Local Motion Planner for Autonomous Navigation in Vineyards with a RGB-D Camera-Based Algorithm and Deep Learning Synergy




Abstract
1. Introduction
2. Related Works
3. Materials and Data
4. Proposed Methodology
4.1. Continuous Depth Map Control
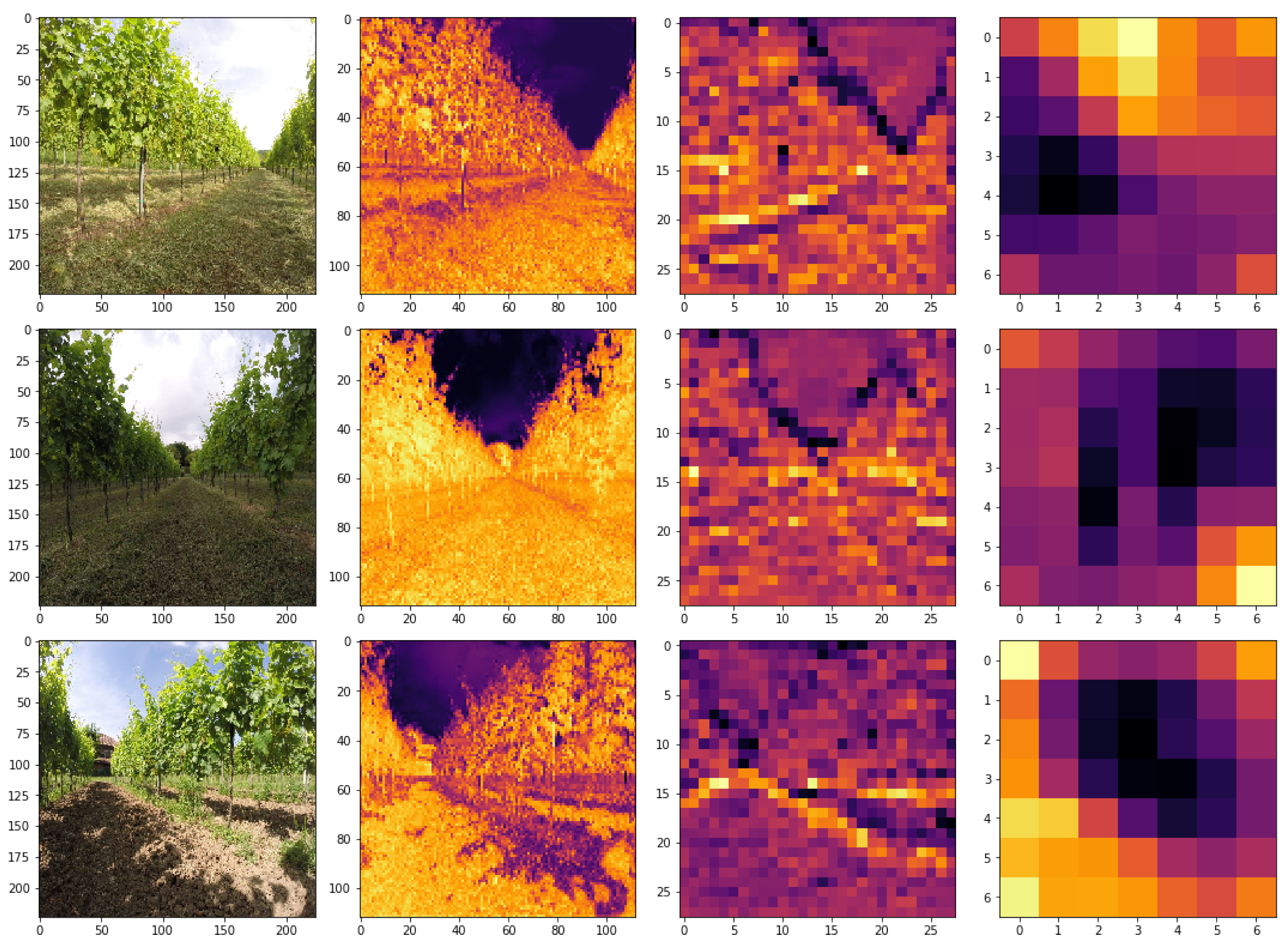
- Matrix normalization: In order to have a solution adaptable to different outdoor scenarios, we need to have a dynamic definition of near field and far-field. Therefore, we employ a dynamic threshold computed proportionally to the maximum acquired depth value. Hence, by normalizing the matrix, we obtain a threshold that changes dynamically depending on the values of the depth map.
- Depth threshold: We apply a threshold on the depth matrix, obtained through a detailed calibration, in order to define which is the near field (represented with a “0”) and the far field (represented with a “1”). At this point the depth matrix is a binary mask.
- Bounding operation: We perform edge detection on the binary image, extrapolating the contours of the white areas, and then, we bound these contours with a rectangle.
- Back-up solution: If no white area is detected or in case the area of the largest rectangle is less than a certain threshold, we activate the back-up model based on machine learning.
- Window selection: On the other hand, if there are multiple detected rectangles, we evaluate only the biggest one in order to get rid of the noise. The threshold value for the area is obtained through a calibration and it is used to avoid false positive detection. In fact, the holes on the sides of the vineyard row can be detected as large areas with all the points beyond the distance threshold, and therefore they can lead to a wrong command computation. To prevent the system from performing an autonomous navigation using an erroneous detection of the end of the vineyard row, we calibrated the threshold to reduce the possibility that this eventuality occurs drastically. From now on, with the term window we will refer to the largest rectangle detected in the processed frame which area is greater than the area threshold.
- Control values: The angular velocity and the linear velocity values are both proportional to the horizontal distance (in pixel) between the center of the detected window and the center of the camera frame and based on a parabolic function. The distance d is computed as:where is the horizontal coordinate of the center of the detected rectangle and is the horizontal coordinate of the center of the frame. Figure 2 shows a graphical representation of the computation of the distance d.The controller value for the angular velocity () is calculated through the following formula:where is the maximum angular velocity achievable and w is the width of the frame.
Algorithm 1 RGB-D camera based algorithm Input:D: Depth Matrix provided by the camera Input:F RGB frame acquired by the camera Input: T threshold on the distance Input: T threshold on the area of the rectangles Input: horizontal coordinate of the center of the camera frame Input: horizontal coordinate of the center of the detected window Output: Control commands for the autonomous navigation 1: D 2: for i = 1,⋯ h and j = 1,⋯ w do 3: if D > T then 4: D = 1 5: else 6: D = 0 7: end if 8: end for 9: cont[] ← contours(D) 10: rect[] ← boundingRect(cont[]) 11: if max(area(rect[]))< T rect[].isEmpty() then 12: continue from line 18 13: else 14: angular_velocity() 15: linear_velocity() 16: acquire next frame and restart from line 1 17: end if 18: I← preprocessing(F) 19: model_prediction(I) 20: ML_controller() As far as the linear velocity () control function is concerned, it is still be a parabola, but this time the lower is the distance d the higher its value gets. Therefore the formula is:where is the maximum linear velocity achievable and w is the width of the frame. Both control characteristics curve are depicted in Figure 3.
4.2. Discrete CNN Control
4.2.1. Network Architecture
4.2.2. Pre-Processing
5. Experimental Discussion and Results
5.1. Dataset Creation
5.2. Model Training
5.3. Machine Learning Model Evaluation and Optimization
5.4. Field Experimentation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- DeSA, U. World Population Prospects: The 2012 Revision; Population Division of the Department of Economic and Social Affairs of the United Nations Secretariat: New York, NY, USA, 2013; Volume 18. [Google Scholar]
- Mulla, D.J. Twenty five years of remote sensing in precision agriculture: Key advances and remaining knowledge gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- R. Shamshiri, R.; Weltzien, C.; Hameed, I.A.; J. Yule, I.; E. Grift, T.; Balasundram, S.K.; Pitonakova, L.; Ahmad, D.; Chowdhary, G. Research and development in agricultural robotics: A perspective of digital farming. Int. J. Agric. Biol. Eng. 2018. [Google Scholar] [CrossRef]
- Payne, C. Technologies for efficient farming. In Proceedings of the Electrical Insulation Conference and Electrical Manufacturing Expo, Indianapolis, IN, USA, 23–26 October 2005; pp. 435–441. [Google Scholar]
- Bac, C.W.; van Henten, E.J.; Hemming, J.; Edan, Y. Harvesting robots for high-value crops: State-of-the-art review and challenges ahead. J. Field Robot. 2014, 31, 888–911. [Google Scholar] [CrossRef]
- Rath, T.; Kawollek, M. Robotic harvesting of Gerbera Jamesonii based on detection and three-dimensional modeling of cut flower pedicels. Comput. Electron. Agric. 2009, 66, 85–92. [Google Scholar] [CrossRef]
- Berenstein, R.; Shahar, O.B.; Shapiro, A.; Edan, Y. Grape clusters and foliage detection algorithms for autonomous selective vineyard sprayer. Intell. Serv. Robot. 2010, 3, 233–243. [Google Scholar] [CrossRef]
- Shapiro, A.; Korkidi, E.; Demri, A.; Ben-Shahar, O.; Riemer, R.; Edan, Y. Toward elevated agrobotics: Development of a scaled-down prototype for visually guided date palm tree sprayer. J. Field Robot. 2009, 26, 572–590. [Google Scholar] [CrossRef]
- Monta, M.; Kondo, N.; Shibano, Y. Agricultural robot in grape production system. In Proceedings of the 1995 IEEE International Conference on Robotics and Automation, Nagoya, Japan, 21–27 May 1995; Volume 3, pp. 2504–2509. [Google Scholar]
- Katupitiya, J.; Eaton, R.; Yaqub, T. Systems engineering approach to agricultural automation: New developments. In Proceedings of the 2007 1st Annual IEEE Systems Conference, Honolulu, HI, USA, 9–13 April 2007; pp. 1–7. [Google Scholar]
- Kohanbash, D.; Valada, A.; Kantor, G. Irrigation control methods for wireless sensor network. In 2012 Dallas, Texas, July 29–August 1, 2012; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2012; p. 1. [Google Scholar]
- Virlet, N.; Sabermanesh, K.; Sadeghi-Tehran, P.; Hawkesford, M.J. Field Scanalyzer: An automated robotic field phenotyping platform for detailed crop monitoring. Funct. Plant Biol. 2017, 44, 143–153. [Google Scholar] [CrossRef]
- Nuske, S.; Achar, S.; Bates, T.; Narasimhan, S.; Singh, S. Yield estimation in vineyards by visual grape detection. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 2352–2358. [Google Scholar]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated Crop Yield Estimation for Apple Orchards. Experimental Robotics; Springer: Berlin, Germany, 2013; pp. 745–758. [Google Scholar]
- Davis, B. CMU-led automation program puts robots in the field. Mission Crit. 2012, 38–40. [Google Scholar]
- Sharifi, M.; Chen, X. A novel vision based row guidance approach for navigation of agricultural mobile robots in orchards. In Proceedings of the 2015 6th International Conference on Automation, Robotics and Applications (ICARA), Queenstown, New Zealand, 17–19 February 2015; pp. 251–255. [Google Scholar]
- Guzmán, R.; Ariño, J.; Navarro, R.; Lopes, C.; Graça, J.; Reyes, M.; Barriguinha, A.; Braga, R. Autonomous hybrid GPS/reactive navigation of an unmanned ground vehicle for precision viticulture-VINBOT. In Proceedings of the 62nd German Winegrowers Conference, Stuttgart, Germany, 27–30 November 2016. [Google Scholar]
- Dos Santos, F.N.; Sobreira, H.; Campos, D.; Morais, R.; Moreira, A.P.; Contente, O. Towards a reliable robot for steep slope vineyards monitoring. J. Intell. Robot. Syst. 2016, 83, 429–444. [Google Scholar] [CrossRef]
- Astolfi, P.; Gabrielli, A.; Bascetta, L.; Matteucci, M. Vineyard autonomous navigation in the echord++ grape experiment. IFAC-PapersOnLine 2018, 51, 704–709. [Google Scholar] [CrossRef]
- Santos, L.; Santos, F.N.; Magalhães, S.; Costa, P.; Reis, R. Path planning approach with the extraction of topological maps from occupancy grid maps in steep slope vineyards. In Proceedings of the 2019 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Porto, Portugal, 24–26 April 2019; pp. 1–7. [Google Scholar]
- Zoto, J.; Musci, M.A.; Khaliq, A.; Chiaberge, M.; Aicardi, I. Automatic Path Planning for Unmanned Ground Vehicle Using UAV Imagery. In International Conference on Robotics in Alpe-Adria Danube Region; Springer: Cham, Switzerland, 2019; pp. 223–230. [Google Scholar]
- Ma, C.; Jee, G.I.; MacGougan, G.; Lachapelle, G.; Bloebaum, S.; Cox, G.; Garin, L.; Shewfelt, J. Gps signal degradation modeling. In Proceedings of the International Technical Meeting of the Satellite Division of the Institute of Navigation, Salt Lake City, UT, USA, 11–14 September 2001. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mazzia, V.; Khaliq, A.; Salvetti, F.; Chiaberge, M. Real-Time Apple Detection System Using Embedded Systems with Hardware Accelerators: An Edge AI Application. IEEE Access 2020, 8, 9102–9114. [Google Scholar] [CrossRef]
- Ruckelshausen, A.; Biber, P.; Dorna, M.; Gremmes, H.; Klose, R.; Linz, A.; Rahe, F.; Resch, R.; Thiel, M.; Trautz, D.; et al. BoniRob: An autonomous field robot platform for individual plant phenotyping. Precis. Agric. 2009, 9, 1. [Google Scholar]
- Stoll, A.; Kutzbach, H.D. Guidance of a forage harvester with GPS. Precis. Agric. 2000, 2, 281–291. [Google Scholar] [CrossRef]
- Thuilot, B.; Cariou, C.; Cordesses, L.; Martinet, P. Automatic guidance of a farm tractor along curved paths, using a unique CP-DGPS. In Proceedings of the 2001 IEEE/RSJ International Conference on Intelligent Robots and Systems. Expanding the Societal Role of Robotics in the the Next Millennium (Cat. No. 01CH37180), Maui, HI, USA, 29 October–3 November 2001; Volume 2, pp. 674–679. [Google Scholar]
- Ly, O.; Gimbert, H.; Passault, G.; Baron, G. A fully autonomous robot for putting posts for trellising vineyard with centimetric accuracy. In Proceedings of the 2015 IEEE International Conference on Autonomous Robot Systems and Competitions, Vila Real, Portugal, 8–10 April 2015; pp. 44–49. [Google Scholar]
- Longo, D.; Pennisi, A.; Bonsignore, R.; Muscato, G.; Schillaci, G. A multifunctional tracked vehicle able to operate in vineyards using gps and laser range-finder technology. Work safety and risk prevention in agro-food and forest systems. In Proceedings of the International Conference Ragusa SHWA2010, Ragusa, Italy, 16–18 September 2010. [Google Scholar]
- Hansen, S.; Bayramoglu, E.; Andersen, J.C.; Ravn, O.; Andersen, N.; Poulsen, N.K. Orchard navigation using derivative free Kalman filtering. In Proceedings of the 2011 American Control Conference, San Francisco, CA, USA, 29 June–1 July 2011; pp. 4679–4684. [Google Scholar]
- Marden, S.; Whitty, M. GPS-free localisation and navigation of an unmanned ground vehicle for yield forecasting in a vineyard. In Recent Advances in Agricultural Robotics, International Workshop Collocated with the 13th International Conference on Intelligent Autonomous Systems (IAS-13); Springer: Berlin, Germany, 2014. [Google Scholar]
- Zaidner, G.; Shapiro, A. A novel data fusion algorithm for low-cost localisation and navigation of autonomous vineyard sprayer robots. Biosyst. Eng. 2016, 146, 133–148. [Google Scholar] [CrossRef]
- Riggio, G.; Fantuzzi, C.; Secchi, C. A Low-Cost Navigation Strategy for Yield Estimation in Vineyards. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2200–2205. [Google Scholar]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using deep learning for image-based plant disease detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep neural networks based recognition of plant diseases by leaf image classification. Comput. Intell. Neurosci. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Mortensen, A.K.; Dyrmann, M.; Karstoft, H.; Jørgensen, R.N.; Gislum, R. Semantic segmentation of mixed crops using deep convolutional neural network. In Proceedings of the International Conference of Agricultural Engineering (CIGR), Aarhus, Denmark, 26–29 June 2016. [Google Scholar]
- Rebetez, J.; Satizábal, H.F.; Mota, M.; Noll, D.; Büchi, L.; Wendling, M.; Cannelle, B.; Pérez-Uribe, A.; Burgos, S. Augmenting a convolutional neural network with local histograms-A case study in crop classification from high-resolution UAV imagery. In Proceedings of the ESANN 2016, European Symposium on Artifical Neural Networks, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Mazzia, V.; Khaliq, A.; Chiaberge, M. Improvement in Land Cover and Crop Classification based on Temporal Features Learning from Sentinel-2 Data Using Recurrent-Convolutional Neural Network (R-CNN). Appl. Sci. 2020, 10, 238. [Google Scholar] [CrossRef]
- Kuwata, K.; Shibasaki, R. Estimating crop yields with deep learning and remotely sensed data. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 858–861. [Google Scholar]
- Minh, D.H.T.; Ienco, D.; Gaetano, R.; Lalande, N.; Ndikumana, E.; Osman, F.; Maurel, P. Deep Recurrent Neural Networks for mapping winter vegetation quality coverage via multi-temporal SAR Sentinel-1. arXiv 2017, arXiv:1708.03694. [Google Scholar]
- Mazzia, V.; Comba, L.; Khaliq, A.; Chiaberge, M.; Gay, P. UAV and Machine Learning Based Refinement of a Satellite-Driven Vegetation Index for Precision Agriculture. Sensors 2020, 20, 2530. [Google Scholar] [CrossRef] [PubMed]
- Khaliq, A.; Mazzia, V.; Chiaberge, M. Refining satellite imagery by using UAV imagery for vineyard environment: A CNN Based approach. In Proceedings of the 2019 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Portici, Italy, 24–26 October 2019; pp. 25–29. [Google Scholar]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting apples and oranges with deep learning: A data-driven approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar]
- Sehgal, G.; Gupta, B.; Paneri, K.; Singh, K.; Sharma, G.; Shroff, G. Crop planning using stochastic visual optimization. In Proceedings of the 2017 IEEE Visualization in Data Science (VDS), Phoenix, AZ, USA, 1 October 2017; pp. 47–51. [Google Scholar]
- Mousavian, A.; Toshev, A.; Fišer, M.; Košecká, J.; Wahid, A.; Davidson, J. Visual representations for semantic target driven navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8846–8852. [Google Scholar]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.L.; Rodríguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Di Caro, G.; et al. A machine learning approach to visual perception of forest trails for mobile robots. IEEE Robot. Autom. Lett. 2015, 1, 661–667. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Vanholder, H. Efficient Inference with TensorRT. 2016. Available online: http://on-demand.gputechconf.com/gtc-eu/2017/presentation/23425-han-vanholder-efficient-inference-with-tensorrt.pdf (accessed on 22 May 2020).
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Berlin, Germany, 2018; pp. 270–279. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. Available online: https://openreview.net/forum?id=rk6qdGgCZ (accessed on 25 May 2020).
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Duane, C.B. Close-range camera calibration. Photogramm. Eng. 1971, 37, 855–866. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Precision | Recall | f1-Score |
|---|---|---|---|
| right | 0.850 | 1.000 | 0.919 |
| left | 1.000 | 0.899 | 0.947 |
| center | 1.000 | 0.924 | 0.961 |
| micro avg | 0.941 | 0.941 | 0.941 |
| macro avg | 0.950 | 0.941 | 0.942 |
| weighted avg | 0.950 | 0.941 | 0.942 |
| Model | Parameters | GFLOPSs | Avg. Acc. |
|---|---|---|---|
| MobileNet [52] | 4,253,864 | 0.579 | 94.7% |
| MobileNetV2 [64] | 3,538,984 | 0.31 | 91.3% |
| EfficientNet-B0 [63] | 5,330,571 | 0.39 | 93.8% |
| EfficientNet-B1 [63] | 7,856,239 | 0.70 | 96.8% |
| ResNet50 [65] | 25,636,712 | 4.0 | 93.1% |
| DenseNet121 [66] | 8,062,504 | 3.0 | 95.3% |
| Mode | Depth | Color |
|---|---|---|
| PPX | 321.910675048828 | 316.722351074219 |
| PPY | 236.759078979492 | 244.21875 |
| Fx | 387.342498779297 | 617.42242431640 |
| Fy | 387.342498779297 | 617.789978027344 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aghi, D.; Mazzia, V.; Chiaberge, M. Local Motion Planner for Autonomous Navigation in Vineyards with a RGB-D Camera-Based Algorithm and Deep Learning Synergy. Machines 2020, 8, 27. https://doi.org/10.3390/machines8020027
Aghi D, Mazzia V, Chiaberge M. Local Motion Planner for Autonomous Navigation in Vineyards with a RGB-D Camera-Based Algorithm and Deep Learning Synergy. Machines. 2020; 8(2):27. https://doi.org/10.3390/machines8020027
Chicago/Turabian StyleAghi, Diego, Vittorio Mazzia, and Marcello Chiaberge. 2020. "Local Motion Planner for Autonomous Navigation in Vineyards with a RGB-D Camera-Based Algorithm and Deep Learning Synergy" Machines 8, no. 2: 27. https://doi.org/10.3390/machines8020027
APA StyleAghi, D., Mazzia, V., & Chiaberge, M. (2020). Local Motion Planner for Autonomous Navigation in Vineyards with a RGB-D Camera-Based Algorithm and Deep Learning Synergy. Machines, 8(2), 27. https://doi.org/10.3390/machines8020027