


A Q-Learning Crested Porcupine Optimizer for Adaptive UAV Path Planning

 , ,
, ,
Abstract
1. Introduction
- This study has incorporated a Q-learning strategy into the CPO algorithm, allowing for adaptive and dynamic parameter adjustment. This enhancement mitigates the dependency on manually tuned parameters inherent in the traditional CPO, thereby improving both the optimization efficiency and the stability of the algorithm in practical engineering applications.
- Drawing inspiration from symbiotic algorithms, we have implemented a vision-audio cooperative mechanism to balance visual and auditory defense strategies. This novel approach effectively addresses the issue of slow early convergence encountered in the original CPO when applied to engineering optimization problems.
- This study has developed a position update optimization strategy and integrated it into the CPO algorithm’s existing framework. This strategy is designed to prevent boundary violations that may occur due to excessive update amplitudes in later iterations, thus enhancing the algorithm’s capability to solve engineering optimization challenges.
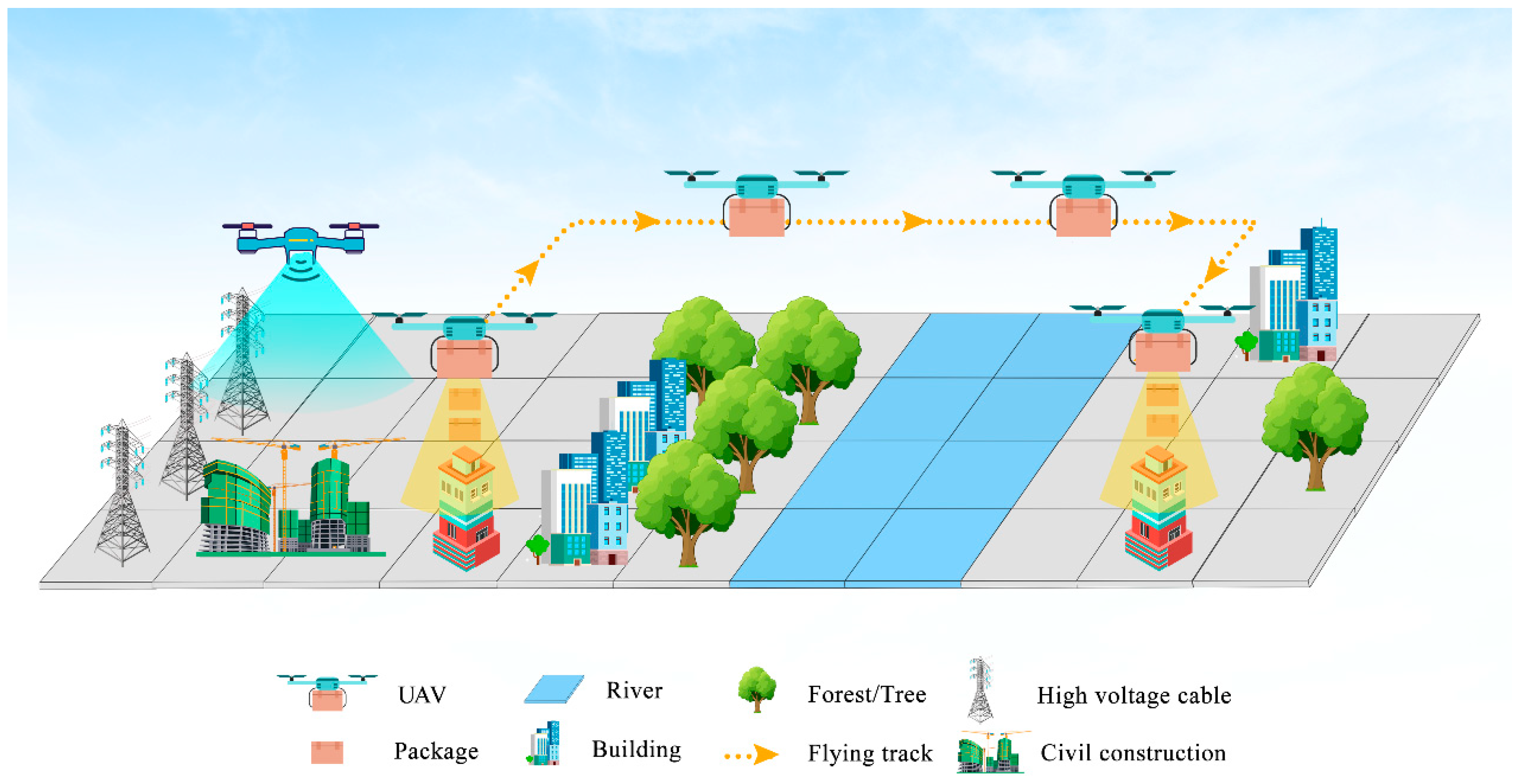
2. Modeling of the UAV Path Planning Problem
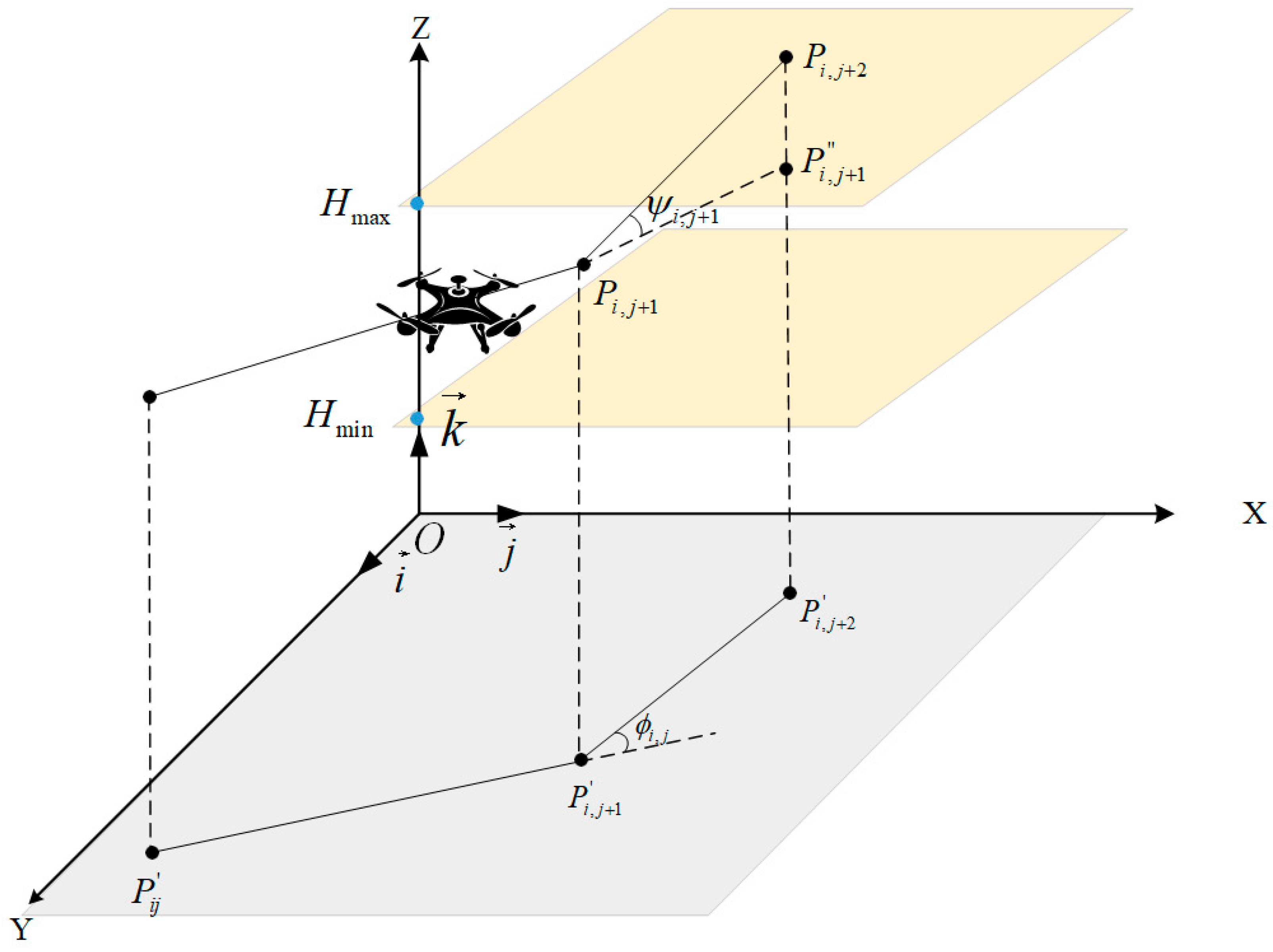
2.1. Path Optimality
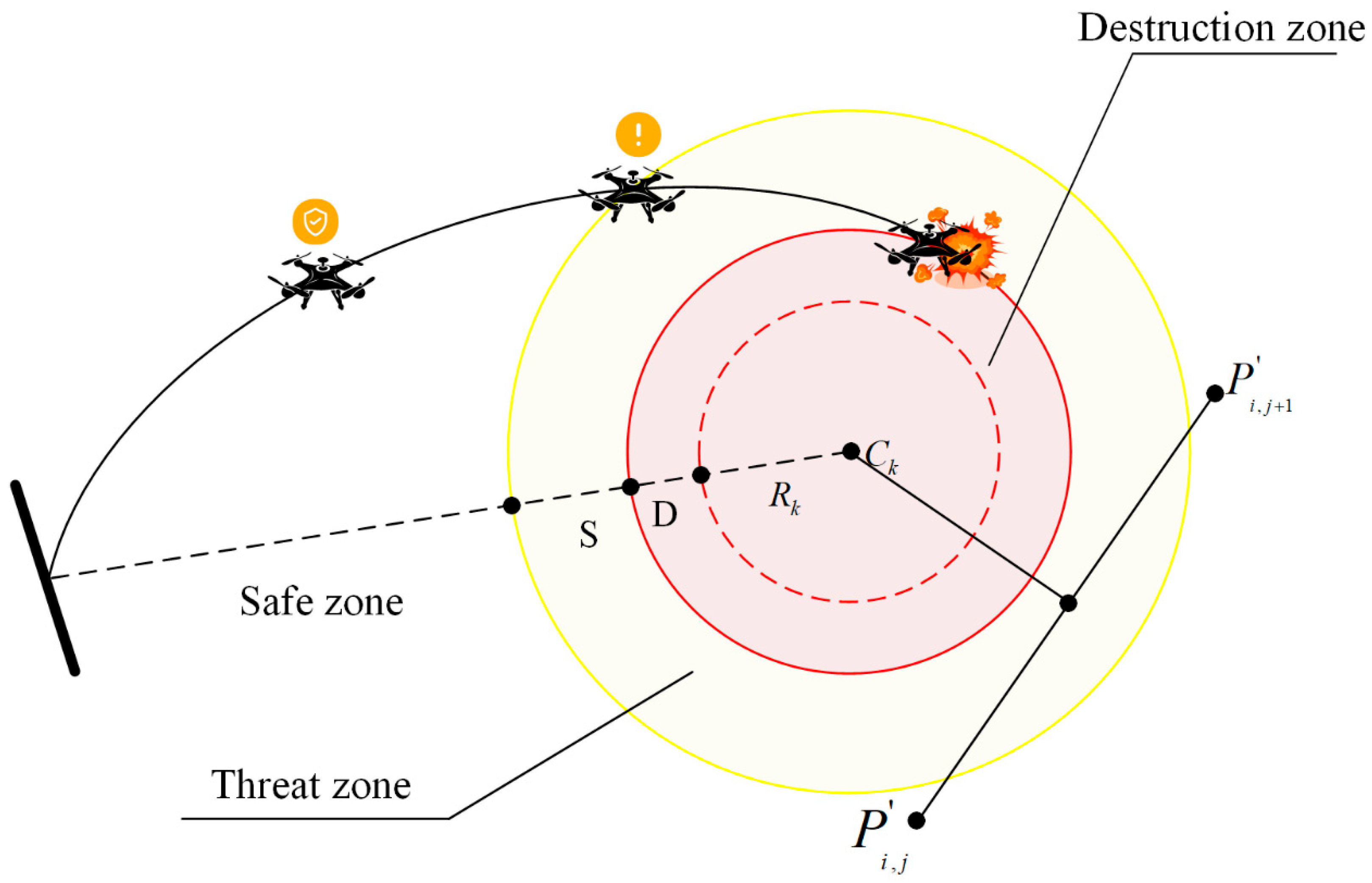
2.2. Security and Feasibility Constraints
2.3. Total Cost Function
3. Methods
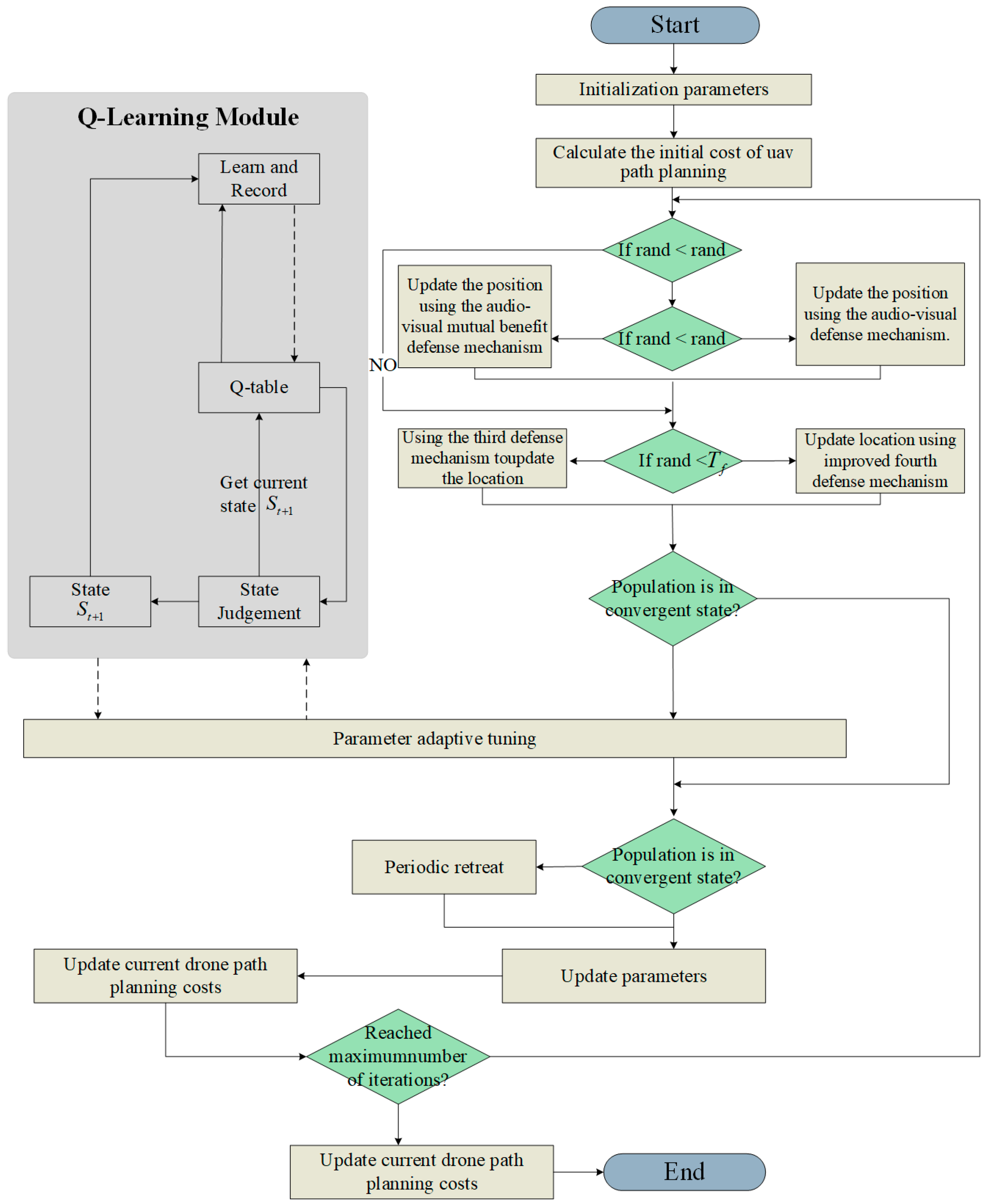
3.1. System Framework
3.2. CPO Algorithm
- (1)
- The initial defensive response is triggered when a porcupine perceives a threat from a distance, leading to the elevation and expansion of its quills to appear more formidable. This reaction is mathematically modeled as:
- (2)
- The second defensive mechanism: If the initial visual deterrent is ineffective, the porcupine resorts to auditory signals to ward off predators. This behavior is mathematically modeled as follows:
- (3)
- The third defensive mechanism: In the event that the first and second mechanisms prove ineffective, the porcupine releases an unpleasant odor as a repellent. This response is encapsulated by the following mathematical expressions:
- (4)
- The fourth defensive mechanism: As a final defensive measure, the porcupine engages in physical attacks against the predator. This strategy is represented by the subsequent mathematical formulas:
3.3. Enhanced CPO Optimization Algorithm
| Algorithm 1. The QCPO Algorithm. |
| 1 : Initialize: Maximum iterations Population size Initial parameters , , , State space , Action space Initialize population P = {, , …, } 2 : Evaluate initial fitness and path cost for each 3 : Set iteration counter t = 0 4 : while t < Tmax do 5 : for each individual do 6 : Generate random number 7 : if r < then 8 : Update using audio-visual mutual benefit mechanism 9 : else if r < then 10: Update using audio-visual defense mechanism 11: else if r < then 12: Update using third defense mechanism 13: else 14: Update using improved fourth defense mechanism 15: else if 16: end for 17: Evaluate fitness of new population P 18: Calculate population diversity and normalized fitness 19: Compute current state based on diversity and fitness measures 20: if population is converged then 21: Select action using policy based on Q(,·) 22: Apply action to adjust , , , 23: Re-evaluate fitness after parameter update 24: Compute reward based on fitness improvement 25: Observe next state 26: Update Q-table: 27: 28: Perform periodic retreat to increase diversity 29: end if 30: Update path planning cost of current population 31: t ← t + 1 32: end while 33: Return best solution in population P |
3.3.1. Q-Learning Based on Adaptive Parameter Tuning
- (1)
- Design Status
- (2)
- Design Action
- (3)
- Designing the Reward Function
3.3.2. Mutually Beneficial Audiovisual Defense Mechanisms
- (1)
- Mutual benefit phase:
- (2)
- Joint Defense Phase:
3.3.3. QCPO Position Update Optimization Strategy
4. Results and Discussion
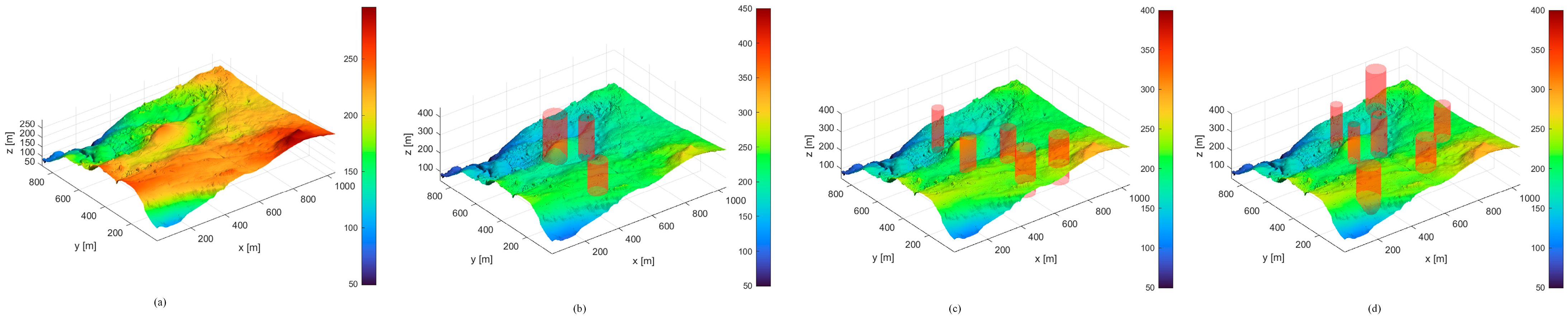
4.1. Setting the Scene
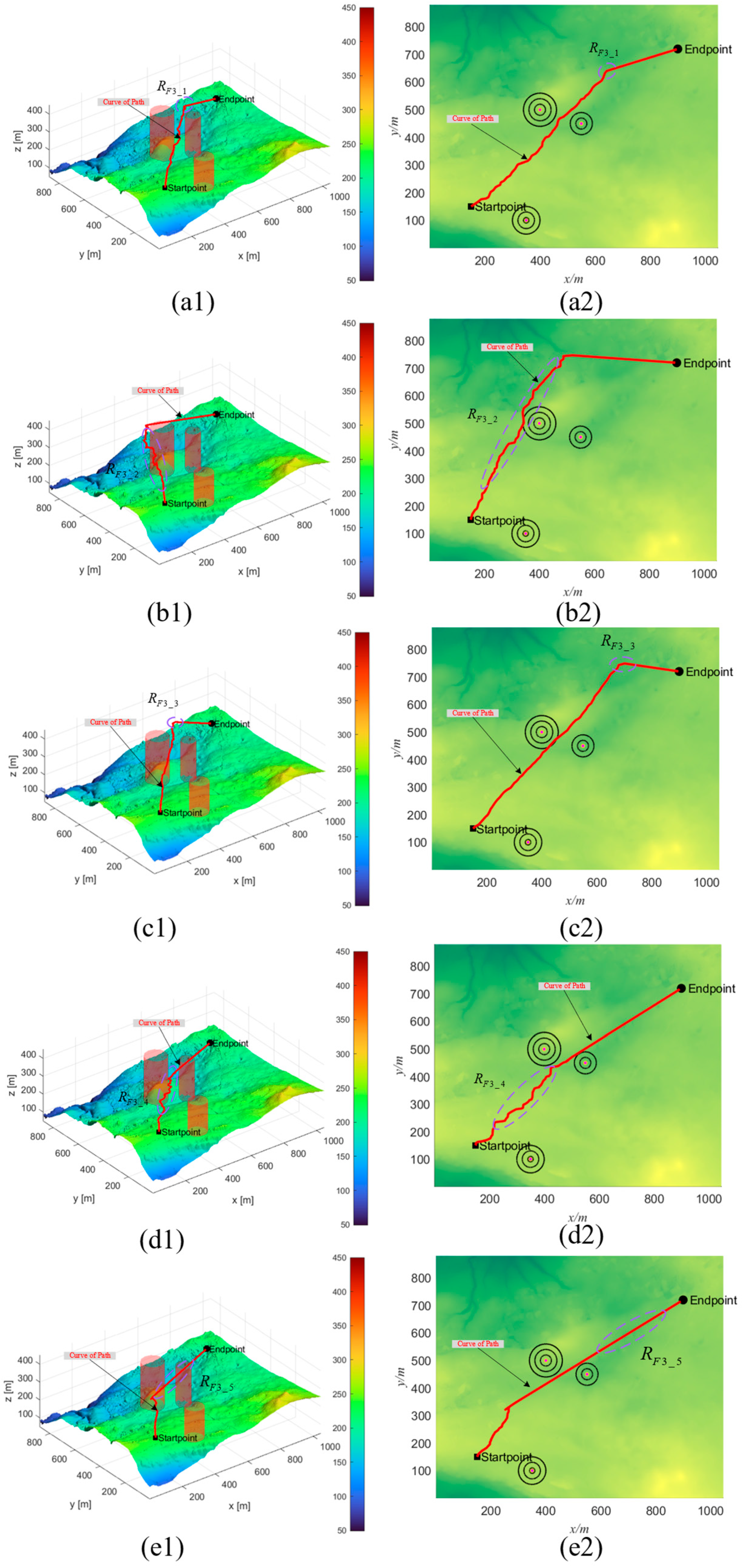
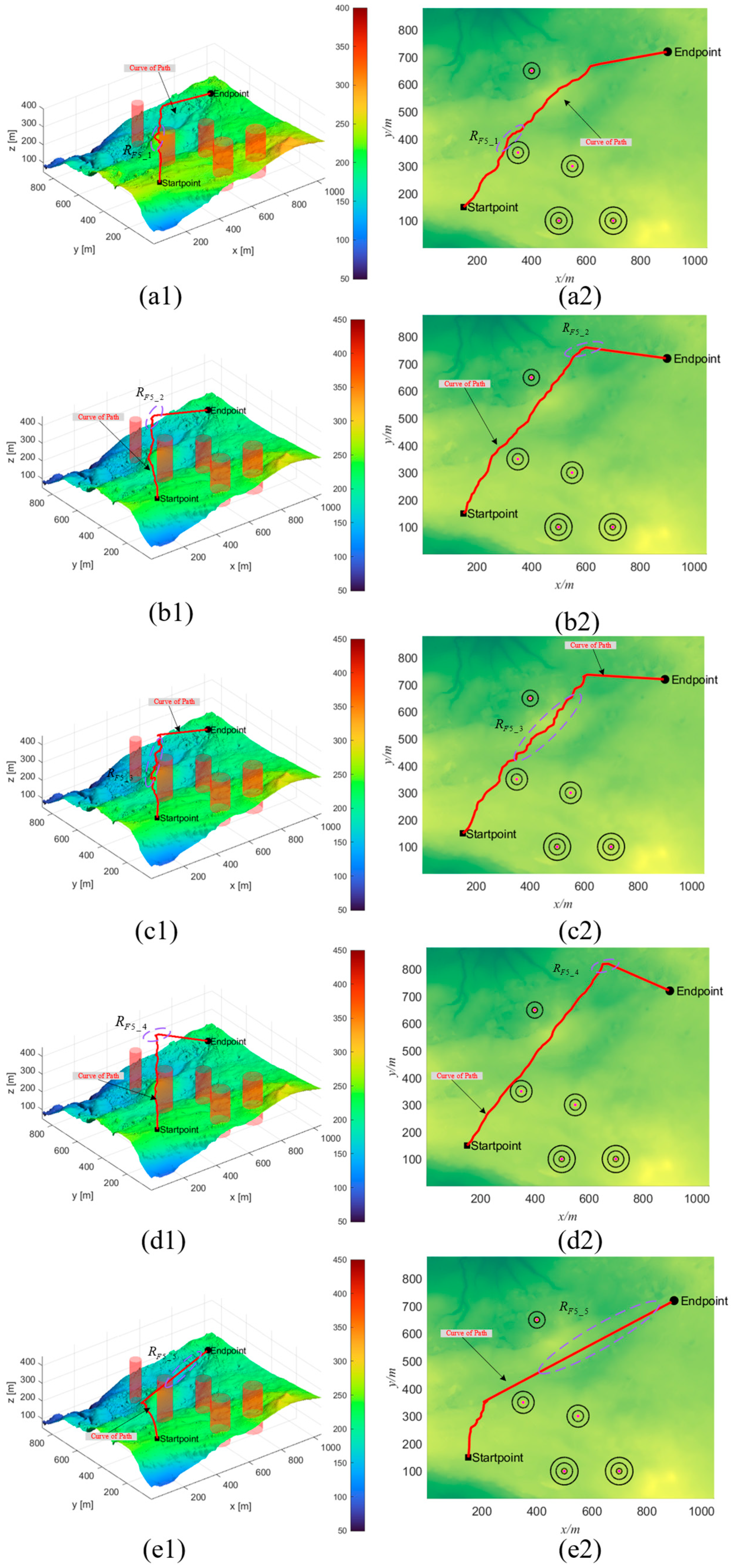
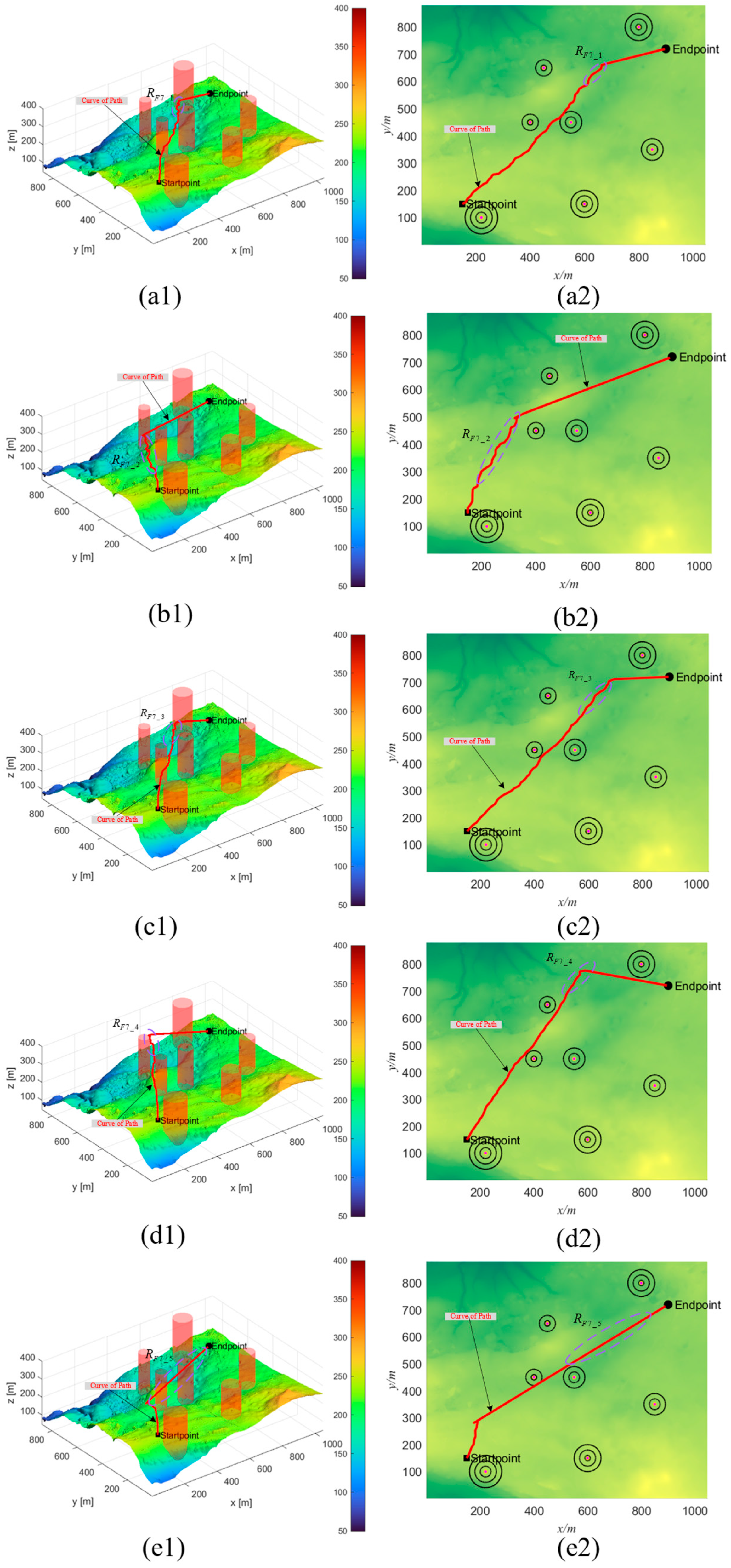
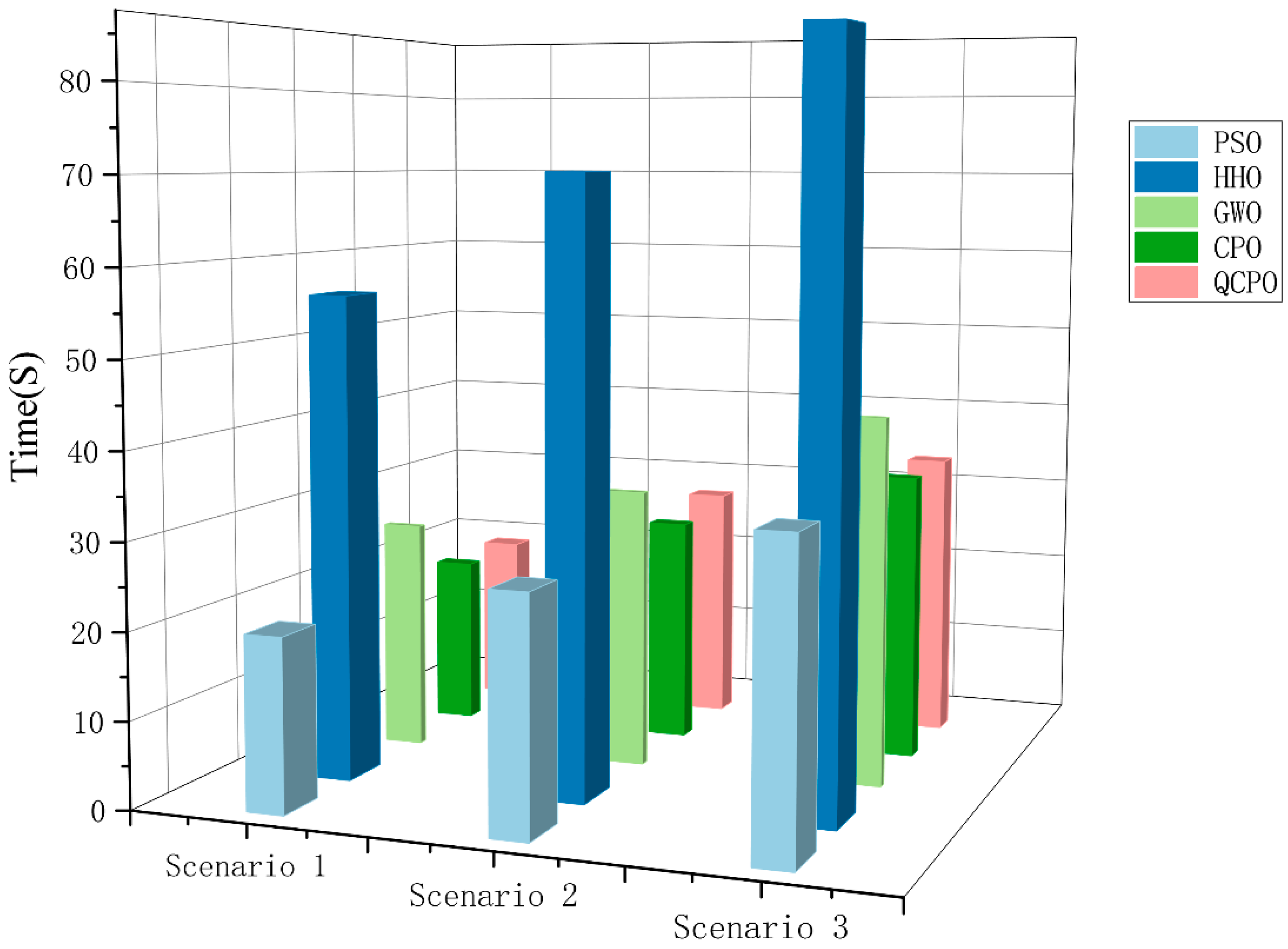
4.2. Simulation Experiment Results and Analysis
4.3. Parameters Tuning
4.4. Analysis of Ablation Experiments
4.5. Time Complexity Analysis
- (1)
- Population Initialization: Initializing individuals, each of a length , results in a computational complexity of .
- (2)
- Population Evolution: During the global and local search processes, if denotes the number of individuals in , the corresponding computational complexity is .
- (3)
- Objective Function Evaluation: The computational complexity for evaluating the objective function is , assuming .
- (4)
- Main Iterative Loop: Considering iterations for the path search, the overall computational complexity is .
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ishiwatari, M. Leveraging drones for effective disaster management: A comprehensive analysis of the 2024 Noto Peninsula earthquake case in Japan. Prog. Disaster Sci. 2024, 23, 100348. [Google Scholar] [CrossRef]
- Kucharczyk, M.; Hugenholtz, C.H. Remote sensing of natural hazard-related disasters with small drones: Global trends, biases, and research opportunities. Remote Sens. Environ. 2021, 264, 112577. [Google Scholar] [CrossRef]
- Mishra, B.; Garg, D.; Narang, P.; Mishra, V. Drone-surveillance for search and rescue in natural disaster. Comput. Commun. 2020, 156, 1–10. [Google Scholar] [CrossRef]
- Evers, L.; Dollevoet, T.; Barros, A.I.; Monsuur, H. Robust UAV mission planning. Ann. Oper. Res. 2014, 222, 293–315. [Google Scholar] [CrossRef]
- Daud, S.M.S.M.; Yusof, M.Y.P.M.; Heo, C.C.; Khoo, L.S.; Singh, M.K.C.; Mahmood, M.S.; Nawawi, H. Applications of drone in disaster management: A scoping review. Sci. Justice 2022, 62, 30–42. [Google Scholar] [CrossRef]
- Jiang, S.; Jiang, W.; Wang, L. Unmanned Aerial Vehicle-Based Photogrammetric 3D Mapping: A survey of techniques, applications, and challenges. IEEE Geosci. Remote Sens. Mag. 2021, 10, 135–171. [Google Scholar] [CrossRef]
- Daud, S.M.S.M.; Yusof, M.Y.P.M.; Heo, C.C.; Khoo, L.S.; Singh, M.K.C.; Mahmood, M.S.; Nawawi, H. Towards autonomous multi-UAV wireless network: A survey of reinforcement learning-based approaches. IEEE Commun. Surv. Tutor. 2023, 25, 3038–3067. [Google Scholar]
- Luo, J.; Tian, Y.; Wang, Z. Research on Unmanned Aerial Vehicle Path Planning. Drones 2024, 8, 51. [Google Scholar] [CrossRef]
- Xie, R.; Meng, Z.; Wang, L.; Li, H.; Wang, K.; Wu, Z. Unmanned aerial vehicle path planning algorithm based on deep reinforcement learning in large-scale and dynamic environments. IEEE Access 2021, 9, 24884–24900. [Google Scholar] [CrossRef]
- Sonny, A.; Yeduri, S.R.; Cenkeramaddi, L.R. Q-learning-based unmanned aerial vehicle path planning with dynamic obstacle avoidance. Appl. Soft Comput. 2023, 147, 110773. [Google Scholar] [CrossRef]
- de Carvalho, K.B.; de O. B. Batista, H.; Fagundes-Junior, L.A.; de Oliveira, I.R.L.; Brandão, A.S. Q-learning global path planning for UAV navigation with pondered priorities. Intell. Syst. Appl. 2025, 25, 200485. [Google Scholar] [CrossRef]
- Cui, H.; Wei, R.X.; Liu, Z.C.; Zhou, K. UAV motion strategies in uncertain dynamic environments: A path planning method based on Q-learning strategy. Appl. Sci. 2018, 8, 2169. [Google Scholar] [CrossRef]
- Boulares, M.; Fehri, A.; Jemni, M. UAV path planning algorithm based on Deep Q-Learning to search for a floating lost target in the ocean. Robot. Auton. Syst. 2024, 179, 104730. [Google Scholar] [CrossRef]
- Lee, G.T.; Kim, K.J.; Jang, J. Real-time path planning of controllable UAV by subgoals using goal-conditioned reinforcement learning. Appl. Soft Comput. 2023, 146, 110660. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, L.; Li, Y.; Song, S.; Ma, S.; Yang, F.; Zhai, L. Path planning of multi-UAVs based on deep Q-network for energy-efficient data collection in UAVs-assisted IoT. Veh. Commun. 2022, 36, 100491. [Google Scholar] [CrossRef]
- Jiang, W.; Cai, T.; Xu, G.; Wang, Y. Autonomous obstacle avoidance and target tracking of UAV: Transformer for observation sequence in reinforcement learning. Knowl.-Based Syst. 2024, 290, 111604. [Google Scholar] [CrossRef]
- Swain, S.; Khilar, P.M.; Senapati, B.R. A reinforcement learning-based cluster routing scheme with dynamic path planning for mutli-uav network. Veh. Commun. 2023, 41, 100605. [Google Scholar] [CrossRef]
- Yu, H.; Gao, K.; Wu, N.; Zhou, M.; Suganthan, P.N.; Wang, S. Scheduling Multiobjective Dynamic Surgery Problems via Q-Learning-Based Meta-Heuristics. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 3321–3333. [Google Scholar] [CrossRef]
- Zhao, F.; Wang, Q.; Wang, L. An inverse reinforcement learning framework with the Q-learning mechanism for the metaheuristic algorithm. Knowl.-Based Syst. 2023, 265, 110368. [Google Scholar] [CrossRef]
- Yu, H.; Gao, K.Z.; Ma, Z.F.; Pan, Y.X. Improved meta-heuristics with Q-learning for solving distributed assembly permutation flowshop scheduling problems. Swarm Evol. Comput. 2023, 80, 101335. [Google Scholar] [CrossRef]
- Chen, Y.; Zhong, J.; Mumtaz, J.; Zhou, S.; Zhu, L. An improved spider monkey optimization algorithm for multi-objective planning and scheduling problems of PCB assembly line. Expert. Syst. Appl. 2023, 229, 120600. [Google Scholar] [CrossRef]
- Li, P.; Xue, Q.; Zhang, Z.; Chen, J.; Zhou, D. Multi-objective energy-efficient hybrid flow shop scheduling using Q-learning and GVNS driven NSGA-II. Comput. Oper. Res. 2023, 159, 106360. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, C.; Wang, Y.; Zhang, T.; Gong, Y. A fast formation obstacle avoidance algorithm for clustered UAVs based on artificial potential field. Aerosp. Sci. Technol. 2024, 147, 108974. [Google Scholar] [CrossRef]
- Ye, S.Q.; Zhou, K.Q.; Zhang, C.X.; Mohd Zain, A.; Ou, Y. An improved multi-objective cuckoo search approach by exploring the balance between development and exploration. Electronics 2022, 11, 704. [Google Scholar] [CrossRef]
- He, Y.; Wang, M. An improved chaos sparrow search algorithm for UAV path planning. Sci. Rep. 2024, 14, 366. [Google Scholar] [CrossRef]
- Tang, K.; Wei, X.F.; Jiang, Y.H.; Chen, Z.W.; Yang, L. An Adaptive Ant Colony Optimization for Solving Large-Scale Traveling Salesman Problem. Mathematics 2023, 11, 4439. [Google Scholar] [CrossRef]
- Ge, F.; Li, K.; Han, Y.; Xu, W.; Wang, Y.A. Path planning of UAV for oilfield inspections in a three-dimensional dynamic environment with moving obstacles based on an improved pigeon-inspired optimization algorithm. Appl. Intell. 2020, 50, 2800–2817. [Google Scholar] [CrossRef]
- Nadimi-Shahraki, M.H.; Taghian, S.; Mirjalili, S. An improved grey wolf optimizer for solving engineering problems. Expert. Syst. Appl. 2021, 166, 113917. [Google Scholar] [CrossRef]
- Gao, Y.; Li, Z.; Wang, H.; Hu, Y.; Jiang, H.; Jiang, X.; Chen, D. An Improved Spider-Wasp Optimizer for Obstacle Avoidance Path Planning in Mobile Robots. Mathematics 2024, 12, 2604. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Abouhawwash, M. Crested Porcupine Optimizer: A new nature-inspired metaheuristic. Knowl.-Based Syst. 2024, 284, 111257. [Google Scholar] [CrossRef]
- Seyyedabbasi, A. A reinforcement learning-based metaheuristic algorithm for solving global optimization problems. Adv. Eng. Softw. 2023, 178, 103411. [Google Scholar] [CrossRef]
- Liang, P.; Chen, Y.; Sun, Y.; Huang, Y.; Li, W. An information entropy-driven evolutionary algorithm based on reinforcement learning for many-objective optimization. Expert. Syst. Appl. 2024, 238, 122164. [Google Scholar] [CrossRef]
- Osaba, E.; Villar-Rodriguez, E.; Del Ser, J.; Nebro, A.J.; Molina, D.; LaTorre, A.; Suganthan, P.N.; Coello, C.A.C.; Herrera, F. A tutorial on the design, experimentation and application of metaheuristic algorithms to real-world optimization problems. Swarm Evol. Comput. 2021, 64, 100888. [Google Scholar] [CrossRef]
- Subramanian, S.P.; Chandrasekar, S.K. Simultaneous allocation and sequencing of orders for robotic mobile fulfillment system using reinforcement learning algorithm. Expert. Syst. Appl. 2024, 239, 122262. [Google Scholar] [CrossRef]
- Cheng, X.; Li, J.; Zheng, C.; Zhang, J.; Zhao, M. An improved PSO-GWO algorithm with chaos and adaptive inertial weight for robot path planning. Front. Neurorobotics 2021, 15, 770361. [Google Scholar] [CrossRef] [PubMed]
- Lu, F.; Feng, W.; Gao, M.; Bi, H.; Wang, S. The Fourth-Party Logistics Routing Problem Using Ant Colony System-Improved Grey Wolf Optimization. J. Adv. Transp. 2020, 2020, 8831746. [Google Scholar] [CrossRef]
- Chai, X.; Zheng, Z.; Xiao, J.; Yan, L.; Qu, B.; Wen, P.; Wang, H.; Zhou, Y.; Sun, H. Multi-strategy fusion differential evolution algorithm for UAV path planning in complex environment. Aerosp. Sci. Technol. 2022, 121, 107287. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, W.; Qin, W.; Tang, W. A novel UAV path planning approach: Heuristic crossing search and rescue optimization algorithm. Expert. Syst. Appl. 2023, 215, 119243. [Google Scholar] [CrossRef]
- Qu, C.; Gai, W.; Zhong, M.; Zhang, J. A novel reinforcement learning based grey wolf optimizer algorithm for unmanned aerial vehicles (UAVs) path planning. Appl. Soft Comput. 2020, 89, 106099. [Google Scholar] [CrossRef]
- Yin, S.; Jin, M.; Lu, H.; Gong, G.; Mao, W.; Chen, G.; Li, W. Reinforcement-learning-based parameter adaptation method for particle swarm optimization. Complex Intell. Syst. 2023, 9, 5585–5609. [Google Scholar] [CrossRef]
- Chen, W.; Yang, Q.; Diao, T.; Ren, S. B-Spline Fusion Line of Sight Algorithm for UAV Path Planning. In International Conference on Guidance, Navigation and Control; Springer Nature: Singapore, 2022; pp. 503–512. [Google Scholar]
- Zhao, P.; Liu, S. An improved symbiotic organisms search algorithm with good point set and memory mechanism. J. Supercomput. 2023, 79, 11170–11197. [Google Scholar] [CrossRef]
- Jia, Y.; Qu, L.; Li, X. Automatic path planning of unmanned combat aerial vehicle based on double-layer coding method with enhanced grey wolf optimizer. Artif. Intell. Rev. 2023, 56, 12257–12314. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Zheng, H.; Li, Q.; Tian, Q. A spherical vector-based adaptive evolutionary particle swarm optimization for UAV path planning under threat conditions. Sci. Rep. 2025, 15, 2116. [Google Scholar]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Australia, G. Digital Elevation Model (DEM) of Australia Derived from LiDAR 5 Metre Grid; Commonwealth of Australia and Geoscience Australia: Canberra, Australia, 2015. [Google Scholar]
- Karpenko, M.; Stosiak, M.; Deptuła, A.; Urbanowicz, K.; Nugaras, J.; Królczyk, G.; Żak, K. Performance evaluation of extruded polystyrene foam for aerospace engineering applications using frequency analyses. Int. J. Adv. Manuf. Technol. 2023, 126, 5515–5526. [Google Scholar] [CrossRef]
- Karpenko, M. Nugaras Vibration damping characteristics of the cork-based composite material in line to frequency analysis. J. Theor. Appl. Mech. 2022, 60, 593–602. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.02 | −0.02 | 5 | −5 | 0.2 | −0.2 | 0.05 | −0.05 |
| Scenario | PSO | HHO | GWO | CPO | QCPO | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| 1 | 4221.41 | 576.365 | 6730.87 | 631.469 | 4328.94 | 275.778 | 5597.99 | 215.47 | 3730.38 | 256.249 |
| 2 | 4436.39 | 342.39 | 6815.49 | 671.839 | 4534.56 | 170.986 | 5200.17 | 118.909 | 3778.24 | 236.723 |
| 3 | 4707.371 | 611.9117 | 6990.1 | 327.2204 | 5252.114 | 267.0055 | 5616.371 | 179.1428 | 3875.059 | 241.3747 |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| (0.4, 0.5, 0.6) | (3, 4, 5) | ||
| (100, 150, 200) | (0.1, 0.2, 0.3) |
| II | III | IV | Scenario 1 (Optimal Cost) | Scenario 2 (Optimal Cost) | Scenario 3 (Optimal Cost) | |
|---|---|---|---|---|---|---|
| QCPO_(I) | 5531.6389 | 5236.8725 | 5695.1956 | |||
| QCPO_(II) | √ | 5328.7431 | 5148.0957 | 5772.6326 | ||
| QCPO_(III) | √ | 4598.7173 | 4929.6655 | 5356.6081 | ||
| QCPO_(IV) | √ | 4737.09 | 4497.909 | 5064.4383 | ||
| QCPO | √ | √ | √ | 3859.3889 | 3853.5015 | 3788.9178 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; He, Y.; Shen, B.; Wang, J.; Wang, P.; Zhang, G.; Zhuang, X.; Chen, R.; Luo, W. A Q-Learning Crested Porcupine Optimizer for Adaptive UAV Path Planning. Machines 2025, 13, 566. https://doi.org/10.3390/machines13070566
Liu J, He Y, Shen B, Wang J, Wang P, Zhang G, Zhuang X, Chen R, Luo W. A Q-Learning Crested Porcupine Optimizer for Adaptive UAV Path Planning. Machines. 2025; 13(7):566. https://doi.org/10.3390/machines13070566
Chicago/Turabian StyleLiu, Jiandong, Yuejun He, Bing Shen, Jing Wang, Penggang Wang, Guoqing Zhang, Xiang Zhuang, Ran Chen, and Wei Luo. 2025. "A Q-Learning Crested Porcupine Optimizer for Adaptive UAV Path Planning" Machines 13, no. 7: 566. https://doi.org/10.3390/machines13070566
APA StyleLiu, J., He, Y., Shen, B., Wang, J., Wang, P., Zhang, G., Zhuang, X., Chen, R., & Luo, W. (2025). A Q-Learning Crested Porcupine Optimizer for Adaptive UAV Path Planning. Machines, 13(7), 566. https://doi.org/10.3390/machines13070566