1. Introduction
In the context of the rapid development of drone technology, quadcopter drones, with their stable structural advantages and flexible control performance, have been widely used in various fields such as aerial photography, surveying, and search and rescue [
1,
2,
3]. However, achieving autonomous navigation for drones in complex environments remains a significant challenge [
4,
5], with obstacle avoidance and path planning being particularly prominent issues [
6,
7,
8,
9,
10]. Traditional APF methods, as classic solutions to these problems, guide drone movement by constructing attraction and repulsion force fields, providing an intuitive physical model for path planning. However, this method has notable drawbacks, especially when dealing with local minima and dynamic obstacles, which often lead drones to become trapped in local minimum values, severely limiting their application in complex scenarios [
11,
12].
At the same time, RL algorithms have demonstrated tremendous potential in the field of drone control [
13,
14]. By learning through interaction with the environment and autonomously optimizing control strategies, they offer new insights into solving complex dynamic decision-making problems. However, the integration of reinforcement learning with artificial potential fields is still in the exploratory stage. Combining the strengths of both to form an efficient autonomous navigation solution has become a focal point and challenge in current research [
15]. While existing RL methods for drone control demonstrate proficiency in motion optimization, they often suffer from three key limitations: (1) direct application of potential field forces to drone dynamics can induce oscillatory behavior; (2) inadequate mechanisms to escape local minima inherent in conventional APFs; and (3) limited synergy where RL and potential fields operate in loosely coupled layers rather than a unified framework. In contrast, this study introduces a fundamentally distinct approach: a layered architecture where a VAPF dynamically adjusts the target position input to a TD3-based motion controller. This design decouples obstacle avoidance from direct force application, leveraging the VAPF’s tangential forces to disrupt force symmetries causing local minima, while the RL controller executes precise trajectory tracking toward the adjusted target. This indirect guidance strategy, combined with the VAPF’s inherent stability properties, represents a significant departure from prior RL-APF integrations.
Since its introduction by Khatib in 1986 [
16], the APF method has remained a significant research direction in the field of mobile robotics and drone path planning. This method constructs a virtual potential field through mathematical modeling, allowing drones to complete obstacle avoidance and navigation tasks under the influence of potential field forces. However, its inherent problem of local minima has not been thoroughly resolved. When a drone is in an environment with symmetrical obstacles or when a specific geometric relationship forms between the target point and the obstacles, local minima with a zero net force can cause the drone to become stagnant.
To address this issue, scholars have proposed numerous improvement schemes. For instance, Guldner and others suggested using planar harmonic artificial potential fields to achieve robot obstacle avoidance in n-dimensional space, enhancing the smoothness of the potential field by introducing harmonic functions [
17]. Domestic scholars Keyu L and others proposed a dynamic obstacle avoidance path planning method for drones based on an improved APF, enhancing the obstacle avoidance effect by adjusting the parameters of the potential field function [
18]. However, most of these methods are still limited to static or simple dynamic environments, and their adaptability in complex scenarios is limited.
In recent years, the application of RL algorithms in the field of drone control has become increasingly widespread [
19]. The emergence of advanced algorithms such as TD3 has provided powerful tools for high-precision motion control [
20]. Park and others have combined dynamic motion primitives with potential fields to achieve motion reproduction and obstacle avoidance through RL [
21]. Phang and Hirata have proposed a shared autonomous control method combining human electroencephalography with TD3, demonstrating the potential of RL in human–robot collaboration [
22].
However, purely RL methods often face challenges such as low training efficiency and difficult convergence when dealing with large-scale state spaces and complex constraints [
23]. To integrate the advantages of APF with RL, some scholars have begun to explore combining the two. Han and others have accelerated formation control based on the Hessian matrix of the APF, providing new insights for the combination of potential fields and optimization algorithms [
24]. Rong and others have proposed an autonomous obstacle avoidance decision-making method for MASSs based on the GMA-TD3 algorithm, attempting to integrate RL with the concept of potential fields [
25]. However, most of these studies are still in the preliminary stages and have not yet formed a systematic solution.
This study aims to break through the limitations of traditional methods of APF and construct an efficient autonomous navigation solution for drones. The specific objectives include
Proposing an obstacle avoidance strategy based on VAPF to address the local minima issue of traditional APF methods.
Integrating RL algorithms to achieve precise control of drone movement.
Validating the effectiveness of the proposed method through simulation experiments, providing theoretical support for practical applications.
This study adopts a technical route of theoretical modeling, algorithm design, and simulation verification. Firstly, based on the vortex principle in fluid mechanics, a mathematical model of VAPF suitable for drone obstacle avoidance is constructed, and its stability and obstacle avoidance mechanism are analyzed. Secondly, a RL motion controller is designed in combination with the TD3 algorithm, achieving precise control of the drone through a layered control strategy. Finally, simulation experiments are conducted in various complex environments to compare and analyze the performance indicators of different methods, verifying the superiority of the proposed scheme.
The innovations of this study are as follows:
Deep Integration of VAPF and RL: A novel layered obstacle avoidance structure is proposed, which organically combines VAPF with RL for motion control. This approach retains the intuitive physical model of APF while endowing the system with the ability to learn and optimize autonomously.
Dynamic Target Adjustment Mechanism: The target position is dynamically adjusted through vortex repulsive forces, enabling the drone to indirectly avoid obstacles. This approach overcomes the limitations of traditional methods where the force field acts directly on the drone.
Efficient Solution to Local Minima: The introduction of the vortex potential field fundamentally disrupts the symmetric conditions of traditional APF methods. By leveraging tangential forces, the drone is guided out of local minima, significantly enhancing the success rate of path planning.
The results of this study can be widely applied in complex scenarios such as drone logistics delivery, post-disaster rescue, and environmental monitoring. In logistics delivery, it enables efficient obstacle avoidance and path planning for drones in urban building complexes; in post-disaster rescue, it helps drones quickly locate targets in complex environments like ruins; and in environmental monitoring, it ensures that drones can complete monitoring tasks under complex terrain and meteorological conditions. Additionally, this method can provide technical support for collaborative operations of multiple drones, offering broad prospects for engineering applications.
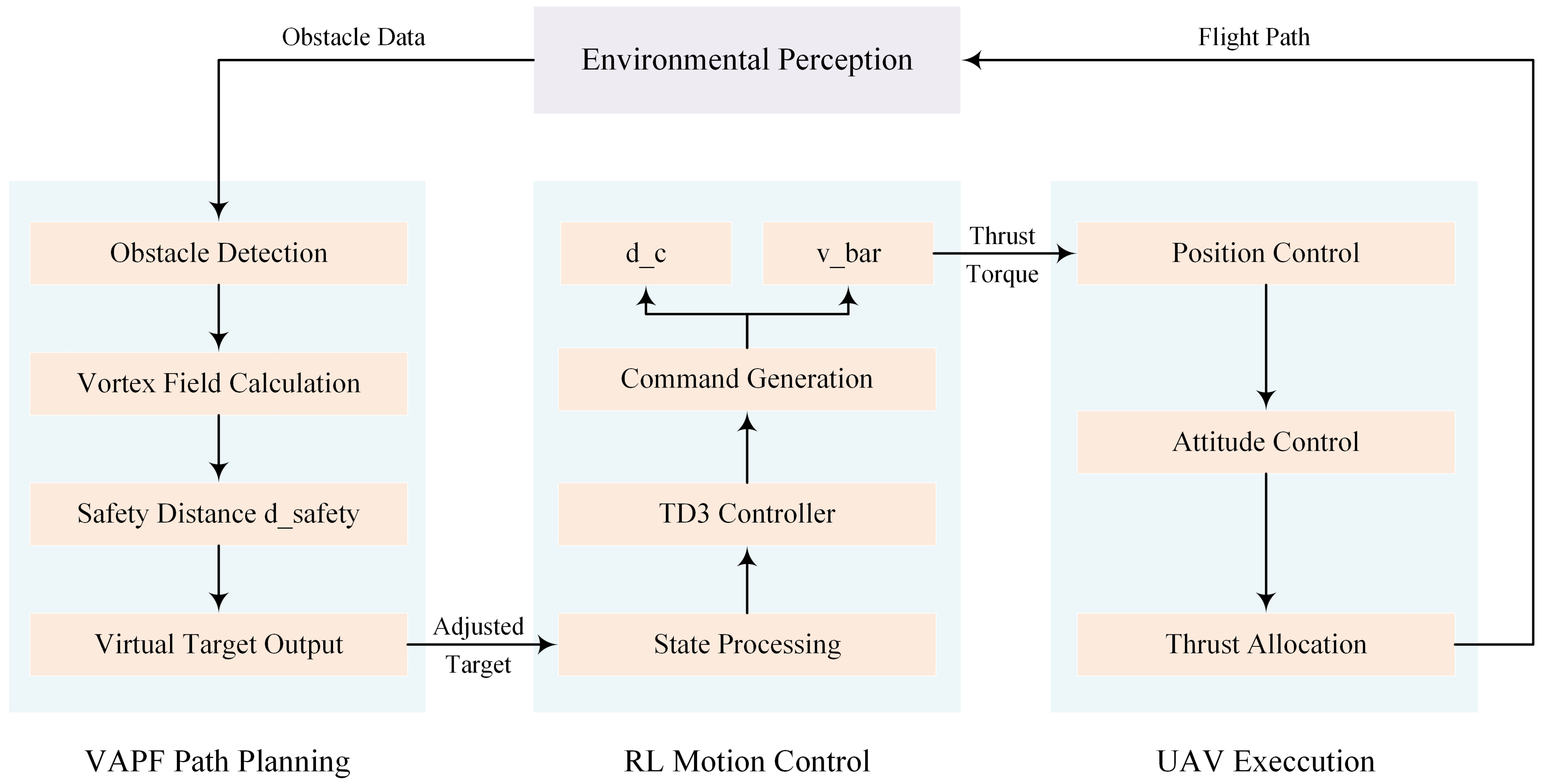
The detailed block diagrams are illustrated in the
Figure 1.
The structure of this paper is as follows:
Section 2 introduces the drone dynamics model and potential field design;
Section 3 details the TD3 algorithm and the layered control architecture;
Section 4 presents the experimental results;
Section 5 concludes the paper and outlines future directions.
Figure 1.
Block diagrams.
Figure 1.
Block diagrams.
4. Results
4.1. Training Parameter Settings
During the training phase, all drones are trained using the TD3 algorithm without considering obstacles and external disturbances. The dynamics of the drones follow the Crazyfile2.0 model. The target neural network is updated every 512 time steps
, with target values randomly selected from a uniform distribution. The angular target values range from
to
, and the translation target values range from −5 to 5. The maximum translation acceleration
is limited to 5 m/s
2, and the maximum angular acceleration
is limited to 20 rad/s
2. The training process involves training two controllers, each consisting of 200 training rounds. The maximum length of each round is set to 500 and 1000. A two-layer MLP is used to build an RL network, with each layer containing 32 nodes. In the TD3 training phase, the discount factor
is set to 0.9, and the capacity of the experience replay buffer
is set to
. Storing a large number of experience samples improves the efficiency and stability of the training process. The batch size
N is set to 512, meaning that 512 samples are selected for calculation and model parameter updates in each training iteration. An appropriate batch size enhances training efficiency without significantly increasing memory requirements and computational costs. The network uses the Adam optimizer for updates, which is a common optimization algorithm used to adjust the weights and biases of the neural network to minimize the loss function. The learning rate (v) is set to
. An appropriate learning rate ensures stable updates without causing instability, oscillation, or falling into local optima. The specific parameter settings are as follows.The specific parameter settings are shown in
Table 1.
4.2. Parameter Sensitivity Analysis
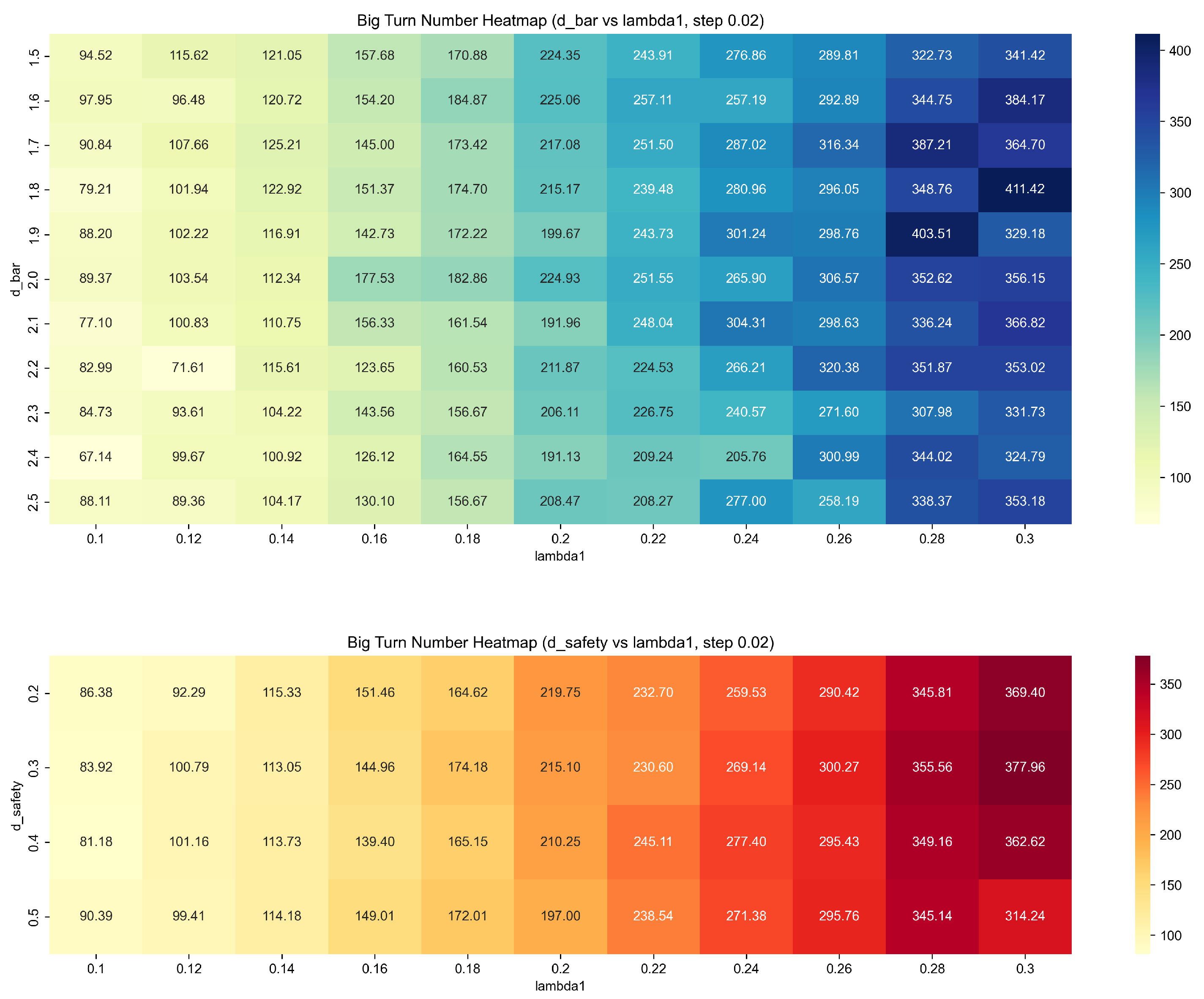
As shown in
Figure 8, comparing the heatmaps of the number of sharp turns in the parameter planes of d_bar and lambda1, it can be observed that lambda1 has the most significant impact on the number of sharp turns, while d_bar has a certain degree of sensitivity, and the influence of d_safety is extremely limited. Therefore, in the actual parameter optimization process, lambda1 and d_bar should be adjusted first to obtain better path smoothness, while d_safety can be flexibly set according to safety requirements.
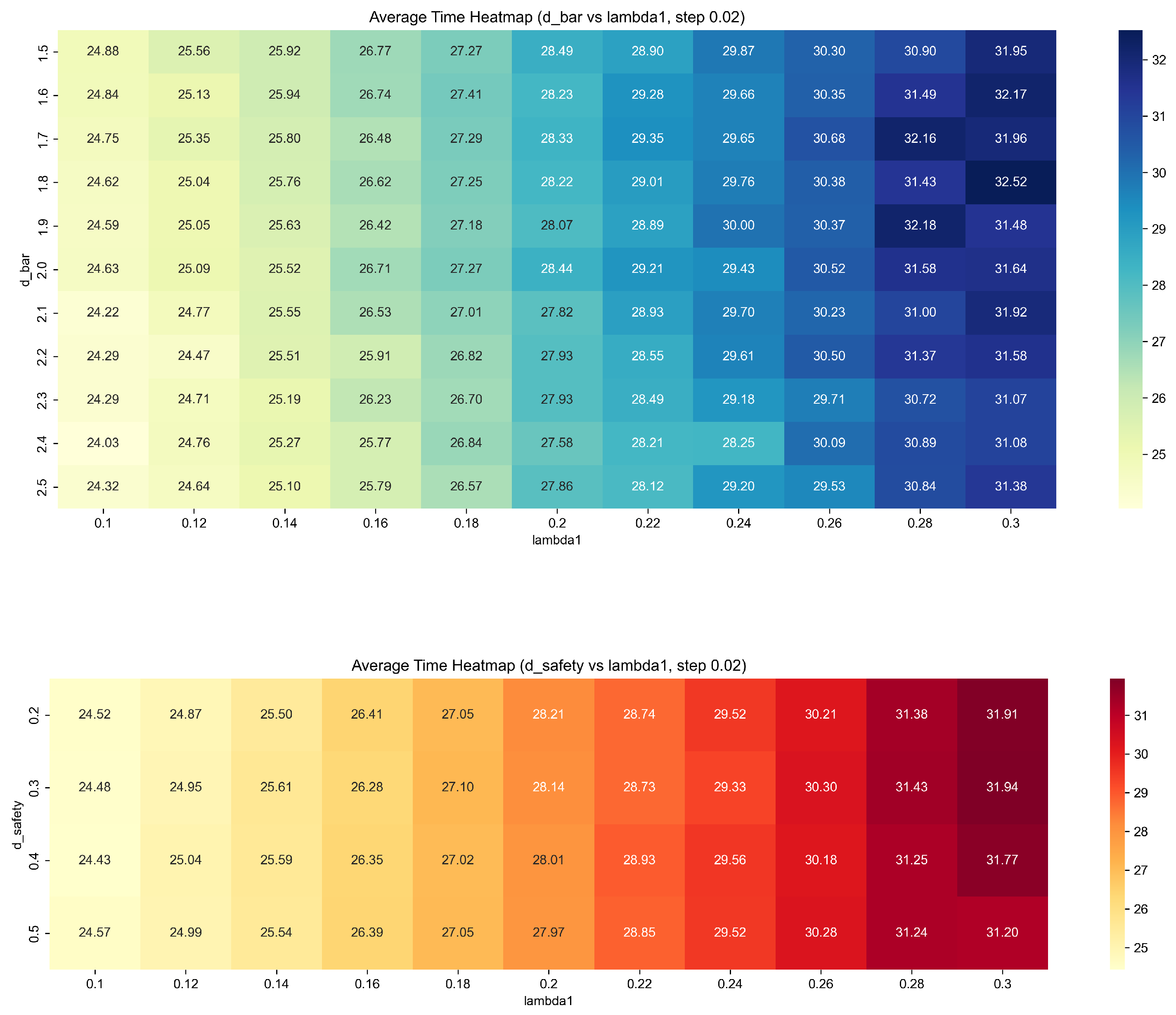
As shown in
Figure 9, the heat map under the parameter plane of (d_bar, lambda1) and (d_safety, lambda1) was drawn. The results show that lambda1 has the most significant impact on the average time, and the average time increases significantly with the increase of lambda1, showing obvious monotonicity. d_bar has a certain influence on the average time, and an appropriate detection radius (such as 1.8 to 2.2) helps to improve efficiency, while d_safety has little effect on the average time, which can be set flexibly according to actual needs. On the whole, lambda1 and d_bar are the key parameters affecting the system efficiency, which should be optimized first in practical application.
The
Figure 10 presents a heat map of the number of times trapped in local minima on the parameter plane of (d_bar, lambda1).
The results indicate that lambda1 has the most significant impact on the frequency of getting stuck in local minima. As lambda1 increases, the risk of being trapped in local minima significantly rises. d_bar also has a certain influence on this metric, with an appropriate detection radius (such as 1.8 to 2.2) helping to enhance the system’s global optimization capabilities. Overall, lambda1 and d_bar are the key parameters affecting the robustness of the system and should be optimized first in practical applications.
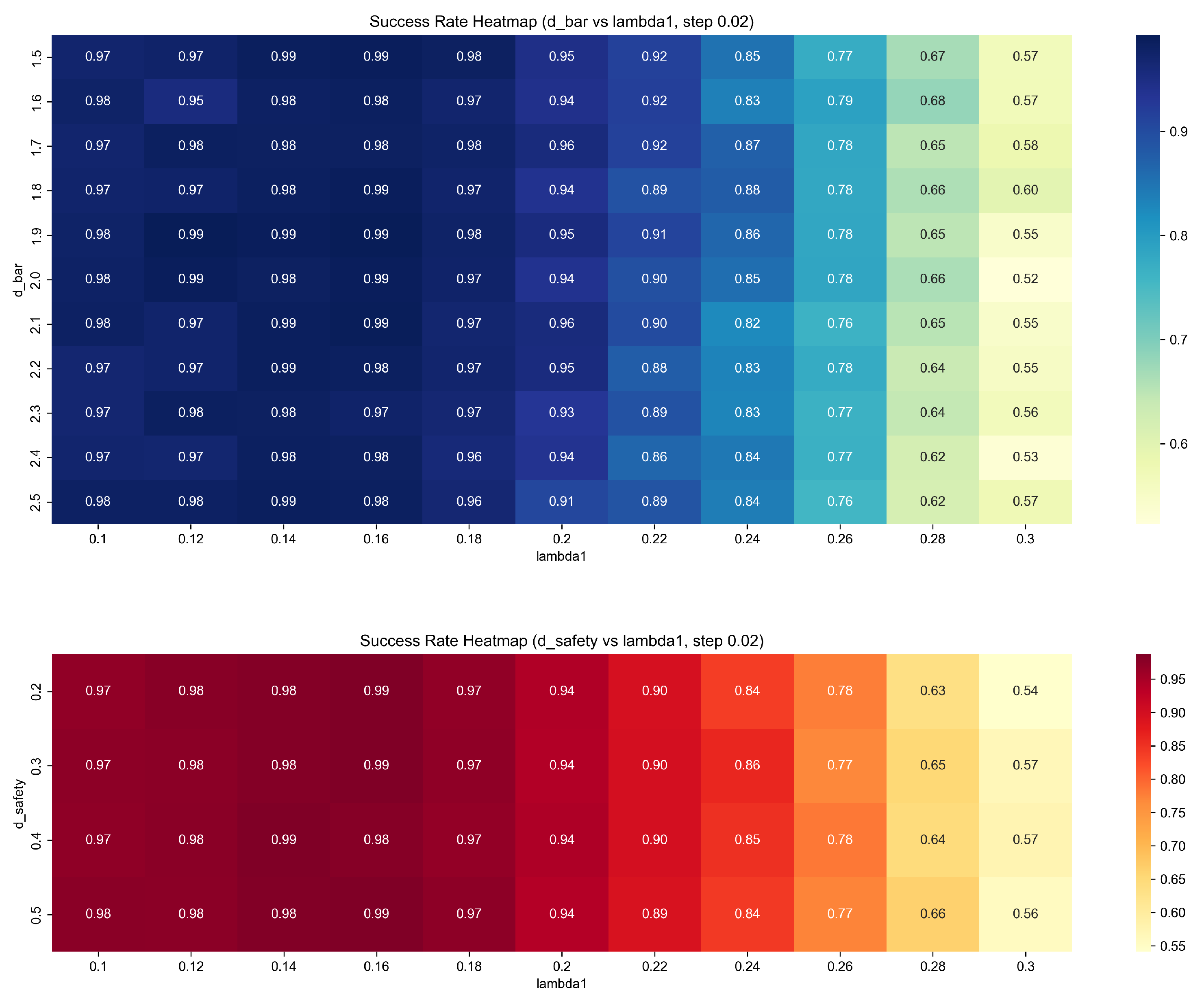
As shown in
Figure 11, heatmaps of the success rate were plotted in the parameter planes of (d_bar, lambda1) and (d_safety, lambda1).
The results indicate that lambda1 has the most significant impact on the success rate. As lambda1 increases, the success rate significantly decreases. d_bar has a certain influence on the success rate, with an appropriate detection radius (such as 1.8 to 2.2) helping to enhance the robustness of the system. In contrast, d_safety has a minimal impact on the success rate and can be flexibly set according to actual needs. Overall, lambda1 and d_bar are the key parameters affecting the system’s success rate and should be prioritized for optimization in practical applications.
4.3. Evaluation Parameter Settings
During the experimental process, the traditional artificial potential field and the A* algorithm were used instead of the VAPF based on RL to achieve path planning for drones. The local minima problem was evaluated mainly through success rate, average arrival time, and local minima count. In a single path planning process, if the distance between all drones and their respective target positions was less than or equal to 0.1 m, the path planning was considered successful. The number of iterations at this point was recorded as the arrival time, and the actual arrival time was expressed as the product of the number of iterations and 0.02 s. 20 groups of 1000 experiments were run to calculate the success rate, average arrival time, and local minima.
Additionally, this paper designs the parameter local minima count to specifically evaluate the number of times the drone gets trapped in local minima. The evaluation criteria are as follows: In the navigation paths where the drone fails to reach the target, if the drone’s movement distance is less than 0.5 m within the last 50 steps and the target position is outside the detection range of the drone’s sensors, it is considered that the drone is trapped in a local minimum. Since the maximum movement speed of the drone is set to 2 m/s in this paper, and the average movement speed during the experiment reaches 1.8 m/s, one of the core characteristics of local minima is that the drone is physically unable to move forward, or moves very slowly, being “trapped” by obstacles. If the drone moves only a very small distance (less than 0.5 m) continuously over a period of time, this strongly indicates that it may be at a point of force balance, where the attraction and repulsion forces cancel each other out, or the resultant force is not enough to overcome inertia, resulting in almost no movement. The 50-step time window is used to distinguish between a normal brief pause of the drones, such as an abrupt stop during obstacle avoidance, and a persistent trapped state. At the same time, in the APF method, when the drone is surrounded by obstacles near the target, it often fails to detect the target while being repelled by the obstacles, leading to stagnation. Therefore, the local minima count parameter can effectively evaluate the local minima situation in path planning.
In the path planning process, smoothness is a crucial evaluation criterion, as it directly impacts the stability of movement, energy efficiency, control performance, equipment lifespan, and operational safety. A path that effectively avoids obstacles while maintaining smoothness is considered practical and efficient.
This study primarily assesses path smoothness using the number of sharp turns and average curvature. The design of the evaluation parameters is as follows. We only count the number of sharp turns and average curvature when the drone successfully reaches the target location. To eliminate the influence of initial instability in the drone’s control system, the first 10 time steps of the trajectory are not considered. A sharp turn is recorded when the curvature of the drone’s trajectory exceeds a certain threshold, indicating a significant change in direction.
4.4. Experimental Results Analysis
4.4.1. Local Minimum Value
By comparing the navigation performance of the three methods under different obstacle environments, we found that when the obstacles are relatively dispersed, all three algorithms effectively complete the path planning task. Although the A* algorithm is relatively mature, the VAPF based on RL designed in this study excels in solving the problem of local minima. The specific results are shown in
Table 2.
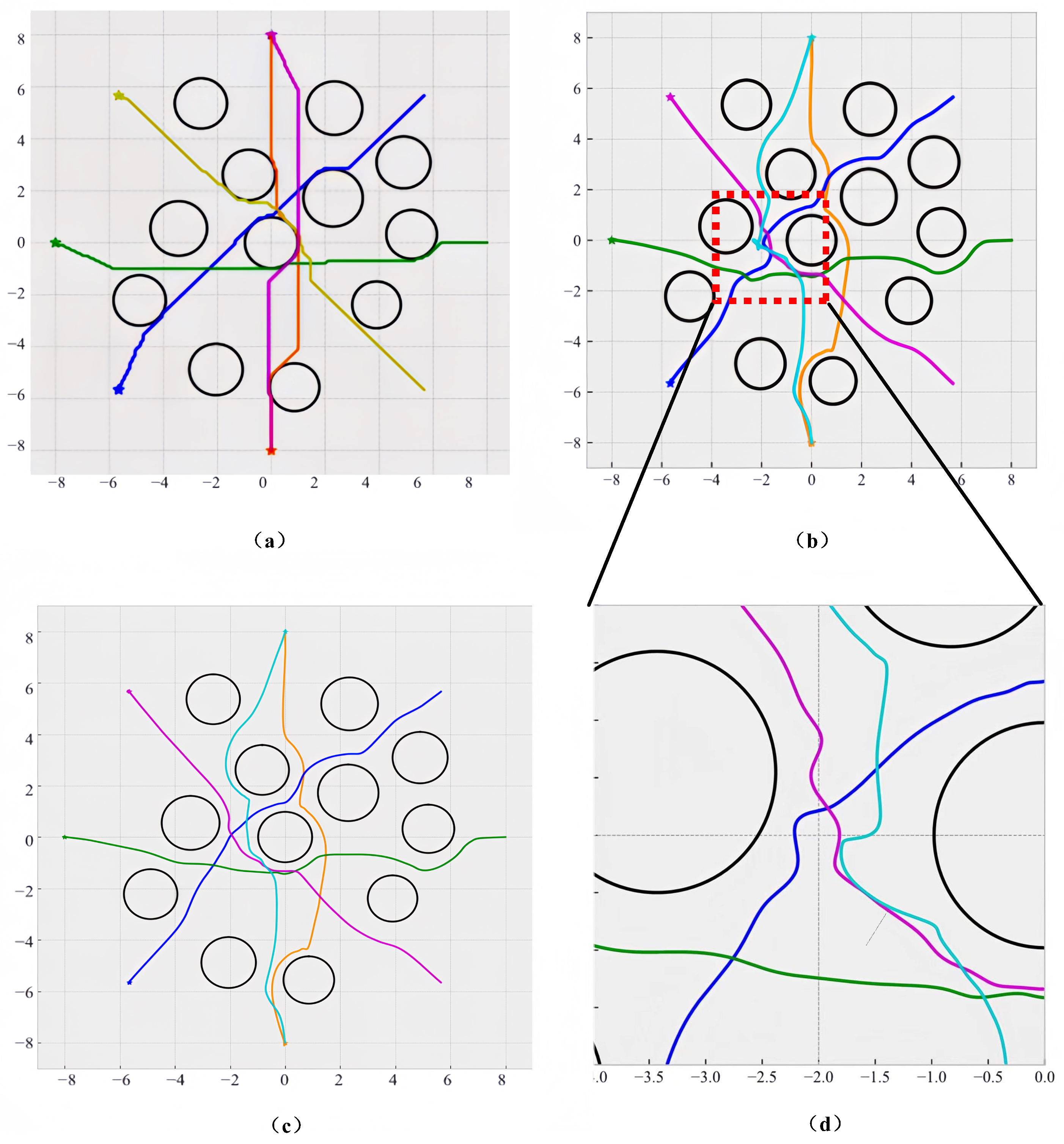
Compared with the traditional APF, the VAPF based on RL effectively solves the problem of local minima. The path diagram is shown in
Figure 12.
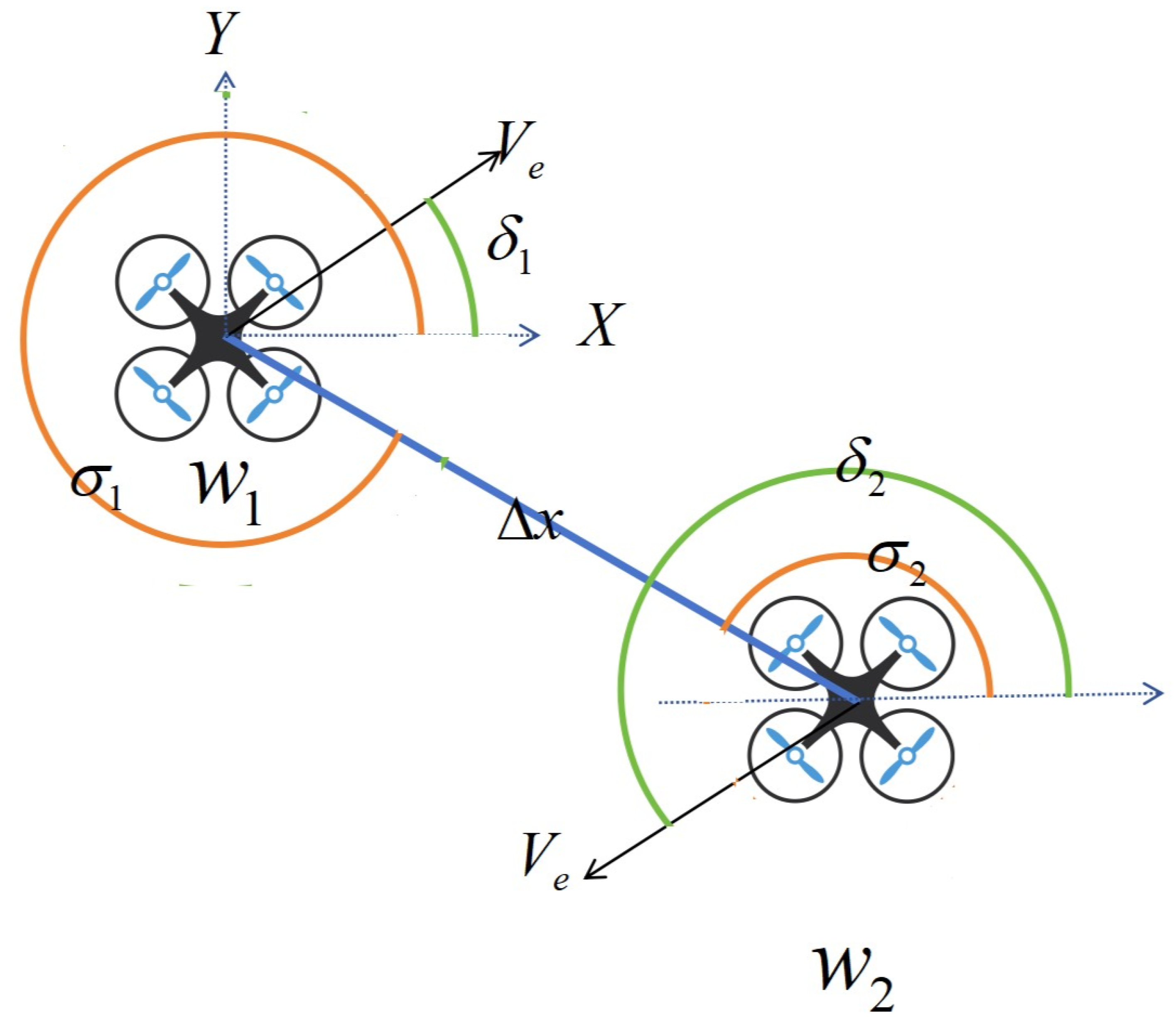
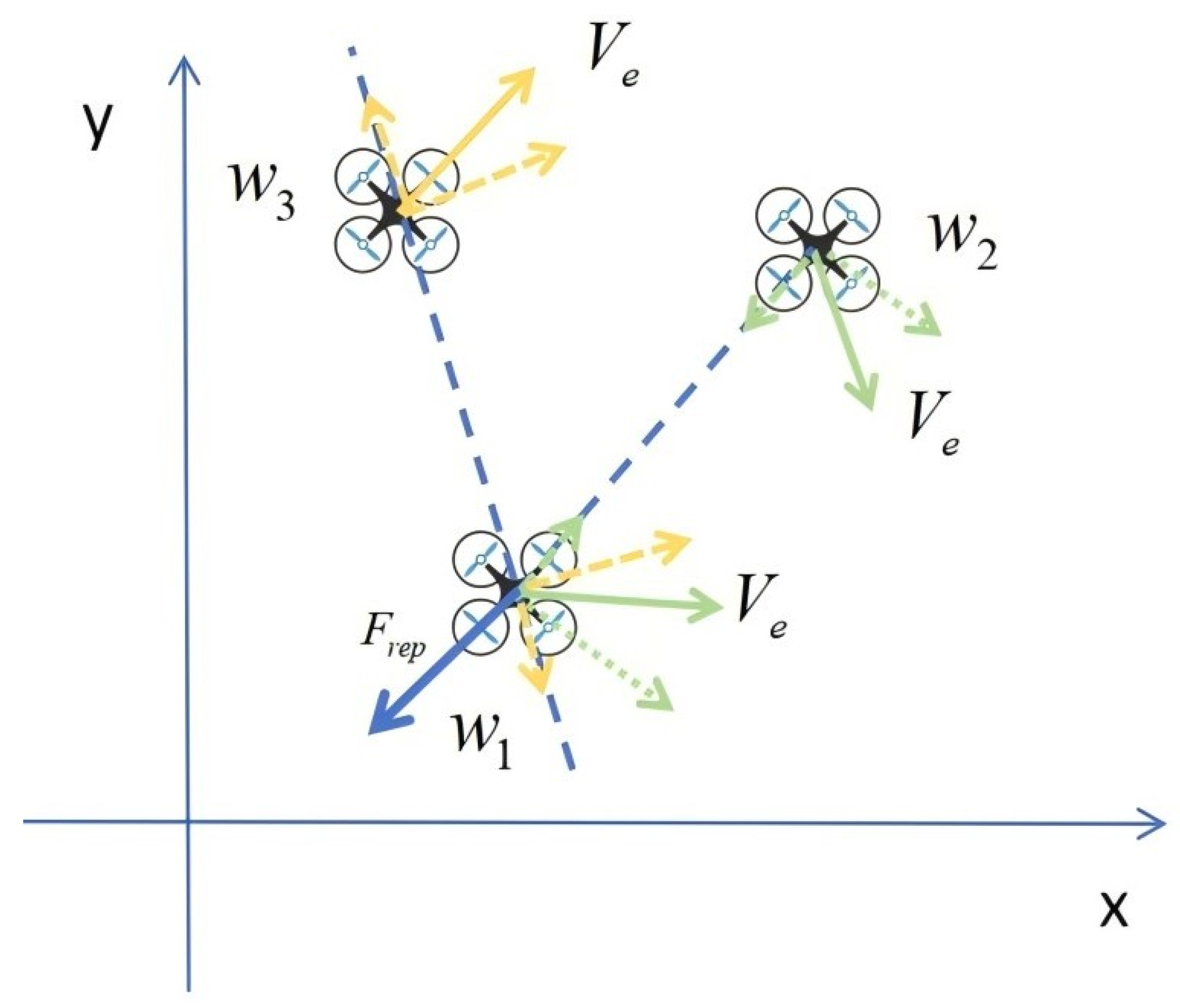
The reason lies in the introduction of vortex repulsive force in the method of VAPF based on RL, which is equivalent to adding a perturbation term to the original force balance equation. When the vortex repulsive force is not exactly opposite to the existing resultant force or points in an ineffective direction, the original balance is broken, and the resultant force is no longer zero or ineffective, so the drone will not fall into local minima. However, when the vortex repulsive force completely cancels out the existing resultant force or points in an ineffective direction, the original balance is not broken, and there is a possibility that the drone may fall into local minima.
4.4.2. Path Smoothness
In the path planning process, smoothness is a crucial evaluation criterion, as it directly impacts the stability of movement, energy efficiency, control performance, equipment lifespan, and operational safety. A path that effectively avoids obstacles while maintaining smoothness is considered practical and efficient. By comparing the performance of three methods in various obstacle-filled environments, we observe that the VAPF based on RL not only outperforms in resolving local minimum issues but also reduces the turning rate and the number of sharp turns compared to the other methods, resulting in a smoother path. The A* algorithm’s discrete search nature and its focus on optimizing only the path length limit its capability to generate smooth trajectories. On the other hand, the VAPF based on RL, by operating in a more continuous space, optimizing a multi-objective reward function that includes smoothness, and utilizing a detailed potential field model for navigation control, naturally learns to produce smoother, more continuous paths. The specific results are shown in
Table 3.
4.4.3. Comparison of Reinforcement Learning Algorithms
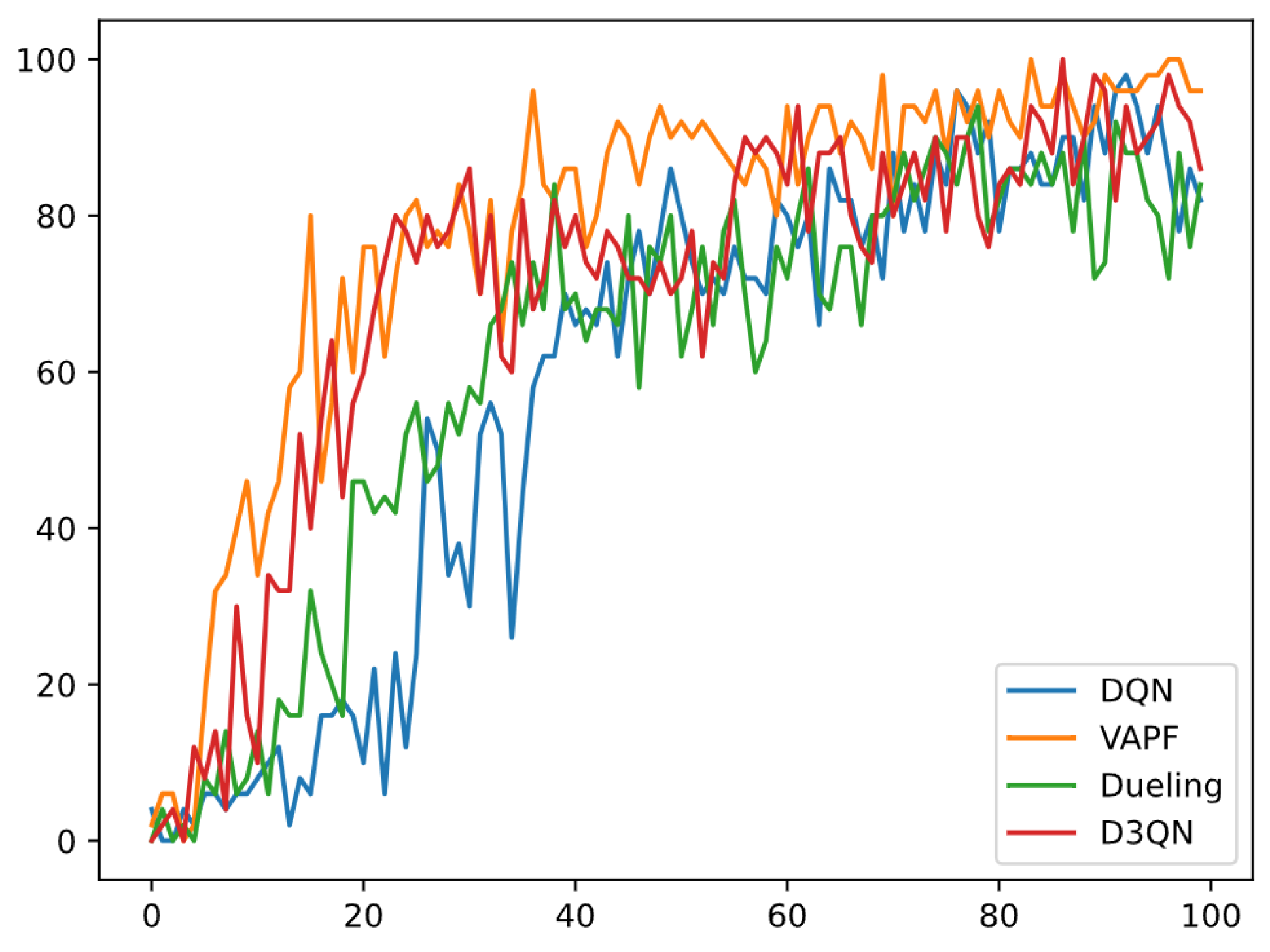
The DQN algorithm is a widely used reinforcement learning method. To effectively compare the VAPF algorithm with other reinforcement learning algorithms, this study evaluates the training performance of four algorithms (DQN, VAPF, Dueling DQN, and D3QN) in path planning tasks. As depicted in the figure, the x-axis indicates the training phase number, with each number corresponding to a saved model, thereby reflecting training progress. The y-axis shows the success rate of each model on a standard test set, which is the average success rate over 50 tests, ranging from 0 to 1.
In the
Figure 13, the blue curve represents the basic DQN, the orange curve denotes the VAPF method used in this study, the green curve illustrates the Dueling DQN variant with an advantage value separation structure, and the red curve depicts the D3QN variant integrating Double and Dueling concepts.
Throughout the training process, the success rates of all four algorithms significantly improve with increasing training rounds, indicating continuous learning and strategy optimization. Ultimately, all algorithms achieve success rates above 0.8, demonstrating robust path planning capabilities. VAPF and D3QN exhibit rapid initial improvement (within the first 20 rounds), with success rates rising early, showcasing quicker convergence.
DQN and Dueling DQN show greater volatility in the early stages, with slower initial improvement, but they eventually stabilize at higher success rates. VAPF and D3QN perform more consistently in the later stages (post-40 rounds), with minimal fluctuations and sustained high success rates. DQN and Dueling DQN experience more variability in the mid-stage (20–60 rounds), with occasional dips, but they also converge to higher success rates over time.
The experimental results indicate that the VAPF and D3QN algorithms excel in learning and generalization for path planning tasks, achieving high success rates more quickly and consistently, with VAPF slightly outperforming D3QN in terms of success rate.
The performance of four control algorithms, DQN, VAPF, Dueling, and D3QN, was compared in a simulation environment. The
Table 4 show that the VAPF algorithm excels in all metrics, with a success rate of 0.985, an average time of 26.27 s, and only 5 local minima. Its average curvature and the number of sharp turns are also superior to other algorithms, with values of 2689 and 94, respectively. In contrast, DQN and D3QN also have high success rates, at 0.980 and 0.982, but they are slightly less effective than VAPF in terms of path smoothness and the number of sharp turns. The Dueling algorithm has the lowest success rate, only 0.845, and its overall performance is not as good as the other methods. Overall, the VAPF algorithm demonstrates stronger advantages and robustness in terms of path planning success rate, efficiency, and path quality.
4.4.4. Summary of Experimental Results
In summary, the VAPF based on RL learning introduces vortex repulsive force on the basis of the APF, which better solves the problem of local minima and improves the smoothness of the path to a certain extent. At the same time, compared with the A* algorithm, which can generate shorter paths in an ideal environment, in the actual application process, the VAPF based on RL has more obvious advantages due to its fast and reliable characteristics. These advantages make the VAPF based on RL more competitive in complex and changeable actual application environments and can provide more effective and reliable navigation strategies for drones.
5. Discussion
In this study, VAPF breaks the symmetric force balance of traditional APF by introducing a tangential force, fundamentally solving the problem of local minima. Experiments show that the perturbation mechanism of VAPF significantly reduces the risk of stagnation in densely obstacle-packed areas. The physical essence of this design lies in: the vortex repulsive force dynamically adjusts the virtual target coordinates, rather than directly acting on the drone, avoiding motion oscillation caused by force field interference. Compared with the repulsive function proposed by Garcia-Delgado et al., VAPF’s “indirect navigation” mechanism is more adaptable to dynamic obstacle environments.
By decomposing motion control into translation control and rotation control and independently training each dimensional controller through reinforcement learning, a balance between motion precision and obstacle avoidance flexibility is achieved. This design solves the problem of path jitter caused by sudden attitude changes in traditional methods. Experimental data show that this structure reduces the average number of turns, verifying its advantage in path smoothness.
Parameter sensitivity analysis reveals the vortex intensity parameter has the most significant impact on path success rate and local minima frequency, while the detection radius mainly affects path efficiency. This provides parameter tuning criteria for actual deployment: prioritize optimizing the vortex intensity parameter and detection radius, which can be flexibly set according to task risk. For example, in the logistics distribution scenario, a smaller radius is needed to reduce and improve efficiency, while post-disaster rescue needs to expand to ensure safety.
Although pure RL algorithms have success rates close to VAPF in the later stages of training, VAPF has advantages in convergence speed and stability. The reason is APF’s prior knowledge reduces the RL exploration space, avoiding waste on invalid actions. However, VAPF’s adaptability to dynamic targets depends on gradient calculations, and future online learning mechanisms can be introduced to deal with sudden obstacles.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}