1. Introduction
Offline multi-point smooth trajectory planning is a critical core technology in robotics, directly determining the operational efficiency and task quality of manipulators [
1]. A multi-point trajectory refers to the functional relationship between each joint’s kinematic variables and time during the manipulator’s sequential movement to two or more desired waypoints. Most manipulation tasks involve multi-point trajectories, such as deburring [
2], harvesting [
3], and milling operations [
4]. The trajectory can be mathematically represented as time-dependent functional relationships describing positional, velocity, and acceleration variables.
The research on offline multi-point trajectory planning can be categorized into operational space trajectory planning and joint space trajectory planning based on the spatial domain of the trajectory. Operational space trajectory planning may face challenges such as increased computational complexity due to singularity avoidance, compromised stability and precision of the manipulator, and the necessity of converting operational space trajectories into joint space trajectories via inverse kinematics for motion control implementation [
5]. Furthermore, during the planning process, the nonlinear mapping between operational and joint spaces may cause operational space trajectories to violate physical or environmental constraints of the manipulator, resulting in degraded tracking accuracy, reduced operational efficiency, or even irreversible component damage. Therefore, conducting in-depth research on joint space trajectory planning for manipulators carries profound significance.
The construction of appropriate trajectory models for interpolation can balance operational efficiency and mechanical impact minimization, which is a key part of joint trajectory planning for manipulators. Multi-point trajectories are typically constructed using piecewise approaches combined with basic functions due to the variable number of desired waypoints in multi-point joint trajectory planning methods and the fixed requirements regarding waypoint quantity in basic function interpolation. This method creates various spline curves to satisfy the universality of trajectory planning while ensuring trajectory continuity when experiencing velocity, acceleration, or jerk. Based on the types of functions employed in the construction, multi-point joint trajectory models can be categorized into algebraic splines [
6,
7], trigonometric splines [
8], basis function splines [
9,
10,
11,
12,
13,
14,
15], and hybrid splines [
16,
17]. Building on Lin’s work [
6], Gasparetto et al. utilized the parabolic characteristics of cubic spline velocity profiles to formulate equations governing maximum velocity, acceleration, and jerk for each joint’s sub-trajectory [
7]. This transformation converted the kinematic constraints of cubic spline trajectories from semi-infinite to finite forms. Simon and Isik developed a known constant matrix for quartic trigonometric splines [
8]. Based on the types of basic functions, basis function splines can be further categorized into radial basis function splines (RBFS) [
9,
10], B-splines [
11,
12,
13], and non-uniform rational B-splines (NURBS) [
14,
15]. Dyllong and Visioli performed a comparative analysis of algebraic cubic splines, cubic and quartic trigonometric splines, and cubic B-splines. The study found that all three types of splines produce trajectories with comparable performance when the sub-trajectory intervals are identical [
18]. By introducing two virtual points at the second and penultimate positions, the trajectories generated by quintic NURBS and quintic non-uniform B-splines ensure jerk values are zero at both the initial and final movements, with a jerk-continuous curve. However, quintic non-uniform B-splines do not require weight assignment, reducing the computational complexity. These characteristics make the quintic non-uniform B-spline the main choice for trajectory models. Hybrid splines represent a class of spline functions constructed by combining algebraic splines of varying degrees or with different types of spline functions [
19,
20]. At present, with the significant advancements in chip computing power and the superior performance of quintic non-uniform B-splines incorporating virtual points, scholarly focus on developing novel hybrid splines has diminished.
The parameter estimation of high-dimensional nonlinear equations under multiple nonlinear constraints in trajectory models constitutes a non-convex optimization problem. Solving this problem to obtain feasible and optimized solutions is another critical part of trajectory planning for manipulators. The optimized trajectory can effectively reduce the manipulator’s operation time and minimize wear on its joint actuators. The nonlinearity and non-convexity of multi-point trajectory models, coupled with the unrestricted number of desired position points and the synchronization requirements across multiple joints, significantly elevate the complexity of optimally solving multi-point joint trajectory problems. With advancements in intelligent algorithms and enhanced computing power, current strategies for optimal multi-point joint trajectory-solving predominantly focus on leveraging intelligent algorithms to explore decision spaces for optimal solutions or solution sets. These include genetic algorithms (GA) [
21], particle swarm optimization (PSO) [
20], grey wolf optimization (GWO) [
22], and cuckoo search (CS) [
23]. While each basic intelligent algorithm exhibits distinct strengths, they also possess inherent limitations. Consequently, some researchers have sought to refine these algorithms for improved target joint trajectory acquisition. For instance, Rout et al. introduced a locally adaptive search probability parameter that linearly evolves with iterations, integrating an achievement scalar function to bolster local search capabilities [
24]. In addition to enhancing basic intelligent algorithms, some scholars have explored hybridizing different intelligent algorithms to achieve complementary strengths, thereby improving their optimization capabilities to obtain solutions or solution sets closer to the global optimum or Pareto optimal front [
25]. Wang et al. integrated the mutation and selection operators of the differential evolution algorithm (DE) into the population initialization stage of the whale optimization algorithm (WOA). Compared to conventional GA, DE, and WOA, this modified WOA demonstrated superior trajectory operational efficiency [
26]. Moreover, intelligent algorithms often incorporate various factors and coefficients to construct their search mechanisms. Zhang et al. established an exponential variation formula for the step size factor of the CS, allowing the step size to adaptively decrease as iterations proceeded, while introducing two additional parameters to be tuned [
27].
For the increasingly prominent multi-objective optimization problems, two primary methods exist for ranking individuals within a population: the weighted summation approach and the non-dominated sorting technique. Gasparetto et al. implemented a weighted processing approach to simultaneously optimize the manipulator’s operation time and joint impacts [
5,
7], while Huang et al. alternatively employed non-dominated sorting for these two indicators [
12]. Liu and Zhang enhanced the multi-objective particle swarm optimization (MOPSO) framework by incorporating a specified number of average distance metrics to rank individuals stored in the external memory [
28]. However, these adopted methodologies primarily focus on the distribution characteristics within the objective space while neglecting diversity preservation in the decision space. Consequently, solutions may exhibit satisfactory dispersion in the objective domain but suffer from crowding in the decision variable space, potentially restricting the practical applicability and scalability of the final decision-making and solution strategies.
Multi-point joint trajectory planning represents a constrained high-dimensional nonlinear optimization problem, necessitating an incorporate effective constraint handling technique. Three prevalent constraint management approaches exist in the current multi-point joint trajectory planning methodologies: penalty function methods [
15,
27], transformation methods [
3], and rule-based methods [
29,
30]. While penalty function and switching methods frequently appear in the single-objective joint trajectory planning literature, transformation and rule-based approaches are primarily integrated with non-dominated sorting techniques in multi-objective optimization frameworks. However, these conventional methods typically restrict exploration to feasible regions within the decision space, neglecting the exploitation of boundaries between feasible and infeasible domains.
The analysis of the previous articles indicates that most offline multi-objective trajectories were optimized by intelligent algorithms with ranking techniques and constraint handling techniques. However, suboptimal parameter settings in the intelligent algorithms can compromise search performance, leading to trajectories that inadequately approximate the optimal solution [
24,
25,
26]. In addition, the limitations of the ranking techniques underscore the need for balanced consideration of both objective and decision space distributions to ensure comprehensive optimization outcomes [
12,
28]. Furthermore, when feasible regions are narrow, the limitations of the constraint handling techniques may produce either infeasible joint trajectories or feasible solutions that inadequately approximate the global optimum or Pareto optimal front, highlighting the need for enhanced boundary exploration mechanisms in constraint handling strategies [
3,
15,
29].
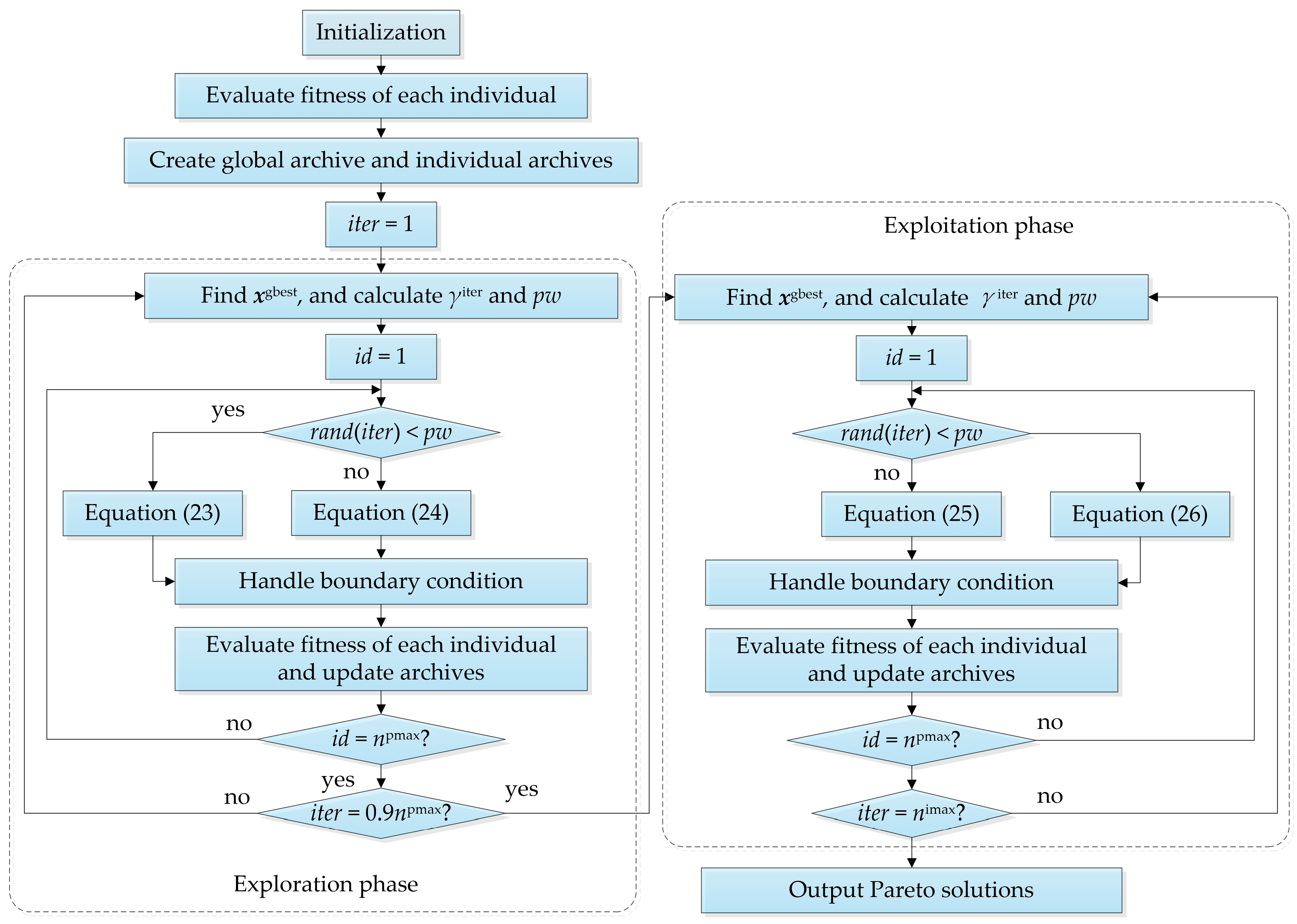
In order to overcome these limits, we propose an offline multi-point trajectory planning technique for manipulators based on quintic non-uniform B-splines and a constrained multi-objective dream optimization algorithm (CMODOA). Quintic non-uniform B-splines with virtual points are utilized for jerk-continuous trajectory, achieving zero values for velocity, acceleration, and jerk at the initial and final motion. CMODOA is a parameter-free algorithm with no specific parameters to be tuned. The proposed algorithm improves and develops the dream optimization algorithm (DOA) via an awakening strategy, an adaptive hyperrectangle, and an adaptive ε-constraint handling method. These enable CMODOA to solve multi-objective optimization problems with various linear and nonlinear constraints. The main contributions of this paper can be summarized as follows:
The boundary constraints of the optimal problem are transformed into equations for coefficient matrix calculation in the trajectory model based on quintic non-uniform B-splines. Additionally, the normalized knot vector maintains consistency among different joints to satisfy synchronization constraints. The transformation and maintenance significantly reduce the computational complexity during optimization.
An awakening strategy with a differential mutation is designed to enhance the global search ability of DOA and the diversity of optimization results from DOA. The strategy mimics the phenomenon where people may be awakened by disturbances, leading to interruption of dream continuity. As the sleep duration increases, the probability of being awakened tends to zero.
An adaptive hyperrectangle is strategically designed to conduct an intensive exploration within the neighbourhood, centred on the dream of the best individual in the global archive. The hyperrectangle serves as a value space for the variables exceeding the boundary condition. The activity coefficient within the hyperrectangle exhibits a nonlinear decay with increasing iterations.
A constrained non-dominated sorting approach is proposed for the population to explore the relaxed boundary between the feasible solution region and the infeasible solution region. This can enhance optimization algorithms’ ability to conduct an in-depth exploration of the feasible and optimal solutions.
The remaining sections of this article are organized as follows. In
Section 2, the problem statement of the time-jerk optimal trajectories is detailed.
Section 3 introduces the trajectory model based on quintic non-uniform B-splines with virtual points. In
Section 4, the proposed multi-objective optimization algorithm is developed, with two phases.
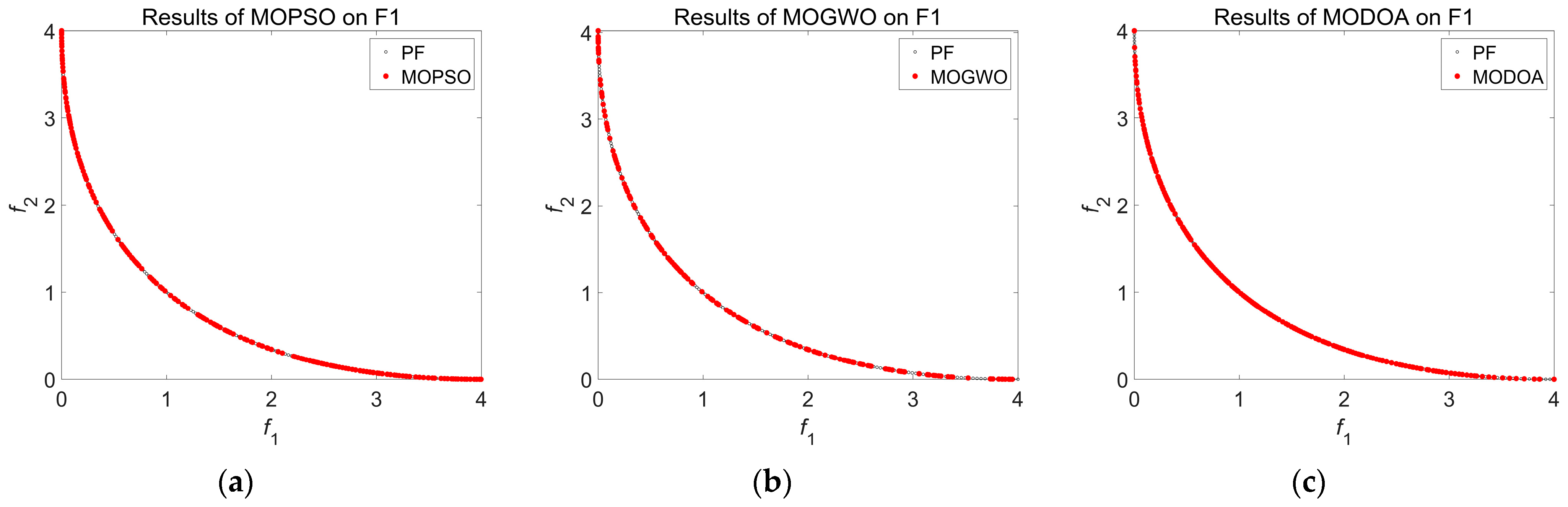
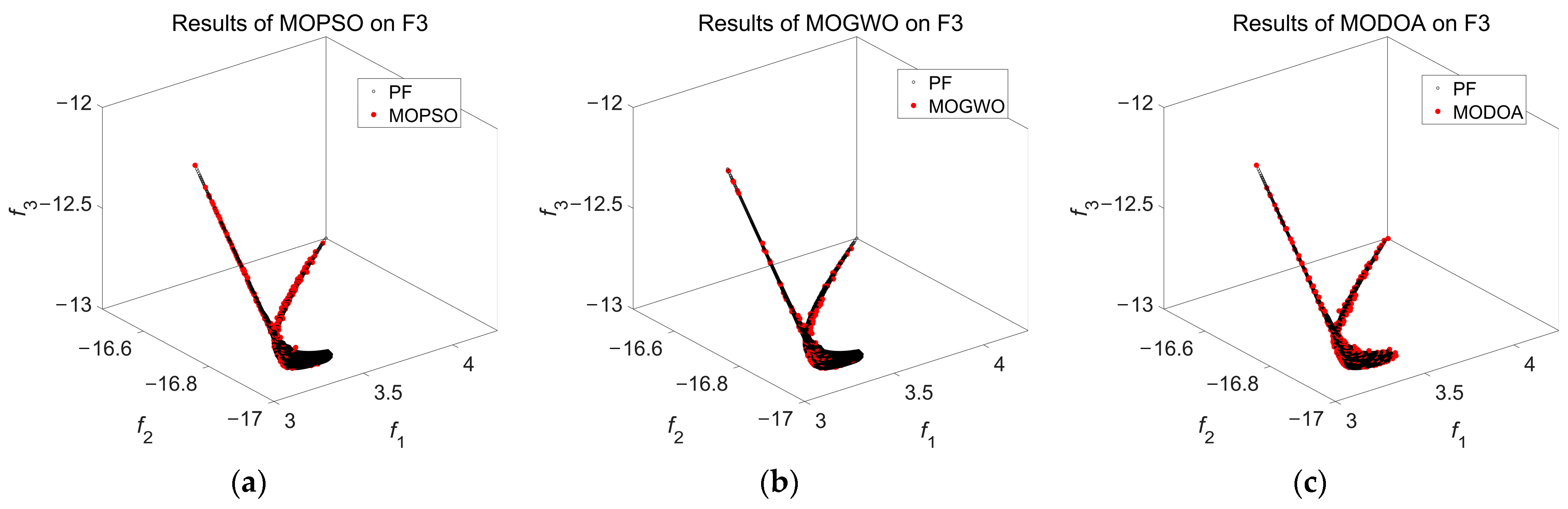
Section 5 presents comparisons with various multi-objective optimization algorithms for test functions, which use different trajectory planning methods for manipulators. Finally,
Section 6 concludes this work.
2. Time–Jerk Optimal Problem Statement
The objective of manipulator trajectory optimization is to generate a motion plan that enables the manipulator to transition smoothly from its initial configuration to the final configuration within the operational workspace, while concurrently enhancing system performance through the systematic consideration of various constraints. A minimum-time trajectory can significantly enhance the operational efficiency of a manipulator, enabling rapid response and maximizing task throughput in dynamic environments. However, faster motions may induce significantly stronger jerk loads [
1]. Therefore, it is desirable to have sufficiently smooth trajectories to avoid excessive mechanical vibrations. A minimum-jerk trajectory can effectively reduce vibrations and mechanical shocks during manipulator motion, thereby enhancing trajectory tracking precision and overall system stability. The travelling time and the absolute mean jerk are formulated as the two objective functions in this study. The definition of the time-jerk optimization problem is similar to that presented in Ref. [
12].
The objective function equations are defined as follows.:
where Δ
ti is the time interval between desired adjacent waypoints,
np denotes the number of desired waypoints,
jerkg is the
gth joint jerk,
T represents the travelling time of an entire manipulator movement, and
nj is the number of the utilized manipulator joints.
f1 denotes the travelling time of the manipulator to accomplish a predetermine task, and minimal travelling time implies high motion efficiency.
f2 represents the optimization objective of the absolute mean jerk, indicating the smoothness of the optimized trajectories.
When the kinematic quantities exceed the physical limits of their manipulators, issues like structural damage, control failure, energy surge, intensified vibration, and safety hazards may emerge, significantly compromising system performance and operational safety. Therefore, the optimized trajectory should be subject to the kinematic constraints, defined as follows:
where
velg and
accg are the velocity and acceleration of the
gth joint, respectively.
vcg,
acg, and
jcg are the constraints of velocity, acceleration, and jerk for the
gth joint, respectively.
The optimized trajectory should also adhere to geometric constraints, ensuring collision-free motion within feasible workspaces and enhancing the reliability of motion planning. The imposed geometric constraints on the joint positions are described as follows:
where
anglg is the
gth joint angle;
and
are the minimum and maximum of the
gth joint angle.
Multi-point joint trajectory planning requires synchronization across all joints. Each joint must start from the initial desired waypoint at the same time, and then sequentially and simultaneously reach every desired waypoint before terminating concurrently at the final desired waypoints. The synchronization constraints are described as follows:
where
pg,i is the
ith desired waypoint of the
gth joint.
In order to prevent abrupt changes and enhance trajectory smoothness and system stability at both the initial and final movements, we suppose that the values of velocity, acceleration, and jerk of all joints at the initial and final movements are zero. The boundary constraints, including velocity, acceleration, and jerk, are described as follows:
In addition to the above constraints, torque constraint is a core dynamic constraint, determining the robot motion performance and trajectory feasibility, defined as follows:
where
τg is the torque of the
gth joint and
is the torque limit of the
gth joint.
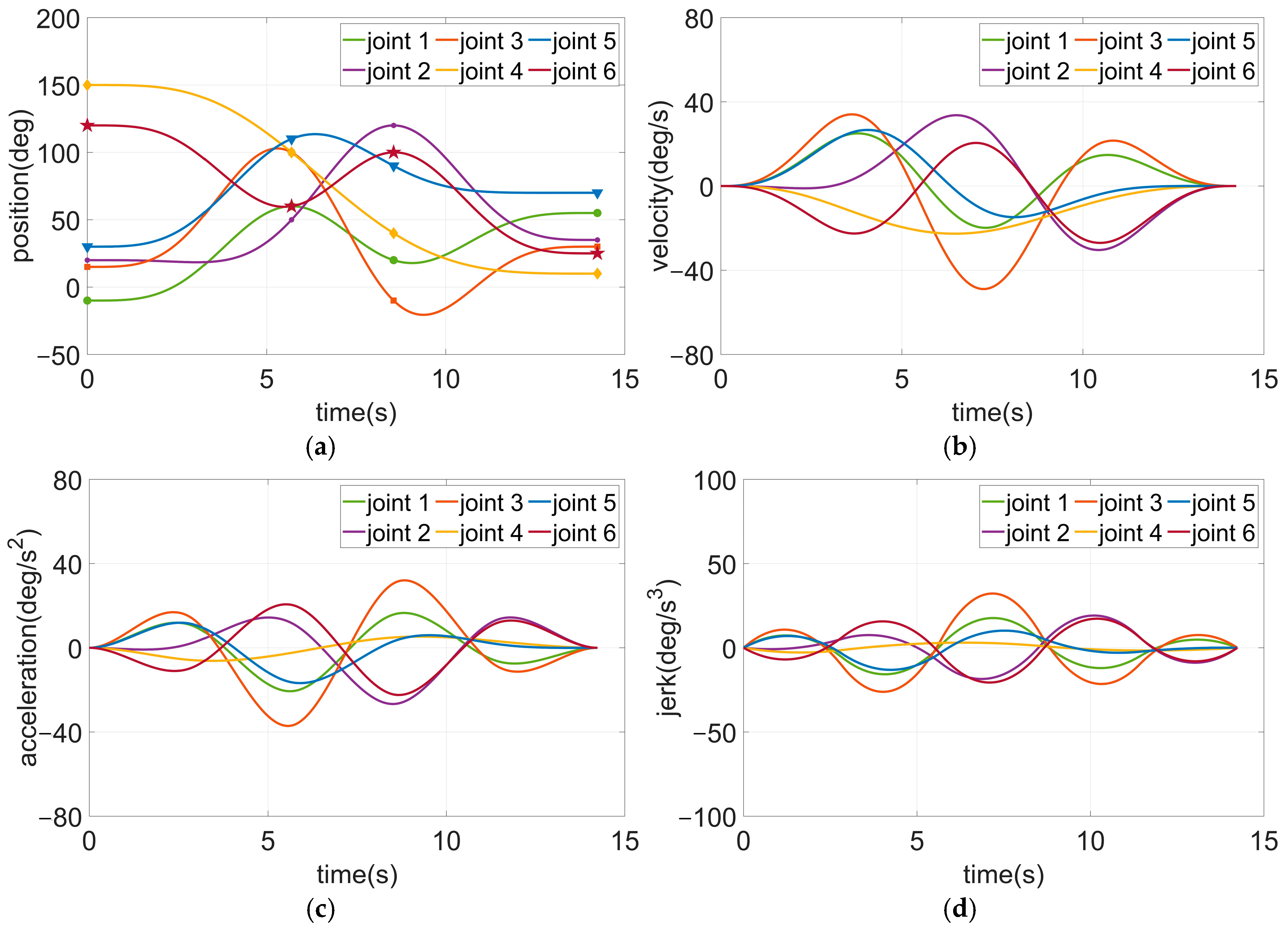
For a given manipulator task, initial joint trajectories are generated via trajectory model interpolation. Then, the joint trajectories are optimized by solving the time-jerk optimal problem via multi-objective optimization algorithms and constraint handling techniques. We will ultimately obtain a Pareto solution set that is available for user selection.
3. Trajectory Model Based on Quintic Non-Uniform B-Splines with Virtual Points
Quintic non-uniform B-splines utilize their fifth-degree polynomial formulation to achieve C4 continuity, enabling the generation of ultra-smooth motion profiles that effectively reduce component wear and mitigate mechanical shocks during trajectory execution. In addition, the local support characteristic ensures that a knot modification only influences localized trajectory segments, enabling extension of trajectory planning methodologies to dynamic mission scenarios. These unique properties establish quintic non-uniform B-splines as the optimal interpolation solution for manipulator trajectory, particularly excelling in scenarios demanding highly efficient and high-precision tasks with kinematic constraint satisfaction.
A quintic non-uniform B-spline function can be expressed mathematically as follows:
where
u is the normalized knot vector variable,
qi is the
i-th control point, and
ncp is the number of control points.
Ni,5(
u) denotes the
ith basis function of the quintic non-uniform B-spline and can be obtained by the Cox-De Boor recursion algorithm, presented as follows:
In order to satisfy the jerk boundary constraint, two virtual points are inserted into the second and penultimate locations of the desired waypoint sequence. Then, Equation (8) is converted to the following:
Furthermore, in order to respect the synchronization constraint, the normalized knot vector
u is calculated from the sequence of time intervals Δ
ti, given as follows:
where
The velocity, acceleration, and jerk are the first-, second-, and third-order derivatives of quintic non-uniform B-spline, respectively:
where
According to Equations (8) and (9), the boundary constraints can be converted into
np + 7 linear equations for control point
q can be obtained from Equations (10) and (15):
where
A is a non-singular coefficient matrix determined by Δ
ti and can be calculated by Equations (9), (11), and (12).
It can be seen that
A is the same for all joints, due to the independence of desired waypoints.
B is a coefficient matrix of synchronization constraints and boundary constraints, presented as follows:
After obtaining the control point
q through reverse calculation, the initial trajectory can be calculated using Equations (8) and (13). However, the scope of the domain of the trajectory is [0,1], and it is necessary to scale the trajectory to the given travelling time. The scaled trajectory can be calculated by
For a specific manipulator task, the multi-point trajectories interpolated by the quintic non-uniform B-splines with virtual points can be immediately calculated to achieve jerk continuity, if Δti (i = 1, …, np − 1) is provided.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}