
Biophysical Interactions Underpin the Emergence of Information in the Genetic Code

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
“The whole case here rests upon the demonstration that codon-amino acid pairing interactions exist and that the codon assignments in some way reflect these interactions… all-or-none specificities are not required for such interactions to determine the form of the codon catalog, either a general form or one specified down to the very last detail. All that is required here is that a sufficient number of slight preferences be shown.” Carl Woese, 1969.
2. Methods
2.1. Molecular Dynamics Pipeline
2.2. Hydrophobicity Trends
2.3. Rings
2.4. NMR
3. Results
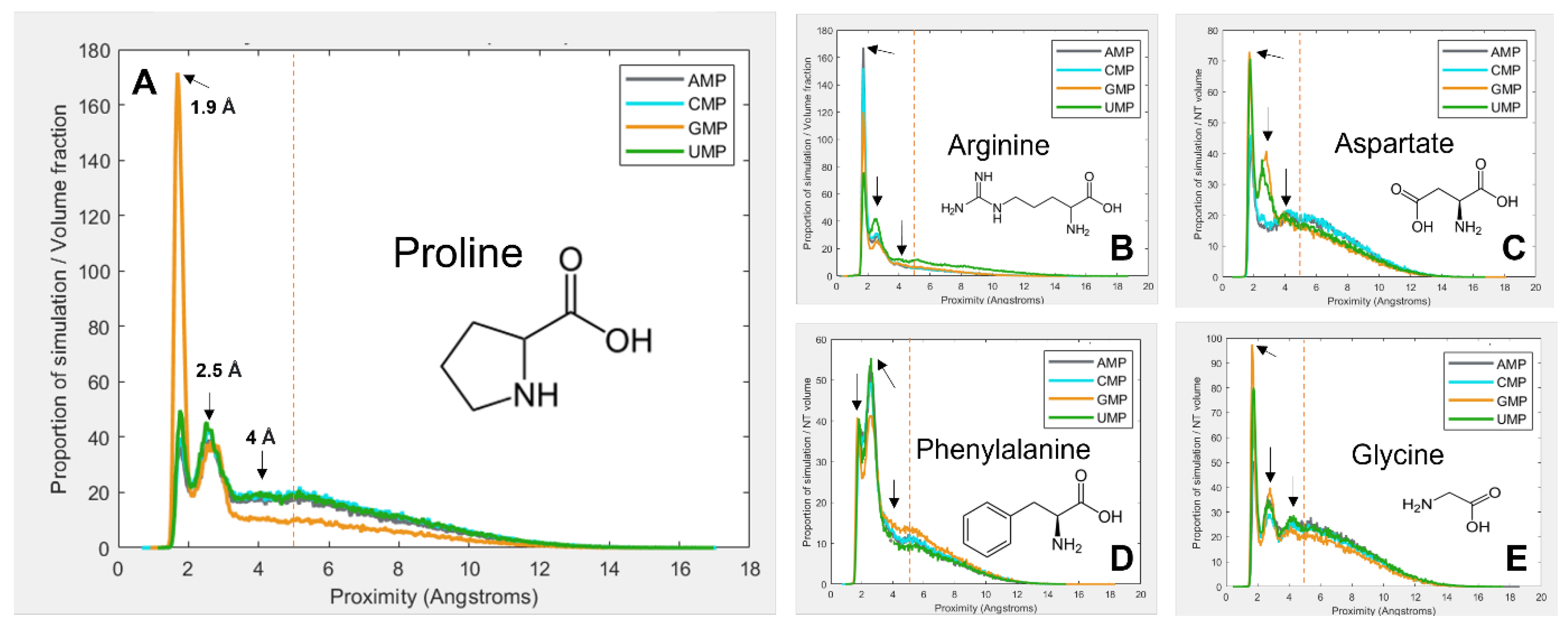
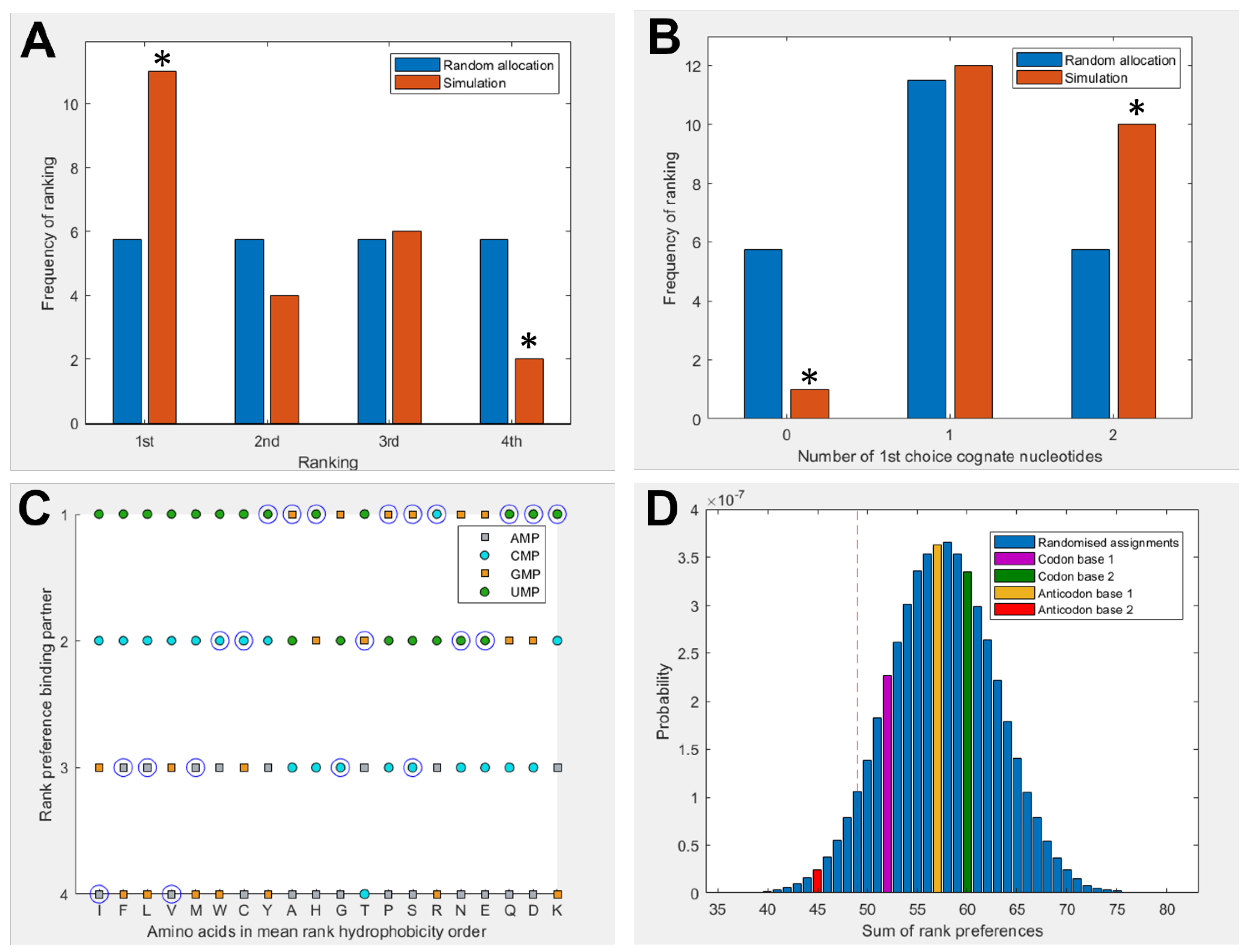
3.1. Amino Acids Prefer Cognate Nucleotides
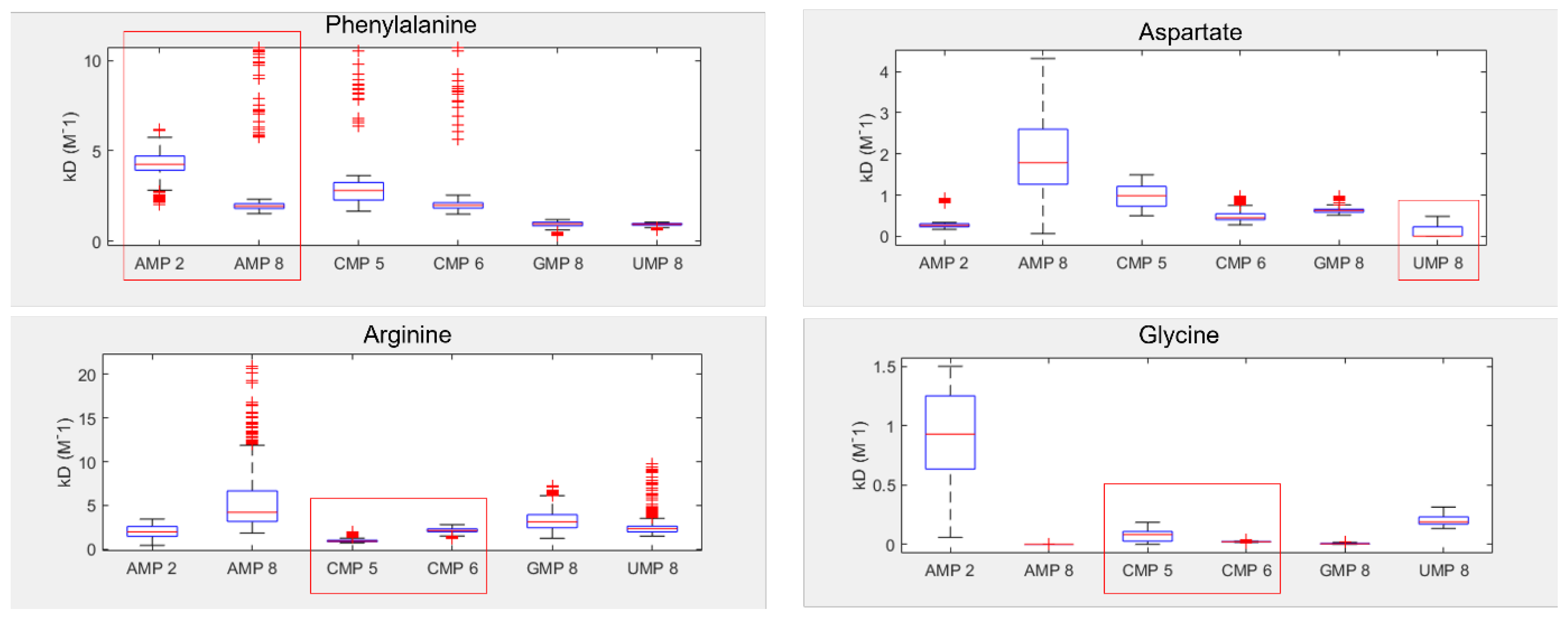
3.2. Hydrophobicity Plays a Role in Binding
3.3. NMR Corroborates Binding Interactions
3.4. Dinucleotides also Show Affinity for Their Cognate Amino Acids
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Woese, C.R. Order in the genetic code. Proc. Natl. Acad. Sci. USA 1965, 54, 71–75. [Google Scholar] [CrossRef] [PubMed]
- Eck, R.V. Genetic Code: Emergence of a Symmetrical Pattern. Science 1963, 140, 477–481. [Google Scholar] [CrossRef] [PubMed]
- Nirenberg, M.W.; Jones, O.W.; Leder, P.; Clark, B.F.C.; Sly, W.S.; Pestka, S. On the Coding of Genetic Information. Cold Spring Harb. Symp. Quant. Biol. 1963, 28, 549–557. [Google Scholar] [CrossRef]
- Taylor, F.J.R.; Coates, D. The code within the codons. Biosystems 1989, 22, 177–187. [Google Scholar] [CrossRef] [PubMed]
- Copley, S.D.; Smith, E.; Morowitz, H.J. A mechanism for the association of amino acids with their codons and the origin of the genetic code. Proc. Natl. Acad. Sci. USA 2005, 102, 4442–4447. [Google Scholar] [CrossRef] [PubMed]
- Wong, J.T. A co-evolution theory of the genetic code. Proc. Natl. Acad. Sci. USA 1975, 72, 1909–1912. [Google Scholar] [CrossRef]
- Di Giulio, M. An Autotrophic Origin for the Coded Amino Acids is Concordant with the Coevolution Theory of the Genetic Code. J. Mol. Evol. 2016, 83, 93–96. [Google Scholar] [CrossRef]
- Trinquier, G.; Sanejouand, Y.H. Which effective property of amino acids is best preserved by the genetic code? Protein Eng. Des. Sel. 1998, 11, 153–169. [Google Scholar] [CrossRef]
- Woese, C.R.; Dugre, D.H.; Saxinger, W.C.; Dugre, S.A. The molecular basis for the genetic code. Proc. Natl. Acad. Sci. USA 1966, 55, 966–974. [Google Scholar] [CrossRef]
- Fontecilla-Camps, J.C. The Stereochemical Basis of the Genetic Code and the (Mostly) Autotrophic Origin of Life. Life 2014, 4, 1013–1025. [Google Scholar] [CrossRef]
- Woese, C. Models for the evolution of codon assignments. J. Mol. Biol. 1969, 43, 235–240. [Google Scholar] [CrossRef]
- Crick, F.H. On protein synthesis. Symp. Soc. Exp. Biol. 1958, 12, 138–163. [Google Scholar] [PubMed]
- Crick, F.H. The origin of the genetic code. J. Mol. Biol. 1968, 38, 367–379. [Google Scholar] [CrossRef] [PubMed]
- Crick, F.H.C.; Hoagland, M. The Nucleic Acids; Chargaff, E., Davidson, J., Eds.; Academic Press: New York, NY, USA, 1960; Volume 3. [Google Scholar]
- Weber, A.L.; Lacey, J.C. Genetic code correlations: Amino acids and their anticodon nucleotides. J. Mol. Evol. 1978, 11, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Lacey, J.C.; Pruitt, K.M. Origin of the genetic code. Nature 1969, 223, 799–804. [Google Scholar] [CrossRef] [PubMed]
- Lacey, J.C.; Mullins, D.W. Experimental studies related to the origin of the genetic code and the process of protein synthesis—A review. Orig. Life 1983, 13, 3–42. [Google Scholar] [CrossRef]
- Shimizu, M. Specific aminoacylation of C4N hairpin RNAs with the cognate aminoacyl-adenylates in the presence of a dipeptide: Origin of the genetic code. J. Biochem. 1995, 117, 23–26. [Google Scholar] [CrossRef]
- Shimizu, M. Molecular basis for the genetic code. J. Mol. Evol. 1982, 18, 297–303. [Google Scholar] [CrossRef]
- Yarus, M.; Widmann, J.J.; Knight, R. RNA–Amino Acid Binding: A Stereochemical Era for the Genetic Code. J. Mol. Evol. 2009, 69, 406–429. [Google Scholar] [CrossRef]
- Yarus, M.; Caporaso, J.G.; Knight, R. Origins of The Genetic Code: The Escaped Triplet Theory. Annu. Rev. Biochem. 2005, 74, 179–198. [Google Scholar] [CrossRef]
- Hobish, M.K.; Wickramasinghe, N.S.M.D.; Ponnamperuma, C. Direct interaction between amino acids and nucleotides as a possible physicochemical basis for the origin of the genetic code. Adv. Space Res. 1995, 15, 365–382. [Google Scholar] [CrossRef]
- Yarus, M. RNA-ligand chemistry: A testable source for the genetic code. RNA 2000, 6, 475–484. [Google Scholar] [CrossRef]
- Yarus, M. A specific amino acid binding site composed of RNA. Science 1988, 240, 1751–1758. [Google Scholar] [CrossRef]
- Root-Bernstein, R. Experimental Test of L- and D-Amino Acid Binding to L- and D-Codons Suggests that Homochirality and Codon Directionality Emerged with the Genetic Code. Symmetry 2010, 2, 1180–1200. [Google Scholar] [CrossRef]
- Saxinger, C.; Ponnamperuma, C.; Woese, C. Evidence for the interaction of nucleotides with immobilized amino-acids and its significance for the origin of the genetic code. Nat. N. Biol. 1971, 234, 172–174. [Google Scholar] [CrossRef]
- Moghadam, S.A.; Preto, J.; Klobukowski, M.; Tuszynski, J.A. Testing amino acid-codon affinity hypothesis using molecular docking. BioSystems 2020, 198, 104251. [Google Scholar] [CrossRef] [PubMed]
- Koonin, E.V.; Novozhilov, A.S. Origin and evolution of the genetic code: The universal enigma. IUBMB Life 2009, 61, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Di Giulio, M. Arguments against the stereochemical theory of the origin of the genetic code. Biosystems 2022, 221, 104750. [Google Scholar] [CrossRef]
- Haig, D.; Hurst, L.D. A quantitative measure of error minimization in the genetic code. J. Mol. Evol. 1991, 33, 412–417. [Google Scholar] [CrossRef]
- Sonneborn, T.M. Evolving Genes and Proteins; Bryson, V., Vogel, H., Eds.; Academic Press: Cambridge, MA, USA, 1965; p. 377. [Google Scholar]
- Barbieri, M. Evolution of the genetic code: The ambiguity-reduction theory. Biosystems 2019, 185, 104024. [Google Scholar] [CrossRef]
- Woese, C.R. On the evolution of the genetic code. Proc. Natl. Acad. Sci. USA 1965, 54, 1546–1552. [Google Scholar] [CrossRef]
- Delarue, M. An asymmetric underlying rule in the assignment of codons: Possible clue to a quick early evolution of the genetic code via successive binary choices. RNA 2007, 13, 161–169. [Google Scholar] [CrossRef] [PubMed]
- Woese, C.R. The fundamental nature of the genetic code: Prebiotic interactions between polynucleotides and polyamino acids or their derivatives. Proc. Natl. Acad. Sci. USA 1968, 59, 110–117. [Google Scholar] [CrossRef] [PubMed]
- Orgel, L.E. Evolution of the genetic apparatus. J. Mol. Biol. 1968, 38, 381–393. [Google Scholar] [CrossRef] [PubMed]
- Kruger, K.; Grabowski, P.J.; Zaug, A.J.; Sands, J.; Gottschling, D.E.; Cech, T.R. Self-splicing RNA: Autoexcision and autocyclization of the ribosomal RNA intervening sequence of Tetrahymena. Cell 1982, 31, 147–157. [Google Scholar] [CrossRef] [PubMed]
- Guerrier-Takada, C.; Gardiner, K.; Marsh, T.; Pace, N.; Altman, S. The RNA moiety of ribonuclease P is the catalytic subunit of the enzyme. Cell 1983, 35, 849–857. [Google Scholar] [CrossRef]
- Cech, T.R. The RNA Worlds in Context. Cold Spring Harb. Perspect. Biol. 2012, 4, a006742. [Google Scholar] [CrossRef]
- Gilbert, W. Origin of life: The RNA world. Nature 1986, 319, 618. [Google Scholar] [CrossRef]
- Leslie, E.O. Prebiotic Chemistry and the Origin of the RNA World. Crit. Rev. Biochem. Mol. Biol. 2004, 39, 99–123. [Google Scholar] [CrossRef]
- Joyce, G.F.; Orgel, L.E. Prospects for understanding the origin of the RNA world. Cold Spring Harb. Monogr. 1993, 24, 49–78. [Google Scholar]
- Bose, T.; Fridkin, G.; Davidovich, C.; Krupkin, M.; Dinger, N.; Falkovich, A.H.; Peleg, Y.; Agmon, I.; Bashan, A.; Yonath, A. Origin of life: Protoribosome forms peptide bonds and links RNA and protein dominated worlds. Nucleic Acids Res. 2022, 50, 1815–1828. [Google Scholar] [CrossRef] [PubMed]
- Joyce, G.F. Evolution in an RNA World. Cold Spring Harb. Symp. Quant. Biol. 2009, 74, 17–23. [Google Scholar] [CrossRef]
- Orgel, L.E. Some consequences of the RNA world hypothesis. Orig. Life Evol. Biosph. J. Int. Soc. Study Orig. Life 2003, 33, 211–218. [Google Scholar] [CrossRef] [PubMed]
- Spiegelman, S.; Haruna, I.; Holland, I.B.; Beaudreau, G.; Mills, D. The synthesis of a self-propagating and infectious nucleic acid with a purified enzyme. Proc. Natl. Acad. Sci. USA 1965, 54, 919–927. [Google Scholar] [CrossRef]
- Szathmáry, E.; Demeter, L. Group selection of early replicators and the origin of life. J. Theor. Biol. 1987, 128, 463–486. [Google Scholar] [CrossRef]
- Matsumura, S.; Kun, Á.; Ryckelynck, M.; Coldren, F.; Szilágyi, A.; Jossinet, F.; Rick, C.; Nghe, P.; Szathmáry, E.; Griffiths, A.D. Transient compartmentalization of RNA replicators prevents extinction due to parasites. Science 2016, 354, 1293–1296. [Google Scholar] [CrossRef] [PubMed]
- Smith, J.M. Hypercycles and the origin of life. Nature 1979, 280, 445–446. [Google Scholar] [CrossRef]
- Eigen, M. Selforganization of matter and the evolution of biological macromolecules. Naturwissenschaften 1971, 58, 465–523. [Google Scholar] [CrossRef]
- Salditt, A.; Keil, L.M.R.; Horning, D.P.; Mast, C.B.; Joyce, G.F.; Braun, D. Thermal Habitat for RNA Amplification and Accumulation. Phys. Rev. Lett. 2020, 125, 048104. [Google Scholar] [CrossRef]
- Joyce, G.F. The RNA world: Life before DNA and protein. In Extraterrestrials: Where Are They; Cambridge University Press: Cambridge, UK, 1995; Volume 2, pp. 139–151. [Google Scholar]
- Ralser, M. The RNA world and the origin of metabolic enzymes. Biochem. Soc. Trans. 2014, 42, 985–988. [Google Scholar] [CrossRef]
- Ralser, M. An appeal to magic? The discovery of a non-enzymatic metabolism and its role in the origins of life. Biochem. J. 2018, 475, 2577–2592. [Google Scholar] [CrossRef] [PubMed]
- Harrison, S.A.; Lane, N. Life as a guide to prebiotic nucleotide synthesis. Nat. Commun. 2018, 9, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Lazcano, A.; Miller, S.L. On the origin of metabolic pathways. J. Mol. Evol. 1999, 49, 424–431. [Google Scholar] [CrossRef] [PubMed]
- Horowitz, N.H. On the Evolution of Biochemical Syntheses. Proc. Natl. Acad. Sci. USA 1945, 31, 153–157. [Google Scholar] [CrossRef]
- Horowitz, N.H. The evolution of biochemical synthesis—Retrospect and prospect. In Evolving genes and Proteins; Bryson, V., Vogel, H.J., Eds.; Academic Press: New York, NY, USA, 1965; pp. 15–23. [Google Scholar]
- Walker, S.I.; Davies, P.C.W. The algorithmic origins of life. J. R. Soc. Interface 2013, 10, 20120869. [Google Scholar] [CrossRef]
- Amend, J.P.; McCollom, T.M. Energetics of Biomolecule Synthesis on Early Earth. In Chemical Evolution II: From the Origins of Life to Modern Society; ACS Symposium Series; American Chemical Society: Washington, DC, USA, 2009; Volume 1025, pp. 63–94. ISBN 978-0-8412-6980-4. [Google Scholar]
- Amend, J.P.; LaRowe, D.E.; McCollom, T.M.; Shock, E.L. The energetics of organic synthesis inside and outside the cell. Philos. Trans. R. Soc. B Biol. Sci. 2013, 368, 20120255. [Google Scholar] [CrossRef] [PubMed]
- Wimmer, J.L.E.; Xavier, J.C.; Vieira, A.d.N.; Pereira, D.P.H.; Leidner, J.; Sousa, F.L.; Kleinermanns, K.; Preiner, M.; Martin, W.F. Energy at Origins: Favorable Thermodynamics of Biosynthetic Reactions in the Last Universal Common Ancestor (LUCA). Front. Microbiol. 2021, 12, 79366. [Google Scholar] [CrossRef]
- Nunes Palmeira, R.; Colnaghi, M.; Harrison, S.A.; Pomiankowski, A.; Lane, N. The limits of metabolic heredity in protocells. Proc. R. Soc. B Biol. Sci. 2022, 289, 20221469. [Google Scholar] [CrossRef]
- Orgel, L.E. Self-organizing biochemical cycles. Proc. Natl. Acad. Sci. USA 2000, 97, 12503–12507. [Google Scholar] [CrossRef]
- Preiner, M.; Igarashi, K.; Muchowska, K.B.; Yu, M.; Varma, S.J.; Kleinermanns, K.; Nobu, M.K.; Kamagata, Y.; Tüysüz, H.; Moran, J.; et al. A hydrogen-dependent geochemical analogue of primordial carbon and energy metabolism. Nat. Ecol. Evol. 2020, 4, 534–542. [Google Scholar] [CrossRef]
- Beyazay, T.; Belthle, K.S.; Farès, C.; Preiner, M.; Moran, J.; Martin, W.F.; Tüysüz, H. Ambient temperature CO2 fixation to pyruvate and subsequently to citramalate over iron and nickel nanoparticles. Nat. Commun. 2023, 14, 570. [Google Scholar] [CrossRef] [PubMed]
- Hudson, R.; de Graaf, R.; Strandoo Rodin, M.; Ohno, A.; Lane, N.; McGlynn, S.E.; Yamada, Y.M.A.; Nakamura, R.; Barge, L.M.; Braun, D.; et al. CO2 reduction driven by a pH gradient. Proc. Natl. Acad. Sci. USA 2020, 117, 22873–22879. [Google Scholar] [CrossRef] [PubMed]
- Varma, S.J.; Muchowska, K.B.; Chatelain, P.; Moran, J. Native iron reduces CO2 to intermediates and end-products of the acetyl-CoA pathway. Nat. Ecol. Evol. 2018, 2, 1019–1024. [Google Scholar] [CrossRef] [PubMed]
- Muchowska, K.B.; Varma, S.J.; Chevallot-Beroux, E.; Lethuillier-Karl, L.; Li, G.; Moran, J. Metals promote sequences of the reverse Krebs cycle. Nat. Ecol. Evol. 2017, 1, 1716–1721. [Google Scholar] [CrossRef] [PubMed]
- Muchowska, K.B.; Varma, S.J.; Moran, J. Synthesis and breakdown of universal metabolic precursors promoted by iron. Nature 2019, 569, 104–107. [Google Scholar] [CrossRef] [PubMed]
- Barge, L.M.; Flores, E.; Baum, M.M.; VanderVelde, D.G.; Russell, M.J. Redox and pH gradients drive amino acid synthesis in iron oxyhydroxide mineral systems. Proc. Natl. Acad. Sci. USA 2019, 116, 4828–4833. [Google Scholar] [CrossRef] [PubMed]
- Huber, C.; Wächtershäuser, G. Primordial reductive amination revisited. Tetrahedron Lett. 2003, 44, 1695–1697. [Google Scholar] [CrossRef]
- Mayer, R.J.; Moran, J. Quantifying Reductive Amination in Nonenzymatic Amino Acid Synthesis. Angew. Chem. Int. Ed. 2022, 61, e202212237. [Google Scholar] [CrossRef]
- Whicher, A.; Camprubi, E.; Pinna, S.; Herschy, B.; Lane, N. Acetyl Phosphate as a Primordial Energy Currency at the Origin of Life. Orig. Life Evol. Biospheres 2018, 48, 159–179. [Google Scholar] [CrossRef]
- Keller, M.A.; Turchyn, A.V.; Ralser, M. Non-enzymatic glycolysis and pentose phosphate pathway-like reactions in a plausible Archean ocean. Mol. Syst. Biol. 2014, 10, 725. [Google Scholar] [CrossRef]
- Messner, C.B.; Driscoll, P.C.; Piedrafita, G.; De Volder, M.F.L.; Ralser, M. Nonenzymatic gluconeogenesis-like formation of fructose 1,6-bisphosphate in ice. Proc. Natl. Acad. Sci. USA 2017, 114, 7403–7407. [Google Scholar] [CrossRef]
- Piedrafita, G.; Varma, S.J.; Castro, C.; Messner, C.B.; Szyrwiel, L.; Griffin, J.L.; Ralser, M. Cysteine and iron accelerate the formation of ribose-5-phosphate, providing insights into the evolutionary origins of the metabolic network structure. PLoS Biol. 2021, 19, e3001468. [Google Scholar] [CrossRef] [PubMed]
- Camprubi, E.; Harrison, S.A.; Jordan, S.F.; Bonnel, J.; Pinna, S.; Lane, N. Do Soluble Phosphates Direct the Formose Reaction towards Pentose Sugars? Astrobiology 2022, 22, 981–991. [Google Scholar] [CrossRef]
- Yi, J.; Kaur, H.; Kazöne, W.; Rauscher, S.A.; Gravillier, L.-A.; Muchowska, K.B.; Moran, J. A Nonenzymatic Analog of Pyrimidine Nucleobase Biosynthesis. Angew. Chem. Int. Ed. 2022, 61, e202117211. [Google Scholar] [CrossRef] [PubMed]
- Harrison, S.A.; Palmeira, R.N.; Halpern, A.; Lane, N. A biophysical basis for the emergence of the genetic code in protocells. Biochim. Biophys. Acta Bioenerg. 2022, 1863, 148597. [Google Scholar] [CrossRef] [PubMed]
- Hanwell, M.D.; Curtis, D.E.; Lonie, D.C.; Vandermeersch, T.; Zurek, E.; Hutchison, G.R. Avogadro: An advanced semantic chemical editor, visualization, and analysis platform. J. Cheminform. 2012, 4, 17. [Google Scholar] [CrossRef]
- Jo, S.; Kim, T.; Iyer, V.G.; Im, W. CHARMM-GUI: A web-based graphical user interface for CHARMM. J. Comput. Chem. 2008, 29, 1859–1865. [Google Scholar] [CrossRef]
- Kim, S.; Lee, J.; Jo, S.; Brooks, C.L.; Lee, H.S.; Im, W. CHARMM-GUI ligand reader and modeler for CHARMM force field generation of small molecules. J. Comput. Chem. 2017, 38, 1879–1886. [Google Scholar] [CrossRef]
- Lee, J.; Cheng, X.; Swails, J.M.; Yeom, M.S.; Eastman, P.K.; Lemkul, J.A.; Wei, S.; Buckner, J.; Jeong, J.C.; Qi, Y.; et al. CHARMM-GUI Input Generator for NAMD, GROMACS, AMBER, OpenMM, and CHARMM/OpenMM Simulations Using the CHARMM36 Additive Force Field. J. Chem. Theory Comput. 2016, 12, 405–413. [Google Scholar] [CrossRef]
- Phillips, J.C.; Hardy, D.J.; Maia, J.D.C.; Stone, J.E.; Ribeiro, J.V.; Bernardi, R.C.; Buch, R.; Fiorin, G.; Hénin, J.; Jiang, W.; et al. Scalable molecular dynamics on CPU and GPU architectures with NAMD. J. Chem. Phys. 2020, 153, 044130. [Google Scholar] [CrossRef]
- Matsunaga, Y. MDToolbox 1.0. Available online: https://mdtoolbox.readthedocs.io/en/latest/introduction.html (accessed on 21 February 2022).
- Tien, M.Z.; Meyer, A.G.; Sydykova, D.K.; Spielman, S.J.; Wilke, C.O. Maximum allowed solvent accessibilites of residues in proteins. PLoS ONE 2013, 8, e80635. [Google Scholar] [CrossRef] [PubMed]
- Williamson, M.P. Using chemical shift perturbation to characterise ligand binding. Prog. Nucl. Magn. Reson. Spectrosc. 2013, 73, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Lacey, J.C.; Mullins, D.W.; Khaled, M.A. The case for the anticode. Orig. Life 1984, 14, 505–511. [Google Scholar] [CrossRef] [PubMed]
- Krigbaum, W.R.; Komoriya, A. Local interactions as a structure determinant for protein molecules: II. Biochim. Biophys. Acta 1979, 576, 204–248. [Google Scholar] [CrossRef]
- Sweet, R.M.; Eisenberg, D. Correlation of sequence hydrophobicities measures similarity in three-dimensional protein structure. J. Mol. Biol. 1983, 171, 479–488. [Google Scholar] [CrossRef]
- Root-Bernstein, R. Simultaneous origin of homochirality, the genetic code and its directionality. BioEssays News Rev. Mol. Cell Dev. Biol. 2007, 29, 689–698. [Google Scholar] [CrossRef]
- Schoch, C.L.; Ciufo, S.; Domrachev, M.; Hotton, C.L.; Kannan, S.; Khovanskaya, R.; Leipe, D.; Mcveigh, R.; O’Neill, K.; Robbertse, B.; et al. NCBI Taxonomy: A comprehensive update on curation, resources and tools. Database J. Biol. Databases Curation 2020, 2020, baaa062. [Google Scholar] [CrossRef]
- Sayers, E.W.; Cavanaugh, M.; Clark, K.; Ostell, J.; Pruitt, K.D.; Karsch-Mizrachi, I. GenBank. Nucleic Acids Res. 2019, 47, D94–D99. [Google Scholar] [CrossRef]
- The Merck Index Online—Chemicals, Drugs and Biologicals. Available online: https://www.rsc.org/merck-index (accessed on 23 February 2023).
- Riniker, S. Fixed-Charge Atomistic Force Fields for Molecular Dynamics Simulations in the Condensed Phase: An Overview. J. Chem. Inf. Model. 2018, 58, 565–578. [Google Scholar] [CrossRef]
- Wang, X.; Yan, J.; Zhang, H.; Xu, Z.; Zhang, J.Z.H. An electrostatic energy-based charge model for molecular dynamics simulation. J. Chem. Phys. 2021, 154, 134107. [Google Scholar] [CrossRef]
- Condon, D.E.; Kennedy, S.D.; Mort, B.C.; Kierzek, R.; Yildirim, I.; Turner, D.H. Stacking in RNA: NMR of four tetramers benchmark molecular dynamics. J. Chem. Theory Comput. 2015, 11, 2729–2742. [Google Scholar] [CrossRef]
- Johnson, D.B.F.; Wang, L. Imprints of the genetic code in the ribosome. Proc. Natl. Acad. Sci. USA 2010, 107, 8298–8303. [Google Scholar] [CrossRef] [PubMed]
- Pinna, S.; Kunz, C.; Halpern, A.; Harrison, S.A.; Jordan, S.F.; Ward, J.; Werner, F.; Lane, N. A prebiotic basis for ATP as the universal energy currency. PLoS Biol. 2022, 20, e3001437. [Google Scholar] [CrossRef] [PubMed]
- Sosunov, V.; Zorov, S.; Sosunova, E.; Nikolaev, A.; Zakeyeva, I.; Bass, I.; Goldfarb, A.; Nikiforov, V.; Severinov, K.; Mustaev, A. The involvement of the aspartate triad of the active center in all catalytic activities of multisubunit RNA polymerase. Nucleic Acids Res. 2005, 33, 4202–4211. [Google Scholar] [CrossRef]
- Unciuleac, M.-C.; Goldgur, Y.; Shuman, S. Two-metal versus one-metal mechanisms of lysine adenylylation by ATP-dependent and NAD+-dependent polynucleotide ligases. Proc. Natl. Acad. Sci. USA 2017, 114, 2592–2597. [Google Scholar] [CrossRef] [PubMed]
- Hopfield, J.J. Origin of the genetic code: A testable hypothesis based on tRNA structure, sequence, and kinetic proofreading. Proc. Natl. Acad. Sci. USA 1978, 75, 4334–4338. [Google Scholar] [CrossRef]
- Betat, H.; Mörl, M. The CCA-adding enzyme: A central scrutinizer in tRNA quality control. BioEssays News Rev. Mol. Cell Dev. Biol. 2015, 37, 975–982. [Google Scholar] [CrossRef] [PubMed]
- Tamura, K. Molecular basis for chiral selection in RNA aminoacylation. Int. J. Mol. Sci. 2011, 12, 4745–4757. [Google Scholar] [CrossRef]
- Li, L.; Francklyn, C.; Carter, C.W., Jr. Aminoacylating urzymes challenge the RNA world hypothesis. J. Biol. Chem. 2013, 288, 26856–26863. [Google Scholar] [CrossRef] [PubMed]
- Krzyzaniak, A.; Sałański, P.; Twardowski, T.; Jurczak, J.; Barciszewski, J. tRNA aminoacylated at high pressure is a correct substrate for protein biosynthesis. Biochem. Mol. Biol. Int. 1998, 45, 489–500. [Google Scholar] [CrossRef]
- Carter, C.W.; Wills, P.R. Hierarchical groove discrimination by Class I and II aminoacyl-tRNA synthetases reveals a palimpsest of the operational RNA code in the tRNA acceptor-stem bases. Nucleic Acids Res. 2018, 46, 9667–9683. [Google Scholar] [CrossRef] [PubMed]
- Davidovich, C.; Belousoff, M.; Bashan, A.; Yonath, A. The evolving ribosome: From non-coded peptide bond formation to sophisticated translation machinery. Res. Microbiol. 2009, 160, 487–492. [Google Scholar] [CrossRef] [PubMed]
- Farias, S.T.; Rêgo, T.G.; José, M.V. Origin and evolution of the Peptidyl Transferase Center from proto-tRNAs. FEBS Open Bio 2014, 4, 175–178. [Google Scholar] [CrossRef] [PubMed]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Halpern, A.; Bartsch, L.R.; Ibrahim, K.; Harrison, S.A.; Ahn, M.; Christodoulou, J.; Lane, N. Biophysical Interactions Underpin the Emergence of Information in the Genetic Code. Life 2023, 13, 1129. https://doi.org/10.3390/life13051129
Halpern A, Bartsch LR, Ibrahim K, Harrison SA, Ahn M, Christodoulou J, Lane N. Biophysical Interactions Underpin the Emergence of Information in the Genetic Code. Life. 2023; 13(5):1129. https://doi.org/10.3390/life13051129
Chicago/Turabian StyleHalpern, Aaron, Lilly R. Bartsch, Kaan Ibrahim, Stuart A. Harrison, Minkoo Ahn, John Christodoulou, and Nick Lane. 2023. "Biophysical Interactions Underpin the Emergence of Information in the Genetic Code" Life 13, no. 5: 1129. https://doi.org/10.3390/life13051129
APA StyleHalpern, A., Bartsch, L. R., Ibrahim, K., Harrison, S. A., Ahn, M., Christodoulou, J., & Lane, N. (2023). Biophysical Interactions Underpin the Emergence of Information in the Genetic Code. Life, 13(5), 1129. https://doi.org/10.3390/life13051129