
Deep Convolutional Neural Network-Based Visual Stimuli Classification Using Electroencephalography Signals of Healthy and Alzheimer’s Disease Subjects


Abstract
:1. Introduction
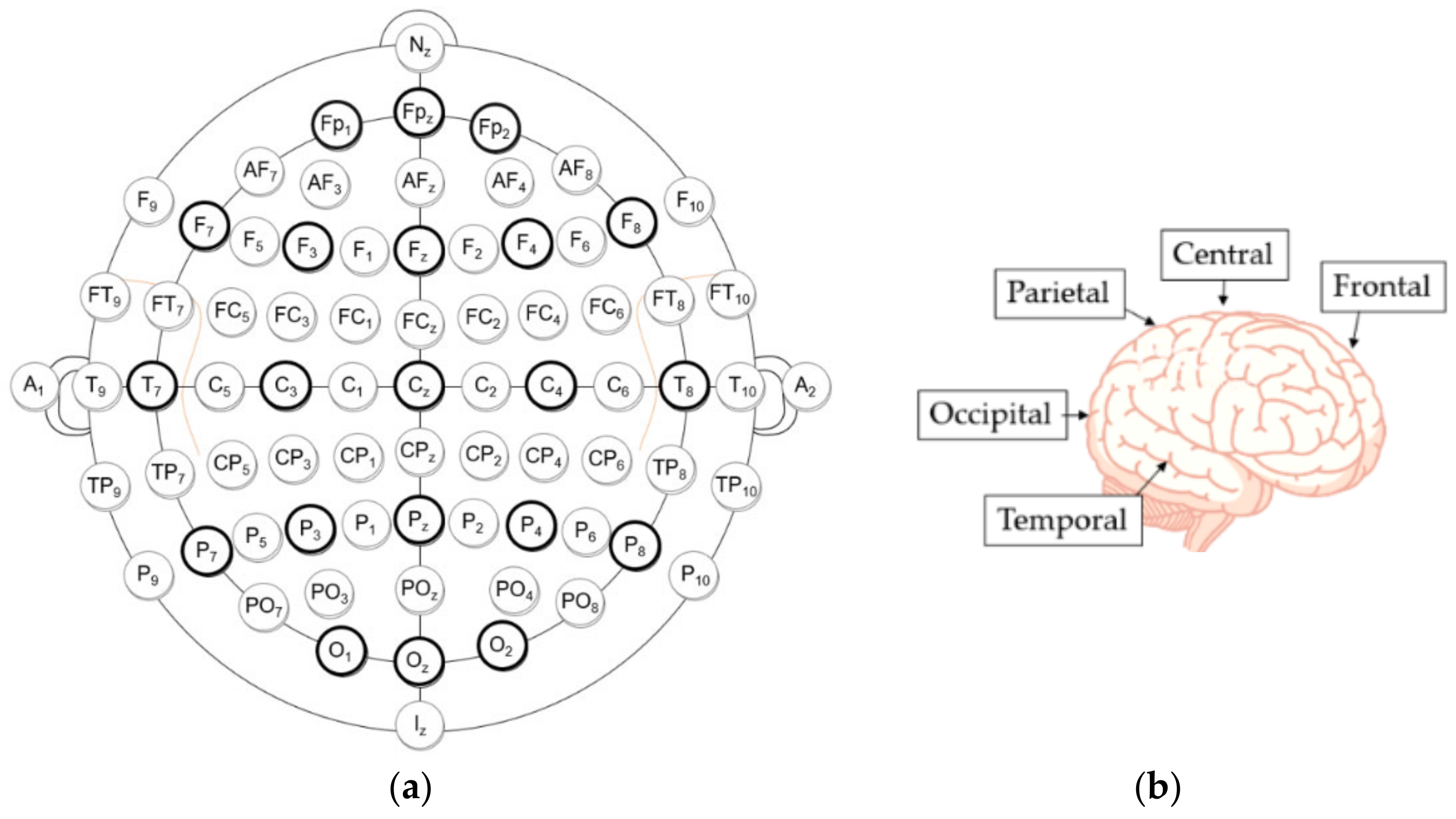
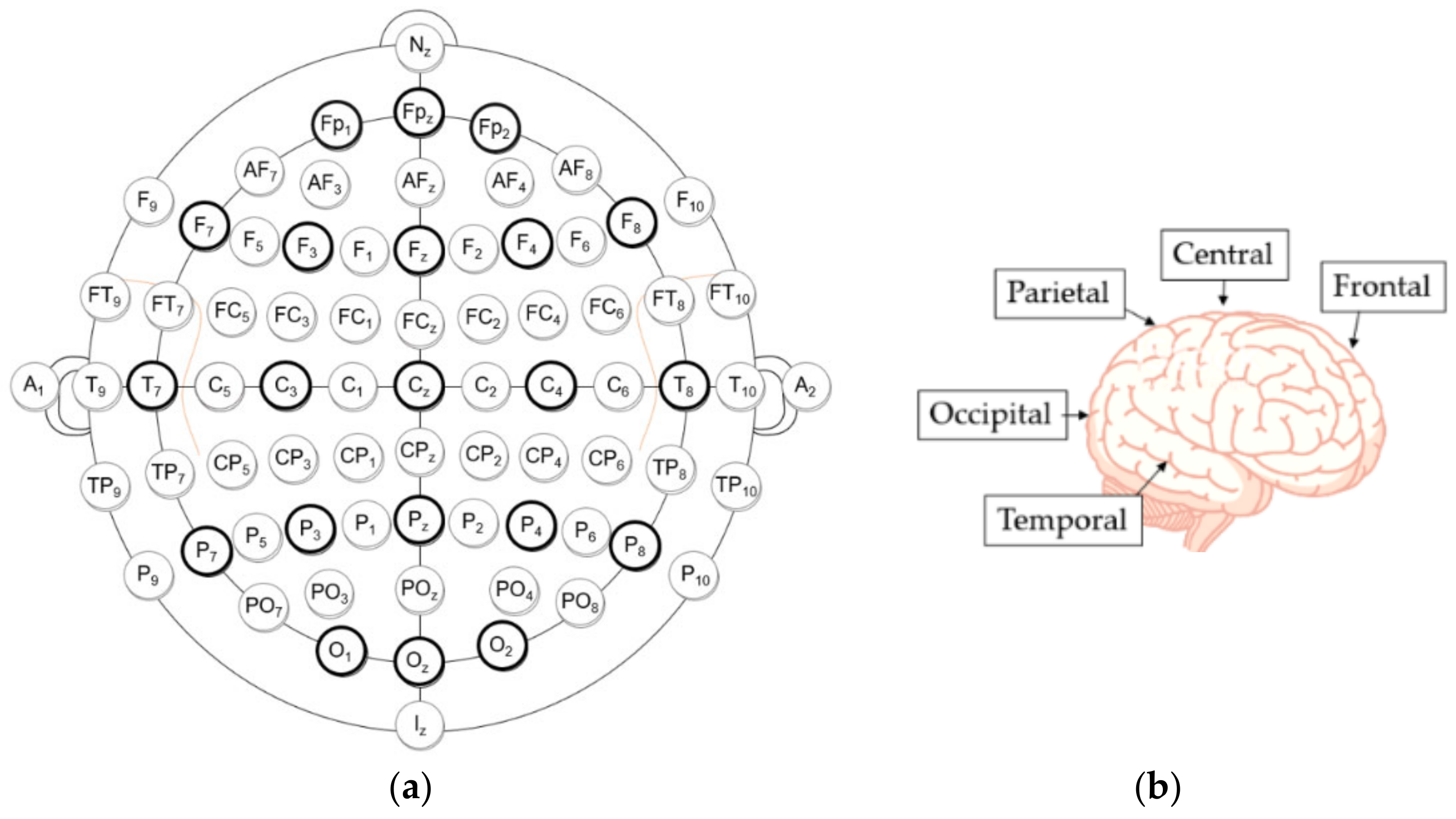
- Frontal lobe (F)—responsible for language, problem solving, decision making, and memory [12].
- Temporal (T) lobe—mainly responsible for auditory information and verbal memory of information, as well as certain aspects of visual perception [12].
- Occipital (O) lobe—responsible for early visual perception [12].
- Investigate whether a trained CNN model can detect categories related to emotions and facial inversion: fear/upright, fear/upside-down, neutral/upright, and neutral/upside-down.
- Investigate whether a trained CNN model can detect categories related to familiarity and facial inversion: famous/upright, famous/upside-down, unfamous/upright, and unfamous/upside-down.
- Investigate how pretrained model weights with augmented data affect model performance.
2. Related Work
3. Methods
3.1. Raw EEG Classification Methods
3.1.1. EEGNet Architecture
3.1.2. DeepConvNet Architecture
3.1.3. EEGNet SSVEP Architecture
3.2. Artificial EEG Data Generation Using the VAE
4. Materials
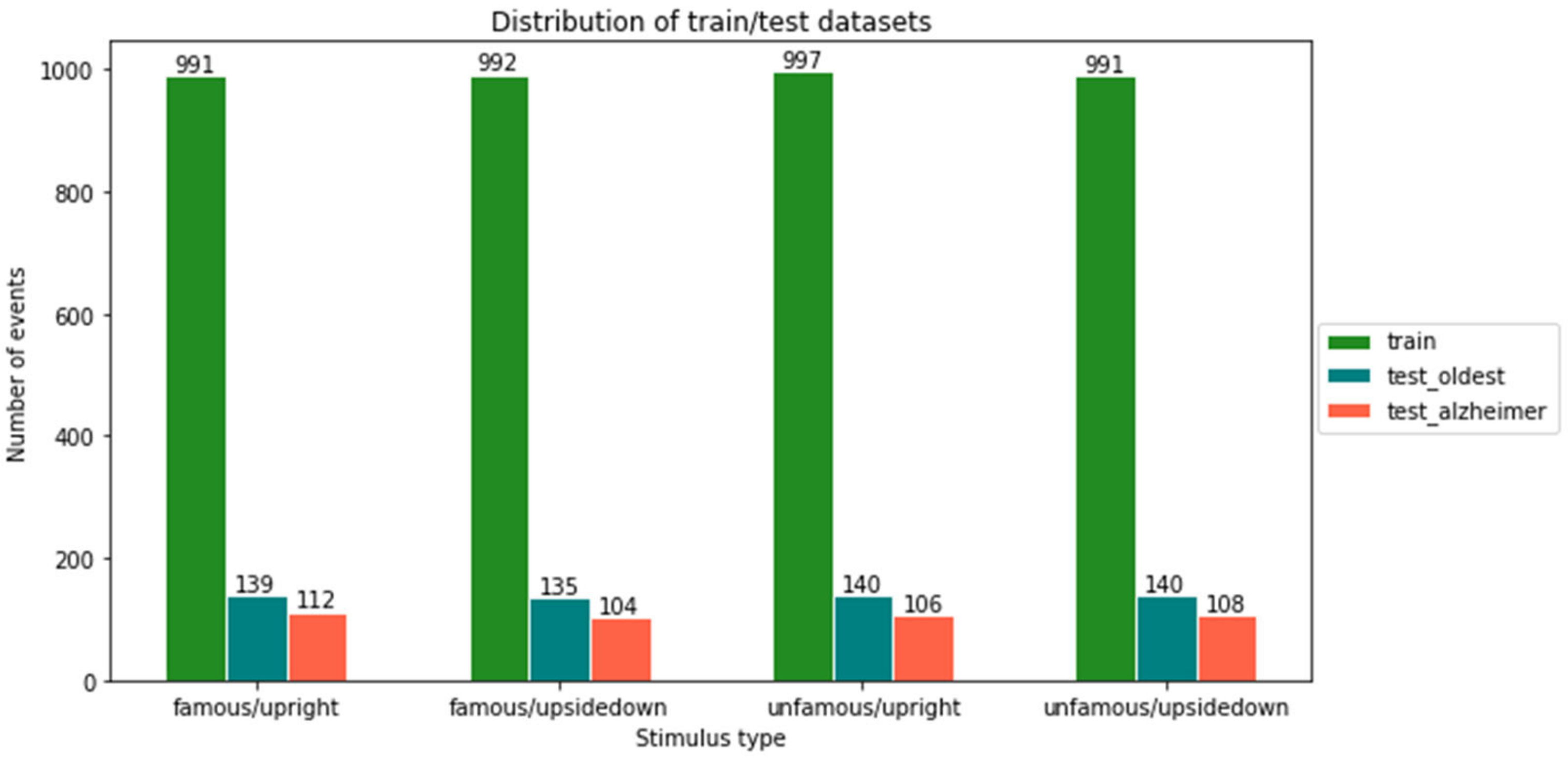
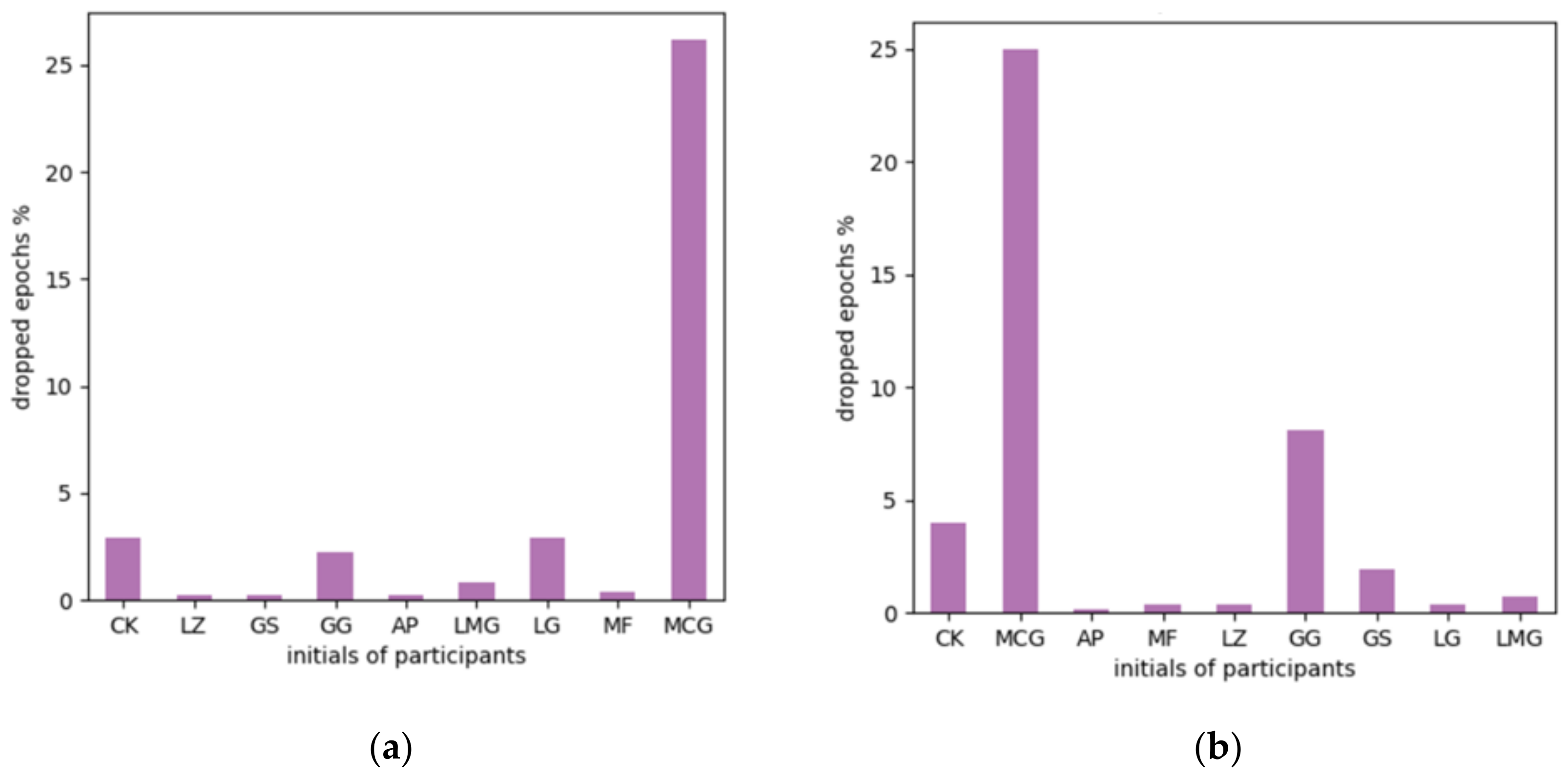
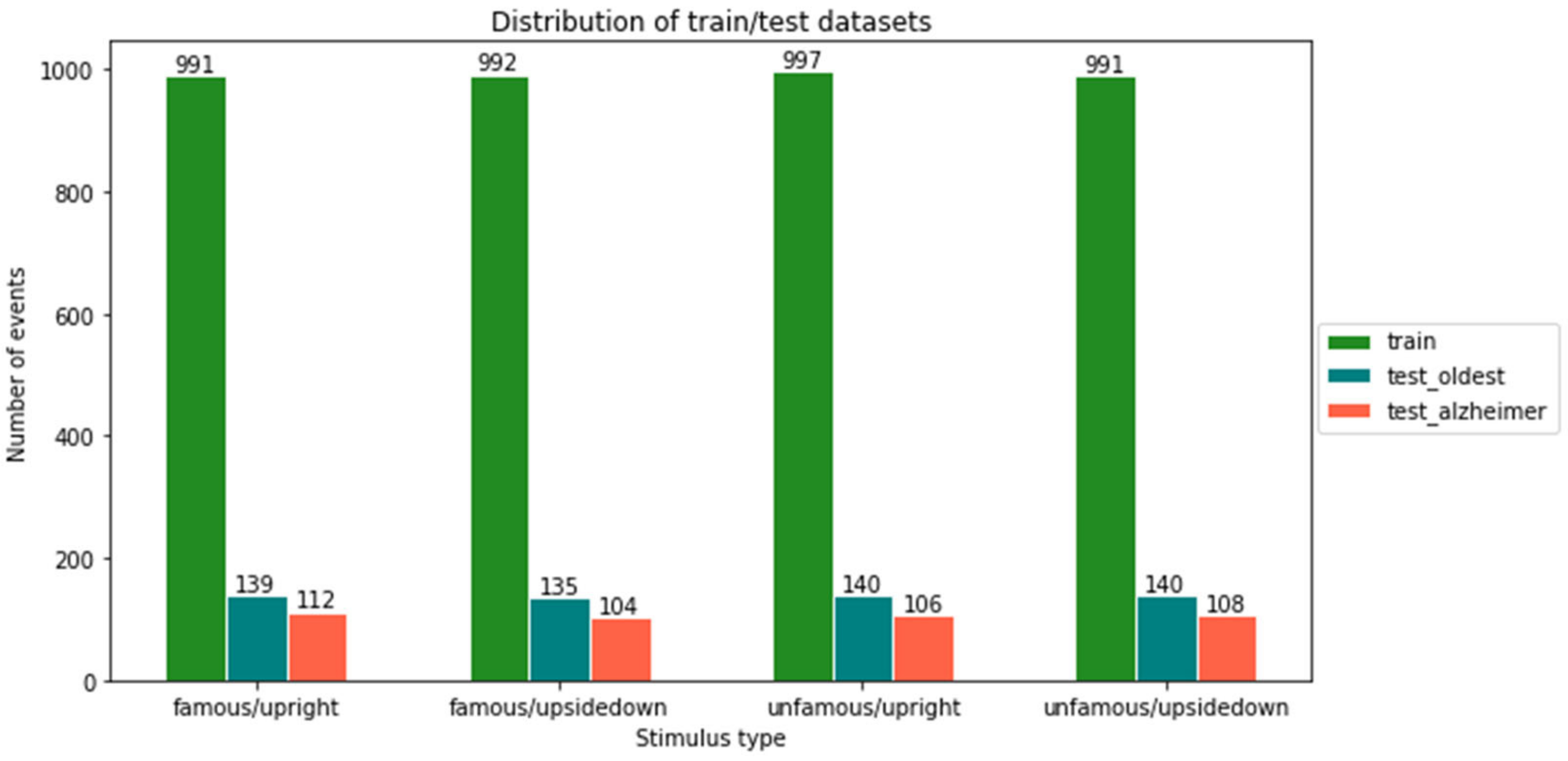
4.1. Participants and Data Source
4.2. Experiment Design
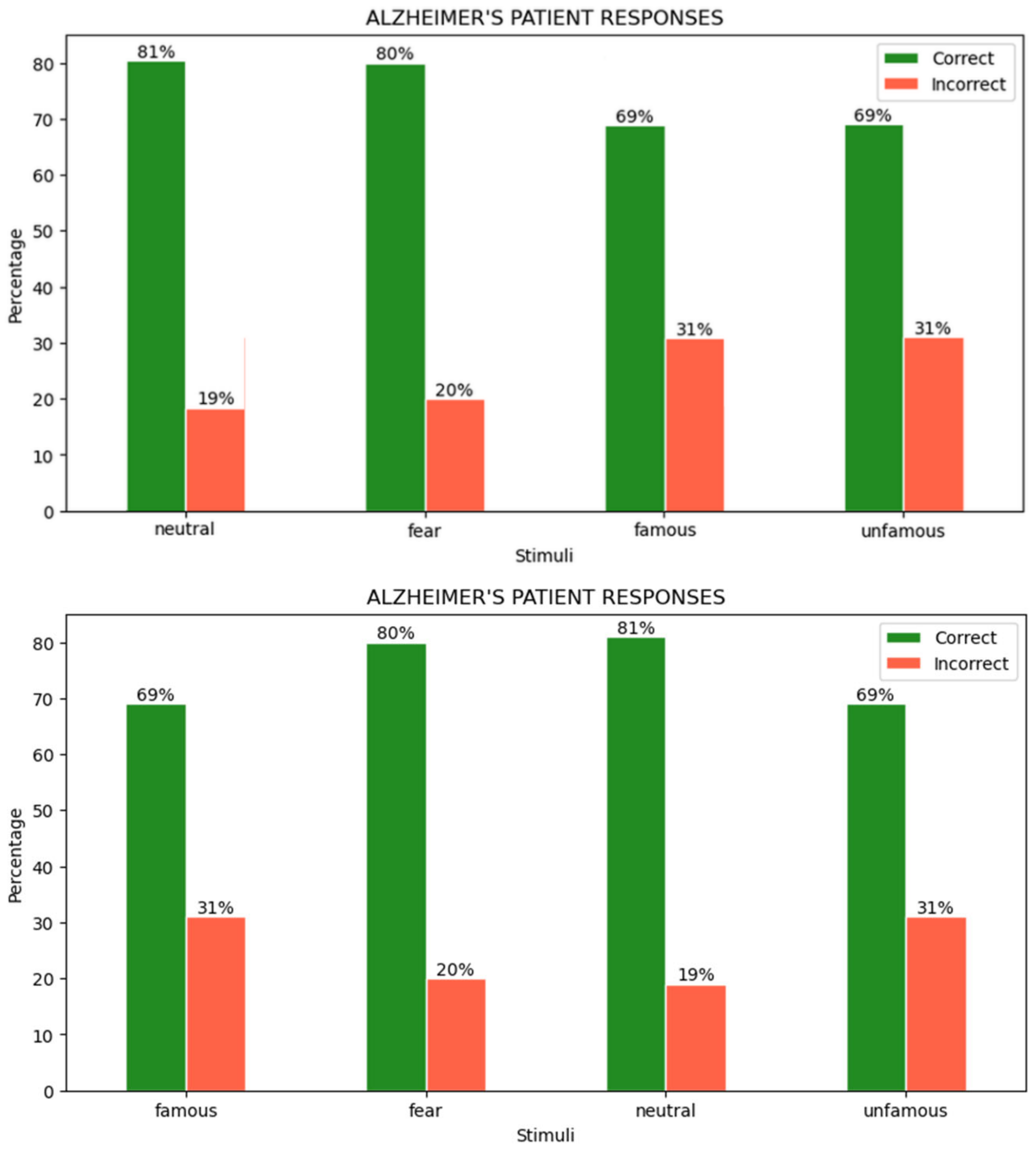
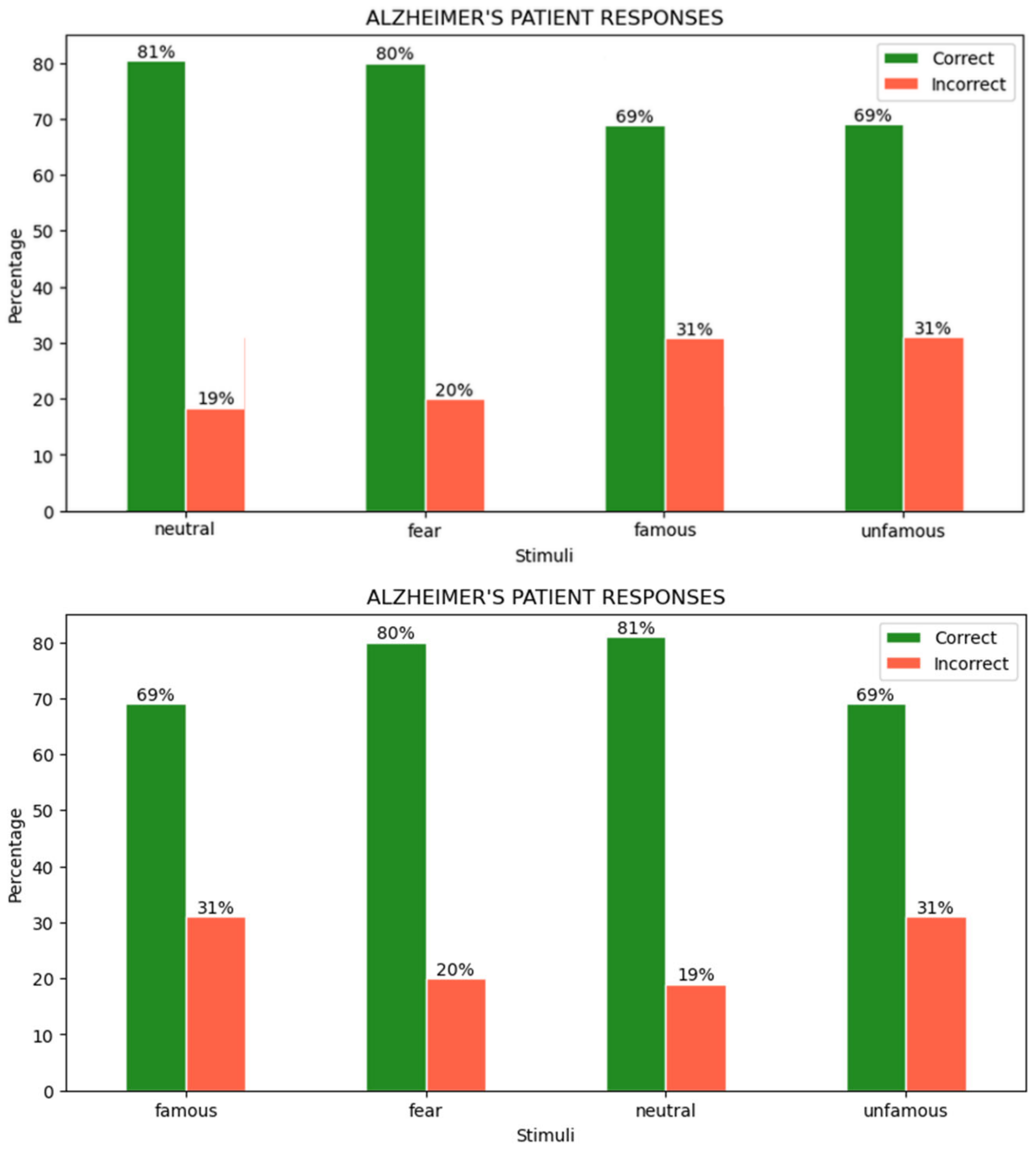
4.3. User Responses
5. Experiment
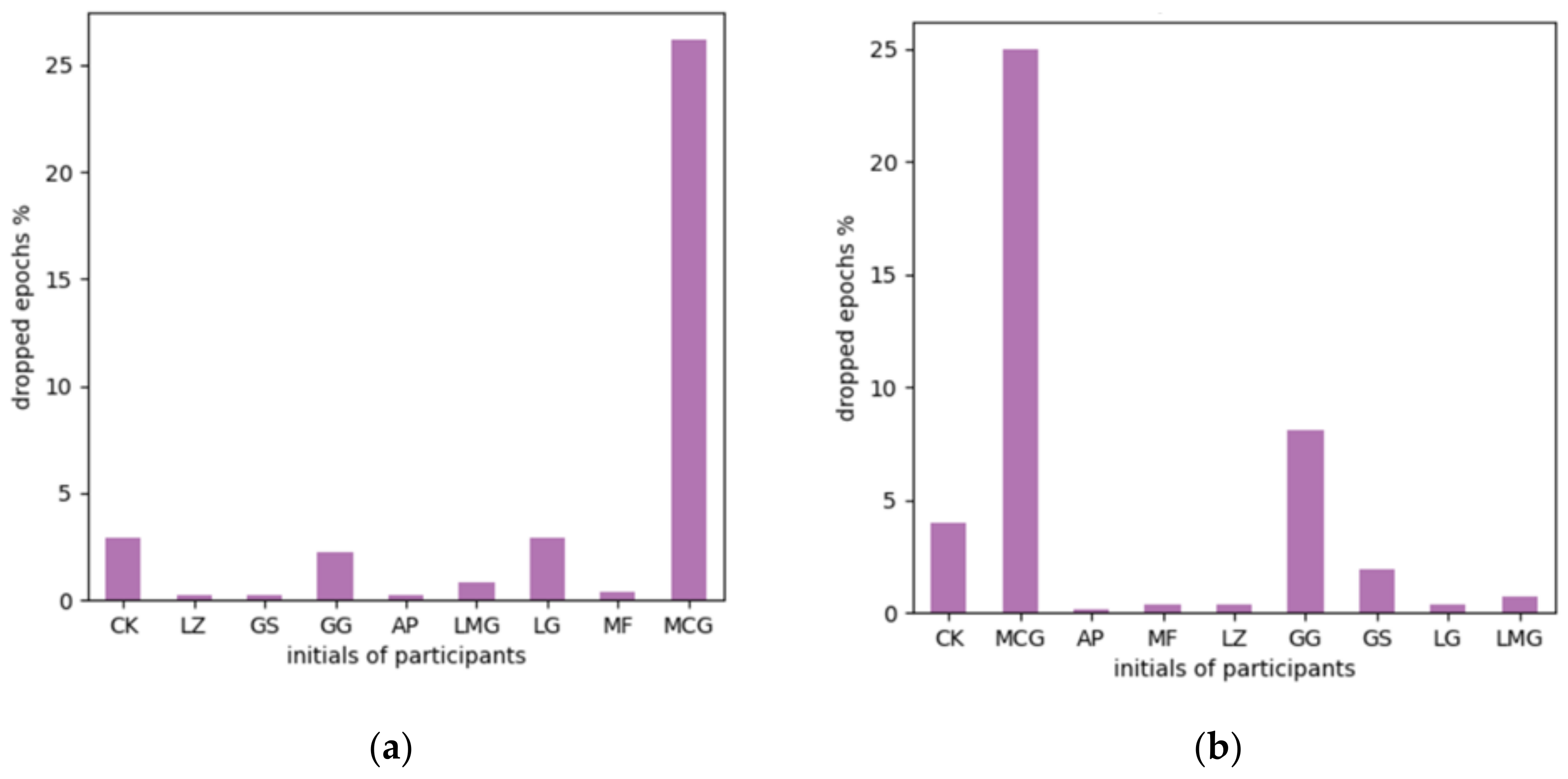
5.1. EEG Data Preprocessing
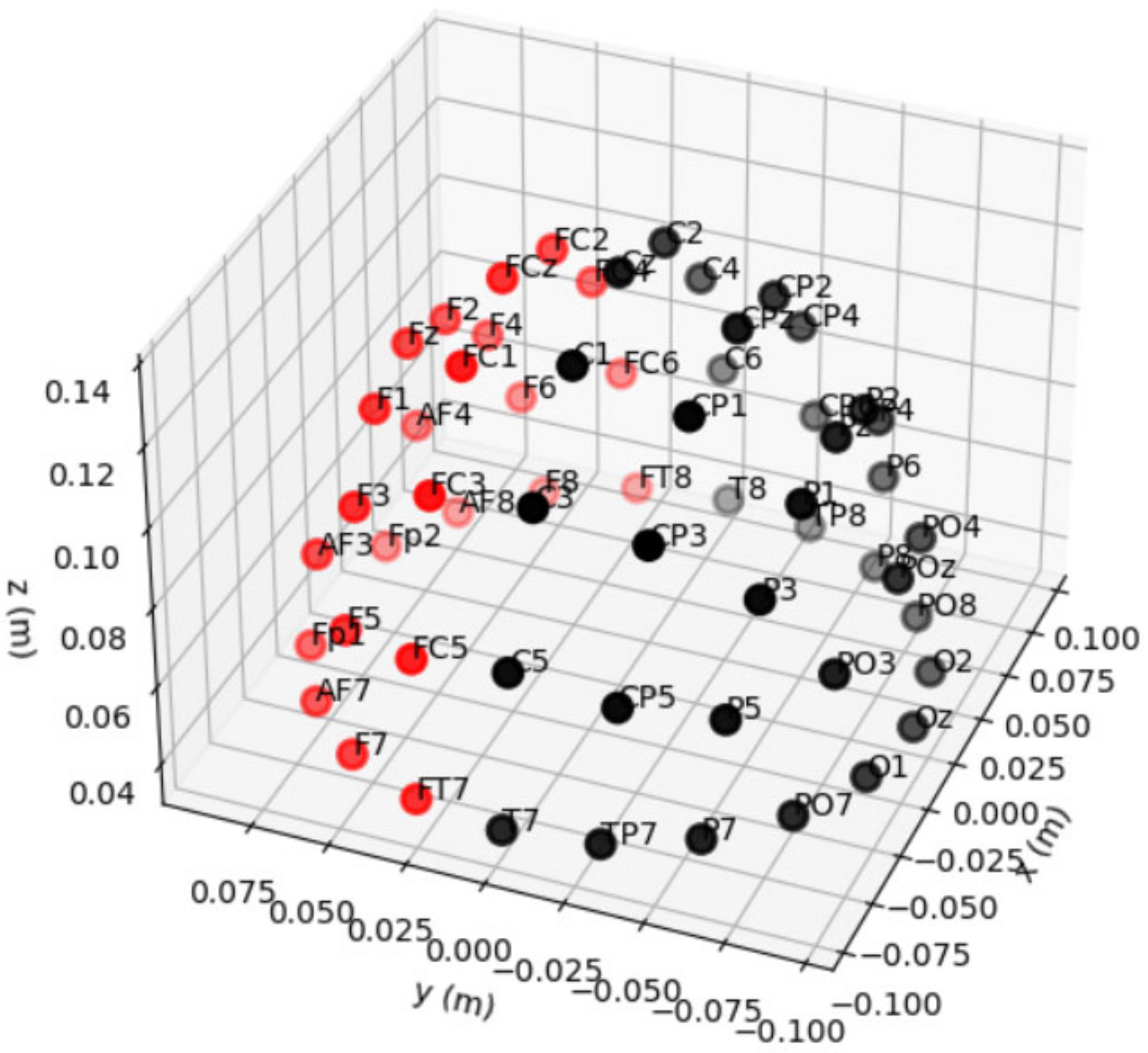
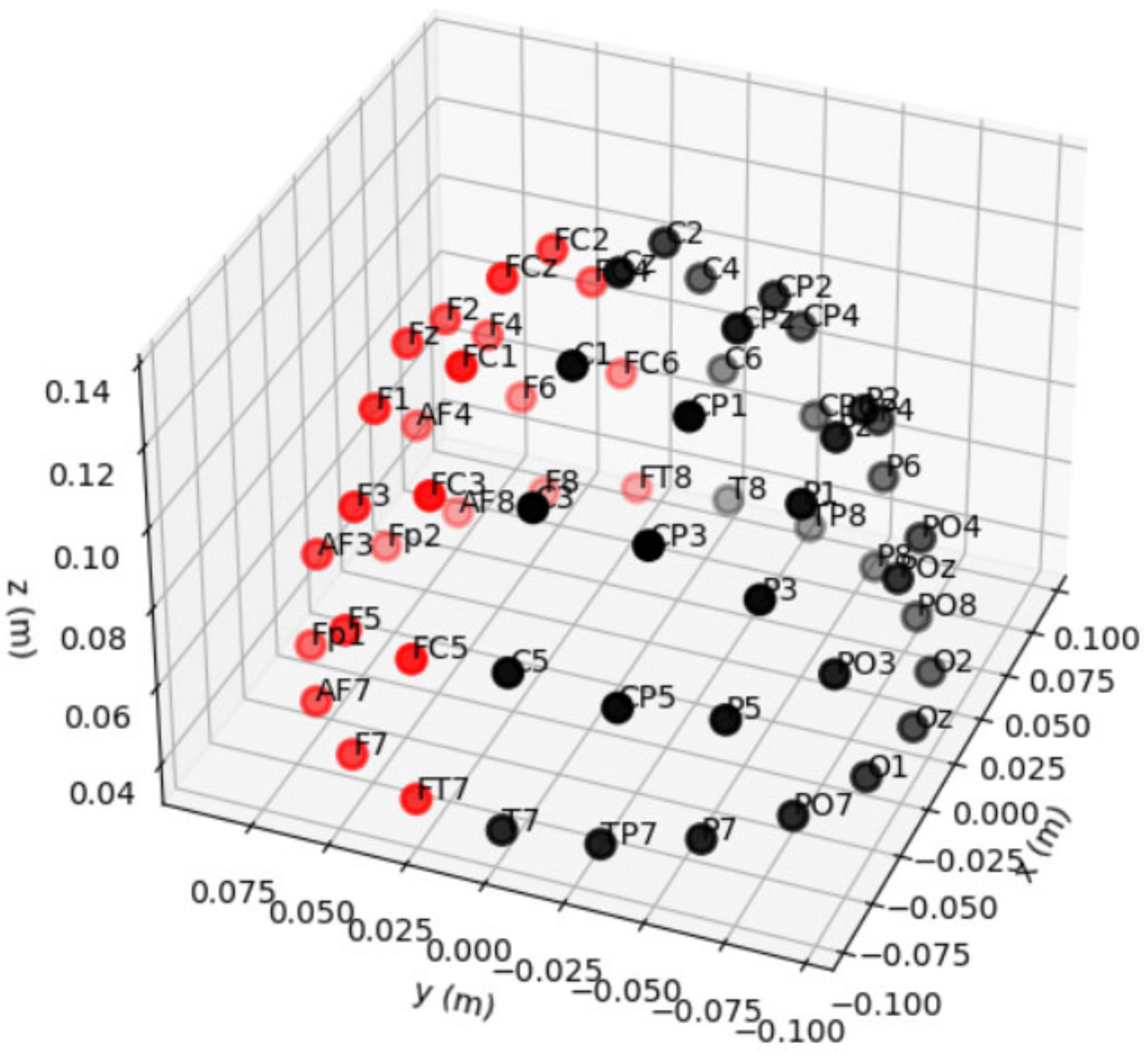
5.2. Channel Selection/Selection of Electrodes
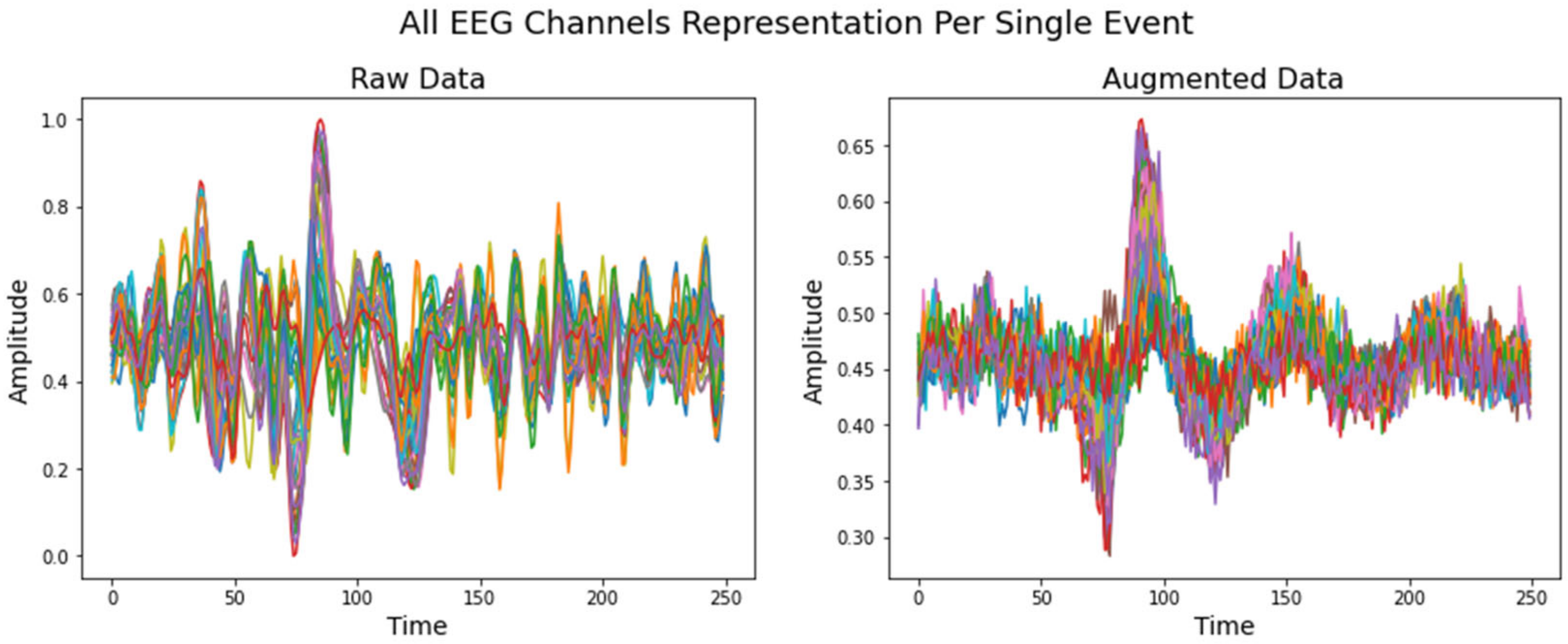
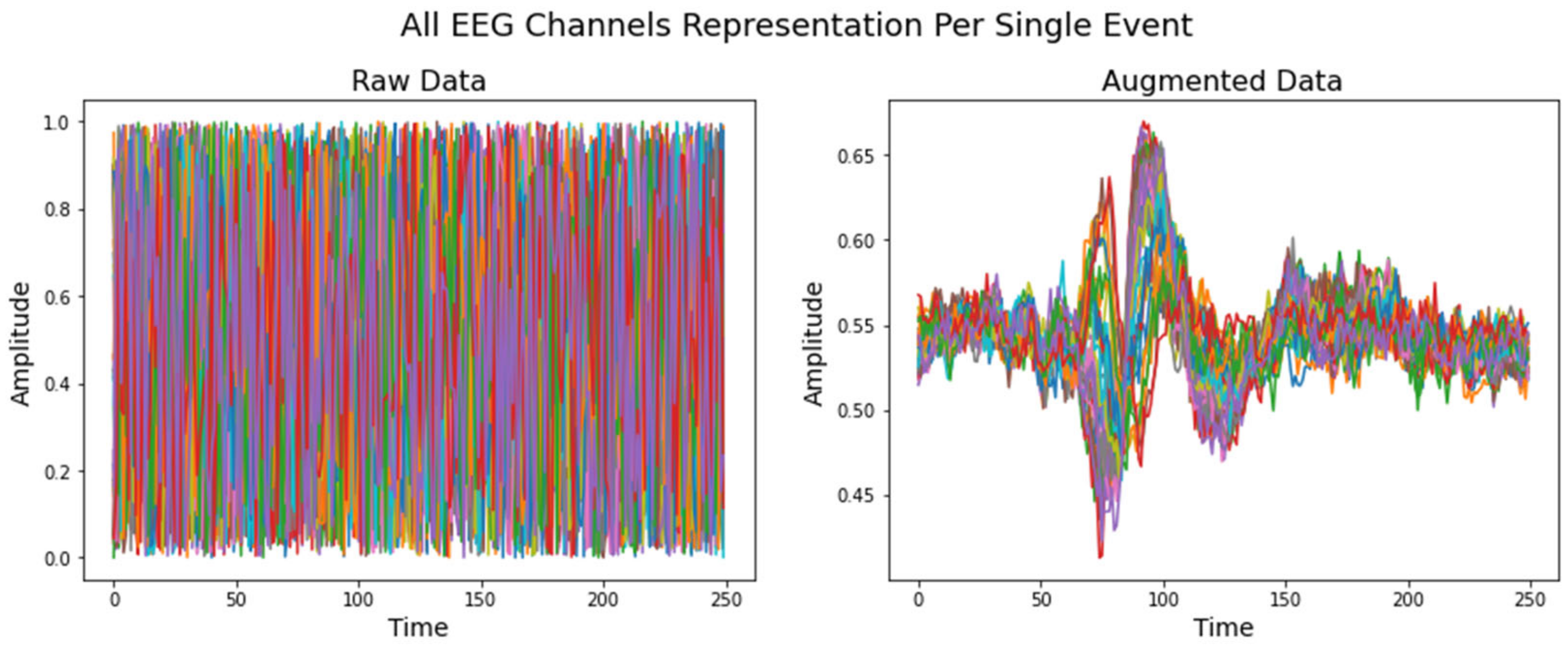
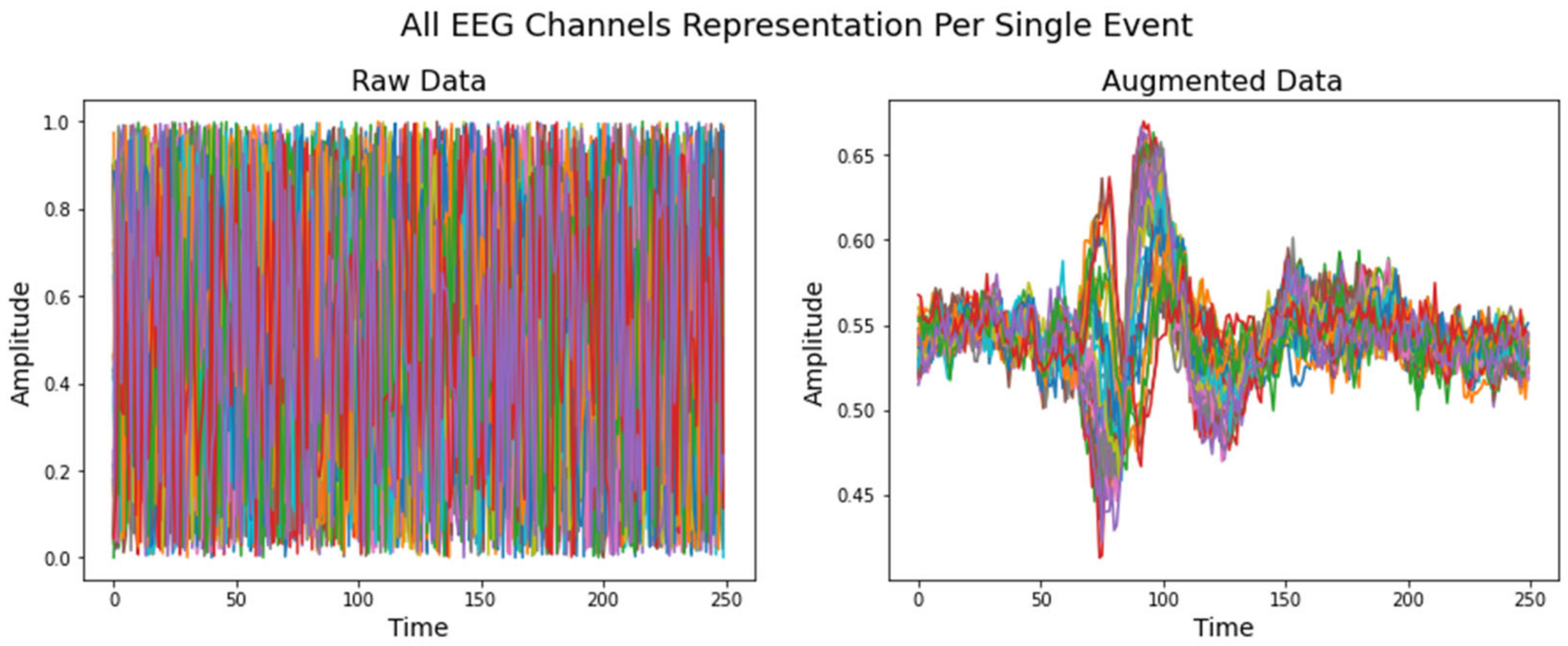
5.3. Data Augmentation Using VAE
5.4. Training Setup
5.5. EEGNet SSVEP Model with Regularization
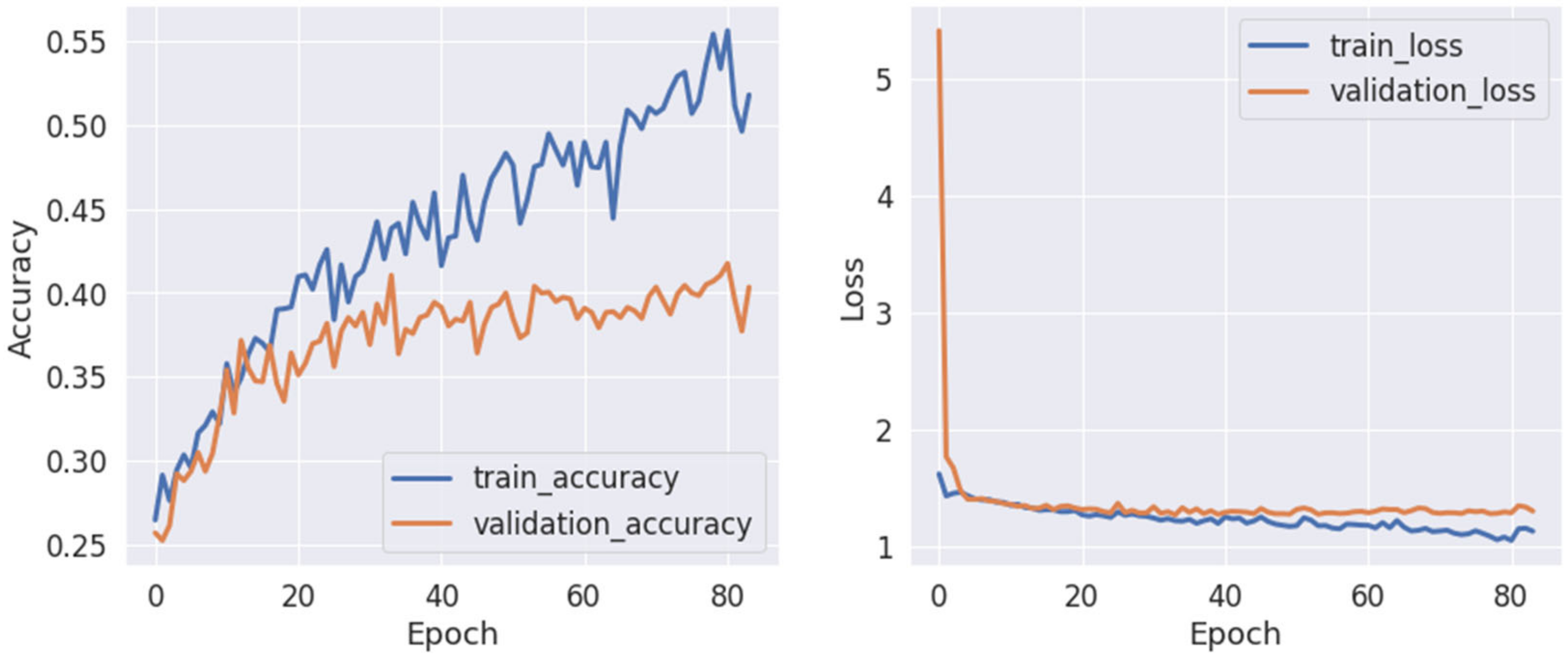
5.6. Training
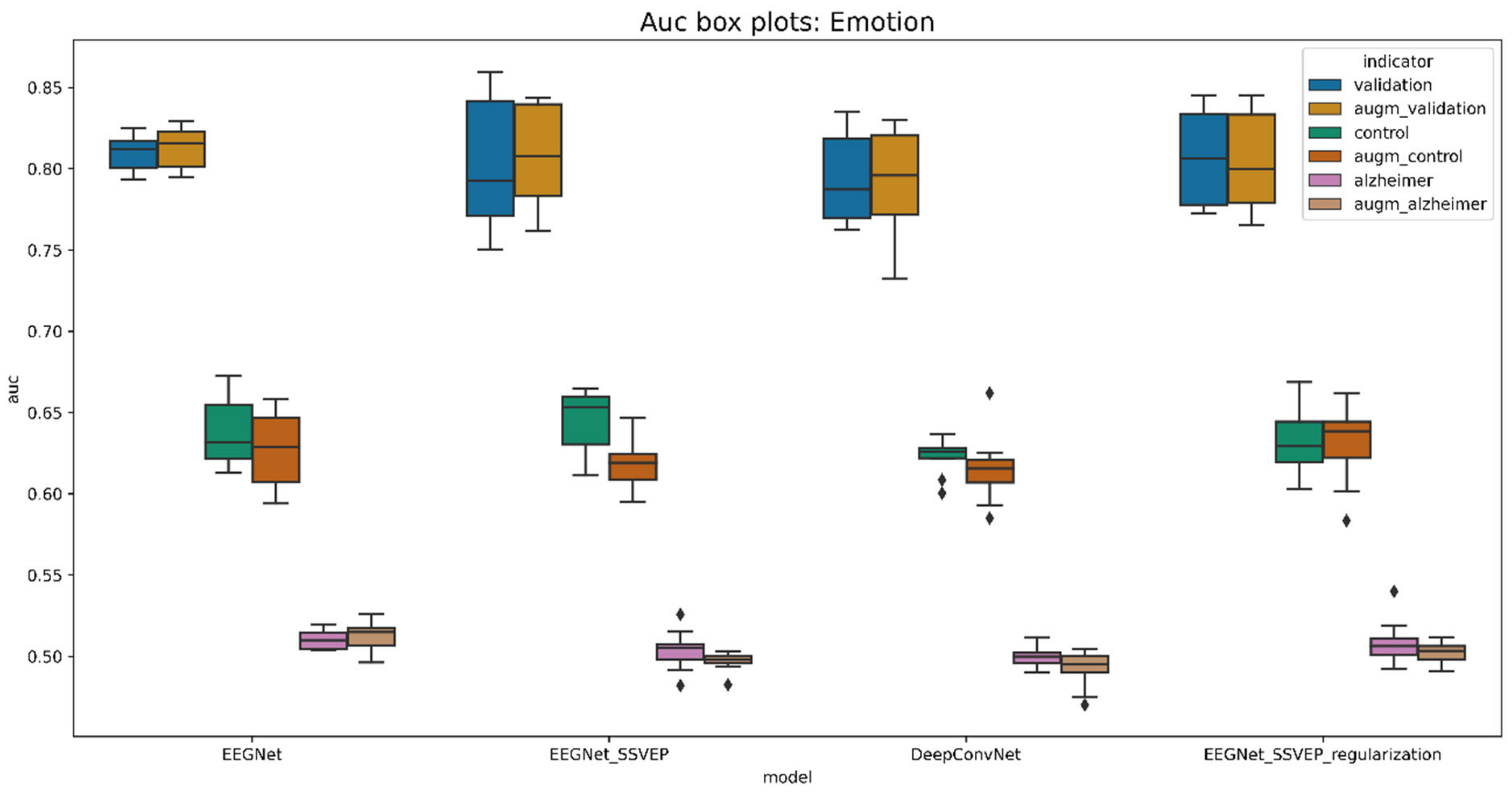
5.6.1. Pretraining with Augmented Data
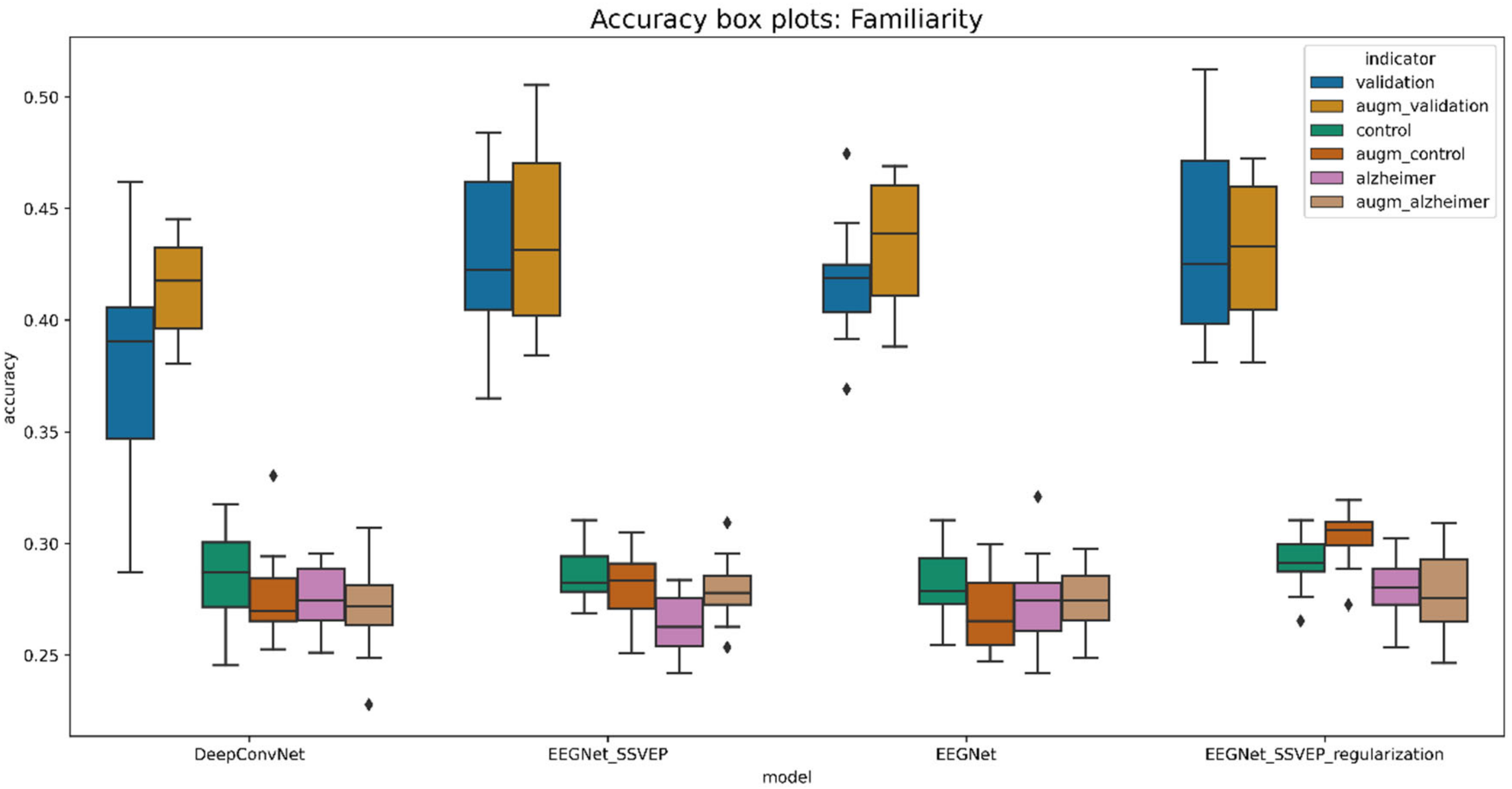
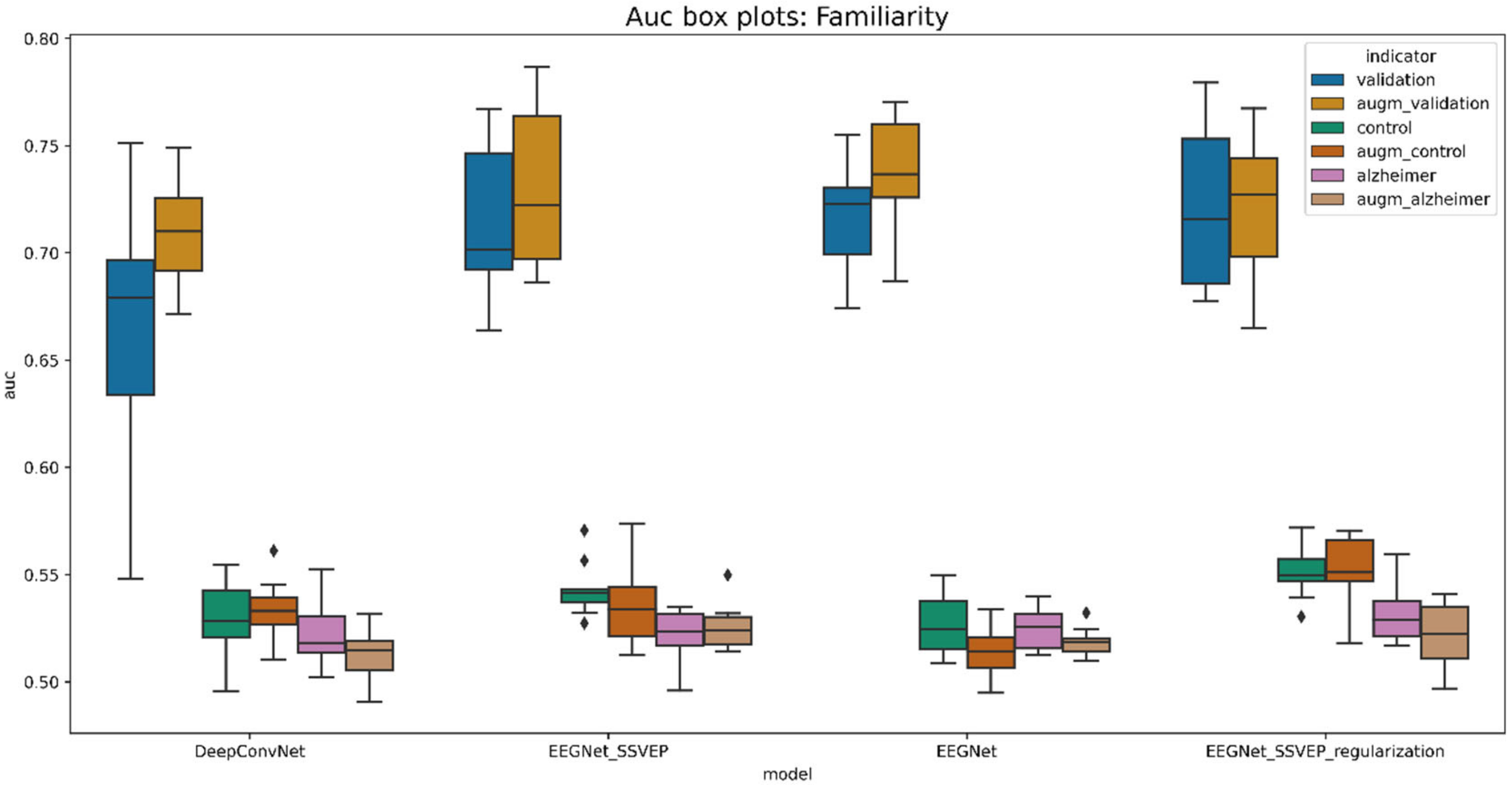
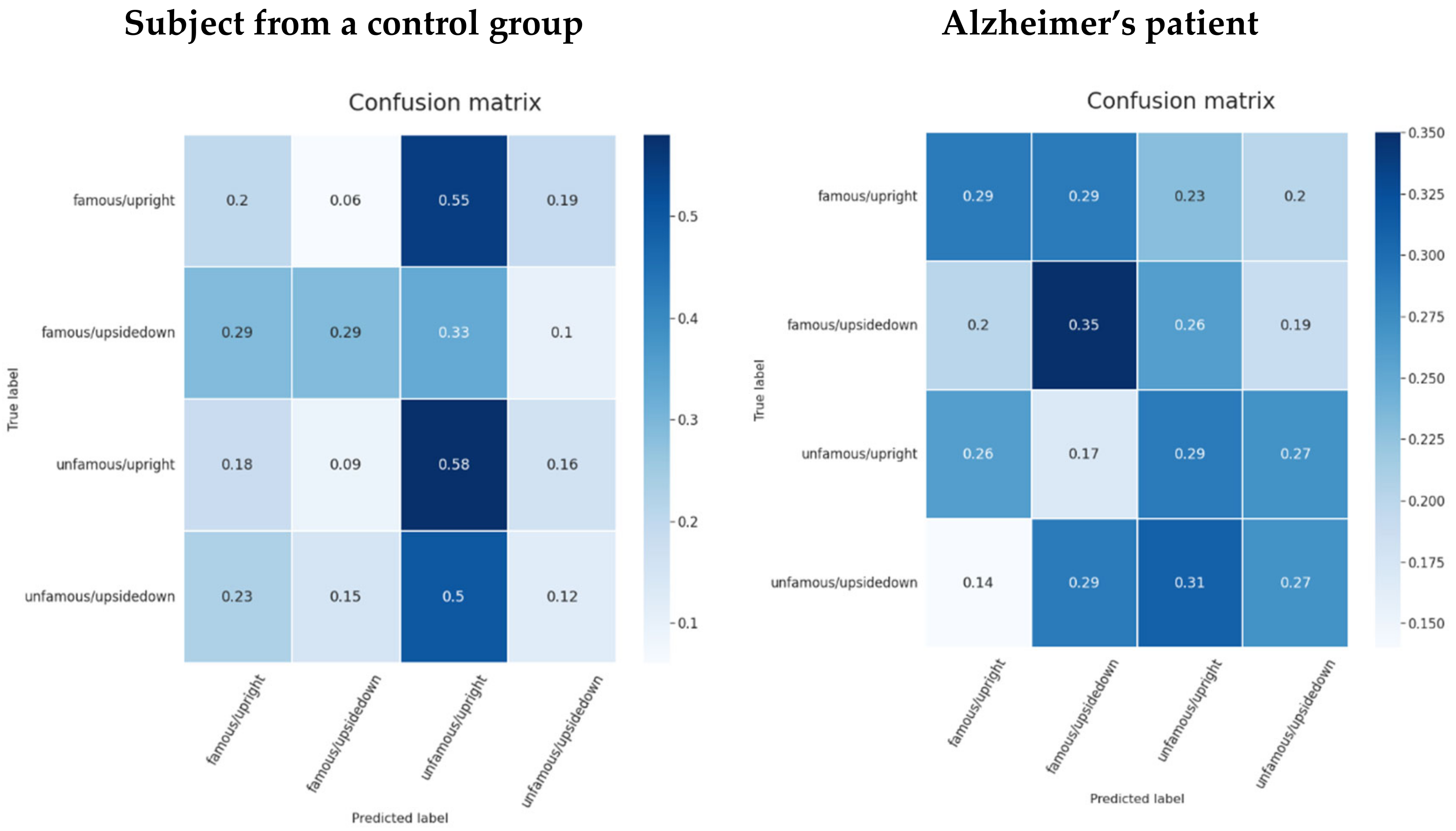
5.6.2. Familiarity and View Stimuli Classification
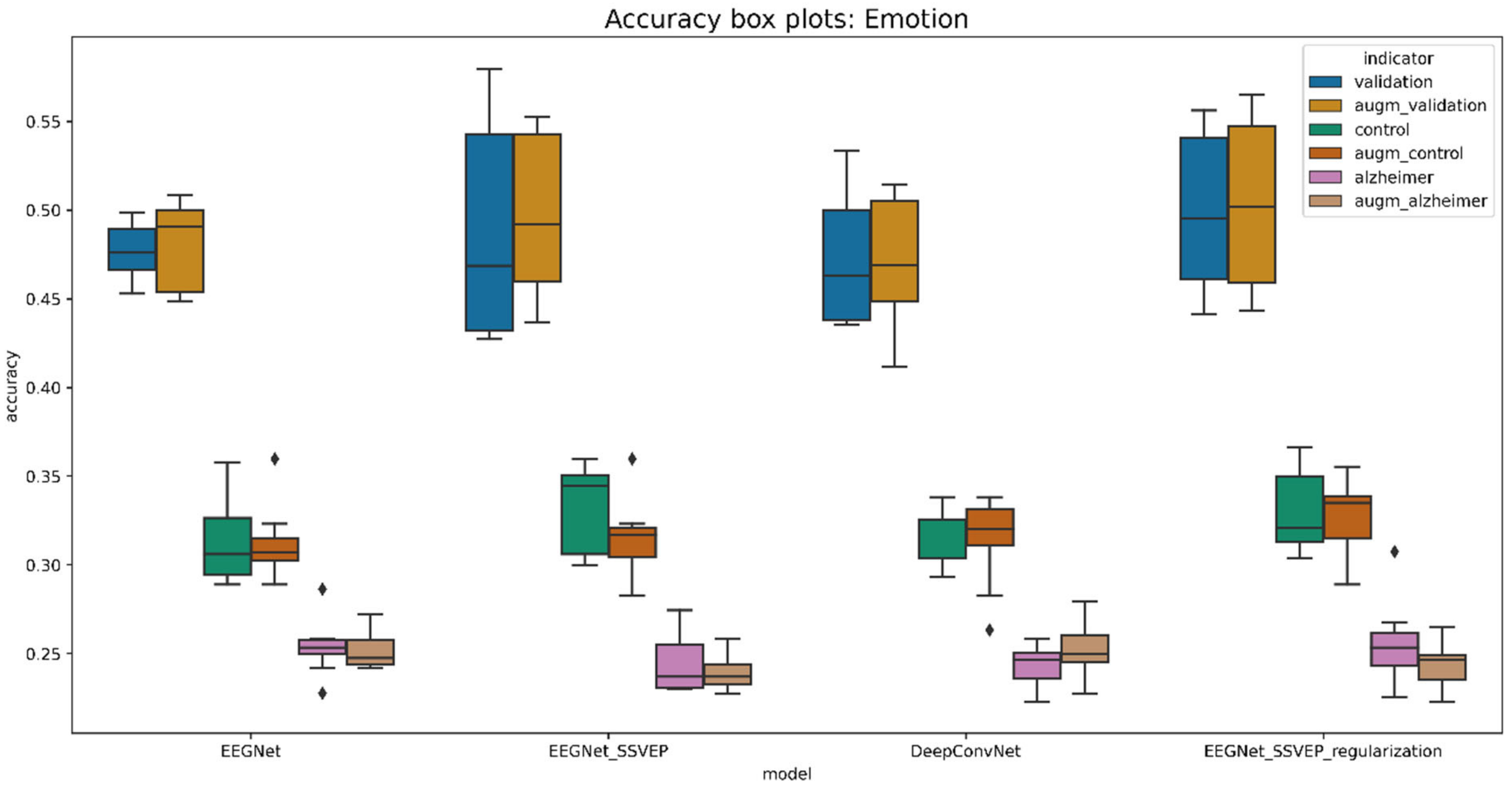
5.6.3. Emotion and View Stimuli Classification
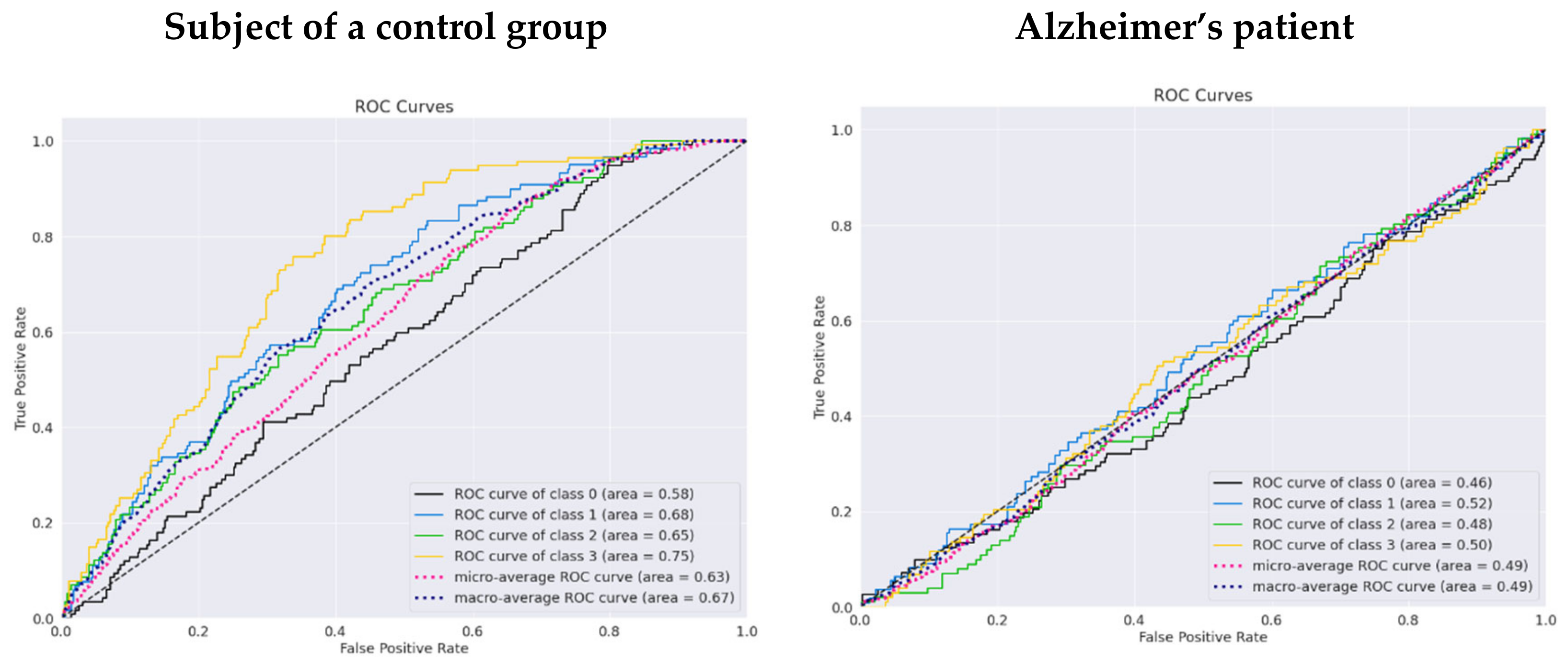
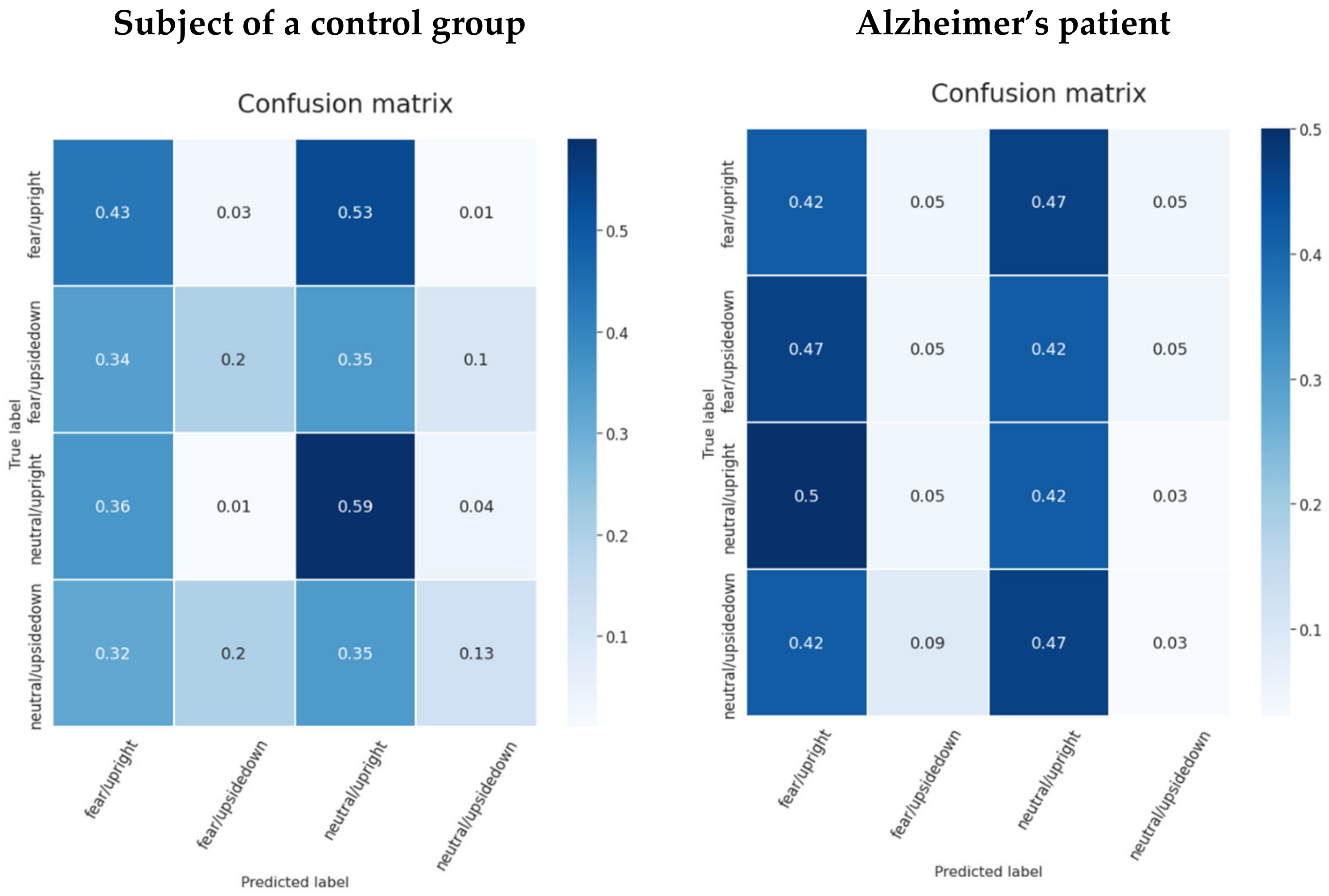
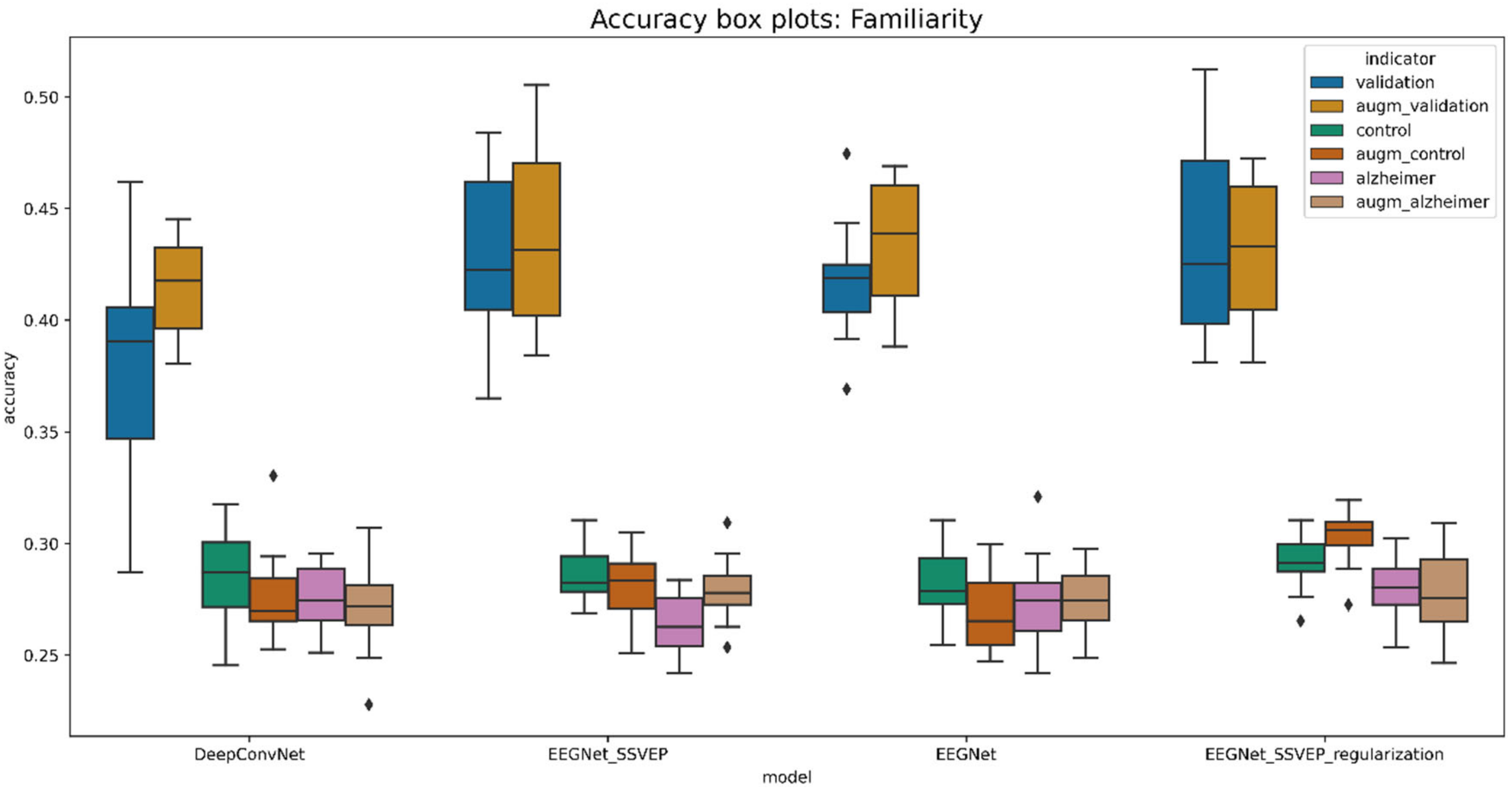
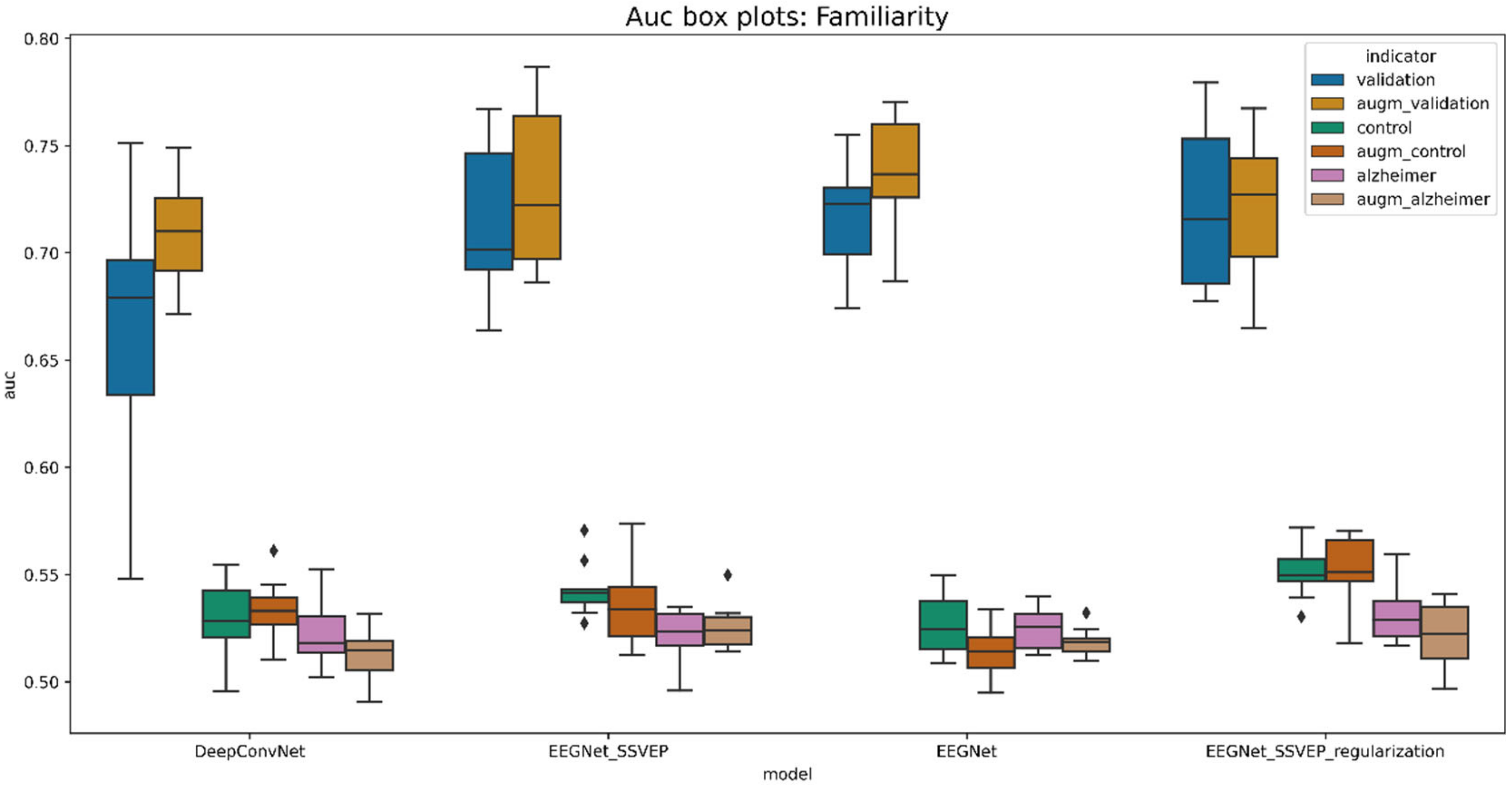
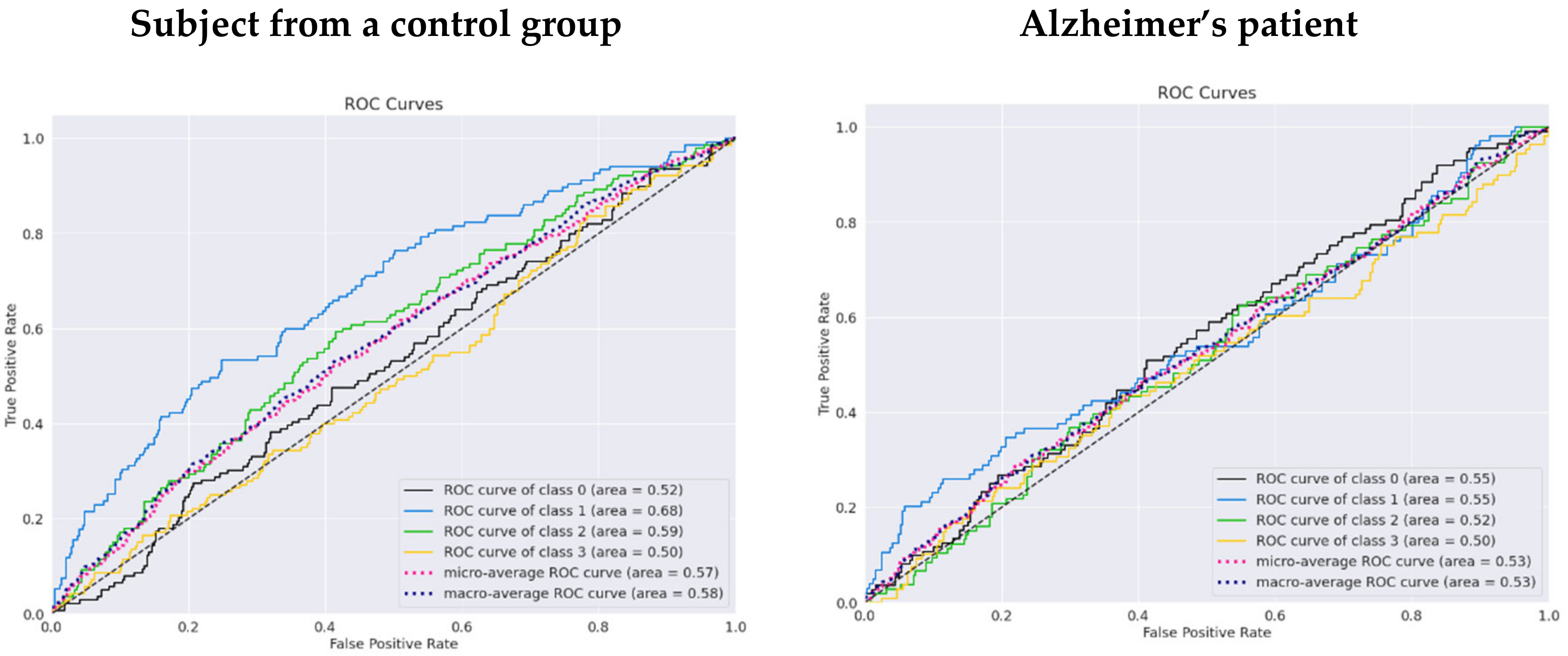
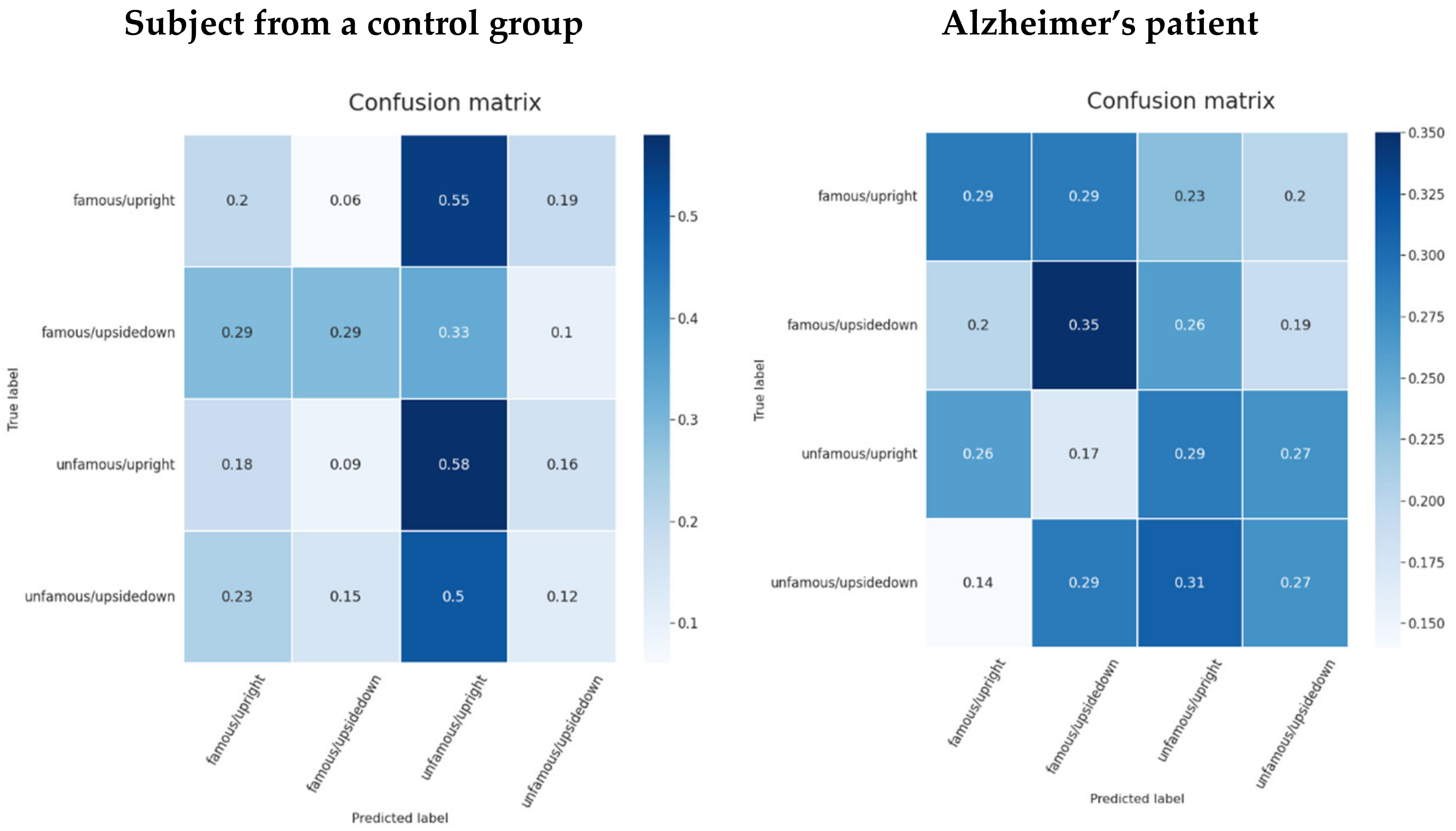
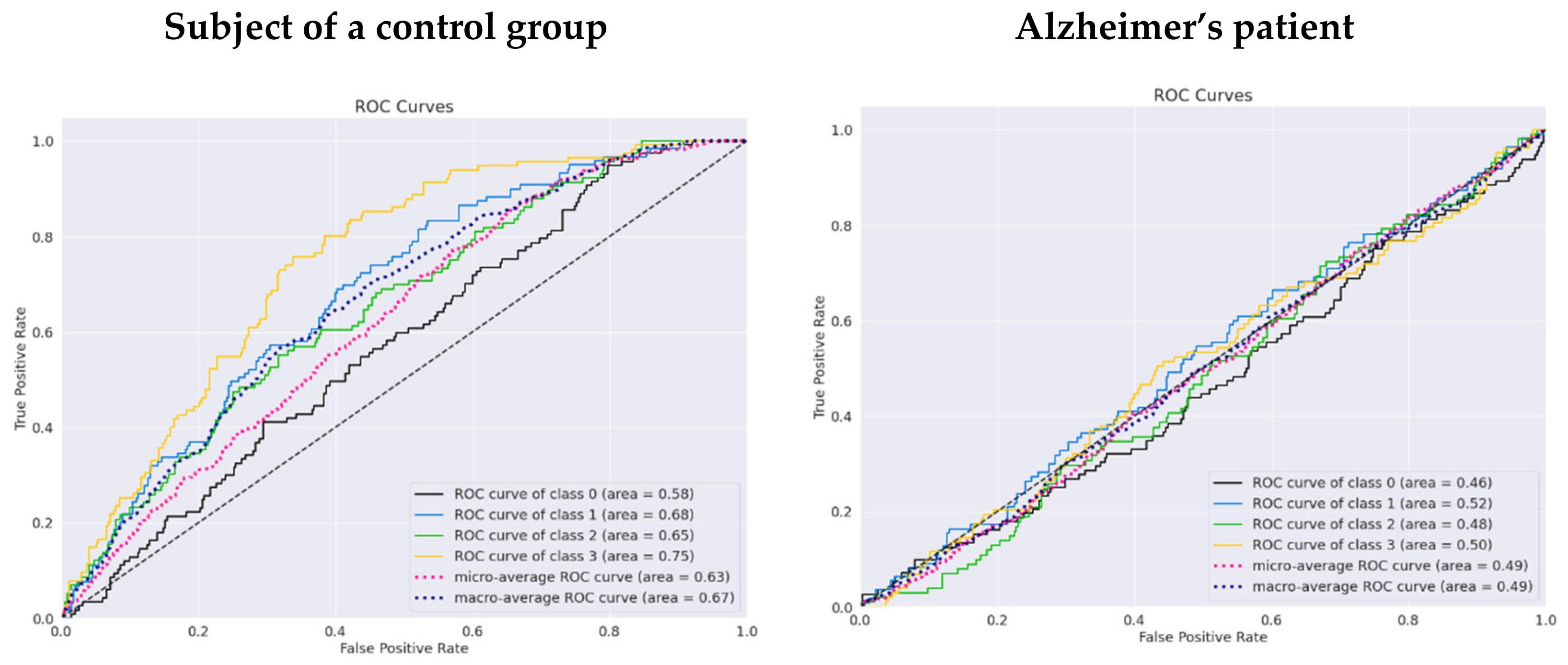
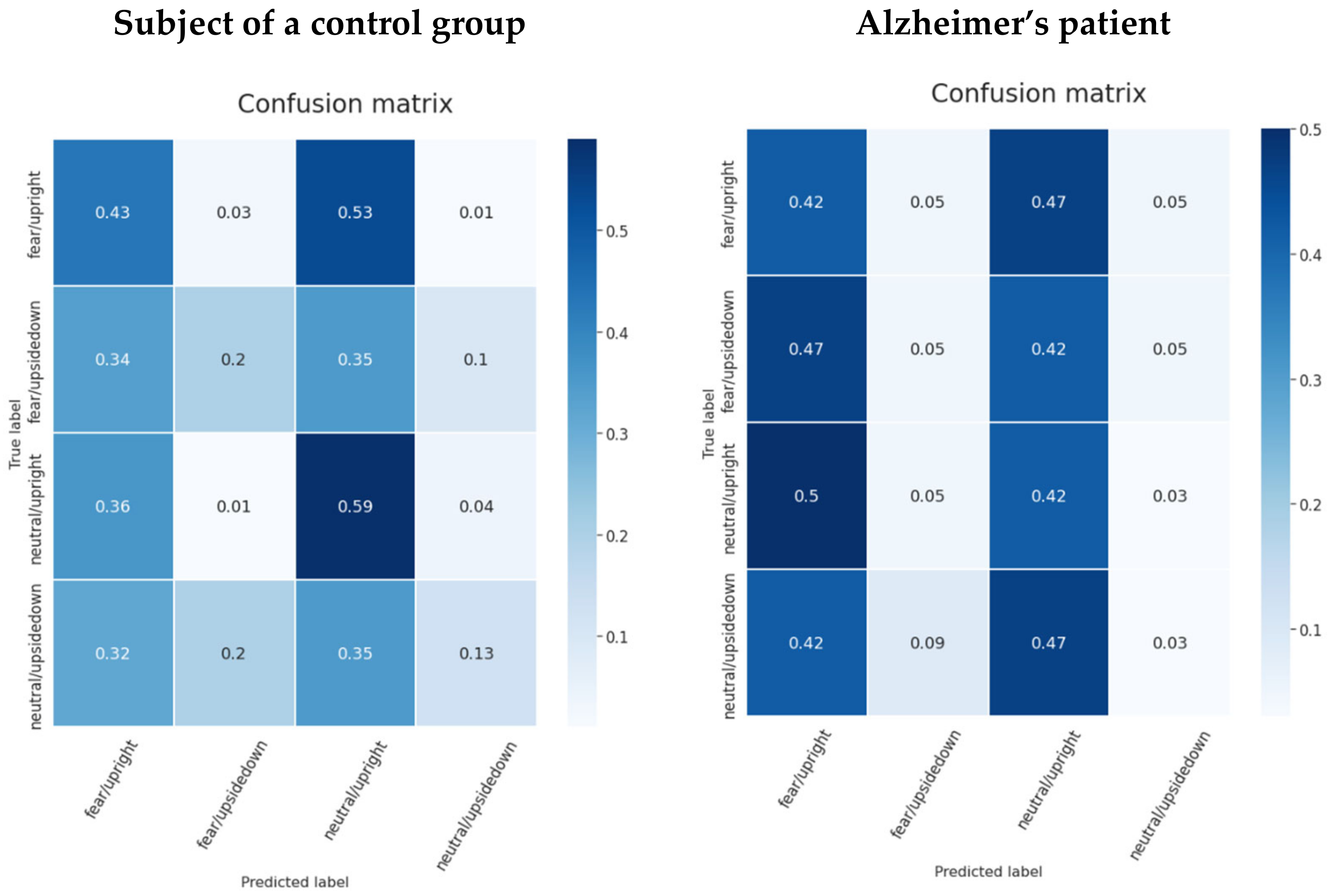
6. Discussion
7. Conclusions
8. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Uhlhaas, P.J.; Pantel, J.; Lanfermann, H.; Prvulovic, D.; Haenschel, C.; Maurer, K.; Linden, D.E. Visual Perceptual Organization Deficits in Alzheimer’s Dementia. Dement. Geriatr. Cogn. Disord. 2008, 25, 465–475. [Google Scholar] [CrossRef] [PubMed]
- Werheid, K.; Clare, L. Are Faces Special in Alzheimer’s Disease? Cognitive Conceptualisation, Neural Correlates, and Diagnostic Relevance of Impaired Memory for Faces and Names. Cortex 2007, 43, 898–906. [Google Scholar] [CrossRef]
- Parekh, V.; Subramanian, R.; Roy, D.; Jawahar, C.V. An EEG-Based Image Annotation System; Springer: Singapore, 2018. [Google Scholar] [CrossRef] [Green Version]
- Kwak, N.-S.; Müller, K.-R.; Lee, S.-W. A convolutional neural network for steady state visual evoked potential classification under ambulatory environment. PLoS ONE 2017, 12, e0172578. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.; Liu, Y.; Zhou, Z.; Yu, Y.; Liang, X. Decoding Visual Motions from EEG Using Attention-Based RNN. Appl. Sci. 2020, 10, 5662. [Google Scholar] [CrossRef]
- Maksimenko, V.A.; Kurkin, S.A.; Pitsik, E.N.; Musatov, V.Y.; Runnova, A.E.; Efremova, T.Y.; Hramov, A.E.; Pisarchik, A.N. Artificial Neural Network Classification of Motor-Related EEG: An Increase in Classification Accuracy by Reducing Signal Complexity. Complexity 2018, 2018, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Mishra, R.; Bhavsar, A. EEG classification for visual brain decoding via metric learning. In Proceedings of the BIOIMAGING 2021—8th International Conference on Bioimaging, Part of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies, BIOSTEC, Vienna, Austria, 11–13 February 2021; Volume 2, pp. 160–167. [Google Scholar] [CrossRef]
- Krishna, N.M.; Sekaran, K.; Vamsi, A.V.N.; Ghantasala, G.S.P.; Chandana, P.; Kadry, S.; Blazauskas, T.; Damasevicius, R.; Kaushik, S. An Efficient Mixture Model Approach in Brain-Machine Interface Systems for Extracting the Psychological Status of Mentally Impaired Persons Using EEG Signals. IEEE Access 2019, 7, 77905–77914. [Google Scholar] [CrossRef]
- Butkeviciute, E.; Bikulciene, L.; Sidekerskiene, T.; Blazauskas, T.; Maskeliunas, R.; Damasevicius, R.; Wei, W. Removal of Movement Artefact for Mobile EEG Analysis in Sports Exercises. IEEE Access 2019, 7, 7206–7217. [Google Scholar] [CrossRef]
- Damaševičius, R.; Maskeliūnas, R.; Kazanavičius, E.; Woźniak, M. Combining Cryptography with EEG Biometrics. Comput. Intell. Neurosci. 2018, 2018, 1867548. [Google Scholar] [CrossRef] [Green Version]
- Rodrigues, J.D.C.; Filho, P.P.R.; Damasevicius, R.; de Albuquerque, V.H.C. EEG-based biometric systems. Neurotechnology 2020, 97–153. [Google Scholar] [CrossRef]
- Kumar, J.S.; Bhuvaneswari, P. Analysis of Electroencephalography (EEG) Signals and Its Categorization—A Study. Procedia Eng. 2012, 38, 2525–2536. [Google Scholar] [CrossRef] [Green Version]
- Cudlenco, N.; Popescu, N.; Leordeanu, M. Reading into the mind’s eye: Boosting automatic visual recognition with EEG signals. Neurocomputing 2019, 386, 281–292. [Google Scholar] [CrossRef]
- Bagchi, S.; Bathula, D.R. EEG-ConvTransformer for Single-Trial EEG based Visual Stimuli Classification. arXiv 2021, arXiv:2107.03983. [Google Scholar]
- Prasanna, J.; Subathra, M.S.P.; Mohammed, M.A.; Damaševičius, R.; Sairamya, N.J.; George, S.T. Automated Epileptic Seizure Detection in Pediatric Subjects of CHB-MIT EEG Database—A Survey. J. Pers. Med. 2021, 11, 1028. [Google Scholar] [CrossRef]
- Remington, L.A. Chapter 13: The Visual Pathway. In Clinical Anatomy and Physiology of the Visual System; Elsevier: Amsterdam, The Netherlands, 2012; pp. 233–252. [Google Scholar] [CrossRef]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 31005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muukkonen, I.; Ölander, K.; Numminen, J.; Salmela, V. Spatio-temporal dynamics of face perception. NeuroImage 2020, 209, 116531. [Google Scholar] [CrossRef]
- Chen, L.-C.; Sandmann, P.; Thorne, J.D.; Herrmann, C.; Debener, S. Association of Concurrent fNIRS and EEG Signatures in Response to Auditory and Visual Stimuli. Brain Topogr. 2015, 28, 710–725. [Google Scholar] [CrossRef]
- Luck, S.J.; Woodman, G.F.; Vogel, E.K. Event-related potential studies of attention. Trends Cogn. Sci. 2000, 4, 432–440. [Google Scholar] [CrossRef]
- Cashon, C.H.; Holt, N.A. Developmental Origins of the Face Inversion Effect. In Advances in Child Development and Behavior; Elsevier: Amsterdam, The Netherlands, 2015; Volume 48, pp. 117–150. [Google Scholar] [CrossRef]
- Rossion, B.; Gauthier, I. How Does the Brain Process Upright and Inverted Faces? Behav. Cogn. Neurosci. Rev. 2002, 1, 63–75. [Google Scholar] [CrossRef]
- Jacques, C.; Jonas, J.; Maillard, L.; Colnat-Coulbois, S.; Koessler, L.; Rossion, B. The inferior occipital gyrus is a major cortical source of the face-evoked N170: Evidence from simultaneous scalp and intracerebral human recordings. Hum. Brain Mapp. 2018, 40, 1403–1418. [Google Scholar] [CrossRef] [Green Version]
- Sommer, W.; Stapor, K.; Kończak, G.; Kotowski, K.; Fabian, P.; Ochab, J.; Bereś, A.; Ślusarczyk, G. The N250 event-related potential as an index of face familiarity: A replication study. R. Soc. Open Sci. 2021, 8, 202356. [Google Scholar] [CrossRef]
- Pourtois, G.; Vuilleumier, P. Modulation of face processing by emotional expression during intracranial recordings in right fusiform cortex and amygdala. Int. J. Psychophysiol. 2010, 77, 234. [Google Scholar] [CrossRef]
- Mukhtar, H.; Qaisar, S.M.; Zaguia, A. Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals. Sensors 2021, 21, 5456. [Google Scholar] [CrossRef] [PubMed]
- Perrottelli, A.; Giordano, G.M.; Brando, F.; Giuliani, L.; Mucci, A. EEG-Based Measures in At-Risk Mental State and Early Stages of Schizophrenia: A Systematic Review. Front. Psychiatry 2021, 12, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Fadel, W.; Kollod, C.; Wahdow, M.; Ibrahim, Y.; Ulbert, I. Multi-Class Classification of Motor Imagery EEG Signals Using Image-Based Deep Recurrent Convolutional Neural Network. In Proceedings of the 8th International Winter Conference on Brain-Computer Interface, BCI, Gangwon, Korea, 26–28 February 2020; pp. 2–5. [Google Scholar] [CrossRef]
- Huggins, C.J.; Escudero, J.; Parra, M.A.; Scally, B.; Anghinah, R.; De Araújo, A.V.L.; Basile, L.F.; Abasolo, D. Deep learning of resting-state electroencephalogram signals for three-class classification of Alzheimer’s disease, mild cognitive impairment and healthy ageing. J. Neural Eng. 2021, 18, 046087. [Google Scholar] [CrossRef] [PubMed]
- Mathur, N.; Gupta, A.; Jaswal, S.; Verma, R. Deep learning helps EEG signals predict different stages of visual processing in the human brain. Biomed. Signal Process. Control. 2021, 70, 102996. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [Green Version]
- Truong, D.; Milham, M.; Makeig, S.; Delorme, A. Deep Convolutional Neural Network Applied to Electroencephalography: Raw Data vs. Spectral Features. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 31 October–4 November 2021; pp. 2–5. [Google Scholar] [CrossRef]
- Mammone, N.; Ieracitano, C.; Morabito, F.C. A deep CNN approach to decode motor preparation of upper limbs from time–frequency maps of EEG signals at source level. Neural Networks 2020, 124, 357–372. [Google Scholar] [CrossRef]
- Fu, B.; Li, F.; Niu, Y.; Wu, H.; Li, Y.; Shi, G. Conditional generative adversarial network for EEG-based emotion fine-grained estimation and visualization. J. Vis. Commun. Image Represent. 2020, 74, 102982. [Google Scholar] [CrossRef]
- Luo, T.-J.; Fan, Y.; Chen, L.; Guo, G.; Zhou, C. EEG Signal Reconstruction Using a Generative Adversarial Network with Wasserstein Distance and Temporal-Spatial-Frequency Loss. Front. Neuroinformatics 2020, 14, 15. [Google Scholar] [CrossRef]
- Luo, Y.; Lu, B.-L. EEG Data Augmentation for Emotion Recognition Using a Conditional Wasserstein GAN. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2018, 2018, 2535–2538. [Google Scholar] [CrossRef]
- Bhat, S.; Hortal, E. GAN-Based Data Augmentation for Improving the Classification of EEG Signals. In Proceedings of the 14th PErvasive Technologies Related to Assistive Environments Conference. PETRA’ 21: The 14th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 29 June–2 July 2021; ACM: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Battaglia, S.; Garofalo, S.; Di Pellegrino, G. Context-dependent extinction of threat memories: Influences of healthy aging. Sci. Rep. 2018, 8, 12592. [Google Scholar] [CrossRef]
- Török, N.; Tanaka, M.; Vécsei, L. Searching for Peripheral Biomarkers in Neurodegenerative Diseases: The Tryptophan-Kynurenine Metabolic Pathway. Int. J. Mol. Sci. 2020, 21, 9338. [Google Scholar] [CrossRef] [PubMed]
- Garofalo, S.; Timmermann, C.; Battaglia, S.; Maier, M.E.; di Pellegrino, G. Mediofrontal Negativity Signals Unexpected Timing of Salient Outcomes. J. Cogn. Neurosci. 2017, 29, 718–727. [Google Scholar] [CrossRef] [PubMed]
- Sreeja, S.; Rabha, J.; Nagarjuna, K.Y.; Samanta, D.; Mitra, P.; Sarma, M. Motor Imagery EEG Signal Processing and Classification Using Machine Learning Approach. In Proceedings of the 2017 International Conference on New Trends in Computing Sciences, ICTCS, Amman, Jordan, 11–13 October 2017; Volume 2018-January, pp. 61–66. [Google Scholar] [CrossRef]
- Lu, N.; Li, T.; Ren, X.; Miao, H. A Deep Learning Scheme for Motor Imagery Classification based on Restricted Boltzmann Machines. IEEE Trans. Neural Syst. Rehabilitation Eng. 2016, 25, 566–576. [Google Scholar] [CrossRef]
- Isa, N.E.M.; Amir, A.; Ilyas, M.Z.; Razalli, M.S. Motor imagery classification in Brain computer interface (BCI) based on EEG signal by using machine learning technique. Bull. Electr. Eng. Informatics 2019, 8, 269–275. [Google Scholar] [CrossRef]
- Amin, S.U.; Alsulaiman, M.; Muhammad, G.; Mekhtiche, M.A.; Hossain, M.S. Deep Learning for EEG motor imagery classification based on multi-layer CNNs feature fusion. Futur. Gener. Comput. Syst. 2019, 101, 542–554. [Google Scholar] [CrossRef]
- Wang, X.; Hersche, M.; Tomekce, B.; Kaya, B.; Magno, M.; Benini, L. An Accurate EEGNet-based Motor-Imagery Brain-Computer Interface for Low-Power Edge Computing. In Proceedings of the 2020 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Bari, Italy, 1 June–1 July 2020. [Google Scholar] [CrossRef]
- Zarief, C.N.; Hussein, W. Decoding the Human Brain Activity and Predicting the Visual Stimuli from Magnetoencephalography (MEG) Recordings. In Proceedings of the 2019 International Conference on Intelligent Medicine and Image Processing, Bali Indonesia, 19–22 April 2019; pp. 35–42. [Google Scholar] [CrossRef]
- List, A.; Rosenberg, M.; Sherman, A.; Esterman, M. Pattern classification of EEG signals reveals perceptual and attentional states. PLoS ONE 2017, 12, e0176349. [Google Scholar] [CrossRef]
- Moulson, M.C.; Balas, B.; Nelson, C.; Sinha, P. EEG correlates of categorical and graded face perception. Neuropsychologia 2011, 49, 3847–3853. [Google Scholar] [CrossRef]
- McFarland, D.J.; Parvaz, M.A.; Sarnacki, W.A.; Goldstein, R.Z.; Wolpaw, J. Prediction of subjective ratings of emotional pictures by EEG features. J. Neural Eng. 2016, 14, 16009. [Google Scholar] [CrossRef]
- Gunawan, A.A.S.; Surya, K. Meiliana Brainwave Classification of Visual Stimuli Based on Low Cost EEG Spectrogram Using DenseNet. Procedia Comput. Sci. 2018, 135, 128–139. [Google Scholar] [CrossRef]
- Canales-Johnson, A.; Lanfranco, R.C.; Morales, J.P.; Martínez-Pernía, D.; Valdés, J.; Ezquerro-Nassar, A.; Rivera-Rei, Á.; Ibanez, A.; Chennu, S.; Bekinschtein, T.A.; et al. In your phase: Neural phase synchronisation underlies visual imagery of faces. Sci. Rep. 2021, 11, 2401. [Google Scholar] [CrossRef] [PubMed]
- Jo, S.-Y.; Jeong, J.-W. Prediction of Visual Memorability with EEG Signals: A Comparative Study. Sensors 2020, 20, 2694. [Google Scholar] [CrossRef] [PubMed]
- Spampinato, C.; Palazzo, S.; Kavasidis, I.; Giordano, D.; Souly, N.; Shah, M. Deep learning human mind for automated visual classification. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 4503–4511. [Google Scholar] [CrossRef] [Green Version]
- Prabhu, S.; Murugan, G.; Cary, M.; Arulperumjothi, M.; Liu, J.-B. EEGNet: A Compact Convolutional NN for EEG-based BCI. On certain distance and degree based topological indices of Zeolite LTA frameworks. Mater. Res. Express 2020, 7, 055006. [Google Scholar] [CrossRef] [Green Version]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raza, H.; Chowdhury, A.; Bhattacharyya, S.; Samothrakis, S. Single-Trial EEG Classification with EEGNet and Neural Structured Learning for Improving BCI Performance. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Aznan, N.K.N.; Atapour-Abarghouei, A.; Bonner, S.; Connolly, J.D.; Al Moubayed, N.; Breckon, T.P. Simulating Brain Signals: Creating Synthetic EEG Data via Neural-Based Generative Models for Improved SSVEP Classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef] [Green Version]
- Waytowich, N.R.; Lawhern, V.J.; Garcia, J.O.; Cummings, J.; Faller, J.; Sajda, P.; Vettel, J.M. Compact convolutional neural networks for classification of asynchronous steady-state visual evoked potentials. J. Neural Eng. 2018, 15, 066031. [Google Scholar] [CrossRef]
- Zhang, K.; Xu, G.; Han, Z.; Ma, K.; Zheng, X.; Chen, L.; Duan, N.; Zhang, S. Data Augmentation for Motor Imagery Signal Classification Based on a Hybrid Neural Network. Sensors 2020, 20, 4485. [Google Scholar] [CrossRef]
- He, C.; Liu, J.; Zhu, Y.; Du, W. Data Augmentation for Deep Neural Networks Model in EEG Classification Task: A Review. Front. Hum. Neurosci. 2021, 15, 15. [Google Scholar] [CrossRef]
- Mazzi, C.; Massironi, G.; Sanchez-Lopez, J.; de Togni, L.; Savazzi, S. Face Recognition Deficits in a Patient with Alzheimer’s Disease: Amnesia or Agnosia? 2020. Available online: https://figshare.com/articles/dataset/Face_recognition_deficits_in_a_patient_with_Alzheimer_s_disease_amnesia_or_agnosia_/11913243/1 (accessed on 16 December 2020).
- Chowdhury, M.; Dutta, A.; Robison, M.; Blais, C.; Brewer, G.; Bliss, D. Deep Neural Network for Visual Stimulus-Based Reaction Time Estimation Using the Periodogram of Single-Trial EEG. Sensors 2020, 20, 6090. [Google Scholar] [CrossRef]
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Hramov, A.E.; Maksimenko, V.; Koronovskii, A.; Runnova, A.E.; Zhuravlev, M.; Pisarchik, A.N.; Kurths, J. Percept-related EEG classification using machine learning approach and features of functional brain connectivity. Chaos: Interdiscip. J. Nonlinear Sci. 2019, 29, 093110. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Keskar, N.S.; Nocedal, J.; Tang, P.T.P.; Mudigere, D.; Smelyanskiy, M. On large-batch training for deep learning: Generalization gap and sharp minima. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017; pp. 1–16. [Google Scholar]
- Aznan, N.K.N.; Bonner, S.; Connolly, J.; Al Moubayed, N.; Breckon, T. On the Classification of SSVEP-Based Dry-EEG Signals via Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Systems, Man and Cybernetics, SMC, Miyazaki, Japan, 7–10 October 2018; pp. 3726–3731. [Google Scholar] [CrossRef] [Green Version]
- Battaglia, S.; Serio, G.; Scarpazza, C.; D’Ausilio, A.; Borgomaneri, S. Frozen in (e)motion: How reactive motor inhibition is influenced by the emotional content of stimuli in healthy and psychiatric populations. Behav. Res. Ther. 2021, 146, 103963. [Google Scholar] [CrossRef] [PubMed]
- Borgomaneri, S.; Vitale, F.; Battaglia, S.; Avenanti, A. Early Right Motor Cortex Response to Happy and Fearful Facial Expressions: A TMS Motor-Evoked Potential Study. Brain Sci. 2021, 11, 1203. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Method | Visual Stimulus Types | Accuracy |
|---|---|---|---|
| Yang et al. [5] | RNN with data augmentation by randomly averaging | contraction/expansion/rotation/translation | 73.72%, 61.74% (without augmentation) |
| Mishra and Bhavsar [7] | Siamese network | Object/Digits/Characters | 77.9%/76.2%/74.8% |
| Cudlenco et al. [13] | Gabor filtering with Ridge Regression | Flowers/Airplanes/Cars/Park/Seaside/Old town | 66.76% |
| Bagchi and Bathula [14] | EEG-ConvTranformer network | Human face/other 11 classes | 78.37% |
| Spampinato et al. [53] | Recurrent Neural Networks (RNN) | 40 objects from ImageNet | 83% |
| List et al. [47] | Multivariate pattern classification analysis | Inverted/upright face | Less than 65% |
| Gunawan et al. [50] | DenseNet | Valence/arousal emotion types | 60.55% |
| Layer | Type | Filters | Size | Pad | Activation | Options |
|---|---|---|---|---|---|---|
| Input | input = (C, T) | |||||
| 1 | Conv2D | (1, T/2) | same | none | ||
| Batch Normalization | ||||||
| 2 | DepthwiseConv2D | (C, 1) | valid | ELU | bias = False, depth multiplier = D, depth wise constraint = max norm (1.) | |
| Batch Normalization | ||||||
| AveragePooling2D | (1, 4) | valid | ||||
| Dropout | rate = 0.5 | |||||
| 3 | SeparableConv2D | (1, 16) | same | ELU | bias = False | |
| Batch Normalization | ||||||
| AveragePooling2D | (1, 8) | valid | ||||
| Dropout | rate = 0.5 | |||||
| 4 | Flatten | |||||
| Classifier | Dense | N | SoftMax | kernel constraint = max norm (0.25) | ||
| Layer | Type | Filters | Size | Pad | Activation | Options |
|---|---|---|---|---|---|---|
| Input | input = (C, T) | |||||
| 1 | Conv2D | 25 | TC | valid | none | kernel constraint = max norm (2) |
| Conv2D | 25 | (C, 1) | valid | ELU | kernel constraint = max norm (2) | |
| Batch Normalization | epsilon = 1e-05 momentum = 0.1 | |||||
| MaxPooling2D | (1, 2) | valid | Strides = (1, 2) | |||
| Dropout | ||||||
| 2 | Conv2D | 50 | TC | valid | ELU | kernel constraint = max norm (2) |
| Batch Normalization | epsilon = 1e-05 momentum = 0.1 | |||||
| MaxPooling2D | (1, 2) | valid | strides = (1, 2) | |||
| Dropout | rate = 0.5 | |||||
| 3 | Conv2D | 100 | TC | valid | ELU | kernel constraint = max norm (2) |
| Batch Normalization | epsilon = 1e-05 momentum = 0.1 | |||||
| MaxPooling2D | (1, 2) | valid | strides = (1, 2) | |||
| Dropout | rate = 0.5 | |||||
| 4 | Conv2D | 200 | TC | valid | ELU | kernel constraint = max norm (2) |
| Batch Normalization | epsilon = 1e-05 momentum = 0.1 | |||||
| MaxPooling2D | (1, 2) | valid | strides = (1, 2) | |||
| Dropout | rate = 0.5 | |||||
| 5 | Flatten | |||||
| Classifier | Dense | N | SoftMax | kernel constraint = max norm (0.5) | ||
| Experiment 2 | Experiment 3 | ||
|---|---|---|---|
| Neutral | Fearful | Famous | Not famous |
 |  |  |  |
 |  |  |  |
| Hyperparameter | Value | Model Parameter | Value |
|---|---|---|---|
| Epochs | 1000 | Kernel Size | 5 |
| Batch Size | 32 | Filters | 16 |
| Learning Rate | 0.0001 | Latent Dimension | 2 |
| Early Stopping Epochs | 25 | Optimizer | Adam |
| Dataset Name | Class Name | Training Time (s) | Validation Loss | Test Loss | Train Size | Val Size | Test Size |
|---|---|---|---|---|---|---|---|
| Emotion & view | fear/upright | 1692.661 | 121.497 | 121.501 | 534 | 134 | 168 |
| fear/upsidedown | 2405.592 | 114.304 | 116.231 | ||||
| neutral/upright | 2442.686 | 114.250 | 115.465 | ||||
| neutral/upsidedown | 2727.987 | 116.240 | 115.464 | ||||
| Familiarity & view | famous/upright | 2156.230 | 117.403 | 121.848 | 633 | 159 | 199 |
| famous/upsidedown | 1541.902 | 116.805 | 121.415 | ||||
| unfamous/upright | 2129.097 | 114.976 | 118.807 | ||||
| unfamous/upsidedown | 3177.764 | 112.945 | 117.052 |
| Hyperparameter | Value |
| Epochs | 500 |
| Batch Size | 64 |
| Learning Rate | 0.001 |
| Early Stopping Epochs | 20 |
| Other settings | Value |
| Optimizer | Adam |
| Stimuli | Model | Run Time (s) | Test Acc | Test Loss | Val Acc | Val Loss | Number of Training Data | Number of Testing Data |
|---|---|---|---|---|---|---|---|---|
| Familiarity & view | DeepConvNet | 82.79 | 1 | 0.001 | 1 | 0 | 1400 | 600 |
| EEGNet | 203.39 | 0.985 | 0.055 | 0.994 | 0.053 | 1400 | 600 | |
| EEGNet SSVEP | 756.52 | 0.995 | 0.009 | 1 | 0.001 | 1400 | 600 | |
| EEGNet SSVEP regularization | 1523.41 | 1 | 0.017 | 1 | 0.015 | 1400 | 600 | |
| Emotion & view | DeepConvNet | 38.59 | 1 | 0.002 | 0.938 | 0.129 | 1400 | 600 |
| EEGNet | 134.89 | 1 | 0.026 | 0.998 | 0.028 | 1400 | 600 | |
| EEGNet SSVEP | 869.69 | 1 | 0.001 | 0.998 | 0.029 | 1400 | 600 | |
| EEGNet SSVEP regularization | 1304.23 | 1 | 0.015 | 1 | 0.016 | 1400 | 600 |
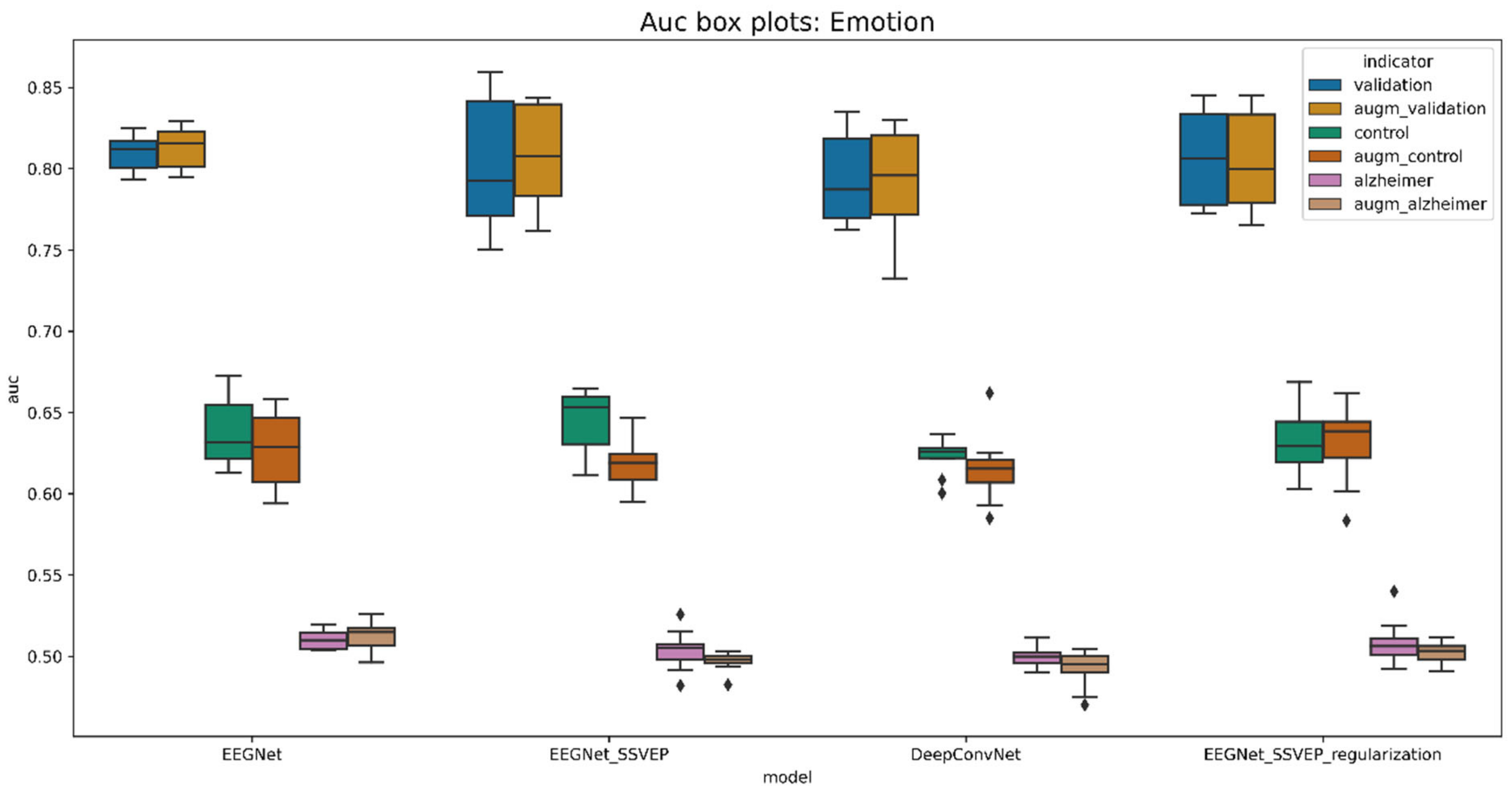
| Model | Validation_Acc | Control_Acc | Alzheimer_Acc | Validation_Auc | Control_Auc | Alzheimer_Auc |
|---|---|---|---|---|---|---|
| DeepConvNet | 0.378101 | 0.285379 | 0.275349 | 0.664231 | 0.530101 | 0.522043 |
| EEGNet | 0.416943 | 0.281388 | 0.272739 | 0.716867 | 0.526350 | 0.524505 |
| EEGNet_SSVEP | 0.428111 | 0.286462 | 0.263488 | 0.714708 | 0.543223 | 0.521810 |
| EEGNet_SSVEP_regularization | 0.434761 | 0.291155 | 0.279767 | 0.720801 | 0.551422 | 0.531294 |
| augmented_DeepConvNet | 0.414258 | 0.277798 | 0.271860 | 0.709143 | 0.533561 | 0.513521 |
| augmented_EEGNet | 0.435262 | 0.267870 | 0.273721 | 0.737287 | 0.513374 | 0.518509 |
| augmented_EEGNet_SSVEP | 0.439497 | 0.280686 | 0.279302 | 0.730503 | 0.536170 | 0.525493 |
| augmented_EEGNet_SSVEP_regularization | 0.432493 | 0.302347 | 0.277209 | 0.722147 | 0.552888 | 0.522122 |
| Model | Validation_Acc | Control_Acc | Alzheimer_Acc | Validation_Auc | Control_Auc | Alzheimer_Auc |
|---|---|---|---|---|---|---|
| DeepConvNet | 0.471126 | 0.317345 | 0.243897 | 0.793737 | 0.623122 | 0.499631 |
| EEGNet | 0.476327 | 0.312848 | 0.253756 | 0.809606 | 0.638286 | 0.510020 |
| EEGNet.SSVEP | 0.486617 | 0.332120 | 0.244131 | 0.802357 | 0.644521 | 0.503745 |
| EEGNet_SSVEP_regularization | 0.498247 | 0.329336 | 0.255634 | 0.806665 | 0.633405 | 0.508321 |
| augmented_DeepConvNet | 0.472622 | 0.314347 | 0.251643 | 0.793103 | 0.615264 | 0.492476 |
| augmented_EEGNet | 0.479862 | 0.311563 | 0.252582 | 0.812790 | 0.627414 | 0.512293 |
| augmented_EEGNet_SSVEP | 0.497408 | 0.315632 | 0.239437 | 0.807479 | 0.619471 | 0.496971 |
| augmented_EEGNet_SSVEP_regularization | 0.501958 | 0.327445 | 0.244131 | 0.804156 | 0.631282 | 0.501964 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komolovaitė, D.; Maskeliūnas, R.; Damaševičius, R. Deep Convolutional Neural Network-Based Visual Stimuli Classification Using Electroencephalography Signals of Healthy and Alzheimer’s Disease Subjects. Life 2022, 12, 374. https://doi.org/10.3390/life12030374
Komolovaitė D, Maskeliūnas R, Damaševičius R. Deep Convolutional Neural Network-Based Visual Stimuli Classification Using Electroencephalography Signals of Healthy and Alzheimer’s Disease Subjects. Life. 2022; 12(3):374. https://doi.org/10.3390/life12030374
Chicago/Turabian StyleKomolovaitė, Dovilė, Rytis Maskeliūnas, and Robertas Damaševičius. 2022. "Deep Convolutional Neural Network-Based Visual Stimuli Classification Using Electroencephalography Signals of Healthy and Alzheimer’s Disease Subjects" Life 12, no. 3: 374. https://doi.org/10.3390/life12030374
APA StyleKomolovaitė, D., Maskeliūnas, R., & Damaševičius, R. (2022). Deep Convolutional Neural Network-Based Visual Stimuli Classification Using Electroencephalography Signals of Healthy and Alzheimer’s Disease Subjects. Life, 12(3), 374. https://doi.org/10.3390/life12030374