1. Introduction
The industrial sector, which is the foundation of contemporary economies, depends significantly on equipment to maintain continuous operations in manufacturing, transportation, energy, and other vital areas [
1]. Advanced maintenance techniques are becoming more and more necessary, as reliance on equipment increases in order to guarantee high uptime and minimal downtime. Yet, wear and tear on machinery eventually results in failures that endanger public safety, cause operational disruptions, and result in high expenses. Although reactive (“run-to-failure”) and preventative maintenance techniques have been employed for a long time, they frequently lack effectiveness and cost-effectiveness. Its inability to predict breakdowns leads to unplanned outages, costly repairs, and operational unpredictability.
Preventive maintenance, on the other hand, is carrying out routine, planned maintenance tasks in accordance with the machine’s usage or operating hours. Although this method can save some failures, it is frequently too cautious, resulting in needless maintenance procedures that waste money and time. Furthermore, preventative maintenance may overlook early warning signals of failure or carry out repairs too soon, which can still lead to unanticipated breakdowns. This is due to the true state of the machinery being ignored.
Advanced and intelligent maintenance solutions are becoming more and more necessary due to the shortcomings of these conventional approaches. With the use of machine learning and advanced analytics, predictive maintenance provides a proactive approach that foresees problems before they arise. In this situation, predictive maintenance emerges as a possible solution. In order to carry out maintenance just in time, before a failure occurs, but not too early, predictive maintenance makes use of data analytics, machine learning, and the Internet of Things (IoT). This method optimizes the distribution of maintenance resources, reduces downtime, and extends the useful life of machinery [
2].
In industrial settings, unplanned equipment breakdowns can result in serious financial losses, safety risks, and decreased production. Many sectors still rely on wasteful reactive maintenance practices, even in the face of abundant operational data availability. Creating a model that can reliably anticipate machine breakdowns and allow for prompt actions to minimize interruption is the main problem. Predictive maintenance models are now much more capable thanks to recent advances in machine learning, especially in the areas of deep learning and ensemble techniques. These models can evaluate enormous volumes of historical and real-time data from sensors and other monitoring systems to find trends and anomalies that precede machine failures. Neural networks have proven to be highly effective in capturing complex nonlinear patterns and temporal dependencies in time-series data, while XGBoost has demonstrated superior predictive accuracy in various industrial applications.
The creation of a proactive predictive model for machine failure forecasting is described in this study, which makes use of machine learning techniques to improve prediction accuracy and optimize maintenance schedules. This study proposes a hybrid predictive model that leverages Neural Networks for learning temporal dynamics and extracting deep sequential features, combined with XGBoost for high-accuracy failure prediction. The proposed approach is expected to improve prediction robustness, making industrial maintenance more proactive and cost-effective.
The contributions of this study are as follows:
Suggestion of a hybrid predictive model that combines XGBoost and Neural Networks, used to address class imbalance and enhance problem detection in industrial machinery;
Use of SHAP and LIME to produce interpretable justifications for model predictions, enhancing transparency and engineer trust;
Use of a variety of performance criteria to show the model’s efficacy by evaluating it on a synthetic dataset created to mimic actual operating situations;
Provision of deployment guidelines and threshold optimization techniques, such as retraining frequency and human-in-the-loop decision-making.
2. Related Work
A 2004 study [
3] showed how LSTMs (Long Short-Term Memory models) might be used to anticipate gearbox failures by accurately modeling the temporal dynamics of the vibration signals that cause failure. When compared to standard models, the authors demonstrated how the proposed method in the study greatly increased prediction accuracy. The main limitation of Malhi and Gao’s study is that it relies on PCA, a linear technique, which cannot capture the nonlinear relationships often present in machine fault data. Additionally, the transformed features lack interpretability, making it difficult for maintenance engineers to understand the model’s outputs, and the approach was not validated in real-world industrial settings.
The authors in [
4] demonstrated a thorough investigation of conventional condition-based maintenance strategies and emphasized the application of statistical methodologies in conjunction with reliability analysis techniques such as Failure Mode Effects Analysis (FMEA) and Weibull distribution. These techniques emphasized the significance of comprehending failure distributions and the probabilistic character of machine failures, laying the foundation for more advanced predictive models. The main limitation of Jardine, Lin, and Banjevic’s study is that while it provides a comprehensive review of condition-based maintenance (CBM) techniques, it primarily focuses on traditional statistical and model-based approaches, offering limited coverage of emerging data-driven and machine learning methods. Additionally, the paper does not deeply address the challenges of real-time implementation, data quality, or scalability in complex industrial environments.
The authors in [
5] applied SVMs (Support Vector Machines) for machine status monitoring. The authors demonstrated that they were successful in distinguishing between working and non-working machine states. The ability of SVMs to handle non-linear correlations in data was highlighted in the study, which is important for precise failure prediction in complicated machinery. However, while it demonstrates the effectiveness of Support Vector Machines (SVM) for fault diagnosis, it primarily focuses on feature-based classification and does not address model interpretability, scalability to large datasets, or the practical integration of SVMs into real-time industrial monitoring systems. The authors in [
6] investigated the idea of “smart maintenance” by utilizing big data analytics and the Internet of Things. They emphasized the significance of real-time data in predictive maintenance approaches. Through continual insights into machine health, their research demonstrated how IoT-enabled systems may lower maintenance costs and increase machine uptime. However, the work is limited, in that while it introduces a conceptual framework for smart analytics and service innovation in Industry 4.0, it lacks empirical validation through real-world case studies or implementation results, making it difficult to assess the practical effectiveness and scalability of the proposed approaches.
For industrial applications, the authors in [
7] presented the use of edge computing in which data are processed closer to the source (i.e., the machinery) as opposed to being sent to centralized cloud servers. This approach shortens response times and improves predictive maintenance systems’ ability to make decisions in real-time. The major limitation of the study is that although it provides a forward-looking vision of edge computing and outlines key challenges, it remains largely theoretical and lacks detailed implementation strategies or empirical evaluations to validate the feasibility of the proposed concepts in real-world IoT environments. The authors in [
8] used XGBoost instead of single-model techniques to estimate the remaining usable life (RUL) of turbofan engines with better results. Though the study proposes a novel health index construction method combined with XGBoost for remaining useful life (RUL) prediction, the approach is primarily validated on limited benchmark datasets and does not assess performance in diverse or real-world industrial environments, which may affect its generalizability and robustness. The authors in [
9] showed that Random Forests outperform conventional statistical models in forecasting the RUL of aviation engines. While the Random Forest-based method shows promising results for predicting the remaining useful life (RUL) of aircraft engines, it is tested only on a single benchmark dataset and does not explore the model’s adaptability to different operating conditions, or its performance compared to more recent deep learning approaches.
Recent studies in predictive maintenance have explored various machine learning approaches for failure prediction. For instance, Susto et al. [
10] proposed a multiple classifier ensemble approach for PdM, achieving strong predictive performance. However, their model lacked interpretability, which is crucial for real-world implementation. A two-level machine learning framework that analyzes different learning formulations for predictive maintenance was proposed in [
11]. The authors proposed building a health indicator at the first level, which entails combining features using a learning method such as SVM. Based on this health indication, a decision-making system was proposed at the second level that sounds an alarm. The authors evaluate several approaches using a case study of a rotating machine in the actual world and found that although basic models were demonstrated to function well, more complex improvements enhanced predictions when parameters were properly selected. The main limitation of the work is that although the study compares multiple learning formulations within a two-level predictive maintenance framework, it relies primarily on simulated datasets and lacks validation on real-world industrial data, which may limit the practical applicability of its findings.
Another noteworthy addition was made by the authors in [
12], who thoroughly assessed deep learning models for failure prediction such as Transformers, Recurrent Neural Networks (RNNs), and Convolutional Neural Networks (CNNs). Their study highlighted how crucial dataset attributes such as size and failure rate are affecting model accuracy. The study found that CNN-based models yielded superior performance under specific conditions. Notably, when the dataset included more than 350 log sequences (or samples) or when the failure rate exceeded 7.5%, CNNs consistently outperformed other architectures. This performance was further enhanced when the models were combined with effective embedding techniques such as Logkey2vec, which helped capture contextual patterns in the log data more accurately. While the study systematically evaluates various deep learning models for failure prediction, it primarily focuses on benchmark datasets and does not explore model interpretability or deployment challenges in real-world industrial settings.
The researchers in [
13] reviewed the application of deep learning techniques, such as CNNs, RNNs, and autoencoders, in machine health monitoring tasks like fault diagnosis and remaining useful life prediction. The study highlights the ability of these models to automatically learn features from raw sensor data. However, its main limitation is the lack of real-world deployment examples and comprehensive performance comparisons across diverse industrial environments, which limits insights into their practical applicability and generalizability. The work in [
14] proposed a hybrid model combining dual-channel attention CNN with XGBoost to enhance fault diagnosis in industrial processes by capturing complex spatial–temporal features and improving classification accuracy. However, the model’s main limitation lies in its limited validation across diverse real-world scenarios and the added computational complexity, which may hinder deployment in real-time or resource-constrained environments. Meanwhile, Xie et al. [
15] employed Neural Networks to predict motor failure, though the absence of threshold tuning or uncertainty quantification limited its practical deployment. Additionally, the study in [
16] evaluated how different data window sizes affected the ability of deep learning and machine learning models to predict failures. The results demonstrated how the prediction window dimensions are important, as well as how well various algorithms are able to predict machine breakdowns. The main limitation of the workis that while the study systematically evaluates various deep learning models for failure prediction, it primarily focuses on benchmark datasets and does not explore model interpretability or deployment challenges in real-world industrial settings.
The authors in [
17] investigated how ensemble learning techniques could be combined with feature selection for predictive maintenance in order to further advance this research space. Their results show that hybrid feature selection techniques greatly enhance the detection of infrequent failure occurrences when used with ensemble classifiers such as Gradient Boosting and ExtraTrees. The main limitation of the study is that although the hybrid ensemble approach improves intrusion detection performance, the evaluation is limited to benchmark datasets and does not assess the model’s effectiveness or scalability in real-world network environments. The research in [
18] used attention-based Temporal Convolutional Networks (TCNs) to simulate the behavior of sequential equipment, showing that TCNs outperformed RNNs in long-term temporal prediction scenarios. However, its limitation is that while the attention-based temporal convolutional network improves remaining useful life prediction, it is primarily validated on benchmark datasets and lacks evaluation on diverse, real-world industrial scenarios, which may affect its generalizability.
The authors in [
19] examined how hyperparameter optimization techniques such as Bayesian optimization affected the predictive maintenance model’s performance and came to the conclusion that model tuning was just as important as model selection. The major limitation of the research is that while it provides valuable post hoc interpretation of transformer hyperparameters using explainable boosting machines, it focuses primarily on NLP tasks and does not evaluate the generalizability of the approach across other domains or model architectures. Furthermore, the authors in [
20] considered federated learning for predictive maintenance, which allows several factories to work together to build failure prediction models while maintaining data security and privacy. The work is however limited in that while it explores federated learning for predictive maintenance and quality inspection, the approach is primarily demonstrated in simulated environments, with limited validation on real industrial systems and no in-depth analysis of communication or system heterogeneity challenges. Furthermore, the authors in [
21] utilized Explainable Boosting Machines (EBMs) and suggested an interpretable predictive maintenance framework that strikes a balance between transparency and accuracy. Their framework demonstrated that explainability-driven models could facilitate improved maintenance decision-making in regulated environments after being evaluated on multi-site industrial data. The main limitation of the study is that although InterpretML provides a unified framework for interpretable machine learning, it offers limited support for deep learning models and unstructured data types, such as images and text, restricting its use in more complex applications.
From early statistical models to contemporary deep learning techniques, predictive maintenance research has made tremendous progress. However, a critical gap still exists in the creation of proactive, interpretable, and generalizable models that successfully strike a balance between practical deployment constraints and predictive accuracy. Earlier studies that utilized Transformers, CNNs, and LSTMs have shown remarkable forecasting ability in controlled settings. Many of these models, however, are highly reliant on domain-specific embeddings or large-scale, labeled time-series data, which restricts their applicability in many industrial contexts with disparate failure patterns and data architectures. Further, techniques such as TCNs or federated learning frequently put scalability or sequence modeling capability ahead of transparency, which is becoming more and more important for high-stakes decisions in industrial settings.
In order to close this gap, this study proposes a proactive prediction framework that combines XGBoost with Neural networks, and is backed by strong cross-validation, class balancing, and preprocessing techniques. The proposed framework incorporates interpretable machine learning (using LIME and SHAP) to explain failure predictions at both local and global levels, in contrast to many prior models that only concentrate on end-performance indicators. This study also emphasizes the following practical solution to the real-world problem of insufficient failure data: simulating diverse machine behavior using realistic yet synthetic datasets. This work contributes to a balanced, operationally ready approach to failure forecasting in predictive maintenance by balancing model performance with interpretability and transferability.
Although newer developments like generative adversarial networks and adaptive diffusion models have demonstrated promise in managing class imbalance and producing synthetic fault data [
22]; furthermore, they frequently have significant computing costs and lengthy reverse generation times. On the other hand, the hybrid strategy put forth in this work combines XGBoost and Neural Networks to obtain good recall and interpretability, with a notably reduced training overhead. The model improves reliability and usability for maintenance engineers by utilizing interpretable machine learning techniques like SHAP and LIME to offer both localized and global insights into failure forecasts. Compared to more computationally demanding methods, this is a useful and effective substitute.
3. Methodology
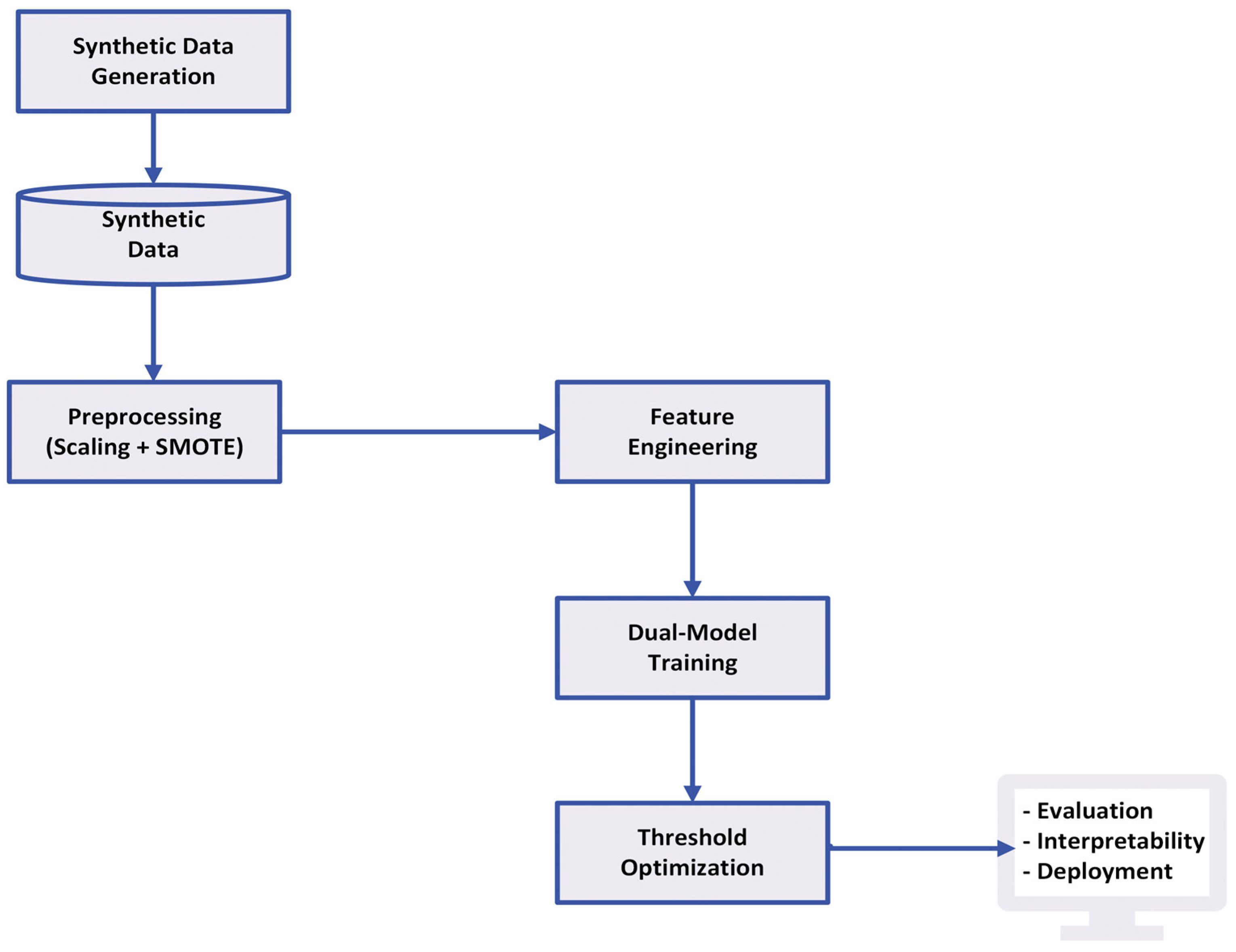
This section describes the detailed procedure used in this work, including data collecting, preprocessing, feature engineering, model construction, evaluation, and interpretability.
Figure 1 shows the process, beginning with synthetic dataset generation, which simulates realistic equipment failure scenarios to provide a robust foundation for model training. Preprocessing steps are then applied, including the use of SMOTE to handle class imbalance and scaling to normalize the data. For model training, both XGBoost and Neural Networks (NN) are employed in parallel to effectively capture complex failure patterns. Following this, threshold optimization is performed to balance precision and recall, ensuring well-calibrated decision thresholds. The evaluation phase involves metrics such as F1-score, precision–recall AUC, and the Confusion Matrix to comprehensively assess model performance. To enhance interpretability, SHAP and LIME are used to explain individual feature contributions and model predictions. Finally, the system is prepared for deployment with a human-in-the-loop framework, enabling practical and trustworthy real-world application.
3.1. Data Collection and Description
Synthetic data are deployed in research to replicate genuine industrial settings and preserve control over data quality and class distribution [
23]. This study utilized a synthetic machine failure dataset that was carefully constructed to simulate realistic maintenance conditions, including typical failure patterns and operational variables. Detailed information on the dataset generation process, as well as the generated dataset, is provided in
Appendix A and
Appendix B, respectively. The dataset considers time-stamped machine activity logs that show how many breakdowns occurred in the last 30, 90, and 180 days, as well as when the last failure occurred.
The dataset used in this study was synthetically generated to simulate failure and non-failure machine states over time. It comprises 12,000 instances and 18 features, including temporal indicators (e.g., time since last failure), operational variables, and simulated sensor outputs. Approximately 5% of the records represent failure events. To address this imbalance, we applied the SMOTE algorithm, increasing minority class instances to match majority class distributions.
We recognize that synthetic datasets might not accurately represent the noise and variability found in actual industrial settings, even while they enable controlled experimentation and solve issues with data scarcity and class imbalance. This was lessened by creating synthetic data that used time-stamped logs, realistic failure intervals, and operational conditions to replicate genuine machine behaviors. However, we acknowledge that external confirmation is necessary. In order to evaluate generalizability across machine types and failure patterns, future work will concentrate on refining and testing this model using actual industry datasets.
3.2. Data Preprocessing
The dataset was cleaned before modeling by eliminating unnecessary columns (such as raw timestamps and Machine ID) and using StandardScaler to normalize all numerical features for equitable scaling. Binary encoding of the target variable, “Failure,” was used (0 for no failure, 1 for failure). The Synthetic Minority Oversampling Technique (SMOTE) was used to rebalance the dataset because of the notable class imbalance (fewer failure cases) [
24] (
Appendix E contains the Python 3.13 codes).
3.3. Training and Testing Data Split
The dataset was split into training and testing sets using an 80:20 ratio to ensure that the model was trained on a sufficient portion of the data while preserving a representative subset for evaluating its generalization performance on unseen cases. Stratified sampling was employed during the 80:20 split to ensure that the proportion of failure and non-failure cases remained consistent across both the training and testing sets. This approach helps maintain class distribution, which is critical for model training and accurate evaluation, especially when dealing with imbalanced datasets. Model fitting and cross-validation were performed on the training set, and evaluation metrics were finally benchmarked against the testing set (
Appendix E contains the python codes).
3.4. Feature Evaluation and Importance Analysis
Preliminary analysis included the evaluation of feature correlations and the derivation of temporal breakdown indicators, such as recent failure windows, to capture patterns over time. Due to the controlled structure of the synthetic dataset, no features were eliminated. Instead, the contributions of individual features were assessed using SHAP values to gain insight into their impact on model predictions. Feature importance analysis confirmed that recent breakdown windows were dominant indicators of potential failures.
3.5. Model Development
For the classification task, the following two models were trained: a Neural network and XGBoost. This dual-model strategy ensures robust evaluation and helps determine whether the added complexity of deep learning yields meaningful gains over a powerful ensemble method like XGBoost. TensorFlow/Keras was used to create the first deep neural network. Three hidden layers with ReLU activation functions made up this model, which also included dropout layers for regularization to avoid overfitting. For binary classification, the output layer employed a sigmoid activation function. The problem of class imbalance was addressed by using class weighting and focal loss [
25] (Equation (1)), the latter of which balanced class importance while directing the model’s learning toward more challenging examples.
where
pt is the predicted probability for the true class
α is deployed to balance the class importance
γ aims at learning on harder/difficult/challenging examples
The XGBoost classifier was the second model, and GridSearchCV was used to tune its hyperparameters [
26]. Learning_rate, max_depth, n_estimators, and scale_pos_weight were among the parameters that were changed during the tuning process in order to improve performance and better manage class imbalance.
GridSearchCV, which does an exhaustive search over a specified parameter grid and chooses the configuration that delivers the best performance based on a scoring metric (in this case, F1-score), was used to undertake hyperparameter tweaking in order to increase model accuracy and avoid overfitting. The XGBoost classifier’s top-performing hyperparameters were as follows:
learning_rate = 0.1: Regulates the learning step size; reliable convergence is guaranteed by a reasonable value.
With max_depth = 7, the model may capture intricate patterns without going overboard with overfitting.
n_estimators = 300: The more trees there are, the greater the learning potential.
weight_scale_pos_5: Giving the minority (failed) class more weight during training is a crucial component for resolving class imbalance.
By reducing false alarms and improving precision–recall trade-offs, these modified parameters allowed the model to more accurately identify infrequent failure events.
Appendix E contains the codes for the model development.
3.6. Model Performance Evaluation
To evaluate the model’s resilience across several data splits and guarantee that the minority class was consistently represented, stratified K-Fold Cross-Validation (k = 5) was employed. With an emphasis on attaining high recall and F1 for the minority failure class, performance indicators included accuracy, precision, recall, F1-score, and precision–recall AUC (PR AUC). After prediction, threshold optimization was used to strike a balance between recall and precision.
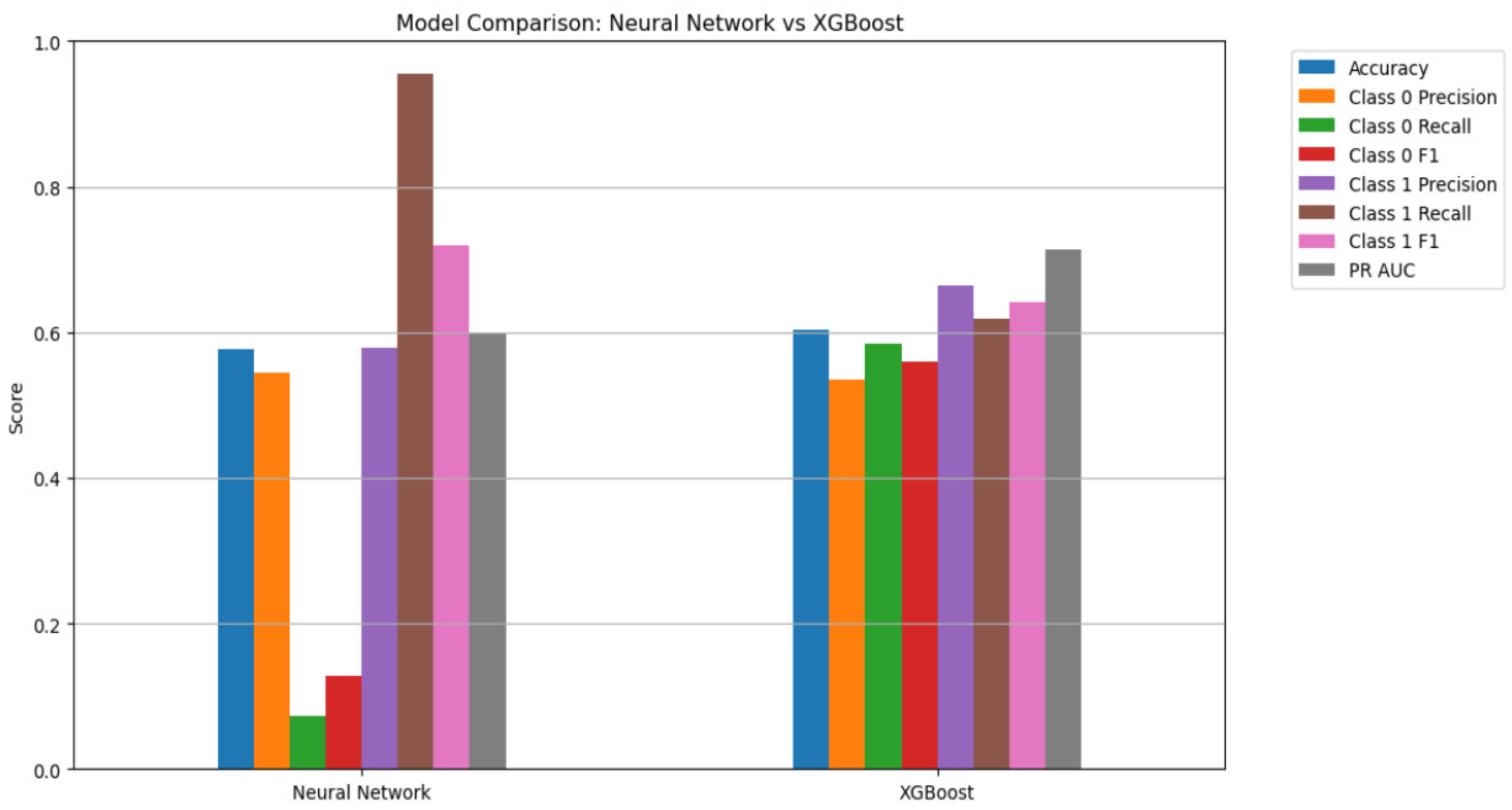
Using stratified k-fold cross-validation, the model’s resilience and equitable generalization across various data partitions were guaranteed. In order to maintain the proportion of the target classes, this method splits the dataset into k equal-sized folds, balancing the amount of failure and non-failure cases in each fold. The model was trained and assessed using a variety of training and validation split combinations, using k = 5. Across all folds, the average F1-score was 0.630. In situations involving imbalanced classification, such as failure prediction, this performance metric shows a great balance between accuracy (the capacity to prevent false positives) and recall (the capacity to identify real failures). The high F1-score indicates that the model performs consistently across unseen data subsets and is not unduly biased toward the majority class.
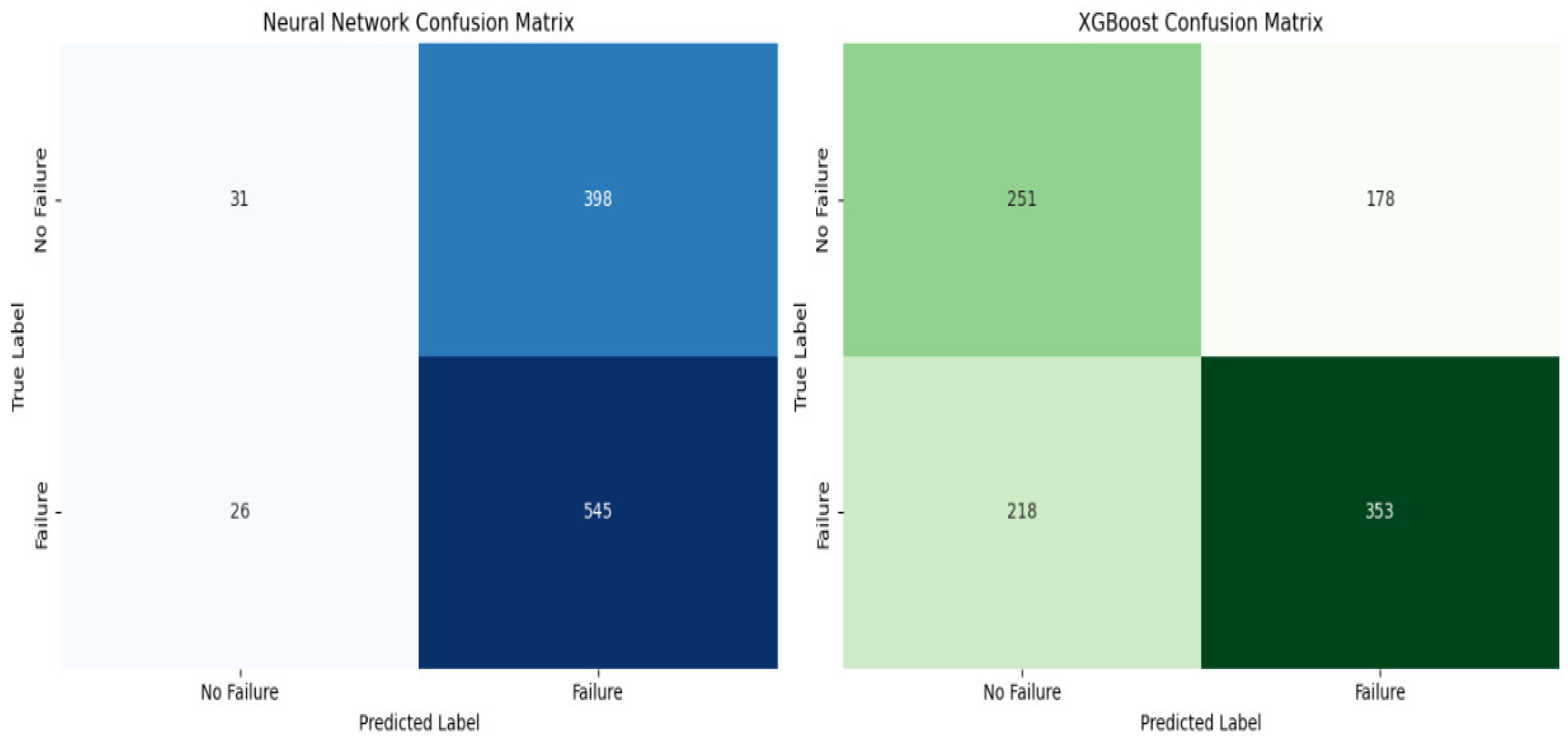
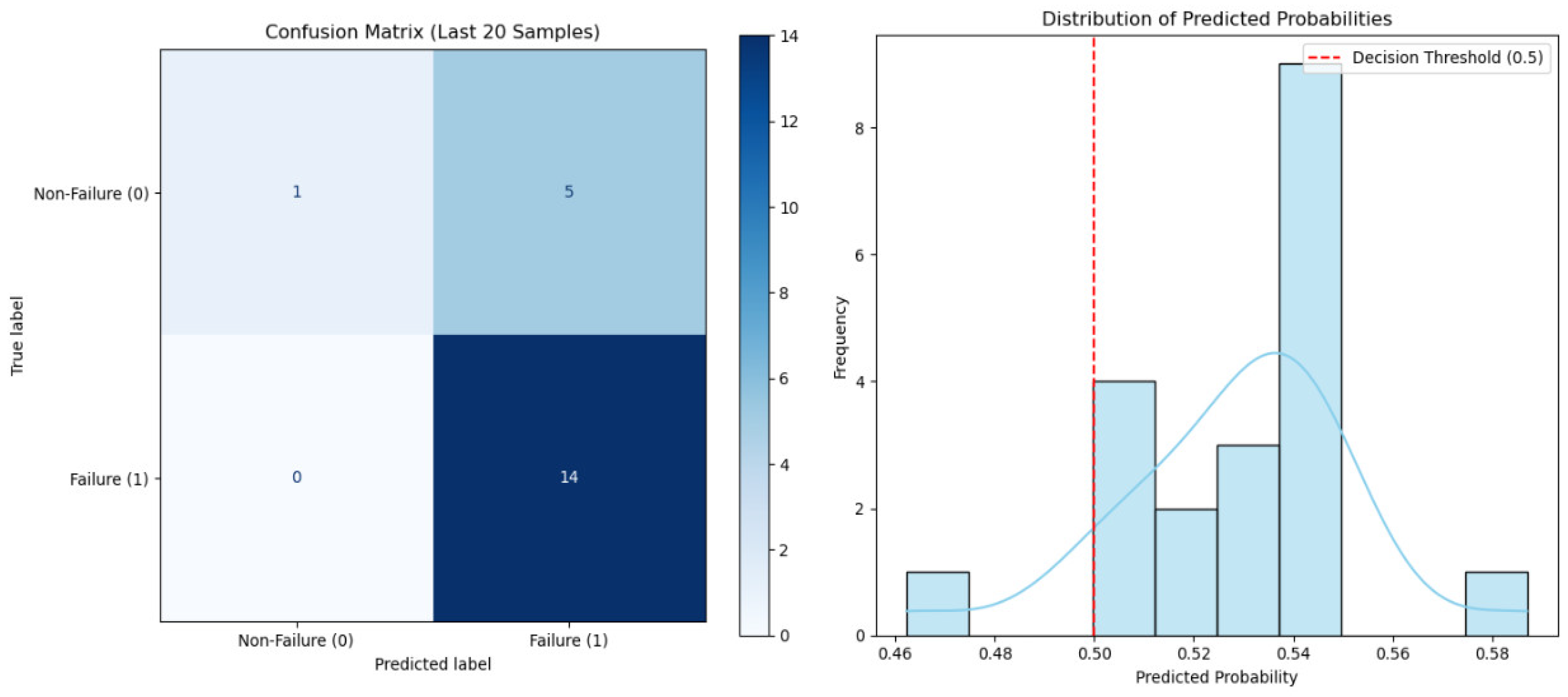
To evaluate the performance of the classification models, the Confusion Matrix and Classification Report were utilized to report performance. The Confusion Matrix assists in measuring how well the model is able to predict. For this study, the emphasis was on true positive (TP), which aids in detecting the actual failure. The Classification Report on the other hand summarizes the performance metrics for each class. This is achieved using Equations (2)–(4).
where
Precision measures the accuracy of positive predictions by prompting the following question: ‘of all predicted failures, how many were correct?’
where
Recall measures the ability of the model to capture all positive occurrences by prompting the following question: ‘of all actual failures, how many did we catch?’
The F1-score is the harmonic mean of both the precision and recall metrics. It balances both well when classes are imbalanced
3.7. Interpretability and Explainability
Two explainability strategies were used to improve the transparency and reliability of the model. First, local, instance-level interpretations of the model’s predictions were produced using Local Interpretable Model-Agnostic Explanations (LIME) (
Figure 4). This confirmed that characteristics like time since last failure and Breakdowns in the Last 30 Days had a substantial impact on decision limits and helped identify the essential features influencing individual classifications [
27].
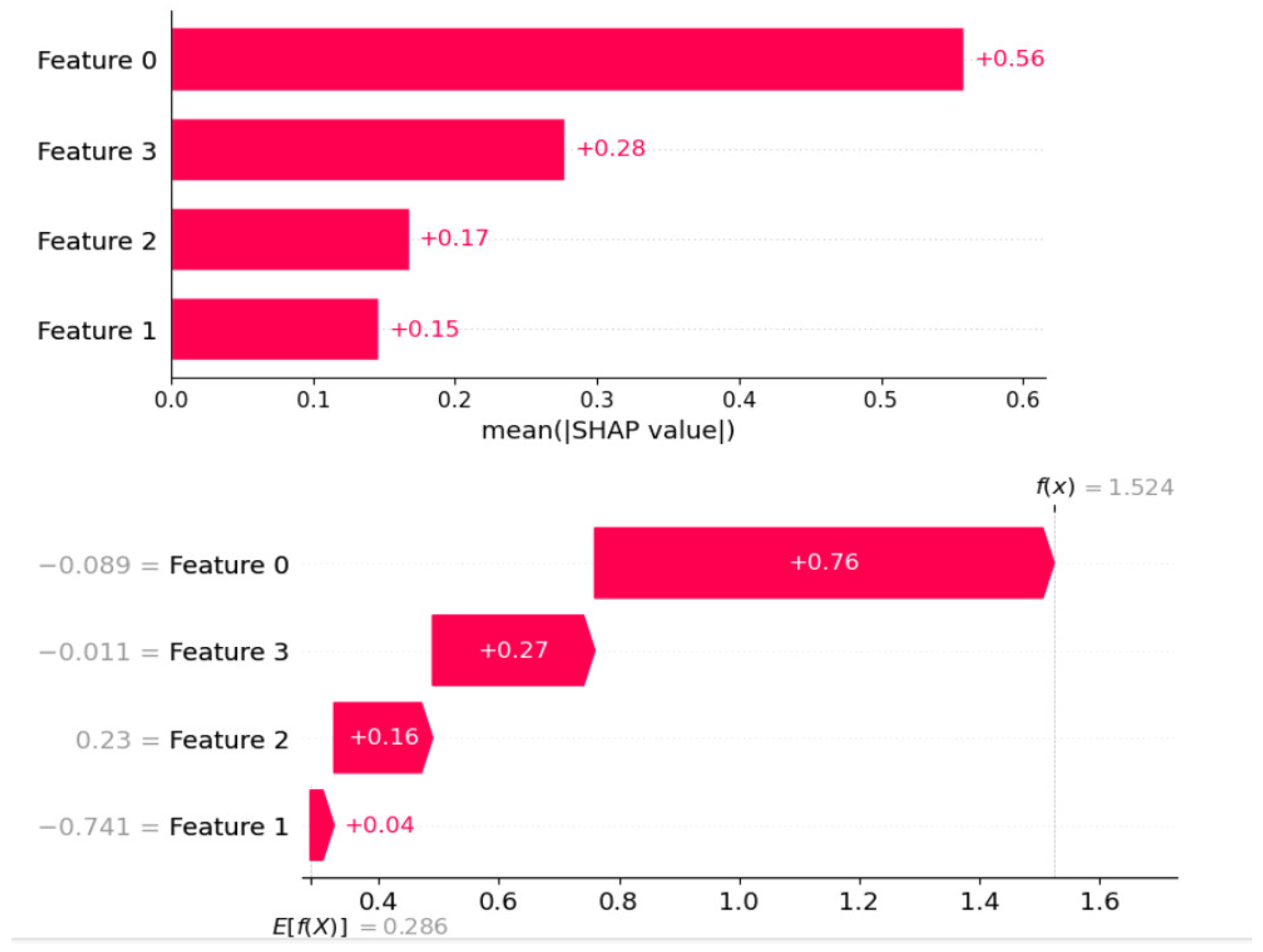
Second, both local and global interpretability were provided using SHapley Additive exPlanations (SHAP) (
Figure 5). The model’s dependence on intuitive and pertinent input features was demonstrated by the summary and waterfall plots that resulted from SHAP’s assignment of importance scores to each feature according to their contribution to the prediction [
28]. When combined, these techniques showed that the model was reliable, comprehensible, and accurate for predictive maintenance scenarios.
5. Conclusions, Recommendations, and Suggestion for Further Research
5.1. Conclusions
This study demonstrated the development of a proactive predictive model for machine failure prediction can be created by utilizing a hybrid strategy that blends XGBoost (XGB) with Neural Networks (NN). The model was trained using a synthetic dataset that mimics actual maintenance situations and includes important temporal characteristics like the duration since the last failure and current breakdown history. Class imbalance was handled by applying focus loss and class weighting, and model behavior was transparently revealed via interpretability tools like SHAP and LIME.
When benchmarked against traditional classifiers (Logistic Regression, Random Forest, SVM), the hybrid approach outperformed all baselines in key metrics such as F1-score and PR AUC, with the neural network achieving the highest recall and F1, and XGBoost yielding the highest precision and PR AUC. These results validate the hybrid model’s practical advantage in real-world predictive maintenance applications, striking a strong balance between sensitivity, specificity, and interpretability.
5.2. Recommendations
Based on the study’s findings and reviewers’ insights, a number of important suggestions are made to improve the predictive model’s accuracy, applicability, and dependability.
First, in order to increase the accuracy of the model’s predictions, threshold optimization ought to be used. Despite having a high recall, the current decision threshold of 0.5 results in a high false positive rate. Cost-aware thresholding techniques are recommended to achieve a better balance between recall and precision, especially in industrial settings where costs are a concern. These include cost-based threshold optimization techniques, in which the relative importance of false positives and false negatives is used to determine threshold values using domain-specific cost matrices. Furthermore, methods like precision–recall curve analysis can be employed to determine thresholds that optimize measures like the F1 or Fβ score, and statistical tools like Youden’s index and ROC curve interpretation provide ways to balance specificity and sensitivity. Using these approaches can greatly lower false alarms and boost trust in AI-assisted decision-making in predictive maintenance systems.
Second, it is imperative that the model be expanded to include more discriminative properties. By strengthening the model’s capacity to differentiate between failure and non-failure scenarios, the addition of further discriminative features such as temperature, vibration levels, usage load, or component health indicators can greatly increase the model’s accuracy. Nevertheless, adding such variables invariably raises the computing cost and complexity of the model. It is advised to use feature selection strategies, such as mutual information analysis, recursive feature elimination, or SHAP-based ranking, to lessen these difficulties and keep only the most significant variables. Additionally, to lessen the computational load without compromising accuracy, post-training model pruning techniques or lightweight modeling methodologies might be used. Using edge computing frameworks or hybrid cloud–edge architectures can guarantee real-time inference while maintaining system efficiency for deployment in settings with constrained computational resources.
Thirdly, to avoid performance deterioration over time, it is advised that the model be regularly retrained using updated or real-time data. Adaptive and planned retraining procedures are crucial for maintaining model performance in dynamic and changing industrial situations. Concept drift detection methods like ADWIN or the Drift Detection Method (DDM), which can detect changes in data distribution over time, should be used to guide retraining rather than depending just on predefined intervals. Furthermore, performance-based triggers can be used as signs to start retraining, such as observable declines in precision, recall, or other important evaluation measures. In order to keep the model responsive to slow operational changes and new failure patterns, frequent retraining windows (such as weekly or monthly) that correspond with industrial maintenance cycles can be used in addition to adaptive methods.
In order to guarantee secure and knowledgeable decision-making, particularly in the early stages of deployment, a human-in-the-loop strategy is advised rather than complete automation. The predictive model serves as a decision-support tool in this setup by producing outputs that are accompanied by textual or visual explanations, like those offered by SHAP or LIME. Maintenance engineers are able to examine every alarm, confirm or contradict forecasts, and offer contextual feedback based on domain knowledge thanks to these insights. In order to promote continuous progress, such input might be methodically incorporated into upcoming model upgrades. Furthermore, by implementing security measures like interface anonymization and multi-user cross-validation, predictive maintenance systems can be made more trustworthy, transparent, and accountable by reducing automation bias and avoiding an excessive dependence on algorithmic outputs.
Lastly, an alert prioritizing mechanism should be incorporated into the predictive maintenance system to reduce operator fatigue brought on by an excessive number of false positives. The model’s output probability scores, asset criticality, the expected severity of possible failures, and forecast confidence should all be taken into consideration when ranking alerts. Maintenance staff can more effectively prioritize interventions, interpret alerts, and manage resources by incorporating these rankings into an intuitive dashboard interface. This method not only increases operational responsiveness, but also boosts the AI system’s usability and credibility in actual industrial environments.
If these recommendations are reckoned with, accuracy, dependability, and usability, particularly in minimizing false alarms in practical predictive maintenance system, will be highly achieved.
5.3. Suggestions for Further Research
Although the hybrid predictive model for machine failure forecasting presented in this paper shows promise, there are still a number of directions that future research might take to improve its usefulness and efficacy.
Future research should focus on investigating ensemble modeling methods other than the current combination of XGBoost and Neural Networks. Combining ensemble techniques like bagging, stacking, and boosting with a larger pool of base learners, such as LightGBM, or even attention-based models, may increase resilience by utilizing the advantages of several algorithms. Moreover, ensemble learning can enhance generalization across various machine types or failure patterns and decrease variation, particularly in diverse industrial settings.
Applying transfer learning techniques, which can lessen reliance on sizable, labeled datasets, is another crucial research trajectory. The infrequency and unpredictable nature of failure events make it difficult to collect failure data in many industrial settings. Through refinement of a pre-trained model using a small domain-specific dataset, transfer learning can assist in the development of flexible models that can adapt to new machine kinds or operating situations while retaining learnt information. Businesses that oversee fleets of various pieces of equipment spread across many locations would find this method especially helpful.
Additionally, this work simulates real-world failure scenarios using synthetic datasets. Future research should try to confirm the suggested model on real-world sensor data from working industrial machinery, vehicular machines, electronic machines, etc., even though synthetic data enables controlled experimentation. In addition to helping determine the model’s viability in terms of system integration, alert fatigue, and real-time responsiveness, real-world deployment and evaluation would offer crucial insights into how the model behaves in situations including noisy, incomplete, or aberrant data.
The use of explainable AI frameworks with feedback loops is another potential topic for future research. Although SHAP and LIME have demonstrated efficacy in post hoc interpretation of model predictions, including them into an operational system that permits domain experts to offer input on the accuracy or pertinence of the explanations can be a potent method for model enhancement. These systems have the potential to develop into interactive learning environments where human knowledge and machine predictions combine to iteratively improve decision-making and model transparency.
Researchers should also look into the application of federated learning to predictive maintenance, particularly in industrial settings where data security and privacy are critical. Without sharing raw data, federated learning allows several dispersed organizations (like factories or production units) to work together to train a common model. In addition to improving data privacy and compliance, this strategy makes it possible to share knowledge between sites with comparable operational traits.
Finally, investigating the optimization of interpretability–performance trade-offs may be beneficial for future research. Deep Neural Networks and other complicated models have a great prediction capability, yet they frequently behave like black boxes. Simpler models, on the other hand, provide transparency, but could perform poorly on challenging tasks. In predictive maintenance contexts, studies that methodically contrast interpretable models (such as Explainable Boosting Machines or rule-based learners) with their black-box counterparts may result in the creation of well-balanced frameworks that provide high-accuracy and stakeholder trust.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}