
Explainable Data Mining Framework of Identifying Root Causes of Rocket Engine Anomalies Based on Knowledge and Physics-Informed Feature Selection


Abstract
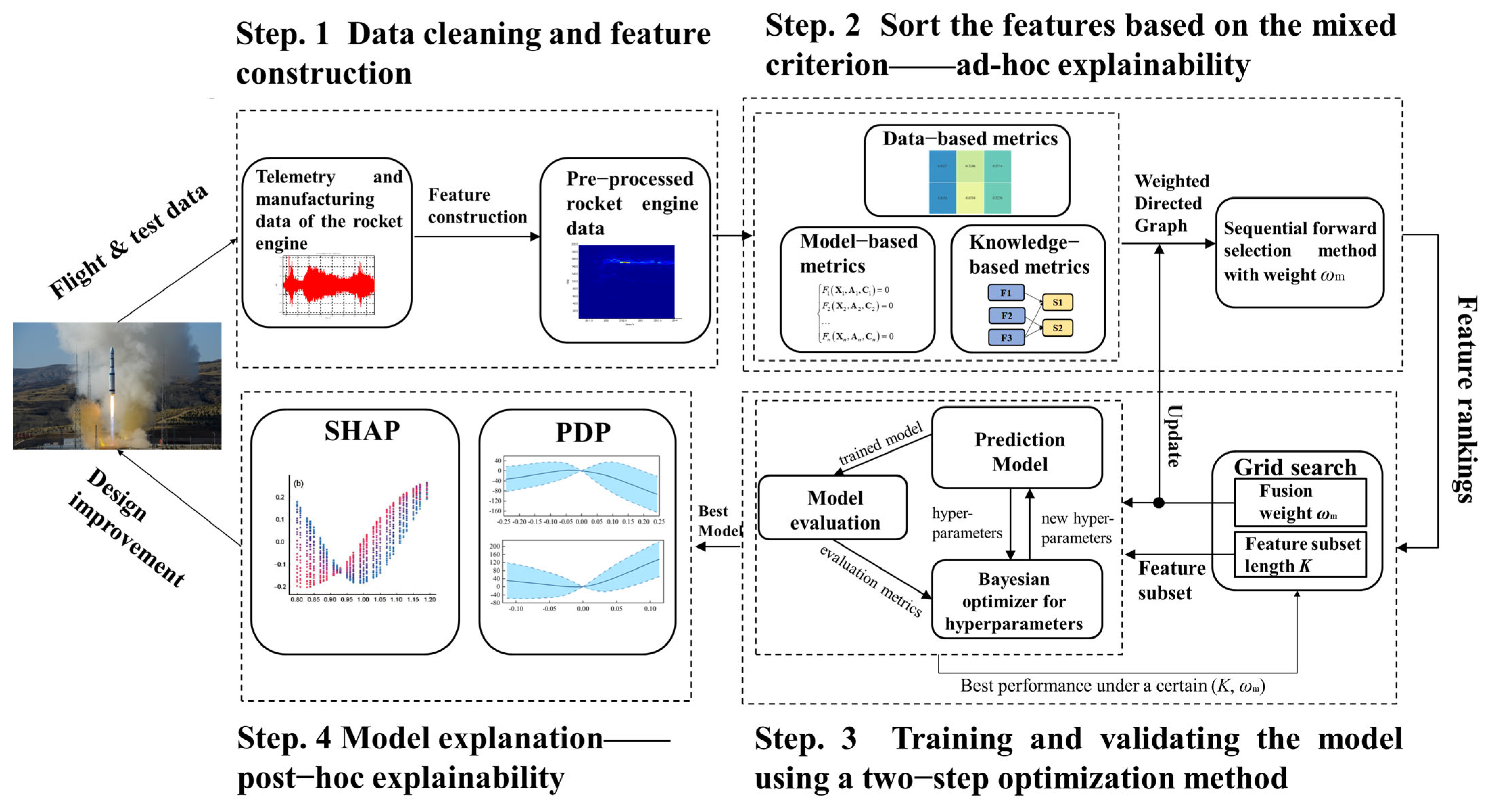
1. Introduction
2. Data Processing and Feature Construction
3. Hybrid Feature Selection Method Integrating Simulation Model, Knowledge, and Data
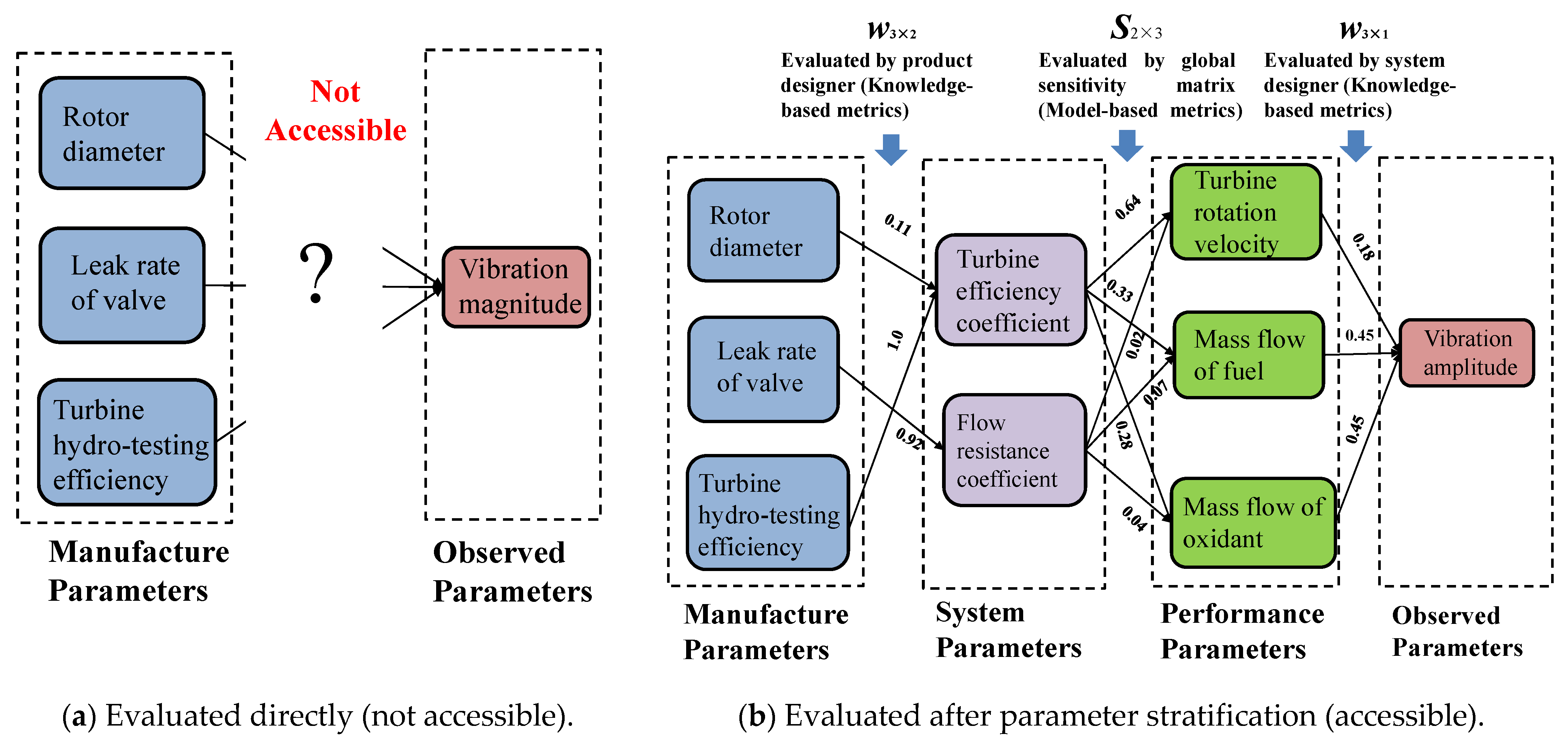
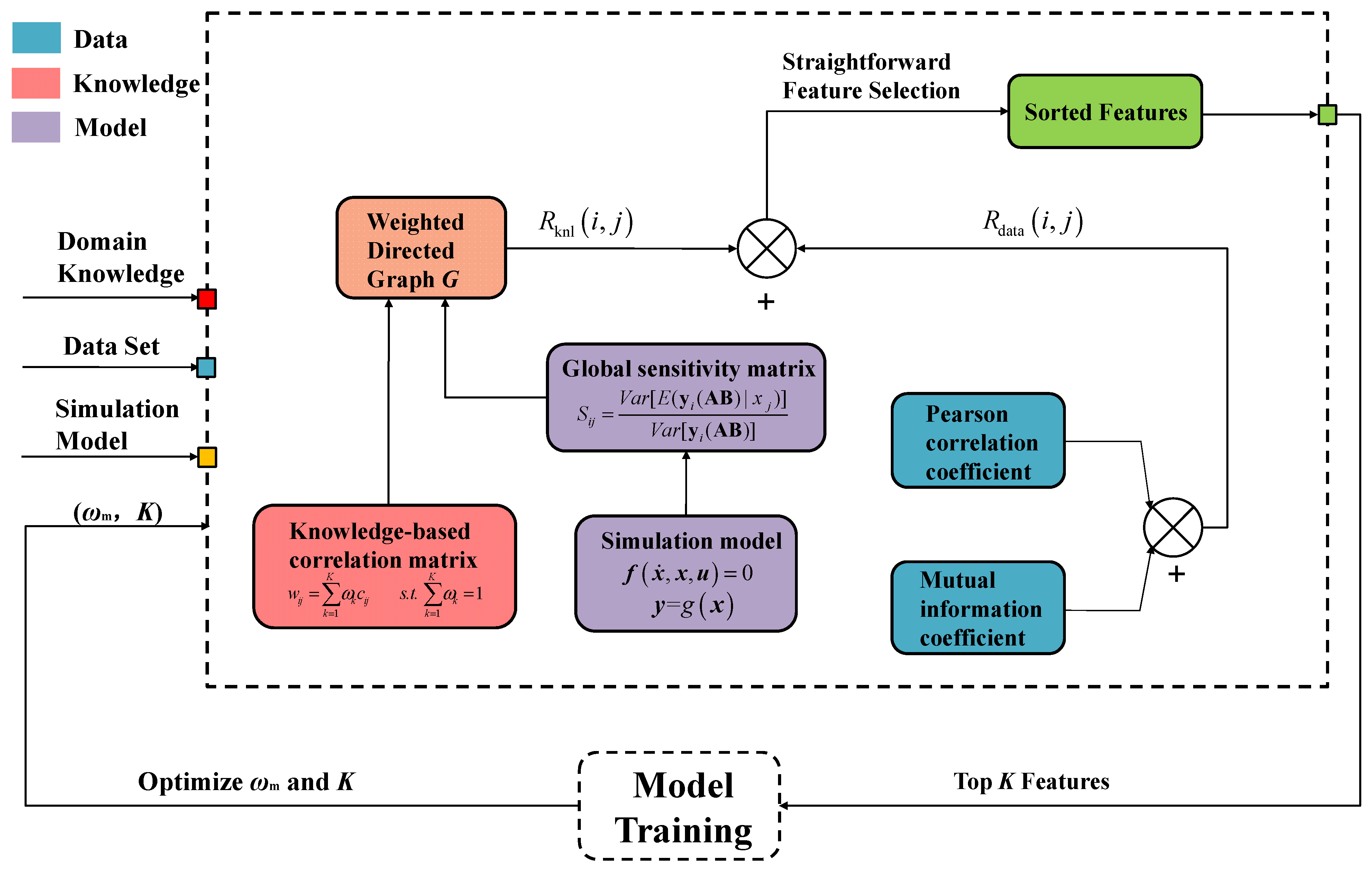
3.1. Model and Knowledge-Based Feature Evaluation Metric
3.1.1. Model-Based Metric
3.1.2. Knowledge-Based Metric
3.2. Data-Based Feature Evaluation Metric
3.3. Hybrid Feature Selection Method Based on Hybrid Metrics
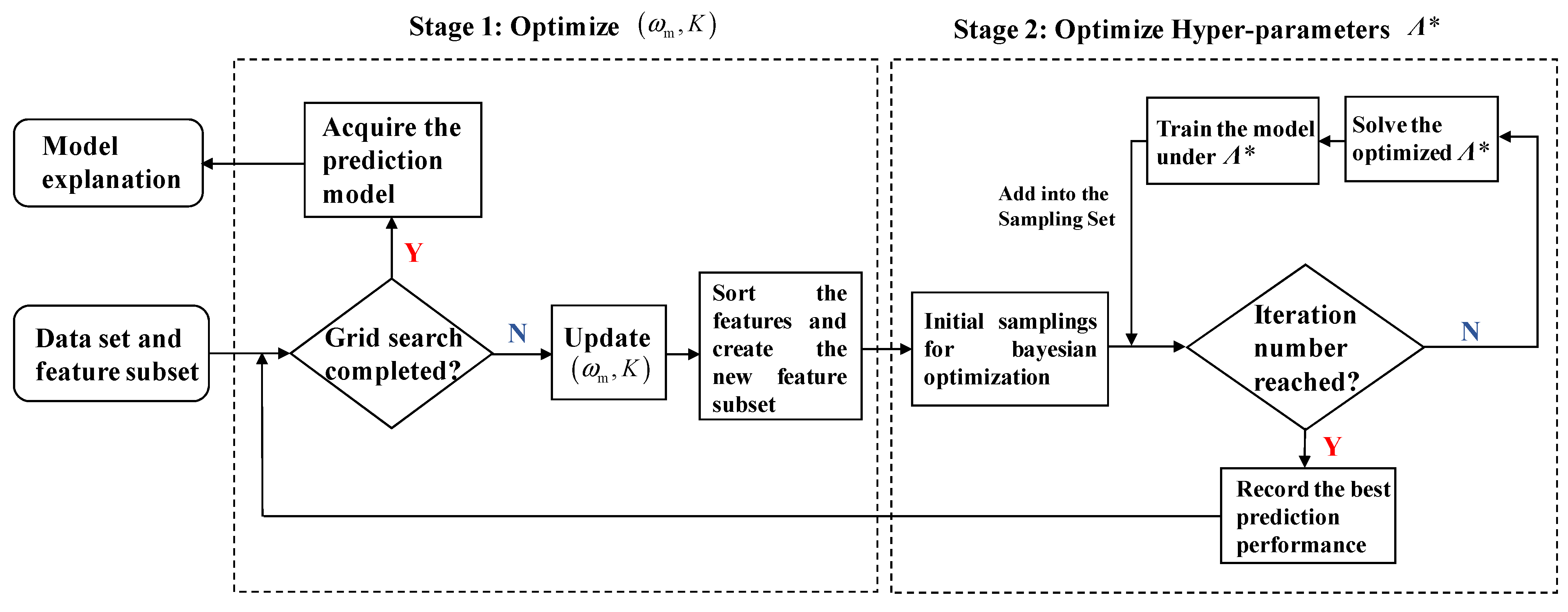
4. Training and Explanation of the Prediction Model
4.1. Model Training and Two-Stage Optimization
4.2. Model Explanation
5. Case Studies and Discussion
5.1. Validation of the Feature Selection Method Using Synthetic Data
- (1)
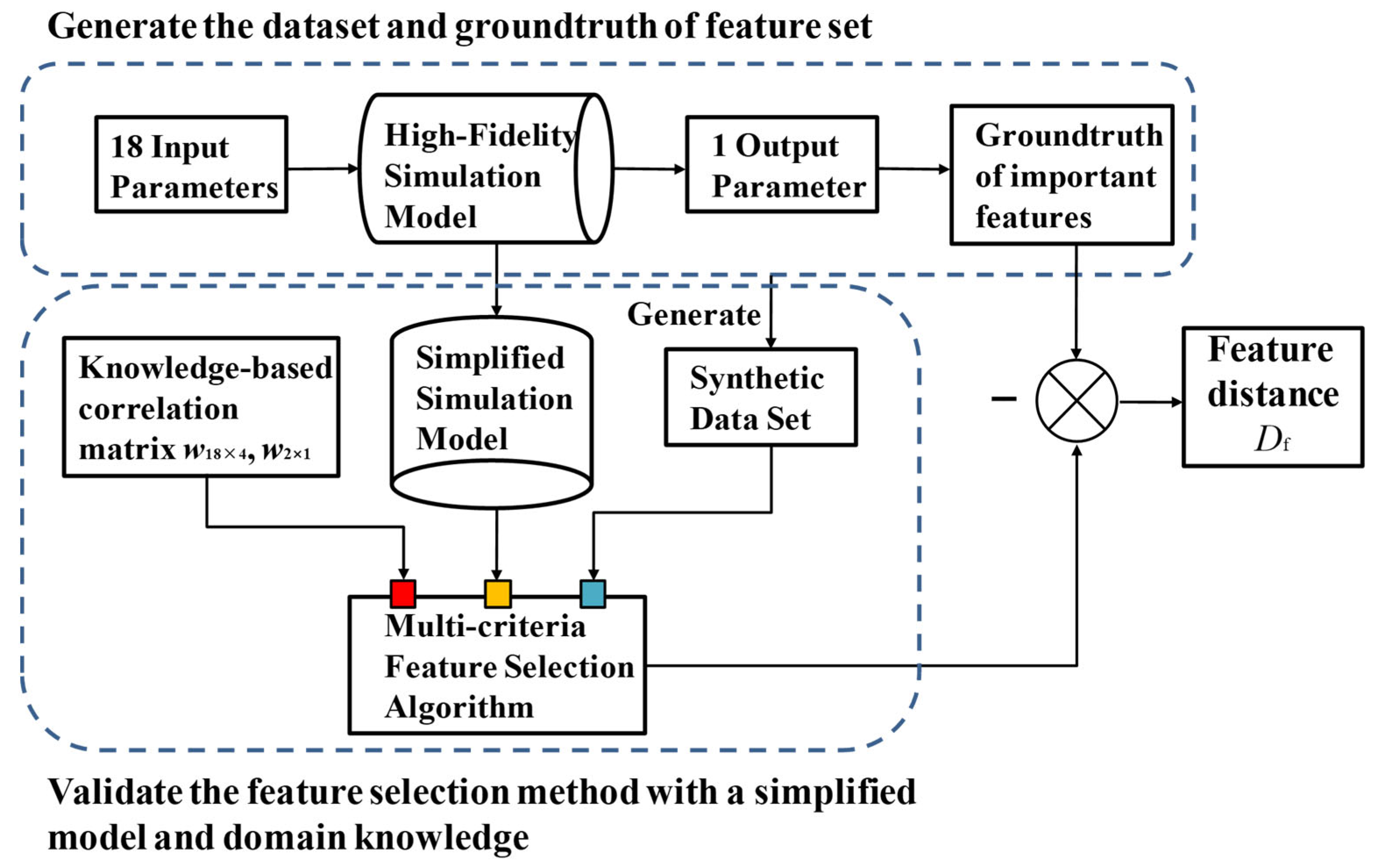
- Determine the input parameters (serve as manufacturing process parameters) and output (serve as observed parameters), build the simulation model, and select the prior key features: select 18 parameters as input and the expected leaky rate of the solenoid valve as output. Establish a high-fidelity simulation model of the pressurization system, calculate the time of valve actions, and eventually obtain the expected leaky rate of the solenoid valve. Then select n key features based on reliable engineering experience.
- (2)
- Generate the data set: determine the fluctuation range of input parameters, use hypercube sampling to form the sampling matrix, and input the simulation model to obtain the training set.
- (3)
- Build the simplified simulation model and three types of correlation matrices: assuming that the high-fidelity simulation model is unknown, construct a simplified simulation model that does not contain all input and output parameters. The simplified model in this paper is shown in Equations (32)–(34).where tr represents the average time for the first opening and closing cycle of the electric valve, and Pctr represents the pressure control bandwidth. The input of the simplified model is considered as system parameters, and the output is considered as performance parameters. The input parameters and output parameters of the high-fidelity model in step (1) are considered manufacturing process parameters and observed parameters, respectively. Evaluate the correlation between 18 high-fidelity model input parameters and the simplified model input parameters and the correlation between the simplified model output and the solenoid valve life using current engineering experience. Calculate the correlation between the simplified model input and output parameters using model-based global sensitivity analysis, and finally form three types of correlation matrices.
- (4)
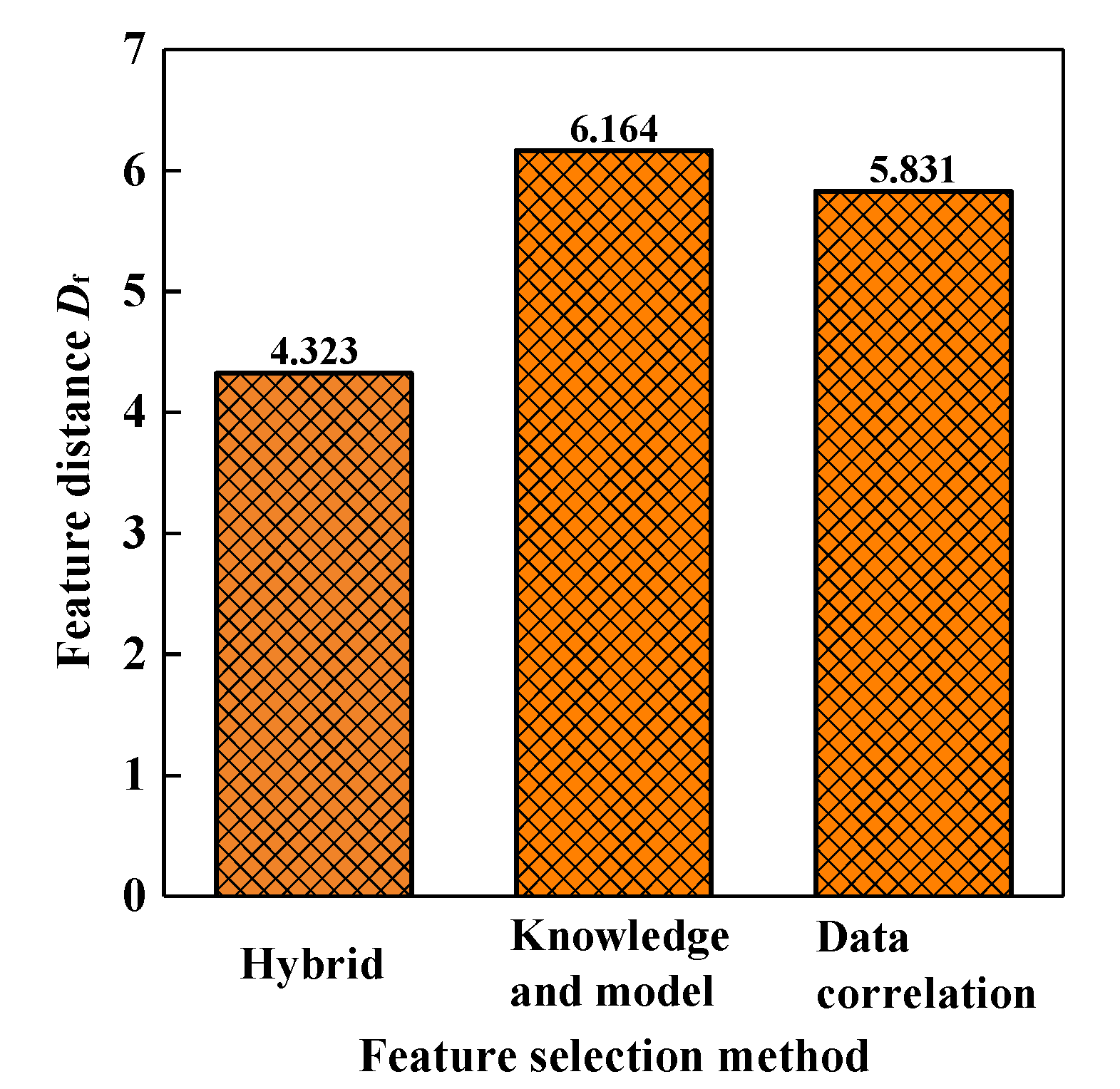
- Perform feature sorting and calculate feature selection performance evaluation metrics. Based on the sensitivity matrix and the knowledge-based correlation matrix obtained in the previous step, use different feature selection methods to rank the features (which are the 18 input parameters). Let fsort be a set composed of the serial numbers of the top n important features after sorting, and calculate the Euclidean distance between fsort and the groundtruth feature set ftrue as the feature sorting performance evaluation metric Df, as shown in Equation (35). The smaller the feature distance Df, the closer the feature sorting obtained by the feature selection method is to the groundtruth feature sorting, the better the method performs, and vice versa.where ftrue = [1, 2, …, n], n is the number of key features. The validation process for feature selection methods is shown in Figure 6.
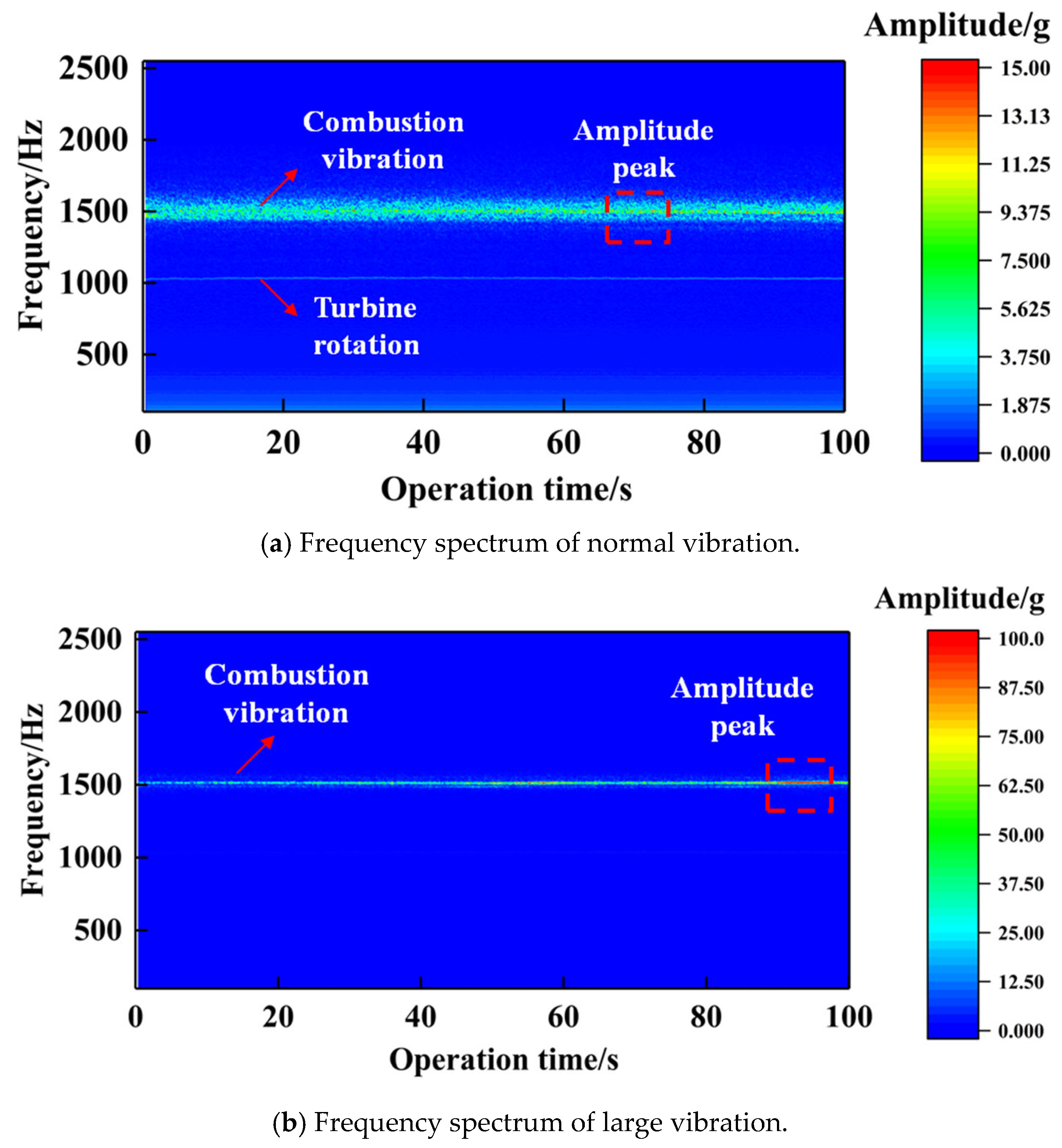
5.2. Data Mining of Large Vibration in an Active Rocket Engine
6. Conclusions
- (1)
- Under different combinations of cognitive biases of knowledge and data noise, the hybrid feature selection method is always superior to one of the two single methods with poorer performance and performs better than any single method under specific noise conditions. However, the performance is not good when there is a large difference in magnitude between the two kinds of noise. In addition, as ωm increases, the high-performance region of the fusion feature selection method gradually moves towards the direction of larger data noise.
- (2)
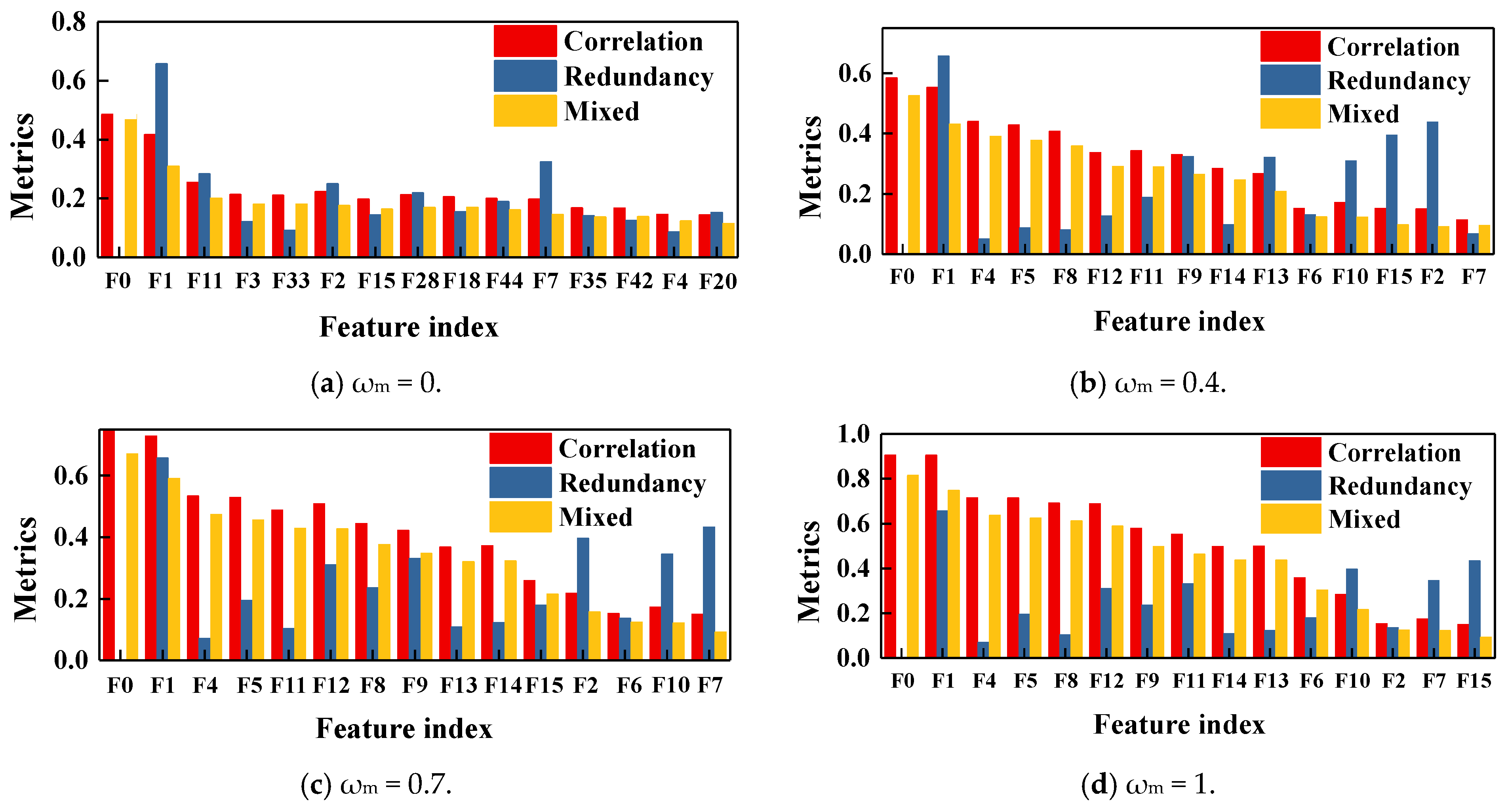
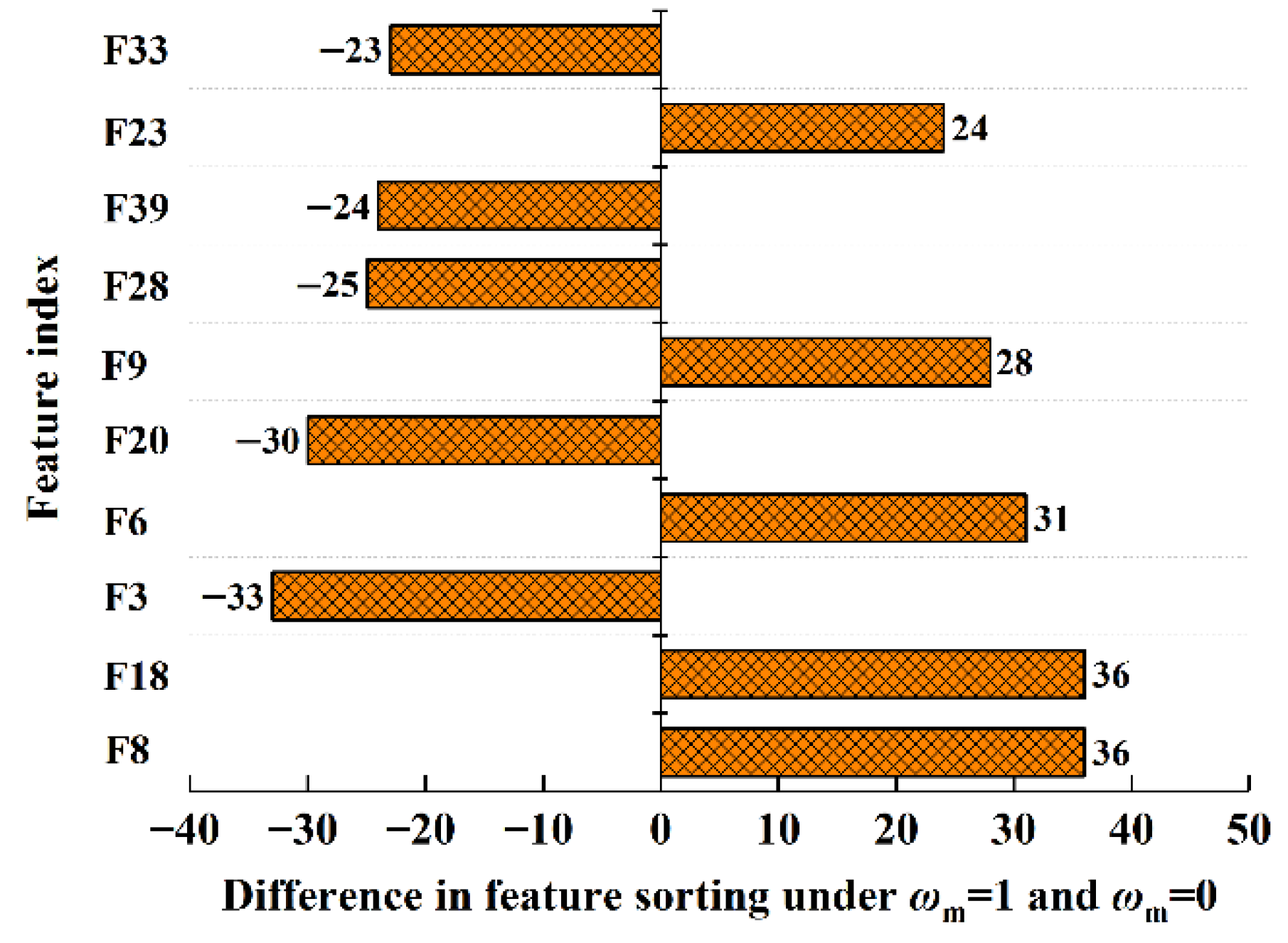
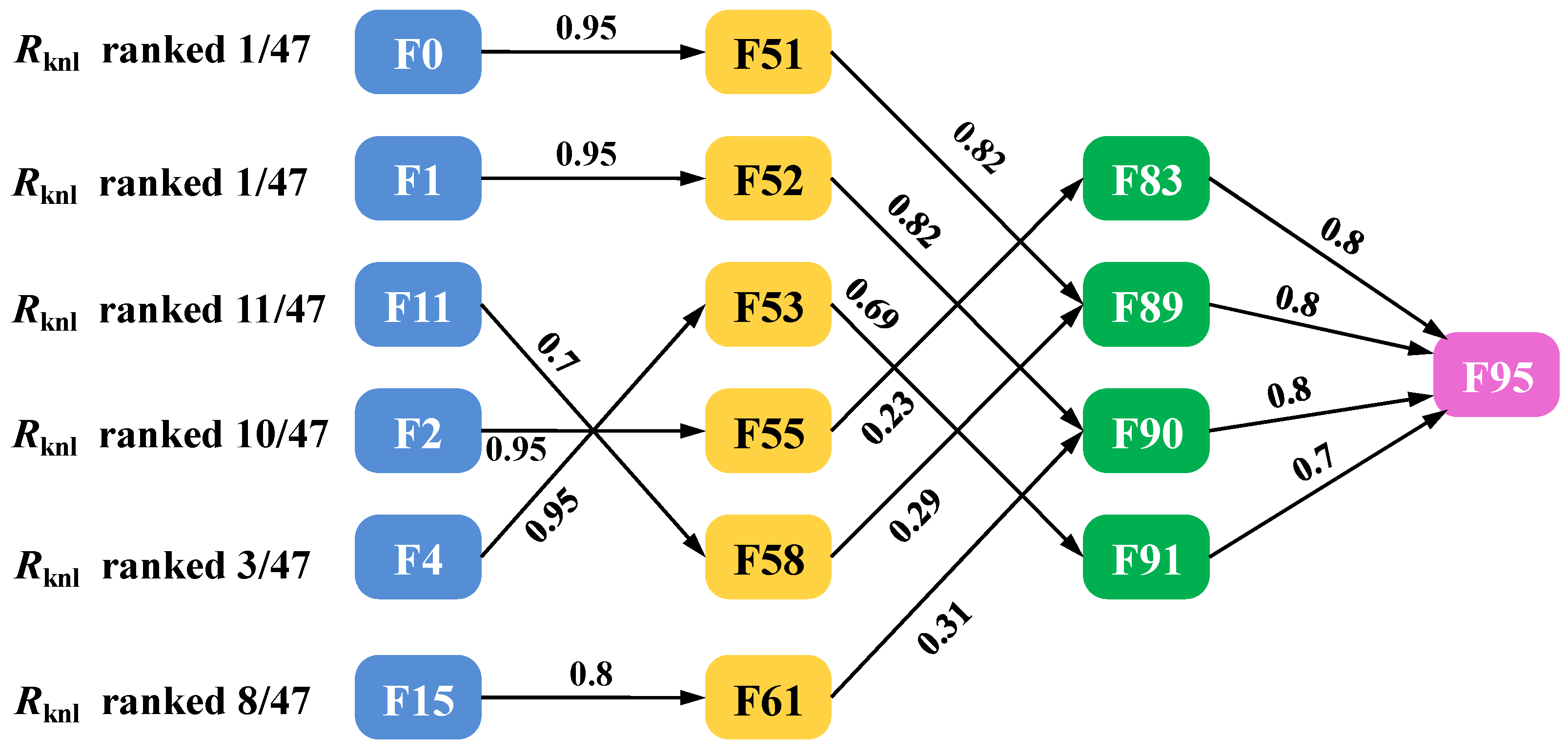
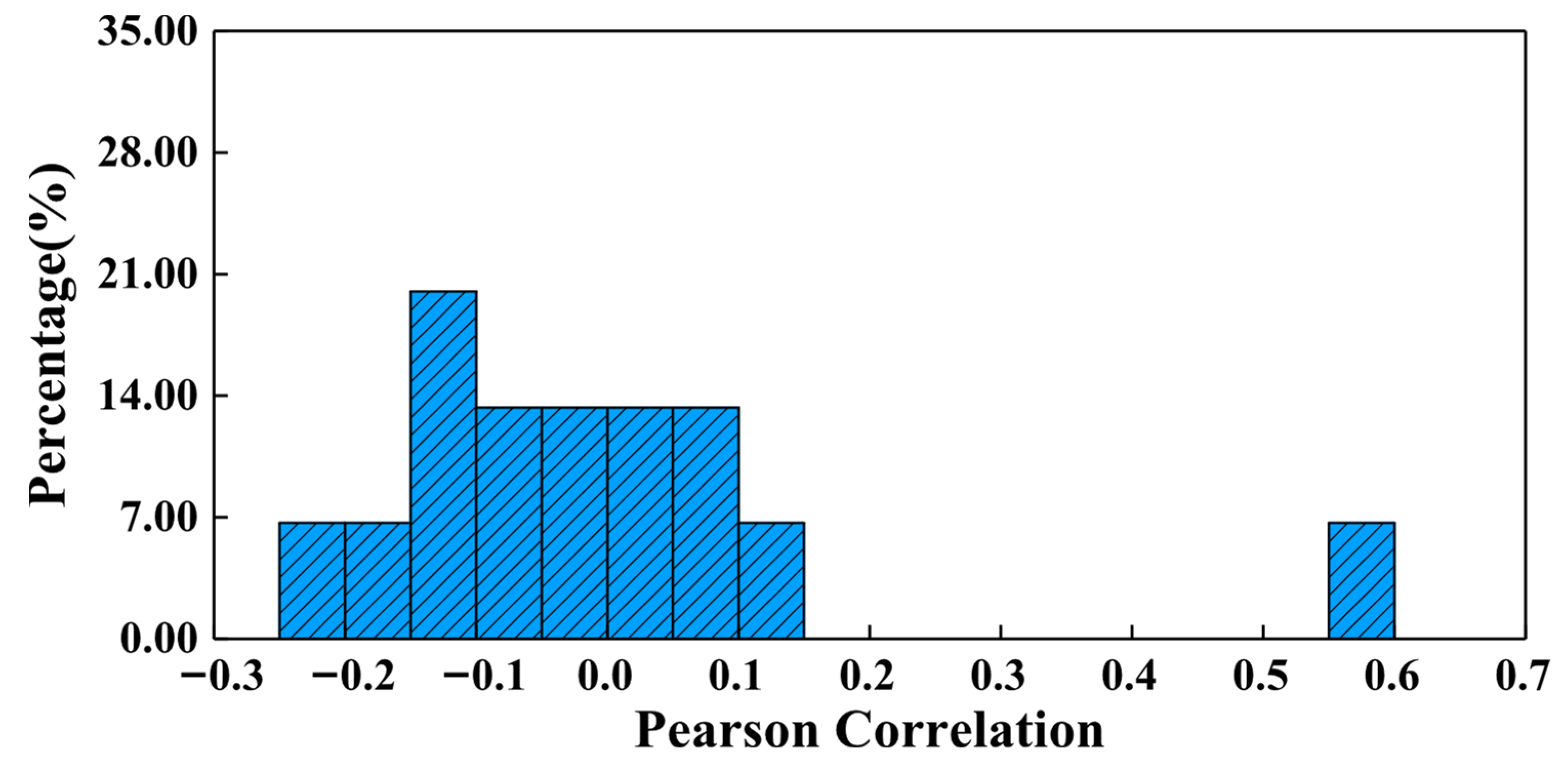
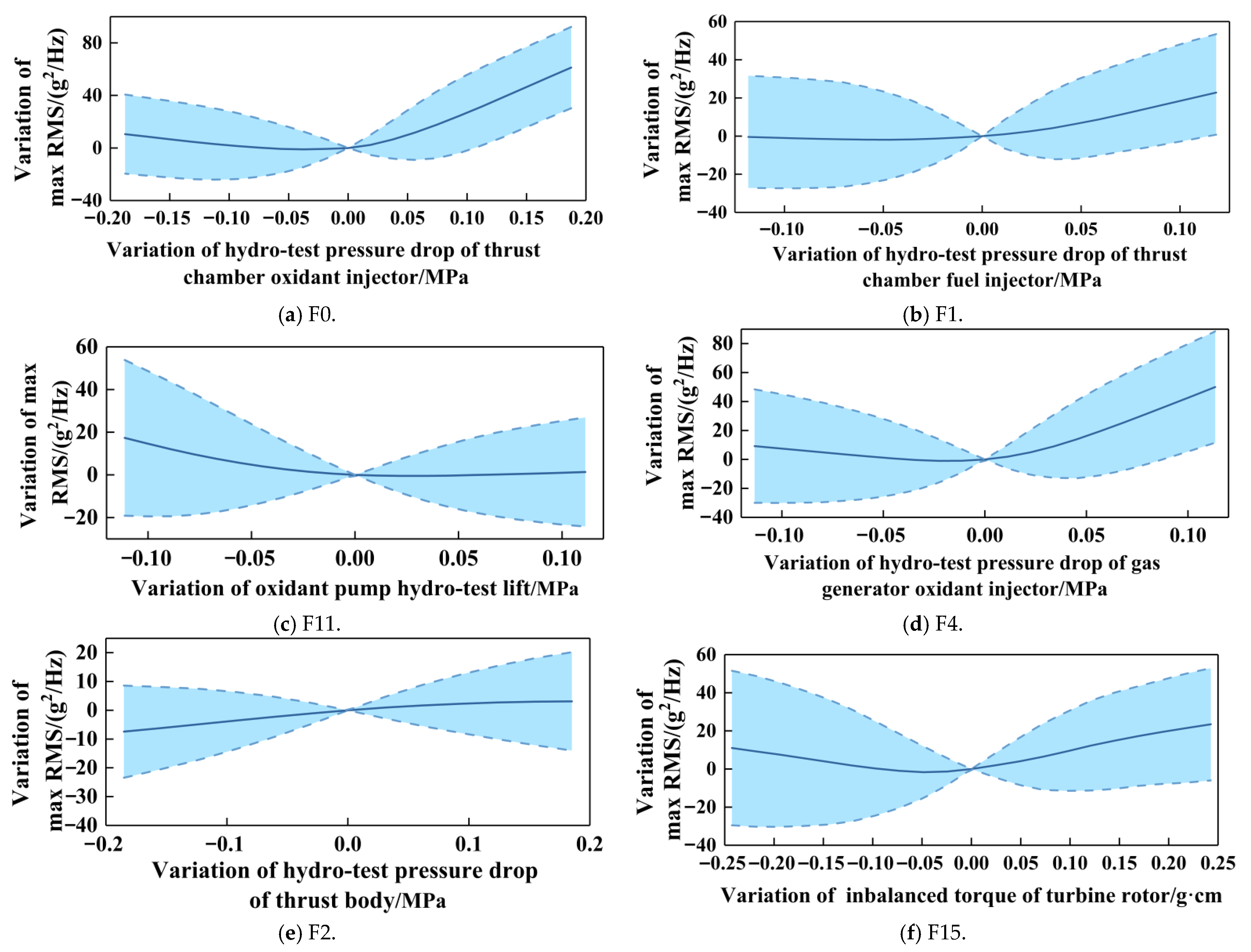
- Analysis of the data of a certain active engine shows that there are significant differences between the feature selection result based on existing expert knowledge (ωm = 0) and the feature selection result based on data correlation (ωm = 1). As the knowledge and model weight ωm gradually increase, the ranking of features related to hydraulic testing significantly grows. This indicates that the knowledge and model methods pay less attention to the data, such as dimension chain data and leaking rate data, making it easier to overestimate the importance of hydraulic testing data. By traversing the values of fusion coefficient ωm and the length of the feature subset K, when ωm = 0.2 and K = 6, the root mean square error of the prediction model is the lowest (0.168). According to the knowledge and data graph, all of the selected features have a clear mechanism towards the large vibration phenomenon, and model and knowledge-based correlation metrics of these features ranked in the top 25% of all features. Among the six features, two turbo-pump parameters change the pump lift by influencing the pump efficiency constant, thereby affecting the pressure and propellant mass flow and changing the boundary conditions of combustion; the four hydraulic testing parameters affect the injection pressure by influencing the pressure balance of the system, ultimately affecting combustion instability. The above results show that the feature selection results conform to the physical mechanism, and the prediction model has both accuracy and explainability.
- (3)
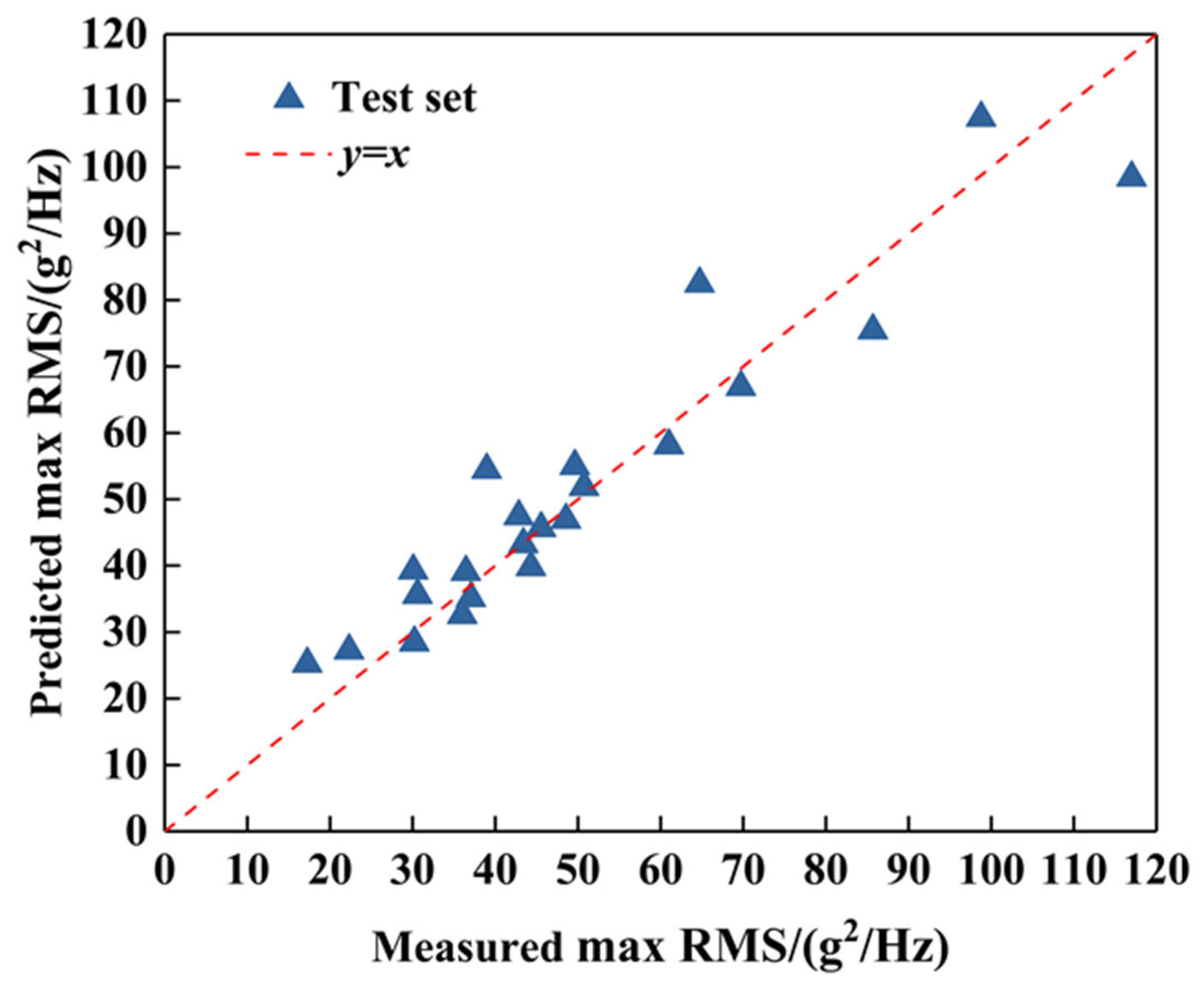
- The SHAP method and partial dependence plot analysis show that the hydraulic testing oxidant injector pressure drop of the thrust chamber has a dominant effect on rocket engine vibration, and both excessively high and low injector pressure drops can cause an increasing trend in amplitude. Improvements were made to this type of engine based on data analysis results, reducing injector flow resistance and improving injector disk roughness. The subsequent test results showed that the average value of maximum RMS decreased by 3.02 g2/Hz, and the number of products with extremely large vibrations significantly decreased. The above results demonstrate the rationality of the method and its great potential in data mining for complex propellant systems.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manufacturing Process Parameters | |||||
|---|---|---|---|---|---|
| Index | Parameters | Index | Parameters | Index | Parameters |
| F0 | Hydraulic testing pressure drop of thrust chamber oxidant injector | F17 | Oxidant pump spring seal leakage rate (under 0.5 MPa) | F34 | Fuel diversion sleeve inner diameter |
| F1 | Hydraulic testing pressure drop of thrust chamber fuel injector | F18 | Fuel pump bellows seal leakage rate (under 0.5 MPa) | F35 | Axial clearance between oxidant impeller and casing |
| F2 | Hydraulic testing pressure drop of thrust chamber body | F19 | Fuel pump spring seal leakage rate (under 0.5 MPa) | F36 | Oxidant sealing casing and block axial gap |
| F3 | Throat diameter of the thrust nozzle | F20 | Gap between the oxidant inducer wheel and the diversion sleeve | F37 | The axial clearance between the inlet edge of the turbine blade and the intake volute |
| F4 | Hydraulic testing pressure drop of gas generator oxidant injector | F21 | Gap between the fuel inducer wheel and the diversion sleeve | F38 | Fuel sealing casing and block axial gap |
| F5 | Hydraulic testing pressure drop of gas generator fuel injector | F22 | Oxidant pump bellows seal pressure | F39 | Axial gap between the sealing protrusion in the back of the fuel impeller and sealing casing |
| F6 | Hydraulic testing pressure drop of gas generator body | F23 | Fuel pump bellows seal pressure | F40 | Axial gap between sealing ring and oxidant impeller |
| F7 | Venturi tube pressure loss of main system oxidant pipeline | F24 | Free height of the stationary ring bellows of the oxidant pump | F41 | Axial gap between the sealing protrusion in front of oxidant impeller and diversion sleeve |
| F8 | Venturi tube pressure loss of main system fuel pipeline | F25 | Assembly compression deformation of the stationary ring bellows of the oxidant pump | F42 | The axial clearance between the outlet edge of the turbine blade and the intake volute |
| F9 | Venturi tube pressure loss of sub- system oxidant pipeline | F26 | Free height of the stationary ring bellows of the fuel pump | F43 | Axial gap between sealing ring (back) and fuel impeller |
| F10 | Venturi tube pressure loss of sub-system fuel pipeline | F27 | Assembly compression deformation of the stationary ring bellows of the oxidant pump | F44 | Axial gap between sealing ring (front) and fuel impeller |
| F11 | Hydraulic testing lift of oxidant pump | F28 | Rotor diameter | F45 | Axial gap between the sealing protrusion in front of fuel impeller and diversion sleeve |
| F12 | Hydraulic testing efficiency of oxidant pump | F29 | Exhaust gas volute inner diameter | F46 | Hydraulic testing efficiency of the turbine |
| F13 | Hydraulic testing lift of fuel pump | F30 | Oxidant sealing ring inner diameter | F47~F50 | NULL |
| F14 | Hydraulic testing efficiency of fuel pump | F31 | Oxidant diversion sleeve inner diameter | ||
| F15 | Rotor imbalance torque | F32 | Fuel sealing ring (front) inner diameter | ||
| F16 | Oxidant pump bellows seal leakage rate (under 0.5 MPa) | F33 | Fuel sealing ring (back) inner diameter | ||
| System parameters | |||||
| Index | Parameters | Index | Parameters | Index | Parameters |
| F51 | Flow resistance coefficient of thrust chamber oxidant injector | F61 | The linear term of the turbine efficiency coefficients | F71 | The linear term of fuel pump efficiency coefficients |
| F52 | Flow resistance coefficient of thrust chamber fuel injector | F62 | Flow resistance coefficient of sub-system orifice | F72 | The linear term of oxidant pump efficiency coefficients |
| F53 | Flow resistance coefficient of gas generator oxidant injector | F63 | Venturi tube cavitation coefficient of main system oxidant pipeline | F73 | The linear term of fuel pump lift coefficients |
| F54 | Flow resistance coefficient of gas generator fuel injector | F64 | Venturi tube cavitation coefficient of main system fuel pipeline | F74 | The linear term of oxidant pump lift coefficients |
| F55 | Flow resistance coefficient of thrust chamber body | F65 | Venturi tube cavitation coefficient of sub-system oxidant pipeline | F75 | The quadratic term of fuel pump lift coefficients |
| F56 | The constant term of turbine efficiency coefficients | F66 | Venturi tube cavitation coefficient of sub-system fuel pipeline | F76 | The quadratic term of oxidant pump lift coefficients |
| F57 | The constant term of fuel pump efficiency coefficients | F67 | Propellant leakage mass flow rate of fuel pump | F77 | The quadratic term of fuel pump efficiency coefficients |
| F58 | The constant term of oxidant pump efficiency coefficients | F68 | Propellant leakage mass flow rate of oxidant pump | F78 | The quadratic term of oxidant pump efficiency coefficients |
| F59 | Throat diameter of thrust chamber | F69 | The constant term of fuel pump lift coefficients | ||
| F60 | The quadratic term of the turbine efficiency coefficients | F70 | The constant term of oxidant pump lift coefficients | ||
| F79 | Turbine rotational velocity | F84 | Pressure before fuel injector of thrust chamber | ||
| Performance parameters | |||||
| Index | Parameters | Index | Parameters | Index | Parameters |
| F79 | Turbine rotational velocity | F85 | Mass flow rate of oxidant in sub- system | F90 | Pressure drop of thrust chamber fuel injector |
| F80 | Total mass flow rate of oxidant | F86 | Mass flow rate of fuel in sub-system | F91 | Pressure drop of gas generator oxidant injector |
| F81 | Total mass flow rate of fuel | F87 | Mixing ratio in sub-system | F92 | Pressure drop of gas generator fuel injector |
| F82 | Mass flow rate of fuel in main system | F88 | Mixing ratio in thrust chamber | F93 | Pressure before oxidant injector of gas generator |
| F83 | Pressure before oxidant injector of thrust chamber | F89 | Pressure drop of thrust chamber oxidant injector | F94 | Pressure before fuel injector of gas generator |
| Observed parameters | |||||
| Index | Parameters | Index | Parameters | Index | Parameters |
| F95 | Maximum vibration amplitude | ||||
Appendix B
| Manufacturing Process Parameters | |||||
|---|---|---|---|---|---|
| Index | Parameters | Index | Parameters | Index | Parameters |
| F0 | Gas bottle volume | F7 | Oxidant tank ullage initial temperature | F13 | Oxidant tank pressure control bandwidth |
| F1 | Gas bottle initial volume | F8 | Oxidant tank ullage initial pressure | F14 | Mixing ratio regulator flow resistance coefficient |
| F2 | Gas bottle initial temperature | F9 | Fuel tank ullage initial pressure | F15 | Thrust regulator flow resistance coefficient |
| F3 | Fuel tank ullage initial volume | F10 | Oxidant tank pressurization orifice inner diameter | F16 | Fuel initial mass |
| F4 | Oxidant tank ullage initial volume | F11 | Fuel tank pressurization orifice inner diameter | F17 | Oxidant initial mass |
| F6 | Fuel tank ullage initial temperature | F12 | Fuel tank pressure control bandwidth | F18 | The consumption of propellant during the descending phase |
| System parameters | |||||
| Index | Parameters | Index | Parameters | Index | Parameters |
| F19 | Tank total inlet mass flow rate | F21 | Rate of volume change in the oxidant tank ullage | ||
| F20 | Rate of temperature change in the tank ullage | F22 | Rate of volume change in the fuel tank ullage | ||
| Performance parameters | |||||
| Index | Parameters | Index | Parameters | Index | Parameters |
| F23 | First opening and closing cycle of fuel pressurization electric valve | F24 | First opening and closing cycle of oxidant pressurization electric valve | ||
| Observed parameters | |||||
| Index | Parameters | Index | Parameters | Index | Parameters |
| F25 | Leaky rate expectation of fuel pressurization electric valve | ||||
References
- Pan, T.; Zhang, S.; Li, F.; Chen, J.; Li, A. A meta network pruning framework for remaining useful life prediction of rocket engine bearings with temporal distribution discrepancy. Mech. Syst. Signal Process. 2023, 195, 110271. [Google Scholar] [CrossRef]
- Li, F.; Chen, J.; Liu, Z.; Lv, H.; Wang, J.; Yuan, J.; Xiao, W. A soft-target difference scaling network via relational knowledge distillation for fault detection of liquid rocket engine under multi-source trouble-free samples. Reliab. Eng. Syst. Safe 2022, 228, 108759. [Google Scholar] [CrossRef]
- Huang, Y.; Tao, J.; Zhao, J.; Sun, G.; Yin, K.; Zhai, J. Graph structure embedded with physical constraints-based information fusion network for interpretable fault diagnosis of aero-engine. Energy 2023, 283, 129120. [Google Scholar] [CrossRef]
- Wang, J.; Wang, B.; Yang, H.; Sun, Z.; Zhou, K.; Zheng, X. Compressor geometric uncertainty quantification under conditions from near choke to near stall. Chin. J. Aeronaut. 2023, 36, 16–29. [Google Scholar] [CrossRef]
- Cartocci, N.; Napolitano, M.R.; Costante, G.; Valigi, P.; Fravolini, M.L. Aircraft robust data-driven multiple sensor fault diagnosis based on optimality criteria. Mech. Syst. Signal Process. 2022, 170, 108668. [Google Scholar] [CrossRef]
- Stanton, I.; Munir, K.; Ikram, A.; El-Bakry, M. Predictive maintenance analytics and implementation for aircraft: Challenges and opportunities. Syst. Eng. 2023, 26, 216–237. [Google Scholar] [CrossRef]
- Xiaozhe, X.; Guangli, L.; Kaikai, Z.; Yao, X.; Siyuan, C.; Kai, C. Surrogate-based shape optimization and sensitivity analysis on the aerodynamic performance of HCW configuration. Aerosp. Sci. Technol. 2024, 152, 109347. [Google Scholar] [CrossRef]
- Júnior, J.M.M.; Halila, G.L.; Kim, Y.; Khamvilai, T.; Vamvoudakis, K.G. Intelligent data-driven aerodynamic analysis and optimization of morphing configurations. Aerosp. Sci. Technol. 2022, 121, 107388. [Google Scholar] [CrossRef]
- Du, B.; Shen, E.; Wu, J.; Guo, T.; Lu, Z.; Zhou, D. Aerodynamic Prediction and Design Optimization Using Multi-Fidelity Deep Neural Network. Aerospace 2025, 12, 292. [Google Scholar] [CrossRef]
- Guan, P.; Huang, D.; He, M.; Zhou, B. Lung cancer gene expression database analysis incorporating prior knowledge with support vector machine-based classification method. J. Exp. Clin. Canc. Res. 2009, 28, 103. [Google Scholar] [CrossRef] [PubMed]
- He, T.; Chen, Y.; Wang, L.; Cheng, H. An Expert-Knowledge-Based Graph Convolutional Network for Skeleton-Based Physical Rehabilitation Exercises Assessment. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 1916–1925. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Yang, W. Knowledge Graph Construction Method for Commercial Aircraft Fault Diagnosis Based on Logic Diagram Model. Aerospace 2024, 11, 773. [Google Scholar] [CrossRef]
- Karasu, S.; Altan, A.; Bekiros, S.; Ahmad, W. A new forecasting model with wrapper-based feature selection approach using multi-objective optimization technique for chaotic crude oil time series. Energy 2021, 212, 118750. [Google Scholar] [CrossRef]
- Jenul, A.; Schrunner, S.; Pilz, J.; Tomic, O. A user-guided Bayesian framework for ensemble feature selection in life science applications (UBayFS). Mach. Learn. 2022, 111, 3897–3923. [Google Scholar] [CrossRef]
- Liu, Y.; Zou, X.; Ma, S.; Avdeev, M.; Shi, S. Feature selection method reducing correlations among features by embedding domain knowledge. Acta Mater. 2022, 238, 118195. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, J.; Avdeev, M. Multi-Layer Feature Selection Incorporating Weighted Score-Based Expert Knowledge toward Modeling Materials with Targeted Properties. Adv. Theory Simul. 2020, 3, 1900215. [Google Scholar] [CrossRef]
- Michelle, S.; Valentin, D. Family Rank: A graphical domain knowledge informed feature ranking algorithm. Bioinformatics 2021, 37, 3626–3631. [Google Scholar] [CrossRef] [PubMed]
- Nanfack, G.; Temple, P.; Frenay, B. Learning Customised Decision Trees for Domain-knowledge Constraints. Pattern Recognit. 2023, 142, 109610. [Google Scholar] [CrossRef]
- Fang, X.; Song, Q.; Wang, X.; Li, Z.; Ma, H.; Liu, Z. An intelligent tool wear monitoring model based on knowledge-data-driven physical-informed neural network for digital twin milling. Mech. Syst. Signal Process. 2025, 232, 112736. [Google Scholar] [CrossRef]
- Lappas, Z.; Yannacopoulos, P.; Athanasios, N. A machine learning approach combining expert knowledge with genetic algorithms in feature selection for credit risk assessment. Appl. Soft Comput. 2021, 107, 107391. [Google Scholar] [CrossRef]
- Sun, Y.N.; Qin, W.; Hu, J. A Causal Model-Inspired Automatic Feature-Selection Method for Developing Data-Driven Soft Sensors in Complex Industrial Processes. Engineering 2023, 3, 82–93. [Google Scholar] [CrossRef]
- Xiong, J.W.; Fink, O.; Zhou, J. Controlled physics-informed data generation for deep learning-based remaining useful life prediction under unseen operation conditions. Mech. Syst. Signal Process. 2023, 197, 110359. [Google Scholar] [CrossRef]
- Saltelli, A.; Annoni, P.; Azzini, I.; Campolongo, F.; Ratto, M.; Tarantola, S. Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput. Phys. Commun. 2010, 181, 259–270. [Google Scholar] [CrossRef]
- Sobol, I.M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Huang, J.; Yan, X. Quality Relevant and Independent Two Block Monitoring Based on Mutual Information and KPCA. IEEE Trans. Ind. Electron. 2017, 64, 6518–6527. [Google Scholar] [CrossRef]
- Alexander, S.; Anastasia, B.; Alexey, D. Efficient High-Order Interaction-Aware Feature Selection Based on Conditional Mutual Information. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Shang, C.; Li, M.; Feng, S.; Jiang, Q.; Fan, J. Feature selection via maximizing global information gain for text classification. Knowl-Based Syst. 2013, 54, 298–309. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2011. [Google Scholar]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2017. [Google Scholar]
- Smith, M.; Alvarez, F. Identifying mortality factors from Machine Learning using Shapley values—A case of COVID19. Expert Syst. Appl. 2021, 176, 114832. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Li, Y.; Ren, F.; Sha, Z.; Xu, P. Research on Virtual Prototype and Digital Test Method of Pump-Fed Propulsion System. Int. J. Aeronaut. Space Sci. 2025, 26, 815–833. [Google Scholar] [CrossRef]










| Parameter Types | Parameter Definitions | Examples |
|---|---|---|
| Manufacturing process parameters | Process parameters during component manufacturing | Rotor diameter |
| System parameters | Component performance parameters that directly impact system performance, abstracted from component testing results | Flow resistance coefficient of orifices Turbine efficiency constants |
| Performance parameters | Telemetry parameters that directly characterize the system performance during flight or hot commissioning | Mixing ratio during the flight |
| Observed parameters | Telemetry parameters that are directly related to abnormal phenomena | Engine vibration spectrum |
| Module Name | Module Function | Module Configuration |
|---|---|---|
| High-fidelity simulation model consisting of Equations (27)–(30) | Generate synthetic data set and groundtruth feature ranking | 18 input parameters and 1 output parameter |
| Knowledge-based correlation matrix I | Validate the hybrid feature selection method | Size 18 × 4 |
| Simplified simulation model consisting of Equations (32)–(34) | 4 input parameters and 2 output parameters, forming the model-based correlation matrix with the size of 4 × 2 | |
| Knowledge-based correlation matrix II | Size 2 × 1 |
| Feature Selection Method | Sorting of the Top 4 Features |
|---|---|
| Groundtruth ranking | [1, 2, 3, 4] |
| Knowledge and model-based method | [1, 8, 2, 3] |
| Data-based method | [1, 5, 3, 9] |
| Hybrid method | [1, 6, 3, 5] |
| Component Names | Abbreviations |
|---|---|
| SFV | Sub-system fuel Venturi tube |
| MFV | Main system fuel Venturi tube |
| SOO | Sub-system oxidant orifice |
| SOV | Sub-system oxidant Venturi tube |
| MOV | Main system oxidant Venturi tube |
| CJ | Cooling jacket |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Miao, W.; Liu, G. Explainable Data Mining Framework of Identifying Root Causes of Rocket Engine Anomalies Based on Knowledge and Physics-Informed Feature Selection. Machines 2025, 13, 640. https://doi.org/10.3390/machines13080640
Zhang X, Miao W, Liu G. Explainable Data Mining Framework of Identifying Root Causes of Rocket Engine Anomalies Based on Knowledge and Physics-Informed Feature Selection. Machines. 2025; 13(8):640. https://doi.org/10.3390/machines13080640
Chicago/Turabian StyleZhang, Xiaopu, Wubing Miao, and Guodong Liu. 2025. "Explainable Data Mining Framework of Identifying Root Causes of Rocket Engine Anomalies Based on Knowledge and Physics-Informed Feature Selection" Machines 13, no. 8: 640. https://doi.org/10.3390/machines13080640
APA StyleZhang, X., Miao, W., & Liu, G. (2025). Explainable Data Mining Framework of Identifying Root Causes of Rocket Engine Anomalies Based on Knowledge and Physics-Informed Feature Selection. Machines, 13(8), 640. https://doi.org/10.3390/machines13080640