A Cost-Effective Person-Following System for Assistive Unmanned Vehicles with Deep Learning at the Edge





Abstract
1. Introduction
2. Related Works
2.1. Person Following
- -
- Eliminating the tracking part and relating an additional filter thanks to the continuous detection of the target, so reducing the computational complexity of the solution;
- -
- Running the detection at the edge, so it can be easily realized on the neural board accelerator, without adding an expensive onboard computer (low-cost).
2.2. Deep Learning for Real-Time Object Detection
3. Materials and Data
3.1. Data Description
3.2. Hardware Description
4. Proposed Methodology
| Algorithm 1 Person-following using an RGB-D camera and YOLOv3-tiny network. |
| 1: Inputs: |
| : Depth Matrix obtained from the camera |
| : Horizontal coordinate of the center of the bounding box |
| : Vertical coordinate of the center of the bounding box |
| : Horizontal coordinate of the center of the camera frame |
| : Number of the detections provided by the network |
| 2: Initialize: |
| 3: while True do |
| 4: if ( == 0) then |
| 5: |
| 6: |
| 7: if then |
| 8: reset: |
| 9: |
| 10: |
| 11: end if |
| 12: else if ( == 1) then |
| 13: |
| 14: |
| 15: |
| 16: |
| 17: reset: |
| 18: else |
| 19: if |
| 20: reset: |
| 21: |
| 22: |
| 23: |
| 24: end if |
| 25: reset: |
| 26: end if |
| 27: , |
| 28: if ( == 1) then |
| 29: stop the algorithm for a prefixed time |
| 30: reset: , |
| 31: end if |
| 32: |
| 33: acquire next Inputs |
| 34:end while |
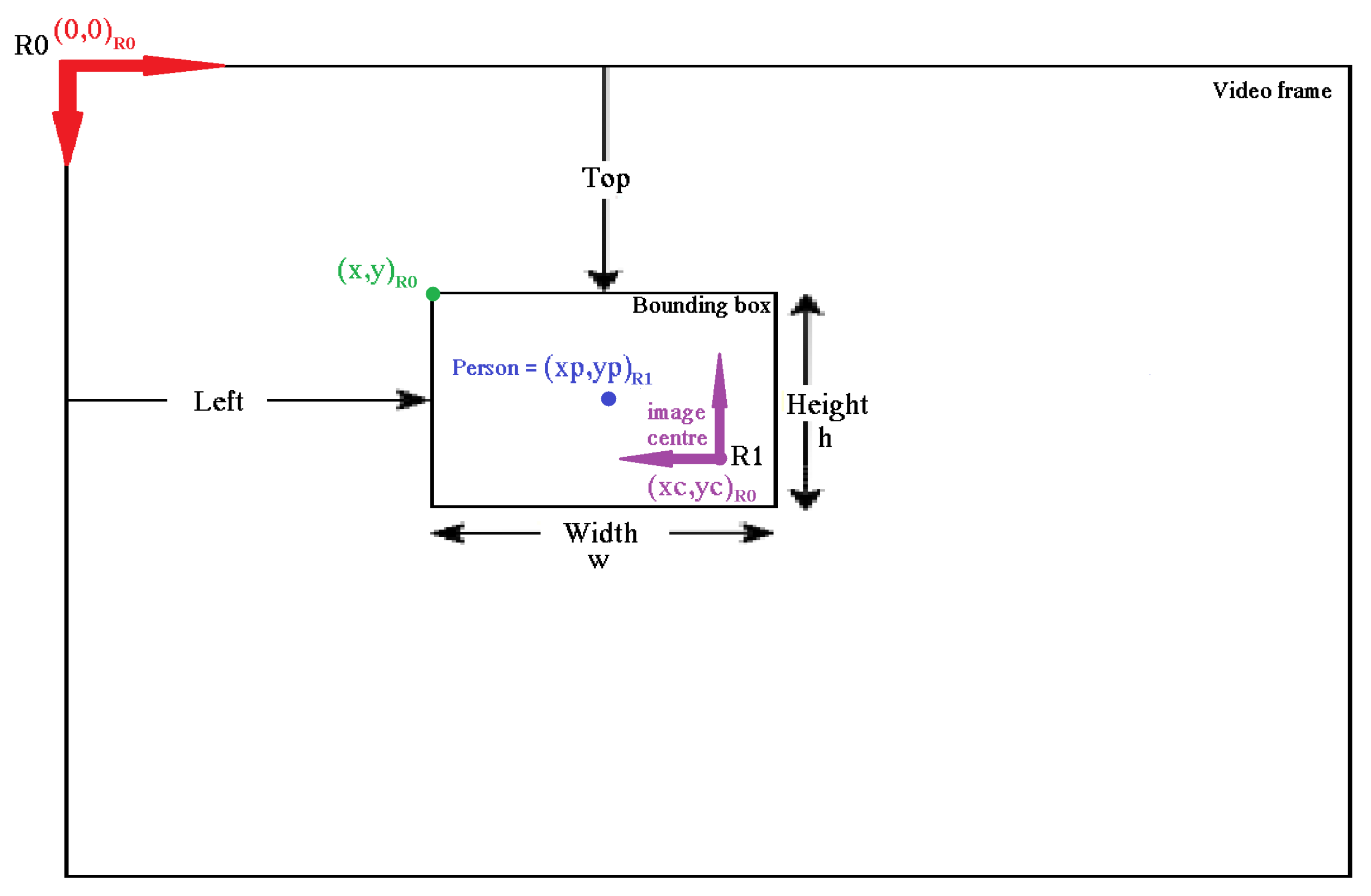
4.1. Person Localization
- The input image is processed with a grid cell as a reference frame.
- Each grid cell generates bounding boxes and predicts their confidence rate. The confidence rate depends on the accuracy of the network during the detection.
- Each grid cell has a probability score for each class. The number of classes depends on the dataset used during the training process of the network.
- The total number of bounding boxes is minimized by setting a minimum confidence rate and using the non-maximum suppression (NMS) algorithm to obtain the final predictions that can be used to generate the final output: an input image with the bounding boxes over the detected objects with the reference classes and the accuracy percentages.
4.1.1. Person Detection and Localization Implementation
4.1.2. Detection Situation Rules
- Nothing detected: If nothing is detected, the robot stops. Differently, suppose the robot loses the person it is following. In that case, it continues to move in the direction of the last detection with the previous velocity commands for a pre-imposed time t. After that, if nothing is detected again, the robot stops.
- One person detected: The robot follows the movement of the person while remaining at a certain safe distance from him.
- More than one person simultaneously detected: The robot stops for a prefixed time and then it restarts the normal detection operation. There could be many other solutions to implement, for example, a person tracking algorithm to follow one of the people detected [55,56,57]. In particular, the presence of a tracking algorithm or an additional filter will have to be considered if the use case is changed—for example, in case this approach will be used in an office environment.
4.2. Person-Following Control Algorithm
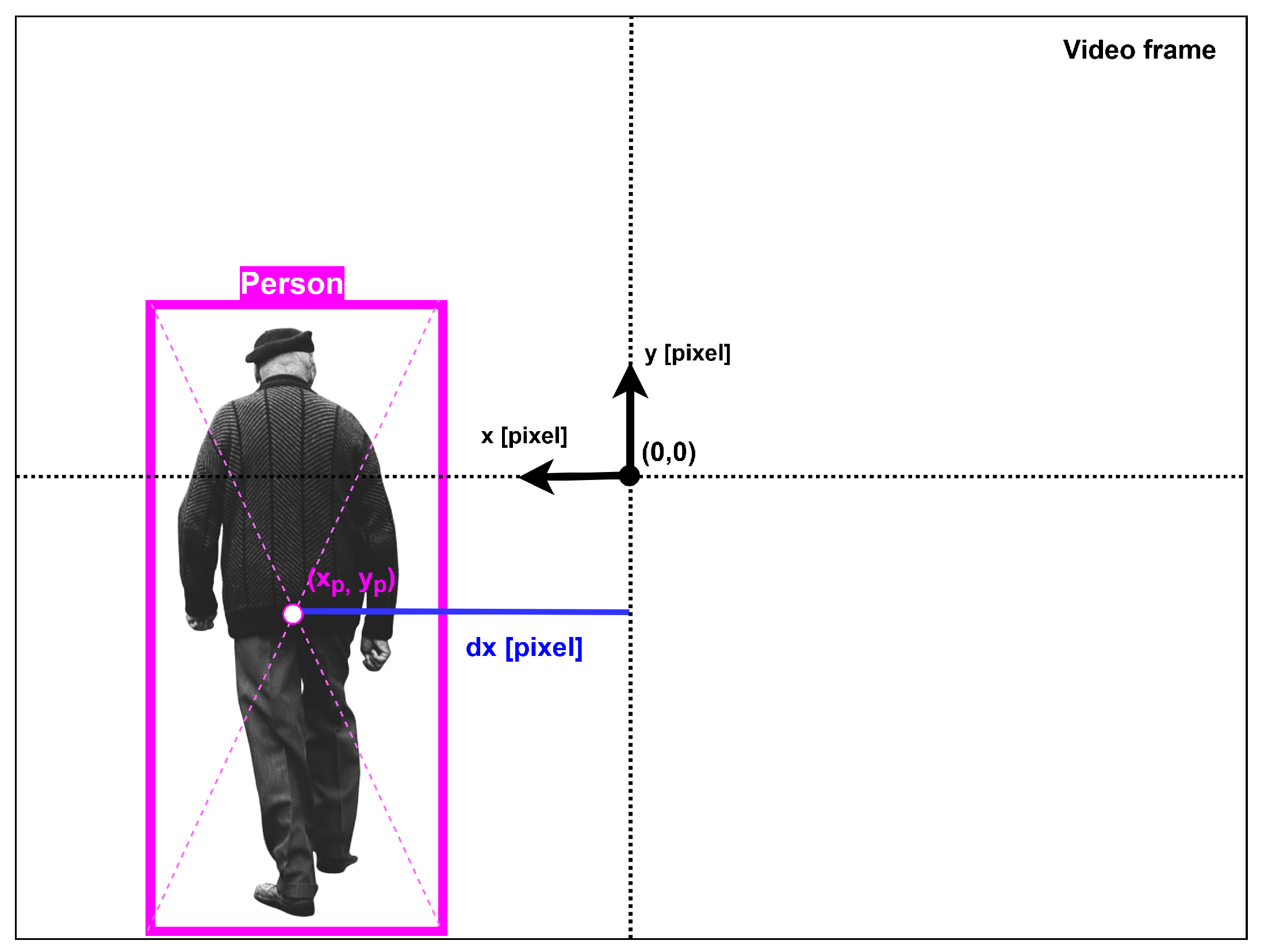
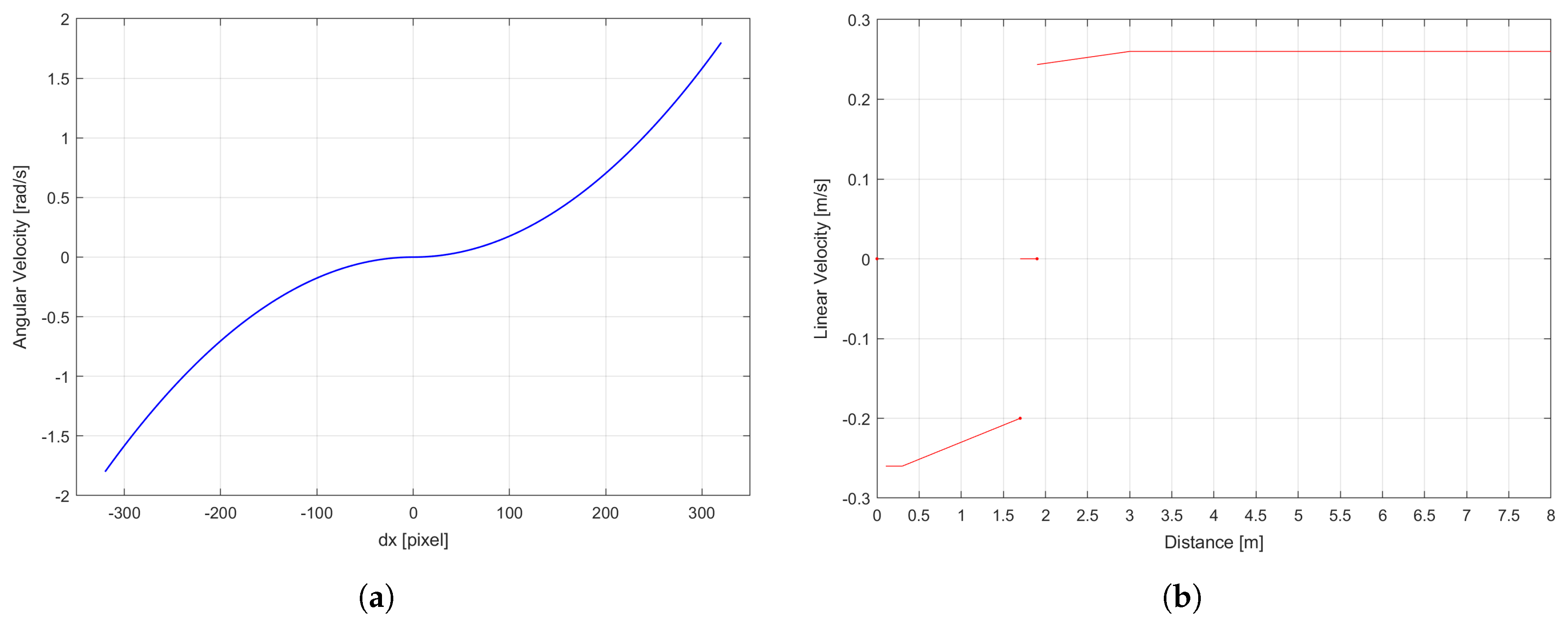
4.2.1. Angular Velocity Control
4.2.2. Linear Velocity Control
5. Experimental Discussion and Results
5.1. Person Detector Training and Optimization
5.2. Inference with Edge AI Accelerators
5.3. Platform Implementation
- -
- The optimal distance limits able to define the three areas of the linear velocity control are defined as = 1.7 m and = 1.9 m. In the range between these two values the robot is in the safe distance zone, so it can only rotate because the linear velocity stays at zero, in order to avoid the generation of any dangerous situations for the target person.
- -
- The best linear increment is computed during both the forward and backward movements of the robot.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Islam, M.J.; Hong, J.; Sattar, J. Person-following by autonomous robots: A categorical overview. Int. J. Robot. Res. 2019, 38, 1581–1618. [Google Scholar] [CrossRef]
- World Population Ageing 2019 (ST/ESA/SER.A/444); Population Division, Department of Economic and Social Affairs, United Nations: New York, NY, USA, 2020.
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Pucci, D.; Marchetti, L.; Morin, P. Nonlinear control of unicycle-like robots for person following. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3406–3411. [Google Scholar]
- Chung, W.; Kim, H.; Yoo, Y.; Moon, C.B.; Park, J. The detection and following of human legs through inductive approaches for a mobile robot with a single laser range finder. IEEE Trans. Ind. Electron. 2011, 59, 3156–3166. [Google Scholar] [CrossRef]
- Morales Saiki, L.Y.; Satake, S.; Huq, R.; Glas, D.; Kanda, T.; Hagita, N. How do people walk side-by-side? Using a computational model of human behavior for a social robot. In Proceedings of the Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction, Boston, MA, USA, 5–8 March 2012; pp. 301–308. [Google Scholar]
- Cosgun, A.; Florencio, D.A.; Christensen, H.I. Autonomous person following for telepresence robots. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 4335–4342. [Google Scholar]
- Leigh, A.; Pineau, J.; Olmedo, N.; Zhang, H. Person tracking and following with 2d laser scanners. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 726–733. [Google Scholar]
- Adiwahono, A.H.; Saputra, V.B.; Ng, K.P.; Gao, W.; Ren, Q.; Tan, B.H.; Chang, T. Human tracking and following in dynamic environment for service robots. In Proceedings of the TENCON 2017–2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 3068–3073. [Google Scholar]
- Cen, M.; Huang, Y.; Zhong, X.; Peng, X.; Zou, C. Real-time Obstacle Avoidance and Person Following Based on Adaptive Window Approach. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; pp. 64–69. [Google Scholar]
- Jung, E.J.; Yi, B.J.; Yuta, S. Control algorithms for a mobile robot tracking a human in front. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 2411–2416. [Google Scholar]
- Cai, J.; Matsumaru, T. Human detecting and following mobile robot using a laser range sensor. J. Robot. Mechatron. 2014, 26, 718–734. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J. Identification of a specific person using color, height, and gait features for a person following robot. Robot Auton. Syst. 2016, 84, 76–87. [Google Scholar] [CrossRef]
- Brookshire, J. Person following using histograms of oriented gradients. Int. J. Soc. Robot. 2010, 2, 137–146. [Google Scholar] [CrossRef]
- Satake, J.; Chiba, M.; Miura, J. A SIFT-based person identification using a distance-dependent appearance model for a person following robot. In Proceedings of the 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; pp. 962–967. [Google Scholar]
- Satake, J.; Chiba, M.; Miura, J. Visual person identification using a distance-dependent appearance model for a person following robot. Int. J. Autom. Comput. 2013, 10, 438–446. [Google Scholar] [CrossRef]
- Chen, B.X.; Sahdev, R.; Tsotsos, J.K. Integrating stereo vision with a CNN tracker for a person-following robot. In International Conference on Computer Vision Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 300–313. [Google Scholar]
- Chen, B.X.; Sahdev, R.; Tsotsos, J.K. Person following robot using selected online ada-boosting with stereo camera. In Proceedings of the 2017 14th Conference on Computer and Robot Vision (CRV), Edmonton, AB, Canada, 16–19 May 2017; pp. 48–55. [Google Scholar]
- Wang, X.; Zhang, L.; Wang, D.; Hu, X. Person detection, tracking and following using stereo camera. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–17 October 2017; p. 106150D. [Google Scholar]
- Doisy, G.; Jevtic, A.; Lucet, E.; Edan, Y. Adaptive person-following algorithm based on depth images and mapping. In Proceedings of the IROS Workshop on Robot Motion Planning, Vilamoura, Portugal, 7–12 October 2012. [Google Scholar]
- Basso, F.; Munaro, M.; Michieletto, S.; Pagello, E.; Menegatti, E. Fast and robust multi-people tracking from RGB-D data for a mobile robot. In Intelligent Autonomous Systems 12; Springer: Berlin/Heidelberg, Germany, 2013; pp. 265–276. [Google Scholar]
- Munaro, M.; Basso, F.; Michieletto, S.; Pagello, E.; Menegatti, E. A software architecture for RGB-D people tracking based on ROS framework for a mobile robot. In Frontiers of Intelligent Autonomous Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 53–68. [Google Scholar]
- Do, M.Q.; Lin, C.H. Embedded human-following mobile-robot with an RGB-D camera. In Proceedings of the 2015 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015; pp. 555–558. [Google Scholar]
- Ren, Q.; Zhao, Q.; Qi, H.; Li, L. Real-time target tracking system for person-following robot. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 6160–6165. [Google Scholar]
- Mi, W.; Wang, X.; Ren, P.; Hou, C. A system for an anticipative front human following robot. In Proceedings of the International Conference on Artificial Intelligence and Robotics and the International Conference on Automation, Control and Robotics Engineering, Kitakyushu, Japan, 12–15 July 2016; pp. 1–6. [Google Scholar]
- Gupta, M.; Kumar, S.; Behera, L.; Subramanian, V.K. A novel vision-based tracking algorithm for a human-following mobile robot. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 1415–1427. [Google Scholar] [CrossRef]
- Masuzawa, H.; Miura, J.; Oishi, S. Development of a mobile robot for harvest support in greenhouse horticulture—Person following and mapping. In Proceedings of the 2017 IEEE/SICE International Symposium on System Integration (SII), Taipei, Taiwan, 11–14 December 2017; pp. 541–546. [Google Scholar]
- Chi, W.; Wang, J.; Meng, M.Q.H. A gait recognition method for human following in service robots. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1429–1440. [Google Scholar] [CrossRef]
- Jiang, S.; Yao, W.; Hong, Z.; Li, L.; Su, C.; Kuc, T.Y. A classification-lock tracking strategy allowing a person-following robot to operate in a complicated indoor environment. Sensors 2018, 18, 3903. [Google Scholar] [CrossRef] [PubMed]
- Chen, E. “FOLO”: A Vision-Based Human-Following Robot. In Proceedings of the 2018 3rd International Conference on Automation, Mechanical Control and Computational Engineering (AMCCE 2018), Dalian, China, 12–13 May 2018; Atlantis Press: Beijing, China, 2018. [Google Scholar]
- Yang, C.A.; Song, K.T. Control Design for Robotic Human-Following and Obstacle Avoidance Using an RGB-D Camera. In Proceedings of the 2019 19th International Conference on Control, Automation and Systems (ICCAS), Jeju, Korea, 15–18 October 2019; pp. 934–939. [Google Scholar]
- Alvarez-Santos, V.; Pardo, X.M.; Iglesias, R.; Canedo-Rodriguez, A.; Regueiro, C.V. Feature analysis for human recognition and discrimination: Application to a person-following behaviour in a mobile robot. Robot. Auton. Syst. 2012, 60, 1021–1036. [Google Scholar] [CrossRef]
- Susperregi, L.; Martínez-Otzeta, J.M.; Ansuategui, A.; Ibarguren, A.; Sierra, B. RGB-D, laser and thermal sensor fusion for people following in a mobile robot. Int. J. Adv. Robot. Syst. 2013, 10, 271. [Google Scholar] [CrossRef]
- Wang, M.; Su, D.; Shi, L.; Liu, Y.; Miro, J.V. Real-time 3D human tracking for mobile robots with multisensors. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5081–5087. [Google Scholar]
- Hu, J.S.; Wang, J.J.; Ho, D.M. Design of sensing system and anticipative behavior for human following of mobile robots. IEEE Trans. Ind. Electron. 2013, 61, 1916–1927. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Twenty-Ninth Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Lect. Notes Comput. Sci. 2016, 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Mittal, S. A Survey on optimized implementation of deep learning models on the NVIDIA Jetson platform. J. Syst. Archit. 2019, 97, 428–442. [Google Scholar] [CrossRef]
- Xu, X.; Amaro, J.; Caulfield, S.; Falcao, G.; Moloney, D. Classify 3D voxel based point-cloud using convolutional neural network on a neural compute stick. In Proceedings of the 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 37–43. [Google Scholar]
- Kang, D.; Kang, D.; Kang, J.; Yoo, S.; Ha, S. Joint optimization of speed, accuracy, and energy for embedded image recognition systems. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 715–720. [Google Scholar]
- Cao, S.; Liu, Y.; Lasang, P.; Shen, S. Detecting the objects on the road using modular lightweight network. arXiv 2018, arXiv:1811.06641. [Google Scholar]
- Yang, T.; Ren, Q.; Zhang, F.; Xie, B.; Ren, H.; Li, J.; Zhang, Y. Hybrid camera array-based uav auto-landing on moving ugv in gps-denied environment. Remote Sens. 2018, 10, 1829. [Google Scholar] [CrossRef]
- Mazzia, V.; Khaliq, A.; Salvetti, F.; Chiaberge, M. Real-Time Apple Detection System Using Embedded Systems With Hardware Accelerators: An Edge AI Application. IEEE Access 2020, 8, 9102–9114. [Google Scholar] [CrossRef]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep Transfer Learning with Joint Adaptation Networks. arXiv 2016, arXiv:1605.06636. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Mitzel, D.; Leibe, B. Real-time multi-person tracking with detector assisted structure propagation. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 974–981. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intel NCS | Intel Movidius NCS2 | Coral USB Accelerator | NVIDIA Jetson AGX Xavier Developer Kit | NVIDIA Jetson Nano | |
|---|---|---|---|---|---|
| AI performance | 100 GFLOPs (FP32) | 150 GFLOPs (FP32) | 4 TOPs (INT8) | 32 TOPs (FP32) | 472 GFLOPs (FP32) |
| HW accelerator | Myriad 2 VPU | Myriad X VPU | Google Edge TPU coprocessor | 512-core NVIDIA Volta GPU with 64 Tensor Cores and 2x NVDLA Engines | 128-core NVIDIA Maxwell GPU |
| CPU | N.A. | N.A. | N.A. | 8-core NVIDIA Carmel Arm v8.2 64-bit CPU 8MB L2 + 4MB L3 | Quad-core ARM Cortex-A57 MPCore processor |
| Memory | 4 GB LPDDR3 | 4 GB LPDDR3 | N.A. | 32 GB 256-bit LPDDR4x 136.5 GB/s | 4 GB 64-bit LPDDR4 25.6 GB/s |
| Storage | N.A. | N.A. | N.A. | 32 GB eMMC 5.1 | Micro SD card slot or 16 GB eMMC 5.1 flash |
| Power | 1 W | 1.5 W | 1 W | 10/15/30 W | 5/10 W |
| Size | 73 × 26 mm | 73 × 26 mm | 65 × 30 mm | 100 × 87 mm | 70 × 45 mm |
| Weight | 18 g | 19 g | 20 g | 280 g | 140 g |
| Price | $70 | $74 | $60 | $700 | $99 |
| Layer | Type | Size/Stride | Filters | Output |
|---|---|---|---|---|
| 0 | Convolution | 3 × 3/1 | 16 | 416 × 416 × 16 |
| 1 | MaxPooling | 2 × 2/2 | 208 × 208 × 16 | |
| 2 | Convolution | 3 × 3/1 | 32 | 208 × 208 × 32 |
| 3 | MaxPooling | 2 × 2/2 | 104 × 104 × 32 | |
| 4 | Convolution | 3 × 3/1 | 64 | 104 × 104 × 64 |
| 5 | MaxPooling | 2 × 2/2 | 52 × 52 × 64 | |
| 6 | Convolution | 3 × 3/1 | 128 | 52 × 52 × 128 |
| 7 | MaxPooling | 2 × 2/2 | 26 × 26 × 128 | |
| 8 | Convolution | 3 × 3/1 | 256 | 26 × 26 × 256 |
| 9 | MaxPooling | 2 × 2/2 | 13 × 13 × 256 | |
| 10 | Convolution | 3 × 3/1 | 512 | 13 × 13 × 512 |
| 11 | MaxPooling | 2 × 2/1 | 13 × 13 × 512 | |
| 12 | Convolution | 3 × 3/1 | 1024 | 13 × 13 × 1024 |
| 13 | Convolution | 1 × 1/1 | 256 | 13 × 13 × 256 |
| 14 | Convolution | 3 × 3/1 | 512 | 13 × 13 × 512 |
| 15 | Convolution | 1 × 1/1 | 255 | 13 × 13 × 18 |
| 16 | YOLO | |||
| 17 | Route 13 | |||
| 18 | Convolution | 1 × 1/1 | 128 | 13 × 13 × 128 |
| 19 | Up-sampling | 2 × 2/1 | 26 × 26 × 128 | |
| 20 | Route 19 8 | |||
| 21 | Convolution | 3 × 3/1 | 256 | 26 × 26 × 256 |
| 22 | Convolution | 1 × 1/1 | 255 | 26 × 26 × 18 |
| 23 | YOLO |
| Network | Gain | |
|---|---|---|
| YOLOv3-tiny | 19.21 % | |
| YOLOv3-tiny | 49.30 % | 30.09 % |
| Device | Mode | [V] | [A] | P [W] | fps |
|---|---|---|---|---|---|
| Raspberry Pi 3B+ | IDLE | 5 | 0.61 | 3.075 | N/A |
| RP3 + Neural Stick 1 | RUNNING | 5 | 1.2 | 6 | 4 |
| RP3 + Neural Stick 2 | RUNNING | 5 | 1.12 | 5.6 | 5 |
| Jetson Nano | IDLE 10W | 5 | 0.32 | 1.6 | N/A |
| RUNNING 10W | 5 | 1.96 | 9.8 | 9 | |
| RUNNNING 5W | 5 | 1.4 | 7 | 6 | |
| Jetson AGX Xavier | IDLE 30W | 19 | 0.35 | 6.65 | N/A |
| RUNNING 30W | 19 | 0.91 | 17.29 | 30+ | |
| RUNNING 15W | 19 | 0.82 | 15.58 | 28 | |
| RUNNING 10W | 19 | 0.62 | 11.78 | 15 | |
| RP3 + Coral Accelerator | MAX | 5 | 1.40 | 7 | 30+ * |
| HW Materials | |
|---|---|
| Robotic Platform | TurtleBot3 Waffle Pi |
| Edge AI Device | NVIDIA Jetson AGX Xavier |
| RGB-D camera | Intel RealSense Depth Camera D435i |
| Straight Line | Points |
|---|---|
| : (, ) | (1 m, 0.23 m/s) |
| (3 m, 0.26 m/s) | |
| : (, ) | (1 m, −0.23 m/s) |
| (0.3 m, −0.26 m/s) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boschi, A.; Salvetti, F.; Mazzia, V.; Chiaberge, M. A Cost-Effective Person-Following System for Assistive Unmanned Vehicles with Deep Learning at the Edge. Machines 2020, 8, 49. https://doi.org/10.3390/machines8030049
Boschi A, Salvetti F, Mazzia V, Chiaberge M. A Cost-Effective Person-Following System for Assistive Unmanned Vehicles with Deep Learning at the Edge. Machines. 2020; 8(3):49. https://doi.org/10.3390/machines8030049
Chicago/Turabian StyleBoschi, Anna, Francesco Salvetti, Vittorio Mazzia, and Marcello Chiaberge. 2020. "A Cost-Effective Person-Following System for Assistive Unmanned Vehicles with Deep Learning at the Edge" Machines 8, no. 3: 49. https://doi.org/10.3390/machines8030049
APA StyleBoschi, A., Salvetti, F., Mazzia, V., & Chiaberge, M. (2020). A Cost-Effective Person-Following System for Assistive Unmanned Vehicles with Deep Learning at the Edge. Machines, 8(3), 49. https://doi.org/10.3390/machines8030049