1. Introduction
Visual–inertial odometry (VIO) combines data from cameras and Inertial Measurement Units (IMUs) and has become a cornerstone in applications such as autonomous driving, augmented reality, and robotic navigation. In end-to-end autonomous systems, although deep learning has been increasingly adopted in perception and decision-making modules, VIO remains a fundamental technique for motion estimation—particularly when GNSS signals are unavailable or during adverse weather conditions. VIO methods can be broadly categorized into two classes: filter-based and optimization-based approaches, each offering a different balance between real-time performance and estimation accuracy. Filter-based methods, such as the Extended Kalman Filter (EKF) and its variants like MSCKF and Rovio, use a recursive estimation strategy that is computationally efficient and suitable for resource-constrained environments. However, standard EKF struggles with highly nonlinear systems, often resulting in degraded estimation accuracy. To address this limitation, the Iterated Extended Kalman Filter (IEKF) refines the observation model through iterative updates, thereby improving robustness to system nonlinearity. Nevertheless, IEKF introduces a higher computational cost, especially with high-dimensional state representations, thus impacting its real-time capability. In contrast, optimization-based VIO methods use graph optimization techniques to perform global optimization, achieving better performance in high-precision odometry, particularly in complex environments and nonlinear systems, effectively reducing estimation errors. However, these methods incur higher computational costs and tend to be less likely to be utilized in real time. To balance accuracy and efficiency within filtering methods, recent research has introduced the Schur complement optimization strategy. The Schur complement method effectively retains covariance information by marginalizing variables, compresses the state dimension, and reduces computational complexity. Integrating this strategy into the EKF framework preserves the real-time recursive advantage of the filter while enhancing its ability to handle high-dimensional states and nonlinear systems, making it an important development direction in current VIO research.
Typical optimization-based methods model the joint pose and corresponding observed landmark points [
1,
2]. In 2013, Leutenegger et al. proposed the OKVIS system, which incorporates both IMU errors and visual reprojection errors within a full probabilistic framework to formulate an objective function. The introduction of a keyframe mechanism limits the sliding window size, achieving a good balance between accuracy and robustness [
3]. In 2017, Mur Artal et al. addressed the scale uncertainty issue inherent in monocular cameras by proposing a high-precision IMU initialization method, which quickly estimates IMU errors and supports loop closure detection and map reuse, thereby achieving centimeter-level positioning accuracy [
4]. In the same year, Shen et al. at the Hong Kong University of Science and Technology introduced the VINS-Mono system, which, by incorporating ideas from pre-integration and sliding windows, integrates IMU and monocular camera data on unmanned aerial vehicle (UAV) platforms to achieve high-precision motion estimation. This system has since become one of the most widely adopted visual–inertial SLAM frameworks [
5]. Some VIN algorithms reuse previously optimized intermediate results to reduce computational load [
6,
7,
8,
9]. In 2018, Jia He et al. proposed the PL-VIO system based on VINS-Mono, which constructs a three-dimensional structured map by fusing point and line features. Through sliding-window optimization of IMU errors and feature reprojection errors, this system achieves more efficient and robust visual–inertial fusion [
10]. In 2019, Shen et al. further launched the VINS-Fusion system, which expands the support for multi-sensor fusion, including binocular cameras and GPS, significantly enhancing the system’s adaptability and positioning accuracy in complex environments. In 2021, Campos et al. at the University of Zaragoza released the ORB-SLAM3 system, the latest version of the ORB-SLAM series. This system integrates various sensors, including IMUs, and is capable of handling moving objects in dynamic environments. It achieves high robustness in localization and mapping through advanced optimization strategies such as real-time sparse map reconstruction, global bundle adjustment, and loop closure detection [
11].
Although optimization-based methods [
12] theoretically offer higher accuracy, they also suffer from high computational complexity. In contrast, filtering-based approaches [
13,
14,
15,
16] achieve considerable accuracy with lower computational overhead. In the research on back-end optimization for Extended Kalman Filter (EKF)-based Simultaneous Localization and Mapping (SLAM) systems, Mourikis introduced the MSCKF algorithm in 2007. This method integrates visual and Inertial Measurement Unit (IMU) data within the EKF framework, enabling high-precision localization and navigation. The algorithm incorporates a sliding window mechanism during the EKF update phase, effectively limiting the scale of the optimization parameters, alleviating the computational burden as time progresses, and significantly enhancing system robustness [
17]. In 2016,. Concha and Civera implemented the first tightly coupled fusion method for visual and inertial navigation data, combined with multithreading optimization techniques, which enabled real-time operation on conventional CPU platforms [
18]. Lupton introduced the pre-integration of IMU data, laying the theoretical foundation for efficient fusion of visual and IMU data in subsequent research [
19]. In 2018, Usenko et al. proposed a direct method-based visual–inertial odometry (VIO) system, which optimizes both camera pose and sparse scene geometry by jointly minimizing photometric and IMU pre-integration errors [
20,
21]. In 2019, Geneva et al. proposed the SEVIS algorithm, which introduced a keyframe-assisted feature matching strategy to suppress navigation drift and applied the Schmidt–EKF method to the tightly coupled process, achieving error-constrained 3D motion estimation [
22].
Given these challenges, there is a pressing need for a VIO algorithm that delivers both high accuracy and real-time performance. Inspired by Fan et al. [
23] and Wang et al. [
24], this paper proposes a novel approach that integrates deep learning-based feature enhancement with Schur complement-optimized IEKF.
The structure of this paper is arranged as follows:
Section 1 introduces the background and related work.
Section 2 discusses the IMU motion model and visual observations.
Section 3 presents the algorithm framework, Schur complement, and IEKF.
Section 4 provides the experiments and result analysis.
Section 5 concludes with a summary and future research directions.
3. Methods
The main parts of the visual–inertial pose estimation algorithm proposed in this paper are MLP combined with Transformer to enhance ORB features and the Schur complement-optimized IEKF algorithm. In the visual processing part, the ORB algorithm is first used to extract feature points. ORB features have good real-time performance and stability in resource-constrained scenarios due to their efficient extraction speed and strong rotation invariance, and can provide reliable input for subsequent feature processing. In order to further improve the expressiveness and environmental adaptability of feature points, this paper uses MLP and Transformer models to enhance the extracted ORB feature points. The MLP captures local spatial dependencies through nonlinear mappings, while the Transformer enables global contextual modeling via a self-attention mechanism. This dual-module design significantly enhances the robustness of features to challenging conditions, such as viewpoint shifts and illumination variations. In the stage of visual and inertial information fusion, this paper adopts a state estimation method based on IEKF. IEKF can improve the consistency and accuracy problems of traditional EKF in strong nonlinear systems through iterative linearization and updating. In order to further improve the computational efficiency and convergence speed in the filtering process, this paper introduces the Schur complement optimization strategy in the IEKF framework. Schur complement optimization can effectively compress the system scale and reduce the computational complexity when marginalizing high-dimensional redundant variables, while maintaining the consistency and accuracy of system state estimation. It is especially suitable for the high-dimensional sparse structure after the joint residual construction in the visual inertial system. The relevant derivation process will be introduced in detail in this section. Through this series of designs, the method proposed in this paper significantly improves the accuracy and robustness of pose estimation in complex environments while maintaining high real-time performance. The overall framework of the algorithm in this paper is shown in
Figure 2.
3.1. Error Integration
To achieve more accurate state estimation by fully utilizing both visual and IMU data, the IMU residual
and the visual residual
should be integrated into a unified error vector:
Its covariance matrix is given by
where
represents the covariance between the IMU prediction and the visual measurements.
3.2. Schur Complement
The Schur complement is an important concept in linear algebra, and is widely used in matrix decomposition, optimization problems, numerical computation, and fields such as SLAM. Its core idea is to eliminate certain variables through block matrix operations, thereby reducing computational complexity and improving the efficiency of numerical solutions. Compared to Cholesky decomposition, which typically operates on the entire system and often struggles to efficiently eliminate local variables while preserving sparsity, the Schur complement enables the selective marginalization of specific variables (such as feature points or past states). This significantly reduces computational overhead and better preserves the sparse structure of the system. As a result, it is particularly well-suited for scenarios involving frequent marginalization and sliding window optimization, as commonly encountered in visual SLAM.
In the optimization process of visual–inertial SLAM, it is necessary to estimate both the camera pose and the positions of three-dimensional feature points simultaneously. The dimension of the joint state variables is extremely high, and a direct solution typically involves enormous computational effort. To avoid directly handling all state variables, the Schur complement is introduced to marginalize the portion of the joint residual model related to the feature points, yielding a residual term that is only dependent on the camera pose. In other words, the Schur complement is used to eliminate certain variables, thus simplifying the computation process. Therefore, we use the Schur complement to accelerate the computation. During this process, the weighted squared error is minimized, where
The error state is used to update the estimated state, where is the constant term of the overall error, and is the Jacobian matrix of the residual with respect to the state variables.
Assume that the optimization variables are also divided into two parts:
The optimization problem can be expressed as
The system of equations is computationally expensive to solve directly; therefore, the Schur complement can be used to eliminate the visual states and solve for :
Solve for
using the second equation expanded from the above formula:
If
is invertible, then the following can be obtained:
Substitute this into the first equation:
The following can be obtained:
Upon rearrangement, the following can be obtained:
where
This results in an equation that contains only the IMU state
:
After solving for
,we can substitute the result back to solve for
:
In this way, only a smaller linear system needs to be solved, thereby improving computational efficiency.
3.3. Iterative Update of IEKF
The IEKF improves the accuracy and stability of the fusion between vision and IMU by leveraging the high-frequency predictions from the IMU and the global corrections from vision, along with iterative optimization for measurement updates. This makes it suitable for tasks such as SLAM, robot localization, and autonomous driving.
In EKF, the measurement update is performed only once, whereas IEKF iteratively optimizes the estimation through multiple iterations. The initial state estimate is denoted as
, the initial covariance as
, and the iteration count is set as
.
Iterative computation is performed to calculate the measurement prediction.
The measurement Jacobian matrix is as follows:
Residual (innovation term):
Calculate the Kalman Gain:
Update the state estimate:
After the Schur complement-based acceleration step, the corresponding solution is obtained. If the value of is smaller than the predefined threshold, the state update is considered to have converged, and the iteration stops. Otherwise, set and continue the iteration.
When the iteration converges, the final updates for the state and covariance matrices are performed as follows:
The pseudocode of the algorithm proposed in this paper is shown in Algorithm 1. The algorithm proposed in this paper takes IMU prediction as the guide, integrates visual and inertial information by constructing joint residual and Jacobian matrix, and uses the Schur complement to marginalize some visual variables to reduce the optimization dimension. It then performs an iterative state update to improve the ability to handle nonlinear errors, and finally updates the state and covariance to achieve accurate and efficient visual–inertial state estimation.
| Algorithm 1 Pseudocode of iterative Extended Kalman Filter based on Schur complement. |
1. Inputs: a_k, ω_k, z_k^I, x0, P0
2. Initialize: x ← x0, P ← P0
3. For each time step k:
4. Propagate x with IMU pre-integration
5. Compute F, Q
6. P ← F P FT + Q
7. For each sliding window:
8. Linearize residual: r = z − h(x)
9. Construct Jacobian H, information matrix Λ
10. Compute normal equations:
11. HT Λ H δx = HT Λ r
12. Apply Schur complement to marginalize landmarks:
13. H_schur δx_s = b_schur
14. For i = 1 to MaxIter:
15. Solve for δx_s
16. x ← x ⊕ δx_s
17. If ||δx_s|| < ε: break
18. Update covariance P via IEKF posterior
19. Output: Optimized state x and covariance P |
It is worth emphasizing that the IEKF is a local optimization method whose convergence is not inherently guaranteed. The IEKF achieves local convergence when the initial estimate is sufficiently close to the true state, the measurement Jacobian is well-conditioned, and the noise covariances are properly bounded [
28]. Under these conditions, the iteration converges quadratically to the local minimum of the nonlinear least squares problem. In practice, we apply a convergence threshold ϵ and terminate the iteration when
< ϵ, ensuring both computational efficiency and robustness.
4. Experimental Results and Analysis
To evaluate the effectiveness of the proposed algorithm, a series of experiments were conducted, including image-matching tests, trajectory estimation on public datasets, and validation on self-collected sequences. The image-matching experiment evaluated the feature extraction and matching performance after the introduction of MLP and Transformer architectures. The visual–inertial odometry trajectory experiment analyzed the stability and robustness of the algorithm in different dynamic environments. The public dataset experiment compared and analyzed the estimation accuracy of the algorithm in different dynamic environments and compared it with existing methods. The self-collected dataset experiment verified the generalization ability and robustness of the algorithm in real scenes. Collectively, these experiments demonstrate the proposed algorithm’s advantages in terms of accuracy, real-time performance, and adaptability to dynamic environments.
Simulation platform: The simulation platform utilizes a computer equipped with an Intel i7-13700H processor, 16 GB RAM, and an RTX3050 graphics card with 4 GB of VRAM. The software environment consists of Ubuntu 22, Docker, C++17, Python 3.8.5, and ROS2 Humble.
4.1. Matching Experiment
Image-matching experiments are carried out under different lighting conditions and viewing angle changes to evaluate the matching accuracy of the enhanced ORB feature points under these environmental changes.
Experimental setup: The ORB feature extraction module was configured to run on the GPU for acceleration. Some key parameters are as follows: the number of feature points extracted per image was set to 3000; the scale factor of the image pyramid was set to 1.2; and the number of pyramid levels was set to 8.
The experimental results presented in
Figure 3 and
Figure 4 demonstrate that, under varying lighting conditions and viewpoint changes, the ORB feature points enhanced by MLP and Transformer show significant improvements. The enhanced feature points can maintain high matching accuracy under uneven illumination or large perspective changes, improving the robustness and adaptability of the feature points. It is verified that the enhanced algorithm can significantly improve the stability and accuracy of feature matching in complex environments, providing reliable feature support for subsequent visual inertial pose estimation.
In order to test the operating efficiency, a video sequence from the KITTI dataset was tested, and the relevant results are presented in
Table 1. The experimental results indicate that, under identical test conditions, the enhanced algorithm achieves a notable improvement in both the number of raw and correct matches, while incurring only a minimal increase in runtime. Specifically, when the number of extracted feature points was increased by 1000 compared to the conventional setting (typically 2000 points), the processing time increased by only 17 ms. This demonstrates the strong parallel computing capability and execution efficiency of the experimental platform, further validating the real-time performance and robustness of the proposed approach.
Table 1.
Average per-frame results of different methods on the KITTI dataset.
Table 1.
Average per-frame results of different methods on the KITTI dataset.
| Method | ORB | OURS |
|---|
| inliers | 515.37 | 730.77 |
| raw matches | 911.23 | 1044.44 |
| extraction time (ms) | 10.9 | 27.3 |
4.2. Visual–Inertial Odometry Trajectory Experiment
Visual–inertial odometry (VIO) is a pose estimation technique that combines visual information from a camera with inertial data from an IMU (Inertial Measurement Unit) to determine the motion of a mobile device. It estimates the relative displacement and orientation changes by detecting and tracking feature points across consecutive frames while integrating inertial measurements to improve accuracy and robustness. To further evaluate the performance of the proposed algorithm, trajectory reconstruction experiments were conducted in dynamic environments. The results demonstrate the algorithm’s stability and robustness in complex and challenging scenarios.
Experimental setup: The experiments were conducted using a laptop equipped with an RTX 3050 GPU. The number of feature points extracted per image was set to 2000; the scale factor of the image pyramid was set to 1.2; the number of pyramid levels was set to 8; and the feature-matching quality threshold was set to 0.7.
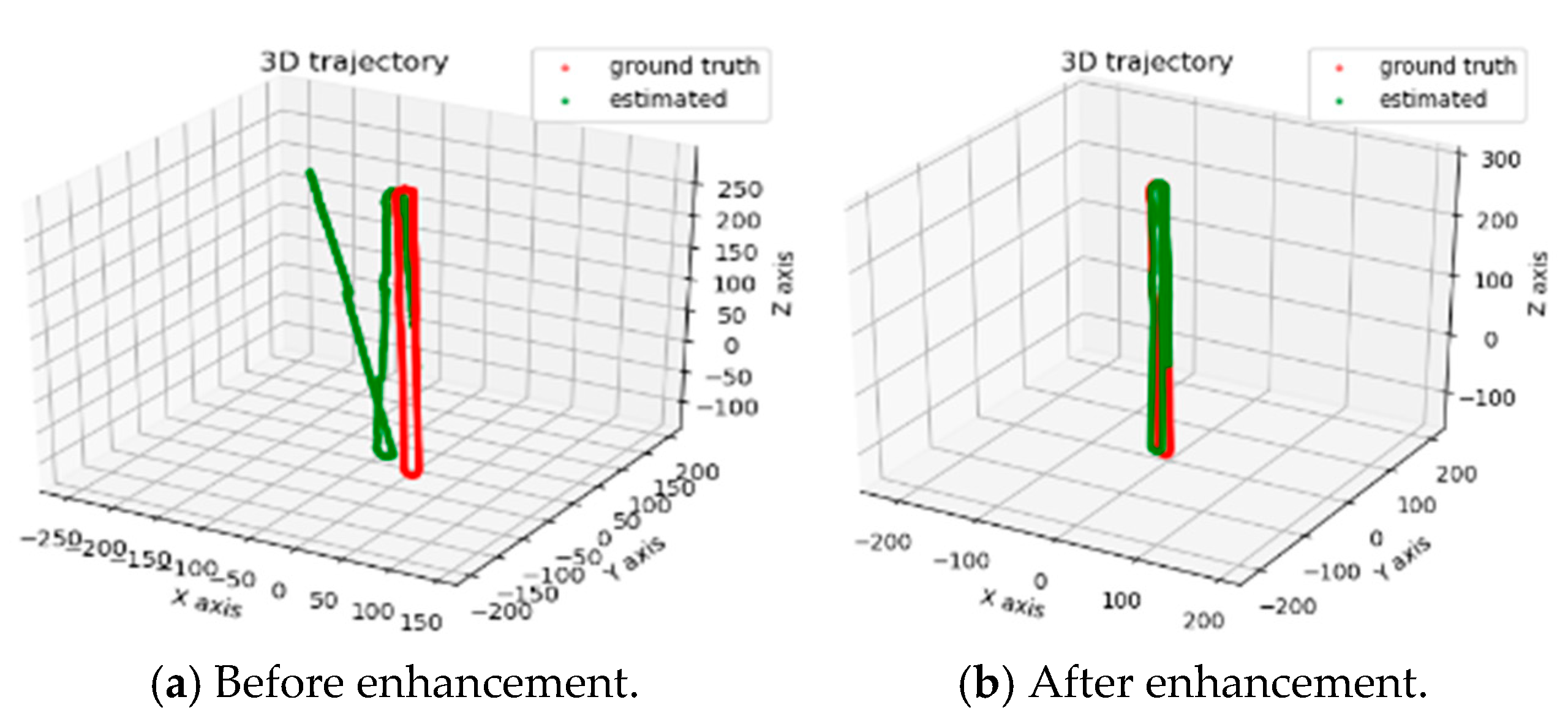
Figure 5a,b illustrate the trajectory results before and after applying the enhancement, respectively.
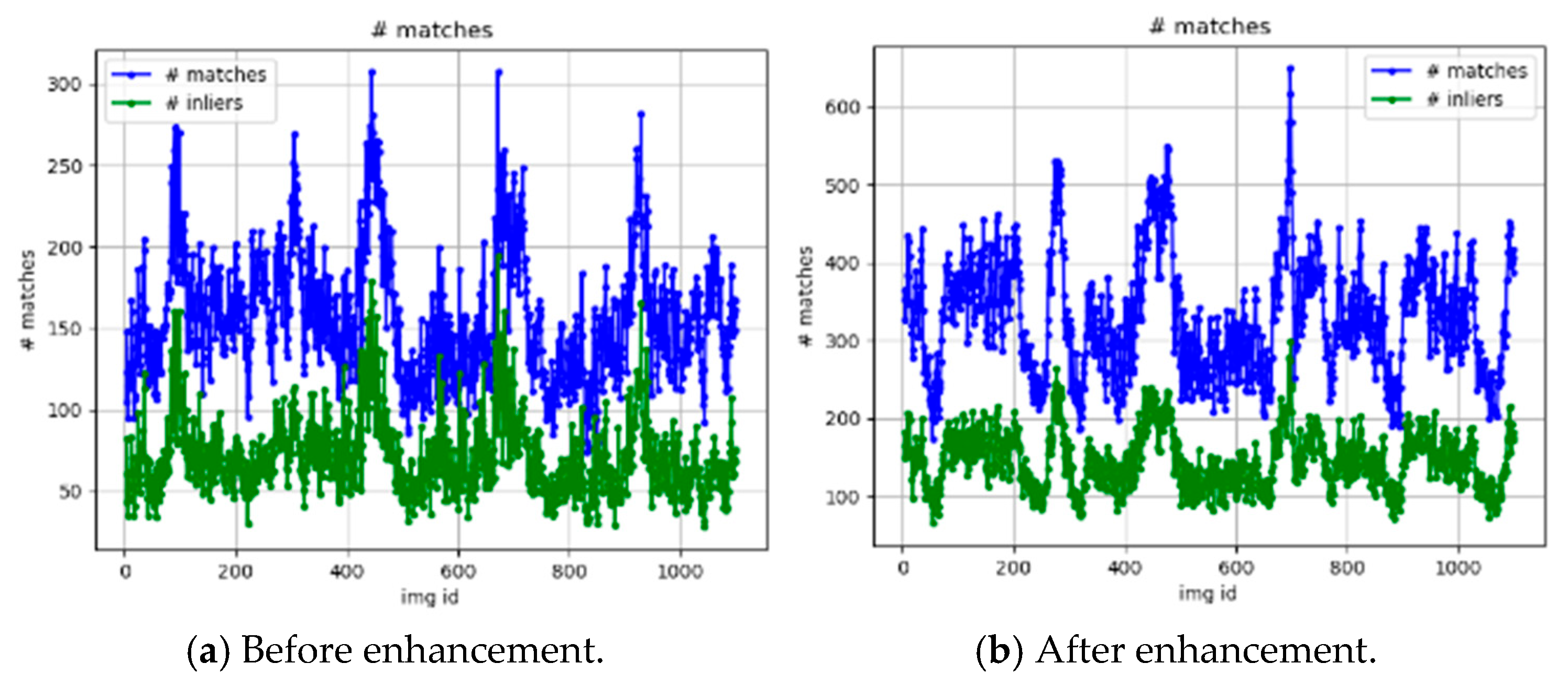
Figure 6 compares the performance of the original and enhanced algorithms in terms of feature extraction, initial matching, and inlier matching.
Figure 7 illustrates the errors of the original and enhanced trajectories along the x, y, and z axes relative to the ground-truth values.
The experimental results presented in
Figure 5 demonstrate the performance differences before and after enhancement. In
Figure 5a, the trajectory error remains small during the initial stage of the sequence but exhibits significant drift in the latter half. This drift becomes particularly severe in scenarios with large numbers of dynamic objects such as pedestrians and vehicles, leading to rapid error accumulation and poor robustness. In contrast,
Figure 5b shows that the trajectory error remains within a relatively small range throughout the entire sequence, indicating a significant improvement in stability under dynamic environments. A comparison between
Figure 6a,b clearly shows that the enhanced algorithm achieves a substantial increase in both the number of initial matches and inlier matches. Furthermore,
Figure 7a,b reveal that, while the original algorithm suffers from continuously increasing error along the
x-axis in the later stages, the enhanced algorithm maintains more stable error control in the x-direction, which is more susceptible to interference from dynamic objects. These results verify the robustness and improved accuracy of the enhanced method in complex, dynamic scenes.
4.3. Experiments on Public Datasets
In the pose estimation experiments using public datasets, the publicly available KITTI dataset was used for testing to evaluate the algorithm’s performance in real-world scenarios. EKF and IEKF were respectively employed for trajectory estimation experiments, and the differences in pose estimation accuracy between the two methods were compared. The corresponding root mean square error (RMSE) was calculated to quantitatively analyze the error performance of the algorithms. The formula for RMSE is as follows:
In the above equation, represents the x-axis coordinate, represents the y-axis coordinate, the subscript denotes the actual coordinates of the algorithm at time step n, and ngt represents the ground truth coordinates at time step n. N denotes the number of data points in the dataset.
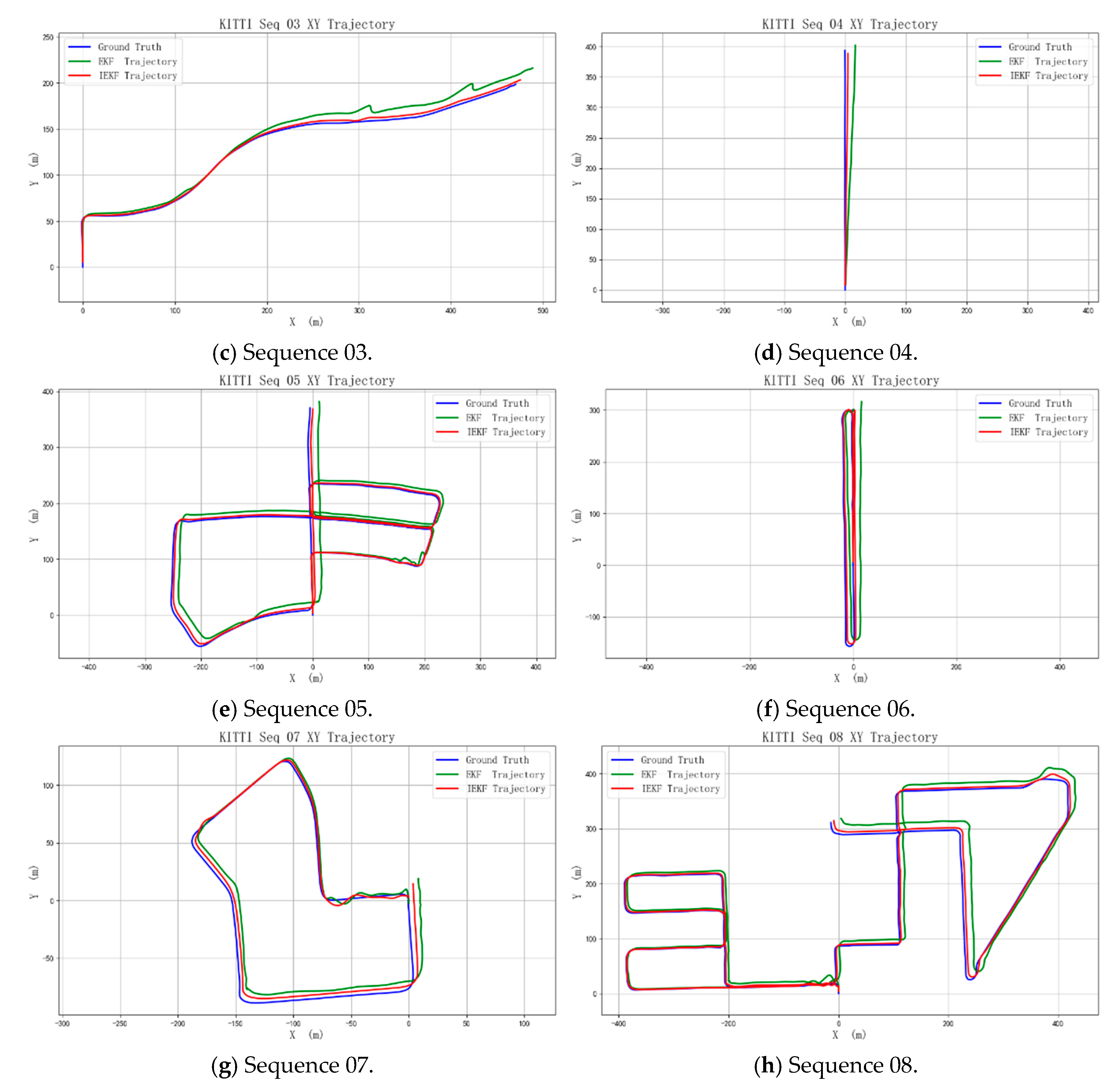
The EKF and the improved IEKF algorithms were applied to process sequences 00, 02, 03, 04, 05, 06, 07, and 08 of the KITTI dataset, as shown in
Figure 8. The results indicate that the EKF estimated trajectory exhibits significant deviation from the true trajectory, while the trajectory estimated by the IEKF algorithm demonstrates much smaller errors, reflecting the higher accuracy of the IEKF.
The results of the attitude accuracy indicator, root mean square error (RMSE), can be found in
Table 2. The proposed method in this paper shows better estimation accuracy than the traditional EKF algorithm on eight test sequences randomly selected from the KITTI dataset. Specifically, the RMSE of IEKF in each sequence is lower than that of EKF, indicating that it is more robust and accurate in dealing with nonlinear systems and fusing visual and inertial information. This result fully verifies the effectiveness of IEKF in attitude estimation, and proves that it can improve the overall state estimation performance of the system compared with the traditional EKF in practical applications.
To evaluate the real-time performance of the algorithm, multiple test runs are conducted to reduce random errors in runtime measurements. Statistical comparisons of different algorithms are performed on sequences 00 to 10 of the KITTI dataset. The average runtime of the EKF is 2.62 s, while the IEKF takes an average of 3.93 s. In contrast, the BA-based optimization with a sliding window shows a significantly higher average runtime of 23.59 s. The test results are shown in
Figure 9.
The results show that EKF achieves the fastest computation due to its low computational complexity but suffers from limited accuracy. The sliding window BA optimization offers higher accuracy but comes with a significantly increased computational load and the longest runtime. In contrast, IEKF strikes a balance by improving accuracy through iterative optimization while maintaining reasonable computational efficiency, demonstrating its advantage in both performance and practicality.
4.4. Validation Through Real-World Vehicle Tests
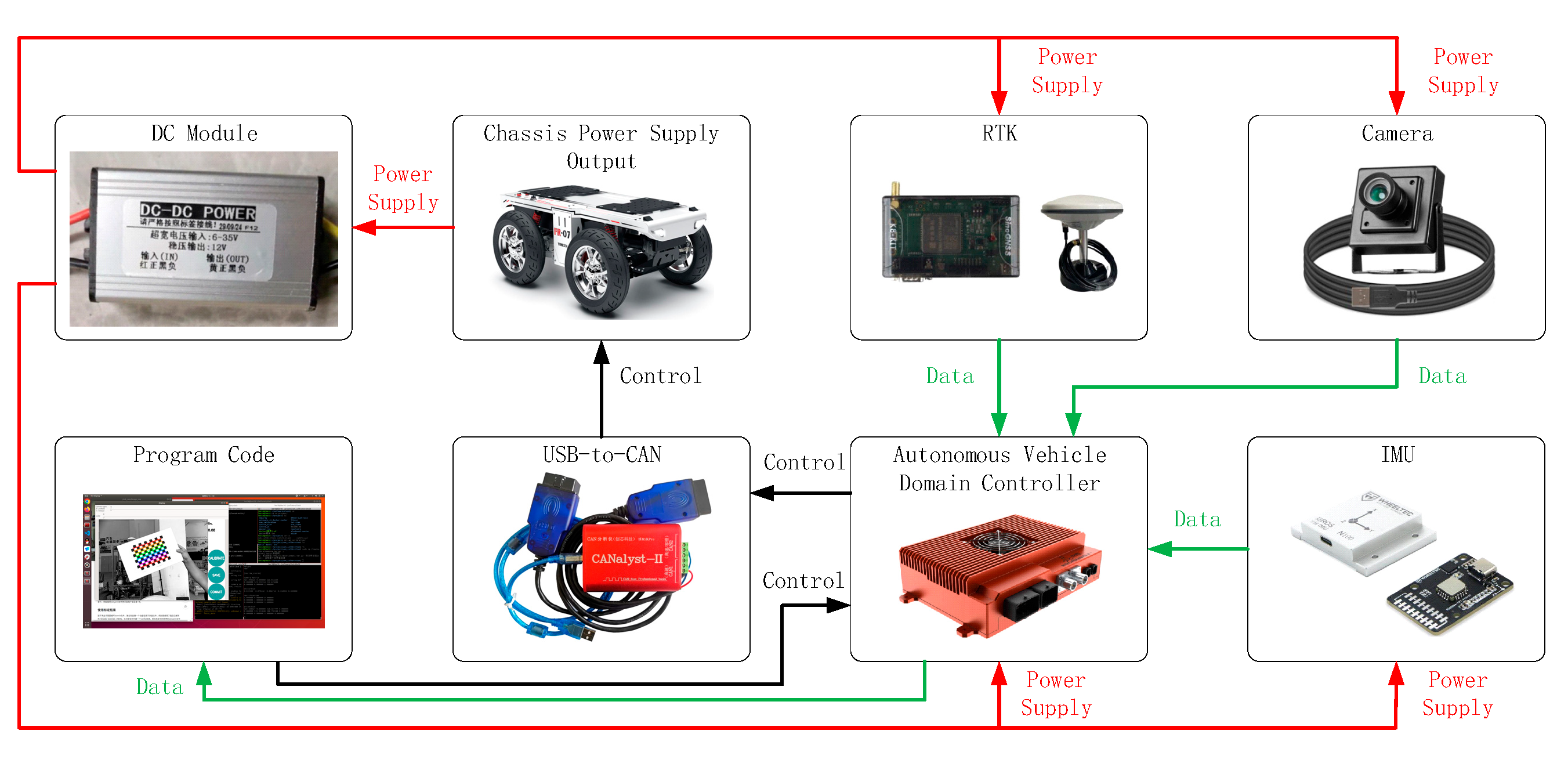
To further validate the practical applicability of the algorithm, a visual–inertial SLAM experimental platform was built based on an intelligent driving suite. The topological diagram of the experimental platform is shown in
Figure 10. In the power supply topology, the output of the chassis with a battery is 48 V. To meet the power supply requirements of various sensors, a DC-DC module is used for voltage conversion, which steps down the 48 V to a stable 12 V output. The converted 12 V power is used to supply sensors such as the domain controller, camera, IMU, and RTK, as indicated by the red connecting lines in the diagram. In the data topology, the camera, IMU, and RTK sensors send their data back to the vehicle’s domain controller, as shown by the green connecting lines. The domain controller processes the data through software and outputs control signals. These control signals are transmitted via the domain controller to the CAN card, thereby controlling the vehicle, as indicated by the black connecting lines.
After the experimental platform was established, data collection was conducted on the regular driving routes within the campus to evaluate the performance of the EKF and IEKF algorithms in pose trajectory estimation. The overall route map is shown in
Figure 11.
Figure 12a shows a photo taken during the data collection process, which includes the autonomous vehicle used for data acquisition and the actual environment during the data collection.
Figure 12b displays the image data from the self-collected dataset.
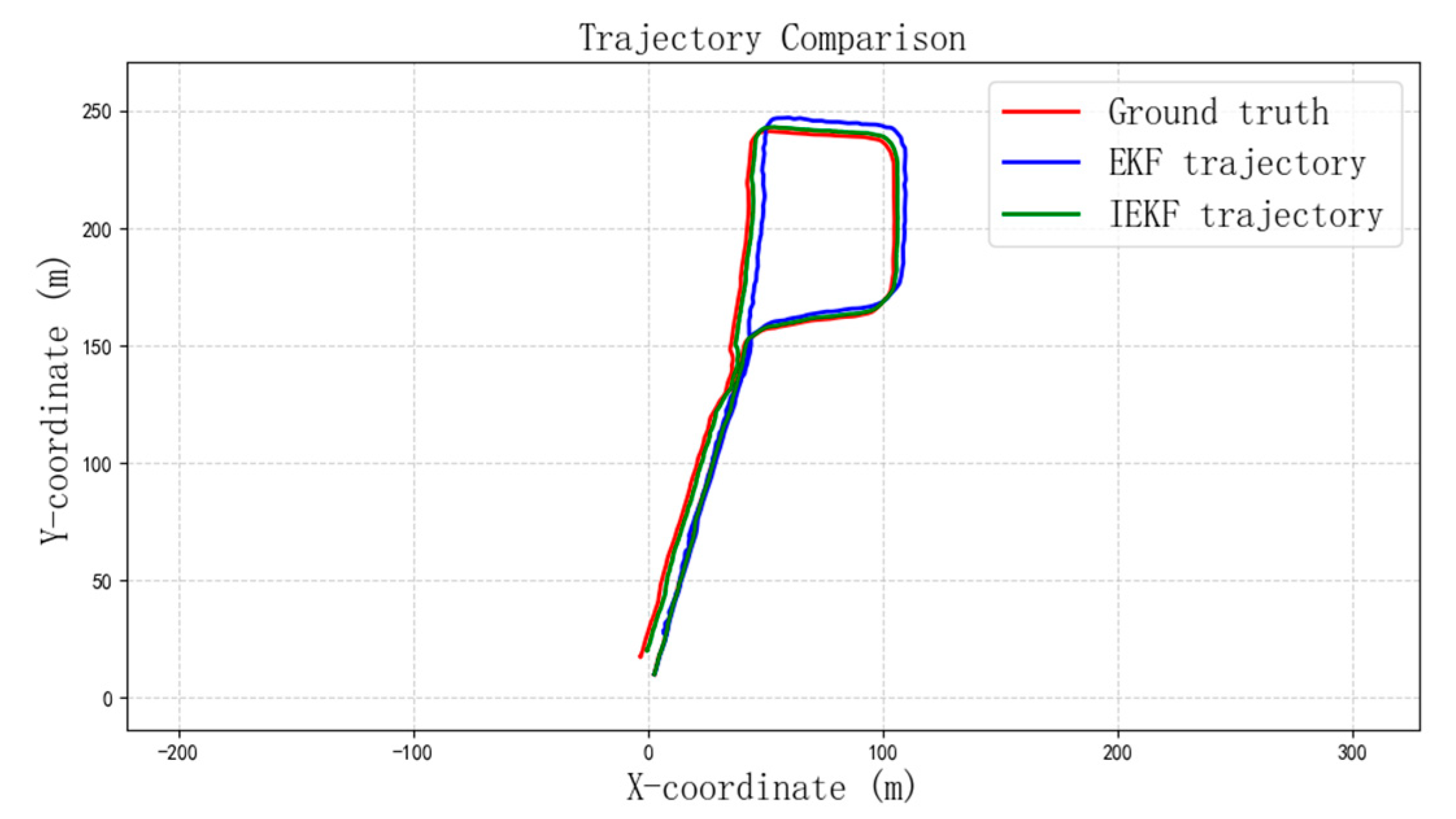
As shown in
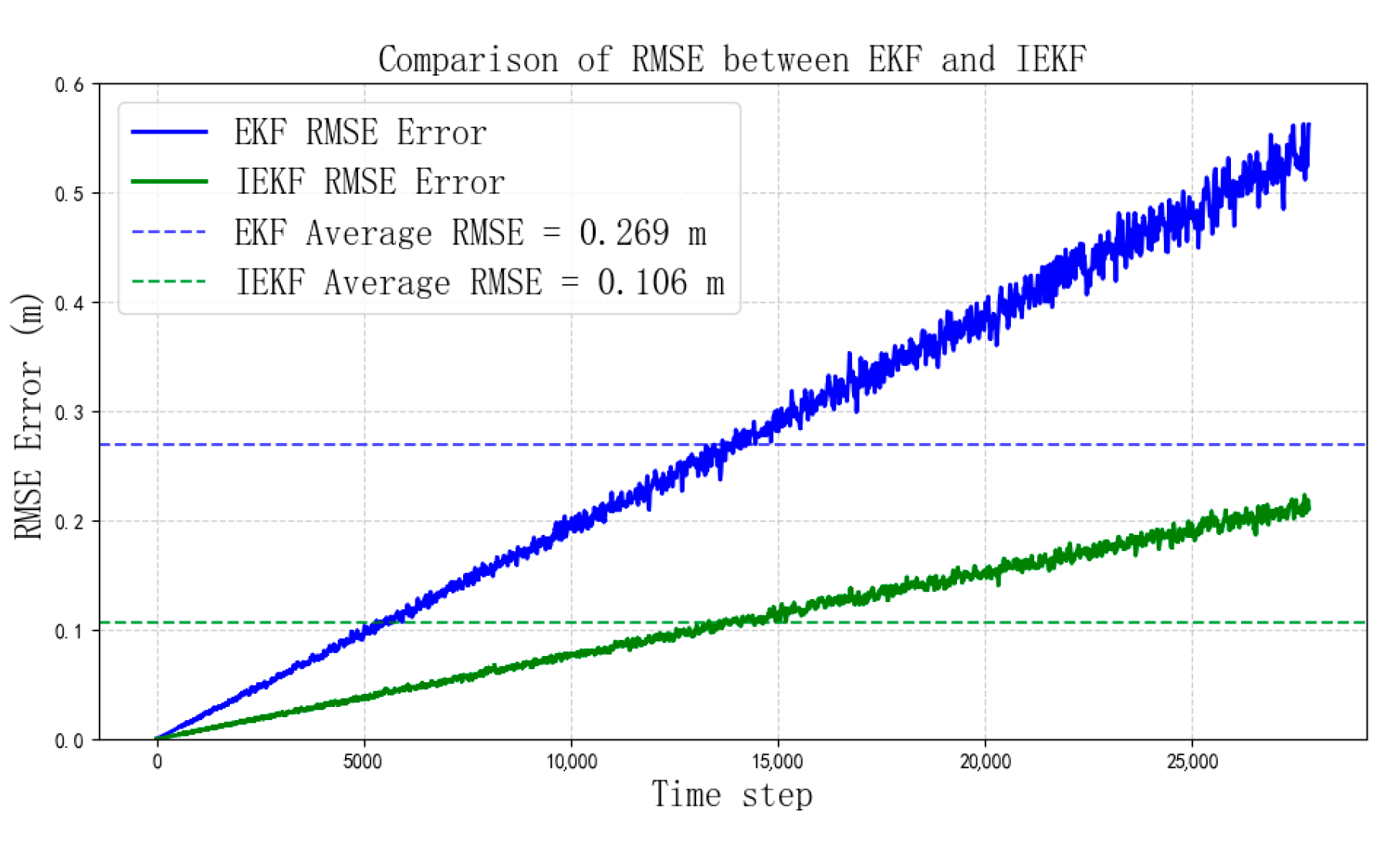
Figure 13, in the trajectory estimation, the EKF trajectory clearly deviates more from the real data compared to the IEKF trajectory. This indicates that the IEKF algorithm has higher accuracy than the EKF algorithm. According to
Figure 14, the RMSE of EKF is 0.268 m, while the RMSE of IEKF is 0.106 m. The error of IEKF is 60.45% lower than that of EKF, representing a significant error reduction. The overall performance of the self-collected dataset is similar to that of the public dataset tests, aligning with the simulation’s expectations. This suggests that the proposed improved algorithm maintains a high level of accuracy and low error, even with a slight sacrifice in computational speed.
5. Conclusions and Future Work
In this paper, a pose estimation model based on the Iterated Extended Kalman Filter (IEKF) is developed to enhance the accuracy and robustness of visual–inertial odometry (VIO). The system integrates visual reprojection error and inertial measurement error into a unified framework and models the state variables accordingly. To improve computational efficiency, Schur complement optimization is introduced to marginalize high-dimensional variables, significantly reducing the computational overhead in large-scale SLAM problems. The main scientific contributions of this work include the following:
The integration of Schur complement acceleration into the IEKF update process for efficient marginalization;
The development of a visual–inertial odometry system with feature enhancement based on MLP and Transformer architectures. An MLP is incorporated into the traditional VIO framework to perform self-enhancement of feature descriptors, improving the matching robustness of individual keypoints under viewpoint and illumination changes;
The demonstration of improved robustness and adaptability through extensive experiments across multiple datasets.
The experimental results demonstrate that the proposed algorithm outperforms traditional EKF-based methods in both accuracy and stability, especially in dynamic environments with moving objects. For instance, the algorithm maintains lower trajectory error (measured by RMSE) and higher matching accuracy while maintaining near real-time performance. Compared to conventional BA-based optimization, it achieves a good balance between efficiency and precision, with an average runtime significantly lower than that of full BA methods. These results validate the algorithm’s ability to provide reliable pose estimation under challenging conditions.
In future research, more advanced nonlinear optimization methods, such as Extended Kalman Filtering based on adaptive iteration strategies or learning-based filters, will be explored to further improve state estimation accuracy. Additionally, in large-scale SLAM tasks, the combination of sparse optimization or distributed computing frameworks could be employed to reduce computational complexity and enhance system scalability.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}