Abstract
Reinforcement learning, a subset of machine learning in the field of engineering informatics, has revolutionized the decision-making and control of industrial pumping systems. A set of 100 peer-reviewed papers on the application of reinforcement learning to pumps, sourced from the Scopus database, were selected. The selected papers were subjected to bibliometric and content analyses. The existing approaches in use, the challenges that have been experienced, and the future trends in the field are all explored in depth. The majority of the studies focused on developing a control system for pumps, with heat pumps being the most prevalent type, while also considering their economic impact on energy consumption in the industry. Future trends include the use of Internet-of-Things sensors on pumps, a hybrid of model-free and model-based reinforcement learning algorithms, and the development of “weighted” models. Finally, ideas for developing a practical reinforcement learning-bundled software for the industry are presented to create an effective system that includes a comprehensive reinforcement learning framework application.
1. Introduction
A pump is a mechanical device that converts electrical energy into hydraulic energy and uses it to move fluids or slurries. Pumps are used in a variety of industries, including water treatment plants; automobile factories; industrial plants; energy industries; oil and gas industries; heating, ventilation, and air conditioning (HVAC) systems; and medical facilities, among others. Pump performance research is primarily focused on two goals: improving pump reliability and lowering energy usage in the industry [1,2]. In the literature, there are several strategies based on artificial intelligence (AI) methods for solving the challenges mentioned above in a manufacturing firm [3]. Some of these AI methods include areas such as engineering informatics [4,5,6,7]. In our work, however, we limit our review to reinforcement learning techniques applied to pump systems. Pump reliability is frequently improved by forecasting the remaining useful life of the pump; examples can be found in some works (see [8,9]). Pump maintenance procedures that are optimized tend to lower maintenance costs, which in turn reduces industrial energy consumption [10,11]. However, the application of reinforcement learning to the pump system or rotating machinery comprising pumps shows an interesting trend toward better and improved control pumping systems that integrate the two-fold performance indices [12,13,14].
Reinforcement learning (RL), which is derived from a neutral stimulus and a response, is a type of machine learning algorithm that has grown in popularity due to its ability to solve the problem of sequential decision-making [15,16]. It is a branch of machine learning that describes how an agent (control mechanism) might respond in a given environment (pump condition monitoring features) to optimize a particular reward (a cost function). The reinforcement learning (RL) techniques used in pump systems area comprises of both model-based and model-free approaches. In model-free strategies, such as Q-learning and deep Q-networks (DQNs), the agent learns optimal control policies directly from interaction with the environment without an explicit model of system dynamics [15,16]. For controlling variables, the flow rate and the pressure in real-time are particularly effective. The advanced models, such as deep deterministic policy gradient (DDPG) and proximal policy optimization (PPO), operate within continuous action spaces, making them suitable for energy management tasks and complex pump scheduling [17,18,19]. These algorithms are capable of learning from raw sensor data and have demonstrated improvements in both operational efficiency and cost reduction in HVAC and industrial pump systems [20,21]. The pump systems, especially those embedded within HVAC, wastewater, and energy infrastructure algorithms, enable autonomous agents to continuously adjust control variables such as pressure, flow rate, or on/off cycles to maximize efficiency and minimize operational costs.
We decided to conduct a systematic literature review to identify the current methods used in reinforcement learning as applied to pumps, main and current assumptions, challenges encountered, prospects in light of this trend, and prospects for the application of the reinforcement learning technique to pump control.
The main contributions of this systematic literature review are as follows:
- We conducted a comprehensive review of 100 peer-reviewed articles on RL applications in pump systems, based on bibliometric and content analyses. The systematic literature review identified the current methods used in reinforcement learning as applied to pumps, the main and current assumptions, challenges encountered, prospects in light of this trend, and prospects for the application of the reinforcement learning technique to pump control.
- We classified RL algorithms, such as Q-learning, DDPG, PPO, and SAC, according to their applicability to operational objectives and different pump types.
- We identified critical challenges in the RL-based control of pump systems, including real-time deployment, data limitations, and algorithm convergence. The work highlights how reinforcement learning, a subset of machine learning, has revolutionized the decision-making and control of industrial pumping systems.
- We explored and suggested the future direction, such as the deployment of multi-agent RLs to address cases where the energy price depends on its demand, because multi-agents learn policies more effectively. They also overcome the curse of dimensionality.
These contributions deliver valued insights into the application of reinforcement learning in the control of industrial pumping systems, offering a foundation for future research and practical applications in the field. This work not only advances academic understanding but also has significant implications for industry practices.
This paper is structured as follows: Section 2 presents the methodological framework used to select the papers for the analysis. Section 3 discusses the bibliometric analysis based on descriptive statistical data. Section 4 talks about the content analysis, and Section 5 examines each paper critically to highlight the main findings according to the research questions. Finally, Section 6 concludes the work and makes some recommendations. All abbreviations used in this text are outlined in Abbreviation part.
2. Methodology
We designed a methodology for a systematic literature review (SLR). This is defined as a procedure that investigates evidence connected to a specific intervention strategy by employing explicit and systematic search methods, critical appraisal, and the synthesis of the information gathered. It finds, analyses, and interprets all published research related to a specific research question [22].
This paper intends to provide the academy with contributions by formulating and answering the research questions outlined below; these questions seek to delve deeper into the significance of applying reinforcement learning techniques to pumps.
- Q1
- What methods of RL are used with pumps?
- Q2
- What are the deficiencies of the methods listed in Q1?
- Q3
- What are the challenges faced in using RL as related to pumps?
- Q4
- What are the challenges and possible solutions involved in optimizing the energy consumption of pumps using RL techniques?
- Q5
- What are the future trends in the application of RL to pumps?
The structure of this paper follows a two-fold review method:
- Bibliometric analysis: This is a qualitative method that describes published articles and aids academics in evaluating academic studies on a certain topic [23]. Our work follows the structure used by Cancino et al. [24], where they used graphical analysis methods such as bibliographic coupling, co-citation, co-authorship, and the co-occurrence of keywords in the VOSviewer_1.6.20 software to map the bibliographic material graphically. The maps generated in our analysis provide insight into the field of RL application to pumps. The functions and advantages of a bibliometric analysis can be found in detail in Börner et al. [25]. The analysis’ contribution is to more directly reflect the status quo and the context of RL applied to pump research, as well as to show significant institutions, journals, and references in the research area, which will aid scholars in finding relevant journals, authors, and publications. The criteria metrics for the bibliometric analysis are highlighted in Table 1, whereas Table 2 lists the documents selected for the analysis.
 Table 1. Bibliometric analysis metrics.
Table 2. Documents for bibliometric analysis.
Table 1. Bibliometric analysis metrics.
Table 2. Documents for bibliometric analysis.
The first result from Table 1 presented us with 217 documents. Each abstract was carefully analyzed to exclude studies unrelated to pumps or pumping systems, resulting in 112 relevant documents. Among these, 12 documents were inaccessible due to subscription restrictions, leaving 100 documents for detailed review. The selected papers cover a 12-year period, from January 2013 to January 2025. Table 2 lists these documents.
Table 2 presents the documents precisely selected for the bibliometric analysis executed in the present paper. These documents were carefully curated based on their pertinence to the research subject, their contribution to the advancement of fundamental concepts, and their citation impact within the domain. Each reference incorporated in the table serves an essential function in clarifying the progression of research trends, methodological frameworks, and thematic important areas.
- 2.
- Content analysis: In this analysis, a critical discussion of selected papers was performed to show the development trend in the research area to assist researchers to understand the evolution and recognize new directions. The adopted structure for the content analysis is based on the work of da Silva et al. [120]. From the content analysis, we were able to draw out inferences, and we answered the research questions highlighted in the methodology.
3. Bibliometric Analysis
Figure 1 shows the number of articles published in the research interest field. The results shown in Figure 1 follow the criterion defined in Table 2. Major works became noticeable starting in the year 2018. This showed the interest of researchers in the field.
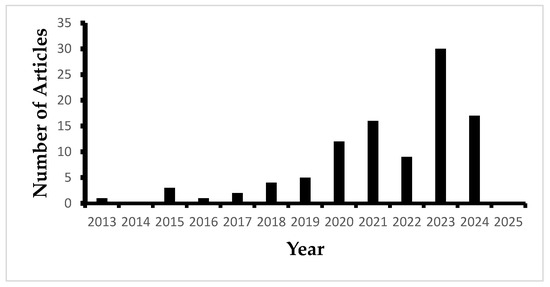
Figure 1.
Number of articles published per year.
3.1. Co-Authorship Analysis
Co-authorship shows the strength of how many publications have been authored by two or more authors. It measures the degree of co-authorship between the most productive sources [24]. Although it was reported by Beaver [121] and Laudel [122] that there are several debates about the meaning and interpretation of a co-authorship analysis, it is still widely used to understand and assess scientific collaboration patterns [123]. The measurement of co-authorship metrics will motivate future researchers to peruse papers with a high co-author link strength, which will encourage collaboration amongst them. Table 3, below, shows the variables assigned.
Table 3.
Co-authorship metrics.
Figure 2 shows the overlay visualization of the analysis in VOSviewer. It should be noted that the size of the node is directly proportional to the number of articles published by each author [124]. According to the results, rank 1 belongs to Ruelens, Frederik, and has the most citations, with four documents and 360 citations; the total link strength is 12. Belmans, Ronnie and Claessens, Bert j., share rank 2 as they have the same number of documents, citations, and total link strength; those are two, 314, and eight, respectively. Rank 3 belongs to Babuska, Robert, and de Schutter, Bart, and Vandael, Stijn, with one document, 258 citations, and a five total link strength. Remember that we have ranked the co-authorship analysis by the number of documents and citations only. To avoid biases, all author’s names have been checked thoroughly as some authors write their names differently in different documents.
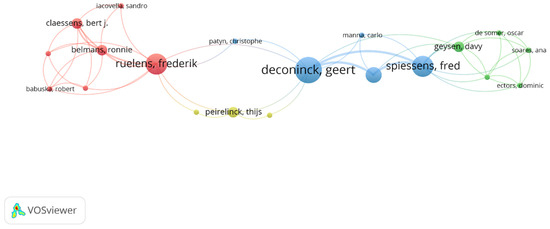
Figure 2.
Co-authorship overlay visualization.
Table 4 shows the top 20 results of the co-authorship analysis. The total link strength defines the major important attribute in this ranking. This total link attribute indicates the total strength of the co-authorship links of a given researcher with other researchers.
Table 4.
Top 20 results of co-authorship analysis.
3.2. Co-Citation Analysis
There exist three different forms of co-citation analysis [124], the first being the co-citation of cited sources, which, according to Small [23], measures the most cited documents and appears when two documents from different sources (journals) receive a citation from the same third work. This strengthens the delineation of publications in a given research field [125]. The second is the co-citation analysis of authors, which aims to identify eminent authors by analyzing citation records [126]. The third is a co-citation analysis of cited references, which shows the most frequently cited references by two or more papers [127]. We performed the first two of these co-citation analyses to gain insight into the importance of each metric. Table 5 shows the input data to the software.
- Type of analysis: co-citation.
- Counting method: full counting [124].
Table 5.
Input for co-citation analysis.
Table 5.
Input for co-citation analysis.
| Unit of Analysis | ||
|---|---|---|
| Cited Sources | Cited Authors | |
| Min. number of citations | 3 | 7 |
| Threshold | 176 | 245 |
3.2.1. Co-Citation Analysis of Cited Sources
The advantage of this metric is to assist researchers in the field to choose the trending journals to publish their works [128]. It is shown in Figure 3 that the topmost three co-citations on cited sources are “applied energy” (appl. energy and appl energy) (187 citations, 3908 link strength), “energy and building” (energy build. and energy build) (109 citations, 2235 link strength), and “energy” (63 citations, 1592 link strength).
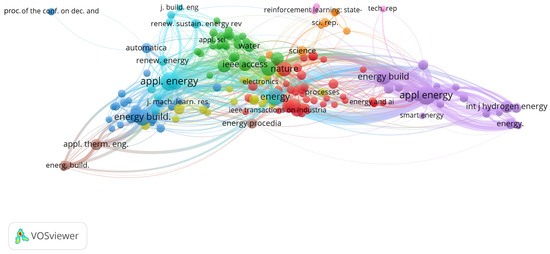
Figure 3.
Co-citation of cited sources (network visualization).
3.2.2. Co-Citation Analysis of Cited Authors
Table 6 shows the rank of the list of co-citation analyses of cited authors. We have listed the top ten authors with the highest total link strength. Silver, D, tops the chart with 80 citations.
Table 6.
Top-10 co-citation analyses on cited authors.
It can be observed from Figure 4 that there exist very strong network links among the authors, excluding Meyn, S. with 13 citations and a 156 total link strength.
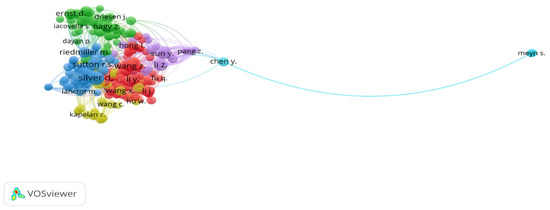
Figure 4.
Co-citation of cited authors (network visualization).
3.3. Bibliographic Coupling
Bibliographic coupling and co-citation analyses tend to complement each other. As earlier defined, co-citation involves two documents receiving a citation from a third document; bibliographic coupling, on the other hand, occurs when two studies cite the same third document [129]. The easiest way to understand the difference is to note that as co-citation views the relationship from the citation perspective, bibliographic coupling views the relationship from the documents’ perspective. They both buttress the importance of the citations and documents (papers) in question. Table 7 shows the metrics of measurement, while Table 8 shows the bibliographic coupling of the documents according to the top-ten ranks.
Table 7.
Bibliographic coupling metrics.
Table 8.
Top-10 ranks of bibliographic coupling analysis.
From Table 8, it can be seen that the topmost document by Ruelens et al. [113] deployed a fitted Q-iteration (FQI) batch RL algorithm for demand response in a building environment; this application shows the interest of the most recent researchers in demand response and the batch RL algorithm. The only other article from the same author in the top rank of the bibliographic coupling analysis by Ruelens et al. [109] also deployed the FQI algorithm to design a learning agent for a heat pump thermostat. The sum of citations of both works by Ruelens et al. [113] and [109], is also the most over the years.
3.4. Co-Occurrence Analysis of Keywords
The co-occurrence of keywords shows the most common keywords that usually appear in either the title or the abstract or in both the title and the abstract [24]. The network connection, therefore, visualizes the keywords that appear more frequently in the same papers. Table 9 shows the metrics for the analysis, and the top-five occurring keywords are listed in Table 10.
Table 9.
Co-occurrence analysis metrics.
Table 10.
Top-5 occurring keywords.
From Table 10, it is easy to acknowledge that the word “reinforcement learning” and “reinforcement learnings” takes the highest rank. This is because the aim of most of the papers reviewed is to develop a “controlled” system using the “reinforcement learning technique” to optimize decision-making and performance. The word “learning” appears in the top five because it highlights the iterative process and the adaptive nature of reinforcement learning models, which are applied across various domains, including robotics, energy systems, and gaming environments.
4. Content Analysis
This section attempts to provide a historical overview of the various RL algorithms’ applications to various types of pumps in the literature from 2013 to 2025. This will consist of the authors’ work, the techniques they employed, and the outcomes they obtained. The subsections give an in-depth overview of the research progression.
4.1. Early Applications (2013–2015)
The early years of RL research in pumps concentrated on HVAC systems, particularly heat pumps. Researchers explored using RL to regulate temperatures, improve energy efficiency, and even manage insulin delivery for diabetic patients. These initial studies demonstrated the potential of RL for pump control but also highlighted the need for more robust algorithms.
Starting from the year 2013, the work of Urieli and Stone [118] built and implemented a comprehensive, adaptive RL agent that applies a control strategy for a heat pump thermostat. Their solution used a regression learning system that used data from weather forecasts and historical measurements. An RL control strategy for geothermal control pumps that are used in low-energy buildings was proposed [112]. They used the MATLAB/Simulink framework to implement tabular Q-learning and batch Q-learning with memory replay. In terms of the heating demand, it performed better by over 10% when compared to a typical rule-based controller. At this stage of development, basic Q-learning appears to be the standard technique, as demonstrated in the work of Oroojeni et al. [111], which used the RL algorithm to control blood glucose levels in type 1 diabetic patients using insulin pumps. This was the first work we came across that dealt with RL being applied in the medical field. Improving the energy efficiency of heat pumps began to be the interest of research from the early works of Kazmi and D’oca (2016) [115], where they developed an RL framework to improve the energy efficiency of domestic water provision using air-source heat pumps. Their results showed approximately a 10-15% energy reduction, depending on the occupants’ behavior.
4.2. Expanding Applications and Addressing Challenges (2015–2018)
In reducing the energy consumption of heat pumps, Ruelens et al. [109] took the work of Kazmi and D’oca [115] a step further by proposing a learning agent for a heat pump thermostat with a set-back strategy, in which they used fitted Q-iteration, batch RL, and an autoencoder to overcome the challenge of data unavailability and the issue of the state being non-measurable by the agent. During summer days, their work reduced the energy use by around 9%. Scheduling a heat pump thermostat is a necessary task; because of that, Ruelens et al. [113] also extended the use of a batch RL technique known as the fitted Q-iteration (FQI) to find the day-ahead schedule of a heat pump thermostat. They compared the performance of the algorithm with Q-learning’s and found out that the batch RL technique provided a valuable alternative to model-based controllers, and that they can be used to construct both closed-loop and open-loop policies.
In the realm of Artificial Intelligence (AI), it is a widely accepted principle that the magnitude of a dataset directly influences the efficacy of optimization techniques. This correlation has led numerous researchers to delve into the application of batch RL. The primary advantage of batch RL lies in its ability to facilitate learning for an agent from a predetermined large dataset, thereby eliminating the need for exploration. This is particularly beneficial as it circumvents the time-intensive process of exploration. To lower the energy consumption of a heat pump while maintaining sufficient comfort temperatures, Vázquez-Canteli, Kämpf, and Nagy [114] used a batch Q-learning (FQI) technique that was implemented into an urban building simulator called CitySim. Batch Q-learning is a model-free method with the benefit of not having to explicitly learn the transition probabilities [130]. Until now, the most commonly used RL methods have been basic Q-learning, FQI, and batch RL. The aforementioned methods have drawbacks that make them unsuitable for optimal RL deployment in pumps (these demerits will be discussed in the following section). This paved the way for the later development of more robust algorithms. Wu et al. [21] made a breakthrough by developing an RL-based algorithm to improve the control efficiency of a pressure pump used in the crude oil transmission process. The deep Q-network algorithm was used (DQN). The temperature and pressure in the pipeline were controlled by the DQN. This DQN is a model-free method, which means that the state transitional probabilities do not need to be explicitly calculated. Zhu and Elbel [74] broadened the scope of RL’s use to include heat pump defrost control for electric vehicles. They also looked into Q-learning, an RL, model-free method for algorithm deployment. Their data came from the heating capacity and Coefficient of Performance (COP) data from a heat pump’s frost growth cycle under various climatic circumstances. Because the algorithm will demand a bigger CPU and more power consumption from the heat pump system, there is a risk of an increase in the initial cost of RL deployment; however, further study should be carried out to reduce these expenses. In the training of the RL algorithm, neural networks are usually deployed in the state–action-prediction stage. This prompted Patyn, Ruelens, and Deconinck [90] to compare several neural network architectures being used for the prediction of state–action. The networks compared were multilayer perception (MLP), convolutional neural networks (CNNs), and long short-term memory (LSTM). They found out that MLP and LSTM outperformed CNN, but the MLP was the most preferred due to the lower computation time of its results.
Peirelinck, Ruelens, and Decnoninck [116] applied an FQI algorithm to thermostatically controlled loads of a heat pump to optimize the pump’s control as a follow-up to previous research on the batch RL approach. To reflect the complex physical system they worked with, they invented a physical modeling software named “Modelica”. A batch RL and a neural fitting Q-learning algorithm are used in their methodologies.
Many works have used RL for HVAC system control, but not many for energy consumption prediction, so Liu et al. [84] proposed a novel deep reinforcement learning (DRL) algorithm known as deep deterministic policy gradient (DDPG)—an actor–critic technique for HVAC system energy consumption prediction. To extract high-level features of state space and optimize the prediction model, an autoencoder (AE), a neural network algorithm, was incorporated into the DDPG. Their research demonstrated that incorporating a neural network as a high-level feature extraction method into a DRL can improve its performance. Candelieri, Perego, and Archetti [131] have attempted to reduce energy consumption by scheduling pumps in a water distribution network using a Q-learning system. Because of the data availability issue, their research proposed that data may be obtained by computer simulations of known distributions. Other papers that deployed RL in pumps to reduce energy consumption can be found in [70,83,107].
Because of the nonlinearities and continuous time properties of hydraulic pump systems, Jingren et al.’s [89] main goal was to achieve pressure control accuracy for the hydraulic pump while keeping its input energy low. They proposed an integral reinforcement learning algorithm.
Regression algorithms are commonly used in conjunction with RL. In the state and action predictions, these algorithms work as function approximators. In this regard, Mbuwir, Spiessens, and Deconinck [88] presented a benchmark of regression models, such as multilayer perception (MLP), extreme gradient boosting machines, light gradient boosting machines, support vector regression, and extreme learning machines (ELMS), to determine which performs best in function approximation. The algorithms were implemented using batch RL with FQI. The ELMS performed the best of these. The research also addressed the issue of tweaking the hyperparameters of the regression algorithm; they proposed the Bayesian optimization technique since it addresses the challenges of the huge computational cost and the time encountered by grid search strategies.
In summary, the above period witnessed a wider range of applications for RL in pumps. Researchers explored RL for pressure control, defrost cycles in heat pumps, and scheduling. The limitations of basic Q-learning methods became apparent, leading to the introduction of more advanced techniques, like DQN and batch RL algorithms. The importance of neural network architectures for state–action prediction was also recognized.
4.3. Deep Reinforcement Learning and Addressing Data Issues (2018–2020)
Deep reinforcement learning (DRL) algorithms have recently emerged with regard to their application to pump operation; this field was investigated by Filipe et al. [81], who devised a preventive control policy for a wastewater variable frequency pump that lowers electrical energy consumption. It is a model-free and data-driven predictive control that combines regression models and DRL in the form of proximal policy optimization (PPO). Their findings resulted in a 16.9 per cent reduction in electrical energy use. Hajgató, Paál, and Gyires-Tóth [102] deployed the use of a dueling deep Q-network, originally introduced by Wang et al. [132], to train an RL agent to maintain pump speeds used in a water distribution system. Their major contribution is that the agent pumps can run the pump in real-time as it depends only on the pressure measurement data.
Moving forward in DRL research, Seo et al. [97] suggested a DRL-based predictive control technique for decreasing the energy consumption and cost of pumping systems in wastewater treatment plants where the pumps are controlled by ON/OFF signals. They used a PPO and a deep Q neural network to operate as the agent, similar to the work proposed by Filipe et al. [81]. Because the DRL accounted for uncertainty induced by predicting mistakes, their suggested solution outperformed existing methods.
To maximize the self-consumption of the local photovoltaic production of heat pump installations, a model-based batch RL was used to learn the stochastic occupants’ behavior of a residential building. This work was accomplished by Soares et al. [76]. The batch RL was incorporated into an FQI algorithm. The results showed an average increase in the local PV generation of the heat pump by up to 14%. Smart sensors attached to residential microgrids can give rise to large volumes of data. Mbuwir et al. [93] explored two model-free RL techniques—policy iteration and FQI—for scheduling the operation of flexibility providers. These flexibility providers were battery and heat pumps in a residential microgrid. Their developed RL methods were tested in both a multi-agent and single-agent setting. The multi-agent setting outperformed the single agent, with a 7.2% increase in PV self-consumption. Both methods performed better than a rule-based controller. In Mullapudi et al. [80], a real-time technique (RL) was developed for controlling urban stormwater systems. The distributed stormwater system’s valves, gates, and pumps all have water level and flow set points that the RL agent was trained to control. The technique used was DQN. Ahn and Park [94] completed another DQN project in which the agent’s objective was to reduce a building’s energy use while maintaining the indoor CO2 concentration. Q-learning, model-free RL was suggested by Qiu et al. [105] to regulate a building’s cooling water HVAC system. The model preserved 11% of the system’s energy.
Slurry circulation pump predictive scheduling issues are typically resolved by taking into account characteristics like the power consumption, emission penalties, and switching frequency. In [104], a model-free, PPO, RL algorithm was used to lower the pumps’ energy usage while still meeting pollution standards. Through the observation of the power load and sulfur content prediction sequences, their algorithm also timed the pumps to prevent frequent switching. According to the results, the suggested framework performed better than conventional scheduling policies.
To reduce flooding during storms, Wang et al. [119] proposed an RL-based stormwater control system. The environment factors were simulated using a stormwater management model. A DDPG connected with a deep neural network was employed as the method, which was an improvement over the comparable technique utilized in Liu et al. [84], where an autoencoder was coupled with the DDPG. In [72,75], one can find other works that made use of DDPG. A DDPG RL algorithm was deployed by [75] to handle noise in the input data of rainfall forecasts and the status information of controlled valves and pumps in a stormwater system. Although their work did not directly show the applicability of RL to pumps, it showed the possibility of handling uncertainties in the input data. This proved that DDPG is robust to noisy input data. In [72], a DDPG method was suggested for training autonomous agents to enable buildings to take part in demand response programs and to coordinate such programs through price fixing in a multi-agent setup. Their work is highly intriguing because it demonstrated how RL resilience has improved in a multi-agent setting. In keeping with the implementation of these multi-agent RL algorithms, Vazquez et al. [78] implemented a multi-agent RL for collaboration to provide efficient load shaping in some connected buildings in a model-free, decentralized, and scalable manner. It was carried out using the soft actor–critic (SAC) RL approach. The SAC is a model-free, off-policy method that can learn from fewer samples and reuse experience. The agents were deployed to forecast electricity use and exchange data among themselves.
In summary, the emergence of deep reinforcement learning (DRL) marked a significant advancement in this period. Researchers achieved impressive results in energy reduction for wastewater pumps and improved control in water distribution systems. Techniques were developed to address uncertainties in data and account for stochastic human behavior.
4.4. Multi-Agent Reinforcement Learning and Continuous Action Spaces (2020–2021)
Mbuwir et al. [101] determined that it was appropriate to benchmark five of the most important RL algorithms used in energy consumption and demand response up until the year 2020 based on the aforementioned publications. These include the FQI, double Q-learning, REINFORCE, policy iteration with the Q-function, and actor–critic approaches. All of the aforementioned were contrasted with model-based, best rule-based, and naive control approaches. The FQI fared better than the others, according to the findings, in terms of computing speed. In contrast to the ideal control, a 7.6% drop in PV self-consumption and a 77% rise in net electricity costs were found.
The type of variables (discrete or continuous) required for the RL agent to learn in the action and state space were the main areas of research in 2021. This is because studies have shown that the majority of real-world data typically appear as continuous variables for the action and state space. Because of this, Ghane et al. [79] created an RL to regulate the temperature of heat pumps connected to four homes. Concerning the reward function of the agent’s weight component, they contrasted a discrete and continuous action space. The RL trained in a continuous action space performed better and offered a more plausible answer, according to the results. PPO was the RL technique employed. Pinto, Deltetto, and Capozzoli [85] also considered a continuous action space for the SAC RL agent, which was used to investigate the benefits of a coordinated approach for energy management on a cluster of buildings’ heat pumps. Their deployed DRL outperformed a rule-based controller by 23% in terms of energy demand reduction. SAC RL was also used [106] as a piston control method for active noise control in a hydraulic axial pump system. Suffice to say that the SAC configuration may lend itself well to the extension as a pump prognostic tool.
Campoverde et al. [108] proposed a system for managing farm irrigation operations based on IoT sensors and smart platforms. Their primary goal was to control irrigation water pumps. In [86], a DDPG RL algorithm was proposed to solve the coordinated control problem of a water pump and a radiator in a stacked heat management system. The method employed consisted of multi-input, multi-output (MIMO) agents that controlled the cooling water velocity of the water pump and the air velocity of the radiator at the same time while monitoring the optimal global stack temperature control performance.
Because training time has become an issue with RL algorithms, ref. [82] focused on the challenge of minimizing the training time for HVAC system control. They used a multi-agent RL and a Markov game instead of modeling the problem as a Markov decision process (MDP). The Markov game consists of multiple agents and one environment, with each agent receiving a reward based on the state of the environment. In a continuous variable and large action space, the Markov game performed better. When compared to a single-agent RL, the results showed a 70% reduction in training time. Ref. [73] used RL to reduce the computational requirements of HVAC model predictive control (MPC). They employed the RL algorithm’s behavioral cloning technique. By utilizing an expert controller that is already in place, behavioral cloning can learn policy more effectively [133], and because it only needs a small quantity of training data, the training time and computing speed can be shortened. Another study to reduce training time was carried out by [87]. They applied transfer learning (TL) to a DRL-based heat pump to leverage energy efficiency in a microgrid; the TL was used to speed up the convergence process. The results showed a 10% savings cost in the application of TL, and the learning time for the RL was reduced by a factor of five.
To solve the issue of inadequate coordination between the water pump and the radiator in a proton exchange membrane fuel cell (PEMFC) stack heat system, [99] established an ideal coordinated control technique. To do this, they employed a multi-agent DDPG RL algorithm. In their work, novel ideas like curriculum and imitation learning were introduced.
An intriguing paper by [77] demonstrated that RL may be applied to pump systems that are inaccessible to humans. They suggested an automated events detection multidimensional state engine that collaborated with an RL agent to regulate submersible pumps utilized in surveillance activities. Ref. [95] used RL in the health sector to solve a decision-making problem that selected the ideal next state in a series of actuation sequences of a microfluidic peristaltic pump.
Researchers found that there exists an issue of the overestimation of actions by deep Q-networks, which led ref. [14] to the invention of a double DQN that eliminates this problem. Therefore, in the work of [117], they developed a double DQN with an RL-based control framework which can learn and adapt to an occupant’s behavior of a building to make the balance between energy use, comfort, and water cleanliness in heat pump water heating systems. This resulted in a 24.5 per cent energy use reduction over the conventional approach.
In the study proposed by Huang et al. [70], a DDQN RL algorithm was applied to train an agent to solve the continuous change in the pumped storage hydro–wind–solar system. The optimal control resulted in flexible operation, tracking the quick load variation and balancing the power of the system to minimize the bus voltage variance. They detected an improvement of 21.8 per cent in cumulative voltage deviation each month, which means that the taught RL can keep the system running in a safe voltage range more effectively. The requirement for the smart scheduling optimization of pumps in water distribution networks motivated Jiahui et al. [107] to design a knowledge-assisted RL framework to meet an arbitrary water distribution network architecture and time-varying water pressure demand.
4.5. Continuous Control and Real-World Implementation (2022–2025)
The majority of procedures are still essentially the same in the year 2022 as they were in earlier years. The majority of contributions focused on adding more features and variables to the environment state, simplifying the rules used to construct the RL framework, and accelerating the algorithms’ convergence times. Based on the Q-learning-based RL approach, Wu et al. [71] developed a real-time control, energy-saving solution for a pip isolation tool (PIT). To increase the energy-saving effectiveness, the RL real-time solution controlled the opening of the PIT’s accumulator valves and hydraulic pump throughout the plugging operation. About 24% more energy was saved with their proposed controller. If the action space had been continuous, their outcomes would have been more optimal. The issue of the unexplained control actions of RL techniques for building control was identified in [91]. As a result, they created a rule reduction framework employing explainable DQN RL to make the control method more workable. The best control method for a geothermal heat pump system in an office building was the subject of their case study. A decision tree was used to condense the agent’s decision-making rules. Their efforts led to a 1.2% reduction in energy use. In Abe et al. [96], a Q-learning, RL algorithm was developed and implemented on a peristaltic micropump to allow the agent to control the flow rate, as well as the position of the particles. Ref. [110] also designed a DQN RL controller to operate an energy system consisting of a photovoltaic terminal (PVT) combined with a heat pump. The RL agent sought to minimize the total operating cost through a flow rate variation. In [92], a PPO-based, RL, data-driven management strategy for managing smart homes with electrical heat pumps and power systems was proposed. The agent tried to reduce the overall cost of energy while abiding by the constraints. The work by Fu et al. [20] used parallel learning to shorten the training convergence time and shrink the action space of their DQN method. Parallel learning is a process whereby a system is trained online with a small amount of data, then when deployed, it makes full use of data collected from related equipment. They proposed a multi-agent method for a building’s cooling water system control. Their method was 11.1% better than the rule-based method and 0.5% better than the model-based method and had a faster convergence time.
Ref. [100] introduced a deep reinforcement learning (DRL) control method based on deep deterministic policy gradients (DDPGs) aimed at enhancing the Coefficient of Performance (COP) in the context of HVAC systems. Their significant contribution involved the utilization of an autoencoder to establish an expansive state space using internal sensor data from the HVAC system. The autoencoder served the purpose of feature extraction. While their work did not include reported quantitative analyses, they asserted that their approach yielded energy savings.
In a similar vein, ref. [98] also employed the DDPG method to evaluate the potential of DRL in controlling a smart home equipped with an air-to-water heat pump, a photovoltaic system, a battery energy storage system, and thermal storage capabilities for floor heating and the hot water supply. This research was conducted in comparison with a model predictive control (MPC) approach. The results revealed that the DDPG method outperformed rule-based strategies and achieved a self-sufficiency rate of 75%, with minimal deviations from the desired comfort levels.
Furthermore, Blad et al. [103] presented a novel framework for offline reinforcement learning (RL) with subsequent online fine-tuning, specifically tailored for HVAC systems. They delved into the application of artificial neural networks (ANNs) for designing efficient controllers. Their study demonstrated that a multi-agent RL algorithm could consistently perform at least as well as an industrial controller. The optimal control policy implemented by the RL agent resulted in a 19.4% reduction in heating costs when compared to traditional control methods.
For the year 2023, there is a notable body of research in the field of reinforcement learning (RL) applied to various aspects of pump systems. In [60], the authors developed an ensemble-based intelligent fault diagnosis model for main circulation pumps and converter valves. Their primary objective was the identification of pump faults. They achieved this by utilizing base learners and a “weighted model” based on deep reinforcement learning (DRL). Their results demonstrated the superiority of the proposed weighted model, yielding an accuracy of 95% and an F1 score of 90.48.
In a similar vein, ref. [17] introduced a model-free, DRL-based strategy for optimizing the operation of heat pumps. The approach leveraged the “rainbow” deep Q-network (DQN) algorithm to minimize electricity costs. The “rainbow” agent comprises seven distributed algorithms with a weighted average. The study illustrated that combining these distributed algorithms led to enhanced performance compared to individual algorithms, resulting in a substantial 22.2% reduction in electricity costs over the entire year.
Ref. [59] ventured into a comparative analysis of RL and model predictive control (MPC) against traditional rule-based controls in a virtual environment for residential heat pump systems. Their distinctive contribution lay in separately testing RL and MPC controllers to provide insights into advanced building control methods. Notably, the RL controllers, employing algorithms such as DDPG, dueling deep Q-networks, and soft actor–critic, outperformed the baseline controller, particularly in typical and peak heating scenarios. Nevertheless, the study acknowledged the challenges associated with hyperparameter tuning, which may not always lead to optimal results when approached as one parameter at a time.
Furthermore, ref. [56] introduced a model-free optimal control method using DRL for heat pump operation and room temperature settings in an HVAC system for residential buildings. They employed advanced RL techniques, including dueling double DQN and prioritized relay DQN, to enhance system performance. The results indicated a 15.3% improvement in comprehensive rewards compared to rule-based methods, emphasizing the applicability of data-driven methods, even in cases where historical operational data are limited.
Addressing scheduling challenges, ref. [66] proposed a multi-agent RL approach using the DDPG framework to tackle uncertainties in the water demand within water distribution networks. Similarly, ref. [40] developed a DRL model for optimizing suspended sediment concentration (SSC) prediction, thus lowering the energy consumption in water intake and pumping stations. Their application of the proximal policy optimization (PPO) algorithm led to a 0.33% reduction in the energy consumption per unit of water, highlighting the potential for efficient scheduling.
Recognizing the limitations of metaheuristics, ref. [61] introduced an exploration-enhanced DRL framework employing PPO to address real-time pump scheduling in water distribution systems. Their findings demonstrated an 11.14% reduction in energy costs, emphasizing the agility and cost-effectiveness offered by DRL approaches in responding to fluctuating water demands.
In alignment with previous research by [46,86], other authors proposed a DDPG-based DRL agent to address control challenges related to the circulating water pumps and radiators in fuel cell thermal management systems.
Ref. [69] focused on the replacement of rule-based decision-making in heating systems, offering a predictive management approach for campus heating systems. They developed a DDPG model-free algorithm to mitigate issues arising from intermittent and volatile heat demands, achieving a 4.52% accuracy gain over rule-based methods, along with improved cost reduction and supply reliability. Concurrently, ref. [52] introduced a self-optimizing defrost imitation controller that harnessed DRL to overcome the limitations of threshold values for defrost initiation in heat pumps. This algorithm outperformed the rule-based method by 12.3%, emphasizing its potential to enhance energy efficiency and control in such systems.
In the study proposed by [50], the authors train the RL algorithms using a simulation model that accurately represents the test rig of a pump-turbine located at the laboratory of TU Wien, and the results show that RL is suitable for finding optimal control strategies that can compete with traditional approaches. One paper [65] proposes a study on the waste heat recovery of a Fuel-Cell Thermal Management System based on RL, and the simulation results of the study proposed showed that the RL control improves the average temperature regulation capability by 5.6% compared to a PID control. Conversely, ref. [43] proposes a real-time pump operation method for rainwater pumping stations using deep reinforcement learning (DRL) based only on currently observable information, such as rainfall, inflow, storage volume, basin water level, and outflow. The performance of the proposed DRL model was then compared with that of the rule-based pump operation currently used at the station. Furthermore, ref. [42] increases the flexibility of Hydropower with RL on a Digital Twin Platform; the work demonstrates the potential of applying RL to control the blow-out process of a hydraulic machine during the pump start-up and when operating in synchronous condenser mode. The research presented the RL implementation in a test environment that enables the safe and effective transfer of the algorithm’s learning strategy from a virtual test environment to a physical asset.
In their research, the authors of [51] intended to minimize the energy cost of WSPS by dynamically adjusting the combination of pumps and their operational states; the authors faced several challenges due to the lack of accurate mechanistic models of pumps, uncertainty in environmental parameters, and temporal coupling constraints in the database. The simulation results based on real-world trajectories show that the proposed algorithm can reduce energy consumption by 13.38% compared with the original scheduling scheme. Ref. [67] developed a novel deep deterministic policy gradient control method based on prior knowledge (DDPG-PK) for the FCU system. The DDPG-PK method improved the FCU system’s 27.5% satisfaction rate and 23.0% energy efficiency rate in the first three years. Similarly, [18] demonstrated the reduction of stress on the electricity grid by using appropriate control strategies to match electricity consumption and production. The research developed and simulated a model of an energy system and RL-based controllers with physical models and compared it with conventional rule-based approaches. Also, [26] proposes a data-driven approach to construct an RL environment and utilizes transfer learning to achieve real-world building control for energy conservation. The results of the research indicate that the RL controller can effectively conserve energy in the experimental environment while maintaining thermal comfort, achieving an 11.33% energy-saving rate. In a similar manner, ref. [19] presents a DRL control method intended to lower energy expenses and elevate renewable energy usage by optimizing the actions of the battery and heat pump in HEMS, and the model achieved a 13.79% reduction in operating costs and a 5.07% increase in PV self-consumption.
The later years saw significant progress in dealing with the continuous control of pumps. Researchers implemented PPO and other algorithms to achieve the real-time scheduling and joint control of pumps and valves in water systems. The focus moved towards practical applications, with studies demonstrating success in wastewater treatment plants and water distribution networks.
4.6. Case Studies of RL Applications in Pump Systems
To enhance the practical applicability of reinforcement learning (RL) in pump system operations, this section presents three representative case studies drawn from the reviewed literature. These studies illustrate the application of various RL algorithms across distinct domains, each providing valuable insights into the role of RL in promoting energy efficiency, optimizing control strategies, and enabling real-time decision-making within pump systems.
- Case Study 1:
Pinto et al. [85] implemented a Soft Actor-Critic (SAC) multi-agent reinforcement learning (MARL) algorithm for coordinated energy management in residential buildings equipped with heat pumps. The system emphasized collaborative decision-making among agents operating within a continuous action space, aiming to reduce overall energy consumption and peak demand. The training of the RL agents was informed by data on energy availability, occupancy patterns, and external temperature conditions. Subsequently, the agents optimized the operational schedules of the heat pumps. Compared to conventional rule-based control strategies, the SAC-based approach achieved a 23% reduction in energy demand, thereby demonstrating the potential of multi-agent RL for enhancing efficiency in distributed residential energy systems.
- Case Study 2:
Seo et al. [97] introduced a hybrid framework for predictive control grounded in deep reinforcement learning (DRL) tailored specifically for wastewater treatment facilities. This investigation employed both proximal policy optimization (PPO) and deep Q-network (DQN) methodologies to regulate the functionality of pumps subject to ON/OFF control protocols. The proposed framework meticulously considered uncertainties stemming from variable flow demands and inaccuracies in sensor predictions. The reinforcement learning agent acquired an optimal switching policy by optimizing a reward function that is intricately associated with energy conservation and operational dependability. In comparison to traditional control methodologies, the DRL-based approach markedly diminished energy expenditure and operational expenses, thereby underscoring the versatility of reinforcement learning within utility-centric infrastructures.
- Case Study 3:
A study conducted by Wu et al. [21] employed a deep Q-network (DQN) algorithm to enhance the operational efficiency of a pressure pump within a crude oil transmission framework. The reinforcement learning (RL) agent underwent training to autonomously regulate the pressure and temperature within the pipeline infrastructure, utilizing real-time sensor information. The DQN algorithm, characterized as a model-free methodology, facilitated the agent’s acquisition of optimal control strategies without necessitating the explicit modeling of state transitions. This methodology yielded improved control accuracy and diminished reliance on manual intervention, thereby illustrating the potential of reinforcement learning in addressing the nonlinear dynamics that are intrinsic to oil pipeline systems.
These case studies deliver concrete illustrations of how different RL techniques (DQN, PPO, and SAC) can be personalized to meet the operational challenges of various pump systems. By analyzing the structure, control objectives, and results of these implementations, readers can gain a deeper appreciation of the real-world applicability and performance benefits of reinforcement learning in pump-related domains.
5. Main Findings
In this section, efforts will be made to answer the research questions that were put forward at the beginning of this review. In so doing, the findings from the context analysis will be used to achieve this. The reinforcement learning (RL) models examined in the studies under review exhibit considerable variability concerning their algorithmic architecture, learning objectives, and environmental assumptions. These models can be systematically classified into three primary categories: value-based methods, policy-based methods, and actor–critic methods. Model-free methods, including Q-learning and deep Q-networks (DQNs), derive estimates of value functions through environmental interactions, whereas policy-based techniques are exemplified by proximal policy optimization (PPO) directly enhancing the policies. Actor–critic algorithms, such as deep deterministic policy gradient (DDPG) and soft actor–critic (SAC), amalgamate both exemplars and have demonstrated superior efficacy in continuous control scenarios pertinent to pump operations [15,17,18,84,85]. These methodologies are particularly beneficial in contexts where system dynamics are only partially observable or exhibit significant nonlinearity, both of which are frequently encountered in hydraulic, HVAC, and wastewater management systems.
- Research question 1: what methods of reinforcement learning are used with pumps?
To answer this question, we listed all the important and frequently used methods from all the papers reviewed.
The classification of RL methods can be performed according to the necessity of a model:
Model-based: Model-based methods learn the model of the environment, and then the agent plans using the model. The models need to be updated often. Model-based classification could be either policy or value-based.
Model-free: The environment’s model is not built. The agent is allowed to choose an optimal way to behave according to an optimal policy or its optimal value function.
Figure 5 shows a reinforcement learning taxonomy that shows the interconnection of these classifications.
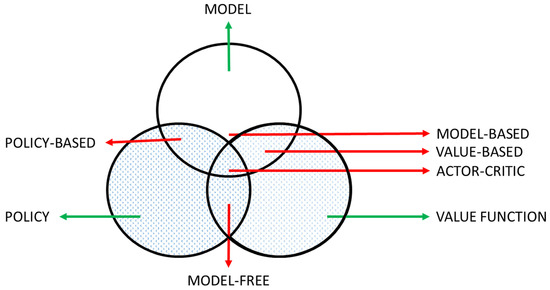
Figure 5.
RL agent’s taxonomy and its proper numbering (source: [134]).
Table 11 presents the most recurrently adopted RL methods. These range from simpler, discrete action-based algorithms, such as Q-learning [105], to advanced continuous-control models, like DDPG and SAC [84,85,106]. The selection of an RL algorithm often depends on the pump system’s complexity, data availability, and operational goals, as detailed below. The classification and references below serve as a guide for practitioners when selecting appropriate RL strategies for different types of pump systems.
Table 11.
Reinforcement learning methods.
- Research question 2: what are the deficiencies of these methods?
In accordance with the findings presented in Table 11, it is discernible that during the examined period, a preponderance of research papers incorporated the deep deterministic policy gradient (DDPG) method into their investigations. Intriguingly, despite the prevalent utilization of the DDPG technique, it is noteworthy that the deep Q-network (DQN) method emerged as the de facto approach of choice, enjoying the highest level of preference among researchers. This could be because DQNs use deep neural networks to compactly represent both high-dimensional observations and the Q-function (an advantage over the basic Q-learning method). It is also the cutting-edge policy RL method for problems involving continuous state space and discrete action space [104]. DQNs, however, suffer from slow convergence and overestimation due to their large action space. This resulted in the creation of a DDQN [117]. The objective behind a double DQN is to reduce overestimations by splitting the target’s maximum operation into action selection and action evaluation [135].
This invariably mitigates poor DQN learning. By performing backward propagation on a single neural network, a double DQN eliminates the concept of a “dog chasing its tail”. The double DQN approach is new in the field of pump application, as seen in Table 11, and its utility and limitations are still being researched.
The fundamental justification for using an RL algorithm in pump scheduling/maintenance, according to [109], is the necessity to achieve an effective decision-making process under uncertainty. The autoencoder was employed in conjunction with batch RL (fitted Q-iteration) to investigate this. The justification for using batch RL in [109] and some of the peer-reviewed articles [114,116] is that it does not take many iterations until convergence to produce good policies because it tends to quickly learn from a fixed batch of data samples previously collected from the system. This is because it remembers and utilizes previous observations, allowing it to learn in less time [136,137,138]. The autoencoder is an artificial neural network that outputs the expected action from the input of the environmental state. Its goal is to operate as a feature extraction tool. The inability of an FQI to explore alternative policies not incorporated into its history, as well as the fact that the model’s quality is strongly dependent on the data quality, are two of its key flaws [139]. Both PPO and DDPG are policy-based techniques. The PPO approach computes an update that minimizes the objective function while keeping a relatively modest departure from the prior policy to strike a compromise between the ease of implementation, sample complexity, and the ease of tuning [140]. By performing numerous mini-batch modifications, PPO can avoid making insignificant policy updates. However, PPO could be computationally expensive and is prone to exploration inefficiency. To increase the effectiveness of the agent, the DDPG algorithm can be used in conjunction with distributed exploration, imitation learning, and curriculum learning [86]. The use of DDPG as a multi-objective optimum MIMO controller, which may accomplish various levels of optimal control under the objective functions, is another benefit. The DDPG does, however, have the disadvantage of having a low capacity for training exploration and a weak control method.
The benefits of the value-based and policy-based approaches are combined in the SAC algorithm. The extension may work well as a predictive tool for pumps given the nature of the actor–critic arrangement. However, because of the strong correlation between the actor and critic networks, SACs sometimes struggle to converge. Since SACs frequently use neural networks for both policy updates and regression analyses, extensive training datasets are frequently required.
In the dueling DQN, there is a non-sequential architecture where the network layers branch into two different subnetworks called the estimate and advantage networks [141]. By this separation, the dueling architecture can learn which states are not valuable, without having to learn the effect of each action state. This helps to keep the training process stable and efficient. However, there is a disadvantage of poor performance because it is not easy to recover the split estimate and advantage networks back to the Q value.
Since BC, TL, and PL are relatively recent techniques (see Table 11), they benefit from the presence of trained or expert controllers and do not require a lot of data. By extrapolating from the expert policy’s behaviors, they learn policies from observations [142]. This helps shorten the duration of the training. The self-learning of optimal policies that have been trained under a generic circumstance can be significantly aided by TL and is easily transferable to various real-world scenarios. BC is typically used when generating training data are expensive or when using an expert controller is impracticable. An example is found in applications to mimic human drivers for autonomous driving purposes [143]. Very few works that use these techniques for pumps are available at the time of this review, therefore, one cannot ascertain the degree of their disadvantages. The novelty of these methodologies has been established, and researchers are encouraged to pursue their investigation. The degree of similarity between the expert controller and the trainee agent is a prevalent problem. Knowing this will make it easier to avoid unnecessary training.
- Research question 3: what are the challenges faced in using reinforcement learning as related to pumps?
The initial expense of installing the algorithm, which is tied to the requirement of faster and more efficient CPUs to run the hardware, is a challenge with RL deployment. This can be minimized by using transfer learning, which seeks to reduce computing costs [144]. In recent publications, there has been a movement toward the use of transfer learning [87].
To learn efficient policies for applications, reinforcement algorithms require a huge amount of data. To obtain this data, computer simulations using known distributions could be used. The topic of how RL can develop a suitable policy with few samples arises when there are sufficient but many irrelevant data samples. This is known as the sample efficiency problem [145]. Examples of solutions include expert demonstrations—in which an expert offers samples with high reward values to the RL algorithm—and the capacity to extract information more effectively from the available data. By scanning through irrelevant data, these solutions tend to avoid the learning algorithm’s ineffectiveness.
The balance between the exploration and the exploitation used in algorithm iterations is another issue of RL deployment. Exploitation describes utilizing known knowledge to maximize reward, whereas exploration denotes acquiring more information about the environment through iterations. There are numerous approaches for dealing with this tradeoff problem, including E-greedy, optimistic initialization, upper confidence bounds, and Thompson sampling. Researchers have looked into notions like imitation learning [146], intrinsic reward/motivation [147], and hierarchy learning to overcome the problem of exploration [148].
We also have the problem of estimating the hyperparameters being used in the models. Most works fix values for the hyperparameters according to the author’s experience [102], which brings about a bias in the iterations. It is suggested that researchers can look towards the design of frameworks that optimize the hyperparameters before they are incorporated into the learning algorithm.
- Research question 4: What are the challenges and possible solutions involved in optimizing the energy consumption of pumps using RL techniques?
This question is necessary because, as earlier stated, HVAC systems, of which pumps are a subset, are special cases where the energy consumption can be impacted, especially when used in industries and buildings.
To provide customer satisfaction and reduce energy usage, RL algorithms have been used as controllers for heat pumps in both residential and commercial buildings [2]. These algorithms have also been used for intelligent home energy management systems [149]. RL controllers gradually adjust their behavior to the unique characteristics of the environment in which they are utilized [150,151]. A benefit of adopting RL in a building is the ability to adapt to changes in environmental parameters as a result of equipment replacement or ageing. Even with these benefits, certain noticeable issues arise, such as the controller’s ability to conduct random actions for a short period, which may result in higher energy consumption during that time. The requirement to train the controller before installation using a zero-exploration value is one such option. Although this results in a longer training time, in the long term, this will result in optimal energy consumption. Another solution to this problem could be based on the work of Kou et al. [152], in which a trained RL agent was prohibited from interfering with a real-world environment’s operation.
The demand response, which is offered by HVAC systems, is a significant area in enhancing demand flexibility by providing consumers with economic incentives, hence optimizing energy usage in buildings [114,116,153].
The use of reinforcement learning (RL) in the demand response (DR) helps to automate energy systems while learning from human behavior to reduce user discomfort and the amount of human–controller interaction. Because DR systems require human feedback to accurately simulate the RL’s reward function, more research is needed to develop models that imitate human activity or to deploy RL in a real-world setting where occupants can provide feedback to help the RL agent to follow the best policies [154].
Most articles studied single-agent systems by assuming that electricity prices are independent of energy demand, according to our findings. In most real-life situations, this assumption is insufficient. To remedy this problem, a multi-agent RL can be used. For example, in [155], a multi-agent RL was utilized to meet the goal of lowering the power usage in an electricity system where electricity prices are determined by demand. More research in this area is possible.
- Research question 5: what are the future trends in the application of reinforcement learning to pumps?
According to [156], the new predictive maintenance strategy makes use of modern tools, such as Internet of Things (IoT) sensors, which can collect vast amounts of data on which to conduct research using RL and predictive analytic tools. According to [157], the Industrial Internet of Things (IIOT) is based on the idea that intelligent machines are superior to humans in terms of data collection and communication accuracy and consistency, thus enabling services for predictive maintenance. Because of the widespread availability of IIoT devices and applications, as well as sophisticated analytical tools and the introduction of AI and RL technologies, it is now possible to integrate many types of sensors into industrial pumps and to network multiples of these pumps in the industry. This will enable the development of multi-agent networks that can cater for the stream of connected pumps.
TL, DQN, and double DQN were used in several recent works [70,87,107]. In its updating rules, the DQN is known to have an overestimation problem using the max operator [145]. This explains why the double DQN, which includes an additional Q-network, is becoming more popular. Although DQNs are known to be effective where action spaces are discrete, action spaces for pumps in the real-world tend to be continuous; recent works are considering this [110,117]. So many rules need to be taken into consideration for an RL agent to be effective. Reducing the rules will enable a slow convergence time for the algorithm. This is a trend in the application of RL, as seen in the work of [71].
There is also a trend toward the hybrid of physical and engineering knowledge with RL modeling; this is observed in knowledge-assisted RL, as seen in the work of [107]. This approach will synergize the advantages of a model-based technique with a model-free RL technique.
A fascinating trend may also be noticed in the oil and gas industry, which uses pumps in its operations. Industry 4.0 is now being implemented in the oil and gas industry, with the prospect of the automatic maintenance of predictive AI models [158], which will improve the ability to solve complicated pump maintenance tasks.
Ultimately, the pioneering research presented in [17,60] has led to a novel paradigm within the realm of deep reinforcement learning (DRL)—the development of a “weighted model”. This innovative framework capitalizes on an ensemble of base learners, which encompass diverse neural network architectures, such as multilayer Perceptron (MLPs), convolutional neural networks (CNNs), long short-term memory (LSTM) networks, and other related methods. The primary function of the DRL algorithm lies in amalgamating these base learners into a cohesive, weighted model. Within this orchestrated system, each base learner’s output is harmoniously synthesized, with distinct weight assignments attributed to each, thereby facilitating markedly improved predictive outcomes. Empirical evidence underscores the enhanced efficacy of this weighted output when compared to the individual methodologies employed.
6. Conclusions
This paper presented a comprehensive systematic literature review on the application of reinforcement learning to pumps between the years 2013 and 2025. We have successfully performed a bibliometric analysis and a content analysis on peer-reviewed journals from Scopus, intending to identify the methods, challenges, and impacts of reducing the energy consumption of HVAC systems; the advancement of RL applied in fault diagnosis in pumping systems; and the prospects in this emerging field of research.
Over the past decade, there has been a surge in research applying reinforcement learning (RL) to pump systems, particularly in the context of heating, ventilation, and air conditioning (HVAC) systems that consume a significant portion of the industry’s energy. Researchers have explored various RL algorithms to optimize pump control, reduce energy consumption, and address scheduling challenges. Studies have demonstrated the effectiveness of RL in scenarios ranging from water distribution networks to stormwater management and even in non-human-operated settings, such as surveillance activities and health applications.
Early research introduced adaptive RL agents for heat pump thermostat control and geothermal control pumps. Some pioneering work extended RL to the medical field for blood glucose control using insulin pumps. Efforts were made to improve energy efficiency in heat pumps, and batch RL techniques, such as fitted Q-iteration (FQI), gained prominence. Subsequent studies showcased the versatility of RL in optimizing various pump systems, including wastewater variable frequency pumps and the real-time control of stormwater systems.
In the years leading up to 2025, RL research has evolved, focusing on optimizing RL algorithms for pump control. Recent developments have introduced ensemble-based fault diagnosis models, “rainbow” DQN algorithms, and multi-agent RL approaches. These advances aim to reduce electricity costs, improve comprehensive rewards, and tackle challenges in water demand scheduling. The field of RL continues to expand its applications and enhance its effectiveness in addressing energy efficiency, control, and optimization in pump systems.
In the light of our review, we, therefore, make the following key recommendations:
- Despite the promise of reinforcement learning (RL) techniques, their application has primarily been limited to theoretical or simulated environments. A significant hurdle to industrial adoption is the lack of readily deployable software solutions. Deploying RL models through user-friendly software could significantly incentivize real-world implementation. Imagine a one-click solution that tackles complex control problems without requiring specialized expertise in RL algorithms. Such an interface would significantly reduce the barrier to entry for industries seeking to leverage the power of RL for pump optimization.
- Most RL control systems are usually designed with a single variable input for the state environment; therefore, the extension of the environment to include more features as covariates will produce a more robust RL model that makes a more informed control decision.
- To optimize the functionality of an RL agent in reducing energy consumption, we suggest further research into the deployment of multi-agent RLs to cater for the case in which the energy price is dependent on its demand, because multi-agents learn policies more effectively. They also overcome the curse of dimensionality.
- RL algorithms require large datasets; research breakthroughs will be of value if more work is carried out by harnessing the merits of using BC, TL, and PL agents that use less data and still achieve a high performance with less training time.
Author Contributions
Conceptualization, A.A.A., U.A.S.G. and C.A.V.C.; methodology, A.A.A., U.A.S.G. and C.A.V.C.; software, A.A.A. and U.A.S.G.; validation, A.A.A., U.A.S.G. and C.A.V.C.; formal analysis, A.A.A., U.A.S.G. and C.A.V.C.; investigation, A.A.A., U.A.S.G. and C.A.V.C.; resources, C.A.V.C.; data curation, A.A.A. and U.A.S.G.; writing—original draft preparation, A.A.A., U.A.S.G. and C.A.V.C.; writing—review and editing, A.A.A., U.A.S.G. and C.A.V.C.; visualization, A.A.A. and U.A.S.G.; supervision, C.A.V.C.; project administration, C.A.V.C.; funding acquisition, C.A.V.C. All authors have read and agreed to the published version of the manuscript.
Funding
The work of Cristiano A.V. Cavalcante and Adetoye Ayokunle Aribisala has been supported by “CNPq (Conselho Nacional de Desenvolvimento Científico e Tecnológico)”. The work of Usama Ali Salahuddin Ghori has been supported by “Coordenação de Aperfeiçoamento de Pessoal de Nivel Superior, Brasil (CAPES)”—Finance code 001.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| Abbreviations | Full Term | Description |
| RL | reinforcement learning | A machine learning technique for decision-making via interaction with the environment. |
| DRL | deep reinforcement learning | The extension of RL using deep neural networks. |
| HVAC | heating, ventilation, and air conditioning | Systems related to thermal comfort and air quality in buildings. |
| DDPG | deep deterministic policy gradient | An RL algorithm for continuous action spaces. |
| DQN | deep Q-network | Model-free RL using deep learning for Q-value approximation. |
| PPO | proximal policy optimization | A policy optimization RL algorithm with stability improvements. |
| FQI | fitted Q-iteration | A batch-mode RL technique for policy learning using previously collected data. |
| SAC | soft actor–critic | An off-policy RL algorithm combining value and policy-based learning. |
| TL | transfer learning | A technique for leveraging a pre-trained model or policies. |
| PL | parallel learning | A method for speeding up training by concurrent agent learning. |
| BC | behavioral cloning | Learning policies by mimicking expert demonstrations. |
| MIMO | multi-input, multi-output | Control systems with multiple inputs and outputs. |
| MARL | multi-agent reinforcement learning | Multiple agents learn to make decisions through interaction with a shared environment and, often, with each other |
References
- Fu, Q.; Han, Z.; Chen, J.; Lu, Y.; Wu, H.; Wang, Y. Applications of reinforcement learning for building energy efficiency control: A review. J. Build. Eng. 2022, 50, 104165. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T. Reinforcement learning for building controls: The opportunities and challenges. Appl. Energy 2020, 269, 115036. [Google Scholar] [CrossRef]
- Kobbacy, K.A.H.; Vadera, S. A survey of AI in operations management from 2005 to 2009. J. Manuf. Technol. Manag. 2011, 22, 706–733. [Google Scholar] [CrossRef]
- Moharm, K. State of the art in big data applications in microgrid: A review. Adv. Eng. Inform. 2019, 42, 100945. [Google Scholar] [CrossRef]
- Tang, S.; Zhu, Y.; Yuan, S. An improved convolutional neural network with an adaptable learning rate towards multi-signal fault diagnosis of hydraulic piston pump. Adv. Eng. Inform. 2021, 50, 101406. [Google Scholar] [CrossRef]
- Ahmed, A.; Korres, N.E.; Ploennigs, J.; Elhadi, H.; Menzel, K. Mining building performance data for energy-efficient operation. Adv. Eng. Inform. 2011, 25, 341–354. [Google Scholar] [CrossRef]
- Singaravel, S.; Suykens, J.; Geyer, P. Deep convolutional learning for general early design stage prediction models. Adv. Eng. Inform. 2019, 42, 100982. [Google Scholar] [CrossRef]
- Tse, Y.L.; Cholette, M.E.; Tse, P.W. A multi-sensor approach to remaining useful life estimation for a slurry pump. Measurement 2019, 139, 140–151. [Google Scholar] [CrossRef]
- Guo, R.; Li, Y.; Zhao, L.; Zhao, J.; Gao, D. Remaining Useful Life Prediction Based on the Bayesian Regularized Radial Basis Function Neural Network for an External Gear Pump. IEEE Access 2020, 8, 107498–107509. [Google Scholar] [CrossRef]
- Kimera, D.; Nangolo, F.N. Predictive maintenance for ballast pumps on ship repair yards via machine learning. Transp. Eng. 2020, 2, 100020. [Google Scholar] [CrossRef]
- Azadeh, A.; Saberi, M.; Kazem, A.; Ebrahimipour, V.; Nourmohammadzadeh, A.; Saberi, Z. A flexible algorithm for fault diagnosis in a centrifugal pump with corrupted data and noise based on ANN and support vector machine with hyper-parameters optimization. Appl. Soft Comput. 2013, 13, 1478–1485. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Xie, M.; Wang, T.; Wang, R.; Wu, Z. A reinforcement ensemble deep transfer learning network for rolling bearing fault diagnosis with Multi-source domains. Adv. Eng. Inform. 2022, 51, 101480. [Google Scholar] [CrossRef]
- Wang, Z.; Xuan, J. Intelligent fault recognition framework by using deep reinforcement learning with one dimension convolution and improved actor-critic algorithm. Adv. Eng. Inform. 2021, 49, 101315. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, L.; Ma, J.; Suo, M.; Tao, L.; Cheng, Y.; Lu, C. Intelligent fault diagnosis for rotating machinery using deep Q-network based health state classification: A deep reinforcement learning approach. Adv. Eng. Inform. 2019, 42, 100977. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef]
- Han, G.; Joo, H.-J.; Lim, H.-W.; An, Y.-S.; Lee, W.-J.; Lee, K.-H. Data-driven heat pump operation strategy using rainbow deep reinforcement learning for significant reduction of electricity cost. Energy 2023, 270, 126913. [Google Scholar] [CrossRef]
- Bachseitz, M.; Sheryar, M.; Schmitt, D.; Summ, T.; Trinkl, C.; Zörner, W. PV-Optimized Heat Pump Control in Multi-Family Buildings Using a Reinforcement Learning Approach. Energies 2024, 17, 1908. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Y.; Gao, W. Comparative Analysis of Reinforcement Learning Approaches for Multi-Objective Optimization in Residential Hybrid Energy Systems. Buildings 2024, 14, 2645. [Google Scholar] [CrossRef]
- Fu, Q.; Chen, X.; Ma, S.; Fang, N.; Xing, B.; Chen, J. Optimal control method of HVAC based on multi-agent deep reinforcement learning. Energy Build. 2022, 270, 112284. [Google Scholar] [CrossRef]
- Wu, Q.; Zhu, D.; Liu, Y.; Du, A.; Chen, D.; Ye, Z. Comprehensive Control System for Gathering Pipe Network Operation Based on Reinforcement Learning. In Proceedings of the Proceedings of the 2018 VII International Conference on Network, Communication and Computing, Taipei, Taiwan, 14–16 December 2018; ACM: New York, NY, USA, 2018; pp. 34–39. [Google Scholar] [CrossRef]
- Kitchenham, B. Procedures for Performing Systematic Reviews, Version 1.0. Empir. Softw. Eng. 2004, 33, 1–26. [Google Scholar]
- Small, H. Co-citation in the scientific literature: A new measure of the relationship between two documents. J. Am. Soc. Inf. Sci. 1973, 24, 265–269. [Google Scholar] [CrossRef]
- Cancino, C.; Merigó, J.M.; Coronado, F.; Dessouky, Y.; Dessouky, M. Forty years of Computers & Industrial Engineering: A bibliometric analysis. Comput. Ind. Eng. 2017, 113, 614–629. [Google Scholar] [CrossRef]
- Börner, K.; Chen, C.; Boyack, K.W. Visualizing knowledge domains. Annu. Rev. Inf. Sci. Technol. 2003, 37, 179–255. [Google Scholar] [CrossRef]
- Wang, M.; Lin, B.; Yang, Z. Energy-Efficient HVAC Control based on Reinforcement Learning and Transfer Learning in a Residential Building. In Proceedings of the 2024 IEEE International Conference on Industrial Technology (ICIT), Bristol, UK, 25–27 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Ludolfinger, U.; Perić, V.S.; Hamacher, T.; Hauke, S.; Martens, M. Transformer Model Based Soft Actor-Critic Learning for HEMS. In Proceedings of the 2023 International Conference on Power System Technology (PowerCon), Jinan, China, 21–22 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Gan, T.; Jiang, Y.; Zhao, H.; He, J.; Duan, H. Research on low-energy consumption automatic real-time regulation of cascade gates and pumps in open-canal based on reinforcement learning. J. Hydroinformatics 2024, 26, 1673–1691. [Google Scholar] [CrossRef]
- Croll, H.C.; Ikuma, K.; Ong, S.K.; Sarkar, S. Systematic Performance Evaluation of Reinforcement Learning Algorithms Applied to Wastewater Treatment Control Optimization. Environ. Sci. Technol. 2023, 57, 18382–18390. [Google Scholar] [CrossRef] [PubMed]
- Kokhanovskiy, A.Y.; Kuprikov, E.; Serebrennikov, K.; Mkrtchyan, A.; Davletkhanov, A.; Gladush, Y. Manipulating the harmonic mode-locked regimes inside a fiber cavity by a reinforcement learning algorithm. In Quantum and Nonlinear Optics X; He, Q., Li, C.-F., Kim, D.-S., Eds.; SPIE: Beijing, China, 2023; p. 20. [Google Scholar] [CrossRef]
- Kaspar, K.; Nweye, K.; Buscemi, G.; Capozzoli, A.; Nagy, Z.; Pinto, G.; Eicker, U.; Ouf, M.M. Effects of occupant thermostat preferences and override behavior on residential demand response in CityLearn. Energy Build. 2024, 324, 114830. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Liu, B. Event-Based Deep Reinforcement Learning for Smoothing Ramp Events in Combined Wind-Storage Energy Systems. IEEE Trans. Ind. Inform. 2024, 20, 7871–7882. [Google Scholar] [CrossRef]
- Masdoua, Y.; Boukhnifer, M.; Adjallah, K.H. Fault Tolerant Control of HVAC System Based on Reinforcement Learning Approach. In Proceedings of the 2023 9th International Conference on Control, Decision and Information Technologies (CoDIT), Rome, Italy, 3–6 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 555–560. [Google Scholar] [CrossRef]
- Bex, L.; Peirelinck, T.; Deconinck, G. Seasonal Performance of Fitted Q-iteration for Space Heating and Cooling with Heat Pumps. In Proceedings of the 2023 IEEE PES Innovative Smart Grid Technologies Europe (ISGT EUROPE), Grenoble, France, 23–26 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Meyn, S.; Lu, F.; Mathias, J. Balancing the Power Grid with Cheap Assets. In Proceedings of the 2023 62nd IEEE Conference on Decision and Control (CDC), Singapore, 13–15 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4012–4017. [Google Scholar] [CrossRef]
- Zhang, C. Intelligent Optimization Algorithm Based on Reinforcement Learning in the Process of Wax Removal and Prevention of Screw Pump. In Proceedings of the 2024 International Conference on Telecommunications and Power Electronics (TELEPE), Frankfurt, Germany, 29–31 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 15–20. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X.; Zhang, H.; Ma, Y.; Chen, S.; Wang, C.; Chen, Q.; Xiao, X. Hybrid model-free control based on deep reinforcement learning: An energy-efficient operation strategy for HVAC systems. J. Build. Eng. 2024, 96, 110410. [Google Scholar] [CrossRef]
- Schmitz, S.; Brucke, K.; Kasturi, P.; Ansari, E.; Klement, P. Forecast-based and data-driven reinforcement learning for residential heat pump operation. Appl. Energy 2024, 371, 123688. [Google Scholar] [CrossRef]
- Cai, W.; Sawant, S.; Reinhardt, D.; Rastegarpour, S.; Gros, S. A Learning-Based Model Predictive Control Strategy for Home Energy Management Systems. IEEE Access 2023, 11, 145264–145280. [Google Scholar] [CrossRef]
- Li, Z.; Bai, L.; Tian, W.; Yan, H.; Hu, W.; Xin, K.; Tao, T. Online Control of the Raw Water System of a High-Sediment River Based on Deep Reinforcement Learning. Water 2023, 15, 1131. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, W.; Cao, H.; He, Q.; Liu, Y. Antagonistic Pump with Multiple Pumping Modes for On-Demand Soft Robot Actuation and Control. IEEEASME Trans. Mechatron. 2024, 29, 3252–3264. [Google Scholar] [CrossRef]
- Tubeuf, C.; Birkelbach, F.; Maly, A.; Hofmann, R. Increasing the Flexibility of Hydropower with Reinforcement Learning on a Digital Twin Platform. Energies 2023, 16, 1796. [Google Scholar] [CrossRef]
- Joo, J.-G.; Jeong, I.-S.; Kang, S.-H. Deep Reinforcement Learning for Multi-Objective Real-Time Pump Operation in Rainwater Pumping Stations. Water 2024, 16, 3398. [Google Scholar] [CrossRef]
- Ludolfinger, U.; Zinsmeister, D.; Perić, V.S.; Hamacher, T.; Hauke, S.; Martens, M. Recurrent Soft Actor Critic Reinforcement Learning for Demand Response Problems. In Proceedings of the 2023 IEEE Belgrade PowerTech, Belgrade, Serbia, 25–29 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Kar, I.; Mukhopadhyay, S.; Chatterjee, A.S. Application of Deep Reinforcement Learning to an extreme contextual and collective rare event with multivariate unsupervised reward generator for detecting leaks in large-scale water pipelines. In Proceedings of the 2023 Fifth International Conference on Electrical, Computer and Communication Technologies (ICECCT), Erode, India, 22–24 February 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Zhao, H.; Pan, S.; Ma, L.; Wu, Y.; Guo, X.; Liu, J. Research on joint control of water pump and radiator of PEMFC based on TCO-DDPG. Int. J. Hydrogen Energy 2023, 48, 38569–38583. [Google Scholar] [CrossRef]
- Moreira, T.M.; De Faria, J.G.; Vaz-de-Melo, P.O.S.; Medeiros-Ribeiro, G. Development and validation of an AI-Driven model for the La Rance tidal barrage: A generalisable case study. Appl. Energy 2023, 332, 120506. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Zhou, G.; Guo, X.; Lu, J.; Shu, X. Discontinuous Rod Spanning Motion Control for Snake Robot based on Reinforcement Learning. In Proceedings of the 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 24–26 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 4437–4442. [Google Scholar] [CrossRef]
- Wu, G.; Yang, Y.; An, W. Multi-scenario operation optimization of electric-thermal coupling renewable energy system based on deep reinforcement learning. In Proceedings of the Ninth International Conference on Energy Materials and Electrical Engineering (ICEMEE 2023), Guilin, China, 6 February 2024; Zhou, J., Aris, I.B., Eds.; SPIE: Bellingham, WA, USA, 2024; p. 4. [Google Scholar] [CrossRef]
- Tubeuf, C.; Aus Der Schmitten, J.; Hofmann, R.; Heitzinger, C.; Birkelbach, F. Improving Control of Energy Systems With Reinforcement Learning: Application to a Reversible Pump Turbine. In Proceedings of the ASME 2024 18th International Conference on Energy Sustainability, Anaheim, CA, USA, 15–17 July 2024; American Society of Mechanical Engineers: New York, NY, USA, 2024; p. V001T01A001. [Google Scholar] [CrossRef]
- Ma, H.; Wang, X.; Wang, D. Pump Scheduling Optimization in Urban Water Supply Stations: A Physics-Informed Multiagent Deep Reinforcement Learning Approach. Int. J. Energy Res. 2024, 2024, 9557596. [Google Scholar] [CrossRef]
- Klingebiel, J.; Salamon, M.; Bogdanov, P.; Venzik, V.; Vering, C.; Müller, D. Towards maximum efficiency in heat pump operation: Self-optimizing defrost initiation control using deep reinforcement learning. Energy Build. 2023, 297, 113397. [Google Scholar] [CrossRef]
- Li, J.; Zhou, T. Active fault-tolerant coordination energy management for a proton exchange membrane fuel cell using curriculum-based multiagent deep meta-reinforcement learning. Renew. Sustain. Energy Rev. 2023, 185, 113581. [Google Scholar] [CrossRef]
- Song, R.; Zinsmeister, D.; Hamacher, T.; Zhao, H.; Terzija, V.; Peric, V. Adaptive Control of Practical Heat Pump Systems for Power System Flexibility Based on Reinforcement Learning. In Proceedings of the 2023 International Conference on Power System Technology (PowerCon), Jinan, China, 21–22 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Tang, Z.; Chai, B.; Li, J.; Wang, Y.; Liu, S.; Shi, X. Research on Capacity Configuration Optimization of Multi-Energy Complementary System Using Deep Reinforce Learning. In Proceedings of the 2023 13th International Conference on Power and Energy Systems (ICPES), Chengdu, China, 8–10 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 213–218. [Google Scholar] [CrossRef]
- Qin, H.; Yu, Z.; Li, T.; Liu, X.; Li, L. Energy-efficient heating control for nearly zero energy residential buildings with deep reinforcement learning. Energy 2023, 264, 126209. [Google Scholar] [CrossRef]
- Athanasiadis, C.L.; Pippi, K.D.; Papadopoulos, T.A.; Korkas, C.; Tsaknakis, C.; Alexopoulou, V.; Nikolaidis, V.; Kosmatopoulos, E. Energy Management for Building-Integrated Microgrids Using Reinforcement Learning. In Proceedings of the 2023 58th International Universities Power Engineering Conference (UPEC), Dublin, Ireland, 30 August–1 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Kokhanovskiy, A.; Kuprikov, E.; Serebrennikov, K.; Mkrtchyan, A.; Davletkhanov, A.; Bunkov, A.; Krasnikov, D.; Shashkov, M.; Nasibulin, A.; Gladush, Y. Multistability manipulation by reinforcement learning algorithm inside mode-locked fiber laser. Nanophotonics 2024, 13, 2891–2901. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Zheng, W.; Wang, Z.; Wang, Y.; Pang, X.; Wang, W. Comparison of reinforcement learning and model predictive control for building energy system optimization. Appl. Therm. Eng. 2023, 228, 120430. [Google Scholar] [CrossRef]
- Zhou, S.; Qin, L.; Yang, Y.; Wei, Z.; Wang, J.; Wang, J.; Ruan, J.; Tang, X.; Wang, X.; Liu, K. A Novel Ensemble Fault Diagnosis Model for Main Circulation Pumps of Converter Valves in VSC-HVDC Transmission Systems. Sensors 2023, 23, 5082. [Google Scholar] [CrossRef]
- Hu, S.; Gao, J.; Zhong, D.; Wu, R.; Liu, L. Real-Time Scheduling of Pumps in Water Distribution Systems Based on Exploration-Enhanced Deep Reinforcement Learning. Systems 2023, 11, 56. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, W.; Liao, Z. Towards coordinated and robust real-time control: A decentralized approach for combined sewer overflow and urban flooding reduction based on multi-agent reinforcement learning. Water Res. 2023, 229, 119498. [Google Scholar] [CrossRef]
- Xiong, Z.; Chen, F.; Guo, H.; Ren, X.; Zhang, J.; Wang, B. Multi-objective combined dispatching optimization of pumped storage and thermal power. J. Phys. Conf. Ser. 2023, 2503, 012004. [Google Scholar] [CrossRef]
- Zaman, M.; Tantawy, A.; Abdelwahed, S. Optimizing Smart City Water Distribution Systems Using Deep Reinforcement Learning. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 228–233. [Google Scholar] [CrossRef]
- He, L.; Xin, Y.; Zhang, Y.; Li, P.; Yang, Y. Study on Waste Heat Recovery of Fuel-Cell Thermal Management System Based on Reinforcement Learning. Energy Technol. 2024, 12, 2400438. [Google Scholar] [CrossRef]
- Hu, S.; Gao, J.; Zhong, D. Multi-agent reinforcement learning framework for real-time scheduling of pump and valve in water distribution networks. Water Supply 2023, 23, 2833–2846. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, X.; Fu, Q.; Chen, J.; Wang, Y.; Lu, Y.; Liu, L. Priori knowledge-based deep reinforcement learning control for fan coil unit system. J. Build. Eng. 2024, 82, 108157. [Google Scholar] [CrossRef]
- Emamjomehzadeh, O.; Kerachian, R.; Emami-Skardi, M.J.; Momeni, M. Combining urban metabolism and reinforcement learning concepts for sustainable water resources management: A nexus approach. J. Environ. Manag. 2023, 329, 117046. [Google Scholar] [CrossRef]
- Chen, M.; Xie, Z.; Sun, Y.; Zheng, S. The predictive management in campus heating system based on deep reinforcement learning and probabilistic heat demands forecasting. Appl. Energy 2023, 350, 121710. [Google Scholar] [CrossRef]
- Huang, Q.; Hu, W.; Zhang, G.; Cao, D.; Liu, Z.; Huang, Q.; Chen, Z. A novel deep reinforcement learning enabled agent for pumped storage hydro-wind-solar systems voltage control. IET Renew. Power Gener. 2021, 15, 3941–3956. [Google Scholar] [CrossRef]
- Wu, T.; Zhao, H.; Gao, B.; Meng, F. Energy-Saving for a Velocity Control System of a Pipe Isolation Tool Based on a Reinforcement Learning Method. Int. J. Precis. Eng. Manuf.-Green Technol. 2022, 9, 225–240. [Google Scholar] [CrossRef]
- Christensen, M.H.; Ernewein, C.; Pinson, P. Demand Response through Price-setting Multi-agent Reinforcement Learning. In Proceedings of the 1st International Workshop on Reinforcement Learning for Energy Management in Buildings & Cities, Virtual Event, 17 November 2020; ACM: New York, NY, USA, 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Lee, Z.E.; Zhang, K.M. Generalized reinforcement learning for building control using Behavioral Cloning. Appl. Energy 2021, 304, 117602. [Google Scholar] [CrossRef]
- Zhu, J.; Elbel, S. Implementation of Reinforcement Learning on Air Source Heat Pump Defrost Control for Full Electric Vehicles. In Proceedings of the WCX World Congress Experience, Detroit, MI, USA, 14–16 April 2018; 2018-01-1193. pp. 1–7. [Google Scholar] [CrossRef]
- Saliba, S.M.; Bowes, B.D.; Adams, S.; Beling, P.A.; Goodall, J.L. Deep Reinforcement Learning with Uncertain Data for Real-Time Stormwater System Control and Flood Mitigation. Water 2020, 12, 3222. [Google Scholar] [CrossRef]
- Soares, A.; Geysen, D.; Spiessens, F.; Ectors, D.; De Somer, O.; Vanthournout, K. Using reinforcement learning for maximizing residential self-consumption—Results from a field test. Energy Build. 2020, 207, 109608. [Google Scholar] [CrossRef]
- Chong, J.; Kelly, D.; Agrawal, S.; Nguyen, N.; Monzon, M. Reinforcement Learning Control Scheme for Electrical Submersible Pumps. In Proceedings of the SPE Gulf Coast Section Electric Submersible Pumps Symposium, Virtual and The Woodlands, TX, USA, 5 October 2021; SPE: Richardson, TX, USA, 2021; p. D021S001R002. [Google Scholar] [CrossRef]
- Vazquez-Canteli, J.R.; Henze, G.; Nagy, Z. MARLISA: Multi-Agent Reinforcement Learning with Iterative Sequential Action Selection for Load Shaping of Grid-Interactive Connected Buildings. In Proceedings of the 7th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, Virtual Event. Japan, 18–20 November 2020; ACM: New York, NY, USA, 2020; pp. 170–179. [Google Scholar] [CrossRef]
- Ghane, S.; Jacobs, S.; Casteels, W.; Brembilla, C.; Mercelis, S.; Latre, S.; Verhaert, I.; Hellinckx, P. Supply temperature control of a heating network with reinforcement learning. In Proceedings of the 2021 IEEE International Smart Cities Conference (ISC2), Manchester, UK, 7–10 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Mullapudi, A.; Lewis, M.J.; Gruden, C.L.; Kerkez, B. Deep reinforcement learning for the real time control of stormwater systems. Adv. Water Resour. 2020, 140, 103600. [Google Scholar] [CrossRef]
- Filipe, J.; Bessa, R.J.; Reis, M.; Alves, R.; Póvoa, P. Data-driven predictive energy optimization in a wastewater pumping station. Appl. Energy 2019, 252, 113423. [Google Scholar] [CrossRef]
- Blad, C.; Bøgh, S.; Kallesøe, C. A Multi-Agent Reinforcement Learning Approach to Price and Comfort Optimization in HVAC-Systems. Energies 2021, 14, 7491. [Google Scholar] [CrossRef]
- He, Y.; Liu, P.; Zhou, L.; Zhang, Y.; Liu, Y. Competitive model of pumped storage power plants participating in electricity spot Market—In case of China. Renew. Energy 2021, 173, 164–176. [Google Scholar] [CrossRef]
- Liu, T.; Xu, C.; Guo, Y.; Chen, H. A novel deep reinforcement learning based methodology for short-term HVAC system energy consumption prediction. Int. J. Refrig. 2019, 107, 39–51. [Google Scholar] [CrossRef]
- Pinto, G.; Deltetto, D.; Capozzoli, A. Data-driven district energy management with surrogate models and deep reinforcement learning. Appl. Energy 2021, 304, 117642. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Yu, T. Distributed deep reinforcement learning-based multi-objective integrated heat management method for water-cooling proton exchange membrane fuel cell. Case Stud. Therm. Eng. 2021, 27, 101284. [Google Scholar] [CrossRef]
- Lissa, P.; Schukat, M.; Keane, M.; Barrett, E. Transfer learning applied to DRL-Based heat pump control to leverage microgrid energy efficiency. Smart Energy 2021, 3, 100044. [Google Scholar] [CrossRef]
- Mbuwir, B.V.; Spiessens, F.; Deconinck, G. Benchmarking regression methods for function approximation in reinforcement learning: Heat pump control. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), Bucharest, Romania, 29 September–2 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Q.; Wang, T. A Two-stage Optimal Controller For Hydraulic Loading System with Mechanical Compensation. In Proceedings of the 2019 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Bangkok, Thailand, 18–20 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 304–309. [Google Scholar] [CrossRef]
- Patyn, C.; Ruelens, F.; Deconinck, G. Comparing neural architectures for demand response through model-free reinforcement learning for heat pump control. In Proceedings of the 2018 IEEE International Energy Conference (ENERGYCON), Limassol, Cyprus, 3–7 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Cho, S.; Park, C.S. Rule reduction for control of a building cooling system using explainable AI. J. Build. Perform. Simul. 2022, 15, 832–847. [Google Scholar] [CrossRef]
- Ding, H.; Xu, Y.; Chew Si Hao, B.; Li, Q.; Lentzakis, A. A safe reinforcement learning approach for multi-energy management of smart home. Electr. Power Syst. Res. 2022, 210, 108120. [Google Scholar] [CrossRef]
- Mbuwir, B.V.; Geysen, D.; Spiessens, F.; Deconinck, G. Reinforcement learning for control of flexibility providers in a residential microgrid. IET Smart Grid 2020, 3, 98–107. [Google Scholar] [CrossRef]
- Ahn, K.U.; Park, C.S. Application of deep Q-networks for model-free optimal control balancing between different HVAC systems. Sci. Technol. Built Environ. 2020, 26, 61–74. [Google Scholar] [CrossRef]
- Abe, T.; Oh-hara, S.; Ukita, Y. Adoption of reinforcement learning for the intelligent control of a microfluidic peristaltic pump. Biomicrofluidics 2021, 15, 034101. [Google Scholar] [CrossRef]
- Abe, T.; Oh-hara, S.; Ukita, Y. Integration of reinforcement learning to realize functional variability of microfluidic systems. Biomicrofluidics 2022, 16, 024106. [Google Scholar] [CrossRef]
- Seo, G.; Yoon, S.; Kim, M.; Mun, C.; Hwang, E. Deep Reinforcement Learning-Based Smart Joint Control Scheme for On/Off Pumping Systems in Wastewater Treatment Plants. IEEE Access 2021, 9, 95360–95371. [Google Scholar] [CrossRef]
- Langer, L.; Volling, T. A reinforcement learning approach to home energy management for modulating heat pumps and photovoltaic systems. Appl. Energy 2022, 327, 120020. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Yu, T. An optimal coordinated proton exchange membrane fuel cell heat management method based on large-scale multi-agent deep reinforcement learning. Energy Rep. 2021, 7, 6054–6068. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Q. Energy Saving Algorithm of HVAC System Based on Deep Reinforcement Learning with Modelica Model. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 5277–5282. [Google Scholar] [CrossRef]
- Mbuwir, B.V.; Manna, C.; Spiessens, F.; Deconinck, G. Benchmarking reinforcement learning algorithms for demand response applications. In Proceedings of the 2020 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), The Hague, The Netherlands, 26–28 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 289–293. [Google Scholar] [CrossRef]
- Hajgató, G.; Paál, G.; Gyires-Tóth, B. Deep Reinforcement Learning for Real-Time Optimization of Pumps in Water Distribution Systems. J. Water Resour. Plan. Manag. 2020, 146, 04020079. [Google Scholar] [CrossRef]
- Blad, C.; Bøgh, S.; Kallesøe, C.S. Data-driven Offline Reinforcement Learning for HVAC-systems. Energy 2022, 261, 125290. [Google Scholar] [CrossRef]
- Shao, Z.; Si, F.; Kudenko, D.; Wang, P.; Tong, X. Predictive scheduling of wet flue gas desulfurization system based on reinforcement learning. Comput. Chem. Eng. 2020, 141, 107000. [Google Scholar] [CrossRef]
- Qiu, S.; Li, Z.; Li, Z.; Li, J.; Long, S.; Li, X. Model-free control method based on reinforcement learning for building cooling water systems: Validation by measured data-based simulation. Energy Build. 2020, 218, 110055. [Google Scholar] [CrossRef]
- Anderson, E.R.; Steward, B.L. Reinforcement Learning for Active Noise Control in a Hydraulic System. J. Dyn. Syst. Meas. Control 2021, 143, 061006. [Google Scholar] [CrossRef]
- Xu, J.; Wang, H.; Rao, J.; Wang, J. Zone scheduling optimization of pumps in water distribution networks with deep reinforcement learning and knowledge-assisted learning. Soft Comput. 2021, 25, 14757–14767. [Google Scholar] [CrossRef]
- Campoverde, L.M.S.; Tropea, M.; De Rango, F. An IoT based Smart Irrigation Management System using Reinforcement Learning modeled through a Markov Decision Process. In Proceedings of the 2021 IEEE/ACM 25th International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Valencia, Spain, 27–29 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Ruelens, F.; Iacovella, S.; Claessens, B.; Belmans, R. Learning Agent for a Heat-Pump Thermostat with a Set-Back Strategy Using Model-Free Reinforcement Learning. Energies 2015, 8, 8300–8318. [Google Scholar] [CrossRef]
- John, D.; Kaltschmitt, M. Control of a PVT-Heat-Pump-System Based on Reinforcement Learning–Operating Cost Reduction through Flow Rate Variation. Energies 2022, 15, 2607. [Google Scholar] [CrossRef]
- Oroojeni Mohammad Javad, M.; Agboola, S.; Jethwani, K.; Zeid, I.; Kamarthi, S. Reinforcement Learning Algorithm for Blood Glucose Control in Diabetic Patients. In Proceedings of the Volume 14: Emerging Technologies; Safety Engineering and Risk Analysis; Materials: Genetics to Structures, Houston, TX, USA, 13–19 November 2015; American Society of Mechanical Engineers: New York, NY, USA, 2015; p. V014T06A009. [Google Scholar] [CrossRef]
- Yang, L.; Nagy, Z.; Goffin, P.; Schlueter, A. Reinforcement learning for optimal control of low exergy buildings. Appl. Energy 2015, 156, 577–586. [Google Scholar] [CrossRef]
- Ruelens, F.; Claessens, B.J.; Vandael, S.; De Schutter, B.; Babuska, R.; Belmans, R. Residential Demand Response of Thermostatically Controlled Loads Using Batch Reinforcement Learning. IEEE Trans. Smart Grid 2017, 8, 2149–2159. [Google Scholar] [CrossRef]
- Vázquez-Canteli, J.; Kämpf, J.; Nagy, Z. Balancing comfort and energy consumption of a heat pump using batch reinforcement learning with fitted Q-iteration. Energy Procedia 2017, 122, 415–420. [Google Scholar] [CrossRef]
- Kazmi, H.; D’Oca, S. Demonstrating model-based reinforcement learning for energy efficiency and demand response using hot water vessels in net-zero energy buildings. In Proceedings of the 2016 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Ljubljana, Slovenia, 9–12 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Peirelinck, T.; Ruelens, F.; Deconinck, G. Using reinforcement learning for optimizing heat pump control in a building model in Modelica. In Proceedings of the 2018 IEEE International Energy Conference (ENERGYCON), Limassol, Cyprus, 3–7 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Heidari, A.; Marechal, F.; Khovalyg, D. An adaptive control framework based on Reinforcement learning to balance energy, comfort and hygiene in heat pump water heating systems. J. Phys. Conf. Ser. 2021, 2042, 012006. [Google Scholar] [CrossRef]
- Urieli, D.; Stone, P. A learning agent for heat-pump thermostat control. In Proceedings of the 12th International Conference on Autonomous Agents and Multiagent Systems, Saint Paul, MN, USA, 6–10 May 2013; pp. 1093–1100. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-84899440153&partnerID=40&md5=42dc765943588e8b391dce1c4a79b654 (accessed on 1 June 2024).
- Wang, C.; Bowes, B.; Tavakoli, A.; Adams, S.; Goodall, J.; Beling, P. Smart stormwater control systems: A reinforcement learning approach. In Proceedings of the 17th International Conference on Information Systems for Crisis Response and Management (ISCRAM 2020), Blacksburg, VA, USA, 11 May 2020; Hughes, A.L., McNeill, F., Zobel, C.W., Eds.; pp. 2–13. Available online: https://www.researchgate.net/profile/Cheng-Wang-109/publication/343426754_Smart_Stormwater_Control_Systems_A_Reinforcement_Learning_Approach/links/645d0691f43b8a29ba44dfad/Smart-Stormwater-Control-Systems-A-Reinforcement-Learning-Approach.pdf (accessed on 1 May 2023).
- Da Silva, L.B.L.; Alencar, M.H.; De Almeida, A.T. Multidimensional flood risk management under climate changes: Bibliometric analysis, trends and strategic guidelines for decision-making in urban dynamics. Int. J. Disaster Risk Reduct. 2020, 50, 101865. [Google Scholar] [CrossRef]
- Beaver, D. Reflections on scientific collaboration (and its study): Past, present, and future. Scientometrics 2001, 52, 365–377. [Google Scholar] [CrossRef]
- Laudel, G. Collaboration and reward. Res. Eval. 2002, 11, 3–15. [Google Scholar] [CrossRef]
- Fonseca, B.D.P.F.E.; Sampaio, R.B.; Fonseca, M.V.D.A.; Zicker, F. Co-authorship network analysis in health research: Method and potential use. Health Res. Policy Syst. 2016, 14, 34. [Google Scholar] [CrossRef]
- van Eck, N.J.; Waltman, L. VOSviewer Manual; Univeristeit Leiden: Leiden, The Netherlands, 2013. [Google Scholar]
- Ferreira, F.A.F. Mapping the field of arts-based management: Bibliographic coupling and co-citation analyses. J. Bus. Res. 2018, 85, 348–357. [Google Scholar] [CrossRef]
- White, H.D.; McCain, K.W. Visualizing a discipline: An author co-citation analysis of information science, 1972-1995. J. Am. Soc. Inf. Sci. 1998, 49, 327–355. [Google Scholar]
- Hsu, C.-L.; Westland, J.C.; Chiang, C.-H. Editorial: Electronic Commerce Research in seven maps. Electron. Commer. Res. 2015, 15, 147–158. [Google Scholar] [CrossRef]
- Surwase, G.; Sagar, A.; Kademani, B.S.; Bhanumurthy, K. Co-citation Analysis: An Overview. In Proceedings of the BOSLA national conference proceedings, CDAC, Mumbai, India, 16–17 September 2011; p. 9. [Google Scholar]
- Mas-Tur, A.; Roig-Tierno, N.; Sarin, S.; Haon, C.; Sego, T.; Belkhouja, M.; Porter, A.; Merigó, J.M. Co-citation, bibliographic coupling and leading authors, institutions and countries in the 50 years of Technological Forecasting and Social Change. Technol. Forecast. Soc. Change 2021, 165, 120487. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Rasmussen, C.E. PILCO: A model-based and data-efficient approach to policy search. In Proceedings of the 28th International Conference on Machine Learning, ICML, Bellevue, WA, USA, 28 June–2 July 2011; pp. 465–472. [Google Scholar]
- Candelieri, A.; Perego, R.; Archetti, F. Intelligent Pump Scheduling Optimization in Water Distribution Networks; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 11353 LNCS. [Google Scholar]
- Wang, Z.; Schaul, T.; Van Hasselt, H.; De Frcitas, N.; Lanctot, M.; Hessel, M. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, ICML, New York, NY, USA, 19–24 June 2016; pp. 2939–2947. [Google Scholar]
- Ivan, B.; Tanja, U.; Claude, S. Behavioural Cloning, Phenomena, Results and Problems. In Automated Systems Based on Human Skill; Pergamon Press: Oxford, UK, 1995; pp. 143–150. [Google Scholar]
- Odonkor, P.; Lewis, K. Control of Shared Energy Storage Assets Within Building Clusters Using Reinforcement Learning. In Proceedings of the Volume 2A: 44th Design Automation Conference, Quebec City, QC, Canada, 26–29 August 2018; American Society of Mechanical Engineers: New York, NY, USA, 2018; p. V02AT03A028. [Google Scholar] [CrossRef]
- Hado, V.H.; Arthur, G.; David, S. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar] [CrossRef]
- Wiering, M.; van Otterlo, M. (Eds.) Reinforcement Learning: State-of-the-Art. In Adaptation, Learning, and Optimization; Springer: Berlin/Heidelberg, Germany, 2012; Volume 12. [Google Scholar] [CrossRef]
- Ernst, D.; Geurts, P.; Wehenkel, L. Tree-based batch mode reinforcement learning. J. Mach. Learn. Res. 2005, 6, 503–556. [Google Scholar]
- Ernst, D.; Capitanescu, F.; Glavic, M.; Wehenkel, L. Reinforcement Learning Versus Model Predictive Control: A Comparison on a Power System Problem. IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 517–529. [Google Scholar] [CrossRef]
- Guo, Y.; Feng, S.; Roux, N.L.; Chi, E.; Lee, H.; Chen, M. Batch Reinforcement Learning Through Continuation Method. In Proceedings of the ICLR, Vienna, Austria, 4 May 2021; pp. 1–11. [Google Scholar]
- Zhan, Y.; Li, P.; Guo, S. Experience-Driven Computational Resource Allocation of Federated Learning by Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), New Orleans, LA, USA, 18–22 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 234–243. [Google Scholar] [CrossRef]
- Sewak, M. Deep Reinforcement Learning Frontier of Artificial Intelligence; Springer: Singapore, 2019. [Google Scholar]
- Faraz, T.; Garrett, W.; Peter, S. Behavioural Cloning from Observation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1–9. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Dong, H.; Ding, Z.; Zhang, S. (Eds.) Deep Reinforcement Learning: Fundamentals, Research and Applications; Springer: Singapore, 2020; ISBN 9789811540943. [Google Scholar] [CrossRef]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation Learning: A Survey of Learning Methods. ACM Comput. Surv. 2018, 50, 1–35. [Google Scholar] [CrossRef]
- Achiam, J.; Sastry, S. Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning. arXiv 2017, arXiv:1703.01732. [Google Scholar]
- Andrew, G.B.; Sridhar, M. Recent advances in hierarchical Reinforcement Learning. Kluwer Acad. Publ. 2003, 13, 41–77. [Google Scholar]
- Ben Slama, S.; Mahmoud, M. A deep learning model for intelligent home energy management system using renewable energy. Eng. Appl. Artif. Intell. 2023, 123, 106388. [Google Scholar] [CrossRef]
- Heidari, A.; Khovalyg, D. DeepValve: Development and experimental testing of a Reinforcement Learning control framework for occupant-centric heating in offices. Eng. Appl. Artif. Intell. 2023, 123, 106310. [Google Scholar] [CrossRef]
- Dalamagkidis, K.; Kolokotsa, D.; Kalaitzakis, K.; Stavrakakis, G. Reinforcement learning for energy conservation and comfort in building. Build. Environ. 2007, 42, 2668–2698. [Google Scholar] [CrossRef]
- Kou, P.; Liang, D.; Wang, C.; Wu, Z.; Gao, L. Safe deep reinforcement learning-based constrained optimal control scheme for active distribution networks. Appl. Energy 2020, 264, 114772. [Google Scholar] [CrossRef]
- Vázquez-Canteli, J.R.; Nagy, Z. Reinforcement learning for demand response: A review of algorithms and modeling techniques. Appl. Energy 2019, 235, 1072–1089. [Google Scholar] [CrossRef]
- Park, J.Y.; Dougherty, T.; Fritz, H.; Nagy, Z. LightLearn: An adaptive and occupant centered controller for lighting based on reinforcement learning. Build. Environ. 2019, 147, 397–414. [Google Scholar] [CrossRef]
- Raju, L.; Sankar, S.; Milton, R.S. Distributed Optimization of Solar Micro-grid Using Multi Agent Reinforcement Learning. Procedia Comput. Sci. 2015, 46, 231–239. [Google Scholar] [CrossRef]
- Fant, S. Predictive Maintenance is a Key to Saving Future Resources. 2021. Available online: https://www.greenbiz.com/article/predictive-maintenance-key-saving-future-resources (accessed on 1 May 2023).
- Ghobakhloo, M. The future of manufacturing industry: A strategic roadmap toward Industry 4.0. J. Manuf. Technol. Manag. 2018, 29, 910–936. [Google Scholar] [CrossRef]
- Fausing Olesen, J.; Shaker, H.R. Predictive Maintenance for Pump Systems and Thermal Power Plants: State-of-the-Art Review, Trends and Challenges. Sensors 2020, 20, 2425. [Google Scholar] [CrossRef]
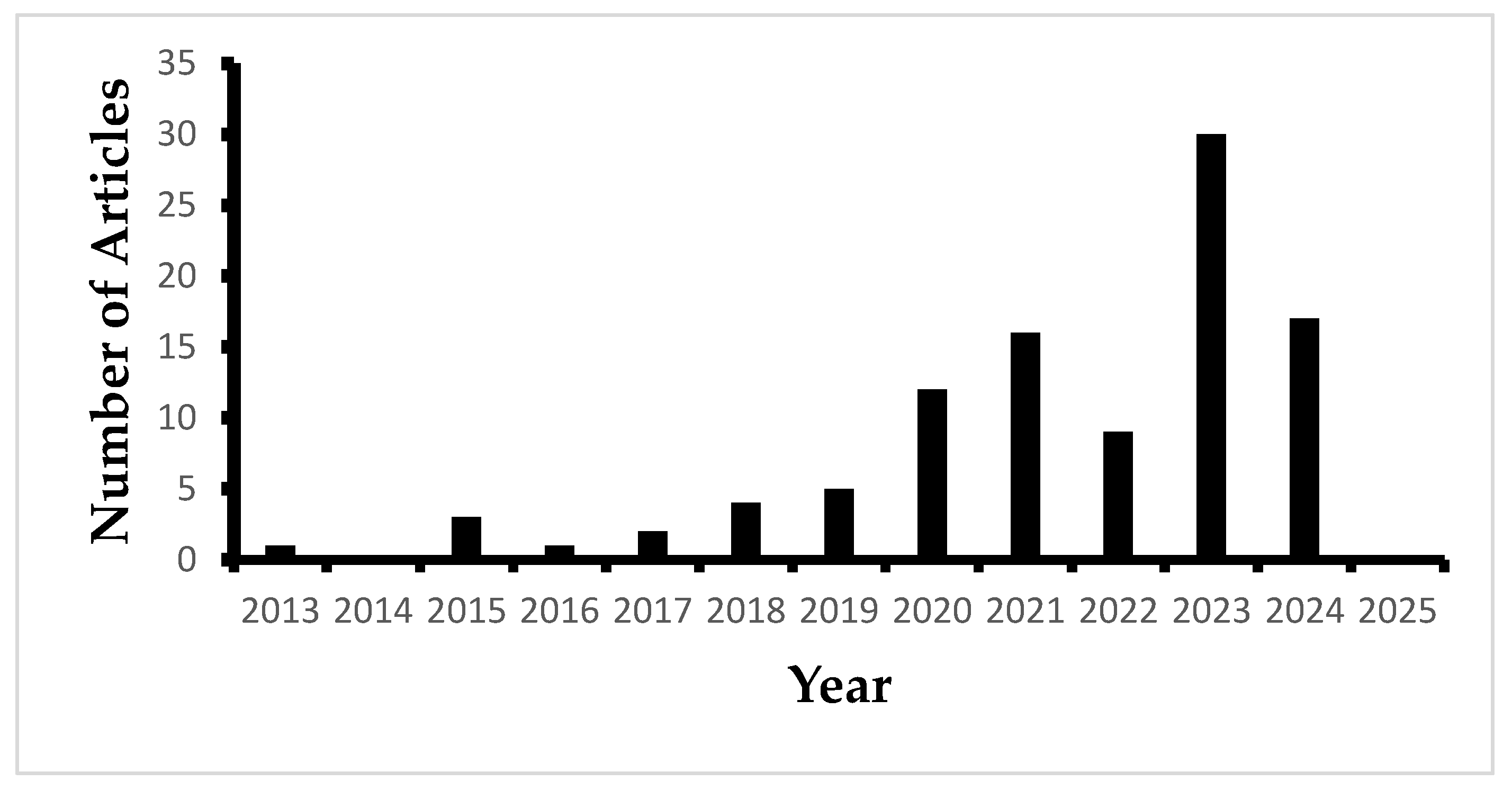
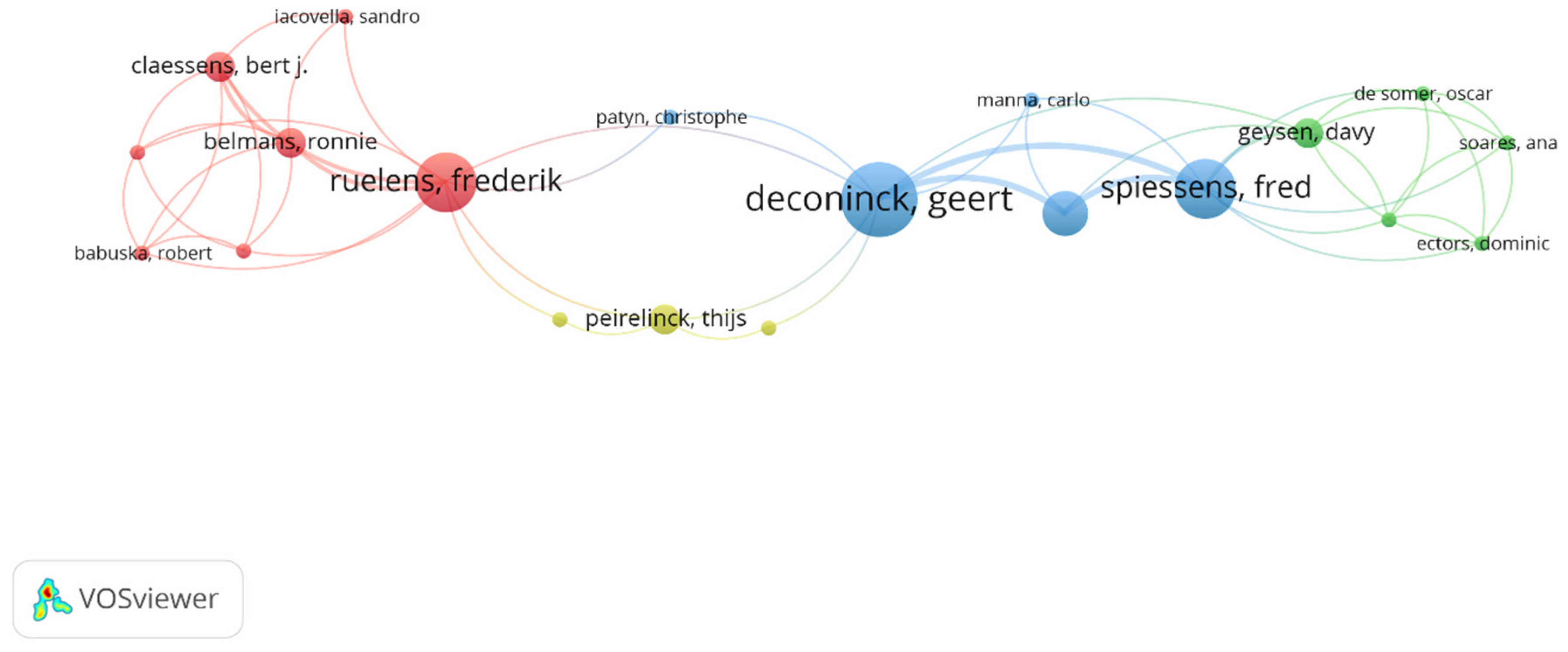
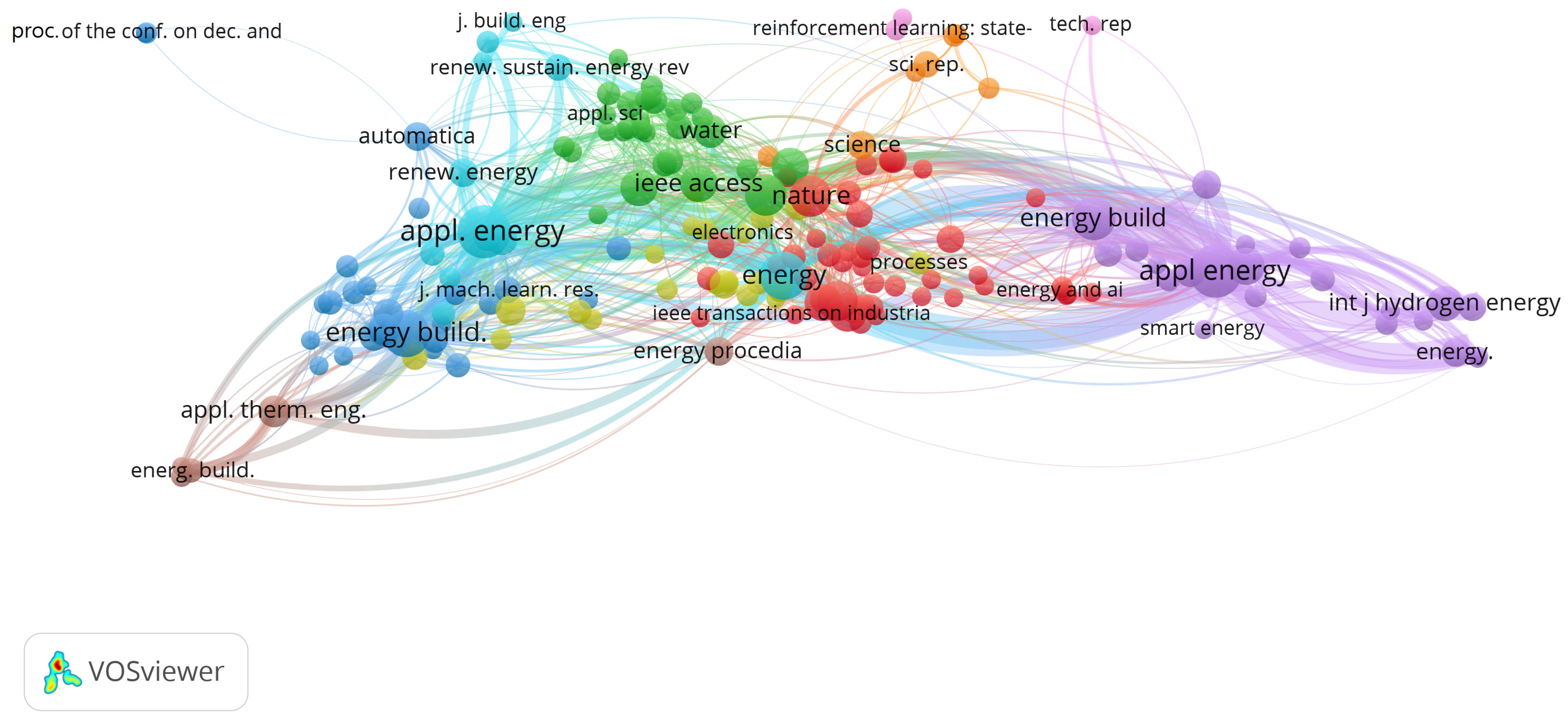
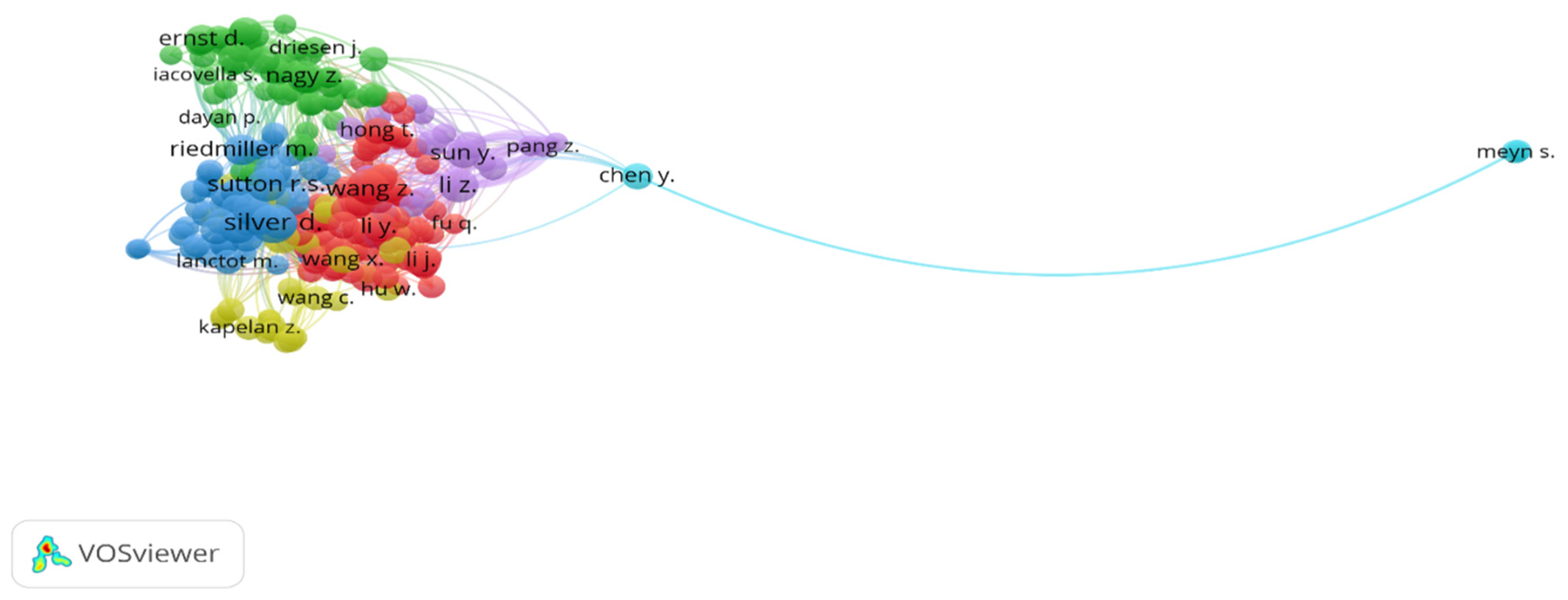
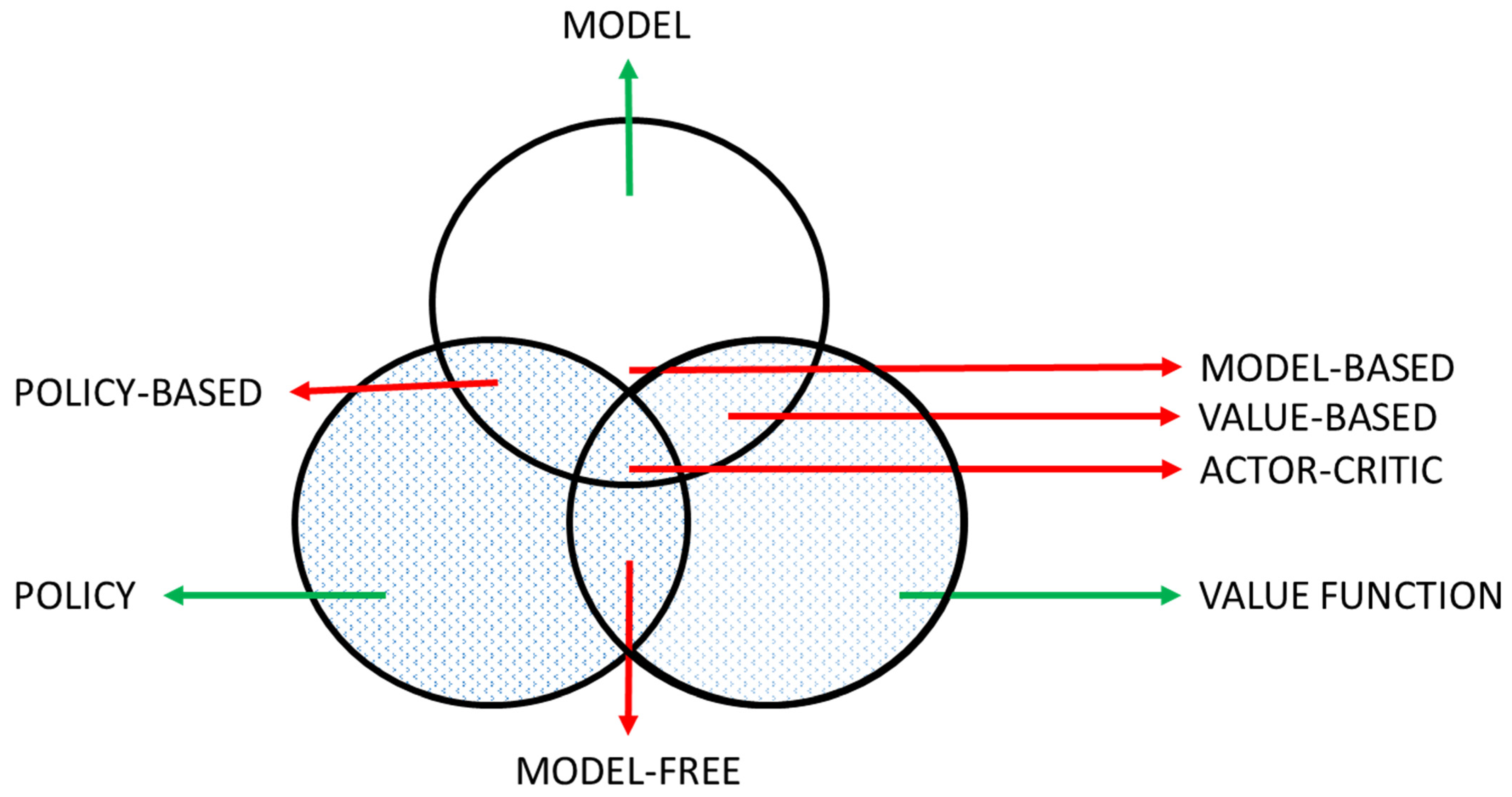
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).