.4 | 83.5 | 85.6 | 86.2 | 88.5 | 86.1 | 87.4 |
| DenseNet121 | 86.7 | 87.3 | 85.5 | 86.1 | 85.3 | 87.4 | 87.6 | 88.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashurov, A.; Chelloug, S.A.; Tselykh, A.; Muthanna, M.S.A.; Muthanna, A.; Al-Gaashani, M.S.A.M. Improved Breast Cancer Classification through Combining Transfer Learning and Attention Mechanism. Life 2023, 13, 1945. https://doi.org/10.3390/life13091945
Ashurov A, Chelloug SA, Tselykh A, Muthanna MSA, Muthanna A, Al-Gaashani MSAM. Improved Breast Cancer Classification through Combining Transfer Learning and Attention Mechanism. Life. 2023; 13(9):1945. https://doi.org/10.3390/life13091945
Chicago/Turabian StyleAshurov, Asadulla, Samia Allaoua Chelloug, Alexey Tselykh, Mohammed Saleh Ali Muthanna, Ammar Muthanna, and Mehdhar S. A. M. Al-Gaashani. 2023. "Improved Breast Cancer Classification through Combining Transfer Learning and Attention Mechanism" Life 13, no. 9: 1945. https://doi.org/10.3390/life13091945
APA StyleAshurov, A., Chelloug, S. A., Tselykh, A., Muthanna, M. S. A., Muthanna, A., & Al-Gaashani, M. S. A. M. (2023). Improved Breast Cancer Classification through Combining Transfer Learning and Attention Mechanism. Life, 13(9), 1945. https://doi.org/10.3390/life13091945