Abstract
As industrial automation evolves towards human-centric, adaptable solutions, collaborative robots must overcome challenges in unstructured, dynamic environments. This paper extends our previous work on developing a digital shadow for industrial robots by introducing a comprehensive framework that bridges the gap between physical systems and their virtual counterparts. The proposed framework advances toward a fully functional digital twin by integrating real-time perception and intuitive human–robot interaction capabilities. The framework is applied to a hospital test lab scenario, where a YuMi robot automates the sorting of microscope slides. The system incorporates a RealSense D435i depth camera for environment perception, Isaac Sim for virtual environment synchronization, and a locally hosted large language model (Mistral 7B) for interpreting user voice commands. These components work together to achieve bi-directional synchronization between the physical and digital environments. The framework was evaluated through 20 test runs under varying conditions. A validation study measured the performance of the perception module, simulation, and language interface, with a 60% overall success rate. Additionally, synchronization accuracy between the simulated and physical robot joint movements reached 98.11%, demonstrating strong alignment between the digital and physical systems. By combining local LLM processing, real-time vision, and robot simulation, the approach enables untrained users to interact with collaborative robots in dynamic settings. The results highlight its potential for improving flexibility and usability in industrial automation.
1. Introduction
In today’s industrial landscape, the evolution towards Industry 4.0 has emphasized automation, inter-connectivity, and artificial intelligence (AI) [1]. Now, however, researchers, industry, and policy-makers are acknowledging the human, societal, and environmental stakes in the Industry 4.0 transition, and a new paradigm is rising: Industry 5.0, which focuses also on the human role in the cyber-physical system [2,3]. One of the key aspects of Industry 5.0, is to use technology to augment humans, which opens up personalized production processes [4] where the behavior of technology is tailored to the product, the process, and the human user. Despite the presence of robots designed/used for collaborative applications (sometimes abbreviated “cobots”), in the market, they have not been used to their complete potential. The reasons for the slow adaptation of human–robot collaboration (HRC) are many, and researchers report uncertainties on how to manage safety [5], lack of knowledge on how to design HRC applications, insufficient understanding of the benefits [6], and a lack of stability of the solution [7]. Safety, stability, and lack of benefits are all related to the technical constraints that hinder these robots’ ability to manage complex and unstructured tasks [8].
A significant challenge in achieving effective automation is the need to operate within dynamic and unpredictable environments. Such environments can disrupt the tasks that robots are assigned, making it difficult for traditional automation systems—often built on static models—to adapt [9]. A real-world case study in this paper illustrates this issue: a collaborative robot deployed in a hospital laboratory interacts with doctors and lab technicians, who possess expertise in their fields but lack training in robotics. In this setting, the robot’s task is to perform the sorting of microscopic slides, a manual process that is both time-consuming and resource-intensive. By enabling the robot to handle this task, valuable human resources can be freed up for more critical activities.
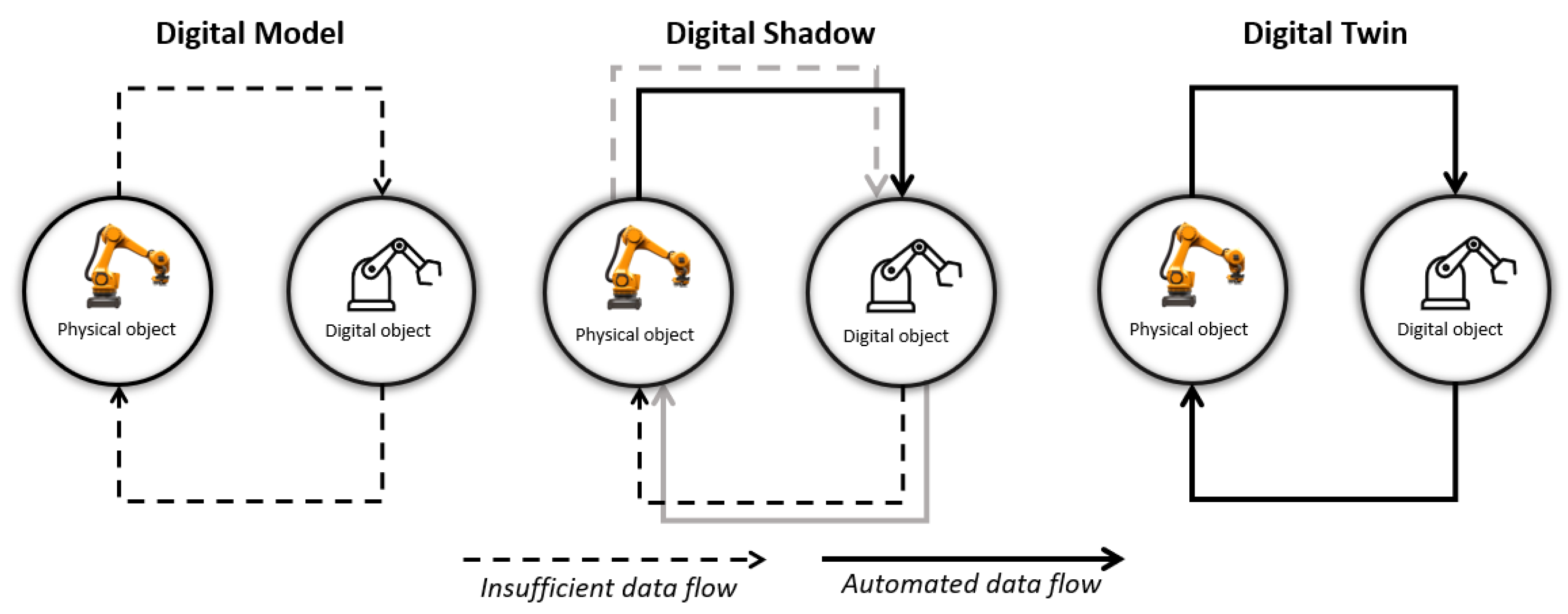
To tackle the challenges posed by unstructured and dynamic environments, implementing a digital twin (DT) offers a promising solution. A DT can simulate real-world systems in real-time, allowing for continuous adaptability to changing conditions by leveraging AI, complex decision-making, scenario exploration, etc. [10]. In our prior work [11], we laid the groundwork for this concept by developing a digital shadow with adaptive ability to adjust a system’s behavior in response to unforeseen situations to meet goals [12] within a virtual environment. A key direction identified for future development was the bi-directional communication between the physical and virtual worlds, as seen in Figure 1, achieving real-time synchronization of changes and enhancing the robot’s ability to respond effectively to physical-world dynamics. The realization of this through integration of vision is covered by this paper, along with extending the framework to promote better collaboration for users. Specifically, to enable real-time interaction with untrained personnel, we introduce a speech recognition module integrated with a large language model. Such a development allows users to verbally instruct the robot on the tasks to be performed, making the system more intuitive and accessible. Furthermore, to evolve the existing digital shadow into a fully functional DT, we incorporate a perception module featuring real-time camera vision. This enhancement ensures that the system can operate efficiently in environments where both task definitions and physical conditions are constantly evolving.
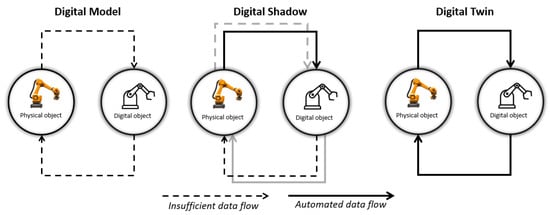
Figure 1.
Schematic overview of data flow for different digital concepts.
The integration of a large language model (LLM) into a robot control framework, as demonstrated in this paper, opens up a wide range of possibilities for enhancing human–robot interaction. Traditionally, robots have been programmed either offline, following rigid, predefined task definitions, or online, using teach pendants for direct programming. Both approaches can limit flexibility in dynamic environments. However, by incorporating an LLM, real-time communication between humans and robots becomes possible. This allows users to issue commands or modify robot actions directly through natural language, without the need for writing new code or making offline adjustments each time the environment changes. In the methodology presented here, a locally running LLM interprets user instructions to define tasks in real-time—specifically, for managing sorting operations and establishing the logic behind the sorting sequences.
In the previous framework [11], while the robot could adapt to changes within the simulated environment, it lacked the ability to replicate changes from the physical world to the digital domain. This resulted in a disconnect between the physical and virtual worlds. To bridge this gap, the framework presented in this paper introduces a perception module that allows the robot to observe its environment in real-time. This module captures and replicates the physical environment in the DT, ensuring that both the robot and users have a synchronized view of the world. By integrating real-time camera vision, the system allows users to see what the robot perceives and provide context-aware instructions. This closed-loop communication, where the physical and digital environments are in constant dialogue, not only strengthens human–robot interaction but also elevates the system from a digital shadow to a fully functional DT. This advancement makes it possible for the robot to adapt autonomously to environmental changes, further enhancing its capacity for dynamic task execution.
This paper addresses the challenge of enabling collaborative robots to operate flexibly in dynamic, unstructured environments through seamless and intuitive human–robot interaction. Existing approaches often lack real-time integration between perception, simulation, and interaction modules, and rely heavily on cloud-based AI services, limiting practical deployment. The objective of this research is to develop and validate a locally deployable, adaptive digital twin framework that enables real-time synchronization between physical and virtual environments, and supports natural language task specification by untrained users. We hypothesize that such a system can significantly enhance usability, adaptability, and responsiveness in collaborative robotic applications. The paper continues with background on unstructured robotics automation, digital twins, and LLM-based HRC in Section 2. Section 3 details the proposed framework and hospital test lab case. Section 4 presents the results and validation. Section 5 discusses key insights, limitations and future work, followed by Section 6, which concludes with a summary.
2. Background
2.1. Unstructured Environment in Robotics
Mass customization, driven by consumer demand for personalized products, has prompted many industries to adopt flexible automation solutions as a strategic business model. While minor product changes can be managed through increased flexibility in individual production units [13], traditional dedicated manufacturing lines often lack the adaptability needed for significant product alterations, particularly in unstructured and unpredictable environments [14]. Plug-and-produce systems offer a promising approach by enabling real-time integration of new devices into existing setups, facilitating automatic adjustments at the logic level [15]. However, these systems are typically limited to structured settings and face challenges in handling the high variability and uncertainty characteristics of unstructured environments.
A significant challenge in robotics within unstructured environments involves reacting to unpredictable physical behaviors of objects. Makris [16] highlighted the need for robust numerical models capable of predicting the behavior of deformable bodies, improving trajectory planning for collaborative robots. Similarly, Wang [17] demonstrated the advantages of robots equipped with mechanical sensors, which can detect and adapt to external forces, enhancing safety and effectiveness in dynamic scenarios. Furthermore, Nambiar [18] introduced a reinforcement learning approach for enabling robots to navigate complex, unstructured environments. These advancements are crucial for safe human–robot collaboration, as they allow robots to adjust their behavior based on real-time environmental feedback [19]. Beyond force-based sensing, visual feedback systems play a vital role in enhancing robot adaptability. Visual perception enables robots to make real-time adjustments based on environmental changes, improving their performance in unstructured settings [20]. Nevliudov et al. [20] demonstrated how visual control systems enhance robotic accuracy and flexibility by dynamically adapting to shifting production conditions.
As industries increasingly deploy robots in shared workspaces with human operators, ensuring adaptability and safety becomes paramount. Dastider [21] introduced a reactive whole-body obstacle avoidance methodology, allowing robots to adjust movements in real-time to prevent collisions. This is essential for maintaining safe interactions in cluttered, dynamic environments. Additionally, Zeng et al. [22] explored bio-inspired impedance adaptation strategies, enabling robots to physically collaborate more effectively with humans by adjusting to the dynamics of human movements, ensuring safer and more compliant interactions. Recent research has also explored mixed-perception approaches that combine multiple sensing modalities to enhance safety and efficiency in human–robot collaboration [23]. By integrating visual and tactile systems, robots can gain a more comprehensive understanding of their surroundings, improving adaptability and enhancing their ability to operate safely alongside humans.
2.2. Digital Twin
The digital twin (DT) is a virtual replica of a physical entity that enables real-time monitoring, analysis, and optimization throughout its life-cycle [24]. Originally introduced by Michael Grieves in 2002 within the context of product life-cycle management, DTs integrate physical and digital systems to enhance efficiency and decision-making [25]. A typical DT comprises three core components: the physical entity, its virtual counterpart, and the data connection between them [26]. By leveraging real-time and historical data, DTs enable high-fidelity simulations of physical systems. Kritzinger et al. [27] categorize digital representations as digital models (static, no data link), digital shadows (one-way data flow from physical to digital), and true DTs, which support bi-directional data flow for simulation, feedback, and control, as illustrated in Figure 1.
In industrial environments, DT technology is particularly valuable for enhancing safety, context awareness, and adaptability, especially when cobots work alongside human operators [28,29]. Context awareness within DTs refers to the ability to tailor the behavior of a virtual model based on its operational context, making it more relevant to the specific application [30]. Achieving context awareness requires integrating context models into the DT’s system behavior component, encompassing aspects such as system tasks, processes, objectives, and operations [12].
In addition to context awareness, adaptivity is a critical feature for deploying DTs in dynamic and unstructured environments. This involves equipping DTs with capabilities to sense and interpret their surroundings, communicate proactively, and make decisions to support cooperative objectives [12,31]. Adaptive DTs significantly enhance human–robot collaboration by enabling real-time interactions and adjustments in response to changes in conditions, such as human behavior or environmental factors [9]. Such adaptability is essential in settings where robots and human operators work closely, as it allows the DT to respond dynamically to variations in the operational context. Furthermore, robots can leverage DT technology to learn from human demonstrations, adapting their actions accordingly—a capability particularly beneficial in collaborative environments like healthcare and service industries [32].
For a DT designed to interact closely with humans, the ability to interpret and respond to both verbal and non-verbal cues is crucial. This capability helps create a seamless interaction environment, making users feel more comfortable and understood [33,34]. Hribernik et al. [12] highlight a research gap regarding the integration of adaptivity and context awareness in DTs for human interaction. Specifically, there is a need for further exploration on how to achieve these capabilities effectively, including representing human behaviors accurately and ensuring the system can dynamically adapt to changes in the interaction context. Additionally, balancing the autonomy of DTs with human agency remains a critical challenge. Ensuring that DTs can operate autonomously without compromising user control is essential for fostering effective collaboration. Recent advancements in natural language processing (NLP) and multi-modal communication systems have significantly enhanced human–robot interaction (HRI). This will enable robots to engage in more meaningful and intuitive dialogues with humans, thereby enhancing the overall user experience [35,36].
2.3. Large Language Model-Based Human–Robot Collaboration
Large language models (LLMs) represent a transformative development in AI, with their roots in natural language processing research. Recent advancements in neural networks and transformer architectures have revolutionized the field, particularly with the introduction of models like Google’s BERT [37] and OpenAI’s GPT [38]. These pre-trained models, fine-tuned for various tasks, have demonstrated remarkable capabilities in understanding and generating human-like text by predicting subsequent words in a sequence. This innovation has enabled diverse applications, from conversational AI and content creation to complex decision-making support.
The integration of LLMs into robotics has fundamentally changed how machines interpret and execute human instructions. Traditionally, robots relied on static, rule-based programming that limited their adaptability in dynamic environments [39]. The introduction of LLMs has enabled robots to process unstructured natural language, interpret complex or ambiguous commands, and dynamically adapt their actions. LLMs can guide robots to decompose high-level commands into executable tasks, making them suitable for open-ended and non-deterministic scenarios. Additionally, the combination of LLMs with sensory data, such as visual or tactile input, has given rise to multimodal robotics. These systems synthesize linguistic understanding with sensory awareness, allowing robots to make informed decisions in complex environments [40].
Recent studies introduce new multimodal and context-aware LLM models that extend robotic capabilities in real-time settings. For instance, PaLM-E, an embodied multimodal language model, integrates vision and language for robotic tasks, supporting sequential manipulation planning and visual question answering [41]. Comprehensive reviews further underscore the versatility of LLMs in robotics, detailing their impact on robot control, perception, decision-making, and path planning [42]. Additionally, LLMs have demonstrated potential in improving a robot’s 3D-scene understanding, thereby enhancing interaction with physical environments [43].
In assembly line contexts, where tasks are complex and frequently change, LLM-powered systems facilitate seamless collaboration by interpreting intricate instructions and performing tasks cooperatively alongside human workers. Such capabilities minimize downtime, as robots can quickly adjust to task changes, contributing to improved efficiency in industrial applications [44].
To summarize, the application of LLMs in HRC transforms robots into adaptable, intuitive partners capable of handling complex, dynamic tasks. With natural language processing, robots can understand and respond to human commands in real-time, making them valuable in industries like healthcare and industrial assembly, requiring minimal programming while adapting to evolving situations.
2.4. Summary
The reviewed literature shows steady progress in enabling robots to operate in unstructured environments, with advancements in visual perception, force adaptation, and DTs. However, as shown in Table 1, most existing approaches treat these capabilities in isolation and fall short of achieving real-time integration between physical and digital systems. Current DT implementations often lack full bi-directional communication, while language-based interaction is still largely reliant on cloud-based LLMs, which introduces concerns related to latency, security, and deployment flexibility.

Table 1.
Comparison of state-of-the-art DT frameworks combining physics-based adaptive simulation models, LLMs for natural language task definition, and real-time perception for dynamic environment sensing.
To address these gaps, this paper proposes an integrated, modular framework that brings together real-time perception, a physics-based digital twin, and a locally hosted LLM interface for natural language task definition. The framework is validated in a real-world hospital test lab scenario involving collaborative slide sorting using a YuMi robot.
The main contributions of this work are as follows: a perception-driven digital twin that dynamically synchronizes with the physical environment, a natural language interface powered by a local LLM, enabling intuitive task definition by untrained users, and a demonstration of the full system in a practical, unstructured use case, highlighting its potential for adaptive, human-centric automation.
3. Methodology
Conventional offline robot programming involves predefined tasks that are tested in simulation software before being executed on an industrial robot. When it comes to unstructured and dynamic environments, a system is needed that can continuously monitor the environment for changes and include a control mechanism capable of adapting to those changes. Additionally, it requires a high level of context awareness to perform the desired tasks effectively.
3.1. Hospital Test Lab Case
The case study in this paper builds upon the one presented in a previous study [11], focusing on a hospital test lab environment. In this setting, lab technicians are responsible for transferring microscopic slides from one type of fixture to another, depending on the testing procedures required. The sorting task is both time-consuming and involves handling a substantial volume of slides daily. Although the task itself is repetitive, the working environment and the samples are highly dynamic due to the variability in the biological specimens and the fact that the personnel handling these samples are not trained industrial professionals. Each slide in the fixture/tray is marked with a color code, indicating different categories of biological samples. The specific task addressed in this paper involves sorting the slides based on an order specified by the operator.
3.2. Overall Framework
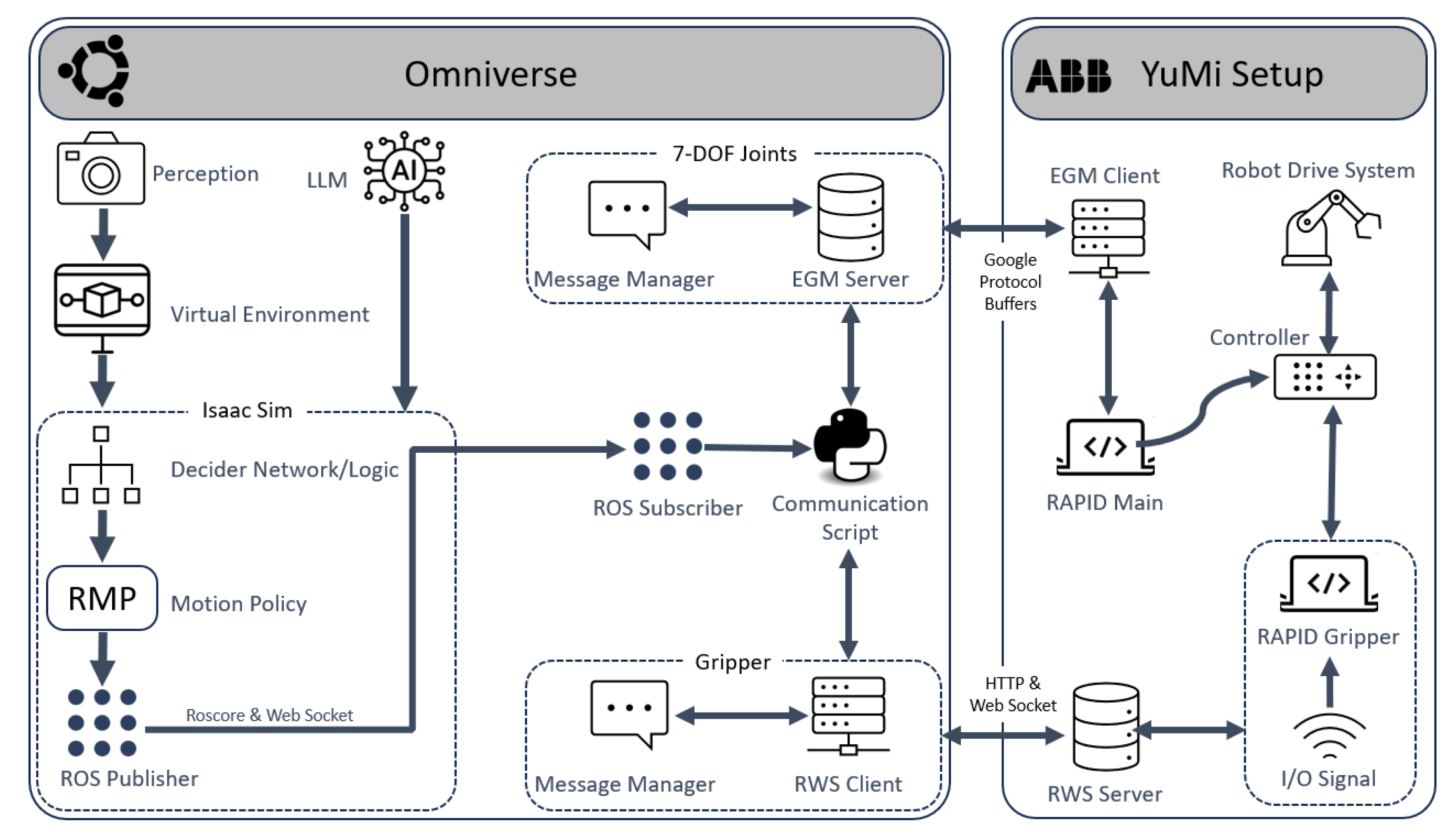
The framework developed for automating a collaborative robot using a physics-based simulation engine in an unstructured and dynamic environment is illustrated in Figure 2. This framework is an updated version of the setup presented in the previous paper [11]. It comprises several key modules: a perception module, an LLM module, a simulation module, a communication module, and a robot controller module. The main additions to this version are the perception module and the LLM module.
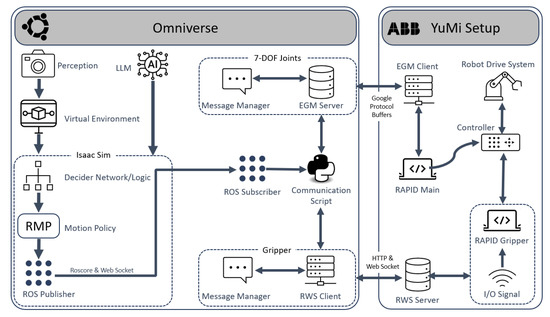
Figure 2.
Detailed overview of the framework.
The first component is the perception module, which uses a camera vision script to capture real-time data from the working environment. The data are then sent to Nvidia’s physics-based simulation software, Isaac Sim 2023.1.1, which contains a virtual representation of the working environment. In addition to the perception data, the user can specify the robot’s task using natural language input.
The virtual environment within Isaac Sim replicates the real-world workspace based on the perception data. A decider network within Isaac Sim defines the logic for the tasks the robot needs to perform. Although the overall objective is to carry out a sorting operation, this task is decomposed into smaller, intermediate goals by the decider network. These intermediate goals serve as inputs for the motion policy, which generates a collision-free trajectory based on the virtual environment.
To transfer information from the simulation module to the robot controller, an ROS server is set up on the system running the simulation engine. Joint state information is published to this server in real time during the simulation. The communication module subscribes to the ROS server and extracts the necessary data through a communication script.
The robot used in this application is the ABB’s collaborative YuMi robot. To control the YuMi robot using external joint data, we implement two key functionalities: Externally Guided Motion (EGM) [50] and Robot Web Services (RWS) [51]. EGM is used exclusively for joint control, while RWS handles the control of the gripper states. Additionally, a RAPID script is executed within the robot controller to prepare the robot for accepting external joint information, bypassing the default robot legacy software. The sequential steps for initializing the simulation environment, establishing all necessary connections, and running the complete framework are summarized in Table 2. This table provides an overview of the operations performed by each module throughout the setup and execution process.
Table 2.
Sequential steps for initializing the simulation environment, setting up all necessary connections, and running the proposed framework.
3.3. Real-Time Perception
In this work, a camera vision system was integrated for the real-time detection, localization, and alignment of objects using a depth-sensing camera and computer vision techniques. The purpose of the perception module is to automate the identification and orientation of the tray containing microscopic slides, as well as to determine the number of glass slides, their positions within the tray, and their respective colors, as shown in Algorithm 1. An Intel RealSense D435i camera, which captures both color (RGB) and depth frames, is employed.
The workspace is defined by initially detecting the tray holding the components using image segmentation techniques. The input RGB image is converted to gray-scale and preprocessed with Gaussian blur to minimize noise. Binary thresholding is applied to emphasize the tray, followed by contour detection to identify the tray boundaries. A minimum area rectangle fitting is performed on the detected contour, extracting the four corners of the tray. These corners define the Region of Interest (ROI), where subsequent slide detection and segmentation tasks are carried out.
Within the defined ROI, colored objects are detected using color segmentation in the HSV color space. Predefined color ranges are used to identify slides of interest based on their unique color characteristics. Masks for each color are generated, and contours of the detected objects are extracted. Each detected slide is characterized by its bounding box and centroid, facilitating precise localization of slide centers. To align the detected slides with specific segments of the tray, midpoints along the tray edges are calculated. These midpoints serve as reference points for mapping the slides to designated locations within the tray. The closest midpoint to each slide center is identified, enabling accurate alignment and association of objects with specific tray segments.
| Algorithm 1:Camera vision algorithm to detect position and orientation of tray and slides in front of the robot. |
 |
In addition to detecting colored slides, the system is configured to identify specific screws which are on the foot of the robot securing it to the workbench. The centers of the detected screws are used to create a direction vector between the two. Direction vectors formed by the screw centers and the tray edges are determined, and the angle between these vectors is computed. The relative position vector of the tray edge from the screw center is also calculated.
Once the scene detection is complete, information such as the relative position of the tray, its orientation, the number of slides, their positions within the tray, and their corresponding colors is published as an ROS node to the ROS server. These data are then subscribed to by the script simulating the virtual environment within Isaac Sim.
3.4. LLM-Based Task Definition
This framework employs a locally hosted large language model (LLM) to enable intuitive, natural language-based task specification for simulation-driven robotic operations. Specifically, the Mistral 7B model, accessed via the Ollama, a lightweight runtime environment designed to efficiently execute open-source LLMs on local hardware without requiring cloud-based resources. Mistral 7B is responsible for processing user commands and generating task definitions, such as the sequence of pick-and-place operations in a slide-sorting scenario. The model was selected after a comparative evaluation against models like LLaMA 2 and LLaMA 3, due to its superior generalization, reasoning, and instruction-following capabilities. The model outperforms LLaMA 2 (13B) on all benchmarks and LLaMA 1 (34B) on many, while approaching the performance of CodeLLaMA 7B in coding tasks—all while offering faster inference via grouped query attention and efficient handling of long sequences using sliding window attention [52].
The LLM requires GPU-based computation, with a minimum recommended setup of NVIDIA RTX 3060 (12 GB VRAM). The system used for development features an 32 GB RAM, NVIDIA GeForce RTX 3080 (8 GB), Intel® Xeon® W-1250 CPU, and runs on Ubuntu 20.04.6 LTS. The Ollama is installed within the same Python environment as NVIDIA Isaac Sim, creating a streamlined pipeline for sending prompts to the LLM and receiving structured responses. Unlike a fully embedded solution, the LLM is not deployed as an asynchronous function within the Isaac Sim scene. Running such a task asynchronously alongside the simulation would impose a significant load on CPU and GPU resources, degrading simulation performance (e.g., reduced FPS, physics calculation errors). Instead, the LLM is activated through a button-based user interaction before the simulation starts, ensuring that task definition and reasoning happen prior to the deployment of the simulation scene, offloading computational burden and ensuring that the simulation runs smoothly without interruptions.
Algorithm 2 illustrates the speech-to-task pipeline that facilitates natural HRI through voice commands, integrating a speech recognition module with a locally deployed LLM. The process begins with the initialization of two core components: the speech recognizer and a text-to-speech (TTS) engine. These components enable the system not only to capture spoken input but also to optionally provide audio feedback to the user. Once initialized, the system enters a continuous listening loop where it monitors the microphone for incoming audio signals. Before processing each command, the system performs ambient noise adjustment to improve transcription accuracy, ensuring reliable performance even in noisy environments.
The captured speech is then transcribed into text using Google’s Speech Recognition API. Upon successful transcription, the resulting text input is forwarded to the LLM interface function, where it is embedded into a structured prompt. This prompt has been carefully engineered to direct the LLM’s behavior—specifically, instructing it to recognize sorting-related commands and respond in a strict format: “Sorting; [item1, item2, item3]”. If no valid items are detected, the LLM is prompted to respond with: “Sorting; [None]”. These constraints are critical to prevent hallucinations, enforce consistent output, and avoid unnecessary verbosity or unsupported formats. The response returned by the LLM is then parsed into two components: a task keyword (e.g., “Sorting”) and the associated list of items (sort order). Finally, this structured output is passed to the robot’s decider network, where it is used to update the robot’s task logic, such as determining the pick sequence for a sorting operation before the simulation is initiated.
| Algorithm 2:Speech-to-LLM algorithm to extract sort order preference from the user command. |
 |
3.5. Virtual Environment
The virtual environment is constructed using Nvidia Omniverse’s Isaac Sim platform, a physics-based simulation platform. It is crucial to accurately define the physical components of the environment, as any discrepancies can negatively impact the entire framework. Within the virtual environment, an ABB IRB 14000 YuMi robot is loaded in Universal Scene Description (USD) format. The scene also includes a digital model of a tray containing microscope slides, as well as a holder where the sorted slides are intended to be placed.
A scene setup script initializes the virtual environment, including an ROS subscriber node that listens for position and orientation data from the perception module. The information is used to update the position and orientation of the slide tray within the virtual environment. Additionally, the ROS node provides information about the number of slides, their positions, and their colors. Using these data, the slides are generated and placed in their corresponding locations within the virtual tray.
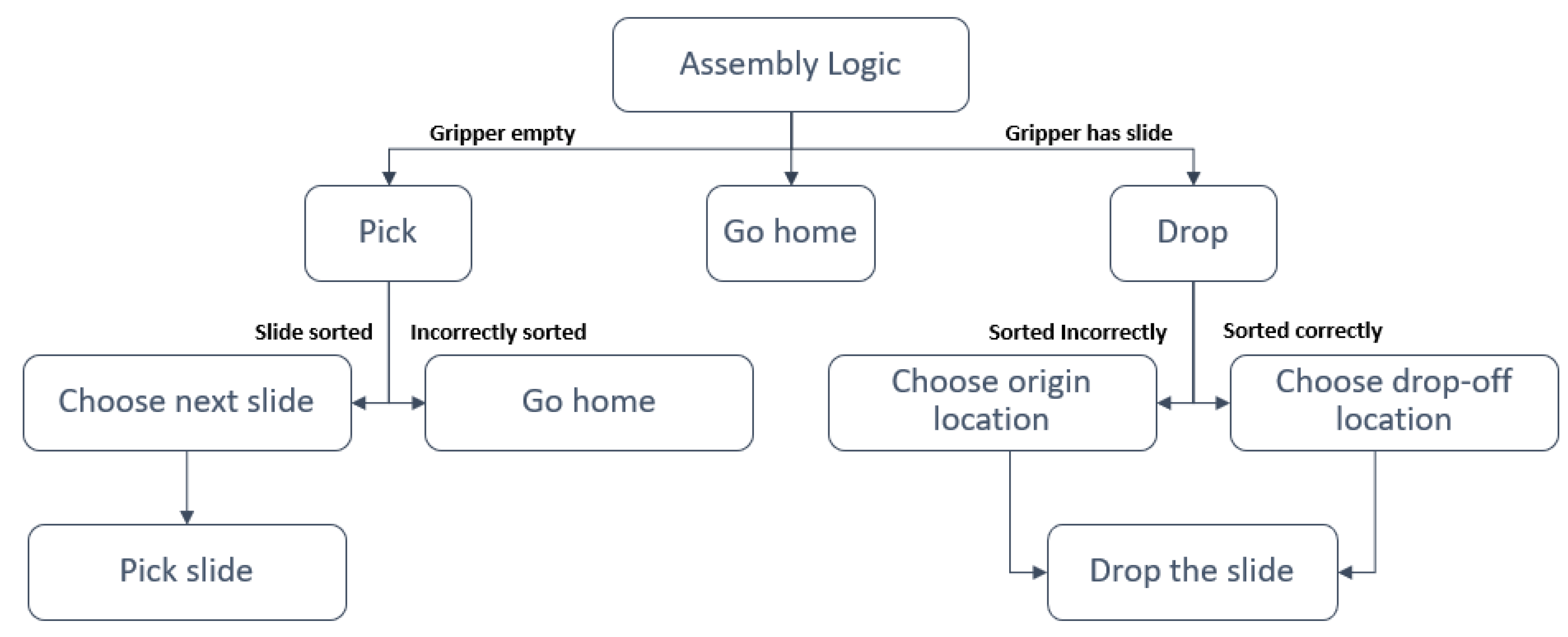
Once the virtual scene is aligned with the real-world setup and a picking sequence is generated by the LLM module, the simulation is initiated within Isaac Sim. The virtual environment relies on two key components: the decider network and the motion policy. The decider network used in this application, shown in Figure 3, is identical to the one from the previous work [11]. Similarly, the motion policy employed here is the Riemannian Motion Policy (RMP) [53], which also remains unchanged from the earlier study. Detailed information on the implementation of these components can be found in [11].
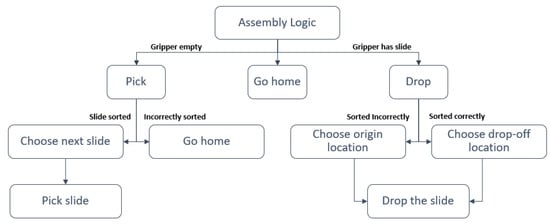
Figure 3.
Decider network responsible for taking decision based on gripper states [11].
When the simulation begins, the control flow follows the sequence defined in the decider network, starting with a check of the gripper’s status. The gripper has two possible states: “has slide” or “empty.” For example, if the gripper is empty, the next logical step is to initiate a pick operation. Before selecting a slide to pick, the system verifies if the currently sorted slides are in the correct order. If the order is correct, a new slide is selected, and the pick operation is performed. The position and orientation of the selected slide are retrieved from the virtual environment to execute the pick action accurately. Once the pick operation is completed, the process thread is finished. Once the slide is picked up, a similar approach is used to drop it off at a desired location. After completing the drop-off sequence, the system checks if there are any remaining slides to pick. If no more slides are left, a “go home” sequence is executed, guiding the robot arm back to its home position.
3.6. Communication Between Digital and Physical World
To facilitate communication between the DT in the virtual environment and the physical YuMi robot, the framework employs the same communication setup as detailed in our previous work [11]. The Joint Control node in Isaac Sim continuously publishes joint states, including joint positions, velocities, and effort, to the ROS server, which are then streamed to the robot controller using Google Protocol Buffers for efficient data serialization.
For controlling the YuMi robot’s joint movements, the EGM with Google protocol buffers is employed. EGM allows for high-frequency position updates, bypassing the internal path planner of the robot controller to achieve real-time responsiveness. Additionally, RWS are used to control the gripper states, as EGM does not support direct manipulation of YuMi’s smart gripper. This setup uses a digital input signal to trigger gripper actions based on the data received from the simulation side. The detailed implementation of these communication strategies and protocols, including data flow diagrams and configuration specifics, can be found in [11].
4. Results
The results from the camera vision system detecting the microscope slides and tray are illustrated in Figure 4. The figure showcases three scenarios where the tray is randomly positioned and oriented within the working environment. The detected tray boundaries are marked in each image, defining the Region of Interest (ROI) for subsequent analysis. Within the ROI, a red-colored rectangular contour is identified and used to determine the origin point of the tray.

Figure 4.
Illustration of the picking sequence, showcasing the randomized positions, orientations, and quantities of slides within the tray, demonstrated in both the digital and physical environments.
The ROI is segmented into two rows and ten columns, creating 20 slots where slides can be placed, as seen in the figure. The algorithm searches within the ROI for predefined colors corresponding to those used by technicians to classify different types of biological materials. Once the colors are detected, their respective slot indices are calculated, resulting in a list associating each identified color with its slot index.
Additionally, the figure highlights two screws securing the robot to the table, marked with distinct colors for identification. These screws along with the origin point of the tray are used to calculate the relative position and orientation of the tray relative to the robot, as detailed in Section 3.3.
After being processed and passed to the digital simulation environment in Isaac Sim, the position and orientation of the respective components are updated accordingly in the virtual environment. This update occurs as the simulation begins running, ensuring the virtual workspace reflects the real-world setup. The updated digital simulation workspace is depicted in Figure 4.
The integration of LLMs into robotic systems is demonstrated by their ability to interpret verbal instructions for performing dynamic sorting tasks, as shown in Figure 5. In this scenario, an operator provides commands specifying the desired sorting order of color-coded slides (e.g., “pink, orange, green”). The LLM interprets these inputs and translates them into actionable instructions, such as “Sorting: pink, orange, green.” This highlights the LLM’s capacity to comprehend and adapt to variations in human input, allowing for reorganization based on different operator preferences. After the LLM generates the task sequence, the sorting order, illustrated in Figure 5, is passed to the decider network, which executes the necessary logical steps for the robot’s task sequence. As the robot performs the slide sorting operation based on the task sequence generated, the real-time joint data from the digital simulation are transmitted to the physical robot.

Figure 5.
Illustration showcasing an LLM’s ability to interpret human verbal inputs as sorting instructions.
4.1. Accuracy Evaluation
To evaluate the accuracy of the simulation data and their correspondence with the motion executed by the physical robot, the 7-joint values from both the simulated and physical models are recorded during each data packet sent to/from the EGM controller.
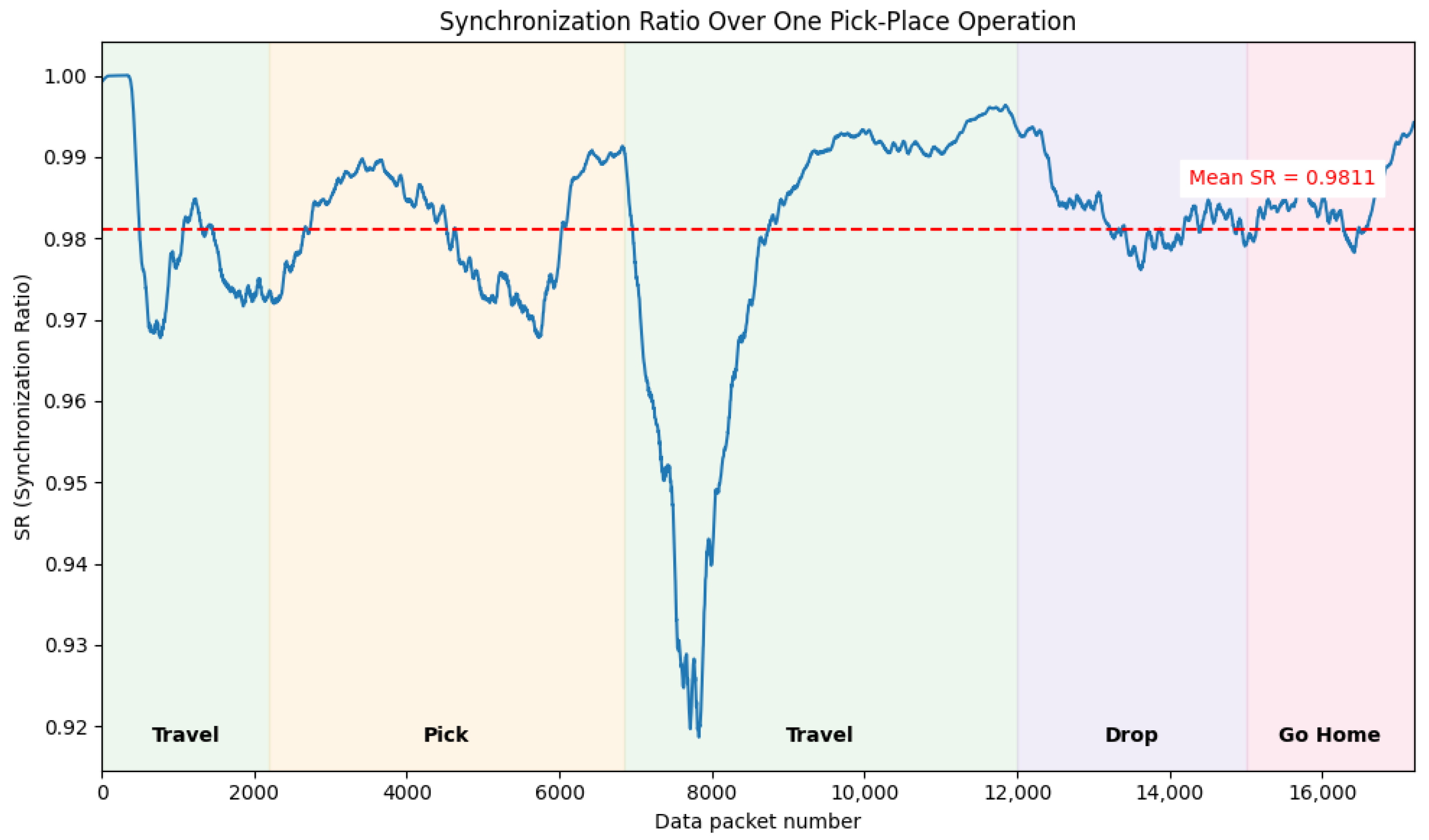
These values are used to compute the Synchronization Rate (), as defined in Equation (1) by Z. Wang, Y. OuYang et al. [54], where represents the joint values from the Isaac Sim model and represents feedback from the physical robot. The current setup achieves an overall synchronization rate of 98.11% showing correct data transmission and good synchronization of the physical robot to the virtual robot. The calculated for each data packet sent to EGM is evaluated for one pick-place sequence, as shown in Figure 6. The plot illustrates varying across different stages of the task, with the most significant deviations occurring during the travel sequence from pick to drop. This is primarily attributed to two factors: (1) the computational load from physics-based collision calculations (gripper and slide) in the simulation, which delays joint data publishing to the ROS node, and (2) changes in the direction of joint motion, which introduce increased intervals in the joint value.
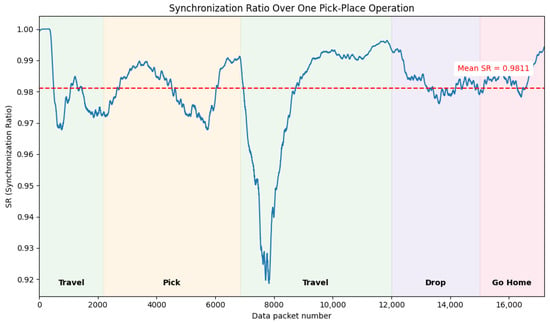
Figure 6.
Synchronization rate between the simulation model and the physical robot for one pick-place operation.
4.2. Validation and Failure Analysis
Given the modular nature of the framework, a validation study was conducted to assess its overall success rate under varying conditions, including different numbers of slide objects, positions, orientations, and natural language (LLM) inputs. The validation was conducted over 20 iterations, as summarized in Table 3, assessing the performance of three core modules: camera vision, LLM, and simulation. In addition to these modules, the overall status of the integrated framework was evaluated.
Table 3.
Operation status of different modules in the framework.
For any failed iterations, the corresponding failure reasons are also documented in the table. In the table, a ‘✓’ indicates a successful run, while an ‘X’ denotes a failure. Some cells are marked with a dash (‘–’) to indicate that the corresponding module did not execute. This typically occurs when an upstream module, such as the camera vision, fails. Since the camera vision module is the first stage of the pipeline, its failure halts the entire process, preventing downstream modules from proceeding. The most common failure modes observed were camera vision failures and speech-to-text failures. Camera vision failed in 10% of the total runs, primarily due to inaccuracies caused by insufficient lighting, while speech-to-text also failed in 10% of the runs, mainly due to incorrect voice input capture in a noisy laboratory environment.
In addition to the common failure modes, most of the failures (20%) occurred during the environment simulation phase. These issues primarily stem from irregularities in the physics modeling. Specifically, the glass slides—being small objects with a collision cross-section of only 1 mm—and the use of a convex hull decomposition collider mesh for the slide holder contributed to unstable interactions. At times, the physics engine failed to compute collisions accurately, skipping simulation steps and leading to erratic behavior when the slides were dropped into the holder. As a result, the slides occasionally slipped out of the holder due to these inconsistencies in collision handling. To reduce simulation failures, future work could include designing a specialized gripper tailored for handling glass slides, replacing the standard smart gripper used with the YuMi robot. Additionally, upgrading the system’s GPU capacity will improve the simulation performance by reducing the above mentioned erratic behavior in complex scenes. Based on the results of the validation and failure analysis, the framework achieved an overall success rate of 60%.
As a baseline, a traditional automated robot cell operates with all objects at known, fixed locations, performing pick-and-place tasks from predefined positions. When properly set up, this approach can achieve near 100% accuracy (successful pick-place operation). Although the accuracy of our proposed framework is lower compared to traditional fixed programming, its flexibility and ability to make real-time adjustments are key advantages, especially in dynamic and unstructured environments. The scripts for creating the virtual environment, simulation, camera vision, and LLM, as well as establishing the connection between the digital and physical robots, are available in the repository titled ‘Isaac-Sim–Adaptive-DT’ [55].
5. Discussion
The current work builds on our previous framework for adaptive DT [11] by incorporating a real-time vision-based perception module capable of updating the digital environment with object positions and orientations. While prior efforts such as Douthwaite et al. [29] have demonstrated strong modular DT architectures for safety assurance, they primarily focus on system-level validation without semantic scene understanding. Similarly, SERA [21] offers efficient real-time trajectory adaptation, but without integration of broader workspace modeling. Recent advances like those by Xia et al. [48] and Abbas et al. [46] represent notable strides in using LLMs for flexible task execution, often within simulated or partially controlled settings. Our approach complements these directions by focusing on grounded perception for dynamic environments, enabling semantic-level adaptation based on visual input. Unlike tactile or impedance-based sensing methods [17,22], which offer valuable low-level feedback, our system prioritizes visual understanding to support more intuitive task execution. Nonetheless, relying solely on vision brings challenges, particularly with occlusions and clutter, which remain open areas for future improvement across the field.
5.1. Real-Time Perception
The current camera setup, positioned directly above the workspace, provides accurate detection only before the robot begins its motion. Once the arm moves, it partially obstructs the view, limiting the system’s ability to update the scene continuously. This constraint affects both adaptability and safety in collaborative settings, especially when human intervention is possible. Compared to mixed-perception approaches that combine visual and tactile sensing for increased robustness [23], our current system lacks redundancy and is more sensitive to lighting and spatial occlusions. A necessary improvement would be the inclusion of an additional camera module specifically designed to monitor the workspace for human interactions, ensuring both task adaptability and operational safety. The implications of these limitations extend beyond the current application. For instance, the issue of camera obstruction could equally impact other industrial contexts, such as assembly lines or packaging stations where precise object tracking is necessary throughout a task. To move the system closer to deployment readiness, further improvements are needed in robustness and fault tolerance. Integrating redundant sensing modalities, such as combining vision with tactile feedback or incorporating multi-camera setups, including robotic arm-mounted cameras, could help ensure continuous visual feedback and mitigate perception failures caused by occlusion or lighting variability.
5.2. LLM-Based Task Definition
The integration of a large language model (LLM) into the framework introduces an innovative way for users to provide verbal inputs for sorting operations. However, during validation, as shown in Table 3, the speech-to-text module demonstrated limitations in recognizing accents, leading to errors in commands passed to the LLM. For instance, certain regional accents caused discrepancies between spoken inputs and their interpreted commands, occasionally resulting in incorrect sorting outcomes. Unlike multi-modal systems such as PaLM-E, which enable real-time task planning and contextual adaptation through continuous vision–language interaction [41], our framework currently supports only pre-simulation input, limiting its ability to adjust to environmental changes once execution begins. A key future improvement involves enabling real-time communication with the LLM during simulation, allowing users to interact with the system dynamically, for example, querying the LLM about the robot’s current status, sorting sequence, or joint positions without needing to inspect back-end processes manually. Such capabilities would enhance user experience, making the framework more interactive and intuitive. To enhance system deployment readiness, robustness must be improved by fine-tuning the LLM with domain-specific vocabulary and incorporating an intent confirmation mechanism with response validation, reducing hallucinations before action dispatch.
5.3. Hardware Constraint and Scalability
The framework’s dependency on hardware resources presents another challenge. The DT relies heavily on GPU resources to run Isaac Sim simulations, and additional components like the LLM and perception module can strain the system. As seen from the synchronization ratio (SR) evaluation (Figure 6), this overload slows down the simulation during the calculation-intensive part of the robot operation, delaying data transmission to the ROS server and, consequently, affecting the physical robot’s responsiveness. Additionally, the system slowdown can lead to bottlenecks in the simulation engine, resulting in irregular physics estimations, such as inaccurate collisions between the gripper and glass slides. This erratic behavior contributes to simulation failures and is a major factor behind the reduced success rate of only 60%. In essence, the primary cause of this low success rate is the hardware constraint, and upgrading to a more powerful GPU could potentially resolve the issue without requiring major changes to the framework. However, this approach raises concerns about scalability, as continuously upgrading hardware to match increasing simulation complexity is not a sustainable long-term solution. From a broader scalability standpoint, the framework’s real-time performance is currently limited by the combined computational load of all modules running on a single machine. Scaling the framework to support larger environments, multiple robots, or continuous operations would necessitate distributed computing, hardware abstraction layers for different robot types, and robust task scheduling mechanisms. These enhancements would enable more flexible and resilient deployments across varied industrial settings.
Another potential improvement involves reintroducing an external computer to offload the LLM and perception tasks, enabling the Linux system to dedicate its resources exclusively to simulation. This reconfiguration is expected to enhance the SR beyond 98.11%, with the hope of reaching or surpassing 99% and an improved success rate >80%. In scenarios involving larger robotic systems or multi-robot configurations, distributing computational loads across multiple systems would prevent bottlenecks and maintain operational efficiency. For example, separating LLM processing from simulation could facilitate the integration of additional perception modules or data analysis components without compromising performance while improving system deployment readiness.
5.4. Safety and Robustness
Safety considerations are critical for deploying this framework in HRC environments. The current system bypasses the robot’s standard controller, thereby disabling built-in safety features like collision avoidance and proximity alerts, placing the responsibility of ensuring operational safety on the developed framework. For instance, without proper monitoring, a technician accidentally placing their hand within the robot’s workspace during operation could lead to dangerous situations. A dedicated safety module, integrated with the perception system, could address this issue by detecting obstacles or human presence and halting operations when necessary. Conducting a comprehensive risk analysis and developing a robust safety protocol would ensure the framework’s readiness for use in unstructured environments. Moreover, achieving industrial-grade reliability requires not only hardware performance but also system-level robustness. This includes compliance with safety certifications, formal verification of behavior under failure conditions, and seamless integration with existing industrial control systems. Conducting a comprehensive risk analysis and developing a robust safety protocol would ensure the framework’s readiness for use in unstructured environments and support its broader adoption in real-world settings.
The framework currently lacks a robust error-handling mechanism, which poses a challenge during disruptions such as broken ROS subscriptions or EGM connections. In such cases, the simulation continues running while the physical robot remains stuck at its last received position, causing operational delays. Resolving these issues often requires manually restarting components like the ROS server, EGM server, or simulation module, resulting in workflow interruptions. To address this, a dynamic multi-agent-based system integrated with the LLM could be a valuable enhancement. For instance, the LLM could detect errors in real time and trigger targeted corrective agents, such as restarting specific modules, reestablishing connections to the ROS or EGM servers, or diagnosing network issues. By streamlining logging, troubleshooting and minimizing downtime, this feature would significantly enhance the framework’s reliability, operational efficiency, and deployment readiness.
While the proposed framework demonstrates promising results in a hospital lab setting, its generalizability to other industrial domains is subject to certain constraints. The current implementation is tailored to a tabletop scenario involving structured trays and small-scale manipulation. Extending it to more variable environments, such as warehouse logistics, automotive assembly, or quality control, would require reiterating the perception system for new object types, geometries, and lighting conditions. Likewise, the LLM-based task interface, while flexible in principle, would need domain-specific prompt engineering and safety filters to handle more complex or ambiguous instructions reliably while avoiding possible hallucinations.
6. Conclusions
The paper advances the framework for adaptive digital twins in collaborative robotics, addressing critical limitations identified in previous work. By introducing a real-time perception module, the system now dynamically captures and updates the physical workspace in the digital environment, enabling seamless synchronization between the two. The integration of an LLM further enhances usability, allowing untrained users to provide verbal instructions for task management. These developments make the framework more intuitive and adaptable to unstructured environments.
Despite the advancements presented, several limitations remain. These include hardware constraints, safety considerations in HRC, and the lack of a fully autonomous error-handling mechanism. In particular, the current framework relies on a single-machine setup, which restricts simulation performance and limits scalability. The implementation is also tailored to a controlled tabletop scenario; adapting it to more complex environments would require reconfiguring the perception system for new object types and spatial layouts. Additionally, some system failures still require manual intervention due to the absence of integrated recovery mechanisms. The speech-to-text interface is also sensitive to background noise and accent variations, which can affect the reliability of natural language task execution.
Nonetheless, this paper contributes not only a novel adaptive digital twin framework but also a detailed validation process that reveals critical insights into its practical implementation. The system was evaluated through 20 test runs in a hospital lab scenario involving a YuMi robot sorting microscope slides. Validation results showed a 60% overall success rate across varying conditions, with a 98.11% synchronization accuracy between the virtual and physical robot joint movements. The validation exposed potential failure points ranging from perception inaccuracies to LLM misinterpretations and highlighted the importance of system integration and timing. These findings underscore the complexity of deploying such frameworks in dynamic environments and serve as a key contribution of this work.
The use of open-source tools, real-time integration, and local LLMs reduces reliance on cloud services, supporting more secure and responsive deployment in industrial settings. Future efforts will focus on addressing challenges observed in the current setup by optimizing hardware utilization, reinforcing safety protocols, and developing a dynamic, LLM-assisted error-handling system to improve overall system resilience.
Overall, this enhanced framework represents a significant step toward realizing adaptive, human-centric collaborative robotics. It lays a solid foundation for deploying robots in dynamic and unstructured environments, fostering efficient, safe, and intuitive human–robot interactions.
Author Contributions
Conceptualization, S.N. and M.T.; methodology, S.N., R.C.P. and O.C.I.; software, S.N., R.C.P. and O.C; validation, S.N., R.C.P. and O.C.I.; formal analysis, S.N.; investigation, S.N.; resources, M.T. and M.J.; writing—original draft preparation, S.N. and R.C.P.; writing—review and editing, S.N., M.J. and M.T.; visualization, S.N.; supervision, M.T. and M.J.; project administration, M.T. and M.J.; funding acquisition, M.T. and M.J. All authors have read and agreed to the published version of the manuscript.
Funding
The authors would like to thank VINNOVA for making this research project possible. This work was supported by VINNOVA under the grants iPROD–Integrated Product Development (2021-02481) and ODEN-AI–Optimized Digitalization for Environmentally NeutrAl Industrialization (2023-02674), as part of the program Advanced Digitalization–Enabling Technologies financed by Sweden’s Innovation Agency (VINNOVA).
Data Availability Statement
The scripts for creating the virtual environment, simulation, camera vision, and LLM, as well as establishing the connection between the digital and physical robots, are available in the repository titled ‘Isaac-Sim—Adaptive-DT’ https://github.com/DesignAutomationLaboratory/Isaac-Sim---Adaptive-DT (accessed on 19 June 2025).
Acknowledgments
During the preparation of this work the authors used ChatGPT-4o in order to improve the readability and language of the manuscript. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the published article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| DT | Digital Twin |
| LLM | Large Language Model |
| HRC | Human–Robot Collaboration |
| EGM | Externally Guided Motion |
| RWS | Robot Web Services |
| ROS | Robot Operating System |
| ROI | Region of Interest |
References
- Liao, Y.; Deschamps, F.; Loures, E.d.F.R.; Ramos, L.F.P. Past, present and future of Industry 4.0-a systematic literature review and research agenda proposal. Int. J. Prod. Res. 2017, 55, 3609–3629. [Google Scholar] [CrossRef]
- Grabowska, S.; Saniuk, S.; Gajdzik, B. Industry 5.0: Improving humanization and sustainability of Industry 4.0. Scientometrics 2022, 127, 3117–3144. [Google Scholar] [CrossRef] [PubMed]
- Leng, J.; Sha, W.; Wang, B.; Zheng, P.; Zhuang, C.; Liu, Q.; Wuest, T.; Mourtzis, D.; Wang, L. Industry 5.0: Prospect and retrospect. J. Manuf. Syst. 2022, 65, 279–295. [Google Scholar] [CrossRef]
- Akundi, A.; Euresti, D.; Luna, S.; Ankobiah, W.; Lopes, A.; Edinbarough, I. State of Industry 5.0—Analysis and identification of current research trends. Appl. Syst. Innov. 2022, 5, 27. [Google Scholar] [CrossRef]
- Hentout, A.; Aouache, M.; Maoudj, A.; Akli, I. Human–robot interaction in industrial collaborative robotics: A literature review of the decade 2008–2017. Adv. Robot. 2019, 33, 764–799. [Google Scholar] [CrossRef]
- Kopp, T.; Baumgartner, M.; Kinkel, S. Success factors for introducing industrial human-robot interaction in practice: An empirically driven framework. Int. J. Adv. Manuf. Technol. 2021, 112, 685–704. [Google Scholar] [CrossRef]
- Andersson, S. Supporting the Implementation of Industrial Robots in Collaborative Assembly Applications; Malardalen University: Västerås, Sweden, 2021. [Google Scholar]
- Schnell, M.; Holm, M. Challenges for manufacturing SMEs in the introduction of collaborative robots. In SPS2022; IOS Press: Amsterdam, The Netherlands, 2022; pp. 173–183. [Google Scholar]
- Ma, X.; Qi, Q.; Tao, F. A Digital Twin–Based Environment-Adaptive Assignment Method for Human–Robot Collaboration. J. Manuf. Sci. Eng. 2024, 146, 031004. [Google Scholar] [CrossRef]
- Grieves, M.; Vickers, J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In Transdisciplinary Perspectives on Complex Systems: New Findings and Approaches; Springer: Cham, Switzerland, 2017; pp. 85–113. [Google Scholar]
- Nambiar, S.; Jonsson, M.; Tarkian, M. Automation in Unstructured Production Environments Using Isaac Sim: A Flexible Framework for Dynamic Robot Adaptability. Procedia CIRP 2024, 130, 837–846. [Google Scholar] [CrossRef]
- Hribernik, K.; Cabri, G.; Mandreoli, F.; Mentzas, G. Autonomous, context-aware, adaptive Digital Twins—State of the art and roadmap. Comput. Ind. 2021, 133, 103508. [Google Scholar] [CrossRef]
- Andersen, R.; Andersen, A.L.; Larsen, M.S.; Brunoe, T.D.; Nielsen, K. Potential benefits and challenges of changeable manufacturing in the process industry. Procedia CIRP 2019, 81, 944–949. [Google Scholar] [CrossRef]
- Fries, C.; Fechter, M.; Nick, G.; Szaller, Á.; Bauernhansl, T. First results of a survey on manufacturing of the future. Procedia Comput. Sci. 2021, 180, 142–149. [Google Scholar] [CrossRef]
- Bennulf, M.; Danielsson, F.; Svensson, B. Identification of resources and parts in a Plug and Produce system using OPC UA. Procedia Manuf. 2019, 38, 858–865. [Google Scholar] [CrossRef]
- Makris, S.; Kampourakis, E.; Andronas, D. On deformable object handling: Model-based motion planning for human-robot co-manipulation. CIRP Ann. 2022, 71, 29–32. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Z. Mechanoreception for soft robots via intuitive body cues. Soft Robot. 2020, 7, 198–217. [Google Scholar] [CrossRef] [PubMed]
- Nambiar, S.; Wiberg, A.; Tarkian, M. Automation of unstructured production environment by applying reinforcement learning. Front. Manuf. Technol. 2023, 3, 1154263. [Google Scholar] [CrossRef]
- Anatoliotakis, N.; Paraskevopoulos, G.; Michalakis, G.; Michalellis, I.; Zacharaki, E.I.; Koustoumpardis, P.; Moustakas, K. Dynamic Human–Robot Collision Risk Based on Octree Representation. Machines 2023, 11, 793. [Google Scholar] [CrossRef]
- Nevliudov, I.; Tsymbal, O.; Bronnikov, A. Improvement of robotic systems based on visual control. Innov. Technol. Sci. Solut. Ind. 2021, 4, 65–74. [Google Scholar] [CrossRef]
- Dastider, A.; Lin, M. SERA: Safe and Efficient Reactive Obstacle Avoidance for Collaborative Robotic Planning in Unstructured Environments. arXiv 2022, arXiv:2203.13821. [Google Scholar]
- Zeng, C.; Yang, C.; Chen, Z. Bio-inspired robotic impedance adaptation for human-robot collaborative tasks. Sci. China Inf. Sci. 2020, 63, 170201. [Google Scholar] [CrossRef]
- Mohammadi Amin, F.; Rezayati, M.; van de Venn, H.W.; Karimpour, H. A mixed-perception approach for safe human–robot collaboration in industrial automation. Sensors 2020, 20, 6347. [Google Scholar] [CrossRef] [PubMed]
- Glaessgen, E.; Stargel, D. The digital twin paradigm for future NASA and US Air Force vehicles. In Proceedings of the 53rd AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference 20th AIAA/ASME/AHS Adaptive Structures Conference 14th AIAA, Honolulu, HI, USA, 23–26 April 2012; p. 1818. [Google Scholar]
- Grieves, M. Digital twin: Manufacturing excellence through virtual factory replication. White Pap. 2014, 1, 1–7. [Google Scholar]
- Tao, F.; Xiao, B.; Qi, Q.; Cheng, J.; Ji, P. Digital twin modeling. J. Manuf. Syst. 2022, 64, 372–389. [Google Scholar] [CrossRef]
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in manufacturing: A categorical literature review and classification. Ifac-PapersOnline 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Ramasubramanian, A.K.; Mathew, R.; Kelly, M.; Hargaden, V.; Papakostas, N. Digital twin for human–robot collaboration in manufacturing: Review and outlook. Appl. Sci. 2022, 12, 4811. [Google Scholar] [CrossRef]
- Douthwaite, J.A.; Lesage, B.; Gleirscher, M.; Calinescu, R.; Aitken, J.M.; Alexander, R.; Law, J. A modular digital twinning framework for safety assurance of collaborative robotics. Front. Robot. AI 2021, 8, 758099. [Google Scholar] [CrossRef] [PubMed]
- Lucke, D.; Constantinescu, C.; Westkämper, E. Smart factory-a step towards the next generation of manufacturing. In Manufacturing Systems and Technologies for the New Frontier, Proceedings of the 41 st CIRP Conference on Manufacturing Systems, Tokyo, Japan, 26–28 May 2008; Springer: London, UK, 2008; pp. 115–118. [Google Scholar]
- Bellavista, P.; Bicocchi, N.; Fogli, M.; Giannelli, C.; Mamei, M.; Picone, M. Requirements and design patterns for adaptive, autonomous, and context-aware digital twins in industry 4.0 digital factories. Comput. Ind. 2023, 149, 103918. [Google Scholar] [CrossRef]
- Carfì, A.; Patten, T.; Kuang, Y.; Hammoud, A.; Alameh, M.; Maiettini, E.; Weinberg, A.I.; Faria, D.; Mastrogiovanni, F.; Alenyà, G.; et al. Hand-object interaction: From human demonstrations to robot manipulation. Front. Robot. AI 2021, 8, 714023. [Google Scholar] [CrossRef] [PubMed]
- Doncieux, S.; Chatila, R.; Straube, S.; Kirchner, F. Human-centered AI and robotics. AI Perspect. 2022, 4, 1. [Google Scholar] [CrossRef]
- Kragic, D.; Gustafson, J.; Karaoguz, H.; Jensfelt, P.; Krug, R. Interactive, Collaborative Robots: Challenges and Opportunities; IJCAI: Stockholm, Sweden, 2018; pp. 18–25. [Google Scholar]
- Tellex, S.; Gopalan, N.; Kress-Gazit, H.; Matuszek, C. Robots that use language. Annu. Rev. Control Robot. Auton. Syst. 2020, 3, 25–55. [Google Scholar] [CrossRef]
- Foster, M.E. Natural language generation for social robotics: Opportunities and challenges. Philos. Trans. R. Soc. B 2019, 374, 20180027. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners; 2019 Semantic Scholar. Available online: https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe (accessed on 19 June 2025).
- Kim, Y.; Kim, D.; Choi, J.; Park, J.; Oh, N.; Park, D. A survey on integration of large language models with intelligent robots. Intell. Serv. Robot. 2024, 17, 1091–1107. [Google Scholar] [CrossRef]
- Shridhar, M.; Manuelli, L.; Fox, D. Perceiver-actor: A multi-task transformer for robotic manipulation. Proc. Conf. Robot. Learn. PMLR 2023, 205, 785–799. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.M.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; et al. PaLM-E: An Embodied Multimodal Language Model. In Proceedings of the International Conference on Machine Learning, Honolulu, United States of America, July 2023; pp. 8469–8488. [Google Scholar]
- Zeng, F.; Gan, W.; Wang, Y.; Liu, N.; Yu, P.S. Large Language Models for Robotics: A Survey. arXiv 2023, arXiv:2311.07226. [Google Scholar] [CrossRef]
- Chen, W.; Hu, S.; Talak, R.; Carlone, L. Leveraging Large Language Models for Robot 3D Scene Understanding. arXiv 2022, arXiv:2209.05629. [Google Scholar]
- Gkournelos, C.; Konstantinou, C.; Makris, S. An LLM-based approach for enabling seamless Human-Robot collaboration in assembly. CIRP Ann. 2024, 73, 9–12. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, J.; Wang, P.; Law, J.; Calinescu, R.; Mihaylova, L. A deep learning-enhanced Digital Twin framework for improving safety and reliability in human–robot collaborative manufacturing. Robot. Comput.-Integr. Manuf. 2024, 85, 102608. [Google Scholar] [CrossRef]
- Abbas, A.N.; Beleznai, C. TalkWithMachines: Enhancing Human-Robot Interaction Through Large/Vision Language Models. In Proceedings of the 2024 Eighth IEEE International Conference on Robotic Computing (IRC), Tokyo, Japan, 11–13 December 2024; pp. 253–258. [Google Scholar]
- Cimino, A.; Longo, F.; Nicoletti, L.; Solina, V. Simulation-based Digital Twin for enhancing human-robot collaboration in assembly systems. J. Manuf. Syst. 2024, 77, 903–918. [Google Scholar] [CrossRef]
- Xia, Y.; Shenoy, M.; Jazdi, N.; Weyrich, M. Towards autonomous system: Flexible modular production system enhanced with large language model agents. In Proceedings of the 2023 IEEE 28th International Conference on Emerging Technologies and Factory Automation (ETFA), Sinaia, Romania, 12–15 September 2023; pp. 1–8. [Google Scholar]
- Chen, J.; Luo, H.; Huang, S.; Zhang, M.; Wang, G.; Yan, Y.; Jing, S. Autonomous Human-Robot Collaborative Assembly Method Driven by the Fusion of Large Language Model and Digital Twin. J. Phys. Conf. Ser. 2024, 2832, 012004. [Google Scholar] [CrossRef]
- ABB AB: Västerås, Sweden. Application Manual—Externally Guided Motion RobotWare 7.7. Available online: https://library.e.abb.com/public/e56fd144e78441eba8d199f8a9d5d59d/3HAC073318%20AM%20Externally%20Guided%20Motion%20RW7-en.pdf?x-sign=eSof27%2Ff9vf2z8m2%2BsgVJwsJNQmeBvfMkCPizxxnpkbiomqFBbAGU1QdxT%2ByZDnu, (accessed on 19 June 2025).
- ABB AB: Västerås, Sweden. Robot Web Services: Introduction. Available online: https://developercenter.robotstudio.com/api/rwsApi/ (accessed on 19 June 2025).
- Albert, Q.J.; Alexandre, S.; Arthur, M.; Chris, B.; Devendra, S.C.; Diego, d.l.C.; Florian, B.; Gianna, L.; Guillaume, L.; Lucile, S.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar] [CrossRef]
- Ratliff, N.D.; Issac, J.; Kappler, D.; Birchfield, S.; Fox, D. Riemannian motion policies. arXiv 2018, arXiv:1801.02854. [Google Scholar] [CrossRef]
- Wang, Z.; OuYang, Y.; Kochan, O. Bidirectional linkage robot digital twin system based on ros. In Proceedings of the 2023 17th International Conference on the Experience of Designing and Application of CAD Systems (CADSM), Jaroslaw, Poland, 22–25 February 2023; Volume 1, pp. 1–5. [Google Scholar]
- Nambiar, S. DesignAutomationLaboratory/Isaac-Sim—Adaptive DT. Available online: https://github.com/DesignAutomationLaboratory/Isaac-Sim—Adaptive-DT.git (accessed on 19 June 2025).



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).